
Webinar: The Anatomy of the Cloudant Data Layer
31
Glynn Bird – Developer Advocate – IBM Cloud Data Services The Anatomy of the Cloudant Data Layer
-
Upload
ibm-cloud-data-services -
Category
Technology
-
view
336 -
download
1
Transcript of Webinar: The Anatomy of the Cloudant Data Layer

Glynn Bird – Developer Advocate – IBM Cloud Data Services
The Anatomy of the Cloudant Data Layer

Introduction
@glynn_bird [email protected]
Glynn BirdDeveloper AdvocateIBM Cloud Data Serviceswww.glynnbird.com

3
Agenda
What is Cloudant? How does it work? Use-cases?

What is Cloudant?

5
Apache CouchDB
NoSQL Database-as-a-Service Free, open-source Schema-less JSON Document Store HTTP API Web dashboard Replication
{ "name": "Glynn", "registration": "2015-02-01", "confirmed": true, "height": 1.905 "tags": ["tall","glasses"], "links": { "email": "[email protected]", "twitter": "glynn_bird", "url": "http://www.glynnbird.com" }, "description": "Developer Advocate for IBM's Cloud Data Services team. Specializing in databases such as Cloudant, MongoDB & Redis, queues and pubsub for microservice workflow and search technology."
}

6
Cloudant Story
2.0
multi-node clustering
Cloudant Geo
Cloudant Query (Mango)
Cloudant Search (Lucene)
Dashboard

7
Cloudant vs CouchDB
Cloudant CouchDBInstallation Run as-a-service Install yourselfNodes Multi Single *Cost Free/PAYG/Dedicated BYOHSupport 24/7 Service
monitoring & management
n/a
Server Location
Cloud, On-Prem n/a
Unique features
Geo, Search n/a

How does it work?

© 2014 IBM Corporation
Eventual consistency
• CAP theorem• simplification - you must choose “P”
• When faced with a network partition, optimize for consistency or availability
• Multiple concurrent versions of data will happen• when modifying a document, pass a version token• CouchDB uses hash histories to track document versions• think git
© 2014 IBM Corporation
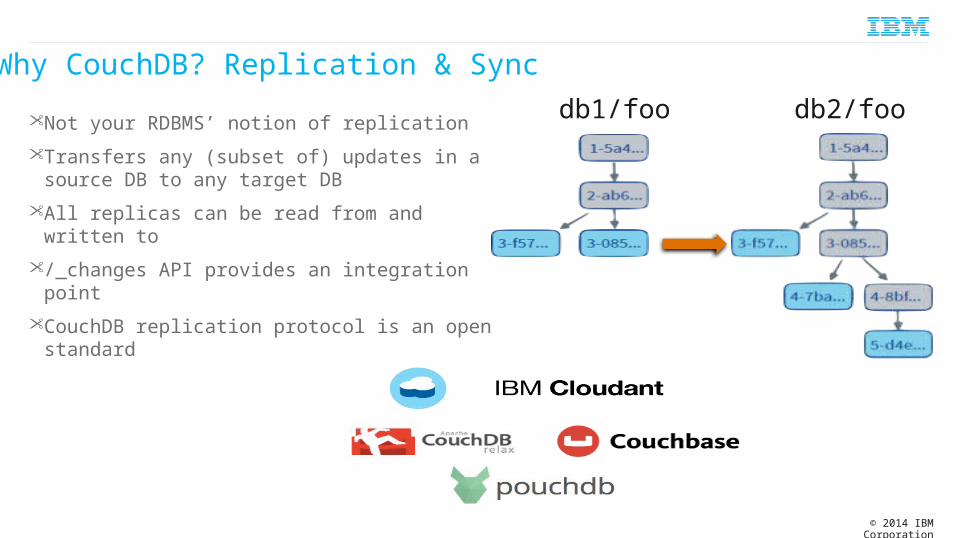
Why CouchDB? Replication & Sync• Not your RDBMS’ notion of replication• Transfers any (subset of) updates in a source
DB to any target DB• All replicas can be read from and written to• /_changes API provides an integration point• CouchDB replication protocol is an open
standard
db1/foo db2/foo

© 2014 IBM Corporation
Cloudant cluster – durable, available & scalable
Horizontally scalable Data is auto-sharded across cluster
All data stored in triplicate Built using a master-master design so no single
point of failure for reads or writes
Cross-data centre replication Geo-load balancing for user access to data
closest to them

© 2014 IBM Corporation12
Sharding
PUT /db2/docid92
DB Computes:• key = hash(“docid92”)• get_shards(key) ==> shard• get_nodes(shard) ==> [N1,N3,N4]• Nodes.foreach: store(doc)

© 2014 IBM Corporation13
Sharding (“Q”)
• Example with Q = 24• 6 Nodes
• Each node handles 4 shards
• General Rule:• Few large DBs use large Q• Many small DBs use small Q
• Q is degree of parallelism
© 2014 IBM Corporation
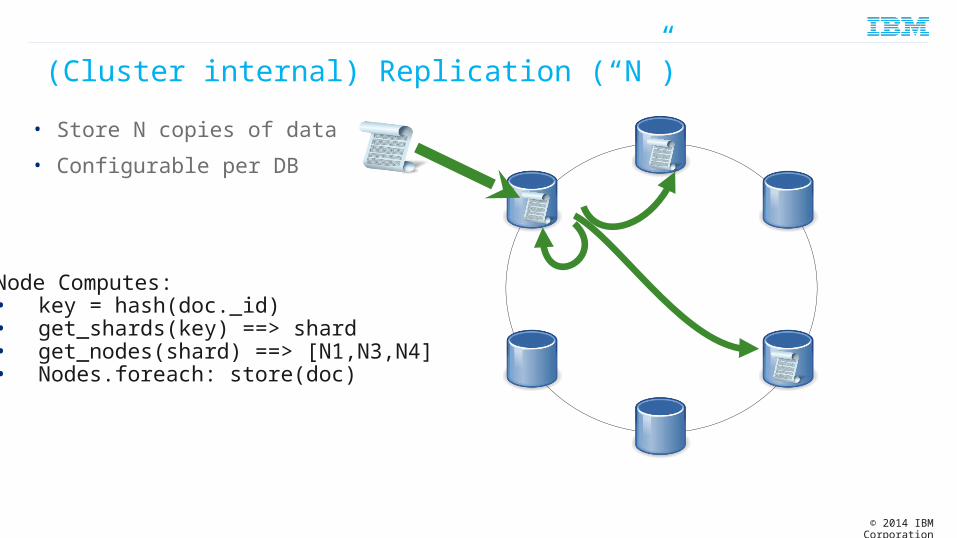
(Cluster internal) Replication (“N”)
• Store N copies of data
• Configurable per DB
Node Computes:• key = hash(doc._id)• get_shards(key) ==> shard• get_nodes(shard) ==> [N1,N3,N4]• Nodes.foreach: store(doc)
© 2014 IBM Corporation15
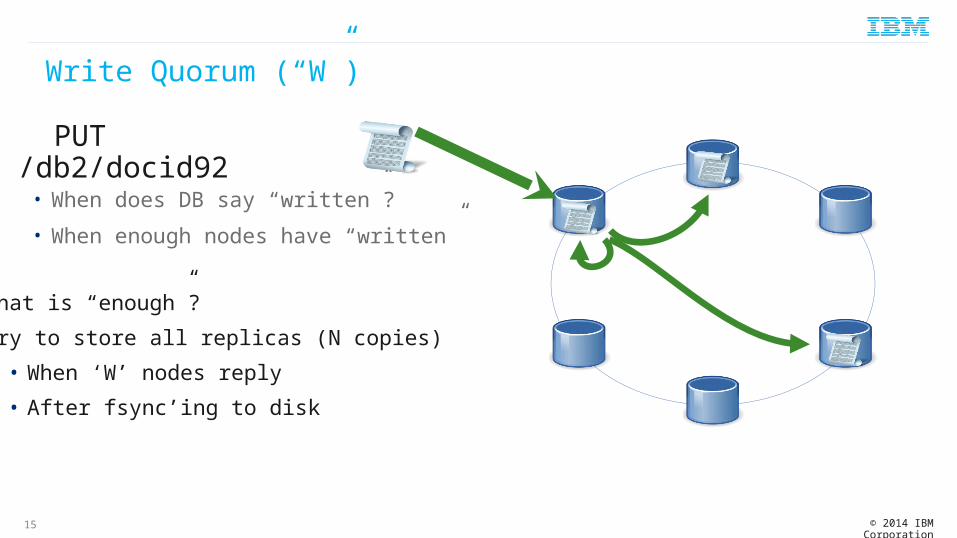
Write Quorum (“W”)
• When does DB say “written”?
• When enough nodes have “written”
• What is “enough”?• Try to store all replicas (N copies)
• When ‘W’ nodes reply• After fsync’ing to disk
PUT /db2/docid92
© 2014 IBM Corporation16
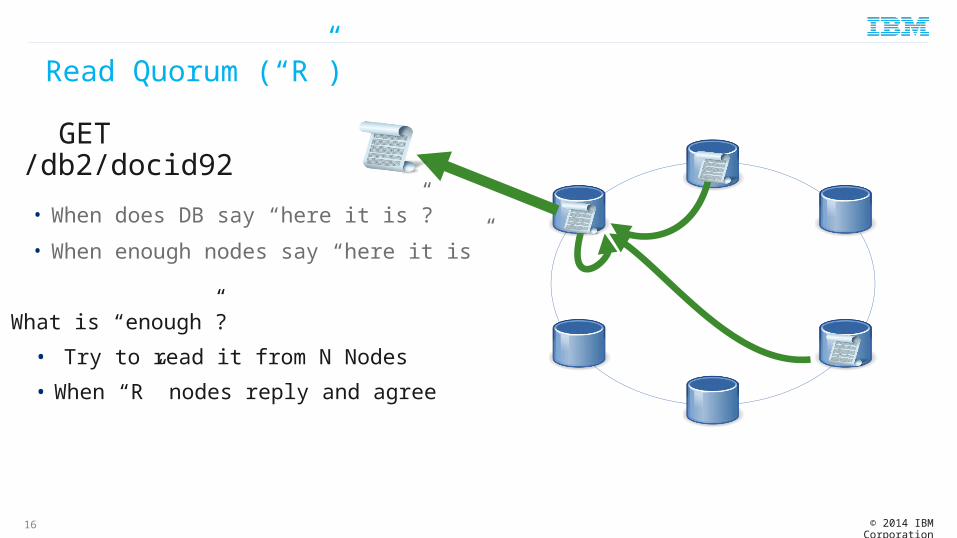
Read Quorum (“R”)
• When does DB say “here it is”?
• When enough nodes say “here it is”
• What is “enough”?• Try to read it from N Nodes• When “R” nodes reply and agree
GET /db2/docid92

© 2014 IBM Corporation17
Architecture
• Routing• DNS maps users to haproxy load balancers (LBs)• SSL termination occurs on LBs• LBs forward requests only to nodes in same data center• DNS failover for LBs within, between data centers
• Key Services• LB nodes run haproxy• DB nodes run Erlang VM and Java VM

Querying
19
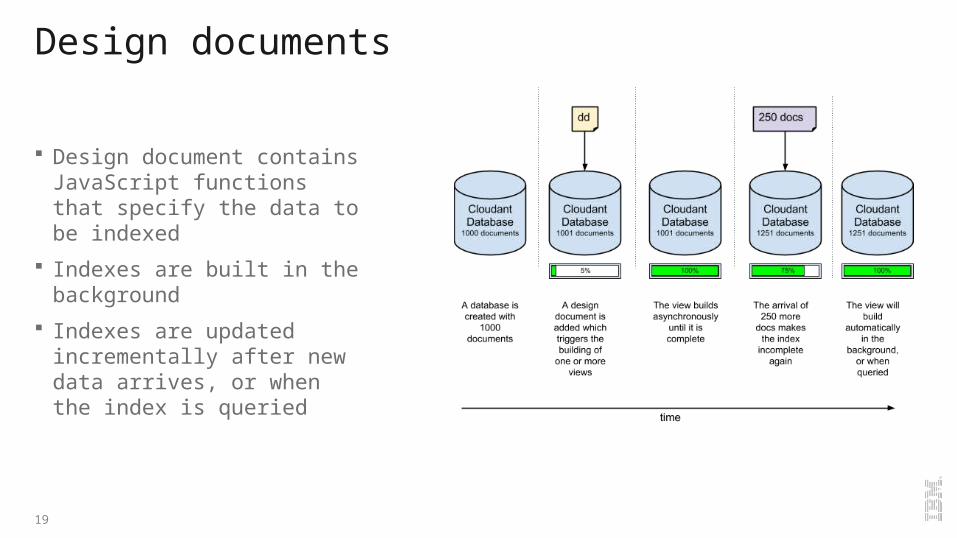
Design documents
Design document contains JavaScript functions that specify the data to be indexed
Indexes are built in the background
Indexes are updated incrementally after new data arrives, or when the index is queried

20
MapReduce – roll-your-own index
Indexing:
map:
function(doc) {
emit(doc.name, doc.height);
}
reduce:
_stats
The data
{ "name": "Glynn", "registration": "2015-02-01", "confirmed": true, "height": 1.905 "tags": ["tall","glasses"], "links": { "email": "[email protected]", "twitter": "glynn_bird", "url": "http://www.glynnbird.com" }, "description": "Developer Advocate for IBM's Cloud Data Services team. Specializing in databases such as Cloudant, MongoDB & Redis, queues and pubsub for microservice workflow and search technology."}

21
Full-text search – Cloudant Search
Indexing:
function(doc) { index("default", doc.name); index("default", doc.description); for(var i in tags) { index("default", tags[i]); } }
The data { "name": "Glynn", "registration": "2015-02-01", "confirmed": true, "height": 1.905 "tags": ["tall","glasses"], "links": { "email": "[email protected]", "twitter": "glynn_bird", "url": "http://www.glynnbird.com" }, "description": "Developer Advocate for IBM's Cloud Data Services team. Specializing in databases such as Cloudant, MongoDB & Redis, queues and pubsub for microservice workflow and search technology."}
Sample Query:
?q=glynn+cloudant+glasses

22
Cloudant Query – simple adhoc queries
Querying:
{ "fields": ["title", "year"], "selector": { "imdb.rating": { "$gt": 9.0 } }, "sort": [ { "year:number": "asc" } ], "limit": 10 }
Indexing – "index everything":
{
"index": {},
"type": "text"}
https://cloudant.com/blog/cloudant-query-grows-up-to-handle-ad-hoc-queries
/
23
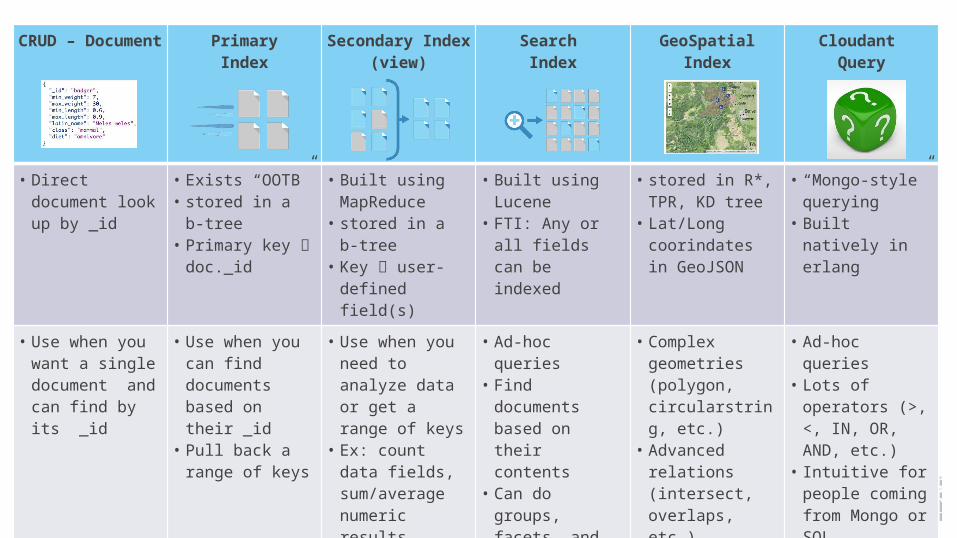
CRUD – Document
PrimaryIndex
Secondary Index (view)
Search Index
GeoSpatial Index
Cloudant Query
• Direct document look up by _id
• Exists “OOTB”• stored in a b-
tree• Primary key
doc._id
• Built using MapReduce
• stored in a b-tree
• Key user-defined field(s)
• Built using Lucene
• FTI: Any or all fields can be indexed
• stored in R*, TPR, KD tree
• Lat/Long coorindates in GeoJSON
• “Mongo-style” querying
• Built natively in erlang
• Use when you want a single document and can find by its _id
• Use when you can find documents based on their _id
• Pull back a range of keys
• Use when you need to analyze data or get a range of keys
• Ex: count data fields, sum/average numeric results, advanced stats, group by date, etc.
• Ad-hoc queries• Find documents
based on their contents
• Can do groups, facets, and basic geo queries (bbox & sort by distance)
• Complex geometries (polygon, circularstring, etc.)
• Advanced relations (intersect, overlaps, etc.)
• Ad-hoc queries• Lots of
operators (>, <, IN, OR, AND, etc.)
• Intuitive for people coming from Mongo or SQL backgrounds

24
Simple Search Service
Free, open-source Bluemix App – install with one click
Upload your .csv or .tsv– Imports data into Cloudant– Indexes everything for search– Presents HTTP Search API
Demo!
https://developer.ibm.com/clouddataservices/simple-search-service/

What can it do?
26
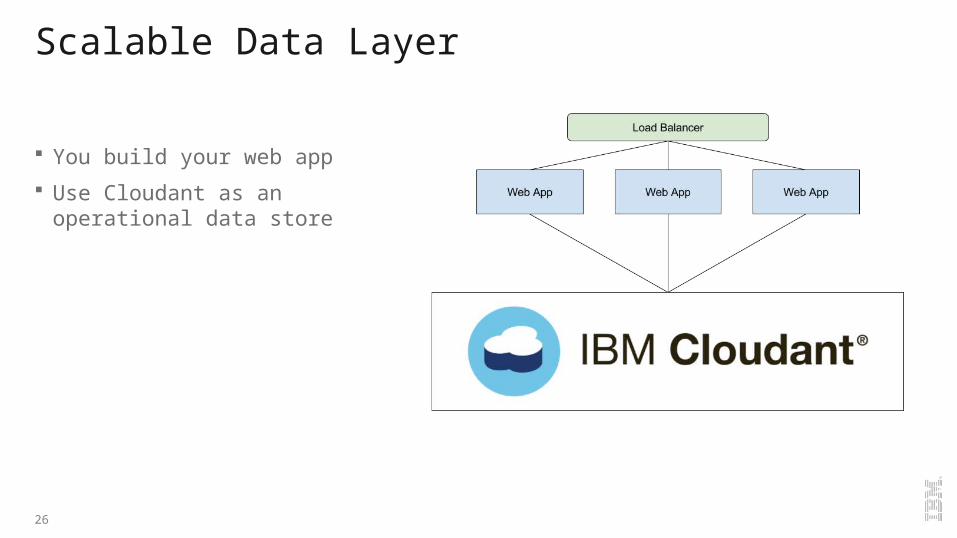
Scalable Data Layer
You build your web app Use Cloudant as an operational
data store

27
Offline-first web/mobile app
Use Cloudant Sync or PouchDB to replicate data to mobile device
Read and write data from offline copy first
Sync only when connected

28
Database and webserver in one
Use Cloudant as an operational database and a web server Store html, css & js as attachments to Cloudant documents
https://github.com/couchapp/couchapp

29
Operational database + data warehouse
Use Cloudant as an operational database
Write data to dashDB for data warehousing
NoSQL to SQL conversion Query in SQL or R
https://cloudant.com/dashdb/

30
Cloudant use-cases
Big Data – Large data sets Scalable operational data store Search – faceted, full-text search Geo-spatial – geographic, GIS systems, GeoJSON Offline-first – replicating data to mobile devices
Glynn BirdDeveloper Advocate, Cloud Data [email protected]@glynn_birdgithub.com/glynnbirdwww.glynnbird.com


















