
Web Mining - 123seminarsonly.com · Outline • Hype of the web • Difficulties with web • Web...
21
Click to edit Master subtitle style Company name Web Mining
Transcript of Web Mining - 123seminarsonly.com · Outline • Hype of the web • Difficulties with web • Web...

Click to edit Master subtitle styleCompany name
Web Mining

Outline
• Hype of the web• Difficulties with web • Web Mining• Advantages / Disadvantages• Categories of Web Mining• Web Usage Mining

Hype Of The Web
§ Information§ Services§ E-mail§ Business§ Communities

Difficulties With Web
§ Very Huge Information§ Semi-Structured Data§ Redundant Data§ Web is noisy§ Customer Behaviour

Web Mining
Process of discovering useful and unknown information or knowledge from the web data.

Web Mining - Sub Tasks
• Resource Finding• Information Selection• Information Preprocessing• Data Mining Techniques• Analysis

Benefits
• Business Organization• Banking Sector• Customer Satisfaction• Researchers• Society

Drawbacks
• Privacy Issues• Security Issues• Mis-Use of Information• Sometimes Expensive
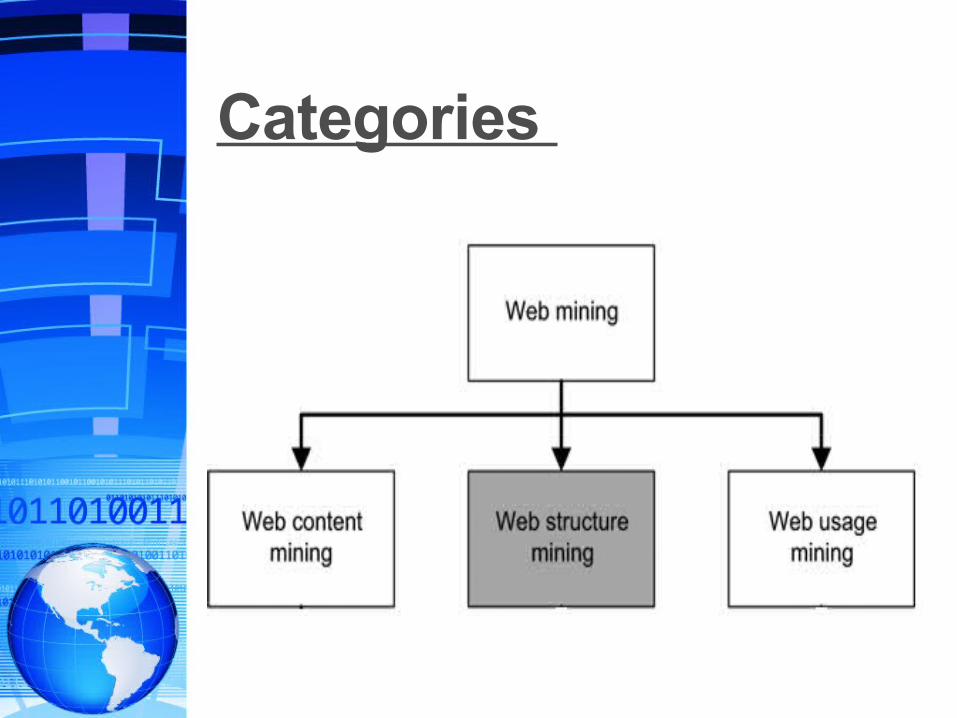
Categories

Web Usage Mining
The Process of Automatic discovering patterns and profile of users interacting with a web site.
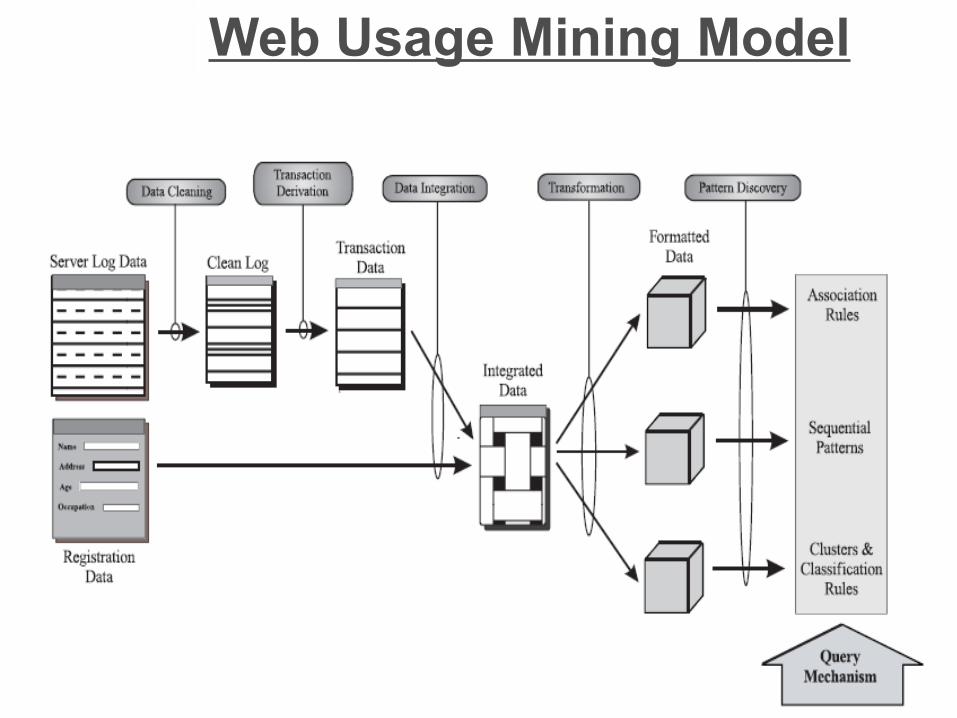
Web Usage Mining Model

Data Cleaning: Clean the raw data,
-Missing value-Redundant data
-Outliers deletion
Trasaction Derivation:
-according to individual user transaction

Data Integration:
- Combines data from multiple sources into a data store
Transformation:
- The data are transformed into appropriate forms for mining such as generalization and normalization

Pattern Discovery
Association Rule:
• X == > Y (support, confidence)• 60% of clients who accessed /products/, also
accessed /products/software/webminer.htm
Sequential Pattern:
• Discovery of frequently occurring ordered events or subsequences as patterns.

Clustering
process of grouping a set of objects into classes of similar objects
Classification
process of finding a model that describes and distinguishes data classes or concepts

K-means Algorithm
Used for clustering, where each cluster’s center is represented by the mean value of the objects in the cluster.
Input: k: the number of clusters, D: a data set containing n objects.Output: A set of k clusters.

Steps:
(1) randomly choose k objects from D as the initial cluster centers;
(2) repeat
(3) (re)assign each object to the cluster to which the object is the most similar , based on the mean value of the objects in the cluster;
(4) update the cluster means, i.e., calculate the mean value of the objects for each cluster;
(5) until no change;

K-Medoids Algorithm
-To over come the limitations found in k-means algorithm -Cluster is represented by the cost value of the objects in the cluster.

Input:
k: the number of clusters,
D: a data set containing n objects.
Output:
A set of k clusters.
Steps:
(1) randomly choose k objects in D as the initial representative objects or seeds;
(2) repeat
(3) assign each remaining object to the cluster with the nearest representative object;
(4) randomly select a nonrepresentative object, orandom;
(5) compute the total cost, S, of swapping representative object, oj, with orandom;
(6) if S < 0 then swap oj with orandom to form the new set of k representative objects;
(7) until no change;
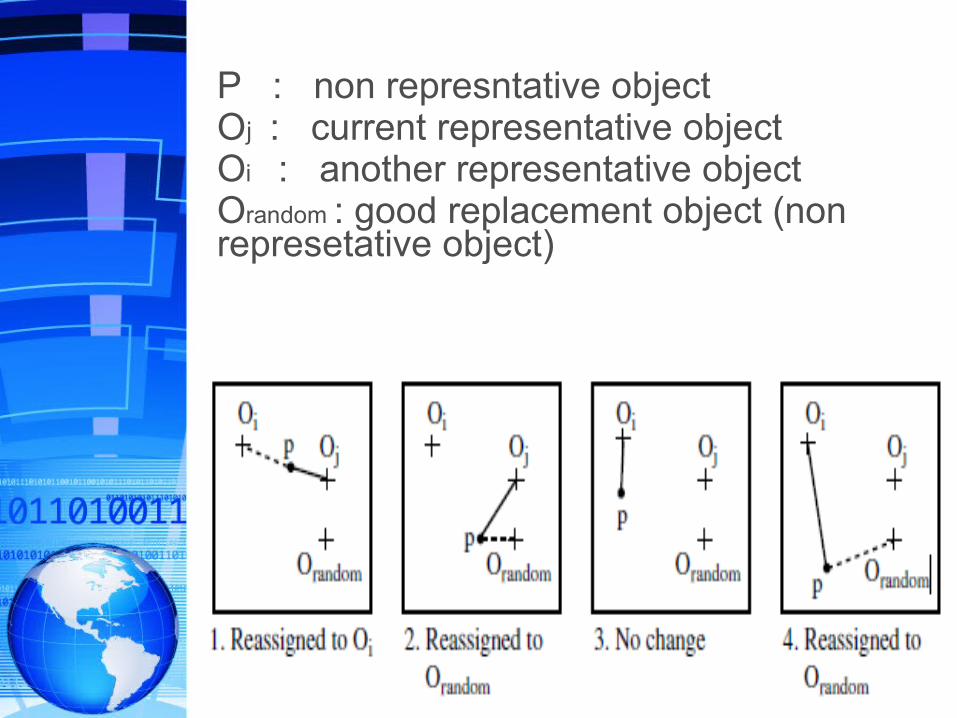
P : non represntative objectOj : current representative objectOi : another representative objectOrandom : good replacement object (non represetative object)

Thank You


















