
VOL 11, NO. 1, FEBRUARI 2017 SUSUNAN REDAKSI
84
BIAStatistics Biomedics, Industry & Business And Social Statistics Jurnal Statistika: Teori dan Aplikasi Journal of Statistics: Theory and Application Universitas Padjadjaran VOL 11, NO. 1, FEBRUARI 2017 SUSUNAN REDAKSI Pelindung Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Penanggung Jawab Kepala Departemen Statistika, FMIPA, Unpad Redaktur Sri Winarni, M.Si Zulhanif, M.Sc Desain Grafis Resa Septiani Pontoh, M.Stat.Sci Defi Yusti Faidah, M.Si Sekretariat Neneng Sunengsih, M.Stat Bertho Tantular, M.Si Gumgum Darmawan, M.Si Alamat Redaksi Jl. Raya Bandung Sumedang km. 21 Telepon/Fax : (022) 7796002 E-mail : [email protected] Website : http://statistics.unpad.ac.id/stats-biastatistika/ Diterbitkan oleh: Departemen Statistika Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Padjadjaran
Transcript of VOL 11, NO. 1, FEBRUARI 2017 SUSUNAN REDAKSI

BIAStatistics Biomedics, Industry & Business And Social Statistics
Jurnal Statistika: Teori dan Aplikasi Journal of Statistics: Theory and Application
Universitas Padjadjaran
VOL 11, NO. 1, FEBRUARI 2017
SUSUNAN REDAKSI
Pelindung
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Penanggung Jawab
Kepala Departemen Statistika, FMIPA, Unpad
Redaktur Sri Winarni, M.Si Zulhanif, M.Sc
Desain Grafis Resa Septiani Pontoh, M.Stat.Sci
Defi Yusti Faidah, M.Si
Sekretariat
Neneng Sunengsih, M.Stat
Bertho Tantular, M.Si
Gumgum Darmawan, M.Si
Alamat Redaksi
Jl. Raya Bandung Sumedang km. 21
Telepon/Fax : (022) 7796002
E-mail : [email protected]
Website : http://statistics.unpad.ac.id/stats-biastatistika/
Diterbitkan oleh: Departemen Statistika
Fakultas Matematika dan Ilmu Pengetahuan Alam
Universitas Padjadjaran


BIAStatistics Biomedics, Industry & Business And Social Statistics
Jurnal Statistika: Teori dan Aplikasi Journal of Statistics: Theory and Application
Universitas Padjadjaran
VOL 11, NO. 1, FEBRUARI 2017
UCAPAN TERIMAKASIH KEPADA MITRA BESTARI
Redaksi Jurnal BIAStatistics mengucapkan terimakasih
kepada para mitra bestari yang telah menelaah naskah pada terbitan Jurnal BIAStatistics Volume 11 No 1 Februari 2017
Mitra Bestari Prof. Dr. Sutawarnir Darwis
(Departemen Matematika FMIPA Institut Teknologi Bandung)
Dr. Muhamad Syamsuddin
(Departemen Matematika FMIPA Institut Teknologi Bandung)
Dr. Lienda Noviyanti, M.Si.
(Program Studi Statistika FMIPA Universitas Padjadjaran)


BIAStatistics Biomedics, Industry & Business And Social Statistics
Jurnal Statistika: Teori dan Aplikasi Journal of Statistics: Theory and Application
Universitas Padjadjaran
VOL 11, NO. 1, FEBRUARI 2017 ISSN 1907-6274
ARTIKEL PENELITIAN
IURAN PROGRAM PENSIUN NORMAL ABCM DENGAN PENDEKATAN PhDP
MELALUI RANTAI MARKOV DARI KENAIKAN PANGKAT PEGAWAI SECARA
BERKALA
Oleh: Achmad Zanbar Soleh, Lienda Noviyanti dan Gatot Riwi Setyanto .............. 1
ANALISIS KORESPONDENSI DATA PENYAKIT JANTUNG
Oleh: Latifah Rahayu Siregar dan Zurnila Marli Kesuma .......................................... 12
MODEL PEMETAAN PENYAKIT DENGAN RESPON GANDA MENGGUNAKAN
SEEMINGLY UNRELATED POISSON REGRESSION (PENDEKATAN BAYESIAN
INLA)
Oleh: I Gede Nyoman Mindra Jaya, Zulhanif dan Bertho Tantular ......................... 19
PERBANDINGAN BEBERAPA METODE KEKAR PADA PENDUGAAN
PARAMETER REGRESI LINIER SEDERHANA UNTUK DATA YANG
MENGANDUNG PENCILAN
Oleh: Riski Apriani Sari, Hari Wijayanto dan Indahwati............................................ 33
PREMI ASURANSI DENGAN SISTEM BONUS MALUS OPTIMAL
Oleh: Lienda Noviyanti, Achmad Zanbar Soleh dan Budhi Handoko ..................... 52
MANAJEMEN RESIKO KREDIT TERHADAP PERUSAHAAN PROPERTI DI
INDONESIA BERDASARKAN RASIO KEUANGANNYA
Oleh: Samsul Anwar, Zulfan dan Radhiah ........................................................................ 64
" Absence of evidence is not evidence of absence"
-Carl Sagan-

TATA CARA PENULISAN JURNAL BIAStatistics
Untuk menghindari duplikasi, BIAStatistics tidak menerima artikel yang telah dipublikasikan
oleh majalah dan jurnal lainnya. Penulis harus menandatangani surat pernyataan dan
disetujui oleh penulis pendamping lainnya. Apabila ditemukan bahwa artikel telah dimuat
pada jurnal atau majalah ilmiah lain, maka status terbit akan dianulir dan digantikan oleh
makalah lain.
Semua artikel akan dibahas oleh para pakar dalam bidang keilmuan yang sesuai (peer
review) beserta dewan redaksi. Artikel yang diterima dengan perbaikan akan dikembalikan
lagi kepada penulis. Artikel penelitian harus mempertimbangkan etika penelitian yang
dapat dipertanggungjawabkan.
PENULISAN ARTIKEL: Artikel diketik pada Ms Word 1,5 spasi pada kertas A4, dengan batas tepi kiri 4 cm dan tepi
atas, bawah dan kanan 3 cm. Jumlah halaman maksimal 20, jenis huruf Times New Roman
11pt. Setiap halaman diberi nomor secara berurutan dimulai dari halaman judul sampai
halaman terakhir. Artikel memuat pokok bahasan yang dituangkan dalam: Abstrak
(Abstract), 1. Pendahuluan (Introduction), 2. Metodologi (Methodology), 3. Hasil dan
Pembahasan (Result), 4. Kesimpulan (Conclusions) dan 5. Daftar Pustaka (Reference).
ABSTRAK (ABSTRACT) Abstrak untuk setiap artikel ditulis dalam bahasa Indonesia dan atau bahasa Inggris. Bentuk
abstrak tidak terstruktur dengan maksimal adalah 200 kata. Abstrak disertai 3-5 kata kunci
yang dapat membantu penyusunan indeks. Penulisan menggunakan jenis huruf Times New
Roman 10pt.
TABEL
Tabel ditampilkan secara jelas (bukan berupa gambar) dengan judul berada diatas Tabel.
Sumber Tabel dapat dicantumkan dibagian bawah tabel sejajar rata kiri dengan ukuran
huruf 10pt. Penomoran Tabel dimulai dari nomor 1 dan seterusnya maksimal 6 tabel.
GAMBAR/FOTO Gambar ditampilkan secara jelas dan proporsional. Gambar/Foto yang mengandung hak
cipta harus disertakan sumbernya. Gambar yang pernah dipublikasikan harus diberi acuan.
Penulisan judul diletakkan dibagian bawah Gambar. Penomoran Gambar dimulai dari
nomor 1 dan seterusnya maksimal 6 gambar.
PERSAMAAN/ FORMULASI MATEMATIKA Persamaan matematis ditulis dan diberi penomoran yang urut dari 1 dan seterusnya
sebanyak persamaan dalam artikel. Penomoran dicantumkan rata kanan tanpa titik-titik
penghubung dan diberi tanda kurung.
DAFTAR PUSTAKA
Rujukan ditulis sesuai dengan aturan penulisan Harvard, diurutkan menurut abjad.
Cantumkan nama penulis maksimal 4 orang pertama selanjutnya dkk. Jumlah rujukan
maksimal 20 buah.
PENGIRIMAN ARTIKEL ILMIAH: Artikel dikirimkan kepada dewan redaksi dengan alamat:
Jl. Raya Bandung Sumedang km. 21, Telepon/Fax : (022) 7796002
E-mail: [email protected]
Website: http://statistics.unpad.ac.id/stats-biastatistika/

1
BIAStatistics (2017) Vol. 11, No. 1, hal. 1-11
IURAN PROGRAM PENSIUN NORMAL ABCM DENGAN
PENDEKATAN PhDP MELALUI RANTAI MARKOV DARI
KENAIKAN PANGKAT PEGAWAI SECARA BERKALA
Achmad Zanbar Soleh1, Lienda Noviyanti2, dan Gatot Riwi Setyanto3 1,2,3Departemen Statistika FMIPA Universitas Padjadjaran
Email : [email protected]
ABSTRAK
Program pensiun normal manfaat pasti atau Accrued Benefit Cost Method (ABCM) adalah program
pensiun yang terlebih dahulu menentukan besar manfaat pensiun yang akan dibayarkan kepada
peserta dan selanjutnya menentukan besar iuran melalui perhitungan aktuaria. Salah satu besaran
yang mempengaruhi perhitungan iuran dalam pensiun adalah Penghasilan Dasar Pensiun (PhDP)
yang bergantung dari gaji terakhir peserta. Selama ini penentuan PhDP pada saat seseorang akan
pensiun diestimasi berdasarkan tabel skala gaji yang telah disediakan sebelumnya. Sedangkan
penelitian ini menggunakan pendekatan Rantai Markov sehingga diperoleh matriks peluang transisi
dari kenaikan pangkat pegawai yang selanjutnya digunakan dalam mengestimasi gaji pada masa
yang akan datang. Akibat perubahan kebijakan dengan mengganti besaran gaji pada saat program
pensiun sedang berjalan dari tabel skala gaji menjadi probabilistik melalui Rantai Markov maka
perhitungan iuran baru akan memperhitungkan kewajiban tambahan (Supplemental Liability).
Kata kunci: Iuran normal, kewajiban tambahan, Matriks Peluang Transisi.
1. PENDAHULUAN
Program dana pensiun merupakan suatu program yang memberikan jaminan
kepada karyawan apabila kelak mereka tidak dapat bekerja kembali. Jaminan tersebut
berupa dana pensiun yang diberikan setiap bulannya sampai karyawan tersebut meninggal
dunia di masa pensiunannya. Program pensiun ini akan memberikan rasa aman dan
kesejahteraan ketika seorang peserta telah pensiun.
Setiap karyawan baru (khususnya PNS) akan langsung diikutsertakan menjadi
anggota program pendanaan pensiun yang diadakan oleh TASPEN. Berkaitan dengan hal
tersebut maka setiap karyawan diwajibkan membayar iuran perbulan selama mereka
bekerja yang didasarkan pada persentase penghasilan dasar pensiun (PhDp).
PhDP adalah pendapatan seorang karyawan per bulannya yang berasal dari
penjumlahan gaji pokok, tunjangan keluarga, serta tunjangan-tunjangan lainnya. Nilai
PhDp seorang PNS akan selalu berubah sesuai dengan kebijakan pemerintah, masa kerja,
dan kepangkatan seseorang.

2 Biastatistics Vol 11, No.1, Februari 2017
Menurut Winklevoss (1993) asumsi yang digunakan dalam menentukan besaran-
besaran dana pensiun adalah (1) penurunan populasi (dalam hal ini kematian), (2) tingkat
suku bunga yang ditetapkan, dan (3) PhDp.
Penelitian ini akan dijelaskan estimasi besar gaji pada usia setahun sebelum
pensiun (yakni pada usia 55 tahun) berdasarkan masa kerja dan kepangkatan seseorang
diakhir masa kerjanya. Sampai dengan saat ini TASPEN masih menggunakan perhitungan
manfaat pensiun dengan pendekatan manfaat pasti atau Accrued Benefit Cost Method
(ABCM) sehingga estimasi gaji PhDp akan menjadi dasar utama dalam menentukan
manfaat pensiun yang akan diterima karyawan di masa pensiunnya.
Program pensiun normal ABCM adalah program pensiun yang terlebih dahulu
menentukan besar manfaat pensiun yang akan dibayarkan kepada peserta dan selanjutnya
menentukan besar iuran melalui perhitungan aktuaria.
Winklevoss dan Howard E. (1993) mengasumsikan skala gaji dalam perhitungan
PhDP berdasarkan perbandingan antara gaji tahun ini dengan gaji pada awal bekerja.
Terlihat pada Tabel 1 yang menunjukkan kenaikan gaji yang hanya bergantung pada masa
kerja.
Faktor lain yang mempengaruhi besar gaji PNS adalah kepangkatan PNS yang
dapat berubah-ubah selama mereka bekerja. Kenaikan pangkat PNS diatur dalam UU
No.12 Tahun 2002 Pasal 7 tentang Kenaikan Pangkat Pegawai Negeri Sipil yaitu PNS dapat
diberikan kenaikan pangkat regular jika sekurang-kurangnya telah empat tahun dalam
pangkat terakhir.
Tabel 1. Skala Gaji berdasarkan masa kerja
Walaupun berdasarkan Undang-undang setiap empat tahun sekali kepangkatan
PNS tersebut naik, Hal berbeda terjadi pada keadaan sesunguhnya dimana masih banyak
PNS yang tidak berubah kepangkatannya dalam jangka waktu lebih dari empat tahun. Oleh

Biastatistics Vol 11, No.1, Februari 2017 3
karena kenaikan pangkat PNS bersifat tidak pasti maka dalam mengestimasi kepangkatan
terakhir seorang PNS diakhir masa kerjanya akan digunakan matriks peluang transisi dari
kepangkatan PNS berdasarkan rantai Markov. Matriks peluang transisi ini merupakan
matriks berderajat n yang menyatakan perubahan kepangkatan PNS berdasarkan masa
kerja dan perundang-undangan yang berlaku.
Penelitian ini akan mengevalusi besarnya iuran yang harus dibayarkan seorang
PNS dikarenakan perubahan kebijakan yang ditetapkan pemerintah guna meningkatkan
kesejahteraan PNS. Perubahan kebijakan ini akan berdampak pada besaran iuran yang
berbeda pada tahun-tahun berikutnya.
Seorang PNS yang mengikuti dana pensiun dari awal bekerja sampai dengan
memasuki usia pensiun (r-1) dimana peserta dalam masa pendanaan pensiun y sampai
dengan x-1, peserta membayar iuran normal untuk kondisi manfaat yang konstan. Namun
dalam kenyataannya selama bekerja dari awal bekerja hingga pensiun PNS terdapat
kemungkinan kenaikkan pangkat sehingga mengubah besaran gaji yang akan diperoleh dan
akan mengubah besar tunjangan atau manfaat yang akan diterima pada saat pensiun. Faktor
penyesuaian ekonomi dari waktu ke waktu juga berpengaruh sehingga pemerintah
membuat kebijakan untuk meningkatkan tunjangan pensiun PNS sebesar 2% per tahun
(lihat Gambar 1). Akibat hal tersebut maka selama masa sisa tahun bekerja (x sampai r-1)
peserta harus membayar kekurangan agar tunjangan atau manfaat pensiun yang lebih besar
dapat terdanai.
Gambar 1. Latar Belakang Perubahan Kebijakan Pendanaan Pensiun ABCM
Hal ini menguntungkan bagi PNS akan tetapi kondisi ini perlu diperhatikan oleh
pemerintah karena akan mengubah besarnya actuarial liability dan supplemental liability
sehingga untuk menanggulangi kekurangan tersebut diperlukan perhitungan iuran
tambahan dan iuran baru yang dibutuhkan agar kekurangan dana bisa tertutupi.
2. METODOLOGI
Bagian ini akan menjelaskan langkah-langkah untuk menentukan iuran pensiun
normal dengan menggunakan metode pendanaan pensiun manfaat pasti dengan terlebih

4 Biastatistics Vol 11, No.1, Februari 2017
dahulu menentukan golongan PNS yang pada saat terakhir bekerja untuk mengetahui
berapa penghasilan terakhir yang akan digunakan sebagai dasar penentuan manfaat
pensiun. Namun besarnya manfaat tersebut dapat berubah akibat adanya perubahan
kebijakan pemerintah yang terjadi setiap tahunnya. Akibat adanya kenaikan tunjangan
pensiun akan menyebabkan terjadinya kekurangan dalam pembayaran iuran pensiun karena
iuran normal yang selama ini dibayarkan tidak seimbang dengan manfaat yang akan
diperoleh.
Asumsi yang digunakan dalam penelitian ini adalah sebagai berikut:
Pensiun normal dengan usia pensiun normal PNS adalah 56 tahun.
Metode Pendanaan pensiun yang digunakan adalah metode manfaat pasti.
Tabel mortalita yang digunakan adalah tabel mortalita TASPEN 2012.
Tingkat bunga aktuaria (i) sebesar 10% per tahun.
Tingkat Inflasi (I) sebesar 1% per tahun.
Tingkat kenaikan tunjangan pensiun sebesar 2% per tahun.
Usia pensiunan PNS masih akan hidup hingga 100 tahun. Sehingga, selisih usia PNS
pada saat pensiun hingga usia 100 tahun (t) adalah 44 tahun.
Titik valuasi pada tahun usia 30 tahun terhadap PNS yang mulai bekerja pada usia 23
tahun.
2.1 Accrued Benefit Cost Method (ABCM)
Prinsip dari pendanaan pensiun adalah terjadinya keseimbangan antara yang
dibayarkan peserta dengan besar manfaat yang dikeluarkan oleh suatu TASPEN. Hal ini
mengakibatkan besar iuran yang harus dibayarkan peserta dana pensiun harus dapat
mencukupi seluruh manfaat pada saat pensiun sampai peserta tersebut meninggal dunia.
ABCM atau lebih dikenal dengan metode manfaat pasti merupakan pendanaan
pensiun bahwa pihak penyelenggara dana pensiun menetapkan terlebih dahulu manfaat
yang akan diterima peserta pada saat pensiun setelah itu baru besaran iuran ditetapkan.
Sehingga pada metode manfaat pasti ini iuran yang dibayarkan dihitung berdasarkan
manfaat yang dinotasikan dengan Br yang akan diterima nantinya.
Secara umum, rumusan penentuan iuran normal untuk metode manfaat pasti
adalah sebagai berikut:
(2.1)

Biastatistics Vol 11, No.1, Februari 2017 5
dengan
(𝑁𝐶)𝑥 : Iuran normal pada usia x
𝑏𝑥 : Besarnya manfaat yang diperoleh saat
membayar NCx
v : Faktor diskonto
: Peluang PNS berusia x masih akan
tetap bekerja r-x tahun kemudian
Persamaan (2.1) selanjutnya akan disesuaikan berdasarkan matriks peluang
transisi kepangkatan PNS. Menurut UU No.11 tahun 1969 tentang Pensiun Pegawai dan
Pensiun Janda/Duda Pegawai telah mengatur tentang besar manfaat yang akan diperoleh
PNS saat pensiun. Perumusannya sebagai berikut:
(2.2)
dengan
GDP : Gaji Dasar Pokok, gaji pada usia 55 tahun
MK : Masa Kerja pegawai terhitung mulai saat
menjadi PNS sampai mencapai usia pensiun.
Pada Persamaan (2.2) di atas besar manfaat yang akan diterima oleh PNS pada
saat pensiun dapat diperhitungkan. Namun, terkadang terjadi perubahan karena perbedaan
pangkat dari awal masuk sampai di usia pensiun (r) yang selanjutnya berdampak kepada
besaran gaji pokok dan kebijakan TASPEN seperti terjadinya kenaikan tunjangan untuk
pensiunan PNS. Hal ini akan menyebabkan perubahan pada besaran manfaat yang akan
diterima pensiunan PNS.
2.2 Matriks Peluang Transisi
Matriks peluang transisi P yang digunakan untuk melihat peluang dari
perpindahan golongan PNS dapat dilihat pada Persamaan (2.3).
(2.3)

6 Biastatistics Vol 11, No.1, Februari 2017
Keadaan dalam matriks peluang transisi menyatakan golongan PNS yang terdiri
dari “0” (golongan 3A), “1” (golongan 3B),…,”8” (golongan 4E). Pij merupakan peluang
transisi seorang PNS yang sebelumnya berada pada golongan i berubah menjadi golongan
j. Nilai Pij diperoleh berdasarkan Persamaan (2.4). Jadi P00 adalah peluang seorang PNS
tetap pada golongan awal (3A) dalam empat tahun terakhir. Sedangkan P01 adalah peluang
seorang PNS akan berpindah dari golongan awal (0/3A) menjadi golongan (1/3B) dalam
empat tahun.
(2.4)
Matriks peluang transisi n langkah digunakan untuk menentukan peluang pangkat
pegawai saat ia berhenti bekerja. Karena satu langkah didefinisikan selama 4 tahun, maka
perumusan n adalah
(2.5)
yang merupakan pembulatan ke bawah dari masa kerja dibagi empat, sehingga
matriks peluang transisi n langkah nya :
(2.6)
Selanjutnya Matriks Peluang Transisi golongan PNS seperti pada persamaan 2.7.
(2.7)
Selanjutnya Persamaan 2.7 dapat digambarkan dalam diagram peluang transisi
sebagai berikut.
Gambar 2. Diagram Alur dari Peluang
transisi golongan PNS

Biastatistics Vol 11, No.1, Februari 2017 7
2.3 Estimasi Gaji Pokok Terakhir
Sebelum menentukan besarnya manfaat yang akan diterima oleh PNS saat
pensiun perlu ditaksir terlebih dahulu gaji terakhir bekerja. Gaji PNS selain ditentukan
berdasarkan masa kerja juga bergantung terhadap golongan saat itu. Pangkat PNS untuk
masa mendatang sifatnya tidak pasti, karena terdapat kemungkinan yang terjadi seperti
tetap berada dipangkatnya saat ini atau naik pangkat. Apabila kenaikan pangkat dimasukan
dalam perhitungan maka akan mengubah besaran dari Salary Scale usia x. Karena besarnya
gaji akan berbeda-beda dan belum diketahui berapa rasio gajinya apabila pangkatnya
berubah. Sehingga besarnya gaji pada usia x merupakan nilai harapan dari semua
kemungkinan gaji yang akan diterima di setiap golongan saat usia tersebut. Maka
perumusan dari estimasi gaji masa akan datangnya adalah sebagai berikut:
(2.8)
dengan
𝑠𝑦 : Besarnya gaji pada usia y (mulai kerja)
(𝑆𝑆)𝑥𝑗 : Salary Scale pada usia x saat golongan j
(𝑆𝑆)𝑦𝑖 : Salary Scale pada usia y saat golongan i
𝐼 : Tingkat Inflasi
2.4 Menentukan Besarnya Manfaat
Berdasarkan Kenaikan Pangkat
Penentuan besar manfaat yang melibatkan peluang dari kenaikan pangkat serta
perubahan kebijakan terhadap kenaikan tunjangan pensiun dirumuskan pada Persamaan
(2.9). Persamaan tersebut merupakan pengembangan dari Persamaan (2.2).
(2.9)
dengan merupakan estimasi gaji pokok terakhir dari seorang PNS
2.5. Increasing Annuity
Increasing Annuity merupakan kenaikan jumlah uang yang harus dibayarkan tiap
periode waktu dengan besar kenaikannya bersifat konstan, dimana kenaikan tersebut pada
kasus ini terjadi pada manfaat pensiun setiap tahunnya. Perumusan increasing annuity
adalah sebagai berikut.
(2.10)
Akibat adanya penyesuaian faktor ekonomi dari waktu ke waktu maka terjadi
kenaikan manfaat pensiun setiap tahunnya dengan besarnya kenaikan diasumsikan konstan

8 Biastatistics Vol 11, No.1, Februari 2017
setiap tahunnya sehingga besar manfaat pensiun yang akan diterima oleh pensiunan PNS
nya akan meningkat setiap tahunnya sebesar Q.
2.6. Actuarial Liability dan Supplemental Liability
Actuarial Liability (Kewajiban aktuaria) adalah kewajiban dana pensiun yang
dihitung berdasarkan asumsi bahwa Dana Pensiun akan terus berlangsung sampai
dipenuhinya seluruh kewajiban kepada Peserta dan Pihak yang berhak.
Secara teori pembayaran iuran oleh PNS harus dapat melunasi seluruh manfaat
yang akan diterimanya nanti sejak awal pensiun sampai dengan meninggal dunia. Dengan
demikian bahwa nilai tunai pada saat mengikuti dana pensiun dari iuran normal yang akan
datang harus menutupi nilai tunai manfaat masa depan (Present Value of Future Benefit
atau PVFB). Persamaan dari PVFB adalah sebagai berikut.
(2.11)
Secara umum dalam menentukan Actuaria Liability (AL) terdapat dua cara yang
biasa digunakan yaitu Metode Prospektif dan Metode Retrospektif. AL dengan pendekatan
Metode Prospektif dirumuskan seperti pada Persamaan (2.12) dan berdasarkan pendekatan
Metode Retrospektif dituliskan pada Persamaan (2.13).
(2.12)
dengan
𝑃𝑉𝐹𝐵 : Present Value Future Benefit
𝑃𝑉𝐹𝑁𝐶 : Present Value Future Normal Cost
(2.13)
dengan
AVPNC : Accumulated Value of Past Normal Cost
Supplemental Liability (iuran tambahan) merupakan dana yang dibutuhkan untuk
menutupi kekurangan pendanaan pensiun atau biaya tambahan yang dikeluarkan oleh pihak
pengelolaan dana pensiun untuk membantu membayar kekurangan pendanaan pensiun
setiap tahunnya.
Supplemental liability akan muncul apabila (𝑃𝑉𝐹𝐵)𝑋 > (𝑃𝑉𝐹𝑁𝐶)𝑥 + (𝐴𝑉𝑃𝑁𝐶)𝑋.
Kemudian jika (𝑃𝑉𝐹𝐵)𝑋 = (𝑃𝑉𝐹𝑁𝐶)𝑥 + (𝐴𝑉𝑃𝑁𝐶)𝑋 maka tidak ada supplemental liability.
Dan jika (𝑃𝑉𝐹𝐵)𝑋 < (𝑃𝑉𝐹𝑁𝐶)𝑥 + (𝐴𝑉𝑃𝑁𝐶)𝑋 maka ada pengembalian.
(2.14)

Biastatistics Vol 11, No.1, Februari 2017 9
2.7. Iuran Normal Cost Baru
Dengan menghitung kembali besarnya manfaat yang diperoleh pada usia x, dapat
diperoleh berapa besarnya iuran normal yang seharusnya dibayarkan oleh PNS setiap
bulannya.
(2.15)
dengan Cn merupakan koefisien dari penambahan atau pengurangan kalinya dari
past service bagi accrual benefit yang tidak terdanai saat peserta baru mulai pendanaan
pensiun.
(2.16)
Dengan manfaat pensiun pada usia z setelah terjadi perubahan, Bz manfaat
pensiun pada usia z sebelum terjadi perubahan, serta Br manfaat yang diperoleh saat
pensiun setelah terjadi perubahan.
Besar iuran normal baru untuk menutupi kekurangan pendanaan akibat
perubahan pangkat PNS dari awal bekerja sampai akhir bekerja dan akibat perubahan
kebijakan terhadap tunjangan pensiun PNS adalah
(2.17)
dengan
3. HASIL DAN PEMBAHASAN
Berdasarkan data kepegawaian di TASPEN maka diperoleh matrik peluang
transisi dari perubahan golongan PNS adalah sebagai berikut.
Peluang seseorang dengan golongan 3A saat masuk bekerja dan empat tahun
kemudian tetap di golongan 3A adalah 0,78. Sedangkan peluang seseorang golongan 3A
saat masuk kerja naik golongan menjadi 3B empat tahun kemudian adalah 0,22.
Sebagai ilustrasi, Gaji pokok yang akan diterima seorang PNS bergolongan III/A
sesuai dengan PP nomor 34 tahun 2014 sebesar Rp. 2.317.600, per bulan, maka gaji yang

10 Biastatistics Vol 11, No.1, Februari 2017
akan diterima saat PNS berusia 23 tahun selama satu tahun sebesar Rp. 27.811.200,00.
Besarnya gaji yang akan diterima PNS pada saat usia 55 tahun dengan menggunakan
persamaan (2.8) yaitu sebagai berikut :
Jadi, besar gaji yang akan diterima PNS pada usia 55 tahun yang memulai kerja
pada usia 23 tahun adalah sebesar Rp.56.924.242 per tahun dengan peluang seseorang
tersebut tetap pada golongan awalnya yaitu III/A atau akan meningkat ke golongan
berikutnya selama masa kerjanya.
Dengan menggunakan Persamaan (2.9) maka besar manfaat tahunan yang akan
diperoleh PNS berdasarkan Undang-Undang yang telah ditentukan tanpa mengikutsertakan
kemungkinan terjadinya kenaikan pensiun sebesar Rp.45.539.294 per tahun.
Selanjutnya dengan menggunakan Persamaan (2.1) diperoleh informasi bahwa
peserta yang mengikuti program dana pensiun sejak awal bekerja yaitu pada usia 23 tahun
maka peserta tersebut harus membayarkan iuran normal pada usia 30 sebesar Rp.762.596
per tahun.
Karena (𝑃𝑉𝐹𝐵)𝑋 > (𝑃𝑉𝐹𝑁𝐶)𝑥 + (𝐴𝑉𝑃𝑁𝐶)𝑋 maka perlu dilanjutkan dengan
menghitung Supplemental Liability untuk mengetahui berapa besar kekurangan atau
kelebihan yang dibutuhkan TASPEN untuk menutupinya. Menggunakan Persamaan (2.14)
diperoleh besar kekurangan dana yang harus ditanggung TASPEN adalah sebesar Rp.
67.753.330.
Besarnya Cn sesuai Persamaan (2.16) adalah sebesar 0.1628 sehingga
berdasarkan Persamaan (2.15) manfaat pensiun yang diperoleh setelah diperhitungkan
kembali adalah sebesar Rp.1.265.074 per tahun.
Jadi dapat ditetapkan bahwa iuran normal baru yang harus dibayarkan PNS pada
usia 30 tahun adalah sebesar Rp.2.243.647 per tahun untuk mendapatkan kenaikan manfaat
secara konstan sebesar 2% selama masa pensiun.
4. KESIMPULAN
Perubahan kebijakan program pensiun ABCM dengan menambahkan pengaruh
dari perubahan kepangkatan PNS dan menaikkan manfaat pensiun secara konstan selama
masa pensiun akan menaikan besarnya iuran baru dibandingkan dengan iuran lama. Namun
demikian perubahan kebijakan ini akan memberikan kesejahteraan kepada PNS di masa
pensiunnya.

Biastatistics Vol 11, No.1, Februari 2017 11
5. DAFTAR PUSTAKA
Peraturan Pemerintah Nomor 12 Tahun 2002 Tentang Kenaikan Pangkat PNS.
Ross, S.M. (1983). Stochastics Processes. Berkeley : John Wiley & Sons, Inc.
Undang-Undang Republik Indonesia Nomor 11 Tahun 1992 Tentang Dana Pensiun.
Undang-Undang Republik Indonesia Nomor 13 Tahun 2003. Tentang Ketenagakerjaan.
Winklevoss, H. E. (1993). Pension Mathematics with Numerical Illustrations, 2nd Edition. USA :
Pension Research Council of Wharton School of The University of Pennsylvania.

12
BIAStatistics (2016) Vol. 10, No. 1, hal. 12-18
ANALISIS KORESPONDENSI DATA PENYAKIT JANTUNG
(Studi kasus di Rumah Sakit Umum Daerah
dr. Zainoel Abidin, Banda Aceh)
Latifah Rahayu Siregar1), Zurnila Marli Kesuma2)
1,2Program Studi Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam,
Universitas Syiah Kuala
Email: [email protected]
ABSTRAK
Informasi tentang penyakit jantung sangat dibutuhkan dewasa ini. Tujuan dari penulisan ini adalah
penggunaan analisis korespondensi untuk mengetahui keterkaitan antara tingkat keparahan penyakit
jantung dengan kolesterol, tekanan darah, gula darah puasa, riwayat merokok dan umur. Data yang
digunakan adalah data sekunder dari Rumah Sakit Umum Daerah dr. Zainoel Abidin, Banda Aceh
pada tahun 2015 dengan jumlah data penderita jantung sebanyak 55 orang. Hasil pada plot analisis
korespondensi menunjukkan bahwa tingkat keparahan penyakit jantung dapat berkaitan dengan
kadar kolesterol, tekanan darah, gula darah puasa dan riwayat merokok.
Kata kunci : Analisis Korespondensi; Uji Eksak Fisher; Penyakit Jantung
1. PENDAHULUAN
Penyakit Jantung merupakan salah satu penyakit yang menyebabkan kematian
nomor satu di dunia. Menurut data dinas kesehatan, berdasarkan diagnosis dokter,
prevalensi penyakit jantung di Indonesia tahun 2013 sebesar 0,5% atau diperkirakan sekitar
883.447 orang, sedangkan berdasarkan diagnosis dokter/gejala sebesar 1,5% atau
diperkirakan sekitar 2.650.340 orang.
Zahrawardani et al. (2013) telah melakukan penelitian pada RSUP Dr. Kariadi
Semarang dengan mendeskripsikan dan menganalisis faktor risiko usia, jenis kelamin,
kolesterol total, kadar trigliserida, hipertensi, dan diabetes melitus dengan kejadian
penyakit jantung koroner, serta untuk mengetahui faktor risiko yang paling berhubungan
dengan kejadian penyakit jantung koroner. Hasil penelitian tersebut mendapati bahwa Usia,
kolesterol total, kadar trigliserida, hipertensi, dan diabetes melitus merupakan fakto resiko
terjadinya penyakit jantung koroner. Faktor yang paling berpengaruh terhadap kejadian
penyakit jantung koroner adalah kolesterol total.
Penelitian yang berkaitan dengan diagnosis penyakit jantung juga telah dilakukan
oleh Kesuma. Z. M et al. (2015) dengan mendiagnosis tingkat keparahan pasien penyakit
jantung menggunakan metode inferensi Mamdani pada pasien RSUD Dr. Zainoel Abidin,
Banda Aceh. Faktor resiko yang terdiri dari kolesterol LDL, usia, tekanan darah, gula darah

Biastatistics Vol 11, No.1, Februari 2017 13
puasa dan riwayat merokok digunakan untuk menguji tingkat keparahan. Hasil penelitian
menunjukkan bahwa pasien penderita penyakit jantung memilki resiko tingkat keparahan
tinggi terhadap terjadinya infark miokard.
Berdasarkan latar belakang diatas, ingin dilihat keterkaitan antara tingkat
keparahan penyakit jantung dengan kolesterol, tekanan darah, gula darah puasa, riwayat
merokok dan umur menggunakan analisis korespondensi. Data yang digunakan adalah data
penderita penyakit jantung dari penelitian Kesuma. Z. M et al. (2015).
Dengan mengetahui keterkaitan antara tingkat keparahan penyakit jantung dengan
kolesterol, tekanan darah, gula darah puasa, riwayat merokok dan umur, diharapkan dapat
memberikan informasi kepada masyarakat untuk mengantisipasi terhadap terjadinya
serangan jantung.
2. KAJIAN LITERATUR
Analisis korespondensi merupakan alat untuk menganalisa hubungan antara baris
dan kolom dari tabel kontingensi (Hӓrdle & Simar, 2003).
2.1 Tabulasi Silang
Tabulasi silang adalah tabel frekuensi dua arah dimana hubungan frekuensi dari
dua variable kualitatif telah diperoleh. Uji yang digunakan untuk mengetahui ada tidaknya
hubungan antara dua Variabel kategori pada tabel kontingensi adalah Uji Khi-Kuadrat. Uji
Khi-Kuadrat dapat digunakan jika nilai harapan kurang dari 5 (mij < 5) tidak lebih dari
20% (maksimal 20%). Jika data yang digunakan kecil, maka alternatif metode yang
digunakan adalah Uji Eksak Fisher (Agresti, 2002).
2.2 Matriks Korespondensi
Jika N adalah matriks data yang unsur-unsurnya merupakan bilangan positif
berukuran a x b dimana a menunjukkan baris dan b menunjukkan kolom, maka P adalah
Matriks korespondensi didefinisikan sebagai matriks yang unsur-unsurnya adalah unsur
matriks N yang telah dibagi dengan jumlah total unsur matriks N.
aNb = [nij] ; nij ≥ 0, . (i = 1…a, j=1...b ) (2.1)
..n
nij
ba (2.2)

14 Biastatistics Vol 11, No.1, Februari 2017
Profil baris dan profil kolom dari matrik P diperoleh dengan cara membagi vektor
baris dan vektor kolom dengan masing-masing massanya.
Profil baris dari matriks 𝐏 adalah 𝑟𝑖 = ∑ = ∑𝑛𝑖𝑗
𝑛. . (2.3)
𝑏
𝑗=1
𝑏
𝑗=1
Profil kolom dari matriks 𝐏 adalah 𝑐𝑗 = ∑ 𝑃𝑖𝑗 = ∑𝑛𝑖𝑗
𝑛. . (2.4)
𝑎
𝑖=1
𝑎
𝑖=1
(Johnson & Wichern, 1988).
2.3 Nilai Singular (Singular Value Decompotition)
Untuk mereduksi dimensi data berdasarkan keragaman data (nilai eigen / inersia)
terbesar dengan mempertahankan informasi yang optimum, diperlukan penguraian nilai
singular. Penguraian nilai singular (SVD) merupakan salah satu konsep Aljabar matriks
dan konsep eigen decomposition yang terdiri dari nilai eigen dan vektor eigen. Penguraian
nilai singular diekspresikan dalam I X J matriks A dengan rank K (Johnson & Wichern,
1998)
2.3.1 Penentuan Jarak Profil
Untuk menghitung jarak profil baris atau kolom dalam kategori yang sama,
digunakan jarak Khi-Kuadrat dengan Jarak Euclid terboboti:
d_i^2=(r_i-c)^' D_c^(-1) (r_i-c) (2.5)
(Johnson & Wichern, 1998)
2.4 Dekomposisi inersia
Inersia berarti varian yang terdapat pada korenpondensi analisis. Total inersia
adalah jumlah dari nilai eigen dan menggambarkan penyebaran dari titik-titik disekeliling
sentroid. Nilai inersia menunjukkan kontribusi dari baris ke–i pada inersia total. Sedangkan
yang dimaksud inersia total adalah jumlah bobot kuadrat jarak titik – titik ke pusat, massa
dan metric(jarak) yang didefinisikan:

Biastatistics Vol 11, No.1, Februari 2017 15
Inersia Total baris :
a
Ii
icii crDcrrain 1' (2.6)
Inersia Total kolom :
b
j
jrjj rcDrccbin1
1' (2.7)
Total inersia =𝑥2
𝑛= 𝑡𝑟𝑎𝑐𝑒(𝐷𝑟
−1(𝑃 − 𝑟𝑐)′𝐷𝑐−1(𝑃 − 𝑟𝑐′′
′)′) = ∑ 𝜆𝐾2 (2.8)
𝑏−1
𝐾=1
(Johnson & Wichern, 1998)
3. METODE PENELITIAN
Untuk mencapai tujuan penelitian, digunakan analisis korespondensi dengan
langkah – langkah sebagai berikut :
1. Membuat tabulasi silang menggunakan perangkat lunak SPSS;
2. Melakukan uji kebebasan dengan melihat nilai uji yang diperoleh, yaitu dengan
menggunakan uji Khi–Kuadrat dan Uji Eksak Fisher;
3. Dari tabel kontigensi data asal disusun kedalam bentuk matriks dan dilakukan
penguraian nilai singular untuk mengetahui nilai variabilitas data asli yang dijelaskan
oleh setiap dimensi yang dihasilkan;
4. Melakukan analisis korespondensi dengan bantuan perangkat lunak SPSS;
5. Mengamati nilai koordinat dan visualisasi plot profil vektor baris dan kolom dalam
setiap titik yang terdekat pada masing – masing segmen untuk mendeskripsikan tingkat
keparahan penyakit jantung.
4. HASIL DAN PEMBAHASAN
Data yang digunakan adalah data sekunder dari Rumah Sakit Umum Daerah dr.
Zainoel Abidin, Banda Aceh pada tahun 2015 dengan jumlah data penderita penyakit
jantung sebanyak 55 orang.
Berdasarkan Uji Khi-Kuadrat antara penderita jantung dengan tingkat kolesterol,
tekanan darah, gula darah, riwayat merokok dan umur, dihasilkan nilai harapan lebih dari
20%, maka Uji Khi-Kuadrat tidak dapat digunakan. Untuk melihat keterkaitan antara
penderita jantung dengan tingkat kolesterol, tekanan darah, gula darah, riwayat merokok
dan umur digunakan Uji Eksak Fisher.

16 Biastatistics Vol 11, No.1, Februari 2017
Tabel 4.1 Uji Eksak Fisher untuk jantung dengan kolesterol, tekanan darah, gula
darah puasa, riwayat merokok dan umur.
Fisher's Exact Test Value Exact Sig. (2-sided)
Kolesterol 26.939 .001
Tekanan darah 18.500 .005
Gula darah puasa 18.234 .000
Riwayat merokok 13.104 .003
Umur 3.656 .745
Pada Tabel 4.6, dapat dilihat bahwa kolesterol, tekanan darah, gula darah puasa
dan riwayat merokok memiliki keterkaitan dengan tingkat keparahan penyakit jantung
karena memiliki nilai signifikan lebih kecil dari 0.05 atau P-value < α. Sedangkan variabel
umur tidak memiliki keterkaitan dengan tingkat keparahan penyakit jantung karena
memiliki nilai signifikan lebih besar dari 0.05 atau P-value > α.
Tabel 4.2 Analisis korespondensi
Dimension Cronbach's
Alpha
Variance Accounted For
Total
(Eigenvalue) Inertia % of Variance
1 .649 2.081 .416 41.615
2 .573 1.847 .369 36.930
Total 3.927 .785
Mean .613a 1.964 .393 39.273
a. Mean Cronbach's Alpha is based on the mean Eigenvalue.
Tabel 4.2 menunjukkan bahwa pada Eigenvalue, nilai eigen pertama sebesar
sumbu satu menerangkan variabilitas data sebesar 41.615%, sumbu dua menerangkan
variabilitas data sebesar 36.930%. Jumlah nilai inersia untuk dua dimensi sebesar 0.785.
Proporsi nilai inersia dimensi 1 adalah (0.416/0.785) × 100% = 52.99%
menunjukkan bahwa dimensi 1 memberikan kontribusi sebesar 52.99%, sedangkan

Biastatistics Vol 11, No.1, Februari 2017 17
proporsi nilai inersia dimensi 2 adalah (0.369/0.785) × 100% = 47% menunjukkan bahwa
dimensi 2 memberikan kontribusi sebesar 47% kepada keseluruhan nilai inersia.
Gambar 4.1. Plot analisis korespondensi tingkat keparahan penyakit jantung dengan
tingkat kolesterol, tekanan darah, gula darah puasa dan riwayat merokok.
Untuk melihat dominasi profil kolom (tingkat keparahan penyakit jantung)
terhadap profil baris (kolesterol, tekanan darah, gula darah puasa dan riwayat merokok),
dapat dilihat pada plot korespondensi dengan mengamati titik terdekat.
Dari Gambar 4.1 dapat dilihat bahwa :
1. Tingkat keparahan jantung sangat tinggi (63.6%-79.4% ) dapat terjadi pada penderita
kolesterol tinggi (160-189 mg/dL), tekanan darah pre-hipertensi (120-139 mmHg), gula
darah puasa diabetes (>= 126 mg/dL) dan memiliki riwayat merokok.
2. Tingkat keparahan jantung tinggi (47.6%-63.5%) dapat terjadi pada penderita
kolesterol ambang batas optimal (130-159 mg/dL), tekanan darah hipertensi 1 (140-159
mmHg), gula darah puasa diabetes (>= 126 mg/dL) dan memiliki riwayat merokok.
3. Tingkat keparahan jantung sedang (31,6%-47.5%) dapat terjadi pada penderita

18 Biastatistics Vol 11, No.1, Februari 2017
kolesterol optimal (<100 mg/dL), tekanan darah pre-hipertensi (120-139 mmHg), gula
darah puasa normal (<= 126 mg/dL) dan memiliki riwayat merokok.
4. Tingkat keparahan jantung ringan (15,5%-31,5%) dapat terjadi pada penderita
kolesterol di atas optimal (100-129 mg/dL), tekanan darah normal (<120 mmHg), gula
darah puasa normal (<= 126 mg/dL) dan tidak memiliki riwayat merokok
5. SIMPULAN
Berdasarkan Uji Eksak Fisher, dapat dikatakan bahwa tidak ada hubungan antara
umur dan tingkat keparahan penyakit jantung pada studi kasus di RSUD dr. Zainoel
Abidin, Banda Aceh.
Tingkat keparahan penyakit njantung dapat berkaitan dengan kadar kolesterol,
tekanan darah, gula darah puasa dan riwayat merokok memiliki keterkaitan pada studi
kasus di RSUD dr. Zainoel Abidin, Banda Aceh.
6. DAFTAR PUSTAKA
Agresti, A. 2002. Categorical Data Analysis. Willey-Interscience. United States of America.
Hardle, W., Simar, L. (2003). Applied Multivariate Statistical Analysis. Springer- Verlag.
Johnson, A., Wichern, W.D. 1998. Applied Multivariate Statistical Analysis. Prectice-Hall
International.inc. New Jersey.
Kesuma, Z.M., Hizir., Izazi. 2015. Application of Fuzzy Logic to Diagnose Severity of Coronary
Heart Disease: Case Study in dr. Zainoel Abidin General Hospital, Banda Aceh Indonesia.
Advances on Science and Technology. ISBN:978-602-99849-2-7.
Zahrawardani Diana., Herlambang Kuntio Sri., Anggraheny Hema Dewi. 2013. Analisis Faktor
Risiko Kejadian Penyakit Jantung Koroner di RSUP Dr Kariadi Semarang. Jurnal
Kedokteran Muhammadiyah.Vol. 1 No. 2.
Wiyatmo, Y., dkk. Efektivitas Bimbingan Tugas Akhir Skripsi (TAS) Mahasiswa Jurusan
Pendidikan Fisika FMIPA UNY. Prosiding Seminar Nasional Penelitian, pendidikan dan
penerapan MIPA, FMIPA UNY. (2010).

19
BIAStatistics (2016) Vol. 10, No. 1, hal. 19-32
MODEL PEMETAAN PENYAKIT
DENGAN RESPON GANDA MENGGUNAKAN
SEEMINGLY UNRELATED POISSON REGRESSION
(Pendekatan Bayesian INLA)
I Gede Nyoman Mindra Jaya1, Zulhanif2 dan Bertho Tantular3
1Mahasiswa Departemen Statistika FMIPA Universitas Padjadjaran
Email: [email protected]
ABSTRAK
Penyakit menular seperti demam berdarah (DB), cikunginya, TB paru, diare dan penyakit menular
lainnya menjadi ancaman serius bagi kesehatan masyarakat. Tidak jarang tingginya angka kasus dari
setiap penyakit tersebut disebabkan oleh faktor yang sama seperti faktor iklim, kebersihan
lingkungan, gaya hidup sehat dan juga vektor yang sama. Kondisi ini dapat dimanfaatkan oleh dinas
kesehatan sebagai lembaga yang memiliki kewenangan penuh dalam mengontrol penyebaran
penyakit menular tersebut. Upaya penanggulangan penyakit menular selama ini dilakukan secara
partial untuk masing masing jenis penyakit, sehingga cara ini kurang efektif. Pengontrolan penyakit
yang memiliki faktor resiko yang sama seharusnya dapat dilakukan secara simultan melalui
pemodelan multiple disease. Penelitian ini mengusulkan metode Seemingly Unrelated Regression
(SUR) untuk memodelkan angka kasus TB Paru dan Diare di Kota Bandung. Hasil analisis
menemukan bahwa Perilaku Hidup Bersih dan Sehat (PHBS) paling berpengaruh terhadap
tingginya resiko relatif kedua jenis penyakit tersebut.
Kata Kunci: Pemetaan Penyakit, Respon Ganda, Seemingly Unrelated Regression
1. PENDAHULUAN
Penyakit menular seperti demam berdarah, cikunginya, TB paru, diare dan
penyakit menular lainnya menjadi ancaman serius bagi kesehatan masyarakat (Hardhana,
2013). Tidak jarang tingginya angka kasus dari setiap penyakit tersebut disebabkan oleh
faktor yang sama seperti faktor iklim, kebersihan lingkungan, gaya hidup sehat dan juga
vektor yang sama. Upaya mendapatkan angka prediksi jumlah kasus dan resiko relatif yang
akurat untuk setiap area alasan utama. Model dasar yang digunakan dalam pemetaan
penyakit adalah model regresi Poisson (Shaddick et al, 2016). Namun karena rentannya
model ini terhadap kasus overdisversi yang diakibatkan karena adanya pengaruh spatial
sehingga model standar regresi Poisson kurang mampu memberikan hasil dengan akurasi
dan presisi yang baik (Clayton and Kaldor, 1987, Maiti, 1998).

20 Biastatistics Vol 11, No.1, Februari 2017
Metode yang umumnya digunakan dalam studi epidemiology dalam menaksir
resiko relatif adalah Standardized Morbidity Ratio (SMR) (Lawson et al, 2003, dan Pringel,
1996). Ukuran ini tidak memberikan hasil yang handal jika diterapkan pada lokasi dengan
jumlah kasus sedikit dan populasi terpapar sedikit. Selain itu ketidakhandalan dari ukuran
SMR sebagai penaksir resiko relatif dikarenakan SMR tidak mampu mengakomodasi
adanya ketergantungan spatial yang umumnya terjadi pada penyakit menular. Salah satu
upaya yang dilakukan untuk mensolusikan ketidakreliablean dari SMR adalah
menggunakan pendekatan pemodelan statistik yang mengakomodasi model pemulusan dan
juga memasukkan informasi ketergantungan spasial dalam model. Pemodelan ini dikenal
dengan Bayesian Conditional Autoregressive Model (CAR) (Besag, 1974 dan Tango,
2010).
Bayesian Conditional Autoregressive Model (BCAR) adalah pemodelan dalam
pemetaan penyakit yang digunakan untuk memuluskan nilai Resiko Relatif (Clayton and
Kaldor, 1987). Model ini merupakan model pemulusan spatial dari resiko relatif dan model
yang mengakomodasi ketergantungan spasial sehingga mampu meperkecil keliruan
taksiran parmeter resiko relatif yang berarti model ini mampu menghasilkan taksiran resiko
relatif yang lebih stabil.
Namun model yang dikembangkan selama ini adalah model univariate, dalam
penelitian ini dikembangan model yang melibatkan lebih dari satu jenis penyakit melalui
pemodelan Seemingly Unrelated Regression (SUR). Penggunaan metoe SUR untuk
memperoleh taksiran yang efisien dikarenakan pemodelan variabel response dengan
prediktor yang sama atau beririsan menyebabkan kekeliruan antara satu model dengan
model yang lain saling berhubungan. Hal ini jika tidak disolusikan maka penaksiran
parameter menjadi tidak efisien (Winkelmann, 2008).
Pemodelan ini dapat dimanfaatkan oleh dinas kesehatan sebagai lembaga yang
memiliki kewenangan penuh dalam mengontrol penyebaran penyakit menular tersebut.
Upaya penanggulangan penyakit menular selama ini dilakukan secara partial untuk masing
masing jenis penyakit, sehingga cara ini kurang efektif. Permasalahan dalam penelitian ini
yaitu bagaimana memodelkan regresi SUR untuk data counting dengan melibatkan ukuran
spatial dependensi.

Biastatistics Vol 11, No.1, Februari 2017 21
2. METODOLOGI
2.1 Metode Pengumpulan Data
Data yang digunakan dalam penelitian ini adalah data kesehatan Tahun 2014
yang diperoleh dari Dinas Kesehatan Kota Bandung. Variabel yang diteliti disajikan dalam
table berikut:
Tabel 1: Variabel Penelitian
Variabel Simbol Satuan
Angka Kasus TB Paru Y1 Orang
Angka Kasus Diare Y2 Orang
Prilaku Hidup Bersih dan
Sehat
X1 %
Rumah Sehat X2 %
Gizi Buruk X3 %
Air Bersih X4 %
2.2 Metode Analisis Data
Model Poisson SUR
Poisson SUR regression dalam penelitian ini diaplikasikan pada kasus Bivariate
yaitu pada kasus TB Paru dan Diare di Kota Bandung. Model Poisson SUR dapat
didefinisikan sebagai berikut (King, 1989):
𝑦𝑖1~𝑃𝑜𝑖𝑠𝑠𝑜𝑛(𝐸𝑖1𝜃𝑖1)
𝑦𝑖2~𝑃𝑜𝑖𝑠𝑠𝑜𝑛(𝐸𝑖2𝜃𝑖2)
Dalam notasi matriks dapat dibuat:
𝒚𝑗~𝑃𝑜𝑖𝑠𝑠𝑜𝑛(𝑬𝑗𝜽𝑗) ; 𝑗 = 1,2 (1)
Untuk Poisson SUR harus didefinidikan satu variabel random yang mewakili kekeliruan
kedua model tersebut:
𝑣𝑖~𝑁𝑜𝑟𝑚𝑎𝑙(0, 𝜎2)∀𝑗 = 1,2 (2)

22 Biastatistics Vol 11, No.1, Februari 2017
Model regresi poisson dapat dinyatakan sebagai berikut:
𝜃𝑖𝑗 = exp (𝛽0𝑗 + ∑ 𝛽𝑘𝑗𝑥𝑖𝑘𝑗
𝐾
𝑘=1
)
ln 𝜃𝑖𝑗 = 𝜂𝑖𝑗 = 𝛽0𝑗 + ∑ 𝛽𝑘𝑗𝑥𝑖𝑘𝑗
𝐾
𝑘=1
(3)
dengan
𝛽0𝑗 = 𝛽0 + 𝑣0𝑗
𝛽𝑘𝑗 = 𝛽𝑘 + 𝑣1𝑗
Ide dasar dari pemodelan SUR ini adalah menambahkan komponen acak pada
setiap parameter model dengan asumsi komponen acak ini antara group 1 dan group 2
berkorelasi. Korelasi ini dijamin karena untuk kedua group ini komponen acak v memiliki
distribusi yang identik. Pendekatan ini identik dengan pendekatan varying coefficien model
(VCM) ( Mindra, et al. 2016)
Untuk memasukkan komponen acak ini ke dalam model dapat dilakukan melalui
pendekatan Bayesian, degan v dipandang sebagai variabel acak yang memiliki distribusi
dengan parameter prior
Untuk pemodelan Bayesian Poisson SUR digunakan Integrated Nested Laplace
Approximation (INLA)
Pendekatan INLA
Tahap pertama dalam pemodelan INLA untu model univariate adalah
mengidentifikasi distribusi data observasi y= (y1, y2…, yn). Pendekatan yang paling umum
dalam mendefinisikan distribusi dari yi menurut parameter (umumnya rata-rata E(yi))
dengan mendefinisikannya sebagai sebuah fungsi struktur aditive prediktor i mealui link
function g(.) misalkan g()=i. Fungsi adaptif linear dapat dituliskan sebagai berikut
(Camelett and Blangiardo, 2015):
𝜂𝑖 = 𝛽0 + ∑ 𝛽𝑘x𝑘𝑖
𝐾
𝑘=1
+ ∑ 𝑓(z𝑙𝑖)
𝐿
𝑙=1
(4)
Dengan 𝛽0menyatakan intersep; 𝛽 = {𝛽1, … , 𝛽𝐾} menyatakan efek linear dari
covariates 𝐱 = (𝐱1, . . . , 𝐱K) terhadap resepon y; dan f={f1(.),…,fL(.)} merupakan
sekumpulan fungsi dari covariate 𝐳 = (𝐳1, . . . , 𝐳L). Fungsi f(.) dapat digunakan untuk
mengakomodasiberbagai tujuan seperti pemulusan, efek nonlinear, trime trend, efek

Biastatistics Vol 11, No.1, Februari 2017 23
musiman, random dan slope acak. Fungsi terakhir ini yang dimanfaatkan dalam pemodelan
SUR.
Hierarichal Model
Model INLA pada persamaan (4) dapat ditulis dalam struktur Hiraki. Level
pertama mengasumsikan bahwa y dapat difaktorisasi sebagai y1, …, yn diasumsikan
exchangeable (distribusi dari faktorisasi y1,…, yn tidak berubah, dengan kata lain distribusi
tidak bergantung pada susunan pengamatan), sehingga distribusi dari y adalah independent
dan identifika dengan parameter dan Hyperparameter (Camelett and Blangiardo,
2015):
𝒚|𝜽, 𝝍𝟏~𝑝(𝒚|𝜽, 𝝍𝟏) = ∏ 𝑝(𝑦𝑖 |𝜃𝑖 , 𝝍𝟏)
𝑛
𝑖=1
(5)
Level kedua, laten field θ dikarakterisasi dari multivariate normal dengan
Hyperprior ψ_1
𝜽|𝝍𝟐~𝑀𝑉𝑁𝑜𝑟𝑚𝑎𝑙(𝟎, 𝑸−1(𝝍𝟐)) (6)
Dengan hyperparameter 𝝍 = {𝝍𝟏, 𝝍𝟐} memiliki distribusi peluang 𝝍~𝑝(𝝍)
Dengan distribusi margijnal diperole dari integaral posteriornya yaitu sebagai
berikut:
𝑝(𝜽|𝝍) = ∫ ∏ 𝑝(𝜃𝑗|𝝍)𝑝(𝝍)𝑑𝝍
𝑱
𝑗=1
(7)
Struktur model hierki dapat digambarkan sebagai berikut:
Gambar 1. Direct Acyclic Graphs (DAG) Untuk Model Hiearchi

24 Biastatistics Vol 11, No.1, Februari 2017
Gambar 2. Direct Acyclic Graphs (DAG) Untuk Model Penelitian SUR
Model Conditional Autoregressive (CAR)
Pengembangan pada model ini, selain pemodelan dilakukan pada respon ganda
melalui model SUR, juga memasukkan informasi spatial melalui model CAR. Model CAR
merupakan model yang dikembangkan oleh Besag (1974) untuk mengakomodasi adanya
ketergantungan spatial dalam kekeliruan. Dalam pemetaan penyakit CAR didefinisikan
sebagai distribusi prior utuk komponen acak parameter resiko relative (𝑢).
Model CAR prior secara umum dimodelkan sebagai berikut (Besag, and Newell,
1991) :
𝑢𝑖|𝑢−𝑖 ~ 𝑁𝑜𝑟𝑚𝑎𝑙 (∑ 𝑤𝑖ℎ𝑢ℎℎ~𝑖
∑ 𝑤𝑖ℎℎ~𝑖,
𝜎𝑢2
∑ 𝑤𝑖ℎℎ~𝑖) (8)
Dengan v_imerupakan pengaruh acak spesifik dari model CAR normal umum
yang diusulkan pertama kali oleh Besag (1974). Menurut Besag, antar wilayah memiliki
keterkaitan yang sangat kuat, hal ini direpresentasikan dengan nilai autokorelasi spasial
antar wilayah (ρ=1).
dengan
𝐸(𝑣𝑖|𝑣−𝑖) = 𝜇𝑖 + 𝜌 ∑ 𝑤𝑖ℎ(𝑢ℎ − 𝜇ℎ) (9)
𝑖~ℎ
𝑉𝑎𝑟(𝑢𝑖|𝑢−𝑖) = 𝜎2 (10)
Dengan 𝜇𝑖 = large scale variation dari observasi ke 𝑖, 𝜌 mengacu pada
autokorelasi spasial atau dependensi spasial dan W adalah matriks pembobot spasial.
Matriks ini bersifat simetris 𝑛 𝑥 𝑛 dan mempunyai diagonal utama yang bernilai nol.
Elemen matriks ini adalah 𝑤𝑖ℎ dengan nilai sebagai berikut :
𝑤𝑖ℎ = { 1, 𝑢𝑛𝑡𝑢𝑘 𝑑𝑎𝑒𝑟𝑎ℎ 𝑖 𝑑𝑎𝑛 𝑗 𝑦𝑎𝑛𝑔 𝑏𝑒𝑟𝑠𝑖𝑛𝑔𝑔𝑢𝑛𝑔𝑎𝑛 0, 𝑢𝑛𝑡𝑢𝑘 𝑑𝑎𝑒𝑟𝑎ℎ 𝑖 𝑑𝑎𝑛 𝑗 𝑦𝑎𝑛𝑔 𝑡𝑖𝑑𝑎𝑘 𝑏𝑒𝑟𝑠𝑖𝑛𝑔𝑔𝑢𝑛𝑔𝑎𝑛
1, 2,
3, 4
0 v0j
𝜎𝑣02
ij
v1kj
𝜎𝑣𝑘2
Xkj Group-
j
yij

Biastatistics Vol 11, No.1, Februari 2017 25
Model Penelitian
Model penelitian yang akan diestimasi dalam penelitian ini adalah:
𝜼𝑗 = 𝛽0𝑗 + ∑ 𝛽𝑘𝑗x𝑘𝑖
𝐾
𝑘=1
+ ∑ 𝑓(z𝑙𝑖) (11)
𝐿
𝑙=1
dengan
𝑓(𝐳𝑖) = v0i + v1i + ui
dan
𝑣0𝑖~𝑁𝑜𝑟𝑚𝑎𝑙(0, 𝜎2)
𝑣1𝑖~𝑁𝑜𝑟𝑚𝑎𝑙(0, 𝜎2)
𝑢𝑖|𝑢−𝑖 ~ 𝑁𝑜𝑟𝑚𝑎𝑙 (∑ 𝑤𝑖ℎ𝑢ℎℎ~𝑖
∑ 𝑤𝑖ℎℎ~𝑖,
𝜎𝑢2
∑ 𝑤𝑖ℎℎ~𝑖)
Distribusi posteriornya adala:
𝑝(𝜷, 𝜎2, 𝜎𝑢2|𝒚) = 𝑝(𝒚|𝜷, 𝜎2, 𝜎𝑢
2)𝑝(𝜷|𝜎2, 𝜎𝑢2)𝑝(𝜎2)𝑝(𝜎𝑢
2) (12)
Metode Metropolis-Hasting dan Gibbs sampling dapat digunakan untuk
melakukan infernsi dari disribusi posterior pada persamaan (12) untuk mendapatkan
statistik dari penaksirnya. Pendekatan lain dapat digunakan untuk menaksir parameter
model Poisson SUR yaitu menggunakan metode integrated nested laplace approximation
(INLA). Pemodelan dilakukan dalam dua tahap yaitu mendefinisikan model observasi
𝝅(𝒚|𝜸), dengan y menyatakan angka prevalensi dan 𝜸 menatakan hyperprameter. Tahap
kedua yaitu mendefinisikan matriks presisi Q dan tahap ketiga proses control
hyperperameter model. Matriks presisi Q didefinisikan (Mindra et al, 2016):
𝐐 = (κv𝐈 −κv𝐈
−κv𝐈 κu𝐑 + κv𝐈). (13)
Fungsi tujuan dari INLA adalah menemukan marginal posterior distribusi untuk
semua parameter dengan fungsi posteriornya didefinisikan sebagai berikut:
π(γi|𝐲) = ∫ π(γi|𝛉, 𝐲)θ
π(𝛉|𝐲)d𝛉, (14)
dengan 𝛉 = (σi2, 𝛃, ρ). Fungsi densitas marginal π(𝛉|𝐲) dari hyperparameters 𝛉
dapat diperoleh dari pendekatan Laplace dengan fungsi sebagai berikut:
π̃(𝛉|𝐲) ∝π(𝛾i, 𝛉, 𝐲)
π̃G(𝛾i|𝛉, 𝐲)|𝛾=𝛾∗(𝛉). (15)

26 Biastatistics Vol 11, No.1, Februari 2017
Untuk proses komputasi digunakan R-Software dengan package INLA
3. HASIL DAN PEMBAHASAN
Angka kasus Diare dan TB paru di Kota Bandung tergolong tinggi dengan rata-
rata angka kasus TB Paru mencapai 53 kasus per kecamatan dan Diare mencapai 1839
kasus.
Tabel 2: Statistik Variabel Penelitian
Variabel Statistik Min Max
Angka Kasus
TB Paru 52.8 8.0 105.0
Angka Kasus
Diare 1838.5 658.0 3857.0
Prilaku Hidup
Bersih dan
Sehat
61.3 50.3 69.1
Rumah Sehat 66.4 33.4 95.6
Gizi Buruk 1.7 0.1 9.7
Air Bersih 96.4 79.3 102.6
Sumber: hasil pengolahan

Biastatistics Vol 11, No.1, Februari 2017 27
Sebaran angka kasus TB Paru dan Diare dapat dilihat pada peta di bawah ini.
Gambar 3a. TB Paru
Gambar 3b. Diare
Terlihat ada beberapa kesamaan pola untuk Angka TB Paru dan Diare. Semisal
untuk kecamatan Bapakan Ciparae memiliki angka TB Paru dan Diare yang tinggi. Namun
tingginya angka kasus di suatu lokasi tidak dapat secara langsung dijadikan rujukan bahwa
di lokasi tersebut memiliki resiko relativ yang tinggi karena angka kasus berkorelasi dengan
angka populasi. Sangat wajar bahwa populasi besar, maka angka kasus yang ditemukan
juga besar. Untuk mengetahui angka resiko relative untuk ukuran populasi yang beragam,
harus ditaksir melalui pemodelan regresi Poisson dengan memanfaatkan informasi
ketergantungan spasial dan berbagai factor yang berpengaruh pada tingginya resiko relatif.
Angkat TBPARU
(7.9,32.2]
(32.2,56.5]
(56.5,80.8]
(80.8,105]
Gedebage
Ujungberung
CinamboBandung Kulon
Andir
Babakan Ciparay
Bojongloa Kaler
Sukajadi
Cidadap
Coblong
CicendoBandung Wetan
Sumurbandung
Batununggal
Cibeunying Kidul
Regol
Bandung Kidul
Astanaanyar
Kiaracondong
Buahbatu
Mandalajati
Cibiru
Bojongloa Kidul
Cibeunying Kaler
Panyileukan
Antapani
Lengkong
Sukasari
Rancasari
Arcamanik
Angka DIARE
(655,1.46e+03]
(1.46e+03,2.26e+03]
(2.26e+03,3.06e+03]
(3.06e+03,3.86e+03]
Gedebage
Ujungberung
CinamboBandung Kulon
Andir
Babakan Ciparay
Bojongloa Kaler
Sukajadi
Cidadap
Coblong
CicendoBandung Wetan
Sumurbandung
Batununggal
Cibeunying Kidul
Regol
Bandung Kidul
Astanaanyar
Kiaracondong
Buahbatu
Mandalajati
Cibiru
Bojongloa Kidul
Cibeunying Kaler
Panyileukan
Antapani
Lengkong
Sukasari
Rancasari
Arcamanik

28 Biastatistics Vol 11, No.1, Februari 2017
Tabel 3. Ketergantungan spasial
Variabel Statistik Moran’s I p.value
Angka Kasus TB
Paru 0.43249295 3.02e-05
Angka Kasus Diare -0.00659342 0.4037
Sumber: hasil pengolahan
Hasil perhitungan indeks ketergantungan spatial Moran’s I menunjukkan bahwa
untuk kasus TB Paru ada ketergantungan spatial yang signifikan pada tingkat signifikansi
5%. Namun berbeda untuk kasus diare dimana tidak terbukti adanya ketergantungan
spatial.
Melihat kondisi ini, maka model Seemingly Unrelated Regression (SUR)
dikembangkan dengan memperhatikan ketergantungan spatial pada TB Paru.
Syntax INLA
formula<-Y~1+X1+X2+X3+X4+f(IDG, model="iid")+
f(IDS, model="bym",graph=W, constr=TRUE)+
f(IDG1,X1, model="iid")+
f(IDG2,X2, model="iid")+
f(IDG3,X3, model="iid")+
f(IDG4,X4, model="iid")
OUTPUT <- inla(formula,family="poisson",data=DATAG, E=E1,
control.predictor=list(compute=TRUE),
control.compute=list(dic=TRUE,cpo=TRUE))
Hasil estimasi parameter model SUR dengan menggunakan INLA disajikan
dalam Tabel 4 berikut:
Tabel 4. Eestimasi Parameter Model SUR
Variabel TB PARU DIARE
Koefisien SD Koefisien SD
Intersep -0.5562 1.5876 -0.5557 1.5876
PHBS -0.0194 0.0293 -0.0141 0.0293
Rumah Sehat -0.0047 0.0108 0.0097 0.0108
Gizi Buruk -0.0172 0.0608 -0.0015 0.0608
Air Bersih 0.0215 0.0221 0.0080 0.0221

Biastatistics Vol 11, No.1, Februari 2017 29
Model ini dapat dinyatakan dalam persamaan matematis sebagai berikut:
Model Regresi TB Paru
�̂�𝑖 = −0.5562 − 0.0194X1 − 0.0047X2−0.0172X3 + 0.0215X4 (16)
Model Regresi Diare
�̂�𝑖 = −0.5557 − 0.0141X1 + 0.0097X2−0.0015X3 + 0.0080X4 (17)
Kedua model ini memiliki kesamaan informasi mengenai dampak dari prilaku
Hidup Sehat (PHBS) terhadap angka kasus TB Paru dan Diare. PHBS memberikan
pengaruh negatif yang artinya semakin tinggi persentase masyarakat yang sadar akan
perilaku hidup bersih dan sehat akan mampu menurunkan resiko relative untuk TB Paru
dan Diare. Peningkatan 1% kesadaran masyarakat akan PHBS akan menurunkan resiko
relatif TB Paru sebesar 0.019 atau 1.9% dan Diare sebesar 0.0141 atau 1.41%. Sedangkan
untuk variabel yang lain memiliki perbedaan pengaruh. Namun secara umum pengaruh
terhadap TB Paru lebih dominan.
Studi pemetaan penyakit memiliki tujuan akhir memetakan resiko relatif dalam
sebuah peta. Di bawah ini disajika tiga peta resiko relatif. Peta pertama untuk pola resiko
relatif untuk TB Paru, peta kedua untuk Diare, dan peta ketiga peta resiko relatif gabungan.
Gambar 4a. Resiko Relative TB PARU
Resiko relatif TB Paru paling tinggi terlihat dari Kecamatan Cinambo dan
Bandung wetan. Sedangkan kecamatan seperti Cibiru Ujung Berung dan yang warnanya
relatif muda menunjukkan angka resiko relatif yang renda. Terlihat adanya
pengelompokkan dari angka resiko relatif TB Paru. Kecamatan yang resiko relatif TB Paru
tinggi cenderung mengelompokk.
RERSIKO RELATIF
(0.276,1.46]
(1.46,2.64]
(2.64,3.82]
(3.82,5]
Gedebage
Ujungberung
CinamboBandung Kulon
Andir
Babakan Ciparay
Bojongloa Kaler
Sukajadi
Cidadap
Coblong
CicendoBandung Wetan
Sumurbandung
Batununggal
Cibeunying Kidul
Regol
Bandung Kidul
Astanaanyar
Kiaracondong
Buahbatu
Mandalajati
Cibiru
Bojongloa Kidul
Cibeunying Kaler
Panyileukan
Antapani
Lengkong
Sukasari
Rancasari
Arcamanik

30 Biastatistics Vol 11, No.1, Februari 2017
Gambar 4b. Resiko Relative DIARE
Resiko relatif Diare paling tinggi terlihat dari Kecamatan Cinambo, Bandung
Wetan, dan Gede Bag. Sedangkan kecamatan seperti Cibiru Ujung Berung dan yang
warnanya relatif muda menunjukkan angka resiko relatif yang renda. Terlihat adanya
pengelompokkan dari angka resiko relatif Diare. Kecamatan yang resiko relatif Diare tinggi
cenderung mengelompokk walaupun dari hasil pengujian angka kasus tidak ada
ketergantungan spasial. Hal ini menunjukkan pentingnya mengukur resiko relatif bukan
angka kasus sebagai rujukan untuk mengidentifikasi pola sebarang penyakit menular.
Gambar 1c. Resiko Relative Gabungan
Peta terakhir ini menjelaskan resiko relative gabungan dari kedua jenis penyakit
TB Paru dan Diare. Terlihat angka resiko relatif ini merupakan angka rata-rata dari kedua
jenis penyakit tersebut. Sehingga pola yang terbentuk jelas menunjukkan adanya kombiasi
dari Pola pada TB Paru dan Diare. Kecamatan dengan Resiko relatif paling tinggi untuk
kedua jenis penyakit tersebut adalah Kecamatan Cinambo dengan angka resiko relatif lebih
besar dari 3.14.
RERSIKO RELATIF
(0.239,1.09]
(1.09,1.95]
(1.95,2.8]
(2.8,3.65]
Gedebage
Ujungberung
CinamboBandung Kulon
Andir
Babakan Ciparay
Bojongloa Kaler
Sukajadi
Cidadap
Coblong
CicendoBandung Wetan
Sumurbandung
Batununggal
Cibeunying Kidul
Regol
Bandung Kidul
Astanaanyar
Kiaracondong
Buahbatu
Mandalajati
Cibiru
Bojongloa Kidul
Cibeunying Kaler
Panyileukan
Antapani
Lengkong
Sukasari
Rancasari
Arcamanik
RERSIKO RELATIF
(0.246,1.21]
(1.21,2.18]
(2.18,3.14]
(3.14,4.11]
Gedebage
Ujungberung
CinamboBandung Kulon
Andir
Babakan Ciparay
Bojongloa Kaler
Sukajadi
Cidadap
Coblong
CicendoBandung Wetan
Sumurbandung
Batununggal
Cibeunying Kidul
Regol
Bandung Kidul
Astanaanyar
Kiaracondong
Buahbatu
Mandalajati
Cibiru
Bojongloa Kidul
Cibeunying Kaler
Panyileukan
Antapani
Lengkong
Sukasari
Rancasari
Arcamanik

Biastatistics Vol 11, No.1, Februari 2017 31
4. KESIMPULAN DAN SARAN
Penggunaan metode Bayesian Seemingly Unrelated Regression (BSUR)
merupakan pendekatan baru dalam pemetaan penyakit menular. Metode ini terbukti
memberikan informasi yang lengkap mengenai resiko relatif penyakit-penyakit yang
diteliti. BSUR memberikan peta partial dan gabungan.
Merujuk pada angka resiko relatif, ditemukan bahwa Kecamatan Cinambo adalah
kecamatan dengan resiko relatif TB Paru dan Diare yang tinggi.
Ucapan Terima Kasih
Ucapan terima kasih pada DRPM Universitas Padjadjaran yang telah membantu
secara inansial.
5. DAFTAR PUSTAKA
Besag, J. and Newell J. (1991) The Detection of Clusters in Rare Diseases, Journal of the Royal
Statistical Society. Series A (Statistics in Society), Vol. 154, No. 1, , pp. 143-155
Besag, J. (1974) Spatial Interaction and the statistical analysis of lattice systems. Journal of the Royal
statistical Socety, series B, 36, pp. 192-236
Camelett, M. and Blangiardo, (2015). M. Spatial and Spatio-Temporal Bayesian Models with R-
INLA. John Wiley & Sons,
Clayton, D., & Kaldor, J. (1987) Empirical Bayes Estimates of Age-Standardized Relative Risks for
Use in Disease Mapping. Biometrics , pp. 671-681.
Hardhana, B., et al. (2013). Profil Kesehatan Indonesia 2012. Jakarta: Kementrian Kesehatan
Republik Indonesia.
Lawson, A. B., Browne, W. J., & Rodeiro, C. L (2003).. Disease Mapping with WinBUGS and
MLwiN. New York: John Wiley & Sons.
Maiti, T. (1998) Hierarchical Bayes estimation of mortality rates disease mapping. Journal of
Statistical Planning and inference, ,pp. 339-348.
Mindra Jaya, I. G. et al. (2016). “Bayesian Spatial Modeling and Mapping of Dengue Fever: A Case
Study of Dengue Fever in The City of Bandung, Indonesia”. International Journal of Applied
Mathematics and Statistics, 54 (3), 94-103
Pringle, D.G. (1996). Mapping Disease Risk Estimates Based on Small Numbers: An Assessment
of Empirical Bayes Techniques The Economic and Social Review, Vol. 27, No. 4, July, pp.
341-363

32 Biastatistics Vol 11, No.1, Februari 2017
Shaddick, G., & Zidek, J. V. (2016) Spatio-Temporal Methods in Environmental Epidemiology.
New York: CRC Press Taylor & Francis Group
Tango, T. (2010) Statistical Methods for Disease Clustering. Japan: Springer
Winkelmann, Rainer (2008). Econometric Analysis of Count Data. Springer-Verlag Berlin
Heidelberg

33
BIAStatistics (2016) Vol. 10, No. 1, hal. 33-51
PERBANDINGAN BEBERAPA METODE KEKAR PADA
PENDUGAAN PARAMETER REGRESI LINIER SEDERHANA
UNTUK DATA YANG MENGANDUNG PENCILAN
Riski Apriani Sari1, Hari Wijayanto2, Indahwati3 1,2,3Departemen Statistika, Institut Pertanian Bogor
Email: [email protected]
ABSTRAK
Analisis regresi adalah alat yang digunakan untuk menduga hubungan antara dua peubah atau lebih.
Keberadaan pencilan pada analisis regresi mengakibatkan dugaan parameter yang dihasilkan
menjadi tidak valid. Alternatif yang dapat dilakukan untuk mengatasi pencilan, terutama pencilan
terhadap peubah respon adalah menggunakan beberapa metode kekar yaitu penimbang ganda Tukey,
simpangan mutlak terkecil, dan metode Theil. Selanjutnya untuk mengetahui keefektifan metode-
metode tersebut dalam menangani pencilan dilakukan pada kajian simulasi. Simulasi diterapkan
pada berbagai ukuran contoh dan persentase pencilan. Kajian simulasi ini secara keseluruhan
menunjukkan bahwa metode penimbang ganda atau biweight Tukey memberikan hasil paling baik
dalam menangani pencilan, terutama pada persentase pencilan kurang dari 30% dan pada ukuran
contoh 40 dan 100. Biweight Tukey merupakan metode yang menerapkan fungsi objektif dan fungsi
penimbang dengan konstanta tuning sebesar 4.685σ. Ketiga metode tersebut juga diterapkan pada
dua data riil yang berbeda kasus, serta ada kecenderungan bahwa metode biweight Tukey
memberikan hasil yang lebih baik dibandingkan kedua metode lainnya.
Keywords: biweight tukey, LAD, pencilan, theil
1. PENDAHULUAN
A. Latar Belakang
Regresi linier merupakan salah satu alat statistika yang paling banyak digunakan
karena menyediakan metode yang sederhana untuk membuat sebuah fungsi hubungan antar
variabel [3]. Suatu amatan dianggap sebagai pencilan ketika amatan tersebut memberikan
nilai sisaan baku yang besar. Sisaan baku yang besar seringkali disebabkan oleh amatan
peubah respon atau peubah-y yang jauh lebih besar atau lebih kecil dibanding amatan lain,
dan amatan seperti ini disebut dengan pencilan-y [12]. Keberadaan pencilan-y ini
mengakibatkan dugaan parameter yang dihasilkan dengan metode MKT bersifat bias dan
menyimpang dari nilai yang seharusnya, sehingga memberikan interpretasi kesimpulan
yang tidak valid. Namun, pencilan tidak bisa dengan sembarang untuk dibuang [2].
Pembuangan pencilan hanya dilakukan jika diketahui dengan pasti ada kesalahan, seperti
kesalahan dalam pencatatan ataupun pengukuran.

34 Biastatistics Vol 11, No.1, Februari 2017
Alternatif yang dapat dilakukan pada analisis regresi untuk mengatasi adanya
pencilan pada data yaitu menggunakan metode regresi kekar. Regresi kekar bertujuan untuk
mengakomodasi adanya keanehan data serta menekan pengaruhnya terhadap hasil analisis
tanpa terlebih dahulu melakukan identifikasi terhadap data yang aneh [2]. Metode regresi
kekar yang resisten terhadap pengaruh pencilan-y salah satunya adalah metode biweight
Tukey atau disebut juga dengan metode penimbang ganda Tukey yang merupakan salah
satu anggota dari penduga-M [7]. Penduga-M ini diselesaikan dengan iterasi yang memiliki
fungsi penimbang dan fungsi objektif. Metode Least Absolute Deviations(LAD) atau
metode simpangan mutlak terkecil merupakan metode kekar lainnya yang juga dapat
mengatasi pengaruh pencilany dengan baik [1]. Metode LAD merupakan perbaikan dari
MKT dengan memanfaatkan konsep meminimumkan jumlah mutlak dari sisaannya .
Secara konsep LAD tidak lebih rumit dibandingkan MMKT, namun secara komputasi
metode LAD lebih kompleks dibandingkan MKT karena menggunakan iterasi. Selain
kedua metode tersebut, metode Theil yang merupakan salah satu metode nonparametrik
juga dikaji pada penelitian ini karena merupakan salah satu metode kekar yang baik
digunakan untuk mengatasi pengaruh pencilan karena tidak memerlukan asumsi-asumsi
kenormalan [10]. Metode Theil menggunakan konsep peringkat dan memanfaatkan median
sebagai ukuran kekekarannya. Selain dengan kajian simulasi ini, penelitian juga
diaplikasikan pada data riil untuk dilakukan analisis lebih lanjut.
B. Tujuan Penelitian
Penelitian ini bertujuan untuk membandingkan performa metode regresi kekar
biweight Tukey, LAD, dan Theil dalam menduga parameter regresi linier sederhana pada
berbagai persentase pencilan dan berbagai ukuran contoh.
2. TINJAUAN PUSTAKA
1.A. Pencilan
Pencilan merupakan nilai ekstrim dari suatu pengamatan. Seperti telah disebutkan
pada latar belakang, pencilan dapat dideteksi dengan melihat amatan yang memberikan sisaan
baku yang besar yaitu:
Dengan i : pengamatan ke-i
ri : sisaan yang dibakukan ke-i
ei : sisaan ke-i dengan formula ei = yi − yˆi
KTG : ragam sisaan.

Biastatistics Vol 11, No.1, Februari 2017 35
Suatu amatan dikatakan pencilan jika memberikan nilai mutlak sisaan baku lebih
besar dari dua [5]. Keberadan pencilan perlu ditinjau lebih lanjut karena pencilan bisa saja
mengganggu proses analisis data, namun pembuangan amatan yang diidentifikasi sebagai
pencilan bukanlah prosedur yang bijaksana, karena adakalanya pencilan memberikan
informasi yang tidak dapat diberikan oleh amatan lain [2].
2.B. Regresi Kekar
1) Metode Penimbang Ganda Tukey (biweight Tukey):
Metode biweight Tukey merupakan bagian dari pendugaM yang komputasinya
menggunakan IRLS (Iteratively Reweighted Least Square). Selain biweight Tukey, Huber
dan kuadrat terkecil juga dapat digunakan sebagai fungsi penimbang. Huber memiliki
fungsi penimbang yang monoton dan tidak memberikan bobot pada residu yang besar
seperti pada kuadrat terkecil. Sedangkan biweight Tukey, memiliki penurunan yang halus,
artinya fungsi penimbangnya asimptotik ke nol [6]. Pada metode biweight Tukey ini
terdapat fungsi penimbang dan fungsi objektif. Fungsi penimbang yang disarankan oleh
Tukey yaitu bisquare weight (penimbang kuadrat ganda) atau biweight (penimbang ganda)
dengan fungsi penimbang (w) yaitu: Pada metode biweight Tukey ini terdapat fungsi
penimbang dan fungsi objektif. Fungsi penimbang yang disarankan oleh Tukey yaitu
bisquare weight (penimbang kuadrat ganda) atau biweight (penimbang ganda) dengan
fungsi penimbang (w) yaitu:
dan fungsi objektif biweight Tukey yaitu:
Nilai k disebut juga dengan konstanta tuning atau tuning constant. Nilai yang lebih
kecil dari k akan lebih bersifat tahan atau kekar terhadap pencilan. Konstanta tuning pada
metode tertimbang ganda ini bernilai k=4.685σ, dengan σ adalah simpangan baku dari
sisaan yang akan menghasilkan efisiensi 95% ketika sisaan menyebar normal, serta tetap
menawarkan ketahanan terhadap pencilan [2].

36 Biastatistics Vol 11, No.1, Februari 2017
2) Metode Simpangan Mutlak Terkecil (LAD):
LAD dikembangkan pertama kali oleh Roger Joseph Boscovich pada tahun 1957.
Metode ini merupakan alternatif dari MKT dengan meminimumkan jumlah mutlak sisaan
atau untuk mendapatkan dugaan kemiringan garis (β1) dan
dugaan intersep (β0). Namun, tidak ada formula yang pasti untuk mendapatkan dugaan
koefisien kemiringan garis regresinya, sehingga diperlukan metode algoritma untuk
mendapatkannya. Algoritma ini dimulai dari data poin (x1, y1) dan mencari garis regresi
terbaik yang melaluinya, selanjutnya garis yang melalui (x1, y1) juga akan melalui data poin
yang lain (x2,y2) lalu dicari garis regresi terbaik yang melaluinya. Begitu seterusnya
algoritma ini trus berlangsung, lalu akan dicari garis regresi yang terbaik yang sama dengan
garis sebelumnya. Garis terbaik inilah yang disebut dengan garis regresi LAD [10].
LAD menggunakan konsep metode EM dan iterasinya menggunakan IRLS
(Iteratively Reweighted Least Square). Metode EM terdiri dari dua tahap yaitu E
(expectation) dan M (maximization). Adanya sifat iterasi ini membuat algoritma metode
LAD menjadi lebih kompleks dan memerlukan waktu lama dalam komputasinya, namun
memberikan hasil yang kekar terhadap adanya pencilan [11]. Prosedur LAD dikembangkan
untuk mengurangi pengaruh dari pencilan-y pada metode kuadrat terkecil, karena pada
metode ini tidak menggunakan sisaan yang dikuadratkan [1].
3) Metode Theil:
Metode Theil adalah salah satu prosedur nonparametrik yang diharapkan
memberikan hasil yang lebih baik tanpa memperhatikan sebaran dari galat [9]. Pada
pendugaan koefisien kemiringan garis regresinya, Theil (1950) dalam [4] mengusulkan
koefisien kemiringan garis regresi sebagai median kemiringan dari seluruh pasangan garis
dari titik-titik dengan nilai peubah penjelas (X) yang berbeda. Tahap pertama yang
dilakukan pada Metode Theil adalah mengurutkan data (xi,yi) berdasarkan besarnya nilai x
mulai dari nilai terkecil hinga nilai yang terbesar, sehingga diperoleh x1 < x2 < x3 < ... < xn.
Sebelum mendapatkan nilai penduga dari β1, terlebih dahulu menghitung semua nilai bij,
dengan bij adalah koefisien kemiringan setiap pasangan garis (xi,yi) dan (xj,yj) yang
dirumuskan sebagai berikut:
dengan:
bij : kemiringan garis dari pasangan (xi,yi) dan (xj,yj)
i : 1, 2, ..., n-1, j : 2, 3, ..., n.

Biastatistics Vol 11, No.1, Februari 2017 37
Maka untuk n pengamatan ada sebanyak n nilaibij yang berbeda.
Penduga koefisien kemiringan garis regresi (β1) dinotasikan dengan βˆ1 dan dinyatakan
sebagai median dari bij, yang dirumuskan sebagai berikut:
βˆ1 = median(bij)
Sedangkan untuk dugaan koefisien intersepnya (βˆ0) terdapat beberapa peneliti terdahulu
yang telah memformulasikannya, seperti yang telah dilakukan oleh Mutan [9] dengan
formula sebagai berikut:
βˆ0 = median (yi − βˆ
1xi)
dengan:
i: observasi ke- 1, 2, ..., n.
3.C. Ukuran Kebaikan
1) Kuadrat Tengah Galat: Penduga yang baik adalah penduga yang memiliki nilai
bias dan ragam minimum. Kuadrat tengah galat (KTG) merupakan salah satu
kriteria evaluasi penduga pada suatu metode. Semakin kecil nilai KTG dari suatu
penduga, maka semakin baik penduga parameternya [9]. Nilai MSE dapat
ditentukan dengan persamaan berikut:
MSE(βˆ) = var(βˆ) + [bias(βˆ)]2
dengan:
MSE(βˆ): KTG penduga parameter
var(βˆ): ragam penduga parameter
bias(βˆ): selisih dugaan parameter dengan parameternya (βˆ − β).
2) Median Absolute Deviance (MAD): Pencilan bukanlah hal yang baru bagi seorang
ilmuwan, namun tidak banyak peneliti yang menggunakan metode yang tidak
sesuai ketika adanya pencilan. Seperti nilai mean dan standar deviasi yang
digunakan untuk mendeteksi pencilan. Namun terdapat 3 hal yang perlu
diperhatikan ketika menggunakan mean sebagai indikator pemusatannya. Pertama,
diasumsikan bahwa sebarannya adalah normal (termasuk pencilan). Kedua, mean
dan standar devasi sangat kuat terpengaruh oleh pencilan. Ketiga, metode ini sangat
tidak suka untuk mendeteksi pencilan pada ukuran contoh kecil. Sebagai
alternatifnya digunakanlah Median Absolute Deviation (MAD) yang baik untuk
mendeteksi adanya pencilan namun jarang digunakan oleh peneliti. MAD
ditemukan dan dipopulerkan oleh Hampel pada tahun 1974. Median yang
digunakan pada konsep MAD ini sama halnya dengan konsep yang digunakan pada

38 Biastatistics Vol 11, No.1, Februari 2017
mean yaitu sebagai indikator pemusatan, namun median memberikan keuntungan
yang lebih dengan memiliki sifat yang tidak sensitif terhadap kehadiran pencilan.
Metode yang memiliki nilai MAD yang lebih adalah metode yang lebih baik. MAD
dirumuskan sebagai berikut [8]:
MAD = bMi(|xi − Mj(xj)|)
dengan:
xj : amatan asli sebanyak n
Mi : median dari serangkaian data
b : suatu konstanta yaitu 1/quantil (3/4) dari suatu sebaran data.
3. METODOLOGI
4.A. Data
Data yang digunakan dalam penelitian ini adalah data hasil simulasi dengan
parameter regresi β0 dan β1 yang telah ditentukan. Data peubah penjelas (X) ditetapkan dari
vektor dengan pertambahan yang sama sebesar satu (xi = 1, 2..., n), sehingga nakan
menyesuaikan dengan banyaknya ukuran contoh. Sisaan dibangkitkan dari sebaran
Normal(µ,σ) kemudian digunakan untuk mencari peubah respon dengan persamaan Yi = β0
+ β1Xi + εi. Banyak pengamatan (n) yang digunakan dalam penelitian ini adalah 20, 40, dan
100 dengan masing-masing persentase pencilan yaitu 0%, 10%, 20%, dan 30%. Proses
simulasi dilakukan menggunakan perangkat R versi 3.3.1.
Selain simulasi dilakukan pula evaluasi pendugaan parameter regresi pada data riil
yang diperoleh dari Aunuddin (1989) mengenai pengaruh tahun (1950 hingga 1973)
terhadap jumlah sambungan telepon internasional di Belgia, serta data yang diperoleh dari
Chatterjee Hadi (2006) mengenai pengaruh tinggi bukit (kaki) terhadap waktu pendakian
(detik).
5.B. Prosedur Analisis Data
Tahapan yang dilakukan dalam penelitian adalah sebagai berikut:
1) Menetapkan nilai β0 dan β1, yaitu β0 = 10 dan β1 =2.
2) Menetapkan nilai-nilai peubah penjelasnya (xi = 1, 2..., n), sebanyak ukuran
contohnya n = 20, 40, dan 100.
3) Menentukan banyaknya persentase pencilan pada setiap n, yaitu 0%, 5%, 10%, 20%,
dan 30%.

Biastatistics Vol 11, No.1, Februari 2017 39
4) Membangkitkan galat1 yang menyebar Normal (0,2) sebanyak n*(1-p), dengan p
adalah besarnya persentase pencilan.
5) Membangkitkan galat2 yang menyebar Normal (0,2) sebanyak n*p yang dikalikan
dengan suatu konstanta yaitu 15, dengan p adalah besarnya persentase pencilan.
6) Menghitung peubah respon dengan menggunakan model regresi, yaitu yi = β0 + β1xi +
εi.
7) Melakukan eksplorasi data untuk melihat banyaknya pencilan dengan diagram
pencar.
8) Mengulangi langkah 4 sampai 8 sebanyak 1000 kali.
9) Melakukan pendugaan parameter dengan metode biweight Tukey, LAD, dan Theil.
10) Menghitung ragam pendugaan, bias mutlak, dan nilai KTG.
11) Membandingkan hasil yang diperoleh dari tiga metode berdasarkan nilai ragam
penduga parameter, bias mutlak, dan KTG dari pendugaan.
Selanjutnya, tahapan analisis data yang dilakukan dalam penelitian untuk data riil
adalah sebagai berikut:
1) Menentukan peubah bebas (X) dan peubah respon (Y) dari data riil.
2) Melakukan eksplorasi data untuk melihat banyaknya pencilan.
3) Menduga parameter dengan biweight Tukey, LAD, dan Theil.
Mengevaluasi ketiga metode berdasarkan nilai-nilai koefisien regresi dan nilai
MAD yang dihasilkan.
4. HASIL PENELITIAN
A. Eksplorasi Data Simulasi
Ukuran pencilan yang digunakan dalam simulasi ini yaitu 0%, 10%, 20%, dan 30%
yang dikaji untuk berbagai ukuran contoh 20, 40, dan 100. Plot tebaran antara peubah
penjelas dan peubah respon dari sebagian data yang digunakan disajikan pada Gambar 1.
Tebaran pebah penjelas dan peubah responnya menunjukkan pola garis yang linier untuk
setiap persentase pencilannya, dan adanya pencilan dideteksi dengan titik-titik amatan yang
berada diluar pola garis utama. Sehingga, model garis regresi linier cocok digunakan pada
kajian simulasi ini.

40 Biastatistics Vol 11, No.1, Februari 2017
B. Performa Penduga Kemiringan Garis
Performa kemiringan garis bagi suatu analisis regresi merupakan koefisien yang
penting untuk di interpretasikan dibandingkan performa koefisien regresi yang lain. Tabel
1 dan Tabel 2 menunjukkan performa dugaan bagi kemiringan garis βˆ1 melalui berbagai
kriteria evaluasi yaitu nilai bias, ragam, serta nilai kuadrat tengah galat (KTG) untuk ukuran
contoh kecil (n=20) dan ukuran contoh besar (n=100). Pada penelitian ini, penggunaan nilai
bias menggunakan nilai bias mutlak untuk mempermudah mengakomodir nilai bias yang
under atau over estimate.
Penetapan nilai awal β1 = 2 membuat nilai-nilai dugaan kemiringan garisnya
terlihat sangat kecil sekali mendekati nol. Bahkan bila ditetapkan dua angka dibelakang
koma, nilai-nilai dugaanya banyak yang berada pada nilai 0.00, sehingga untuk melihat
perbedaannya dibuatlah empat angka desimal. Nilai yang sangat kecil ini disebabkan oleh
pergeseran kemiringan garis regresinya yang sedikit. Namun, jika ditetapkan nilai β1 yang
lebih besar lagi, maka akan mendapatkan nilai-nilai dugaan yang semakin besar pula.
Ketiga metode kekar pada penelitian ini akan dilihat performanya apabila suatu data
terdapat pencilan, dengan
Gambar 1. Tebaran data simulasi untuk ukuran contoh 20
pada berbagai persentase pencilan

Biastatistics Vol 11, No.1, Februari 2017 41
persentase pencilan yang berbeda-beda. Jadi, seberapa besar metode-metode ini dapat
mengatasi pengaruh dari pencilan apabila pencilan pada suatu data semakin bertambah, dan
ingin dilihat pula pengaruh dari ukuran contoh terhadap dugaan koefisien regresinya.
Suatu penduga yang baik adalah penduga yang memiliki nilai bias terkecil dan
ragam terkecil. Metode biweight Tukey atau penimbang ganda Tukey dapat mengakomodir
pencilan yaitu ketika persentase pencilan sebesar 10% dan 30%, artinya metode ini
memiliki nilai bias mutlak terkecil dan ragam terkecil untuk pencilan 10%, namun ketika
pencilan naik menjadi 30% metode Tukey ini tetap memiliki bias terkecil tetapi memiliki
ragam yang paling besar. Ketika ukuran contoh diperbesar menjadi 100, metode biweight
Tukey menjadi sangat baik dalam mengatasi pencilan, bahkan sampai pencilan diperbesar
menjadi 30%. Sedangkan metode LAD tidak pernah memiliki nilai ragam terkecil, bahkan
hampir di semua persentase pencilan memiliki ragam yang terbesar. Hal ini pun tidak
berubah ketika ukuran contohnya diperbesar. Begitu pula halnya dengan metode
nonparametrik Theil yang tidak pernah memiliki nilai bias mutlak tekecil dan ragam
terkecil, kecuali saat pencilan 30%. Ketika ukuran contoh diperbesar, metode ini juga tidak
memberikan hasil yang baik dalam mengatasi pengaruh dari pencilan, terlihat dari nilai bias
dan ragamnya yang terbesar.
Suatu penduga dengan proses simulasi jarang sekali bahkan tidak pernah
ditemukan suatu penduga yang benar-benar tak berbias. Hal ini dapat didekatkan dengan
memilih nilai bias yang terkecil dengan ragam terkecil. Penyebab ini yang memunculkan
adanya kuadrat tengah galat bagi suatu
Tabel I
KRITERIA EVALUASI PENDUGA KEMIRINGAN GARIS (β1= 2)
UNTUK N=20
Metode Bias Ragam
mutlak
KTG
Persentase pencilan = 0 %
Biweight Tukey -5.2302 -7.7366 -6.7981
LAD 0.1098 0.1564 0.1387
Theil 0.1117 0.3318 0.2125

42 Biastatistics Vol 11, No.1, Februari 2017
Persentase pencilan = 10 %
Biweight Tukey 0.0007 0.0105 0.0105
LAD 0.0032 0.0176 0.0177
Theil 0.0009 0.0162 0.0162
Persentase pencilan = 20 %
Biweight Tukey 0.0025 0.0333 0.0333
LAD 0.0018 0.0408 0.0408
Theil 0.0020 0.0354 0.0354
Persentase pencilan = 30 %
Biweight Tukey 0.0135 0.2035 0.2037
LAD 0.0138 0.1298 0.1300
Theil 0.0167 0.0833 0.0836
Tabel II
KRITERIA EVALUASI PENDUGA KEMIRINGAN GARIS (β1= 2)
UNTUK N=100
Metode Bias Ragam
mutlak
KTG
Persentase pencilan = 0 %
Biweight Tukey 0.0001 0.0001 0.0001
LAD 0.0001 0.0001 0.0001
Theil 0.0001 0.0001 0.0001
Persentase pencilan = 10 %
Biweight Tukey 0.0001 0.0001 0.0001
LAD 0.0001 0.0001 0.0001
Theil 0.0001 0.0001 0.0001

Biastatistics Vol 11, No.1, Februari 2017 43
Persentase pencilan = 20 %
Biweight Tukey 0.0001 0.0002 0.0002
LAD 0.0002 0.0003 0.0003
Theil 0.0003 0.0003 0.0003
Persentase pencilan = 30 %
Biweight Tukey 0.0015 0.0005 0.0005
LAD 0.0015 0.0007 0.0007
Theil 0.0015 0.0006 0.0006
dugaan. Grafik yang ditunjukkan pada Gambar 2 dan Gambar 3 untuk mempermudah
pembaca dalam melihat kriteria evaluasi KTG yang nilai-nilainya tertera secara lengkap
pada Tabel 1 dan Tabel 2.
Gambar 2. Performa kuadrat tengah galat bagi
dugaan kemiringan garis regresi untuk n=20
Gambar 3. Performa kuadrat tengah galat bagi
dugaan kemiringan garis regresi untuk n=100
Berdasarkan Gambar 2 dan Gambar 3 terlihat performa dari kuadrat tengah galat
yang berbeda-beda dari ketiga metode kekar yang dikaji pada penelitian ini. Terlihat bahwa
ketiga metode tersebut memiliki pola yang sama, artinya semakin meningkatnya persentase

44 Biastatistics Vol 11, No.1, Februari 2017
pencilan maka nilai KTG dugaannya akan semakin meningkat pula. Terlihat peningkatan
yang drastis ketika persentase pencilan terbesar yaitu 30%. Selain dilihat dari polanya,
dapat dilihat pula bahwa semakin bertambahnya ukuran contoh maka nilai-nilai dugaan
KTG akan semakin mengecil. Hal ini berhubungan dengan konsep konsistensi suatu
penduga. Penduga yang konsisten adalah penduga yang memiliki nilai dugaan parameter
atau dugaan statistiknya yang semakin mendekati parameternya apabila ukuran contoh
bertambah. Metode biweight Tukey merupakan metode penduga yang memiliki nilai KTG
terkecil untuk ukuran contoh 100, serta ketika persentase pencilan bertambah. Namun, saat
pencilan terbesar 30%, metode ini menunjukkan performa yang tidak baik untuk ukuran
contoh 20 karena memiliki nilai KTG terbesar dibandingkan kedua metode lainnya. Metode
Theil juga menunjukkan performa yang cukup baik saat ukuran contoh yang kecil, bahkan
memiliki KTG terkecil saat pencilan 30%. Metode lainnya yaitu LAD menunjukkan
performa yang paling jelek, terutama untuk ukuran contoh besar.
Sedikit membahas ketiga metode tersebut pada ukuran contoh sedang yaitu n=40,
metode Theil memiliki performa nilai bias mutlak dan ragam yang baik pada ukuran
pencilan tertinggi 30%, sedangkan metode biweight Tukey hampir pada semua ukuran
pencilan memiliki performa yang baik, namun tidak untuk pencilan 30%. Berbeda dengan
yang lainnya metode LAD selalu menunjukkan performa yang jelek.
C. Performa Penduga Intersep
Parameter β0 pada analisis regresi menunjukkan titik perpotongan antara garis
regresi dengan sumbu y saat x bernilai nol. Tabel 3 dan Tabel 4 menunjukkan beberapa
kriteria kebaikan dari penduga intersep untuk ukuran contoh terkecil 20 dan ukuran contoh
tebesar 100. Sedangkan untuk ukuran contoh yang sedang yaitu 40 akan dibahas sekilas
pada pembahasan ini. Nilai-nilai pada Tabel 3 dan Tabel 4 memperlihatkan nilai-nilai
dugaan yang lebih besar dibandingkan nilai-nilai dugaan pada penduga kemiringan garis
regresi. Hal ini disebabkan karena penentuan nilai awal intersep yang besar yaitu 10,
sehingga nilai-nilai dugaannya akan cenderung besar pula. Pada ukuran contoh terkecil ini,
metode Theil memiliki performa yang baik dengan memiliki bias mutlak terkecil saat
persentase pencilan 0% dan 10%. LAD memiliki nilai bias mutlak terkecil untuk pencilan
20% dan 30%. Sedangkan, metode biweight Tukey memiliki nilai bias mutlak terbesar saat
pencilan 20% dan 30%. Namun, metode ini memiliki ragam terkecil untuk semua pencilan,
kecuali saat pencilan terbesar yaitu 30%. Kemudian, saat ukuran contoh bertambah menjadi
100, metode biweight Tukey merupakan penduga paling efisien karena memiliki ragam
yang paling minimum.

Biastatistics Vol 11, No.1, Februari 2017 45
Saat suatu penduga terkadang memiliki bias terkecil namun ragam terbesar, dalam
penentuan penduga yang terbaik yang akan dipilih dapat dilihat dengan menggunakan
kriteria kuadrat tengah galat (KTG). Seperti pada ketiga metode tersebut, terkadang metode
LAD memiliki nilai bias terkecil, namun ragam terkecil dimiliki oleh metode biweight
Tukey. Kriteria evaluasi KTG dapat digunakan untuk membantu peneliti dalam penentuan
metode mana yang lebih baik untuk dipilih. Gambar 4 dan Gambar 5 menunjukkan
performa ketiga metode biweight Tukey, LAD, dan Theil melalui nilainilai KTG-nya.
Berdasarkan hasil Gambar 4 dan Gambar 5 diatas, memiliki karakteristik pola yang
sama dengan dugaan KTG pada kemiringan garis regresi. Metode biweight Tukey memiliki
nilai-nilai KTG yang lebih kecil dibandingkan kedua metode lainnya, terutama untuk
ukuran contoh besar pada berbagai persentase pencilan. Namun, saat pencilan 30% ukuran
contoh terkecil metode biweight Tukey ini memiliki KTG terbesar. Metode kedua yang
lebih baik yaitu metode Theil, dilanjut dengan metode LAD.
Tabel III
KRITERIA EVALUASI PENDUGA INTERSEP (β0= 10)
UNTUK N=20
Metode Bias Ragam Mutlak KTG
Persentase pencilan = 0 %
Biweight Tukey 0.02240.9533 0.9538
LAD 0.02241.3408 1.3414
Theil 0.00931.0320 1.0321
Persentase pencilan = 10 %
Biweight Tukey 0.03021.1131 1.1140
LAD 0.04751.7489 1.7512
Theil 0.02231.5368 1.5373
Persentase pencilan = 20 %
Biweight Tukey 0.02331.9379 1.9385
LAD 0.00512.4560 2.4561
Theil 0.00862.1509 2.1510

46 Biastatistics Vol 11, No.1, Februari 2017
Persentase pencilan = 30 %
Biweight Tukey 0.08217.8175 7.8243
LAD 0.07325.5767 5.5821
Theil 0.10183.5741 3.5844
Tabel IV
KRITERIA EVALUASI PENDUGA INTERSEP (β0= 10)
UNTUK N=100
Metode Bias Ragam Mutlak KTG
Persentase pencilan = 0 %
Biweight Tukey 0.0189 0.1708 0.1711
LAD 0.0083 0.2462 0.2463
Theil 0.0194 0.1916 0.1919
Persentase pencilan = 10 %
Biweight Tukey 0.0134 0.1895 0.1897
LAD 0.0158 0.3076 0.3079
Theil 0.0115 0.2713 0.2714
Persentase pencilan = 20 %
Biweight Tukey 0.0033 0.2634 0.2634
LAD 0.0041 0.4400 0.4400
Theil 0.0072 0.3923 0.3924
Persentase pencilan = 30 %
Biweight Tukey 0.0302 0.5326 0.5335
LAD 0.0257 0.6971 0.6977
Theil 0.0332 0.5749 0.5760

Biastatistics Vol 11, No.1, Februari 2017 47
Gambar 4. Performa kuadrat tengah galat
bagi dugaan intersep untuk n=20
Gambar 5. Performa kuadrat tengah galat
bagi dugaan intersep untuk n=100
Sekilas membahas ukuran contoh sedang yaitu ukuran contoh 40 untuk nilai bias
mutlak dan ragam penduga intersep, terlihat bahwa metode LAD tidak pernahmenunjukan
performa nilai bias mutlak ragam yang baik. Sedangkan metode Theil menunjukan
performa yang cukup baik pada pencilan tertinggi yaitu 30%. Metode bitweight Tukey
menunjukan performa yang paling baik, namut tidak untuk pencilan yang paling ekstrim
yaitu 30%.
D. Penerapan pada Data Riil
Terdapat dua data riil yang digunakan dalam penelitian ini yaitu pertama data
mengenai jumlah sambungan telepon internasional per tahun di Belgia (sebagai peubah
respon) dengan peubah tahun mulai 1950 hingga 1973 (sebagai peubah penjelas). Data
yang kedua yaitu data mengenai pengaruh ketinggian bukit (sebagai peubah penjelas)
terhadap waktu pendakian (sebagai peubah respon) pada 35 bukit di Skotlandia. Kedua data
riil ini memiliki kasus yang berbeda terhadap adanya pencilan. Pada data riil pertama,
terdapat pencilan-y yang menggerombol diatas dan diperkirakan terdapat sekitar 25% data
yang teridentifikasi sebagai pencilan, yaitu antara tahun 1964 hingga 1969. Sedangkan,
pada data riil yang kedua amatan yang teridentifikasi sebagai pencilan-y menyebar diatas
dan bawah, seperti perlakuan yang diberikan pada tahapan simulasi.
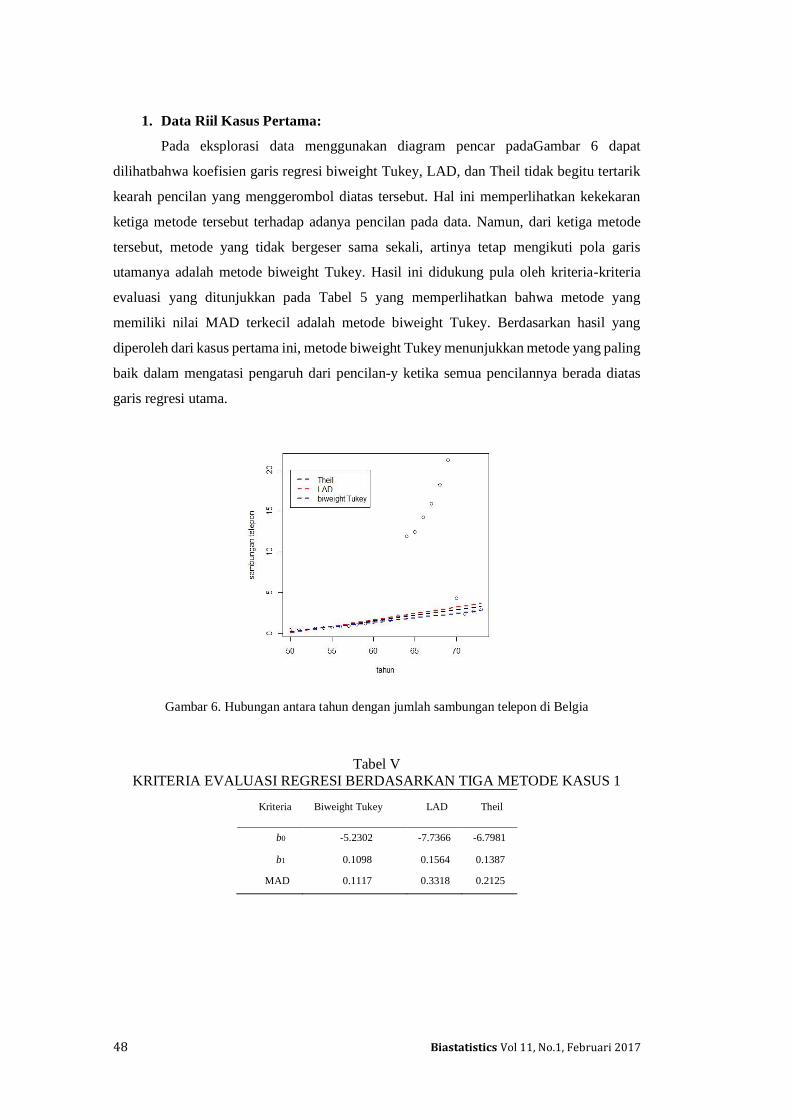
48 Biastatistics Vol 11, No.1, Februari 2017
1. Data Riil Kasus Pertama:
Pada eksplorasi data menggunakan diagram pencar padaGambar 6 dapat
dilihatbahwa koefisien garis regresi biweight Tukey, LAD, dan Theil tidak begitu tertarik
kearah pencilan yang menggerombol diatas tersebut. Hal ini memperlihatkan kekekaran
ketiga metode tersebut terhadap adanya pencilan pada data. Namun, dari ketiga metode
tersebut, metode yang tidak bergeser sama sekali, artinya tetap mengikuti pola garis
utamanya adalah metode biweight Tukey. Hasil ini didukung pula oleh kriteria-kriteria
evaluasi yang ditunjukkan pada Tabel 5 yang memperlihatkan bahwa metode yang
memiliki nilai MAD terkecil adalah metode biweight Tukey. Berdasarkan hasil yang
diperoleh dari kasus pertama ini, metode biweight Tukey menunjukkan metode yang paling
baik dalam mengatasi pengaruh dari pencilan-y ketika semua pencilannya berada diatas
garis regresi utama.
Gambar 6. Hubungan antara tahun dengan jumlah sambungan telepon di Belgia
Tabel V
KRITERIA EVALUASI REGRESI BERDASARKAN TIGA METODE KASUS 1
Kriteria Biweight Tukey LAD Theil
b0 -5.2302 -7.7366 -6.7981
b1 0.1098 0.1564 0.1387
MAD 0.1117 0.3318 0.2125

Biastatistics Vol 11, No.1, Februari 2017 49
2. Data Riil Kasus Kedua:
Pada kasus kedua ini, terlihat pola tebarannya lebih menyebar dibandingkan pada
kasus pertama. Terdapat tiga amatan yang mencurigakan, yang menjauh dari pola garis
utamanya yaitu amatan ke-7, ke11, dan amatan ke -18. Berdasarkan data yang tersedia,
amatan tersebut masing-masing adalah bukit bens of jura, bukit lairig ghru, serta bukit
knock Hill. Dari ketiga amatan ini artinya terdapat sekitar 8% data tersebut mengandung
pencilan. Amatan ke-18 kuat teridentifikasi sebagai pencilan karena letaknya yang jauh
sekali dari pola garis utamanya, sedangkan amatan ke-7 dapat dianggap sebagai amatan
berpengaruh karena masih berada di sekitar pola garis uama regresi. Berdasarkan garis
regresinya, dapat dilihat bahwa ketiga metode tersebut memiliki kemiringan garis regresi
yang tidak jauh berbeda, terutama terlihat untuk garis regrsi LAD dan Theil. Sedangkan
garis regresi metode biweight Tukey sedikit terlihat perbedaannya pada nilai b1 dan b0
yang dapat dilihat pada Tabel 6 dan garis ini berada disebelah kiri dari pencilan. Jika dilihat
dari kedua kasus pada data riil ini, saat suatu data mengandung pencilan, terutama pencilan-
y, baik pencilannya berada diatas garis regresi utama maupun berada diatas dan bawah atau
dengan kata lain menyebar, metode yang paling baik dalam mengatasi pencilan tersebut
adalah metode biweight Tukey.
Gambar 7. Hubungan antara jarak
(ketinggian bukit) dengan waktu pendakian

50 Biastatistics Vol 11, No.1, Februari 2017
Tabel VI
KRITERIA EVALUASI REGRESI BERDASARKAN TIGA METODE KASUS 2
Kriteria Biweight Tukey LAD Theil
b0 -232.3145 -481.3636 -405
b1 448.2012 481.6364 474
MAD 382.7052 380.7273 373
5. KESIMPULAN & SARAN
A. Simpulan
Performa metode analisis dalam menangani pencilan yang dikaji dalam penelitian
ini berbeda-beda. Metode terbaik dalam menangani pengaruh dari pencilan-y melalui
kajian simulasi adalah metode biweight Tukey, terutama untuk ukuran contoh sedang dan
besar yaitu 40 dan 100 dengan persentase pencilan dibawah 30%. Dua metode lainnya yaitu
Theil dan LAD menunjukkan suatu penduga yang cukup baik dalam mengatasi pencilan
untuk ukuran contoh kecil, dengan persentase pencilan paling besar yang baik untuk
metode Theil, dan pencilan berukuran kecil untuk LAD. Pada kajian aplikasi terhadap data
riil, ada kecenderungan bahwa metode biweight Tukey juga lebih baik daripada kedua
metode lainnya.
B. Saran
Pada penelitian selanjutnya disarankan untuk melakukan penelitian dengan
mengembangkan metode kekar lainnya pada analisis regresi berganda yang lebih
kompleks.
6. DAFTAR PUSTAKA
N.H. Al-Noor, A.A. Mohammad, “Model of regression with parametric and nonparametric methods”,
Mathematical Theory and Modelling, vol. 3, no. 5. 2013.
Aunuddin, Analisis Data. Bogor (ID): IPB Press. 1989.
S. Chatterjee, A.S. Hadi, Regression Analysis by Example. Ed ke-4. New Jersey (US): John Wiley & Sons, Inc.
2006.
W.W. Daniel, Applied Nonparametric Statistics. Ed ke-2. Boston (US): PWS-KENT Publishing Company.
1990.

Biastatistics Vol 11, No.1, Februari 2017 51
N. Draper, H. Smith, Analisis Regresi Terapan. Ed ke-2. B. Sumantri, penerjemah. Terjemahan dari: Applied
Regression Analysis. Jakarta (ID): Gramedia Pustaka Utama. 1992.
N. Hajarisman, “Algoritma pendugaan model regresi kekar melalui penduga-M”, Jurnal Mat Stat, vol. 11, no.
1, page 63-74. 2011.
K. Kafadar, “The efficiency of the biweight as a robust estimator of location”, Journal of Research of The
National Bureau of Standards, vol. 88, no. 2. 1983.
C. Leys, C. Ley, O. Klein, P. Bernard, L. Licata, “Detecting outliers: do not used standard deviation around the
mean, used absolute deviation around the median”, Journal of Experimental Sosial Psychology, vol.
30, no. 3. 2013.
O.C. Mutan, “Comparison of regression techniques via monte carlo simulation”. [tesis]. Turki: Middle East
Technical University. 2004
O.C. Mutan, “A monte carlo comparison of regression estimators when the error distribution is long tailed
symmetric”, Journal of Modern Applied Statistical Methods, vol. 8, no. 1, page 161-172. 2009.
R.F. Phillips, “Least absolute deviations estimation via the EM algorithm”, Statistics and Computing, vol. 12,
page 281285. 2002.
D.K. Srivastava, J. Pan, I. Sarkar, G.S. Mudholkar, “Robust winsorized regression using bootstrap approach”,
Communication in Statistics Simulation and Computation, vol. 30, no. 1, page 45-67, doi:
10/1080/03610910903308423. 2010.

52
BIAStatistics (2016) Vol. 10, No. 1, hal. 52-63
PREMI ASURANSI
DENGAN SISTEM BONUS MALUS OPTIMAL
Lienda Noviyanti1, Achmad Zanbar Soleh2 dan Budhi Handoko3
1Departemen Statistika FMIPA Universitas Padjadjaran
Email : [email protected]
ABSTRAK
Sistem Bonus Malus (SBM) adalah sistem penentuanbesaran premi pada periode berikutnya yang
didasarkan pada sejarah klaim pemegang polis. Pemegang polis yang pernah mengajukan klaim di
periode sebelumnya akan memperoleh kenaikan premi (malus) pada periode berikutnya dan
sebaliknya, jika tidak mengajukan klaim maka akan memperoleh penurunan premi (bonus).Biasanya
BMS diterapkan pada pemegang polis yang loyal terhadap satu perusahaan asuransi selama beberapa
periode. Penelitian ini menggunakan pendekatan bayesian untuk memperoleh fungsi densitas
posterior dari parameter rata-rata banyak klaim dan parameter rata-rata besar klaim dari seorang
pemegang polis. Selanjutnya besar premi optimal untuk periode berikutnya diperoleh dengan
mengasumsikan frekuensi klaim berdistribusi Geometri dan besar klaim berdistribusi Weibull.
Bonus dan malus diberikan sesuai dengan lama periode proteksi asuransi, frekuensi klaim, dan juga
besar klaim.
Keywords: SBM Optimal, Pendekatan Bayesian, Distribusi Frekuensi Klaim, dan
distribusi Besar Klaim.
1. PENDAHULUAN
Asuransi kendaraan bermotor merupakan salah satu cabang dari asuransi non
jiwa.Diberbagai negara, asuransi kendaraan bermotor merupakan peraih pendapatan total
premi yang terbesar (Kaas et al., 2001). Indonesia termasuk ke dalam negara yang
memperoleh total premi asuransi terbesar dari cabang asuransi kendaraan bermotor.Salah
satu faktor pendorong yang menyebabkan industri asuransi kendaraan bermotor
berkembang pesat adalah adanya peningkatan jumlah kendaraan bermotor setiap tahun.
Mulai tahun 2104, Otoritas Jasa Keuangan (OJK) menetapkan ketentuan mengenai
tarif premi asuransi kendaraan bermotor. Bila sebelumnya masing-masing perusahaan
asuransi bebas menentukan tarif premi asuransi mobil, maka sejak tahun 2014 seluruh tarif
premi asuransi kendaraan bermotor seluruh perusahaan asuransi di Indonesia mengacu
kepada aturan baru tersebut, yang salah satunya dapat dilihat pada Tabel 1. Dengan telah
ditetapkannya ketentuan tarif premi OJK tersebut maka tarif premi asuransi mobil seluruh
perusahaan asuransi menjadi sama, sehingga diharapkan tidak ada lagi perang tarif yang
pada akhirnya akan merugikan kesehatan keuangan dari perusahaan asuransi itu sendiri.
Ketetapan ini membuat tarif premi menjadi lebih mahal, tapi dampak positifnya ialah
kompetisi perusahaan asuransi bukan didasarkan pada harga premi tapi lebih di pelayanan
klaim kepada pemegang polis.

Biastatistics Vol 11, No.1, Februari 2017 53
Tabel 1: Tarif Premi Asuransi Kendaran
Bermotor (Wilayah II)
Kategori
(kelas)
Uang
Pertanggungan
(juta rupiah)
RateComprehensive
Batas
Bawah
Batas
Atas
Kendaraan Non-Truck dan Non-Bus
1 0 s/d125 3.44% 3.78%
2 >125 s/d200 2.47% 2.72%
3 >200s/d 400 1.71% 1.88%
4 >400 s/d 800 1.20% 1.32%
5 >800 1.05% 1.16%
Perpanjangan polis diberlakukan sebesar 10%
Sumber: OJK
Adapun yang menjadi fokus penelitian ini berdasarkan tabel tersebut adalah bahwa
untuk tarif premi perpanjangan polis (renewal) diberlakukan sebesar 10%, tanpa
memandang sejarah klaim pemegang polis.Yang haarus lebih dicermati adalah pada
ketetapan tahun 2015, pemberlakuan perpanjangan polis tersebut ditiadakan. Hal ini
menimbulkan ketidakadilan pada pemegang polis yang tidak mengajukan klaim pada
periode sebelumnya.
Sistem bonus malus (SBM) optimal merupakan sistem dalam asuransi yang
memperhatikan pembagian kelas premi yang dipengaruhi oleh banyak klaim dan besar
klaim yang diajukan pemegang polis tiap tahunnya. Pada SBM, disetiap awal periode
pemegang polis membayarkan premi dengan besar premi yang sama, berdasarkan katagori
/ kelas masing-masing. Pada periode selanjutnya, apabila terjadi perpanjangan polis, terjadi
perubahan pembayaran premi sesuai dengan pengalaman selama satu periode sebelumnya.
Umumnya, persentase pemegang polis yang loyal tidak pernah mengajukan klaim cukup
besar, maka sebaiknya dalam penentuan premi diterapkan sistem keadilan. Pada SBM,
pemegang polis yang telah mengajukan satu atau lebih klaim akan dikenakan kenaikan
premi (malus). sedangkan bagi pemegang polis yang tidak mengajukan klaim akan
diberikan penghargaan berupa penurunan premi (bonus) di periode pembayaran
berikutnya.
Sistem SBM diperkenalkan pertama kali di Eropa awal tahun 1960. SBM sudah
diterapkan di beberapa negara seperti Asia Timur, Eropa, Kenya dan Brazil, dimana tiap
negara memiliki perbedaan sesuai dengan karakteristik masing-masing seperti jumlah kelas
premi, aturan perpindahan kelas premi, dan besar persentase premi yang berbeda-beda.
Menurut Lemaire (1985), setiap pemegang polis dari sebuah risk cell akan dibagi
berdasarkan kelas bonus-malus dan riwayat klaim mereka, yang kemudian akan
memodifikasi kelas tersebut ketika terjadi perpanjangan polis. Frangos dan Vrontos (2001)
membuat sistem bonus-malus optimal, yaitu sistem yang sudah dimodifikasi sehingga
bukan hanya frekuensi klaim saja yang digunakan, tetapi besar klaim dimasukkan juga ke
dalam perhitungan serta menggunakan distribusi Eksponensial ( ) yang
merepresentasikan rata-rata besar klaim. Parameter merupakan nilai dari peubah acak
dengan distribusi Levy. Kombinasi dari dua distribusi ini membentuk distribusi baru, yaitu
distribusi Weibull. (Weihong Ni et al., 2013). Mahmoudvand dan Hassani (2009)
melanjutkan penelitian Frangos dan Vrontos (2001) dengan membuat sistem bonus-malus
optimal tergeneralisasi. Mert dan Saykan (2005) menggunakan distribusi Pareto dengan
alasan untukbesar klaim yang menggunakan distribusi lognormal, eksponensial, Weibull,
ataupun gamma, hasilestimasinya terlalu besar atau terlalu kecil dari yang seharusnya.
Umumnya, negara-negara yang tidak memberlakukan SMB, penentuan tarif premi
hanya berdasarkan pada pemberian bonus bila tidak ada klaim selama periode sebelumnya
dan bonus akan dihapus apabila ada klaim yang diajukan (Park, Lemaire dan Choong,
2010).

54 Biastatistics Vol 11, No.1, Februari 2017
Di Nigeria, SBM dikelompokkan ke dalam beberapa state untuk kendaraan pribadi,
sedangkan untuk kendaraan komersial dikelompokkan dalam duastate. Besar premi tidak
hanya dilihat dari sisi frekuensi klaim, tetapi di tinjau dari besar nilai klaim, tingkat
kerusakan (severity) kendaraan, dan penyusutan nilai kendaraan (depreciation). Distribusi
yang digunakan adalah Poisson-Eksponential dan Poisson-Gamma. (Ibiwoye, et.al, 2011).
Menurut Grandell (1997) distribusi Poisson secara luas digunakan dalam masalah
asuransi untuk model proses klaim. Waktu klaim tidak bisa diprediksi karena kecelakaan
terjadi dalam waktu yang berbeda-beda. Kejadian ini sifatnya relatif jarang jika
dibandingkan dengan jumlah pemegang polis yang mengikuti asuransi. Ini menjadi
gambaran untuk perusahaan asuransi yang memiliki ribuan nasabah akan memiliki peluang
kecelakaan yang kecil. Peluang ini akan konvergen ke distribusi Poisson(λ). Seringkali
parameter λ adalah nilai dari suatu peubah acak yang memiliki distribusi tertentu.
Kombinasi dari dua distribusi ini membentuk distribusi baru, dikenal dengan distribusi
Poisson campuran. Jika parameter λ nilai dari peubah acak yang memiliki distribusi
Eksponensial, maka kombinasi distribusi ini adalah distribusi Geometri. (Mert & Saykan,
2005).
Sesuai dengan eksplorasi data awal, penelitian ini menggunakan distribusi
geometri untuk frekuensi klaim dan distribusi Weibull untuk besar klaim dalam
menentukanbesar tarif premi dengan SBM Optimal pada asuransi kendaraan bermotor.
2. TINJAUAN PUSTAKA
2.1 Teorema Bayes
Pendekatan Bayesian digunakan untuk mencari rata-rata posterior yang dianggap
sebagai penduga premi risiko. Dalam membentuk rata-rata posterior digunakan fungsi
likelihood untuk menganalisis data hasil observasi. Misalkan variabel acak X berdistribusi
tertentu dengan parameter θ. Dengan probability distribution function (pdf) bersama f(x│θ)
yang merupakan fungsi likelihood terhadap x_i, yaitu
𝑓(𝑥|𝜃) = ∏ 𝑓(𝑥𝑖|𝜃)
𝑛
𝑖=1
(1)
Dalam pendekatan bayes, parameter θ nilainya berubah-ubah sehingga disebut
sebagai variabel acak. Fungsi distribusi peluang dari θ dinotasikan f(θ) yang dinamakan
fungsi distribusi prior. Perkalian dari fungsi likelihood dan fungsi distribusi prior akan
membentuk distribusi posterior f(θ│x).
Secara aturan peluang, fungsi gabungan antara X dan θ, dinyatakan oleh
𝑓(𝑥, 𝜃) = 𝑓(𝑥|𝜃)𝑓(𝜃). (2)
Distribusi posterior yang terbentuk diperoleh dari
𝑓 (𝜃|𝑥) =𝑓(𝑥, 𝜃)
𝑓(𝑥), (3)
sehingga diperoleh fungsi distribusi posterior sebagai berikut
𝑓(𝜃|𝑥) =𝑓(𝑥|𝜃)𝑓(𝜃)
𝑓(𝑥), (4)

Biastatistics Vol 11, No.1, Februari 2017 55
dengan 𝑓(𝑥) = ∫ 𝑓(𝑥|𝜃) 𝑓(𝜃)𝑑𝜃 merupakan fungsi densitas marjinal dari X.
Untuk 𝑥 = (𝑥1, 𝑥2, … , 𝑥𝑛) perumusan (4) menjadi
𝑓(𝜃|𝑥1, 𝑥2, … , 𝑥𝑛) =𝑓(𝑥1,𝑥2,…,𝑥𝑛|𝜃)𝑓(𝜃)
∫ 𝑓(𝑥1,𝑥2,…,𝑥𝑛|𝜃)𝑓(𝜃)𝑑𝜃 (5)
Rumus pada persamaan (4) bisa dituliskan sebagai berikut
𝑓(𝜃|𝑥) = 𝑘𝑓(𝑥|𝜃)𝑓(𝜃) (6)
Secara umum dari Persamaan (6) dapat disimpulkan bahwa
Posterior likelihood x prior
Metode-metode yang dapat digunakan pada SBM optimal terkait distribusi prior dan
posterior dari beberapa peneliti disajikan pada Tabel 2.
Tabel 2. SBM Berdasarkan
Distribusi Frekuensi dan Besar Klaim
2.2 Distribusi Frekuensi Klaim
Distribusi Poisson biasa digunakan untuk mendeskripsikan kejadian yang memiliki
sifat acak dan independen, seperti frekuensi kecelakaan pada kendaraan bermotor.
Frekuensi kecelakaan yang dialami seorang pemegang polis i pada periode t, dinotasikan
dengan 𝐾𝑖𝑡, diasumsikan berdistribusi Poisson (𝜆). Pdf dari poisson (𝜆) adalah
𝑃(𝐾𝑖𝑡 = 𝑘) =
𝑒−𝜆𝜆𝑘
𝑘!, 𝑘 = 0,1,2, …
𝜆 > 0 (8)
dengan k adalah nilai dari variabel random K_i^t dan λ adalah parameter dari distribusi
Poisson. Nilai parameterλ dapat ditaksir dengan rata-rata frekuensi klaim menggunakan
metode maximum likelihood.
Pada distribusi Poisson di atas diasumsikan semua pemegang polis mempunyai
rata-rata frekuensi klaim yang sama. Jika variasi antar pemegang polis berbeda, maka
diasumsikan parameter λ adalah nilai dari variabel random Λ yang mengikuti distribusi
Poisson campuran.

56 Biastatistics Vol 11, No.1, Februari 2017
Apabila diasumsikan parameter λ adalah nilai dari variabel random Λ yang
berdistribusi Eksponensial (θ), maka distribusi K^t adalah distribusi Geometri dengan
parameter (θ/(1+θ)) (Mert & Saykan, 2005).
Pdf dari Λ adalah
𝑢(𝜆) = 𝜃𝑒−𝜆𝜃 𝜆 > 0, 𝜃 > 0, (9)
dengan mean 𝐸(Λ) =1
𝜃 dan variansi 𝑉𝑎𝑟(Λ) =
1
𝜃2.
Berdasarkan Law of Total Probability, fungsi distribusi tidak bersyarat dari 𝐾𝑡
menjadi
𝑃(𝐾𝑡 = 𝑘) = ∫ 𝑃(𝐾𝑖𝑡 = 𝑘|𝜆)𝑢(𝜆)𝑑𝜆
∞
0= (
𝜃
1+𝜃) (
1
1+𝜃)
𝑘
(10)
Jadi, probabilitas banyak kecelakaan di suatu populasi pada periode tertentu, 𝐾𝑡,
mengikuti distribusi Geometri(𝜃
1+𝜃) dengan mean 𝐸(𝐾𝑡) =
1
𝜃 dan variansi 𝑉𝑎𝑟(𝐾𝑡) =
(1+𝜃)
𝜃2 . Parameter 𝜃 dari distribusi Geometri(𝜃
1+𝜃) dapat ditaksir dengan menggunakan
metode maximum likelihood.
2.3 Distribusi Besar Klaim
Misalkan besar klaim yang dialami seorang pemegang polis i pada periode t,
dinotasikan dengan 𝑋𝑖𝑡 , diasumsikan berdistribusi Eksponensial (𝜃). Pdf dan Cumulative
distribution function (cdf) dari Eksponensial (𝜃) masing-masing adalah
𝑓(𝑋𝑖𝑡 = 𝑥|𝜃) = 𝜃𝑒−𝜃𝑥 ,𝑥 ≥ 0, 𝜃 > 0, (11)
dan
𝐹(𝑋𝑖𝑡 ≤ 𝑥|𝜃) = 1 − 𝑒−𝜃𝑥 , (12)
dengan 𝑥 adalah nilai dari variabel random 𝑋𝑖𝑡 dan 𝜃 adalah parameter dari distribusi
Eksponensial.
Pada distribusi Eksponensial di atas diasumsikan semua pemegang polis
mempunyai rata-rata besar klaim yang sama. Jika variasi antar pemegang polis berbeda,
maka diasumsikan parameter 𝜃 adalah nilai dari variabel random 𝜃∗ yang mengikuti
distribusi Levy, dimana pdf dari 𝜃∗ adalah
𝑓(𝜃) =𝑐
2√𝜋𝜃3𝑒𝑥𝑝 (−
𝑐2
4𝜃) 𝑐 ≥ 0, 𝜃 > 0. (13)
Berdasarkan Law of Total Probability didapat fungsi distribusi tidak bersyarat dari
𝑋𝑡 menjadi
𝐹(𝑋𝑡) = ∫ 𝐹(𝑋𝑖𝑡 ≤ 𝑥|𝜃)𝑓(𝜃)𝑑𝜃
∞
0. (14)

Biastatistics Vol 11, No.1, Februari 2017 57
Apabila persamaan (12) dan (14) disubstitusikan ke persamaan (14) akan diperoleh
CDF tidak bersyarat dari x, sebagai berikut
𝐹(𝑋𝑡) = 1 − exp (−𝑐√𝑥) 𝑥 ≥ 0, 𝑐 > 0. (15)
Parameter 𝑐 dari distribusi Weibull (𝑐, 0,5) dapat ditaksir dengan menggunakan
metode maximum likelihood (Ni et al., 2013).
2.4 Estimasi Frekuensi Klaim periode t+1
Desain SBM melibatkan pdf posterior dari Λ untuk pemegang polis i pada periode
t, dinotasikan dengan 𝐾𝑖𝑡. Jika 𝐾𝑖
𝑡 saling independenden, maka 𝐾 = ∑ 𝐾𝑖𝑗𝑡
𝑗=1 adalah total
frekuensi kecelakaaan yang dialami seorang pemegang polis selama periode t. Pdf posterior
dari Λ didapat dengan menerapkan teorema Bayes.Dengan mensubstitusikan persamaan
(10) dan (11) ke persamaan(6), diperoleh fungsi densitas bersyarat
𝑓(𝜆|𝑘𝑖1, 𝑘𝑖
2, … , 𝑘𝑖𝑡) =
𝑓(𝑘𝑖1,𝑘𝑖
2,…,𝑘𝑖𝑡|𝜆)𝑢(𝜆)
∫ 𝑓(𝑘𝑖1,𝑘𝑖
2,…,𝑘𝑖𝑡|𝜆)𝑢(𝜆)𝑑𝜆
=
(𝑒−𝜆𝑡𝜆𝐾
𝑘𝑖1! 𝑘𝑖
2! … 𝑘𝑖𝑡!
) (𝜃𝑒−𝜆𝜃)
(𝜃Γ(𝐾 + 1)
𝑘𝑖1! 𝑘𝑖
2! … 𝑘𝑖𝑡! (𝑡 + 𝜃)𝐾+1)
𝑓(𝜆|𝑘𝑖1, 𝑘𝑖
2, … , 𝑘𝑖𝑡) =
(𝑡+𝜃)𝐾+1𝜆𝐾𝑒−𝜆(𝑡+𝜃)
Γ(𝐾+1). (16)
Pdf Posterior dari Λ adalah Gamma dengan parameterK+1 dan 𝑡 + 𝜃.
Penentuan premi untuk seorang pemegang polis didapatkan dari ekspektasi
frekuensi kecelakaan yang dialami pada periode sebelumnya. SBM akan menghasilkan
estimator terbaik dengan diketahui sejarah kecelakaan selama t periode sebelumnya.
Misalkan estimasi frekuensi klaim pada t+1 periode adalah �̂�𝑖𝑡+1(𝑘𝑖
1, 𝑘𝑖2, … , 𝑘𝑖
𝑡). Nilai
estimasi dari ekspektasi frekuensi kecelakaan (�̂�), tentu akan berbeda dengan frekuensi
kecelakaan yang sebenarnya (𝜆). Perbedaan ini dapat direpresentasikan dengan fungsi
kerugian kuadrat (�̂�, Λ) = 𝑘(�̂� − Λ)2, 𝑘 > 0. Pada estimasi titik Bayesian, penaksir titik
untuk Λ adalah �̂� yang meminimumkan nilai ekspektasi dari fungsi kerugian tersebut, yaitu
mean dari distribusi posterior 𝜆 sbb.
�̂�𝑖𝑡+1(𝑘𝑖
1, 𝑘𝑖2, … , 𝑘𝑖
𝑡) = 𝐸(Λ|𝑘𝑖1, 𝑘𝑖
2, … , 𝑘𝑖𝑡) =
𝐾+1
𝑡+𝜃. (17)

58 Biastatistics Vol 11, No.1, Februari 2017
2.5 Estimasi Besar Klaim periode t+1
Frekuensi klaim untuk pemegang polis i pada periode t, dinotasikan dengan 𝐾𝑖𝑡.
Jika 𝐾𝑖𝑡 saling independenden, maka 𝐾 = ∑ 𝐾𝑖
𝑗𝑡𝑗=1 adalah total frekuensi kecelakaaan yang
dialami seorang pemegang polispada periode t. Misalkan perusahaan asuransi menerima
serangkaian pembayaran biaya klaim (𝑥1, 𝑥2, … , 𝑥𝐾) dari pemegang polis dengan total
sebesar K klaim dan 𝑋 = ∑ 𝑥𝑖𝐾𝑖=1 ≥ 0 merupakan total dari jumlah semua besar klaim. Pdf
posterior dari rata-rata besar klaim θ∗ didapatkan dengan menerapkan teorema Bayes.
Dengan mensubstitusikan persamaan (13) dan (15) ke persamaan (5), didapatkan fungsi
densitas bersyarat
𝑓(𝜃|𝑥1, 𝑥2 , … , 𝑥𝐾) =𝑓(𝑥1, 𝑥2, … , 𝑥𝐾|𝜃)𝑢(𝜃)
∫ 𝑓(𝑥1, 𝑥2, … , 𝑥𝐾|𝜃)𝑢(𝜃)𝑑𝜃
𝑓(𝜃|𝑥𝑖1, 𝑥𝑖
2, … , 𝑥𝑖𝑡) =
(𝛼′
𝛽′)
𝑣2
𝜃𝑣−1𝑒𝑥𝑝(−1
2(𝛼′𝜃+
𝛽′
𝜃))
2𝐵𝑣(√𝛼′𝛽′), (18)
Dengan 𝛼′ = 2𝑋, 𝛽′ =𝑐2
2, 𝑣 = 𝐾 −
1
2.
Penentuan premi untuk seorang pemegang polis diperoleh dari besar klaim yang
dialami pada periode sebelumnya. SBM akan menghasilkan estimator terbaik dengan
diketahui sejarah kecelakaan selama t periode sebelumnya. Menurut metode Bayes,
estimator harus menggunakan seluruh informasi yang tersedia. Estimator yang digunakan
adalah distribusi posterior karena menggabungkan informasi sampel dan informasi
sebelum pengambilan sampel. Jika fungi kerugian 𝐿(𝑎, 𝜃) dapat ditentukan, maka estimasi
titik dapat diperoleh menurut kerangka teori keputusan. Pada estimasi titik Bayesian, jika
fungsi kerugian adalah
𝐿(𝑎, 𝜃) = 𝑘(𝑎 − 𝜃)2𝑘 > 0,
maka penaksir titik untuk 𝜃 adalah mean dari distribusi 𝜃
Misalkan estimasi besar klaim pada t+1 periode adalah 𝜃𝑡+1(𝑥1, 𝑥2 , … , 𝑥𝐾). Nilai
estimasi dari ekspektasi besar klaim (𝜃), akan berbeda dengan besar klaim yang
sebenarnya (𝜃). Perbedaan ini dapat direpresentasikan dengan fungsi kerugian kuadrat
𝐿(𝜃,̂ θ∗) = 𝑘(𝜃 − θ∗)2, 𝑘 > 0. Pada estimasi titik Bayesian, dengan menggunakan fungsi
Bessel, penaksir titik untuk θ∗ adalah 𝜃 yang meminimumkan nilai ekspektasi dari fungsi
kerugian tersebut, yaitu rata-rata dari disribusi posterior 𝜃, sbb.
𝜃𝑡+1(𝑥1, 𝑥2, … , 𝑥𝐾) = 𝐸(𝜃|𝑥1, 𝑥2, … , 𝑥𝐾) =2√𝑋
𝑐
𝐵𝐾−
32
(𝑐√𝑋)
𝐵𝐾−
12
(𝑐√𝑋). (19)

Biastatistics Vol 11, No.1, Februari 2017 59
2.6 Premi SBM Optimal
Suatu SBM dikatakan optimal, yaitu adil bagi para pemegang polis karena pada
setiap awal periode pembayaran premi sebanding dengan estimasi frekuensi kecelakaan
ataupun besar klaim yang akan dialami, yang melibatkan semua informasi dari masa
lalu.Untuk total klaim sebesar X, prinsip premi bersih menyatakan bahwa perusahaan
asuransi yang menganut prinsip risk neutral bersedia menerima premi sebesar 𝐸(𝑋), yakni
𝑃𝑟𝑒𝑚𝑖 = 𝐸(𝑋). (20)
Seorang pemegang polis i mempunyai total klaim sebesar 𝑋𝑖 yang dihasilkan pada
titik waktu acak, yaitu
𝑋𝑖 = 𝑋𝑖1 + 𝑋𝑖
2 + ⋯ + 𝑋𝑖𝐾𝑖, (21)
dengan 𝑋𝑖𝑗 menyatakan besar klaim ke j dari pemegang polis i dan 𝐾𝑖 menyatakan banyak
klaim yang diajukan oleh pemegang polis i kepada perusahaan asuransi. Banyak klaim 𝑘𝑖
adalah variabel random. Diasumsikan bahwa 𝑋𝑖𝑗 saling independen dan berdistribusi
identik serta 𝑋𝑖𝑗 dan 𝐾𝑖 saling independen, sehingga nilai ekspektasi dari total klaim yang
dialami oleh pemegang polis i(Kass, 2001) sebagai berikut.
𝐸(𝑋𝑖) = 𝐸(𝑋𝑖𝑗)𝐸(𝐾𝑖). (22)
Berdasarkan persamaan (20) dan (22), diperoleh bentuk hubungan berikut
𝑃𝑟𝑒𝑚𝑖 = 𝐸(𝑋𝑖) = 𝐸(𝑋𝑖𝑗)𝐸(𝐾𝑖). (23)
Selanjutnya, besar premi yang dikenakan terhadap pemegang polis i pada t+1 sebanding
dengan ekspektasi frekuensi dan besar klaim jika diketahui informasi yang telah dialami
selama t tahun. Dengan mensubstitusikan persamaan (17) dan (19) ke persamaan (23)
didapatkan nilai premi sebagai berikut.
�̂�𝑖𝑡+1(𝑘𝑖
1, 𝑘𝑖2, … , 𝑘𝑖
𝑡) = �̂�𝑖𝑡+1(𝑘𝑖
1, 𝑘𝑖2, … , 𝑘𝑖
𝑡)𝜃𝑡+1(𝑥1, 𝑥2, … , 𝑥𝐾). (24)
Jika frekuensi klaim berdistribusi Geometri dan besar klaim berdistribusi Weibull, maka
nilai premi adalah
�̂�𝑖𝑡+1(𝑘𝑖
1, 𝑘𝑖2, … , 𝑘𝑖
𝑡) =𝐾+1
𝑡+𝜃
2√𝑋
𝑐
𝐵𝐾−
32
(𝑐√𝑋)
𝐵𝐾−
12
(𝑐√𝑋), (25)
yang merepresentasikan premi yang dibayarkan pemegang polis pada periode t+1.
Persamaan (25) belum melibatkan premi di awal pemegang polis mengikuti asuransi,
sehingga dengan menggunakan modifikasi diperoleh
�̂�𝑖𝑡+1(𝑘𝑖
1, 𝑘𝑖2, … , 𝑘𝑖
𝑡) = {(𝐾+1
𝑡+𝜃) (
2√𝑋
𝑐
𝐵𝐾−
32
(𝑐√𝑋)
𝐵𝐾−
12
(𝑐√𝑋))} {
𝑃1
𝑃1}, (26)
dengan

60 Biastatistics Vol 11, No.1, Februari 2017
𝑃1 = (1
𝜃)
2
𝑐2. (27)
Secara umum, persamaan (27) dapat dituliskan kembali menjadi
�̂�𝑖𝑡+1(𝑘𝑖
1, 𝑘𝑖2, … , 𝑘𝑖
𝑡) = 𝑃1 {(𝐾+1
𝑡+𝜃) (
2√𝑋
𝑐
𝐵𝐾−
32
(𝑐√𝑋)
𝐵𝐾−
12
(𝑐√𝑋))} {𝜃 (
𝑐2
2)}, (28)
dengan :
𝑃1 :: premi awal
𝑡 :: banyak tahun pemegang polis berada
dalam pengamatan
𝐾 :: total banyak kecelakaan selama t tahun
𝑋 :: total besar klaim selama t tahun
𝜃 :: parameter yang berasal dari gabungan
distribusi Poisson-Exsponensial
𝑐 :: parameter yang berasal dari gabungan
distribusi Eksponensial-Levy.
Persamaan (28) dapat dirinci kembali sbb.
Pada saat tidak pernah mengajukan klaim
�̂�𝑖𝑡+1 = 𝑃1 {(
𝐾+1
𝑡+𝜃)} {𝜃} (29)
Pada saat mengajukan 1 klaim
�̂�𝑖𝑡+1 = 𝑃1 {(
𝐾+1
𝑡+𝜃) (
2√𝑋
𝑐)} {𝜃 (
𝑐2
2)} (30)
Pada saat mengajukan 2 klaim
�̂�𝑖𝑡+1 = 𝑃1 {(
𝐾+1
𝑡+𝜃) (
2𝑋
(1+𝑐√𝑋))} {𝜃 (
𝑐2
2)} (31)
Pada saat mengajukan 3 klaim
�̂�𝑖𝑡+1 = 𝑃1 {(
𝐾+1
𝑡+𝜃) (
2𝑋(𝑐√𝑋+1)
𝑐2𝑋+3𝑐𝑋+3)} {𝜃 (
𝑐2
2)} (32)
Pada saat mengajukan 4 klaim
�̂�𝑖𝑡+1 = 𝑃1 {(
𝐾+1
𝑡+𝜃) (
2𝑋(3+3𝑐√𝑋+𝑐2𝑋)
(15+15𝑐√𝑋+6𝑐2𝑋+𝑐3𝑋3/2))} {𝜃 (
𝑐2
2)} (33)

Biastatistics Vol 11, No.1, Februari 2017 61
3. HASIL DAN PEMBAHASAN
Data yang digunakan adalah sampel dari 681 pemegang polis asuransi kendaraan
bermotor untuk pertanggungan Comprehensive pada suatu perusahaan asuransi umum,
yang mengajukan dan tidak mengajukan klaim periode 2012 sampai 2015. Berikut
disajikan data frekuensi klaim untuk jenis perlindungan risiko Comprehensive:
Tabel 2 Data Frekuensi Klaim Asuransi
Kendaraan Bermotor periode 2012 –2015
Kate-gori
Uang Pertanggungan
(juta rupiah)
Frekuensi Klaim
(2012 - 2015)
0 1 2 3 4
1 0 s/d 125 168 79 41 9 3
2 > 125 s/d 200 123 75 37 8 1
3 > 200 s/d 400 57 24 13 6 0
4 > 400 s/d 800 21 9 6 1 0
Tabel tersebut memperlihatkan bahwa untuk semua katagori, banyak pemegang
polis yang tidak mengajukan klaim, sehingga untuk pemegang polis yang melalukan
perpanjangan klaim, sebaiknya diperlalukan secara adil dengan menggunakan konsep
SBM.
3.1 Estimasi Frekuensi dan Besar Klaim pada periode t+1
Hasil penelitian menunjukkan bahwa dengan menggunakan uji Chi-Kuadrat,
untuk semua katagori, frekuensi klaim berdistribusi Geometri. Sedangkan untuk besar
klaim, dengan menggunakan uji Kolmogorov-Smirnov, untuk semua katagori berdistribusi
Weibull. Penaksiran parameter frekuansi dan besar dilakukan dengan menggunakan
metode maximum likelihood, dengan hasil seperti yang disajikan pada Tabel 3.
Tabel 3.Estimasi Nilai Parameter
3.2 Penentuan Premi SBM Optimal
Sebagai contoh, pada Tabel 4 disajikan sejarah klaim dari enam orang pemegang
polis yang memiliki premi awal yang sama (Rp. 2.470.000) dengan masing-masing besar
klaim yang berbeda. Dengan uang pertanggungan Rp100.000.000, untuk kategori 2 dan
nilai parameter 𝜃 = 1,942, serta = 0,000512, diperoleh hasil seperti pada Tabel 4.
Berdasarkan Tabel 4, premi yang dibayarkan pada awal periode (𝐏𝟏) oleh semua
pemegang polis sebesar Rp 2.470.000. Nilai premi awal ini diperoleh dari batas bawah OJK
sebesar 2,47% (Tabel 1) dari uang pertanggungan. Semua pemegang polis mendapatkan
premi awal yang sama. Setelah satu tahun mengikuti asuransi, ke-6 pemegang polis
mempunyai sejarah klaim yang berbeda-beda.

62 Biastatistics Vol 11, No.1, Februari 2017
Tabel 4 Premi Awal dan Premi SBM untuk
Enam Orang Pemegang Polis
Pemegang polis A selama satu tahun mengikuti asuransi tidak pernah
mengajukan klaim sehingga berdasarkan BMS, A berhak mendapat bonus dengan premi
sebesar Rp. 1.630.435, yakni berdasarkan persamaan 29. Pemegang polis B dan C
mengajukan satu klaim, dimana besar klaim masing-masing sebesar Rp 2.250.000 dan Rp
2.600.000, sehingga berdasarkan BMS, B dan C mendapatmalus dengan premi masing-
masing sebesar Rp.2.504.349 dan Rp. 2.692.094, yakni berdasarkan persamaan 30.
Demikian selanjutnya penjelasan untuk pemegang polis D, E dan F.
4. KESIMPULAN
Menentukan nilai premi dengan menggunakan SBM Optimal memberikan
keadilan bagi pemegang polis yang melakukan perpanjangan polis padatahun berikutnya,
karena SBM Optimal mempertimbangkan sejarah frekuensi dan besar klaim pemegang
polis. Apabila dalam satu periode terdapat dua orang pemegang polis memiliki frekuensi
klaim yang sama, maka penentuan nilai premi akhir pada saat kedua pemegang polis
tersebut melakukan perpanjangan polis akan berbeda karena besar klaim dari masing-
masing pemegang polis yang berbeda. Kajian lanjut penentuan premi SBM dapat dilakukan
dengan mengasumsikan perilaku dependen antara frekuensi dan besar klaim menggunakan
Copula.
5. DAFTAR PUSTAKA
Arnold, S. F. (1990). Mathematical Statistics. New Jersey: Prentice Hall.
Frangos, N.E. & Vrontos, S.D. (2001). Design of optimal bonus-malus system with a frequency and
a severity component onan individual basis in automobile insurance. ASTIN Bulletin 31,
1-22.
Grandell, J., (1997). Mixed Poisson Prosesses. Chapman and Hall/CRC Statistics and Mathematics.
New York
Herzog, T.N. (1996). Introduction to Credibility Theory. Second Edition. ACTEX, Winsted.
Hogg, R. V. dan Craig, A. T., (2005). Introducion to Mathematical Statistics. Ed Ke-6.
Ibiwoyed, A., I.A. Adeleke & S.A. Aduloju. (2011). International Business Research. Vol. 4, No. 4.
Kaas,R., Goovaerts, M., Dhaene, J. & Denuit, M. (2001). Modern actuarial risk theory. Kluwer
Academic Publishers, Boston.
Lemaire, J. (1985). Automobile Insurance Actuarial Models. Netherlands: Kluwer-Nijhoff.
Mahmoudvand, R. & Hassani, H. (2009). Generalized Bonus-Malus System with a Frequency and
a Severity Component on an Individual Basis in Automobile Insurance. Astin Bulletin.
39(1).
Mert, M., & Saykan, Y. (2005). On a Bonus-Malus System Where The Claim Frequency
Distribution is Geometric and The Claim Severity Distribution is Pareto. Hacettepe Journal
of Mathematics and Statistics.

Biastatistics Vol 11, No.1, Februari 2017 63
Ni, W., Constantinescu, C., & A. Pantelous, A., (2014). Bonus-Malus Systems with Weibull
Distribted Claim Severities.Analls of Actuarial Science. Vol. 8. Part 2.
Park, S. C., J. Lemaire, &Chong. (2010) Is the Design of Bonus-Malus Systems Influenced by
Insurance Maturity or National Culture - Evidence from Asia? The Geneva Paper. Vol. 15.
Tremblay, L. (1992). Using the Poisson Inverse Gaussian in Bonus-Malus System, Astin Bulletin.
22(1).

64
BIAStatistics (2016) Vol. 10, No. 1, hal. 64-75
MANAJEMEN RESIKO KREDIT TERHADAP PERUSAHAAN
PROPERTI DI INDONESIA
BERDASARKAN RASIO KEUANGANNYA
Samsul Anwar1), Zulfan 2), Radhiah 3) 1Jurusan Statistika, Fakultas MIPA, Universitas Syiah Kuala
2Jurusan Informatika, Fakultas MIPA, Universitas Syiah Kuala 3Jurusan Matematika, Fakultas MIPA, Universitas Syiah Kuala
Email: [email protected]
ABSTRAK
Sistem manajemen resiko merupakan hal yang sangat penting untuk dimiliki oleh para kreditor. Hal
ini diperlukan untuk meminimalisir terjadinya kredit macet pada suatu perusahaan yang telah
diberikan kredit. Peluang terjadinya kredit macet akan lebih besar terjadi pada perusahaan dengan
kondisi kesehatan keuangan yang buruk dibandingkan dengan perusahaan dengan kondisi kesehatan
keuangan yang baik. Kondisi kesehatan suatu perusahaan dapat dilihat dari analisis laporan
keuangannya. Salah satu analisis yang dapat dipakai adalah analisis rasio keuangan. Rasio keuangan
ini terdiri dari rasio likuiditas, solvabilitas, profitabilitas dan aktivitas perusahaan. Populasi
perusahaan kemudian dikelompokkan berdasarkan rasio keuangan tersebut. Salah satu metode yang
dapat digunakan adalah metode K-Means Cluster. Metode ini akan mengelompokkan elemen yang
memiliki karakteristik yang sama dalam satu kelompok. Terdapat 32 perusahaan properti dalam
penelitian ini, 11 perusahaan di antaranya dikelompokkan ke dalam cluster 1, 17 perusahaan
dikelompokkan ke dalam cluster 2, dan sisanya 4 perusahaan dikelompokkan ke dalam cluster 3.
Dari sudut pandang kreditor, cluster yang paling aman untuk diberikan kredit adalah perusahaan
properti yang termasuk ke dalam cluster 1, karena perusahaan pada cluster 1 tersebut memiliki rasio
keuangan yang paling baik, terutama untuk rasio likuiditas dan solvabilitas.
Keywords: manajemen resiko, rasio keuangan, likuiditas, solvabilitas, profitabilitas, aktivitas,
metode K-Means Cluster.
1. PENDAHULUAN
Prospek bisnis properti di Indonesia terus mengalami peningkatan dari tahun ke
tahun. Beberapa faktor yang mempengaruhi perkembangan bisnis properti ini antara lain:
kebijakan Bank Indonesia (BI) yang menurunkan suku bunga acuan atau BI rate, kondisi
ekonomi yang terus membaik, demand masyarakat yang besar, dan adanya dukungan oleh
kenaikan properti dari kredit perbankan. Beberapa bank besar diperkirakan tetap konsisten
menyalurkan kreditnya ke sektor properti. Sejak tahun 2005, sektor perbankan lewat kredit
konstruksi dan kredit real estat telah mendanai proyek-proyek yang dibangun oleh para
pengembang yang dinilai prospektif. Namun demikian, pihak perbankan juga harus
berhati-hati dalam mendanai sektor properti ini. Mereka diharuskan memiliki sistem

Biastatistics Vol 11, No.1, Februari 2017 65
manajemen resiko yang baik. Sehingga dapat meminimalisir kerugian akibat terjadinya
kredit bermasalah (non performing loan/NPL), ketidakmampuan membayar bunga, dan
masalah-masalah lain yang tidak diharapkan. Salah satu solusi dari resiko permasalahan
tersebut adalah dengan penyaluran kredit yang tepat sasaran. Ini artinya pihak perbankan
harus mengenal betul perusahaan properti calon klien mereka. Salah satu indikator yang
dapat dijadikan sebagai pegangan adalah keadaan keuangan perusahaan tersebut, dalam hal
ini adalah laporan keuangannya. Dengan melihat laporan keuangan, pihak perbankan dapat
menganalisis seberapa baik sebuah perusahaan properti beroperasi. Sehingga pihak
perbankan dapat memutuskan layak tidaknya dalam memberikan dukungan dana kepada
perusahaan properti tersebut.
Berdasarkan data dari Indonesian Capital Market Tahun 2011, diketahui bahwa
terdapat 51 perusahaan properti di Indonesia yang telah terdaftar di Bursa Efek Jakarta
(BEJ). Para pengembang besar yang terus melakukan ekspansi di bisnis properti ini antara
lain: Grup Lippo, Grup Summarecon Agung, Grup Duta Pertiwi, Grup Jakarta Setiabudi
Internasional, Grup Ciputra, Grup Bakrie, Grup Jababeka, Grup Modern, Grup Suryamas
Duta Makmur, dan Grup Pakuwon. Dengan banyaknya perusahaan properti saat ini,
dibutuhkan suatu sistem pengelompokan. Hal ini dilakukan karena tidak semua perusahaan
memiliki tingkat kemampuan keuangan yang sama. Sehingga perlu mengelompokkan
perusahaan-perusahaan itu ke dalam cluster-cluster tersendiri berdasarkan kemampuan
keuangannya. Dengan mengamati kinerja satu sampel perusahaan, dapat dilakukan prediksi
terhadap kemampuan perusahaan lain yang terdapat dalam satu kelompok dengan
perusahaan sampel. Hal ini dimungkinkan karena perusahaan yang berada dalam satu
cluster memiliki ciri-ciri atau karakteristik yang sama. Keuntungan metode pengclusteran
ini adalah kreditor tidak perlu melakukan penelitian untuk setiap perusahaan apabila ingin
memberikan pinjaman kredit.
2. KAJIAN LITERATUR
2.1 Analisis Cluster
Analisis cluster adalah salah satu teknik statistika multivariat untuk
mengelompokkan objek-objek berdasarkan kesamaan karakteristik tertentu. Sehingga
objek-objek yang berada dalam satu cluster akan mempunyai kemiripan satu dengan yang
lainya, sedangkan yang berada pada cluster berbeda akan mempunyai perbedaan satu
dengan yang lainya. Konsep dasar analisis cluster adalah konsep pengukuran jarak atau
kemiripan. Terdapat beberapa metode yang dapat digunakan untuk mengukur jarak, tetapi
metode jarak yang paling sering digunakan adalah metode jarak Euclidean, yang mengukur

66 Biastatistics Vol 11, No.1, Februari 2017
jarak sesungguhnya di antara dua pengamatan. Jarak Euclidean antara dua pengamatan xi
dan xj diukur dengan menggunakan rumus:
𝑑(𝑥𝑖 , 𝑥𝑗) = √(𝑥𝑖 − 𝑥𝑗)′(𝑥𝑖 − 𝑥𝑗) = √∑ (𝑥𝑖 − 𝑥𝑗)
2𝑝𝑖,𝑗=1 (1)
Dalam analisis cluster, terdapat dua metode yang dapat digunakan. Metode yang
pertama adalah metode berhierarki dan yang kedua adalah metode tak berhierarki. Metode
K-Means cluster adalah salah satu metode tak berhierarki, dimana proses pembentukan
cluster diawali dengan dengan penentuan jumlah cluster terlebih dahulu, dan kemudian
memproses seluruh objek secara bersamaan sekaligus. Metode K-Means Cluster disebut
juga teknik partisi (partitioning techniques) [2].
Untuk sekumpulan data observasi (x1, x2, ... , xn), dimana setiap data adalah d-dimensional
riil vector, K-means cluster bertujuan untuk membagi n observasi tersebut ke dalam k (≤n)
cluster. Metode K- means menggunakan K pusat cluster untuk mengategorikan data
observasi. Hal ini dicapai dengan meminimalisir jumlah error kuadrat, 𝐽𝐾 =
∑ ∑ (𝑥𝑖 − 𝑚𝑘)2𝑖𝜖𝐶𝑘
𝐾𝑘=1 . Dimana (x1, x2, ... , xn) = X adalah data matriks dan 𝑚𝑘 = ∑
𝑥𝑖
𝑛𝑘𝑖𝜖𝐶𝑘
adalah pusat cluster 𝐶𝑘 , dan 𝑛𝑘 adalah jumlah observasi dalam cluster 𝐶𝑘 [3]. Solusi
standar untuk K-means cluster didapat melalui proses iterasi sampai semua data observasi
terbagi ke dalam K buah cluster.
2.2 Rasio Keuangan
Analisis terhadap keuangan perusahaan merupakan hal yang umumnya dilakukan
oleh para kreditor (pemberi pinjaman) seperti bank. Kreditor memerlukan analisis
keuangan untuk memperoleh informasi mengenai posisi keuangan, hasil-hasil yang
dicapai, serta prospek perusahaan peminjam di masa datang. Hal ini perlu dilakukan karena
sebelum kreditor memberikan keputusan memberi atau menolak atas suatu permohonan
kredit, mereka harus memperkirakan risiko potensial yang dihadapi oleh para peminjam
dikaitkan dengan adanya jaminan kelangsungan pembayaran bunga yang ditentukan
maupun melunasi pokok pinjamannya. Analisis keuangan yang sering dipakai adalah
analisis rasio keuangan. Jenis-jenis rasio keuangan yang digunakan untuk menganalisis
kinerja perusahaan adalah rasio neraca (likuiditas dan solvabilitas), rasio laba-rugi
(profitabilitas) dan rasio neraca aktivitas [4].
2.2.1 Rasio Likuiditas
Rasio likuiditas adalah rasio yang bertujuan untuk mengetahui kemampuan
perusahaan dalam membayar kewajiban jangka pendek. Jika perusahaan tidak mampu
mempertahankan kemampuan membayar utang jangka pendek maka pada umumnya

Biastatistics Vol 11, No.1, Februari 2017 67
perusahaan tersebut tidak akan mampu membayar utang jangka panjang. Rasio likuiditas
antara lain:
a. Current Ratio (CR)
Current ratio adalah kemampuan aktiva lancar perusahaan dalam memenuhi
kewajiban jangka pendek (current liabilities) dengan aktiva lancar (current assets) yang
dimiliki. Semakin tinggi rasio lancar seharusnya semakin besar pula kemampuan
perusahaan untuk membayar kewajiban jangka pendek. Nilai current ratio dihitung melalui
persamaan:
𝐶𝑅 =𝐶𝑢𝑟𝑟𝑒𝑛𝑡 𝐴𝑠𝑠𝑒𝑡𝑠
𝐶𝑢𝑟𝑟𝑒𝑛𝑡 𝐿𝑖𝑎𝑏𝑖𝑙𝑖𝑡𝑖𝑒𝑠
b. Quick Test Ratio (QTR)
Quick test ratio adalah kemampuan aktiva lancar minus persediaan untuk
membayar kewajiban lancar. Rasio ini memberikan indikator yang lebih baik dalam
melihat likuiditas perusahaan dibandingkan dengan rasio lancar, karena penghilangan
unsur persediaan dan pembayaran di muka serta aktiva yang kurang lancar dari perhitungan
rasio. Nilai quick test ratio dihitung melalui persamaan:
𝑄𝑇𝑅 =𝐶𝑢𝑟𝑟𝑒𝑛𝑡 𝐴𝑠𝑠𝑒𝑡𝑠 − 𝐼𝑛𝑣𝑒𝑛𝑡𝑜𝑟𝑖𝑒𝑠
𝐶𝑢𝑟𝑟𝑒𝑛𝑡 𝐿𝑖𝑎𝑏𝑖𝑙𝑖𝑡𝑖𝑒𝑠
2.2.2 Rasio Solvabilitas
Rasio solvabilitas adalah rasio untuk mengetahui kemampuan perusahaan dalam
membayar kewajiban jangka panjang, jika perusahaan tersebut dilikuidasi. Rasio ini juga
disebut dengan rasio pengungkit (leverage) yaitu menilai batasan perusahaan dalam
meminjam uang. Rasio solvabilitas antara lain :
a. Debt to Asset Ratio (DAR).
Debt to asset ratio adalah rasio total kewajiban (total liabilities) terhadap total aset
(total assets). Rasio ini menekankan pentingnya pendanaan hutang dengan jalan
menunjukkan persentase aktiva perusahaan yang didukung oleh hutang. Nilai debt asset
ratio dihitung melalui persamaan:
𝐷𝐴𝑅 =𝑇𝑜𝑡𝑎𝑙 𝐿𝑖𝑎𝑏𝑖𝑙𝑖𝑡𝑖𝑒𝑠
𝑇𝑜𝑡𝑎𝑙 𝐴𝑠𝑠𝑒𝑡𝑠

68 Biastatistics Vol 11, No.1, Februari 2017
b. Debt to Equity Ratio (DER).
Rasio ini menunjukkan persentase persediaan dana oleh pemegang saham terhadap
pemberi pinjaman. Semakin tinggi rasio, semakin rendah pendanaan perusahaan yang
disediakan oleh pemegang saham. Dari perspektif kemampuan membayar kewajiban
jangka panjang, semakin rendah rasio akan semakin baik kemampuan perusahaan dalam
membayar kewajiban jangka panjang.
Dimana nilai debt to equity ratio dihitung melalui persamaan:
𝐷𝐸𝑅 =𝑇𝑜𝑡𝑎𝑙 𝐿𝑖𝑎𝑏𝑖𝑙𝑖𝑡𝑖𝑒𝑠
𝑇𝑜𝑡𝑎𝑙 𝐸𝑞𝑢𝑖𝑡𝑦
2.2.3 Rasio Profitabilitas
Rasio profitabilitas adalah rasio yang mengukur efektifitas manajemen secara
keseluruhan yang ditunjukkan oleh besar kecilnya keuntungan yang diperoleh, dalam
hubungannya dengan penjualan dan investasi. Rasio yang digunakan dalam analisis
profitabilitas antara lain:
a. Net Profit Margin (NPM)
Rasio ini menggambarkan besarnya laba bersih yang diperoleh oleh perusahaan
pada setiap penjualan (sales) yang dilakukan. Laba bersih (net income) adalah laba yang
diterima perusahaan setelah dikurangi pajak. Nilai net profit margin dihitung melalui
persamaan:
𝑁𝑃𝑀 =𝑁𝑒𝑡 𝐼𝑛𝑐𝑜𝑚𝑒
𝑆𝑎𝑙𝑒𝑠
b. Return of Asset (ROA)
Rasio ini menggambarkan kemampuan perusahaan untuk menghasilkan
keuntungan dari setiap satu rupiah aset yang digunakan. Keuntungan yang dimaksud di sini
adalah keuntungan bersih (net income). Nilai return of asset dihitung melalui persamaan:
𝑅𝑂𝐴 =𝑁𝑒𝑡 𝐼𝑛𝑐𝑜𝑚𝑒
𝑇𝑜𝑡𝑎𝑙 𝐴𝑠𝑠𝑒𝑡𝑠
c. Return of Equity (ROE)
Rasio ini biasanya digunakan untuk mengevaluasi kinerja perusahaan karena rasio
tersebut mengukur kemampuan perusahaan untuk memperoleh keuntungan dari hutang
jangka panjang dan modal pemegang saham. Rasio ini menunjukkan kesuksesan
manajemen dalam memaksimalkan tingkat kembalian pada pemegang saham. Nilai return
of equity dihitung melalui persamaan:
𝑅𝑂𝐸 =𝑁𝑒𝑡 𝐼𝑛𝑐𝑜𝑚𝑒
𝑇𝑜𝑡𝑎𝑙 𝐸𝑞𝑢𝑖𝑡𝑦

Biastatistics Vol 11, No.1, Februari 2017 69
d. Earning Per Share (EPS)
Alat analisis yang dipakai untuk melihat keuntungan dengan dasar saham adalah
earning per share yang dicari dengan laba bersih (net income) dibagi saham yang beredar.
Rasio ini menggambarkan besarnya pengembalian modal untuk setiap satu lembar saham.
Nilai earning per share dihitung melalui persamaan:
𝐸𝑃𝑆 =𝑁𝑒𝑡 𝐼𝑛𝑐𝑜𝑚𝑒
𝑁𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑆ℎ𝑎𝑟𝑒
2.2.4 Rasio Aktivitas
Rasio ini berkaitan dengan aktivitas yang dilakukan perusahaan berkenaan dengan
kemampuan perusahaan untuk menggunakan investasi maupun aset yang dimilikinya untuk
menghasilkan keuntungan. Beberapa rasio aktivitas antara lain :
a. Inventory Turn Over (ITO)
Rasio ini berguna untuk mengetahui kemampuan perusahaan dalam mengelola
persediaan, dalam arti berapa kali persediaan yang ada akan diubah menjadi penjualan.
Dengan mengetahui rasio ini, kita bisa mengetahui likuiditas dari persediaan yang dimiliki
oleh perusahaan. Semakin tinggi rasio akan semakin cepat persediaan diubah menjadi
penjualan. Nilai inventory turn over dihitung melalui persamaan:
𝐼𝑇𝑂 =𝐶𝑜𝑠𝑡 𝑜𝑓 𝐺𝑜𝑜𝑑 𝑆𝑜𝑙𝑑
𝐼𝑛𝑣𝑒𝑛𝑡𝑜𝑟𝑦
b. Total Asset Turn Over (TATO)
Kemampuan perusahaan dalam menggunakan aktiva yang dimiliki untuk
menghasilkan penjualan digambarkan dalam rasio ini. Dengan melihat rasio ini, bisa
diketahui efektivitas penggunaan aktiva dalam menghasilkan penjualan. Nilai total asset
turn over dihitung melalui persamaan:
𝑇𝐴𝑇𝑂 =𝑆𝑎𝑙𝑒𝑠
𝑇𝑜𝑡𝑎𝑙 𝐴𝑠𝑠𝑒𝑡𝑠
3. METODOLOGI
Data yang dipakai dalam penelitian ini adalah jenis data sekunder. Data sekunder
merupakan data yang diperoleh dari pihak lain, dalam hal ini adalah data dari Indonesian
Capital Market Tahun 2011 [5]. Data yang diambil adalah data mengenai Financial
Statement dari perusahaan properti di Indonesia yang terdaftar di Bursa Efek Jakarta.
Jumlah populasi perusahaan properti berdasarkan data tersebut adalah sebanyak 51
perusahaan. Namun dengan adanya keterbatasan informasi keuangan dari beberapa
perusahaan, maka jumlah perusahaan yang diikutsertakan dalam penelitian ini hanya 32

70 Biastatistics Vol 11, No.1, Februari 2017
perusahaan. Metode analisis statistik yang digunakan dalam penelitian ini adalah metode
K-Means Cluster. Tujuan penggunaan metode ini adalah untuk mengelompokkan
perusahaan properti di Indonesia berdasarkan rasio keuangannya, sehingga dapat diketahui
ciri-ciri untuk masing-masing cluster. Pengolahan data dengan metode K-Means Cluster
menggunakan software SPSS versi 15.
4. HASIL DAN PEMBAHASAN
Variabel yang digunakan untuk mengukur ketidakmiripan suatu cluster dalam
penelitian ini adalah variabel rasio keuangan perusahaan. Rasio keuangan tersebut
mencerminkan kemampuan perusahaan dalam hal likuiditas (Currrent Ratio (CR) dan
Quick Rasio (QTR)), solvabilitas (Debt to Assets (DAR) dan Debt to Equity (DER)),
profitabilitas (Net Profit Margin (NPM), Return on Asset (ROA), Return on Equity (ROE),
dan Earnings Per Share (EPS)), dan aktivitas (Inventory Turnover (ITO) dan variabel Total
Assets Turnover (TATO)). Standarisasi data (Z score) dilakukan untuk menghilangkan
pengaruh perbedaan skala yang digunakan, serta menghilangkan efek penyebaran data
yang tidak teratur karena interval nilai data yang terlalu besar.
Populasi dalam penelitian ini dikelompokkan menjadi 3 kelompok (cluster),
dengan alasan ingin dilihat kemampuan perusahaan properti dengan kategori kurang baik,
cukup baik, dan paling baik berdasarkan perbandingan nilai-nilai variabel dari cluster yang
terbentuk. Penentuan kategori ketiga cluster dilakukan dengan memperhatikan nilai cluster
center untuk masing-masing variabel, seperti yang tersaji dalam tabel 1 di bawah ini.
Tabel 1. Nilai Final Cluster Center
Variabel Cluster
1 2 3
ZCR 0.856 -0.428 -0.537
ZQTR 0.888 -0.455 -0.509
ZDAR -0.946 0.487 0.534
ZDER -0.927 0.470 0.552
ANPM -0.180 0.175 -0.248
ZROA -0.349 0.536 -1.316
ZROE -0.487 0.656 -1.448
ZEPS -0.440 0.471 -0.793
ZITO -0.141 0.162 -0.303
ZTATO -0.491 -0.048 1.555

Biastatistics Vol 11, No.1, Februari 2017 71
Melalui nilai cluster center dalam tabel 1 di atas, dapat ditentukan kategori masing-
masing cluster untuk setiap variabelnya. Cluster dengan nilai center terbesar untuk setiap
variabelnya akan dikategorikan tinggi, dan nilai center terkecil akan dikategorikan rendah.
Sedangkan nilai center yang tengah akan dikategorikan sebagai kategori sedang. Dengan
demikian, diketahui ciri-ciri dari setiap cluster sebagai berikut:
Cluster 1, memiliki ciri-ciri:
- Nilai CR dan QTR paling tinggi, nilai DAR dan DER paling rendah, nilai NPM, ROA,
ROE dan EPS kategori sedang, nilai ITO kategori sedang, dan yang terakhir, nilai TATO
paling rendah.
Cluster 2, memiliki ciri-ciri:
- Nilai CR dan QTR kategori sedang, nilai DAR dan DER kategori sedang, nilai NPM,
ROA, ROE dan EPS paling tinggi, nilai ITO paling tinggi, nilai TATO kategori sedang.
Cluster 3, memiliki ciri-ciri:
- Nilai CR dan QTR paling rendah, nilai DAR dan DER paling tinggi, nilai NPM, ROA,
ROE dan EPS paling rendah, nilai ITO paling rendah sedangkan nilai TATO adalah yang
paling tinggi.
Dengan memperhatikan ciri masing-masing cluster di atas, dapat dilakukan analisis
finansial perusahaan untuk masing-masing cluster sebagai berikut:
Analisis keuangan untuk cluster 1
- Berdasarkan nilai CR dan QTR, dapat disimpulkan bahwa perusahaan-perusahaan pada
cluster 1 memiliki kemampuan likuditas yang paling baik jika dibandingkan dengan
cluster yang lain. Artinya bahwa perusahaan pada cluster 1 tergolong memiliki
kemampuan yang sangat baik dalam memenuhi kewajiban jangka pendek jika
dibandingkan dengan cluster 2 dan 3.
- Sejalan dengan kemampuan likuiditasnya, perusahaan pada cluster 1 tergolong
memiliki kemampuan solvabilitas yang paling baik. Hal ini dapat dilihat pada nilai DAR
dan DER yang paling rendah jika dibandingkan dengan cluster yang lainnya. Artinya,
perusahaan pada cluster 1 memiliki kemampuan membayar hutang jangka panjang yang
paling baik jika dibandingkan dengan cluster 2 dan 3.
- Kemampuan profitabilitas dilihat melalui nilai variabel NPM, ROA, ROE, dan EPS.

72 Biastatistics Vol 11, No.1, Februari 2017
Diketahui bahwa seluruh rasio keuangan tersebut berada pada kategori cukup, dengan
demikian dapat dikatakan bahwa keuntungan yang dihasilkan perusahaan berada pada
kategori cukup baik yang bersumber dari seluruh komponen rasio keuangan di atas,
yaitu berasal dari penjualan bersih, aset yang dimiliki, penjualan saham dan modal
pemilik perusahaan.
- Kemampuan aktivitas yang menunjukkan kemampuan perusahaan dalam menghasilkan
penjualan, dapat dilihat melalui nilai variabel ITO dan TATO. Perusahaan pada cluster
1 lebih mampu menghasilkan penjualan melalui inventori yang dimilikinya
dibandingkan dengan menggunakan aset perusahaan. Namun demikian, penjualan
melalui inventori tersebut masih termasuk dalam kategori cukup baik jika dibandingkan
dengan cluster yang lainnya.
Analisis keuangan untuk cluster 2
- Dengan melihat nilai CR dan QTR, dapat disimpulkan bahwa perusahaan-perusahaan
pada cluster 2 memiliki kemampuan likuditas dalam kategori cukup baik jika
dibandingkan dengan cluster yang lain. Artinya bahwa perusahaan pada cluster 2
tergolong memiliki kemampuan yang cukup dalam memenuhi kewajiban jangka pendek
jika dibandingkan dengan cluster 1 dan 3.
- Perusahaan-perusahaan pada cluster 2 juga memiliki kemampuan solvabilitas yang
tergolong cukup baik. Hal ini dapat dilihat pada nilai DAR dan DER. Artinya,
perusahaan pada cluster 2 cukup memiliki kemampuan untuk memenuhi kewajiban
jangka panjang.
- Kemampuan profitabilitas dilihat melalui nilai variabel NPM, ROA, ROE, dan EPS.
Keempat rasio keuangan tersebut berada pada kategori yang paling baik. Hal ini dapat
diartikan bahwa keuntungan yang dihasilkan perusahaan merupakan yang paling tinggi
jika dibandingkan dengan cluster yang lainnya. Keuntungan tersebut diperoleh dari
penjualan bersih, penggunaan aset, penjualan saham serta berasal dari modal pemilik
saham.
- Kemampuan aktivitas perusahaan-perusahaan pada cluster 2 lebih bertumpu kepada
kemampuan menghasilkan penjualan melalui inventori (ITO) yang merupakan kategori
yang paling baik di antara cluster yang lain, selain itu perusahaan pada cluster ini juga
memiliki kemampuan menghasilkan penjualan melalui aset yang dimiliki (TATO) dan
termasuk dalam kategori cukup jika dibandingkan dengan cluster yang lainnya.

Biastatistics Vol 11, No.1, Februari 2017 73
Analisis keuangan untuk cluster 3
- Berdasarkan nilai CR dan QTR, dapat disimpulkan bahwa perusahaan-perusahaan pada
cluster 3 memiliki kemampuan likuditas paling rendah jika dibandingkan dengan
cluster yang lain. Artinya bahwa perusahaan pada cluster 3 memiliki kemampuan yang
kurang baik dalam memenuhi kewajiban jangka pendek jika dibandingkan dengan
cluster 2 dan 1.
- Sejalan dengan kemampuan likuiditasnya, perusahaan yang termasuk ke dalam cluster
ini juga memiliki kemampuan kemampuan solvabilitas (DAR dan DER) yang paling
rendah. Artinya, perusahaan-perusahaan pada cluster 3 memiliki kemampuan
membayar hutang jangka panjang yang kurang baik jika dibandingkan dengan cluster 2
dan 1.
- Kemampuan profitabilitas dapat dilihat melalui nilai variabel NPM, ROA, ROE, dan
EPS. Diketahui bahwa keempat rasio keuangan tersebut berada pada kategori yang
paling rendah, dengan demikian dapat dikatakan bahwa cluster 3 memiliki kemampuan
menghasilkan keuntungan yang kurang baik jika dibandingkan dengan cluster yang
lainnya.
- Kemampuan perusahaan dalam menghasilkan penjualan sangat dominan dipengaruhi
oleh aset yang dimiliki perusahaan (TATO), sedangkan penjualan melalui inventori
(ITO) berada pada kategori yang kurang baik. Nilai rasio TATO yang dimiliki
perusahaan dalam cluster 3 merupakan nilai yang paling tinggi di antara ketiga cluster.
Dengan demikian, jika ditinjau dari sudut pandang kreditor, maka dapat
disimpulkan bahwa perusahaan pada cluster 1 merupakan perusahaan dengan kondisi
keuangan yang paling layak untuk diberikan pinjaman kredit keuangan, karena memiliki
kondisi keuangan yang paling baik terutama dalam hal likuiditas dan solvabilitas. Sehingga
diharapkan peluang terjadinya kredit macet pada cluster ini menjadi seminimal mungkin.
Urutan selanjutnya adalah perusahaan yang berada pada cluster 2, dan yang terakhir adalah
perusahaan-perusahaan yang termasuk ke dalam cluster 3. Berikut adalah rincian nama-
nama perusahaan properti yang menjadi anggota masing-masing cluster. Diketahui bahwa
terdapat 11 perusahaan yang termasuk ke dalam cluster 1, 17 perusahaan termasuk ke
dalam cluster 2, dan 4 perusahaan termasuk ke dalam cluster 3.

74 Biastatistics Vol 11, No.1, Februari 2017
Tabel 2. Hasil Pengelompokan Perusahaan Properti
dengan Metode K-Means Cluster
No. Nama Perusahaan Cluster
1 PT. Alam Sutera Realty Tbk. 2
2 PT. Bumi Citra Permai Tbk. 2
3 PT. Bhuwanatala Indah Permai Tbk. 3
4 PT. Bukit Darmo Property Tbk. 1
5 PT. Sentul City Tbk. 1
6 PT. Bintang Mitra Semestaraya Tbk. 3
7 PT. Bumi Serpong Damai Tbk. 2
8 PT. Cowell Development Tbk. 3
9 PT. Ciputra Development Tbk. 1
10 PT. Ciputra Property Tbk. 1
11 PT. Ciputra Surya Tbk. 2
12 PT. Intiland Development Tbk. 1
13 PT. Duta Pertiwi Tbk. 2
14 PT. Bakrieland Development Tbk. 1
15 PT. Gowa Makassar Tourism Development Tbk. 2
16 PT. Indonesian Paradise Property Tbk. 1
17 PT. Jakarta Iternasional Hotel & Development Tbk. 2
18 PT. Jaya Real Property Tbk. 2
19 PT. Jakarta Setiabudi Internasional Tbk. 2
20 PT. Dayaindo Resources International Tbk. 1
21 PT. Jababeka Tbk. 2
22 PT. Lamicitra Nusantara Tbk. 2
23 PT. Laguna Cipta Griya Tbk. 1
24 PT. Lippo Cikarang Tbk. 2
25 PT. Lippo Karawaci Tbk. 2
26 PT. Mas Murni Indonesia Tbk. 1
27 PT. Modernland Realty Tbk. 2
28 PT. Indonesia Prima Property Tbk. 2
29 PT. Pembangunan Jaya Ancol Tbk. 2
30 PT. Resources Asia Fasifik Tbk. 3
31 PT. Pudjiadi Prestige Tbk. 1
32 PT. Pakuwon Jati Tbk. 2

Biastatistics Vol 11, No.1, Februari 2017 75
5. KESIMPULAN
Penelitian ini mengambil data 32 perusahaan property. Sebelas perusahaan di
antaranya termasuk ke dalam cluster 1, 17 perusahaan termasuk ke dalam cluster 2, dan 4
perusahaan termasuk ke dalam cluster 3. Perusahaan pada cluster 1 tergolong memiliki
kemampuan yang paling baik dalam memenuhi kewajiban jangka pendek (likuiditas) jika
dibandingkan dengan cluster 2 dan 3. Sejalan dengan kemampuan likuiditasnya,
perusahaan pada cluster 1 juga tergolong memiliki kemampuan solvabilitas (kemampuan
membayar hutang jangka panjang) yang paling baik. Perusahaan pada cluster 2 tergolong
memiliki kemampuan yang cukup baik dalam memenuhi kewajiban jangka pendek
(likuiditas) jika dibandingkan dengan cluster 1 dan 3. Demikian juga dalam hal memenuhi
hutang jangka panjang yang tergolong kategori cukup baik. Perusahaan pada cluster 3
memiliki kemampuan yang kurang baik dalam memenuhi kewajiban jangka pendek
(likuiditas) jika dibandingkan dengan cluster 2 dan 3. Sejalan dengan hal itu, perusahaan
yang termasuk ke dalam cluster ini juga memiliki kemampuan yang kurang baik dalam hal
memenuhi kewajiban jangka panjang. Dengan demikian, dapat disimpulkan bahwa
perusahaan pada cluster 1 merupakan perusahaan dengan kondisi keuangan yang paling
layak untuk diberikan pinjaman kredit.
6. DAFTAR PUSTAKA
Sichah, I.A., dan Safitri, D. Statistika Multivariat. Semarang: Jurusan Matematika F-MIPA UNDIP,
2005
Hartigan, J.A. Clustering Algoritm. New York: John Wiley & Sons, 1975.
Chris Ding dan Xiaofeng He. K-means Clustering via Principal Component Analysis. Proceedings
of International Conference Machine Learning (ICML 2004): 225–232
Munawir, S. Analisis Informasi Keuangan. Yogyakarta: Liberty, 2002.
ECFIN. Indonesian Capital Market Directory 2011. Sumber online:
http://www.jcholse.tk/2012/04/download-indonesian-capital-market.html. Diakses 9
September 2012.


Biastatistics Vol 10, No.1, Februari 2016
Indeks Penulis
A
Achmad Zanbar Soleh .............. 1, 52
B
Bertho Tantular ................................ 19
Budhi Handoko ................................ 52
G
Gatot Riwi Setyanto ......................... 1
H
Hari Wijayanto ................................. 33
I
I Gede NYoman Mindra Jaya ...... 19
Indahwati .......................................... 33
L
Latifah Rahayu Siregar .................. 12
Lienda Noviyanti ......................... 1, 52
R
Radhiah ............................................. 64
Riska Apriani Sari ............................. 33
S
Samsul Anwar ................................. 64
Z
Zulfan ................................................. 64
Zulhanif .............................................. 19
Zurnila Marli Kesuma ....................... 12

Biastatistics Vol 10, No.1, Februari 2016
Indeks Subject
A
Aktivitas ................................................... 64
Analisis Korespondensi.......................... 12
B
Biweight Tukey ....................................... 33
D
Distribusi Besar Klaim ............................. 52
Distribusi Frekuensi Klaim ...................... 52
I
Iuran Normal............................................. 1
K
Kewajiban Tambahan ............................ 1
L
LAD........................................................... 33
Likuiditas .................................................. 64
M
Manajemen Resiko ............................... 64
Matriks Peluang Transisi .......................... 1
Metode K-Means Cluster ..................... 64
P
Pemetaan Penyakit .............................. 19
Pencilan .................................................. 33
Pendekatan Bayesian .......................... 52
Penyakit Jantung .................................. 12
Profitabilitas ............................................ 64
R
Rasio Keuangan .................................... 64
Respon Ganda ...................................... 19
S
SBM Optimal ........................................... 52
Seemingly Unrelated Regression ........ 19
Solvabilitas .............................................. 64
T
Theil .......................................................... 33
U
Uji Eksak Fisher ........................................ 12


















