Native Simulation of Complex VLIW Instruction Sets Using Static Binary Translation and Hardware
Upload
bridget-roadsCategory
view
221download
1
VLIW
Very Large Instruction Word

Introduction Very Long Instruction Word is a concept for
processing technology that dates back to the early 1980s.
The term VLIW refers to the size of each instruction that is carried out by a processor. This instruction is "very long" in comparison to the instruction word size utilized by most current mainstream (superscalar) processors.

Introduction Most non-VLIW processors use complex
hardware units to schedule processes in an overlapping fashion known as pipelining.
This process allows multiple operations to execute simultaneously, in a cascading fashion, to achieve the maximum utilization of processing power.
It is implemented at runtime, which has the result that the hardware is under pressure to accurately order instructions as they fly by.

Introduction Many techniques are used to predict the
upcoming instructions for maximum efficiency in scheduling: what branches the code will take, what registers will be accessed next, what operations will be requested.
These algorithms are complicated and tend to bloat the processing hardware. Since the scheduling has to be done on-the-fly, there is potential for time-wasting error.

Introduction Since VLIW code is ordered for the processor
at compile time, this is all done before the code is ever actually executed.
As a VLIW compiler sorts through the code, it examines it to determine which instructions will be able to be executed simultaneously.
This is often done via a process called trace scheduling. It pairs these instructions up to form the lengthy instruction words the technology is named for.

Introduction The long instructions can be executed
easily by the hardware, which in turn is made less complex by the structure of the bits being fed to it. The hardware generally consists of identical multiple execution units.

Introduction VLIW processing ideas have roots in
Alan Turing's 1946 parallel computing studies and
Maurice Wilkes's 1951 microprogramming work.

Introduction Microprogrammed CPUs have a
macroinstruction that corresponds to each program instruction. Each of these macroinstructions has a corresponding sequence of microinstructions, kept in ROM on the CPU.
These microinstructions can be ordered into wide sets of control signals. This is called horizontal microprogramming.

Introduction When Joseph Fisher was working on writing
horizontal microcode for a CDC-6600 emulator in 1979, he began to work on the problem of generating long instruction words from short sequential instructions.
The techniques he developed, called "trace scheduling" were essential for generating VLIW-compatible code.

Introduction VLIW has been slow to gain market
acceptance due in large part to the human programming difficulties involved.
VLIW's advantages come largely from having an intelligent compiler that can schedule many instructions simultaneously (in a large word).

Introduction Early VLIW implementations looked
only into basic program blocks to obtain instruction level parallelism (ILP), and could not follow complex branches.
As such, little optimization was possible.

Introduction Authoring a compiler to effectively
predict code paths is easily the largest hurdle of VLIW design.
Hence the interest in SequenceL as a VLIW language.

Introduction Another big problem is that any VLIW-
compatible code is largely proprietary to the hardware of the chip it is designed for.
Code written for a processor using five execution units will be incompatible with one using seven. The inflexibility inherent in microchip design makes this a problem.

Introduction VLIW also has some problems with the
inflexibility of its compiler-first design. Since instructions are ordered at compile time, any unanticipated memory conflicts that occur (e.g., latency, cache misses) can not be accounted for without deviation from a pure VLIW design; that is, adding superscalar elements to the processor.

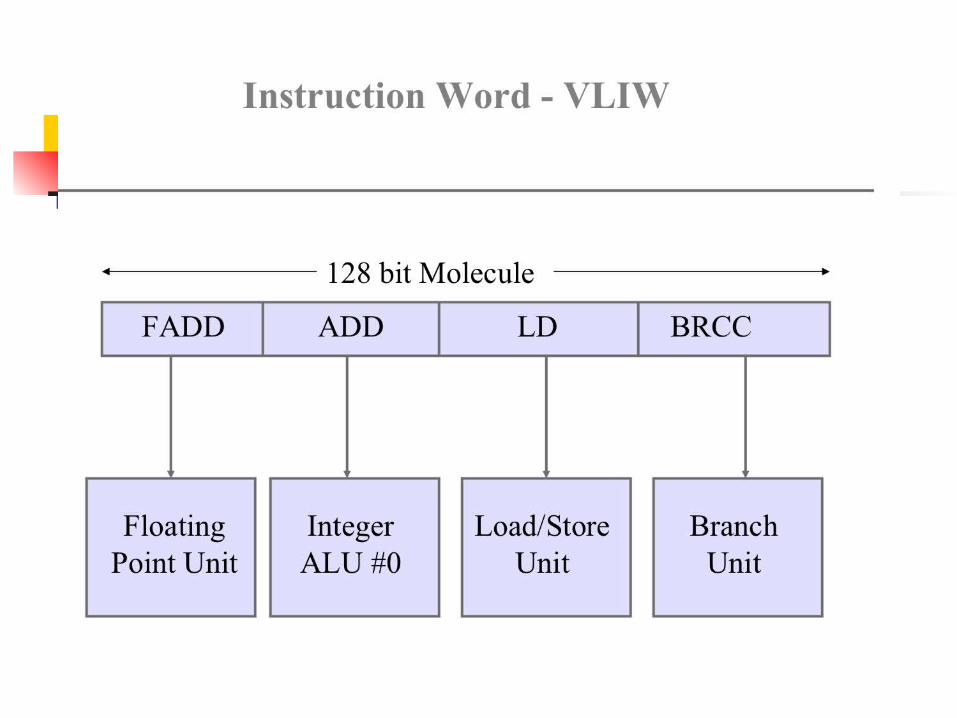
Example of a VLIW
VLIW instruction Set of independent operations that are to be issued
simultaneously (no sequential notion within a VLIW) 1 instruction issued every cycle – provides notion of time Resource assignment indicated by position in VLIW
add sub load load store mpy shift branch

Add Add Mpy Mem Mem
Register File
add nop nop load storeVLIW instruction =5 independent operations
Icache

VLIW How can the processing units be kept
busy by the compiler?

VLIW How can the processing units be kept
busy by the compiler? Unroll loops?

Unroll loopsfor(i=0; i < n; i++){
a[i]=b[i]*c[i];}Becomesfor(i=0; i < n; i++){
a[i]=b[i]*c[i];a[i+1]=b[i+1]*c[i+1];i++;
}

Optimizing unrolled loops
r1 = load(r2)r3 = load(r4)r5 = r1 * r3r6 = r6 + r5r2 = r2 + 4r4 = r4 + 4if (r4 < 400) goto loop
loop: r1 = load(r2)r3 = load(r4)r5 = r1 * r3r6 = r6 + r5r2 = r2 + 4r4 = r4 + 4
r1 = load(r2)r3 = load(r4)r5 = r1 * r3r6 = r6 + r5r2 = r2 + 4r4 = r4 + 4
r1 = load(r2)r3 = load(r4)r5 = r1 * r3r6 = r6 + r5r2 = r2 + 4r4 = r4 + 4if (r4 < 400) goto loop
iter1
iter2
iter3
Unroll = replicate loop body n-1 times.
Hope to enable overlap ofoperation execution fromdifferent iterations
Not possible!
loop:
unroll 3 times

r1 = load(r2)r3 = load(r4)r5 = r1 * r3r6 = r6 + r5r2 = r2 + 4r4 = r4 + 4
r1 = load(r2)r3 = load(r4)r5 = r1 * r3r6 = r6 + r5r2 = r2 + 4r4 = r4 + 4
r1 = load(r2)r3 = load(r4)r5 = r1 * r3r6 = r6 + r5r2 = r2 + 4r4 = r4 + 4if (r4 < 400) goto loop
iter1
iter2
iter3
loop: r1 = load(r2)r3 = load(r4)r5 = r1 * r3r6 = r6 + r5r2 = r2 + 4r4 = r4 + 4
r11 = load(r2)r13 = load(r4)r15 = r11 * r13r6 = r6 + r15r2 = r2 + 4r4 = r4 + 4
r21 = load(r2)r23 = load(r4)r25 = r21 * r23r6 = r6 + r25r2 = r2 + 4r4 = r4 + 4if (r4 < 400) goto loop
iter1
iter2
iter3
loop:
Register renaming on unrolled loop

Register renaming is not enough!
Still not much overlap possible
Problems r2, r4, r6 sequentialize
the iterations Need to rename these
2 specialized renaming optimizations
Accumulator variable expansion (r6)
Induction variable expansion (r2, r4)
r1 = load(r2)r3 = load(r4)r5 = r1 * r3r6 = r6 + r5r2 = r2 + 4r4 = r4 + 4
r11 = load(r2)r13 = load(r4)r15 = r11 * r13r6 = r6 + r15r2 = r2 + 4r4 = r4 + 4
r21 = load(r2)r23 = load(r4)r25 = r21 * r23r6 = r6 + r25r2 = r2 + 4r4 = r4 + 4if (r4 < 400) goto loop
iter1
iter2
iter3
loop:

Accumulator variable expansion
Accumulator variable x = x + y or x = x – y where y is loop variant!!
Create n-1 temporary accumulators
Each iteration targets a different accumulator
Sum up the accumulator variables at the end
r1 = load(r2)r3 = load(r4)r5 = r1 * r3r6 = r6 + r5r2 = r2 + 4r4 = r4 + 4
r11 = load(r2)r13 = load(r4)r15 = r11 * r13r16 = r16 + r15r2 = r2 + 4r4 = r4 + 4
r21 = load(r2)r23 = load(r4)r25 = r21 * r23r26 = r26 + r25r2 = r2 + 4r4 = r4 + 4if (r4 < 400) goto loop
iter1
iter2
iter3
loop:r16 = r26 = 0
r6 = r6 + r16 + r26

Induction variable expansion
Induction variable x = x + y or x = x – y where y is loop invariant!!
Create n-1 additional induction variables
Each iteration uses and modifies a different induction variable
Initialize induction variables to init, init+step, init+2*step, etc.
Step increased to n*original step
Now iterations are completely independent !!
r1 = load(r2)r3 = load(r4)r5 = r1 * r3r6 = r6 + r5r2 = r2 + 12r4 = r4 + 12
r11 = load(r12)r13 = load(r14)r15 = r11 * r13r16 = r16 + r15r12 = r12 + 12r14 = r14 + 12
r21 = load(r22)r23 = load(r24)r25 = r21 * r23r26 = r26 + r25r22 = r22 + 12r24 = r24 + 12if (r4 < 400) goto loop
iter1
iter2
iter3
loop:r16 = r26 = 0
r6 = r6 + r16 + r26
r12 = r2 + 4, r22 = r2 + 8r14 = r4 + 4, r24 = r4 + 8

Better induction variable expansion
With base+displacement addressing, often don’t need additional induction variables
Just change offsets in each iterations to reflect step
Change final increments to n * original step
r1 = load(r2)r3 = load(r4)r5 = r1 * r3r6 = r6 + r5
r11 = load(r2+4)r13 = load(r4+4)r15 = r11 * r13r16 = r16 + r15
r21 = load(r2+8)r23 = load(r4+8)r25 = r21 * r23r26 = r26 + r25r2 = r2 + 12r4 = r4 + 12if (r4 < 400) goto loop
iter1
iter2
iter3
loop:r16 = r26 = 0
r6 = r6 + r16 + r26

Scheduling Loop unrolling that generates straight
line code is scheduled for parallel execution using local scheduling techniques.
For scheduling code across branches a more complex global scheduling algorithm must be used.

Global Scheduling One global scheduling technique is trace
scheduling. Trace scheduling utilized two steps
1. Trace selection, trying to find sequences of basic blocks that could be put together into a smaller number of instructions. This sequence is called a trace.
2. Trace compaction, which tries to squeeze the trace into a small number of wide instructions.

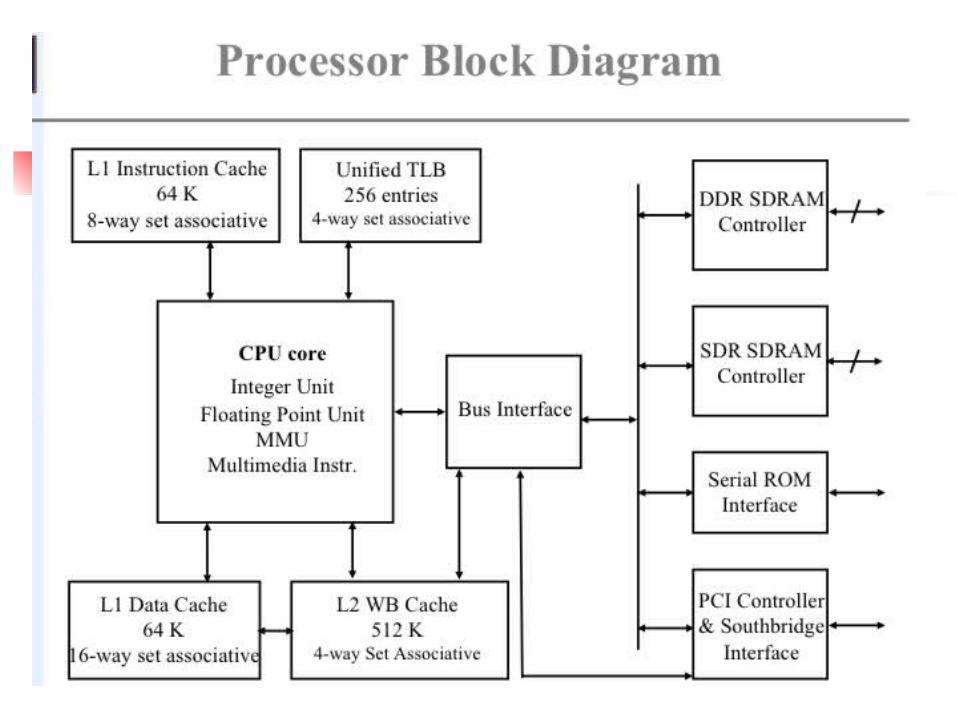
VLIW Processor Transmeta’s Crusoe line of processors is one
of the first all-purpose VLIW architecture implementations to be launched.
It was designed with mobile applications in mind, running at low temperatures and consuming little power--60 to 70% less than a comparable RISC chip, according to Transmeta.
The chip can be found in notebook computers. Toshiba Satellite R15-829