
Video Coding. Introduction Video Coding The objective of video coding is to compress moving images....
36
Video Coding
-
Upload
vincent-goodwin -
Category
Documents
-
view
225 -
download
0
Transcript of Video Coding. Introduction Video Coding The objective of video coding is to compress moving images....

Video Coding

Introduction
Video Coding The objective of video coding is to compress moving images.
The MPEG (Moving Picture Experts Group) and H.26X are the major standards for video coding.
Basic Concept Use interframe correlation for attaining better rate-distorion perf
ormance.

Chronological Table of Video Coding Standards
H.261
(1990)
MPEG-1
(1993)
H.263
(1995/96)
H.263+
(1997/98)
H.263++
(2000)
H.264
( MPEG-4
Part 10 )
(2002)MPEG-4 v1
(1998/99)MPEG-4 v2
(1999/00)MPEG-4 v3
(2001)
1990 1992 1994 1996 1998 2000 2002 2003
MPEG-2
(H.262)
(1994/95)ISO/IEC
MPEG
ITU-TVCEG

Features of Moving Pictures
Moving images contain significant temporal redundancy– successive frames are very similar

Intraframe and Interframe Coding Video coding algorithms usually contains tw
o coding schemes :
1. Intraframe coding 2. Interframe coding.

Intraframe Coding Intraframe coding does not exploit the correla
tion among adjacent frames; Intraframe coding therefore is similar to the still image coding.

Interframe Coding
The interframe coding should include motion estimation/compensation process to remove temporal redundancy.

Motion Estimation and Compensation
The amount of data to be coded can be reduced significantly if the previous frame is subtracted from the current frame.

Block-Matching
The MPEG and H.26X standards use block-matching technique for motion estimation /compensation.
In the block-matching technique, each current frame is divide into equal-size blocks, called source blocks.
Each source block is associated with a search region in the reference frame.

The objective of block-matching is to find a candidate block in the search region best matched to the source block.
The relative distances between a source block and its candidate blocks are called motion vectors.
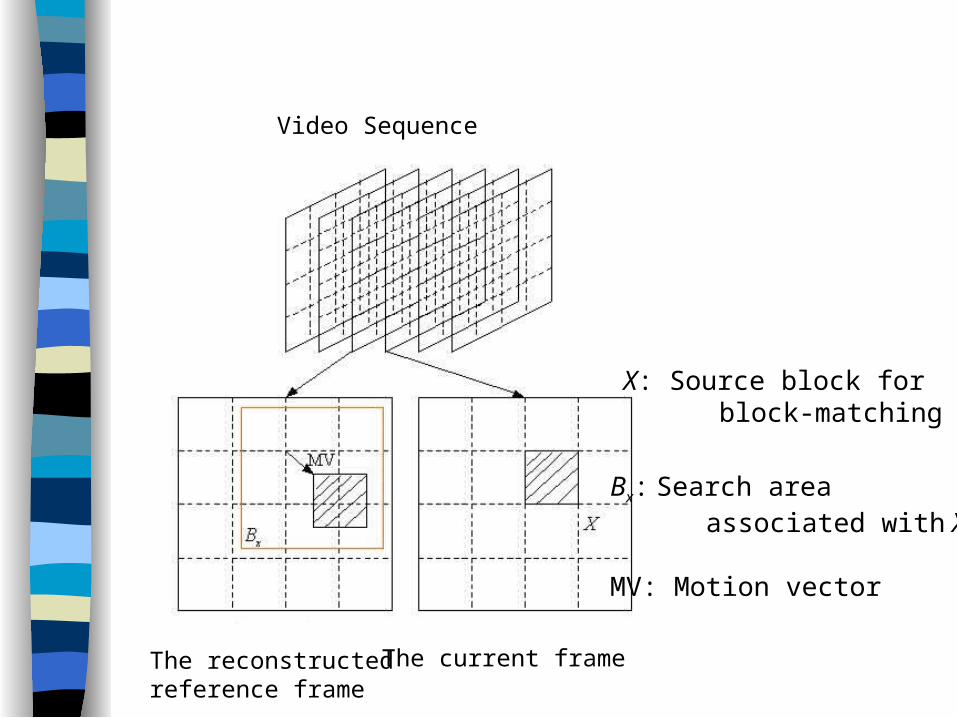
Video Sequence
The current frameThe reconstructed reference frame
Bx: Search area associated with X
MV: Motion vector
X: Source block for block-matching

The reconstructed previous frame The current frame
Results of block-matching
The predictedcurrent frame

Predicted Current Frame
Displaced Frame Difference(DFD,估測誤差 )

Search Area
Source block
Candidate block
pnpn 22 Search Area:
Motion vector: (u, v)
Motion vector and search area

Full-search algorithm
If p=7, then there are(2p+1)(2p+1)=225 candidate blocks.
u
vSearch Area
CandidateBlock

-6
-5
-4
-3
-2
-1
0
1
2
3
4
5
6
7
11 1
11
11 1
-7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7
3
3
333
3
3 3
2 2 2
2
222
2
Three-step algorithm

The first step involves block-matching based on 4-pel resolution at the nine location.
The second step involves block-matching based on 2-pel resolution around the location determined by the first step.
The third step repeats the process in the second step (but with resolution 1-pel).

Video Coding Based on Block-Matching
Assume frame f-1 has been encoded and reconstructed, and frame f is the current frame to be encoded.

Encoder side
1. Divide frame f into equal-size blocks.
2. For each source block obtained in step1,
(2.1) Find its motion vector using the block-matching algorithm based on the reconstructed frame f-1. (2.2) Compute the DFD of the block.

3. Transmit the motion vector of each block to decoder.
4. Compress DFD’s of each block.
5. Transmit the encoded DFD’s to decoder.

EntropyCoding
Deq./Inv. Transform
Motion-Compensated
Predictor
ControlData
0
Intra/Inter
CoderControl
Decoder
MotionEstimator
Transform/Quantizer-
Video in DFD
Motion Vector
Encoded DFD
Reconstructed DFD
Reconstructed currentframe
The block diagram of an encoder based on block-matching
Predicted current frame

Decoder side
1.Receive motion vector of each block from encoder.
2.Based on the motion vector ,find the best-matching block from the reference frame.That is, find the predicted current frame from thereference frame.

3.Receive the encoded DFD of each block from encoder.
4.Decode the DFD.
5.Each reconstructed block in the current frame = Its decompressed DFD + the best-matching block.

Encodedbitstream in
Motion vector
Encoded DFD
Predictedcurrent frame Reconstructed DFD
Reconstructedcurrent frame
The block diagram of a decoder based on block-matching

Bidirectional Prediction
The block-matching operations can be extended for bi-directional prediction, where a block in the current frame is estimated from a block in:
(a) Previous frame
(b) Future frame

Each block in a bi-directional frame is the average of a block in the previous frame and a block in the future frame.

A video sequences therefore may contain three different types of frames: (a) Intra frames, (I-frames)(b) Predicted frames (P-frames),(c) Bi-directional frames (B-frames)

The MPEG standards uses all the three types of frames as shown below.
Encoding order: I0, P3, B1, B2, P6, B4, B5, I9, B7, B8.
Playback order: I0, B1, B2, P3, B4, B5, P6, B7, B8, I9.

Video Structure
Video standards such as MPEG and H.26X code video sequences in hierarchy of layers.
There are usually 5 layers:
1. GOP (Group of pictures)
2. Picture
3. Slice
4. Marcoblock
5. Block
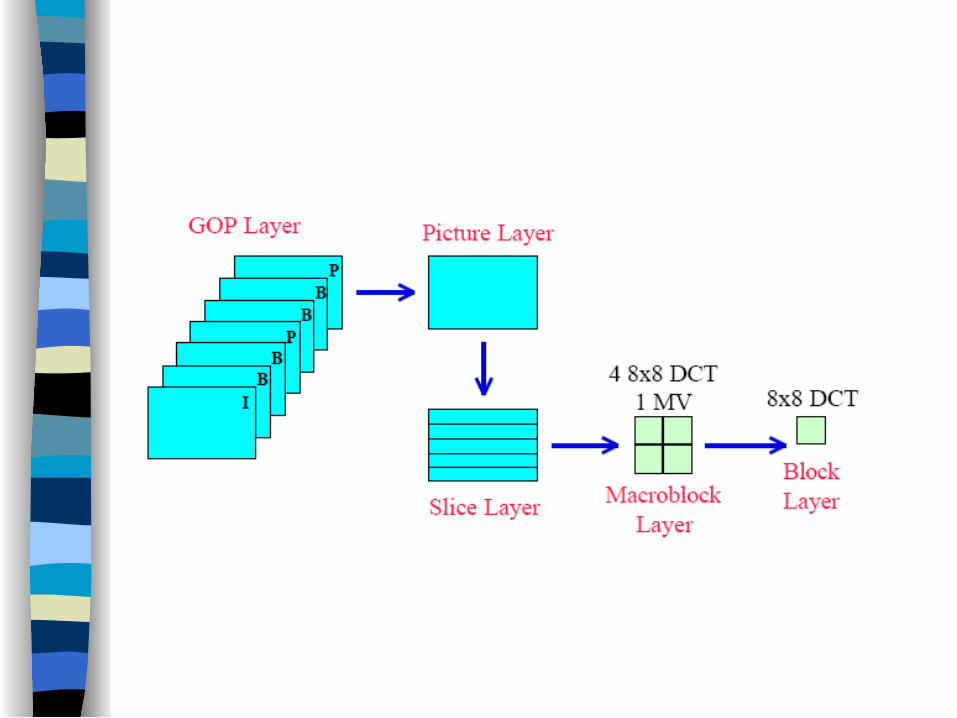

A GOP usually started with I frame, followed by a sequence of P and B frames.
A Picture is indeed a frame in the video sequence.
A Slice is a portion in a picture. Some standards do not have slices. Some view a slice as a row. Each slice in H.264 is not necessary to be a row. It can be any shape containing integral number of macroblocks.

A Macroblock is a 16×16 block. Many standards use Marcoblocks as the basic unit for block-matching operations.
A Block is a 8×8 block. Many standards use the Blocks as the basic unit for DCT.

Scalable Video Coding
Three classes of scalable video coding techniques:– Temporal Scalability– Spatial Scalability– SNR Scalability

Temporal Scalability
We can use B frames for attaining temporal scalability.
• B frames depend on other frames.• No other frames depend on B frames.• We can discard B frames without affecting other frames.

Spatial (Resolution) Scalability
Here the base layer is the low resolution version of the video sequence.

SNR Scalability
The base layer uses coaser quantizer for DFD coding.
The residuals in the base layer is refined in the enhancement layer.


















