
Vibrato and vowel identification - Royal Institute of ... · STL-QPSR 2-3/1975 Introduction Vibrato...
18
Dept. for Speech, Music and Hearing Quarterly Progress and Status Report Vibrato and vowel identification Sundberg, J. journal: STL-QPSR volume: 16 number: 2-3 year: 1975 pages: 049-060 http://www.speech.kth.se/qpsr
Transcript of Vibrato and vowel identification - Royal Institute of ... · STL-QPSR 2-3/1975 Introduction Vibrato...

Dept. for Speech, Music and Hearing
Quarterly Progress andStatus Report
Vibrato and vowelidentification
Sundberg, J.
journal: STL-QPSRvolume: 16number: 2-3year: 1975pages: 049-060
http://www.speech.kth.se/qpsr


STL-QPSR 2-3/1975
111. MUSICAL ACOUSTICS
A. VIBRATO AND VOWEL IDENTIFICATION
J. Sundberg
Abstract
The influence of vibrato on vowel identification i s studied in synthesized vowel sounds with fundamental frequencies between 300 and 1000 Hz. Phonetically trained subjects were asked to identify these stimuli presented with and without vibrato a s any of 12 Swedish long vowels. Small and occasional effects a r e ob- served on the mean formant frequencies and the scatter between the responses.
However, the effects a r e greater and more frequent$haai would be expected by chance. In a majority of the cases, where the vibrato affected the responses, the vowel identification became somewhat harder when the stimulus was presented with vibrato.

STL-QPSR 2-3/1975
Introduction
Vibrato occurs in music performed on many types of instruments,
such a s s t r ing and wind instruments and i n singing. Physically it cor - responds to an almost sinusoidal modulatio~t of the fundamental frequency.
Provided that the r a t e and extent of the vibrato i s kept within certain l im-
i t s , the vibrato i s generally considered a useful means of musical ex-
pression in a variety of musical styles. I
Acoustic character is t ics typical of music sounds can be assumed to
serve some purpose in musical communication. One commonly heard
hypothesis i s that the vibrato covers up small e r r o r s in the fundamental
frequency. In a previous investigation no support was found for this hypo-
thesis a s fa r a s the pitch of single tones - and thus not chords - i s con-
cerned (Sundberg 197 2). In the present investigation another commonly
heard hypothesis will be tested, namely that the vibrato facil i tates vowel
identification. This hypothesis seems plausible, because as the part ia ls
move in frequency (e . g. owing to a vibrato) their amplitudes scan small
p a r t s of the vocal-tract t ransfer function, and m o r e information on the , formant frequencies i s communicated. The effect would be particularly
strong in the soprano range where the fundamental frequency may be even
higher than 1000 Hz and the information on the formant frequencies would
be ha rd to decode f r o m the acoustic spectrum.
Experiment
A se r i e s of high-pitched sounds were synthesized with and without
vibrato using a terminal analogue. Six formant-frequency combinations
were used, each of which corresponds to a Swedish long vowel: [u , o,
a , e , i , y ] . The vowel formant frequencies ( s e e Table 111-A-I)
were typical of soprano singing according to previous measurements on
a singer singing a t a fundamental of 262 Hz (Sundberg 1975). Contrary to
what was found in this soprano, each of these s ix combinations of formant
frequencies were used without changes for four different pitches within
the soprano range: 300, 450, 675, and 1000 Hz. In this way the mater ia l
included sounds ranging f rom maximum ease to maximum difficulty a s
regards vowel identification. The vibrato consisted of a sinusoidal modu-
lation of the fundamental frequency. The r a t e was six ondulations per
second, and the extent was 50 cents. These values a r e found in normal
singing, even though the extent i s normally slightly narrower.
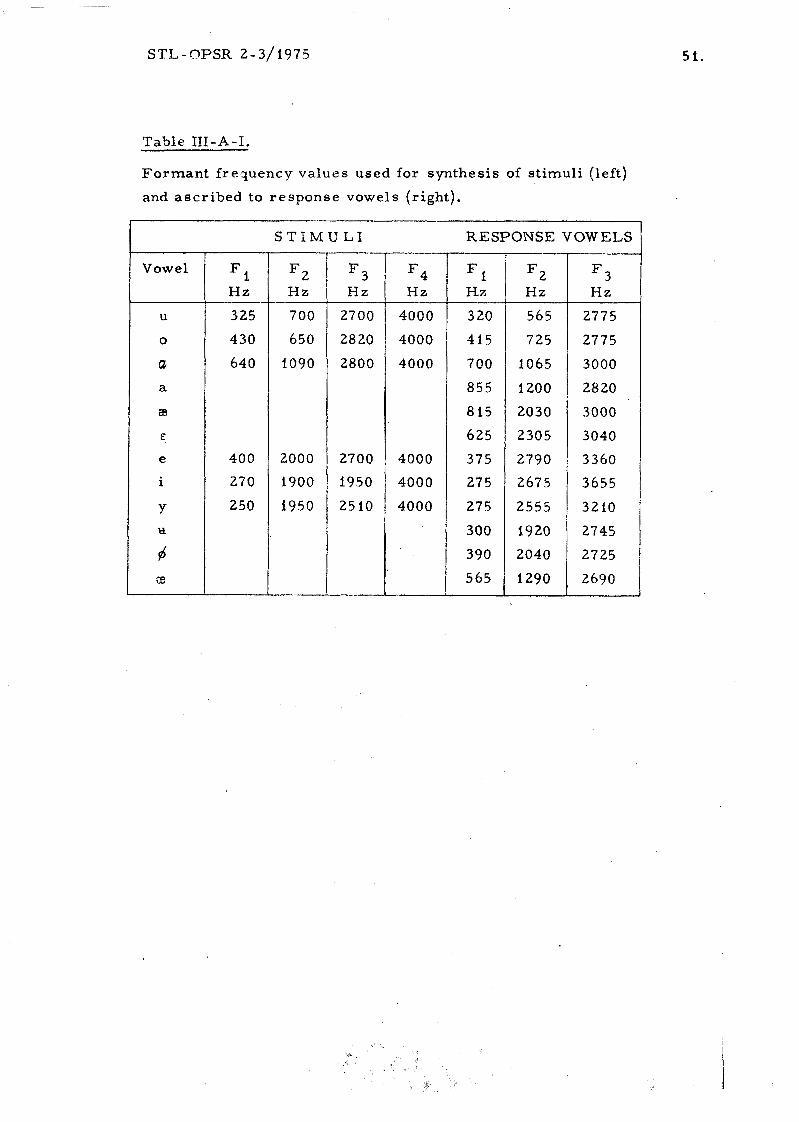
Table 111-A-I.
F o r m a n t f requency va lues used for syn thes i s of s t imul i ( lef t)
and a s c r i b e d t o r e s p o n s e vowels ( r ight ) .
I STIMULI RESPONSE VOWELS
Vowel
u
o
a a
a3
E
e
1
Y u
d ce
1 Hz
325
430
640
400
270
250
=2 H z
700
650
1090
2000
1900
1950
F3 H z
F4 H z
= 1 H z
I
2700 1 4000 320
415
700
855
815
625
375
275
275
300
390
565
2820
2800
2700
1950
2510
F2 H z
4000
4000
4000
4000
4000
Hz F3
565
725
1065
1200
2030
2305
2790
2675
2555
1920
2040
1290
2775
2775
3000
2820
3000
3040
3360
3655
3210
2745
2725
2690 J

STL-QFSR 2-3/1975 52.
Four samples of each vowel stimulus were tape recorded a t a constant
overall amplitude. The t ime and the shape of the onsets and decays were
a l l s imilar . The stimuli samples were arranged in random order avoid-
ing m o r e than one repetition of a given stimulus in sequence. The ent i re
tape contained a total of 192 vowel samples: six formant-frequency com-
binations x four fundamental frequencies x four presentations x two cases
(with and without vibrato). Each stimulus had a duration of I sec and was
followed by a silent interval of 4 sec.
The stimuli were presented in head-phones (Sennheiser HD 414) a t an
overall SPL of 70 dB, approximately, to ten phonetically trained subjects.
Their task was to decide which one of 12 given Swedish long vowels [ u, o,
a, a, ;e, E, e, i , y, u, 4 , c e ] sounded most s imilar to the stimulus they
heard and to write that vowel in phonetic symbols on a tes t chart. These
vowels suggested by the subjects a s interpretations of the stimuli will be
r e fe r red to a s response vowels. The test , including three short breaks,
took, i n all , about 30 min.
Evaluation of r e snons e s
I t seems reasonable to hypothesize that the process of identifying an I
isolated stimulus a s a specific vowel involves three major steps. The
f i r s t is a purely sensory one in which the acoustic stimulus i s converted
into some kind of sensory information. The second step involves an ex-
traction of an ensemble of sensory character is t ics f rom this sensory
information. In the third step a comparison i s made between these sen-
sory character is t ics and corresponding character is t ics of vowels s tored
in the subject ' s internal reference. The difficulty of identifying a sound
a s a specific vowel would depend on the degree of s imilar i ty between the
ensemble of sensory character is t ics and the character is t ics in the internal
reference.
The vibrato may affect the sensory information in various ways. Let
us assume that i t affects the extraction of sensory character is t ics . If so,
the responses for a given vibrato stimulus should differ f rom those ob-
tained when the same stimulus was presented without vibrato. In the tes t
responses the effect would then be that the mean formant frequencies of
the response vowels for a given stimulus would differ between the cases
with and without vibrato. In that case the identification difficulties may

STL-QPSR 2- 3/1975 53.
be affected i n various ways, depending on whether the vibrato makes the
sensory character is t ics (1) more s imi lar , (2) l e s s s imi lar , o r (3) equally
s imilar to the subject' s reference features. The cases (1) and (2) would
affect the scatter of the responses.
The above considerations show the need for measures of the average and
scat ter of the response vowels. In order to obtain such measures a set of
formant frequencies was ascr ibed to each of the 12 response vowels in ac-
cordance with data on female speakers , given by Fant (197 3). These values
a r e l is ted in Table 111-A-I. I t should be noted that the same formant f re -
quencies were ascr ibed to a given response vowel regard less of the funda-
mental fr equency of the corresponding stimulus. The formant frequencies
were expressed in .Mels and the mean formant frequencies of the response
vowels were computed for each stimulus.
Resul ts
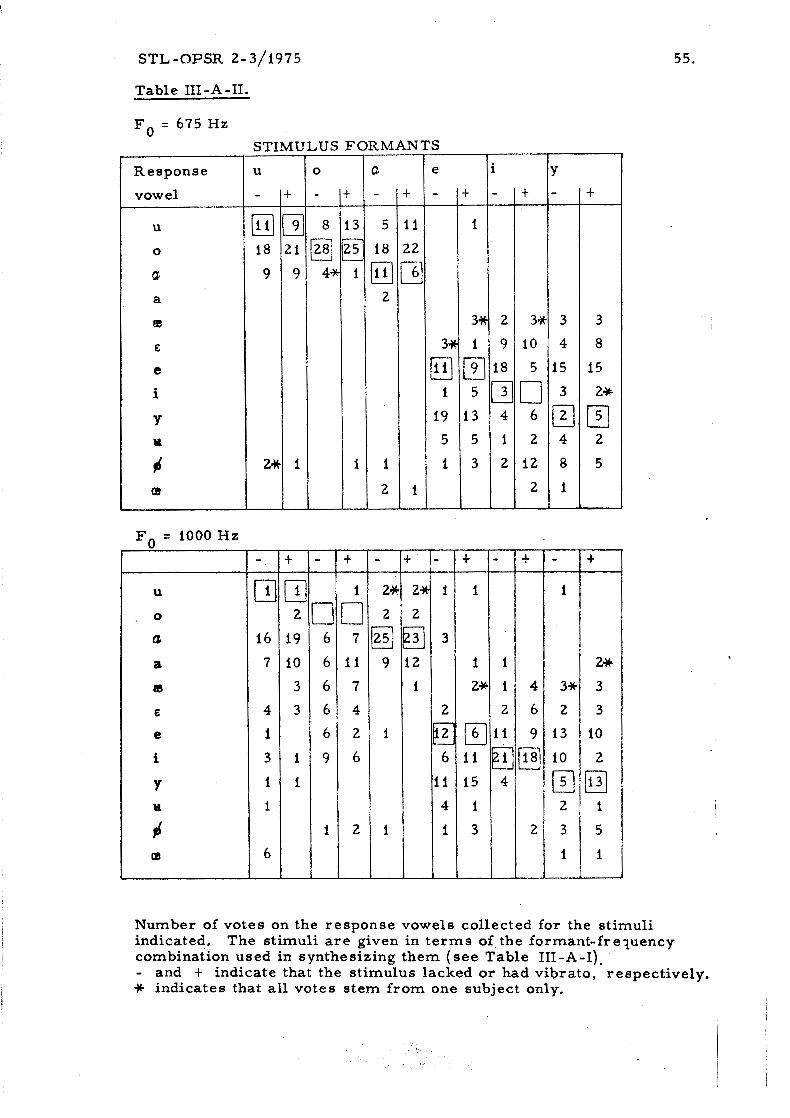
The responses a r e l is ted in Table 111-A-11. One of the subjects refused
to give an answer to three of the stimuli, a l l of which happened to lack vib-
rato. The inter- subject differences rkgarding the internal reference were
ra ther small: three o r four unique votes on a specific response vowel were
given by the same subject only occasionally, a s can be seen in Table 111-A-II.
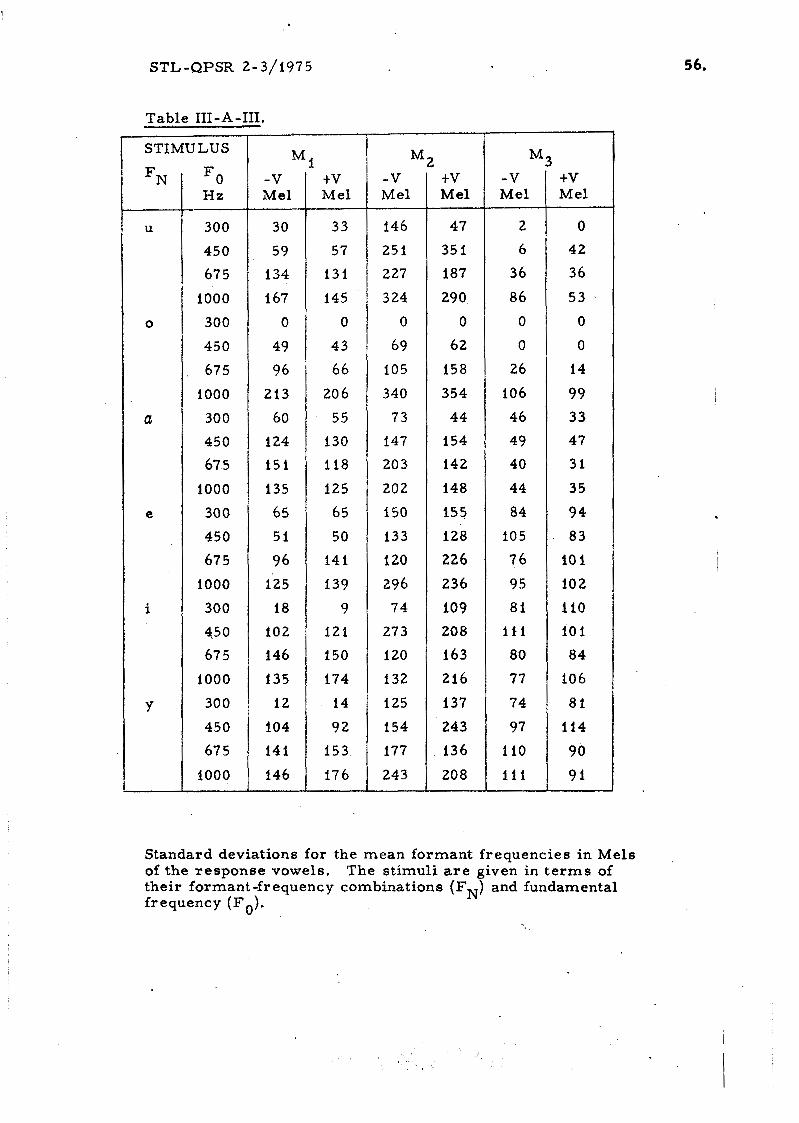
The mean formant frequencies of the response vowels a r e shown in Fig.
111-A- 1 and the corresponding standard deviations a r e given in Table 111-A-111.
The relationships between the mean formant frequencies of the r espon-
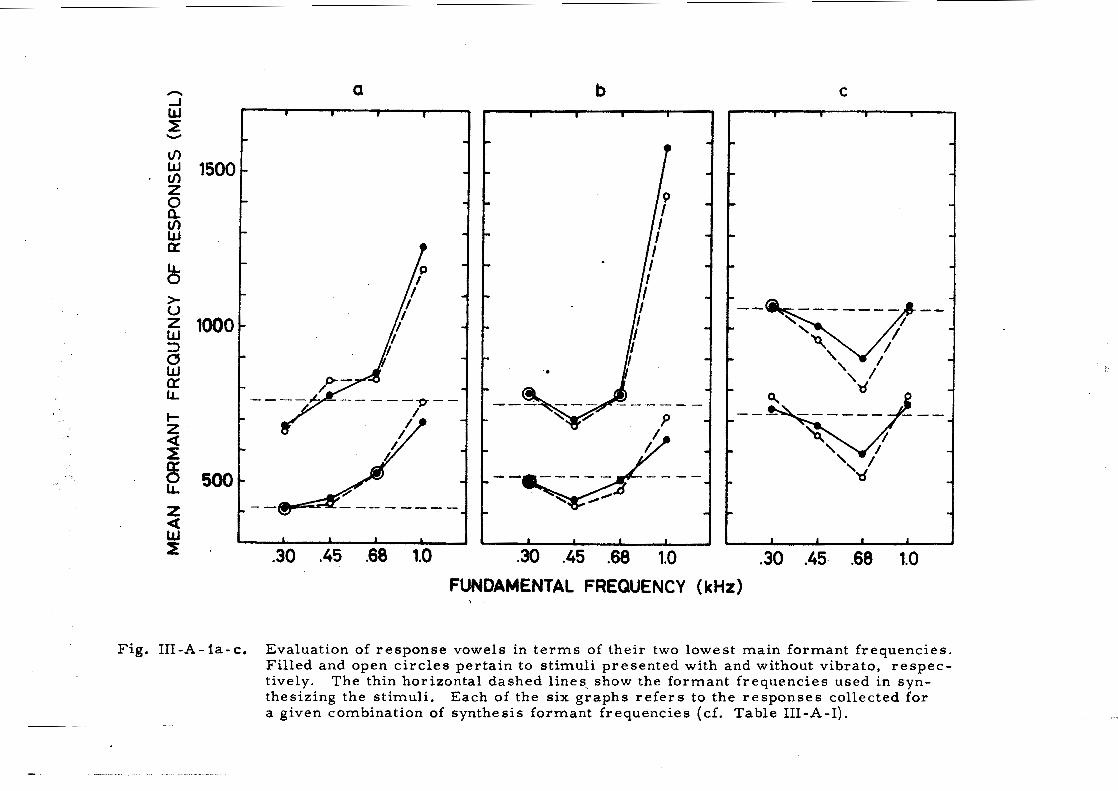
s e s and the stimulus spectra can be studied in Fig. 111-A-1, where, in
par t icular , the case of the stimuli synthesized with [I?]-formants offer an
i l lustrative example (Fig. 111-A- lc). The mean formant frequencies of the
responses drop with r is ing fundamental frequency up to 675 Hz. The r ea -
son for this is probably that, in o rde r to retain the vowel quality when the
fundamental is ra i sed , i t i s necessary to r a i s e the formant frequencies
slightly. Slawson (19 68) found an average increase of 10 b/o in the formant
frequencies to be required per octave r i s e of the fundamental. If the funda-
mental i s ra i sed while the formant frequencies a r e kept constant, a s was
done in our experiment, the vowel quality will shift towards a vowel with
lower formant frequencies. This effect can be seen i n the case of Fig.
111-A- 1 c. Presumably, the subjects identified the two lowest formant f re -
quencies correctly, and the formant frequencies ascr ibed to the response
vowels contain an e r r o r which i s dependent on the fundamental frequency.
A correction would be needed, but i t i s not known exactly how this cor rec-
tion should be made. F o r instance, Slawson's correction of 10 % in-
c rease in formant frequency pe r octave r i s e in the fundamental does not
FUNDAMENTAL FREQUENCY (kHz)
Fig. 111-A-la-c. Evaluation of response vowels in t e r m s of their two lowest main formant frequencies. Fil led and open c i r c l e s per ta in to s t imul i presented with and without vibrato, r e spec - tively. The thin horizontal dashed lines, show the formant f requencies used in s y n - thesizing the st imuli . Each of the s ix graphs r e f e r s to the r e sponses collected for a given combination of synthesis formant frequencies (cf. Table 111-A-I).
MEAN FORMANT FREQUENCY OF RESPONSES (MEL)
8 8 8 b 8 0 0 0
t I I 1 I I
I I I \ \\, k - I
P
& cn
$
s - I
1 I
I I
1 I I 1 I
1 I I I 1 \\ i I 1 I I I I I i I
k - I I I
- ( I
-* I cn ' I
I I @
t~ 1 4 I \ I
1 \ I ;5 - d 1 b 1
1 I I
I I I - I I I I 1 I I I - 1 I I 1 I I I I I 1 1
1 tl 6 1 I
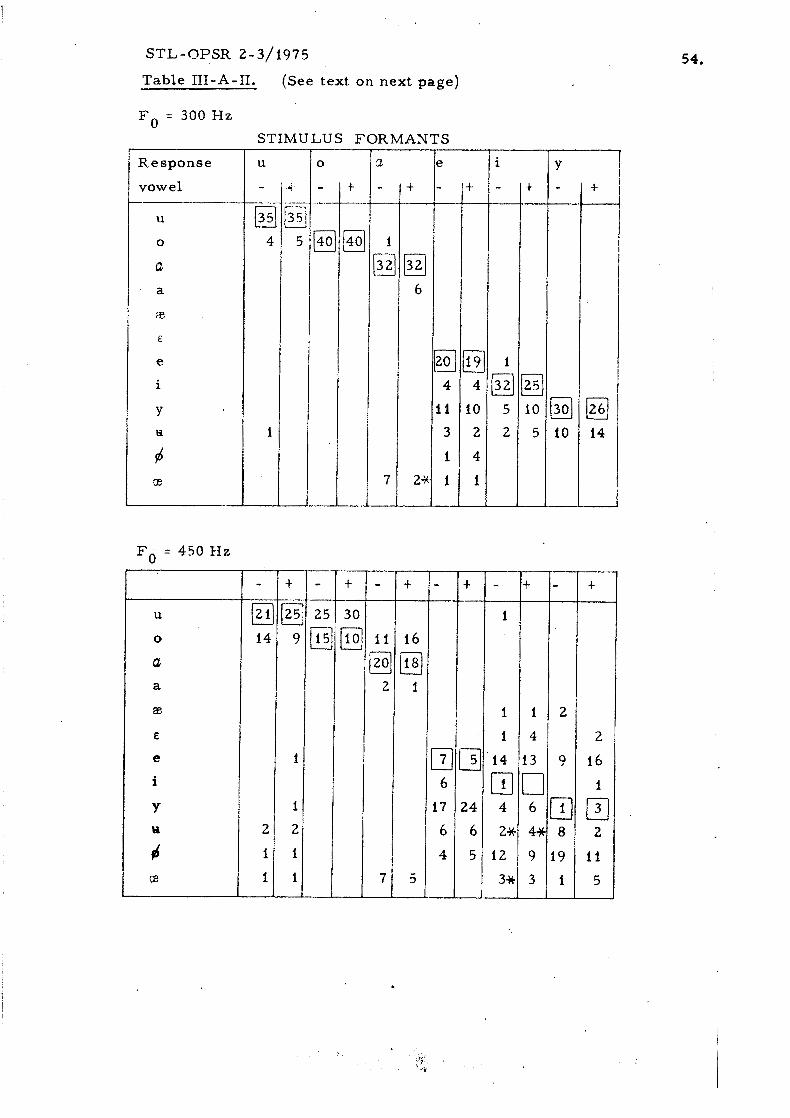
STL-OPSR 2-3/1975 54. Table 111-A-11. (See text on next page)
STL-OPSR 2-3/1975
Table 111-A-11.
STIMULUS FORMANTS
Response u o a e i Y
Number of votes on the response vowels collected for the stimuli indicated. The stimuli a r e given in t e r m s of the formant-freluency combination used in synthesizing them ( see Table 111-A-I), - and t indicate that the stimulus lacked or had vibrato, respectively. Sc indicates that a l l votes s tem f rom one subject only.
STL-QPSR 2 - 3 / 1 9 7 5
Standard deviations for the mean formant frequencies in Mels of the response vowels. The stimuli are given in terms of their formant frequency combinations (FN) and fundamental frequency (I?*).

STL-QPSR 2-3/1975 57.
fully compensate the effect in Fig. III-A- lc. I t should a l so be mentioned,
that a lmost invariably, a l l stimuli with a fundamental of 67 5 Hz gave r e -
sponse vowels in which one of the (assumed) formants matched one of the
stimulus par t ia ls in frequency almost perfectly. This fact may tempt us
to speculate that the formant frequencies ascr ibed to the response vowels
may be cor rec t when the pitch i s very high. Some additional support for
the same speculation may be found in the close frequency agreement be-
tween the formants of the responses and those of the stimulus in the case
of the 1000 Hz fundamental in Fig. 111-A- l c . However, i t s eems definite-
ly unsafe to study the relationships between the stimulus spectrum and the
mean formant frequencies of the responses i n our material . These f re -
quencies should not be compared between stimuli with differing funciamental
frequency.
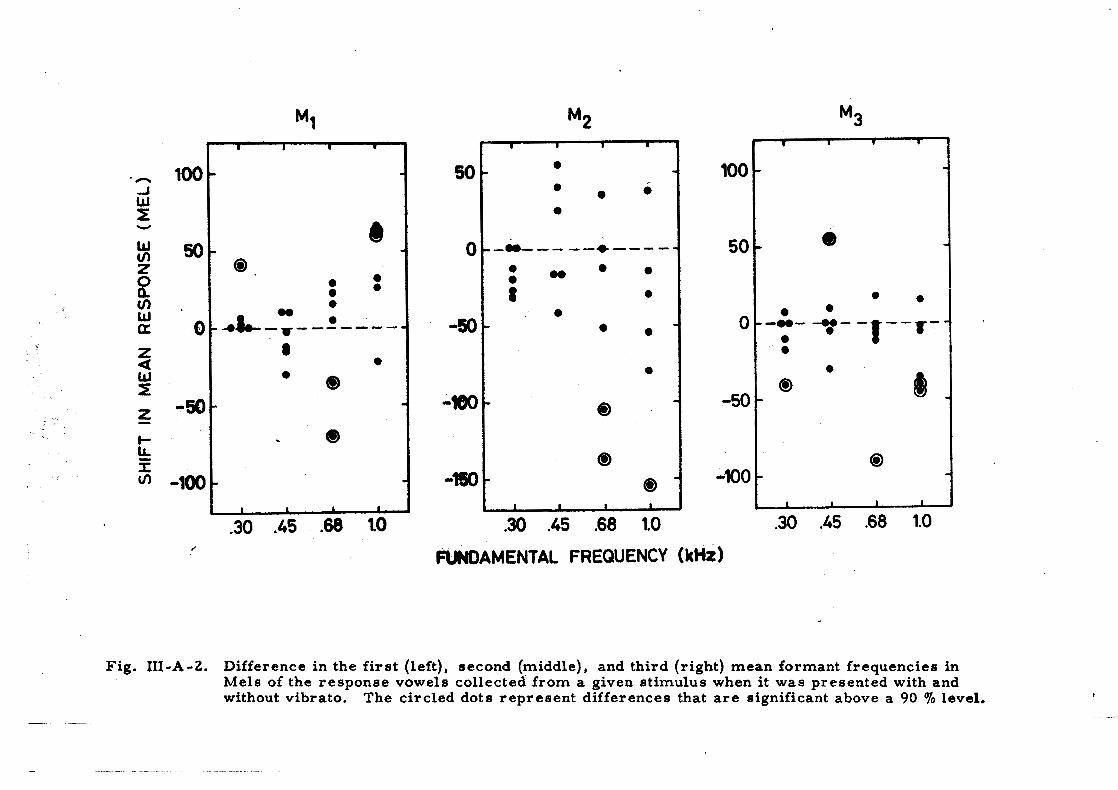
A comparison of the mean formant frequencies of the response vowels
obtained with and without vibrato would inform u s on the effect that the vibrato
may have on the extraction of sensory character is t ics , a s mentioned. Such
comparisons can be made i n Fig. III-A-2. I t shows the difference in the
mean formant frequencies of the response vowels. Negative values indi-
cate that the mean dropped when the stimulus had a vibrato. According to
a t - tes t the difference i s significant above a 90 O/o level in 13 cases out of
72. This suggests that, under cer tain conditions, the vibrato has an effect
on the extraction of the charactexistics f r o m the sensory information on
the stimulus.
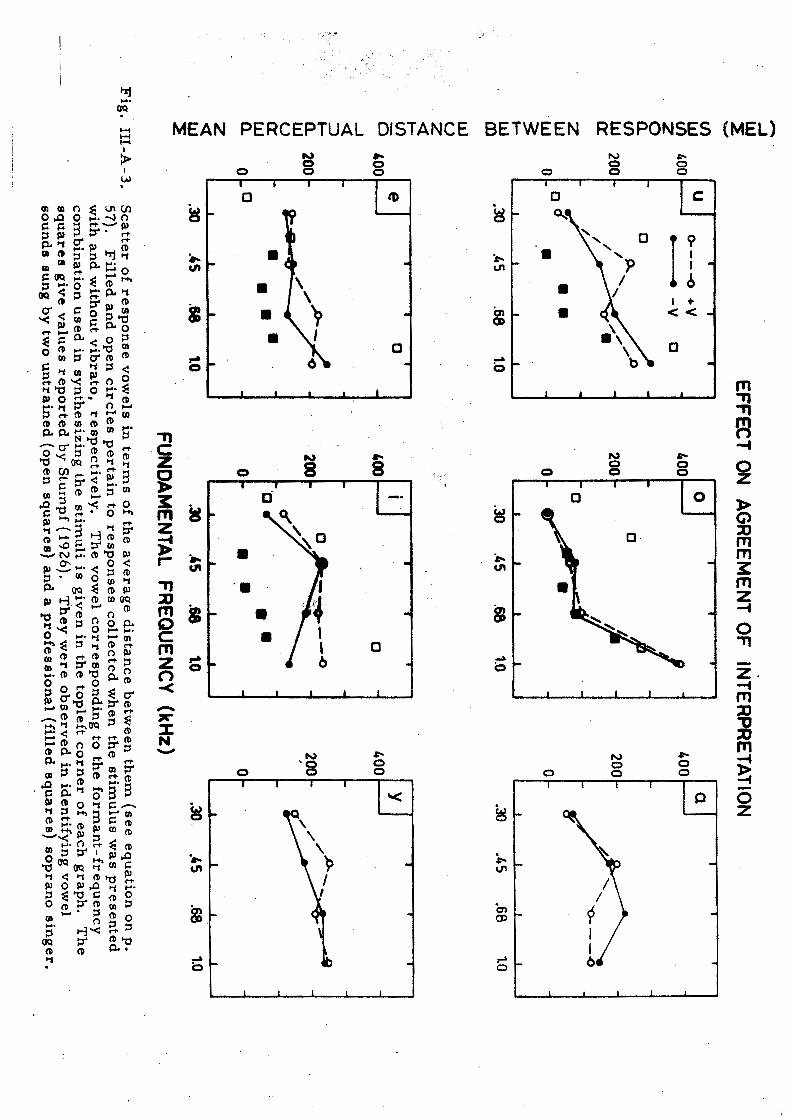
The scat ter between the responses can be computed a s the mean per -
ceptual distance between them. Recently Lindblom (1 97 5) following ideas
of Plomp (1970) has established that the perceptual distance D between any
two Swedish vowels can be approximated a s
where A M i s the frequency difference in d s in the n:th formant between n the two vowels. Using this equation the perceptual distance between the
mean formant frequencies of the response vowels ( see Fig. III-A- 1)
and the individual responses was calculated for each stimulus, and the
average was determined. These mean perceptual distances between the
responses can be studied in Fig. III-A- 3. They can be assumed to r e -
flect the difficulty with which the stimulus is identified a s a specific
FUNDAMENTAL FREQUENCY (kHz)
Fig. 111-A-2. Difference in the first (left), second (middle), and third (right) mean formant frequencies in Mels of the response vowels collected from a given stimulus when it was presented with and without vibrato. The circled dots represent differences that are significant above a 90 O/o level.
- -
MEAN PERCEPTUAL DISTANCE BETWEEN RESPONSES (MEL)

STL-QPSR 2- 3/1975 58.
vowel. In the back vowels the identification seems to be simple when the
fundamental is 300 Hz, and a s the fundamental i s ra i sed , the identification
becomes m o r e difficult. In the front vowels the identification is ha rd even
when the fundamental i s low. This i s certainly a consequence of the fact
that the formant frequencies used in synthesizing these stimuli were rath-
e r devient f rom those which a r e typical of normal speech. Rather they
a r e typical of the type of singing which i s often called "covered". In
these stimuli the uncertainty of the identification is not substantially af-
fected by the fundamental frequency. Comparing the values pertaining to
the cases of with and without vibrato revea ls that the identification of vib-
r a to stimuli is harder in approximately a s many cases a s i t i s simpler.
However, the cases of particular interest a r e those which, according to
the t - tes t , changed signfikantly in the mean formant frequency of the r e -
sponse vowels. This occurred in ten cases , and he re the outstanding
features shifted somewhat when the stimulus was presented with a vibrato.
Out of these ten cases the identification became more uncertain in seven
cases. This seems to support the assumption that the vibrato may have
a slight effect on the difficulty with which a sound i s identified a s a vowel,
and the effect i s that the identification i s somewhat harder to per form
when the sound has a vibrato. However, the effect is ve ry weak in our
material .
I t may be argued that the stimuli used in our experiment a r e typical
neither of singing, nor of speech, and hence the subjects' react ions have
l i t t le relevance to the pract ical situation. I t is then interesting to com-
p a r e our resu l t s with data collected f rom similar experiments where the
stimuli were natural, non- synthesized vowels. Such re su l t s have been
presented by Stumpf ( 19 2 6 ) . In h is experiments untrained and profession-
a l s ingers sang high-pitched vowels, and a jury attempted to identify the
intended vowels. Stumpf gave h is r e su l t s in t e r m s of a confusion ma t r ix
and they vYrer e converted into mean per ceptual distance between response
vowels in exactly the same way a s the resu l t s f rom our experiment.
Stumpf' s data a r e a l so given in Fig. 111-A-3. I t is clear f rom the figure
that our stimuli did not give extreme re su l t s a s compared with the natural
stimuli. Thus, vowel identification was not m o r e difficult in our experi- .
ment than i t may be in practice.


STL -0PSR 2- 3/ 197 5 60.
vibrato may change the vowel quality slightly. In such cases , the identifica-
tion of the sound a s a specific vowel seems to be slightly m o r e difficult
when the stimulus h a s a vibrato. I t i s believed that in pract ice, a singer
may profit systematically f rom this effect of the vibrato so a s to reduce
the per ceptability of her deviations f rom the formant frequencies of normal
speech.
Acknowledgments
Stefan Paul i is acknowledged for h i s assis tance in computer program-
ming. The work was supported by The Bank of Sweden Tercentenary
Foundation.
References
CARLSON, R. , FANT, G. , and GRANSTROM, B (1973): "Two-formant models, pitch and vowel perception", paper presented a t the Symp. on Auditory Analysis and Perception of Speech, Leningrad 1973; to be publ. by Academic P r e s s , London 1975.
FANT, G. (1973): Speech Sounds and Fea tures , MIT-Press , Cambridge, Mass . , p. 36 and p. 84.
FLANAGAN, J. L . (1955): "A difference l imen for vowel formant f r e - quency", J.Acoust.Soc.Am. - 27:3, p. 613.
LINDBLOM, B. (197 5): "Experiments in sound structure", paper presented a t the 8th Int. Congr. of Phonetic Sciences, Leeds, Aug.
PLOMP, R. (1970): "Timbre a s a multidimensional attribute of complex tones", in Frequency Analysis and Periodicity Detection in Hearing, ed. by R. Plomp and G . F. Smocrenburg, A. W . Sijthoff, Leiden, p. 397.
SLAWSON, A. W. ( 1968): "Vowel quality and musical t imbre a s functions of spectrum envelope and fundamental frequencyt1, J. Acoust. Soc. Am. 43:1, p. 87. 7
STUMPF, C. (1926): Die Sprachlaute, Springer, Berlin, pp. 77-85. I SUNDBERG, J. ( 1970): "Formant s t ructure and articulation in spoken and
sung vowels", Fol. Phon. 22: 1, p. 28. - SUNDBERG, J. (1972): "Pitch of synthetic sung vowels", STL-QPSR
1/1972, p. 34. ! SUNDBERG, J. (197 5): "Formant technique in a professional female
singer", Acustica 32:3, p. 90. -





![Acoustic and psychoacoustic aspects of vocal · PDF fileSTL-QPSR 2-31] 994 Acoustic and psychoacoustic aspects of vocal vibrato Johan sundberg Abstract This article reviews research](https://static.fdocuments.net/doc/165x107/5a9e0aef7f8b9a29228ccf45/acoustic-and-psychoacoustic-aspects-of-vocal-2-31-994-acoustic-and-psychoacoustic.jpg)












