
Using R for HPC Data Science -...
24
Using R for HPC Data Science Session: Parallel Programming Paradigms George Ostrouchov Oak Ridge National Laboratory and University of Tennessee and pbdR Core Team Course at IT4Innovations, Ostrava, October 6-7, 2016
Transcript of Using R for HPC Data Science -...

Using R for HPC Data Science
Session: Parallel Programming Paradigms
George OstrouchovOak Ridge National Laboratory and University of Tennessee
and ppppppbbbbbbddddddRRRRRR Core Team
Course at IT4Innovations, Ostrava, October 6-7, 2016
Parallel Programming Paradigms Outline
Outline
Brief introduction to parallel hardware and software
Parallel programming paradigms
Shared memory vs. distributed memoryManager-workers and fork-joinMapReduceSPMD - single program, multiple dataData-flow
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science
Parallel Programming Paradigms Brief introduction to parallel hardware and software
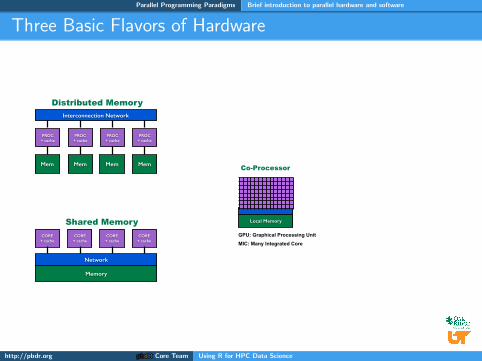
Three Basic Flavors of Hardware
Interconnection Network
PROC + cache
PROC + cache
PROC + cache
PROC + cache
Mem Mem Mem Mem
Distributed Memory
Memory
CORE + cache
CORE + cache
CORE + cache
CORE + cache
Network
Shared Memory Local Memory
Co-Processor
GPU: Graphical Processing Unit
MIC: Many Integrated Core
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science
Parallel Programming Paradigms Brief introduction to parallel hardware and software
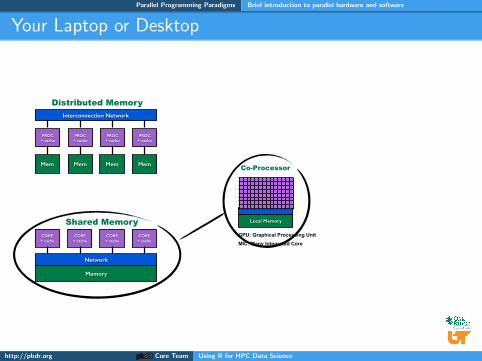
Your Laptop or Desktop
Interconnection Network
PROC + cache
PROC + cache
PROC + cache
PROC + cache
Mem Mem Mem Mem
Distributed Memory
Memory
CORE + cache
CORE + cache
CORE + cache
CORE + cache
Network
Shared Memory Local Memory
Co-Processor
GPU: Graphical Processing Unit
MIC: Many Integrated Core
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Parallel Programming Paradigms Brief introduction to parallel hardware and software
Server to Cluster to Supercomputer
Interconnection Network
PROC + cache
PROC + cache
PROC + cache
PROC + cache
Mem Mem Mem Mem
Distributed Memory
Memory
CORE + cache
CORE + cache
CORE + cache
CORE + cache
Network
Shared Memory Local Memory
Co-Processor
GPU: Graphical Processing Unit
MIC: Many Integrated Core
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science
Parallel Programming Paradigms Brief introduction to parallel hardware and software
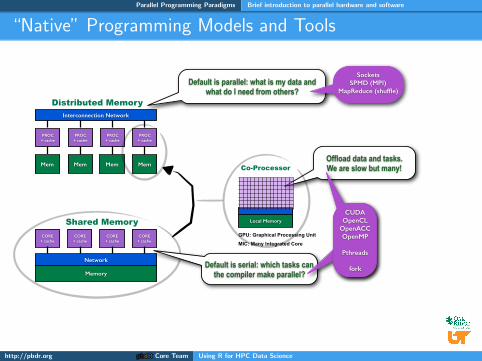
“Native” Programming Models and Tools
Interconnection Network
PROC + cache
PROC + cache
PROC + cache
PROC + cache
Mem Mem Mem Mem
Distributed Memory
Memory
CORE + cache
CORE + cache
CORE + cache
CORE + cache
Network
Shared Memory
Default is parallel: what is my data and what do I need from others?
Default is serial: which tasks can the compiler make parallel?
Offload data and tasks. We are slow but many!
Sockets SPMD (MPI)
MapReduce (shuffle)
Local Memory
Co-Processor
GPU: Graphical Processing Unit
MIC: Many Integrated Core
CUDA OpenCL
OpenACC OpenMP Pthreads
fork
CUDA OpenCL
OpenACC OpenMP
Pthreads
fork
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Parallel Programming Paradigms Brief introduction to parallel hardware and software
30+ Years of Parallel Computing Research
Local Memory
Co-Processor
GPU: Graphical Processing Unit
MIC: Many Integrated Core
Default is parallel (SPMD): what is my data and what do I need from others?
Default is serial: which tasks can the compiler make parallel?
Offload data and tasks. We are slow but many!
Sockets MPI
MapReduce
Interconnection Network
PROC + cache
PROC + cache
PROC + cache
PROC + cache
Mem Mem Mem Mem
Distributed Memory
Memory
CORE + cache
CORE + cache
CORE + cache
CORE + cache
Network
Shared MemoryCUDA
OpenCL OpenACC OpenMP Pthreads
fork
CUDA OpenCL
OpenACC OpenMP Pthreads
fork
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Parallel Programming Paradigms Brief introduction to parallel hardware and software
Last 10 years of Advances
Local Memory
Co-Processor
GPU: Graphical Processing Unit
MIC: Many Integrated Core
Default is parallel (SPMD): what is my data and what do I need from others?
Default is serial: which tasks can the compiler make parallel?
Offload data and tasks. We are slow but many!
Sockets MPI
MapReduce
Interconnection Network
PROC + cache
PROC + cache
PROC + cache
PROC + cache
Mem Mem Mem Mem
Distributed Memory
Memory
CORE + cache
CORE + cache
CORE + cache
CORE + cache
Network
Shared MemoryCUDA
OpenCL OpenACC OpenMP Pthreads
fork
CUDA OpenCL
OpenACC OpenMP Pthreads
fork
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Parallel Programming Paradigms Brief introduction to parallel hardware and software
Distributed Programming Works in Shared Memory
Local Memory
Co-Processor
GPU: Graphical Processing Unit
MIC: Many Integrated Core
Default is parallel: what is my data and what do I need from others?
Default is serial: which tasks can the compiler make parallel?
Offload data and tasks. We are slow but many!
Interconnection Network
PROC + cache
PROC + cache
PROC + cache
PROC + cache
Mem Mem Mem Mem
Distributed Memory
Memory
CORE + cache
CORE + cache
CORE + cache
CORE + cache
Network
Shared Memory
Sockets SPMD (MPI)
MapReduce (shuffle)
CUDA OpenCL
OpenACC OpenMP Pthreads
fork
CUDA OpenCL
OpenACC OpenMP
Pthreads
fork
✔ ✘✘
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Parallel Programming Paradigms Brief introduction to parallel hardware and software
R Interfaces to Low-Level Native Tools
Local Memory
Co-Processor
GPU: Graphical Processing Unit
MIC: Many Integrated Core
Interconnection Network
PROC + cache
PROC + cache
PROC + cache
PROC + cache
Mem Mem Mem Mem
Distributed Memory
Memory
CORE + cache
CORE + cache
CORE + cache
CORE + cache
Network
Shared Memory
Default is parallel (SPMD): what is my data and what do I need from others?
Default is serial: which tasks can the compiler make parallel?
Offload data and tasks. We are slow but many!
Sockets MPI
MapReduce
CUDA OpenCL
OpenACC OpenMP Pthreads
fork
CUDA OpenCL
OpenACC OpenMP Pthreads
fork
snow + multicore = parallel
multicore
Foreign Language Interfaces:
.C .Call Rcpp
OpenCL inline
.
.
.
snow Rmpi Rhpc
pbdMPI
RHadoop SparkR
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Parallel Programming Paradigms Brief introduction to parallel hardware and software
Some packages in R for parallel computing
parallel: multicore + snow
multicore: an interface to unix fork (no Windows)snow: simple network of workstations
pbdMPI, pbdDMAT and other pbd: use HPC concepts, simplify, and usescalable libraries
foreach, doParallel: iterface to hide hardware reality, can be difficult to debug
Rmpi: simplified with pbdMPI for SPMD
RHadoop, RHipe: needs HDFS, slow because file-backed
datadr: divide-recombine, currently MapReduce/HADOOP back end
SparkR: in-memory, needs HDFS, limited to Shuffle, MPI generally faster andmore flexible
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Distributed Parallel Computing Paradigms Manager-Workers
Manager-Workers
1 A serial program (Manager) divides up work and/or data
2 Manager sends work (and data) to workers
3 Workers run in parallel without interaction
4 Manager collects/combines results from workers
Divide-Recombine fits this model
Concept appears similar to interactive and to client-server
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Distributed Parallel Computing Paradigms MapReduce
MapReduce
A concept born of a search engine
Decouples certain coupled problems with an intermediate communication:shuffle
User needs to decompose computation into Map and Reduce steps
User writes two serial codes: Map and Reduce
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Distributed Parallel Computing Paradigms MapReduce
MapReduce: a Parallel Search Engine Concept
Search MANY documents Serve MANY users
WebPages
(records)
p0
p1
p2
p3
Index Words (keys)A1 A2 A3 A4
B1 B2 B3 B4
C1 C2 C3 C4
D1 D2 D3 D4
Shuffle−→
MPI Alltoallv
IndexWords(keys)
p0
p1
p2
p3
Web Pages (records)A1 B1 C1 D1
A2 B2 C2 D2
A3 B3 C3 D3
A4 B4 C4 D4
Matrix transpose in another language?
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Distributed Parallel Computing Paradigms MapReduce
Can use different sets of processors
WebPages
(records)
p0
p1
p2
p3
Index Words (keys) B1 B2 B3 B4
Streaming
Shuffle−→
MPI Scatter
IndexWords(keys)
p4
p5
p6
p7
Web Pages (records)B1
B2
B3
B4
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Distributed Parallel Computing Paradigms SPMD
SPMD: Single Program Multiple Data
Write one general program so many copies of it can run asynchronously andcooperate (usually via MPI) to solve the problem.
The prevalent way of distributed programming in HPC for 30+ years
Can handle tightly coupled parallel computations
It is designed for batch computing
There is usually no manager - rather, all cooperate
Prime driver behind MPI specification
Way to program server side in client-server
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Distributed Parallel Computing Paradigms SPMD
SPMD A = XTX , where X =
X1
...X8
(Row-Block partition)
1
A = reduce( crossprod( Xi ) ) A = allreduce( crossprod( Xi ) )
1Ostrouchov (1987). Parallel Computing on a Hypercube: An overview of the architectureand some applications. Proceedings of the 19th Symposium on the Interface of ComputerScience and Statistics, p.27-32.
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Distributed Parallel Computing Paradigms SPMD
SPMD and MapReduce (MPI and Shuffle)
Both Concepts are about Communication
SPMD makes communication explicit, gives choices (MPI)
MapReduce hides communication, uses one choice (shuffle)
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Distributed Parallel Computing Paradigms Data-Flow
Data-flow: Parallel Runtime Scheduling and ExecutionController (PaRSEC)
Graphic from icl.cs.utk.edu
Bosilca, G., Bouteiller, A., Danalis, A., Faverge, M., Herault, T., Dongarra, J. ”PaRSEC: Exploiting Heterogeneity to Enhance Scalability,” IEEEComputing in Science and Engineering, Vol. 15, No. 6, 36-45, November, 2013.
Master data-flow controller runs distributed on all cores.
Dynamic generation of current level in flow graph
Effectively removes collective synchronizations
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Distributed Parallel Computing Paradigms Libraries
Recall: Hardware flavors and Low-Level Native Tools
Local Memory
Co-Processor
GPU: Graphical Processing Unit
MIC: Many Integrated Core
Interconnection Network
PROC + cache
PROC + cache
PROC + cache
PROC + cache
Mem Mem Mem Mem
Distributed Memory
Memory
CORE + cache
CORE + cache
CORE + cache
CORE + cache
Network
Shared Memory
Default is parallel (SPMD): what is my data and what do I need from others?
Default is serial: which tasks can the compiler make parallel?
Offload data and tasks. We are slow but many!
Sockets MPI
MapReduce
CUDA OpenCL
OpenACC OpenMP Pthreads
fork
CUDA OpenCL
OpenACC OpenMP Pthreads
fork
snow + multicore = parallel
multicore
Foreign Language Interfaces:
.C .Call Rcpp
OpenCL inline
.
.
.
snow Rmpi Rhpc
pbdMPI
RHadoop SparkR
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Distributed Parallel Computing Paradigms Libraries
Scalable Libraries Mapped to Hardware
Local Memory
Co-Processor
GPU: Graphical Processing Unit
MIC: Many Integrated Core
Interconnection Network
PROC + cache
PROC + cache
PROC + cache
PROC + cache
Mem Mem Mem Mem
Distributed Memory
Memory
CORE + cache
CORE + cache
CORE + cache
CORE + cache
Network
Shared Memory
Trilinos
PETSc
PLASMA
DPLASMALibSci (Cray) MKL (Intel)
ScaLAPACK PBLAS BLACS
cuBLAS (NVIDIA)
MAGMA
PAPI
Tau
MPImpiP
fpmpi
NetCDF4
ADIOSACML (AMD)
CombBLAS
cuSPARSE (NVIDIA)
ZeroMQ
Profiling
I/O
Most are built for SPMD.
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Distributed Parallel Computing Paradigms Libraries
R and ppppppbbbbbbddddddRRRRRR Interfaces to HPC Libraries
Local Memory
Co-Processor
GPU: Graphical Processing Unit
MIC: Many Integrated Core
Interconnection Network
PROC + cache
PROC + cache
PROC + cache
PROC + cache
Mem Mem Mem Mem
Distributed Memory
Memory
CORE + cache
CORE + cache
CORE + cache
CORE + cache
Network
Shared Memory
Trilinos
PETSc
PLASMA
DPLASMALibSci (Cray) MKL (Intel)
ScaLAPACK PBLAS BLACS
cuBLAS (NVIDIA)
MAGMA
PAPI
Tau
MPImpiP
fpmpi
NetCDF4
ADIOS
ACML (AMD)
OpenBLAS
CombBLAS
cuSPARSE (NVIDIA)
pbdDMATpbdDMATpbdDMATpbdDMAT
pbdBASE pbdSLAP
ZeroMQ
Profiling
I/O
Learning pbdR
Released Under Development
pbdADIOS
pbdNCDF4
pbdPAPI
pbdPROF pbdPROF pbdPROF pbdMPI
pbdDEMO
pbdCS pbdZMQ remoter getPass
pbdIO
Machine Learning
pbdML
HDF5rhdf5
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Distributed Parallel Computing Paradigms Libraries
Recall: Hardware flavors and Low-Level Native Tools
Local Memory
Co-Processor
GPU: Graphical Processing Unit
MIC: Many Integrated Core
Interconnection Network
PROC + cache
PROC + cache
PROC + cache
PROC + cache
Mem Mem Mem Mem
Distributed Memory
Memory
CORE + cache
CORE + cache
CORE + cache
CORE + cache
Network
Shared Memory
Default is parallel (SPMD): what is my data and what do I need from others?
Default is serial: which tasks can the compiler make parallel?
Offload data and tasks. We are slow but many!
Sockets MPI
MapReduce
CUDA OpenCL
OpenACC OpenMP Pthreads
fork
CUDA OpenCL
OpenACC OpenMP Pthreads
fork
snow + multicore = parallel
multicore
Foreign Language Interfaces:
.C .Call Rcpp
OpenCL inline
.
.
.
snow Rmpi Rhpc
pbdMPI
RHadoop SparkR
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science

Distributed Parallel Computing Paradigms Acknowledgments
Prepared by ppppppbbbbbbddddddRRRRRR Core Team
pbdR Core Team DevelopersWei-Chen Chen, FDAGeorge Ostrouchov, ORNL & UTKDrew Schmidt, UTK
DevelopersChristian Heckendorf, Pragneshkumar Patel, GauravSehrawat
ContributorsWhit Armstrong, Ewan Higgs, Michael Lawrence,Michael Matheson, David Pierce, Andrew Raim, BrianRipley, ZhaoKang Wang, Hao Yu
Engaging parallel libraries at scale
R language unchanged
New distributed concepts
New profiling capabilities
New interactive SPMD
In situ distributed capability
In situ staging capability via ADIOS
Plans for DPLASMA GPU capability
SupportThis material is based upon work supported by the National Science Foundation Division of Mathematical Sciences under Grant No. 1418195. This workused resources of the Oak Ridge Leadership Computing Facility at the Oak Ridge National Laboratory, which is supported by the Office of Science of theU.S. Department of Energy under Contract No. DE-AC05-00OR22725. This work also used resources of the National Institute for Computational Sciencesat the University of Tennessee, Knoxville, which is supported by the Office of Cyberinfrastructure of the U.S. National Science Foundation.
http://pbdr.org ppppppbbbbbbddddddRRRRRR Core Team Using R for HPC Data Science


















