
Using OpenMP to Program Embedded …...Using OpenMP to Program Embedded HeterogeneousEmbedded...
32
Using OpenMP to Program Embedded Heterogeneous Embedded Heterogeneous Systems Eric Stotzer, PhD Senior Member Technical Staff Software Development Organization Compiler Team Software Development Organization, Compiler Team Texas Instruments February 16, 2012 Presented at SIAM PP12 Savannah GA Presented at SIAM-PP12 Savannah, GA
Transcript of Using OpenMP to Program Embedded …...Using OpenMP to Program Embedded HeterogeneousEmbedded...

Using OpenMP to Program Embedded HeterogeneousEmbedded Heterogeneous
Systems
Eric Stotzer, PhDSenior Member Technical Staff
Software Development Organization Compiler TeamSoftware Development Organization, Compiler TeamTexas InstrumentsFebruary 16, 2012
Presented at SIAM PP12 Savannah GAPresented at SIAM-PP12 Savannah, GA

AbstractEfficiency improvements with respect to power, performance, and silicon area motivate the
specialization of processor resources including accelerators. Heterogeneous processors and accelerators are common in embedded computing, where they tend to be programmed using low-level vendor specific APIs. Currently, the dominant heterogeneous system in general purpose computing is the general purpose host CPU + GPU accelerator platform. The dominant programming models for these systems are currently CUDA and OpenCL. Both allow the programmer to extract performance from the accelerator, but the low level approach is repetitive, error-prone and focused on data movement. Compilers can implement significant portions of this repetitive code.
The OpenMP language committee is working on extensions to OpenMP that allow the programmer to accelerate key kernels or entire applications by adding directives to the original source code (Fortran C or C++) The extensions support rapid maintainableoriginal source code (Fortran, C or C++). The extensions support rapid, maintainable accelerator code development while leaving performance optimizations to the compiler and runtime environment. In keeping with the philosophy of OpenMP, these directives do not alter the existing code that runs well on the host CPU. In this presentation, we will present an overview of the current proposal for extending OpenMP to programpresent an overview of the current proposal for extending OpenMP to program accelerators and how it can also be used as a more general heterogeneous multicore programming model.

Outline
–Why OpenMPOpenMP in embedded systems–OpenMP in embedded systems
–OpenMP for accelerators (heterogeneous t )systems)

Why OpenMP?
• Industry standard for shared memory parallel programming – website: http://www.openmp.org
• Productivity and flexibility– Data parallelism (omp parallel for)– Task parallelism (omp tasks)Task parallelism (omp tasks)
• Easy migration for existing code base: C/C++ based directives (#pragma) used to express parallelism
• Language is evolving to support tasking models, heterogeneous systems, and streaming programming models
• Embedded programmers want a standard parallel programming model for high performance shared memory multicore devicesfor high performance shared memory multicore devices

OpenMP Execution Model
• Master thread spawns a team of threads as needed.
P ll li i dd d i t ll til d i d• Parallelism is added incrementally until desired performance is achieved: i.e. the sequential program evolves into a parallel program.
Master
Parallel Regions
Thread

OpenMP Memory Model
• Threads have access to a shared memory– for shared data– each thread can have a temporary view of the shared memory
(e.g. registers, cache, etc.) between synchronization barriers.
Threads ha e pri ate memor• Threads have private memory– for private data– Each thread has a stack– data local to each task it executes

OpenMP: Parallel Regions
• You create threads in OpenMP with the “omp parallel” pragma.
• For example, To create a 4-thread Parallel region:p g
float A[1000];
omp set num threads(4);p_ _ _ ( );
#pragma omp parallel
{
int id = omp get thread num();
Each thread redundantly executes the code within the structured blockint id = omp_get_thread_num();
lots_of_work(id,A);
}
the structured block
Each thread calls lots_of_work(id,A) for id = 0 to 3

OpenMP: Work-sharing construct
#pragma omp parallel for reduction(+:s)for (int i=0; i<N; i++)( ; ; )
s += x[i] * c[i];
B1=0; E2=N/4; s1=0;for (i1=B1; i1<E1; i1++)
s1 += x[i1]*c[i1];
B2=N/4; E2=N/2; s2=0;for (i2=B2; i2<E2; i2++)
s2 += x[i2]*c[i2];
B3=N/2; E3=3*N/4; s3=0;for (i3=B3; i3<E3; i3++)
s3 += x[i3]*c[i3];
B4=3*N/4; E4=N; s4=0;for (i4=B4; i4<E4; i4++)
s4 += x[i4]*c[i4];
s = s1+s2+s3+s4;
• A single copy of x[] and c[] is shared by all the threads

OpenMP: Task Construct• Task model supports irregular data dependent parallelism
• Tasks are assigned to a queue
• Threads execute tasks that they remove from a task queue
#pragma omp parallel{ #pragma omp single{ {p = listhead;while (p) {
#pragma omp taskprocess(p);
t( )p=next(p);}
} }

C66x CorePac Overview
• 16 Flops/cycle (6 DP/cycle)L1P
SRAM/Cache32KB
• 8-Wide VLIW Architecture
• Integrated fixed point / floating point
L1PEmbedded
Debug
Power M t
Interrupt controller
Emulation Fetch point
• 64-bit datapaths on .L and .S, 128-bit datapaths on .M unit
C66x DSP
L2
Management
L M S D L M S D
Dispatch Exectute
• Automated L2 cache Pre-fetch
• Integrated Power SwitchesL1D
PrefetchRegister file A Register file B
DMA
L M S D L M S D
L1D
L1DSRAM/Cache
32KB
L2SRAM/Cache
1MB

Embedded HPCHigh Performance Mission Critical Medical Imagingg
ImagingMission Critical Medical Imaging
Software Defined R di
High Performance MultimediaRadio Multimedia
Multichannel & Next Generation Video –H 265 SVC tH.265, SVC, etc.

Shannon (TMS320C6678) – Block Diagram
Multicore Navigator8 x CorePac Network
• Multi-Core KeyStone SoC• Fixed/Floating CorePac
• 8 CorePac @ 1.25 GHzC66x DSP
L1 L2
C66x DSP
L1 L2
C66x DSP
L1 L2
C66x DSP
L1 L2
C66x C66x C66x C66x
Crypto
Packet Accelerator
CoProcessors@
• 4.0 MB Shared L2 • 320G MAC, 160G FLOP, 60G DFLOPS• ~10W
• Navigator
Tera
NetDSP
L1 L2
DSP
L1 L2
DSP
L1 L2
DSP
L1 L2 GbESwitch
SGMIISGMII
IP Interfaces
Multicore Shared Memory Controller
Memory Subsystem
• Queue Manager, Packet DMA
• Multicore Shared Memory Controller
• Low latency, high bandwidth memory access
SRIOx4
PCIex2
EMIF16
Peripherals & IO
P M
Multicore Shared Memory Controller(MSMC)
Shared Memory 4MB
DDR3-64b
S
System Elements
• Network Coprocessor• IPv4/IPv6 Network interface solution• 1.5M pps (1Gb Ethernet wire-rate)• IPSec, SRTP, Encryption fully offloaded
3 t Gi E S it h (L 2) TSIP2x
I2CSPI UART
Power ManagementDebug EDMA
SysMon• 3-port GigE Switch (Layer 2)• HyperLink
• 50G Baud Expansion Port• Transparent to Software
HyperLink50
12

User Applications
OpenMP on a lightweight RTOS
Multicore Software Development KitMulticore Software Development Kit
User ApplicationsMaster Thread Master Thread
Worker Thread
Worker Thread
Worker Thread
Worker Thread
• TI SYS/BIOS RTOS with IPC product
• Each core is running
OpenMP Programming Layer
Worker Thread
Worker Thread
Worker Thread
Worker Thread
Each core is running SYS/BIOS RTOS
• OpenMP master and worker p g g y
Compiler Directives
OpenMPLibrary
EnvironmentVariables
threads execute inside dedicated SYS/BIOS tasks
• IPC is used forApplication Binary Interface
OpenMP ABI
Parallel Thread Interface
IPC is used for communication and synchronization
O MP ti t t dOperating System
SYS/BIOS
• OpenMP run-time state and user data is allocated in shared memory

S G “ C f C S fSource: F. D. Igual, R. A. van de Geijn, and M. Ali, “Exploring the Capabilities of Multi-Core DSPs for Dense Linear Algebra Operations”, Poster presented at SIAM-PP12.

Quad-Shannon PCIe Development Card
•512 Gflops•50 W
• Available from Advantech
• 8 Lanes PCIe out, sRIO / Hyperlink for intra-DSP data movement
• 8xShannon board under development

BenchmarksBenchmark C6678 TI Quad PCIe
SP Flops 160 512
Cores 8 32
Processor speed 1 1
( )L2 Memory (MB) 8 32
L3 Memory (GB) ECC 8 4
Memory BW (GB/s) 12.8 42.6
Power Consumption 10 54p
( board power)
Benchmarks (Gflops)
FFT (SP) (4096pt) 60 240
/FFT Gflops/W 6.00 4.44
SGEMM (matrix multiply) 72 288
SGEMM Gflops/W 7.2 5.3
• C6678 provides the highest performance/W• Standard programming modelp g g

OpenMP Accelerator programming model Why a new model? There are already many ways to program:
CUDA, OpenCL, MCA, vendor-specific All are quite low-level and closely coupled to GPUs Hard to write, debug, and port to new platforms
Directives provide high-level approach Based on original source code Easier to maintain/port/extend code Run the same code on a multi-core CPURun the same code on a multi core CPU
What about OpenHMPP, OpenACC, PGI accelerator, etc...? Unclear how these directives interact with existing OpenMP programs OpenMP will borrow ideas from these approaches gcc implements OpenMP 3 1 gcc implements OpenMP 3.1
OpenMP accelerator sub-committee Members: Cray (co-chair), Texas Instruments (co-chair), Intel, Nvidia, PGI, IBM,
CAPS, NASA, BSC, TACC, LLNL, Compunity, and more.G l i t t d di ti b d h th t t d t t k d l t Goal: an integrated directive based approach that supports data, task and accelerator-style parallelism (not just gpu) available in the 4.0 OpenMP specification.
J. C. Beyer, E. J. Stotzer, A. Hart, B. R. de Supinski, ”OpenMP for Accelerators”, IWOMP'2011: Proceedings of the International Workshop on OpenMP, June 2011 pp.108~121.
17

Disclaimer
• The OpenMP accelerator sub-committee is still working on the proposal.
• The names and syntax are subject to change.
• Your getting my (non-gpu) perspective.

Serial for-loop
int main(int argc, char *argv[]) {int n = ...;float *x, *y;x = new float[n+1];x = new float[n+1];y = new float[n+1];
... // fill x, y
// do computation// do co putat ofloat e = 0;for (int i=1; i<n; ++i) {x[i] += ( y[i+1] + y[i-1] )*.5;e += y[i] * y[i];
}
... // output x, e
delete[] x, y;return 0;
}
Code source for all “for-loop” examples: http://parallel-for.sourceforge.net/index.html
}

CUDA for-loop (1/2)Serial for-loop
int main(int argc, char *argv[]) {int n = ...;
#include <cuda.h>
// kernel__global__ void sub1(float* fx, float* fy, float* fe) {#define BLOCK (512)
int t = threadIdx x; // builtin
se[t] += se[t+256];__syncthreads();
}if (t<128) {
se[t] += se[t+128];syncthreads();float *x, *y;
x = new float[n+1];y = new float[n+1];
... // fill x, y
// do computation
int t = threadIdx.x; // builtinint b = blockIdx.x; // builtinfloat e;__shared__ float se[BLOCK];__shared__ float sx[BLOCK];
shared float sy[BLOCK+2];
__syncthreads();}if (t<64) {
se[t] += se[t+64];__syncthreads();
}// do computationfloat e = 0;for (int i=1; i<n; ++i) {x[i] += ( y[i+1] + y[i-1] )*.5;e += y[i] * y[i];}
__s a ed__ oat sy[ OC ];// copy from device to processor memorysx[t] = fx[BLOCK*b+t];sy[t] = fy[BLOCK*b+t];if (t<2)
sy[t+BLOCK] = fy[BLOCK*b+t+BLOCK];
}if (t<32) { // warp size
se[t] += se[t+32];se[t] += se[t+16];se[t] += se[t+8];se[t] += se[t+4];
... // output x, e
delete[] x, y;return 0;
}
__syncthreads();
// do computationsx[t] += ( sy[t+2] + sy[t] )*.5;e = sy[t+1] * sy[t+1];// copy to device memory
se[t] += se[t+2];se[t] += se[t+1];
}if (t==0)
fe[b] = se[0];}// copy to device memory
fx[BLOCK*b+t] = sx[t];// reductionse[t] = e;__syncthreads();if (t<256) {
}
( ) {

CUDA for-loop (2/2)Serial for-loop
int main(int argc, char *argv[]) {int n = ...;
int main(int argc, char *argv[]) {int n = ...;float *x, *y;x = new float[n+1];y = new float[n+1];
cudaMemcpyDeviceToHost);cudaMemcpy(fe, &de[1-1], (n-1+2)/BLOCK * sizeof(float),cudaMemcpyDeviceToHost);
// release GPU memorycudaFree(fe);cudaFree(fy);float *x, *y;
x = new float[n+1];y = new float[n+1];
... // fill x, y
// do computation
... // fill x, y
// allocate GPU memoryfloat *fx, *fy, *fe;cudaMalloc((void**)&fx, (n-1+2) * sizeof(float));
cudaFree(fy);cudaFree(fx);float e_local = 0;for (int i=0; i<(n-1+2)/BLOCK; ++i)e_local += de[i];
e += e local;// do computationfloat e = 0;for (int i=1; i<n; ++i) {x[i] += ( y[i+1] + y[i-1] )*.5;e += y[i] * y[i];}
cuda a oc(( o d )& , ( ) s eo ( oat));cudaMalloc((void**)&fy, (n-1+2) * sizeof(float));cudaMalloc((void**)&fe, (n-1+2)/BLOCK * sizeof(float));float *de = new float[(n-1+2)/BLOCK];// copy to GPU memorycudaMemcpy(fx+1, &x[1],
e e_ oca ;delete[] de;
... // output x, e
delete[] x, y;... // output x, e
delete[] x, y;return 0;
}
(n-1) * sizeof(float), cudaMemcpyHostToDevice);cudaMemcpy(fy, &y[1-1],(n-1+2) * sizeof(float), cudaMemcpyHostToDevice);
dim3 dimBlock(BLOCK, 1, 1);dim3 dimGrid((n-1+2)/BLOCK, 1, 1);
return 0;}
float e = 0;// call GPUsub1<<<dimGrid, dimBlock>>>(fx, fy, fe);// copy to host memorycudaMemcpy(fx+1, &x[1], (n-1) * sizeof(float),py( , [ ], ( ) ( ),

OpenCL for-loop (1/2)Serial for-loop
int main(int argc, char *argv[]) {int n = ...;
#include <cl.h>#include <malloc.h>
// kernel#define BLOCK (512)
barrier(CLK_LOCAL_MEM_FENCE);\}\if (t<64) {\se[t] += se[t+64];\barrier(CLK_LOCAL_MEM_FENCE);\
}\float *x, *y;x = new float[n+1];y = new float[n+1];
... // fill x, y
// do computation
#define BLOCK (512)const char *source = "__kernel void sub1(__global float* fx,\
__global const float* fy,\__local float* se, __global float* fe) {\
const unsigned int t = get global id(0);\
}\if (t<32) {\se[t] += se[t+32];\se[t] += se[t+16];\se[t] += se[t+8];\se[t] += se[t+4];\// do computation
float e = 0;for (int i=1; i<n; ++i) {x[i] += ( y[i+1] + y[i-1] )*.5;e += y[i] * y[i];}
co st u s g ed t t get_g oba _ d(0);\const unsigned int b = get_group_id(0);\const unsigned block = 512;\const unsigned int i = block*b+t;\float e;\/* do computation */\
se[t] se[t ];\se[t] += se[t+2];\se[t] += se[t+1];\
}\if (t==0)\fe[b] = se[0];\
... // output x, e
delete[] x, y;return 0;
}
fx[t] += ( fy[t+2] + fy[t] )*.5;\e = fy[t+1] * fy[t+1];\/* reduction */\se[t] = e;\barrier(CLK_LOCAL_MEM_FENCE);\if (t<256) {\
}";
if (t<256) {\se[t] += se[t+256];\barrier(CLK_LOCAL_MEM_FENCE);\
}\if (t<128) {\se[t] += se[t+128];\[ ] [ ];

OpenCL for-loop (2/2)Serial for-loop
int main(int argc, char *argv[]) {int n = ...;
int main(int argc, char *argv[]) {int n = ...;float *x, *y;x = new float[n+1];y = new float[n+1];
float e = 0;cl_command_queue queue =
clCreateCommandQueue(ct, aDevices[0], 0, 0);
// allocate GPU memorycl mem fx = clCreateBuffer(ct
// call GPUconst unsigned int size = BLOCK;const unsigned int dim = n-1+2;clEnqueueNDRangeKernel(queue,
kern, 1, 0, &dim, &size, 0, 0, 0);// copy to host memoryfloat *x, *y;
x = new float[n+1];y = new float[n+1];
... // fill x, y
// do computation
... // fill x, y
// allocate GPUcl_context ct =
clCreateContextFromType(0,
cl_mem fx = clCreateBuffer(ct, CL_MEM_READ_WRITE | CL_MEM_COPY_HOST_PTR,
(n-1)*sizeof(cl_float), &x[1], 0);cl_mem fy = clCreateBuffer(ct,
CL MEM READ ONLY |
// copy to host memoryclEnqueueReadBuffer(queue, fx,
CL_TRUE, 0,(n-1) * sizeof(cl_float), &x[1], 0, 0, 0);clEnqueueReadBuffer(queue, fe,
CL TRUE, 0,// do computationfloat e = 0;for (int i=1; i<n; ++i) {x[i] += ( y[i+1] + y[i-1] )*.5;e += y[i] * y[i];}
c C eateCo te t o ype(0,CL_DEVICE_TYPE_GPU, 0, 0, 0);
size_t ctsize;clGetContextInfo(ct,
CL_CONTEXT_DEVICES, 0, 0, &ctsize);
C _ _ _O |CL_MEM_COPY_HOST_PTR,
(n-1+2)*sizeof(cl_float), &y[1-1], 0);cl_mem se = clCreateBuffer(ct,
CL_MEM_READ_WRITE,BLOCK*sizeof(cl_float), 0, 0);
C _ U , 0,(n-1) * sizeof(cl_float), d, 0, 0, 0);float ee = 0;for (int i=0; i<(n-1)/BLOCK; ++i)ee += d[i];
e += ee;... // output x, e
delete[] x, y;return 0;
}
cl_device_id *aDevices = (cl_device_id*)malloc(ctsize);
clGetContextInfo(ct, CL_CONTEXT_DEVICES, ctsize, aDevices, 0);
// compile kernel
cl_mem fe = clCreateBuffer(ct, CL_MEM_WRITE_ONLY,
(n-1)/BLOCK*sizeof(cl_float), 0, 0);clSetKernelArg(kern, 0,
sizeof(cl_mem), (void *)&fx);clSetKernelArg(kern 1
delete[] d;// release GPU memoryclReleaseMemObject(fx);clReleaseMemObject(fy);clReleaseMemObject(se);clReleaseMemObject(fe);// compile kernel
cl_program prog = clCreateProgramWithSource(ct, 1, &source, 0, 0);
clBuildProgram(prog, 0, 0, 0, 0, 0);cl kernel kern = clCreateKernel(prog,
clSetKernelArg(kern, 1, sizeof(cl_mem), (void *)&fx);
clSetKernelArg(kern, 2, sizeof(cl_mem), (void *)&se);
clSetKernelArg(kern, 3, sizeof(cl mem), (void *)&fe);
clReleaseMemObject(fe);
... // output x, e
delete[] x, y;return 0;_ (p g,
"sub1", 0);( _ ), ( ) );
float *d = new float[(n-1)/BLOCK];;
}

accelerate construct
• Goal: Extend OpenMP to support accelerator parallelism
• Model: “Offload” data and code to an accelerator.Model: Offload data and code to an accelerator.
• Accelerate region: A region of code that executes using accelerator parallelism.
// fill x y... // fill x, y
// do computationfloat e = 0;#pragma omp accelerate loop reduction(e:+) locale(dsp)for (int i=1; i<n; ++i) {
x[i] += ( y[i+1] + y[i-1] )*.5;e += y[i] * y[i];
}
... // output x, e
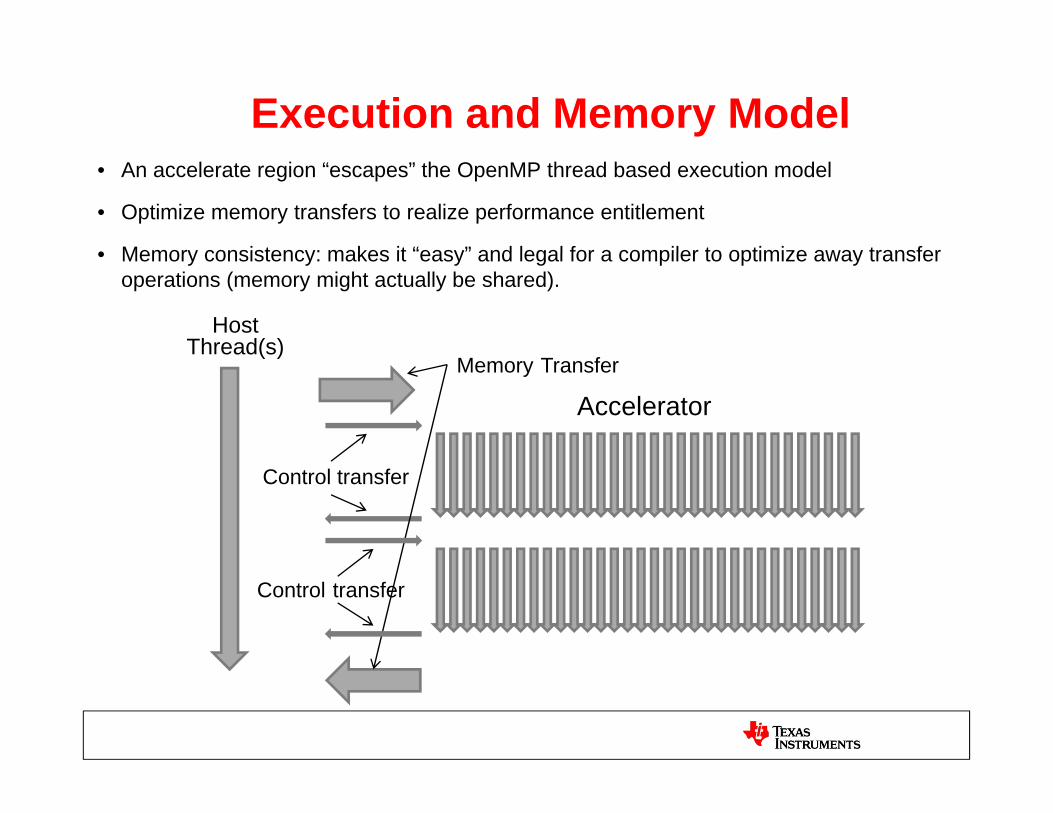
Execution and Memory Model• An accelerate region “escapes” the OpenMP thread based execution model
• Optimize memory transfers to realize performance entitlement
• Memory consistency: makes it “easy” and legal for a compiler to optimize away transfer
Host Thread(s)
• Memory consistency: makes it easy and legal for a compiler to optimize away transfer operations (memory might actually be shared).
( )
AcceleratorMemory Transfer
Control transfer
Control transfer

data region constructD fi d t i t• Define a data environment– Keep data persistent on accelerator to minimize memory transfers
• Data region spans two accelerator regions The runtime checks if b is already on the accelerator:The runtime checks if b is already on the accelerator:
yes: it uses this without copies; no: it follows the copy(b) clause Can also call double_me() from outside a data region
Do not need to inline the subroutine (manually or by compiler)( y y ) Can even be in different source file
PROGRAM mainREAL :: a(N)
SUBROUTINE double_me(b)REAL :: b(N)REAL :: a(N)
!$omp data alloc(a)!$omp accelerate loop
DO i = 1,Na(i) = i
( )
!$omp accelerate loop present(b) copy(b)DO i = 1,N
b(i) = 2*b(i)ENDDO
$ENDDO!$omp end accelerate loop
CALL double_me(a)!$omp end dataEND PROGRAM main
!$omp end accelerate loop
END SUBROUTINE double_me

Loop Construct - example• We cannot describe accelerator-style parallelism using OpenMP constructs
– i.e. GPU warps/blocks/kernels/grids– simd vector size
• Need more control expressing non-thread-style parallelism to exploit accelerator hardware
• In this example think of the simd datapath as an accelerator
#define NLANES 4 // width of SIMD datapath
void add2d(char A[], char B[], char C[], int nrows, int ncols){
p p
{#pragma omp parallel for schedule(static)for (int i=0; i < nrows; i++) // go parallel on threads{
#pragma omp accelerate loop simd(NLANES) locale(SSE)for (int j=0; j < ncols; j++) // each thread uses SIMD{
int index = (i * ncols) + j;C[index] = A[index] + B[index];
} }
}}

F28M3x Concerto™ Series


DSP HPC Cluster Architecture
• Compute Nodes (Shannon)
• I/O Nodes (ARM A15 or other) running Linux( ) g
• Linux-compatible Compute Node Kernel
• High speed interconnect
Shannon
Host
MPI OpenMP
Linux runtime shell
File I/O
High Speed Serdes
Shannon (8 cores)Memory
PCIe
HostPCIe
Compute Nodes
Memory Shannon (8 cores)
Shannon
Host

Heterogeneous dispatch constructDi t h ( ffl d) d /d t t l (l l )• Dispatch (offload) code/data to a place (locale)
• Creates a new OpenMP environment
// Code executing on armf();
#pragma omp dispatch copyin(A,B) copyout(C) locale(dsp0){
// New OpenMP environment on dsp0
#pragma omp parallel for schedule(static)for (int i=0; i < nrows; i++) // go parallel on threads{
# l t l i d(NLANES) #pragma omp accelerate loop simd(NLANES) for (int j=0; j < ncols; j++) // each thread uses SIMD{
int index = (i * ncols) + j;C[index] = A[index] + B[index];
} } }
}
#pragma omp taskwait // wait for dispatched region to complete// more code executing on armg();

Summary
• OpenMP is the industry standard for shared memory parallel programming (or directive based parallel programming?)OpenMP can execute on an embedded RTOS or perhaps even• OpenMP can execute on an embedded RTOS or perhaps even “bare-metal”
• OpenMP will be successful in embedded systems: Just like other high level languages have been adapted to– Just like other high level languages have been adapted to embedded systems
• HPC computing looks like embedded computingPerformance and Po er– Performance and Power
• Accelerator(s) (heterogeneous) programming model– Accelerator regions: use accelerator parallelism (power-tool for a g p (p
thread)– Data regions: Copy (Stream via DMA) data in/out from host to
acceleratorDi t h i l h t ffl d bilit– Dispatch regions: more general heterogeneous offload capability


















