
User Input Anonymization in Graphical Applications · User Input Anonymization in Graphical...
103
User Input Anonymization in Graphical Applications Nuno Matos Gr´ acio Cora¸ c˜ ao Dissertation submitted to obtain the Master Degree in Information Systems and Computer Engineering Jury Chairman: Prof. Jo˜ ao Ant´ onio Madeiras Pereira Advisor: Prof. Jo˜ ao Coelho Garcia Co-Advisor: Prof. Paolo Romano Members: Prof. Lu´ ıs Manuel Antunes Veiga October 2012
Transcript of User Input Anonymization in Graphical Applications · User Input Anonymization in Graphical...

User Input Anonymization in Graphical Applications
Nuno Matos Gracio Coracao
Dissertation submitted to obtain the Master Degree inInformation Systems and Computer Engineering
Jury
Chairman: Prof. Joao Antonio Madeiras PereiraAdvisor: Prof. Joao Coelho GarciaCo-Advisor: Prof. Paolo RomanoMembers: Prof. Luıs Manuel Antunes Veiga
October 2012


Acknowledgements
First of all, I wish to thank my advisor, Professor Joao Garcia, for his patience, motivation,
and great ideas which made the past year a unique experience for my life, and ultimately, lead
this work to a achieve the best possible outcome. Also, a special word for the remaining team
members working on FastFix project: Luis Rodrigues, Paolo Romano, Nuno Machado, Pedro
Louro, Joao Matos and Alejandro Tomsic. Thank you all for the priceless help along this long
path.
To all my colleagues from the GSD group at INESC-ID, specially Ricardo Brilhante, for
your support, great ideas, and solutions, which made my life in room 601 a lot more bearable.
To my family and friends, but above all my girlfriend, Sara, which always supported, en-
couraged, and helped me in the hard times. Her continuous patience and hope truly made this
past year much more easy.
This work was partially supported by FCT (INESC-ID multi-annual funding) through the
PIDDAC program funds, and by the European project FastFix (FP7-ICT-2009-5-258109).
Lisbon, October 2012
Nuno Matos Gracio Coracao


To Sara.


Resumo
Com as actuais restricoes no desenvolvimento de software, as empresas nao tem tempo ou
dinheiro para produzir software completamente testado. Isto acontece porque a fase de testes
e um processo muito longo e caro. Portanto, as empresas tem que recorrer a um processo de
depuracao apos o software ser distribuıdo. Nesta abordagem, o software e distribuido aos clientes
ainda com alguns erros, e a partir daı e melhorado por uma equipa de manutencao atraves do
feedback dos utilizadores.
Este tipo de tecnicas utilizam core dumps para descrever o erro. Esta abordagem possui
duas desvantagens: a falta de privacidade do cliente, e a informacao irrelevante que e fornecida
a equipa de manutencao, pois apenas descreve o estado final da aplicacao no momento da falha.
A maior parte destas tecnicas reune dados sobre um erro, e envia essa informacao para os
programadores. Na maioria das vezes, a privacidade do cliente nao e tida em conta, e portanto,
os relatorios podem conter informacao sensıvel sobre o utilizador, como senhas ou numeros de
cartao de credito. Alem disso, a informacao contida no relatorio muitas vezes nao e suficiente,
e por vezes e mesmo irrelevante, para descobrir e corrigir o erro.
Nesta tese apresentamos o GAUDI, uma ferramenta para a gravacao, reproducao, e anon-
imizacao de execucoes graficas. O sistema funciona atraves da gravacao de uma interacao do
utilizador com a aplicacao, e da sua posterior anonimizacao. Este processo tem duas vanta-
gens: por um lado, o sistema remove dados privados do utilizador, e por outro lado reduz o
relatorio ao mınimo necessario para reproduzir o erro. Portanto, o GAUDI e capaz de melhorar
as tecnicas de anonimizacao existentes e proporcionar uma visao mais clara do erro para a equipa
de manutencao.


Abstract
With the modern constraints of software development, software manufactures do not have
the time or money to produce completely tested software. This happens because testing a
computer program is very long and expensive process. Therefore, companies have to rely on
a process called post-deployment debugging. In this approach, the software is deployed to the
clients still with some errors, and from then on is improved by a maintenance team through
feedback from the end-users.
These techniques rely on core dumps to describe the fault. This approach has mainly two
handicaps: the lack of privacy, and the useless information, which is provided to the maintenance
team, because it only describes the final state of the application. Most of these techniques collect
data about an error, when one happens, and send that information to the developers. Most of
the times, the client privacy is not taken into account, and therefore the reports may contain
sensitive user information, such as passwords, or credit card numbers. Moreover, the information
contained in the report is often not enough, and sometimes even unrelated, to the discovery and
correction of the bug.
In this thesis we present GAUDI, a tool for recording, replaying, and anonymizing GUI-
based applications. GAUDI works by recording a user interaction with the application, and then
anonymizing it. This process has two advantages: on one hand, the system removes private user
data from the log, therefore anonymizing it, and on the other hand GAUDI reduces the log to
them minimum amount of information needed to replay the error. Therefore, the system is able
to improve current anonymization techniques and provide a more straightforward view of the
error to the maintenance team.


Palavras Chave
Keywords
Palavras Chave
Anonimizacao
Aplicacoes Graficas
Replicacao de Faltas
Depuracao
Reproducao Determinıstica
Usabilidade
Keywords
Anonymization
Graphical Applications
Fault Replication
Debugging
Deterministic Replay
Usability


Index
1 Introduction 3
1.1 Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.2 Goals . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.3 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.4 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.5 Research Context . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.6 Structure of the Document . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Related Work 9
2.1 Deterministic Replay . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1.1 Sources of Non-Determinism . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.1.2 Overheads of Deterministic Replay . . . . . . . . . . . . . . . . . . . . . . 13
2.1.3 Privacy and Security . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2 Record and Replay Techniques . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.2.1 JRapture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.2.2 LEAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.2.3 ORDER . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3 Execution Replay of Graphical Applications . . . . . . . . . . . . . . . . . . . . . 17
2.3.1 Jedemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3.2 Barad . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
i

2.3.3 PATHS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.3.4 GUI Ripper . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.3.5 GUITAR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.4 Privacy-Aware Application Replay . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.4.1 Scratch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.4.2 Panalyst . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.4.3 Castro et al. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.4.4 Camouflage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.4.5 MultiPathPrivacy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.5 Privacy Legislation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.6 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3 GAUDI System 33
3.1 GAUDI Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.1.1 Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.1.1.1 Transformer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.1.1.2 Ripper . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.1.1.3 Replayer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.1.2 Client . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.1.2.1 Recorder . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.1.2.2 Anonymizer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.1.2.3 Converter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.1.2.4 Tester . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.2 Dynamic Widget Identification . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.3 Widget and Listener Graph . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
ii

3.4 Minimum-Set Listener Reduction . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.4.1 Invalid Test Removal Heuristic . . . . . . . . . . . . . . . . . . . . . . . . 48
3.4.2 An Example of the Minimum-Set Listener Reduction Algorithm . . . . . 48
3.5 Symbolic Execution for a Better Anonymization . . . . . . . . . . . . . . . . . . 50
3.6 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.6.1 Instrumentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.6.2 DWI implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
3.6.3 WLG Extraction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
3.6.4 Other Functionalities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
3.6.5 Standard Widget Toolkit . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4 Evaluation 55
4.1 Evaluation Goals and Criteria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.2 Experimental Setting . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.3 Description of Test Subjects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.4 Test Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.4.1 Calculator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.4.2 MyJpass . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.4.3 ZooManager . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.4.4 Lexi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
4.4.5 Pooka . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.5 Pre-Deployment Phase Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
4.6 Scenarios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
4.7 Post-Deployment Phase Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
4.7.1 Recording . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
iii

4.7.2 Anonymization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4.7.2.1 Minimum-Set Listener Reduction . . . . . . . . . . . . . . . . . 63
4.7.2.2 Invalid Test Removal Heuristic . . . . . . . . . . . . . . . . . . . 64
4.7.3 Replay . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
4.8 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
5 Conclusion 69
5.1 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
5.2 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
Bibliography 73
A Bug Repository Samples 75
B User Description 77
C Evaluation Description 79
D Scenarios 81
iv

List of Figures
2.1 Summary of the related work. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.1 Example of a user interaction, the events that were triggered and the listeners
invoked. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.2 GAUDI pre-deployment phase. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.3 GAUDI post-deployment phase. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.4 Dynamic Widget Identification example. . . . . . . . . . . . . . . . . . . . . . . . 42
3.5 DWI with new windows example. . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.6 An example of a WLG. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.7 Bug repository sample. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3.8 Example of a set of events and their listeners triggered during a user execution. . 48
3.9 Example of the test cases generated in the delimitation phase. . . . . . . . . . . . 49
3.10 Example of the test cases generated in the reduction phase. . . . . . . . . . . . . 50
4.1 Test subjects’ characterization. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.2 A snapshot of the Java Calculator. . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.3 Snapshot of MyJpass application. . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.4 Snapshot of the ZooManager application. . . . . . . . . . . . . . . . . . . . . . . 59
4.5 Snapshot of the Lexi text editor. . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
4.6 Snapshot of the Pooka mail client. . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.7 Instrumentation and ripping results . . . . . . . . . . . . . . . . . . . . . . . . . . 61
v

4.8 Comparison between the number of events monitored and the number of recorded
listeners. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
4.9 Comparision between the number of recorded listeners and the number of listeners
in the final sequences . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4.10 Comparison between the number of test cases generated with and without the
heuristic. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4.11 Comparison between the time needed to find a solution with and without the
heuristic. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
4.12 Comparision between the time of recording and the time replaying. . . . . . . . . 66
4.13 Comparision between the recording and replaying. . . . . . . . . . . . . . . . . . 66
4.14 Summary of the evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
A.1 Bug repository ticket sampling. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
B.1 Population sample description. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
C.1 Scenarios guide. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
D.1 Scenario 1 complete results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
D.2 Scenario 2 complete results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
D.3 Scenario 3 complete results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
D.4 Scenario 4 complete results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
D.5 Scenario 5 complete results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
D.6 Scenario 6 complete results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
D.7 Scenario 7 complete results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
D.8 Scenario 8 complete results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
vi

Acronyms
GUI Graphical User Interface
WER Windows Error Reporting
WLG Widget and Listener Graph
DWI Dynamic Widget Identification
GAUDI Graphical Anonymization of User Domain Input
I/O Input and Output
RDTSC Read Timestamps Command
API Application Programming Interface
SIS System Interaction Sequence
AWT Abstract Window Toolkit
SWT Standard Window Toolkit
JDK Java Development Kit
EFG Event Flow Graph
1

2

1IntroductionAll our knowledge has its origins in our perceptions.
– Leonardo da Vinci
Increasingly software applications are released with errors, mainly due to the fact that com-
pletely test an application is a time consuming, expensive task and sometimes even impossible
because of the complexity of the system. Some studies estimate that testing can consume fifty
percent, or even more, of the development costs (Bertolino 2007). As a result, software vendors
have to correct errors after their applications have been released. To achieve this, developers
make use of bug report systems, which provide information to developers on how to further
improve their products. However, most bug reports do not provide useful information needed
to debug an application (Bettenburg, Just, Schroter, Weiss, Premraj, & Zimmermann 2008).
In these kinds of solutions an error report is created and sent to the debugging team when
a crash occurs in the user machine. The report usually contains information about the state of
the environment in which the error occurred. One of the most widely used error reporting tools
is Microsoft’s Windows Error Reporting (WER) (Castro, Costa, & Martin 2008) which gathers
information from a huge amount of users all over the world1. Essentially WER is a tool that,
when it detects a crash, records a core dump and sends it to Microsoft’s servers upon the user’s
consent. Afterwards, a debugging team analyzes that information in order to further understand
the error.
One of the greatest disadvantage of this method is that it raises several privacy problems
since there is no effort being made to prevent the disclosure of sensitive user information, e.g. a
credit card number or a password2 . Therefore, users often choose not to send the report since
they do not know which information will in fact be revealed (Clause & Orso 2011). Moreover,
as the report only contains information about the final state in which the error was detected,
1http://technet.microsoft.com/en-us/library/bb490841.aspx2http://oca.microsoft.com/en/dcp20.asp

4 CHAPTER 1. INTRODUCTION
opposite to containing information about the execution that led to the error, finding the cause
of the problem may turn itself to be a hard and complex task (Cornelis, Georges, Christiaens,
Ronsse, Ghesquiere, & Bosschere 2003).
Another argument to take in consideration is the way programmers comprehend software in
order to debug a given application. Usually, developers start the debugging process by putting
themselves in the role of the end-user and interacting the graphical user interface. In this way the
developer is able to capture the user intent when the error was triggered and discover important
information about the cause of the error, maybe locating some starting points to analyze the
source code (Roehm, Tiarks, Koschke, & Maalej 2012).
In summary, there is a demand to develop new solutions for error report systems in order to
improve the user privacy and to provide more useful information to the programmers debugging
the applications. For this reason, we present a system which is capable of reducing a already
recorded execution of a graphical applications and then replay it. In this way we are able to,
on one hand, anonymize the user execution, and also help the developers get a straightforward
view of the error.
1.1 Approach
In the last years a significant amount of research has been performed with the goal to develop
new solutions to the previously stated problems. One of the main ideas proposed in several
works is that, instead of providing information about the point of failure of the application, it
would be better to provide information about the execution that led to the error. In this sense
several record and replay systems that try to deterministically replay a faulty execution have
been developed (Steven, Ch, Fleck, & Podgurski 2000; Broadwell, Harren, & Sastry 2003; Wang,
Wang, & Li 2008; Castro, Costa, & Martin 2008; Clause & Orso 2011; Louro, Garcia, & Romano
2012). These systems work in two phases, the record phase in which the information needed to
reproduce the error is recorded in a trace file, and the replay phase in which the information
recorded is forced onto the application in such a way that the execution replayed is the same as
the one recorded.
In order to deterministically replay a crash, the trace files should include all the relevant
sources of non-determinism that made the software fail (Castro, Costa, & Martin 2008). In

1.1. APPROACH 5
other words, all the variables that make two executions different. Since nowadays most software
applications are mainly driven by the interaction between users and a Graphical User Interface
(GUI) (Memon 2007), the graphical input made by the end-user is one of the most common
sources of non-determinism and therefore bugs are often triggered by it (Herbold, Grabowski,
Waack, & Bu andnting 2011).
The previously referred techniques have the goal to decrease, or even totally remove, the
sensitive information on the bug report. Some solutions rely on the developers to identify
which information is sensitive (Broadwell, Harren, & Sastry 2003), while other focus on trying
to obfuscate the path that led to the error (Castro, Costa, & Martin 2008; Clause & Orso 2011).
In other words, once they know the path that led to the crash, they try to force the execution
of the same path with a different set of values. This way, the user actual inputs are concealed
and therefore anonymized. More recent solutions have tried to go beyond this and search for
entirely new alternative paths to the error in order to improve the level of anonymization (Louro,
Garcia, & Romano 2012). The downside with these types of solutions is that they do not take into
account event-based applications. This makes the debugging harder because the programmer
does not have access to the end-user’s execution of the bug, i.e. the sequence of graphical events
that triggered it.
Despite the fact that the GUI is one of the main source of non-deterministic inputs and also
the observation of a generalized lack of privacy in bug reporting, there are no real solutions that
address both problems simultaneously.
Our approach is based on the fact that one can actually make use of a graphical execution to
provide a better anonymization technique and a more intuitive way of comprehending the error.
A user graphical execution can be described as a set of events that consequently trigger a set
of listeners within the source code of the application (Ganov, Kilmar, Khurshid, & Perry 2009).
If we record only the listeners we can decrease the size of the trace file while still providing a
correct replay. Moreover, we can use a heuristic to reduce a given sequence of listeners to a
minimum set needed to replay the error, anonymizing the original user execution and providing
the debug team the necessary steps to reproduce the error.

6 CHAPTER 1. INTRODUCTION
1.2 Goals
This work addresses the problem of anonymizing user input while recording and reproducing
executions of graphical applications.
Goals: This work proposes a mechanism for efficiently anonymizing user interac-
tions in error reports of event-based GUI applications.
To attain this goal, we will study how to reduce an execution on a graphical application, in
order to protect sensitive user information and provide a better understanding of the error to
developers.
1.3 Contributions
The contributions of the thesis are the following:
• A model, named Widget and Listener Graph (WLG), which describes the graphical ap-
plication structure and behavior.
• A dynamic identification system for widgets at runtime, named Dynamic Widget Identifi-
cation (DWI), which is able to identify the same widgets trough different executions.
• A new paradigm for recording and replaying graphical applications in a deterministic way.
• A algorithm, named Minimum-Set Listener Reduction, that provides a way to reduce a
given listener sequence into the minimum set which triggers the error.
1.4 Results
This thesis produced the following results:
• A prototype of a deterministic replay system which provides graphical anonymization,
called GAUDI (Graphical Anonymization of User Domain Input). GAUDI Implements a
record and replay mechanism for graphical applications which is able to anonymize the

1.5. RESEARCH CONTEXT 7
user interaction to the minimum amount of steps needed to replay the error. GAUDI is
also able to extract the WLG of a graphical application.
• An experimental evaluation of the implemented prototype based on real user interactions
trough eight different scenarios, consisting of five different application.
1.5 Research Context
This work was performed in the context of the FastFix project3. One of the main goals
of this project is to build a platform for remote software maintenance, capable of monitor-
ing execution environments and replicate application failures. The prototype described in this
document is included in the Error Report Generation and the Error Reproduction subsystems
of FastFix (Pagano, Juan, Bagnato, Roehm, Brugge, & Maalej 2012), which are responsible for
generating a obfuscated error report and deterministic replay the error in graphical applications.
1.6 Structure of the Document
The rest of this thesis is structured as follows: Chapter 2 presents some background con-
cepts related to this work, as well as an overview of some deterministic replay, GUI testing
and privacy-aware systems. Chapter 3 introduces GAUDI, describing in detail all the system.
Chapter 4 shows the results of the experimental evaluation study. Finally, Chapter 5 concludes
this document by summarizing its main points and future work.
3https://services.txt.it/fastfix-pro ject

8 CHAPTER 1. INTRODUCTION

2Related WorkIf knowledge can create problems, it is not through ignorance that we can solve them.
– Isaac Asimov
There are various approaches to correct bugs in a program, either through testing or through
allowing debugging after the release of the software. Despite being several ways to address the
problem, we will focus on a specific subset of solutions, which use a technique called determinist
replay. In section 2.1 we will describe this approach and in section 2.2 some examples will be
presented. Moreover, we will also analyze some techniques used for GUI testing in section 2.3,
in order to further understand the structure and behavior of modern graphical interfaces. In
section 2.4 we will discuss some tools that specifically address the problem of maintaining user
privacy. Section 2.5 presents some of the current legislation regarding user privacy. Finally,
section 2.6 concludes with a brief summary of the related work.
2.1 Deterministic Replay
When debugging a faulty program, developers often employ a technique called cyclic de-
bugging to locate the origin of the bug (Cornelis, Georges, Christiaens, Ronsse, Ghesquiere, &
Bosschere 2003). This approach relies on executing the code several times in order to incremen-
tally uncover information on the bug and ultimately its cause. However, when trying to debug
errors that do not manifest themselves in every run of the program, this technique is not the
best approach. We call these kind of errors non-deterministic bugs, as they are originated by one
of the existing non-deterministic events of the system (Cornelis, Georges, Christiaens, Ronsse,
Ghesquiere, & Bosschere 2003), e.g. a bug triggered by the return of gettimeofday UNIX call.
In order to address the problem of non-determinism one may use a technique called de-
terministic replay. Deterministic replay works in two phases: the record phase and the replay
phase. During the first phase all relevant deterministic events are recorded into a trace file.

10 CHAPTER 2. RELATED WORK
Then, on the second phase, the trace file is used to replay the non-determinism events that were
previously recorded, therefore removing the non-determinism and thus, enabling the replay of
the error whenever needed.
Despite the most important motivation for the use of deterministic replay in this work being
its use for debugging, we would also like to refer its importance for areas such as security and fault
tolerance (Pokam, Pereira, Danne, Yang, & Torrellas 2009). In the security field, developers can
replay the past execution of applications looking for exploits of newly discovered vulnerabilities,
to inspect the actions of an attacker, or to run expensive security checks in parallel with the
primary computation. In the area of fault tolerance, system designers can use replay as an
efficient mechanism for recreating the state of a system after a crash.
As a deterministic replay system may seem rather simple in theory, in practice it may turn
out to be awfully complex. For a execution replay system to be used in practice in needs to
satisfy a certain number of properties (Cornelis, Georges, Christiaens, Ronsse, Ghesquiere, &
Bosschere 2003). The first one is accuracy; the system must assure that the replay resembles
the original execution as much as possible. The system must be non-intrusive; in order to
avoid bugs induced by the recording system itself and also to record a typical execution and not
one which has been altered due to the recording being performed. Moreover, the solution must
be space efficient and time efficient in order to be possible to generate trace files without
compromising the execution of the program being recorded.
When debugging an application we are primarily trying to reproduce the instruction stream
of that application and the resulting modifications to the state of the application. There are two
main approaches on how to achieve the replay of an application (Cornelis, Georges, Christiaens,
Ronsse, Ghesquiere, & Bosschere 2003). The first one is called “content-based” replay, and
consists of storing all the data that is read by the instructions from the registers and from the
main memory during the record phase. When replaying, the trace file would have the input to
each and every instruction. The second one is called “ordering-based”, and consists on forcing
the environment of the replay phase to be equal to the one in the original execution and then as a
consequence force the ordering of the interactions between the environment and the application.
Both of these techniques in their pure form are mainly for theoretical purposes since both of
them operate on a very low level of abstraction and therefore require too much trace data.
In the remaining of this section, we will further discuss some challenges that arise with

2.1. DETERMINISTIC REPLAY 11
a deterministic replay approach, namely: the various types of non-determinism sources, the
overheads generated by the system, privacy and security.
2.1.1 Sources of Non-Determinism
Deterministic replay can be achieved at different levels of abstraction: at a top level, where
one can replay the user-level instructions that are executed, at a lowest level where a system
can record and replay all the machines instructions, or even both simultaneosly (Pokam, Pereira,
Danne, Yang, & Torrellas 2009). The choice of at which level to address the problem depends
on which kind of application is being developed, because each approach has advantages an dis-
advantages. Despite the level at which one may choose to work, the sources of non-determinism
can be divided in two sets, input non-determinism, the input read by the program, and memory
non-determinism, the memory interleavings across different threads of execution.
Input Non-Determinism
These kind of inputs differ depending on the level of abstraction at which the recording
system is working (Pokam, Pereira, Danne, Yang, & Torrellas 2009). At an abstract level one
can consider the non-deterministic inputs to be all inputs that are consumed by the system being
recorded, which are not generated within the layer where the system is running. For instance,
when talking about user-level replay, all inputs coming from the underlying operating system
are non-deterministic inputs. On the other hand, when talking about system-level replay, one
kind of non-deterministic inputs are the inputs coming from external devices, such as I/O or
system interrupts.
Regarding the user-level inputs we have the following list of sources.
System Calls: In general, system calls are non-deterministic. For instance, a system call
reading information from a network card or from a disk may return different results each
time they are called. A classic example is the UNIX call gettimeofday which, due to its
time-dependent nature, returns a different value at each call.
Signals: Signals that are delivered asynchronously to a program can be received at dif-
ferent times in two distinct runs, therefore making the control flow non-deterministic.

12 CHAPTER 2. RELATED WORK
Special Architectural Instructions: Most of architectures have some instructions
which are non-deterministic. For example, on the x86 there exist some instructions such
as RDTSC (read timestamp) which returns different values on each execution. Moreover,
across processor generations, there is also CPUID that returns different values; this may
be troublesome if the replay happens on a different machine from the one in which the
recording happened.
In terms of system level non-determinism we list the following.
I/O: As most architectures allow memory mapped I/O, which means that loads and stores
in reality read from and write to devices, there is no guarantee that the reads and the writes
are repeatable. Therefore, every value read and written from the I/O must be recorded.
Hardware Interrupts: These kinds of interrupts trigger an interrupt service routine,
which changes the control-flow of the system. As hardware interrupts happen at any given
moment in time, the recorder needs to log when it happened, its contents and from which
devices it came.
Direct Memory Access: Direct memory accesses write directly to memory bypassing
the processor. The values written and the time at which they occur need to be recorded
to ensure the reproducibility of the execution.
Memory Non-Determinism
In addition to the input non-determinism, deterministic replay systems also have to deal
with the non-determinism created by the order on which the threads access the shared memory
of a given process. That order usually is not the same across different runs, because of memory
races, in other words, different threads may win the race when accessing a piece of shared
memory. The races could occur between synchronization operations or between data accesses,
synchronization races and data races respectively. This happens because the several differences
in the overall state of the system from one run to another: interrupts being delivered at different
times, cache misses, memory latencies, and also the load of the system. As a result, there is
possibly a different scheduling of threads each time the application runs. In order to address
this problem to guarantee a deterministic replay the order of the accesses to shared memory
section must be recorded.

2.1. DETERMINISTIC REPLAY 13
2.1.2 Overheads of Deterministic Replay
When developing a deterministic replay system, one of the main concerns one has to take in
consideration are the overheads created while in the record phase (Cornelis, Georges, Christiaens,
Ronsse, Ghesquiere, & Bosschere 2003). On one hand, if the system can replay an execution
with great accuracy regarding the original production run, consequently it will incur in a great
recording overhead. On the other hand, with the decrease of the collected information, it
becomes more difficult to provide a replay which resembles the original execution. Therefore,
the choice of the level of abstraction at which to operate is of crucial importance, in order to
provide an accurate and non-intrusive solution as referred previously. Independently of the level
of abstraction, the solution must be efficient in terms of both time and space. Therefore, While
recording an application, there are more instructions to run and the initial performance will be
degraded. Hence, the number of extra instructions needed during replay should be minimized
in order to maintain the use of the program acceptable. Moreover, recording implies saving
the information in a trace file. The trace file may include a snapshot of the system or other
relevant information on the original production. As a result, the trace file could turn out to be
a large file. Thus, in order to decrease the space required by the trace file, the total amount of
information recorded should be minimized.
2.1.3 Privacy and Security
One of the main uses for deterministic replay systems is post-deployment debugging. In these
scenarios, upon a crash, a client sends a bug report to the developers in order to understand
and fix the bug. With a deterministic replay system, the developing team uses the bug report to
replay the original failed execution on the client machine. This creates some security and privacy
issues (Broadwell, Harren, & Sastry 2003; Wang, Wang, & Li 2008; Castro, Costa, & Martin
2008; Clause & Orso 2011) concerning the sensitivity and the confidentiality of user information
sent to the developer team. For instance, the bug report may contain passwords, addresses and
credit card numbers. Moreover, a third party attacker may eavesdrop on the connection between
the client and the server, in order to collect information on the user.
Addressing these problems is not trivial and it may prove a complex task. The easy way
around is to provide the client with some way to examine the bug reports, shifting the respon-

14 CHAPTER 2. RELATED WORK
sibility of whether or not to send the bug report to the user. These solutions have a essential
problem, which is the fact that the client usually does not want to waste time inspecting the
report, and therefore simply chooses not to send the report. Consequently, without the client
participating willingly, the process of post-deployment renders itself useless.
Nowadays, some techniques have been developed in order to reduce the amount of user
information revealed by the report (Broadwell, Harren, & Sastry 2003; Wang, Wang, & Li 2008;
Castro, Costa, & Martin 2008; Clause & Orso 2011), however they are not able to fully anonymize
the sent information. Regarding the security issues, they can be solved employing cryptographic
mechanisms, such as asymmetric keys and digital signatures.
2.2 Record and Replay Techniques
As one can foresee, achieving a correct deterministic replay of an application is not a trivial
matter. For that reason, we will review some systems, in order to provide a better insight on
how to solve the problems mentioned in the previous sections of this chapter, namely choosing
the right level of abstraction and also how to address the different sources of non-determinism.
2.2.1 JRapture
JRapture is a tool designed to capture interactions between a Java application and underly-
ing system, thus recording and execution, in such a way that it is possible to later reproduce the
execution. JRapture records and reproduces a several amount of interactions, namely, keyboard,
files and even the user interface (Steven, Ch, Fleck, & Podgurski 2000).
The system works in two phases: the recording phase and the replay phase. During the
first phase it records the input sequence of all the provided sources of non-determinism. In the
replay phase it forces the same input sequence that was first recorded on to the application. As
Java applications interact with the host operating system through the Java API, the latter was
chosen as the place on which to perform capture and replay. The prototype implementation of
JRapture provides modified versions of the Java API classes that interact with the operating
system or windowing system. Then, when the system is started the modified code is loaded
instead of the usual Java API libraries. During the capture mode the new API classes construct

2.2. RECORD AND REPLAY TECHNIQUES 15
a system interaction sequence (SIS), which represents the sequence of inputs together with
auxiliary information needed for correctly replay the execution.
The authors distinguished three ways in which the state of a process can be modified by
a method call: by returning a value, by changing the values of parameters and by changing
the values accessible to the method. Thus, these were the kind of java API methods that
were modified in order to record their effect on a program’s state and to reproduce that effect
during replay. The two major drawbacks with JRapture are: (i) the fact that it cannot replay
the interleaving of threads nor (ii) it can guarantee that the absolute order in which threads
are created. According to Steven et al. they are able to mitigate these problems by forcing
the correct sequential execution of each thread, addressing (i), and ensure that each thread
creates its children (threads) in the same order, addressing (ii). These capabilities are useful for
debugging concurrent applications.
The system also records and replays GUI events, since, in the major part of the cases, they
are the only or at least the major source of interaction between the user and the application.
Currently, JRapture only works with AWT events. Despite the fact that the AWT library
provides a way to intersect events the authors decided not to use it. This is due to the control
flow of the graphical event handling. For example, each AWT component has a peer component
(the platform specific implementation of that component), and the original event arrives at that
peer component and only after is propagated to the AWT component which then calls the event
handler. Therefore, and in order to capture the original event, the authors modified the action
method of each peer component, wrapping them in such a way that, when an event arrives at the
peer component, it is recorded before being propagated to the corresponding AWT component.
The biggest disadvantage of JRapture is that it relies on the use of modified versions of the
Java APIs. This makes it rather difficult to deploy on user machines and renders the system
very inflexible for using in post-deployment debugging.
2.2.2 LEAP
As relying on modified libraries may cause the system to be inflexible, there are solutions
which prefer to rely on code instrumentation. In this way, an application is injected with code
that does not change its behavior but adds the capability of recording executions. LEAP is a

16 CHAPTER 2. RELATED WORK
recent deterministic replay system for concurrent Java programs (Huang, Liu, & Zhang 2010).
Generally, the standard approach for deterministically replaying a concurrent application is to
ensure the global order in which each thread accesses shared memory locations. LEAP, on the
other hand, relies on the observation that one only needs to ensure the local-order of thread
accesses to each memory location instead of the global-order. The authors use mathematical
models to prove the soundness of this statement.
The system has three phases: the transformation phase, the recording phase and the replay
phase. In the transformation phase LEAP instruments the Java bytecode of the application in
order to generate drivers for the replay and the record phases. In this step all shared variables are
identified and each one is associated with an access vector. During the record phase, whenever
a thread reads or writes in a shared variable, the thread ID is stored in the access vector. In the
replay phase, the system forces the same access order on each shared variable, therefore ensuring
the local order of accesses to each shared memory location instead of a global order.
With this local ordering approach, LEAP provides a lightweight solution to deterministically
replay concurrent programs, since it reduces the overheads of recording the global-order of
accesses to shared memory location by only recording local-order. However, the system has
some limitations. As LEAP always replay the application from the beginning it is not suitable
for applications which may run for long periods of time. Moreover, the system cannot record
shared variables from external Java libraries. For instance, LEAP is unable to reproduce bugs
arising from data races in JDK library. Finally, LEAP is not able to distinguish between two
different instances of the same class, which may lead to false dependencies between instances
and consequently to an increase in the performance overhead (Yang, Yang, Xu, Chen, & Zang
2011).
2.2.3 ORDER
As referred above, LEAP cannot reproduce non-determinism introduced by external code,
such as libraries or class files dynamically loaded, and also it is not able to differentiate two
instances of the same class. In order to improve the previous system trying to solve its main
problems, a new approach was created in ORDER (Yang, Yang, Xu, Chen, & Zang 2011).
This approach identifies data access dependencies at object granularity. In this way, record-

2.3. EXECUTION REPLAY OF GRAPHICAL APPLICATIONS 17
ing massive unnecessary dependencies introduced by approaches like LEAP, or even by object
movements from the Java garbage collector, may be avoided. As the garbage collector is used to
reclaim non-reachable memory spaces, this usually requires moving or even modifying objects
in the heap, which may cause additional, unintended, dependencies.
In order to achieve a correct deterministic replay at object level, ORDER records the object
access timeline. This structure is local to each object and contains how many times a thread
accessed the object before it is accessed by another thread. The framework instruments the
application bytecodes in order to add metadata to each object, namely a object identifier,
a accessing thread identifier (AT) , a access counter (AC) and an object-level lock. While
recording, the system counts how many times a thread access a given object and records that
pair (thread ID and access count) onto the timeline. During replay, it uses the recorded timeline
and the object-level lock to ensure the local-order onto which thread accesses the object.
By working at object granularity, ORDER is able to reduce unwanted performance overheads
generated by false dependencies between instances of the same class, on both record and replay
phases. However, the system is not able to treat all sources of non-determinism, such as graphical
input.
2.3 Execution Replay of Graphical Applications
This thesis is mainly focused on the graphical interaction between the user and the appli-
cation, very often trough some kind of GUI. Despite the fact that in the previous section we
obtained a better notion on how deterministic replay systems work and their main flaws, it is im-
portant to study and understand graphical user interfaces (GUIs) and what kind of applications
handle them.
Therefore, in this section we will review various techniques that have been created in order
to correctly manipulate applications with a graphical user interface, namely for deterministic
replay and for testing. The goal is to provide some important concepts regarding GUIs and
to understand the challenges that arise when dealing with them. First of all, and since we are
going to refer to them through the rest of this report, let us provide a definition of a graphical
user interface.

18 CHAPTER 2. RELATED WORK
GUI: is a hierarchical, graphical front-end to a software system that accepts
as input user-generated and system-generated events from a fixed set of event and
produces deterministic graphical output (Memon 2007). The GUI contains graphical
objects, which we call widgets. Each widget has a fixed set of properties. The set
of all the discrete values that belong to each property of each widget of the user
interface constitutes the state of the GUI.
This defines a specific class of GUIs that have a fixed set of events with deterministic outcome
that can be performed on objects with discrete-valued properties. This definition concerns only
this specific type of graphical interfaces. If we wanted to define other classes of GUI such as web
interfaces we would have the need to extend this definition.
2.3.1 Jedemo
Jedemo (Miura & Tanaka 1998) is a framework for performing even-driven demonstrations
in Java applets. An event-driven demonstration shows the behavior of an applications by re-
executing the captured events (Miura & Tanaka 1998). When addressing applications that pos-
sess a GUI, the authors suggest that it is easier to explain graphical operations with an actual
demonstration than with a textual explanation.
When using a demonstration method to provide insight on how to use a graphical interface,
one has two ways to do so: event-driven demonstration and image-driven demonstration. In an
event-driven demonstrations, events are recorded in such a way that they can be replayed, thus
enabling the user to understand how to use the application. In an image-driven demonstrations,
the actual images of the application are recorded and then replayed as a video. This kind of
demonstration is inflexible, due to the lack of adaptability regarding the user needs and also
because image-data consumes a vast amount of disk space. On the other hand, event-driven
demonstrations are flexible as they allow the developer to add more information and the data
recorded is substantially less.
In Jedemo an event-driven approach is used. Therefore, the developer records an execution
on the recorder and then that execution is replayed, when needed, by the user using the player.
While recording an execution, a tree-structure representing the hierarchy of the GUI is gen-
erated. This structure provides the information on the interface’s components and containers.

2.3. EXECUTION REPLAY OF GRAPHICAL APPLICATIONS 19
A component is a graphical widget which can receive user input and perform corresponding
actions. In turn, a container adds components and other containers an lays them out. Then,
the listeners of each component are identified and used to catch all the events.
When replaying, for each event the player calls the method in the target system and it also
displays a pseudo mouse cursor to provide the user with visual information on what is happening.
In order to correctly replay an event, one needs to know what was the source component of that
event. In Java this is done using the memory addresses, which changes from one execution
to another. Thus, the authors developed a way of tracking the components of the GUI called
tracking by path. The latter consists of using the order in which a component was added to its
container as an identifier of the component.
As Jedemo works at the event level, it does not take into account the underlying code that
is being executed. Therefore this kind of approach is not very useful to help developers find the
origin of the bug, since it does not provide a clear mapping between the events and the listeners
that being invoked in the logic layer.
2.3.2 Barad
In order to provide a mapping between the graphical components and the actual code that is
being executed, a new kind of approach was created. One of these examples is Barad, which is a
GUI testing framework based on symbolic execution. Despite not being a recorder and replayer
solution, the interesting thing about this framework is the fact that it provides a systematic
approach that uniformly addresses event-flow as well as data-flow (Ganov, Kilmar, Khurshid, &
Perry 2009). One of the main challenges in graphical user interface testing is the combinatorial
nature of the possible sequences of events. Therefore, in traditional GUI testing usually there
can be a large number of test cases without achieving acceptable branch and statement coverage.
Barad addresses this by using symbolic execution to generate fewer tests while improving brach
and statement coverage.
The system instruments Java bytecodes to symbolically execute a graphical application to
obtain the path conditions that will then be used to obtain a sequence of tests that tries to achieve
full code coverage. In order to symbolically execute a graphical application, Barad creates an
abstraction for widgets called symbolic widgets. These entities enable Barad to symbolically

20 CHAPTER 2. RELATED WORK
manipulate standard widgets, therefore providing a way to explore multiple states of execution
without having to use concrete values. Each symbolic widgets represents its concrete counterpart
of the SWT Java library. For example the symbolic widget for org.eclipse.swt.widgets.Text is
mapped into barad.symboliclibrary.ui.widgets.SymbolicText.
After the instrumentation, system uses symbolical widgets to detect event listeners. The
framework does not consider events that do not possess an event listener, since other kinds of
events are irrelevant to increase code coverage. Once the path conditions have been produced
and all the event listeners have been found, Barad will generate an event listener graph that
will be transversed several times in order to generate test cases. A test case is generated as a
chain of event listener method invocations that subsequently is mapped to an event sequence
that forces the execution of these invocations. Barad is composed by two main components, the
symbolic agent and the concrete agent.
Symbolic Agent: instruments the bytecodes of the application under test, performs sym-
bolic execution of the instrumented version, and generates test cases as event sequences
and data inputs. These functionalities are divided among the following components. The
Class Loader enables parallel execution of a symbolic and concrete version of the same
application in the same JVM. The Instrumenter performs the java bytecode manipulation.
The Symbolic Analyzer executes the symbolic and event listener analysis and finally, Test
Generator generates tests from the data obtained during the symbolic and event listener
analysis.
Concrete Agent: generates tests adopting a traditional testing generation approach and
executes tests on the application under test, generated either by itself, or by the symbolic
agent. The main components are the following. The Test Generator generates tests in
a traditional GUI testing approach, the Test Executor executes tests on the application
under test and Barad Studio provides visualization aids and controls the testing process.
One of the most interesting achievements in Barad is the creation of widget abstractions, which
allows the application to be analyzed in terms of a path through code, while considering the
input from the GUI, thus allowing Barad to map a relation between what happened in the
user interface and the logic layer of the application. However, when considering GUI testing,
measures like code coverage are not a good criteria to evaluate the application, because what

2.3. EXECUTION REPLAY OF GRAPHICAL APPLICATIONS 21
matters is not only how much code is tested, but also in how many different possible states of
the software each piece of code is tested (Memon, Pollack, & Soffa 2001).
2.3.3 PATHS
One of the earliest approaches to generate test cases is using automated planning, a well-
developed and used technique in artificial intelligence. One of the systems developed that uses
this approach is PATHS (Memon, Pollack, & Soffa 1999; Memon, Pollack, & Soffa 2001). Given a
set of operators, an initial state and a goal state, this approach generates a sequence of operators
which take the application from the initial state to the goal state. The key concept is that the
test designer is likely to have a good idea of the possible goals of a GUI user. Moreover, it is
simpler and more effective to define these goals than to specify sequences of events which lead
to them.
PATHS works in two phases, the setup phase and the plan-generation phase. In the first
step, the system creates a hierarchical model of the GUI and returns a list of operators from the
model to the test designer. Afterwards, the test designer defines the set of preconditions and
effects of the operators in a simple language provided by the planning system. During the plan-
generation phase, the test designer specifies scenarios by defining a set of initial and goal states
for test generation. Finally, PATHS performs a restricted form of hierarchical plan generation
to produce multiple hierarchical plans, therefore generating a test suite for all the scenarios.
The main feature of PATHS is the plan generation system. The input of the planning system
is a initial state, a goal state and a set of operators, which model events and are specified in
terms of preconditions and effects, conditions that must be true for the action to be performed
and conditions that will be true after the action is performed. The output of the plan generation
system is a set of steps to achieve the goal, which, in this case, are events.
However, the fact that the test designer has to insert all of the preconditions and effects of
each operator by hand can make the process complicated and error prone. Moreover, as one
puts the responsibility of finding the errors on the test designer. That task may turn out to be
complex and time-consuming, and probably not all the errors will be uncovered.

22 CHAPTER 2. RELATED WORK
2.3.4 GUI Ripper
As discussed previously, one of the approaches to GUI testing is to create a model of the
interface in order to generate tests with various criteria, namely code coverage. However, because
most of these models were developed to address specific problems, they have a narrow focus.
GUI Ripper appears with the goal of consolidating a model that fully describes the GUI and
its events, and automating the creation of this model, by reverse engineering the GUI model
directly from an executing user interface (Memon, Banerjee, & Nagarajan 2003; Memon 2007).
GUI Ripper is a dynamic process that is applied to an executing software’s graphical user
interface. Starting from the application’s first window, or set of windows, the GUI is explored
by opening all child windows. All the windows widgets, their properties and their values are
extracted. Consequently, two models are generated: one to describe the structure and another
to describe the behavior of the GUI. The structure is represented as a GUI forest, and the
behavior is represented as event-flow graphs and an integration tree.
The GUI forest represents the structure of the graphical interface windows (nodes) and
the hierarchical relationship between them (edges). A GUI window is considered to be a set
of widgets, which constitute the window, and their respective set of properties and values.
The authors distinguish between two types of windows: modal windows and modeless windows.
Modal windows, once invoked, monopolizes the GUI interaction, restricting the focus of the
user to a specific range of events within the window, until the window is terminated (Memon,
Banerjee, & Nagarajan 2003). Modeless windows, on the other hand, do not restrict the user
focus; they merely expand the set of events available to the user.
As the GUI forest is not useful for testing by itself, the tool collects additional information
during ripping, in order to develop a model of the interface behavior, called the flow of events.
Therefore, the first step is to identify parts of the interface which are isolated. A user always
interacts with a modal window, and possibly with a set of modeless windows invoked by the
modal window, directly or indirectly. Thus, the authors define a modal window and their
respective set of modeless windows as a component. After that, the even-flow graph for each
components is generated. This graph represents all possible interactions among the events in a
component, i.e. which events may follow a given one. Finally, GUI Ripper generates a integration
tree which describes the event flow amongst components.

2.3. EXECUTION REPLAY OF GRAPHICAL APPLICATIONS 23
With both these structures created, it is easy to transverse the graph and generate test
cases, which are sequences of events (Memon 2007). As this approach provides a great definition
of a GUI model, it is still not able to fully automatically model the interface, this is due to
the existence of infeasible paths, for instance, when a window is only available after a correct
password is provided.
2.3.5 GUITAR
Consequence of the work done in GUI Ripper (Memon 2007), the authors started working
on a framework for GUI testing called GUITAR (Memon 2011). The system is able to reverse
engineer the application graphical structure, generate the EFG and the integration tree, generate
test suites with various algorithms, execute those tests and a verify the results of the tests.
The system works in three phases. In the first phase it generates a model of the GUI, more
specifically, a Integration Tree and a Event-Flow Graph (EFG), which are the same used in GUI
Ripper (Memon 2007). Secondly, it generates test cases, which depend on the generation method
selected (Hackner & Memon 2008). This enables the possibility of testing the interface using
different approaches, i.e. code coverage or goal-driven tests. Finally, the tests are replayed. The
whole system is constituted by four main components: the GUI ripper, the EFG generator, the
Test Case Generator and the Replayer.
GUI Ripper: is used to reverse engineer a running GUI, in order to extract the GUI
hierarchy, in other words the relations between each component of the interface. This
model is called the Integration Tree.
EFG Generator: using the model generated by the GUI Ripper, it generates the EFG,
which represents all possible interaction between GUI objects and events at any given
time.
Test Case Generator: Using the Integration Tree and the EFG, it generates tests de-
pending on the generation method selected.
Replayer: Replays the tests.
The greatest achievement in GUITAR is the test case generator. Mainly because it can use

24 CHAPTER 2. RELATED WORK
the EFG and the integration tree to navigate the various states of the application, therefore
exploring various event sequences to generate tests.
2.4 Privacy-Aware Application Replay
As previously mentioned in this report, one of the most common uses for deterministic
replay systems is for debugging applications. Hence, as one of the possible scenarios for the
debugging of the application may be after its release, the system will work in the following way:
the recording phase will happen on the client side, and the replay phase will occur on the server
side. Whenever a crash is detected in the client a trace file is generated and sent to the server,
where it will be used to replay the error and debug the application.
In this kind of scenarios there is a huge problem that arises: maintaining user privacy.
When sending a trace file to a server, one cannot forget that it may, and it usually does, contain
sensitive user information. Although such data cannot be revealed without the user consent,
that same information may be of extreme importance to accurately reproduce the error. There
have been several solutions which tried to deal with this problem: to correctly reproduce a bug
while trying to reduce, or remove, sensitive user information.
2.4.1 Scratch
One of the first solutions developed to address the leakage of user privacy in remote error
report system was Scratch. This tool was designed to remove all sensitive information from the
bug report, before it is sent to the debugging team (Broadwell, Harren, & Sastry 2003).
During the development phase, fields that may contain sensitive information are marked.
While executing the program, every instruction that depends on a sensitive field is also marked
as sensitive, therefore propagating the information of which data is sensitive throughout the
entire application. When a crash occurs, an error report is created. Consequently, this report is
analyzed and all sensitive information is removed from it. This is done by grouping all sensitive
data in a specific memory region identified by special delimiters. Afterwards, Scratch only has to
inspect the report and find the delimiters in order to remove all sensitive data from the memory
dump contained in the file.

2.4. PRIVACY-AWARE APPLICATION REPLAY 25
Scratch’s major disadvantage is concerned with the need to mark all sensitive fields before
deploying the application. First, this means trusting on the developers to choose which fields are
sensitive and which are not; that is equivalent to granting developers access to the sensitive data.
On other hand, Scratch relies on the transformation of the source code of an application; this
may not be convenient for deployed applications. Moreover, this technique removes all sensitive
information, which consequently may lead to the incapacity to reproduce the bug, therefore
rendering the bug report useless.
2.4.2 Panalyst
Panalyst appeared as an effort to increase the reproducibility of application crashes. In order
to achieve this, the system tries to find an alternative input, which differs from the original one
but still triggers the same bug (Wang, Wang, & Li 2008). Panalyst uses symbolic execution to
generate the new input. The symbolic execution of a program consists in running the application
on a controlled environment, replacing the inputs with symbols (King 1976). Input is considered
to be either user input or the result of system calls.
Panalyst includes a client component and a server component. When a crash occurs, the
client sends to the server the type and structure of the input that lead to the bug. Then, the
server symbolically executes the application until it reaches a conditional instruction, where it
needs more information on the input in order to continue. The server sends a question to the
client to retrieve more information on the input concerned with the specific instruction, so that
the server may proceed with the symbolical execution. To identify the input fields concerned
with conditional instruction the system performs a dynamic tainting analysis. The analysis
marks each field of the input with an identifier, which is propagated in every operation that
depend on the identified fields.
Upon receiving the server question, the client verifies its privacy policies and sends an answer
to the server. The privacy policies limit how much information can be revealed by each field
(these limits are defined by the user). Therefore, the answer which is sent to the server must be
within the limits of the privacy policies.
The major advantage of this technique is the fact that it removes the computational over-
heads on the client side. Therefore, as the majority of the processing is done remotely, the

26 CHAPTER 2. RELATED WORK
system can be used in devices with reduced computational power, like smartphones. However,
it presents the same problems as Scratch (Broadwell, Harren, & Sastry 2003) since the sys-
tem does not send sensitive information to the server, the reproducibility of the crash may be
compromised. Moreover, the user needs to previously define the privacy policies.
2.4.3 Castro et al.
One of the main problems with the previous solutions is that they simply do not send
sensitive information in the report, which reduces the reproducibility of the error. In order to
increase the reproducibility of the crash without revealing sensitive user information, solutions
like the one developed by Castro et al. (Castro, Costa, & Martin 2008) were created. The goal
of this technique is to, given a log of a program’s failed execution, anonymize it. For that, the
authors implemented a prototype to produce a anonymized report that still allows a correct
reproduction of the failure, and developed an application-independent technique that provides
the user with information about the amount of the original input revealed by the resulting
report. Thus, helping the end-user to choose whether he wants to send or not the report to the
debugging team (Castro, Costa, & Martin 2008).
The technique assumes that the application to which one would like to generate a sanitized
report is being constantly monitored, and that upon a failure it is able to produce a log with all
the user input recorded during the execution. Afterwards, resorting to the original input, the
execution that generated the error is replayed in order to compute its path conditions. In other
words, the logic conditions which define a domain of inputs that follow the same same path as
the one of the original execution. For this, they use symbolic execution.
In this technique, the symbolic execution transverses the same execution path of the original
production and then, at each conditional instruction, adds the specific predicate to the path
conditions. These constrains are consequently fed to a Satisfiability Modulo Theories (SMT)
solver to compute the new input. The prototype described in (Castro, Costa, & Martin 2008)
uses a SMT solver called Z3 to generate the new inputs. In order to use Z3, the path conditions
generated must be converted to bit vector types and primitives of the solver. There are some x86
instructions that the prototype cannot convert to the language of the solver, therefore forcing
the use of the original input. Despite this fact, the Z3 is still able to largely anonymize the
original input in little amount time.

2.4. PRIVACY-AWARE APPLICATION REPLAY 27
Privacy loss can be calculated through the path conditions generated when symbolically
executing the program. This is due to the fact that the new input is calculated using the path
conditions; therefore the new input reveals as much information about the original input as
the path conditions. The loss of privacy is inversely proportional to the number of possible
paths that can be covered with the same path conditions, therefore if we have very restrictive
conditions we will have a great loss of privacy. This measure may not be relevant to show the
end-user what was the privacy loss in a particular run, since the actual percentage of the original
input that remains the same in the sanitized input is not revealed.
The resulting anonymized input causes the software to follow the same execution without
revealing the original input of the user. In fact, in a best-case scenario, the only thing revealed
is the execution path of the original execution. After the user has sent the generated report to
the debugging team, they use new input to reproduce the bug. This technique has the problem
of putting the computational overhead of anonymizing input data on the client, which may lead
to a client not sending the report. Moreover, in some specific scenarios, even the amount of
information reveled by only knowing the original execution path may allow the debugging team
to infer important information on the user.
2.4.4 Camouflage
The technique used in Camouflage (Clause & Orso 2011) is very similar to the one developed
by Castro et al. (Castro, Costa, & Martin 2008). In other words, given the user’s original input
it generates the path conditions that lead to the crash. Afterwards it computes an anonymized
input that forces the execution to transverse the same path of the original input. The current
prototype has two separate components the constraint generator and the input anonymizer. The
record/replay tool is assumed to be an external component.
To obtain the path conditions the authors use an extension of an explicit state software
model checker called Java PathFinder1. They use the method interception capabilities to wrap all
native methods of the java.io.package. In this way, it is possible to assign a symbolic variable with
every input read by these methods, which enables Java PathFinder to then generate the desired
path conditions. After, the input anonymizer transforms the constraints into a format that is
1http://babelfish.arc.nasa.gov/trac/jpf

28 CHAPTER 2. RELATED WORK
understood by the constraint solver and invokes it. The constraint solver used in Camouflage
was YICES2 because it allows discardable constraints and bit vectors operations. Finally, the
input anonymizer transforms the result of the constraint solver into a new input.
As we can notice, these kinds of solutions raise some problems due to the limitations inherent
to the use of path conditions. First, the solution found by the solver should be independent
from the original input. In other words it should not be possible to recover the original input
from the anonymized input. Second, the set of possible inputs that can be derived from the
path conditions must be large enough to make an enumeration of the domain impractical in
a reasonable amount of time. And third, the new input should be as different as possible of
the original. The first aspect is solved as Camouflage uses a constraint solver, and as most of
them use some kind of randomness in their search (Clause & Orso 2011), the selection of the
new input should be considered pseudo-random. Regarding the second and third aspects this
technique extended the basic approach with two new techniques: path condition relaxation for
solving the second aspect, and breakable input conditions to the address the third.
Path Condition Relaxation: It consists of a set of optimizations that specialize the
constraint generation part of the dynamic symbolic execution to increase the number
of possible solutions to the path constraints. Intuitively, the technique relaxes overly
restrictive constraints, thus allowing a larger number of solutions.
Breakable Input Conditions: Forces the constraint solver to choose values that are
different from the corresponding ones on the original input. However, as the goal is to
find a satisfying assignment of values to the constraints, it may not be possible to do this,
since there could be path conditions which require a given input to have a specific value.
This approach improves some of the main ideas of Castro et al. (Castro, Costa, & Martin
2008), mainly by relaxing the path conditions and therefore increasing the privacy. However,
like Castro, Camouflage maintains the computational overhead of anonymizing the input on the
client side, which may lead to a decrease in the number of users sending the reports.
2http://yices.csl.sri.com/tool-paper.pdf

2.5. PRIVACY LEGISLATION 29
2.4.5 MultiPathPrivacy
One of the main limitations with the previously two systems is that, when calculating the
path conditions in order to generate a new input set, they only take into account the single
path made by the faulty execution. If one was able to take into account all the possible paths
which lead to the same error, it would be possible to further anonymize the user input. With
this motivation in mind a system called MultiPathPrivacy (Louro, Garcia, & Romano 2012) was
created.
The system consists of two components: a client and a server. The server has the respon-
sibility of generating the path conditions for each line of code on a given program, the client
records a failed execution and generates a new input which crashes the application but is un-
related to the original input and also to the original path followed. A sample execution of the
MultiPathPrivacy resembles the following: a error is detected in the client, the line of code where
the program crashed is sent to the server, the server answers with the path conditions needed
to get to that specific line, the client then uses the path conditions to generate an alternative
input and send it to the client.
Despite the approach to search for other paths to the error providing a decrease in the
sensitive information contained in a bug report, the fact that the system needs to generate all
the path conditions for each line of code is not feasible for large applications.
2.5 Privacy Legislation
Although having realistic error reports for replaying previous crashes is very useful for soft-
ware producers, collecting and storing private user information raises legal and ethical questions.
In 1995 the European Union (EU) approved the 95/46/EC3 directive, which aims to protect
the privacy and personal information collected from EU citizens. The directive defines how such
information should be processed used and exchanged. This directive includes all the elements
of the article 8 of the European Convention of Human Rights4, which declares the intention
3http://eur-lex.europa.eu/LexUriServ/LexUriServ.do?uri=CELEX:31995L0046:en:HTML4http://www.hri.org/docs/ECHR50.html

30 CHAPTER 2. RELATED WORK
to respect the privacy rights of citizens in private and family life, home and correspondence.
Despite the fact that the above statement is specific for the EU, almost every country has some
kind of laws regarding user privacy. For example, the United State of America have some federal
laws5 regarding the protection of sensitive user information of several kinds: medical records,
financial information, communication records and others.
Therefore, the software vendors have a great deal of interest in not receiving this kind of
sensitive information, since it forces a more careful treatment when storing and processing user
data, due to legal obligations imposed by the previously referred legislations, therefore adding
to the costs of the company. Moreover, if we take into account that not all the files which
are sent in a bug report are in a readable format, a user would prefer not to send a report
instead of analyzing the given files in order to understand which kind of information is being
revealed (Bettenburg, Just, Schroter, Weiss, Premraj, & Zimmermann 2008).
In conclusion, software vendors do not wish to possess user information since it will add
the cost of maintaining that data. Furthermore, since the user also does not want to reveal
his private data, there is a need form both sides to create solution which protect the user from
sending sensitive information and consequently releases the burden of software vendors from
having to deal with such information.
2.6 Summary
Figure A.1 summarizes the systems previously presented. The systems are classified accord-
ing to their main objective and the most important techniques they use. As not all solution
address the same kind of problems, and moreover they were evaluated with different benchmarks,
one cannot perform a precise comparison between them. However, it is possible to highlight some
conclusions regarding our work.
Generally, deterministic replay systems and privacy-aware systems do not focus on repro-
ducing graphical non-determinism, and therefore, they are not very interesting when trying
to analyze how to deterministic replay and anonymize graphical applications. However, the
solutions discussed in this section provide some ideas to solve the challenges inherent to all de-
terministic replay systems. On the other hand, when analyzing the privacy-aware systems we
5http://www.cdt.org/privacy/guide/protect/laws.php

2.6. SUMMARY 31
Figure 2.1: Summary of the related work.
conclude that most of them use a method in which they generate a new sequence of input in
order to replay the error. This is very similar to what happens with some of the GUI testing
tools described, which generate test sequences (input sequences) in order to uncover an error.
Generally, this is done by using some kind of model of the interface. Finally, we conclude that
currently there is no system that is able to maintain user privacy while providing a correct GUI
deterministic replay system for debugging.
With these observations, we can conclude that our approach will need to provide: 1) an
accurate model of the GUI, 2) an algorithm to generate new graphical input and 3) a correct
deterministic replay system for graphical applications.

32 CHAPTER 2. RELATED WORK

3GAUDI System
All truths are easy to understand once they are discovered; the point is to discover them.
– Galileo Galilei
In this chapter we will describe the GAUDI system. This tool is designed to add anonymiza-
tion functionalities into already compiled applications, without the need to recompile them or
change the source code. After the system in embedded into an application, it records faulty user
executions and anonymizes them. Finally, the system replays the anonymized traces to aid the
maintenance team in the task of correcting the error.
The system needs to run in the end-users machines, along with the target application, and
at same time in the maintenance team’s servers. Therefore, GAUDI is divided into a client and a
server. The client runs in the end-user machine and monitors a transformed version of the target
application. When a faulty execution is detected, a log is generated and anonymized. Finally,
the anonymized log is sent to the server. All these actions are executed on the background so
that the user is not disturbed, and the normal behavior of the target application is not disrupted.
The server saves the anonymized logs, which can then be replayed by the maintenance team.
Furthermore, the server also provides the tools to transform the original applications before the
final deployment of GAUDI to the end-user’s machine.
GAUDI is a deterministic replay system, designed to interact with application that possess a
graphical interface. Modern graphical frameworks work by modeling user interactions into code
invocations. When a user performs a certain action, an event is triggered in the GUI. The event
is saved in a event queue, with the information regarding the event itself plus the widget where
it was triggered. The event queue will dispatch the event to the corresponding listener, which
is a piece of code that will be invoked whenever a specific action happens on a specific widget.
If the widget has any registered listeners for the kind of event triggered, it will consequently
cause the listener to be invoked. Ultimately, this will execute the application code and change
the state of the program.

34 CHAPTER 3. GAUDI SYSTEM
In any given application the number of events triggered by a user is always greater than the
number of listeners being invoked in the source code (Memon 2007; Ganov, Khurshid, & Perry
2004; Ganov, Kilmar, Khurshid, & Perry 2009). As shown in figure 3.1 each user interaction
tends to trigger a graphical event. However developers are only interested in some of those
events to invoke their code, the listeners. This means that all the changes to the application
state can be described by the listeners, and consequently, so can an error.
Figure 3.1: Example of a user interaction, the events that were triggered and the listenersinvoked.
Therefore, we designed GAUDI to monitor which listeners are triggered during a user ex-
ecution. In this way, the system is able to record only the relevant changes to the logic layer
while still being able to perceive the relevant graphical interactions made by the user. However,
the listeners alone are not enough to completely reproduce the execution. This is because of
the events, which despite not triggering any listener, change the state of the application. As a
result, GAUDI needs to save these changes to the state of the application as preconditions to the
listener that is going to be executed. The system generates these preconditions by monitoring
read commands made to graphical variables during a listener invocation. So, if during a listener
call, a read command is done to some specific values from the GUI, then those values need to be
available during the replay. When the listener is replayed, these values will be the preconditions
to that listener. By representing an user execution with listeners instead of events, the system
reduces the size of the trace files and automatically discards irrelevant events. Moreover, in this
way, related actions are aggregated and treated as a single step, which would not happened if
we used event sequences to describe an execution.
With a listener sequence, and a representation of the GUI called the Widget and Listener
Graph, GAUDI can then anonymize any given execution by reducing the sequence to the mini-
mum set needed to reproduce the error. The WLG is extracted, in the server, from the original
application and provides a static map to the application structure and behavior, which can be

3.1. GAUDI ARCHITECTURE 35
used to infer information about the user executions.
In order to add all these functionalities to the target application without the need to recom-
pile it, we use an instrumentation technique that will transform an application to enable the
monitoring and the recording. As such, GAUDI automatically transforms any given program,
by injecting new compiled code, so that the application can communicate with the client-side of
the system enabling all the recording functionalities.
In the remainder of this chapter we will explain in detail the architecture of GAUDI,
the structures and algorithms developed, and how they are used to achieve a deterministic
anonymized replay of a faulty execution.
3.1 GAUDI Architecture
As was previously referred, GAUDI works in two separate phases, a pre-deployment phase
and a post-deployment phase. In the first phase the goal is to: 1) instrument the target applica-
tion in order to enable it to be monitored by the system, and 2) extract the widget and listener
graph (WLG) so as to have a static map of all the graphical components. The second phase
occurs when the application is being run in the end-user machine and a error happens. After
this, the listener log is anonymized using the WLG and then converted to an event log. Finally
the anonymized event log is sent to the developing team and replayed at will.
The system functionalities are divided in order to remove from the client as much of the
computational overhead as possible. Because of this, the instrumentation and the ripping of
the GUI are done one time in the server application. This way, the client can use static files
that provide the needed information. However, the client still needs to be entrusted with the
anonymization of the log because otherwise there would be sensitive information being sent to
the server, which ultimately invalidates the whole process. Therefore, the architecture which
will be described next, was designed with three main goals in mind: 1) reduce the computational
overhead on the client side, 2) do not disrupt the target application’s normal behavior, and 3)
provide developers with the tools they need to inject GAUDI into their own applications.

36 CHAPTER 3. GAUDI SYSTEM
Figure 3.2: GAUDI pre-deployment phase.
3.1.1 Server
Our architecture is divided into a client and a server; the server is responsible for enabling
the maintenance team to perform the tasks present in the pre-deployment phase and replaying
an event log. For this reason the server application is composed of four main sub-systems as we
can see in figure 3.2: the Dynamic Widget Indentifier (DWI), the Transformer, the Ripper, and
the Replayer. The DWI is a system designed to create unique identifiers for widgets, in order to
provide a correct mapping between widgets and event throughout different executions. Nowa-
days, graphical frameworks do not provide a way to identify widgets within several executions
of the same application, because that information is not needed to run the GUI. However, in
order to deterministically replay a graphical execution, we need to be able to identify widgets
throughout different execution. The DWI was developed to execute at runtime on top of the
graphical framework, generating and managing those IDs. As this specific system is not trivial,
and because the client also uses it, the DWI will be explained in detail later in this chapter.

3.1. GAUDI ARCHITECTURE 37
3.1.1.1 Transformer
This module is responsible for applying the GAUDI instrumentation to the target applica-
tion’s compiled code. In order to do this the Transformer receives the file with the entry point
for the application and automatically transverses all the files of the application, analyzing each
method. For each function, the module checks if it is a listener, if so the transformer injects a
call to the GAUDI Recorder in the begin and in the end of the method in order to identify the
beginning and the ending of a listener call. Moreover, we also instrument all the attributions
which have as a right operand a graphical widget in order to build the preconditions for the
listener call. With these modifications we are able to monitor when a listener call is made and
which graphical variables were read within a listener call. Finally, the Transformer generates
a instrumented version of the compiled code, as seen in figure 3.2, which when executed with
GAUDI enables recording and anonymization. This version of the target application can then
be distributed to the end-users.
3.1.1.2 Ripper
The Ripper is in charge of extracting the WLG. This process is semi-automatic, since the
program cannot find windows which are not created when the application starts. In a similar
way to the Transformer, this module receives as an argument the file with the entry point for
the target application and executes it. When the application is fully loaded and all the root
graphical components are initiated the ripping process starts. The Ripper automatically extracts
the root windows of the application and after that initiates a depth first search for the children
widgets until everything is ripped. In the process every widget is attributed a unique ID using
the DWI. Furthermore, the relevant properties of the widget are recorded in the WLG e.g. the
name of the class that represents the widget or its listeners.
After this, the developer needs to open the remaining windows of the application in order
for the process to repeat itself. This could be done automatically. However, this way we are able
to create a more accurate model of the application. If this process was done automatically, like
in GUITAR (Memon 2011), then some interactions with the GUI would not be captured and the
developer team would need to correct the model by hand. For example, a login interaction, a
creation of a new entry, or filling a form, need to have some values, and sometimes specific ones,

38 CHAPTER 3. GAUDI SYSTEM
inserted before the application may proceed. In order to capture all the windows, we decided to
shift this effort to the developer team which knows the applications and can easily open all the
windows enabling the Ripper to extract all the relevant information to create a accurate WLG.
When the ripping process is completed, one just has to shutdown the application and a
static WLG is saved onto a file, which can then be distributed to the end-users.
3.1.1.3 Replayer
This sub-system is entrusted with replaying an event log to the developer who is analyzing
the bug. The Replayer receives a log which it uses to reproduce the execution using a non-
instrumented version of the target application, thereby providing a visual aid for the developer
to further understand the error. This is done by recreating the events which are present in
the log and injecting them in the specific widget at which they were recorded. In almost every
modern graphical framework an event is defined by a pair (e, w) in which e is the event which
was triggered and w is the widget where the event was triggered. As such, the task of the
Replayer is to reconstruct the recorded event, identify the widget in which the event happened
trough the DWI (as shown in figure 3.3) and inject the new event in the specific widget. In the
end of the replay, the original exception, included in the log, will be shown to the developer in
order to confirm that it was the same error.
3.1.2 Client
The client is responsible for most of the post-deployment phase: monitoring and recording
the listener sequence and its preconditions, and anonymizing the log. Five different modules
compose the client as seen in figure 3.3: the DWI, the Recorder, the Anonymizer, the Converter,
and the Tester. All the sub-systems will be explained in this section, apart from the DWI which
will be explained in detail later.
3.1.2.1 Recorder
The Recorder is responsible for monitoring the instrumented target application and record-
ing a listener log. The listener log is a structure composed of the raised exception at the time of
the error and the sequence of listeners and their pre-conditions recorded since the beginning of

3.1. GAUDI ARCHITECTURE 39
Figure 3.3: GAUDI post-deployment phase.
the recording. This module is initialized simultaneously with the application being monitored.
After this, each time a listener starts or ends, or a graphical variable is read within a listener
the Recorder is called through of the code injected by the Transformer.
When a listener is called, a structure is created in order to the identify the listener later
in the WLG. After this, every read command done to a graphical variable before the listener
ends is recorded as a precondition to that listener. When the call ends, the listener and its
preconditions are recorded as a single step in the listener log. When a read command is invoked,
the application passes, as an argument, to the Recorder the type of value which was read, the
concrete value which was read and the instance of the widget where the read occurred. With
this, the Recorder uses the DWI to get the widget ID, which will be recorded along with all of
the previous referred information as a read access.
The other task for which this sub-system is responsible is error detection. For this, the
Recorder creates a special thread which is called when an exception is raised and not caught
in the target application. When this happens, the thread stops recording and saves the current
sequence, and the exception that was triggered, to a file.

40 CHAPTER 3. GAUDI SYSTEM
3.1.2.2 Anonymizer
After the listener log is recorded, the resulting file is fed onto the Anonymizer which will
try to find an alternative graphical execution that triggers the error. For this purpose, the
Anonymizer makes use of two other bundles, the Converter and the Tester. These are re-
spectively responsible for converting a listener log into a event log and for testing if a given
log produces a specific error. This module applies the Minimum-Set Listener Reduction algo-
rithm to a given listener log with the goal of reducing it. In order to apply the algorithm, the
Anonymizer uses the WLG to infer information about the GUI e.g. in which widget a given
listener is located.
After an error has been detected and saved onto a file, the Anonymizer reads it and manages
all the conversions and tests that need to be done while applying the algorithm. In the end,
the new anonymized execution is translated into an event log and sent to the server. All the
auxiliary files created in the process (the converted logs and the test hypothesis) are deleted in
the end.
3.1.2.3 Converter
The Converter is used by the Anonymizer module in order to convert a listener sequence
into an event sequence which can then be injected into the GUI of the target application. The
original sequence of listeners is processed from the beginning to end. For each listener, its
preconditions are analyzed and converted into a sequence of events in the end the listener itself
is converted into a sequence of events. Finally all the events are added into a new sequence of
events. When a listener sequence is fully converted, the resulting event sequence is recorded
onto a file so that other modules can use it later.
For example, if a given listener has a precondition which states that a read operation was
made from a text field widget with a given id, and the value read was a string, the converter
is going to create all the necessary events to put the specific value onto the indicated widget.
In this case it would be something similar to: 1) selecting the widget, and 2) typing all the
characters of the string (one event per character). If the listener is registered for clicks and its
placed in a widget that is a button, then the Converter knows it has to generate a click in that
widget in the end.

3.2. DYNAMIC WIDGET IDENTIFICATION 41
3.1.2.4 Tester
This module is entrusted with receiving an event log and testing it, in order to check if
it triggers an exception, and if that exception is the same as the one which happened in the
original execution. The Tester injects the events in the log into the target application in the
same way the Replayer does, which is, recreating the events and injecting them in a given widget
that is found using the DWI. When the log is fully replayed the module compares the resulting
exception, if any, with the one in the original log. If they match, then the hypothesis is marked
as a valid one.
Currently the Tester only checks for the same exception, if it is not the same exception
it fails the test case. One improvement that could be made, in order to optimize the testing
operation, would be to generate new logs to be anonymized again if a new error is found. In
this way GAUDI could be performing an automatic error search and find new errors before the
user has to deal with them.
3.2 Dynamic Widget Identification
One of the greatest challenges when trying to develop a deterministic replay system, which
has to manage graphical components, is the fact that there are no unique widget identifiers built
into any graphical frameworks. This means that, if an event is recorded in a specific widget
there is no way of finding that widget in the replay phase. Moreover, as widgets are created
dynamically or even programmatically, one cannot simply use a sequence identification number
because in two different executions widgets can be created in a different order.
However, as stated in several articles analyzed in our related work (Miura & Tanaka 1998;
Memon 2007; Ganov, Kilmar, Khurshid, & Perry 2009; Snyder, Edwards, & Perez-Quinones
2011) GUIs have a hierarchical structure which can be used to our advantage. Moreover, we
can compare this problem to the one systems like LEAP (Huang, Liu, & Zhang 2010) or OR-
DER (Yang, Yang, Xu, Chen, & Zang 2011), which deal with memory non-determinism, had to
solve when reproducing thread creation. In these systems one of the major issues is to repro-
duce global thread creation, which they chose not to do. Instead, the authors of the previously
referred systems decided to reproduce local order of thread creation, meaning that each thread
creates its children in the same order as the original execution.

42 CHAPTER 3. GAUDI SYSTEM
This means that, if we generate unique identifiers based of the hierarchical structure of the
GUI, we are able to generate the same IDs throughout different executions. As such, we start
at the root windows and generate an identifier for each one in the order they are created. The
algorithm then proceeds downwards finding all the children and using the parent’s id as a prefix
for the children’s id. The children’s id is generated in a sequential manner, similar to the one
done for the root windows.
Figure 3.4: Dynamic Widget Identification example.
In figure 3.4 we can see an example of the identification attributed to a root window and all
its children. The DWI starts in W1 and attributes the ID ”/0”, it then explores all the children
and generates their ID using as a prefix the parent’s ID. For example, for W7 its identification
string is generated using the prefix of the parent ”/0/1” plus ”/2” since this is the third children
of W3.
One other aspect the system has to take into account is dynamically created windows. New
windows cannot be treated as root windows or otherwise it would not be possible to generate the
IDs in a deterministic way, since they can be opened whenever a user wants. For this reason,
we map a newly created window as a children of the widget which created it, e.g. when a
button is pressed a new window is opened. Figure 3.5 continues the example shown in figure
3.4 by showing what happened if W4 and W7 both opened new windows. Despite figure 3.5
not showing the identification strings they would be generated in the same way as if their new
windows were simple children.
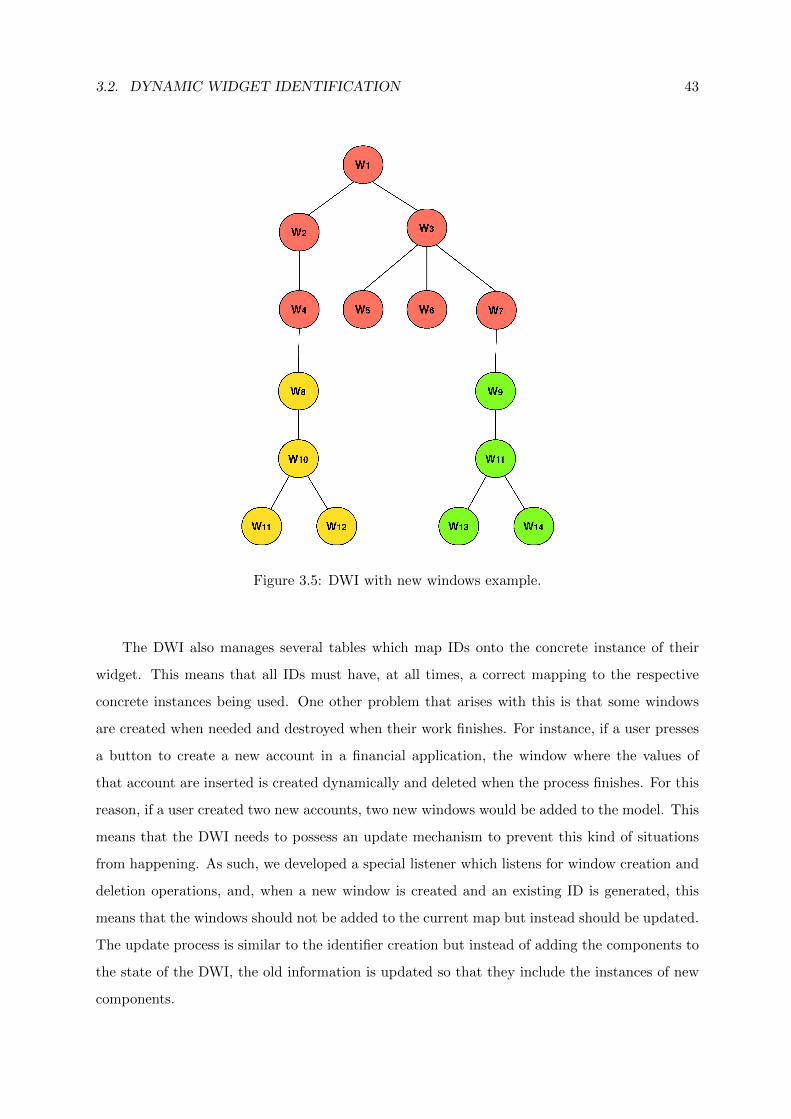
3.2. DYNAMIC WIDGET IDENTIFICATION 43
Figure 3.5: DWI with new windows example.
The DWI also manages several tables which map IDs onto the concrete instance of their
widget. This means that all IDs must have, at all times, a correct mapping to the respective
concrete instances being used. One other problem that arises with this is that some windows
are created when needed and destroyed when their work finishes. For instance, if a user presses
a button to create a new account in a financial application, the window where the values of
that account are inserted is created dynamically and deleted when the process finishes. For this
reason, if a user created two new accounts, two new windows would be added to the model. This
means that the DWI needs to possess an update mechanism to prevent this kind of situations
from happening. As such, we developed a special listener which listens for window creation and
deletion operations, and, when a new window is created and an existing ID is generated, this
means that the windows should not be added to the current map but instead should be updated.
The update process is similar to the identifier creation but instead of adding the components to
the state of the DWI, the old information is updated so that they include the instances of new
components.

44 CHAPTER 3. GAUDI SYSTEM
3.3 Widget and Listener Graph
The DWI and all its algorithms provide a solution to dynamically identify the widgets at
runtime. However, in order to infer information over a recorded log it is essential to have a
static model of the graphical application. The Widget and Listener Graph is built in the pre-
deployment phase by the ripper as described previously in this chapter. A developer guides the
process, so that each window is opened and consequently added to the WLG. The WLG is a
structure which contains the hierarchal structure of a graphical application and the IDs of each
widget. Both, the structure of the hierarchy and IDs are generated exactly in the same way as
the DWI does at runtime.
However, the WLG contains other data about the GUI which is not present in the model
generated by the DWI. At the time when the Ripper extracts each widget, it also extracts
information about the widget itself e.g. the class name, the type of events that it support or the
listeners that have been registered. In fact, the addition of the listeners to the model is the most
important part of the process because it enables GAUDI to infer information about the relation
between listeners, where the listeners are located, and which listeners open new windows.
GAUDI builds all this information into a graph that maps the hierarchical structure of
the concrete GUI, and uses auxiliary hash tables to provide a faster search within the graph.
Figure 3.6 shows an example of a Widget and Listener Graph. There, one can obtain some
information about the target application: 1) the application has one root window, 2) there are
two widgets which open new windows (W4 and W7), 3) five of the displayed widgets contain
registered listeners, etc. With the creation of the model, GAUDI has a static representation of
the target application’s user interface, and consequently is able to infer useful information from
it. Namely, as we will explain in the next section, the WLG allows the Anonymizer to apply
the Minimum-Set Listener Reduction algorithm.
3.4 Minimum-Set Listener Reduction
The central part of GAUDI is the anonymization of graphical information, in order to protect
sensitive information from the end-users and improve the task of debugging an application to
the maintenance team. We consider that every graphical interaction between the user and the

3.4. MINIMUM-SET LISTENER REDUCTION 45
Figure 3.6: An example of a WLG.
GUI could potentially reveal sensitive information, and as such, instead of trying to find which
information should be anonymized we will try to anonymize everything we can.
The Anonymizer module applies the Minimum-Set Listener Reduction algorithm when a
faulty execution is detected, with the goal of detecting the essential listeners to reproduce the
error. This is done in two phases, the delimitation phase, and the reduction phase. In the
first phase, the goal of the algorithm is to find the boundaries of the final sequence. In other
words, the first listener needed to trigger the error, and the listener which in fact crashes the
application. The second phase is responsible for; given the boundaries of the final sequence, find
out which listeners can be still removed.
In the delimitation phase the goal is to find out where the error starts. For this purpose,
the algorithm generates all the test cases with the n last listeners from the original sequence,
starting with n = 1 and ending when n reaches the size of the original sequence.
After all the test cases are generated, they are sorted increasingly by size, and they start
being tested. When one of the tests is valid, this means we have found the first listener of the

46 CHAPTER 3. GAUDI SYSTEM
Algorithm 1 Delimitation Phase Test Generation
oseq = original listener sequenceseqlist = ∅newseq = ∅for oseq.size 6= 0 do
newseq.addF irst(oseq.removeLast())seqlist.add(newseq)
end for
final reduced sequence. All the generated test cases are deleted, except the valid one which is
passed to the new phase of the algorithm.
The reduction phase uses the first listener and the last listener of the output sequence of the
first phase, and then generate all the possible combinations of the listeners in between, always
maintaining the order of the listeners in the original sequence. This is described in the following
algorithm.
Algorithm 2 Reduction Phase Test Generation
oseq = original listener sequenceseqlist = ∅newseq = ∅if oseq.size > 2 then
newseq.addLast(oseq.getF irst())newseq.addLast(oseq.getLast())Scramble(oseq, newseq, seqlist, 1)
end if
In order to generate all the possible sequences to be tested between the first and last listener
we developed a scramble algorithm which transverses the list and for each element creates two
scenarios: one in which the element is on the list, and one in which it is not. After this, each
possibility recursively calls the algorithm. With this we are able to generate all combinations of
listeners while still preserving the order of the original sequence.
After all the sequences of the reduction phase are found, they are sorted increasingly by
size and tested until a valid one is found. In the end we will have a reduced sequence that still
triggers the error.
As one can notice both phases of the algorithm rely on brute-force techniques, e.g. generating
the test cases and actually testing them. The creation of the test cases is not a problem because
the algorithm is only identifying them, the problem lies in the need to test them. Here, one
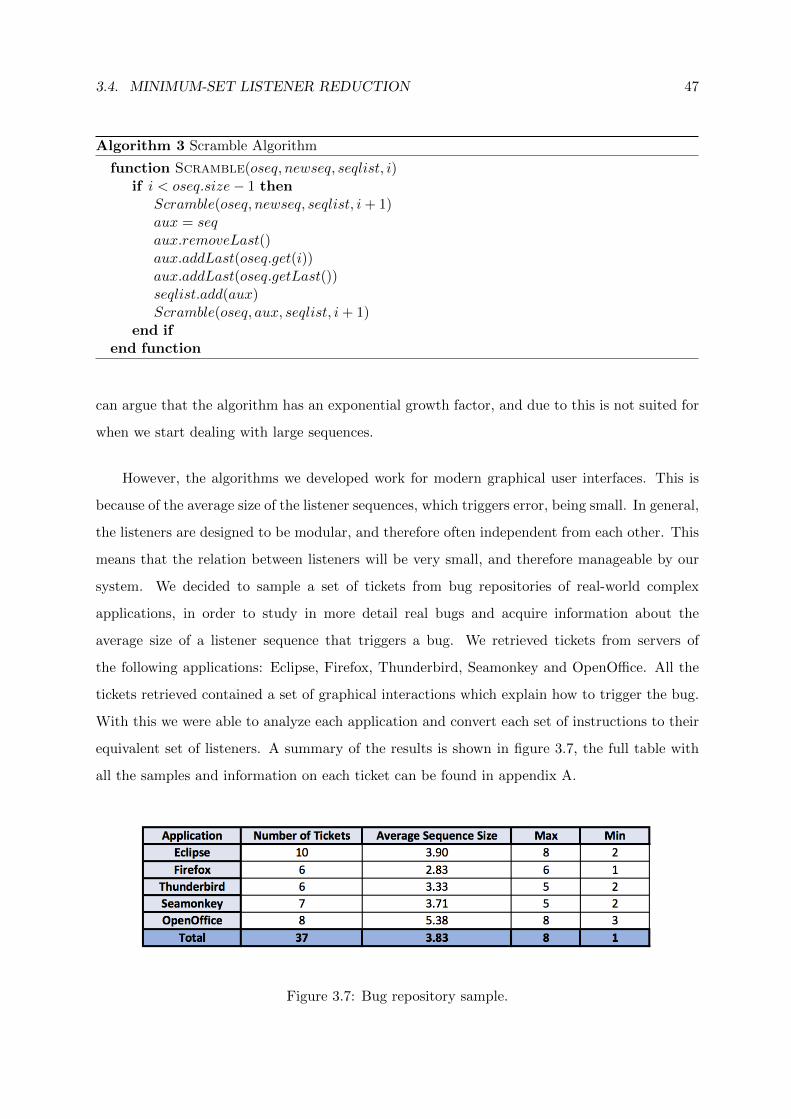
3.4. MINIMUM-SET LISTENER REDUCTION 47
Algorithm 3 Scramble Algorithm
function Scramble(oseq, newseq, seqlist, i)if i < oseq.size− 1 then
Scramble(oseq, newseq, seqlist, i + 1)aux = seqaux.removeLast()aux.addLast(oseq.get(i))aux.addLast(oseq.getLast())seqlist.add(aux)Scramble(oseq, aux, seqlist, i + 1)
end ifend function
can argue that the algorithm has an exponential growth factor, and due to this is not suited for
when we start dealing with large sequences.
However, the algorithms we developed work for modern graphical user interfaces. This is
because of the average size of the listener sequences, which triggers error, being small. In general,
the listeners are designed to be modular, and therefore often independent from each other. This
means that the relation between listeners will be very small, and therefore manageable by our
system. We decided to sample a set of tickets from bug repositories of real-world complex
applications, in order to study in more detail real bugs and acquire information about the
average size of a listener sequence that triggers a bug. We retrieved tickets from servers of
the following applications: Eclipse, Firefox, Thunderbird, Seamonkey and OpenOffice. All the
tickets retrieved contained a set of graphical interactions which explain how to trigger the bug.
With this we were able to analyze each application and convert each set of instructions to their
equivalent set of listeners. A summary of the results is shown in figure 3.7, the full table with
all the samples and information on each ticket can be found in appendix A.
Figure 3.7: Bug repository sample.

48 CHAPTER 3. GAUDI SYSTEM
As one can see in figure 3.7, the reason why our algorithms work in practice is because
usually the number of listeners needed to reproduce the error is very small. And even in the
worst case, if GAUDI generated hundreds of hypothesis generally only a small percentage of
those would be tested before a solution is found, because only an average of four listeners are
required to reproduce a bug. Moreover, as our system finds these minimum sets of listeners,
the job of the maintenance will be eased in the sense they will obtain from the start only the
relevant listeners to the error.
3.4.1 Invalid Test Removal Heuristic
Despite the observation that our algorithm works in practice, even with complex GUIs, we
developed a heuristic to optimize the process of testing for valid test cases, therefore mitigating
the use of brute-force techniques. The goal of the heuristic is to identify invalid tests and remove
them without the need to convert and test them. After each turn of generating tests, the systems
consults the WLG and verifies if all constrains between listeners are maintained, if not the test
case is deleted. This is done by, consulting the graph and observing whether each listener of a
given sequence needs to have any specific listener executed before it can be invoked.
An example of this is a login window. Lets say we have a window containing widget W1
with listener L1 registered to it, when that listener is invoked a new login window is created. In
the new window there is another widget W2 with listener L2 registered to it. This means that
if a sequence has listener L2 but does not include before L1, then the sequence is not valid since
there is no way of generating an event for a window that is not created.
With this we are able to remove a large amount of invalid test cases without the need to
actually test them. Consequently, the growth factor of the brute-force techniques used within
the algorithm is reduced.
3.4.2 An Example of the Minimum-Set Listener Reduction Algorithm
In order to better understand the Minimum-Set Listener Reduction algorithm we would
like to give a concrete example of how it works. Let us imagine a sequence of events S1 =
{E1, E2, E3, . . . , E10} as shown in figure 3.8. In this case, some of the events possessed registered
listeners in their widgets, and as such, the corresponding listeners were triggered. With the

3.4. MINIMUM-SET LISTENER REDUCTION 49
mechanisms used in the Recorder we can generate a equivalent listener sequence to S1. In the
end we would have S1 ≡ {L1, L2, L3, L4, L5, L6}.
Figure 3.8: Example of a set of events and their listeners triggered during a user execution.
Now, that we have a listener sequence, the next step is to understand which listeners are
relevant to the error. For this we will use the Minimum-Set Listener Reduction algorithm. In
the first phase, the delimitation phase, the algorithm will generate the sequences shown in figure
3.9. The listeners colored in black are not included in the sequence, they are just there to show
which part of the original sequence is being ignored.
Figure 3.9: Example of the test cases generated in the delimitation phase.
After all the test cases are generated they are each one tested in a growing size order. Let’s
imagine that the first listener needed to trigger the error is L3, this means that all the tests
would fail until the one that contains L3. When the sequence {L3, L4, L5, L6} is indicated as
valid, no more tests are done and all the other sequences generated are deleted before proceeding
to the next phase. The result of the first phase tells us the boundaries of the location of the
error, meaning that somehow the error starts with L3 and is triggered by the final listener L6.

50 CHAPTER 3. GAUDI SYSTEM
The next phase, the reduction phase starts precisely where the other left of. It starts by
generating, from the resulting sequence, all the possible combinations of listeners which maintain
the same local order. All the sequences generated are presented in figure 3.10.
Figure 3.10: Example of the test cases generated in the reduction phase.
With this the algorithm will start testing sequences. In this case, lets say the sequence
{L3, L5, L6} passes the test and therefore crashes the applications. This means we have found
an alternative listener sequence to the original user graphical input. Finally this sequence will
be converted into a event sequence and sent to the server.
3.5 Symbolic Execution for a Better Anonymization
Until now we have only discussed one aspect of anonymization, the graphical interactions
between the user and the GUI. The other one that is worth mentioning is the data anonymization,
present in solutions like Castro et al. (Castro, Costa, & Martin 2008), CAMOUFLAGE (Clause
& Orso 2011), and MultiPathPrivacy (Louro, Garcia, & Romano 2012).
We argue that it is possible to achieve a further level of anonymization by using this kind of
techniques over a reduced listener sequence. As this specific aspect is out of this work’s context,
we did not implement this functionality into GAUDI. However, we think that one could apply
these mechanisms in order to anonymize concrete values present in the preconditions of the
listeners.
The values in the preconditions can be described as input values to the graphical variables.
Because of this comparison, one of the techniques, such as CAMOUFLAGE, or MultyPathPri-

3.6. IMPLEMENTATION 51
vacy, could be used to find an alternative input. This would be achieved be both generating
the path conditions for each listener, and finding an alternative input within each listener. Or
alternatively, generating the path conditions for the complete listener execution, and computing
an alternative input for the complete executions. The alternative input just had to be converted
to replace the original precondition.
The techniques which would be used to anonymize the data, all use symbolical execution
to test the input, find new paths, or test alternative inputs. Currently, there are some tools
available to apply symbolical execution to a console application. However, there are none that
can be applied to graphical applications. This is one of the main technical difficulties, applying
symbolical execution to a graphical application.
Adding these techniques to GAUDI would provide a even better level of anonymization,
because the system would be able to anonymize the graphical data and the input data of the
user. Therefore, the output of GAUDI would be a complete different graphical execution that
still triggered the error.
3.6 Implementation
Before ending this chapter, we would like to discuss some implementation aspects that may
be important to understand the system. Our prototype was written in Java and is designed
to work with applications which use the AWT or SWING graphical frameworks. The complete
source code of GAUDI is available online at GoogleCode1.
3.6.1 Instrumentation
For instrumenting the bytecode, we used SOOT2, which is a Java library for bytecode
optimization. SOOT provides a intermediate representation for Java bytecodes, which provides
an easier way to understand code. With this library, we were able to automatically traverse all
the code and analyze each method. With this, we just have to 1) identify which methods are
listeners and add static calls to the monitor, and 2) instrument the read commands to graphical
1http://code.google.com/p/gsd-gaudi/2http://www.sable.mcgill.ca/soot/

52 CHAPTER 3. GAUDI SYSTEM
variables. To identify which methods are listeners, we check the class hierarchy of each class
to see if it inherits from a listener class. If so, we check the method which is called when the
listener is invoked, e.g. a performAction() method in a listener class. For the second item, we
just need to identify an assignment and check whether or not the right operand is a graphical
variable. If so we inject a call to the monitor.
The monitor itself only implements static methods. This decision enables a simple instru-
mentation, since we do not need to instantiate the monitor itself and make sure each call uses
the same instance of it. The monitor then communicates with a singleton of the listener recorder
which computes everything.
3.6.2 DWI implementation
For updating the DWI when new windows are created or destroyed, we register a window
listener to the core of the GUI. This enables the system to know whenever a window is opened,
or closed. When a new window is created or deleted, the listener dispatches the event to a
method within the recorder that can tell whether the window has already been registered or is
a new window. With this we are able to correctly built and update the DWI.
3.6.3 WLG Extraction
In order to extract information about the interface we had to study how this information
is saved in the graphical components. In order to rip the graphical components information we
used their context, which is a data structure that includes all the registered listeners, all the
type of events supported for the widget, etc. In order to extract class names, and other class
related information we used the Java built-in reflection.
3.6.4 Other Functionalities
The first functionality to be implemented into GAUDI was the possibility of recording and
replaying events. When working in this mode the system simply records a event sequence on
the client side and is able to replay it in the server. If one wants to use this mode, then there
is no need to instrument the bytecode. As to be expected, when working at the level of events,

3.6. IMPLEMENTATION 53
GAUDI is not able to provide anonymization, since it does not have a correct mapping to the
listeners and the GUI structure.
3.6.5 Standard Widget Toolkit
We also developed a version of GAUDI for the SWT graphical framework. However, since
SWT is relatively new framework and used mainly for developing Eclipse applications and plug-
ins, it possesses some limitations which prevented the use of anonymization. The main reason
for this is that in SWT it is not possible to find some widgets. For example, when a user right
clicks an application and a new menu appears, the framework is not able to find the instance
of that menu. This is a limitation of the framework itself. In SWT a developer can access, in
runtime, at all the windows and widgets, e.g. accessing all window is done using the method
Windows.getWindows(). However, some of the widgets created at runtime, like the right click
menu, are directly connected to the operating system and because of that the SWT does not
provide a way to access them. Consequently, all the systems like the DWI and the WLG, which
are the basis of this work, are rendered useless. As such, the version of GAUDI for the SWT is
only able to record and replay events directly.

54 CHAPTER 3. GAUDI SYSTEM

4EvaluationEverything that can be counted does not necessarily count; everything that counts cannot
necessarily be counted.
– Albert Einstein
In this chapter we will present the result of the experimental study, which aims to evaluate
the anonymization and replay capabilities of GAUDI. We developed a set of tests with real users,
in order to simulate a real world environment. We will describe, in detail, the metrics used to
evaluate the system, the experimental setting, the applications we used, the scenarios developed,
and the results we have obtained.
4.1 Evaluation Goals and Criteria
This study evaluates the following characteristics of the system: 1) obfuscation, 2) recording
overhead, 3) replay time, 4) instrumenting and ripping overheads, and 5) removal heuristics. To
evaluate all this capabilities, we performed and analyzed several user interactions with applica-
tions being monitored by GAUDI. With this we were able to evaluate the percentage of listeners,
which are removed from the original sequence by the anonymization algorithm. To evaluate the
reduction of the recording overhead, we compared the number of events that are processed by
the system to the number of listeners that are recorded. And finally, we compared the usage of
anonymization with and without the invalid test removal heuristic. We also analyzed the time
it took to instrument and rip the applications used in the scenarios.
4.2 Experimental Setting
For the experimental setting we asked 28 users to perform 8 interaction scenarios on appli-
cations being monitored by GAUDI. Each user was given a description of each of the scenarios,

56 CHAPTER 4. EVALUATION
which they proceeded to execute. There was always someone available to answer the user’s
questions about the scenarios. Questions related to the applications were not answered so that
the users would not be guided trough the scenario.
All the experiments were conducted on a Intel Core 2 Duo machine at 2.4 Ghz, with 4 GB
of RAM and running Mac OS X. Every application was instrumented and ripped before the
users opened them.
4.3 Description of Test Subjects
As most of our evaluation is based on user tests, we will start by describing the subjects
that performed the tests. The complete table is shown in appendix B. As figure 4.1 shows,
our test subject group is constituted by 32% males and 68% females. 57% of the sample are
students and from the rest of them 19% work on software development. Finally, most of the
subjects have ages between 20 an 30 years.
Figure 4.1: Test subjects’ characterization.

4.4. TEST APPLICATIONS 57
4.4 Test Applications
In this section we present each application we used on the experimental tests and why we
chose each one. We used a set of 5 different applications: three developed by us to test specific
complex error cases, and two real-world applications. All applications are written in Java and
use Swing or AWT for the GUI. Both these frameworks are compatible with GAUDI. All the
errors, either the ones developed for the scenarios as the real ones, were chosen because they are
the most common errors in software development (Roehm, Tiarks, Koschke, & Maalej 2012), e.g
a unhandled exception or lack of input validation.
4.4.1 Calculator
Figure 4.2: A snapshot of the Java Calculator.
This application was developed in the scope of the FastFix project. The Calculator, shown
in figure 4.2, is characterized by having only one window and several widgets, which contain each
one a listener. Therefore, we chose it to illustrate how GAUDI will perform in cases in which all
actions are available from the start. In that way, we will be able to show that even in this kind
of environment, in which the user can achieve an error from a large set of different combinations
of action, GAUDI will always be able to find the same reduced sequence for each type of error.
This application has two errors built in: one happens when the user tries to divide by zero which
triggers a null pointer exception is triggered, the other happens when a user produces a result
bigger than the size of the variable which holds the value.

58 CHAPTER 4. EVALUATION
4.4.2 MyJpass
Figure 4.3: Snapshot of MyJpass application.
MyJpass was developed to test GAUDI. It is based on a existing password management soft-
ware called Jpass. This application was developed to test the most standard cases of anonymiza-
tion. The application possesses various windows, which enable the creation and edition of pass-
word entries as shown in figure 4.3. With this we are able to test different execution which
lead to the same error, and also the complexity of having to manage different windows at the
same time. This application has three errors built into it, the first one is a null pointer exception
which is triggered when a user tries to delete an entry from the table without selecting anything.
The second and third ones, happen when a user tries to create or delete an entry with empty
fields.
4.4.3 ZooManager
ZooManager was developed to test the worst case scenarios we found when sampling the
repositories for error ticket, in other words, when the error needs a large number of listeners
to happened e.g. six or seven. For this we designed an application with a great number of

4.4. TEST APPLICATIONS 59
dependencies between listeners, and also a large number of windows and widgets. ZooManager
was designed to emulate a system that manages an entire zoo, a user can create animals, create
housings for the animals, feed and clean them. The user is also able to rate the Zoo, the rating
will be greater depending on how many animals will be fed and houses clean. With all these, we
are able to test the worst and larger sequences one can have. This application has only one error:
when a user is able to achieve a perfect score the application crashes triggering an exception.
Figure 4.4: Snapshot of the ZooManager application.
4.4.4 Lexi
Figure 4.5: Snapshot of the Lexi text editor.

60 CHAPTER 4. EVALUATION
Lexi1 is a Java word processor. Lexi implements a GUI in Swing, with several complex and
not standard widgets and listeners as shown in figure 4.5. This real world application provides
a complex user environment, and enables us to test GAUDI in a real world context. For the
experimental user evaluation we used a real error, which happens when a user tries to consult
the main options of the program triggering a null pointer exception.
4.4.5 Pooka
Pooka2 is a mail client. It is designed to manage several email accounts with different
preferences and configurations, as shown in figure 4.6. Pooka has an added complexity when
compared with the other applications we chose, because it is a network application that can
send and receive emails. For Pooka we used a real error existing in the present version of the
application, when a user tries to create a new email without any account being created, the
applications throws an exception.
Figure 4.6: Snapshot of the Pooka mail client.
1http://lexi.sourceforge.net2http://www.suberic.net/pooka/

4.5. PRE-DEPLOYMENT PHASE RESULTS 61
4.5 Pre-Deployment Phase Results
Figure 4.7 shows the evaluation results of the pre-deployment phase. The instrumentation
of each target application is done one time by the developer, along with the ripping of the GUI.
As explained before, the transformation of the bytecodes is achieved by indicating to GAUDI
the entry point of the application. The system will then analyze each method of every class and
perform the necessary changes. The ripping is done by using GAUDI to monitor the application
while a developer transverses all the windows and the WLG is generated.
Our results show that our instrumentation is very quick even for larger applications like
Pooka, which contains several hundreds of classes and thousands of methods. And even for a
developer that has not worked on the application, the process is very quick. Therefore, even if
both the ripping and the instrumentation are processes that only need to be performed once,
and therefore a larger duration would be acceptable, GAUDI only takes a couple of minutes
with complex applications.
Figure 4.7: Instrumentation and ripping results
4.6 Scenarios
The scenarios were developed so that the users could have some guidelines without having
a detail set of instructions, which would lead to every execution being the same, and therefore
invalidating the experiment. We developed eight scenarios with the previously mentioned appli-
cations. The tasks were designed to illustrated something that a user would actually do with the
given software, guiding the user through the task without being two restrictive. The complete
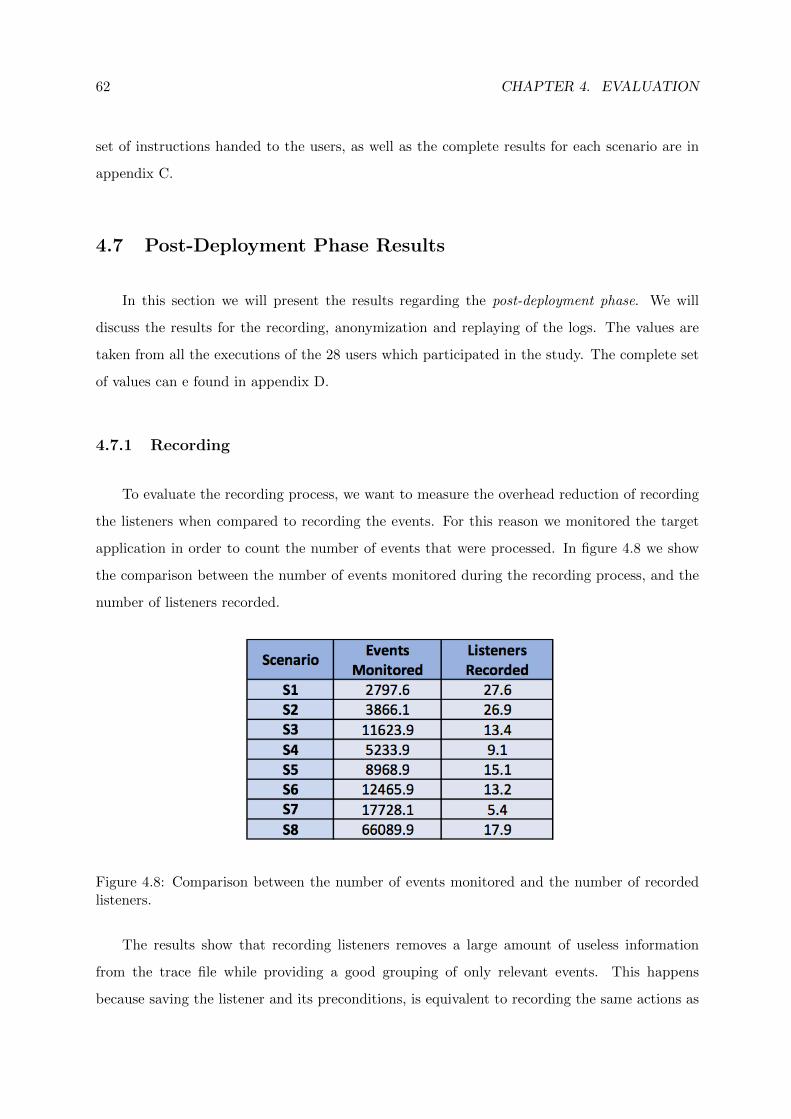
62 CHAPTER 4. EVALUATION
set of instructions handed to the users, as well as the complete results for each scenario are in
appendix C.
4.7 Post-Deployment Phase Results
In this section we will present the results regarding the post-deployment phase. We will
discuss the results for the recording, anonymization and replaying of the logs. The values are
taken from all the executions of the 28 users which participated in the study. The complete set
of values can e found in appendix D.
4.7.1 Recording
To evaluate the recording process, we want to measure the overhead reduction of recording
the listeners when compared to recording the events. For this reason we monitored the target
application in order to count the number of events that were processed. In figure 4.8 we show
the comparison between the number of events monitored during the recording process, and the
number of listeners recorded.
Figure 4.8: Comparison between the number of events monitored and the number of recordedlisteners.
The results show that recording listeners removes a large amount of useless information
from the trace file while providing a good grouping of only relevant events. This happens
because saving the listener and its preconditions, is equivalent to recording the same actions as

4.7. POST-DEPLOYMENT PHASE RESULTS 63
events. However, if we saved the events, we would not know how the events are related between
themselves and we would record a noticeable amount of useless information.
4.7.2 Anonymization
When evaluating the anonymization process, we want to measure two aspects: 1) the effi-
ciency of the Minimum-Set Listener Reduction algorithm, and 2) the relevance of the Invalid
Test Removal Heuristic when compared to a version of GAUDI which does not use it.
4.7.2.1 Minimum-Set Listener Reduction
To evaluate the efficiency of the Minimum-Set Listener Reduction algorithm we analyzed the
number of listeners of the final anonymized sequences, and compared them to the ones which
were previously recorded. We consider that every listener reveals something about the user
interaction and that may be sensitive information. For that reason, and in order to facilitate the
developer team task of correcting the error, GAUDI reduces the listener sequence to a minimum
which triggers the error. It the process all useless and private user information is removed from
the sequence.
Figure 4.9: Comparision between the number of recorded listeners and the number of listenersin the final sequences

64 CHAPTER 4. EVALUATION
In figure 4.9 is shown the comparison between the number of recorded listeners and the
number of listener present in the anonymized sequence of each scenario. The results show that
GAUDI is able to reduce the amount on graphical information revealed on average to only 17.8%
of the original execution. These values do not take into account the ignored events which do
not trigger listeners. In scenario six, the event sequence needed to reproduce the error has seven
listeners, which explains why that scenario does not have a similar reduction to the others.
4.7.2.2 Invalid Test Removal Heuristic
To measure the gain of using the Invalid Test Removal Heuristic we anonymized each se-
quence two times, one with the heuristic, and one without. In this way we can analyze the
usage of the heuristic regarding the number of sequences generated and the time it took to find
a solution.
Figure 4.10: Comparison between the number of test cases generated with and without theheuristic.
In figure 4.10 are shown the results of the comparison between the number of sequences
generated, both, with and without the Invalid Test Removal Heuristic. The figure shows that
the heuristic is more effective on complex cases like scenario six. On the other hand it also shows
that the usage of the heuristic never increases the number of generated sequences. One other
fact that may affect the efficiency of the heuristic is the hierarchy of the GUI. For example, in

4.7. POST-DEPLOYMENT PHASE RESULTS 65
scenario one and two, the Calculator interface only has one window, as such the heuristic will
never find sequences to remove because every action is always available, making every sequence
possible.
One other aspect we evaluated was the time the algorithm needed to find a solution. Figure
4.11 shows the evaluation results. Our experiments show that the heuristic is able to reduce the
time to as little as 56% in complex cases, while on the other hand the overhead of running the
heuristic when it is not able to remove tests is very small.
Figure 4.11: Comparison between the time needed to find a solution with and without theheuristic.
These times are strongly related to the number of sequences that are tested, since testing
the hypothesis is the step that takes more time in the process. Because of this, the number
of sequences the heuristic removes will leave fewer sequences to test, and therefore less time is
needed to find a correct solution.
4.7.3 Replay
For evaluating the replay, we compared both the times and the events that happened during
the recording with the ones during the replay. We did not evaluate the degree of replayability
of the logs because we were able to always find a solution and replay the anonymized sequence.
Figure 4.12 shows the results for the comparison of time between the recording and the
replaying. The results show that with GAUDI we are able to provide the maintenance team with
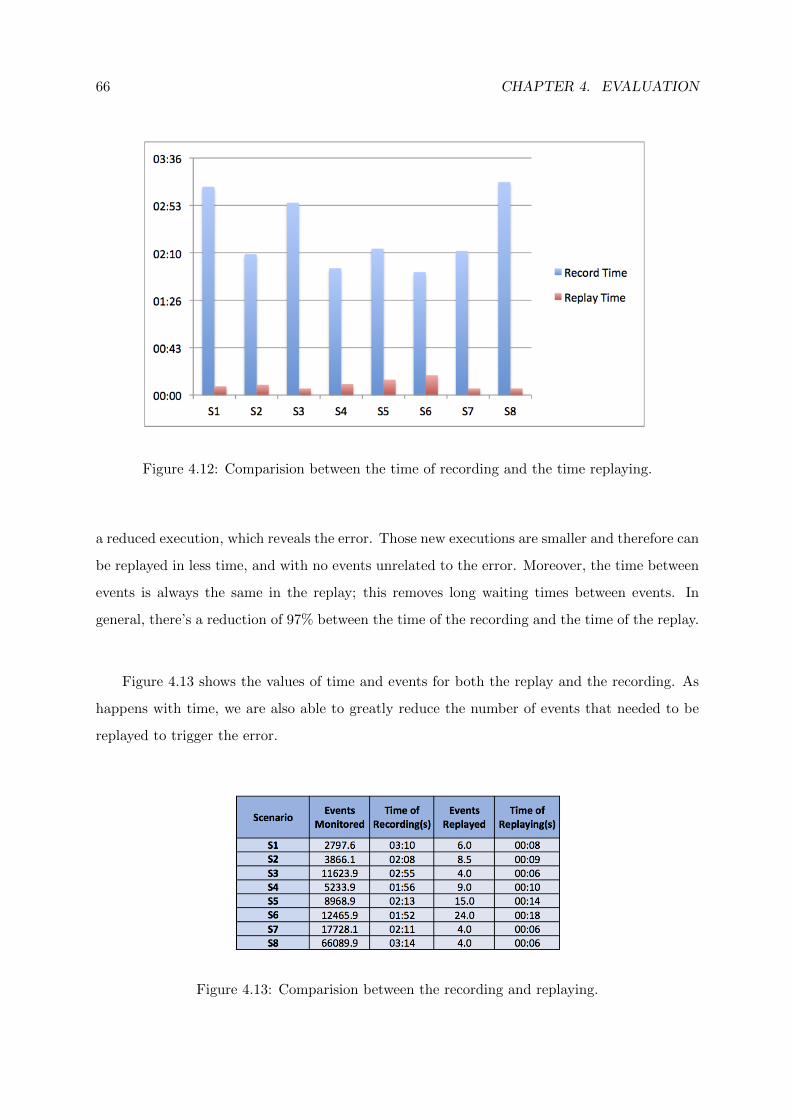
66 CHAPTER 4. EVALUATION
Figure 4.12: Comparision between the time of recording and the time replaying.
a reduced execution, which reveals the error. Those new executions are smaller and therefore can
be replayed in less time, and with no events unrelated to the error. Moreover, the time between
events is always the same in the replay; this removes long waiting times between events. In
general, there’s a reduction of 97% between the time of the recording and the time of the replay.
Figure 4.13 shows the values of time and events for both the replay and the recording. As
happens with time, we are also able to greatly reduce the number of events that needed to be
replayed to trigger the error.
Figure 4.13: Comparision between the recording and replaying.

4.8. SUMMARY 67
4.8 Summary
In figure 4.14 we show a summary of the evaluation results for each scenario. From our
experimental evaluation we are able to conclude that GAUDI is able to reduce the listener se-
quences to the minimum needed to trigger the error. This means that for different execution
which triggered the same error, the sequence of listeners sent to the server is always the same.
With this the system is able to anonymize the graphical execution of the user, protecting pri-
vate user data. And at the same time ease the task of debugging by reducing the amount of
information to the essential.
Figure 4.14: Summary of the evaluation
Moreover, GAUDI is able to find correct solutions for the bigger listener sequences, as
the ones shown in our sampling of bug report tickets. This means that even with brute-force
techniques, the system is able to solve a seven-listener sequence in a matter of ten minutes.
Giving that this process is executed in the background, the amount of time needed to find a
solution is more that acceptable. The anonymized logs are able to always show the original error,
and also provide a way to pin point the error much faster that with a normal deterministic replay
tool, which forces the debug team to watch the entire user interaction.
Finally, we conclude that GAUDI improves on the work started by some of the solutions
referred on chapter 2 by providing a new anonymization paradigm for graphical applications,
which are the modern standard for software applications.

68 CHAPTER 4. EVALUATION

5ConclusionThe end of a melody is not its goal: but nonetheless, had the melody not reached its end
it would not have reached its goal either. A parable.
– Friedrich Nietzsche
5.1 Conclusion
Allowing software maintenance teams to quickly identify the causes of errors is critical.
Error reports are very useful tools but their quality and likelihood of being submitted needs
to be improved. Users do not usually participate willingly in the post-deployment debugging
process, mainly due to privacy issues in the bug reports. As such, there is a need to improve
the current systems to provide on one hand, a better anonymization to the participating users,
and on the other hand, a better debugging tool for the maintenance teams.
In this thesis we have presented GAUDI, a system which provides anonymization of graphical
executions. GAUDI anonymizes execution traces using the Minimum-Set Listener Reduction
algorithm, which shortens the listener sequence to the minimum needed to reproduce the error.
In our evaluation, we showed that GAUDI is able to reduce the original listener sequences on
average by 82.2%, and that using our Invalid Test Removal Heuristic we are able to manage
large and complex GUI applications. The anonymization provided by GAUDI can be further
enhanced by techniques such as (Castro, Costa, & Martin 2008), (Clause & Orso 2011), (Louro,
Garcia, & Romano 2012) which calculate alternative execution paths in console applications.
GAUDI provides a reduced execution trace which is easier to further anonymize both because
it is shorter and because systems like MultiPathPrivacy can then look at each listener as a
sequential piece of code outside of the traditional event loop of GUI applications.

70 CHAPTER 5. CONCLUSION
5.2 Future Work
We are continuing the work presented in this thesis by integrating GAUDI with anonymiza-
tion techniques in line with those of Castro et al., Camouflage or MultiPathPrivacy. These
techniques allow us to take the concrete values present in the preconditions of listeners and
calculate anonymized values for them thereby further enhancing the results of GAUDI.

Bibliography
Bertolino, A. (2007, may). Software testing research: Achievements, challenges, dreams. In
Future of Software Engineering, 2007. FOSE ’07, pp. 85 –103.
Bettenburg, N., S. Just, A. Schroter, C. Weiss, R. Premraj, & T. Zimmermann (2008). What
makes a good bug report? In Proceedings of the 16th ACM SIGSOFT International Sym-
posium on Foundations of software engineering, SIGSOFT ’08/FSE-16, New York, NY,
USA, pp. 308–318. ACM.
Broadwell, P., M. Harren, & N. Sastry (2003). Scrash: a system for generating secure crash
information. In Proceedings of the 12th conference on USENIX Security Symposium -
Volume 12, Berkeley, CA, USA, pp. 19–19. USENIX Association.
Castro, M., M. Costa, & J.-P. Martin (2008, March). Better bug reporting with better privacy.
SIGPLAN Not. 43, 319–328.
Clause, J. & A. Orso (2011). Camouflage: automated anonymization of field data. In Pro-
ceeding of the 33rd international conference on Software engineering, ICSE ’11, New York,
NY, USA, pp. 21–30. ACM.
Cornelis, F., A. Georges, M. Christiaens, M. Ronsse, T. Ghesquiere, & K. D. Bosschere (2003).
A taxonomy of execution replay systems. In In Proceedings of the International Conference
on Advances in Infrastructure for Electronic Business, Education, Science, Medicine, and
Mobile Technologies on the Internet.
Ganov, S., S. Khurshid, & D. Perry (2004). Symbolic execution for GUI testing.
Ganov, S., C. Kilmar, S. Khurshid, & D. Perry (2009). Barad – a GUI testing framework
based on symbolic execution.
Hackner, D. R. & A. M. Memon (2008). Test case generator for GUITAR. In Companion
of the 30th international conference on Software engineering, ICSE Companion ’08, New
York, NY, USA, pp. 959–960. ACM.
71

72 CHAPTER 5. CONCLUSION
Herbold, S., J. Grabowski, S. Waack, & U. Bu andnting (2011, march). Improved bug report-
ing and reproduction through non-intrusive gui usage monitoring and automated replaying.
In Software Testing, Verification and Validation Workshops (ICSTW), 2011 IEEE Fourth
International Conference on, pp. 232 –241.
Huang, J., P. Liu, & C. Zhang (2010). LEAP: lightweight deterministic multi-processor replay
of concurrent java programs. In Proceedings of the eighteenth ACM SIGSOFT international
symposium on Foundations of software engineering, FSE ’10, New York, NY, USA, pp.
385–386. ACM.
King, J. C. (1976, July). Symbolic execution and program testing. Commun. ACM 19, 385–
394.
Louro, P., J. Garcia, & P. Romano (2012, may). MultiPathPrivacy: Enhanced privacy in fault
replication. In Dependable Computing Conference (EDCC), 2012 Ninth European, pp. 203
–211.
Memon, A. (2011). http://sourceforge.net/apps/mediawiki/guitar/index.php.
Memon, A., I. Banerjee, & A. Nagarajan (2003). GUI ripping: Reverse engineering of graphical
user interfaces for testing. In Proceedings of the 10th Working Conference on Reverse
Engineering, WCRE ’03, Washington, DC, USA, pp. 260–. IEEE Computer Society.
Memon, A., M. Pollack, & M. Soffa (1999, may). Using a goal-driven approach to generate
test cases for GUIs. In Software Engineering, 1999. Proceedings of the 1999 International
Conference on, pp. 257 –266.
Memon, A. M. (2007, September). An event-flow model of GUI-based applications for testing:
Research articles. Softw. Test. Verif. Reliab. 17, 137–157.
Memon, A. M., M. E. Pollack, & M. L. Soffa (2001, February). Hierarchical GUI test case
generation using automated planning. IEEE Trans. Softw. Eng. 27, 144–155.
Miura, M. & J. Tanaka (1998, jul). A framework for event-driven demonstration based on
the java toolkit. In Computer Human Interaction, 1998. Proceedings. 3rd Asia Pacific, pp.
331 –336.
Pagano, D., M. A. Juan, A. Bagnato, T. Roehm, B. Brugge, & W. Maalej (2012). Fast-
Fix: monitoring control for remote software maintenance. In Proceedings of the 2012 In-
ternational Conference on Software Engineering, ICSE 2012, Piscataway, NJ, USA, pp.

5.2. FUTURE WORK 73
1437–1438. IEEE Press.
Pokam, G., C. Pereira, K. Danne, L. Yang, & J. Torrellas (2009, January). Hardware and
software approaches for deterministic multi-processor replay of concurrent programs. Intel
Technology Journal (13), 20 – 41.
Roehm, T., R. Tiarks, R. Koschke, & W. Maalej (2012). How do professional developers
comprehend software? In Proceedings of the 2012 International Conference on Software
Engineering, ICSE 2012, Piscataway, NJ, USA, pp. 255–265. IEEE Press.
Snyder, J., S. H. Edwards, & M. A. Perez-Quinones (2011). LIFT: taking GUI unit testing to
new heights. In Proceedings of the 42nd ACM technical symposium on Computer science
education, SIGCSE ’11, New York, NY, USA, pp. 643–648. ACM.
Steven, J., P. Ch, B. Fleck, & A. Podgurski (2000). jRapture: A capture/replay tool for
observation-based testing. In In Proceedings of the International Symposium on Software
Testing and Analysis, pp. 158–167. ACM Press.
Wang, R., X. Wang, & Z. Li (2008). Panalyst: privacy-aware remote error analysis on com-
modity software. In Proceedings of the 17th conference on Security symposium, Berkeley,
CA, USA, pp. 291–306. USENIX Association.
Yang, Z., M. Yang, L. Xu, H. Chen, & B. Zang (2011). ORDER: object centric deterministic
replay for java. In Proceedings of the 2011 USENIX conference on USENIX annual tech-
nical conference, USENIXATC’11, Berkeley, CA, USA, pp. 30–30. USENIX Association.

74 CHAPTER 5. CONCLUSION

ABug Repository Samples
Figure A.1: Bug repository ticket sampling.

76 APPENDIX A. BUG REPOSITORY SAMPLES

BUser Description
Figure B.1: Population sample description.

78 APPENDIX B. USER DESCRIPTION

CEvaluation Description
Figure C.1: Scenarios guide.

80 APPENDIX C. EVALUATION DESCRIPTION

DScenarios
Fig
ure
D.1
:S
cen
ario
1co
mp
lete
resu
lts.

82 APPENDIX D. SCENARIOS
Fig
ure
D.2
:S
cen
ario
2co
mp
lete
resu
lts.
Fig
ure
D.3
:S
cen
ario
3co
mp
lete
resu
lts.

83
Fig
ure
D.4
:S
cen
ario
4co
mp
lete
resu
lts.
Fig
ure
D.5
:S
cen
ario
5co
mp
lete
resu
lts.

84 APPENDIX D. SCENARIOS
Fig
ure
D.6
:S
cen
ario
6co
mp
lete
resu
lts.
Fig
ure
D.7
:S
cen
ario
7co
mp
lete
resu
lts.

85
Fig
ure
D.8
:S
cen
ario
8co
mp
lete
resu
lts.

![Graphical-based User Authentication Schemes for Mobile Devices · Graphical Passwords (GP) as an alternative Better memorability [Paivio, 2006] Ease of input (touchscreen) Higher](https://static.fdocuments.net/doc/165x107/5f1ea9da83f3625cdf74270c/graphical-based-user-authentication-schemes-for-mobile-devices-graphical-passwords.jpg)
















