
UNICORE OPTIMIZATION William Jalby · independent instructions Key unicore performance ... the...
30
1 UNICORE OPTIMIZATION William Jalby LRC ITA@CA (CEA DAM/ University of Versailles St-Quentin-en-Yvelines) FRANCE
-
Upload
truongdiep -
Category
Documents
-
view
228 -
download
3
Transcript of UNICORE OPTIMIZATION William Jalby · independent instructions Key unicore performance ... the...

1
UNICORE OPTIMIZATION
William Jalby
LRC ITA@CA (CEA DAM/ University of Versailles St-Quentin-en-Yvelines)
FRANCE

2
Outline The stage Key unicore performance limitations
(excluding caches) Multimedia Extensions Compiler Optimizations
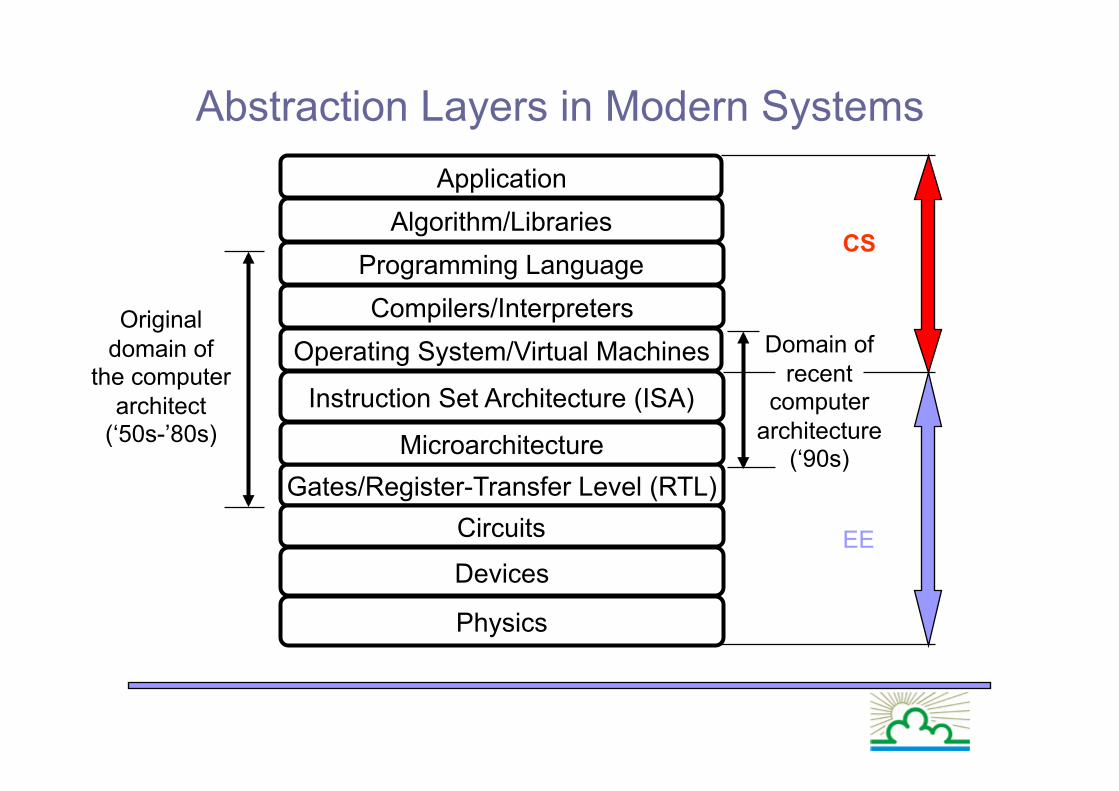
Abstraction Layers in Modern Systems
Programming Language
Gates/Register-Transfer Level (RTL)
Algorithm/Libraries
Instruction Set Architecture (ISA)
Operating System/Virtual Machines
Microarchitecture
Devices
Compilers/Interpreters
Circuits
Physics
Original domain of
the computer architect
(‘50s-’80s)
Domain of recent
computer architecture
(‘90s)
Application
CS
EE

Key issue
Algorithm/Libraries
Microarchitecture
Application
Understand the relationship/interaction between Architecture Microarchitecture and Applications/Algorithms
We have to take into account the intermediate layers
Don’t forget also the lowest layers
KEY TECHNOLOGY:
Performance Measurement and Analysis

Performance Measurement and Analysis
AN OVERLOOKED ISSUE HARDWARE VIEW: mechanism description and
a few portions of codes where it works well (positive view)
COMPILER VIEW: aggregate performance number (SPEC), little correlation with hardware Lack of guidelines for writing efficient programs
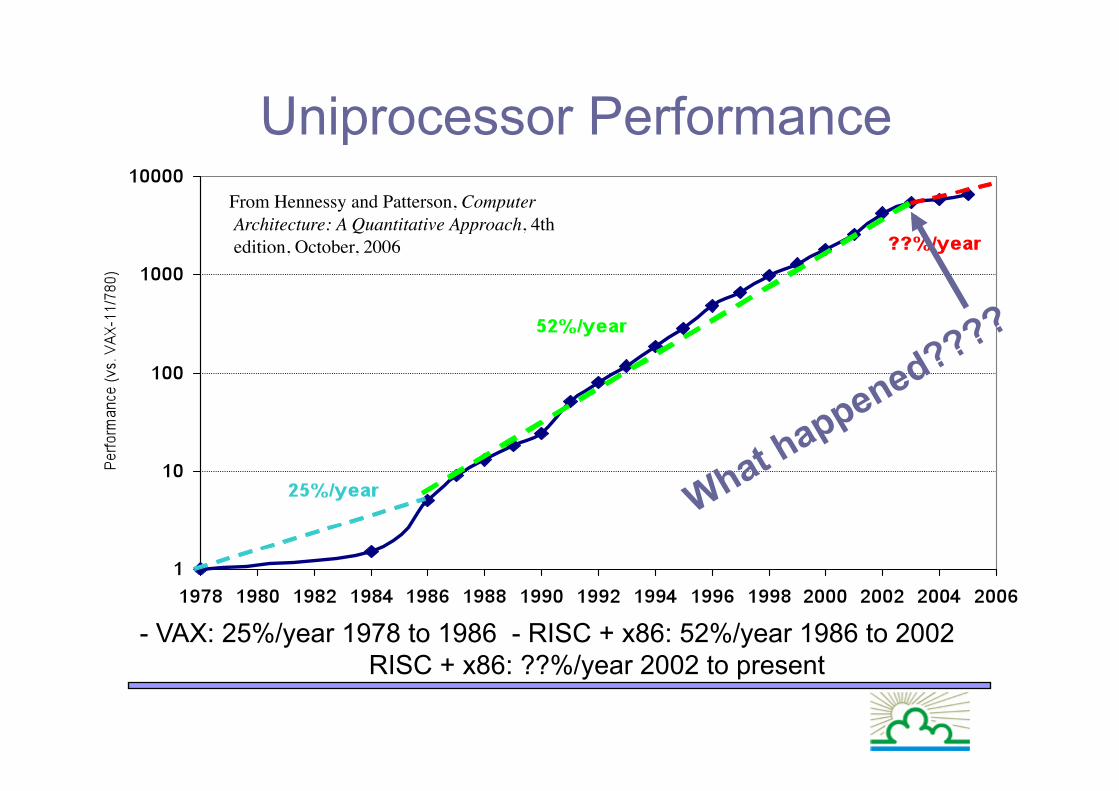
Uniprocessor Performance
- VAX: 25%/year 1978 to 1986 - RISC + x86: 52%/year 1986 to 2002 RISC + x86: ??%/year 2002 to present
From Hennessy and Patterson, Computer Architecture: A Quantitative Approach, 4th edition, October, 2006
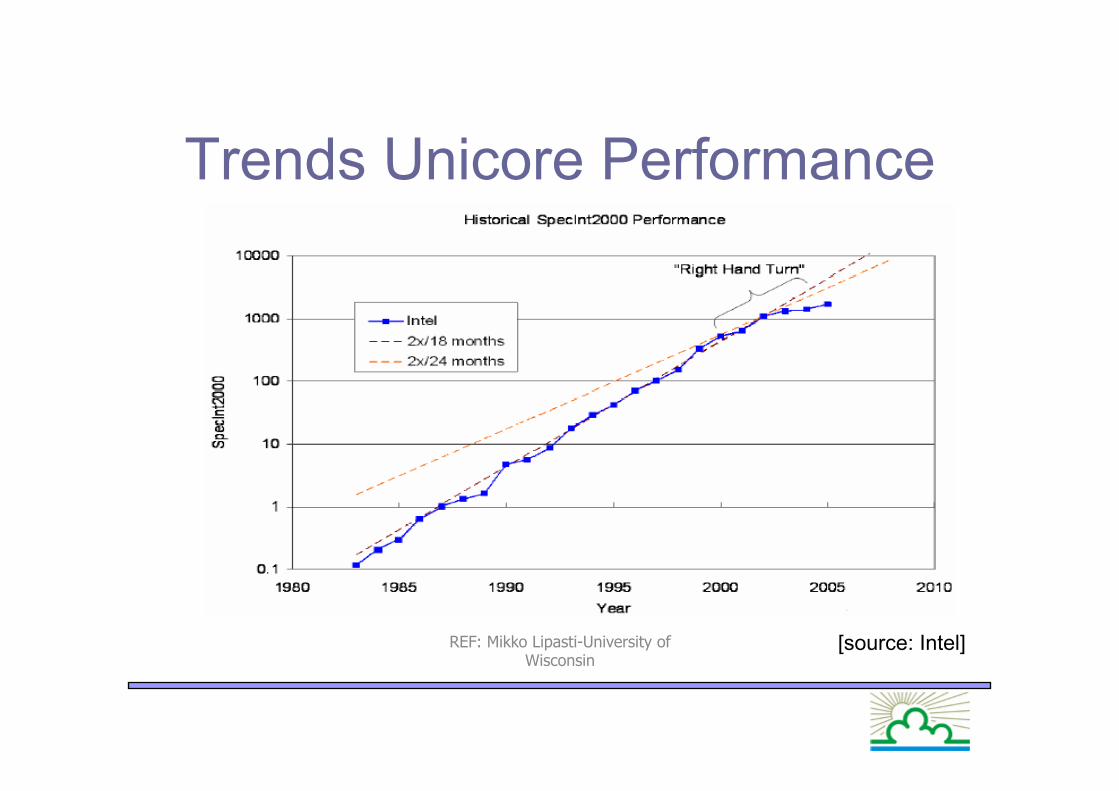
Trends Unicore Performance
[source: Intel] REF: Mikko Lipasti-University of Wisconsin

8
Modern Unicore Stage KEY PERFORMANCE INGREDIENTS ILP: Instruction Level Parallelism:
Pipeline: interleave execution of several instructions: degree of (partial) parallelism: 10 - 20
Superscalar: parallel execution of several instructions: degree of parallelism: 3 to 6
Out of Order execution Specialized units: multimedia units: degree of
parallelism 2 to 4 Compiler Optimizations Large set of Registers (really true only on
Itanium)

9
ILP limitations
In the previous slide, wherever I used the term degree of parallelism = k : it means that the compiler has to k independent instructions Key unicore performance limitations (excluding caches)
The compiler and the hardware is in charge of finding such ILP An easy case: basic block: a sequence of instructions which will
be executed in a continous flow (no branch, no labels). Basic Block sizes constitute a good indicator of easy ILP.
A more complex case: in a loop, the hardware will try to overlap execution of several iterations
In general, this is not a big issue BUT ….

10
Hard ILP limitation (1): data dependency
DO I = 1, 100 S = S + A(I)
ENDDO
Iteration I +1 is strictly dependant upon Iteration I Very limited ILP In fact, the code computes a sum. Using associativity it is easy to rewrite it by computing for
example 4 partial sums
DO I = 1, 100, 4 S1 = S1 + A(I) S2 = S2 + A(I+1) S3 = S3 + A(I+2) S4 = S4 + A(I+3)
ENDDO S = S1 + S2 + S3 + S4
The code above has much more ILP but unfortunately since FP additions are not associative, well accuracy may suffer
The associativity trick works on simple cases: might to be complex to use in general Remark: MAX is an associative operator even in FP

11
Hard ILP limitation (2): branches CASE 1 : subroutine calls Easy to overcome: SOLUTION = inlining. At the call site, insert the suroutine Iteration I +1 is strictly dependant upon Iteration I ADVANTAGES OF INLINING: increase basic block size, allows specialization (see later) DRAWBACKS OF INLINING: increase severly code size
CASE2: Conditional branches.
DO I = 1, 100 IF (A(I) > 0) THEN B(I) = C(I) (statement S1(I)) ELSE F(I) = G(I) (statement S2(I)) ENDIF
ENDDO Basically, you need to know the outcome of the test before proceeding with execution of S1(I) or
S2(I) SOLUTION: the hardware will bet on the result on the test and decide to execute ahead one of
the two outcomes of the branch (branch prediction). The hardware will use the past to predict the future.
DRAWBACK: if the hardware has mispredicted, recovery might be costly On the code above, we might think that the hardware had 50/50% of mispredicting (which is true).
In practice, branch predictors are very performant : they can reach up to 97% correct predictions (and even more) success because …. There are many loops
REAL SOLUTION: avoid branches in your code

12
A subtle ILP limitation DO I = 1, 100
A(I) = B(I) ENDDO In FORTRAN, the use of different identifiers implies that
the memory regions are distinct: A(1:100) and B(1:100) do not have any overlap in memory. Therefore we are sure that “logically” the iterations are independent
In C, the situation is radically different: there is no guarantee that the regions A(1:100) and B(1:100) do not overlap. Therefore, the iterations might dependant upon each other. Furthermore the loads and the stores have to be executed in the strict order B(1), A(1), B(2), A(2) etc ….This implies strong limitations on the use of out of order mechanisms.

13
Trick 1 for overcoming ILP limitations
Increase basic block size Use unrolling: DO I 1= 100 DO I = 1,100, 2
A(I) = B(I) is replaced by A(I) = B(I) ENDDO A(I+1) = B(I+1)
ENDDO
ADVANTAGES: increase basic block sizes and always applicable. Can be combined with jamming, reordering the statements with the increased loop body.
DRAWBACKS Choose the right degree of unrolling not always obvious Might increase register usage Increase code size Does not always improve performance in particular on modern Out of Order
machines. In fact on such machines, hardware is somewhat performing dynamically loop unrolling.
Don’t forget tail code when iteration number is not a multiple of unrolling degree. The tail code is in charge of dealing with the “remainder”

14
Trick 2 : specialization The code generation/optimization strategy is completely dependent upon
the number of iterations: if the number of iterations is systematically equal to 5, choose systematically full unrolling. If the number of iterations is large, then don’t use full unrolling
Go against genericity (against sound principles of software engineering)
STANDARD DAXPY CODE DO I = 1, N
Y(INCY*I) = Y(INCY*I) + a * X(INCX*I) ENDDO
Never use such a code Instead notice that very often, INCX = INCY = 1 !! And generate a specific
version for this very common case. SIMPLIFY COMPILER’S LIFE: try to give him as much info as possible ADVANTAGE: almost always usable DRAWBACK: increase code size, too many specialized versions.

Multimedia instructions
IDEA: provide special instructions to speedup multimedia code (don’t forget multimedia = mass market)
Very often multimedia code contains loops operating on arrays (each element of the array being accessed in turn) and perform the same operation
DO I = 1, 100 A(I) = B(I) + C(I) Regular (contiguous) array access
ENDDO

Mediaprocesing: Vectorizable? Vector Lengths?
Kernel Vector length Matrix transpose/multiply # vertices at once DCT (video, communication) image width FFT (audio) 256-1024 Motion estimation (video) image width, iw/16 Gamma correction (video) image width Haar transform (media mining) image width Median filter (image processing) image width Separable convolution (img. proc.) image width
(from Pradeep Dubey - IBM, http://www.research.ibm.com/people/p/pradeep/tutor.html)
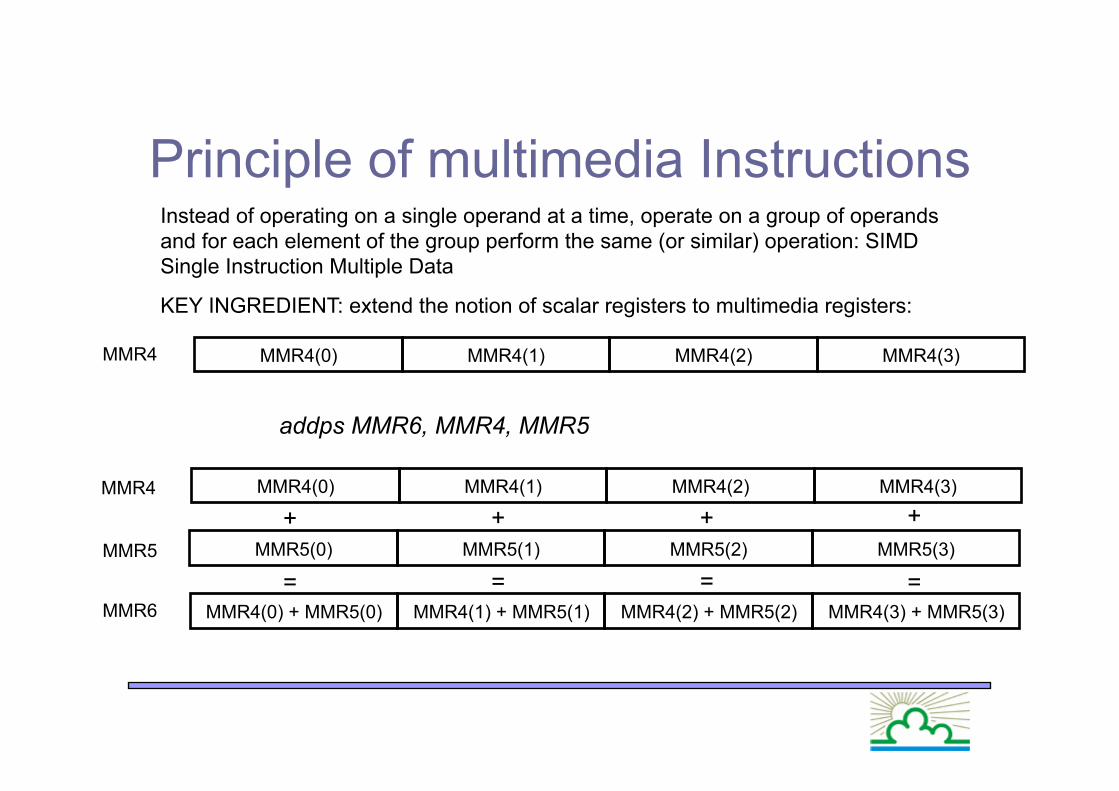
Principle of multimedia Instructions
MMR4(0) MMR4(1) MMR4(2) MMR4(3)
Instead of operating on a single operand at a time, operate on a group of operands and for each element of the group perform the same (or similar) operation: SIMD Single Instruction Multiple Data
KEY INGREDIENT: extend the notion of scalar registers to multimedia registers:
MMR4(0) MMR4(1) MMR4(2) MMR4(3)
MMR5(0) MMR5(1) MMR5(2) MMR5(3)
MMR4(0) + MMR5(0) MMR4(1) + MMR5(1) MMR4(2) + MMR5(2) MMR4(3) + MMR5(3)
MMR4
addps MMR6, MMR4, MMR5
MMR4
MMR5
MMR6
+ + + +
= = = =
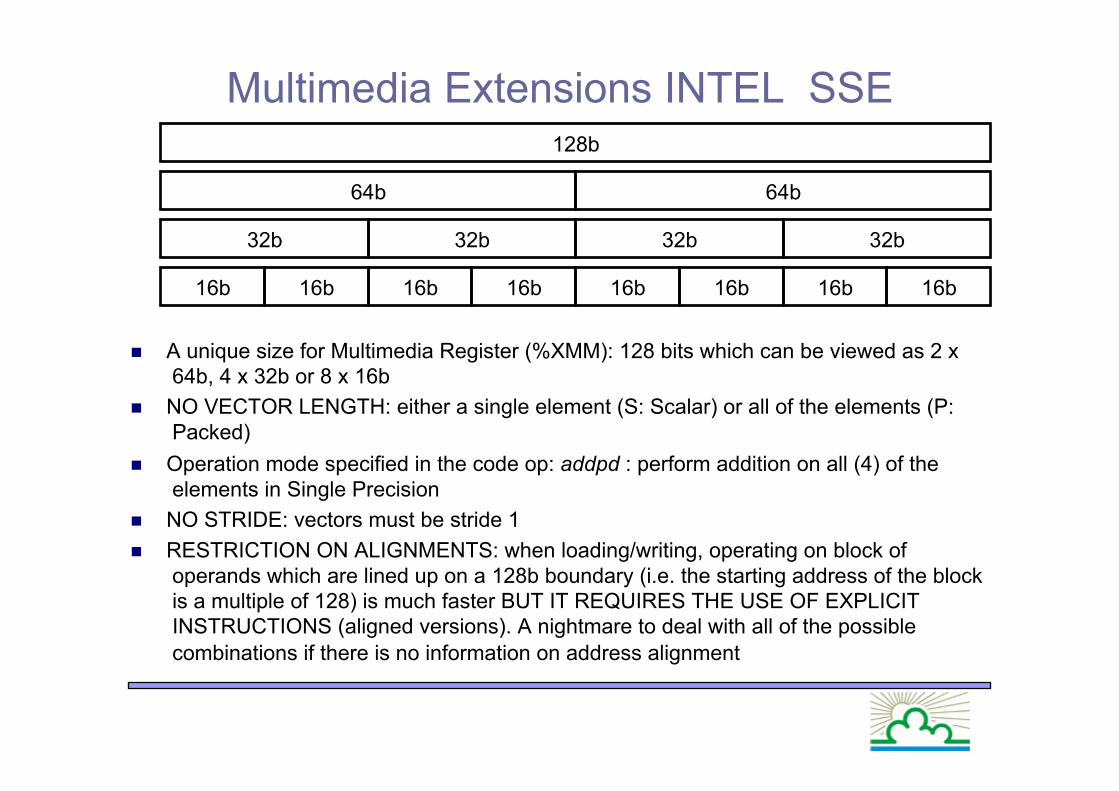
Multimedia Extensions INTEL SSE
A unique size for Multimedia Register (%XMM): 128 bits which can be viewed as 2 x 64b, 4 x 32b or 8 x 16b
NO VECTOR LENGTH: either a single element (S: Scalar) or all of the elements (P: Packed)
Operation mode specified in the code op: addpd : perform addition on all (4) of the elements in Single Precision
NO STRIDE: vectors must be stride 1 RESTRICTION ON ALIGNMENTS: when loading/writing, operating on block of
operands which are lined up on a 128b boundary (i.e. the starting address of the block is a multiple of 128) is much faster BUT IT REQUIRES THE USE OF EXPLICIT INSTRUCTIONS (aligned versions). A nightmare to deal with all of the possible combinations if there is no information on address alignment
32b 32b 32b 32b
64b 64b
128b
16b 16b 16b 16b 16b 16b 16b 16b

INTEL SSE Intel started with MMX then SSE, SSE2, SS3 and SSE4 (and it
keeps on going): the size of the instruction set manual has doubled from 700 pages up to 1400 pages
Extremely Rich Instruction Set (back to CISC) BUT NO REAL SCATTER/GATHER
BIG BENEFIT IN USING MULTIMEDIA INSTRUCTIONS: for SP (resp DP), 4x (resp 2x) speedup over scalar equivalent
Needs to rely on the compiler (vectorizer) to get such instructions or use “assembly-like” instructions called “intrinsics”
MULTIMEDIA INSTRUCTIONS IS A “DEGENERATE” (much more restricted) FORM OF THE OLD VECTOR INSTRUCTIONS (Cf CRAY) but it’s OK for multimedia applications (less for HPC applications )

A Vicious One
MMR4(0) MMR4(1) MMR4(2) MMR4(3)
MMR5(0) MMR5(1) MMR5(2) MMR5(3)
MMR4(0) + MMR5(0) MMR4(1) - MMR5(1) MMR4(2) + MMR5(2) MMR4(3) - MMR5(3)
addsubps MMR6, MMR4, MMR5
MMR4
MMR5
MMR6
+ + - -
= = = =
It is a miracle if the compiler can succeed in using this one!!

Multimedia Instructions
Everybody has it now: besides Intel, IBM has Altivec, SUN has VIS
Characteristics of VIS and Altivec very similar to SSE
Simple architecture mechanism; easy to implement and not very power hungry

22
The compiler A key actor in unicore performance: can in the way (i.e.
preventing from getting good performance) Always check code produced by the compiler: main purpose of
MAQAO (tool developed by LRC ITACA): Modular Assembly Quality Analyzer and Optimizer
The compiler can get lost in its optimizationS: this an NP problem to determine what is the best sequence (order of optimizations) to be applied)
Some optimizations are very complex Compiler organization induces inefficiencies: strict order of phases.
A quick example, in general unrolling is decided very early close to front end, now a major issue with unrolling is register consumption which will be handled in the back end!!
A partial solution: iterative compilation: tries different optimizations, runs them, and pick the most effective one. A typical trial and error process. Compiler has to offer fast response time: no time to explore (for example use iterative compilation)
Compiler very often lacks key information

23
Driving the compiler WRITE SIMPLE CODE Use compiler flags to specify some optimizations to be performed: force
vectorization, unrolling etc… KEY DRAWBACK: applies to the whole file!! Use pragmas inserted in the code: can specify precisely optimization scope
(a given loop level) Unroll and Unroll and Jam: avoids complex/long code generated by hand
unrolling No alias: informs the compiler that the memory regions are disjoints: allows load
and store reordering Likely number of iterations: the compiler will generate specialized code Vectorize: forces vectorization, use of multimedia instructions Align: allows to use aligned instructions
WARNING: pragmas are just suggestions provided to the compiler, there is no guarantee that the pragmas will be followed
Write code using intrinsics: assembly coding at high level Use libraries but check performance first and don’t use a matrix multiply (N1
x N2) (N2 x N3) to perform a dot product (1 x N) (N x 1) Use state of the art compiler: use icc or ifort not gcc

Textbooks
Classical Textbook (A trial for combining CS and EE perspective): J. L. Hennessy and D. A. Patterson, Computer Architecture: a quantitative approach. 4/5th Edition, Morgan Kauffman, 2005
GENERAL PROBLEM WITH TEXTBOOKS: DUE TO PUBLISHING DELAYS, OUT OF SYNC WITH REAL HARDWARE PROGRESS

Textbooks (2) Excellent Itanium Textbook (A programmer perspective)
M. Cornea, J. Harrison and P. T. P. Tang Scientific Computing on Itanium Based Systems, First edition, INTEL PRESS.
Classical Textbook (An excellent methodology book for performance measurement):
R. Jain The art of computer systems performance analysis: techniques for experimental design, measurement, simulation and modeling. 1st Edition, John Wiley 1991 (but still valid )

Courses on the WEB Lectures + Lab Sessions CS 152, Berkeley, Krste Asanovic ECE/CS 752, University of Wisconsin at Madison, M.H. Lipasti CS 232 and CS533, University of Illinois at Urbana Champaign, J. Torellas
CHECK THE SEMESTER: but in general regularly updated.

Documents on the WEB (1) http://www.agner.org/optimize : a gold mine for X86 processors : a real expert user perspective. Agner Fog (has a strong background in Biology), University of Copenhagen, College of Engineering. Four very comprehensive documents available, updated every 6 months
Optimizing Software in C++ Optimizing subroutines in assembly language The microarchitecture of INTEL and AMD CPU Instruction Tables
http://people.redhat.com/drepper/cpumemory.pdf: Ulrich Drepper, “What every programmer should know about memory”. Reference document on memory/cache, with some performance analysis

Documents on the WEB (2)
http://www.intel.com Check for optimization guides, reference documents http://www.ibm.com, Check for optimization guides, reference documents, excellent IBM R & D Journal)
http://www.wikipedia.org the english version (of course).

Acknowledgements These slides contain material developed and copyright by:
Arvind (MIT) Krste Asanovic (MIT/UCB) Joel Emer (Intel/MIT) James Hoe (CMU) John Kubiatowicz (UCB) David Patterson (UCB) Mikko Lipasti (UWisc) INTEL IC Knowledge LLC

30
Software
NIKLAUS WIRTH’s LAW: “ Software gets faster slower than hardware gets faster”
Productivity of software developers does not increase exponentially


















