
Understanding Microservice Performance
54
Understanding Microservice Performance Rob Harrop
-
Upload
rob-harrop -
Category
Software
-
view
377 -
download
0
Transcript of Understanding Microservice Performance

Understanding Microservice PerformanceRob Harrop

The performance of a distributed system is the combined performance of
its collaborating services and their communication links

Services and
aggregations of services

Who am I?
▸ CTO @ Skipjaq▸ ML-driven performance optimisation
▸ Co-founder of SpringSource
▸ Once upon a time I…▸ Contributed to Spring Framework
▸ Wrote a book about Spring
▸ Talked a lot about Spring

Who am I?
▸ I’m on Twitter: ▸ @robertharrop
▸ I’m on Github: ▸ github.com/robharrop
▸ I write about maths and performance ▸ https://robharrop.github.io
If you have questions after the session, {grab, tweet} me.

Agenda

After this talk you will know how to:
▸ Measure performance correctly
▸ Find potential performance disasters
▸ Identify the best candidates for optimisation
▸ Model complex micro services systems
▸ Forecast system scalability


What is performance?

How fast can I do a thing, and
how many things can I do every period?
What do we mean by performance?

What measures performance?
Latency (how fast) and
Throughput (how many)

Throughput
▸ The rate of processing: x per y
▸ Requests per second
▸ Records per minute
▸ Messages per second
▸ Tasks per day

Latency
▸ Time taken… for something▸ Service time?
▸ First byte?
▸ First response complete?
▸ Last byte?
▸ Render?
▸ Moral of the story: define what you mean by latency

Measuring

This is where everything goes wrong

Crib Sheet
▸ Record timestamped requests with observed latency and success/error
▸ Throughput▸ Min, max, mean
▸ Varying time windows (10s, 30s, 1m, 5m, …)
▸ Latency▸ Min, max, 95th, 99th, 99.9th and other tail percentiles
▸ Mean just means meaningless

We need to talk about latency
▸ Latency isn’t exponentially-distributed▸ And it certainly isn’t normally-distributed
▸ Latency distributions have heavy tails
▸ Latency distributions are multi-modal
▸ Customers see tail latencies way more than you think▸ Don’t let percentiles trick you
▸ Understand what latency means to your business
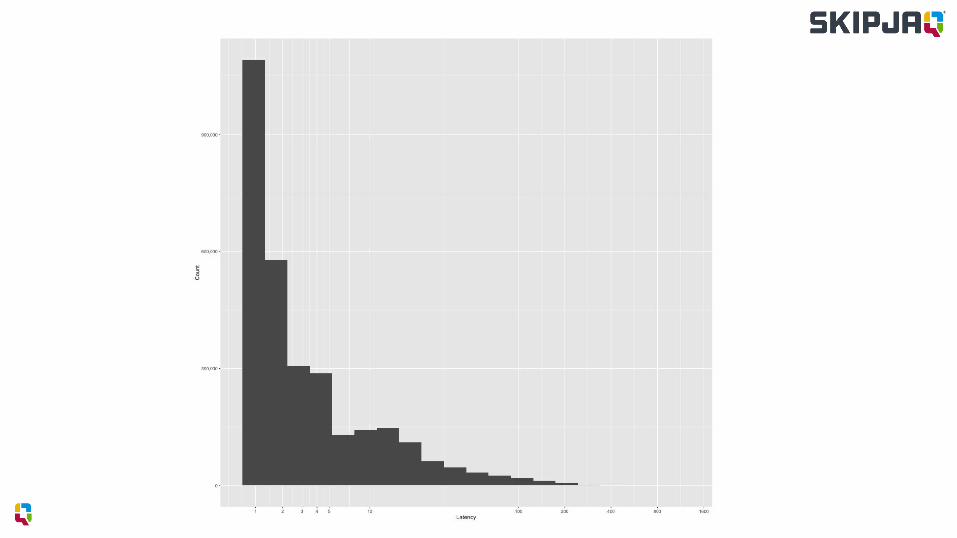

Tail Latencies

Is my customer getting good service?

What does this mean in reality?

Is my customer getting good service?
95th percentile
42 requests

Most customers will see tail latencies

Visualising Tail Latencies

Are latency and throughput useful when considered in isolation?

Attribution: http://www.cowboyjedi.com/comics/2010-03-10-i-made-the-kessel.gif

Little’s Law

Queueing Theory - Little’s Law
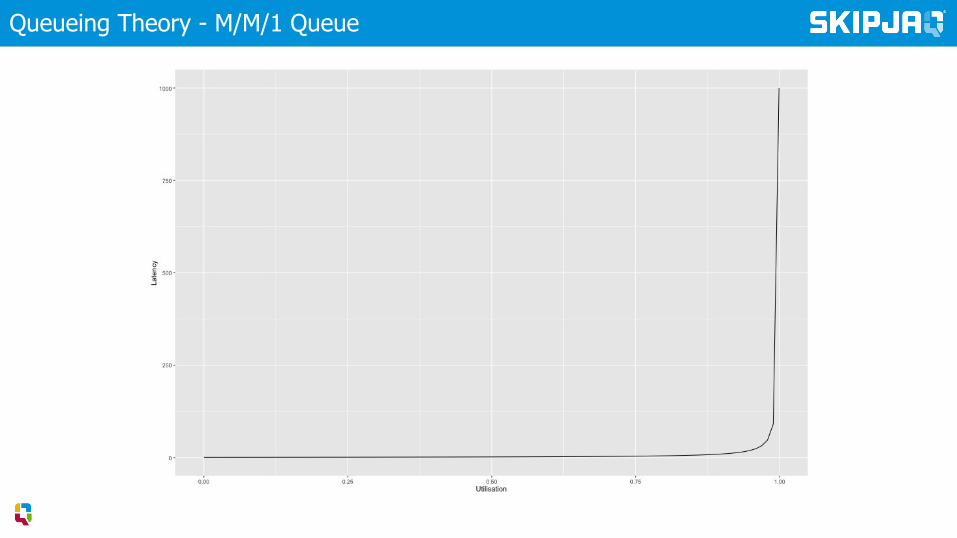
Queueing Theory - M/M/1 Queue

What can we conclude?
▸ Latency and throughput work in tandem
▸ At high throughput, latency degrades considerably

High utilisation is an
early-warning sign

Latency Stacking

Service latencies stack
▸ For simple cases (feed-forward networks), latencies are additive▸ Analytical models are available
▸ http://robharrop.github.io/maths/performance/2016/03/15/queue-networks.html
▸ For most interesting cases this cannot be assumed▸ Simulation is the best option▸ Pretty Damn Quick (PDQ) is a great tool, but requires a chunk of effort▸ Guesstimate is great for quick and dirty models

Analytical Stacking

Simulating Latency Stacking


Amdahl’s Law

How much improvement can we get from an optimisation?

Amdahl’s Law
▸ Theoretical improvement in latency given a fixed workload
Theoretical max system speedup
Speedup of part under optimisation
Percentage of execution time in part under optimisation

Amdahl’s Law in the Limit
▸ Theoretical max is limited by parts of the system not under improvement
Theoretical max system speedup Percentage of execution time in part
under optimisation
Speedup of part under optimisation
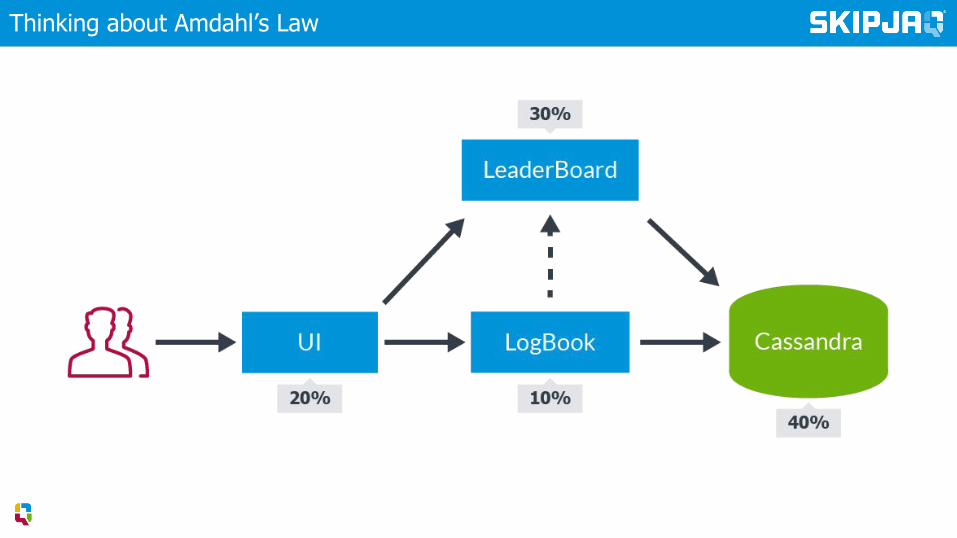
Thinking about Amdahl’s Law
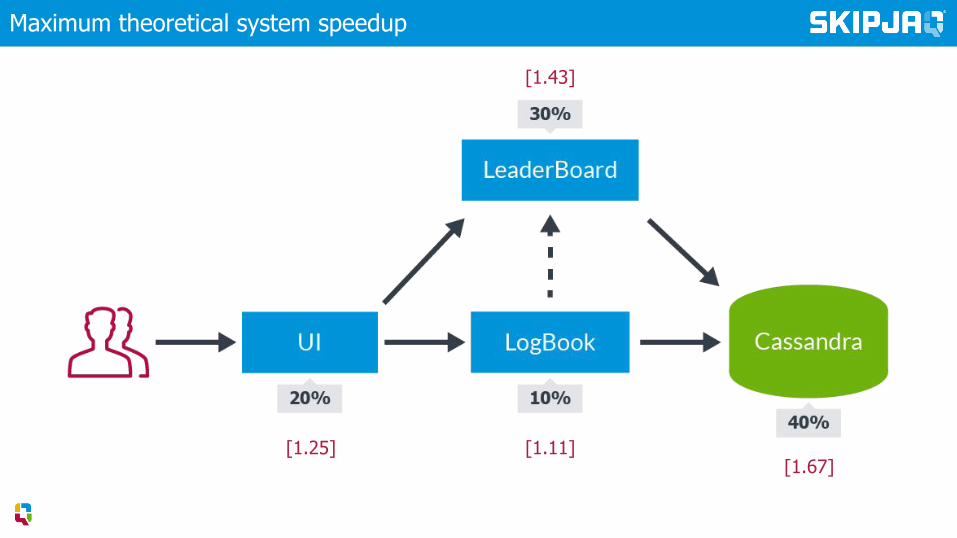
Maximum theoretical system speedup
[1.11][1.67]
[1.25]
[1.43]

Drive optimisation choices by service utilisation

Universal Scalability Law

Can increasing capacity reduce performance?

TL;DR - Yes
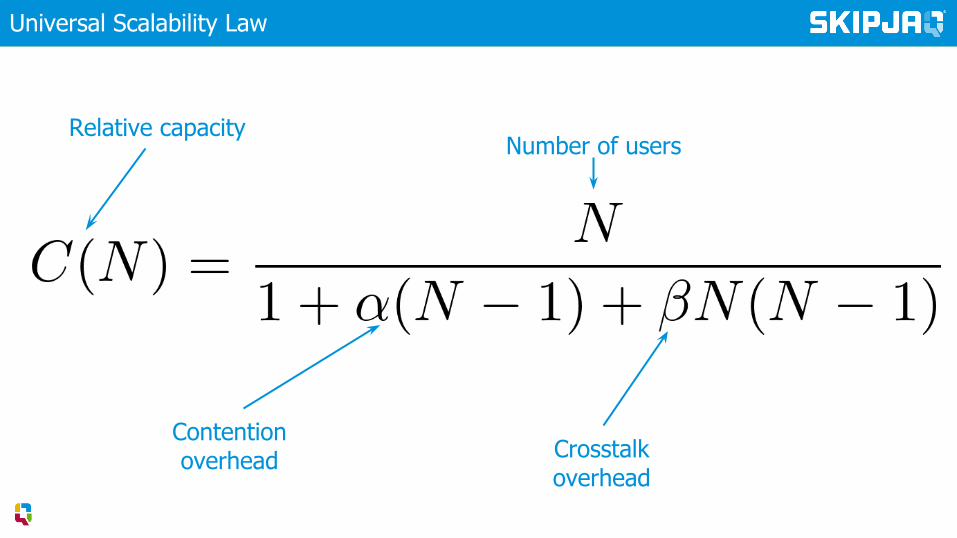
Crosstalk overhead
Universal Scalability Law
Contention overhead
Relative capacityNumber of users
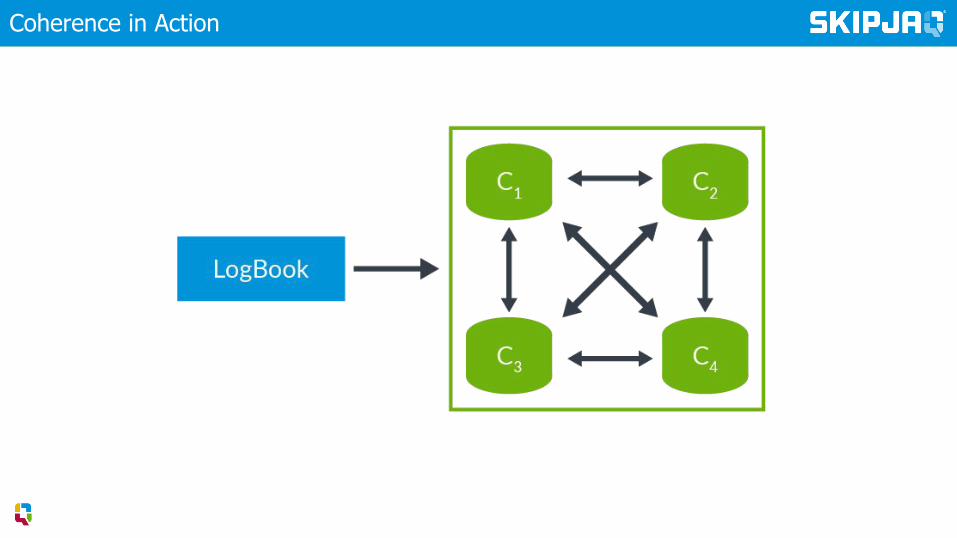
Coherence in Action

Visualising the USL

Measure crosstalk and target it for optimisation



Summary
▸ Measurements are critical▸ Garbage in, garbage out
▸ Monitor utilisation for early-warning of disaster▸ Little’s Law
▸ Monitor latency per-user, not just per-request
▸ Select optimisation targets carefully▸ Amdahl’s Law
▸ Monitor crosstalk to forecast scalability▸ Universal Scalability Law

Reading List and Q&A
▸ Release It! - Michael Nygard
▸ Systems Performance - Brendan Gregg
▸ Guerrilla Capacity Planning - Dr. Neil Gunther
▸ Practical Scalability Analysis - Baron Schwartz


















