
T.Sharon - A.Frank 1 Internet Resources Discovery (IRD) Web IR.
21
T.Sharon - A.Frank 1 Internet Resources Discovery (IRD) Web IR
-
date post
20-Dec-2015 -
Category
Documents
-
view
221 -
download
0
Transcript of T.Sharon - A.Frank 1 Internet Resources Discovery (IRD) Web IR.

T.Sharon - A.Frank1
Internet Resources Discovery (IRD)
Web IR

T.Sharon - A.Frank
2
Web IR
• What’s Different about Web IR?
• Web IR Queries
• How to Compare Web Search Engines?
• The ‘HITS’ Scoring Method

T.Sharon - A.Frank
3
What’s different about the Web?
• Bulk ……………... (500M); growth at 20M/month• Lack of Stability ..… Estimates: 1%/day--1%/week• Heterogeneity
– Types of documents …. text, pictures, audio, scripts...
– Quality
– Document Languages ……………. 100+
• Duplication• Non-running text• High Linkage ..…………. 8 links/page average> =
T.Sharon - A.Frank
4
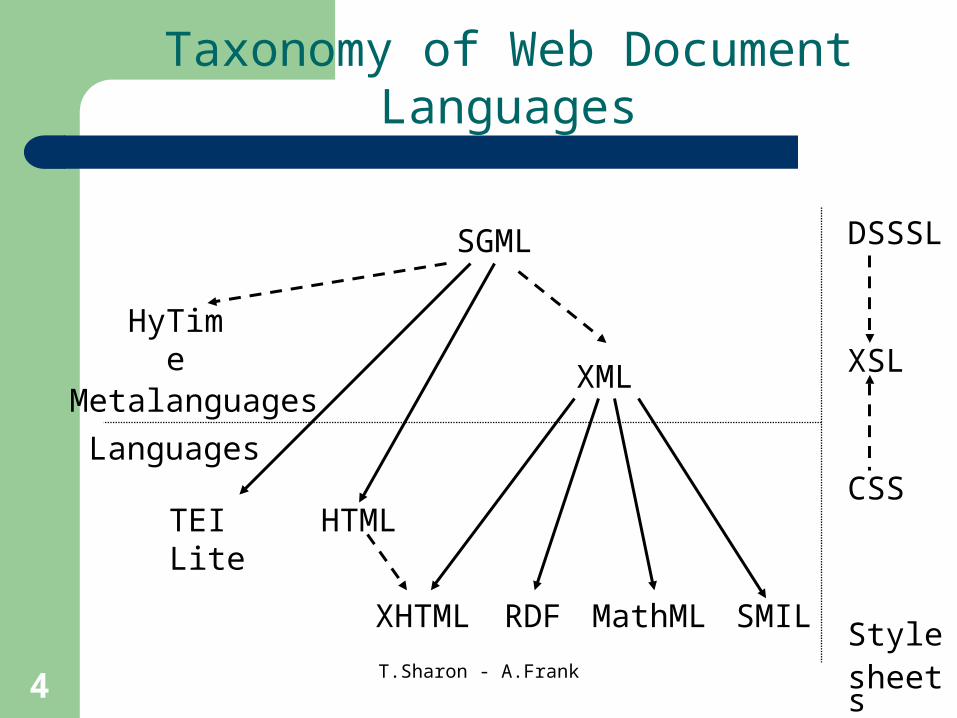
Taxonomy of Web Document Languages
SGML
HyTime
XMLMetalanguages
Languages
SMILMathMLRDFXHTML
HTMLTEI Lite
DSSSL
XSL
CSS
Style sheets

T.Sharon - A.Frank
5
Non-running Text

T.Sharon - A.Frank
6
What’s different about the Web Users?
Make poor queries– short (2.35 terms average)– imprecise terms– sub-optimal syntax (80%
without operators)– low effort
Wide variance on– Needs– Expectations– Knowledge– Bandwidth
Specific behavior– 85% look over one
result screen only
– 78% of queries not modified

T.Sharon - A.Frank
7
Why don’t the Users get what they Want?
User need
User request(verbalized)
Query toIR system
Results
Translationproblems
PolysemySynonymy
Example
I need to get rid of mice in the basement
What’s the best way to trap mice alive?
Mouse trap
Computer suppliessoftware, etc
T.Sharon - A.Frank
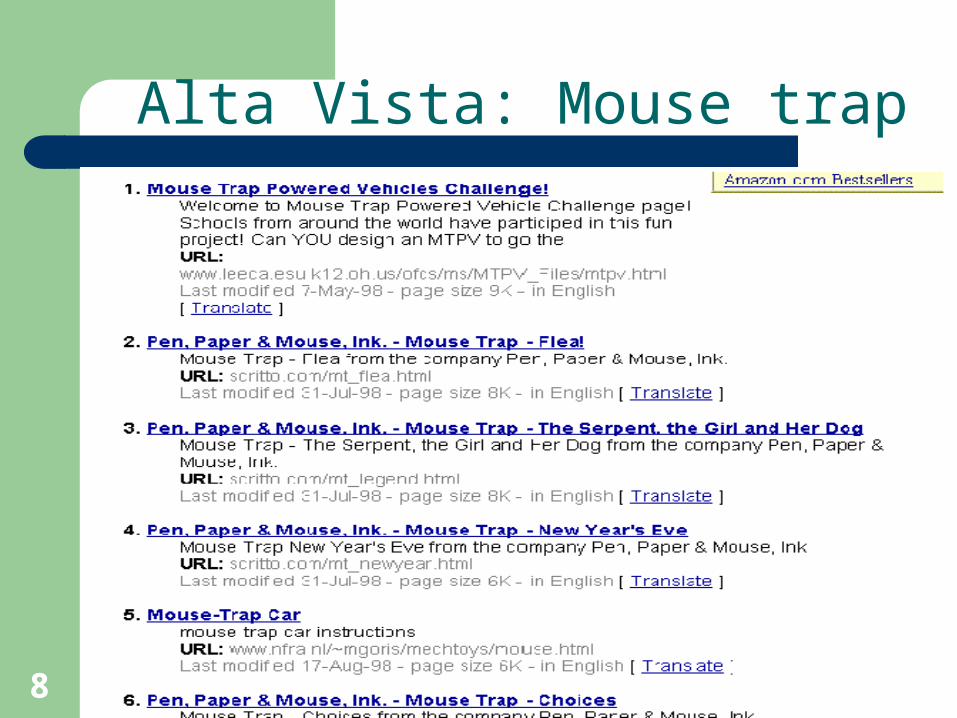
8
Alta Vista: Mouse trap

T.Sharon - A.Frank
9
Alta Vista: Mice trap

T.Sharon - A.Frank
10
Challenges on the Web
• Distributed data
• Dynamic data
• Large volume
• Unstructured and redundant data
• Data quality
• Heterogeneous data

T.Sharon - A.Frank
11
Web IR Advantages
High LinkageInteractivity Statistics
– easy to gather
– large sample sizes

T.Sharon - A.Frank
12
Evaluation in the Web Context
• Quality of pages varies widely
• Relevance is not enough
• We need both relevance and high quality = value of page

T.Sharon - A.Frank
13
Example of Web IR Query Results
T.Sharon - A.Frank
14
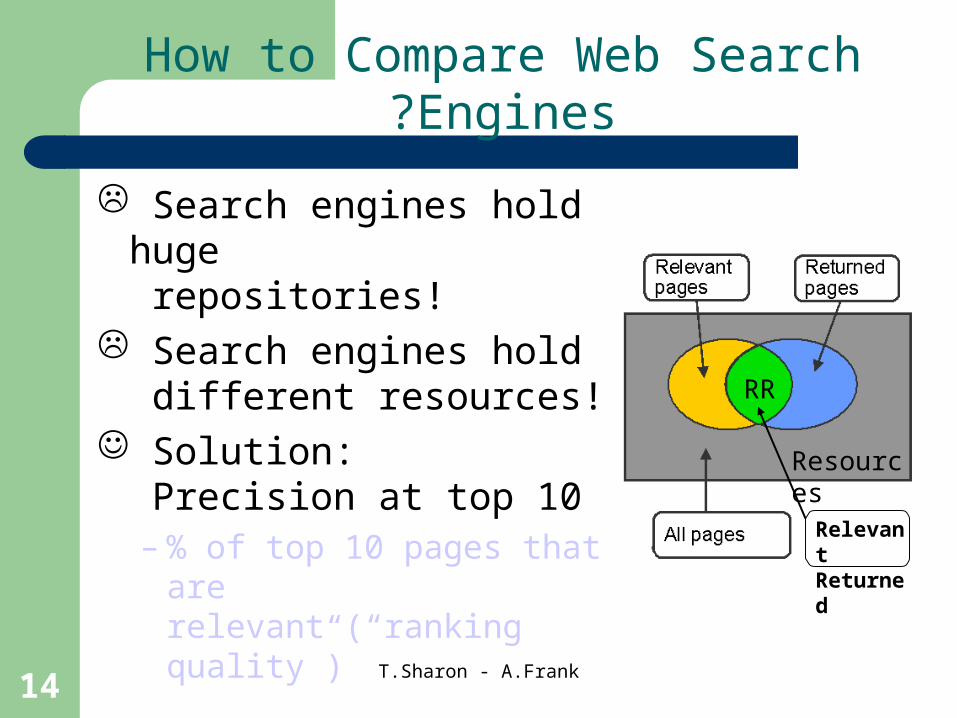
How to Compare Web Search Engines?
Search engines hold huge repositories!
Search engines hold different resources!
Solution: Precision at top 10 – % of top 10 pages that are
relevant (“ranking quality”)
Retrieved(Ret)
Resources
RR
RelevantReturned

T.Sharon - A.Frank
15
The ‘HITS’ Scoring Method
• New method from 1998:– improved quality– reduced number of retrieved documents
• Based on the Web high linkage • Simplified implementation in Google
(www.google.com)• Advanced implementation in Clever
Reminder: Hypertext -nonlinear graph structure

T.Sharon - A.Frank
16
‘HITS’ Definitions
• Authorities: good sources of content
• Hubs: good sources of links
A
H
T.Sharon - A.Frank
17
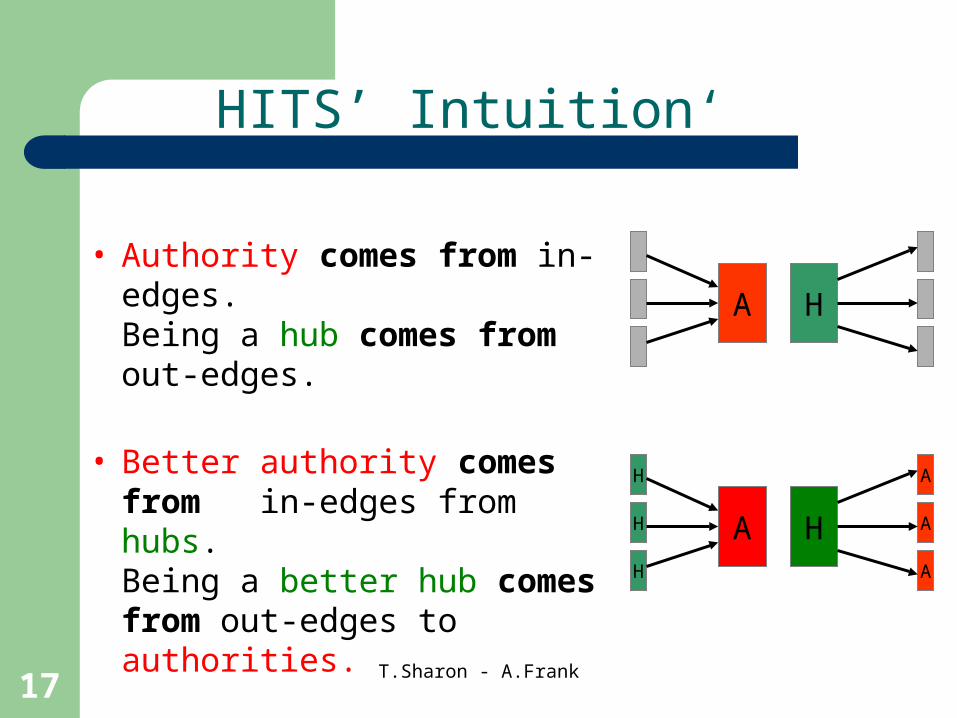
‘HITS’ Intuition
• Authority comes from in-edges.Being a hub comes from out-edges.
• Better authority comes from in-edges from hubs.Being a better hub comes from out-edges to authorities.
A H
A
H
H
H
H
A
A
A

T.Sharon - A.Frank
18
v
‘HITS’ Algorithm
A
w1
Hw2
wk
...
u1
u2
uk
...
Repeat until HUB and AUTH converge:
Normalize HUB and AUTH
HUB[v] := AUTH[ui] for all ui with Edge(v,ui)
AUTH[v] := HUB[wi] for all wi with Edge(wi,v)

T.Sharon - A.Frank
19
Google Output: Princess Diana
T.Sharon - A.Frank
20
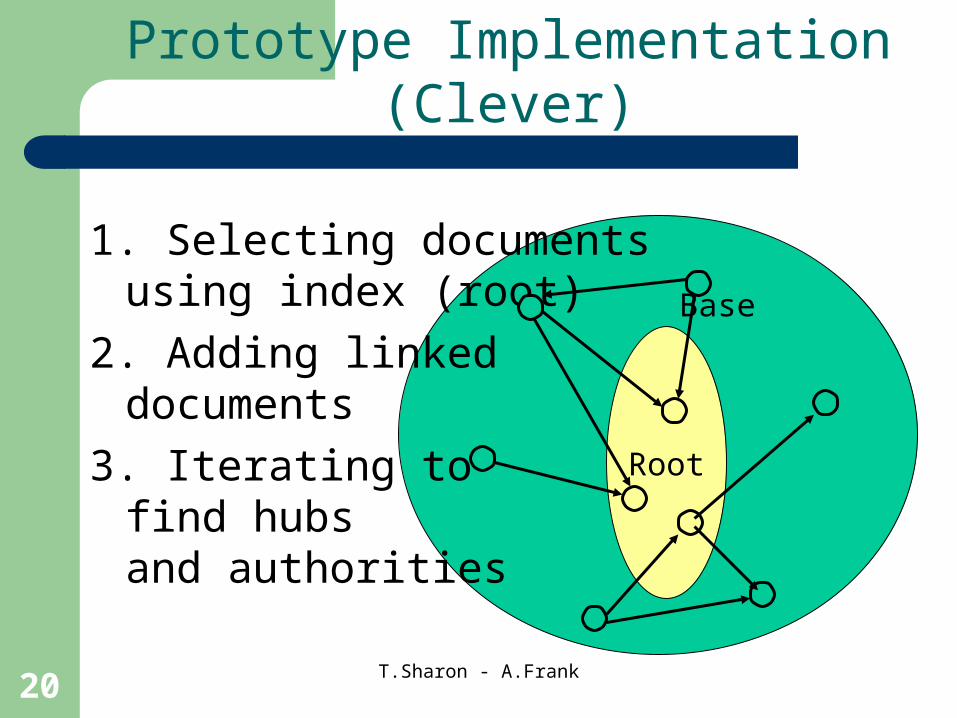
Prototype Implementation (Clever)
Base
Root
1. Selecting documents using index (root)
2. Adding linkeddocuments
3. Iterating tofind hubs and authorities

T.Sharon - A.Frank
21
By-products
• Separates Web sites into clusters.
• Reveals the underlying structure of the World Wide Web.


















