
Jan. 20041 Java Networking TCP Yangjun Chen Dept. Business Computing University of Winnipeg.
date post
18-Dec-2015Category
view
213download
0
Tree Inclusion, Signatures, and Evaluation ofPath-Oriented Queries
Dr. Yangjun Chen
Dept. Applied Computer Science, University of Winnipeg, Canada
• Motivation• Path-Oriented Queries and Tree Inclusion Problem• Evaluation of Path-Oriented Queries
- Top-down Algorithm for Tree Inclusion- Integration of Signatures into Top-down Tree Inclusion
• Experiment Results• Summary and Future Work

Motivation
• Local Information Resource Management – document databases• Internet – Distributed Document Databases• Document Databases
- Storage of documents in relational databasesnon-structured data, semi-structured data
- Evaluation of path-oriented queries in document databasespath-oriented languages: XQL, XPath, and XML-QLQuery evaluation methods:
•inverse-file based•signature based
•string-matching based: suffix trees, Pat-trees
•tree-inclusion based• Integrating signatures into top-down tree inclusion algorithm

Path-Oriented Queries and Tree Inclusion Problem
• XML Documents and Path-Oriented Queries
<ho tel-roo m-reservat ion filecod=”1302 ”>< name>Travel-lodeg</name>
<num ber> 500< /num ber>
< locat ion><c ity-or-d istrict>Winnipeg</city-o r-d istric t><s tate> Manitoba< /state>
< /reservation -time>
</location>
< /hotel-room-reservat ion>
<country >Canada< /country><address>
<street>P ortage Ave .< /stree t><pos t-code>R3B 2E9< /post-code>
</address>
<typ e>< room s>one-bed -room </ro om><price> $119.00</price>
</ty pe>< reservation -time>
< from> April 20, 2002</from>< to>A pril 28, 2002< /to>
XML document:
/letter//body [para $contains$‘visited’].
/hotel-room-reservation/name ?x
/hotel-room-reservation/location
/hotel-room-reservation/location
Path-oriented queries:
/address [street = ‘510 Portage Ave.’].
[city-or-district = ‘Winnipeg’]
Single-path query:
Multiple-path query:

Path-Oriented Queries and Tree Inclusion Problem
• Tree Inclusion Problem
Definition (tree embedding) Let T and P be two labeled trees. A mapping M from the nodes of P to the nodes of T is an embedding of P
into T if it preserves labels and ancestorship. That is, for all nodes u and v of P, we require that
a) M(u) = M(v) if and only if u = v,
b) label(u) = label(M(u)),
c) u is an ancestor of v in P if and only if M(u) is an ancestor of M(v) in T, and
d) v is to the left of u iff M(v) is to the left of M(u).
An embedding is root preserving if M(root(P)) = root(T). It can be shown that restricting to root-preserving embedding does not lose generality.

Path-Oriented Queries and Tree Inclusion Problem
Example:
Hotel-room-reservation Hotel-room-reservation
name location type reservation name location
Travel-lodge City-or-district
state country address rooms price from to ?x City-or-district
number
515 Portage Ave.
street
address
Winnipeg Manitoba Canada
number
street
Post-code
one-bed-room
$119.00 April 20,2005
April 28,2005
Winnipeg
515 Portage Ave.R3B 2E9
T: P:
M (P .h o t e l -r o o m - re s e r v a t io n ) = T .h o t e l -r o om -r e s e r va t io n
M (P .n a m e ) = T . n a m e
M (P .l o ca t io n ) = T .l o ca ti o n
M ( P . Tr a v e l - l o d g e ) = T .? x
M ( P . c i t y -o r-d i s tr ic t ) = T. c i ty - o r-d i st r i c t M ( P . a d d re s s) = T .a d d re s s
M (P . W i n n i p e g ) = T .W i n n ip e g
M (P . 5 15 ) = T .5 1 5
M (P . ‘P o r ta g e e A v e .’) = T .‘ P o rt a g e A v e .’

Path-Oriented Queries and Tree Inclusion Problem
- Algorithms for Tree Inclusion Problem
Bottom-up algorithm:
• Kilpelainen-Mannila’s Algorithm (Pekka Kilpelainen and Heikki
Mannila, Ordered and unordered tree inclusion, SIAM Journal of
Computing, 24:340-356, 1995.)
O(|T| |P|) time
O(|T| |P|) space
• Chen’s Algorithm (W. Chen, More efficient algorithm for ordered
tree inclusion, Journal of Algorithms, 26:370-385, 1998.)
O(T|leaves(P)|) time
O(|leaves(P)|min{height(P), |leaves(T)|}) space

Path-Oriented Queries and Tree Inclusion Problem
- Algorithms for Tree Inclusion Problem
Top-down algorithms:• Y. Chen and Y.B. Chen, An Efficient Top-down Algorithm for Tree
Inclusion, in Proc. of 18th Intl. Conf. Symposium on High Performance
Computing System and Application, Winnipeg, Canada: IEEE,
May 2004, pp. 183-187.)
O(|T| |leaves(P)|) time, need no extra space
• Y. Chen and Y.B. Chen, On the Top-down Tree Inclusion Algorithm,
submitted to Information Processing Letters.)
O(T|height(P)|) time, need no extra space
• Advantages of top-down over bottom-up:
- better computational complexities
- checking trees page-wise (suitable for the cases of large data volume)
- integrating signatures into tree inclusion to cut useless subtree checkings
as early as possible

Evaluation of Path-Oriented Queries
- Top-down Algorithm
Target tree: T = <t; T1, ..., Tk>, where t = root(T) and each Ti (i = 1, …, k)
is the subtrees of t;
Pattern forest: G = <P1, ..., Pq>, where each Pj (j = 1, …, q) is a subtree.
• Main idea:
The algorithm attempts to find the number of subtrees j () within an
ordered forest G = <P1, ..., Pq> (q ), which are embedded in a target
tree T. If j = q, we say that G is embedded in T. If j < q, then only the trees
P1, ..., and Pj are embedded in T. Let p1, ..., pq and t be the roots of P1, ..., Pq
and T, respectively. Since a forest does not have a root, we use a virtual
node pv to serve as a substitute for root(G). Thus, root(G) will return pv if
G = <P1, ..., Pq> with q , and will return p1 if q = 1.

Evaluation of Path-Oriented Queries
- Top-down Algorithm
Case 1: root(G) pv (i.e., G = <P> is a tree and root(G) = p), and
label(p) label(t). If G is embedded in T, then there must exist a subtree Ti of
t such that it contains the whole G. The algorithm should return 1 if an
embedding can be found and 0 if it cannot.
Ti
label(root(T)) label(root(G))
Tree G is included in Ti.
T: G:

Evaluation of Path-Oriented Queries
- Top-down Algorithm
Case 2: root(G) pv (i.e., G = <P> and root(G) = p), and label(p) label(t).
Let <P1, ..., Pl> (l ) be the forest of subtrees of p and <T1, ..., Tk> the forest
of subtrees of t. If G is embedded in T, there must exist two sequences of
integers: k1, ..., kg and l1, ..., lg (g l) such that includes < , ..., >
(i = 1, ..., g, l0 = 0, lg = l), where < , ..., > represents a forest containing
subtrees , ..., and . Thus, if lg = l, the algorithm should return 1 since we
have a root preserving inclusion of G in T. Otherwise, it should return 0.
TkiPli 1 1 Pli
Pli 1 1 Pli
Pli 1 1 Pli
T: t p
T1
… … … … … …
label(root(T)) = label(root(G))
includeinclude
Tk1Tk g Tk P1
Pl1 Plg 1 1= Pl
Plg
G:

Evaluation of Path-Oriented Queries
- Top-down Algorithm
Case 2: root(G) = pv and there exists an integer j (0 j q) such that
<P1, ..., Pj> is included in T. If j = q, then the whole G is embedded in T.
There are two possibilities to be considered when looking for j. The first
possibility is similar to Case 2, where there are two sequences of integers:
k1, ..., kg and l1, ..., lg (g q) that represent the order, in which the subtrees
of root(G) are embedded in the subtrees of root(T). In thiscase, j = lg.
If j = 0, we will check the second possibility to see whether there exists a
root preserving inclusion of P1 in T, i.e., label(p1) = label(t) and the subtrees
of p1 are included in the subtrees of t. In this case, j = 1.

Evaluation of Path-Oriented Queries
- Top-down Algorithm
T:t
qv (virtual node)
T1
… … … … … …include
include
Tk1Tk g Tk P1
Pl1 Plg 1 1= Pl
Plg
G:
possibility 1:
T:t
qv (virtual node)
T1
… … … … … …
include
Tk1Tk g Tk P1
Pl1 Plg 1 1= Pl
Plg
G:possibility 2:
label(root(T)) = label(root(P1))

Evaluation of Path-Oriented Queries
- Top-down Algorithm
function top-down-process(T, G)
input: T = <t; T1, ..., Tk>, G = <p; P1, ..., Pq>(*p may or may not be a virtual node.*)output: if root(G) is virtual, returns j 0;else returns 1 if T includes G; otherwise returns 0.begin1. if root(G) is virtual then2. if (|T | < |P1| + |P2| or p has only one child)3. then G := P1; 4. else {j := bottom-up-process(T, G);5. if (j = 0 and label(t) = label(P1’s root))
(*second possibility in Case 3*)6. then {change P1’s root to a virtual node;
x := bottom-up-process(T, P1);7. if (x = the number of the children of P1’s root)
then j := 1 else j := 0;} 8. return j;}}9. if |T| |G | return 0;10.else {if (label(t) = label(p)) (*handling Case 2*)11. then {p := virtual node;
12. j := bottom-up-process(T, G);13. if (j = l) then return 1 else 0;}
else {if t is a leaf then return 0;14. (*handling Case 1*)15. i := 1;16. while (i k) do17. {if top-down-process(Ti, G) > 0 then return 1;18. i := i + 1;}19. return 0;} }end
function bottom-up-process(T, G)
input: T = <t; T1, ..., Tk>, G = <p; P1, ..., Pq>
output: j - an integer
begin
1. j := 0; i := 1;
2. while (j < q and i k) do
3. { x := top-down-process(Ti, G);
4. j := j + x; G := <p; Pj+1, ..., Pq>; i := i + 1; }
end

Integration of Signatures into Top-down Inclusion
Definition A signature for a key word or an attribute value is
hash-coded bit string.
- Example: (constructing a signature for a word with m = 4 and F = 12)
“database”
letter triplets: dat, ata, tab, aba, bas, ase
H(dat) = 5, H(ata) = 1, H(tab) = 8, H(aba) = 1, H(bas) = 10,
H(ase) = 8.
D. Dervos, Y. Manolopulos and P. Linardis, “Comparison of signature
File models with superimposed coding,” J. of Information Processing
Letters 65 (1998) 101 - 106.

Integration of Signatures into Top-down Inclusion
Definition A signature for a key word or an attribute value is
hash-coded bit string.
- Important parameters:
m: number of 1s in bit string
F: length of bit string
D: size of a block (or average number of the key words of an element)
optimal choice of the parameters:
F ln2 =mD
S. Christodoulakis and C. Faloutsos, “Design consideration for a message
file server,” IEEE Trans. Software Engineering, 10(2) (1984) 201-210.

Integration of Signatures into Top-down Inclusion
- Assigning signatures to tree nodes
Let v be a node in a tree T. If v is a leaf node, its signature svis equal
to the signature assigned to its label. Otherwise, sv= s v1 ... vn, where
s represents the signature for the label associated with v, and s1, ... ,
and sn are the signatures of v’s children: v1, ..., vn, respectively.t0
t1 t2
t11 t12 t21 t22
T: a
b e
f e c d
a:b:c:d:e:f:
010100110001001010101100
000010000101100010000000
t0
t1 t2
t11 t12 t21 t22
T: a
be
f e c d1010 1000 1100 0000 0001 0101 0010 1000
1111 1000 1111 1101
1111 1101

Integration of Signatures into Top-down Inclusion
- Cutting off useless subtree checks by examining signatures
We assign each node v in T a bit string sv (called a signature), and each node
u in P a bit string su in such a way that if su matches sv then the subtree Tv
rooted at v may includes the subtree Pu rooted at u. Otherwise, Tv definitely
does not contain Pu. By “matching”, we mean that for each bit set to 1 in su,
the corresponding bit in sv is also set to 1 while for a bit set to 0 in su, the
corresponding bit in sv can be 0 or 1. In the following, we discuss this
technique in great detail.
t0
t1
t11 t12
T:a
b
f e
1010 1000 1100 0000
1111 1000 t2
t21 t22
e
c d
0001 0101 0010 1000
1111 1101
1111 1101
p0
p1 p2
a
c d
0001 0101 0010 1000
0011 1101
P:This subtree willnot be explored.
virtualnode

Integration of Signatures into Top-down Inclusion
- Determine the length of signatures
Consider s = s1 / s2, where s1 and s2 are of length F and with m1
and m2 bits set to 1, respectively.
How to determine the length of S?
l - the number of 1s in s
= l - m’, where m’ = max(m1, m2).
length(s) = F + c, where c is a constant and should be tuned for different
applications.
The value of can be estimated as follows.
- random variable representing the number of positions, in which both
s1 and s2 have 1s.

Integration of Signatures into Top-down Inclusion
- Determine the length of signatures
E = p( = 1) + 2 p( = 2) + ... + m’’ p( = m’’) (2)
m’’ = min(m1, m2) and p( = i) represents the probability that is equal to i.
p( = i) = (3)
= l - m = m1 + m2 - - max(m1, m2).
21
2
1
1
m
F
m
F
im
mF
im
iF

Evaluation of Path-Oriented Queries
- Procedure for calculating signature length
1) Identify the key words in a document, which can be done by using
Connexor-analyzer (http://www.connexor.com/demos/index.html.)
2) Determine the length of the signatures for the nodes of a document tree,
which can be done in two steps:
- First, use formula (1) to determine the initial length of the signatures
according to the number of the chosen key words and their distribution
- Secondly, use formula (2) and (3) to determine the length of the
signatures for each document according to the initial length set for
signatures.
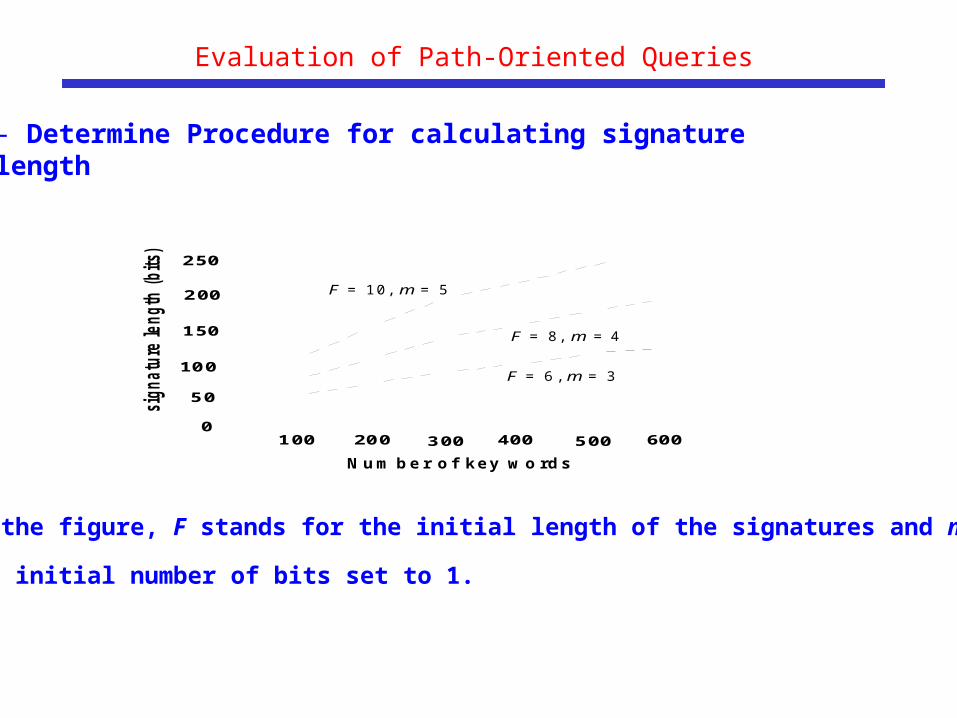
Evaluation of Path-Oriented Queries
- Determine Procedure for calculating signature length
0
100
50
150
200
250
Num be r of key w o rds
sign
atur
e le
ngth
(bits
)
100 200 300 400 500 600
F = 6 , m = 3
F = 8, m = 4
F = 10, m = 5
In the figure, F stands for the initial length of the signatures and m for
the initial number of bits set to 1.

Experiment Results
- Test Platform
Computer - DELL desktop PC equipped with Pentium III 864Ghz processor,
512MB RAM and 20GB hard disk.
Database system - Oracle-9i Enterprise Edition, The default buffer cache of
Oracle-9i is of size 4MB.
Language - Oracle PL/SQL language.
Data - all the 37 Shakespeare’s plays in a database
Size
1 2 M B
8 M B
re la ti o n N a m e
< 6 4 K B
< 6 4 K B
E le m e n t
Te x t
A tt r ib u te
S ig n a tu r e

Experiment Results
- Storage of XML documents in databases
All the documents are stored in three tables.
The relation Element has the following structure:{DocID: <integer>, ID: <integer>, Ename: <string>,firstChildID: <integer>, siblingID: <integer>, attributeID: <integer>}
docID ID Ename firstChildID siblinID attribute
1 1 Hotel-room-reservation 2 * 1
1 2 Name% 1 3 *
1 3 Location 4 11 *
1 4 City-or-district% 2 5 *
1 5 State% 3 6 *
1 6 Country% 4 7 *
1 7 Address 8 * *
1 8 Number% 5 9 *1 9 Street% 6 10 *
1 10 Post-code% 7 * *
1 11 Type 12 14 *
1 12 Rooms% 8 13 *
1 13 Price% 9 * *
1 14 Reservation-time 15 * *
1 15 From% 10 15 *
1 16 To% 11 * *

Experiment Results
- Storage of XML documents in databases
The relation Text is of a simpler structure:
{DocID: <integer>, textID: <integer>, value: <string>},
where “textID” is for the identifiers of texts as the values of the corresponding elements
in the original document. One should notice that a text takes always an element as the
parent node. See the following table for illustration.docID textID value
1 1 Travel-lodge
1 2 Winnipeg
1 3 Manitoba
1 4 Canada
1 5 500
1 6 Portage Ave.
1 7 R3B 2E9
1 8 One-bed-room1 9 $119.00
1 10 April 20, 2005
1 11 April 28, 2005

Experiment Results
- Storage of XML documents in databases
The relation Attribute has five data fields:
{DocID: <integer>, att-ID: <integer>, parentID: <integer>, att-name: <string>,
att-value: <string>}.
docID Att-ID parentID Att-name Att-value
1 1 1 Filecode 1302

Experiment Results
- Tested queries
Group I - for testing path length impact
Group II - for testing node degree impact
Query Path Expression
Q1 /play//’magnificence’
Q2 /play/act//’magnificence’
Q3 /play/act/scene//’magnificence’
Q4 /play /act/scene/speech//’magnificence’
Q5 /play/act/scene/speech/line/’magnificence’
Query Path Expression
Q6 /play//line/’magnificence’
Q7 /play/act//’magnificence’ /play//line/’churchyard’
Q8 /play/act//’magnificence’ /play//line/’churchyard’ /play//line/’reverence’
Q9/play/act//’magnificence’ /play//line/’churchyard’ /play//line/’reverence’ /play//line/’frequent’
Q10/play/act//’magnificence’ /play//line/’churchyard’ /play//line/’reverence’ /play//line/’frequent’ /play//line/’heirless’

Experiment Results
- Tested queries
Group III - for testing impact of matching at higher level
Group IV - for testing impact of matching at middle level
Query Path Expression
Q11 /play//line/’magnificence’ /play//line/’perpetuity’
Q12 /play//line/’churchyard’ /play//line/’ladyship’
Q13 /play//line/’reverence’ /play//line/’continent’
Q14 /play//line/’frequent’ /play//line/’linen’
Q15 /play//line/’heirless’ /play//line/’delivery’
Query Path Expression
Q16 /scene//line/’magnificence’ /scene//line/’utterance’
Q17 /scene//line/’churchyard’ /scene//line/’barbarism’
Q18 /scene//line/’reverence’ /scene//line/’carriage’
Q19 /scene//line/’frequent’ /scene//line/’imagination’
Q20 /scene//line/’heirless’ /scene//line/’successor’

Experiment Results
- Tested queries
Group V- for testing impact of matching at lower level
Query Path Expression
Q21 /speech//line/’magnificence’ /speech//line/’unintelligence’
Q22 /speech//line/’churchyard’ /speech//line/’crickets’
Q23 /speech//line/’reverence’ /speech//line/’ceremonious’
Q24 /speech//line/’frequent’ /speech//line/’exercise’
Q25 /speech//line/’heirless’ /speech//line/’companion’

Experiment Results
- Tested methods
- Inversion on Elements and Words (IEW)
(C. Zhang, J. Naughton, D. DeWitt, Q. Luo and G. Lohman, “On Supporting
Containment Queries in Relational Database Management Systems, in Proc. of ACM
SIGMOD Intl. Conf. On Management of Data, California, USA, 2001.)
- Inversion on Paths and Words (IPW)
(C. Seo, S. Lee, and H. Kim, An Efficient Index Technique for XML Documents
Using RDBMS, Information and Software Technology 45(2003) 11-22, Elsevier
Science B.V.)
- Tree Inclusion Algorithm (TIA)
- Tree Inclusion with Signatures (TIS)

Experiment Results
- Tested methods
Inversion on Elements and Words (IEW)
- (Dno, Wposition, level) for a text word
- (Dno, Eposition, level) for an element
(1, <1, 45>, 0) ...(1, <2, 4>, 1) ...(1, <5, 28>, 2) ...... ...
hotel-room-reservationnamelocation... ......
E-index:
(1, 3, 2) ...(1, 7, 3) ...(1, 10, 3) ...... ...
Travel-lodgeWinnipegManitoba... ......
T-index:
Example:

Experiment Results
- Tested methods
To evaluate the query: /hotel-room-reservation/location/address [street = Portage Ave.],
four joins are performed:
self-joins on E-index relation to connect ‘hotel-room-reservation’ and ‘location’,
‘location’ and ‘address’,
‘address’ and ‘street’,
the join between E-index and T-index relations to connect ‘street’ and ‘Portage Ave.’

Experiment Results
- Tested methods
Inversion on Paths and Words (IPW)
- Path(path, pathID),
- PathIndex(pathID, docno, begin, end)
- Word(word, wordID)
- WordIndex(wordID, docno, pathID, position)

Experiment Results
- Tested methods
In order to process the same query:
/hotel-room-reservation/location/address [street = Portage Ave.],
two joins are needed.
- First join between Path and WordIndex relations with the following join condition:
Path.path = ‘hotel-room-reservation/location/address/street’ and
Path.pathID = WordIndex.pathID.
- The second join between the result R of the first join and the Word relation with the
join condition:
R.wordID = Word.wordID and Word.word = ‘Portage Ave.’.

Experiment Results
- Tested results
1
2
Q1 Q2 Q3 Q4 Q5
Exe
cuti
on ti
me
(sec
.)
Results of Group I
+
*
IPWTISTIAIEW
•• ** ++
100
1000
Q6 Q7 Q8 Q9 Q10
Exe
cuti
on ti
me
(sec
.)
Results of Group II
+
*
IPWTISTIA
* *+ +• •
6
12
Q1 Q2 Q3 Q4 Q5
Exe
cuti
on ti
me
(sec
.)
Results of Group III
+
*
IPWTISTIA
* *
++
•• •
+
6
12
Q1 Q2 Q3 Q4 Q5
Exe
cuti
on ti
me
(sec
.)
Results of Group IV
+
*
IPWTISTIA
* *
++
•• •
+
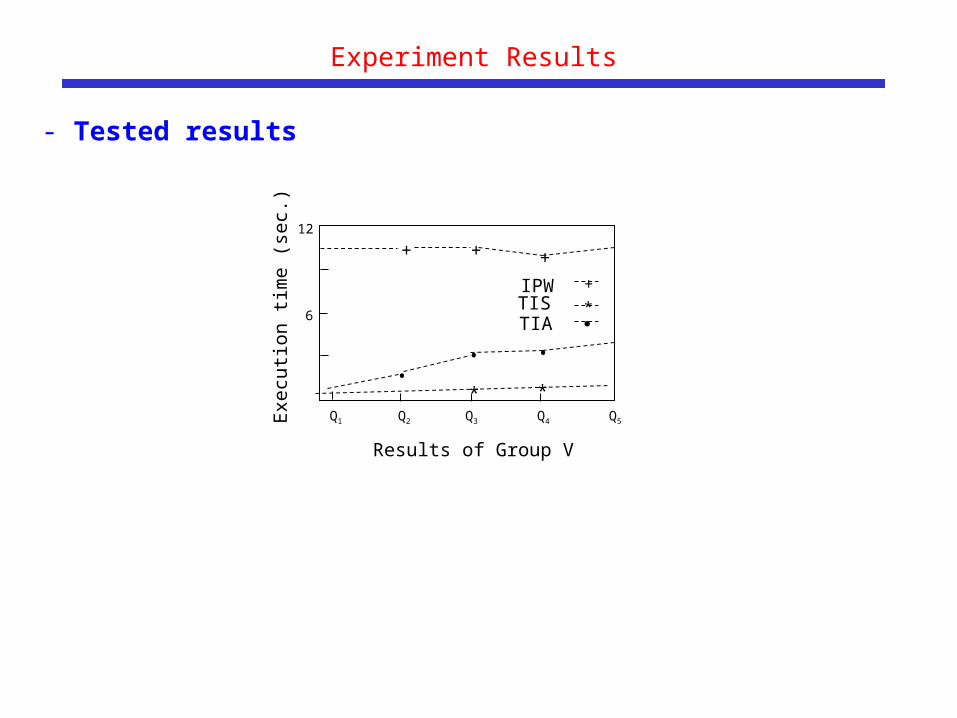
Experiment Results
- Tested results
6
12
Q1 Q2 Q3 Q4 Q5
Exe
cuti
on ti
me
(sec
.)
Results of Group V
+
*
IPWTISTIA
* *
++
••
•
+

Summary and Future Work
• Path-oriented queries in document databases
• Evaluation of path-oriented queries
- top-down algorithm for tree inclusion problemsignatures
- Integration of signatures into top-down tree inclusion
Future work:
document recognition using
tree inclusion
probabilistic analysis
Benford low
Zipf low


















