
Transferring information using Bayesian priors on object categories Li Fei-Fei 1, Rob Fergus 2,...
38
S. Savarese, 2003
-
date post
20-Dec-2015 -
Category
Documents
-
view
223 -
download
0
Transcript of Transferring information using Bayesian priors on object categories Li Fei-Fei 1, Rob Fergus 2,...

S. Savarese, 2003

P. Buegel, 1562

Constellation model of Constellation model of object categoriesobject categories
Fischler & Elschlager 1973 Yuille ‘91Brunelli & Poggio ’93 Lades, v.d. Malsburg et al. ‘93Cootes, Lanitis, Taylor et al. ’95 Amit & Geman ‘95, ’99Perona et al. ‘95, ‘96, ’98, ’00, ’03 Many more recent works…

X (location)
(x,y) coords. of region center
A (appearance)
Projection ontoPCA basis
c1
c2
c10
…..
normalize
11x11 patch

X (location)
(x,y) coords. of region center
A (appearance)
Projection ontoPCA basis
c1
c2
c10
…..
normalize
11x11 patchX A
h
XX
I
AA
The Generative Model

Hypothesis (h) node
X A
h
XX
I
AA
h is a mapping from interest regions to parts
3
5
91
2
46
7 10
8
e.g. hi = [3, 5, 9]

X A
h
XX
I
AA
h is a mapping from interest regions to parts
3
5
91
2
46
7 10
8
e.g. hj = [2, 4, 8]
The hypothesis (h) node

(x1,y1)
(x2,y2)
(x3,y3)X A
h
XX
I
AA
The spatial node

Spatial parameters node
X A
h
I
AA
Joint Gaussian
Joint density over all parts
XX

The appearance node
PCA coefficients on fixed basis
Pt 1. (c1, c2, c3,…)
Pt 2. (c1, c2, c3,…)
Pt 3. (c1, c2, c3,…)
X A
h
I
AAXX

X A
h
I
Appearance parameter node
Gaussian
Independence assumed between the P parts
P
Fixed PCA basis
XX AA

X A
h
I
P
Maximum Likelihood interpretation
observed variables
hidden variable
parametersXX AA
Also have background model – constant for given image

X A
h
I
PXX AA
a0X
B0X
m0X
β0X
a0A
B0A
m0A
β0A
MAP solutionChoose conjugate form:
Normal – Wishart distributions:
P(, ) = p(|)p() = N(|m, β ) W(|a,B)
observed variables
hidden variable
parameters
Introduce priors over parameters
priors

X A
h
I
PXX AA
a0X
B0X
m0X
β0X
a0A
B0A
m0A
β0A
Variational Bayesian model
observed variables
hidden variable
parameters
Estimate posterior distribution on parameters – approximate with Normal – Wishart-- has parameters: {mX, βX, aX, BX, m A, βA, aA, BA}
priors

ML/MAP LearningML/MAP Learning
n
1
2
where = {µX, X, µA, A}
ML/MAP
Weber et al. ’98 ’00, Fergus et al. ’03
X A
h
I
PAAXX
Performed by EM

Bayesian
Variational LearningVariational Learning
n
1
2
Parameters to estimate: {mX, βX, aX, BX, mA, βA, aA, BA}i.e. parameters of Normal-Wishart distributionFei-Fei et al. ’03, ‘04
X A
h
I
PXX AA
a0X
B0X
m0X
β0X
a0A
B0A
m0A
β0A
Performed by Variational Bayesian EM

E-Step
Random initializationVariational EMVariational EM
prior knowledge of p()
new estimate of p(|train)
M-Step
new ’s
(Attias, Hinton, Beal, etc.)

No labeling No segmentation
No alignment
Weakly supervised learningWeakly supervised learning

ExperimentsExperimentsTraining:
1- 6 images
(randomly drawn)
Detection test:
Datasets: foreground and background
The Caltech-101 Object Categories
www.vision.caltech.edu/feifeili/Datasets.htm
50 fg/ 50 bg images
object present/absent




The prior
• Captures commonality between different classes
• Crucial when training from few images
• Constructed by:– Learning lots of ML models from other classes– Each model is a point in θ space– Fit Norm-Wishart distribution to these points using moment
matching i.e. estimate {m0X, β0
X, a0X, B0
X, m0A, β0
A, a0A, B0
A}

What priors tell us? – 1. meansAppearanc
e
likely unlikely
Shape

What priors tell us? – 2. variability
Renoir
Picasso, 1951
Picasso, 1936
Miro, 1949
Warhol, 1967
Magritte, 1928
Arcimboldo, 1590
Da Vinci, 1507
likely
un
likely
Appearance Shape
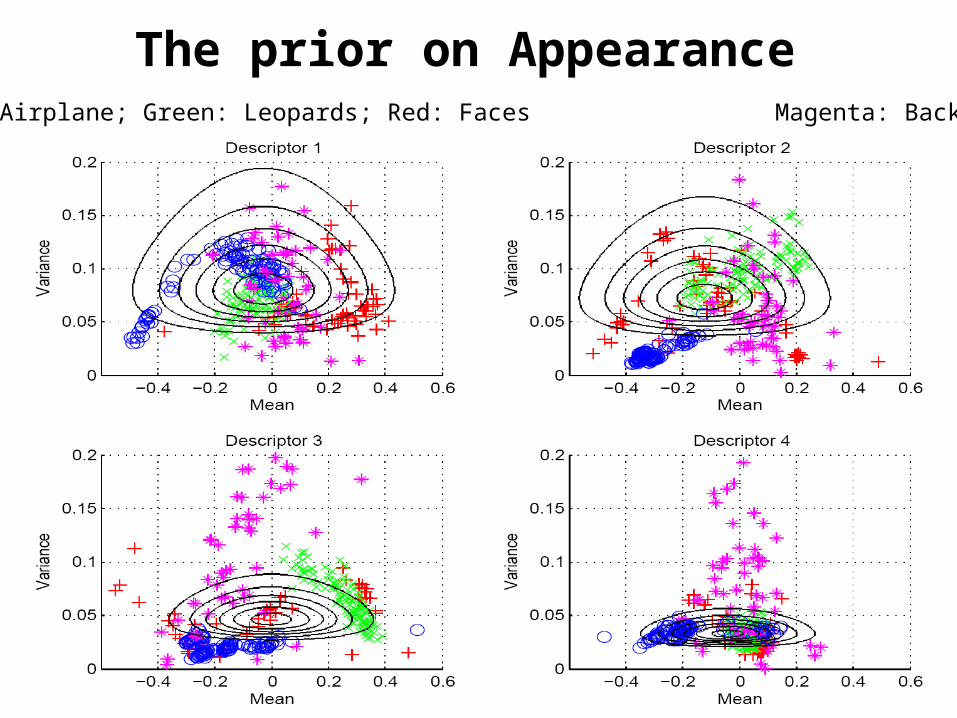
The prior on AppearanceBlue: Airplane; Green: Leopards; Red: Faces Magenta: Background

The prior on Shape
X-coord Y-coord
Blue: Airplane; Green: Leopards; Red: Faces Magenta: Background

Motorbikes• 6 training images• Classification task (Object present/absent)

Grand piano

Cougar faces

Number of classes in prior

How good is the prior alone?

Performance over all 101 classes

Conclusions
• Hierarchical Bayesian parts and structure model
• Learning and recognition of new classes assisted by transferring information from unrelated object classes
• Variational Bayes superior to MAP


Visualization of learning

Sensitivity to quality of feature detector

Discriminative evaluation
Mean on diagonal:18%
More recent workby Holub, Welling & Perona40%Using gen./disc hybrid










![Learning Active Basis Modelsby EM-Type Algorithmssczhu/papers/Stat_Science_AB.pdfof the learning process. The EM algorithm has been used by Fergus, Perona and Zisserman [9] in training](https://static.fdocuments.net/doc/165x107/60648f8b3d49352ad828c55a/learning-active-basis-modelsby-em-type-sczhupapersstatscienceabpdf-of-the-learning.jpg)

![arXiv:1505.03873v1 [cs.CV] 14 May 2015Kevin Tang 1, Manohar Paluri2, Li Fei-Fei , Rob Fergus 2, Lubomir Bourdev 1Computer Science Department, Stanford University 2Facebook AI Research](https://static.fdocuments.net/doc/165x107/5f3d33e6f435b52f5b21629b/arxiv150503873v1-cscv-14-may-2015-kevin-tang-1-manohar-paluri2-li-fei-fei.jpg)





