
Transfer in Reinforcement Learning via Markov Logic Networks Lisa Torrey, Jude Shavlik, Sriraam...
21
Transfer in Reinforcement Learning via Markov Logic Networks Lisa Torrey, Jude Shavlik, Sriraam Natarajan, Pavan Kuppili, Trevor Walker University of Wisconsin-Madison, USA
-
Upload
jasmine-mccoy -
Category
Documents
-
view
215 -
download
0
Transcript of Transfer in Reinforcement Learning via Markov Logic Networks Lisa Torrey, Jude Shavlik, Sriraam...

Transfer in Reinforcement Learning via Markov Logic
NetworksLisa Torrey, Jude Shavlik,
Sriraam Natarajan, Pavan Kuppili, Trevor WalkerUniversity of Wisconsin-Madison, USA
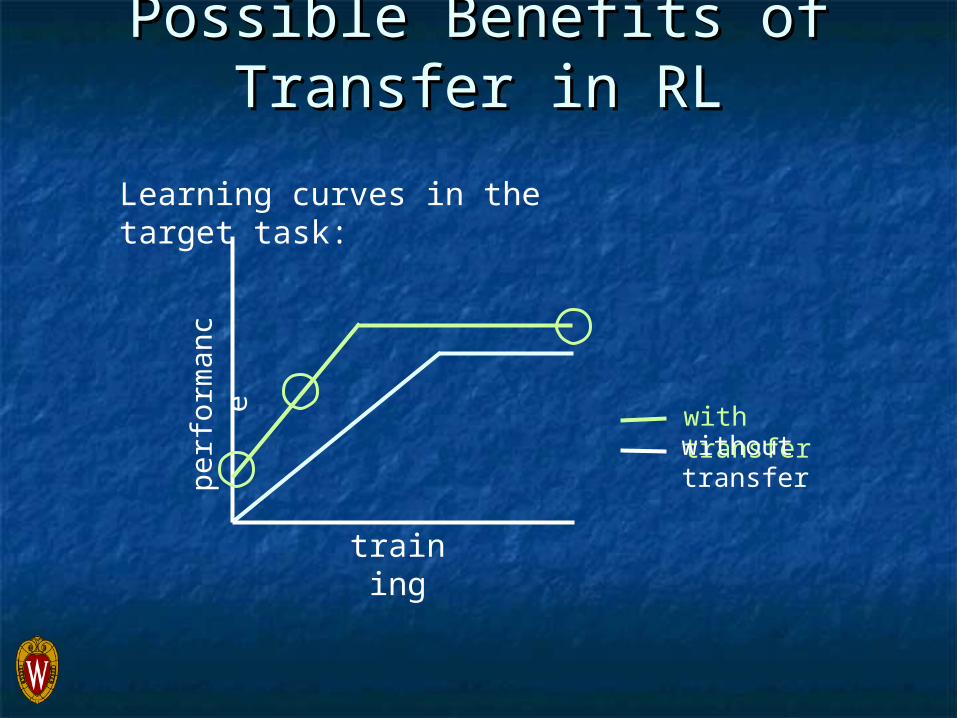
Possible Benefits of Transfer in Possible Benefits of Transfer in RLRL
Learning curves in the target task:
perf
orm
ance
training
with transferwithout transfer

The RoboCup DomainThe RoboCup Domain
2-on-1 BreakAway
3-on-2 BreakAway

Reinforcement LearningReinforcement Learning
Environment
Agent
action rewardstate
distance(me,teammate1) = 15distance(me,opponent1) = 5angle(opponent1, me, teammate1) = 30…
States are described by features:
MovePassShoot
Actions are:
+1 for scoring 0 otherwise
Rewards are:

Our Previous MethodsOur Previous Methods
Skill transferSkill transfer Learn a rule for when to take each Learn a rule for when to take each
actionaction Use rules as adviceUse rules as advice
Macro transferMacro transfer Learn a relational multi-step action planLearn a relational multi-step action plan Use macro to demonstrateUse macro to demonstrate

Transfer via Markov Logic Transfer via Markov Logic NetworksNetworks
MLNQ-function
Analyze
Target-tasklearner
MLNQ-function
Demonstrate
Source-tasklearner
Learn Source-taskQ-functionand data

Markov Logic NetworksMarkov Logic Networks A Markov network models a joint distributionA Markov network models a joint distribution
A Markov Logic Network combines probability with A Markov Logic Network combines probability with logic logic Template: a set of first-order formulas with weightsTemplate: a set of first-order formulas with weights Each grounded predicate in a formula becomes a nodeEach grounded predicate in a formula becomes a node Predicates in grounded formula are connected by arcsPredicates in grounded formula are connected by arcs
Probability of a world: (1/Z) exp( Probability of a world: (1/Z) exp( ΣΣ W WiiNNi i ))
Richardson and Domingos, ML 2006
X Y Z
A B

MLN Q-functionMLN Q-function
IF distance(me, Teammate) < 15
AND angle(me, goalie, Teammate) > 45
THEN Q є (0.8, 1.0)
IF distance(me, GoalPart) < 10
AND angle(me, goalie, GoalPart) > 45
THEN Q є (0.8, 1.0)
Formula 1
W1 = 0.75
N1 = 1 teammate
Formula 2
W1 = 1.33
N1 = 3 goal parts
Probability that Q є (0.8, 1.0): __exp(W1N1 + W1N1)__
1 + exp(W1N1 + W1N1)

Grounded Markov NetworkGrounded Markov Network
Q є (0.8, 1.0)
distance(me, teammate1) < 15
angle(me, goalie, teammate1) > 45
distance(me, goalRight) < 10
angle(me, goalie, goalRight) > 45
distance(me, goalLeft) < 10
angle(me, goalie, goalLeft) > 45

Learning an MLNLearning an MLN Find good Q-value bins using Find good Q-value bins using
hierarchical clusteringhierarchical clustering
Learn rules that classify examples into Learn rules that classify examples into bins using inductive logic programmingbins using inductive logic programming
Learn weights for these formulas to Learn weights for these formulas to produce the final MLNproduce the final MLN

Binning via Hierarchical Binning via Hierarchical ClusteringClustering
Fre
quen
cy
Q-value
Fre
quen
cy
Q-value
Fre
quen
cy
Q-value

Classifying Into Bins via ILPClassifying Into Bins via ILP
Given examplesGiven examples Positive: inside this Q-value binPositive: inside this Q-value bin Negative: outside this Q-value binNegative: outside this Q-value bin
The Aleph* ILP learning system finds The Aleph* ILP learning system finds rules that separate positive from rules that separate positive from negativenegative Builds rules one predicate at a timeBuilds rules one predicate at a time Top-down search through the feature spaceTop-down search through the feature space
* Srinivasan, 2001

Learning Formula WeightsLearning Formula Weights
Given formulas and examplesGiven formulas and examples Same examples as for ILPSame examples as for ILP ILP rules as network structureILP rules as network structure
Alchemy* finds weights that make the Alchemy* finds weights that make the probability estimates accurateprobability estimates accurate Scaled conjugate-gradient algorithmScaled conjugate-gradient algorithm
* Kok, Singla, Richardson, Domingos, Sumner, Poon and Lowd, 2004-2007

Using an MLN Q-functionUsing an MLN Q-function
Q є (0.8, 1.0) P1 = 0.75
Q є (0.5, 0.8) P2 = 0.15
Q є (0, 0.5) P2 = 0.10
Q = P1 ● E [Q | bin1]
+ P2 ● E [Q | bin2]
+ P3 ● E [Q | bin3]
Q-value of most similar
training example in bin

Example SimilarityExample Similarity
1
-1
1
1
1
-1
E [Q | bin] = Q-value of most similar training example in bin
Similarity = dot product of example vectors
Example vector shows which bin rules the example satisfies Rule 1
Rule 2
Rule 3
…

ExperimentsExperiments
Source task: 2-on-1 BreakAwaySource task: 2-on-1 BreakAway 3000 existing games from the learning 3000 existing games from the learning
curvecurve Learn MLNs from 5 separate runsLearn MLNs from 5 separate runs
Target task: 3-on-2 BreakAwayTarget task: 3-on-2 BreakAway Demonstration period of 100 gamesDemonstration period of 100 games Continue training up to 3000 gamesContinue training up to 3000 games Perform 5 target runs for each source runPerform 5 target runs for each source run

DiscoveriesDiscoveries
Results can vary widely with the source-Results can vary widely with the source-task chunk from which we transfertask chunk from which we transfer
Most methods use the “final” Q-function Most methods use the “final” Q-function from the last chunkfrom the last chunk
MLN transfer performs better from MLN transfer performs better from chunks halfway through the learning chunks halfway through the learning curvecurve

Results in 3-on-2 BreakAwayResults in 3-on-2 BreakAway
0
0.1
0.2
0.3
0.4
0.5
0.6
0 500 1000 1500 2000 2500 3000Training Games
Pro
bab
ilit
y o
f G
oal
MLN Transfer
Macro Transfer
Value-function Transfer
Standard RL

ConclusionsConclusions
MLN transfer can significantly improve MLN transfer can significantly improve initial target-task performanceinitial target-task performance
Like macro transfer, it is an aggressive Like macro transfer, it is an aggressive approach for tasks with similar strategiesapproach for tasks with similar strategies
It “lifts” transferred information to first-It “lifts” transferred information to first-order logic, making it more general for order logic, making it more general for transfertransfer
Theory refinement in the target task may Theory refinement in the target task may be viable through MLN revisionbe viable through MLN revision

Potential Future WorkPotential Future Work
Model screening for transfer learningModel screening for transfer learning
Theory refinement in the target taskTheory refinement in the target task
Fully relational RL in RoboCup using Fully relational RL in RoboCup using MLNs as Q-function approximatorsMLNs as Q-function approximators

AcknowledgementsAcknowledgements
DARPA Grant HR0011-07-C-0060DARPA Grant HR0011-07-C-0060
DARPA Grant FA 8650-06-C-7606DARPA Grant FA 8650-06-C-7606
Thank You















![· Web viewnakakalapusani, matumanculakayani sahityakartta Carata Natarajan. -- Cennai : Carata Natarajan, 2005. [14], 44 p. : ill. Acc. no. 2260 Carata Natarajan. Sri Civamrutam kirttanam](https://static.fdocuments.net/doc/165x107/5aaedc3e7f8b9a3a038ca992/viewnakakalapusani-matumanculakayani-sahityakartta-carata-natarajan-cennai.jpg)


