Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS...
25
First International Workshop on Business Intelligence for the Real Time Enterprise September 11, 2006 Seoul, Korea Transaction Reordering and Grouping for Continuous Data Loading Gang Luo 1 Jeffrey F. Naughton 2 Curt J. Ellmann 2 Michael W. Watzke 3 IBM T.J. Watson Research Center 1 University of Wisconsin-Madison 2 NCR 3 [email protected] [email protected] [email protected] [email protected]
Transcript of Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS...
![Page 1: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/1.jpg)
First International Workshop on Business Intelligence for the Real Time Enterprise
September 11, 2006 Seoul, Korea
Transaction Reordering and Grouping for Continuous Data Loading
Gang Luo1 Jeffrey F. Naughton2
Curt J. Ellmann2 Michael W. Watzke3
IBM T.J. Watson Research Center1
University of Wisconsin-Madison2 NCR3
[email protected] [email protected]@wisc.edu [email protected]
![Page 2: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/2.jpg)
2
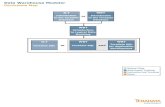
Continuous Data Loading
• For operational data warehousing, it is critical that the data in the warehouse be as up-to-date as possible
• Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading
operational data warehouse
client
operational data store
operational data store
![Page 3: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/3.jpg)
3
Immediate Materialized View Maintenance
• Necessity:
– Inconsistency between materialized views and base relations may not be acceptable to all applications (e.g., real-time decision making)
– Mandated in the TPC-R benchmark
• Problem: Concurrent updates to multiple base relations of the same materialized join view cause deadlocks
– Reason: Materialized join view maintenance changes update-only transactions to update-read transactions
• Solution: Reorder the updates
![Page 4: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/4.jpg)
4
Outline
• Existing Continuous Load Utilities
• Problem with Immediate Materialized Join View Maintenance
• Solution with Reordering
• Performance
![Page 5: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/5.jpg)
5
Continuous Data Loading Architecture
• Data comes in the form of modification operations (insert, delete, update)
• Load data in the form of transactions through sessions
RDBMS
continuous load utility
data source
data source
data source
![Page 6: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/6.jpg)
6
Assumptions
• The system has no control over the order in which modification operations arrive at the RDBMS
• The continuous load utility looks to the RDBMS like a series of transactions, each containing a single modification operation
• No order imposed or assumed for the load transactions
– The load process can arbitrarily reorder the single-modification-operation transactions
• No requirement on whether multiple modification operations can or cannot commit/abort together
– The load process can arbitrarily group the single-modification-operation transactions
![Page 7: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/7.jpg)
7
Assumptions - Continued
• Use strict two-phase locking protocol
• Use multiple-granularity locking protocol
– Two levels in the locking hierarchy: table-level locks and tuple-level locks
• Each modification operation can be done with tuple-level locks
![Page 8: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/8.jpg)
8
Common Wisdom• Grouping to improve efficiency
– Combine multiple modification operations into a single transaction
• Partitioning to avoid deadlock
– Partition tuples among different sessions
– Modification operations on the same tuple are always through the same session
O1: Update tuple t1
O2: Update tuple t2
Transaction T1
O3: Update tuple t2
O4: Update tuple t1
Transaction T2
![Page 9: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/9.jpg)
9
Outline
• Existing Continuous Load Utilities
• Problem with Immediate Materialized Join View Maintenance
• Solution with Reordering
• Performance
![Page 10: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/10.jpg)
10
Join View
• A join view JV on two relations A and B pre-computes a selection and projection (and aggregation) of A B
create join view JV asselect *from A, Bwhere A.c=B.d;
![Page 11: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/11.jpg)
11
Impact of Immediate Join View Maintenance
• Two transactions
– T1: Modify tuple t1 in A whose c=v
– T2: Modify tuple t2 in B whose d=v
L11: X lock for tuple t1
in A
L12: S lock for all tuples in B whose d=v
Transaction T1
L21: X lock for tuple t2
in B
L22: S lock for all tuples in A whose c=v
Transaction T2
![Page 12: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/12.jpg)
12
Deadlock Probability
• k>1 concurrent transactions
• Each transaction T contains n modification operations
– T modifies A with probability p
– T modifies B with probability 1-p
– Each modification operation modifies a random tuple in A (B)
• Totally s distinct values for A.c (B.d)
• Deadlock probability: min(1, p(1-p)(k-1)n2/(2s))
![Page 13: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/13.jpg)
13
Outline
• Existing Continuous Load Utilities
• Problem with Immediate Materialized Join View Maintenance
• Solution with Reordering
• Performance
![Page 14: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/14.jpg)
14
Intuition for Transaction Reordering
• Only run “compatible” transactions concurrently
– Reorder transactions so that transactions updating A are executed, then transactions updating B are executed
![Page 15: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/15.jpg)
15
Rules for Transaction Reordering
• Rule 1: At any time, for any join view JV, only allow data to be loaded into one base relation of JV
• Rule 2: For those modification operations on the same base relation, use the partitioning method
• Rule 3: Use a high concurrency locking protocol (e.g., the V locking protocol) on join views
![Page 16: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/16.jpg)
16
Justification
• Rules 1 and 2 avoid deadlocks resulting from lock conflicts on the base relations
• Rule 3 avoids deadlocks resulting from lock conflicts on the join views
![Page 17: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/17.jpg)
17
Data Structures for Transaction Reordering
• For each base relation Ri, maintain a number Ji
– Ji records the number of running transactions that modify Ri
• For each session Sm, maintain a queue Qm
– Qm records the transactions waiting to be run through Sm
![Page 18: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/18.jpg)
18
Transaction Reordering Algorithm Outline
• Analyze potential lock conflicts using the data structures
– Transaction starts execution: Increment Ji
– Transaction finishes execution: Decrement Ji
• Desirable transaction updating Ri: Does not conflict with any running transaction
– Check whether or not Jj = 0 for each base relation Rj of the same join view as Ri
![Page 19: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/19.jpg)
19
Outline
• Existing Continuous Load Utilities
• Problem with Immediate Materialized Join View Maintenance
• Solution with Reordering
• Performance
![Page 20: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/20.jpg)
20
Performance
• Testing environment
– Commercial parallel RDBMS
– Windows 2000 OS
– Intel workstation, each data server node has one 400MHz CPU, 250M memory, one 8GB disk
• System configuration in the parallel RDBMS
– Allocate a processor and a disk for each data server
– Test system configuration has four data server nodes
![Page 21: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/21.jpg)
21
Performance - Continued
• Definition of base relations and join view:
• Modification operations:
– O1: Update one tuple in the inventory relation with a specific partkey value and today’s date
– O2: Insert one tuple into the demand relation with a specific partkey value and today’s date
demand (partkey, date, quantity, custkey, comment)inventory (partkey, date, quantity, extended_cost, extended_price)
create join view onhand_demand asselect d.partkey, d.date, d.quantity, d.custkey, i.quantityfrom demand d, inventory iwhere d.partkey=i.partkey and d.date=i.datepartitioned on d.custkey;
![Page 22: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/22.jpg)
22
Performance - Continued
• Compare the naive method vs. the transaction reordering method
– Run a stream of T1’s and T2’s (50% are T1’s, 50% are T2’s)
– Only combine modification operations on the same base relation into a single transaction
– Each transaction contains the same number n of modification operations
– 10,000 active parts
– k sessions
– Measure throughput of modification operations
![Page 23: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/23.jpg)
23
Performance - Deadlock Probability
• Deadlock probability of the naive method increases with both n and k
0%
20%
40%
60%
80%
100%
1 10 100 1000n
dead
lock
pro
babi
lity
k=2k=4k=8k=16
![Page 24: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/24.jpg)
24
0%
100%
200%
300%
400%
500%
1 10 100 1000n
thro
ughp
ut ra
tio k=2k=4k=8k=16
Performance - Throughput Improvement
• Improvement of throughput gained by transaction reordering increases with both n and k
![Page 25: Transaction Reordering and Grouping for Continuous Data ... [Read-Only].pdf · • Commercial RDBMS vendors (Oracle, Teradata, etc.) provide tools for continuous data loading operational](https://reader030.fdocuments.net/reader030/viewer/2022022520/5b1ea7257f8b9a116d8bd337/html5/page/25.jpg)
25
Questions?