
TRADEOFFS & MITIGATING SPRAWL WITH MICROSERVICES
16
Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent. TRADEOFFS & MITIGATING SPRAWL WITH MICROSERVICES Susan Fowler, Uber Velocity NYC 2016
Transcript of TRADEOFFS & MITIGATING SPRAWL WITH MICROSERVICES

Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent.
TRADEOFFS & MITIGATING SPRAWL WITH MICROSERVICESSusan Fowler, Uber
Velocity NYC 2016

Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent.
A little bit about myself...
Site Reliability Engineer @ Uber, standardizing Uber microservices
Author of Production-Ready Microservices and Microservices in Production
@susanthesquark
Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent.
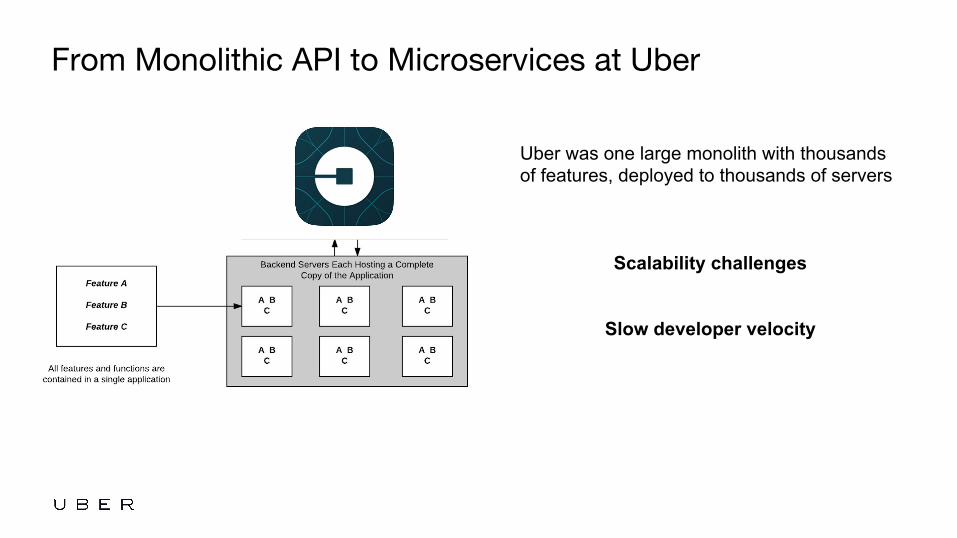
From Monolithic API to Microservices at Uber
Uber was one large monolith with thousands of features, deployed to thousands of servers
Scalability challenges
Slow developer velocity
Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent.
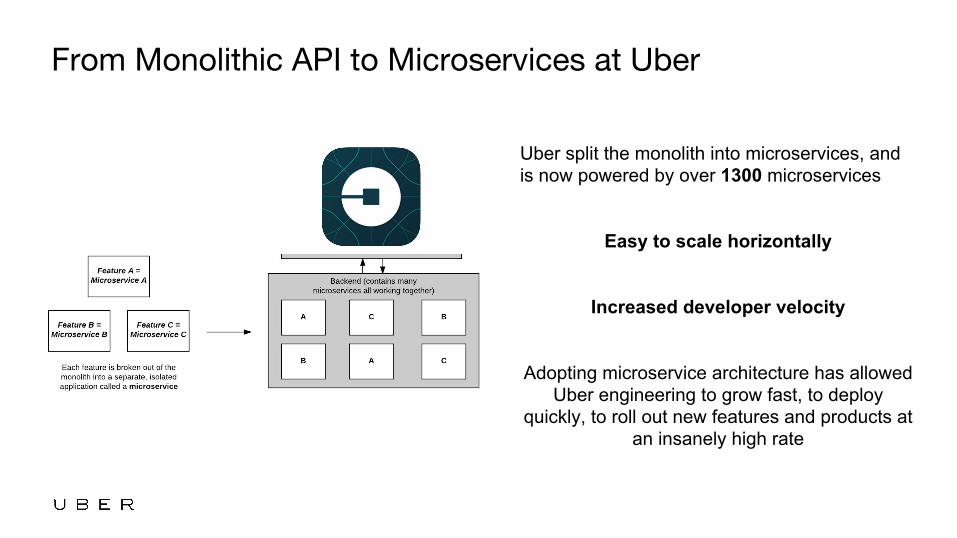
From Monolithic API to Microservices at Uber
Uber split the monolith into microservices, and is now powered by over 1300 microservices
Easy to scale horizontally
Increased developer velocity
Adopting microservice architecture has allowed Uber engineering to grow fast, to deploy
quickly, to roll out new features and products at an insanely high rate

Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent.
Why We Are Here
No Silver Bullet
“There is no single development, in either technology or management technique, which by itself promises even one order-of-magnitude improvement
within a decade in productivity, in reliability, in simplicity” - Brooks, The Mythical Man-Month
When presented with a something that seems like a silver bullet, look for the tradeoffs

Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent.
Why We Are Here
SPRAWL
Organizational structure is determined by the architecture of your product
(Conway’s Law)
1300+ microservices = ~1300 teams
Leads to siloing, poor cross-team communication, poor alignment of goals

Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent.
Why We Are Here
TRADEOFFS
The Velocity Budget
You have to pay for developer velocity!
• Imperfect Design• Poor communication• Technical Debt• More Ways to Fail• Outages and Incidents

Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent.
Mitigation StrategiesHow the Uber SRE Org Mitigates Microservice Tradeoffs and Sprawl
Step One: Standardization
Mitigate tradeoffs and sprawl through production-readiness standardization.
Step Two: Process Management
Mitigate tradeoffs and sprawl through production-readiness reviews.
Step Three: Evangelizing, Teaching, and Sticking To It
Mitigate tradeoffs and sprawl through organizational alignment and proper outage
and incident response procedures.

Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent.
StandardizationMitigate tradeoffs and sprawl with production-readiness standardization.
KEY PRINCIPLES
stabilityreliabilityscalability
performancefault-tolerance
catastrophe-preparednessmonitoring
documentation
Each standard is accompanied by quantifiable requirements that produce
measureable results

Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent.
StandardizationMitigate tradeoffs and sprawl with production-readiness standardization.
Example: Monitoring
• All key metrics are identified and monitored• Microservice has appropriate logging• Dashboards are easy to interpret and track all key metrics• All alerts are actionable and defined by signal-providing
thresholds• There is a dedicated on-call rotation responsible for
monitoring the microservice and resolving incidents and outages
• There is a standardized on-call procedure in place for handling incidents and outages
MO
NIT
OR
ING

Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent.
StandardizationMitigate tradeoffs and sprawl with production-readiness standardization.
Another Example: Fault-Tolerance
• No single point of failure (SPOF)• All failure scenarios and possible catastrophes have been
identified, planned for, mitigated, and (if possible) architected away
• Planned and scheduled load testing through Hailstorm• Planned and scheduled chaos testing through uDestroy
FAU
LT-T
OLE
RA
NC
E

Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent.
Process ManagementMitigate tradeoffs and sprawl with production-readiness reviews
What we do:
• SREs hold quarterly production-readiness
reviews (PRRs) with development teams of
services they support.
• Services are compared to
production-readiness standards and
corresponding requirements: is this service
stable? Is it fault-tolerant? Does it have a
SPOF? Does it roll out new deployments
incrementally? Is it Dockerized?
Production-Readiness Reviews
Why We Do It:
• Leads to developer, team, and
organizational understanding of each
microservice
• Cuts down on tech debt
• Keeps architecture and infrastructure
current
• Catches potential failures
• Updated architecture diagram of service
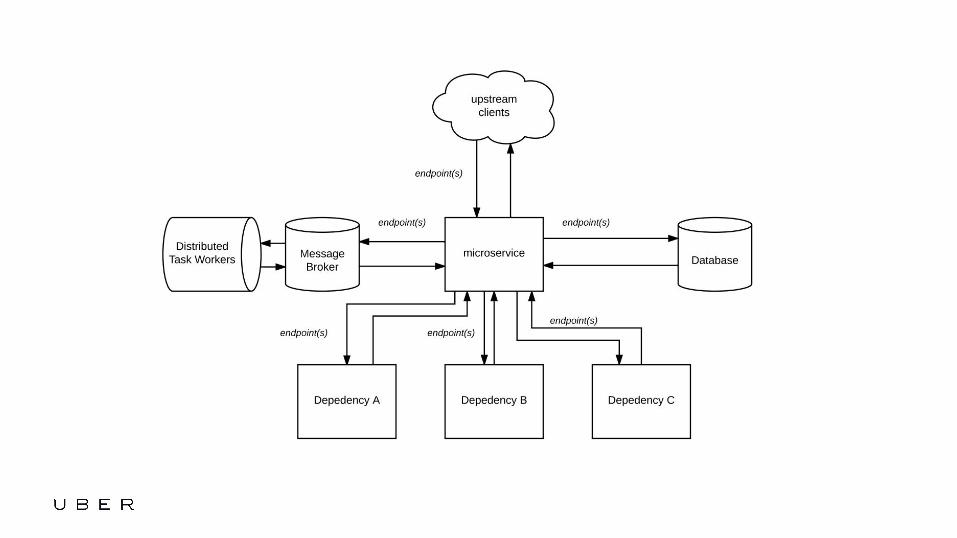
Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent.

Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent.
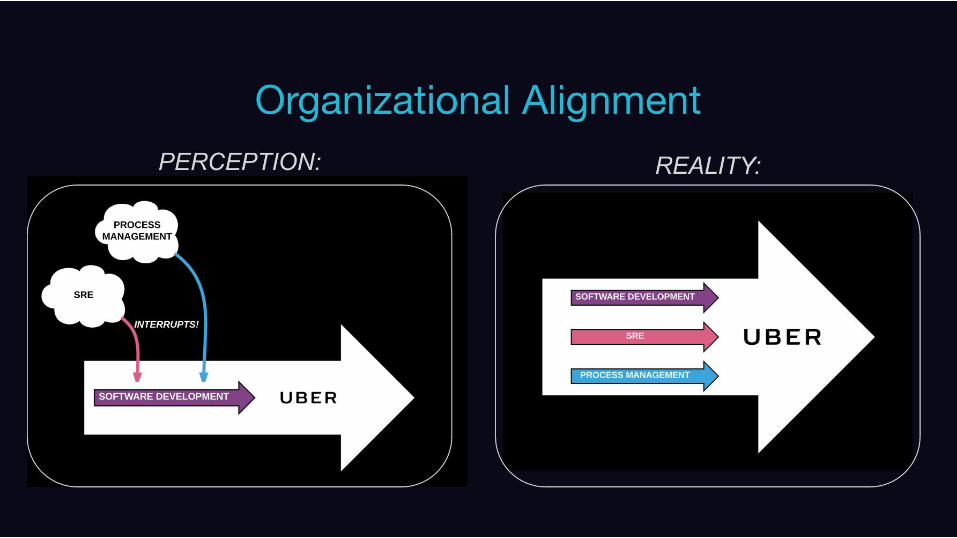
Evangelism, Teaching, and Sticking to ItMitigate tradeoffs and sprawl through organizational alignment and proper outage and incident response procedures.
What we do:
• Hold blameless outage review meetings
• Assign action items from each outage
• Detailed postmortems for each outage with
root cause analysis, timeline of events,
what we can learn from the outage, and
how the outage could have been
prevented
Outage and Incident Response Procedures
Why We Do It:
• Good engineering is about learning from
our mistakes and sharing them with others
so that they avoid making the same
mistakes in the future
• Slice through technical debt for all
microservices and every layer of the stack
• Smart handling of outages and incidents =
more reliable system
Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent.

Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent.
Questions?
@susanthesquark


















