
Towards A Dual Process Approach to Computational Explanation in Human-Robot Social Interaction
21
Towards A Dual Process Approach to Computational Explanation in Human-Robot Social Interaction Agnese Augello, Ignazio Infantino, Antonio Lieto, Umberto Maniscalco, Giovanni Pilato, Filippo Vella ICAR-CNR, National Research Council, Palermo, Italy Dipartimento di Informatica, University of Turin, Italy IJCAI 2017 Workshop on Cognition and Artificial Intelligence for Human-Centred Design, 19 Aug. 2017, Melbourne, Australia
-
Upload
antonio-lieto -
Category
Technology
-
view
257 -
download
0
Transcript of Towards A Dual Process Approach to Computational Explanation in Human-Robot Social Interaction

Towards A Dual Process Approach to Computational Explanation in Human-Robot Social Interaction
Agnese Augello, Ignazio Infantino, Antonio Lieto, Umberto Maniscalco, Giovanni Pilato, Filippo Vella
ICAR-CNR, National Research Council, Palermo, ItalyDipartimento di Informatica, University of Turin, Italy
IJCAI 2017 Workshop on Cognition and Artificial Intelligence for Human-Centred Design, 19 Aug. 2017, Melbourne, Australia

Topics/Outline
- Explanatory Capabilities of AI Systems
- Current Problems
- Proposal based on a dual process-approach to computational explanation
2

“Explanatory Needs” are not New in AI
3
CyberneticsComputational Cognitive Science
From Human to Artificial Cognition (and back)

Explainable AI - Nowadays
- The current request for Explainable AI (XAI) is something different with respect to the previous notion of “explanation”
- AI is looking for systems able to provide a transparent account of the reasons determining their behaviour (both in cases of a successful or unsuccessful output)
4

Explainable AI - Nowadays
- The current request for Explainable AI (XAI) is something different with respect to the previous notion of “explanation”.
- AI is looking for systems able to provide a transparent account of the reasons determining their behaviour (both in cases of a successful or unsuccessful output)
Problem: The adoption of current Machine Learning and Deep Learning techniques faces the classical problem of opacity in artificial neural networks (this classical problem explodes in Deep Nets)
5

6
Clarification: “Opacity” does not mean, in principle, “impossible to Explain”
Inputs can be either removed or modified until the output changesin a way that is important to the user. This is a trial and error process, time consuming…very complicated in practice.
E.g. Model based neural networks (mid’80): their connections are parametrised to satisfy specific constraints implied by a putative causal model (e.g. approximated).
There are also recent attempts to provide an interpretation of deep nets (e.g. Zhou et al. 2015) but the general problem remains largely unsolved.
Opacity and Explanation

7
Since the adoption of deep ANNs is important for improving the performance of artificial systems but is problematic for solving the explanatory problem we demanded the latter task to a second component:
- inspiration from the dual process theory of reasoning (Stanovitch and West, 2001; Evans and Frankish 2009; Kahnemann 2011).
- the two software components perform different types of reasoning.
Our Proposal

Dual Process Reasoning
11
(Stanovitch and West, 2000; Kahnemann 2011).
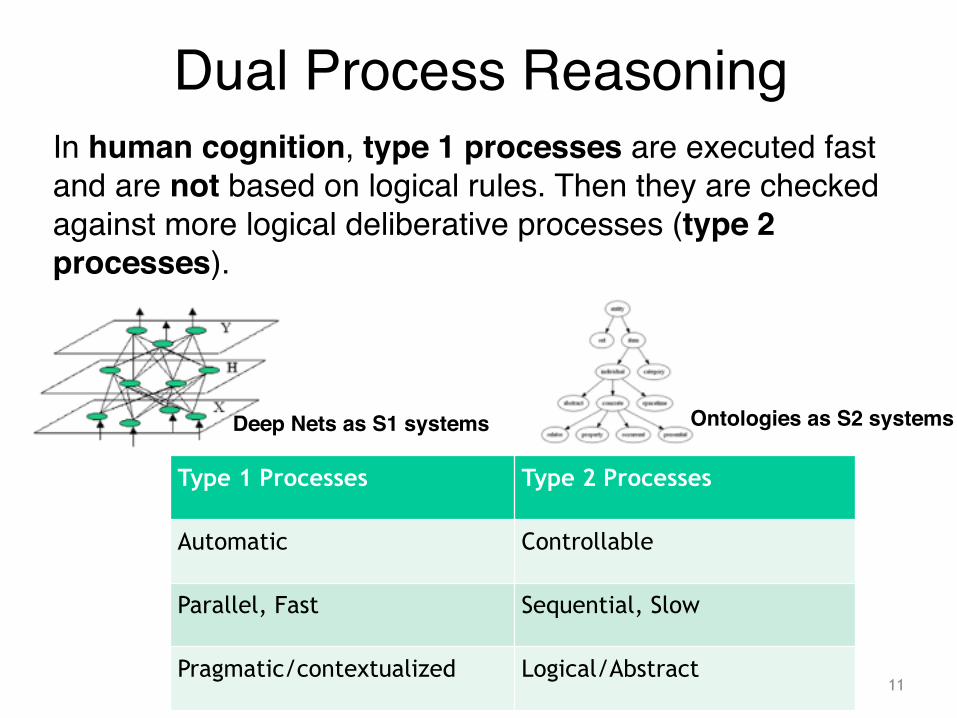
In human cognition, type 1 processes are executed fast and are not based on logical rules. Then they are checked against more logical deliberative processes (type 2 processes).
… …
Type 1 Processes Type 2 Processes
Automatic Controllable
Parallel, Fast Sequential, Slow
Pragmatic/contextualized Logical/Abstract
Dual Process Reasoning
11
In human cognition, type 1 processes are executed fast and are not based on logical rules. Then they are checked against more logical deliberative processes (type 2 processes).
Type 1 Processes Type 2 Processes
Automatic Controllable
Parallel, Fast Sequential, Slow
Pragmatic/contextualized Logical/Abstract
Deep Nets as S1 systems Ontologies as S2 systems

The Scenario
• Robotic Reception in a public office welcoming visitors in the waiting room and directing them to proper office rooms
• The robot must be able to discriminate the not appropriate behaviors of the visitors and act accordingly.

The Scenario
• The robot learns how to detect not appropriate and in particular aggressive behaviors, by examining the postures and the gestures of people during a training phase.
• During the interaction, considering its expectations and its experience, he must be able to quickly recognize the exhibited social signs (S1 component).
• If required, the robot must be able to provide an explanatory account of some sort of this process of interpretation (S2 Component).
The S1 System
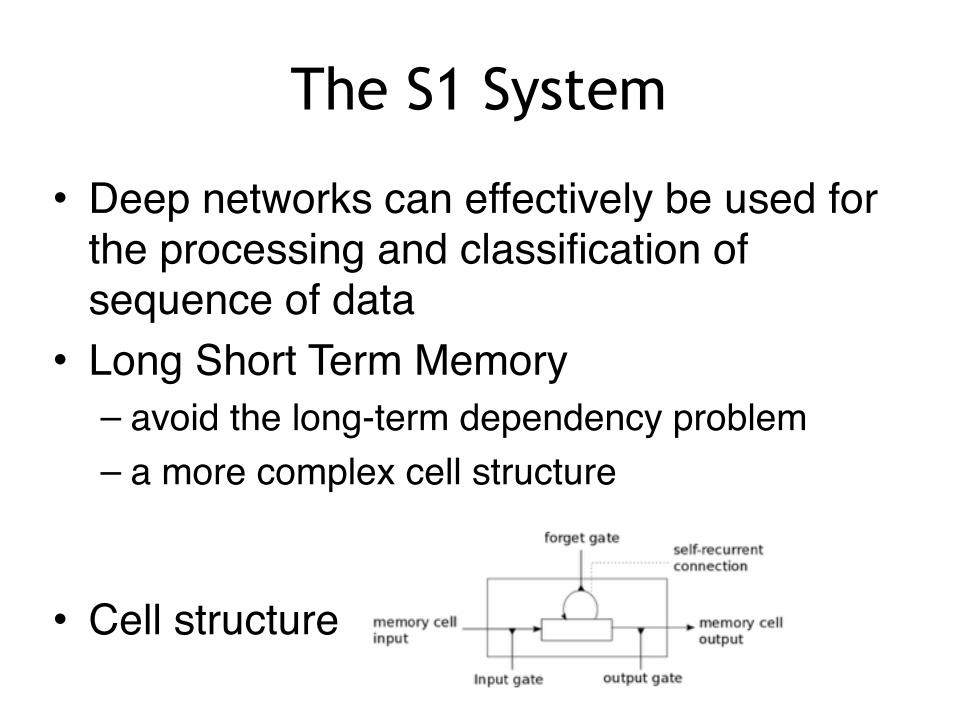
• Deep networks can effectively be used for the processing and classification of sequence of data
• Long Short Term Memory – avoid the long-term dependency problem – a more complex cell structure
• Cell structure
The Proposed Network Architecture

The S1 System
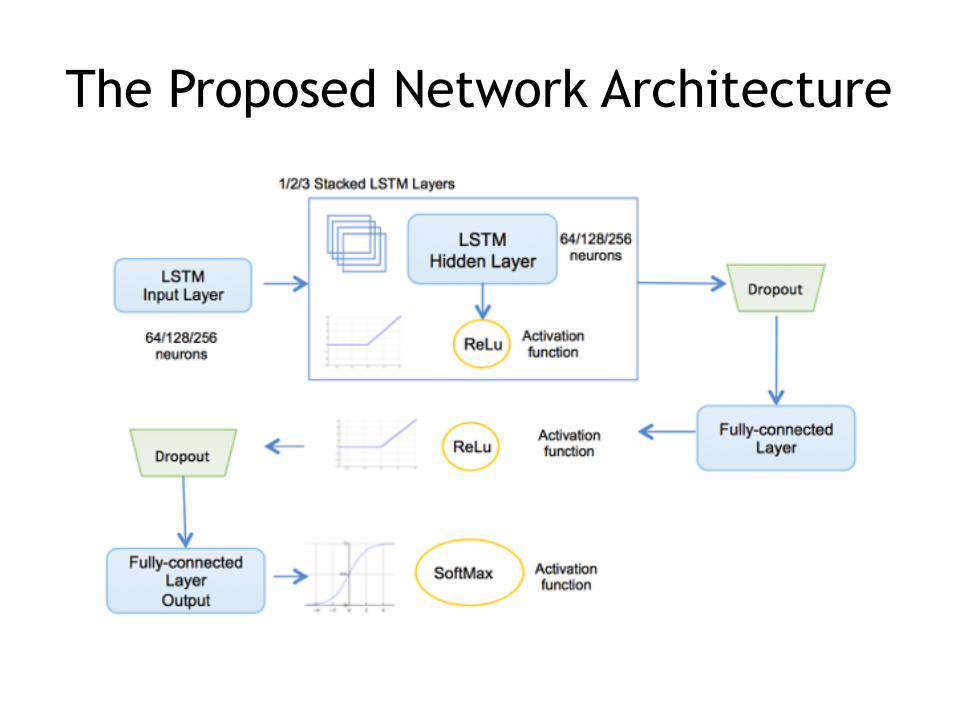
• We have chosen to gradually stack LSTM layers and measure the trend of the F1-score to determine what the correct number of layers can be.
• Each LSTM layer is separated from the next one by a Rectified Linear Unit function.
• Given a sequence length, we attempted to determine how many neurons are needed for the representation to be of good quality.

The S1 System
• Number of neurons in the LSTM layers – set to 64, 128 or 256;
• Considered stacked LSTM levels– one, two or three
• sliding window – from 2 to 20
• The training has been performed for 10 epochs.

The S1 System
• A dataset of 20 different actions has been used used to train the network (subset of the Vicon Physical Action dataset)
• The actions of the dataset have been divided in – “normal” behavior
(Bowing, Clapping and Handshaking) – “not friendly” behavior
(Punching, Slapping and Frontkicking)

The S2 System
• The main perceptual differences between different classes of gestures (e.g. aggressive vs not aggressive ones) are represented through an explicit ontological model (available at: http://www.di.unito.it/~lieto/ExpActOnto.html)
17

The S2 System
• Example of ontological features considered to distinguish among these two classes of gestures are: velocity of the gesture execution, distance of the final gesture position from the body etc.
• In other words: we tried to provide an explanatory account of the output of the opaque S1 component by using an apriori ontological model of a given situation
• The S2 component allows also to model the differences between gestures. These models can be used to describe why a particular sign, e.g. categorized as ’aggressive’, has been additionally recognized, for example, as a “Punching” Action.

Ex. Provided Explanation for the Detected “Punching” Action
“Punching Action” is characterized by the fact of being an action executedat a certain velocity (X), categorized as ’High Velocity’, and at a certain distance (Y) from the Body, categorized as ’Close Distance’ according to the ontology.
In addition to these traits, common to all the “Aggressive Actions”, the“Punching” action is also characterized by the fact of being executed with “Close Hands”. 19

Ex. Provided Explanation: “why” punching and not slapping
The S2 additional model-based explanation about why the previous ’Punching’ cannot be classified, for example, as a ’Slapping’ (both are ’Aggressive Actions’).
Also in this case the fact that the detected body part executing the gesture is a ’Close Hand’ and not a ’Open Hand’ (as in the case of ’Slapping’) represent a crucial element for explaining that categorization decision. 20

Upshot and Future Work
We sketched a preliminary account of a dual process based framework able to provide a partial explanation of the reasons driving a robotic system to some decisions in task of gesture recognition is a social scenario. As a future work we plan to evaluate in detail the feasibility of the proposed framework with a Pepper robot interacting in a real environment.
We want to extend the level of detail of the possible explanation provided by such framework by considering more complex scenarios and a multimodal interaction involving both visual and linguistic elements.
Finally, we plan to provide a tighter integration of the two software components that, currently, operate in a relatively independent way.
21


















