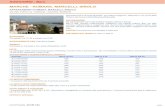
Relationships between PGA PGV and Modified Marcelli Intensity

Tommaso MarcelliIntroduction to Data ScienceJune 25, 2021

About meI currently work in Kotuko as Chief Technology Officer. In recent years, I have been working as full-stack developer on several web and mobile projects.
Before that, I spent around 10 years doing academic research and teaching in experimental and computational organic chemistry..
Tommaso MarcelliDeveloper and chemist

AboutThis lecture aims at giving an overview of the exciting field of Data Science, highlighting some of the key concepts and providing information and relevant resources.
In the first part, we will focus on the definition of Data Science and on the underlying concepts, with as little math as possible.
We will then move to notebooks and look at the most common tools which are used to clean, manipulate and visualize data, with a case study.
Finally, we will look at an interactive example, where we will load a real-world dataset and try to work with it, in order to extract meaningful information and visualize relevant data.

Bibliography

What is Data Science?
http://drewconway.com/zia/2013/3/26/the-data-science-venn-diagram

● A form of analytics in which software programs learn about data and find patterns or insights
● Uses a variety of algorithms and analytical models to support different types of data analysis
● Includes a combination of supervised, unsupervised and reinforcement learning mechanisms
Data Science vs ML vs AI
Data Science Machine Learning Artificial Intelligence● Development of computerized
applications that simulate human intelligence and interaction
● Handles specific tasks now; general intelligence and cognitive capabilities are a future goal
● Uses algorithms for machine learning, natural language processing, automation and more
● The process of using advanced analytics to extract relevant information from data
● Involves a wide range of analytics applications that can aid decision-making in organizations
● Incorporates predictive modeling statistical analysis, machine learning and other functions
https://searchbusinessanalytics.techtarget.com/feature/Data-science-vs-machine-learning-vs-AI-How-they-work-together

Data Science Applications
https://www.edureka.co/blog/what-is-data-science/

https://theblog.okcupid.com/the-most-important-questions-on-okcupid-32e80bad0854

https://techcrunch.com/2020/04/27/google-medical-researchers-humbled-when-ai-screening-tool-falls-short-in-real-life-testing

The GIGO principleThe principle of Garbage In, Garbage Out summarizes that computers simply process the data that they are fed.
Garbage is a broad and expanding category in data science: poorly labeled or inaccurate data, data that reflects underlying human prejudices, incomplete data.
This means the quality of the output depends on the quality of the input. With bad data, applications will produce results that are inaccurate, incomplete or incoherent.
https://towardsdatascience.com/data-quality-garbage-in-garbage-out-df727030c5eb

COVID data overflowSince the beginning of the COVID pandemic, a stunning amount of data has been produced and made available to the general public.
Experts, journalists and data nerds have been trying to make sense of them and try to rationalize the numbers which came from all around the world.
● Is the case-fatality a good metric to compare countries?
● What is the underlying assumption for it to make any sense?
● What about the number of deaths?
https://coronavirus.jhu.edu/data/mortality

COVID data overflow
https://www.ft.com/content/6bd88b7d-3386-4543-b2e9-0d5c6fac846c

JargonData set A collection of data
Model A mathematical representation of a real-world process
Outlier An observation that lies an unusual distance from other values
Bias A systematic difference from the population parameter being considered
Feature An individual independent variable that act as the input in your system
Label The variable which needs to be predicted by a model

The process
https://towardsdatascience.com/5-steps-of-a-data-science-project-lifecycle-26c50372b492

How do you get data?
DatabasesData can be obtained from a variety of databases, such as relational (MySQL, Oracle) and non-relational ones (MongoDB).Most likely, a series of queries need to be executed to return data which can be used in the subsequent steps of a data science project.
APIAPI stands for Application Programming Interface and indicates a way for a service to expose data and functionality. This approach involves a series of requests to a service to obtain the data required before moving to the next step.
ScrapingScraping indicates an automated process where many web pages are downloaded and analyzed in a programmatic manner to extract data. In some cases it is illegal and the scraping algorithm should be very robust to avoid getting incomplete or corrupted data.

Real data are messy

Exploring datasetsOnce a dataset has been cleaned, simple data visualization can be valuable to get a rough idea of trends.
Plotting the distribution of the values for a specific feature (on the main diagonal) can help identify problems with the dataset, such as an unexpected distribution or capping.
Plotting the relation between the values for each couple of features shows the level of correlation between them.
This can be used to obtain insights and to identify redundant features in the dataset.

Data Modeling
https://towardsdatascience.com/polynomial-regression-bbe8b9d97491

Train, test, validate
https://en.wikipedia.org/wiki/Training,_validation,_and_test_sets

Underfitting and Overfitting
https://datascience.foundation/sciencewhitepaper/underfitting-and-overfitting-in-machine-learning

Model interpretationComplex models (such as neural networks) are notoriously difficult to interpret (black box). Model interpretability is necessary to verify that what the model is doing is in line with what is expected and it allows to create trust with the users and ease the transition from manual to automated processes.
Why is it essential to do an in-depth analysis of your models?
● Identify and mitigate bias● Accounting for the context of the problem● Improving generalisation and performance● Ethical and legal reasons
https://towardsdatascience.com/interpretability-in-machine-learning-70c30694a05f

Human BiasMachine learning models are not inherently objective. Engineers train models by feeding them a data set of training examples, and human involvement in the provision and curation of this data can make a model's predictions susceptible to bias.
Common types of human bias
● Reporting Bias● Automation Bias● Selection Bias● Group Attribution Bias● Implicit Bias
https://developers.google.com/machine-learning/crash-course/fairness/types-of-bias

Bias / Variance TradeoffGeneralization of a model is affected by three different types of error:
BiasDue to wrong assumptions. High-bias models underfit the training data
VarianceDue to excessive sensitivity to small variations. High-variance models overfit the training data.
Irreducible errorPart of the error due to data noiseness.
Increasing a model complexity increases variance and reduces bias (and the other way around).
https://en.wikipedia.org/wiki/Bias%E2%80%93variance_tradeoff

Why Python?In recent years, Python quickly became the language of choice for machine learning and for data science in general.
Python is considered to have a soft learning curve and to be quite intuitive to read, which makes it the language of choice for beginners.
Also, when compared to other languages, Python offers a stunning ecosystem of libraries and software which can be used for data science.
Although a basic understanding of the language is fundamental, it might be more wise to focus efforts on the underlying theory and the use of popular libraries.
https://www.python.org/about/gettingstarted/
~]# python3 variable-args.py<class 'tuple'>Output of our function is: 40

MarkDown
https://guides.github.com/features/mastering-markdown/

JupyterJupyter notebooks are the de facto standard for prototyping and sharing data science projects.
Python Jupyter notebooks (.ipynb files) are documents made up by a list of cells, which can contain either MarkDown or Python code.
In Jupyter, the Python code can be executed inline, displaying the results directly under code blocks.
Markdown blocks can be used to integrate the code by adding comments and documentation to the content of the notebook.
Jupyter can be installed and run on a local machine (see docs for your platform)
https://jupyter-notebook.readthedocs.io/en/stable/notebook.html

Google ColabGoogle Colaboratory (mostly abbreviated as Colab) is a free cloud-hosted Jupyter Notebook service, which can be accessed using a Google account.
Google Colab offers storage and the possibility to use small CPUs, GPUs or TPUs to carry out relatively simple analyses directly in the browser.
Colab files are saved in Google Drive and the software is nicely integrated with the storage service, allowing easy inclusion of files in a notebook.
Artifacts can be easily downloaded from Colab.
https://colab.research.google.com/notebooks/basic_features_overview.ipynb

NumPyNumPy is the leading Python scientific library for working with arrays and matrices.
NumPy vectors (one-dimensional arrays) are significantly easier to work with than with Python lists of numbers, their native counterparts.
Machine learning (and data science in general) requires many mathematical operations on vectors: NumPy has optimized implementations for all most common operations and, in general, it performs significantly better than with Python lists.
In addition to that, NumPy provides methods to solve common mathematical problems (for instance solving linear equations).
https://numpy.org/doc/stable/user/quickstart.html

PandasPandas is the most renowned Python library to work with data sets.
It allows loading, manipulating and visualizing information from large data sets, providing useful metrics (for instance the amount of missing values).
Results can be rendered inline to get a quick overview of what a data set looks like (Scrub and Explore steps).
When working with Pandas, the key data structure is the DataFrame, defined as two-dimensional, size-mutable, potentially heterogeneous tabular data.
https://pandas.pydata.org/Pandas_Cheat_Sheet.pdf

MatplotlibMatplotlib is a powerful data-visualization library in Python, which is particularly useful to get a graphical representation of data.
Matplotlib allows a detailed customization of the produced charts using a number of parameters; however, the library has rather standard default, which lets beginner getting results quickly.
Matplotlib handles a stunning amount of different visualizations, from standard charts (scatter plots, pie charts, histograms) up to very complex representations, giving full control on colors, scales, legends and other graphical details
https://matplotlib.org/stable/gallery/index.html

Milano Melting PotBackgroundhttps://github.com/spaghetti-open-data/-milano-melting-pot
Datasethttps://dati.comune.milano.it/dataset/ds27-popolazione-residenti-cittadinanza-quartiere-serie-storica
Interactive Maphttps://musing-haibt-1009e9.netlify.app/
Milan suburbshttps://datawrapper.dwcdn.net/r5VQV/3/

California House PricesDatasethttps://www.kaggle.com/camnugent/california-housing-prices
Training Notebookhttps://colab.research.google.com/drive/1EYjbKopbv5DKJSDmYWIlUbB23mlo1p3C?usp=sharing
Original Notebookhttps://colab.research.google.com/github/ageron/handson-ml2/blob/master/02_end_to_end_machine_learning_project.ipynb

Other Resources
Kaggle Courseshttps://www.kaggle.com/learn
Machine Learning Crash Coursehttps://developers.google.com/machine-learning/crash-course

Thank you for listening!