
The Scalable HeterOgeneous Computing -...
31
Transcript of The Scalable HeterOgeneous Computing -...


The Scalable HeterOgeneous Computing (SHOC) Benchmark SuiteKyle Spafford | Oak Ridge National Laboratory
SHOC Contributors:Anthony Danalis | Collin McCurdy | Gabriel Marin | Jeremy Meredith | Phil Roth | Vinod Tipparaju | Jeffrey Vetter

History & Motivation
3
“An experimental high performance
computing system of innovative design.”
“Outside the mainstream of what is routinely
available from computer vendors.”National Science Foundation, Track2D Call Fall, 2008

QuestionsIn 2008, there was no available benchmark suite for OpenCLNew heterogeneous architectures
Which architecture performs specific operations best?New programming systems
New – rapidly improving – by how much?How efficient is it?How does it compare to existing methods?
Multiple OpenCL stacksCompare different runtimes, compilers, SDKs
Energy efficiency
©2010 Advanced Micro Devices, Inc. All rights reserved. 4

The SHOC Benchmark SuiteWhat ?
An OpenCL benchmark suite focused on distributed (MPI) scientific computing workloads
Where?Download source code at http://ft.ornl.gov/doku/shoc/start“The Scalable Heterogeneous (SHOC) Benchmark Suite.” GPGPU 2010 Workshop. ACM Portal
Why?1) Use SHOC to help you understand hardware performance2) Measure the performance of scientific kernels3) Validate your hardware and set standards for a procurement4) Use SHOC as example code to help you learn OpenCL and get familiar with the toolchain
5

SHOC - OrganizationOrganized into 3 Levels
Level 0 – “Feeds and Speeds”Level 1 – Parallel PrimitivesLevel 2 – Real Application Kernels
3 Modes of ParallelismSerial – Just a single OpenCL deviceEmbarrassingly Parallel – Do a copy of the same small problem on > 1 deviceTrue Parallel – Use multiple devices to work on the same problem (MPI)
6

Performance Tests“Feeds and Speeds”
MaxFLOPS, DeviceMemory (Global, Local, Image), BusSpeed (PCIe)kernelCompile, queueDelay
Parallel PrimitivesFFT, GEMMReduction, Scan, SortSpMVStencil2DTriad
Real ApplicationsS3DMD (from LAMMPS)
7

Use #1: Better Understand Your Hardware
8
NB: Unless otherwise noted, results are shown using OpenCL on AMD APP SDK 2.4 or NV SDK 4.0

Simple Example – Memory BandwidthGPUs attain the best memory bandwidth by coalescing memory accesses
SHOC’s DeviceMemory test quantifies this advantage.
©2010 Advanced Micro Devices, Inc. All rights reserved. 9
Coalesced
WI sequential /Uncoalesced
Work Item 1Work Item 2Work Item 3Work Item 4

10
Results
130
0.98
99.94
60.42
26.9315.02
AMD FirePro v8800 (Cypress)
Intel Xeon 5500 2.7Ghz
NV Tesla C2050 (Fermi)
Global Memory BW (4 byte granularity, GB/s)
Coalesced Strided

Simple Example #2: Measure (and pay attention to) Precision
2540.88
60.44512.85
34.04
AMD FirePro v8800 (Cypress) Intel Xeon 5500 2.7Ghz
MaxFLOPS (GFLOPS)
Single Double
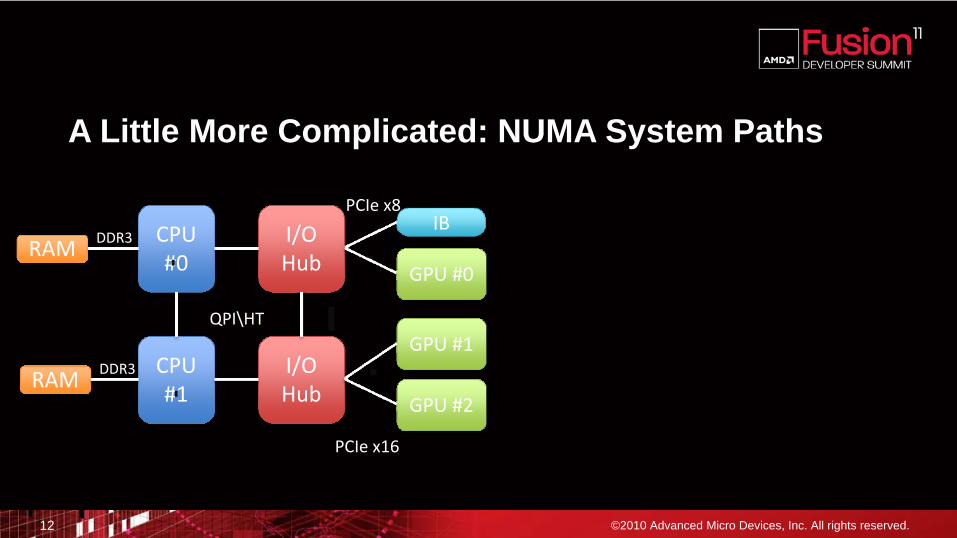
A Little More Complicated: NUMA System Paths
©2010 Advanced Micro Devices, Inc. All rights reserved. 12
DDR3DDR3CPU #0
GPU #1
GPU #2
QPI\HT
IBI/O Hub GPU #0
PCIe x8
PCIe x16
RAM
DDR3DDR3CPU #1
I/O Hub
RAM

A Little More Complicated: NUMA System Paths
©2010 Advanced Micro Devices, Inc. All rights reserved. 13
DDR3DDR3CPU #0
GPU #1
GPU #2
QPI\HT
IBI/O Hub GPU #0
PCIe x8
PCIe x16
RAM
DDR3DDR3CPU #1
I/O Hub
RAM
Bandwidth Penalty CPU #0 H->D Copy

A Little More Complicated: NUMA System Paths
©2010 Advanced Micro Devices, Inc. All rights reserved. 14
DDR3DDR3CPU #0
GPU #1
GPU #2
QPI\HT
IBI/O Hub GPU #0
PCIe x8
PCIe x16
RAM
DDR3DDR3CPU #1
I/O Hub
RAM
Bandwidth Penalty CPU #0 D->H Copy
~2 GB/s
K. Spafford, J. Meredith, J. S. Vetter. Quantifying NUMA and Contention Effects in Multi‐GPU Systems. Proceedings of the Workshops on General Purpose Computation on Graphics Processors (GPGPU ‘11).
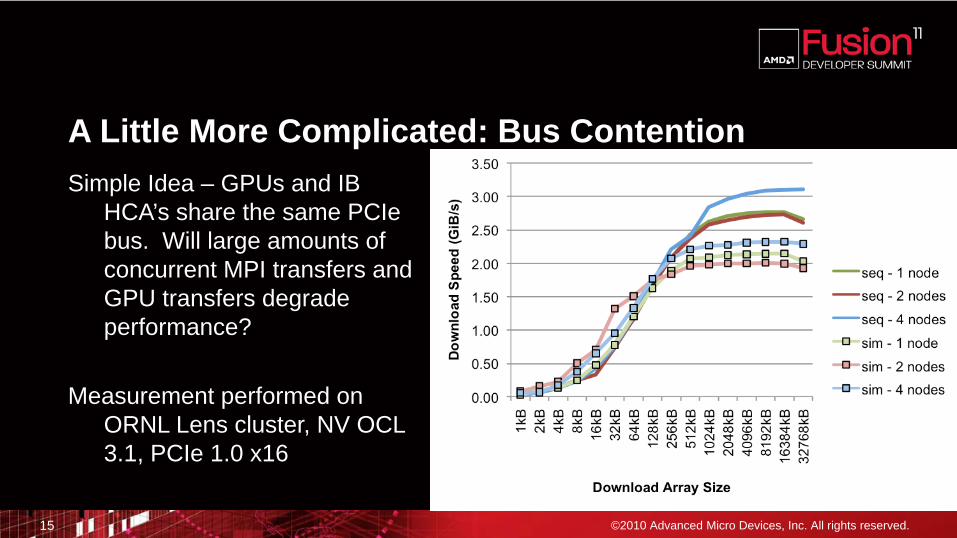
A Little More Complicated: Bus ContentionSimple Idea – GPUs and IB
HCA’s share the same PCIebus. Will large amounts of concurrent MPI transfers and GPU transfers degrade performance?
Measurement performed on ORNL Lens cluster, NV OCL 3.1, PCIe 1.0 x16
©2010 Advanced Micro Devices, Inc. All rights reserved. 15

Use #2: Measure the Performance of Scientific Kernels
16

Example -- Stencil2DMotivation
Supports investigation of acceleratorusage within parallel application contextGood representative of data movement in real apps
Basic design9-point stencil operation applied to 2D data setMPI uses 2D Cartesian data distribution, with periodic halo exchangesApplies stencil to data in local memory
17

Stencil2D Scaling Study on Keeneland
©2010 Advanced Micro Devices, Inc. All rights reserved. 18
Our FAQ page walks you through generating scaling studies like this one.

Example -- S3DMotivation
Used by DoE to model the combustion of biofuelsFLOP intensive and scales to 230k+ cores on Jaguar
Basic designS3D solves the incompressible Navier-Stokes equations for a regular 3D domain.Parallelize by assigning each grid point to a work item
19

S3D Performance
©2010 Advanced Micro Devices, Inc. All rights reserved. 20
K. Spafford, J. Meredith, J. S. Vetter, J. Chen, R. Grout, and R. Sankaran. Accelerating S3D: A GPGPU Case Study. Proceedings of the Seventh International Workshop on Algorithms, Models, and Tools for Parallel Computing on Heterogeneous Platforms (HeteroPar 2009) Delft, The Netherlands.
0.199
0.1690.192
AMD FirePro v8800 (Cypress)
NV Tesla C2050 (Fermi)
NV ION
S3D Single Precision per TDP (GFLOPS / watt)
S3D‐SP

Example: Sparse Matrix Vector Multiplication (SpMV)Motivation
Extremely common scientific kernelBandwidth bound, and much harder to get performance than GEMM
Basic design3 Algorithms, padded & unpadded dataCSR and ELLPACKR data formatsSupports random matrices or matrix market formatExample: Gould, Hu, & Scott: expanded system-3D PDE, visualized at UF.
21

Example: Sparse Matrix Vector Multiplication (SpMV)Motivation
Extremely common scientific kernelBandwidth bound, and much harder to get performance than GEMM
Basic design3 Algorithms, padded & unpadded dataCSR and ELLPACKR data formatsSupports random matrices or matrix market formatExample: Gould, Hu, & Scott: expanded system-3D PDE.
22

SpMV Performance
23
1.10.64
3.994.69
3.62
0.179
3.95 4.05
0.18
AMD FirePro v8800 (Cypress)
NV Tesla C2050 (Fermi) Intel Xeon 5500 2.7Ghz
DP SpMV Random Matrix (10k x 10k, 1% sparsity)
CSR‐Scalar CSR‐Vector ELLPACKR

Example: Molecular DynamicsMotivation
Classic n-body pairwisecomputation, important to all MD codes such as GPU-LAMMPS, AMBER, NAMD, and Gromacs
Basic designComputation of the Lennard-Jones potential force3D domain, random distributionNeighbor list algorithm
24

Reduction and Scan
©2010 Advanced Micro Devices, Inc. All rights reserved. 25
MotivationTwo fundamental primitives for almost all parallel algorithmsScan, e.g. (1, 1, 1, 1) (1, 2, 3, 4)
Basic designBoth use a tree-based algorithm operating on local memoryReduction uses linear access strided by total number of threads for coalesced reads
b d

Reduction and Scan
©2010 Advanced Micro Devices, Inc. All rights reserved. 26
107.1
89.5
6.9219.97 25.7
1.37
AMD FirePro v8800 (Cypress)
NV Tesla C2050 (Fermi) NV ION
Reduction and Scan (SP, GB/s)
Reduction Scan

Radix SortMotivation
Most common GPU sort, but nontrivial to obtain performancePopular GPU libraries use radix sort, ends up in a lot of apps
Basic designIteratively sort data 4 bits at a timeHighly parallel, takes advantage of fast shared memory for shuffling results
Performance ObservationsOpenCL/CUDA exhibit comparable performanceBoth perform at a small fraction of peak memory bandwidth
24 June 201127

Use #3: Validate your hardware and set standards for procurement
28

Validate - Prime95-Style “Torture Test”SHOC includes a stability test which
repeatedly runs and checks FFTsJust like prime95• Extremely sensitive to:
- Stuck bits- Other HW errors
Looking to burn in that new cluster?mpirun –np num_nodes $SHOC_BIN/Stability –minutes 60
29
FFT
Inverse
FFT
Inverse

SummarySHOC is an open source OpenCL benchmark suite focused on scientific
computingIt’s the only OpenCL + MPI benchmark suiteIt’s available for download today: http://ft.ornl.gov/doku/shoc/start• Send any questions to: [email protected]
Questions?
30

31
Disclaimer & AttributionThe information presented in this document is for informational purposes only and may contain technical inaccuracies, omissions and typographical errors.
The information contained herein is subject to change and may be rendered inaccurate for many reasons, including but not limited to product and roadmap changes, component and motherboard version changes, new model and/or product releases, product differences between differing manufacturers, software changes, BIOS flashes, firmware upgrades, or the like. There is noobligation to update or otherwise correct or revise this information. However, we reserve the right to revise this information and to make changes from time to time to the content hereof without obligation to notify any person of such revisions or changes.
NO REPRESENTATIONS OR WARRANTIES ARE MADE WITH RESPECT TO THE CONTENTS HEREOF AND NO RESPONSIBILITY IS ASSUMED FOR ANY INACCURACIES, ERRORS OR OMISSIONS THAT MAY APPEAR IN THIS INFORMATION.
ALL IMPLIED WARRANTIES OF MERCHANTABILITY OR FITNESS FOR ANY PARTICULAR PURPOSE ARE EXPRESSLY DISCLAIMED. IN NO EVENT WILL ANY LIABILITY TO ANY PERSON BE INCURRED FOR ANY DIRECT, INDIRECT, SPECIAL OR OTHER CONSEQUENTIAL DAMAGES ARISING FROM THE USE OF ANY INFORMATION CONTAINED HEREIN, EVEN IF EXPRESSLY ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
AMD, the AMD arrow logo, and combinations thereof are trademarks of Advanced Micro Devices, Inc. All other names used in this presentation are for informational purposes only and may be trademarks of their respective owners.
The contents of this presentation were provided by individual(s) and/or company listed on the title page. The information and opinions presented in this presentation may not represent AMD’s positions, strategies or opinions. Unless explicitly stated, AMD is not responsible for the content herein and no endorsements are implied.


















