The Neuroscience Information Framework: A Scalable … Summer Institute: Discover Big Data, August 5...
36
2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California Amarnath Gupta
Transcript of The Neuroscience Information Framework: A Scalable … Summer Institute: Discover Big Data, August 5...

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
Amarnath Gupta

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
NIF is an initiative of the NIH Blueprint consortium of institutes What types of resources (data, tools, materials, services) are available to the neuroscience community? How many are there? What domains do they cover? What domains do they not cover? Where are they?
Web sites Databases Literature Supplementary material
Who uses them? Who creates them? How can we find them? How can we make them better in the future?
http://neuinfo.org
• PDF files • Desk drawers

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California http://neuinfo.org June10, 2013 dkCOIN Investigator's Retreat 3
A portal for finding and using neuroscience resources
A consistent framework for describing resources
Provides simultaneous search of multiple types of information, organized by category
Supported by an expansive ontology for neuroscience
Utilizes advanced technologies to search the “hidden web”
UCSD, Yale, Cal Tech, George Mason, Washington Univ
Literature
Database Federation
Registry

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
How do we create an information infrastructure that is able to connect a person or a community with the resources they need to accomplish their task at hand? Resource
Anything that is tangible and accessible a product, a person, an institution, a piece of data, a connection …
Information Infrastructure Enables the entire life cycle of information from acquisition to (potential)archival Allows people to find, access, understand and work with information
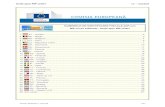
A domain-specific example:
2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
Credit: Bhaskar Ghosh, LinkedIn
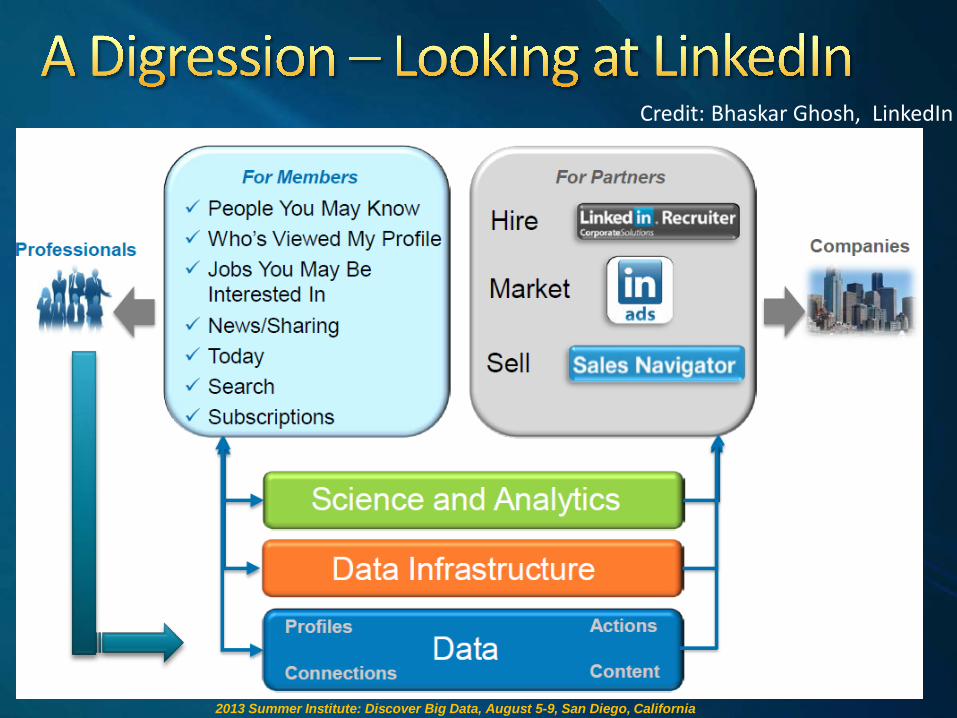
2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
Credit: Bhaskar Ghosh, LinkedIn
Oracle, MySQL, Voldemort, Espresso
Zoei, Bobo, Sensei, GraphDB
Kafka, Databus
Hadoop, Teradata, Azkaban

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
Oracle or Espresso
Search Index
Graph Index
Read Replica
Updates
Standardization
Data Change Events
Credit: Hien Luu, Sid Anand, LinkedIn
Oracle or Espresso
Updates
Databus
Web Servers
Teradata

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
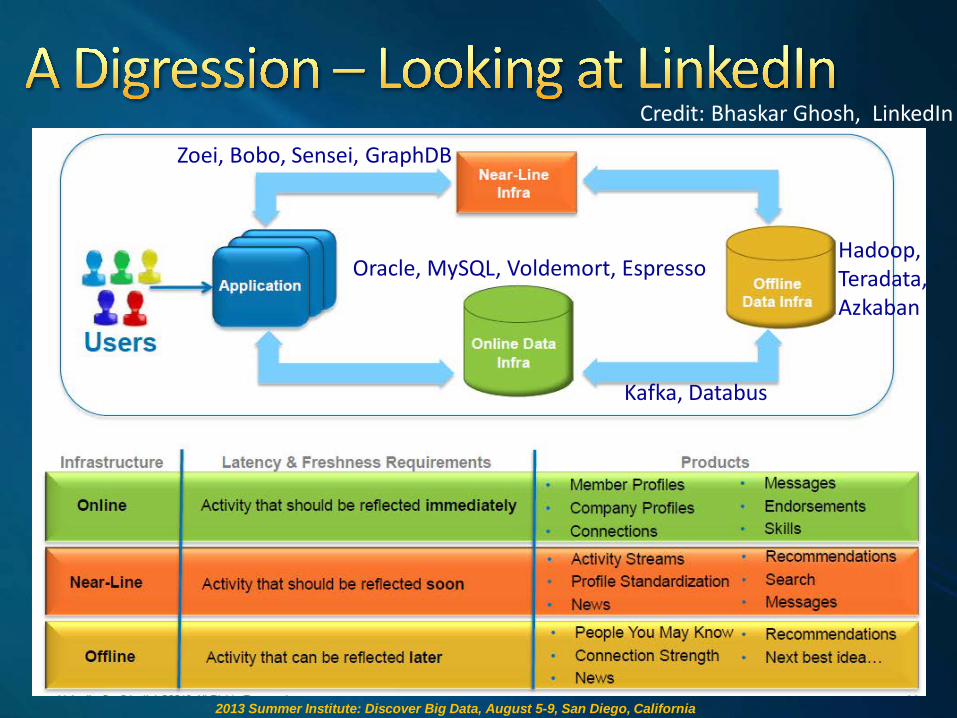
Where is data about X? How does Y relate to Z? Accumulate and Analyze Compare X and Y Subscribe to topic T Recommend Resource Funding reports Search and Explore News
Resource Promotion
Utilization Search
Cross-Utilization
Experiential Services
Researcher Activity Resource Activity
Data
Data Infrastructure
Analysis & Science

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
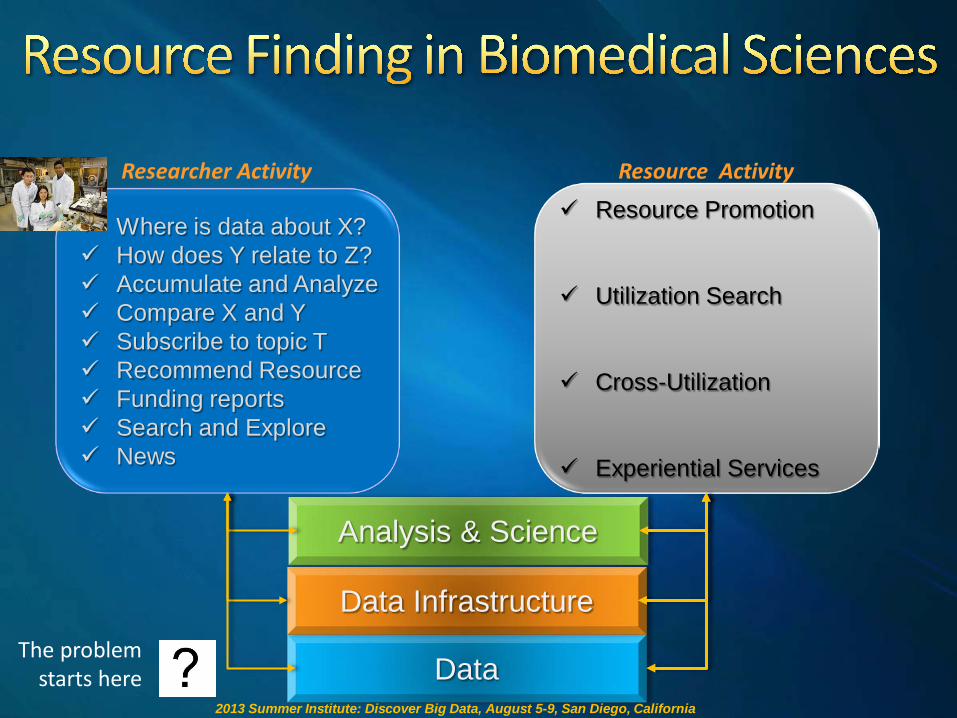
Where is data about X? How does Y relate to Z? Accumulate and Analyze Compare X and Y Subscribe to topic T Recommend Resource Funding reports Search and Explore News
Resource Promotion
Utilization Search
Cross-Utilization
Experiential Services
Researcher Activity Resource Activity
Data
Data Infrastructure
Analysis & Science
The problem starts here

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
Given an infinite number of web accessible resources, which are relevant for Neuroscience? Easy Case
A resource assigned by a trusted source Reasonably Easy Case
A resource recommended by a potentially trustable source
Not-so-easy Case “Mine” for resources from literature/crawler Auto-filter by semantic classification Fully validate by curatorial staff/community

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
Is this a potential neuroscience resource? Two-pronged classification problem
If it belongs to the class, a reasonable portion of the document term vector will align with a neuroscience vocabulary
Necessary but not sufficient The “spread” of the document term vector with respect to a reasonable domain ontology will be limited
Pragmatic problems What additional (recognizable) descriptors does the resource have? Is the resource “current”? Are there “other ways” of getting to the content of the site?

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
DISCO – NIF’s Ingestion Manager and Data Tracker
“Relationalizes” incoming data when needed Feeds the curators’ dashboard for ingestion, update and index management Executes automatic updates per schedule Keeps track of chains of derived views defined by curators Maintains annotations on data and its views Propagates data updates to all derived views through curator notification

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
The data come From too many disparate sources
6000+ neuroscience resources In too many different formats and models
Relational, XML, RDF, Text, domain-specific, … Having all too diverse semantics
“GRM1”: a string, a gene, a chromosomal region, a list of interesting SNPs in mice?
There is a massive data integration problem because only integration of data will lead to insight
What possible drugs might be repurposed for human inclusion body myopathy (HIBM)? Data about/from the following to be integrated
Organisms, diseases, cross-organism anatomy, phenotypes, genes, proteins, interactions, pathways, genomic variations, pharmaceutical compounds, assays and publications

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
Data integration using schema mappings for similar resources Semantics-based integration
Using ontologies as the unifying structure Using vocabularies as the connecting substrate
Using linked-data graph where applicable Link inference Link prediction
Using machine learning Term association using active learning with conditional random fields
When possible

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
Commercial solutions exist They are not very scalable as number of schemas increase
Many groups working on it Data Tamer – an MIT-Intel partnership project on Big Data
Matches schema where possible Crowd-sources ambiguous cases Performs entity-consolidation by data clustering
Our approach Curators use small scale schema mappings using ontology and Google Refine

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
Gather the language of the domain Terms, their variations and term properties “Verbs”, relationships, their linguistic variations and their properties Constraints that hold in the domain
Sources Ontologies Folksonomies
image tags, text annotations, … Literature
figure and table captions Data (structured or semi-structured)
2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
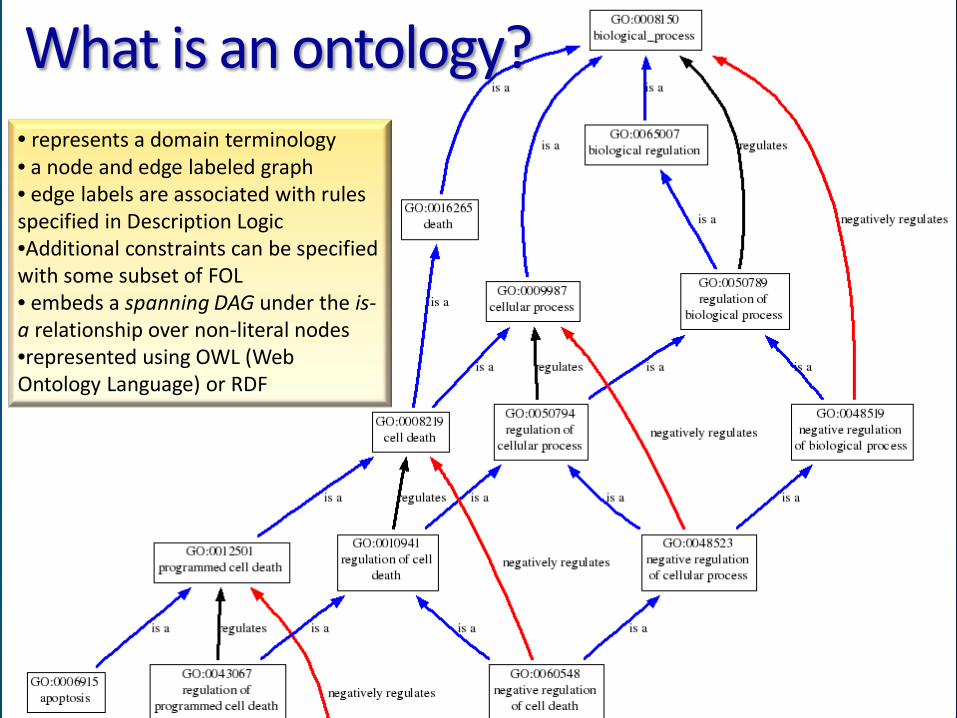
What is an ontology? • represents a domain terminology • a node and edge labeled graph • edge labels are associated with rules specified in Description Logic •Additional constraints can be specified with some subset of FOL • embeds a spanning DAG under the is-a relationship over non-literal nodes •represented using OWL (Web Ontology Language) or RDF

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
A graph query engine for ontological graphs Accepts OWL, RDFS, RDF Ingestors for special cases can be developed
MESH XML DTD Has a service API
1. Get all human phenotypes http://nif-services-stage.neuinfo.org/ontoquest-lamhdi/concepts/search/HP_ 2. Find superclasses of "exocrine pancreas" First: http://nif-services-stage.neuinfo.org/ontoquest-lamhdi/concepts/term/exocrine+pancreas Then, from the result of the above: http://nif-services-stage.neuinfo.org/ontoquest-lamhdi/rel/superclasses/UBERON_0000017 3. Find all direct properties of UBERON_0000017 http://nif-services-stage.neuinfo.org/ontoquest-lamhdi/rel/children/UBERON_0000017 COMBINED WITH http://nif-services-stage.neuinfo.org/ontoquest-lamhdi/rel/parents/UBERON_0000017

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
Which skeletal structures in the zebrafish develop from the mesenchyme?
Return $x where ($x (subclassOf)* ‘skeletal element’) and ($x develops_from* ‘ZFA:mesenchyme’) Return $y where
($y subclassOf* $x) Query Rewriting Return $x where
($x develops_from* `mesenchyme’) and ($x has_ontology $o) ($x equivalent_to $z) ($z has_ontology ‘ZFA’) and ($x (subclassOf)* ‘skeletal element’)

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
“develops_from” http://nif-services-stage.neuinfo.org/ontoquest-lamhdi/rel/edge-relation/id/RO_0002202
Subclasses of “skeletal element” (incl. its equivalenceClasses) in ZFA http://nif-services-stage.neuinfo.org/ontoquest-lamhdi/rel/subclasses/term/skeletal%20element?level=3
<relationship> <subject InternalId="778440-1" id="ZFA_0001635">intramembranous bone</subject><property InternalId="5389-15" id="subClassOf">subClassOf</property><object InternalId="777874-1" id="ZFA_0001514">bone element</object> </relationship>
“equivalenceClass” http://nif-services-stage.neuinfo.org/ontoquest-lamhdi/rel/children/term/skeletal%20element?level=1

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
Tagging of Antibody Records using a machine learning technique with Conditional Random Fields

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
A high-level statement The ontology O is a graph of concepts and inter-concept relationships The data is a semistructured object S with groupings A mapping structure is a graph of mapping edges from S to O + intra-source map edges + intra-ontology map edges Table: protein(ID, symbol, name, pathway)
Mapping: pathway mapsTo ontoID(Pathway). (exhibitedIn(ontoID(Pathway), ontoID(mammal)) AND occursIn(value(ID), value(pathway)))

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
What are the top 10 genes you have most information about?
Which sources have information about “genes”? Find the ontology term for gene CHEBI_23367 Call http://cm.neuinfo.org:8080/cm_services/column/mapping/ontoterm?ontologyTermId=CHEBI_23367
http://cm.neuinfo.org:8080/cm_services/column/valuefreqs?srcNifId=nlx_146253&tableNifId=nlx_146253-1&columnName=transgenic_line
Now group and rank merge in parallel if needed
Get top 10
For each table and column thus found, call

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
Lucene Query Language FIND:(image video) hippocampus anatomy:hippocampus component:"plasma membrane“ anatomy::organism:human anatomy:hippocampus[::organism:human] RELATED:(Tenascin rabbit) RELATED::measuredBy:(“cell signaling” cytometry)
+

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
FIND:(image video) hippocampus Find the ontological class of the query term “hippocampus”
Ans: anatomical_entity Does “hippocampus” have a non-empty has_part tree underneath?
Every node in the ontology keeps an approximate statistics of descendant counts across various edge labels
Rewrite query to: FIND: (image video) has_part*(synonyms(hippocampus))
Issue: A cell is a part of any brain region.
Should the expansion include the cells of hippocampus? No, because “cell” is a different module of the ontology whose top-level is “cell”. Partonomic expansion stays within module of the ontology
Final rewrite: FIND: (image video) anatomy::(has_part*(synonyms(hippocampus)))

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
The PDSP Ki database is a unique resource in the public domain which provides information on the abilities of drugs to interact with an expanding number of molecular targets. The Ki database serves as a data warehouse for published and internally-derived Ki, or affinity, values for a large number of drugs and drug candidates at an expanding number of G-protein coupled receptors, ion channels, transporters and enzymes.
Which marijuana related genes are of interest to NCI? Let’s just use PDSP as an example.
Which marijuana related genes are of interest to NCI? Let’s just use PDSP as an example.

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
public static final String THC_QUERY = "cannabis thc marijuana"; public void demonstrateFederation() throws Exception { final String kiDatabaseId = "nif-0000-01866-1"; FederationQuery query = FederationQuery.builder(kiDatabaseId, THC_QUERY).get(); for (Facets facets: searcher.getFacets(query, 10, 0, 1)) { // Find all receptor (gene) facets if (!facets.getCategory().equals("Receptor")) { continue; } for (Facet facet: facets.getFacets()) { // Get grants related to these genes from NCI query = FederationQuery.builder("nif-0000-10319-1", "\"" + facet.getFacet() +"\"") .facet("Funding Institute", "national cancer institute") .exportType(ExportType.data) .rows(1000).get(); TableData data = searcher.getTableData(query); for (FederationModelData model: data.getResult()) { System.out.println(facet.getFacet() + "," + model.get("project_number") + "," + model.get("project_title")); } } } }

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
Which marijuana related genes are of interest to NCI?

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
Running on Gordon (with no tweaking)
Configuration • 1 server
• 98 GB RAM • 24 core Intel Xeon CPU @2.8GHz
• RAID 5 SSD • 2 Solr instances serving the • Federation and literature cores.

2013 Summer Institute: Discover Big Data, August 5-9, San Diego, California
The Neuroscience Information Framework is not really dependent on Neuroscience Applying it to
Diabetes and kidney diseases Model organisms Earthcube for geo-science data (Hopefully) social science data for economists
We need More scalability Improved complex query handling A distribution framework