
The Definitive Guide to Backup and Recovery for Cassandra · 2019-12-31 · Key features of...
11
The Definitive Guide to Backup and Recovery for Cassandra
Transcript of The Definitive Guide to Backup and Recovery for Cassandra · 2019-12-31 · Key features of...

The Definitive Guide to Backup and Recovery for Cassandra

Table of Contents
Executive Summary
1. Cassandra Technology
Overview
2. The Need for Backup &
Recovery for Cassandra
3. Backup and Recovery
Requirements
4. Existing Practices for Backup
and Recovery
5. RecoverX Overview
6. Compare and Contrast
Cassandra Backup &
Recovery Solutions
7. Fortune 100 Retailer
Customer Success Story
The Definitive Guide to Backup and Recovery for Cassandra
E B O O K
Executive Summary
In today’s era of big data, enterprise applications
create a large volume of data that may be
structured, semi-structured or unstructured in nature.
Additionally, application development cycles are
much shorter and application availability is a critical
requirement. Given these requirements, enterprises
are forced to look beyond traditional relational
databases to onboard next-generation applications
(on IaaS or cloud-based PaaS). NoSQL databases
such as Apache Cassandra are now being adopted
and evaluated by enterprises for these applications,
including eCommerce, content management, etc.
2EBOOK www.datos.io [email protected]

Part I: Cassandra Technology Overview
Apache Cassandra™ is an open source, distributed and decentralized storage system (database) for managing large
amounts of structured data across many commodity servers, while providing highly available service and no single
point of failure. Apache Cassandra offers capabilities including continuous availability, linear scale performance,
operational simplicity and easy data distribution across multiple data centers and cloud availability zones.
Key features of Cassandra include the following:
• Elastic scalability: Cassandra is highly scalable; more hardware can be added to accommodate more customers and additional data.
• Always on architecture: Cassandra has no single point of failure and is continuously available for business-critical applications.
• Fast linear-scale performance: Cassandra is linearly scalable, i.e., it increases throughput as a user increases the number of nodes in the cluster. Therefore, it maintains a quick response time.
• Flexible data storage: Cassandra accommodates all possible data formats including structured,
semi-structured, and unstructured. It can dynamically accommodate changes to data structures.
• Easy data distribution: Cassandra provides the flexibility to distribute data by replicating data across multiple data centers.
• Transaction support: Cassandra supports properties like Atomicity, Consistency, Isolation, and Durability (ACID).
• Fast writes: Cassandra was designed to run on cheap commodity hardware. It performs fast
writes and can store hundreds of terabytes of data, without sacrificing read efficiency.
Apache Cassandra’s architecture is responsible for its ability to scale, perform, and offer continuous uptime. All
nodes play an identical role as each node communicates with each other equally. Apache Cassandra’s built-for-
scale architecture is capable of handling large amounts of data and thousands of concurrent users or operations
per second — even across multiple data centers — as easily as it can manage much smaller amounts of data and
user traffic. Apache Cassandra’s architecture has no single point of failure and therefore is capable of offering true
continuous availability and uptime — simply add new nodes to an existing cluster without having to take it down.
In Cassandra, one or more of the nodes in a cluster act as replicas for a given piece of data. If it is detected
that some of the nodes responded with an out-of-date value, Cassandra will return the most recent value to the
client. After returning the most recent value, Cassandra performs a read repair in the background to update the
stale values.
3EBOOK www.datos.io [email protected]

Part II: The Need for Backup & Recovery for Cassandra
As organizations increasingly rely upon NoSQL databases for their business-critical applications, and as these same
organizations adopt a cloud-first strategy, the need for a comprehensive backup and recovery strategy has never
been more critical. In this section, we will explore the need for a complete data protection strategy.
One of the advantages of Cassandra is that it provides scalability and high availability without compromising
performance. Put simply, replication creates an alternative copy of an original and changes with the original in real
time. So while native replication is good for protecting against media and network failures by replicating data across
nodes, it can be a serious detriment in the case of data corruption or loss whereby the corrupted data set gets
replicated, exacerbating an already bad situation.
Furthermore, the most common cause for data corruption and loss today is human error including operator error,
fat finger mistakes, and accidental deletions. Recently, more malicious cyber threats have propagated including
malware and ransomware. To protect against these threats, a comprehensive backup and recovery strategy is
required. Unlike replication, backup is a copy of data taken at a certain point in time that does not change with time.
A backup copy enables an administrator to restore data at a certain time in the past, typically a time before the data
loss or ransomware attack occurred.
In summary, backup plays a critical role in an organization’s overall data protection strategy. In the next section, we’ll
discuss in more detail the technical requirements for backup and recovery of Cassandra databases.
This section will introduce the key requirements for protecting data that resides on Apache Cassandra, deployed
either on-premise, or on private cloud with as-a-service model, or in public cloud with Amazon AWS, Google
Cloud Platform.
Requirement #1: Online Cluster-Consistent Backups
One of the key requirements of next-generation applications that are deployed on Apache Cassandra is the always-
on nature. This means that quiescing the database for taking backups is not feasible and moreover, the backup
operation should not impact the performance of the application. As the application scales, the underlying Apache
Cassandra also needs to scale-out to multiple shards. In this case, a backup solution must provide a consistent
backup copy across shards without disrupting database and application performance during backup operations.
Requirement #2: Flexible Backup Options
Depending on the application, data may have different change rate and patterns. For example, in a product catalog,
certain items may be refreshed everyday (fast selling goods), while the others may have longer shelf life (premium
items). Based on the application requirements, some collections may need to be backed up every hour versus the
Part III: Requirements of Protection for Cassandra
4EBOOK www.datos.io [email protected]

others that may be backed up daily. Providing this flexibility to schedule backups at any interval and at collection
level granularity is another requirement that we have heard from customers who are using Apache Cassandra.
More importantly, these backups should always be stored on the secondary storage in native formats to avoid
vendor lock-in.
Requirement #3: Handling Failure
Failures are a norm in the distributed database world. However, the backup solution should be resilient to database
process failures, node failures, network failure and even logical corruption of data during backup and recovery
operations. Finally, the backup solution should be able to handle failures of Apache Cassandra configuration
servers that store metadata.
1. Traditional Backup and Recovery Solutions.
Traditional solutions were architected for IT applications deployed on traditional scale-up and static resources of
compute and storage. They were designed for scale-up application environments with uncompressed workloads
built to be operated within walls of on-premises infrastructure.
Media server based legacy backup architecture has no place in the cloud. Likewise, legacy media server based
architectures have no place protecting next generation scale-out data.
Legacy backup solutions from long established backup vendors (e.g., Veritas, EMC/Legato, CommVault), are all
based on the same legacy architecture: single vendor, end to end architectures which centralize the control of the
backup process (the “control plane”) and moving/storing the backed-up data (the “data plane”). In these legacy
backup solutions “media servers” act as the consolidated “control plane” and “data plane”.
Each backup vendor’s unique client “agent” software, installed on each host, used database specific APIs to
invoke and process backups of structured data (e.g., Oracle RMAN). Likewise, client agents installed on each file
server processed backing up unstructured files on each file server or used APIs on each NAS (an appliance based
dedicated file server).
With an average architecture age of 20 years, legacy backup and recovery products from vendors including
Veritas, Dell EMC, and CommVault were all designed before the advent of the cloud and modern applications, and
are not architected to support the new, modern IT stack.
2. Manual Scripted Solutions
Manual solutions leverage native Apache Cassandra snapshot utility and scripts to transfer data to secondary
storage. The scripts are customized for each Apache Cassandra cluster and require significant operational effort
to scale or adapt to any topology changes. Further, these scripts are not resilient to failure scenarios e.g., failure
Part IV: Existing Solutions in the Marketplace
5EBOOK www.datos.io [email protected]

of a node (primary or secondary) or intermittent network issues. Finally, recovery is a manual process, hence,
time consuming and results in very high application downtime and contains data loss risk due to any bugs in the
scripts. Overall, these solutions work when the Apache Cassandra environment is small and some data loss may be
permitted in the application.
3. Backup and Recovery Via Replication
One of the longest running discussion threads in the backup world is explaining why “replication is not backup.”
In the early days of backup applications were built predominantly on relational databases and hosted on-premises
in customers’ data centers. Users thought they were protected by creating copies of production data, on disk,
replicated by disk arrays from a primary data site to a D/R site. If the primary site failed or went offline for whatever a
reason, production could resiliently continue a D/R site. But replication quickly propagated data loss. Whatever the
cause, if data becomes corrupted it gets replicated across multiple sites.
Whether it was before or after users suffered an unrecoverable data loss, customers eventually understood the
reality that array-based replication enabled operational resiliency but was not “backup.” Backup solutions were
required to deliver point in time, application consistent versions of data to enable rapid, point-in-time recovery in
the event of data loss or corruption.
Next-generation scale-out databases do employ multi-node replication to guarantee operational resiliency.
Even with the failure of one or more nodes in Apache Cassandra cluster transaction processing and application
data access continues on, uninterrupted. But, next generation databases suffer the same inherent limitations of
replication — accidental deletion of one or more data tables, fat finger errors, ransomware attacks all can result in
unrecoverable data loss.
In fact, the clustered replication that makes next generation databases so resilient also makes them even more
reliant upon backup to protect against data loss, corruption, and ransomware attack. But, traditional backup
solutions that depend on silos of media servers and backup appliances, and store backups in a proprietary format
on dedicated storage don’t address the application consistency and scalability requirements of next generation
databases. Replication is NOT backup.
Part VI: RecoverX Overview
Rubrik Datos IO RecoverX: The Leading Solution for Scalable and Reliable Apache Cassandra
Backup and Recovery
Rubrik Datos IO RecoverX is application-centric, data management solution providing backup and recovery for
NoSQL, Non-Relational enterprise database systems. RecoverX delivers scalable versioning, single-click recovery,
and industry-first semantic de-duplication, reducing redundant data and lowering storage costs. RecoverX includes
any point-in-time backup and orchestrated recovery to safeguard against logical and human errors, malicious
data corruption, application schema corruption, and other soft errors. Organizations can protect their data at
any granularity and any point in time (flexible RPOs) to reduce application downtime with recovery in minutes
6EBOOK www.datos.io [email protected]

(low RTOs), save up to 80% on secondary storage costs, and increase productivity of applications and DevOps
teams. RecoverX enables continuous integration and development by fully automating the refresh of test and
development environments using production data.
Advanced Features
• Advanced Recovery: The amount of data organizations need to protect is rapidly increasing but
customers are constantly demanding faster RTOs to meet their business agility requirements and
to address mandatory IT requirements such as those required by GDPR. These same organizations
are typically building customer-centric applications that span hundreds of tables, with hundreds
of TB’s of data (aka “Big Data”), with change rates approaching 300%, yet they expect recovery
times of just a few hours. To address this new class of recovery requirements, RecoverX 2.5
now delivers advanced features including queryable recovery enabling fast, sub-table level
recovery, as well as incremental and streaming recovery, both of which reduce recovery times
down to minutes and minimize storage requirements for large scale restore operations.
• Backup Anywhere, Recover Anywhere: Cyber-attacks like ransomware present a real threat and
organizations need to protect their data across data sources, applications, and any geographical
boundary. Increasingly, customers have database tables spanning multiple data centers and multiple
continents, but they want their data to be backed up and restored at the granularity of a single data
center location. RecoverX 2.5 now delivers on this requirement with support for local backup of geo-
distributed applications enabling local data center recovery for faster and more flexible RTO.
• Enterprise-Grade Security: Rubrik Datos IO is experiencing massive adoption in large enterprise
customers across retail, ecommerce, financial services and healthcare organizations all of which have
significant security requirements. RecoverX 2.5 introduces support for TLS/SSL encryption, support
for X.509 certificates, LDAP authorization and Kerberos authentication to deliver optimized security
between RecoverX and data sources and integration with enterprise security management tools.
Benefits
RecoverX provides organizations with the following benefits:
• Minimize application downtime through application consistent point-in-time backups by removing database repairs post recovery operations
• Reduce secondary storage costs by ~80% using industry-first global semantic deduplication
• Failure resiliency and elastic performance via highly-available software-only product
• Operational efficiency through fully orchestrated recovery
• Lightweight deployment in public cloud or private datacenter
7EBOOK www.datos.io [email protected]
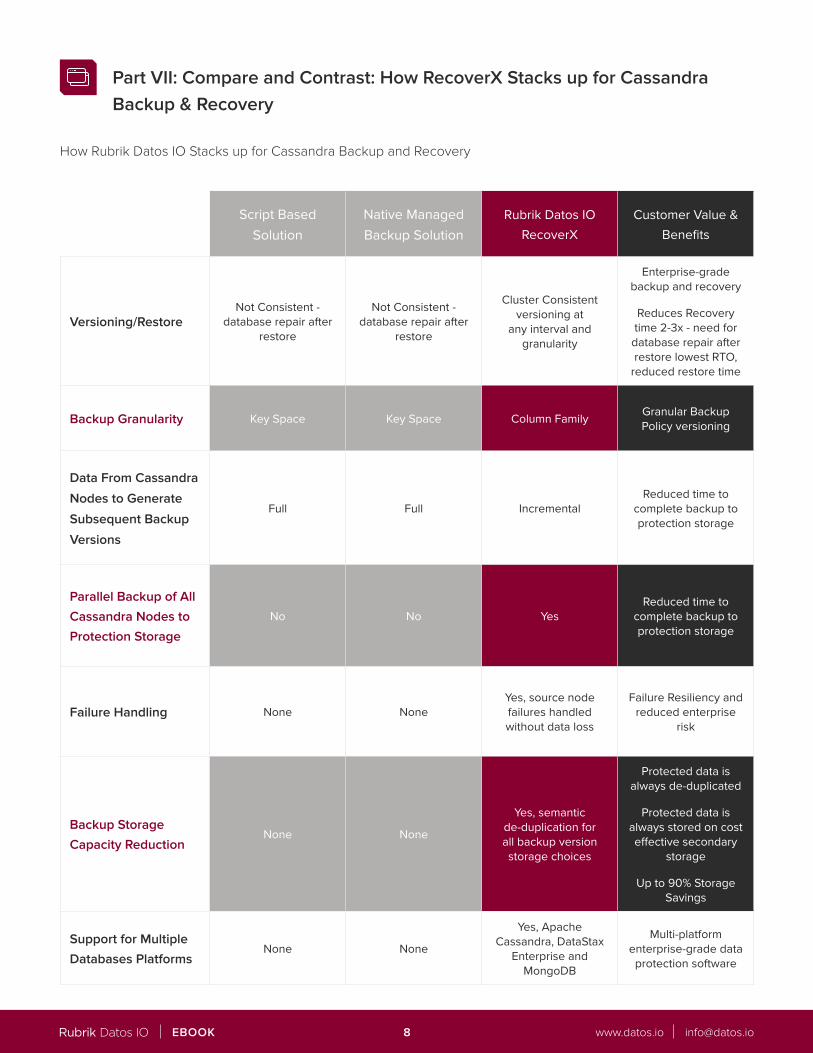
Script Based Solution
Native Managed Backup Solution
Rubrik Datos IORecoverX
Customer Value & Benefits
Versioning/RestoreNot Consistent -
database repair after restore
Not Consistent - database repair after
restore
Cluster Consistent versioning at
any interval and granularity
Enterprise-grade backup and recovery
Reduces Recovery time 2-3x - need for
database repair after restore lowest RTO,
reduced restore time
Backup Granularity Key Space Key Space Column Family Granular Backup Policy versioning
Data From Cassandra
Nodes to Generate
Subsequent Backup
Versions
Full Full Incremental Reduced time to
complete backup to protection storage
Parallel Backup of All
Cassandra Nodes to
Protection Storage
No No YesReduced time to
complete backup to protection storage
Failure Handling None NoneYes, source node failures handled without data loss
Failure Resiliency and reduced enterprise
risk
Backup Storage
Capacity ReductionNone None
Yes, semantic de-duplication for all backup version storage choices
Protected data is always de-duplicated
Protected data is always stored on cost effective secondary
storage
Up to 90% Storage Savings
Support for Multiple
Databases PlatformsNone None
Yes, Apache Cassandra, DataStax
Enterprise and MongoDB
Multi-platform enterprise-grade data protection software
Part VII: Compare and Contrast: How RecoverX Stacks up for Cassandra Backup & Recovery
How Rubrik Datos IO Stacks up for Cassandra Backup and Recovery
8EBOOK www.datos.io [email protected]

Part VIII: Customer Case Study (Fortune 100 Home Improvement Retailer)
The Rubrik Datos IO team listens. Over the last 9 months, we have given them a number of product features, and the team delivers at a record pace.“ ”
Our Customer Achieved:
Using RecoverX, our
customer was able to
backup multiple Cassandra
databases and recover
from data loss with an SLA
of 1 hour. In addition, our
customer increased their
compute and memory
resources during peak
seasons for seasonality, and
was able to get the required
backup performance.
The Customer
Our customer is a Fortune 100 home improvement retailer with
thousands of brick and mortar stores in the U.S., Canada and
Mexico. In addition, they have an eCommerce application that is
central to their digital transformation journey. Their hyper-scale
application is built with a cloud-first methodology that is deployed
natively on Google Cloud Platform (GCP).
The Need
Our customer’s challenges can be summarized in three broad
categories.
The first is Backup and Recovery for Cassandra in Google Cloud.
The company is in the midst of their digital transformation journey
and as their online business grew, they experienced challenges
in scaling their existing relational databases. They re-architected
their online business application using a microservices based cloud
native application architecture. This new application is deployed in
1 Hour
Google Cloud Platform, and uses underlying Cassandra (DataStax) databases to populate information for different
customer-facing platforms. Given that their core online business is based on this webscale eCommerce application,
any data loss is detrimental for their business. Our customer requires the ability to backup multiple Cassandra
databases and recover from any data loss with an SLA of 1 hour.
The second category is Backup Software Elasticity. Being in the e-commerce industry, our customer experiences
huge spikes in data volume during the holidays, especially Thanksgiving and Christmas. They could not rely on a
static infrastructure footprint, and instead, wanted to scale resources only during peak seasons, and reduce the
resources back after the season ended. This would ultimately allow them to optimize the cost of operating a data
protection solution, without sacrificing high-availability.
The third category is Test Cluster Refresh Using Production Data. Our customer has multiple production and test
clusters, and they implement continuous integration and continuous development (CI/CD) methodologies. Initially, they
had to spend a considerable amount of time refreshing their test clusters because they are of different topologies.
9EBOOK www.datos.io [email protected]

Key Challenges
• Cloud-Native Backups of
Cassandra (DataStax Enterprise)
• Data protection SLA of 1 hour and
minimize application downtime
• Automate refresh of test
clusters using production
data at regular intervals
Why Rubrik Datos IO:
• The only cloud-native data protection solution for
Apache Cassandra and DataStax Enterprise in
Google Cloud
• Cluster consistent backups that don’t require repairs on
recovery, leading to low RTO 80% reduction in
secondary storage costs
• High-performance to guarantee 1 hour SLA using elastic
compute/storage resources
They needed a data management solution that would automate the refresh of test clusters using production data at
regular intervals.
The Solution
Initially, our customer’s DevOps team used database native tools, but could not achieve the enterprise level data
protection features that they needed. To quantify the impact of this any outage, it is estimated to be hundreds of
thousands of dollars in lost business.
Rubrik Datos IO RecoverX was deployed natively in Google Cloud. RecoverX software was deployed in a
clustered configuration to achieve high availability. A single RecoverX cluster was deployed to protect as many
as 6 Cassandra clusters with a 1-hour backup interval. The data was stored on Google Cloud Storage for cost
effectiveness.
The Results
Using RecoverX industry-first features, the customer was able to achieve operational and capital cost savings. At
the same time, they were able to meet the organizational goal of 1-hour SLA.
Semantic deduplication resulted in 82% storage cost savings. Further, customer optimized its infrastructure costs by
allocating appropriate compute resources depending on their application requirements.
10EBOOK www.datos.io [email protected]
About Rubrik Datos IO
Rubrik Datos IO is the application-centric data management company for the multi-cloud world. Our flagship Rubrik
Datos IO RecoverX delivers a radically novel approach to data management helping organizations embrace the
cloud with confidence by delivering solutions that protect, mobilize, and monetize their data — at scale. Rubrik
Datos IO was recently awarded Product of the Year by Storage Magazine, and was recognized by Gartner in the
2016 and 2017 Hype Cycle for Storage Technologies. Rubrik Datos IO is headquartered in Palo Alto, California.

www.datos.io | 408.708.4136 | [email protected]
1001 Page Mill Rd, Bldg 2, Palo Alto, CA 94304
The Definitive Guide to Backup and Recovery for Cassandra


















