
Text Analytics Software Choosing the Right Fit · Text Analytics Software Choosing the Right Fit...
23
Text Analytics Software Choosing the Right Fit Tom Reamy Chief Knowledge Architect KAPS Group http://www.kapsgroup.com Text Analytics World San Francisco, 2013
Transcript of Text Analytics Software Choosing the Right Fit · Text Analytics Software Choosing the Right Fit...

Text Analytics Software Choosing the Right Fit
Tom Reamy Chief Knowledge Architect
KAPS Group http://www.kapsgroup.com
Text Analytics World San Francisco, 2013

2
Agenda
§ Introduction – Text Analytics Basics § Evaluation Process & Methodology
– Two Stages – Initial Filters & POC § Proof of Concept
– Methodology – Results
§ Text Analytics and “Text Analytics” § Conclusions

3
KAPS Group: General § Knowledge Architecture Professional Services § Virtual Company: Network of consultants – 8-10 § Partners – SAS, SAP, FAST, Smart Logic, Concept Searching, etc. § Consulting, Strategy, Knowledge architecture audit § Services:
– Taxonomy/Text Analytics development, consulting, customization – Evaluation of Enterprise Search, Text Analytics – Text Analytics Assessment, Fast Start – Technology Consulting – Search, CMS, Portals, etc. – Knowledge Management: Collaboration, Expertise, e-learning – Applied Theory – Faceted taxonomies, complexity theory, natural
categories

4
Introduction to Text Analytics Text Analytics Features § Noun Phrase Extraction
– Catalogs with variants, rule based dynamic – Multiple types, custom classes – entities, concepts, events – Feeds facets
§ Summarization – Customizable rules, map to different content
§ Fact Extraction – Relationships of entities – people-organizations-activities – Ontologies – triples, RDF, etc.
§ Sentiment Analysis – Rules – Objects and phrases

5
Introduction to Text Analytics Text Analytics Features § Auto-categorization
– Training sets – Bayesian, Vector space – Terms – literal strings, stemming, dictionary of related terms – Rules – simple – position in text (Title, body, url) – Semantic Network – Predefined relationships, sets of rules – Boolean– Full search syntax – AND, OR, NOT – Advanced – DIST(#), ORDDIST#, PARAGRAPH, SENTENCE
§ This is the most difficult to develop § Build on a Taxonomy § Combine with Extraction
– If any of list of entities and other words

Case Study – Categorization & Sentiment
6
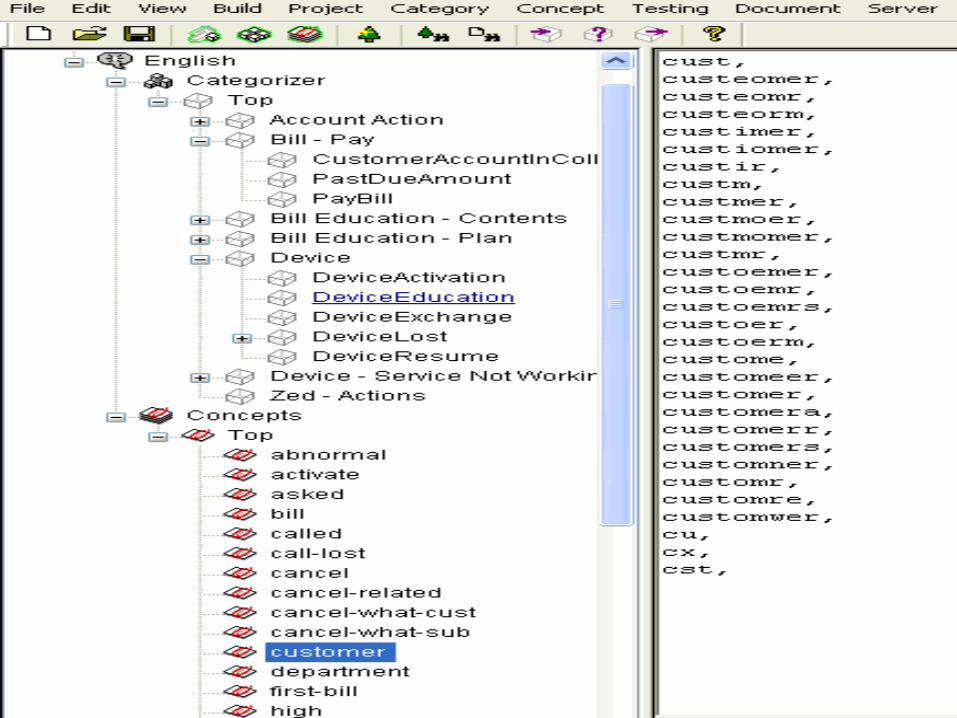
Case Study – Categorization & Sentiment
7
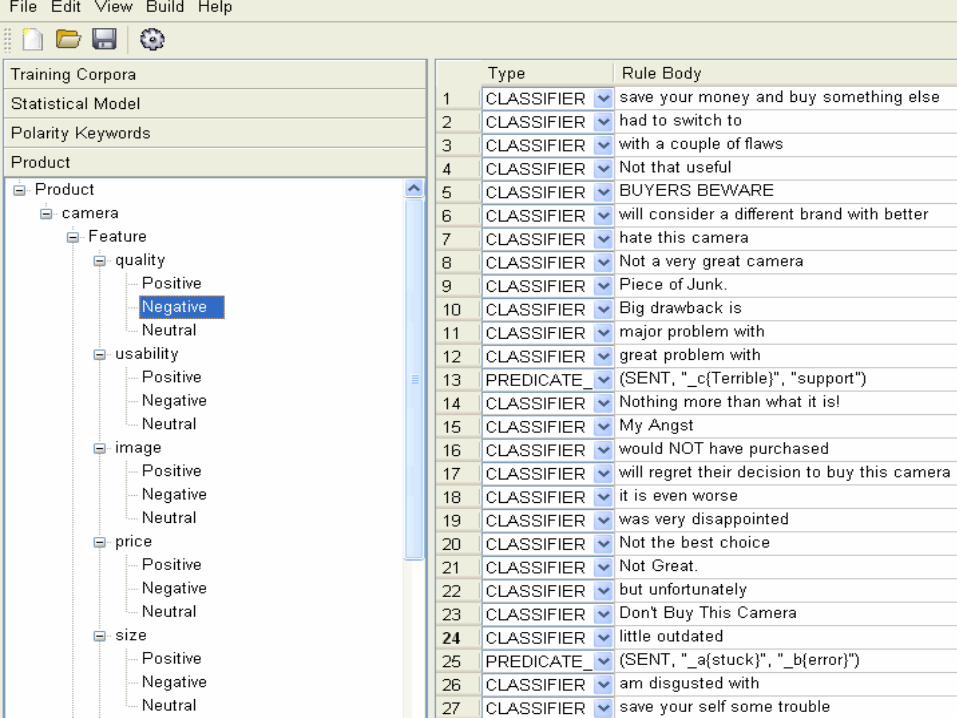
8

Evaluation Process & Methodology Overview § Start with Self Knowledge
– Think Big, Start Small, Scale Fast § Eliminate the unfit
– Filter One- Ask Experts - reputation, research – Gartner, etc. • Market strength of vendor, platforms, etc. • Feature scorecard – minimum, must have, filter to top 3
– Filter Two – Technology Filter – match to your overall scope and capabilities – Filter not a focus
– Filter Three – In-Depth Demo – 3-6 vendors § Deep POC (2) – advanced, integration, semantics § Focus on working relationship with vendor.
9

Design of the Text Analytics Selection Team Traditional Candidates – IT&, Business, Library § IT - Experience with software purchases, needs assess, budget
– Search/Categorization is unlike other software, deeper look
§ Business -understand business, focus on business value § They can get executive sponsorship, support, and budget
– But don’t understand information behavior, semantic focus § Library, KM - Understand information structure § Experts in search experience and categorization
– But don’t understand business or technology
10

Design of the Text Analytics Selection Team § Interdisciplinary Team, headed by Information
Professionals § Relative Contributions
– IT – Set necessary conditions, support tests – Business – provide input into requirements, support project – Library – provide input into requirements, add understanding
of search semantics and functionality § Much more likely to make a good decision § Create the foundation for implementation
11

Evaluating Taxonomy/Text Analytics Software Start with Self Knowledge § Strategic and Business Context § Info Problems – what, how severe § Strategic Questions – why, what value from the text analytics,
how are you going to use it – Platform or Applications?
§ Formal Process - KA audit – content, users, technology, business and information behaviors, applications - Or informal for smaller organization,
§ Text Analytics Strategy/Model – forms, technology, people – Existing taxonomic resources, software
§ Need this foundation to evaluate and to develop
12

13
Varieties of Taxonomy/ Text Analytics Software
§ Taxonomy Management – Synaptica, SchemaLogic
§ Full Platform – SAS, SAP, Smart Logic, Linguamatics, Concept Searching, Expert
System, IBM, GATE § Embedded – Search or Content Management
– FAST, Autonomy, Endeca, Exalead, etc. – Nstein, Interwoven, Documentum, etc.
§ Specialty / Ontology (other semantic) – Sentiment Analysis – Lexalytics, Clarabridge, Lots of players – Ontology – extraction, plus ontology

Vendors of Taxonomy/ Text Analytics Software
– Attensity – Business Objects –
Inxight – Clarabridge – ClearForest – Concept Searching – Data Harmony / Access
Innovations – Expert Systems – GATE (Open Source) – IBM Infosphere
– Lexalytics – Linguamatics – Multi-Tes – Nstein – SAS – SchemaLogic – Smart Logic – Synaptica – Temis
14

15
Initial Evaluation – Factors Traditional Software Evaluation - Deeper § Basic & Advanced Capabilities § Lack of Essential Feature
– No Sentiment Analysis, Limited language support § Customization vs. OOB
– Strongest OOB – highest customization cost § Company experience, multiple products vs. platform § Ease of integration – API’s, Java
– Internal and External Applications – Technical Issues, Development Environment
§ Total Cost of Ownership and support, initial price § POC Candidates – 1-4

16
Initial Evaluation – Factors Case Studies § Amdocs
– Customer Support Notes – short, badly written, millions of documents – Total Cost, multiple languages, Integration with their application – Distributed expertise – Platform – resell full range of services, Sentiment Analysis – Twenty to Four to POC (Two) to SAS
§ GAO – Library of 200 page PDF formal documents, plus public web site – People – library staff – 3-4 taxonomists – centralized expertise – Enterprise search, general public – Twenty to POC with SAS

Phase II - Proof Of Concept - POC
§ Measurable Quality of results is the essential factor § 4 weeks POC – bake off / or short pilot § Real life scenarios, categorization with your content § 2 rounds of development, test, refine / Not OOB § Need SME’s as test evaluators – also to do an initial categorization of
content § Majority of time is on auto-categorization § Need to balance uniformity of results with vendor unique capabilities –
have to determine at POC time § Taxonomy Developers – expert consultants plus internal taxonomists
17

18
POC Design: Evaluation Criteria & Issues
§ Basic Test Design – categorize test set – Score – by file name, human testers
§ Categorization & Sentiment – Accuracy 80-90% – Effort Level per accuracy level
§ Quantify development time – main elements § Comparison of two vendors – how score?
– Combination of scores and report § Quality of content & initial human categorization
– Normalize among different test evaluators § Quality of taxonomists – experience with text analytics software and/or
experience with content and information needs and behaviors § Quality of taxonomy – structure, overlapping categories

Text Analytics POC Outcomes Evaluation Factors § Variety & Limits of Content
– Twitter to large formal libraries § Quality of Categorization
– Scores – Recall, Precision (harder) – Operators – NOT, DIST, START,
§ Development Environment & Methodology – Toolkit or Integrated Product – Effort Level and Usability
§ Importance of relevancy – can be used for precision, applications § Combination of workbench, statistical modeling § Measures – scores, reports, discussions
19

POC and Early Development: Risks and Issues § CTO Problem –This is not a regular software process § Semantics is messy not just complex
– 30% accuracy isn’t 30% done – could be 90% § Variability of human categorization § Categorization is iterative, not “the program works”
– Need realistic budget and flexible project plan § Anyone can do categorization
– Librarians often overdo, SME’s often get lost (keywords) § Meta-language issues – understanding the results
– Need to educate IT and business in their language
20

Text Analytics and “Text Analytics” – Text Mining § TA is pre-processing for text mining § TA adds huge dimensions of unstructured text
– Now 85-90% of all content, Social Media § TA can improve the quality of text
– Categorization, Disambiguated metadata extraction § Unstructured text into data - What are the possibilities?
– New Kinds of Taxonomies – emotion, small smart modular – Information Overload – search, facets, auto-tagging, etc. – Behavior Prediction – individual actions (cancel or not?) – Customer & Business Intelligence – new relationships – Crowd sourcing – technical support – Expertise Analysis – documents, authors, communities
21

Conclusion § Start with self-knowledge – what will you use it for?
– Current Environment – technology, information § Basic Features are only filters, not scores § Integration – need an integrated team (IT, Business, KA)
– For evaluation and development § POC – your content, real world scenarios – not scores § Foundation for development, experience with software
– Development is better, faster, cheaper § Categorization is essential, time consuming § Text Analytics opens up new worlds of applications
22

Questions? Tom Reamy
[email protected] KAPS Group
Knowledge Architecture Professional Services http://www.kapsgroup.com


















