
SK planet intro PlayDoll for Singapore Book Council Publishers Writers Night 6 Nov 2012
Upload
tae-young-leeCategory
view
8.868download
3
딥러닝을 위한 TENSORFLOW
WRITTEN BY TAE YOUNG LEE

2014 2015 2017 2016
Open Stack VM을
통해 바라본
Docker의 활용
AutoML & AutoDraw
딥러닝을 위한
TensorFlow
Sequence Model and
the RNN API
OpenStack으로 바라보는 클라우드 플랫폼
Machine Learning
In SPAM
Python Network
Programming
Neural Network의 변천사를 통해 바라본 R
에서 Deep Neural
Net활용
Change the world in
IOT (Falinux)
Game based on the
IOT (KGC)

Contents
• Deep Learning Process
• 실전 Deep Learning Algorithm 활용
•Data Flow 관점
• Chatbot 활용 딥러닝 알고리즘 Flow(1)
• Chatbot 활용 딥러닝 알고리즘 Flow(2)
• Automation Car
• Deep Learning Framework Architecture

Deep Learning Process
• Data
• Train
• Hyper Parameter Tuning
• Optimization
• Model
• Prediction
Data
Model

Data Selection Data Cleaning Streaming Data Data Augmentation
Data Pre-Processing
Feature Engineering
Model Generation Model Selection
Hyper parameter optimization
Model Tuning
Prediction
Data Flow 관점

Chatbot 활용 딥러닝 알고리즘 Flow (1)
Pattern Generation
시나리오 정의
Intent Mapping
Entity Mapping Pattern Pre-Processing
Feature Engineering Model Generation
char - CNN Hyper Parameter Tuning
Model Selection Model Tuning
Prediction

Chatbot 활용 딥러닝 알고리즘 Flow (2)
Hyper Parameter Tuning
실 Data
Data Selection
Data Cleaning
Rest API
Dictionary
MECAB
Data Augmentation
plain(txt)
IOB(csv)
Model Generation
Data Pre-Processing
질문패턴
(pattern.txt)
패턴 Data 생성에 필요한
Data (dict.csv)
Feature Engineering
W2V bilstmcrf Model Selection Model Tuning
Prediction

Automation Car (1)
• Open CV
• Recognition
• Object Detection
•YOLO2
• Reinforcement Learning

Automation Car (2)

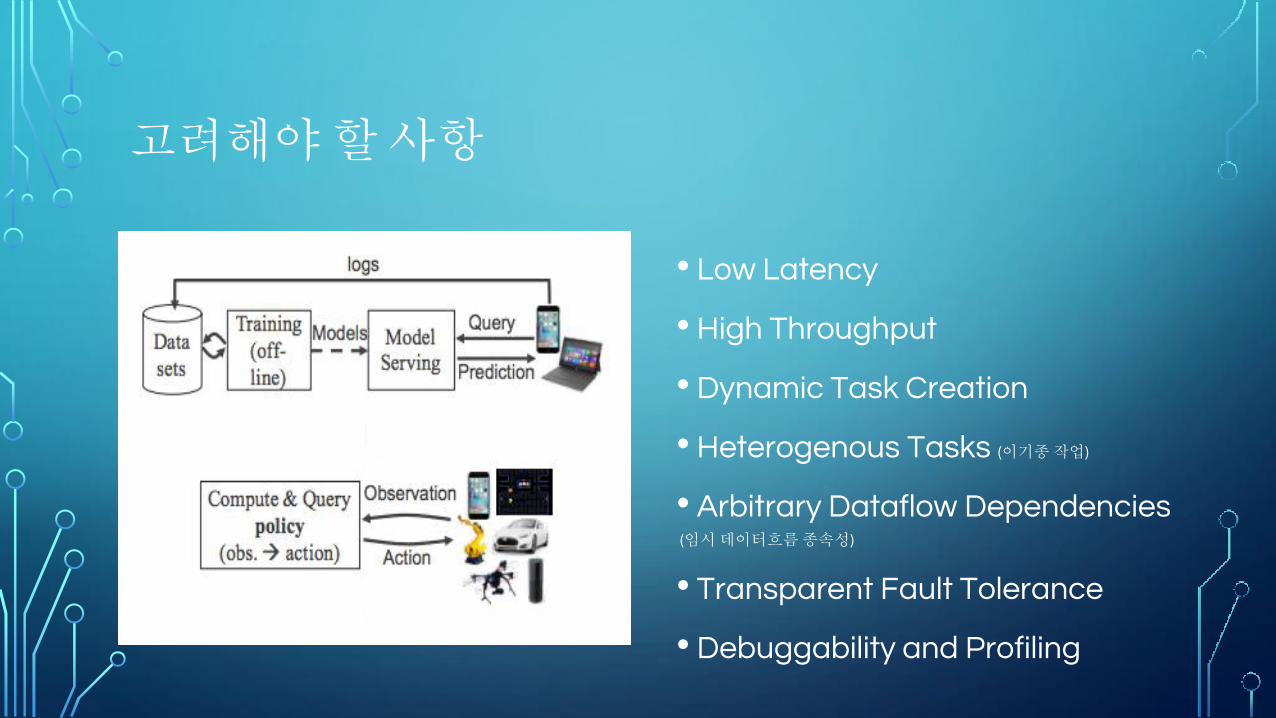
고려해야 할 사항
• Low Latency
• High Throughput
• Dynamic Task Creation
• Heterogenous Tasks (이기종 작업)
• Arbitrary Dataflow Dependencies (임시 데이터흐름 종속성)
• Transparent Fault Tolerance
• Debuggability and Profiling

Based on Big Data architecture
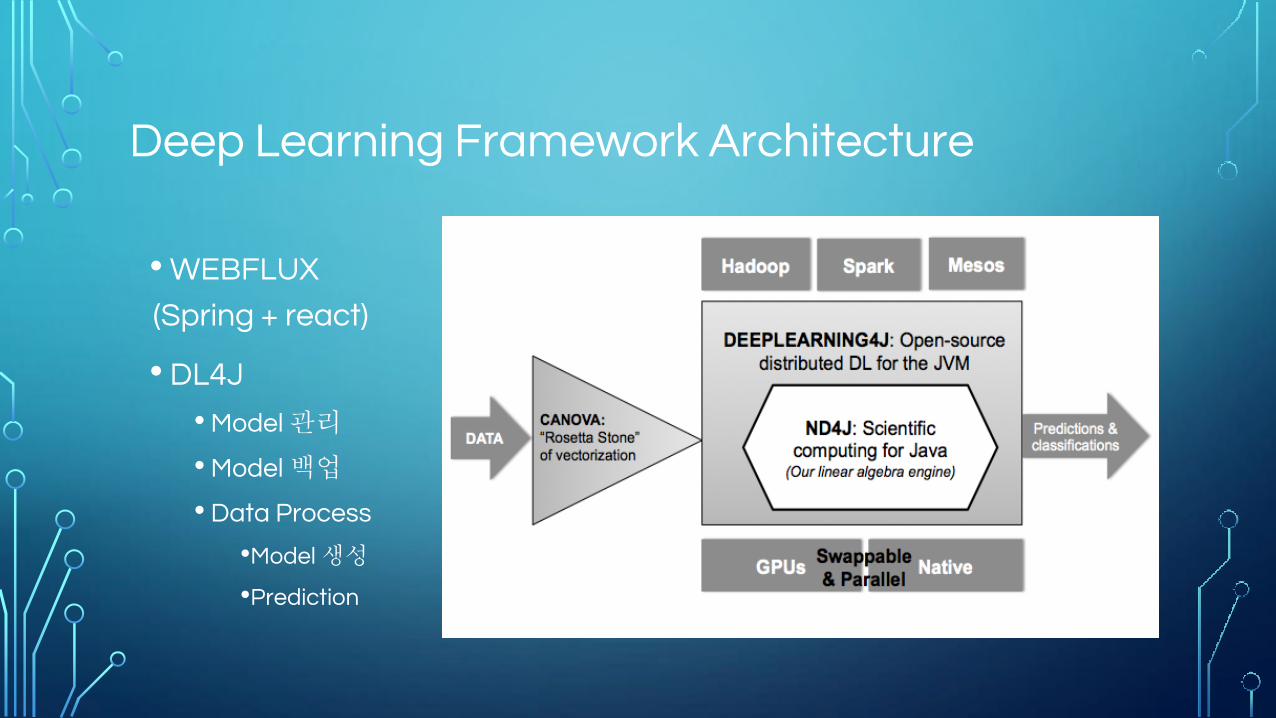
Deep Learning Framework Architecture
• WEBFLUX
(Spring + react)
• DL4J
• Model 관리
• Model 백업
• Data Process
•Model 생성
•Prediction

DL4J
•주체
•Created by
•Adam Gibson @Skymind (CTO)
•Chris Nicholson @Skymind (CEO)
•Maintained by
•Skymind (https://skymind.ai/)
•릴리즈
•Jun. ‘2014
•적용 사례
•은행 Fraud Detection 연구
파트너쉽 with Nextremer in Japan
(https://skymind.ai/press/nextreme
r)
•Motivation
•가장 많은 프로그래머를 보유하는
Java 기반의 딥러닝 프레임워크
개발
•추론엔진에 대해 엔터프라이즈
서비스급 안정성을 보장

DL4J
• 특징
• 장점
•Java를 기반으로 한 쉬운 이식성 및 엔터프라이즈 시스템 수준의 안전성 제공
•Spark 기반의 분산 처리 지원
•문서화가 잘 되어 있음 / 학습 디버깅을 위한 시각화 도구 DL4J UI 제공
• 단점
•Java 언어로 인한 학습 및 테스트 과정의 번거로움
•협소한 사용자 커뮤니티
•부족한 예제
F/W 주체 플랫폼 모바일 언어 인터페이스 OpenMP CUDA OpenC
L 멀티GPU 분산
DL4J SkyMind
Cross-
platform
(JVM)
Android Java Java, Scala,
Python
Y
Y
- Y
Y
(Spark)

TENSORFLOW OVERVEIW

Contents
• 딥러닝의 역사
• XOR문제
• 선형성
• SVM의 등장
• Computer vs Brain
• TensorFlow의 출현 배경
• 딥러닝과 머신러닝의 차이
• 딥러닝 프로세스

딥러닝의 역사

XOR Problem

선형성

SVM(Spport Vector Machine)
• 비선형 문제를 Infra cost down하여 풀 수 있는 Machine Learning 기법

Computer vs Brain

TENSORFLOW의 출현 배경
• 기술의 변천
• CLOUD INFRA → BIG Data → IOT, IOE → 4차 산업혁명
• 통계 모델 (R, SPSS, SAS) → Machine Learning → Deep Learning
• Paradigm Shift
• Solution (해결책) → Optimize (최적화)

딥러닝과 머신러닝의 차이
머신러닝 프로젝트 R분석을 통한 PCA(주성분 분석)기반으로 Factor를 찾고 변수의 조정 및 변인의 조절을 통한 변수와의 관계를 규정한 뒤 앙상블 기법을 통한 예측 수행
능력을 확인
딥러닝 프로젝트 Data가 제공하는 factor들의 관계를 Vectorize화 하여 다양한 기법과 알고리즘을 적용하여 다차원 분포를 통한 Matching관계 정립을 한 후 차원
축소를 통한 정밀 분석을 수행 후 모델링화 하여 예측을 수행함
하지만 단순히 알고리즘을 적용하는 것이 아니라 데이터 특성에 맞추어 Customizing이 수반되어야 한다.

Deep Learning Process
• 데이터 로딩 - ( 데이터 생성, 데이터 Agumentation(R-VAE))
• 학습 데이터/평가 데이터로 분리
• 학습 (Training) - DNN, RNN, CNN, VAE 다양한 알고리즘 Customizing
• 평가 - GAN
• 모델 저장 - Accuracy rate확인 및 Data 정제 수행
• 서비스 활용

TENSORFLOW BASIC

Contents
• TensorFlow 개념
•Tensor, Variable
• Computational Graph
• Why Graph?
• Supervised Learning
• Classifier
• Multi-Classifier

TensorFlow 개념
• Edges (tensors)
• Nodes(operations)
• Graph
• Session
• Run
• Devices
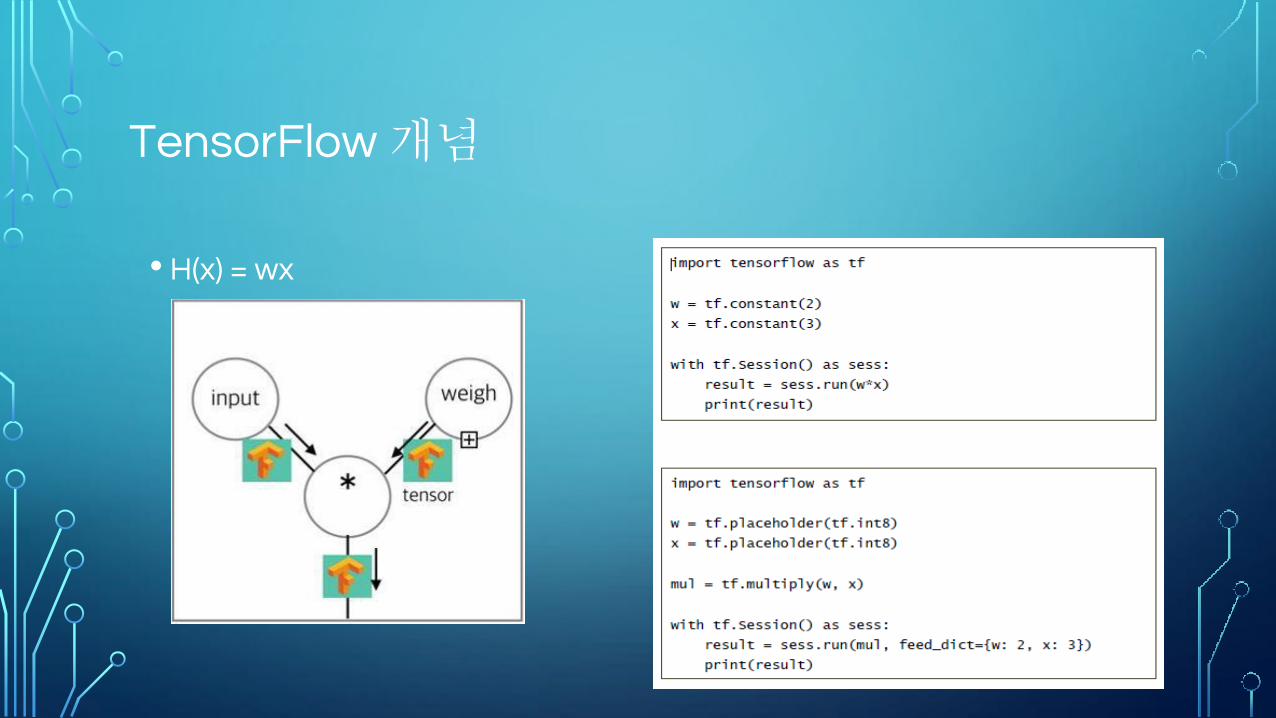
TensorFlow 개념
• H(x) = wx


Tensor
• 임의의 차원을 가지는 행렬
• 스칼라, 벡터, 행렬 등의 일반적인 형태

Variable

Computational Graph

Why Graphs?
1. 계산 저장 (가져올 값으로 연결되는 하위 그래프 만 실행)
2. 계산을 작은 차동 조각으로 나누어 자동 차별화를 촉진합니다.
3. 분산 컴퓨팅을 촉진하고 여러 CPU, GPU 또는 장치에 작업을
분산시킵니다.
4. 많은 일반적인 기계 학습 모델은 일반적으로 지시 그래프로 이미
가르쳐지고 시각화됩니다

Supervised Learning

Classifier란?

Classifier (분류기)

Classifier (분류기)

Classifier (분류기)

Classifier (분류기)

Multi-Class Classifier
• Multi-Class 분류 문제에 관한 classifier 디자인
• Softmax 함수
•[0, 1] 로 값을 정규화
• 미분 가능하기 때문에 Max함수 대신 많이 사용됨

Gradient Descent (경사하강법)

GRADIENT DESCENT로 인자 찾아내기
import tensorflow as tf
import numpy as np
# Numpy random으로 100개의 가짜 데이터 2개 만들기
a_data = np.float32(np.random.rand(2, 100))
# Learning Lable은 아래 식으로 산출 (W = [0.1, 0.2], b = 0.3)
b_data = np.dot([0.100, 0.200], a_data) + 0.300


B_DATA = NP.DOT([0.100, 0.200], A_DATA) + 0.300

PYTHON NUMPY기초 - 선형대수 다뤄보기
행렬 연산의 기초
dot( )함수는 두 행렬의 곱
T는 전치행렬(transpose)를 의미
y.T = [ 1 1
0 1
-1 0 ]

NUMPY 과제
A = [ 2, 2, 0 역행렬을 구하라
-2, 1, 1
3, 0, 1 ]

과제 정답

하기 식을 행렬로 표현하고 변수의 해를 구하라

과제 정답
http://pinkwink.kr/191

TensorFlow Operations
Basic operations
Tensor types
Project speed dating
Placeholders and feeding inputs
Lazy loading

TENSORFLOW basic operation
https://www.tensorflow.org/api_guides/python/math_ops

TensorBoard 맛보기

TensorBoard를 활용하여 모델을 튜닝할 factor를 찾을 수 있고
이를 통해 bagging과 boosting 여부를 결정할 수 있다.
Bagging(Bootstrap Aggregating)
bootstrap 샘플링 방법을 이용해서 여러개의 트레이닝 데이터를
생성하는 방법이다. 이렇게 생성된 데이터 셋은 하나의 모델을 생성
Boosting
약한 learner들을 합쳐서 강한 learner로 만들어주는 알고리즘을 말한다.

Constants
tf.constant(value,
dtype=None,
shape=None,
name='Const',
verify_shape=False)

Tensors filled with a specific value

Constants as sequences
tf.linspace(start, stop, num, name=None) # slightly different from np.linspace
tf.linspace(10.0, 13.0, 4) ==> [10.0 11.0 12.0 13.0]
tf.range(start, limit=None, delta=1, dtype=None, name='range')
# 'start' is 3, 'limit' is 18, 'delta' is 3
tf.range(start, limit, delta) ==> [3, 6, 9, 12, 15]
# 'limit' is 5
tf.range(limit) ==> [0, 1, 2, 3, 4]
Tensor objects are not iterable for _ in tf.range(4): # TypeError

Tensorflow library 내 function

Tensorflow library 살펴보기(1)

Tensorflow library 살펴보기(2)

TENSORFLOW Project 란?

Contents
• Deep Learning을 이해하는 첫 걸음
• TensorFlow Project에서 만나는 문제
• TensorFlow로 구현 가능한 Project

Deep Learning을 이해하는 첫 걸음
SI 와 Deep Learning의 가장 근본적인 차이는
SI = SOLUTION
DEEP LEARNING = OPTIMIZATION
이라는 것이다
결과와 해결책 보다는 문제를 해결해가는 과정에 초점을 두어야 한다는 것이다
또한 이는 바로 현 시대의 불확실성과 연관이 있으며, 다양성을 인정하고 다름을
수용하는 문화적 기반이 뒷받침 되어야 한다는 의미다.

TENSORFLOW PROJECT에서 만나는 문제

TENSORFLOW PROJECT에서 만나는 문제
• version
• data 정합성 / 실 data 부족 / 현업 및 PM의 데이터에 대한 무지
• optimization
• si식으로 deep learning 프로젝트에 접근하는 개발 문화

TENSORFLOW 환경 확인
import tensorflow as tf
dir(tf)
tf.__version__
Version확인을 통해 하위 호환성 지원이 되지 않는 tensorflow의 api확인

TENSORFLOW VERSION 문제
• Deprecated
• Tensorflow1.0.0
• tf.multiply, tf.subtract, tf.negative 가 추가되고 tf.mul, tf.sub, tf.neg 는 deprecated
• tf.scalar_summary, tf.histogram_summary 같은 summary 연산자가 삭제되고
tf.summary.scalar, tf.summary.histogram 이 추가
• TensorFlow 1.2.0-rc1
• https://github.com/tensorflow/tensorflow/releases
• 적용 스크립트
• http://github.com/Finfra/TensorflowInstallMultiVersionWithJupyter

TENSORFLOW 구현 가능한 프로젝트는?

Neural Style Translation
Chat bot

Tensorflow playground 이해 및 기본 활용 실습





Contents
• Batch Size
• Epoch(Iteration)
• Activation
• Regularization
• Problem Type
• Over-shooting 과 Over-fitting
• Early-Stopping
• Dropout

HTTP://PLAYGROUND.TENSORFLOW.ORG

Batch Size
배치(batch)는 한 번에 처리하는 사진의 장 수를 말합니다.
batch_size: 100 이라는 부분이 있습니다.
한 번에 100장의 사진을 처리한다는 의미

EPOCH(ITERATION IS BACKPROPACTION)

Iteration(epoch)
훈련용 사진 전체를 딱 한 번 사용했을 때 한 세대 (이폭, epoch)
만약, 사진 60,000장 중 50,000장이 훈련용, 10,000장이 검사용으로
지정되어 있다고 가정한다.
max_iter에서 훈련에 사진 6,000,000장을 사용하기로 했기 때문에
50,000장의 훈련용 사진이 여러번 재사용되게 됨
6,000,000 / 50,000 = 120 이니 한 사진이 120번 씩 재사용될 것입니다.
이 경우 120 세대(epoch)라고 말합니다.

ACTIVATION(ACTIVATE FUNCTION)

Activation
ReLU : Geoffrey Hinton
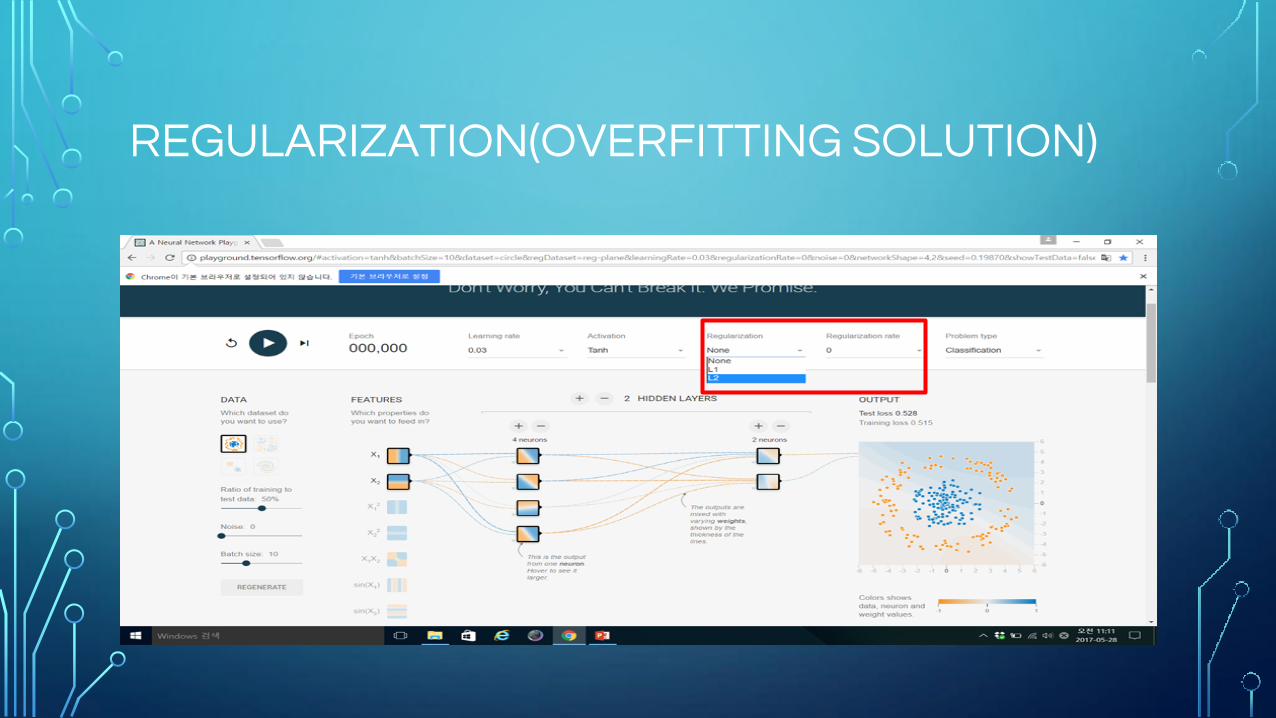
REGULARIZATION(OVERFITTING SOLUTION)

Regularization
Overfitting이나 Underfitting이 일어나는 것을 방지하기 위하여
Regularization을 해야 한다.
이는 Classification Error를 줄이는 것에 목적이 있으며, 그렇기 때문에
Baysian 추론 관점에서의 설명도 가능하다.
file:///C:/Users/Home/Documents/강의%20자료/tensorflow%20강의/Bayesian%20Learning.pdf

Regularization(1)

Regularization(2)

L1 Regularization
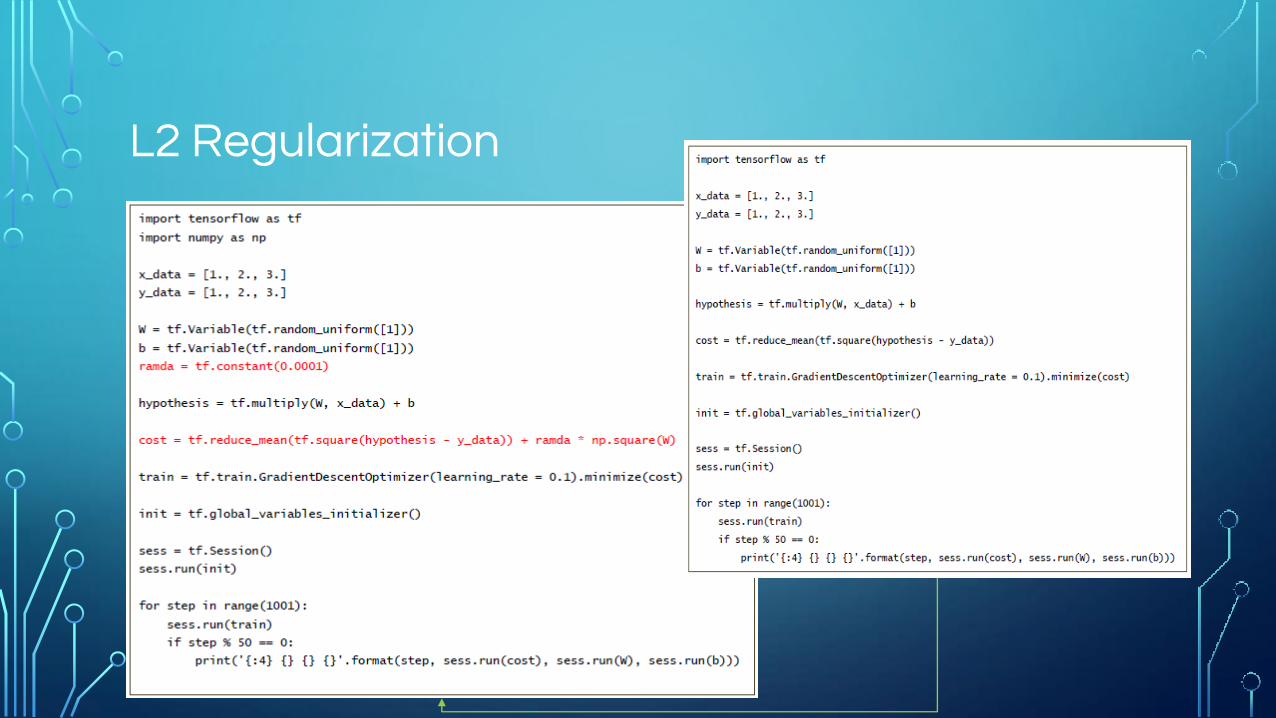
L2 Regularization

PROBLEM TYPE

• 발걸음이 너무 커서 bowl을
벗어남
Over-shooting

Over-shooting 실습 코드

Early Stopping

Dropout

딥러닝 심화 학습

Contents
• Classification VS Regression
• Regression
• Linear Regression
• TensorBoard의 활용 (심화)
• GPU 사용 확인법

CLASSIFICATION VS REGRESSION
• Classification • Model → Class (categorical data 범주형 데이터)
• Regression • Model → 실수
• Model → Class (categorical data 범주형 데이터)
• Logistic Regression은 Classfication으로 볼 수 있다.
• 종속 변수가 많을 수록 y값을 예측할 수 있는 방정식을 만들 때 유리하다. • Jupyter notebook 예제 실행

Linear Regression

TENSORBOARD의 활용 (심화)

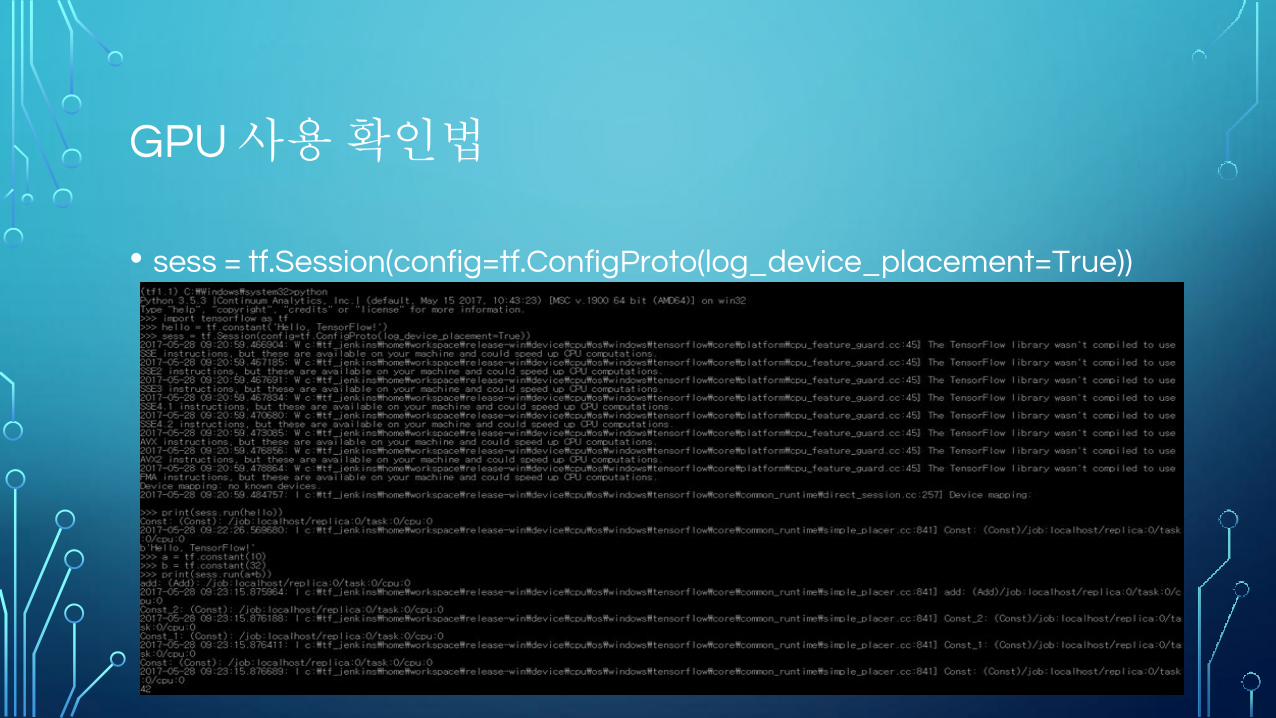
GPU 사용 확인법
• sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))

MNIST 필기체 인식 실습 및 과제 수행

Contents
• MNIST의 유래
• MNIST 다운로드
• MNIST Datafile 소개
• MNIST 필기체 인식 실습
• MNIST Data 확인
• Numpy를 활용한 실 Data확인
• Data Script 확인

MNIST의 유래
MNIST의 이름은 NIST(표준 기술 미국 국립 연구소)에 의해 수집된
데이터 셋 일부가 수정되었다하여 MNIST라 붙여짐

MNIST 다운로드

MNIST Data file 소개

MNIST 필기체 인식 실습

mnist data 확인
dir(mnist)
mnist.__class__
mnist.train.__class__
dir(mnist.train) #image, label확인
mnist.train.images[0]
mnist.train.images[0].__class__

Numpy를 활용한 mnist image 확인
28 * 28 = ?
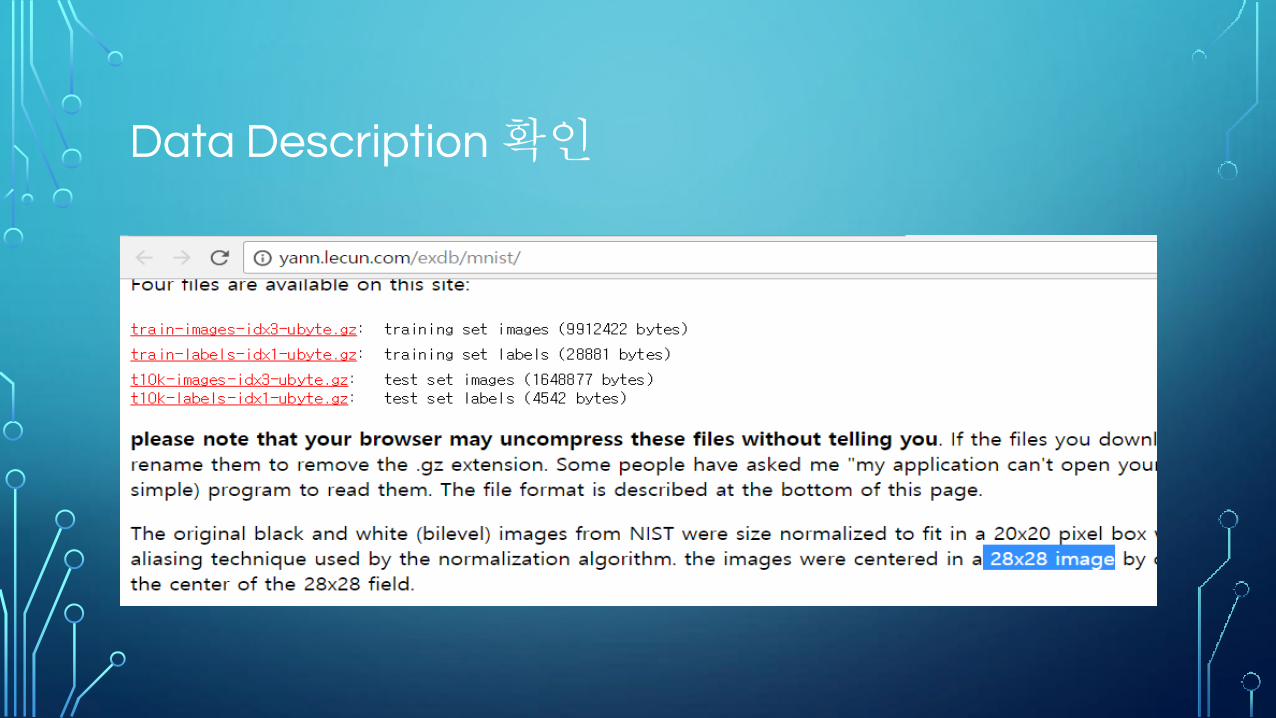
Data Description 확인

MNIST Data 확인

MNIST Data 확인

실습 후 Data 확인

mnist data에 대한 라벨값 확인
0 1 2 3 4 5 6 7 8 9

MNIST train label data 정보 보기

MNIST train label data 정보 보기
반디집으로 압축 풀기 sublime text에서 열면 windows에서 바로
hexa값으로 표기됨 (리눅스에선 vi편집기 모드에서 %!xxd 입력
원상 복구 %!xxd -r)

image저장하고 읽기

MNIST 과제
• 과제 hidden lay(256 * 512) matrix를 추가하고 accuracy rate을 비교하라
# all the variables are allocated in GPU memory W1 = tf.Variable(tf.zeros([784, 256])) # create (784 * 256) matrix b1 = tf.Variable(tf.zeros([256])) # create (1 * 256) vector weighted_summation1 = tf.matmul(x, W1) + b1 # compute --> weighted summation h1 = tf.sigmoid( weighted_summation1 ) # compute --> sigmoid(weighted summation) W2 = tf.Variable(tf.zeros([256, 10])) # create (256 * 10) matrix b2 = tf.Variable(tf.zeros([10])) # create (1 * 10) vector weighted_summation2 = tf.matmul(h1, W2) + b2 # compute --> weighted summation y = tf.nn.softmax(weighted_summation2) # compute classification --> softmax(weighted summation)

과제 정답

optimizer 종류와 활용 방안

Optimizer란?
Data의 특성 및 유형에 따라 어떤 Optimizer를 쓰는가가 성능에 많은
영향을 미친다.
그렇기 때문에 대부분의 논문의 서문에서 전제사항을 통해 Data의
특성과 유형을 정의한다.
Machine Learning에서는 Object의 전처리 수행만으로도 다수의 논문이
출간되었으나, Deep Learining의 도래로 전처리 보다는 선험적인
알고리즘 적용이 선호되고 있는 추세이다.

Optimize Selection

Full Batch - Online Learning

Optimization Method
https://github.com/tylee33/DeepLearning_Tutorial/blob/master/fastcampus/optimizer_simulation.ipynb

CNN (Convolutional Neural Network)

Contents • CS231n (http://cs231n.github.io/convolutional-networks/)
• CNN의 구조
• Convolution
• Convolution Layer의 특징과 Operation
• Convolution Process
• Pooling
• Pooling Layer의 특징
• Pooling Process
•Graphic과 Vision의 차이
• CNN의 활용
•MNIST(CNN)

CS231n

CNN의 구조

Convolution Layer의 특징
• 입력 이미지 속 다양한 위치에서 동일한 특징들을 탐색

Convolution Layer의 특징
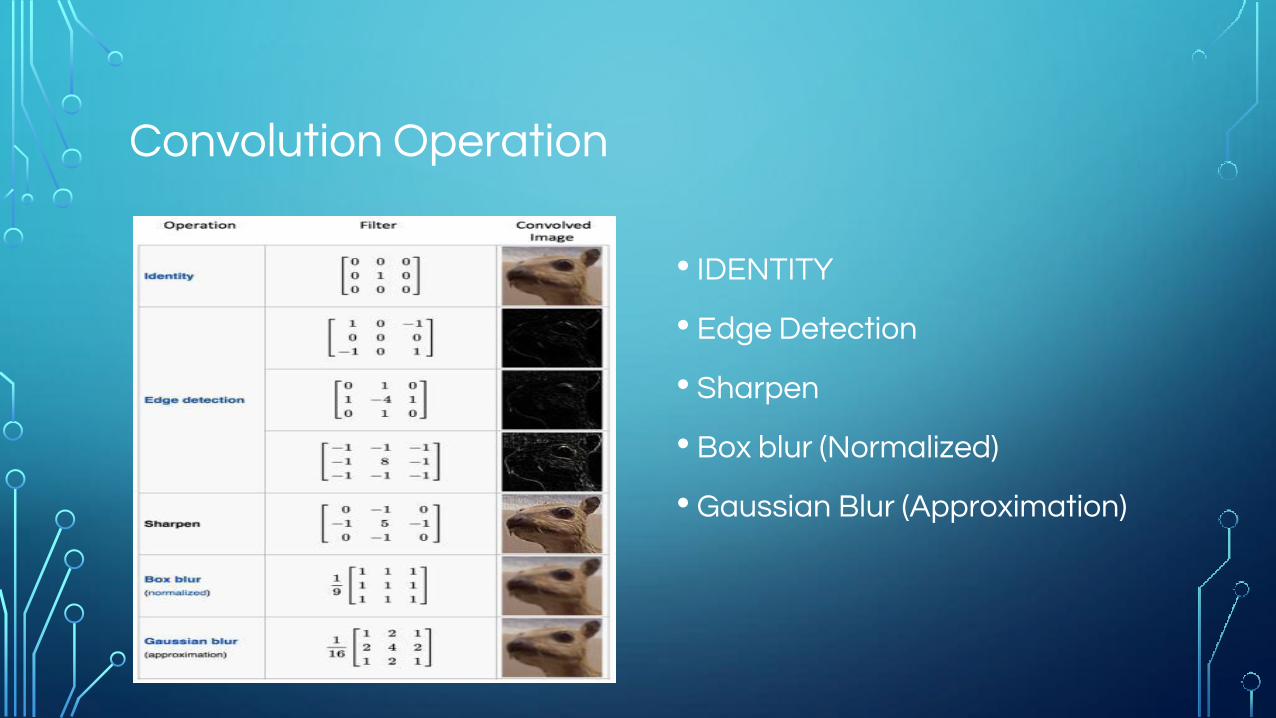
Convolution Operation
• IDENTITY
• Edge Detection
• Sharpen
• Box blur (Normalized)
• Gaussian Blur (Approximation)

Convolution Operation

Convolution Process

Convolution Process 정리
• 한 개의 Feature Map이 Convolution 과정을 통해 Feature를 탐색할 때
Feature Map의 가중치 값은 변경되지 않음 (가중치 공유)
• 이와 같은 방식으로 Feature Map은 입력 이미지의 다양한 위치에서
동일한 특징을 탐색할 수 있음
• 모델이 갖는 파라미터의 개수를 줄여줌
• Feature Map이 나타내고자 하는 템플릿과 이미지의 국소 부분이
일치한다면, Feature Map의 Neuron이 발화

Pooling Layer의 특징

Pooling Layer의 특징

Pooling Layer의 특징

Pooling Process
• 물체의 위치와 각도 변화에 잘 대처할 수 있게 해줌
• 각 Feature Map의 해상도를 줄여줌 -> 모델의 Parameter의 개수를 줄임
• Max / Average Pooling을 주로 사용

Graphic 과 Vision의 차이는?

CNN의 활용
Convolution layer 여러 층을 가진 deep learning model
DBN은 overfitting issue를 initialization으로 해결하였지만, CNN은
overfitting issue를 모델 complexity를 줄이는 것으로 해결한다. CNN은
convolution layer와 pooling layer라는 두 개의 핵심 구조를 가지고
있는데, 이 구조들이 model parameter 개수를 효율적으로 줄여주어
결론적으로 전체 model complexity가 감소하는 효과를 얻게 된다.

CNN은 이렇게 convolution layer와 pooling layer가 결합된 형태로 deep 하게 구성
http://inspirehep.net/record/1252539/plots
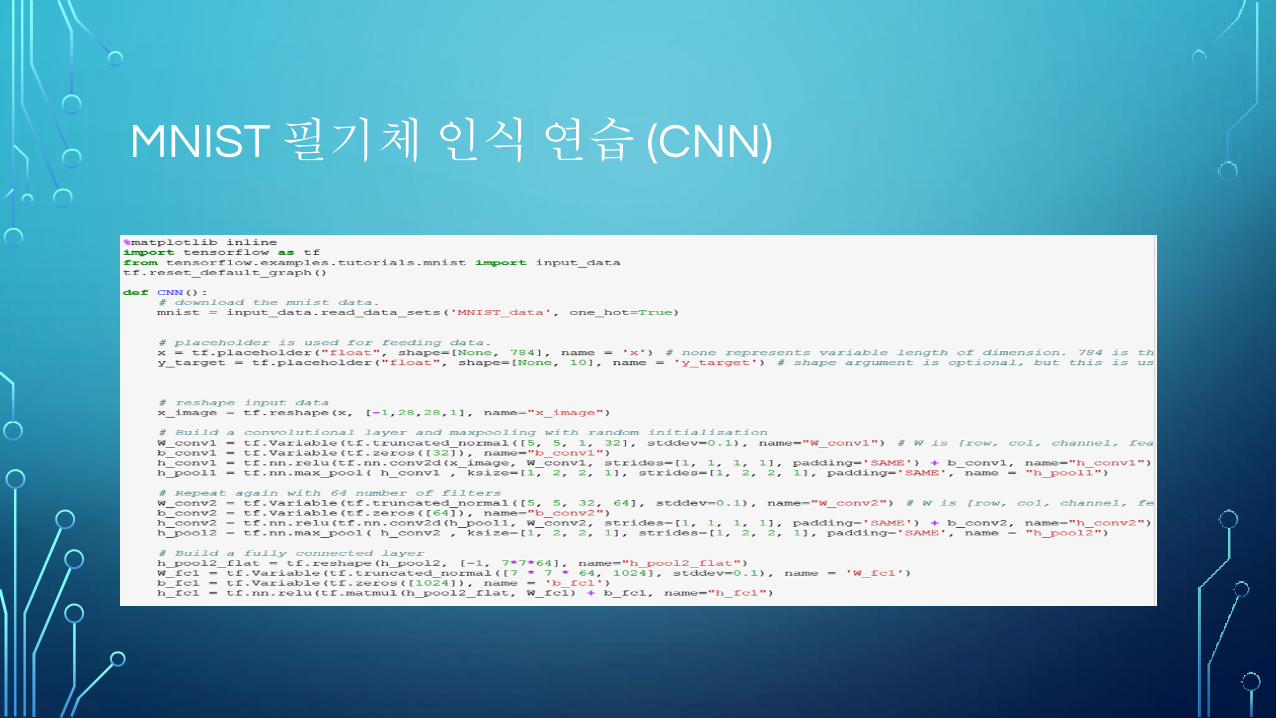
MNIST 필기체 인식 연습 (CNN)

additive and subtractive color combinations
RGB (Red, Green, Blue)는 빛의 혼합 즉
더하면 더할수록 밝아지는 가산혼합인데 반해
CMYK (Cyan, Magenta, Yellow, Black)는
물감의 혼합 즉 더하면 더할수록 어두워 져서
최종적으로 Black이 되는 감산혼합을 의미
CMYK 모드는 밝고 화려한 색은 제대로 표현할 수 없습니다. 잉크의
표현력에 한계가 있고, 특히 모니터와 달리 잉크는 빛을 내지 않기
때문입니다.
즉 RGB모드에서 CMYK 모드로 변환하면 손실되는 색이 있습니다.
손실되는 모든 색들을 회색으로 표시

PNG와 JPEG파일의 차이
PNG파일은 비손실압축 방식이라 원본이 훼손되지 않음
JPEG 알고리즘에는 DCT(discrete cosine transform)를 적용한 후 데이터를 줄이기 위해
Quantization(양자화)를 함 쉽게 말하면 자연스러운 색상을 단순화함
양자화를 하면 색수가 줄어듬
이 때 데이터 손실 발생

Imagemagick 설치와 사용법

Imagemagick란?
ImageMagick은 이미지를 생성하고 수정하고 변환하는 시스템 툴이다.
대개는 서버에서 업로드된 이미지의 썸네일 버전을 생성하거나 다양한
변화를 주기 위해 사용한다.
공식 사이트 : https://www.imagemagick.org/script/index.php

왜 뜬금없는 Imagemagick?
Image Training Data 표본의 단일성 보장
Image 정제를 통한 Size 축소 및 Training시 퍼포먼스 확보
Linux상에 shell script 작성을 통한 많은 Training Data 처리에 용이함
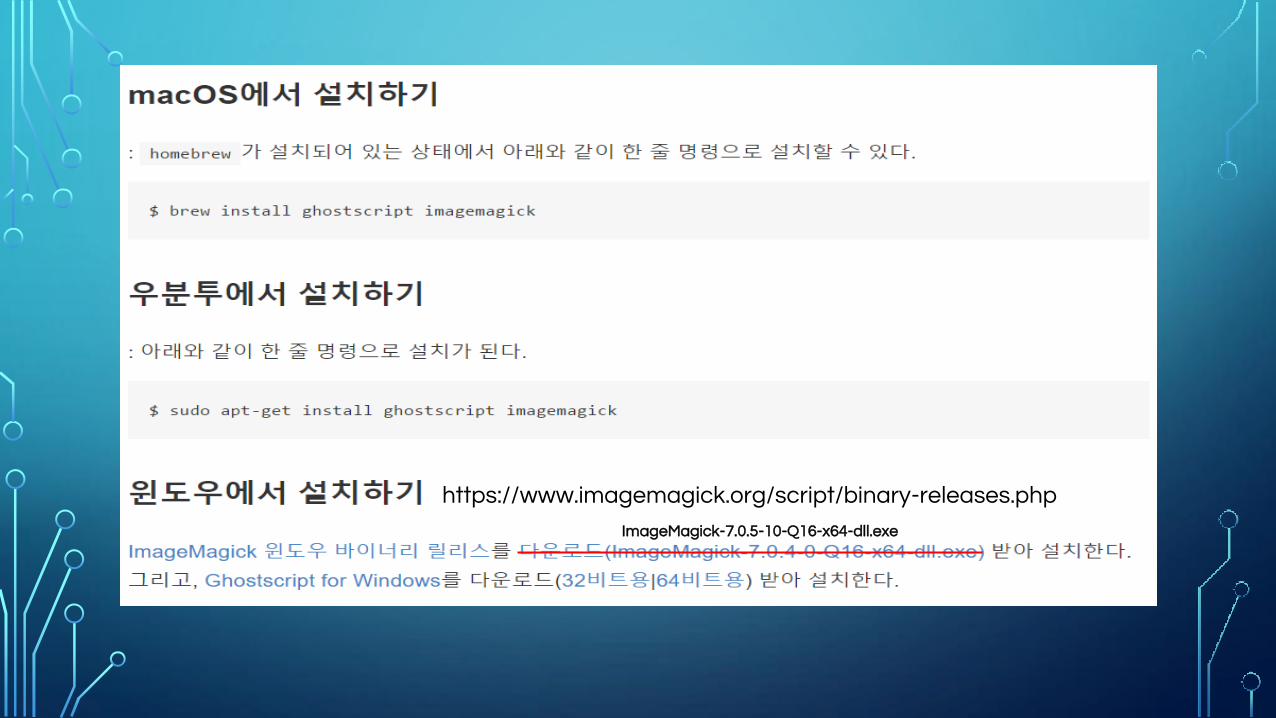
https://www.imagemagick.org/script/binary-releases.php
ImageMagick-7.0.5-10-Q16-x64-dll.exe

파일포맷변경
convert image_org.gif image_out.jpg
[설명] image_org.gif 이미지를 image_out.jpg로 바꾼다.
convert image_org.png image_out.jpg
[설명] image_org.png 이미지를 image_out.jpg로 바꾼다.
http://www.imagemagick.org/Usage/를 참고

확대, 축소, 리사이즈
convert image_org.jpg -resize 25%x25% -quality 100 image_out.jpg
[설명] image_org.jpg 이미지를 1/4 축소한 image_out.jpg로 바꾼다.
convert image_org.jpg -resize 800x600 -quality 100 image_out.jpg
[설명] image_org.jpg 이미지를 800x600픽셀로 리사이즈 하지만 비율을
유지하며 큰사이즈 비율 기준으로 image_out.jpg를 생성한다.
convert image_org.jpg -resize 800x600\! -quality 100 image_out.jpg
[설명] image_org.jpg 이미지를 800x600픽셀로 강제적으로 바꾸어
image_out.jpg를 생성한다.

회전
convert image_org.png -matte -background none -rotate 90
image_out.png
[설명] 이미지를 90도 회전하고 나머지 영역은 투명하게한다.
convert image_org.png -matte -background none -rotate -15
image_out.png
[설명] 이미지를 -15도 회전하고 나머지 영역은 투명하게한다.
http://www.imagemagick.org/Usage/를 참고

좌우반전, 상하반전
convert -flop image_org.jpg image_out.jpg
[설명] image_org.jpg 이미지를 좌우반전시켜 image_out.jpg 이미지를
생성한다.
convert -flip image_org.jpg image_out.jpg
[설명] image_org.jpg 이미지를 상하반전시켜 image_out.jpg 이미지를
생성한다.
http://www.imagemagick.org/Usage/를 참고

밝게, 어둡게
convert image_org.jpg -sigmoidal-contrast 3,0% image_out.jpg
[설명] image_org.jpg 이미지를 밝게 하여 image_out.jpg 이미지를
생성한다.
convert image_org.jpg -sigmoidal-contrast 3,100% image_out.jpg
[설명] image_org.jpg 이미지를 어둡게 하여 image_out.jpg 이미지를
생성한다.
http://www.imagemagick.org/Usage/를 참고

자르기(crop)
convert image_org.jpg -crop 800x600+10+20 image_out.jpg
[설명] image_org.jpg를 Left 10픽셀 Top 20픽셀 부터 800x600픽셀까지
자르고 그 결과로 image_out.jpg 이미지를 생성한다.
convert image_org.jpg -crop 800x600+10-30 image_out.jpg
[설명] image_org.jpg를 Left 10픽셀 Top -30픽셀 부터 800x600픽셀까지
자르고 그 결과로 image_out.jpg 이미지를 생성한다.
http://www.imagemagick.org/Usage/를 참고

Linux에서 실습

Linux Shell Program을 통한 이미지 처리

Neural Network Architecture




[ 실습] Neural Art 제작하기

Neural Art
내용 : ‘artistic style’을 learning하는 neural network algorithm
논문 : A Neural Algorithm of Artistic Style
https://arxiv.org/abs/1508.06576
구현 예 : https://github.com/anishathalye/neural-style
참고 자료 : http://sanghyukchun.github.io/92/

구글 이미지 검색 : 임지현 training 시 iteration : 1000 https://www.tumblr.com/search/isobel%20francisco


README.md를 통해 Requirements 환경 구성
git clone https://github.com/anishathalye/neural-style.git

Windows10에서 library설치

실습


Iteration Default 1000

명령어 수행
mkdir ./out cpu client pc환경에선 iterations 20도
10분 이상 소요
python neural_style.py --content ./n.jpg --styles ./s.jpg --output ./o.jpg --iterations 20 --print-
iterations 20 --checkpoint-output ./out/%s.jpg --checkpoint-iterations 20

RNN 시계열 분석 실습

Deep Learing에서의 시계열 개념
Data Mining의 시계열 분석은 예측 자체
Deep Learing에서 시계열은 예측이 아닌 Sequence다.
뇌는 예측과 Sequence가 혼재되어 있다.
예측) 날이 흐리니 비가 오려나? - 내재적/외재적 상호작용
Sequence) 동해물과 백두산이 마르고 - 내재적 흐름

RNN(Recurrent Neural Networks)
Recurrent Neural Networks 기존에 널리 쓰이던 Hidden Markov
Model을 뉴럴넷을 이용하여 구현한 것임.





Dynamic RNN
https://github.com/hunkim/DeepLearningZeroToAll/blob/master/lab-
12-5-rnn_stock_prediction.py

NLP 실습 (Data Training)

NLP 실습 (Prediction Test)

Word Embedding 실습
https://ronxin.github.io/wevi/ [입력 샘플]
king|kindom,queen|kindom,king|palace,queen|palace,king|royal,queen
|royal,king|George,queen|Mary,man|rice,woman|rice,man|farmer,wom
an|farmer,man|house,woman|house,man|George,woman|Mary
왕|왕국,여왕|왕국,왕|왕궁,여왕|왕궁,왕|왕가,여왕|왕가,왕|조지,여왕|메리
,남자|쌀,여자|쌀,남자|농부,여자|농부,남자|집,여자|집,남자|조지,여자|메
리

https://www.facebook.com/groups/1174547215919768/?fref=ts

https://github.com/explosion/spaCy/issues/929

[별첨] TENSORFLOW 설치

TENSORFLOW 환경 구성
• https://www.python.org/downloads/release/python-353/

ANACONDA 설치
• https://www.continuum.io/downloads
• Anaconda Prompt관리자 권한으로 실행

TENSORFLOW 설치 및 확인

JUPYTER NOTEBOOK환경 설정 및 실행
• Command (jupyter notebook --generate-config) 입력
• 사용자 폴더에 .jupyter 폴더 진입
• jupyter_notebook_config.py 열기
• #c.NotebookApp.notebook_dir = '' 열찾기 (179 번째 line 정도) 주석제거
• '' 란 안에 원하는 폴더의 절대 경로 삽입. 단 \ --> / 로 변경
• 저장 후 jupyter notebook 재실행

참조 사이트
• http://sanghyukchun.github.io/
• http://poppk.org/220871310699
• http://yujuwon.tistory.com/entry/TENSOR-FLOW-MNIST-인식하기
•http://blog.naver.com/PostView.nhn?blogId=nanona3260&logNo=14
0187304042
•https://rorlab.gitbooks.io/railsguidebook/content/appendices/image
magick.html
•http://dlwiki.finfra.com/


















