
La gerarchia di memorie Lucidi realizzati in collaborazione con Valeria Cardellini.

Università degli Studi di Roma “Tor Vergata” Dipartimento di Ingegneria Civile e Ingegneria Informatica
Systems for Resource Management
Corso di Sistemi e Architetture per Big Data A.A. 2016/17
Valeria Cardellini
The reference Big Data stack
Matteo Nardelli - SABD 2016/17
1
Resource Management
Data Storage
Data Processing
High-level Interfaces Support / Integration

Outline
• Cluster management systems – Mesos – YARN – Borg – Omega – Kubernetes
• Resource management policies – DRF
Valeria Cardellini - SABD 2016/17
2
Motivations
• Rapid innovation in cloud computing
• No single framework optimal for all applications
• Running each framework on its dedicated cluster: – Expensive – Hard to share data
Valeria Cardellini - SABD 2016/17
3

A possible solution
4
• Run multiple frameworks on a single cluster
• How to share the (virtual) cluster resources among multiple and non homogeneous frameworks executed in virtual machines/containers?
• The classical solution:
Static partitioning
• Is it efficient?
Valeria Cardellini - SABD 2016/17
What we need
• The Datacenter as a Computer idea by D. Patterson – Share resources to maximize their utilization – Share data among frameworks – Provide a unified API to the outside – Hide the internal complexity of the infrastructure
from applications • The solution:
A cluster-scale resource manager that employs dynamic partitioning
Valeria Cardellini - SABD 2016/17
5

Apache Mesos
6 Valeria Cardellini - SABD 2016/17
Dynamic partitioning
• Cluster manager that provides a common resource sharing layer over which diverse frameworks can run
• Abstracts the entire datacenter into a single pool of computing resources, simplifying running distributed systems at scale
• A distributed system to run distributed systems on top of it
Apache Mesos (2)
Valeria Cardellini - SABD 2016/17
7
• Designed and developed at the University of Berkeley - Top open-source project by Apache mesos.apache.org
• Twitter and Airbnb as first users; now supports some of the largest applications in the world
• Cluster: a dynamically shared pool of resources Dynamic partitioning Static partitioning

Mesos goals
• High utilization of resources
• Supports diverse frameworks (current and future)
• Scalability to 10,000's of nodes
• Reliability in face of failures
Valeria Cardellini - SABD 2016/17
8
Mesos in the data center
• Where does Mesos fit as an abstraction layer in the datacenter?
Valeria Cardellini - SABD 2016/17
9

Computation model
• A framework (e.g., Hadoop, Spark) manages and runs one or more jobs
• A job consists of one or more tasks • A task (e.g., map, reduce) consists of one or
more processes running on same machine
Valeria Cardellini - SABD 2016/17
10
What Mesos does
Valeria Cardellini - SABD 2016/17
11
• Enables fine-grained resource sharing (at the level of tasks within a job) of resources (CPU, RAM, …) across frameworks
• Provides common functionalities: - Failure detection
- Task distribution
- Task starting
- Task monitoring
- Task killing
- Task cleanup

Fine-grained sharing
• Allocation at the level of tasks within a job • Improves utilization, latency, and data locality
Valeria Cardellini - SABD 2016/17
12
Coarse-grain sharing Fine-grain sharing
Frameworks on Mesos
• Frameworks must be aware of running on Mesos – DevOps tooling: Vamp (deployment and workflow
tool for container orchestration) – Long running services: Aurora (service scheduler), …
– Big Data processing: Hadoop, Spark, Storm, MPI, …
– Batch scheduling: Chronos, … – Data storage: Alluxio, Cassandra, ElasticSearch, … – Machine learning: TFMesos (Tensorflow in Docker
on Mesos) See the full list at mesos.apache.org/documentation/latest/frameworks/
Valeria Cardellini - SABD 2016/17
13

Mesos: architecture
Valeria Cardellini - SABD 2016/17
14
• Master-slave architecture
• Slaves publish available resources to master
• Master sends resource offers to frameworks
• Master election and service discovery via ZooKeeper
Source: Mesos: a platform for fine-grained resource sharing in the data center, NSDI'11
Mesos component: Apache ZooKeeper • Coordination service for maintaining configuration
information, naming, providing distributed synchronization, and providing group services
• Used in many distributed systems, among which Mesos, Storm and Kafka
• Allows distributed processes to coordinate with each other through a shared hierarchical name space of data (znodes) – File-system-like API – Name space similar to a standard file system – Limited amount of data in znodes – It is no really a: file system, database, key-value store, lock
service
• Provides high throughput, low latency, highly available, strictly ordered access to the znodes
Valeria Cardellini - SABD 2016/17
15

Mesos component: ZooKeeper (2) • Replicated over a set of machines that maintain an
in-memory image of the data tree – Read requests processed locally by the ZooKeeper server – Write requests forwarded to other ZooKeeper servers and
consensus before a response is generated (primary-backup system)
– Uses Paxos as leader election protocol to determine which server is the master
• Implements atomic broadcast – Processes deliver the same messages (agreement) and
deliver them in the same order (total order) – Message = state update
Valeria Cardellini - SABD 2016/17
16
Mesos and framework components
Valeria Cardellini - SABD 2016/17
17
• Mesos components - Master
- Slaves or agents
• Framework components - Scheduler: registers with
the master to be offered resources
- Executors: launched on agent nodes to run the framework’s tasks

Scheduling in Mesos
Valeria Cardellini - SABD 2016/17
18
• Scheduling mechanism based on resource offers - Mesos offers available resources to frameworks
• Each resource offer contains a list of <agent ID, resource1: amount1, resource2: amount2, ...> !
- Each framework chooses which resources to use and which tasks to launch
• Two-level scheduler architecture - Mesos delegates the actual scheduling of tasks to
frameworks
- Improves scalability: the master does not have to know the scheduling intricacies of every type of application that it supports
Mesos: resource offers
• Resource allocation is based on Dominant Resource Fairness (DRF)
Valeria Cardellini - SABD 2016/17
19

Mesos: resource offers in details
Valeria Cardellini - SABD 2016/17
20
• Slaves continuously send status updates about resources to the Master
Mesos: resource offers in details (2)
Valeria Cardellini - SABD 2016/17
21

Mesos: resource offers in details (3)
Valeria Cardellini - SABD 2016/17
22
• Framework scheduler can reject offers
Mesos: resource offers in details (4)
Valeria Cardellini - SABD 2016/17
23
• Framework scheduler selects resources and provides tasks
• Master sends tasks to slaves

Mesos: resource offers in details (5)
Valeria Cardellini - SABD 2016/17
24
• Framework executors launch tasks
Mesos: resource offers in details (6)
Valeria Cardellini - SABD 2016/17
25

Mesos: resource offers in details (7)
Valeria Cardellini - SABD 2016/17
26
Mesos fault tolerance
• Task failure • Slave failure • Host or network failure • Master failure • Framework scheduler failure
Valeria Cardellini - SABD 2016/17
27

Fault tolerance: task failure
Valeria Cardellini - SABD 2016/17
28
Fault tolerance: task failure (2)
Valeria Cardellini - SABD 2016/17
29
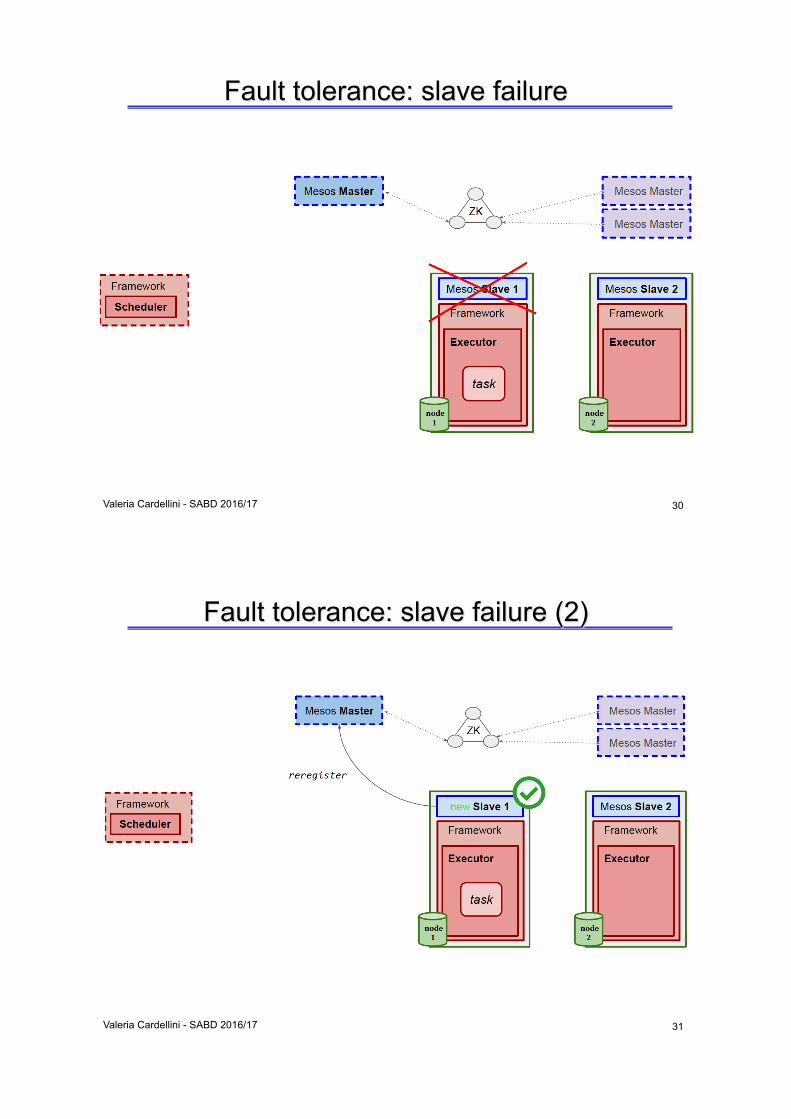
Fault tolerance: slave failure
Valeria Cardellini - SABD 2016/17
30
Fault tolerance: slave failure (2)
Valeria Cardellini - SABD 2016/17
31
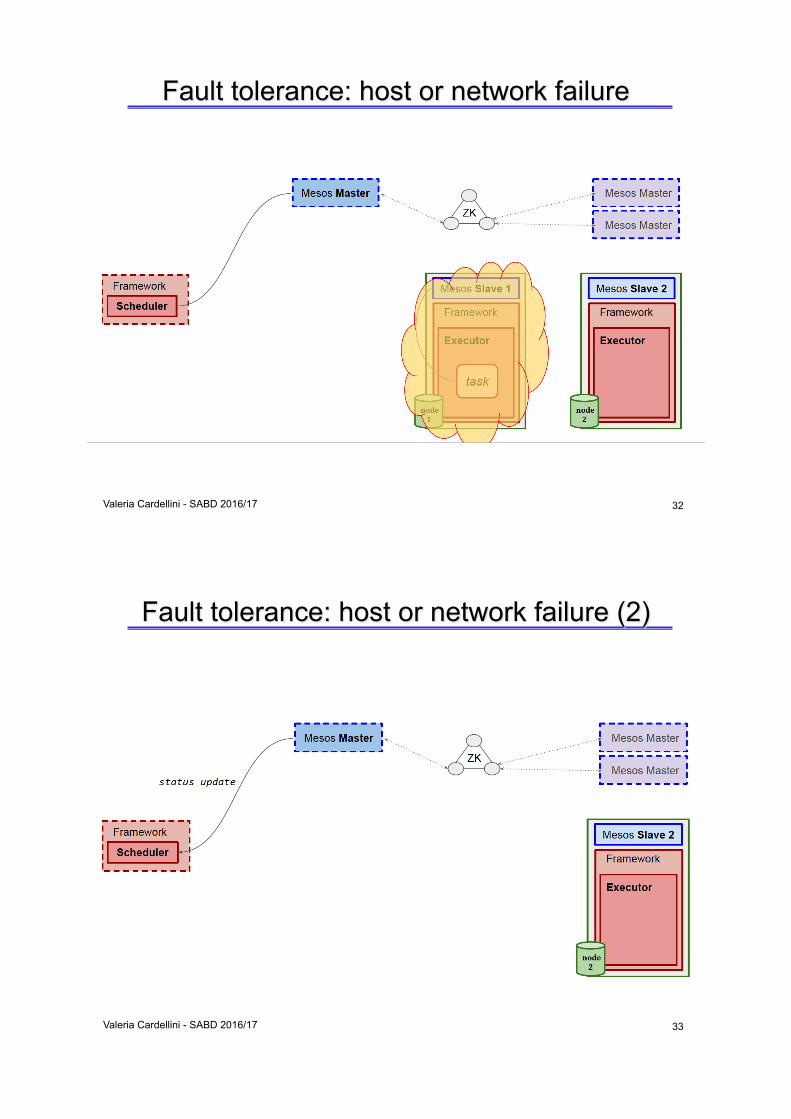
Fault tolerance: host or network failure
Valeria Cardellini - SABD 2016/17
32
Fault tolerance: host or network failure (2)
Valeria Cardellini - SABD 2016/17
33

Fault tolerance: host or network failure (3)
Valeria Cardellini - SABD 2016/17
34
Fault tolerance: master failure
Valeria Cardellini - SABD 2016/17
35

Fault tolerance: master failure (2)
Valeria Cardellini - SABD 2016/17
36
• When the leading Master fails, the surviving masters use ZooKeeper to elect a new leader
Fault tolerance: master failure (3)
Valeria Cardellini - SABD 2016/17
37
• The slaves and frameworks use ZooKeeper to detect the new leader and reregister

Fault tolerance: framework scheduler failure
Valeria Cardellini - SABD 2016/17
38
Fault tolerance: framework scheduler failure (2)
Valeria Cardellini - SABD 2016/17
39
• When a framework scheduler fails, another instance can reregister to the Master without interrupting any of the running tasks

Fault tolerance: framework scheduler failure (3)
Valeria Cardellini - SABD 2016/17
40
Fault tolerance: framework scheduler failure (4)
Valeria Cardellini - SABD 2016/17
41

Resource allocation
1. How to assign the cluster resources to the tasks? – Design alternatives
• Global (monolithic) scheduler • Two-level scheduler
2. How to allocate resources of different types?
Valeria Cardellini - SABD 2016/17
42
Global (monolithic) scheduler
• Job requirements – Response time – Throughput – Availability
• Job execution plan – Task direct acyclic graph (DAG) – Inputs/outputs
• Estimates – Task duration – Input sizes – Transfer sizes
Valeria Cardellini - SABD 2016/17
43
• Pros – Can achieve optimal
schedule (global knowledge) • Cons:
– Complexity: hard to scale and ensure resilience
– Hard to anticipate future frameworks requirements
– Need to refactor existing frameworks

Two-level scheduling in Mesos
• Resource offer – Vector of available
resources on a node – E.g., node1: <1CPU, 1GB>,
node2: <4CPU, 16GB>
• Master sends resource offers to frameworks
• Frameworks select which offers to accept and which tasks to run
Valeria Cardellini - SABD 2016/17
44
• Pros: – Simple: easier to scale and
make resilient – Easy to port existing
frameworks and support new ones
• Cons: – Distributed scheduling
decision: not optimal
Push task placement to frameworks
Mesos: resource allocation
• Based on Dominant Resource Fairness (DRF) algorithm
Valeria Cardellini - SABD 2016/17
45

DRF: background on fair sharing • Consider a single resource: fair sharing
– n users want to share a resource, e.g., CPU – Solution: allocate each 1/n of the shared
resource • Generalized by max-min fairness
– Handles if a user wants less than its fair share
– E.g., user 1 wants no more than 20% • Generalized by weighted max-min
fairness – Gives weights to users according to
importance – E.g., user 1 gets weight 1, user 2 weight 2
Valeria Cardellini - SABD 2016/17
46
Max-min fairness • 1 resource type: CPU • Total resources: 20 CPU • User 1 has x tasks and wants <1CPU> per task • User 2 has y tasks and wants <2CPU> per task
max(x, y) (maximize allocation) subject to
x + 2y ≤ 20 (CPU constraint) x = 2y (fairness)
Solution: x = 10 y = 5
Valeria Cardellini - SABD 2016/17
47

Why is fair sharing useful?
• Proportional allocation – User 1 gets weight 2, user 2 weight 1
• Priorities – Give user 1 weight 1000, user 2 weight 1
• Reservations: – Ensure user 1 gets 10% of a resource, so give
user 1 weight 10, sum weights 100 • Isolation policy:
– Users cannot affect others beyond their fair share
Valeria Cardellini - SABD 2016/17
48
Why is fair sharing useful? (2)
• Share guarantee – Each user can get at least 1/n of the resource – But will get less if its demand is less
• Strategy-proof – Users are not better off by asking for more than
they need – Users have no reason to lie
• Max-min fairness is the only reasonable mechanism with these two properties
• Many schedulers use max-min fairness – OS, networking, datacenters (e.g., YARN),
Valeria Cardellini - SABD 2016/17
49

Max-min fairness drawback • When is max-min fairness not enough? • Need to schedule multiple, heterogeneous
resources (CPU, memory, disk, I/O) • Single resource example
– 1 resource: CPU – User 1 wants <1CPU> per task – User 2 wants <2CPU> per task
• Multi-resource example – 2 resources: CPUs and memory – User 1 wants <1CPU, 4GB> per task – User 2 wants <3CPU, 1GB> per task
• What is a fair allocation? Valeria Cardellini - SABD 2016/17
50
A first (wrong) solution • Asset fairness: gives weights to resources (e.g., 1
CPU = 1 GB) and equalizes total value allocated to each user
• Total resources: 28 CPU and 56GB RAM (e.g., 1 CPU = 2 GB) – User 1 has x tasks and wants <1CPU, 2GB> per task – User 2 has y tasks and wants <1CPU, 4GB> per task
• Asset fairness yields: max(x, y) x + y ≤ 28 2x + 4y ≤ 56 4x = 6y
• User 1: x = 12 i.e. <43%CPU, 43%GB> (sum = 86%) • User 2: y = 8 i.e. <29%CPU, 57%GB> (sum = 86%)
Valeria Cardellini - SABD 2016/17
51

A first (wrong) solution (2)
• Problem: violates share guarantee – User 1 gets less than 50% of both CPU and RAM – Better off in a separate cluster with half the
resources
Valeria Cardellini - SABD 2016/17
52
What Mesos needs
• A fair sharing policy that provides: – Share guarantee – Strategy-proofness
• Challenge: can we generalize max-min fairness to multiple resources?
• Solution: Dominant Resource Fairness (DRF)
Valeria Cardellini - SABD 2016/17
53
Source: Dominant Resource Fairness: Fair Allocation of Multiple Resource Types, NSDI'11

DRF
• Dominant resource of a user: the resource that user has the biggest share of – Example:
• Total resources: <8CPU, 5GB> • User 1 allocation: <2CPU, 1GB> • 2/8 = 25%CPU and 1/5 = 20%RAM • Dominant resource of user 1 is CPU (25% > 20%)
• Dominant share of a user: the fraction of the dominant resource allocated to the user – User 1 dominant share is 25%
Valeria Cardellini - SABD 2016/17
54
DRF (2) • Apply max-min fairness to dominant shares: give
every user an equal share of its dominant resource • Equalize the dominant share of the users
– Total resources: <9CPU, 18GB> – User 1 wants <1CPU, 4GB> – Dominant resource for user 1: RAM (1/9 < 4/18) – User 2 wants <3CPU, 1GB> – Dominant resource for user 2: CPU (3/9 > 1/18)
max(x, y) x + 3y ≤ 9 4x + y ≤ 18 (4/18)x = (3/9)y
• User 1: x = 3 <33%CPU, 66%GB> • User 2: y = 2 <66%CPU, 16%GB>
Valeria Cardellini - SABD 2016/17
55

Online DRF
• Whenever there are available resources and tasks to run: – Presents resource offers to the framework with the
smallest dominant share among all frameworks
Valeria Cardellini - SABD 2016/17
56
DRF: efficiency-fairness trade-off
Valeria Cardellini - SABD 2016/17
57
Efficiency-Fairness Trade-off
• DRF has under-utilized resources
• DRF schedules at the level of tasks (lead to sub-optimal job completion time)
• Fairness is fundamentally at odds with overall efficiency (how to trade-off?)

Mesos and containers
• Mesos plays well with existing container technologies (e.g., Docker) and also provides its own container technology – Docker containers: tasks run inside Docker
container – Mesos containers: tasks run with an array of
pluggable isolators provided by Mesos • Also supports composing different container
technologies (e.g., Docker and Mesos) • Which scale? 50,000 live containers
Valeria Cardellini - SABD 2016/17
58
Mesos deployment and evolution
• Mesos clusters can be deployed – On nearly every IaaS cloud provider infrastructure – In your own physical datacenter
• Mesos platform evolution towards microservices • Mesosphere’s Datacenter Operating System (DC/OS)
Valeria Cardellini - SABD 2016/17
59
– Open source operating system and distributed system built upon Mesos
• Marathon – Container orchestration platform
for Mesos and DC/OS

Apache Hadoop YARN • YARN: Yet Another Resource Negotiator
– A framework for job scheduling and cluster resource management
• Turns out Hadoop into an analytics platform in which resource management functions are separated from the programming model – Many scheduling-related functions are delegated to per-job
components
• Why separation? – Provides flexibility in the choice of programming framework – Platform can support not only MapReduce, but also other
models (e.g., Spark, Storm)
Valeria Cardellini - SABD 2016/17
60
Source: Apache Hadoop YARN: Yet Another Resource Negotiator, SoCC'13
YARN architecture • Global ResourceManager (RM) • A set of per-application ApplicationMasters (AMs) • A set of NodeManagers (NMs)
Valeria Cardellini - SABD 2016/17
61

YARN architecture: ResourceManager • One RM per cluster
– Central: global view – Enable global properties: fairness, capacity, locality
• Job requests are submitted to RM – Request-based – To start a job (application), RM finds a container to spawn AM
• Container – Logical bundle of resources (CPU, memory)
• Only handles an overall resource profile for each application – Local optimization is up to the application
• Preemption – Request resources back from an application – Checkpoint snapshot instead of explicitly killing jobs/migrate
computation to other containers Valeria Cardellini - SABD 2016/17
62
YARN architecture: ResourceManager (2) • No static resource partitioning • RM: resource scheduler in the system
– Organizes the global assignment of computing resources to application instances
• Composed of Scheduler and ApplicationsManager – Scheduler: responsible for allocating resources to the
various running applications • Pluggable scheduling policy to partition the cluster resources
among the various applications • Available pluggable schedulers:
– CapacityScheduler and FairScheduler – ApplicationsManager accepts job submissions and
negotiates the first set of resources for job execution
Valeria Cardellini - SABD 2016/17
63

YARN architecture: ApplicationMaster • One AM per application • The head of a job • Runs as a container • Issues resource requests to RM to obtain containers
– # of containers, resources per container, locality preferences, ...
• Dynamically changing resource consumption, based on the containers it receives from the RM
• Requests are late-binding – The process spawned is not bound to the request, but to the
lease – The conditions that caused the AM to issue the request may not
remain true when it receives its resources • Can run any user code, e.g., MapReduce, Spark, etc. • AM determines the semantics of the success or failure of
the container Valeria Cardellini - SABD 2016/17
64
YARN architecture: NodeManager
• One NM per node – The worker daemon – Runs as local agent on the execution node
• Registers with RM, heartbeats its status and receives instructions
• Reports resources to RM: memory, CPU, ... – Responsible for monitoring resource availability, reporting
faults, and container lifecycle management (e.g., starting, killing)
• Containers are described by a container launch context (CLC) – The command necessary to create the process – Environment variables, security tokens, …
Valeria Cardellini - SABD 2016/17
65

YARN architecture: NodeManager (2)
• Configures the environment for task execution • Garbage collection • Auxiliary services
– A process may produce data that persist beyond the life of the container
– Output intermediate data between map and reduce tasks.
Valeria Cardellini - SABD 2016/17
66
YARN: application startup
• Submitting the application: passing a CLC for the AM to the RM
• The RM launches the AM, which registers with the RM
• Periodically advertises its liveness and requirements over the heartbeat protocol
• Once the RM allocates a container, AM can construct a CLC to launch the container on the corresponding NM – It monitors the status of the running container and stops it
when the resource should be reclaimed
• Once the AM is done with its work, it should unregister from the RM and exit cleanly
Valeria Cardellini - SABD 2016/17
67

Comparing Mesos and YARN
Valeria Cardellini - SABD 2016/17
68
Mesos YARN Two-level scheduler Two-level scheduler (limited) Offer-based approach Request-based approach Pluggable scheduling policy (DRF as default)
Pluggable scheduling policy
Framework gets resource offer to choose (minimal information)
Framework asks a container with specification + preferences (lots of information)
General-purpose scheduler (including stateful services)
Designed and optimized for Hadoop jobs (stateless batch jobs)
Multi-dimensional resource granularity
RAM/CPU slots resource granularity
Multiple Masters Single ResourceManager Written in C++ Written in Java Linux cgroups (performance isolation)
Simple Linux processes
Cluster resource management: Hot research topic
• Borg @EuroSys 2015 – Cluster management system used by Google for
the last decade, ancestor of Kubernetes • Firmament @OSDI 2016 firmament.io
– Scheduler (with a Kubernetes plugin called Poseidon) that balances the high-quality placement decisions of a centralized scheduler with the speed of a distributed scheduler
• Slicer @OSDI 2016 – Google’s auto-sharding service that separates out
the responsibility for sharding, balancing, and re-balancing from individual application frameworks
Valeria Cardellini - SABD 2016/17
69

Container orchestration
• Container orchestration: set of operations that allows cloud and application providers to define how to select, deploy, monitor, and dynamically control the configuration of multi-container packaged applications in the cloud – The tool used by organizations adopting containers
for enterprise production to integrate and manage those containers at scale
• Some examples – Cloudify – Kubernetes – Docker Swarm
Valeria Cardellini - SABD 2016/17
70
Container-management systems at Google
• Application-oriented shift “Containerization transforms the data center from being machine-oriented to being application-oriented”
• Goal: to allow container technology to operate at Google scale – Everything at Google runs as a container
• Borg -> Omega -> Kubernetes – Borg and Omega: purely Google-internal systems – Kubernetes: open-source
Valeria Cardellini - SABD 2016/17
71

Borg
Cluster management system at Google that achieves high utilization by: • Admission control • Efficient task-packing • Over-commitment • Machine sharing
Valeria Cardellini - SABD 2016/17
72
The user perspective • Users: Google developers and system
administrators mainly • Heterogeneous workload: production and
batch, mainly • Cell: subset of cluster machines
– Around 10K nodes – Machines in a cell are heterogeneous in many
dimensions • Jobs and tasks
– A job is a group of tasks – Each task maps to a set of Linux processes
running in a container on a machine • task = container
Valeria Cardellini - SABD 2016/17
73

The user perspective • Alloc (allocation)
– Reserved pool of resources on a machine in which one or more tasks can run
– The smallest deployable units that can be created, scheduled, and manage
– Task = alloc – Job = alloc set
• Priority, quota, and admission control – Job has a priority (preempting) – Quota is used to decide which jobs to admit for scheduling
• Naming and monitoring – Service’s clients and other systems need to be able to find
tasks, even after their relocation to a new machine – BNS example: 50.jfoo.ubar.cc.borg.google.com !– Monitoring health of the task and thousands of performance
metrics Valeria Cardellini - SABD 2016/17
74
Scheduling a job
Valeria Cardellini - SABD 2016/17
75
job hello_world = {
runtime = { cell = “ic” } //what cell should run it in?
binary = ‘../hello_world_webserver’ //what program to run?
args = { port = ‘%port%’ }
requirements = {
RAM = 100M
disk = 100M
CPU = 0.1
}
replicas = 10000
}

Borg architecture
Valeria Cardellini - SABD 2016/17
76
• Borgmaster – Main BorgMaster process
• Five replicas – Scheduler
• Borglets – Manage and monitor tasks
and resource – Borgmaster polls Borglets
every few seconds
Borg architecture
Valeria Cardellini - SABD 2016/17
77
• Fauxmaster: high-fidelity Borgmaster simulator – Simulate previous runs from
checkpoints – Contains full Borg code
• Used for debugging, capacity planning, evaluate new policies and algorithms

Scheduling in Borg
• Two-phase scheduling algorithm 1. Feasibility checking: find machines for a given
job 2. Scoring: pick one machine
– User preferences and build-in criteria • Minimize the number and priority of the preempted tasks • Picking machines that already have a copy of the task’s
packages • Spreading tasks across power and failure domains • Packing by mixing high and low priority tasks
Valeria Cardellini - SABD 2016/17
78
Borg’s allocation policies
• Advanced bin-packing algorithms – Avoid stranding of resources – Bin packing problem: objects of different volumes
vi must be packed into a finite number of bins each of volume V in a way that minimizes the number of bins used
– Bin packing: NP-hard problem -> many heuristics, among which: best fit, first fit, worst fit
• Evaluation metric: cell-compaction – Find smallest cell that we can pack the workload
into… – Remove machines randomly from a cell to
maintain cell heterogeneity Valeria Cardellini - SABD 2016/17
79

Design choices for scalability in Borg
• Separate scheduler • Separate threads to poll the Borglets • Partition functions across the five replicas • Score caching
– Evaluating feasibility and scoring a machine is expensive, so cache them
• Equivalence classes – Group tasks with identical requirements
• Relaxed randomization – Wasteful to calculate feasibility and scores for all
the machines in a large cell Valeria Cardellini - SABD 2016/17
80
Borg ecosystem
• Many different systems built in, on, and around Borg to improve upon the basic container-management services – Naming and service discovery (the Borg Name
Service, or BNS) – Master election, using Chubby – Application-aware load balancing – Horizontal (instance number) and vertical
(instance size) auto-scaling – Rollout tools for deployment of new binaries and
configuration data – Workflow tools – Monitoring tools
Valeria Cardellini - SABD 2016/17
81

Omega
• Offspring of Borg • State of the cluster stored in a centralized
Paxos-based transaction-oriented store – Accessed by the different parts of the cluster
control plane (such as schedulers), using optimistic concurrency control to handle the occasional conflicts
Valeria Cardellini - SABD 2016/17
82
Mesos Borg
Kubernetes (K8s)
• Google’s open-source platform for automating deployment, scaling, and operations of application containers across clusters of hosts, providing container-centric infrastructure kubernetes.io kubernetes.io/docs/tutorials/kubernetes-basics/
• Features: – Portable: public, private, hybrid, multi-cloud – Extensible: modular, pluggable, hookable,
composable – Self-healing: auto-placement, auto-restart, auto-
replication, auto-scalingValeria Cardellini - SABD 2016/17
83

Borg and Kubernetes
Valeria Cardellini - SABD 2016/17 84
Directly derived
• Borglet => Kubelet • alloc => pod • Borg containers =>
Docker • Declarative specifications
Improved
• Job => labels • Managed ports => IP per
pod • Monolithic master =>
Micro-services
• Loosely inspired by Borg
Pod
• Pod: basic unit in Kubernetes – Group of containers that are co-
scheduled • A resource envelope in which
one or more containers run
Valeria Cardellini - SABD 2016/17 85
– Containers that are part of the same pod are guaranteed to be scheduled together onto the same machine, and can share state via local volumes
• Users organize pods using labels – Label: arbitrary key/value pair attached to pod – E.g., role=frontend and stage=production !

IP per pod
• Containers running on a machine share the host’s IP address, so Borg assigns the containers unique port numbers – Burdens on infrastructure
and application developers, e.g., it requires to replace DNS service
• IP address per pod, thus aligning network identity (IP address) with application identity – Easier to run off-the-shelf
software on Kubernetes
Valeria Cardellini - SABD 2016/17 86
Borg Kubernetes
Omega and Kubernetes
• Like Omega, shared persistent store – Components watch for changes to relevant
objects • In contrast to Omega, state accessed
through a domain-specific REST API that applies higher-level versioning, validation, semantics, and policy, in support of a more diverse array of clients – Stronger focus on experience of developers
writing cluster applications
Valeria Cardellini - SABD 2016/17 87

Kubernetes architecture
Valeria Cardellini - SABD 2016/17 88
• Master: cluster control plane
• Kubelets: node agents
• Cluster state backed by distributed storage system (etcd, a highly available distributed key-value store)
Kubernetes on Mesos
• Mesos allows dynamic sharing of cluster resources between Kubernetes and other first-class Mesos frameworks such as HDFS, Spark, and Chronos kubernetes.io/docs/getting-started-guides/mesos/
Valeria Cardellini - SABD 2016/17 89

References
• B. Burns et al., Borg, Omega, and Kubernetes. Commun. ACM, 2016.
• A. Ghodsi et al., Dominant resource fairness: fair allocation of multiple resource types, NSDI 2011.
• B. Hindman et al., Mesos: a platform for fine-grained resource sharing in the data center, NSDI 2011.
• M. Schwarzkopf et al., Omega: flexible, scalable schedulers for large compute clusters, EuroSys 2013.
• V. K. Vavilapalli et al., Apache Hadoop YARN: yet another resource negotiator, SOCC 2013.
• A. Verma et al., Large-scale cluster management at Google with Borg, EuroSys 2015.
Valeria Cardellini - SABD 2016/17
90


















