
Sweeny ux-seo om-cap 2014_v3
59
1
-
Upload
marianne-sweeny -
Category
Internet
-
view
255 -
download
1
Transcript of Sweeny ux-seo om-cap 2014_v3

1

2

3

4

Throughout time, we have codified our existence and stored information using text. Humans are text-based
info-vores and recent studies from Google show a strong user preference for text over imagery.
5
Our first “search engines” were librarians, people just like us who were trained in how to organize, store and
retrieve needed information. They did not rely on cookies to extract personal information from which they
would “predict” what we wanted. They di d not need to because they could ask in way that we understood and
conclude what we wanted based on our answers.
Nice librarians gave us cookies of the other kind but we had to eat them outside.
6

7
A spider returns information about each word on each page it crawls.
This information is stored in the index where it is compressed based on grammatical requirements such as
stemming [taking the word down to its most basic root] and stop words [common articles and others stipulated by
the company]. A complete copy of the Web page may be stored in the search engine’s cache.
This index is then inverted so that lookup is done on the basis of record contents and not the document ID.
With brute force calculation, the system pulls each record from the inverted index [mapping of words to where they
appear in document text]. This is recall or all documents in the corpus with text instances that match your the
term(s).
The “secret sauces” for each search engine are algorithms that sort order the recall results in a meaningful fashion.
This is precision or the number of documents from recall that are relevant to your query term(s).
All search engines use a common set of values to refine precision. If the search term used in the title of the
document, in heading text, formatted in any way, or used in link text, the document is considered to be more
relevant to the query. If the query term(s) are used frequently throughout the document, the document is considered
to be more relevant.
An example the complexity involved in refinement of results is Term Frequency - Inverse Document Frequency [TF-
IDF] weighting. Here the raw term frequency (TF) of a term in a document by the term's inverse document
frequency (IDF) weight [frequency of occurrence in a particular document multiplied the number of documents
containing the term divided by the number of documents in the entire corpus. [caveat emptor: high-level, low-level,
level-playing-field math are not my strong suits].
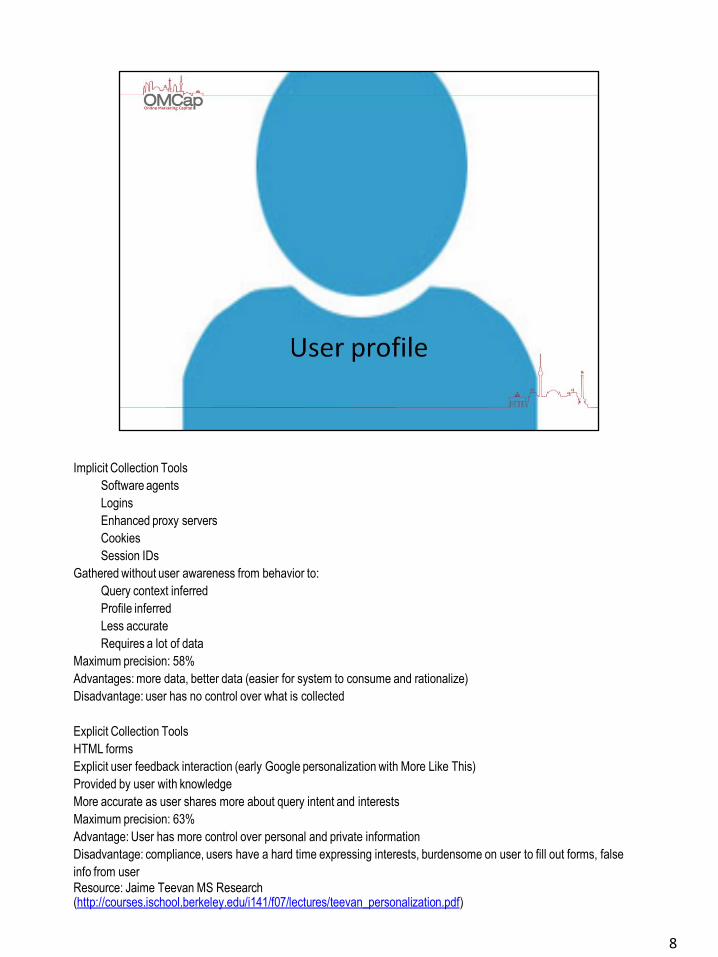
Implicit Collection Tools
Software agents
Logins
Enhanced proxy servers
Cookies
Session IDs
Gathered without user awareness from behavior to:
Query context inferred
Profile inferred
Less accurate
Requires a lot of data
Maximum precision: 58%
Advantages: more data, better data (easier for system to consume and rationalize)
Disadvantage: user has no control over what is collected
Explicit Collection Tools
HTML forms
Explicit user feedback interaction (early Google personalization with More Like This)
Provided by user with knowledge
More accurate as user shares more about query intent and interests
Maximum precision: 63%
Advantage: User has more control over personal and private information
Disadvantage: compliance, users have a hard time expressing interests, burdensome on user to fill out forms, false
info from user
Resource: Jaime Teevan MS Research (http://courses.ischool.berkeley.edu/i141/f07/lectures/teevan_personalization.pdf)
8

In 2002, Google acquired personalization technology Kaltix and founder Sep Kamver who has been head of Google
personalization since. Defines personalization: “product that can use information given by the user to provide tailored, more
individualized experience”
Query Refinement
System adds terms based on past information searches
Computes similarity between query and user model
Synonym replacement
Dynamic query suggestions - displayed as searcher enters query
Results Re-ranking
Sorted by user model
Sorted by Seen/Not Seen
Personalization of results set
Calculation of information from 3 sources
User: previous search patterns
Domain: countries, cultures, personalities
GeoPersonalization: location-based results
Metrics used for probability modeling on future searches
Active: user actions in time
Passive: user toolbar information (bookmarks), desktop information (files), IP location, cookies
9

10

In January 2002, 52% of all Americans used search engines. In February 2012 that figure grew to 73% of all
Americans.
On any given day in early 2012, more than half of adults using the internet use a search engine (59%). That is double
the 30% of internet users who were using search engines on a typical day in 2004.
Moreover, users report generally good outcomes and relatively high confidence in the capabilities of search engines:
• 91% of search engine users say they always or most of the time find the information they are seeking
when they use search engines
• 73% of search engine users say that most or all the information they find as they use search engines is
accurate and trustworthy
• 66% of search engine users say search engines are a fair and unbiased source of information
• 55% of search engine users say that, in their experience, the quality of search results is getting better
over time, while just 4% say it has gotten worse
• 52% of search engine users say search engine results have gotten more relevant and useful over time,
while just 7% report that results have gotten less relevant.
Resource: Pew Internet Trust Study of Search engine behavior
http://www.pewinternet.org/Reports/2012/Search-Engine-Use-2012/Summary-of-findings.aspx
11

Resource: Pew Internet Trust Study of Search engine behavior
http://www.pewinternet.org/Reports/2012/Search-Engine-Use-2012/Summary-of-findings.aspx
12

How to search:
56% constructed poor queries
55% selected irrelevant results 1 or more times
Get Lost in data:
33% had difficulty navigating/orienting search results
28% had difficulty maintaining orientation on a website
Discernment
36% did not go beyond the first 3 search results
91% did not go beyond the first page of search results
Resource: Using the Internet: Skill Related Problems in User Online Behavior; van Deursen & van Dijk; 2009
13

14

15

Based on academic citation model
1998 named one of the top 100 Websites by PC Magazine “uncanny knack for returning extremely relevant results”
Ranking based on number of links to the page
Random Surfer (spider follows “randomly selected links) examines all of the links and follows one to destination,
does that at destination
Random Surfer authority score: % of time random surfer would spend visiting the page (added to the hyperlink
score)
Restart probability = 15%, surfer does not select a link and instead “jumps” to another page
First introduction of “loose authority” determined by adding up the “authority” scores of the pages linking in
Discounted pages linking to each other (black hat link ring)
Complications:
Assumes link vote of authority, does not consider commercial value of links
Ability to link limited to subset of users
Orphan pages
Users no longer “surf” randomly
Does not scale
16

Quality of links more important than quantity of links
Segmentation of corpus into broad topics
Selection of authority sources within these topic areas
Hilltop was one of the first to introduce the concept of machine-mediated “authority” to combat the human
manipulation of results for commercial gain (using link blast services, viral distribution of misleading links. It is used
by all of the search engines in some way, shape or form.
Hilltop is:
Performed on a small subset of the corpus that best represents nature of the whole
Authorities: have lots of unaffiliated expert document on the same subject pointing to them
Pages are ranked according to the number of non-affiliated “experts” point to it – i.e. not in the same site or
directory
Affiliation is transitive [if A=B and B=C then A=C]
The beauty of Hilltop is that unlike PageRank, it is query-specific and reinforces the relationship between the
authority and the user’s query. You don’t have to be big or have a thousand links from auto parts sites to be an
“authority.” Google’s 2003 Florida update, rumored to contain Hilltop reasoning, resulted in a lot of sites with
extraneous links fall from their previously lofty placements as a result.
Photo: Hilltop Hohenzollern Castle in Stuttgart

Consolidation of Hypertext Induced Topic Selection [HITS] and PageRank
Pre-query calculation of factors based on subset of corpus
Context of term use in document
Context of term use in history of queries
Context of term use by user submitting query
Computes PR based on a set of representational topics [augments PR with content analysis]
Topic derived from the Open Source directory
Uses a set of ranking vectors: Pre-query selection of topics + at-query comparison of the similarity of query to topics
Creator now a Senior Engineer at Google
18

Indexing infrastructure
Made it easier for engineers to “add signals” that impact ranking
Pre announced and open to public testing
19

20
21

SEO always reverse engineering the algorithms
SE Update – tactic, tactic, tactic
SE Update – tactic, tactic, tactic
SE Update – tactic, tactic, tactic
UX
Drawing on white boards while singing Kumbaya
22

Vince update 2009
http://searchenginewatch.com/article/2288128/Vince-The-Google-Update-We-Should-Be-Talking-About
Big brands can afford better sites
Big brands spend more $$ in adwords
“The internet is fast becoming a "cesspool" where false information thrives, Google CEO Eric Schmidt said
yesterday. Speaking with an audience of magazine executives visiting the Google campus here as part of
their annual industry conference, he said their brands were increasingly important signals that content can be
trusted. …Brands are the solution, not the problem," Mr. Schmidt said. "Brands are how you sort out the
cesspool….Brand affinity is clearly hard wired," he said. "It is so fundamental to human existence that it's not
going away. It must have a genetic component.” Eric Schmidt, Google, October 2008
http://www.seobook.com/google-branding
23

About content: quality and freshness
About agile: frequent iterations and small fixes
About UX: or so it seems (Vanessa Fox/Eric Enge: Cllick-through, Bounce Rate, Conversion)
Panda 1.0: Google’s first salvo against “spam” (shallow, thin content sites) in the form of content
duplication and low value original content (i.e. “quick, give me 200 words on Brittany Spear’s vacation in
the Maldives”) – biggest target was content farms – Biggest Impact: keyword optimization and link building.
Panda 2.1: Having unique content not enough – quality factors introduced (some below)
Trustworthiness: with my credit card information
Uniqueness: is this saying what I’ve found somewhere else
Origination: does the person writing the content have “street cred,” do I believe that this is
an authoritative resource on this topic
Display: does the site look professional, polished
Professional: is the content well constructed, well edited and without grammatical or spelling errors
24
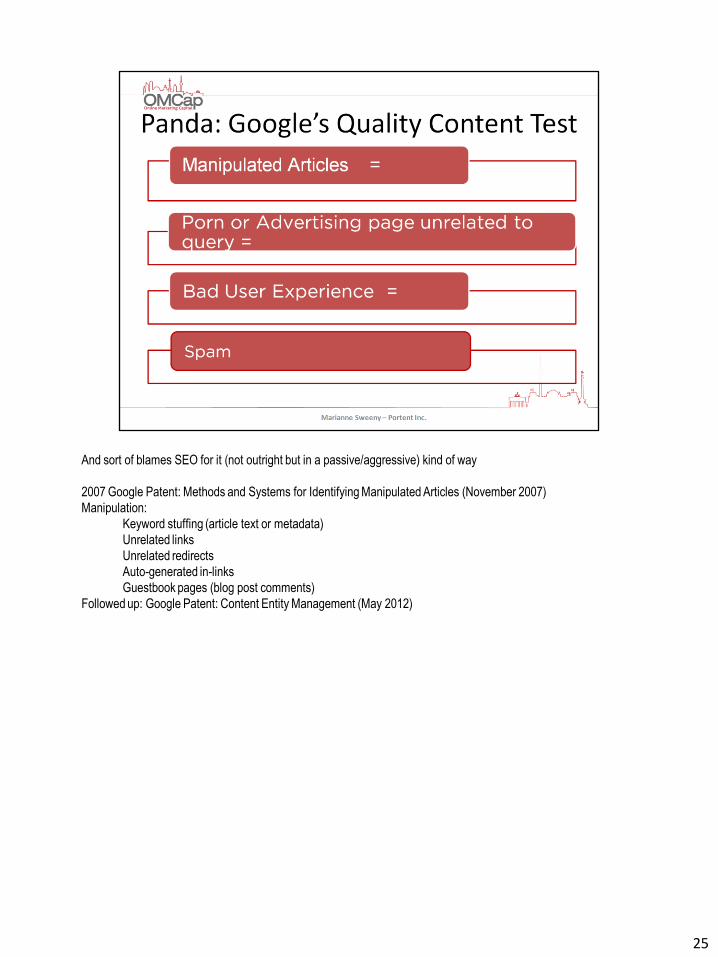
And sort of blames SEO for it (not outright but in a passive/aggressive) kind of way
2007 Google Patent: Methods and Systems for Identifying Manipulated Articles (November 2007)
Manipulation:
Keyword stuffing (article text or metadata)
Unrelated links
Unrelated redirects
Auto-generated in-links
Guestbook pages (blog post comments)
Followed up: Google Patent: Content Entity Management (May 2012)
25

Entity=anything that can be tagged as being associated with certain documents, e.g. Store, news source, product
models, authors, artists, people, places thing
The entity processing unit looks at “candidate strings and compares to query log to extract: most clicked entity,
most time spent by user)
Query logs (this is why they took away KW data – do not want us to reverse engineer as we have in past)
User Behavior information: user profile, access to documents seen as related to original document, amount of time
on domain associated with one or more entities, whole or partial conversions that took place
26
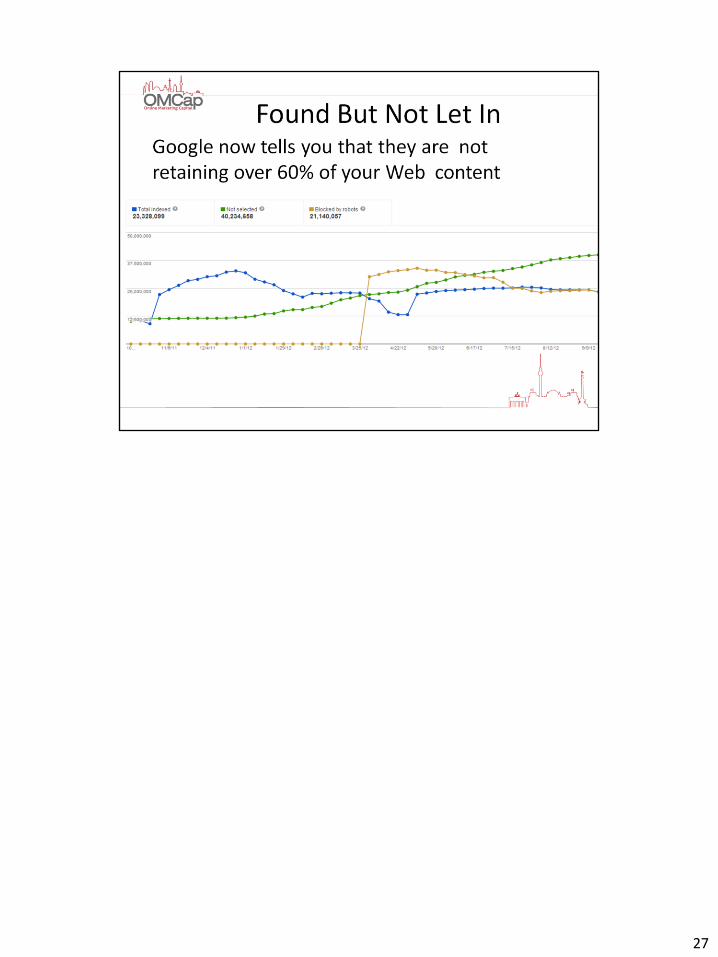
27

28

29

30
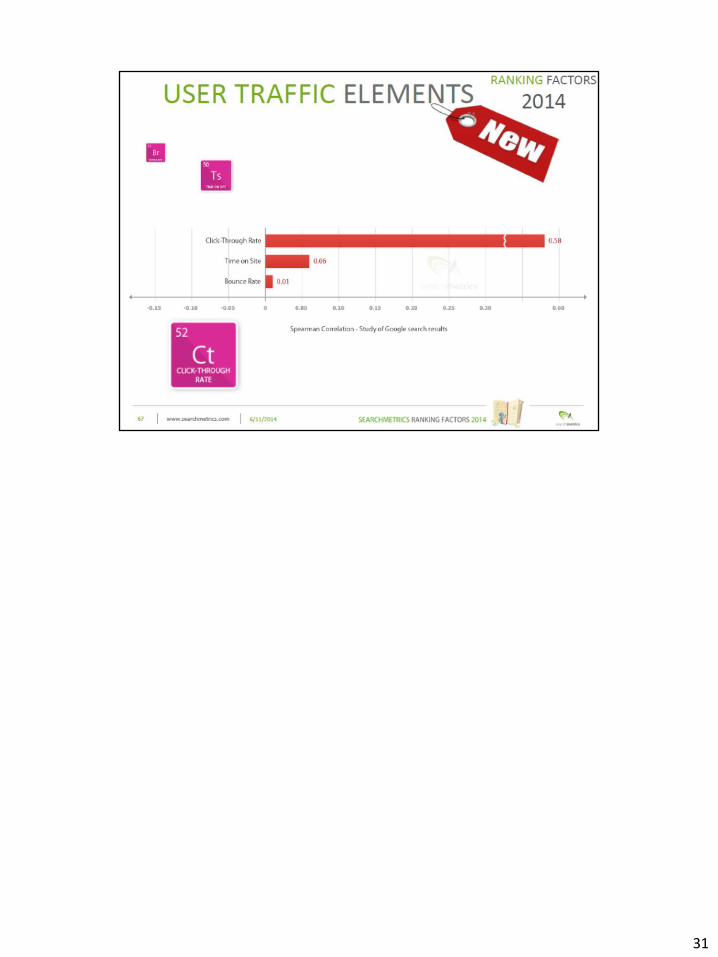
31
32
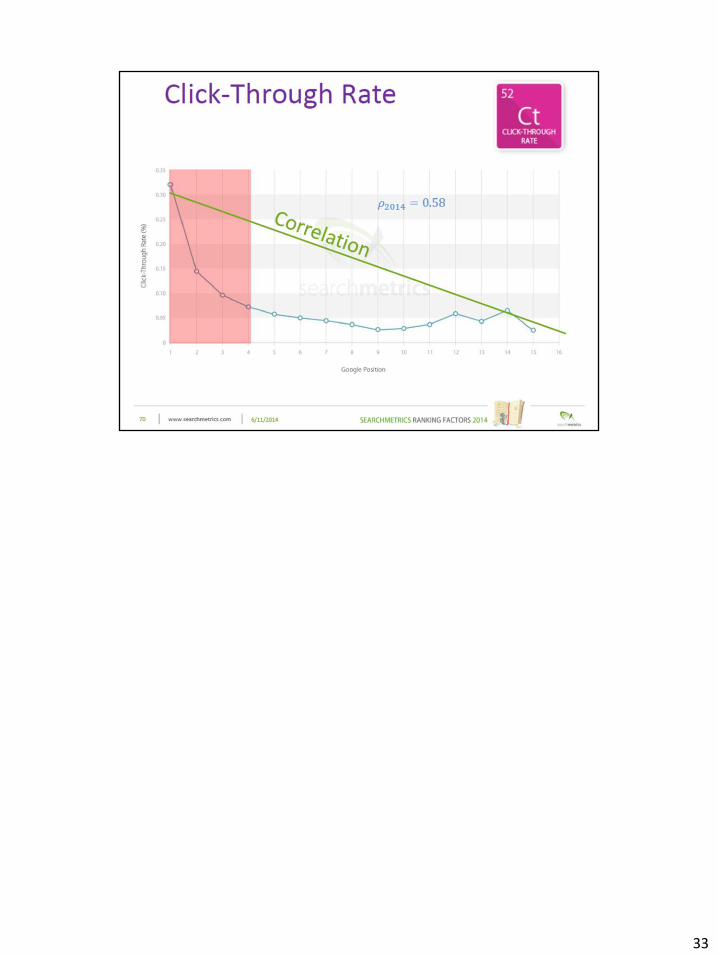
33
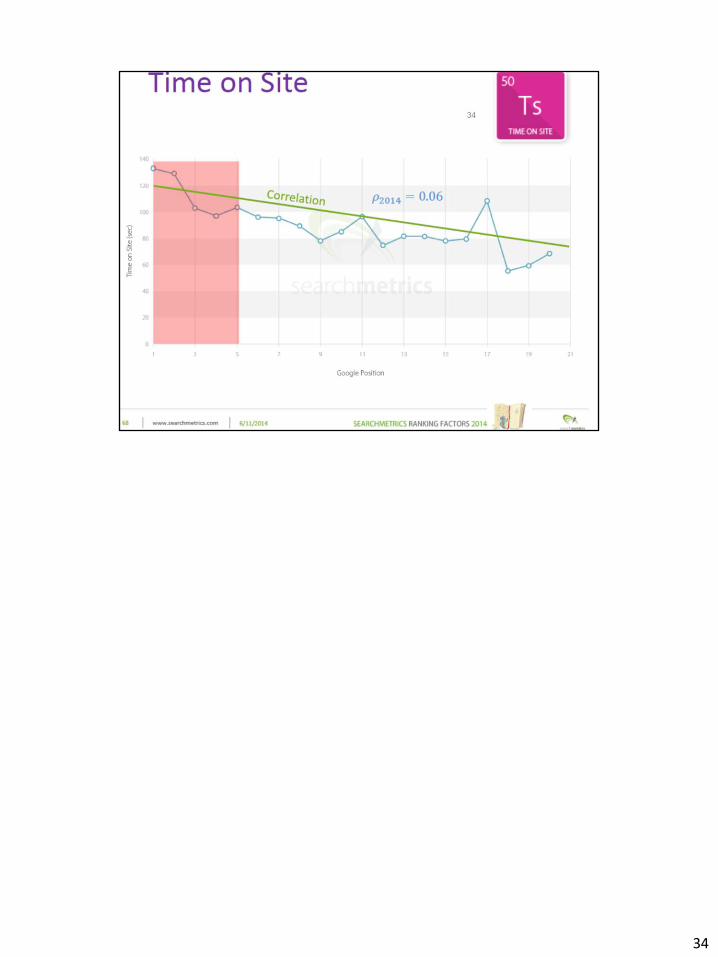
34

Selection: Do they pick you from the results
Engagement: Do they do anything once they get to your page that would indicate it is relevant to their query
(information need)
Content: Is the content of high quality
Links: Baked in legacy relevance: Are they contextually relevant? From Authority Resources? Earned, not purchased.
35

36

KWIC influences selection
Placement influences selection
Recent changes make larger, reduce characters
Matt Cutts on the importance of well crafted <title> and description http://www.youtube.com/watch?v=THYguer_JrM
“Think about maximizing your click through – compelling, something that invites clicks, then think about conversion
rates…Title and description can absolutely maximize click through rate…What matters is how much you get clicked
on and how often you take those clicked on visits and convert those to whatever you really want.”
37

Little influence on relevance ranking
Demonstrated influence on selection
Information scent to take them to the page
38

Legacy newspaper structure of “the fold.”
Proto-typicality: user mental models
Visual complexity: ratio of images to text favors text
10/11/2014
39
40
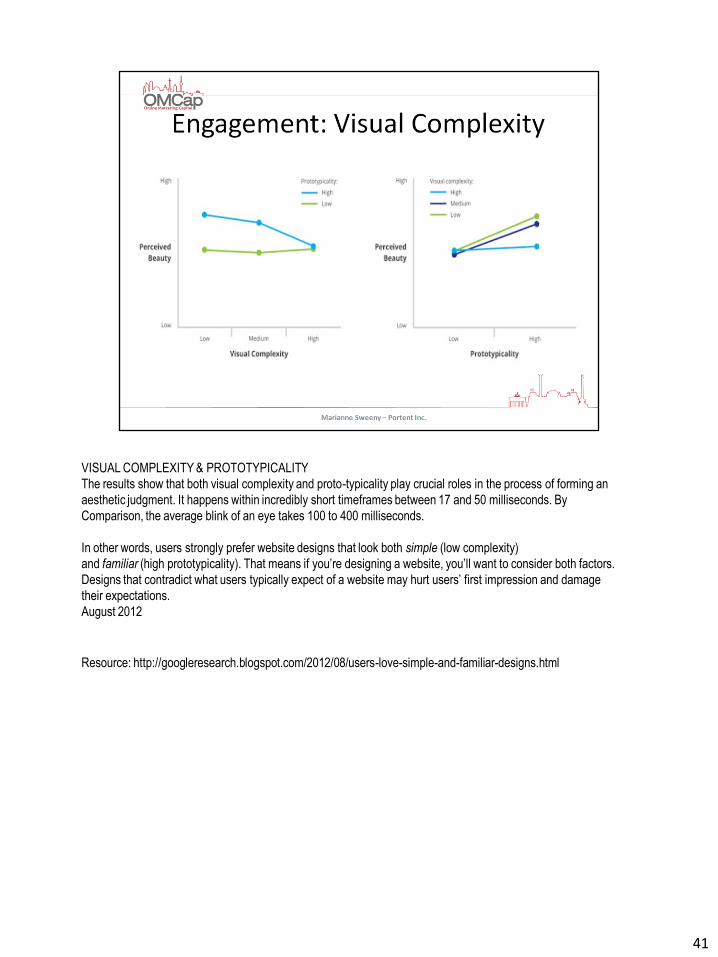
VISUAL COMPLEXITY & PROTOTYPICALITY
The results show that both visual complexity and proto-typicality play crucial roles in the process of forming an
aesthetic judgment. It happens within incredibly short timeframes between 17 and 50 milliseconds. By
Comparison, the average blink of an eye takes 100 to 400 milliseconds.
In other words, users strongly prefer website designs that look both simple (low complexity)
and familiar (high prototypicality). That means if you’re designing a website, you’ll want to consider both factors.
Designs that contradict what users typically expect of a website may hurt users’ first impression and damage
their expectations.
August 2012
Resource: http://googleresearch.blogspot.com/2012/08/users-love-simple-and-familiar-designs.html
41

Flat structure that allows for proximity relevance and cross-walk to other directories Topicality hubs: Sections of the site that focus on high-level entity (topic, subject) with increasing granularity Click Distance: the further from an authority page, the less important it must be URL Depth: the further from the homepage, the less important it must be
42

Put the sidewalks where the footprints are
Resource: Stuart Brand: How Buildings Learn
43
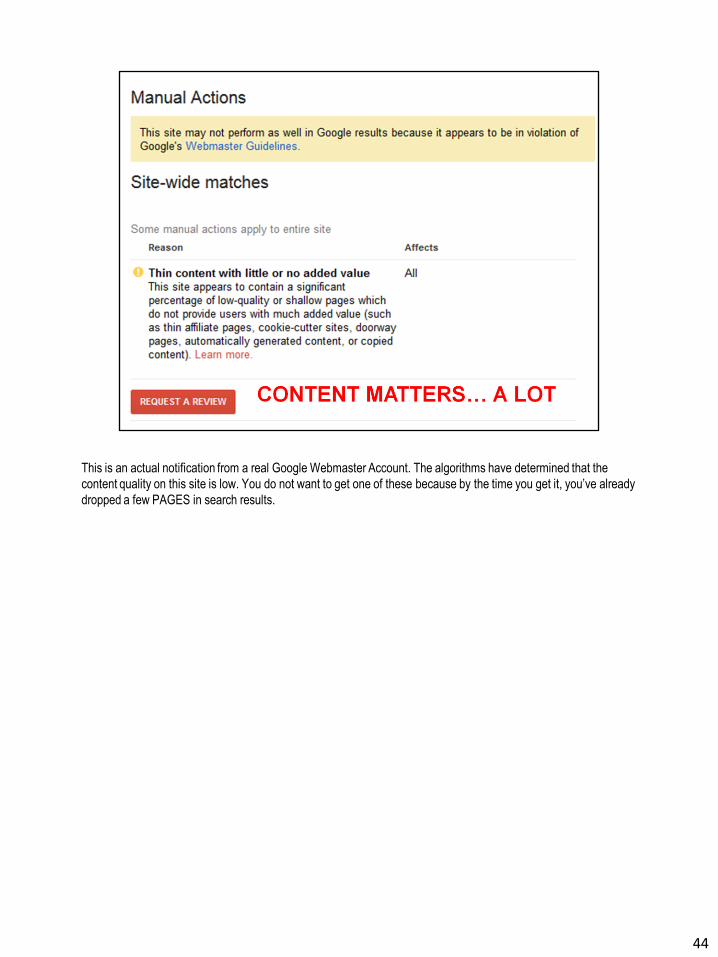
This is an actual notification from a real Google Webmaster Account. The algorithms have determined that the
content quality on this site is low. You do not want to get one of these because by the time you get it, you’ve already
dropped a few PAGES in search results.
44
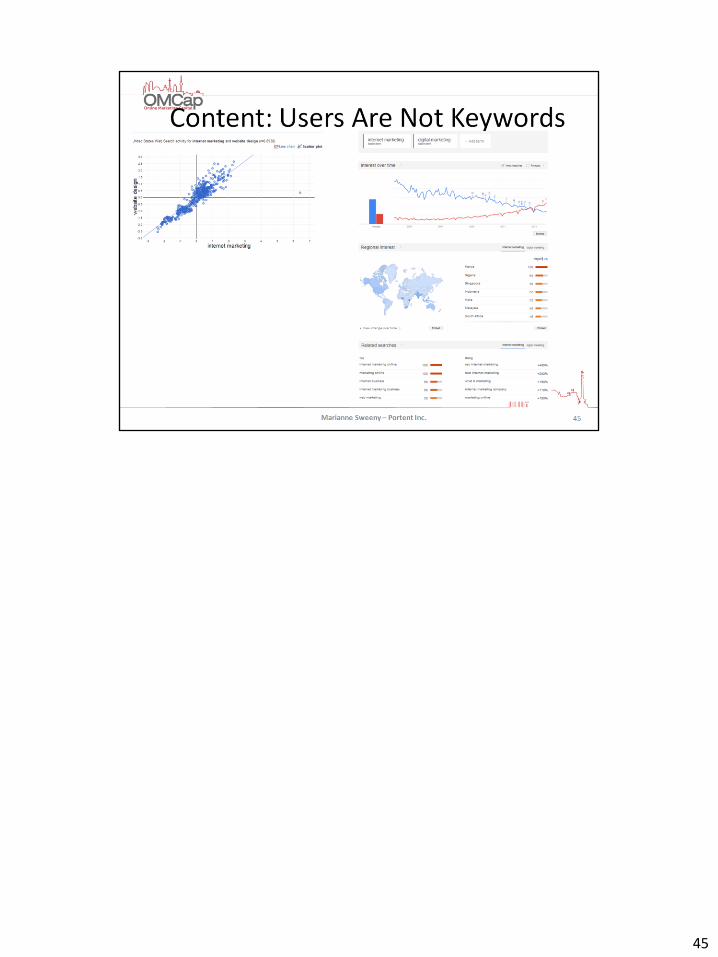
45
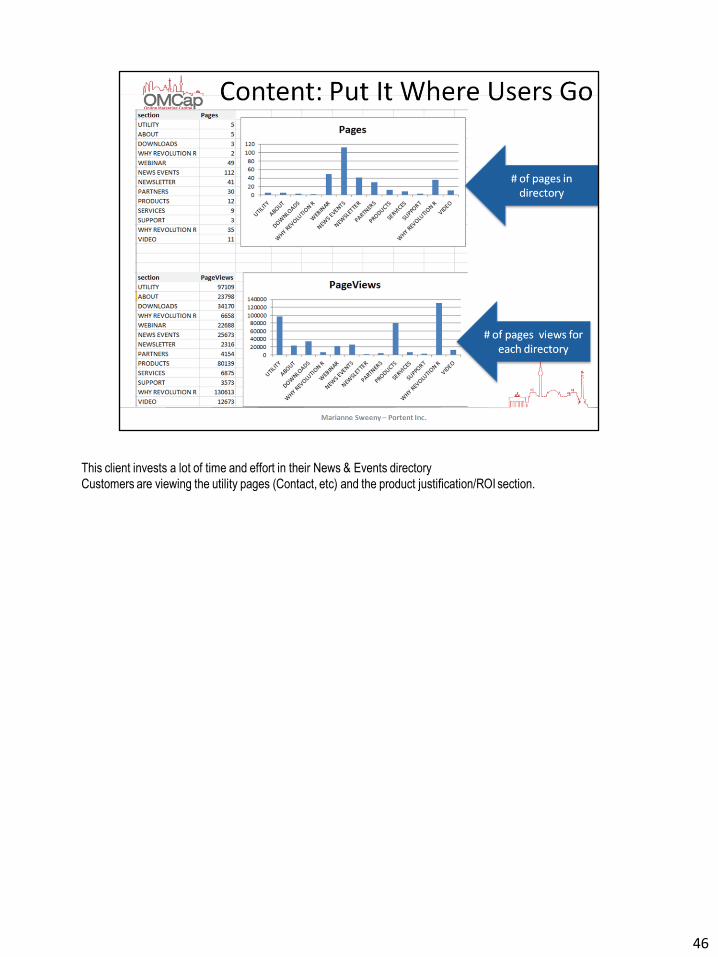
This client invests a lot of time and effort in their News & Events directory
Customers are viewing the utility pages (Contact, etc) and the product justification/ROI section.
46
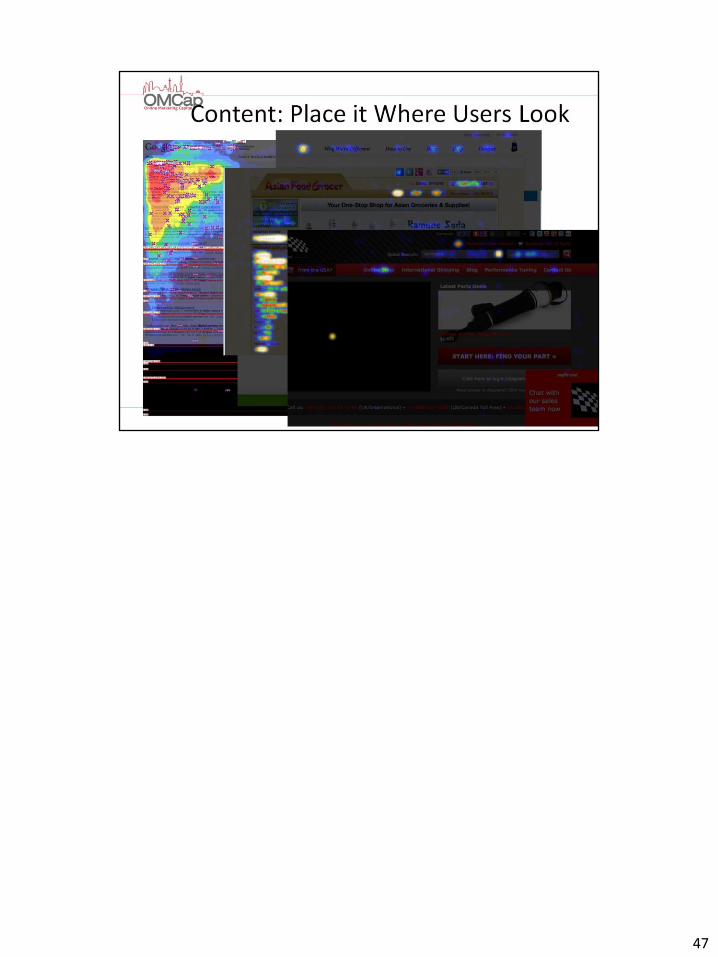
47

48

49

50

“As we’ve mentioned previously, we’ve heard complaints from users that if they click on a result and it’s
difficult to find the actual content, they aren’t happy with the experience. Rather than scrolling down the
page past a slew of ads, users want to see content right away. So sites that don’t have much content
“above-the-fold” can be affected by this change.”
http://googlewebmastercentral.blogspot.com/2012/01/page-layout-algorithm-improvement.html
If you’ll recall, this is the Google update that specifically looks at how much content a page has “above
the fold”. The idea is that you don’t want your site’s content to be pushed down or dwarfed by ads and
other non-content material….“Rather than scrolling down the page past a slew of ads, users want to see
content right away. So sites that don’t have much content “above-the-fold” can be affected by this
change. If you click on a website and the part of the website you see first either doesn’t have a lot of
visible content above-the-fold or dedicates a large fraction of the site’s initial screen real estate to ads,
that’s not a very good user experience. Such sites may not rank as highly going forward.”
http://www.webpronews.com/google-updated-the-page-layout-algorithm-last-week-2014-02
Resources
http://searchenginewatch.com/article/2328573/Google-Refreshes-Page-Layout-Algorithm
http://www.seobythesea.com/2011/12/10-most-important-seo-patents-part-3-classifying-web-blocks-with-
linguistic-features/
http://www.seobythesea.com/2008/03/the-importance-of-page-layout-in-seo/
http://searchenginewatch.com/article/2140407/Googles-New-Page-Layout-Update-Targets-Sites-With-
Too-Many-Ads
51

Each page has an H1 heading (that is not an image unless with text overlay) Each page has a lead off (introduction) paragraph that call out the story focus Rest of content follows. Longer content uses headings to break up text (for scanning) and sub-topic focus areas
52

53
54

Organic search channel up 31% (Google 31%, Bing 10%, Yahoo 74%)
New Users up 31%
Bounce Rate down 11%
55

56

Mom and creampuffs
The search engines think that we’re superfluous because we don’t “get search” That’s what I’m here to end. I
want you to “get search.” We are information professionals, not mice! We’re going to use every neuron,
synapsis and gray cell to fight back.
We will shift from trying to optimize search engine behavior to optimizing what the search engines consume,
move from search engine optimization to information optimization
We will Focus
We will be Collaborative
We will get Connected
We will stay Current
Because we are user experience professionals, not Matt Cutts, Sergey Brin or Larry Page.
57

58

59

















