

Streaming Data Flow with Apache Flink @ Paris Flink Meetup 2015
66
-
Upload
till-rohrmann -
Category
Technology
-
view
1.576 -
download
0
Transcript of Streaming Data Flow with Apache Flink @ Paris Flink Meetup 2015
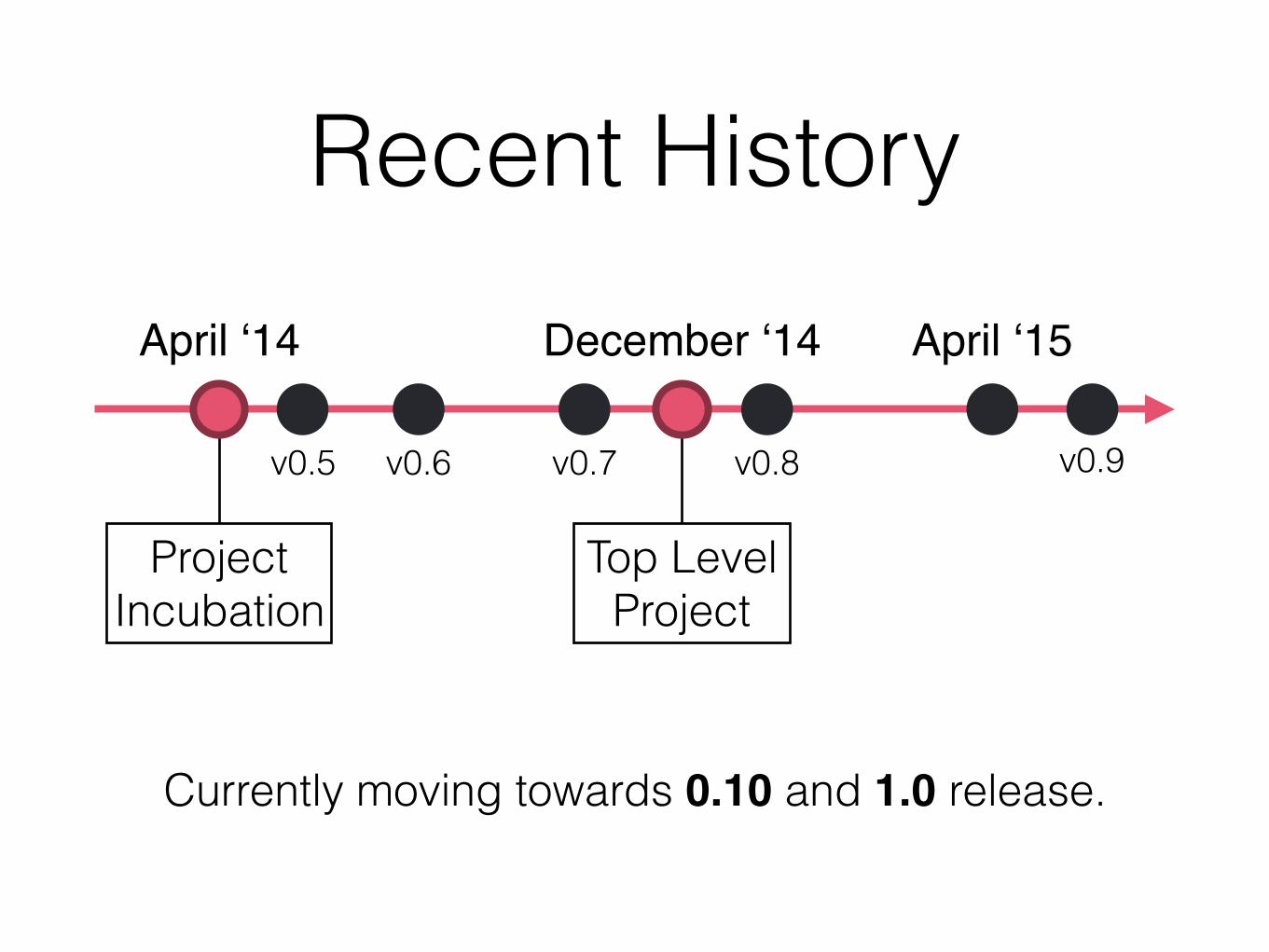
Recent HistoryApril ‘14 December ‘14
v0.5 v0.6 v0.7
April ‘15
Project Incubation
Top Level Project
v0.8 v0.9
Currently moving towards 0.10 and 1.0 release.
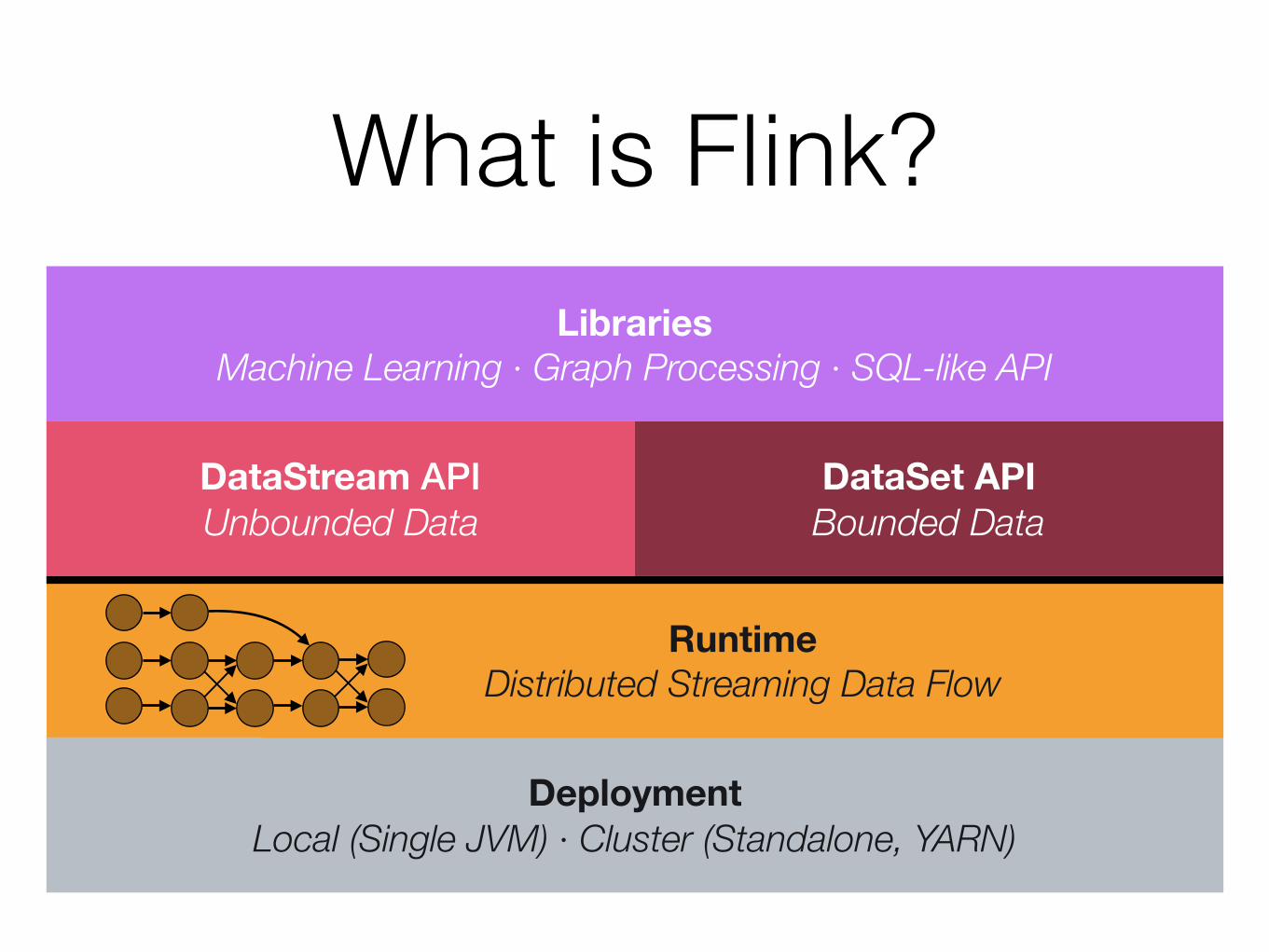
What is Flink?
DeploymentLocal (Single JVM) · Cluster (Standalone, YARN)
DataStream API Unbounded Data
DataSet API Bounded Data
Runtime Distributed Streaming Data Flow
Libraries Machine Learning · Graph Processing · SQL-like API
What is Flink?
StreamingTopologies
Stream TimeWindow Count
Low Latency
Long Batch PipelinesResource Utilization
1.2
1.4
1.5
1.2
0.8
0.9
1.0
0.8
Rating Matrix User Matrix Item Matrix
1.5
1.7
1.2
0.6
1.0
1.1
0.8
0.4
W X Y ZW X Y Z
A
B
C
D
4.0
4.5
5.0
3.5
2.0
3.5
4.0
2.0
1.0
= XUse
r
Machine LearningIterative Algorithms
Graph Analysis
53
1 2
4
0.5
0.2 0.9
0.3
0.1
0.40.7
Mutable State
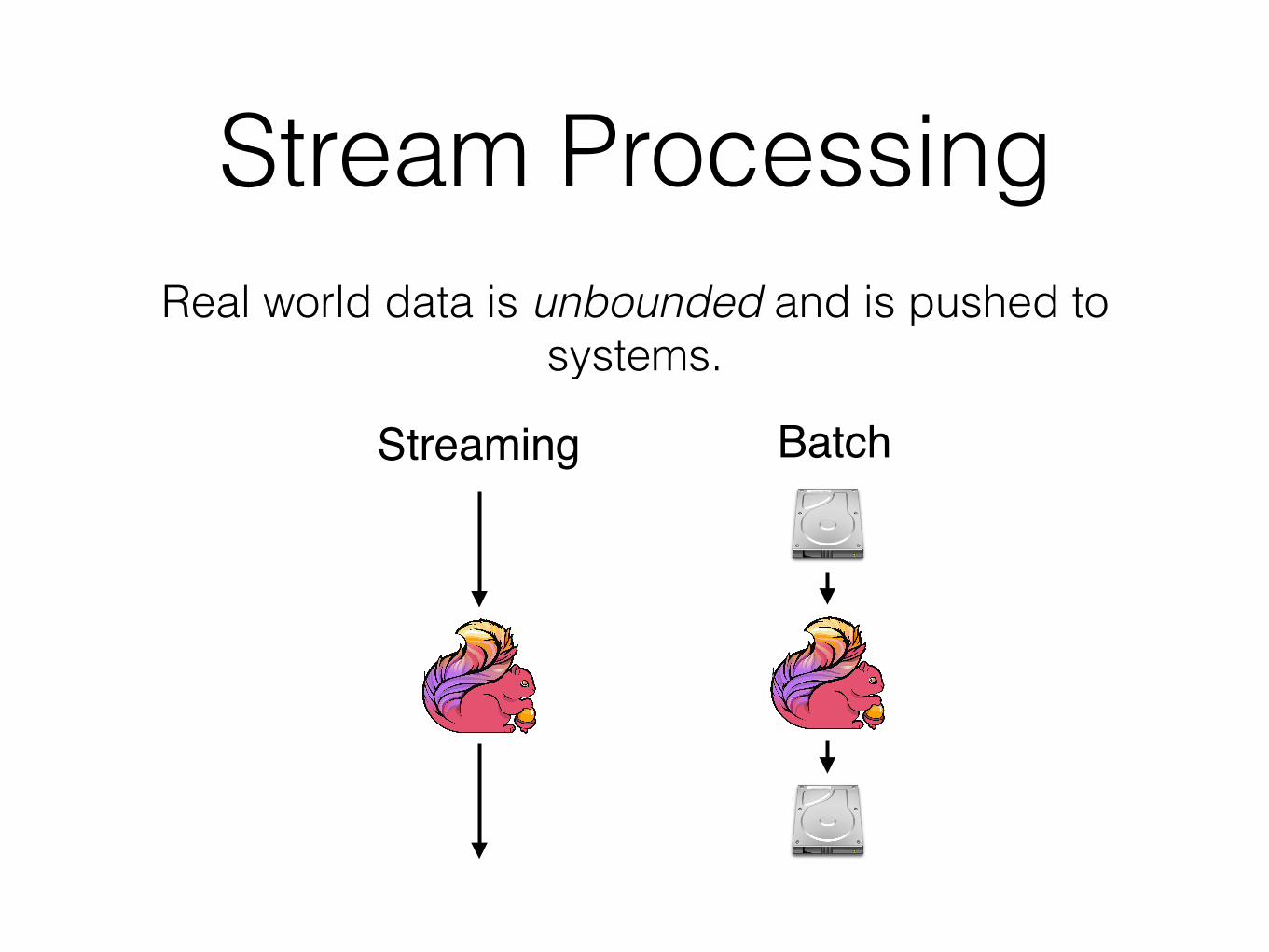
Stream ProcessingReal world data is unbounded and is pushed to
systems.
BatchStreaming
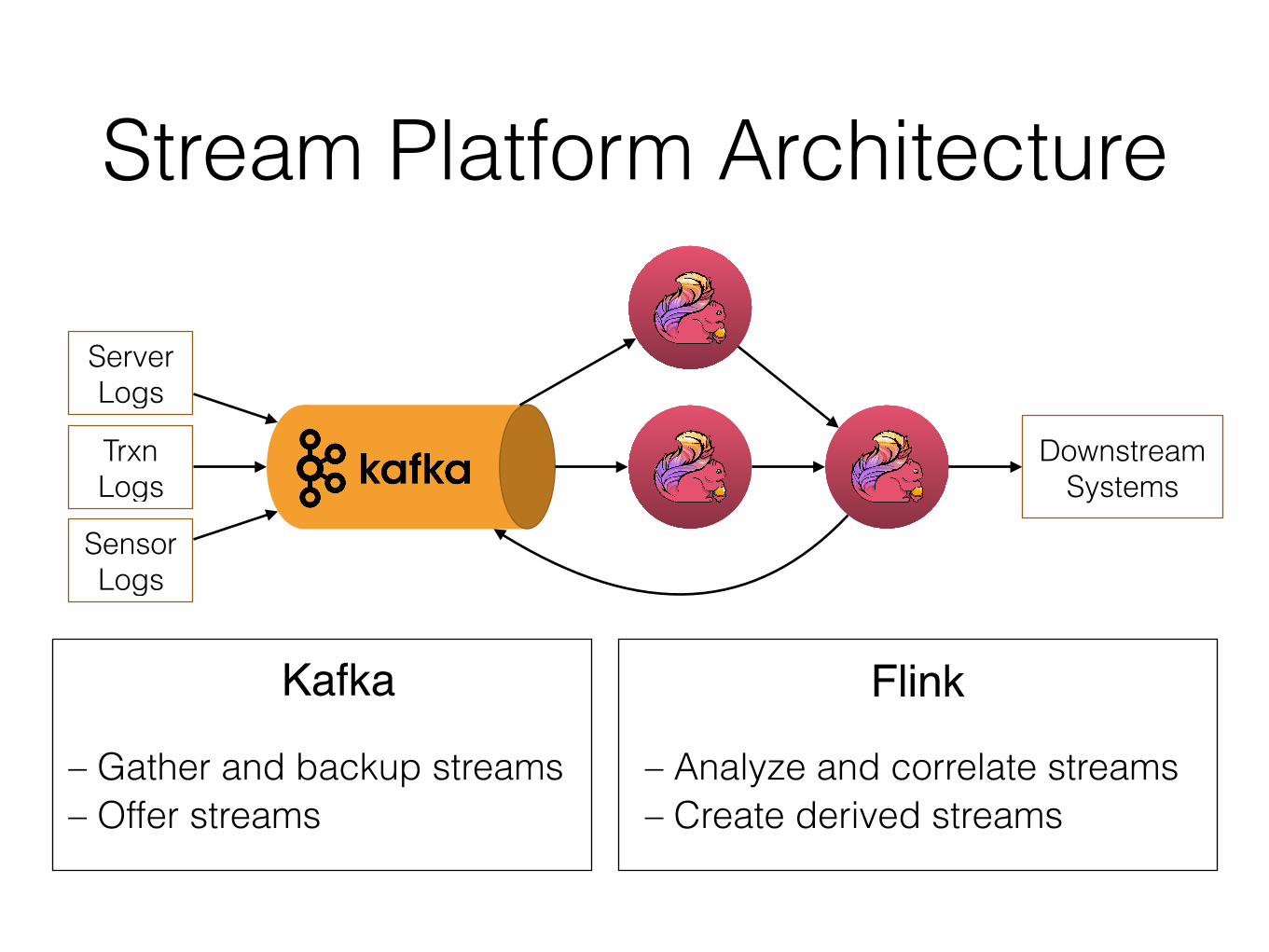
Stream Platform Architecture
Server Logs
Trxn Logs
Sensor Logs
Downstream Systems
Flink
– Analyze and correlate streams – Create derived streams
Kafka
– Gather and backup streams – Offer streams

Cornerstones of Flink
Low Latency for fast results.
High Throughput to handle many events per second.
Exactly-once guarantees for correct results.
Expressive APIs for productivity.
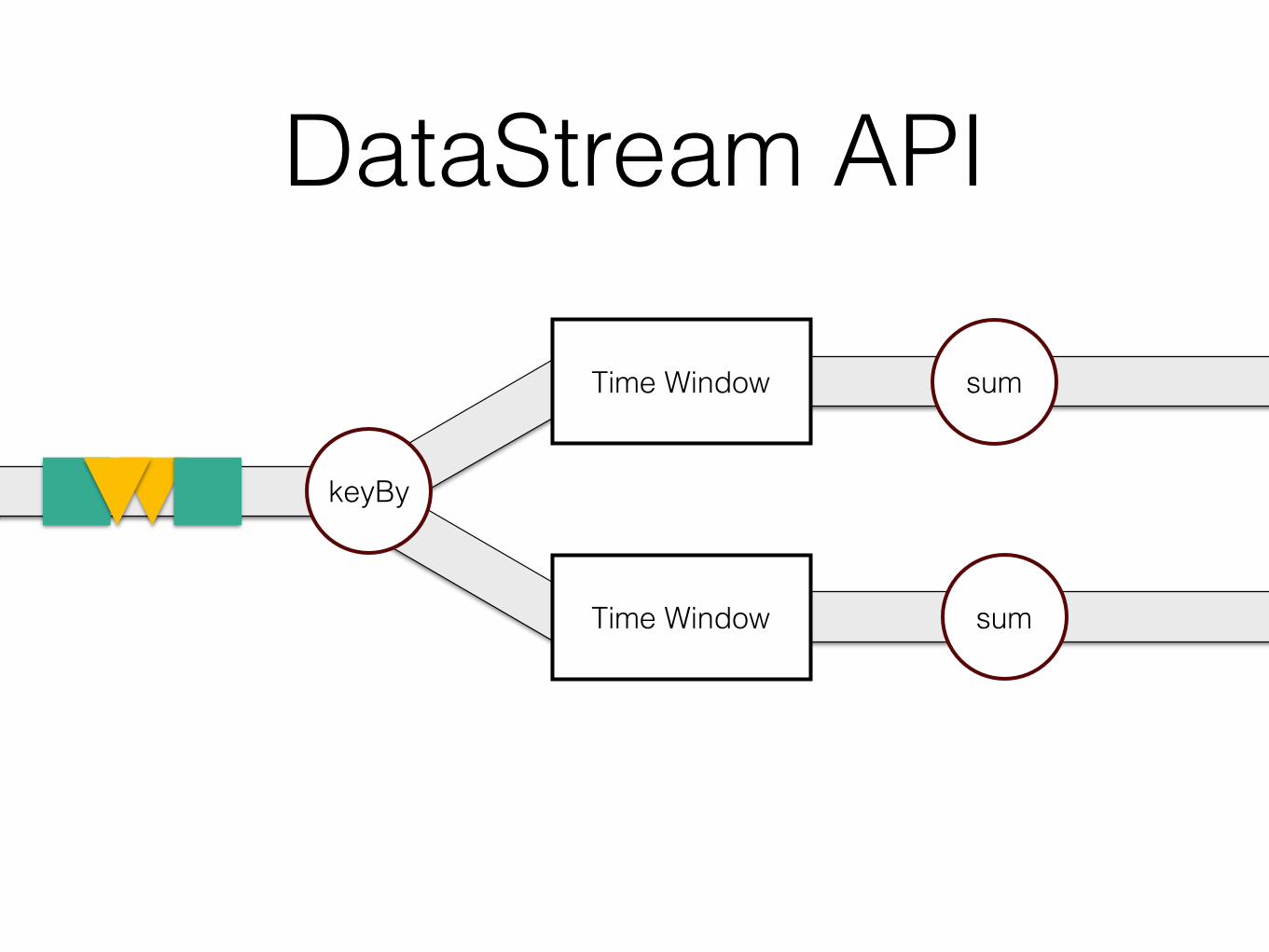
sum
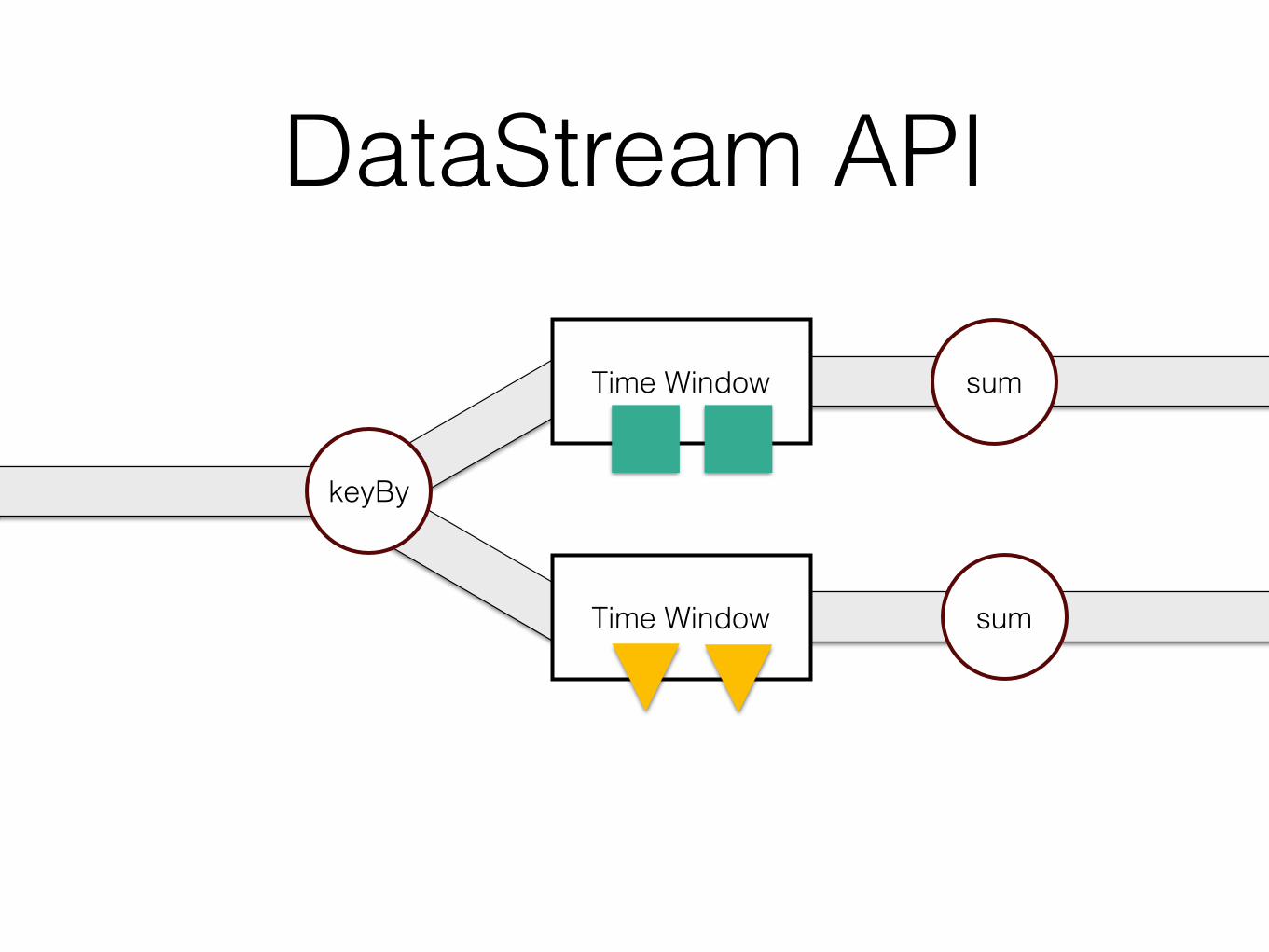
DataStream API
keyBy
sumTime Window
Time Window
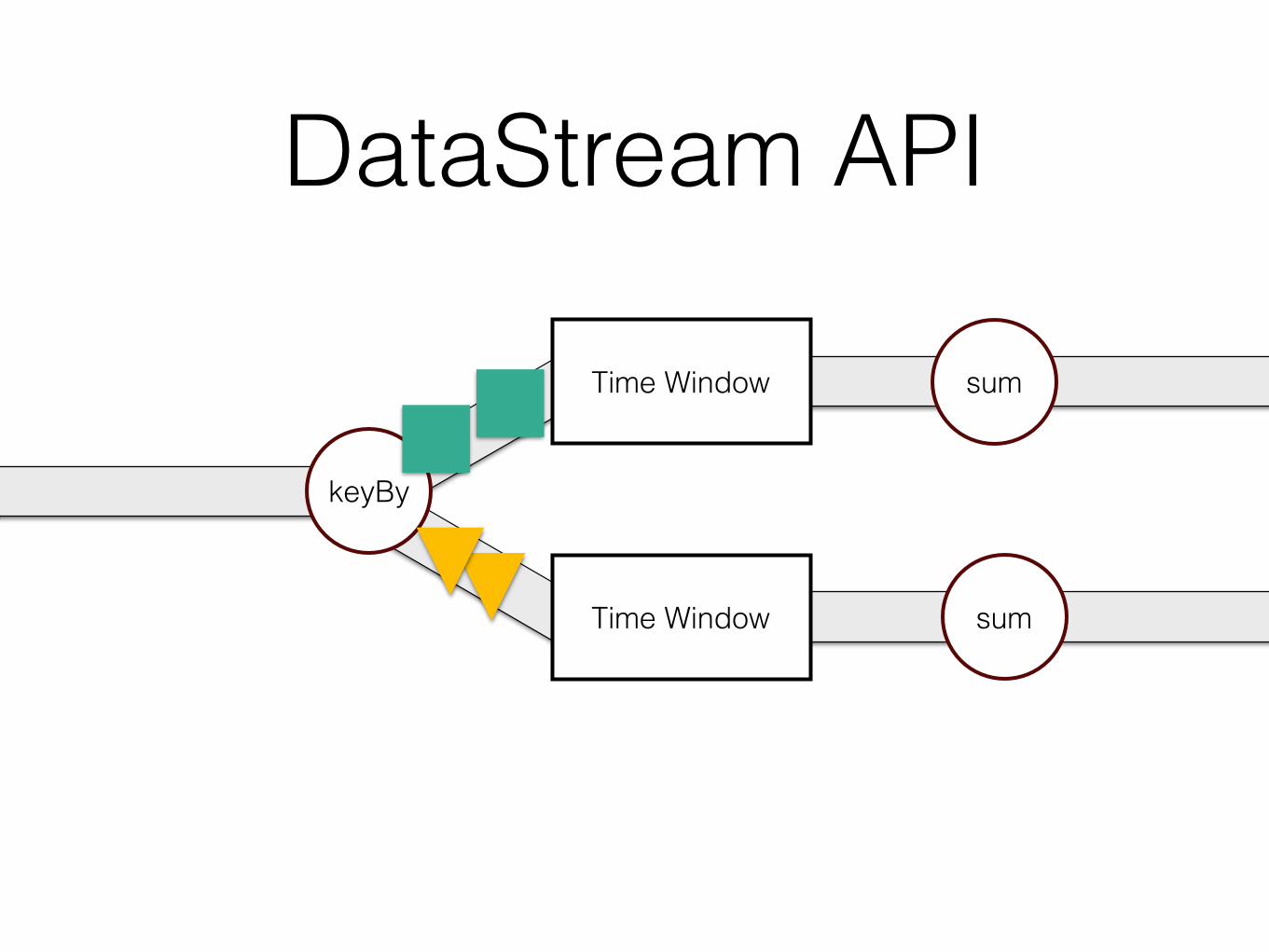
sum
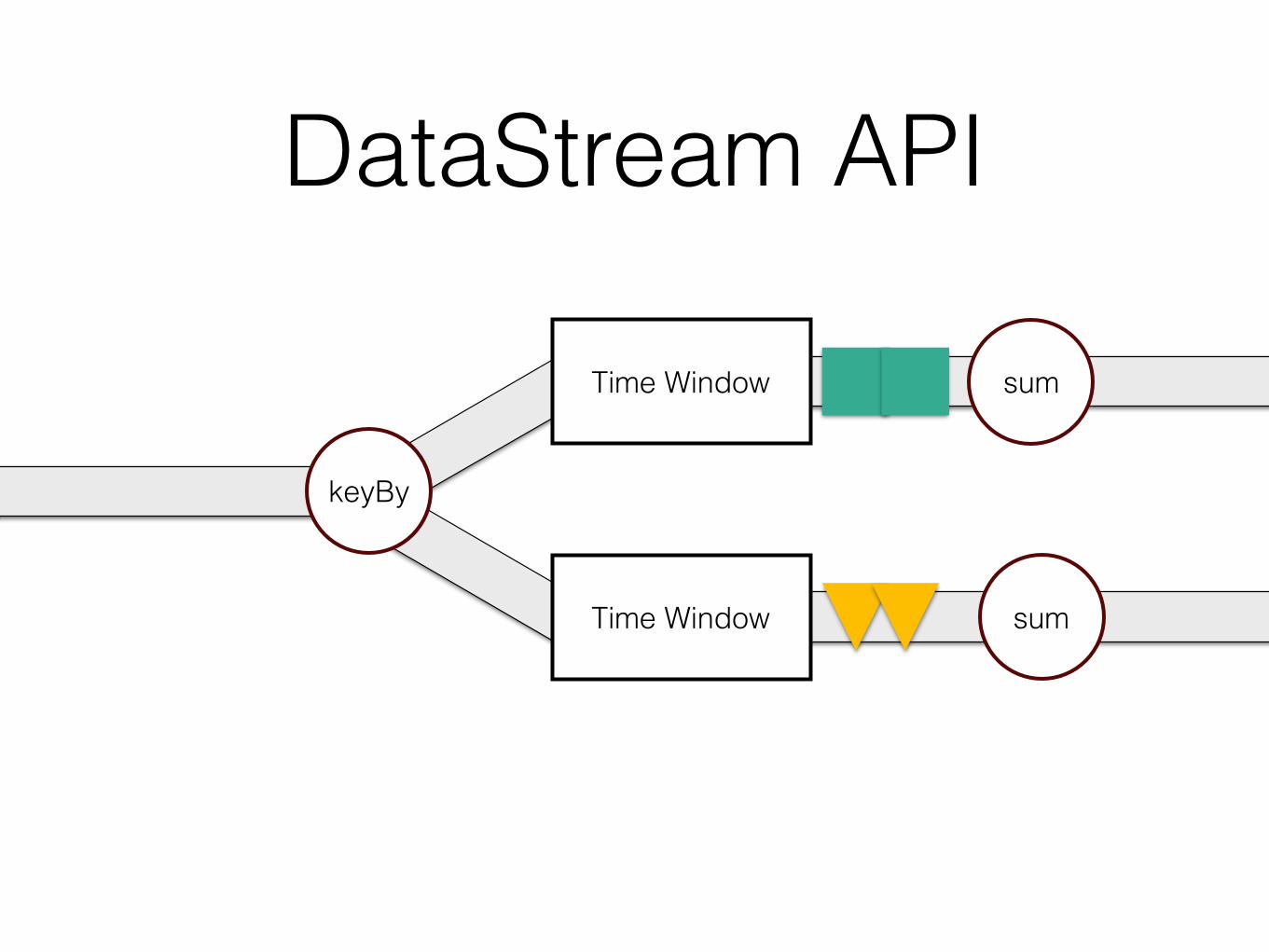
DataStream API
keyBy
sumTime Window
Time Window
sum
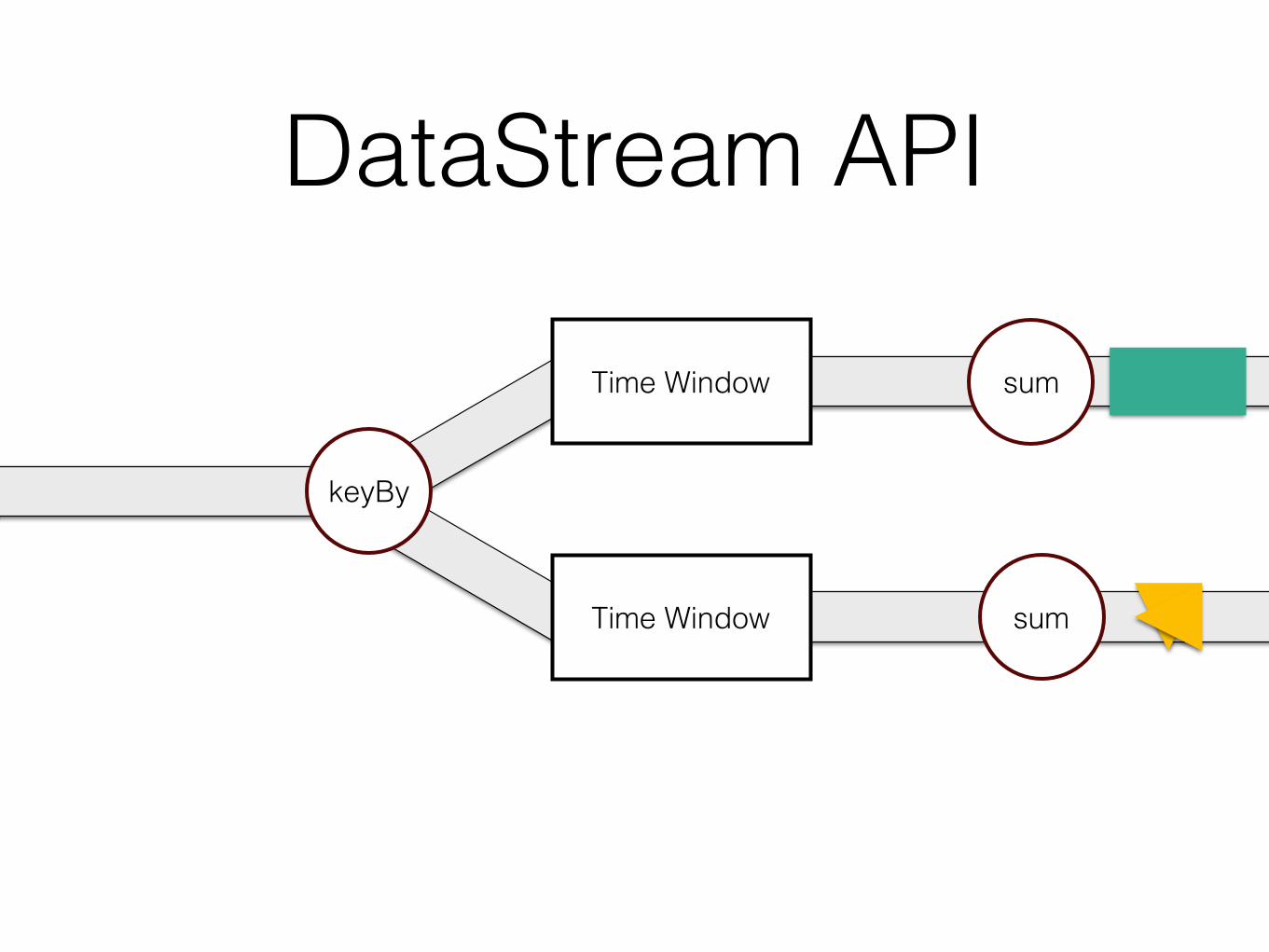
DataStream API
keyBy
sumTime Window
Time Window
sum
DataStream API
keyBy
sumTime Window
Time Window
sum
DataStream API
keyBy
sumTime Window
Time Window

DataStream APIStreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment()
DataStream<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataStream Windowed WordCount DataStream<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) // (word, 1) .keyBy(0) // [word, [1, 1, …]] for 10 seconds .timeWindow(Time.of(10, TimeUnit.SECONDS)) .sum(1); // sum per word per 10 second window
counts.print();
env.execute();

DataStream APIStreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment()
DataStream<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataStream Windowed WordCount DataStream<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) // (word, 1) .keyBy(0) // [word, [1, 1, …]] for 10 seconds .timeWindow(Time.of(10, TimeUnit.SECONDS)) .sum(1); // sum per word per 10 second window
counts.print();
env.execute();

DataStream APIStreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment()
DataStream<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataStream Windowed WordCount DataStream<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) // (word, 1) .keyBy(0) // [word, [1, 1, …]] for 10 seconds .timeWindow(Time.of(10, TimeUnit.SECONDS)) .sum(1); // sum per word per 10 second window
counts.print();
env.execute();

DataStream APIStreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment()
DataStream<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataStream Windowed WordCount DataStream<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) // (word, 1) .keyBy(0) // [word, [1, 1, …]] for 10 seconds .timeWindow(Time.of(10, TimeUnit.SECONDS)) .sum(1); // sum per word per 10 second window
counts.print();
env.execute();

DataStream APIStreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment()
DataStream<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataStream Windowed WordCount DataStream<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) // (word, 1) .keyBy(0) // [word, [1, 1, …]] for 10 seconds .timeWindow(Time.of(10, TimeUnit.SECONDS)) .sum(1); // sum per word per 10 second window
counts.print();
env.execute();

DataStream APIStreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment()
DataStream<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataStream Windowed WordCount DataStream<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) // (word, 1) .keyBy(0) // [word, [1, 1, …]] for 10 seconds .timeWindow(Time.of(10, TimeUnit.SECONDS)) .sum(1); // sum per word per 10 second window
counts.print();
env.execute();

DataStream APIStreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment()
DataStream<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataStream Windowed WordCount DataStream<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) // (word, 1) .keyBy(0) // [word, [1, 1, …]] for 10 seconds .timeWindow(Time.of(10, TimeUnit.SECONDS)) .sum(1); // sum per word per 10 second window
counts.print();
env.execute();

DataStream APIStreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment()
DataStream<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataStream Windowed WordCount DataStream<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) // (word, 1) .keyBy(0) // [word, [1, 1, …]] for 10 seconds .timeWindow(Time.of(10, TimeUnit.SECONDS)) .sum(1); // sum per word per 10 second window
counts.print();
env.execute();

DataStream APIpublic static class SplitByWhitespace implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap ( String value, Collector<Tuple2<String, Integer>> out) { String[] tokens = value.toLowerCase().split("\\W+"); for (String token : tokens) { if (token.length() > 0) { out.collect(new Tuple2<>(token, 1)); } } }}

DataStream APIpublic static class SplitByWhitespace implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap ( String value, Collector<Tuple2<String, Integer>> out) { String[] tokens = value.toLowerCase().split("\\W+"); for (String token : tokens) { if (token.length() > 0) { out.collect(new Tuple2<>(token, 1)); } } }}

DataStream APIpublic static class SplitByWhitespace implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap ( String value, Collector<Tuple2<String, Integer>> out) { String[] tokens = value.toLowerCase().split("\\W+"); for (String token : tokens) { if (token.length() > 0) { out.collect(new Tuple2<>(token, 1)); } } }}

DataStream APIpublic static class SplitByWhitespace implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap ( String value, Collector<Tuple2<String, Integer>> out) { String[] tokens = value.toLowerCase().split("\\W+"); for (String token : tokens) { if (token.length() > 0) { out.collect(new Tuple2<>(token, 1)); } } }}

DataStream APIpublic static class SplitByWhitespace implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap ( String value, Collector<Tuple2<String, Integer>> out) { String[] tokens = value.toLowerCase().split("\\W+"); for (String token : tokens) { if (token.length() > 0) { out.collect(new Tuple2<>(token, 1)); } } }}

DataStream APIpublic static class SplitByWhitespace implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap ( String value, Collector<Tuple2<String, Integer>> out) { String[] tokens = value.toLowerCase().split("\\W+"); for (String token : tokens) { if (token.length() > 0) { out.collect(new Tuple2<>(token, 1)); } } }}

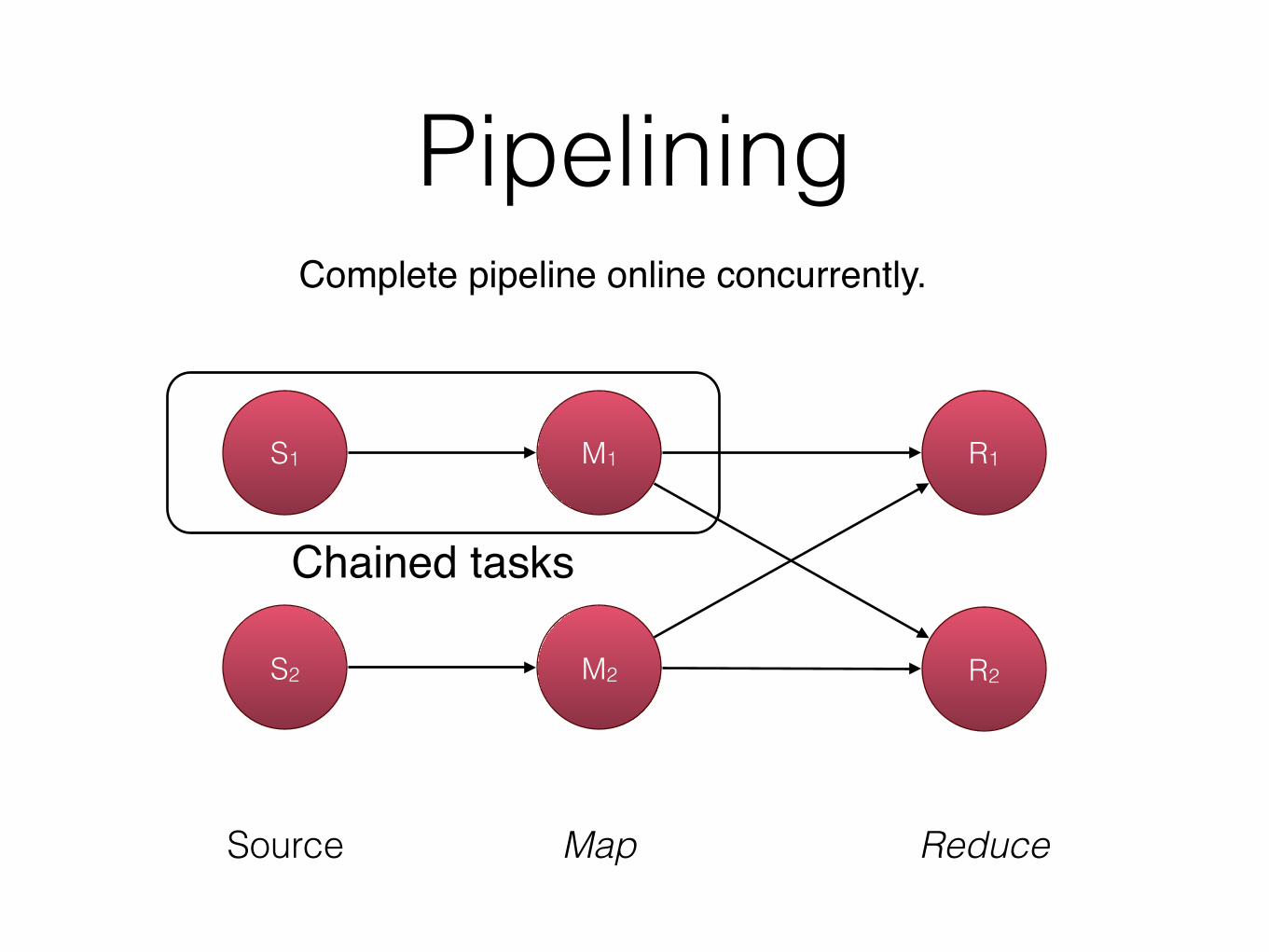
Pipelining
DataStream<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?”, …);
// DataStream WordCount DataStream<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) // (word, 1) .keyBy(0) // split stream by word .sum(1); // sum per word as they arrive
Source Map Reduce
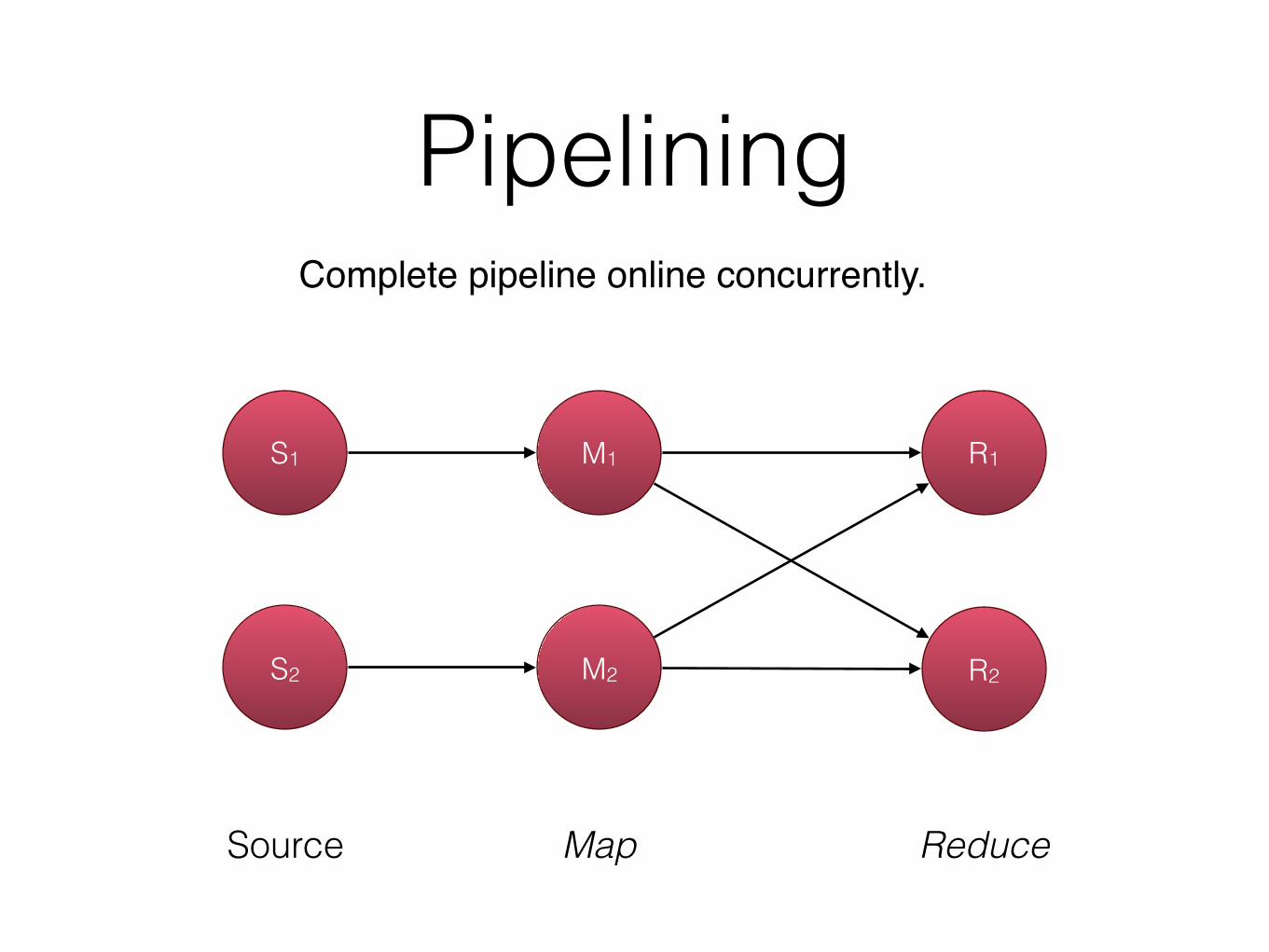
Pipelining
S1 M1 R1
S2 M2 R2
Source Map Reduce
Complete pipeline online concurrently.
Pipelining
S1 M1 R1
S2 M2 R2
Chained tasks
Complete pipeline online concurrently.
Source Map Reduce
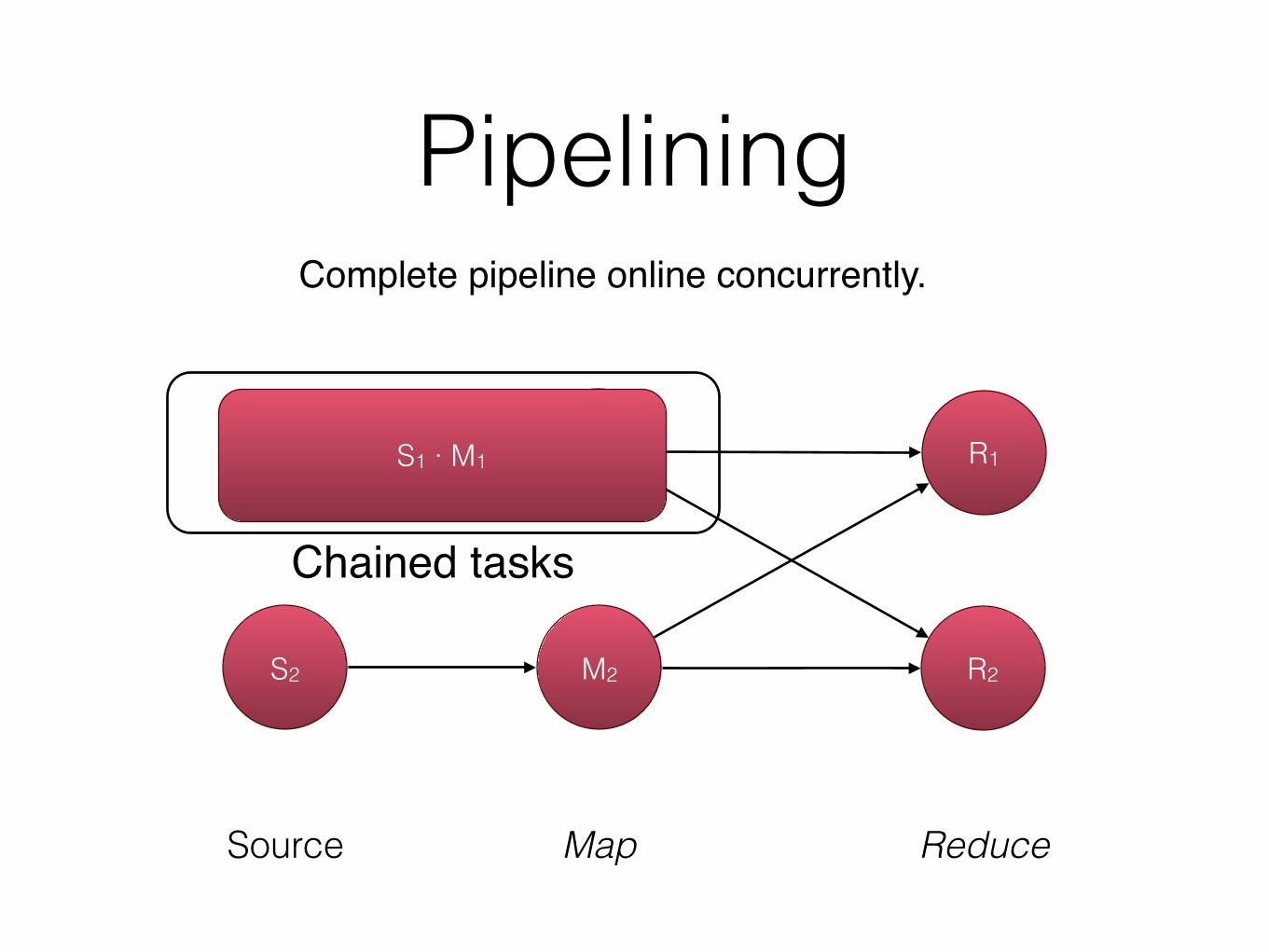
Pipelining
S1 M1 R1
S2 M2 R2
Chained tasks
Complete pipeline online concurrently.
Source Map Reduce
S1 · M1
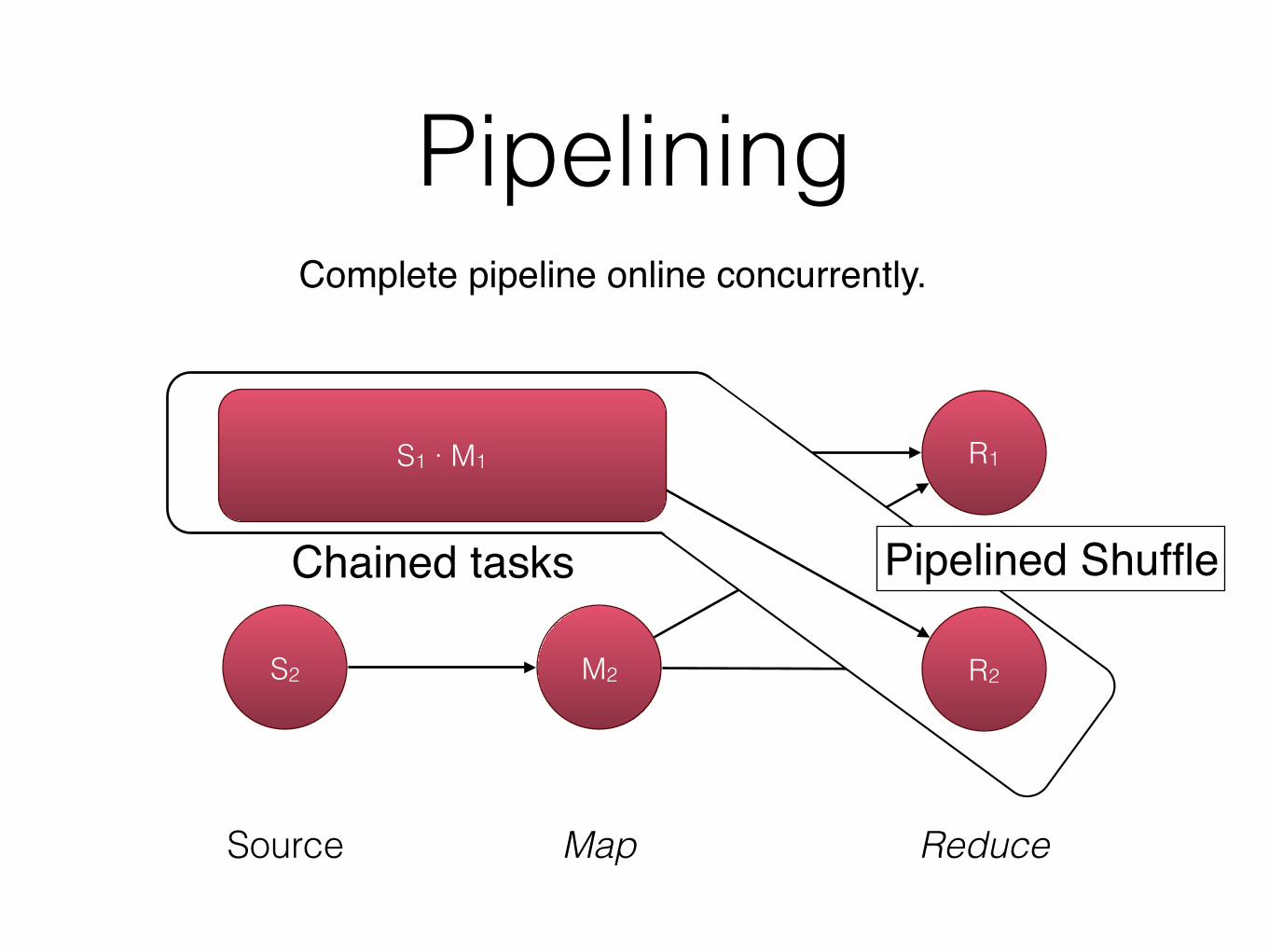
Pipelining
S1
S2 M2
M1 R1
Complete pipeline online concurrently.
Chained tasks Pipelined Shuffle
Source Map Reduce
S1 · M1
R2
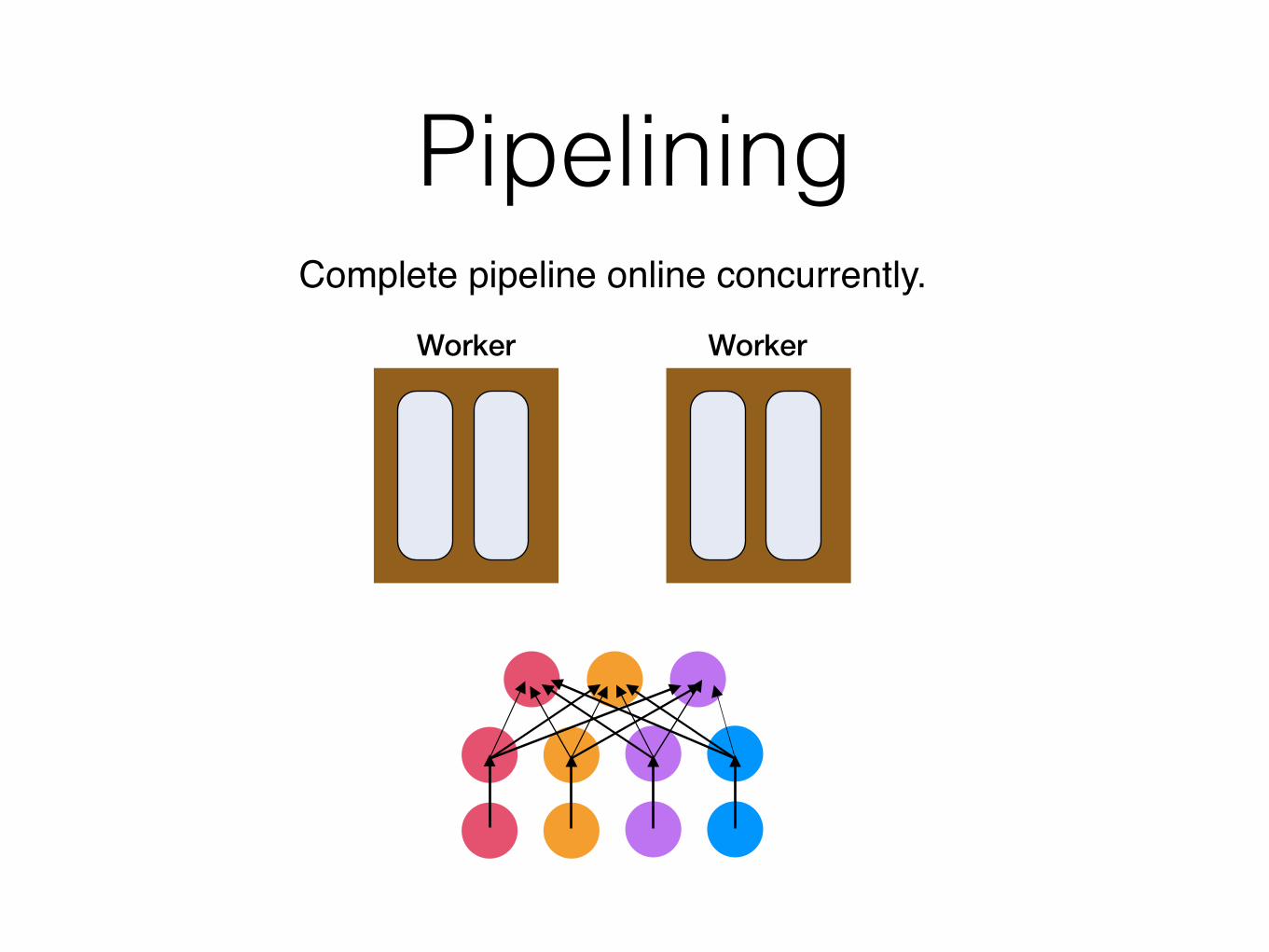
PipeliningComplete pipeline online concurrently.
Worker Worker
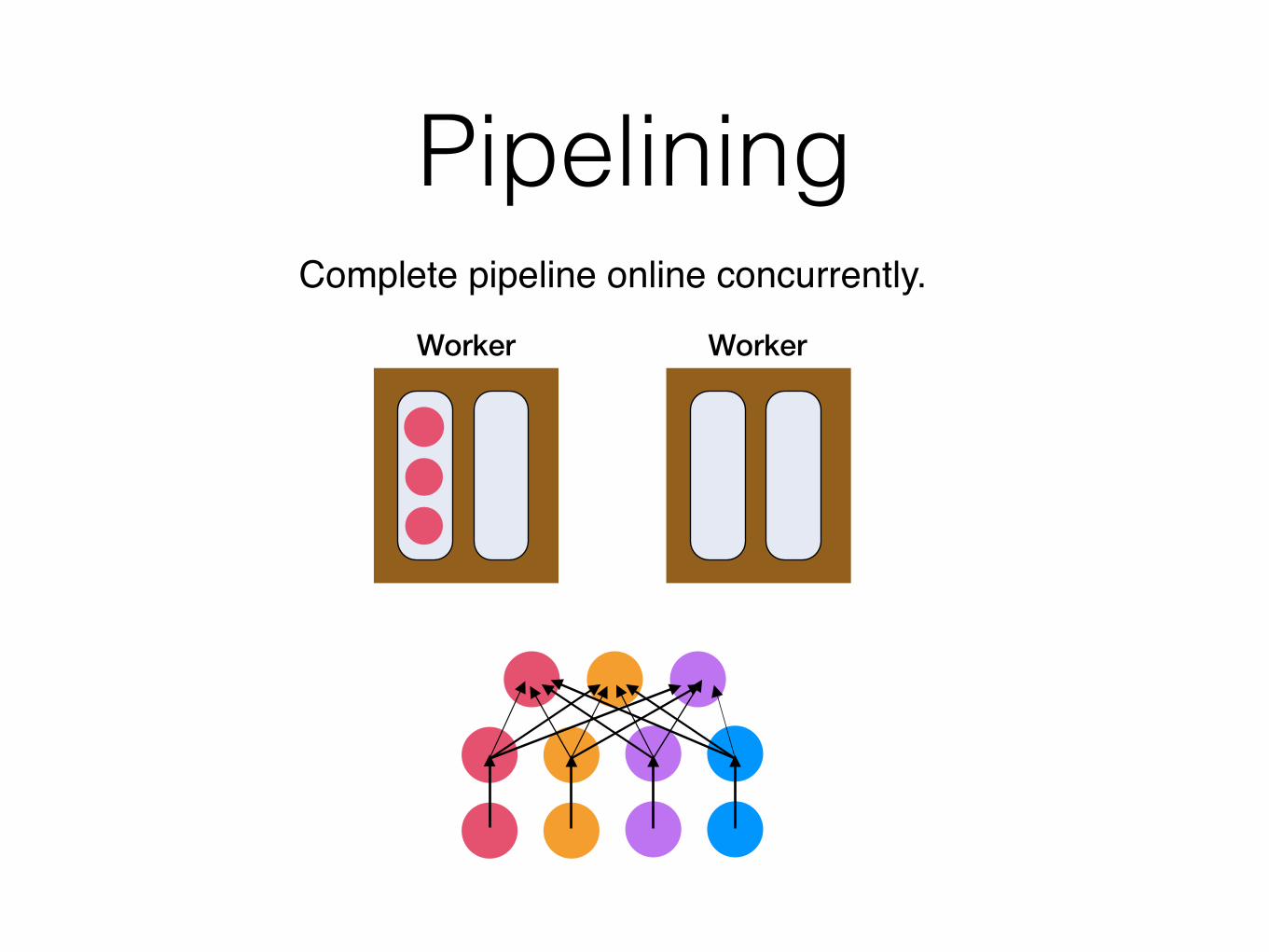
PipeliningComplete pipeline online concurrently.
Worker Worker
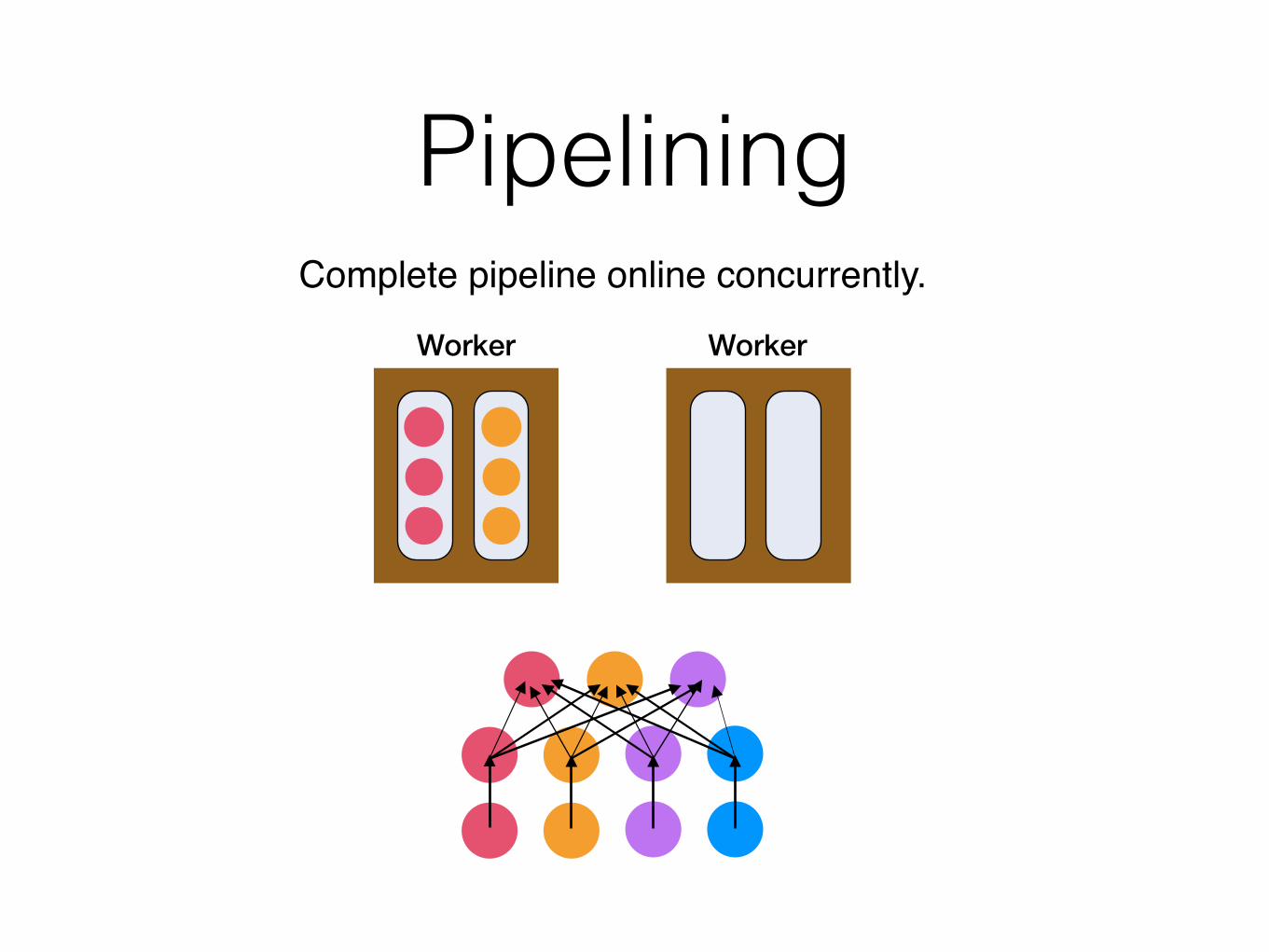
PipeliningComplete pipeline online concurrently.
Worker Worker
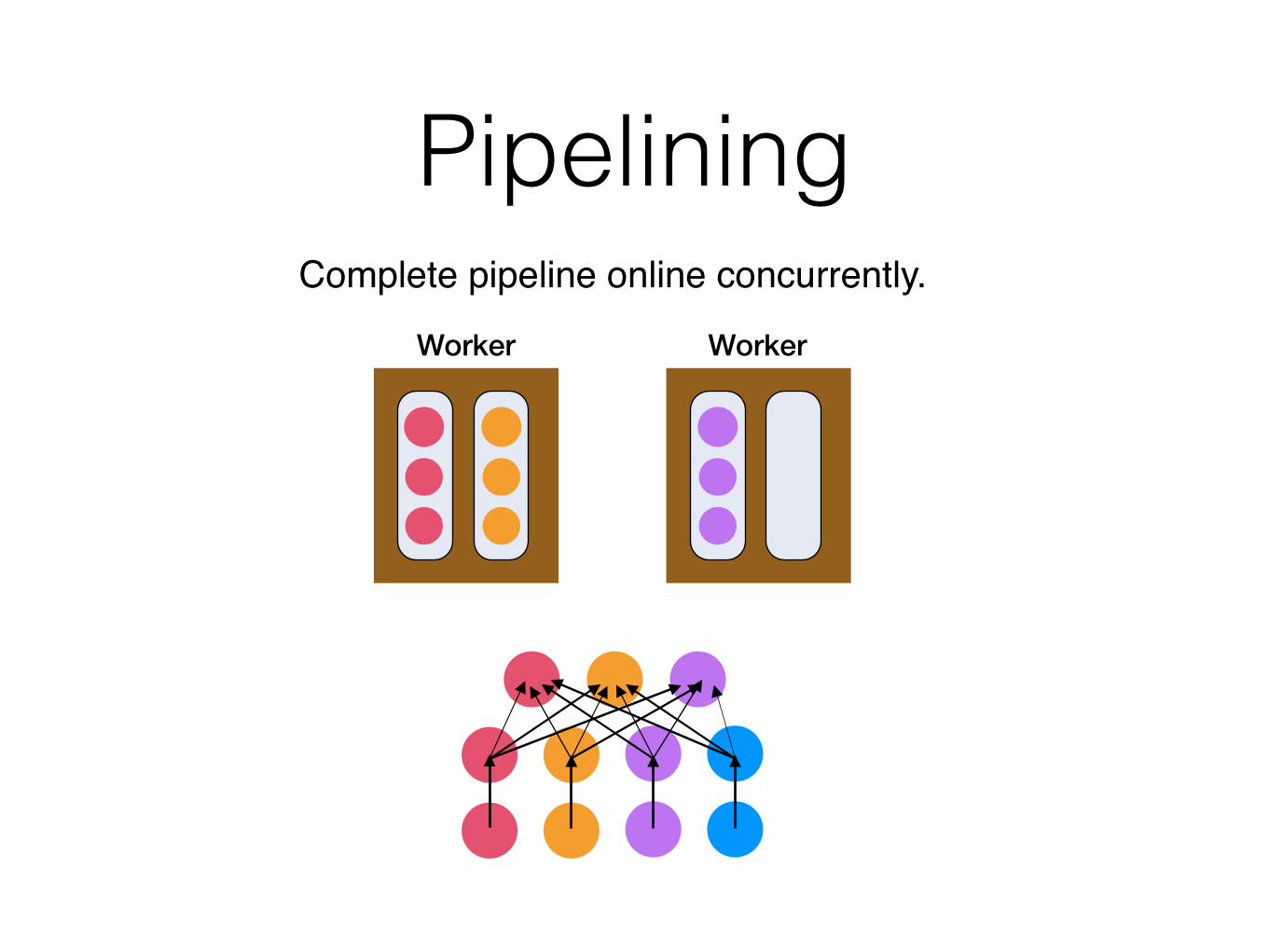
PipeliningComplete pipeline online concurrently.
Worker Worker
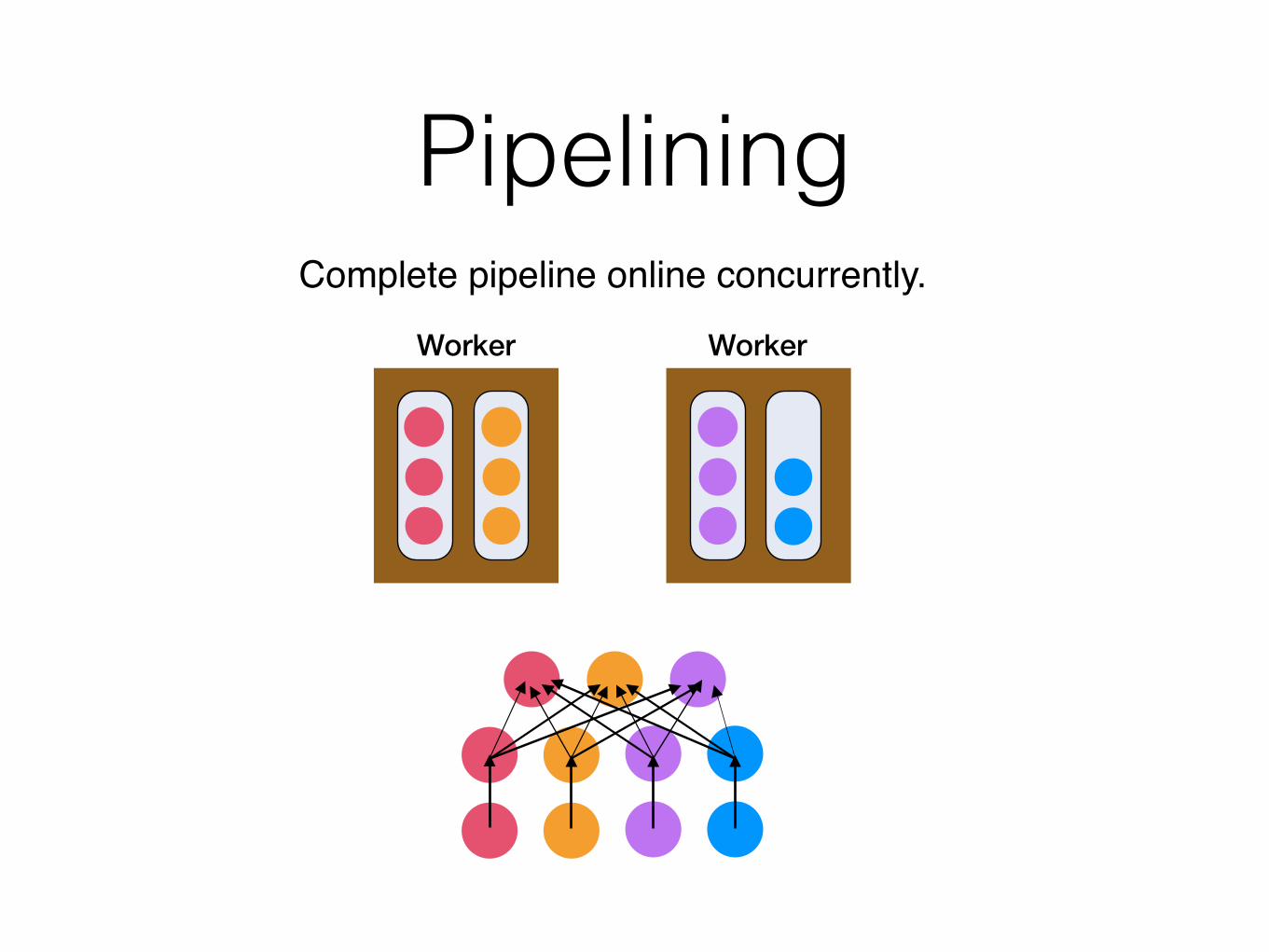
PipeliningComplete pipeline online concurrently.
Worker Worker
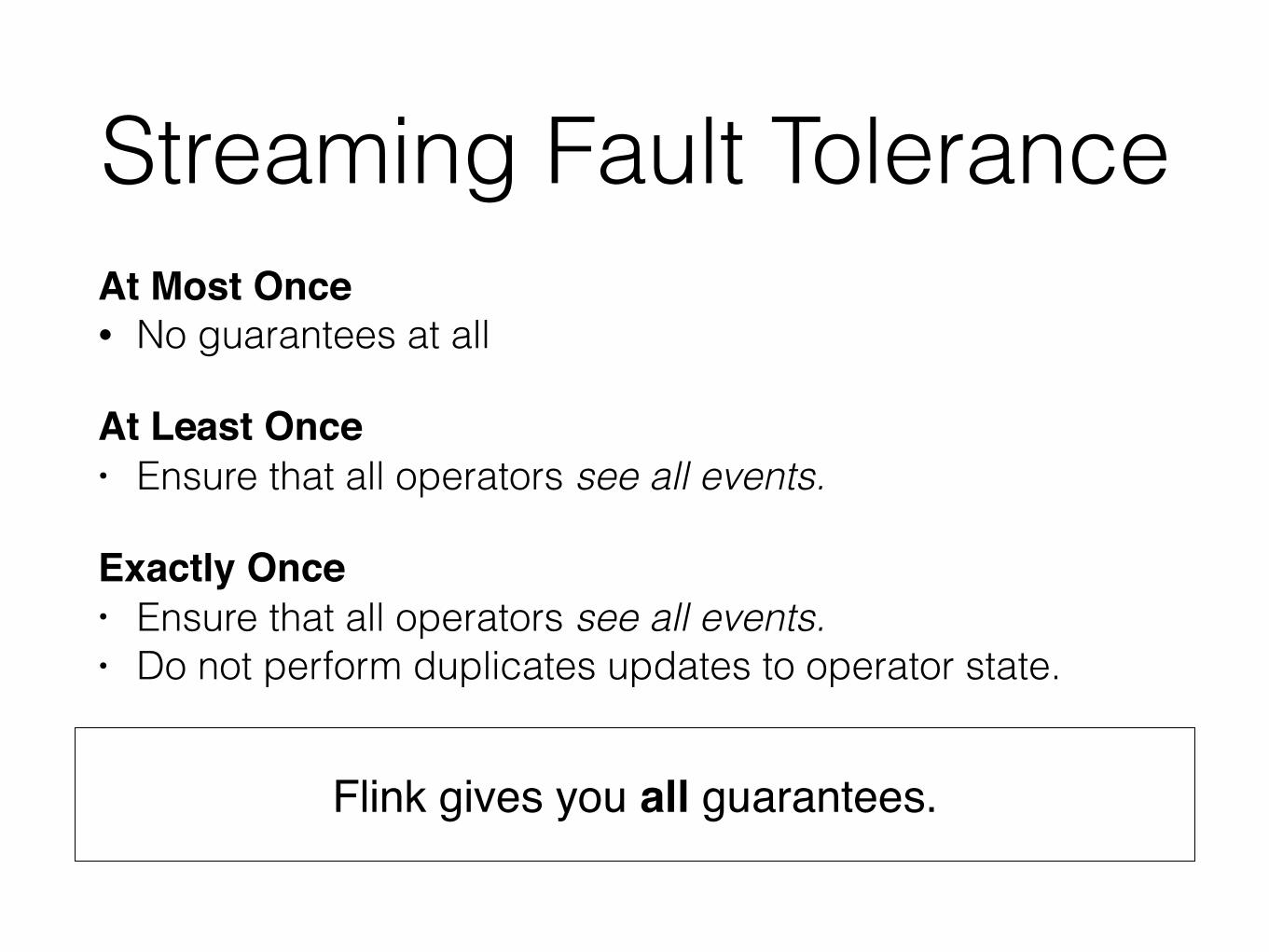
Streaming Fault ToleranceAt Most Once• No guarantees at all
At Least Once • Ensure that all operators see all events.
Exactly Once• Ensure that all operators see all events. • Do not perform duplicates updates to operator state.
Flink gives you all guarantees.
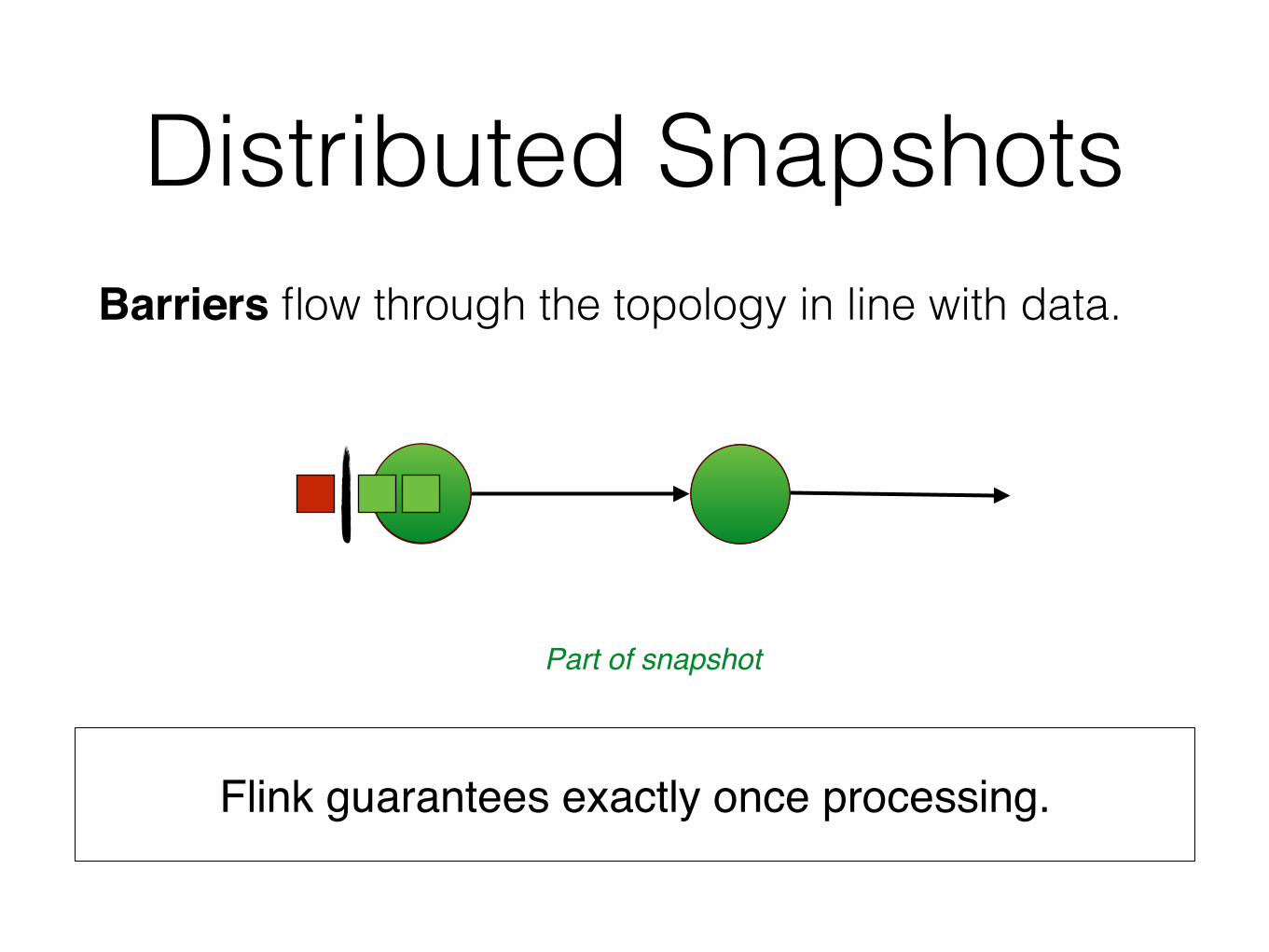
Distributed SnapshotsBarriers flow through the topology in line with data.
Flink guarantees exactly once processing.
Part of snapshot
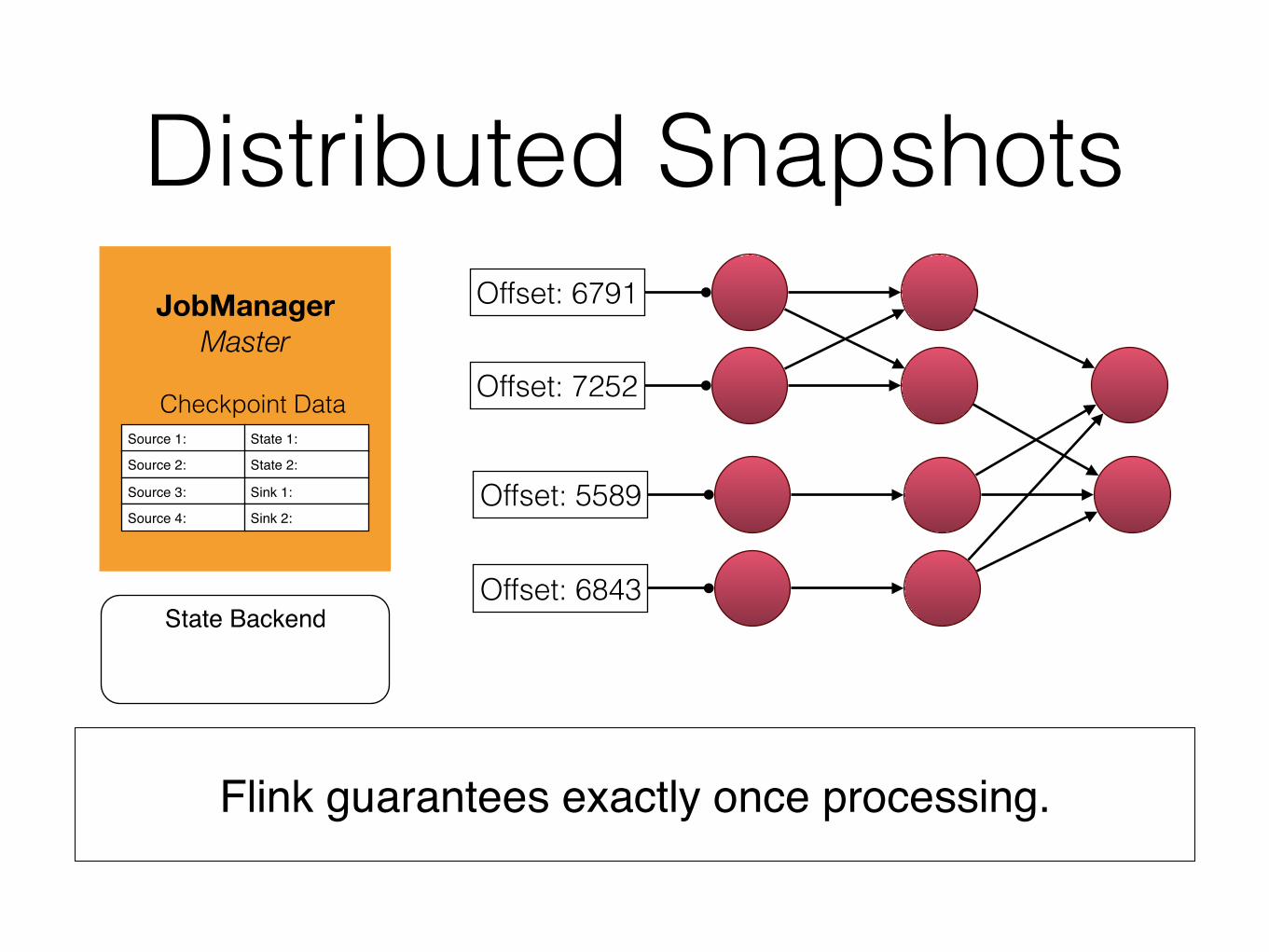
Distributed Snapshots
Flink guarantees exactly once processing.
JobManager
Master
State Backend
Checkpoint DataSource 1: State 1:
Source 2: State 2:
Source 3: Sink 1:
Source 4: Sink 2:
Offset: 6791
Offset: 7252
Offset: 5589
Offset: 6843
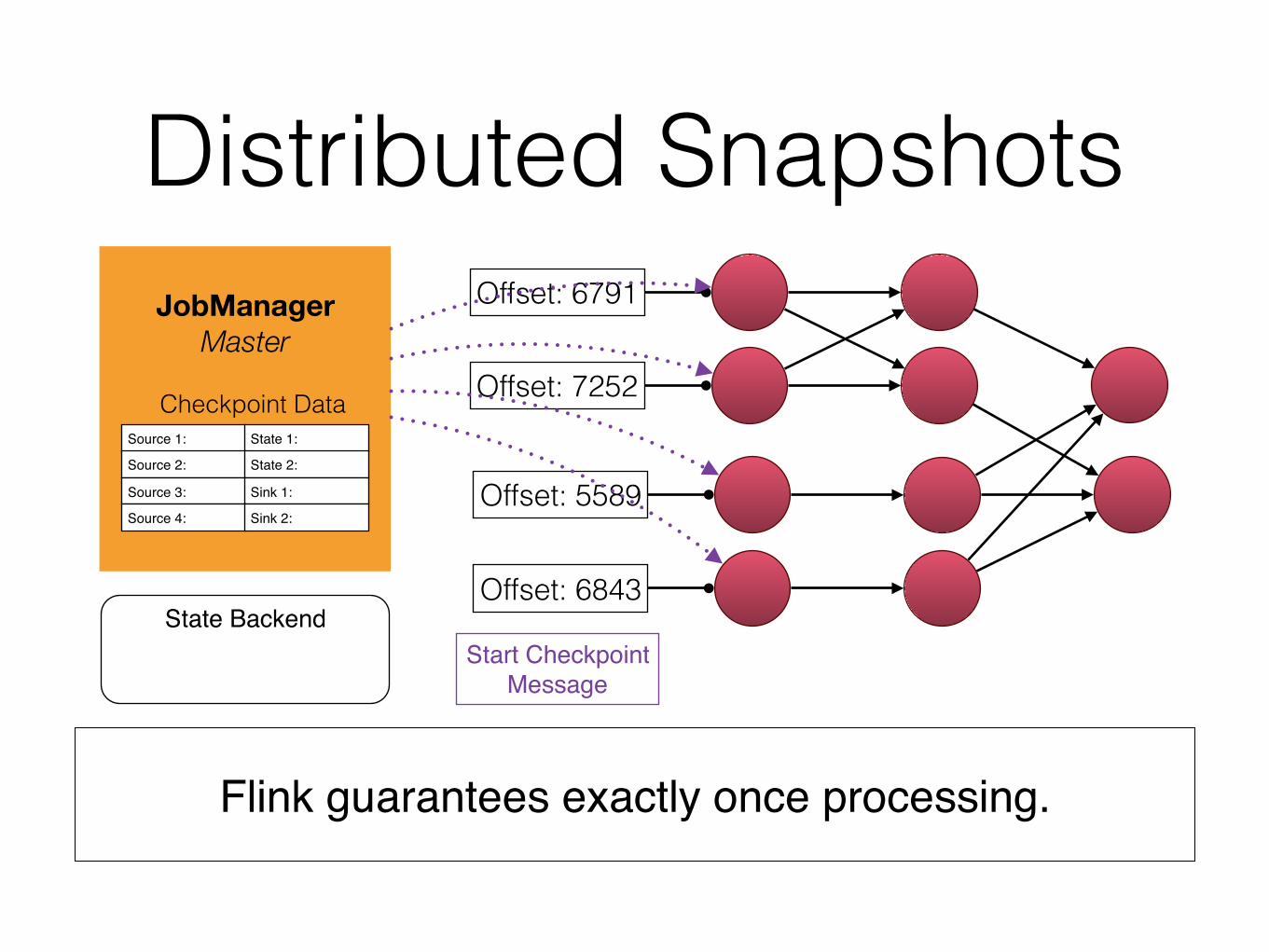
Distributed Snapshots
Flink guarantees exactly once processing.
JobManager
Master
State Backend
Checkpoint DataSource 1: State 1:
Source 2: State 2:
Source 3: Sink 1:
Source 4: Sink 2:
Offset: 6791
Offset: 7252
Offset: 5589
Offset: 6843
Start CheckpointMessage
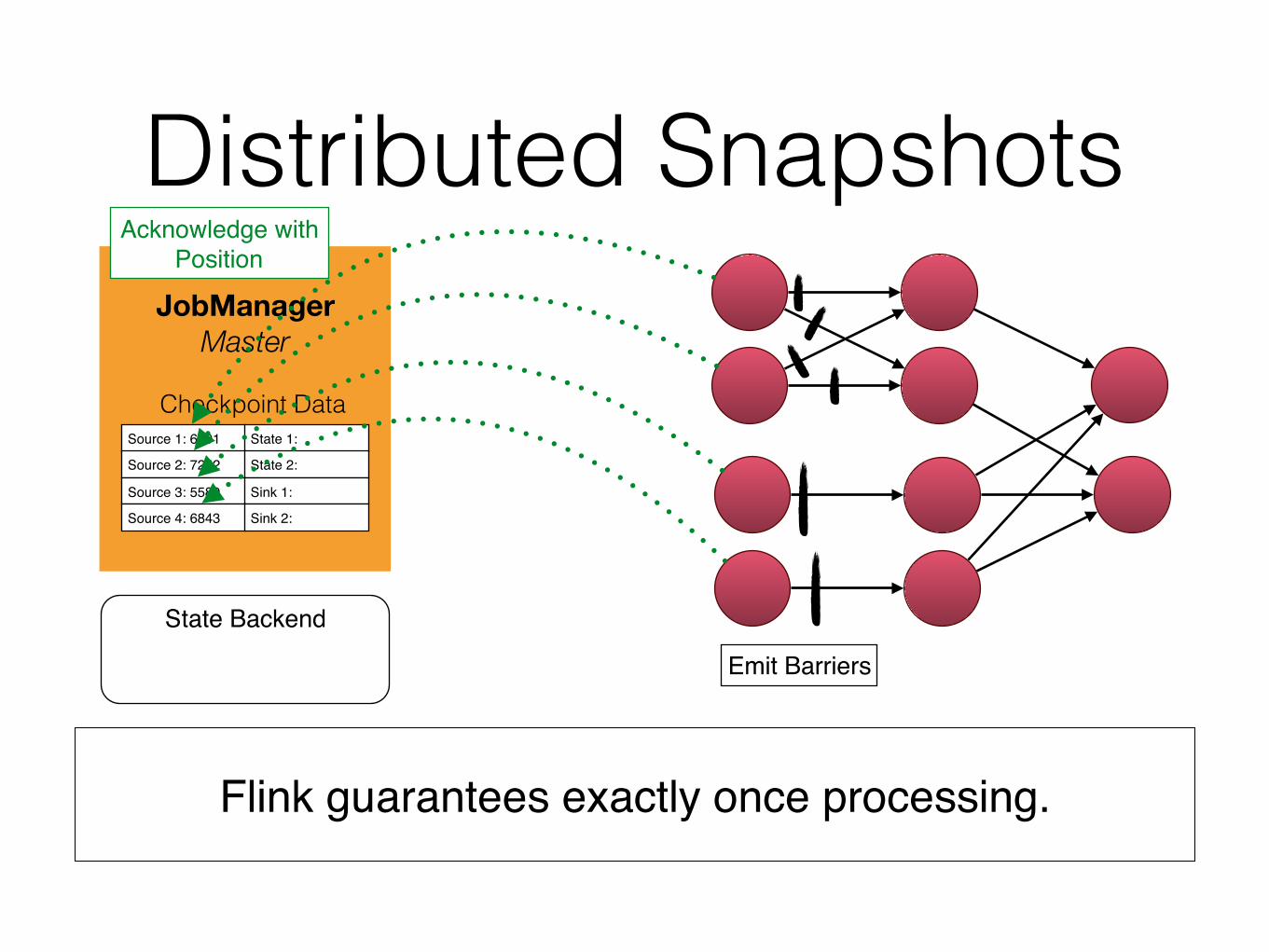
Distributed Snapshots
Flink guarantees exactly once processing.
JobManager
Master
State Backend
Checkpoint DataSource 1: 6791 State 1:
Source 2: 7252 State 2:
Source 3: 5589 Sink 1:
Source 4: 6843 Sink 2:
Emit Barriers
Acknowledge withPosition
Distributed Snapshots
Flink guarantees exactly once processing.
JobManager
Master
State Backend
Checkpoint DataSource 1: 6791 State 1:
Source 2: 7252 State 2:
Source 3: 5589 Sink 1:
Source 4: 6843 Sink 2:
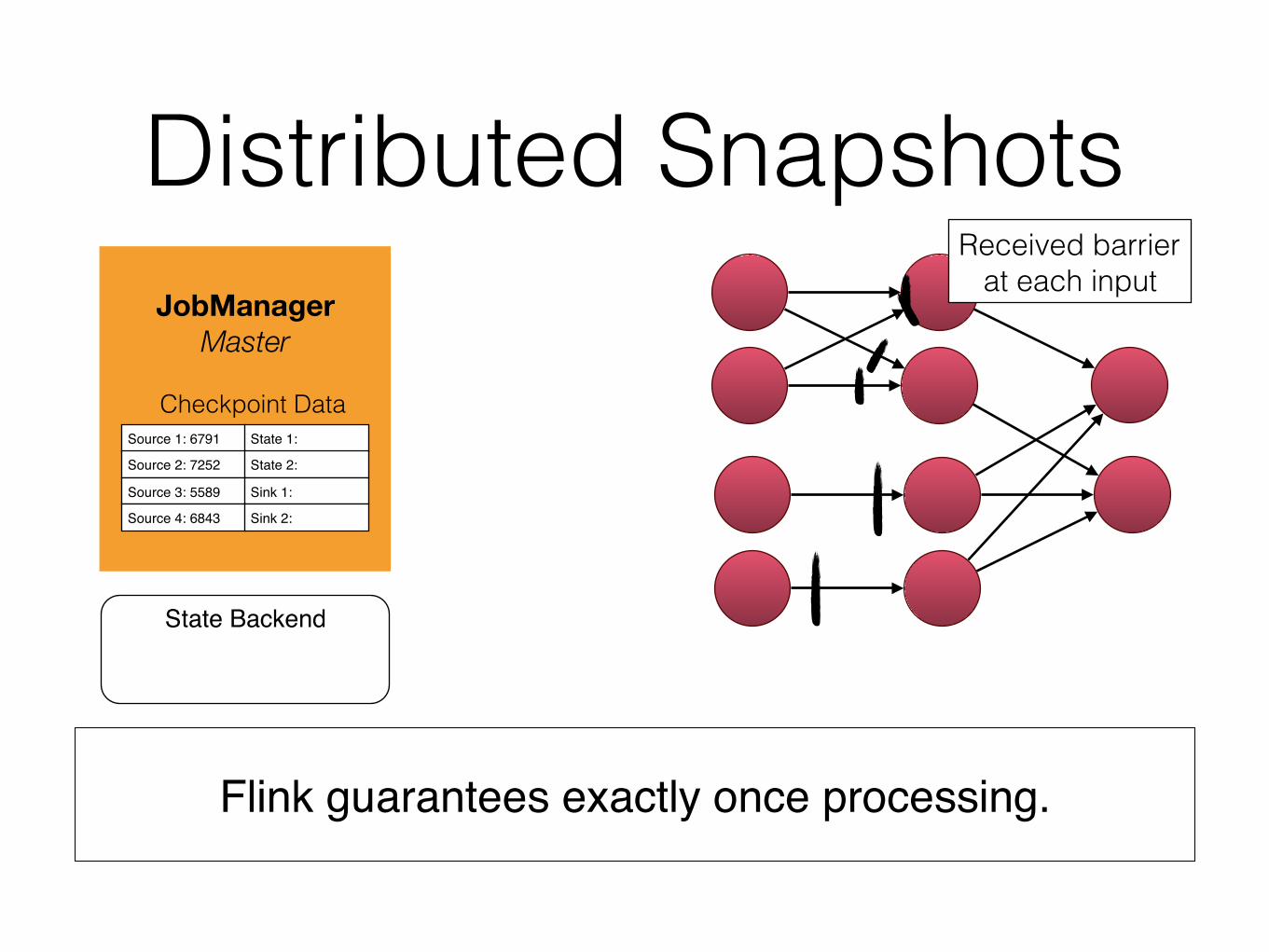
Received barrier at each input
Distributed Snapshots
Flink guarantees exactly once processing.
JobManager
Master
State Backend
Checkpoint DataSource 1: 6791 State 1:
Source 2: 7252 State 2:
Source 3: 5589 Sink 1:
Source 4: 6843 Sink 2:
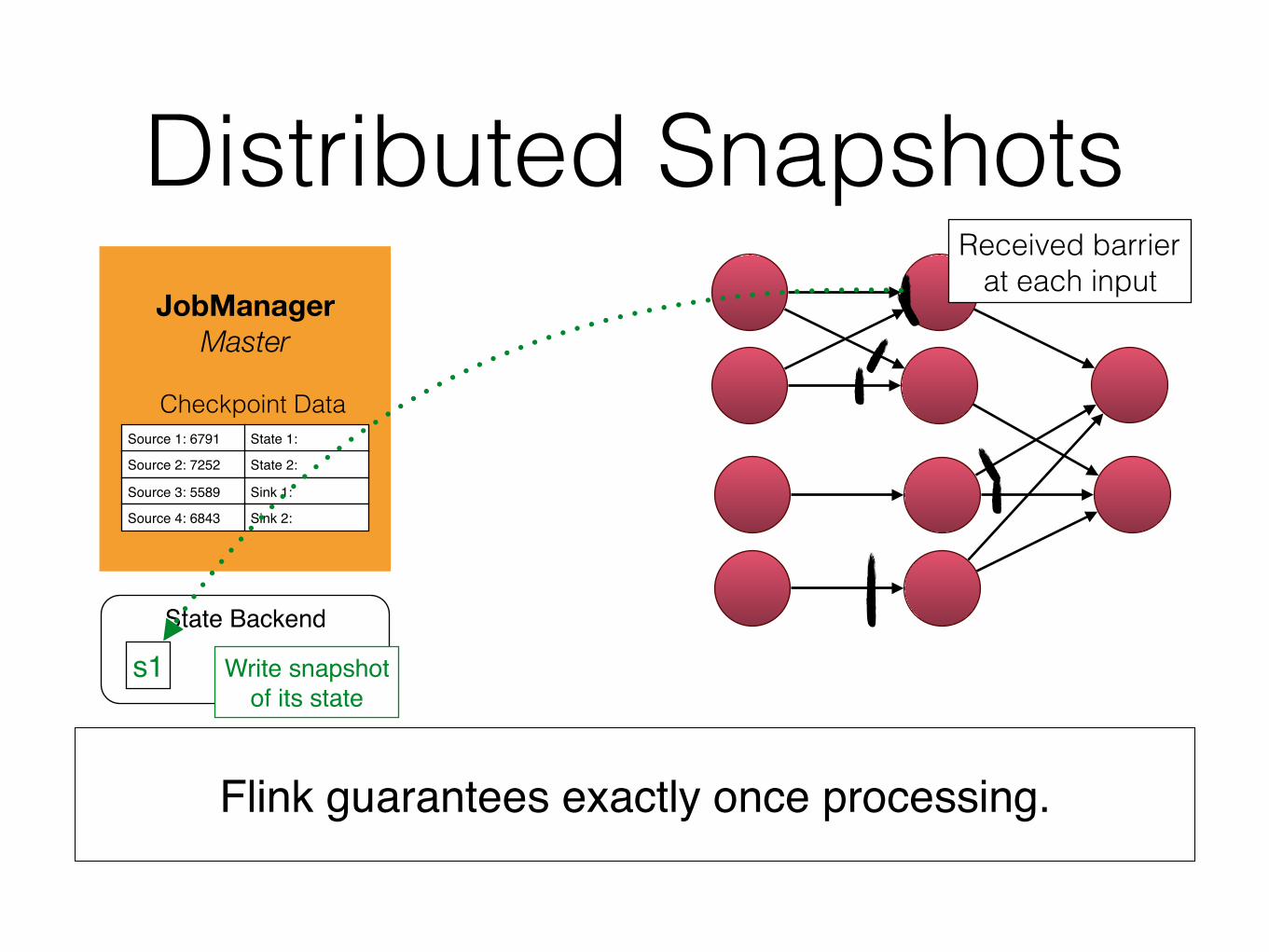
s1 Write snapshotof its state
Received barrier at each input
Distributed Snapshots
Flink guarantees exactly once processing.
JobManager
Master
State Backend
Checkpoint DataSource 1: 6791 State 1: PTR1
Source 2: 7252 State 2: PTR2
Source 3: 5589 Sink 1:
Source 4: 6843 Sink 2:
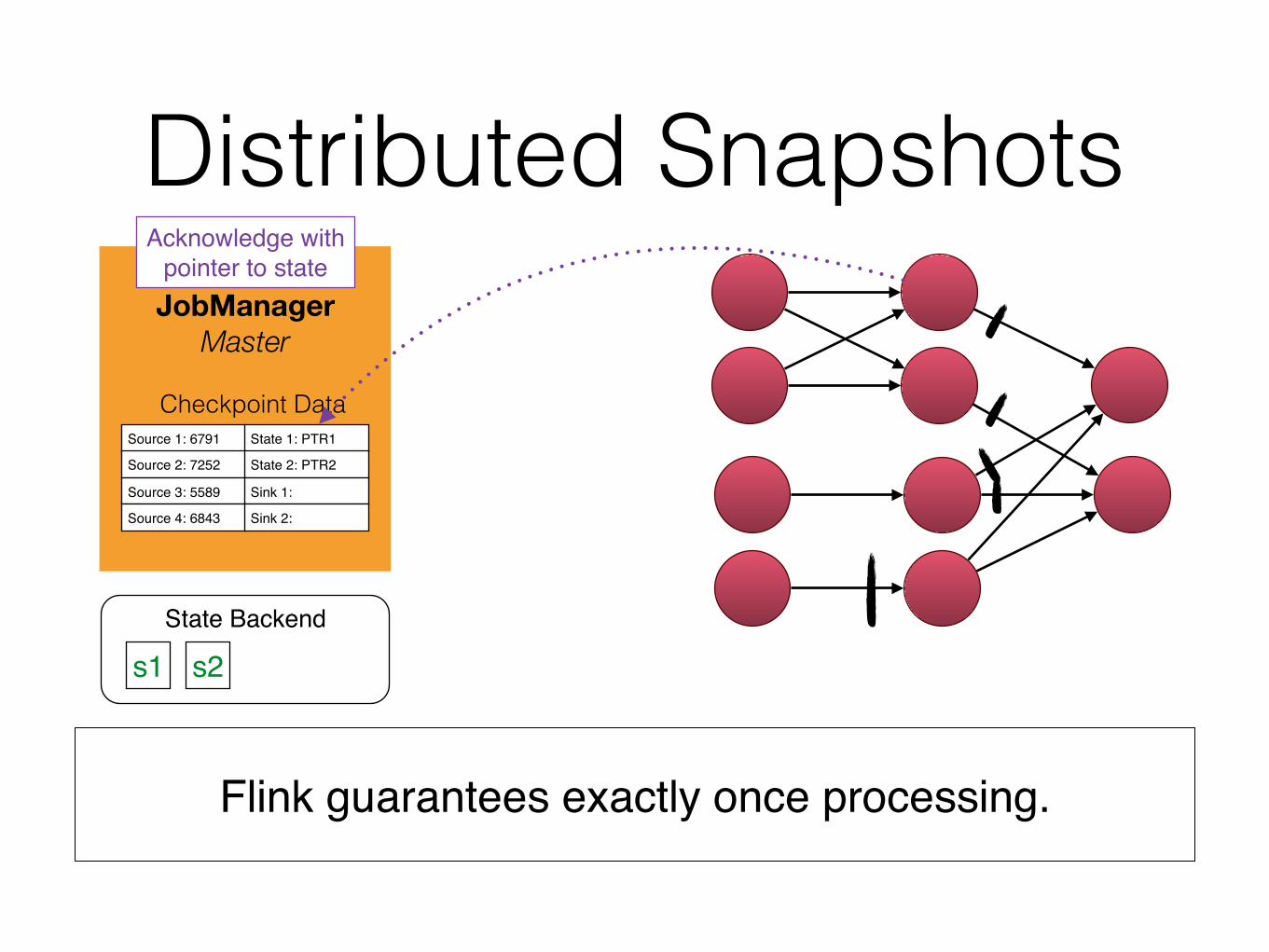
s1
Acknowledge withpointer to state
s2
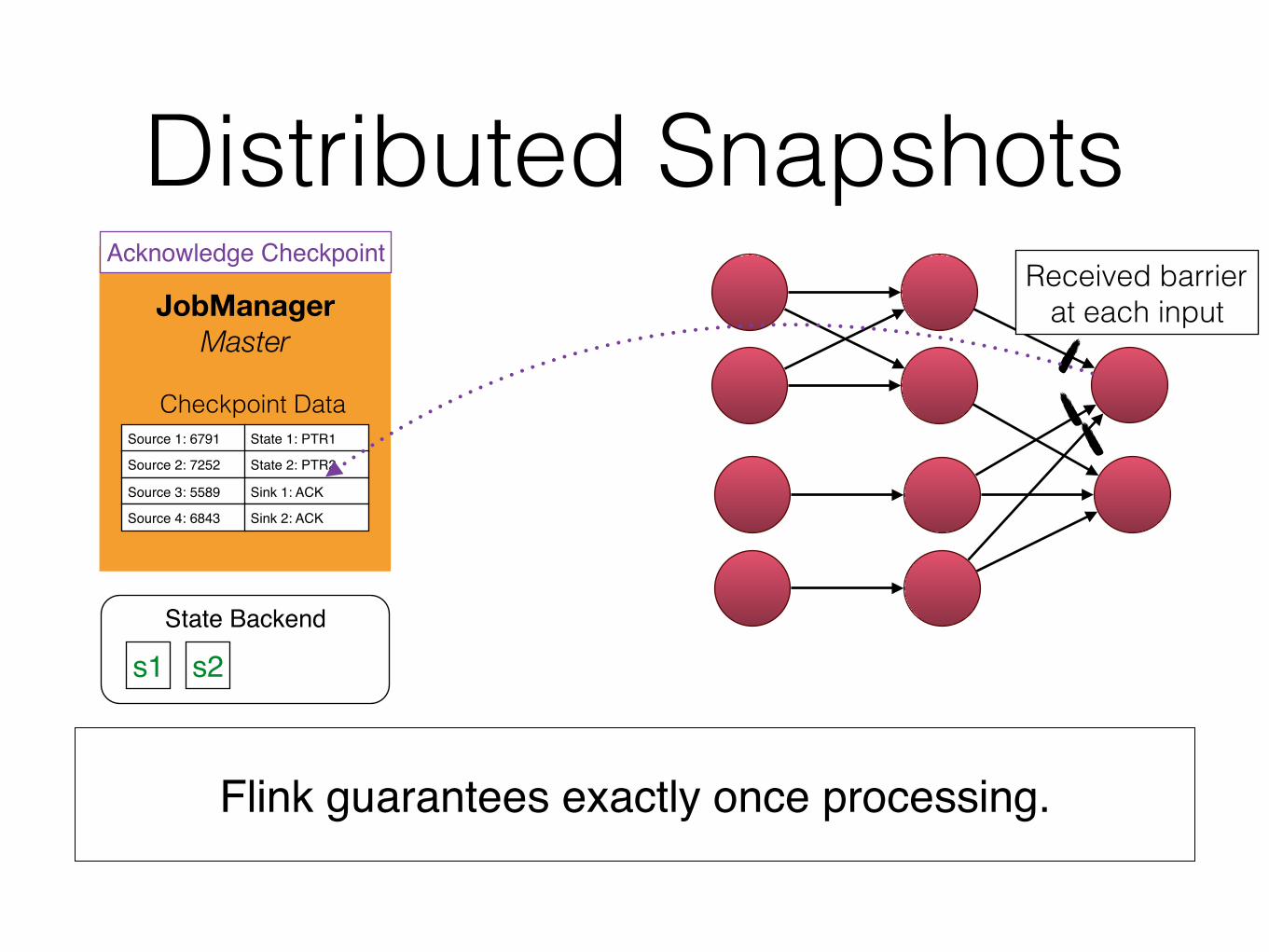
Distributed Snapshots
Flink guarantees exactly once processing.
JobManager
Master
State Backend
Checkpoint DataSource 1: 6791 State 1: PTR1
Source 2: 7252 State 2: PTR2
Source 3: 5589 Sink 1: ACK
Source 4: 6843 Sink 2: ACK
s1 s2
Acknowledge CheckpointReceived barrier
at each input
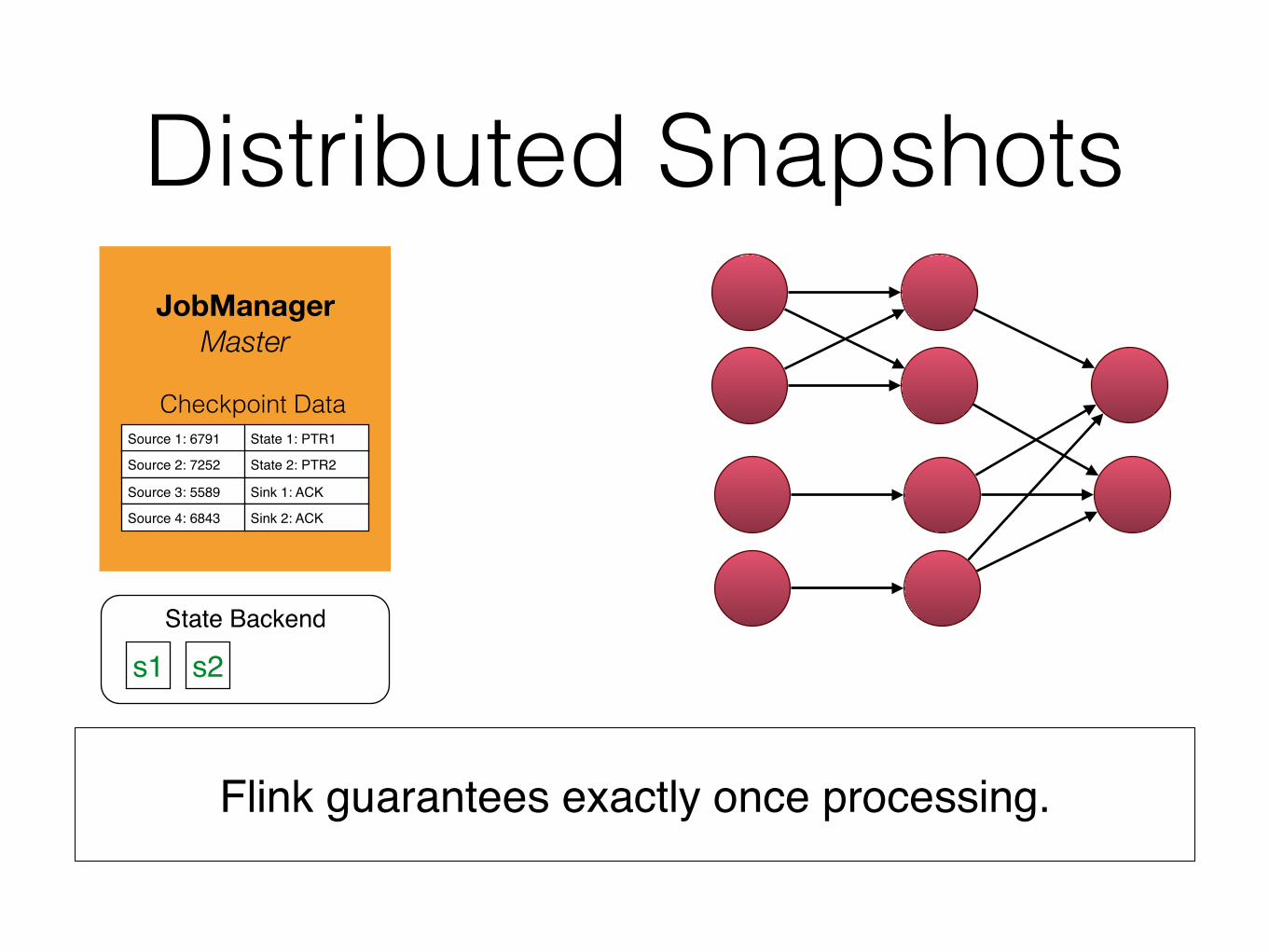
Distributed Snapshots
Flink guarantees exactly once processing.
JobManager
Master
State Backend
Checkpoint DataSource 1: 6791 State 1: PTR1
Source 2: 7252 State 2: PTR2
Source 3: 5589 Sink 1: ACK
Source 4: 6843 Sink 2: ACK
s1 s2

Operator StateStateless Operatorsds.filter(_ != 0)
System stateds.keyBy(0).window(TumblingTimeWindows.of(5, TimeUnit.SECONDS))
User defined statepublic class CounterSum implements RichReduceFunction<Long> { private OperatorState<Long> counter;
@Override public Long reduce(Long v1, Long v2) throws Exception { counter.update(counter.value() + 1); return v1 + v2; }
@Override public void open(Configuration config) { counter = getRuntimeContext().getOperatorState(“counter”, 0L, false); } }
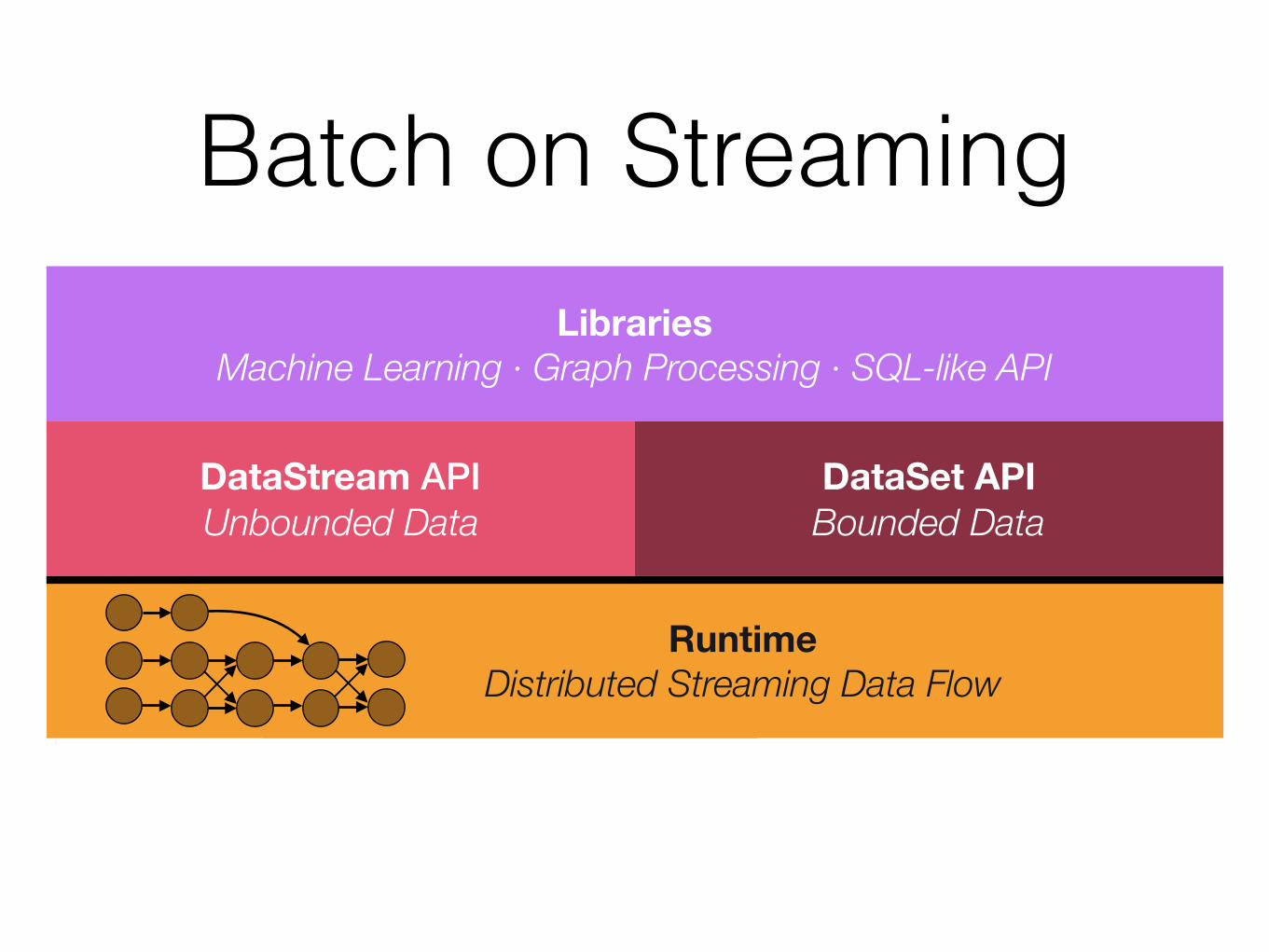
Batch on Streaming
DataStream API Unbounded Data
DataSet API Bounded Data
Runtime Distributed Streaming Data Flow
Libraries Machine Learning · Graph Processing · SQL-like API
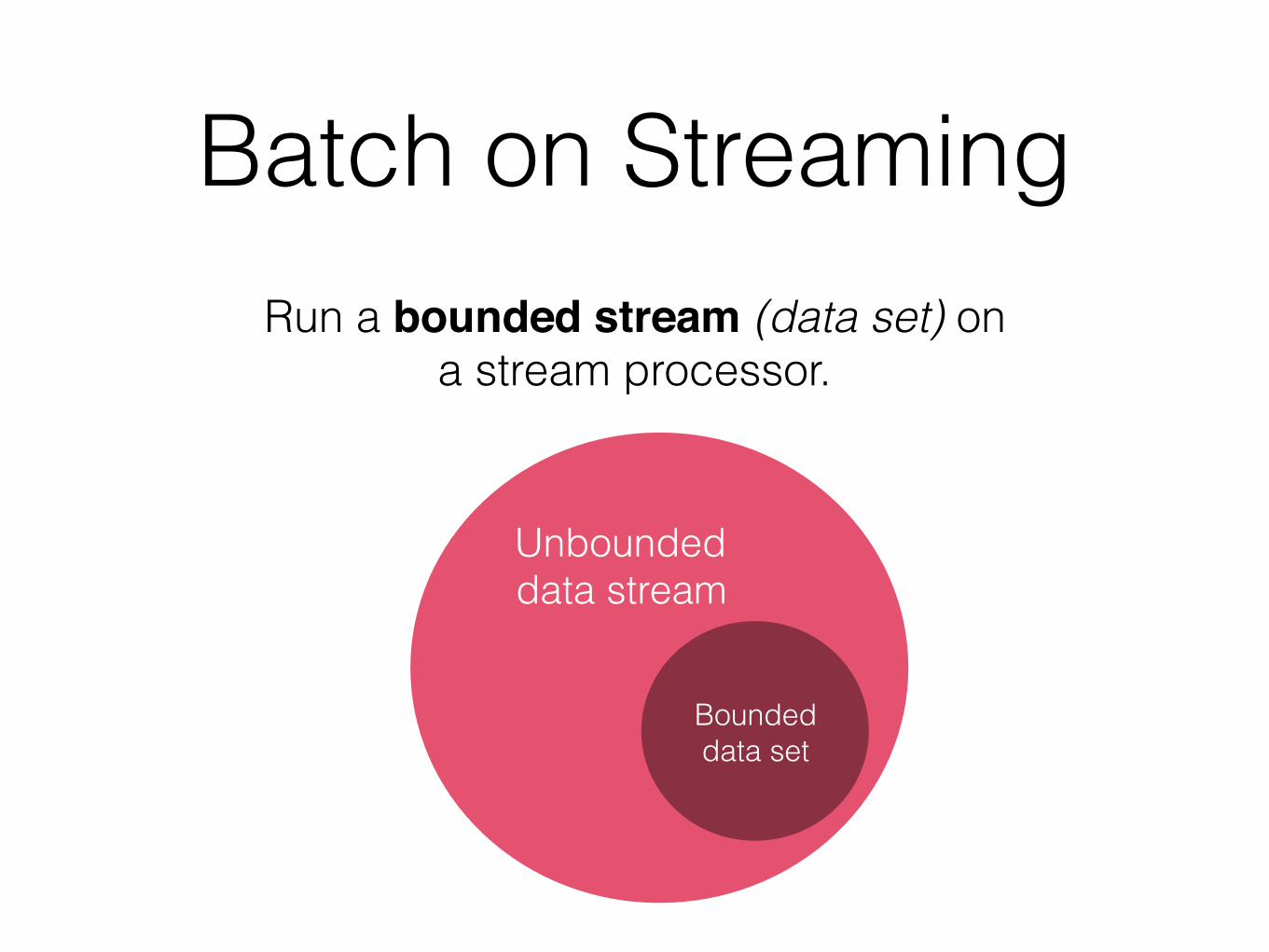
Batch on StreamingRun a bounded stream (data set) on
a stream processor.
Bounded data set
Unbounded data stream

Batch on Streaming
Stream Windows
PipelinedData Exchange
Global View
Pipelined or BlockingData Exchange
Infinite Streams Finite Streams
Run a bounded stream (data set) ona stream processor.
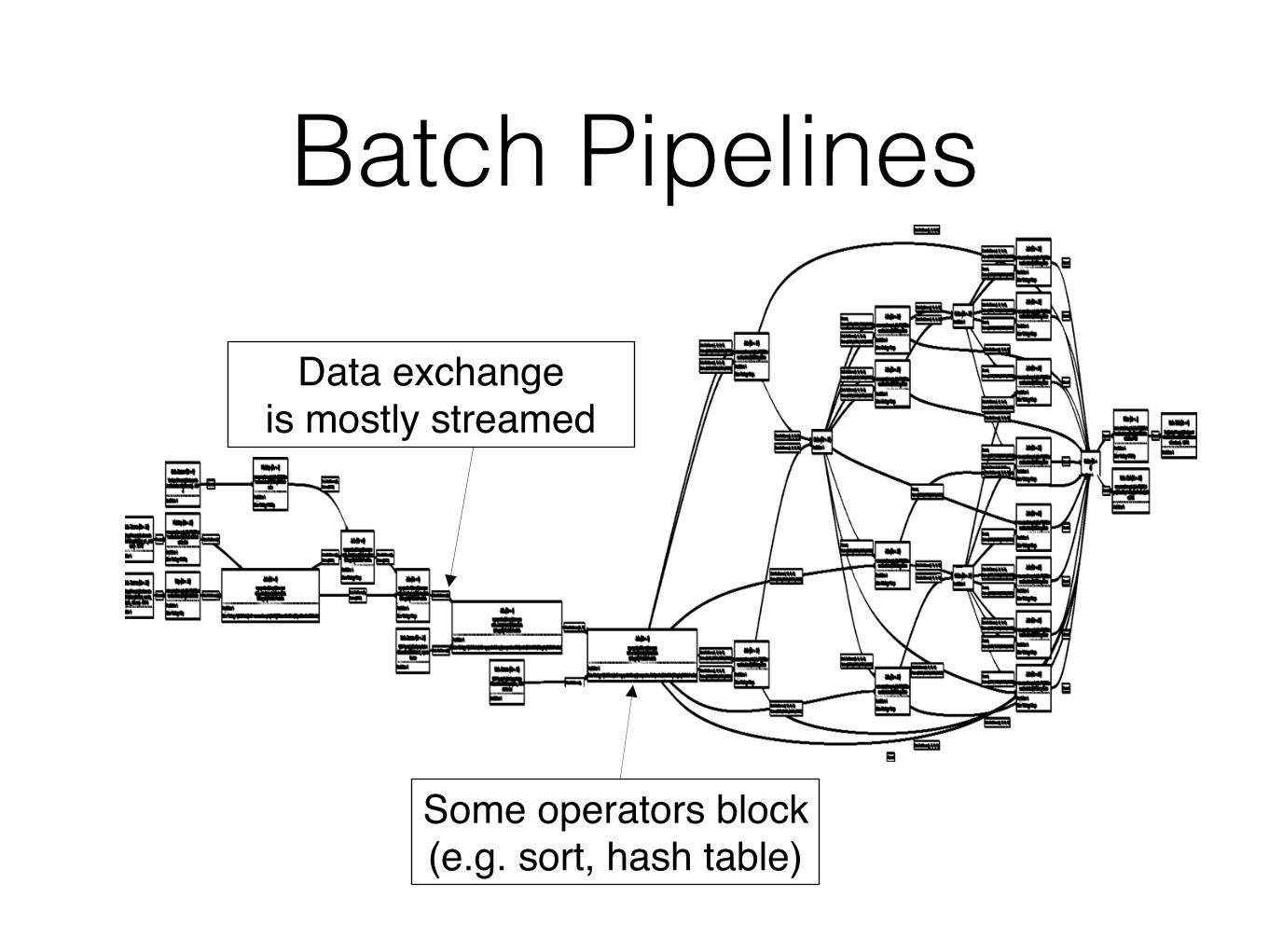
Batch Pipelines
Data exchange is mostly streamed
Some operators block (e.g. sort, hash table)

DataSet APIExecutionEnvironment env = ExecutionEnvironment .getExecutionEnvironment()
DataSet<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataSet WordCount DataSet<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) // (word, 1) .groupBy(0) // [word, [1, 1, …]] .sum(1); // sum per word for all occurrences
counts.print();

DataSet APIExecutionEnvironment env = ExecutionEnvironment .getExecutionEnvironment()
DataSet<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataSet WordCount DataSet<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) // (word, 1) .groupBy(0) // [word, [1, 1, …]] .sum(1); // sum per word for all occurrences
counts.print();

DataSet APIExecutionEnvironment env = ExecutionEnvironment .getExecutionEnvironment()
DataSet<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataSet WordCount DataSet<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) // (word, 1) .groupBy(0) // [word, [1, 1, …]] .sum(1); // sum per word for all occurrences
counts.print();

DataSet APIExecutionEnvironment env = ExecutionEnvironment .getExecutionEnvironment()
DataSet<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataSet WordCount DataSet<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) // (word, 1) .groupBy(0) // [word, [1, 1, …]] .sum(1); // sum per word for all occurrences
counts.print();

DataSet APIExecutionEnvironment env = ExecutionEnvironment .getExecutionEnvironment()
DataSet<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataSet WordCount DataSet<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) // (word, 1) .groupBy(0) // [word, [1, 1, …]] .sum(1); // sum per word for all occurrences
counts.print();

DataSet APIExecutionEnvironment env = ExecutionEnvironment .getExecutionEnvironment()
DataSet<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataSet WordCount DataSet<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) // (word, 1) .groupBy(0) // [word, [1, 1, …]] .sum(1); // sum per word for all occurrences
counts.print();

DataSet APIExecutionEnvironment env = ExecutionEnvironment .getExecutionEnvironment()
DataSet<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataSet WordCount DataSet<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) // (word, 1) .groupBy(0) // [word, [1, 1, …]] .sum(1); // sum per word for all occurrences
counts.print();

Batch-specific optimizations
Cost-based optimizer• Program adapts to changing data size
Managed memory • On- and off-heap memory • Internal operators (e.g. join or sort) with out-of-core
support • Serialization stack for user-types

Demo Time
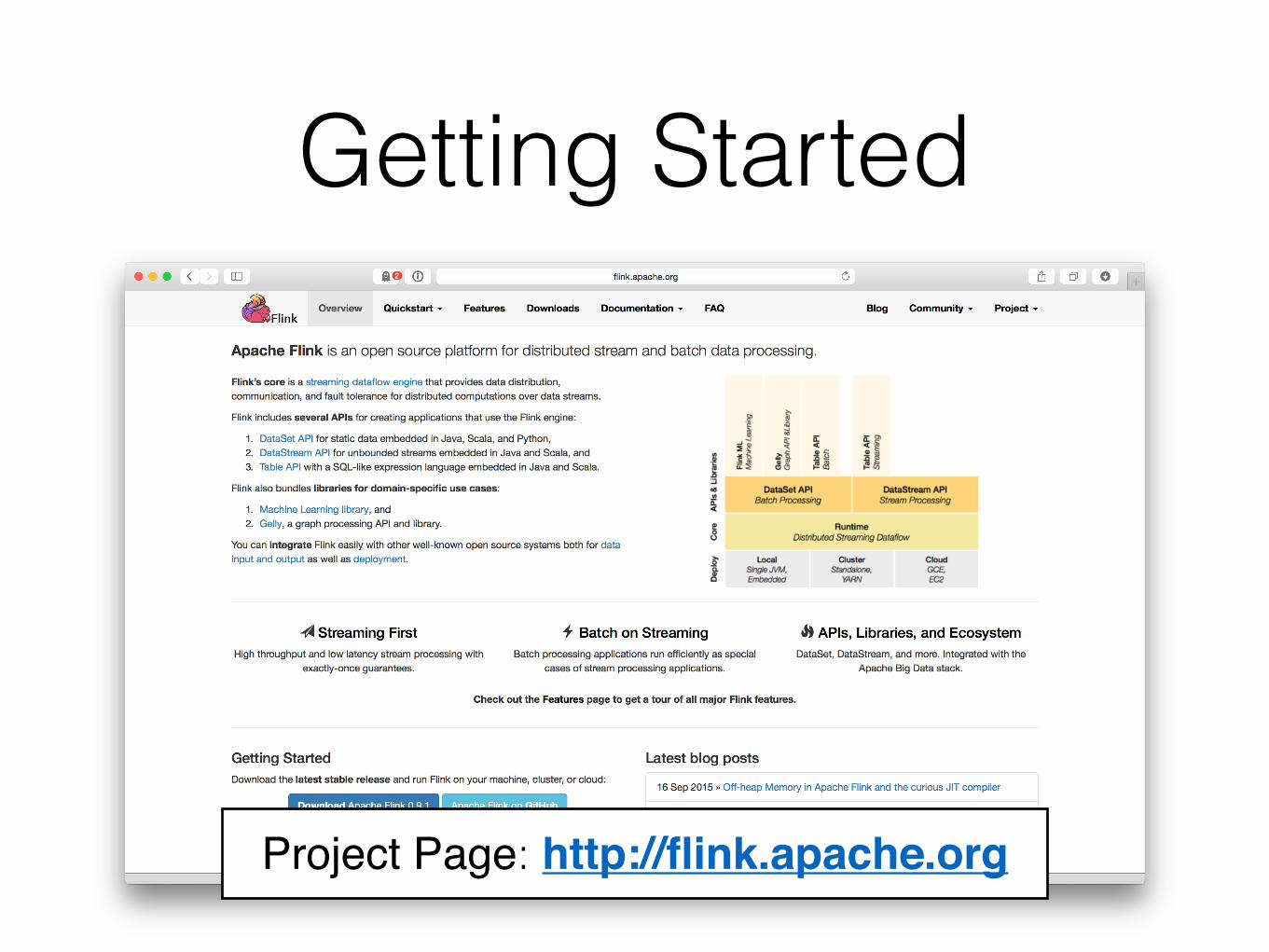
Getting Started
Project Page: http://flink.apache.org
Quickstarts: Java & Scala API
Getting Started
Project Page: http://flink.apache.org
Docs: Programming Guides
Getting Started
Project Page: http://flink.apache.org
Get Involved: Mailing Lists, Stack Overflow, IRC, …

Blogs http://flink.apache.org/blog http://data-artisans.com/blog
Twitter @ApacheFlink
Mailing lists (news|user|dev)@flink.apache.org
Apache Flink

Thank You!


















