
SPSS15 (2011)_1s
375
Yrd.Doç.Dr.Yüksel TERZĐ 1 SPSS 15.0 Statistical Packages for the Social Sciences YRD.DOÇ.DR.YÜKSEL TERZİ ONDOKUZ MAYIS ÜNİVERSİTESİ FEN-ED.FAK. İSTATİSTİK BÖLÜMÜ [email protected]
description
yuksel hocanin notlari ALI DUYAN
Transcript of SPSS15 (2011)_1s

Yrd.Doç.Dr.Yüksel TERZĐ 1
SPSS 15.0Statistical Packages for the Social Sciences
YRD.DOÇ.DR.YÜKSEL TERZ İ
ONDOKUZ MAYIS ÜN İVERSİTESİFEN-ED.FAK.
İSTATİSTİK BÖLÜMÜ[email protected]

Yrd.Doç.Dr.Yüksel TERZĐ 2
DATA VIEW (VERDATA VIEW (VER İİ SAYFASI)SAYFASI)
SPSS DOSYALARININ UZANTILARISPSS DOSYALARININ UZANTILARI
SAV : SAV : Data EditData Edit öörde olurde olu şşturulan verilerin uzantturulan verilerin uzant ııssıı,,SPO :SPO : SonuSonu çç--OutputOutput dosyalardosyalar ıınnıın uzantn uzant ııssıı,,SPS :SPS : SyntaxSyntax EditEdit öörde olurde olu şşturulan dosyanturulan dosyan ıın uzantn uzant ııssıı,,SBS :SBS : ScriptScript EditEdit öörde olurde olu şşturulan dosyanturulan dosyan ıın uzantn uzant ııssıı, , SGT :SGT : Grafik dosyalarGrafik dosyalar ıınnıın uzantn uzant ııssıı,,

Yrd.Doç.Dr.Yüksel TERZĐ 3
Variable name : Değişkenin adı Type : Tipi Numeric : Sayısal Comma : virgül Dot : Nokta Scientific notation : özel sembol Data : Tarih Dollar : Diyez,dolar
Custom currency : özel tanımlanmış veri giri şi String : Dizi Width : genişlik Decimal places : ondalık basamak Labels : Tanımlama, sınıflandırma Values : Tanımlanacak değişken Value : Değeri Value label : Değerin alacağı isim Missing values : Eksik verilerin hangi kodla gösterileceğini belirler. Columns : Sütun genişili ği Align : Hizalama left : Sol Center : Orta Right : Sağ Measure : Ölçek Scale :Cetvel Ordinal : Sıra Nominal : Nitel
VARIABLE VIEW (DEVARIABLE VIEW (DE ĞİŞĞİŞKEN SAYFASI)KEN SAYFASI)

Yrd.Doç.Dr.Yüksel TERZĐ 4
NNüümericmeric: : Rakamlarla ifade edilen deRakamlarla ifade edilen değğiişşkenlerin tankenlerin tanıımmıı yapyapııllıır.r.CommaComma (virg(virgüül): l): BBüüyyüük verilerin tam kk verilerin tam kıısmsmıınnıı virgvirgüül ile l ile üçüçer er basamak, ondalbasamak, ondalııklklıı kkıısmsmıınnıı ise nokta ile ayise nokta ile ayıırrıır. (567,346.05)r. (567,346.05)DotDot (nokta) :(nokta) : BBüüyyüük verilerin tam kk verilerin tam kıısmsmıınnıı nokta ile nokta ile üçüçer basamak, er basamak, ondalondalııklklıı kkıısmsmıınnıı ise virgise virgüül ile ayl ile ayıırrıır. (567.346,05)r. (567.346,05)ScientificScientific NotationNotation :: SaySayıısal verileri sal verileri üüssel olarak ifade eder. ssel olarak ifade eder. (1000000=1E+6)(1000000=1E+6)StringString :: AlfasayAlfasayıısalsal verilerin tanverilerin tanıımladmladığıığı seseççenek.enek.

Yrd.Doç.Dr.Yüksel TERZĐ 5
SyntaxSyntax ve ve ScripScripEditEdit öörleri rleri iişşlemlere ililemlere ili şşkin kin kodkodSistemlerinin Sistemlerinin oluolu şşturulduturuldu ğğu u ve kullanve kullan ııccıınnıın n oluolu şşturacaturaca ğığıkomut komut kodlarkodlar ıınnıın yer n yer aldald ığıığıbbööllüümlerdir.mlerdir.

Yrd.Doç.Dr.Yüksel TERZĐ 6
DiDiğğer veri tabaner veri taban ıı programlarprogramlar ıındaki veri ndaki veri dosyalardosyalar ıınnıı aaççar.ar.FarklFarkl ıı uzantuzant ıılara sahip dosyalardaki lara sahip dosyalardaki verileri verileri SPSSSPSS’’ee aktaraktar ıır (r (xlsxls , , datdat , , txttxt gibi).gibi).
Bilgisayardaki bir dosya hakkBilgisayardaki bir dosya hakk ıında bilgi verir.nda bilgi verir.
Veri dosyasVeri dosyas ıınnıın gen ge ççici bir kopyasici bir kopyas ıınnıı verir.verir.
Son kullanSon kullan ıılan sav uzantlan sav uzant ııll ıı dosyalardosyalar ıı belirtir.belirtir.
Sav uzantSav uzant ııll ıı olmayan dosyalarolmayan dosyalar ıı ggöösterir. sterir.
ÜÜzerinde zerinde ççalal ışıışılan dosya hakklan dosya hakk ıında bilgi verir.nda bilgi verir.
KullanKullan ııccıı adadıı ve ve şşifre girilerek, Network ifre girilerek, Network üüzerindeki dosyalarda izerindeki dosyalarda i şşlem yaplem yap ııll ıır. r.
Veriler Veriler dBasedBase , , excelexcel , , accessaccess ortamortam ıına na aktaraktar ııll ıır.r.
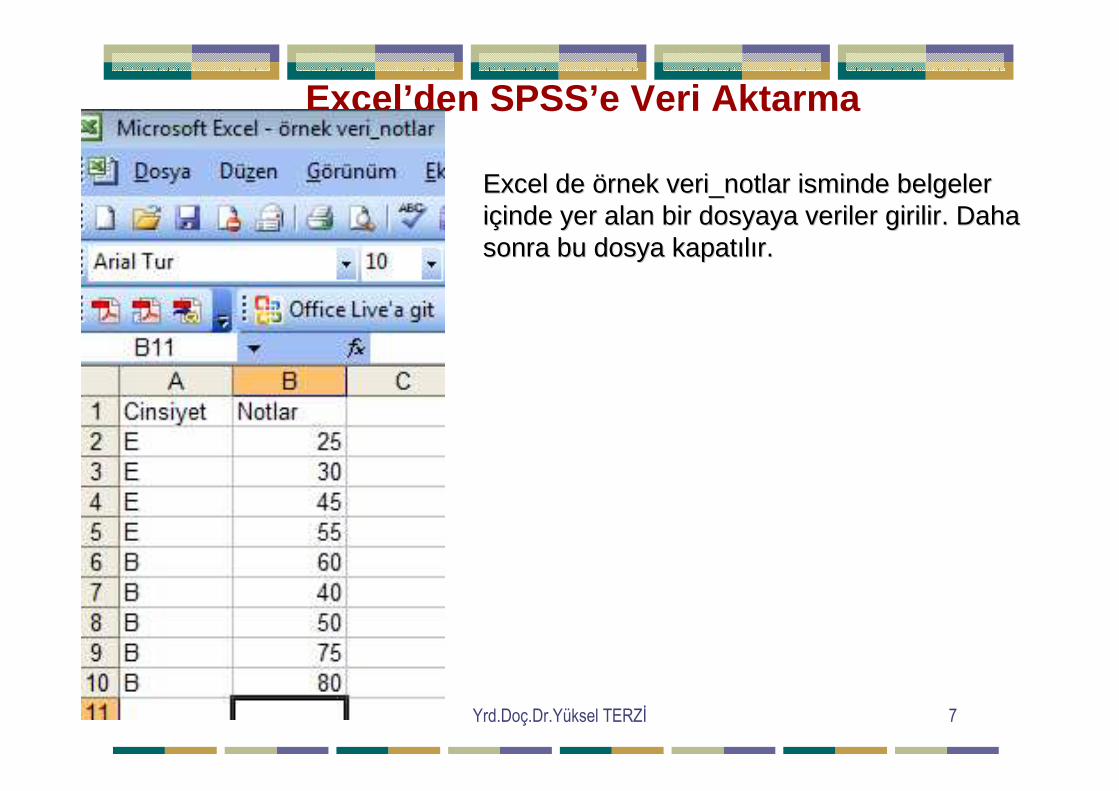
Yrd.Doç.Dr.Yüksel TERZĐ 7
Excel’den SPSS’e Veri Aktarma
Excel de Excel de öörnek veri_notlar isminde belgeler rnek veri_notlar isminde belgeler iiççinde yer alan bir dosyaya veriler girilir. Daha inde yer alan bir dosyaya veriler girilir. Daha sonra bu dosya kapatsonra bu dosya kapatııllıır.r.

Yrd.Doç.Dr.Yüksel TERZĐ 8
File>File>OpenOpen>Data>Data
Dosya tDosya tüürrüünde Excel (*.nde Excel (*.xlsxls) ) uzantuzantııssıı seseççilir. ilir.

Yrd.Doç.Dr.Yüksel TERZĐ 9

Yrd.Doç.Dr.Yüksel TERZĐ 10
Son yapSon yap ıılan delan de ğğiişşiklikleri geri aliklikleri geri al ıır. Analiz r. Analiz ile ilgili iile ilgili i şşlemleri geri almaz.lemleri geri almaz.Geri alGeri al ıınan inan i şşlemleri bir lemleri bir öönceki konuma nceki konuma getirir.getirir.
VariableVariable ViewView sayfassayfas ıında kopyalanan bir denda kopyalanan bir de ğğiişşkeni keni farklfarkl ıı bir isimle babir isimle ba şşka bir yere yapka bir yere yap ışıştt ıırr ıır.r.
SeSeççilen silen s üütunun satunun sa ğığına yeni bir dena yeni bir de ğğiişşken eklerken ekler
SeSeççilen satilen sat ıırr ıın n üüstst üüne yeni bir satne yeni bir sat ıır eklerr ekler
SPSS ayarlarSPSS ayarlar ıınnıın yapn yap ııldld ığıığı yer.yer.

Yrd.Doç.Dr.Yüksel TERZĐ 11
GENERALGENERAL
Variable list : Değişkenlerin listelenmesi Display labels : etiketle göster Display names : değişkenin adını göster Alphabetical: Alfebetik sıraya göre değişkenleri versin File : Dosyadaki sıraya göre değişkenleri versin. Append : Komutları peş peşe ekle Owerwrite : Đkinci işlemi birincinin üstüne ekle Recently used file list : Gelen dosya isimlerinin sayısını gösterir. Open syntax window at start-up : syntax penceresini başlangıçta aç. Measurement system : Ölçü sistemi (grafik gibi). Point : nokta Inches : inç Centimeters : cm. Output notfication : Sonuçların gösterilmesi Raise viewer window : Gösterici penceresinde göster Scroll to new output : özel ses koyar.

Yrd.Doç.Dr.Yüksel TERZĐ 12
VIEWERVIEWER
Log : sonuçları nasıl göstersin. Shown : göster , Hidden : gizli Display command in the log : Hangi komutların kullanıldığı sonuçlarda gösterir. Text output page size : Çıktılar için kağıt genişliğini belirler. Length : Uzunluk , Width : genişlik Infinite : sürekli kağıt takılı olup, çıktıda kullanılır. Monospaced fonts : Tüm harfler ve karakterler aynı standartta yazılır.

Yrd.Doç.Dr.Yüksel TERZĐ 13
PIVOT TABLEPIVOT TABLE

Yrd.Doç.Dr.Yüksel TERZĐ 14
CURRENCYCURRENCY
Veri tipinde özel karakterlerin nereye yazılacağını belirler ($, TL gibi). Prefix : Önce , Suffix : Sonra Decimal separator : Veri aktarımı yaparken ondalık kısım için virgül ise comma, nokta ise period kullanılır.
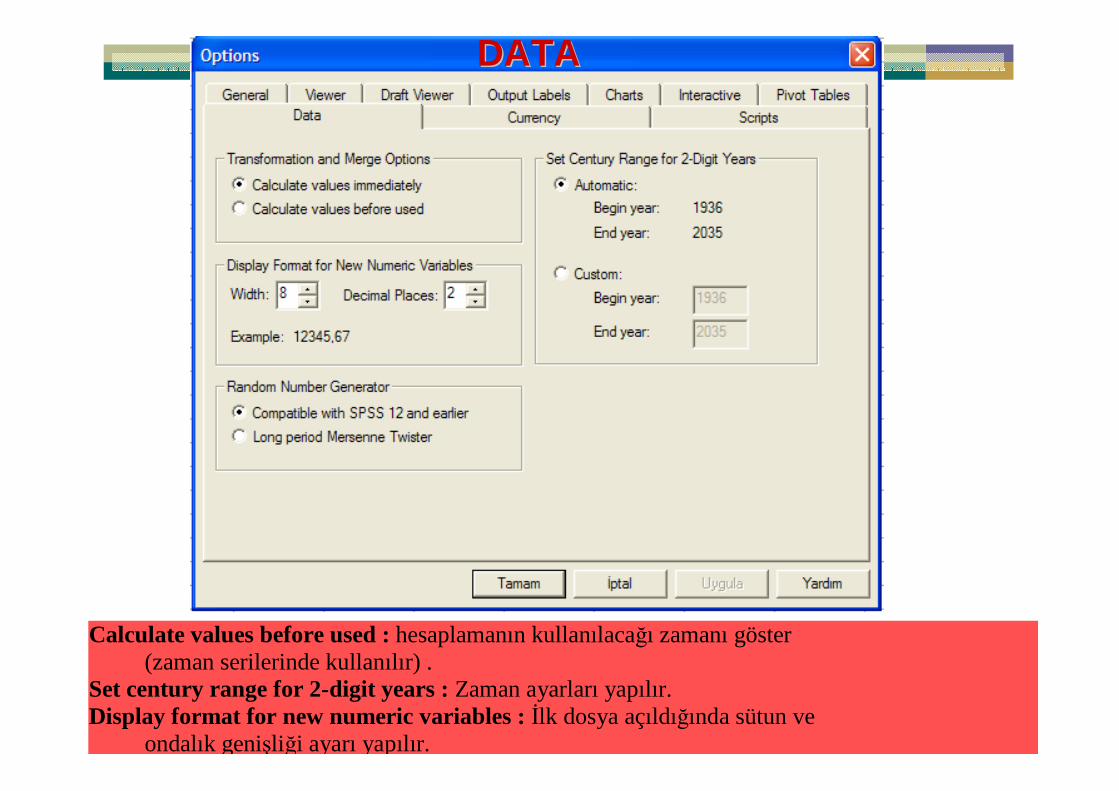
Yrd.Doç.Dr.Yüksel TERZĐ 15
DATADATA
Calculate values before used : hesaplamanın kullanılacağı zamanı göster (zaman serilerinde kullanılır) .
Set century range for 2-digit years : Zaman ayarları yapılır. Display format for new numeric variables : Đlk dosya açıldığında sütun ve
ondalık genişliği ayarı yapılır.

Yrd.Doç.Dr.Yüksel TERZĐ 16
Status Bar :SPSS penceresinde menülerin yer almasını sağlayan/kaldıran bir seçenektir. Toolbars :Araçların SPSS penceresinde yer alıp almamasını sağlar. Font :Yazım şekli ve büyüklüğünü düzenler. Grid Lines :Veri dosyasındaki çizgileri kaldırır. Value Labels:Çıktı ekranında ve grafiklerde değerlerin isimlerinin yer alıp almamasını belirler.
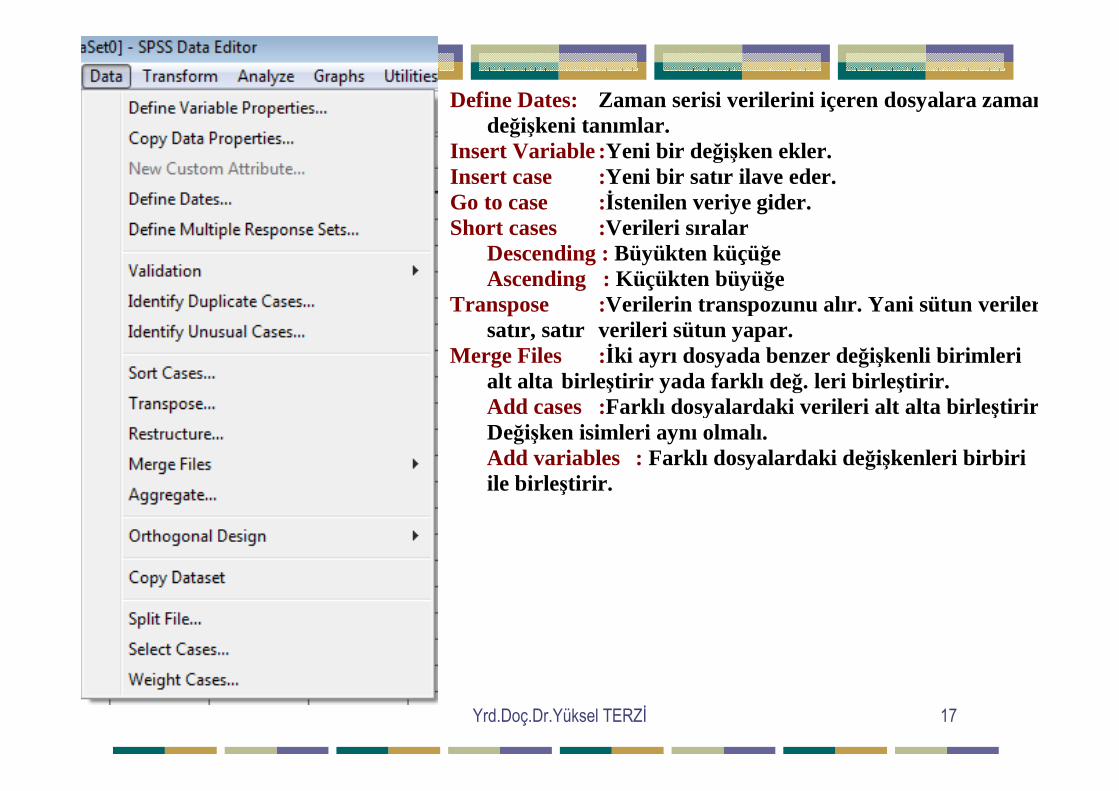
Yrd.Doç.Dr.Yüksel TERZĐ 17
Define Dates: Zaman serisi verilerini içeren dosyalara zaman değişkeni tanımlar. Insert Variable :Yeni bir değişken ekler. Insert case :Yeni bir satır ilave eder. Go to case :Đstenilen veriye gider. Short cases :Verileri sıralar Descending : Büyükten küçüğe Ascending : Küçükten büyüğe Transpose :Verilerin transpozunu alır. Yani sütun verileri satır, satır verileri sütun yapar. Merge Files :Đki ayrı dosyada benzer değişkenli birimleri alt alta birleştirir yada farklı de ğ. leri birle ştirir.
Add cases :Farklı dosyalardaki verileri alt alta birle ştirir. Değişken isimleri aynı olmalı. Add variables : Farklı dosyalardaki değişkenleri birbiri ile birleştirir.

Yrd.Doç.Dr.Yüksel TERZĐ 18
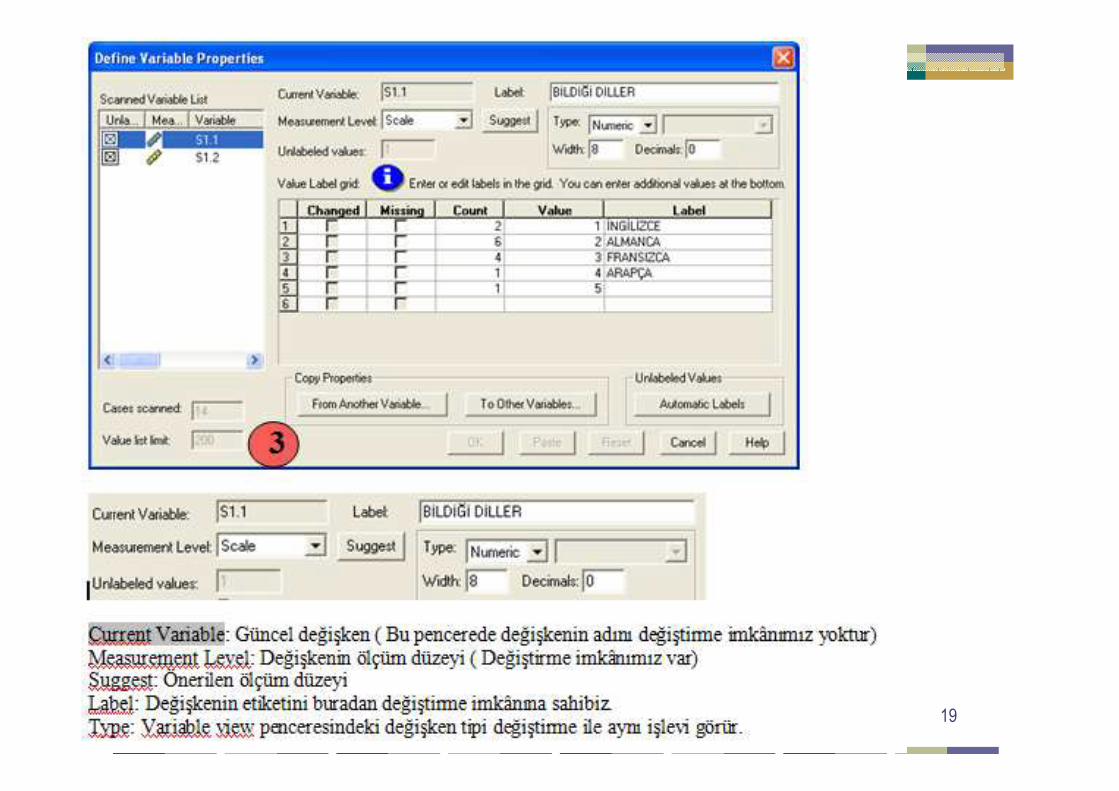
Yrd.Doç.Dr.Yüksel TERZĐ 19
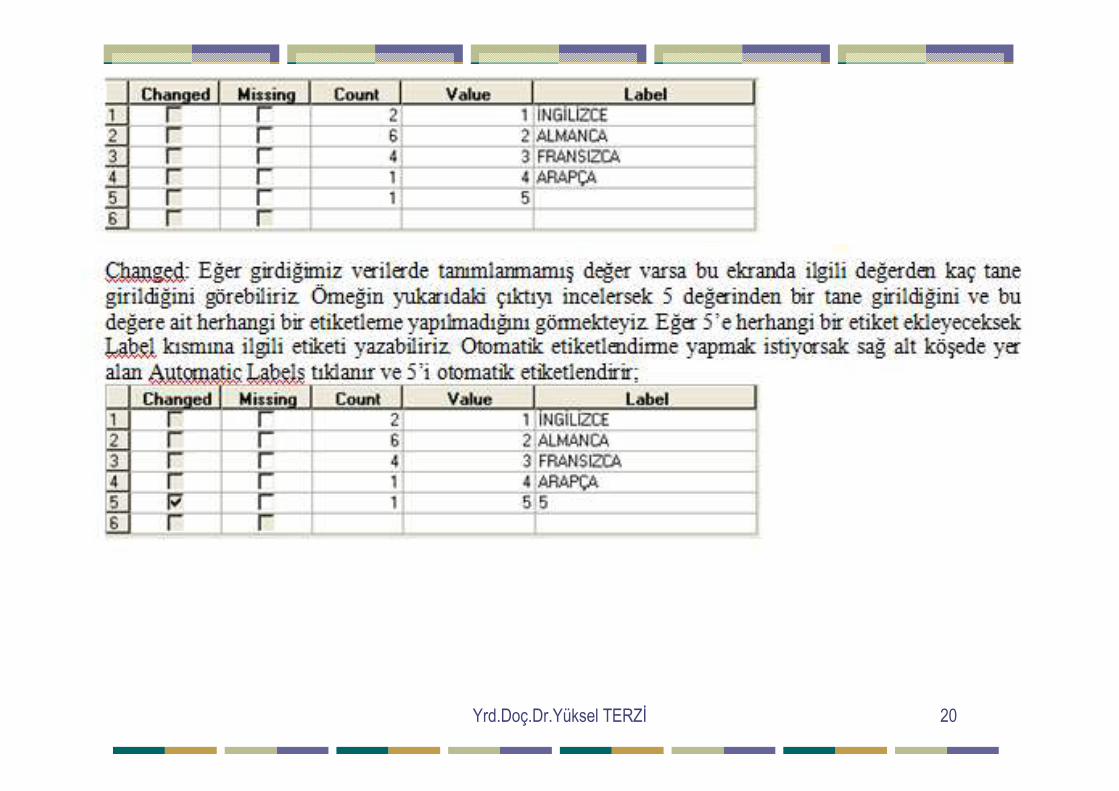
Yrd.Doç.Dr.Yüksel TERZĐ 20

Yrd.Doç.Dr.Yüksel TERZĐ 21
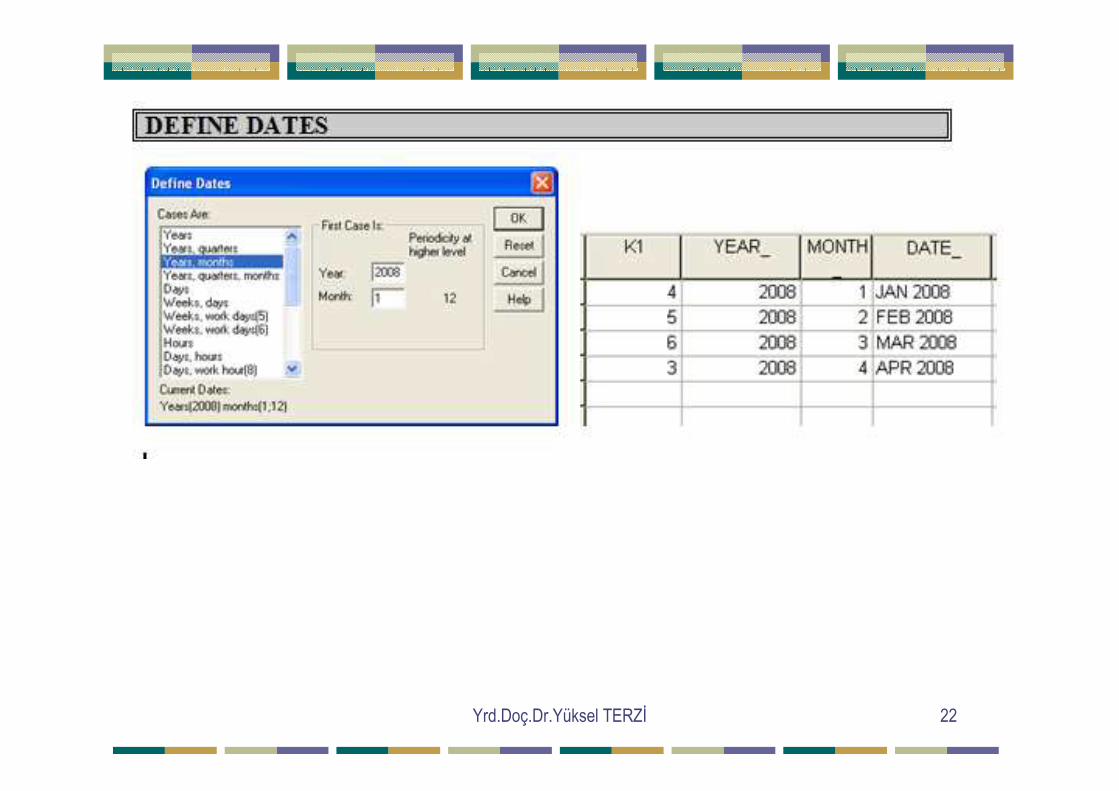
Yrd.Doç.Dr.Yüksel TERZĐ 22

Yrd.Doç.Dr.Yüksel TERZĐ 23

Yrd.Doç.Dr.Yüksel TERZĐ 24

Yrd.Doç.Dr.Yüksel TERZĐ 25

Yrd.Doç.Dr.Yüksel TERZĐ 26

Yrd.Doç.Dr.Yüksel TERZĐ 27

Yrd.Doç.Dr.Yüksel TERZĐ 28
Agreegate : Bir grubu özet olarak birleştirilmi ş veri halinde toplar. Break variables : Gurup yapılacak değişkenler girilir. Aggregate variables:Yukarıdaki gruplarda üzerinde i şlem yapılacak değişkenler. Function : Grupların hesaplanacağı fonksiyonlar: Mean of value : Aritmetik ortalama, First value : ilk değer Number of cases : olay sayısı Sum os values :Değerler toplamı
Percentage above :Belli değerden büyük değerler yüzdesi. Percentage below : Belli değerden küçük değerler yüzdesi. Percentage inside : Đki değer arasındaki değerler yüzdesi. Percentage outside : Đki değer dışındaki değerler yüzdesi. Fraction above : Bir değerden büyük değerlerin o grup içindeki yüzdesi Fraction below : Bir değerden küçük değerlerin o grup içindeki yüzdesi Fraction inside : Đki değer içindeki değerlerin o grup içindeki yüzdesi Fraction outside : Đki değer dışındaki değerlerin o grup içindeki yüzdesi
Belli değerler value kutusuna, beli iki değer de Low ve High kutularına yazılır. Creata new data file:Yapılan hesaplamaların yeni bir dosyaya kayıt edilmesi. File ile kayıt yapılır. Replace data working data file : Yapılan düzenlemeleri mevcut dosyaya kayıt eder. Save number of cases in break group as variable: Gruplar içindeki olay sayısının bir değişken gibi kaydı Ortogonal Design : Bağımsız deneme düzeni türetmeyi(generate) ve bu düzeni görüntüler.

Yrd.Doç.Dr.Yüksel TERZĐ 29
Split file:(Veri dosyası ayırma )Veri dosyasını istenilen değişkenin alt seviyelerine göre parçalar. Böylece veri dosyası, değişken kaç farklı değer alıyorsa o sayıda alt dosyalara ayrılır. Analysis all cases : Gruplamanın olmadığı durum

Yrd.Doç.Dr.Yüksel TERZĐ 30
Select cases :Veri süzme veya seçme- Farklı değerler alan değişkenlerin istenilen değerlerinin analize katılmasını sağlar.
If condition is satisfied : Değişkenlerle ilgili hesap ve fonksiyon işlemleri yapar. Random sample of cases : Bazı örnekler üzerinde işlem yapar.

Yrd.Doç.Dr.Yüksel TERZĐ 31

Yrd.Doç.Dr.Yüksel TERZĐ 32
Do not Do not weightweight casescases :: AAğığırlrl ııklkl ıı durum yokdurum yok
WeightWeight casescases byby –– FrequencyFrequency VariableVariable ::Bir sBir s üütunda yer alan detunda yer alan de ğğerlerin dierlerin di ğğer bir deer bir de ğğiişşken iken i ççin ain ağığırlrl ıık k
olarak olarak tantan ıımlanmasmlanmas ıınnıı sasağğlar. lar.

Yrd.Doç.Dr.Yüksel TERZĐ 33
Compute :Mevcut değişkenlerle matematiksel işlem yaparak, yeni değ. elde edilir. Target variable : Yapılan işlem sonunda bulunacak yeni değişkenin adı. Random number seed : Rasgele üretilecek olan sayıların ilk değerini belirler. Count :Bir değişkendeki aynı değere sahip birimleri belirler. Categorize variables : Verilere sıra numarası verilir. Rank cases :Değişkenleri sıralama değerine dönüştürür ve yeni değişken olarak atar. Değişik sırala türleri vardır.(Blom, Tukey, Rankit gibi) Autumatic Recode : Değişkenin değerlerini büyüklük sırasına göre dizerek yeni değişken 1 den başlayarak kod numarası verir. Create Time Series : Bir veriyi alarak zaman serisi değişkeni türetir. Difference : Farklı Seasonal : Mevsimlik Smooth : Düzgün Replace Missing Values : Seride yer alan eksik gözlem yerine bir değer atar. Bu değer ya serinin ortalaması yada zaman serisi fonksiyonlarından birisidir.

Yrd.Doç.Dr.Yüksel TERZĐ 34
Verileri deVerileri de ğğiişştirme veya yeniden kodlamatirme veya yeniden kodlama --RecodeRecode komutu:komutu:
Veri sayfasVeri sayfas ıında bir denda bir de ğğiişşkene ait verileri matematiksel ikene ait verileri matematiksel i şşlem yapmadan lem yapmadan isteiste ğğe ge gööre dere değğiişştirmek veya yeni kodlarla ifade etmede kullantirmek veya yeni kodlarla ifade etmede kullan ııll ıır. r. Genelde sGenelde s üürekli olan bir veri gruplanarak kategorik hale getirilir. rekli olan bir veri gruplanarak kategorik hale getirilir. YukarYukar ııdaki tabloda sdaki tabloda s üürekli derekli de ğğiişşken olan masraf ken olan masraf numericnumeric variablevariablekkıısmsm ıına girilir ve na girilir ve outputoutput variablevariable kkıısmsm ıına da yeni oluna da yeni olu şşturulacak turulacak dedeğğiişşkenin adkenin ad ıı girilir ve girilir ve changechange yapyap ııll ıır. Daha sonra r. Daha sonra OldOld andand New New ValuesValueskkıısmsm ıından kodlamalar tanndan kodlamalar tan ıımlanmlan ıır.r.

Yrd.Doç.Dr.Yüksel TERZĐ 35
Masraf deMasraf de ğğiişşkeni <200 keni <200 YtlYtl iiççin 1, 201in 1, 201 --300 300 YtlYtl arasaras ıı 2, >301 aras2, >301 aras ııda 3 da 3 olsun. olsun. LowestLowest throughthrough kkıısmsm ıına (< 200) 200 yazna (< 200) 200 yaz ııll ıır, sonra r, sonra ValueValue 1 verilir 1 verilir ve ve AddAdd yapyap ııll ıır. 201 r. 201 throughthrough 300 yaz300 yazııll ıır, r, ValueValue 2 girilir ve 2 girilir ve AddAdd yapyap ııll ıır. r. ThroughThrough highesthighest kkıısmsm ıına 301 girilir, na 301 girilir, ValueValue 3 ve 3 ve AddAdd yapyap ııll ıırsa veri rsa veri gruplanmgruplanm ışış hale gelir. hale gelir.

Yrd.Doç.Dr.Yüksel TERZĐ 36
AutomaticAutomatic RecodeRecode
StringString olarak girilen nitel deolarak girilen nitel de ğğiişşkenleri, kenleri, AutomaticAutomatic recoderecode komutu ile komutu ile kodlayarak, kodlayarak, NumericNumeric dedeğğiişşkene kene ççevrilir. evrilir.

Yrd.Doç.Dr.Yüksel TERZĐ 37
New name kNew name k ıısmsm ıına na stringstring dedeğğiişşkenlerin yani ismi yazkenlerin yani ismi yaz ııll ıır ve r ve AddAdd New New Name butonuna basName butonuna bas ııll ıır. r. LowestLowest valuevalue iişşaretlenirse aretlenirse stringstring dedeğğiişşkenin aldkenin ald ığıığı dedeğğerlere baerlere ba şştan sona tan sona dodoğğru kod numarasru kod numaras ıı verilir (B=1, E=2 olur). verilir (B=1, E=2 olur). HighestHighest valuevalue seseççilirse sondan ilirse sondan aaşşa doa doğğru kod numarasru kod numaras ıı verilir (E=1, B=2). verilir (E=1, B=2).

Yrd.Doç.Dr.Yüksel TERZĐ 38

Yrd.Doç.Dr.Yüksel TERZĐ 39
Reports : OLAP Cubes : Seçilen değişkenlerin istatistiksel işlemlerini yapar. Case summaries :Verilerin frekans ve çapraz tablolarının oluşturulması, belirtici istatistiklerin hesaplanması, grafik çizimi ve raporlanmasını sağlar. Report Summaries in Row : Sıralara ilişkin özet istatistikler hesaplar.
Report Summaries in Column : Değişkenlerle ilgili özet istatistikler hesaplar. Descriptive Statistics : Frequencies :Verilerin frekans tablosunu, belirtici istatistikle ri, dağılım ölçülerini hesaplar ve grafiklerini çizer. Descriptives :Verilerin belirtici istatistiklerini ve asimetrik d ağılım ölçüleri olan çarpıklık (kurtosis), basıklık (skewnes) ölçülerini hesaplar. Explore :Tüm birimlerin yada her bir gruptaki birimlerin bel irtici istatistiklerini hesaplar ve yayılım grafiklerini çizer. Bir değişkenin diğer değişkene göre istatistiklerini bulur. Crosstabs :Đki yada daha fazla değişkenin ikili çapraz tablolarını düzenler. Hazırlanan tablolara testler yapılır ve özet istatistikler bulunur. Sayısal değişkenler kodlama ile az sayıdaki gruba bölünerek çapraz tablolar düzenlenir.

Yrd.Doç.Dr.Yüksel TERZĐ 40
Compare Means : Gruplara göre verilerin belirtici istatistiklerini hesaplayan, bağımlı ve bağımsız örneklerde iki yada daha fazla ortalama arasındaki farkları test eden yöntemleri içerir. Means :Değişkenlerin tek başına ya da diğer bağımsız değişkenlere göre alt grupların istatistiklerini hesaplar. One Sample T test :Tek örnek T testi yapar. Independent Samples T Test:Bağımsız iki örneklem T testi yapar. Paired Samples T Test :Bağımlı iki örneklem T Testi yapar. One Way ANOVA :Bağımsız k-örneklem ortalamalarının önemliliğini test etmek için tek yönlü varyans analizi uygular. General Lineer Model : Genelleştirilmi ş lineer modellerle ilgili işlemleri yapar. Univariate :Tek değişkenli Multivariate : Çok değişkenli Repeated Measures :Tekrarlı ölçümlü denemelerde kullanılır.

Yrd.Doç.Dr.Yüksel TERZĐ 41
Correlate : Đki yada daha fazla değişkenin arasındaki ikili ( Bivariate) ili şkinin;
yönünü, büyüklüğünü ve önemliliğini belirler. Ayrıca kısmi ( partial)korelasyon analizi de yapılır. En az bir değişkene göre birimlerin birbiriyle olan benzerlik uzaklıkları (similarity) yada farklılıklarını gösteren uzaklıklar (dissimilarity) hesaplanır. Çeşitli uzaklık ve benzeerlik ölçülerine (öklid, karesel öklid, minkowski) göre birimlerin yada değişkenlerin benzerlik/farklılık matrisleri bulunur. Regression : Linear: Verilere basit doğrusal ve çoklu doğrusal regresyon analizi uygular. Curve Estimation:Verilere uygun eğri uydurulması için model denenmesi sağlar. Model seçimi için çoklu regresyon katsayısından yararlanılır. Logistic : Đkili ( Binary) ve çoklu (Multinominal) lojistik regresyon analizi yapılmasını sağlar. Probit :Probit regresyon analizi Nonlineer : Doğrusal olmayan regresyon analizi uygulaması yapar. Loglinear : Kategorik verilere genel ve aşamalı loglinear ve lojit loglinear analiz uygular.

Yrd.Doç.Dr.Yüksel TERZĐ 42
Classify :Verilere kümeleme analizi (cluster analysis) ve ayırma analizi (discriminant analysis) uygular. K-Means Cluster : Kümelenecek birim yada değişkenlerin kaç kümeye ayrılacağı belirlenerek guruplamalar yapılır. Hierarchical Cluster : Değişkenlere aşamalı kümeleme analizi uygular. Discriminant : Grupları önceden belirli birimleri rasyonel biçimd e birbirinden ayırmaya yarayan fonksiyonlar türetmeyi ve verilerin sınıflandırır. Data Reduction: Veilere faktör analizi ve uyum (Correspendance) analizi uygular. Scale : Đsimsel fakat kodlanmış sıralı yada aralıklı ölçekle elde edilmiş verilere güvenilirlik ve çok boyutlu ölçekleme analizi uygular. Nonparametrics Tests : Tek örneklem, bağımlı/bağımsız iki ve k örneklem verilerine parametrik olmayan test yöntemlerinin uygulanmasının sağlar. Times Series : Zaman serisi analizi ile ilgili üssel düzeltme, otokorelasyonlu regresyon, ARIMA, mevsimsel çözümleme, spectral analiz gibi yöntemleri yapar. Survival : Sağkalım verilerin yaşam tablosu, Kaplan-Meier ve Cox regresyon analizi modelleri ile analiz işlemlerini yapar. Multiple Response : Çoklu cevap yada çoklu ikili setlerin belirlenmesi ve analizi işlemlerini yapar.

Yrd.Doç.Dr.Yüksel TERZĐ 43
GRAPHS (GRAFĐKLER) : Interactive :Çizilen grafiklerin çeşitli özelliklerine göre oluşturur. Bar:Verilerin basit çubuk, kümelenmiş çubuk ve yığılımlı çubuk grafi ğini çizer. 3-Bar : Üç boyutlu bar grafiği Line :Verilerin basit ve çoklu çizgi grafiğini çizer. Area :Verilerin basit ve yığılımlı alan grafiğini çizer. Pie :Basit daire veya birleşik çubuk grafi ğini çizer. High Low: Verilerin ikili yada üçlü de ğerlerden yararlanarak yüksek ve düşük değerleri içeren grafiklerini çizer. Boxplot :Verilerin ortanc a değerini, dörtte birlikler arası geni şlik ve aşırı değer
içeren birimleri gösteren kutu grafiklerini çizer. Error Bar: Ortalama ve güven aralığını gösteren kutu grafiği çizer. Scatter :Verilere uyan basit ve üst üste gelen ilişki grafikleri, matrix grafi ği yada üç boyutlu dağılım grafiklerini çizer. Histogram:Bir değişkenin dağılım hakkında bilgi veren histogram grafiklerini çizer. P – P :Bir değişkenin yığılımlı ortalamalarını Normal dağılımın yığılımlı ortalamalarına karşı gösteren grafiklerini çizer. Q – Q :Bir değişkenin dağılımının dörtte birliklerini Normal da ğılımın dörtte birliklerine kar şı gösteren grafiklerini çizer.

Yrd.Doç.Dr.Yüksel TERZĐ 44
UTILITIES :SPSS ile çalı şırken yararlanılan kolaylıkları sunan seçenekleri içerir.Variables : Değişkenlerle ilgili bilgi verir. De ğişkenin tipi, özelli ği, ölçü birimi gibi.File Info: Üzerinde çalı şılan değişkenlerin özellikleri konusunda toplu bilgi verir.Run Script : Matrix dille yazılmı ş bir macronun çalı ştırılmasını sa ğlayan bir seçenektir.

Yrd.Doç.Dr.Yüksel TERZĐ 45
HELP : SPSS ile çalışırken SPSS komutları hakkında ayrıntılı yardım almayı sağlayan bir seçenektir. Topics:SPSS konuları hakkında yardım seçenekleri görüntülemeyi sağlar. Tutorial : SPSS ile çalışmaya yeni başlayanlara bilgi veren bir seçenektir. SPSS Home Page : Đnternete bağlı bir bilgisayar ile SPSS INC tarafından oluşturulan WEB sayfasına ulaşarak bilgilenmeyi sağlayan bir seçenektir. Command Syntax Reference : SPSS’de menüler aracılığı ile yapılan işlemlerin SPSS komutları cinsinden yazılımlarını irdelemek amacıyla bilgi alınan bir seçenektir.

Yrd.Doç.Dr.Yüksel TERZĐ 46
1. İSTATİSTİĞE GİRİŞKarşımıza çıkan bir istatistik sonucun sorgulanması:
� Önce bilinçli sapma olup olmadı ğına bakılır. İşe yarayan veriler seçilmi ş, işe yaramayan veriler örtbas edilmi ş olabilir.
� Uygun olmayan ölçü kullanılmı ş olabilir. Medyan yerine aritmetik ortalama gibi.
� Örneklem güvenilir bir sonuç verecek kadar büyük mü? Korelasyon bir anlam verecek kadar büyük mü?
� Güvenilirlik ölçüsü (olası hata, standart hata) verilmeden önünüze konan bir korelasyon ciddiye alınmaz.

Yrd.Doç.Dr.Yüksel TERZĐ 47
� Bazen oranlar verilir, ancak sayılar ortada görünme z. Bu yanıltıcı olabilir. Mesela sınıftaki %33 (1/3) banka cılar ile evlenmi ştir. Ancak burada kızların sayısı belirtilmemi ştir. Bu sınıfta 3 kız vardır ve biri bankacı ile evlenmi ştir.
� Bazen olgulardaki de ğişikli ğe neden olan faktör görünmez. Mesela Ekim ayı perakende satı şları geçen yılın Ekim ayına göre artı ş göstermi ştir. Ancak burada özel olan durum, bu seneki ekim ayının ramazan ayına denk gelmesidir. B u ayrıntı açıklamada yer almamı ştır.
� İstatisti ği değerlendirirken elde edilmi ş sayılardan sonuca giderken bir saptırma yapılıp yapılmadı ğına bakılır. Mesela Çin’de bir bölgenin nüfusu 28 milyon bulunmu ştur. Aynıbölgenin 5 yıl sonraki nüfus sayımı ise 105 milyon ç ıkmıştır. Ancak burada hangi sayımın yapıldı ğı belirtilmemi ştir. Birinci sayım vergi ve askerlik için, ikinci sayım ise gıda yardımı üzerine yapılmı ştır.

Yrd.Doç.Dr.Yüksel TERZĐ 48
ĐSTATĐSTĐKTE YAPILAN HATALAR� Sürekli verilerin kategorik verilere dönü ştürülerek analiz edilmesi � Eşli gözlemlerin ortalamalarının e şler arası farklılı ğın belirtilmeden
verilmesi � Tanımlayıcı istatistiklerin yanlı ş kullanılması (örn: ortalamanın
kullanılmaması gereken yerde ortalamanın kullanılması vb ) � Metin içindeki, tablodaki ve grafiklerdeki verilen ist atistiklerin
uyumlu olmaması� Değişim ölçüsü olarak ortamla yanında SEM (ortalamanın stand art
hatası)in kullanılması (Bu ölçüt daha küçük oldu ğu için örneklemin daha hassas oldu ğunu i şaret için kullanılmaktadır. Ortalamanın değişimi ile ilgili bir istatistik verilmek istenirse %95 l ik güven sınırınıvermek daha uygundur)
� Test İstatistikler verilmeden, sadece p de ğerinin verilmesi � İstatistik testler için gerekli olan varsayımlar kar şılanmadan bu
testlerin analiz için kullanılması� İlişkinin do ğrusal olup olmadı ğı kontrol edilmeden do ğrusal
regresyon analizinin kullanılması� Tüm deneklerin veya verinin analizde kullanılmaması, aşırı
değerlerin beklenen sonucu desteklemesi durumunda analizd e bırakılması, aksi halde atılması

Yrd.Doç.Dr.Yüksel TERZĐ 49
ĐSTATĐSTĐKTE YAPILAN HATALAR
•• Çoklu kar şılaştırma testlerinde düzeltme gereksiniminin kontrol edilmemesi veya ne şekilde bir düzeltme yapıldı ğının açıklanmaması
•• ŞŞekil ve tablolarekil ve tablolar ıın okuyucuya yardn okuyucuya yard ıımcmc ıı olmasolmas ıınnıı sasağğlamak yerine lamak yerine sadece verileri depolamak amasadece verileri depolamak ama ççll ıı kullankullan ıılmaslmas ıı
•• Grafik ve Grafik ve ççartlarartlar ıınn verdiverdi ğği gi g öörsel mesajlarrsel mesajlar ıın verinin san verinin sa ğğladlad ığıığımesajlarla uyumsuz gmesajlarla uyumsuz g öörrüünmesi nmesi
•• TanTanıı testleri rapor edilirken testleri rapor edilirken ““ normalnormal ”” ve ve ““ anormalanormal ”” kelimelerinin kelimelerinin kullankullan ıılmaslmas ıı ((çüçü nknk üü normalin tannormalin tan ıımmıı farklfarkl ıı yerlerde farklyerlerde farkl ııanlamlarda kullananlamlarda kullan ıılabilmektedir) labilmektedir)
•• TanTanıı testlerinin sonutestlerinin sonu ççlarlar ıı ( Duyarl( Duyarl ııll ıık ve k ve öözgzgüüllll üük vb) verilirken k vb) verilirken hesaplamada kullanhesaplamada kullan ıılan testlerin lan testlerin öözellikleri azellikleri a ççııklanmamasklanmamas ıı
•• SonuSonu ççlarlar ıın yorumlanmasn yorumlanmas ıı ve rapor edilmesi esnasve rapor edilmesi esnas ıında nda ggöözlemlerin birimlerinin karzlemlerin birimlerinin kar ışıştt ıırr ıılmaslmas ıı veya gveya g ööz ardz ard ıı edilmesi edilmesi
•• Test sonucunda bulunan istatistiki olarak Test sonucunda bulunan istatistiki olarak öönemsiz nemsiz karkarşışılalaşştt ıırmalarrmalar ıın hin hi ççbir anlambir anlam ıı olmadolmad ığıığı ddüüşşüüncesi ile ncesi ile verilmemesi verilmemesi

Yrd.Doç.Dr.Yüksel TERZĐ 50
İstatistik üç farklı anlamda kullanılır.� Yığın olayları incelemek, olaylarla ilgili toplanan verileri analiz etmek, olayların sebep ve sonuçlarını açıklamak, aralarındaki ilişkileri ortaya koymak için kendine özgü yöntemleri olan bir bilim dalıdır.
� Olayların nicel ve nitel yönlerinin tablolar, grafikler veya sayısal değerler şeklindeki özet ifadelerdir. Ölüm istatistikleri, doğum istatistikleri, göç istatistikleri, kaza istatistikleri gibi özet bilgiler istatistikler olarak adlandırılır.
� Örneği oluşturan birimlerden hesaplanmış, ana kütleyi tanımlayan değerlere karşılık gelen değerlerdir. Örnek ortalaması, örnek varyansı gibi.
İstatistik, geçmi şi ve şimdiki durumu çe şitli sayısal tekniklerle analiz ederek gelecek hakkında karar ve rmeyi sağlayan bir bilim dalıdır.

Yrd.Doç.Dr.Yüksel TERZĐ 51
BAZI ÖNEMLĐ TERĐMLER
� Anakütle (Populasyon=Evren=Toplum) :Üzerinde inceleme veya ara ştırma yapılacak olayın gözlenebilece ği tüm birimlerin yer aldı ğıtopluluktur. Bir fabrikanın üretti ği aynı türden ilaçlar anakütleyi olu şturur.
� Örnek(sample=örneklem): Anakütleyi temsil edebilecek özelliklere sahip daha az sayıda birimden olu şan topluluktur. Fabrikada üretilen ilaçlardan rasgele alınan 20 kutu ilaç örnektir.

Yrd.Doç.Dr.Yüksel TERZĐ 52
Birim(olgu=case=denek): Üzerinde gözlem ve ölçüm yapılan ve anakütleyi olu şturan en küçük ö ğe. Birimler canlı yada cansız varlıklar olabilece ği gibi, kurum, kurulu ş da olabilir. Her ilaç(veya her kutu) bir birimi olu şturabilir.
Birimlerin mutlaka sayılabilir veya ölçülebilir öze lliklere sahip olması gerekir. Bu yüzden zevk, koku, rüya gibi ifadeler birime örnek kabul edilemez.
İstatistikte birimin homojen(e şitlik) olması şartı da aranır. Aynı tanıma uygun birimlere homojen denir. Birimler belli bir tanıma uyduklarında “biçimsel homojenlik” olur. Örne ğin Üniversite ö ğrencileri arasında biçimsel homojenlik vardır. E ğer öğrenciler arasında boy, ya ş gibi e şitlik varsa (ki bu zordur) “maddi homojenlik” oldu ğu söylenebilir. İstatisti ğin ilgi duydu ğu biçimsel homojenliktir. Maddi homojenli ğe zor ender rastlanılır.
Biçimsel homojenli ği gerçekle ştirebilmek için birimin açık ve kesin bir tanımı muhakkak verilmelidir. Böyle bir ta nımın verilmemesi durumunda gözlemcilerin topladıkları ver iler bir araya getirildi ğinde elde edilen sonuç bir anlam ta şımaz. Çünkükütle homojen olmayan birimlerden olu şmuş olur. Örne ğin genel nüfus sayımında kimler hakkında bilgi toplayaca ğız? Sayımın yapıldı ğı ülkenin vatanda şlarını mı, yoksa hem bunları hem de sayım anında ülke sınırları içinde ya şayan veya bulunan yabancıları mı dikkate alaca ğız? Bu gibi durumlarda tanımın çok açık yapılması gerekmektedir.

Yrd.Doç.Dr.Yüksel TERZĐ 53
µ
σ2
AnakütleÖrnekÖrnekleme
N n
Parametre İstatistik
S2X
Parametre: Anakütleyi tanımlamada kullanılabilen tipik değerlerdir. Anakütle ortalaması, anakütle varyansı gib i değerlerdir.
İstatistik: Örneği olu şturan birimlerden hesaplanmı ş, anakütleyi tanımlayan de ğerlere kar şılık gelen de ğerlerdir. Örnek ortalaması, örnek varyansı gibi.

Yrd.Doç.Dr.Yüksel TERZĐ 54
ÖRNEKLEME NĐÇĐN GEREKLĐDĐR ?1. Popülasyonun hepsini incelemek çok masraflı
olabilir. Popülasyondan alınacak küçük örnekler yardımı ile gerçeğe yakın bilgiler elde edilebilir.
2. Popülasyonla yapılacak bir çalışma çok uzun zamana ihtiyaç gösterebilir. Halbuki örnekle çalışılırsa kısa zamanda gerçeğe yakın bilgiler kısa zamanda elde edilebilir.
3. Bir çok durumda gözlemlerin elde edilmesi deneklerin yok edilmesini gerektirebilir. Örneğin bir ilaç üzerinde deneme yapılıyorsa fabrikanın ürettiği tüm ilaçları denemeye almak ve yok etmek mümkün değildir.
4. Küçük sayıda örneklerle çalışılırken daha hassas çalışma yapmak ve daha dikkatli ölçüm almak, daha hassas alet ve yöntemler kullanmak mümkündür. Yapılan işin denetlenmesi de daha kolay olur.

Yrd.Doç.Dr.Yüksel TERZĐ 55
ÖÖrneklem brneklem b üüyyüüklkl üüğğüünnüün hesaplanmasn hesaplanmas ıına ilina ili şşkin formkin form üüllerller
Nitel(oran)
Nicel(Ortalama)
N>10.000N<10.000Değişken
Türü
222
22
))(1( α
ασ
σZSHN
ZNn
+−= 2
22
)(SH
ZNn ασ=
22
2
))(1( α
αPQZSHN
NPQZn
+−=
22
2
)( α
αPQZSH
PQZn
+=
P: evrende bir olayP: evrende bir olayıın gn göözlenme oranzlenme oranııQ=1Q=1--PP

Yrd.Doç.Dr.Yüksel TERZĐ 56
Evren bEvren b üüyyüüklkl üüklerine karklerine kar şışıll ıık k öörneklem brneklem b üüyyüüklkl üüğğüü
100.000-3848000-3672600-3351400-302750-254420-201270-159180-12395-7650-44
75000-3827000-3642400-3311300-297700-248400-196260-155170-11890-7345-40
50000-3816000-3612200-3271200-291650-242380-191250-152160-11385-7040-36
40000-3805000-3572000-3221100-285600-234360-186240-148150-10880-6635-32
30000-3794500-3541900-3201000-278550-226340-181230-144140-10375-6330-28
20000-3774000-3511800-317950-274500-217320-175220-140130-9770-5925-24
15000-3753500-3461700-313900-269480-241300-169210-136120-9265-5620-19
10000-3703000-3411600-310850-265460-210290-165200-132110-8660-5215-14
9000-3682800-3381500-306800-260440-205280-162190-127100-8055-4810-10
N – nN – nN – nN – nN – nN – nN – nN – nN – nN – n

Yrd.Doç.Dr.Yüksel TERZĐ 57
ÖLÇME DÜZEYLERİ1. Adlandırma2. Sıralama3. Aralık4. Oran1. Adlandırma Ölçeğinde sayılar sadece bir isim gibidir,
büyüklük, küçüklük söz konusu de ğildir. Bir ko şu pistinde 6 numaralı ko şucu ile 10 numaralıkoşucunun iyilik yönünden farklı olmadı ğı gibidir. Örneğin, psikiyatride hastalar şizofrenik, paranoid, manyak depresif, psikonörotik gibi isimlendirilir. B u isimler hastalı ğın tipine ait sembollerdir. Bu isimlendirme A,B,C,D, veya 1,2,3,4,5 diye de yapılabilirdi. Bu tip verilerde özellikle parametr ik olmayan istatistikler kullanılır.

Yrd.Doç.Dr.Yüksel TERZĐ 58
2. Sıralama ölçeği: Bu ölçekte bir büyüklük veya önemlilik söz konusudur. Ki şilerin e ğitim durumunu gösterirken, E ğitimsiz=1, İlkokul=2, Ortaokul=3, Lise=4, Üniversite=5, Yüksek lisans=6 kodları verildi ğinde sayı büyüdükçe eğitim düzeyinin arttı ğı anlaşılır. Ancak 1 ile 2 arasındaki mesafe ile 5 ile 6 arsındaki mesafe aynı değildir. Yani sıralama ölçe ğinde kod olarak kullanılan sayılar arasındaki mesafe önemli değildir . Sıralamada en iyiye büyük sayıverilebilece ği gibi küçük sayıda verilebilir, bu kullanılacak analiz yöntemini de ğiştirmez. Bu ölçekle elde edilmi ş verilerde ortalama yerine medyan kullanılır, daha çok parametrik olmayan testler kullanılır.

Yrd.Doç.Dr.Yüksel TERZĐ 59
3. Aralık Ölçeği: Bu ölçekte kod sayıları arasındaki mesafenin önemi vardır . Ölçü biriminin ve sıfır noktasının seçimi arzuya ba ğlıdır. Sayılar arasımesafelerin anlamı önemlidir. Bu tip sayılar toplanarak ortalama alınabilir.
Bu ölçekte sıfır de ğeri hiçlik belirtmez. Örneğin bir ersin sınavından sıfır puan alan öğrencilerin ders konuları ile ilgili hiçbir şey bilmedi ği düşünülemez. Sıcaklık, zeka, yetenek, performans puanı gibi nicel de ğişkenlere ait ölçümler aralık ölçe ğindedir.

Yrd.Doç.Dr.Yüksel TERZĐ 60
4. Oran Ölçeği: Bu ölçekte her zaman bir mutlak sıfır noktası vardır. A ğırlık oran ölçeğinde bir de ğişkendir, çünkü sıfır ağırlığında olabilir. Sayılarak elde edilen değişkenlerin ço ğu oran ölçe ğindedir, örneğin; geçen 6 aydaki hasta sayısı nedir dendi ğinde, bu sıfır olabilir. 1. Altı aydaki hasta 2. Altı aydaki hastanın iki katıdır dendi ğinde bunu bir anlamı vardır.

Yrd.Doç.Dr.Yüksel TERZĐ 61
Ölçeklerin Güç Hiyerarşisi
Sonuçlar sadece isim(en zayıf ölçek)
Adlandırma
Sonuçlar sıralanabilirSıralama
Değerler arası mesafe önemliAralık
Mutlak sıfır noktası var(en güçlü ölçek)
Oran

Yrd.Doç.Dr.Yüksel TERZĐ 62

Yrd.Doç.Dr.Yüksel TERZĐ 63
İSTATİSTİĞİN GÖREVİ
İstatistikte genellikle şu sıraya uyulur:
1. Verilerin toplanması2. Toplanan verilerin işlenip düzenlenmesi3. Düzenlenmiş verilerin tablolar ve/veya
grafikler şeklinde gösterilmesi4. İstatistiksel analiz, tahmin5. Karar vermek

Yrd.Doç.Dr.Yüksel TERZĐ 64
UYGUN ĐSTATĐSTĐK TEKN ĐĞĐN BELĐRLENMESĐ
� Araştırmanın Amacı : Uygulanacak test araştırmanın amacına uymalıdır.� Örneklem Yöntemi : Örneklemin yansız olarak seçilmesi gerekir.� Değişkenlerin Türü : Değişkenlerin hangisinin bağımlı-bağımsız ve
hangisinin nitel-nicel olduğu belirlenmelidir.� Bağımlı Değişkenlerin Ölçüm Düzeyi : Sınıflama-sıralama-aralık-oran� Kar şılaştırmanın bağımsız gruplar arasında mı yoksa ilişkili ölçümler arasında mı olduğu belirtilmelidir.� Parametrik Test Koşulları:
�Veriler nicel olmalı� Veriler Normal Dağılıma sahip olmalı� Varyanslar homojen olmalı yani dağılımların yaygınlıkları benzer olmalı� Örneklemi oluşturan birimler popülasyondan (evrenden) yansız olarak seçilmeli� Örneklemi olu şturan birimler birbirinden ba ğımsız olmalı (bir birimin seçimi di ğer birimin seçimini etkilememeli)� Örneklem büyüklü ğü 10’dan az olmamalıdır.

Yrd.Doç.Dr.Yüksel TERZĐ 65
Friedman TestiTekrarlı ölçümler için ANOVA
İlişkili III veya daha fazla grup
Kruskal-Wallis H Testi
Varyans AnaliziBağımsız III veya daha fazla grup
Wilcoxon Eşleştirilmi ş Testi
İlişkili Ölçümler için T Testi
İlişkili-Ba ğımlıII.Grup
Mann-WhitneyU Testi
Bağımsız örnekler için T testi
Bağımsız II Grup
İşaret TestiTek grup için Z ve T testi
I.Grup-örneklem
Parametrik Olmayan Testler
Parametrik TestlerKarşılaştırma

Yrd.Doç.Dr.Yüksel TERZĐ 66
Adlandırma Ölçe ğinde ölçülen verilerin Farklılı ğının Testi
Z yakla şımıile test
n.p >=5n.q>=5
Binom testi
n.p<5n.q<5
1 Grup Var
Mc NemarTesti
GruplarBağımsız
Değil
FisherExact testi
BeklenenDeğerKüçük
Khi Kare testiveya
Z yakla şımı
BeklenenDeğerBüyük
GruplarBağımsız
2 Grup Var
Khi Kare Analiziiçin SınıfBirle ştir
BeklenenDeğerKüçük
Khi KareAnalizi
BeklenenDeğerBüyük
GruplarBağımsız
Cochran-Qtesti
GruplarBağımlı
3 veya DahaFazla Grup Var
Grup Sayısı
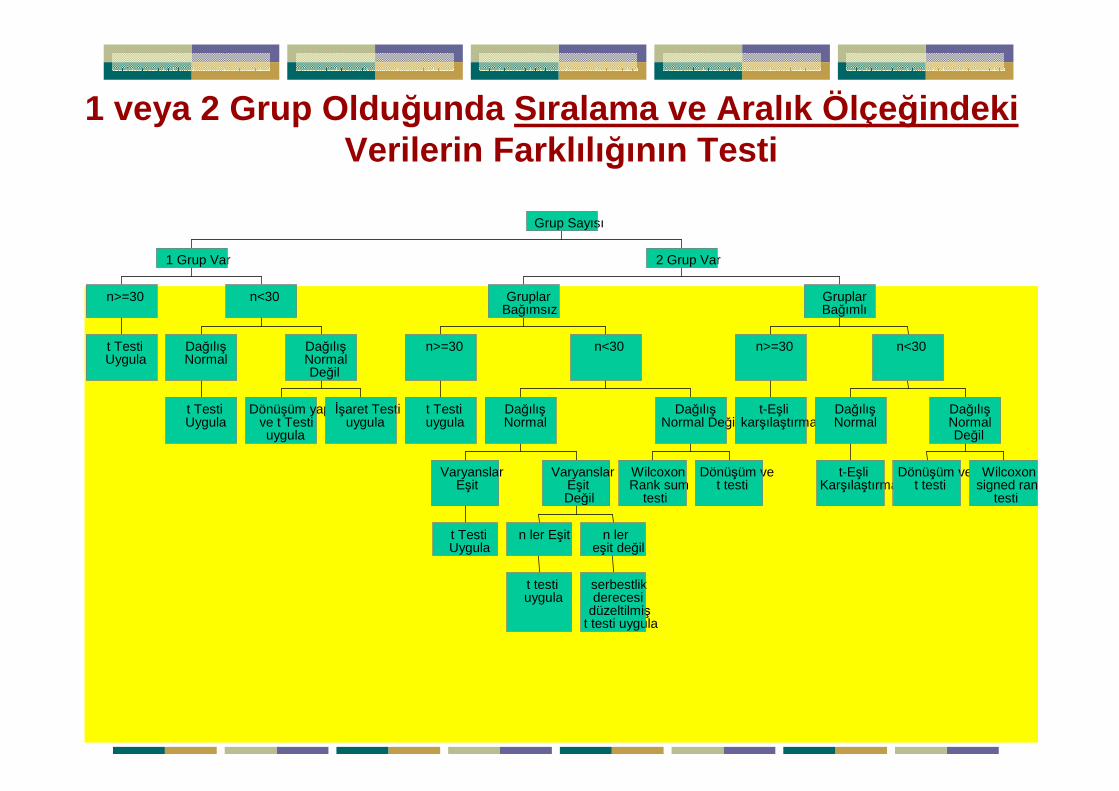
Yrd.Doç.Dr.Yüksel TERZĐ 67
1 veya 2 Grup Oldu ğunda Sıralama ve Aralık Ölçe ğindekiVerilerin Farklılı ğının Testi
t TestiUygula
n>=30
t TestiUygula
DağılışNormal
Dönüşüm yapve t Testiuygula
İşaret Testiuygula
DağılışNormalDeğil
n<30
1 Grup Var
t Testiuygula
n>=30
t TestiUygula
VaryanslarEşit
t testiuygula
n ler Eşit
serbestlikderecesi
düzeltilmişt testi uygula
n lereşit değil
VaryanslarEşitDeğil
DağılışNormal
WilcoxonRank sum
testi
Dönüşüm vet testi
DağılışNormal Değil
n<30
GruplarBağımsız
t-Eşlikarşılaştırma
n>=30
t-EşliKarşılaştırma
DağılışNormal
Dönüşüm vet testi
Wilcoxonsigned rank
testi
DağılışNormalDeğil
n<30
GruplarBağımlı
2 Grup Var
Grup Sayısı

Yrd.Doç.Dr.Yüksel TERZĐ 68
Sıralama ve Aralık Ölçe ğinde 3 veya Daha Fazla Grup Oldu ğunda Farklılı ğın Testi
k-Faktör içinKruskal-Wallis
Testi
DağılışNormalDeğil
2 Yönlü veyaDiğer Varyans
Analizleri
2 veya Daha Fazla faktör var
Tek YönlüVaryansAnalizi
1 FaktörVar
DağılışNormal
GruplarBağımsız
TekrarlananÖlçümlüVaryansAnalizi
DağılışNormal
FriedmanTesti
DağılışNormalDeğil
GruplarBağımlı
3 veya DahaFazla Grup
Var

Yrd.Doç.Dr.Yüksel TERZĐ 69
1 Bağımlı 1 Bağımsız Değişken Durumundaİlişki Bulunması
Göreli(Relative)Risk Analizi
SınıflayıcıÖlçekte
SpearmanSıra Korelasyon
Katsayısı
SıralayıcıÖlçekte
RegresyonAnalizi
Bir DeğişkenDiğerinden
TahminEdilecek
PearsonKorelasyonKatsayısı
Bir DeğişkenDiğerinden Tahmin
Edilmeyecek
AralıkÖlçeğinde
Heriki DeğişkeninÖlçeği

Yrd.Doç.Dr.Yüksel TERZĐ 70
Bağımsız Değişken Sayısı 2 Veya Daha Fazla Olması Durumu
Kaplan-Meier veyaActuarialAnaliz
Sansürlenmiş(censored)Gözlem Var
Log-LinearAnaliz
Etki Karışımlı(Confounding)Değişken Yok
Mantel-HaenselAnalizi
Etki Karışımlı(Confounding)Değişken Var
SansürlenmişGözlem Yok
BağımlıDeğişkenSınıfsalÖlçekli
Cox-ProportinalHazard Modeli
SansürlenmişGözlem Var
Varyans Analizi
SansürlenmişGözlem Yok
Bağımlı DeğişkenAralıkÖlçekli
SınıfsalÖlçekli
LojistikRegresyon
BağımsızDeğişken Şık
Sayısı 2(Binary)
DiskriminantAnalizi
BağımsızDeğişken Şık
Sayısı 3veya Daha fazla
Bağımlı DeğişkenSınıfsalÖlçekli
Cox- ProportionalHazardModeli
SansürlenmişGözlem
Var
KovaryansAnalizi
ConfoundingDeğişken
Var
ÇokluRegresyon
Analizi
ConfoundingDeğişken
Yok
SansürlenmişGözlem
Yok
Bağımlı DeğişkenAralıkÖlçekli
Sıralayıcıveya Aralık Ölçekli
Bağımsız DeğişkenlerinÖlçeği

Yrd.Doç.Dr.Yüksel TERZĐ 71
GRAFİKLER
Grafikler gözlem sonuçlarının anlaşılmasıkolaylaştırır. Çünkü ilk bakışta görsel kolaylık sağlarlar. Ancak grafikler rakamlar derecesinde önemli değildir. Çünkü grafiksiz istatistik olabilir ancak rakamsız grafik asla olamaz. Ayrıca grafikler büyük farkları ve değişimleri gösterebilir. Ancak küçük farklar ve değişimleri gösteremez. Çeşitli grafik türleri vardır.
Bar (Çubuk) Grafi ği: Nominal ve ordinal verilerin grafiklerinin yapılması için uygundur. Bu grafik yatay eksende kategori etiketleri belirtilirken, her kategori ile frekans veya yüzdeyi temsil eden dikey çubuklar çiziminde oluşur.

Yrd.Doç.Dr.Yüksel TERZĐ 72

Yrd.Doç.Dr.Yüksel TERZĐ 73

Yrd.Doç.Dr.Yüksel TERZĐ 74

Yrd.Doç.Dr.Yüksel TERZĐ 75

Yrd.Doç.Dr.Yüksel TERZĐ 76
ScatterScatter //DotDot GrafiGrafi ğğii

Yrd.Doç.Dr.Yüksel TERZĐ 77

Yrd.Doç.Dr.Yüksel TERZĐ 78
PiePie (pasta) Grafikleri(pasta) Grafikleri

Yrd.Doç.Dr.Yüksel TERZĐ 79

Yrd.Doç.Dr.Yüksel TERZĐ 80
HistogramHistogram GrafikleriGrafikleri

Yrd.Doç.Dr.Yüksel TERZĐ 81

Yrd.Doç.Dr.Yüksel TERZĐ 82
BoxplotBoxplot (Kutu) Grafikleri(Kutu) Grafikleri

Yrd.Doç.Dr.Yüksel TERZĐ 83

Yrd.Doç.Dr.Yüksel TERZĐ 84
398N =
Gelir
50
40
30
20
10
0
330
KUTU GRAF İĞİ (BOX PLOT)
Uç nokta
Uç nokta olmayanen büyük değer
75. yüzdelik(3. çeyrek)
50. yüzdelik(medyan)
25. yüzdelik(1. çeyrek)
Uç nokta olmayanen küçük değer
Yüzdeliklere dayanan ve tanımlayıcı istatistikleri kullanan bir grafik türüdür.

Yrd.Doç.Dr.Yüksel TERZĐ 85
STEM&LEAF GRAF ĐĞĐ (DAL VE YAPRAK GRAF ĐĞĐ) YAS StemYAS StemYAS StemYAS Stem----andandandand----Leaf PlotLeaf PlotLeaf PlotLeaf Plot Frequency Stem & Leaf Frequency Stem & Leaf Frequency Stem & Leaf Frequency Stem & Leaf 1,00 2 . 9 1,00 2 . 9 1,00 2 . 9 1,00 2 . 9 4,00 3 . 0234 4,00 3 . 0234 4,00 3 . 0234 4,00 3 . 0234 5,00 3 . 56789 5,00 3 . 56789 5,00 3 . 56789 5,00 3 . 56789 5,00 4 . 01234 5,00 4 . 01234 5,00 4 . 01234 5,00 4 . 01234 5,00 4 . 56789 5,00 4 . 56789 5,00 4 . 56789 5,00 4 . 56789 5,00 5 . 01234 5,00 5 . 01234 5,00 5 . 01234 5,00 5 . 01234 4,00 5 . 6789 4,00 5 . 6789 4,00 5 . 6789 4,00 5 . 6789 4,00 6 . 0123 4,00 6 . 0123 4,00 6 . 0123 4,00 6 . 0123 2,00 6 . 69 2,00 6 . 69 2,00 6 . 69 2,00 6 . 69 3,00 7 . 013 3,00 7 . 013 3,00 7 . 013 3,00 7 . 013 3,00 7 . 578 3,00 7 . 578 3,00 7 . 578 3,00 7 . 578 Stem width: 10,00 Stem width: 10,00 Stem width: 10,00 Stem width: 10,00 Each leaf: 1 case(s) Each leaf: 1 case(s) Each leaf: 1 case(s) Each leaf: 1 case(s) Analyze>Descriptive statistics>Explore yolu ile Plots tuşu seçilerek Stem-and leafişaretlenir. Burada stem (dal) ve leaf (yaprak) anlamındadır. Yukarıdaki tabloda örneğin “4,00 3.0234” satırı 30 ile 34 değerleri arasında 4 değer olduğunu gösterir. Tablo altındaki Stem width : dal genişliğini, Each leaf : her yapraktaki deneklerin tek tek gösterildiğini ifade eder.

Yrd.Doç.Dr.Yüksel TERZĐ 86
2. MERKEZ Đ EĞĐLĐM ÖLÇÜLER Đ (ORTALAMALAR) (Measures of Central Tendency)
“ Başı fırında ayakları buzdolabında olan bir adam ortalama olarak rahattır” Malcolm E.Lines Bir mahalledeki ortalama gelir düzeyi bir araştırmaya göre yılda 15000€, diğerine göre ise 5000€ çıkmıştır. Đki sonuçta aynı kişi ve yerden bulunmuştur. Burada ki hile “ortalama” kelimesidir. Çünkü hangi ortalama olduğu belirtilmemiştir. Eğer büyük bir sayıya ulaşmak istiyorsanız aritmetik ortala, küçük bir sayıya ulaşmak için en çok tekrarlanan değer olan mod kullanılabilir. Sayı yığınlarının kolayca anlaşılması için sayı yığınlarının en fazla yığıldığı bölgeyi tarif eden tipik değerlerin verilmesi gerekir. Bu değerler dağılışın merkezini gösterdikleri için merkezi eğilim ölçüleri olarak da bilinir. Đstatistikte bir seriyi temsil etmeye yarayan tek bir rakama ortalama denir. Ortalamalar serinin bütün terimlerinin hesaba katıldığı ortalamalar (duyarlı ortalamalar) ve serinin bütün terimlerinin hesaba katılmadığı ortalamalar (duyarlı olmayan ortalamalar) diye ikiye ayrılır.

Yrd.Doç.Dr.Yüksel TERZĐ 87
2.1. Duyarlı Ortalamalar
Tablo 2.1. Duyarlı ortalamalara ilişkin genel formüller aşağıdaki gibidir:
Basit Serilerde r
ri
r N
XO
∑=
Sınıflanmış Serilerde r
i
rii
r f
XfO
∑∑=
Duyarlı Ortalamalar Gruplanmış Serilerde
r
i
rii
r f
mfO
∑∑=
Burada r’ye -∞ ile +∞ arasında değerler verilerek sonsuz ortalama bulunabilir. r=-∞ olması durumunda ortalamanın Xmin olmasına, r=+∞ olması durumunda ise Xmax olacağı ispatlanabilir. Yani r arttıkça ortalama büyümekte, r azaldıkça ise küçülmektedir.

Yrd.Doç.Dr.Yüksel TERZĐ 88
2.1.1. Aritmetik Ortalama
Aritmetik ortalama deneklerin aldıkları değerlerin toplanıp denek sayısına bölünmesiyle elde edilen değerdir. Tablo 2.1.’de r=1 alındığında aritmetik ortalama formülleri elde edilir.
Basit Serilerde N
XX i∑=
Sınıflanmış Serilerde ∑
∑=i
ii
f
XfX
Aritmetik Ortalama
Gruplanmış Serilerde ∑
∑=i
ii
f
mfX

Yrd.Doç.Dr.Yüksel TERZĐ 89
2.1.2. Geometrik Ortalama
X i: {X 1,X2,…, Xn} pozitif sayılar kümesinin geometrik ortalaması, sayıların çarpımlarının N nci dereceden köküdür.
Tablo 2.1.’de r=0 yada r→0 için limit alınarak geometrik ortalama formülleri bulunabilir.
Basit Serilerde
N
XGO i∑=
loglog
Sınıflanmış Serilerde
∑∑=
i
ii
f
XfGO
loglog
Geometrik Ortalama Gruplanmış Serilerde
∑∑=
i
ii
f
mfGO
loglog
Geometrik ortalama, terimlerinin logaritmalarının aritmetik ortalamasının antilogaritmasına eşittir.
NnXXX ....GOOrtalamaGeometrik 21==

Yrd.Doç.Dr.Yüksel TERZĐ 90
Geometrik Ortalamanın Özellikleri I. Geometrik ortalama özellikle aynı oranda artma yada azalma
eğilimi gösteren olaylara ilişkin serilere uygulanır. Örneğin nüfus çoğalması, bakteri üremesi gibi geometrik dizilerde birim zamandaki artışı bulmak için GO kullanılır.
II. Simetrik olmayan ancak logaritmaları alındığında simetrik hale dönüşen serilere geometrik uygulama uygulanabilir.
III. Serideki terimler arasında bazı değerler sıfır veya negatifse GO hesaplanamaz.
IV. Geometrik uygulama aşırı uç değerlerden aritmetik ortalamaya göre daha az etkilenir.
V. GO ≤ AO ilişkisi vardır. Bütün Xi ler eşitse GO=AO olur. VI. Seri terimlerinin k. kuvvetlerinin geometrik ortalaması,
geometrik ortalamanın k. kuvvetine eşittir.
[ ] [ ] [ ] kkNN
NkN
NkN
kk GOXXXXXXXXX === /121
/121
/121 )()()()()( KKK

Yrd.Doç.Dr.Yüksel TERZĐ 91
2.1.3. Harmonik Ortalama X i:{ X 1,X2,…, Xn } değerlerinin harmonik ortalaması:
Harmonik ortalama terimlerin terslerinin aritmetik ortalamasının tersidir. Tablo 2.1.’de r=-1 alınırsa harmonik ortalama formülleri elde edilir.
Basit Serilerde ∑=
iX
NHO
1
Sınıflanmış Serilerde ∑
∑=
i
i
i
X
f
fHO
Harmonik Ortalama
Gruplanmış Serilerde ∑
∑=
i
i
i
m
f
fHO
∑=
=N
i iX1
1N1
1OrtalamaHarmonik

Yrd.Doç.Dr.Yüksel TERZĐ 92
Harmonik Ortalamanın Özellikleri I. Serideki terimlerden biri sıfır ise harmonik ortalama sıfır çıkar.
II. Seri terimleri farklı işaretli olursa harmonik ortalamanın sonucu
anlam taşımaz. Mesela verilerimiz -4, -2, 1,2,5 olsun. Buna göre HO=5.05 çıkar. Bu sonuç, bir ortalama maksimum değerden daha büyük bir değere sahip olamayacağı için, ortalama olarak kabul edilmez.
05.5
5
1
2
1
1
1
2
1
4
15 =
+++−
+−
=HO
III. HO ≤ GO ≤ AO ili şkisi vardır. IV. HO sınırlı hallerde kullanılır. Tersine çevrildiğinde taşıyacağı
anlama önem verilen oran türündeki niceliklerin ortalamasını bulmak için kullanılır. Bu niceliklere örnek olarak fiyat=para/mal, prodüktivite=iş/emek, verim=ürün/ekim alanı, hız=uzaklık/zaman verilebilir.

Yrd.Doç.Dr.Yüksel TERZĐ 93
2.1.4. Kareli Ortalama Kareli ortalama fiziksel uygulamalarda çok sık kullanılır. Tablo 2.1.’de r=2 alınırsa terimlerin karelerinin aritmetik ortalamasının kareköküne eşit olan kareli ortalama formülleri bulunur.
Basit Serilerde N
XKO i∑=
2
Sınıflanmış Serilerde ∑
∑=i
ii
f
XfKO
2
Kareli Ortalama Gruplanmış
Serilerde ∑∑=
i
ii
f
mfKO
2

Yrd.Doç.Dr.Yüksel TERZĐ 94
Kareli Ortalamanın Özellikleri
1. Kareli ortalama negatif işaretleri de dikkate alabileceğinden HO ve GO’ya göre daha üstündür.
2. KO bazı istatistiksel işlemlerin kolaylıkla uygulanmasını
mümkün kılar. Örneğin bir değişkenlik ölçüsü olan standart sapmanın hesabında kareli ortalamadan yararlanılır.
3. HO ≤ GO ≤ AO ≤ KO ilişkisi vardır.

Yrd.Doç.Dr.Yüksel TERZĐ 95
2.2. Duyarlı Olmayan Ortalamalar Duyarlı ortalamalarda bütün terimler veya sınıflar dikkate alınır. Hesaplamalarda bazen serinin bütün terimleri veya sınıfları dikkate alınmayabilir. Bu durumda duyarlı olmayan ortalamalar ortaya çıkar. 2.2.1. Ortanca (Medyan)
Sayılar kümesini iki eşit yarıya bölen değer ortanca değerdir [(N+1)/2]. Gözlem değerleri büyüklük sırasına dizildiğinde tam ortada kalan değer yada iki orta değerin aritmetik ortalamasıdır. Örnek 2.22. Xi : { 3,1,13,27,6,8,6 } gözlem değerlerinin ortancası nedir?
Sayılar büyüklük sırasına dizilirse, { 1, 3, 6, 6, 8, 13, 27 } olur. Ortada kalan sayı 6 olduğundan
Ortanca=6 olur.

Yrd.Doç.Dr.Yüksel TERZĐ 96
Medyanın Özellikleri I. Basit bir sıralama ile bulunması mümkün olduğundan, medyan bir
çok durumda pratiktir. Örne ğin bir grup öğrencinin boy uzunluğunu teker teker ölçmeye gerek yoktur. Öğrenciler küçükten büyüğe doğru sıralanıp ortadaki öğrenci (ler) ölçülerek ortanca boy uzunluğu bulunabilir.
II. Seride açık (alt sınırı veya üst sınırı belli olmayan) sınıfların varlığı halinde medyan hesabı önem kazanır.Medyan sınıfı serinin ilk sınıfı olduğunda, sınıfın alt sınırı tahminsel olarak ele alınır.
III. Diğer ortalamaların aksine, gruplanmış serinin medyan hesabında sınıf genişliklerinin tamamının eşit olması gerekmez.
IV. Medyan serideki anormal terimlerden etkilenmez. Ortanca Kullanmanın sakıncaları nedir?
I. Ortancanın standart hatası aritmetik ortalamadan daha büyüktür. II. Ortanca üzerinde cebirsel işlemler yapılamaz.
III. Farklı alt grupların ortancaları biliniyorsa bu gru plar birleştiğinde ortanca nedir sorusu hesaplama ile bulunamaz.

Yrd.Doç.Dr.Yüksel TERZĐ 97
2.2.2. Kartiller
Küçükten büyüğe doğru sıralanmış bir seriyi 4, 10, 100 eşit kısma bölen terimler vardır. Genel olarak kantil adı verilen bu değerlerden dörde bölenler kartil (çeyreklikler ), ona bölenler desil (ondabirlikler) ve yüze bölenler santil (yüzdebirlikler) olarak adlandırılır. Kartillerin sayısı 3, desillerin 9 ve santillerin sayısı 99 dur. Medyan 2. kartile, 5. desile ve 50. santile eşittir.
Kümeyi dört eşit parçaya bölen değerleri Q1, Q2, Q3 ile gösterelim. Bunlar birinci, ik inci ve üçüncü yüzdelik olarak adlandırılır. Burada Q 2 medyandır.
Basit seride 1. kartil yani 1. yüzdelik (N+1)/4’üncü terimdir. 3. kartil ise 3(N+1)/4’üncü terimdir.

Yrd.Doç.Dr.Yüksel TERZĐ 98
2.2.3. Tepe Değer(Mod)
Bir sayı kümesi içinde en fazla tekrarlanan değer varsa o seriye tek modlu seri denir. Eğer bir seride birden fazla aynı sayıda tekrarlanan değer varsa, bu tür serilere çok modlu seri denir.

Yrd.Doç.Dr.Yüksel TERZĐ 99
Modun Özellikleri I. Ortalamalar arasında mod en temsili olanıdır. Çünkü kütledeki
birimleri önemli bir kısmına uyar. II. Sınıflanmış serilerde modun tamsayı olması gerçeğin daha iyi
yansıtılmasını sağlar. Örneğin bir bölgedeki ailelerin ortalama çocuk sayıları hesaplandığında kesirli bir rakam elde edilebilir. Oysa ortalama olarak mod alınırsa bu değer tam sayı çıkacaktır.
III. Mod anormal terimlerin etkisi altında kalmaz. Örneğin çok zengin bir kişinin köye taşındığını varsayalım. Bu kişinin gelir düzeyi tek ve serinin sonunda olacağından modu etkilemez.
IV. Mod uygulamada farkına varılmadan en çok başvurulan ortalamalardan biridir. Örneğin kundura ve hazır giyim eşyası üretiminde en çok satılan numaralar ve bedenler dikkate alınır. Buda mod demektir.
V. Adlandırma (nominal) ölçekli değişkenlerde mod kullanımı uygundur.

Yrd.Doç.Dr.Yüksel TERZĐ 100
Modun Sakıncaları
� Modun güvenirliliği azdır. Yani örnekten elde edilen mod popülasyon modundan çok farklı olabilir.
� Ortancada olduğu gibi mod üzerinde de cebirsel işlemler
yapılamaz. � Bazen verilerin ortalaması, ortancası olduğu halde modu
olmayabilir. Bütün değerler farklı ise mod yoktur.

Yrd.Doç.Dr.Yüksel TERZĐ 101
ORTALAMA T ĐPĐNĐN SEÇĐMĐ ���� Ortalama kıyaslama amacıyla hesaplandığında Aritmetik Ortalama tercih
edilir. Çünkü Aritmetik Ortalama bütün terimler yada sınıflar üzerinden hesaplanan en duyarlı ortalamadır.
���� Araştırmanın amacı seriyi kıyaslamayıp, seriyi temsil etmek ise yerine göre Mod yada Medyan tercih edilir.
���� Terimlerin kendileri yerine oranları bizi ilgilendiriyorsa Geometrik Ortalama tercih edilir.
���� Terimlerin tersleri ile ilgileniliyorsa Harmonik ortalama kullanılır. ���� Sıfır veya negatif işaretli değerlere sahip serilerde Harmonik ve Geometrik
Ortalama hesaplanamaz. ���� Sınıf genişlikleri eşit olamayan gruplanmış serilerde Medyanın hesaplanması
uygundur. ���� Seri terimleri arasında önem farkı bulunduğunda Tartılı Ortalama uygulanır. ���� Ortalama, ortanca ve mod arasında aşağıdaki genel ilişki vardır.
Ortalama – Mod= 3* ( Ortalama – Ortanca) ���� Sıralamalı ölçümlü özelliklerde veya bütün değerlerin elde edilmesinin uzun
zaman aldığı bazı durumlarda Medyanın kullanılması uygundur. Örneğin öğrenme davranışının incelendiği bir araştırmada bazı bireyler çok geç öğrenebilir, ortalama için bunu beklemek gerekir, Medyan için bunu beklemeye gerek kalmaz.

Yrd.Doç.Dr.Yüksel TERZĐ 102
3. DEĞĐŞĐM ÖLÇÜLER Đ (Measures of Variation)
Bir anakütleyi (popülasyonu) tanıtmak için, başka ana
kütlelerle kar şılaştırabilmek için merkezi ölçüleri yanında dağılışın genişliğini, değişkenliğin büyüklüğünü gösteren bir başka tipik değerin verilmesi gerekmektedir. Bu tipik değer değişim ölçüsüdür.
Ortalamaları eşit olan seriler, değişkenlikleri veya bölüne şekilleri farklı oldu ğunda birbirine benzemez. Bu nedenle serileri tam olarak tanımlayabilmek için ortalamayı, değişimlerini ve bölünme şekillerini incelemek gerekir.

Yrd.Doç.Dr.Yüksel TERZĐ 103
Örnek. X i: { 49,49,49,50,51,52 } ; X =AO(X)= 50 Y i : { 35,41,50,55,58,61 } ; Y =AO(Y)= 50 Zi: { 15,21,33,49,90,92 } ; Z =AO(Z)= 50
Bu üç değişkenin ortalaması aynı olduğu halde X, Y ve
Z değişkenlerinin aldığı değerlerin en küçük ve en büyük değerlerine bakıldığında birbirlerinden çok farklıdır. X değerleri 50’nin etrafında çok yakın kümelendiği halde Z değerleri 50 den çok uzakta yer almakta, yani daha büyük değişim göstermektedir.
Bir popülasyonun bireylerinin değerleri arasındaki bu değişimin bir ölçü ile ifade edilmesi gerekir. Bu ölçülere yayılım veya değişim ölçüleri denir.

Yrd.Doç.Dr.Yüksel TERZĐ 104
3.1. Değişim Genişliği (Range) En basit değişim ölçüsü Değişim Genişliğidir.
Değişim Genişliği = (En Büyük Gözlem – En Küçük Gözlem)
DG(X)= 52-49= 3 DG(Y)= 61-35= 26 DG(Z)= 92-15= 77
olur. Bu dağılışların grafiklerine bakıldığında aşağıdaki şekilde bir görünüş söz konusudur.

Yrd.Doç.Dr.Yüksel TERZĐ 105Z
X Y

Yrd.Doç.Dr.Yüksel TERZĐ 106
3.2.Standart Sapma Kareli ortalama sapma adı verilen bu ölçü, terimlerin aritmetik ortalamadan cebirsel sapmalarının kareli ortalamasıdır. Standart sapma gözlemlerin ortalamadan ne kadar uzaklaştığını gösterir. Yani gözlemler arasında ne kadar yaygınlık olduğunu ifade eder.
Standart sapma varyansın kare köküdür. Varyans birimsiz ifade edildiği halde standart sapma ölçülen özelliğin birimi ile ifade edilir. Yani milimetre yerine milimetre kare gibi veri biriminin karesinin kullanılması uygun olmadığından, standart sapma kullanılır.
Ortalama etrafındaki saçılma fazla ise varyans büyük olacak, dolayısıyla standart sapma da büyük çıkacaktır. Veri seti içinde aşırı değer fazla ise bunların varyansı etkilemesi olağan karşılanabilir, ancak birkaç aşırı değerin varyansı büyütmesi olağan karşılanmaz.
Dağılımdaki maksimum ve minimum değerler arasındaki farkı dörde bölmek suretiyle, standart sapma kabaca tahmin edilebilir.
Moses’e göre standart sapma değeri, örnekteki gözlem değerleri arasındaki varyasyonun derecesini tanımlayan bir istatistiktir. Değişkenin dağılışı normal dağılış gösteriyorsa, standart sapma verilerin ortalama etrafındaki dağılışını iyi bir şekilde açıklar.

Yrd.Doç.Dr.Yüksel TERZĐ 107
Bazen örnek verisine ilişkin standart sapma hesaplanırken paydada N yerine N-1 alınır. Çünkü elde edilen değer örneğin alındığı yığının standart sapmasını daha iyi verir. N’in büyük değerleri için (N>30) iki tanım arasında bir fark yoktur. Gözlem değerlerinin tamamı birbirine e şit olamayacağından standart sapmanın değerleri pozitiftir.

Yrd.Doç.Dr.Yüksel TERZĐ 108
Basit Serilerde N
XXs i∑ −
=2)(
Sınıflanmış Serilerde
∑∑ −
=i
ii
f
XXfs
2)(
Standart Sapma
Gruplanmış Serilerde
∑∑ −
=i
ii
f
Xmfs
2)(
Kitle :
Örnek:
Standart Sapma Varyans
∑−−=
=
n
i
i
n
xxs
1
22
1
)(∑
−−=
=
n
i
i
n
xxs
1
2
1
)(

Yrd.Doç.Dr.Yüksel TERZĐ 109
Standart ayrılış ölçüsü ve standart hata Normal dağılış gösteren özellikler için oldukça kullanışlıdır. Normal dağılışta bireylerin %68.27 si ortalamanın bir standart sapma solunda ve bir standart sapma sağındaki noktalar arasında bulunur. Bireylerin %95.45 i ortalamanın iki standart sapma sağında ve solunda bulunur.

Yrd.Doç.Dr.Yüksel TERZĐ 110
VARYANS (Variance) Dağılış ölçüsü olarak kullanılan en uygun ölçü standart ayrılı ş ölçüsüdür. Standart ayrılış ölçüsü varyansın kareköküdür. Varyans gözlemlerin ortalamadan olan sapmalarının kareleri toplamının anakütle için N’e, örneklem için ise serbestlik derecesi n-1’e bölünmesidir.
X i: { X1,X2,…, Xn} değerler kümesinin varyansı:
∑=
−−
==N
ii XX
NsVaryans
1
22 )()1(
1
−−
= ∑∑
=
N
i
ii N
XX
N 1
22 )(
)1(
1
Örnek 3.8. Xi:{49,49,49,50,51,52} değişkeninin varyansı nedir? X = 300/6=50 s2=[(49-50)2+(49-50)2+…+(52-50)2]/(6-1)=(1+1+1+0+1+4)/5= 8/5=1.6 veya s2=[(492+492+492+502+512+522)-3002/6]/5=(1500815000)/5=8/5=1.6

Yrd.Doç.Dr.Yüksel TERZĐ 111
Serbestlik DerecesiSerbestlik Derecesi((DegreesDegrees of of FreedomFreedom ))
Serbestlik derecesi gSerbestlik derecesi g öözlemlere konulan kzlemlere konulan k ııssııtlamalara tlamalara babağğll ııddıır. Verilere getirilen bazr. Verilere getirilen baz ıı kkııssııtlamalardan sonra, detlamalardan sonra, de ğğiişşmekte mekte serbest olan deserbest olan de ğğerlerin sayerlerin say ııssııddıır. r. ÖÖrnerneğğin bir grup verinin in bir grup verinin ortalamaya gortalamaya g ööre olan sapmalarre olan sapmalar ıınnıın toplamn toplam ıı ssııff ıırdrd ıır. r. Bu sapmalarBu sapmalar ıın sadece Nn sadece N --11’’ i serbesti serbest ççe see seççilebilir. Toplam ilebilir. Toplam sapmalarsapmalar ıın sn s ııff ııra era eşşit olmasit olmas ıı kokoşşulu, ulu, NN’’ncinci sapmansapman ıın den değğerini erini ssıınnıırlandrland ıırr ıır. r.
Serbestlik derecesi Serbestlik derecesi öörnekle ilgili bir istatistirnekle ilgili bir istatisti ğğin in hesaplanmashesaplanmas ıında veya bir parametrenin tahmin edilmesinde, nda veya bir parametrenin tahmin edilmesinde, babağığımsms ıız birimlere ait sayz birimlere ait say ıınnıın bilgisinin ifade eden bir terimdir. n bilgisinin ifade eden bir terimdir. Genelde bu terim modeldeki parametre sayGenelde bu terim modeldeki parametre say ııssıına karna kar şışıll ıık k gelmektedir. gelmektedir.
0)( =∑ − xx

Yrd.Doç.Dr.Yüksel TERZĐ 112
3.3. Standart Hata (Standard Error of Estimate) Standart hata bir istatistiğin örnekleme dağılımının standart sapmasıdır. Seçilecek örneklerde ortalamalar arasındaki yaygınlığı gösterir. Standart hata örnek büyüklüğünün fonksiyonudur. Böylece n attıkça hata küçülür. Standart hata ortalamalarla ilgilidir, deneklerle i lgili değildir. Standart hata ortalamanın ne kadar değiştiğini gösterir.
N
s
N
VaryanssHS X ===..
Örnek 2.42’de verilen değerlerden hareketle standart hata aşağıdaki gibi bulunur.
52.06
6.1.. ===
N
VaryansHS

Yrd.Doç.Dr.Yüksel TERZĐ 113
Bir serinin ortalaması verilirken standart hatası ile birlikte verilir. Popülasyondaki değişimi göstermek için standart hata kullanılır. Veri setindeki değişim araştırılıyorsa standart sapma tercih edilir. Aritmetik Ortalama ±±±± Standart Hata
XSX m
Böylece ortalamaya ait değişkenlik yanında ifade edilmiş olur.

Yrd.Doç.Dr.Yüksel TERZĐ 114
3.4.Değişim (varyasyon) Katsayısı (Coefficient of Variation)
Bir serinin standart sapmasının aritmetik ortalamasına bölünüp 100 ile çarpılması sonucu elde edilen değere değişim katsayısı adı verilir. Değişim katsayısının ölçü birimi yoktur.
D.K= Standart Sapma*100/ Ortalama
100*..X
KDσ=
Değişim katsayısı farklı serilerin değişkenliklerini kıyaslamada iyi bir ölçü olabilir. Değişim katsayısı küçük olan serilerin diğerlerine göre aha az değişken olduğu söylenir. Bunun anlamı ise seri terimlerinin aritmetik ortalama etrafında daha homojen olarak dağıldığıdır.
Yrd.Doç.Dr.Yüksel TERZĐ 115
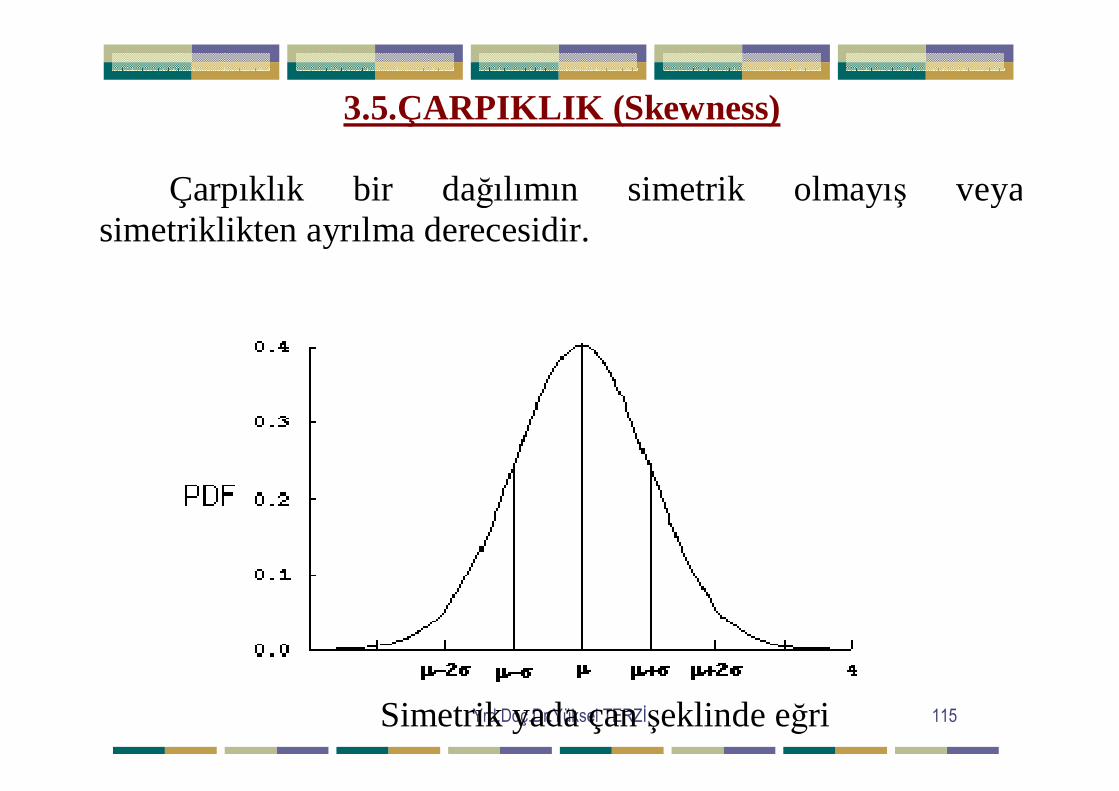
3.5.ÇARPIKLIK (Skewness) Çarpıklık bir dağılımın simetrik olmayış veya simetriklikten ayrılma derecesidir.
Simetrik yada çan şeklinde eğri

Yrd.Doç.Dr.Yüksel TERZĐ 116
Simetrik yada çan şeklindeki frekans eğrileri, merkezdeki maksimumdan eşit uzaklıkta yer alan gözlemlerin aynı frekansa sahip olduğunu gösterir. Yani frekansların serinin maksimum noktası etrafında simetrik olarak dağılması seriye simetrik seri adını kazandırır. Normal eğri buna örnektir. Normal eğride serinin tam ortasında maksimuma ulaşan frekanslar, sonra hızla düşmeye başlar. Simetrik seri sivri, basık ve normal seri gibi olabilir. Normal eğrinin özelliği grafikte maksimum noktanın belirli bir yüksekliğe sahip olmasıdır. Bu yüksekliğin normalin üstüne çıkması durumunda sivri seri, normalin altına düşmesi durumunda ise basık seriden söz edilir. Simetrik seri belli bir yüksekliğe sahip olmadığında normal olmaktan çıkar. Ayrıca simetrik seri sağa veya sola doğru eğilim gösterdiğinde de simetriklik özelliğini kaybeder. Frekanslar serinin tam ortasında değil de, ortadan önceki bir noktada yığıldığında “sağa çarpık seri”, ortadan sonraki bir noktada yığıldığında ise “sola çarpık seri” den söz edilir.
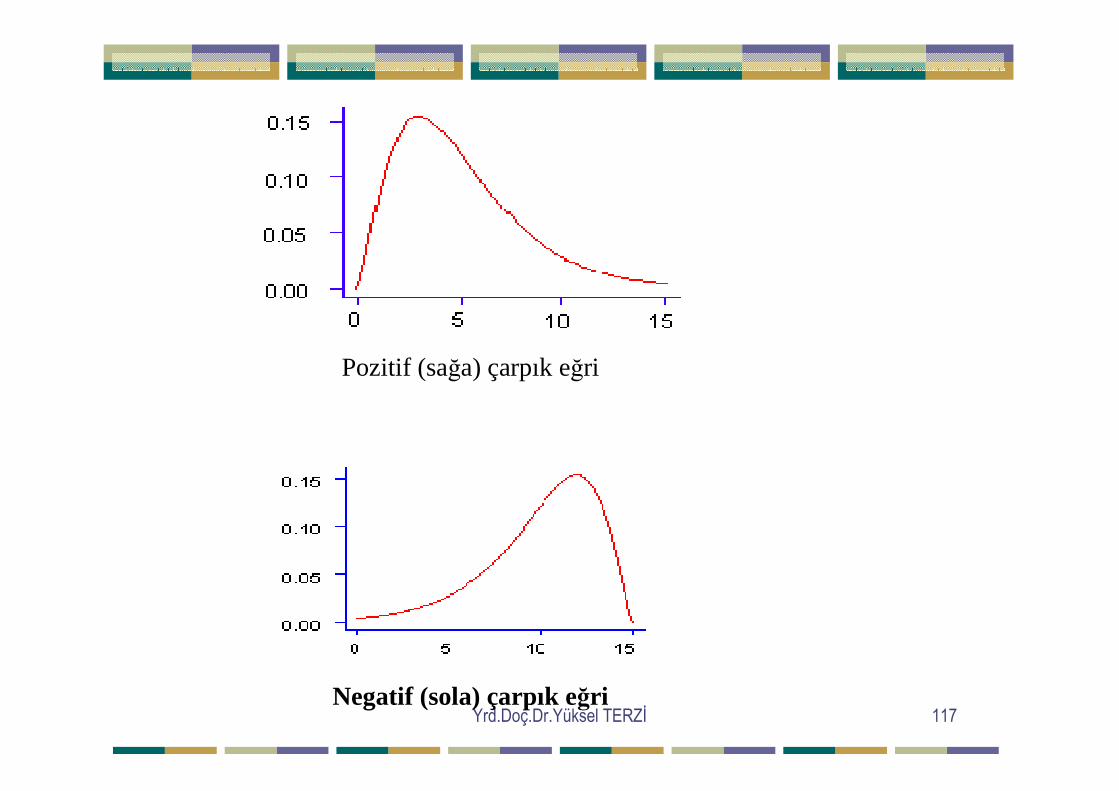
Yrd.Doç.Dr.Yüksel TERZĐ 117
Pozitif (sağa) çarpık eğri
Negatif (sola) çarpık eğri

Yrd.Doç.Dr.Yüksel TERZĐ 118
Çarpıklık=33
32
33
σµ
µ
µα ==
Seri simetrik ise 3α =0 dır. Ancak 3α =0 ise serinin mutlaka simetrik olması gerekmez. 3α >0 ise seri sağa (pozitif) çarpık, 3α <0 ise sola (negatif) çarpıktır. 5.03 >α ise genelde çarpıklık kuvvetli kabul edilir.

Yrd.Doç.Dr.Yüksel TERZĐ 119
3.6. BASIKLIK (Kurtosis) Basıklık bir dağılımın sivrilik derecesidir ve çoğunlukla normal dağılıma göre ele alınır. Normal seri simetrik serinin özel bir şeklidir. Bir serinin normal olabilmesi için hem simetrik olması (3α =0) hem de normal bir yüksekliğe sahip olması gerekir. 4α simgesiyle gösterilen ve momentlere dayanan basıklık ölçüsü aşağıdaki gibi bulunur: Basıklık=
44
22
44
σµ
µµα ==
Normal bir seride 4α =3, sivri bir seride 4α >3 ve basık bir seride 4α <3’tür. 4α formülünde kesrin pay ve paydası pozitif olduğundan basıklık ölçüsü pozitif değere sahiptir.

Yrd.Doç.Dr.Yüksel TERZĐ 120
Not: Bir serinin normal seri olup olmadığını çarpıklık ve basıklık katsayılarına bakarak anlayabiliriz.
Normal seride Çarpıklık( 3α )=0 ve Basıklık( 4α )=3’tür. Buna normallik testi denir.

Yrd.Doç.Dr.Yüksel TERZĐ 121
Frekans, Ortalamalar, Standart Sapma ve VaryansFrekans, Ortalamalar, Standart Sapma ve Varyans ıın Bulunun Bulunu şşuu

Yrd.Doç.Dr.Yüksel TERZĐ 122
Quartiles: KartillerMean:Aritmetik ortalamaMedian: MedyanMode: ModSum: ToplamSkewness: ÇarpıklıkKurtosis: BasıklıkStd.deviation: Standart sapmaVariance: VaryansRange: Değişim aralı ğı(max-min)S.E.mean (Standard errormean): ortalamanın standart hatası

Yrd.Doç.Dr.Yüksel TERZĐ 123
Statistics
notlar10
0
55,00
4,534
52,50
50
14,337
205,556
,318
,687
,587
1,334
50
30
80
550
48,75
52,50
63,75
Valid
Missing
N
Mean
Std. Error of Mean
Median
Mode
Std. Deviation
Variance
Skewness
Std. Error of Skewness
Kurtosis
Std. Error of Kurtosis
Range
Minimum
Maximum
Sum
25
50
75
Percentiles

Yrd.Doç.Dr.Yüksel TERZĐ 124
ANALANAL İİZ Z ÖÖNCESNCESİİ VERVERİİ TARAMATARAMA
1.1. Verilerin doVerilerin do ğğrulurulu ğğu (u (accuracyaccuracy ))2.2. KayKay ııp dep değğerlererler3.3. UUçç dedeğğerlererler4.4. Normallik Normallik vasayvasay ıımmıı5.5. DoDoğğrusallrusall ııkk6.6. EEşşvaryanslvaryansl ııll ııkk (Homojenlik)(Homojenlik)

Yrd.Doç.Dr.Yüksel TERZĐ 125
ANALANAL İİZ Z ÖÖNCESNCESİİ VERVERİİ TARAMATARAMA
1. 1. Verilerin doVerilerin do ğğrulurulu ğğuu ((accuracyaccuracy ) incelenmesi ) incelenmesi gerekir. Analiz sonugerekir. Analiz sonu ççlarlar ıınnıın kalitesi, veri kalitesine n kalitesi, veri kalitesine babağğll ııddıır. Hatalr. Hatal ıı (uygun olmayan) verilerle yap(uygun olmayan) verilerle yap ıılan lan analizlerden elde edilecek sonuanalizlerden elde edilecek sonu ççlar ve bu lar ve bu sonusonu ççlara dayallara dayal ıı oluolu şşturulan yorumlar geturulan yorumlar ge ççerli erli olmayacaktolmayacakt ıır.r.
Nicel veriler iNicel veriler i ççin frekanslara bakin frekanslara bak ıılarak alt ve larak alt ve üüst dest de ğğerler belirlenebilir. Ortalama ve s.sapma erler belirlenebilir. Ortalama ve s.sapma dedeğğerlerine bakerlerine bak ııll ıır. r.
Nitel veriler de ise kodlamalara dikkat edilir, Nitel veriler de ise kodlamalara dikkat edilir, yanlyanl ışış kodlama yapkodlama yap ııll ııp yapp yap ıılmadlmad ığıığı tespit edilir. tespit edilir.

Yrd.Doç.Dr.Yüksel TERZĐ 126
2.2. KayKay ııp (eksik)p (eksik) verilerin deverilerin de ğğerlendirilmesi gerekir. Kayerlendirilmesi gerekir. Kay ııp veri p veri ööllççme me aracarac ıınnıın ban başşararııssıızlzl ığıığından, deneklerin tndan, deneklerin t üüm sorulara cevap m sorulara cevap vermemesinden ya da veri girivermemesinden ya da veri giri şşi si s ıırasras ıında yapnda yap ıılan hatalardan lan hatalardan kaynaklanabilir. kaynaklanabilir.
EEğğer kayer kay ııp veri az ise o silme yapp veri az ise o silme yap ıılabilir. Ancak kaylabilir. Ancak kay ııp veri p veri ççok ok ise o deneklerin veya deise o deneklerin veya de ğğiişşkenin silinmesi ciddi veri kaybkenin silinmesi ciddi veri kayb ıına sebep na sebep olabilir. olabilir. ÖÖrneklem brneklem b üüyyüüklkl üüğğüü ddüüşşer ve eer ve eğğer araer araşştt ıırma irma i ççin gruplar arasin gruplar aras ııkarkarşışılalaşştt ıırmalar isteniyorsa, bazrmalar isteniyorsa, baz ıı gruplar analiz igruplar analiz i ççin uygun olmayan in uygun olmayan öörneklem brneklem b üüyyüüklkl üüğğüüne inerek karne inerek kar şışılalaşştt ıırmalarrmalar ıı tehlikeye sokabilir. tehlikeye sokabilir.
KayKay ııp veriler ip veriler i ççin kestirim yapin kestirim yap ıılabilir. Ancak kestirim ya da labilir. Ancak kestirim ya da yaklayakla şışık dek değğer atama ier atama i şşlemi sadece nicel delemi sadece nicel de ğğiişşkenler ikenler i ççin in yapyap ıılabilmektedir. labilmektedir.
KayKay ııp dep değğer kestirimi ier kestirimi i ççin in bir yaklabir yakla şışım eldeki verilerden ortalamam eldeki verilerden ortalamabulup, kaybulup, kay ııp dep değğerlere bu deerlere bu de ğğeri atamakteri atamakt ıır. Bu durumda genel ortalama r. Bu durumda genel ortalama dedeğğiişşmezken, mezken, varyansvaryans bir miktar dbir miktar d üüşşecektir. ecektir.
KayKay ııp veri kestirimi ip veri kestirimi i ççin in didiğğer bir yaklaer bir yakla şışım regresyonm regresyonyaklayakla şışımmııddıır. Kayr. Kay ııp dep değğerler ierler i ççeren deeren de ğğiişşken baken ba ğığımlml ıı dedeğğiişşken alken al ıınnıır. r. Ortalama yOrtalama y öönteme gnteme g ööre gre g ööre daha objektif bir kestirim yapre daha objektif bir kestirim yap ııll ıır. r.
AraAraşştt ıırmacrmac ıı hem kayhem kay ııp gp g öözlemli durum izlemli durum i ççin hem de kestirim in hem de kestirim yapyap ııldld ııktan sonraki durum iktan sonraki durum i ççin analizleri yapmalin analizleri yapmal ıı ve sonuve sonu ççlarlar ııkarkarşışılalaşştt ıırmalrmal ııddıır (Mertler ve r (Mertler ve VannattaVannatta , 2005). , 2005).

Yrd.Doç.Dr.Yüksel TERZĐ 127
SPSS de kayıp verileri tahmin etmek için 5 yöntem vard ır (Çokluk ve ark,2010):1. Seriler Ortalaması (Series Mean): Tüm verilerin belirli bir de ğişkene göre aritmetik ortalamasıdır. 2. Yakın Noktaların Ortalaması (Mean of Nearby Points):Eksik gözlemin yakınındaki verilerin ortalamasıdır. Çev releyen de ğerlerinsayısı, yakın noktaların uzaklı ğı ( span of nearby points) seçene ğiKullanılarak belirlenir. E ğer 2 alınırsa eksik verinin öncesi ve sonrasıalınarak ortalama bulunur.3. Yakın Noktaların Medyanı (Median of Nearby Points):Eksik verinin yakınındaki verilerin medyanıdır (ortanca sıdır). Çevreleyendeğerlerin sayı ara ştırmacı tarafından belirlenir.4. Doğrusal De ğer Kestirimi (Linear Interpolation):Bu değer, eksik veriden önceki son tam gözlem de ğeri ve eksik veridensonraki ilk tam gözlem de ğerinin eksik verilerin yerine atanmasıdır. E ğerserideki ilk gözlem ve son gözlem eksik ise, kayıp d eğerin yerineherhangi bir de ğer atanmaz.5. Noktanın Do ğrusal E ğimi (Linear Trend of Point):Verilerin e ğilimi (trend) ile uyumlu olarak belirlenir. Örne ğin değerler ilkveriden son veriye do ğru yükselme e ğiliminde olabilir.

Yrd.Doç.Dr.Yüksel TERZĐ 128

Yrd.Doç.Dr.Yüksel TERZĐ 129

Yrd.Doç.Dr.Yüksel TERZĐ 130
3. 3. UUçç dedeğğerlerinerlerin etkilerinin deetkilerinin de ğğerlendirilmesi gerekir. Alerlendirilmesi gerekir. Al ışıışılageldik lageldik dedeğğerlerin derlerin d ışıışındaki dendaki de ğğerlere ya da aerlere ya da a şışırr ıı dedeğğerlere sahip olan denekler erlere sahip olan denekler uuçç dedeğğerler olarak adlanderler olarak adland ıırrııll ıır. Ur. Uçç dedeğğerlerin erlerin üçüç temel nedeni vardtemel nedeni vard ıır:r:
i) Arai) Ara şştt ıırmacrmac ıılarca veri girilarca veri giri şşinde yapinde yap ıılan hatalarlan hatalariiii ) Dene) Deneğğin in öörneklemin alrneklemin al ıındnd ığıığı evrenin bir evrenin bir üüyesi olmamasyesi olmamas ııiiiiii ) Dene) Deneğğin in öörneklemin geri kalan krneklemin geri kalan k ıısmsm ıından farklndan farkl ıı olmasolmas ıı
UUçç dedeğğerler istatistik testlerin sonuerler istatistik testlerin sonu ççlarlar ıınnıı bozabilir. Pek bozabilir. Pek ççok ok istatistiksel iistatistiksel i şşlem ortalamadan olan sapmalarlem ortalamadan olan sapmalar ıın karesine dayann karesine dayan ıır. Er. Eğğer er bir gbir g öözlem ortalamadan zlem ortalamadan ççok uzakta ise sapma deok uzakta ise sapma de ğğeri beri b üüyyüüyecektir. Tek yecektir. Tek bir ubir u çç dedeğğer bir istatistik test sonucunu etkileyebilir. er bir istatistik test sonucunu etkileyebilir.
tek detek de ğğiişşkenli veri setlerinde ukenli veri setlerinde u çç dedeğğerleri belirlemek ierleri belirlemek i ççin frekans in frekans dadağığıll ıımmıına veya na veya histogramlarhistogramlar ıınana bakbak ıılarak glarak g öörrüülebilir.lebilir.
ÖÖrnek :rnek : 10 dene10 deneğği bir kaygi bir kayg ıı ööllççeeğğinden elde ettikleri puanlar ainden elde ettikleri puanlar a şşaağığıdaki daki gibidir.gibidir.Denek:1Denek:1 22 33 44 55 66 77 88 9 10 9 10 Puan:55Puan:55 4848 9595 4848 5151 5555 4545 5353 5555 4545
3 3 nolunolu denek didenek di ğğerlerinden oldukerlerinden olduk çça farkla farkl ıı bir puan sahip oldubir puan sahip oldu ğğundan uundan u ççdedeğğerdir.erdir.

Yrd.Doç.Dr.Yüksel TERZĐ 131
UUçç dedeğğerer

Yrd.Doç.Dr.Yüksel TERZĐ 132
Tek deTek değğiişşkenli ukenli u çç dedeğğerler daerler da ğığıll ıımdaki puanlarmdaki puanlar ıın standart n standart puanlara dpuanlara d öönnüüşşttüürrüülmesiyle de belirlenebilir. Bunun ilmesiyle de belirlenebilir. Bunun i ççin ham puanlar in ham puanlar standart Z puanlarstandart Z puanlar ıına dna d öönnüüşşttüürrüüllüür. Bu durumda verilerin %99r. Bu durumda verilerin %99 ’’u u ortalamadan ortalamadan ±±3 s.sapma uzakl3 s.sapma uzakl ııkta olacaktkta olacakt ıır. Br. B ööylece +3 den bylece +3 den b üüyyüük ya da k ya da --33’’den kden k üçüüçü k Z dek Z değğerine sahip olan gerine sahip olan g öözlemler uzlemler u çç dedeğğer olarak er olarak ddüüşşüünnüüllüür. Kr. K üçüüçü k k öörneklemlerde (n<10) bu kural rneklemlerde (n<10) bu kural ±±2,5 s.sapma olarak 2,5 s.sapma olarak kabul edilir.kabul edilir.
UUçç dedeğğerer

Yrd.Doç.Dr.Yüksel TERZĐ 133
MedyanMedyan
UUçç dedeğğerer
Tek deTek değğiişşkenlikenli uuçç dedeğğerler kutu grafierler kutu grafi ğği (i (BoxBox PlotsPlots ) ) iledeilede bulunabilir. bulunabilir. Kutu grafiKutu grafi ğğinde kutu iinde kutu i ççinde yer almayan denek uinde yer almayan denek u çç dedeğğer olarak er olarak belirtilir. belirtilir.

Yrd.Doç.Dr.Yüksel TERZĐ 134
Uç değere sebep olan yanlı ş tespit edilemezse, uçdeğerlerin yer durumdaki analiz ile uç de ğerlerin çıkarıldı ğıdurumdaki analizler yapılır ve sonuçlar kar şılaştırılır (Mertler ve Vannatta, 2005).
Çok değişkenli analizlerde uç de ğerler Mahalanobisuzaklığı kullanılarak belirlenir.
Yrd.Doç.Dr.Yüksel TERZĐ 135

Yrd.Doç.Dr.Yüksel TERZĐ 136

Yrd.Doç.Dr.Yüksel TERZĐ 137

Yrd.Doç.Dr.Yüksel TERZĐ 138
Extreme Values
10 7,98991
13 5,55067
2 5,27463
7 3,31692
8 3,27989
9 ,59264
3 ,75239
15 ,82909
5 ,87433
1 ,94168
1
2
3
4
5
1
2
3
4
5
Highest
Lowest
Mahalanobis DistanceCase Number Value

Yrd.Doç.Dr.Yüksel TERZĐ 139
10. G10. Göözlem uzlem uçç dedeğğerer

Yrd.Doç.Dr.Yüksel TERZĐ 140
4.4. Normallik varsayNormallik varsayıımmıı::İstatistikte uygulanan birçok analiz ve tahmin
yöntemleri X de ğişkeninin Normal da ğılışgöstermesi halinde geçerlidir. Bu nedenle dağılışın Normal olamadı ğı hallerde yapılan analiz geçerlili ğini kaybeder. Dolayısıyla bu dağılış istatistikte önemli bir yere sahiptir.
Eldeki de ğişken sürekli ve tek modlu ise Normal da ğılış göstermese de bazı dönü şümlerle dağılışı Normal da ğılışa yakla ştırmak mümkün olabilir. Bunun için √√√√X, log(X), 1/X gibi dönü şümler kullanılabilir.
1809 tarihinde Alman matematikçi Gauss tarafından bulunmu ştur.

Yrd.Doç.Dr.Yüksel TERZĐ 141
Simetrikliğin Bozulması
� Normal da ğılım simetrik bir da ğılımdır. Bu simetriklik sa ğa veya sola çarpık olacak şekilde bozulabilir. Sa ğda uzun kuyruk varsa pozitif çarpık, solda uzun kuyruk varsa negatif çarpık olur.

Yrd.Doç.Dr.Yüksel TERZĐ 142
Variyansı FarklıNormal Dağılışlar
Ortalaması FarklıNormal Dağılışlar
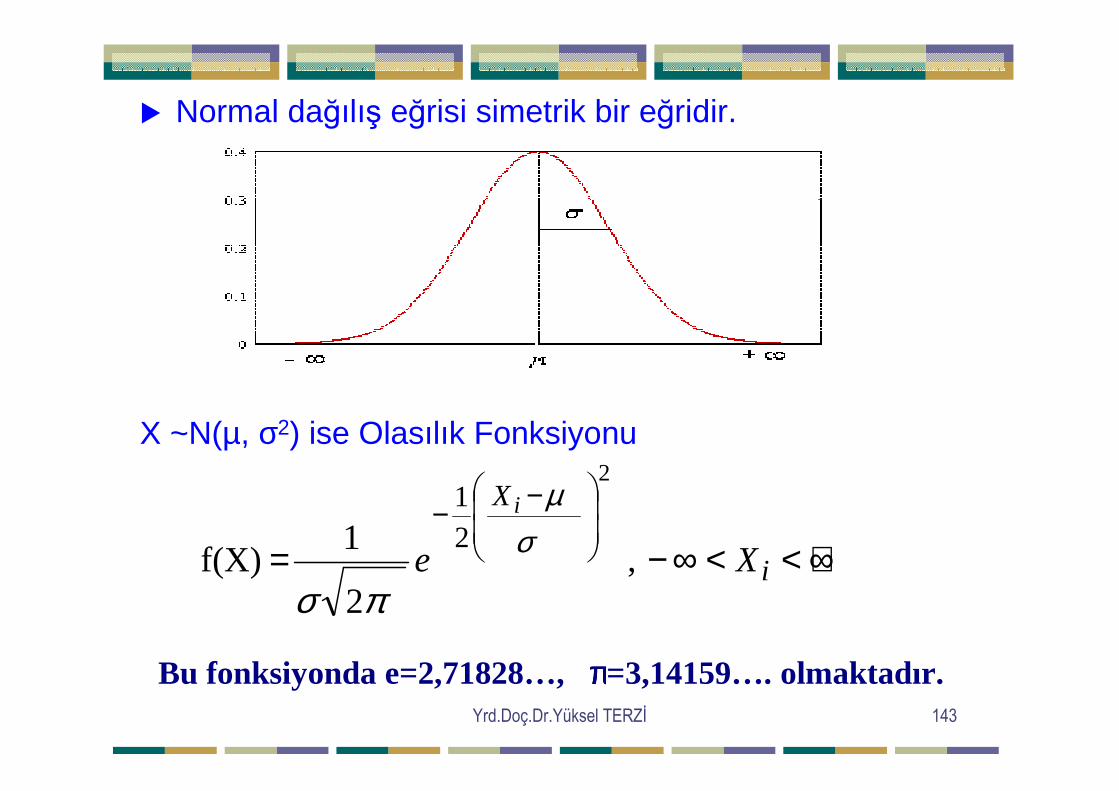
Yrd.Doç.Dr.Yüksel TERZĐ 143
� Normal dağılış eğrisi simetrik bir eğridir.
X ~N(µ, σ2) ise Olasılık Fonksiyonu
+∞<<∞−=
−−
i
X
Xe
i
,2
1f(X)
2
21
σµ
πσ
Bu fonksiyonda e=2,71828…, ππππ=3,14159…. olmaktadır.

Yrd.Doç.Dr.Yüksel TERZĐ 144
NORMALL ĐK TESTĐ Verilere parametrik testlerin uygulanabilmesi için verilerin dağılımının normal olması gerekmektedir. Tek değişkenli normallik , örneklemde bir değişkene ilişkin gözlemlerin normal dağılım gösterdiği anlamına gelir. Normallik varsayımı için önce veriler SPSS paket programına girilir ve a şağıdaki işlemler yapılır. Analyze>Descriptive Statistics>Explore>plots>normality plots with tests – histogram Eğer Sig=P>0.05 ise veriler normal dağılıma sahiptir denilir.
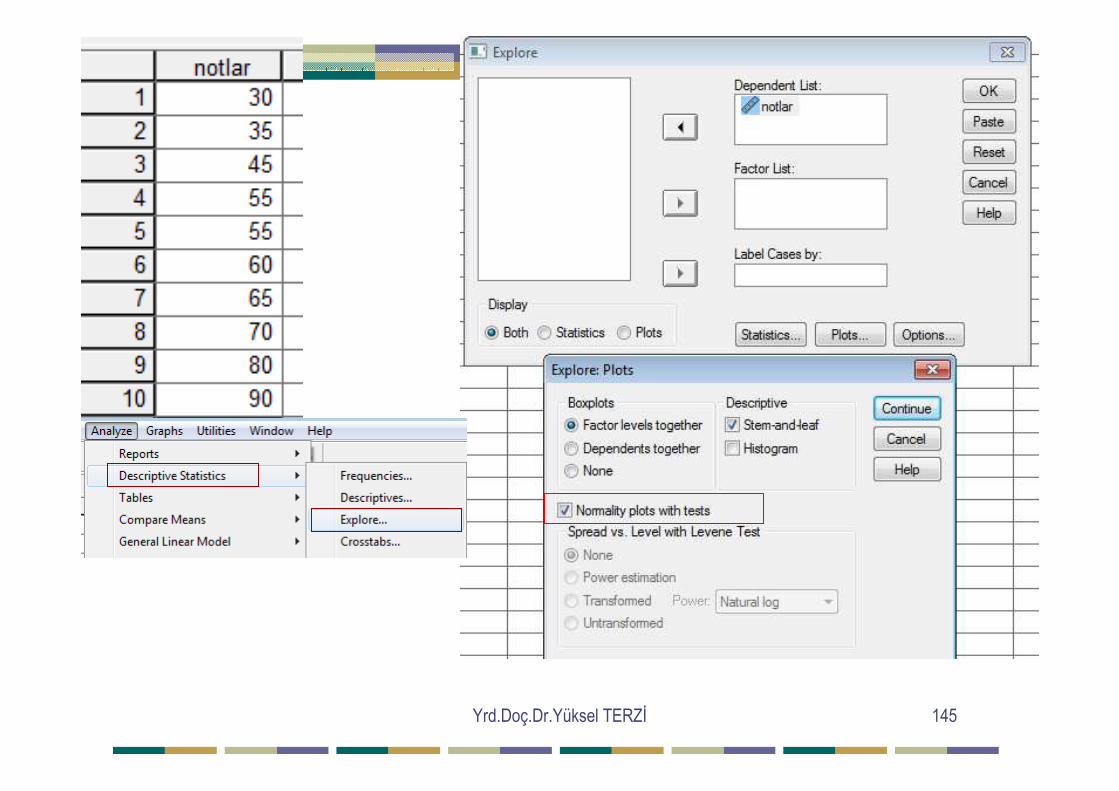
Yrd.Doç.Dr.Yüksel TERZĐ 145

Yrd.Doç.Dr.Yüksel TERZĐ 146
Tests of Normality
,126 10 ,200* ,980 10 ,964notlarStatistic df Sig. Statistic df Sig.
Kolmogorov-Smirnova Shapiro-Wilk
This is a lower bound of the true significance.*.
Lilliefors Significance Correctiona.
HH00: Veriler normal da: Veriler normal da ğığıll ııma ema eşşittir (Mertler ve ittir (Mertler ve VannattaVannatta , 2005)., 2005).
P=0,964>0,05 olup H0 hipotezi kabul edilir. Yani veri ler normal P=0,964>0,05 olup H0 hipotezi kabul edilir. Yani veri ler normal dadağığıll ışışggöösterir.sterir.
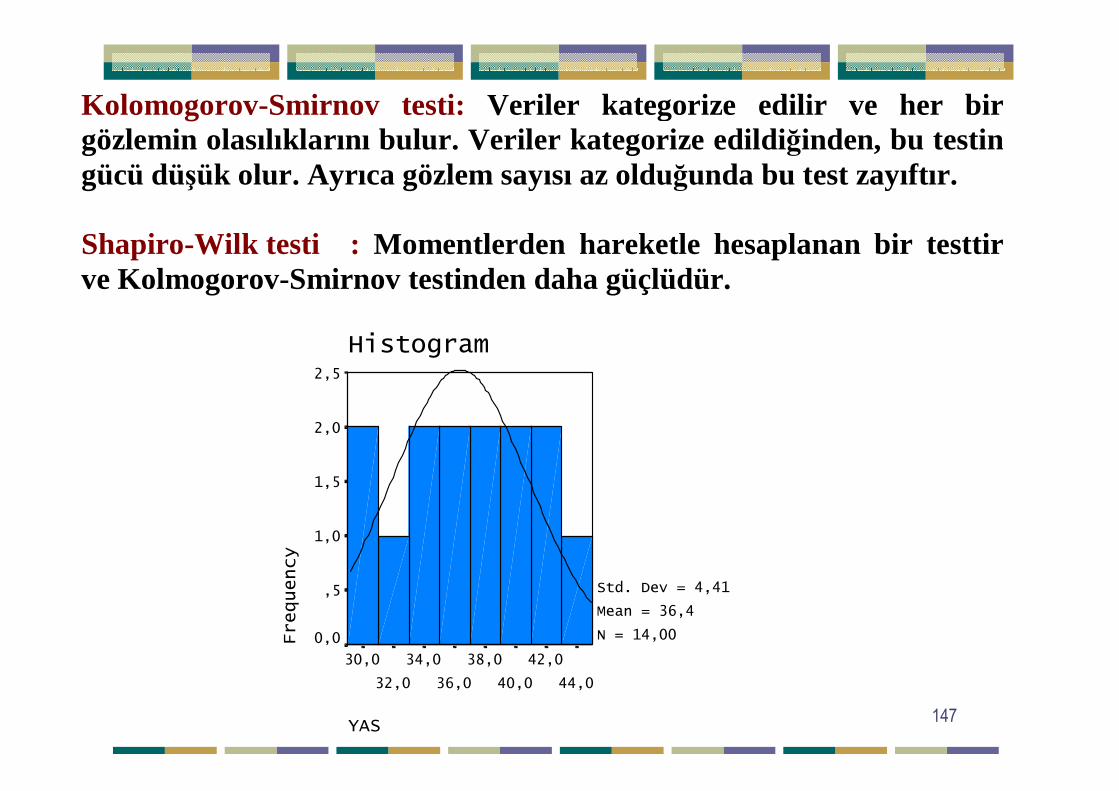
Yrd.Doç.Dr.Yüksel TERZĐ 147
Kolomogorov-Smirnov testi: Veriler kategorize edilir ve her bir gözlemin olasılıklarını bulur. Veriler kategorize edildi ğinden, bu testin gücü düşük olur. Ayrıca gözlem sayısı az olduğunda bu test zayıftır. Shapiro-Wilk testi : Momentlerden hareketle hesaplanan bir testtir ve Kolmogorov-Smirnov testinden daha güçlüdür.
YAS
44,0
42,0
40,0
38,0
36,0
34,0
32,0
30,0
Histogram
Frequency
2,5
2,0
1,5
1,0
,5
0,0
Std. Dev = 4,41
Mean = 36,4
N = 14,00
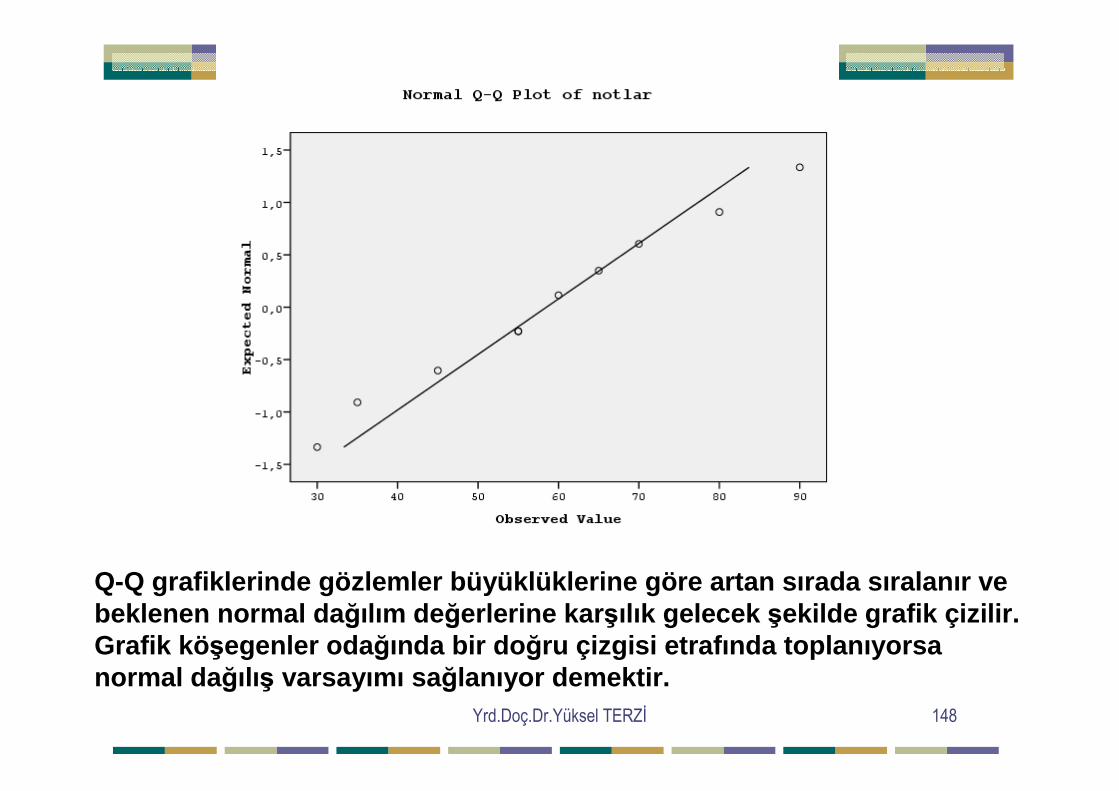
Yrd.Doç.Dr.Yüksel TERZĐ 148
Q-Q grafiklerinde gözlemler büyüklüklerine göre artan s ırada sıralanır ve beklenen normal da ğılım değerlerine kar şılık gelecek şekilde grafik çizilir. Grafik kö şegenler oda ğında bir do ğru çizgisi etrafında toplanıyorsa normal da ğılış varsayımı sa ğlanıyor demektir.
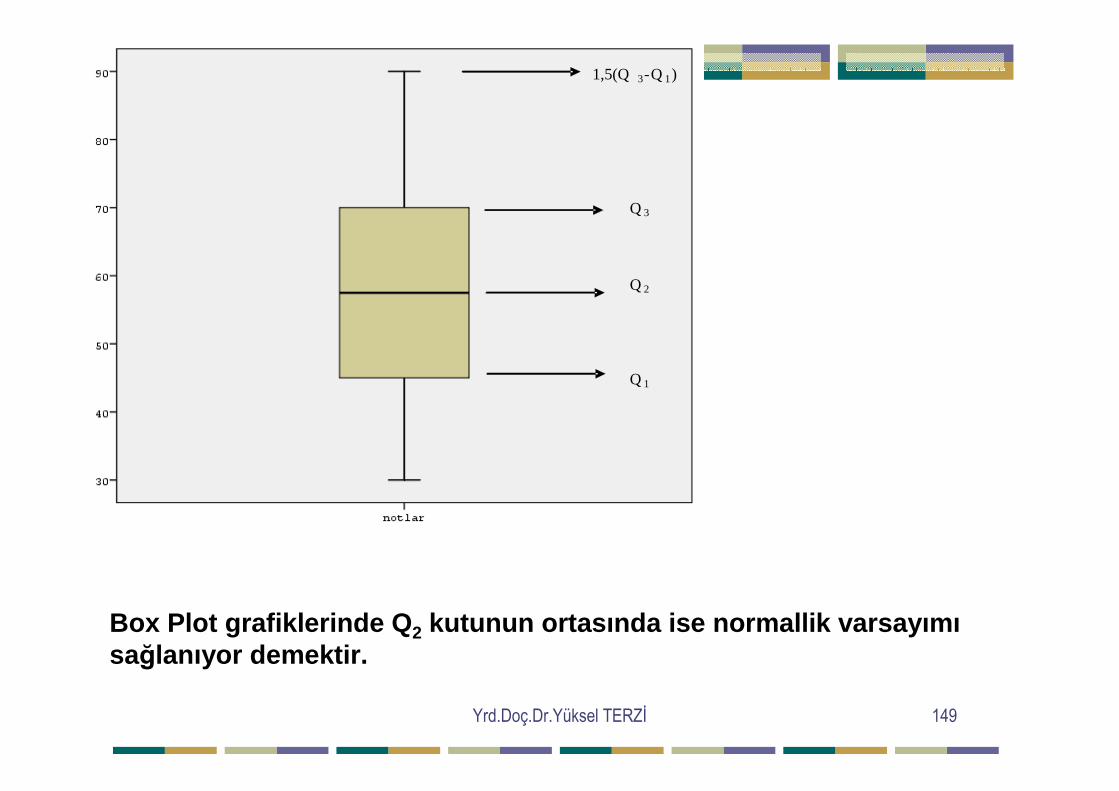
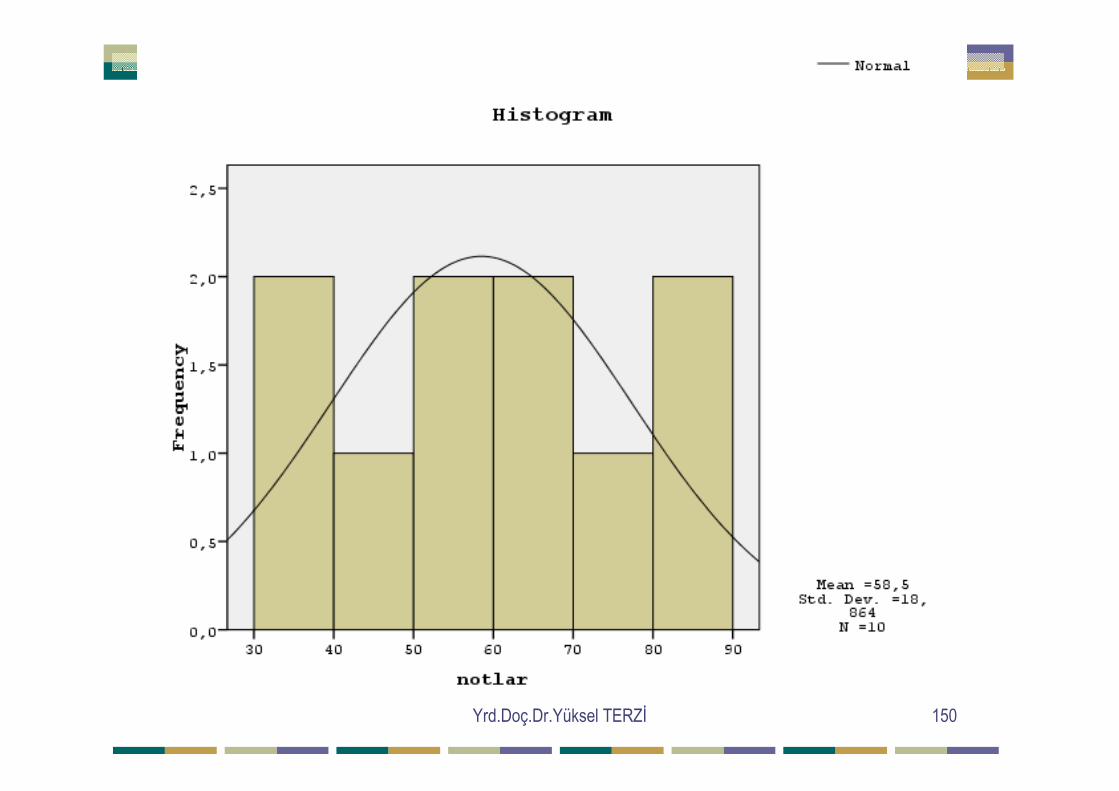
Yrd.Doç.Dr.Yüksel TERZĐ 149
Box Plot grafiklerinde Q 2 kutunun ortasında ise normallik varsayımısağlanıyor demektir.
Q3
Q2
Q1
1,5(Q 3-Q1)
Yrd.Doç.Dr.Yüksel TERZĐ 150

Yrd.Doç.Dr.Yüksel TERZĐ 151
Normallik varsayımı çarpıklık ve basıklık katsayılar ına bakılarak ta incelenebilir. Standart normal da ğılımda çarpıklık ve basıklık katsayıları sıfırdır. Bu de ğerlerin ±1arasında kalması da ğılımın normalden a şırı sapma göstermedi ğini gösterir.
Descriptive Statistics
10 ,089 ,687 -,520 1,334
10
notlar
Valid N (listwise)
Statistic Statistic Std. Error Statistic Std. Error
N Skewness Kurtosis
SkewnessSkewness : : ÇÇarparp ııklkl ııkk KurtosisKurtosis : Bas: Bas ııklkl ııkk

Yrd.Doç.Dr.Yüksel TERZĐ 152
ÇÇok deok de ğğiişşkenli (kenli ( MultivariateMultivariate ) normallik) normallik , , öörneklemde rneklemde yer alan gyer alan g öözlemlerin tzlemlerin t üüm kombinasyonlarm kombinasyonlar ıı aaççııssıından normal ndan normal dadağığıll ıım gm g ööstermesi gerekmektedir. Bunun istermesi gerekmektedir. Bunun i ççin ain aşşaağığıdaki daki şşartlarartlar ıın san sağğlanmaslanmas ıı gerekir (Mertler ve gerekir (Mertler ve VannattaVannatta , 2005), 2005) ::
i)i) Her bir deHer bir de ğğiişşken tek baken tek ba şışına normal dana normal da ğığıll ııma sahip ma sahip olmalolmal ııddıır. r. iiii )) DeDeğğiişşkenlerin dokenlerin do ğğrusal kombinasyonlarrusal kombinasyonlar ıı normal normal dadağığılmallmal ııddıır.r.iiiiii )) DeDeğğiişşken setlerinin tken setlerinin t üüm alt setleri (her tm alt setleri (her t üürlrl üü ikili ikili kombinasyon) kombinasyon) ççok deok de ğğiişşkenli normallikenli normalli ğğe sahip olmale sahip olmal ııddıır (iki r (iki dedeğğiişşkenli normallikkenli normallik --bivariatebivariate normalitynormality ).).
iki deiki de ğğiişşkenli normallik ikenli normallik i ççin, her bir dein, her bir de ğğiişşken ken ççiftinin iftinin sasaççıılma diyagramlarlma diyagramlar ıınnıın elips n elips şşeklinde olmaseklinde olmas ıı gerekir. gerekir.

Yrd.Doç.Dr.Yüksel TERZĐ 153

Yrd.Doç.Dr.Yüksel TERZĐ 154

Yrd.Doç.Dr.Yüksel TERZĐ 155
İİkili grafiklerde ekili grafiklerde e ğğer grafikler er grafikler elips elips şşeklinde ise iki deeklinde ise iki de ğğiişşkenli kenli normallik varsaynormallik varsay ıım sam sağğlanlan ııyor yor demektir.demektir.

Yrd.Doç.Dr.Yüksel TERZĐ 156
NORMALLNORMALL İİK VARSAYIMI SAK VARSAYIMI SA ĞĞLANMADILANMADIĞĞINDA VERINDA VER İİ DDÖÖNNÜÜŞŞTTÜÜRME RME (TRANSFORMASYON)(TRANSFORMASYON)
EEğğer veriler normal daer veriler normal da ğığıll ıım gm g ööstermiyorsa verilere dstermiyorsa verilere d öönnüüşşüüm m uygulanarak veriler normal dauygulanarak veriler normal da ğığıll ııma yaklama yakla şştt ıırr ııll ıır. Veri dr. Veri d öönnüüşşttüürme irme i şşlemi lemi verileri farklverileri farkl ıı birimlerle yeniden ifade etmektir(Mertler ve birimlerle yeniden ifade etmektir(Mertler ve VannattaVannatta , 2005)., 2005).
YaygYayg ıın Olarak Kullann Olarak Kullan ıılan Veri Dlan Veri D öönnüüşşttüürme rme İşİşlemlerilemleri
1/(b-X)bYansıtma & Ters çevirme
Aşırı negatif çarpık
LG10(b-X)bYansıtma &Logaritma
Yüksek düzeyde negatif çarpık
SQRT(b-X)bYansıtma & karekökOrta düzeyde negatif çarpık
1/XTers (Inverse)Aşırı pozitif çarpık
LG10(X)Lg10(X+a)a
LogaritmaLogaritma
Yüksek düzeyde pozitif çarpıkDeğer<0
SQRT(X)KarekökOrta düzeyde pozitif çarpık
SPSS ComputeKomutu
Dönüştürme TürüDağılım Şekli

Yrd.Doç.Dr.Yüksel TERZĐ 157
DDÖÖNNÜÜŞŞTTÜÜRMENRMENİİN YAPILMAMASININ TAVSN YAPILMAMASININ TAVS İİYE EDYE EDİİLDLD İĞİİĞİ DURUMLARDURUMLAR�� EEğğer normallikten ve doer normallikten ve do ğğrusallrusall ııktan ktan ççok sapma yoksa,ok sapma yoksa,�� Veriler kg, mm veya IQ gibi anlamlVeriler kg, mm veya IQ gibi anlaml ıı bir bir ööllçüçü m biriminin oldum biriminin oldu ğğu u
durumlarda,durumlarda,�� ÖÖrneklem 30rneklem 30 ’’dan bdan b üüyyüük olduk oldu ğğunda, unda, �� DaDağığıll ıım ve m ve öörneklem brneklem b üüyyüüklkl üükleri benzer olan kleri benzer olan öörneklemler mevcut rneklemler mevcut
ise dise d öönnüüşşüüm yapm yap ıılmaz.lmaz.
DDÖÖNNÜÜŞŞTTÜÜRMENRMENİİN YAPILMASININ TAVSN YAPILMASININ TAVS İİYE EDYE EDİİLDLD İĞİİĞİ DURUMLARDURUMLAR�� Veriler Veriler ççok ok ççarparp ıık ise,k ise,�� ÖÖllçüçü m birimi yaygm birimi yayg ıın olarak bilinmiyorsa,n olarak bilinmiyorsa,�� ÖÖrneklem 30rneklem 30 ’’dan kdan k üçüüçü k ise,k ise,�� Normallik ve doNormallik ve do ğğrusallrusall ıık varsayk varsay ıımmıı ihlal edildiihlal edildi ğğinde, inde, �� Gruplar arasGruplar aras ıında nda öörneklem brneklem b üüyyüüklkl üüğğüü ve dave dağığıll ıımlarmlar ıı bakbak ıımmıından ndan
bbüüyyüük farklk farkl ııll ıık var isek var ise
ddöönnüüşşüüm yapm yap ıılmallmal ııddıır.r.

Yrd.Doç.Dr.Yüksel TERZĐ 158
5. Doğrusallık
Doğrusallık, iki de ğişken arasında bir do ğru ile özetlenebilen bir ili şki oldu ğu anlamına gelir. Do ğrusallık çok de ğişkenli analizler açısından önemlidir.
Doğrusallık varsayımı Regresyon analizi yöntemi ile incelenebilir. Regresyon analizindeki artık grafi ği (residuals plot) doğrusal olmayan ili şkileri de gözlemeye yarar. Artıklar çok de ğişkenli analizlerce açıklanamayan puan oranlarıdır. Artıklar bir de ğişkene ili şkin elde edilen değerler ile tahmin de ğerleri arasındaki farktır. Standardize edilmi ş artık grafikleri çizilir. Grafikte artıklar bazı tah min değerleri için çizginin altında bazıları için de çizgin in üstünde yer alıyorsa, do ğrusallık varsayımı sa ğlanmıyor demektir (Tabachnick ve Fidell, 1996). E ğer noktalar sıfır çizgisi etrafında kümeleniyorsa, do ğrusallık varsayımısağlanır.

Yrd.Doç.Dr.Yüksel TERZĐ 159
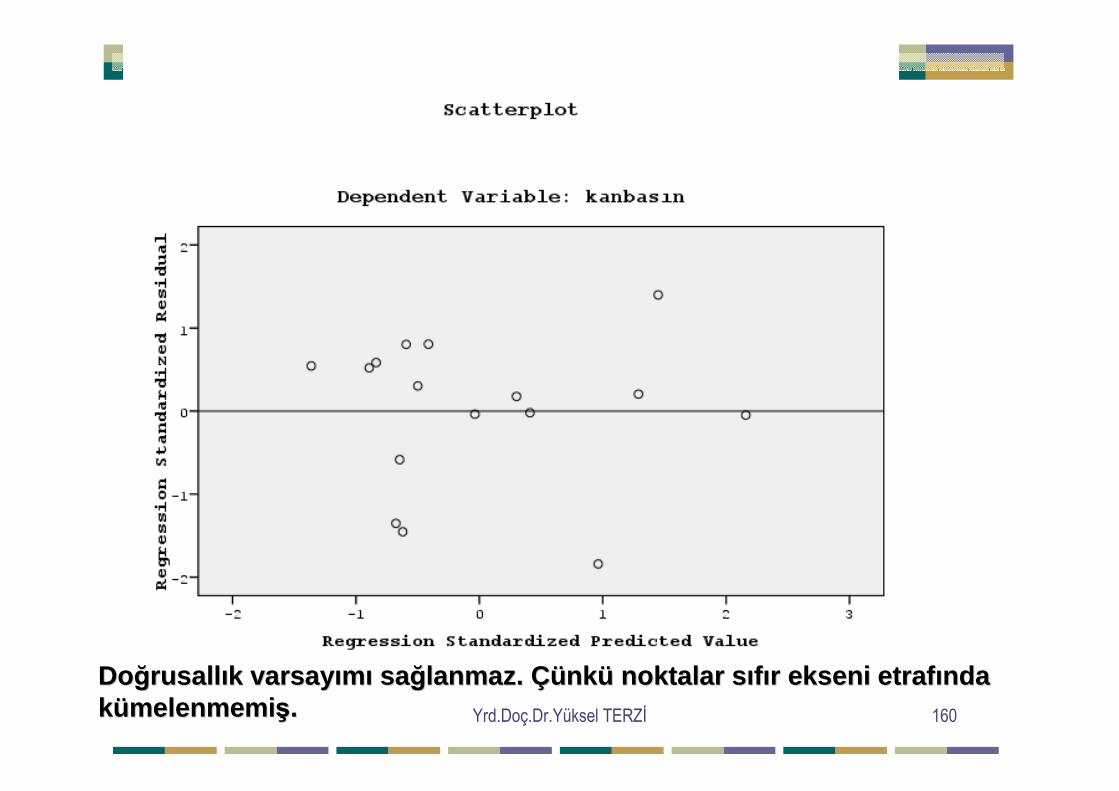
Yrd.Doç.Dr.Yüksel TERZĐ 160
DoDoğğrusallrusall ıık varsayk varsay ıımmıı sasağğlanmaz. lanmaz. ÇüÇünknk üü noktalar snoktalar s ııff ıır ekseni etrafr ekseni etraf ıında nda kküümelenmemimelenmemi şş..

Yrd.Doç.Dr.Yüksel TERZĐ 161
6. Eşvaryanslılık (Homojenlik)
Eşvaryanslılık (homojenlik) bir sürekli de ğişkendeki puanlarda gözlenen de ğişimin, di ğer değişkene ili şkin puanlarda da benzer şekilde gözlenmesidir.
Tek değişkenli durumlarda homojenlik testi Levenetesti ile test edilir. Bu istatistik örneklemin aynı varya nsasahip bir evrenden geldi ğini ifade eder.
H0: Varyanslar e şittir (homojendir)
Levene testi sonucunda p>0,05 ise homojenlik varsayımı sa ğlanmı ş olur.
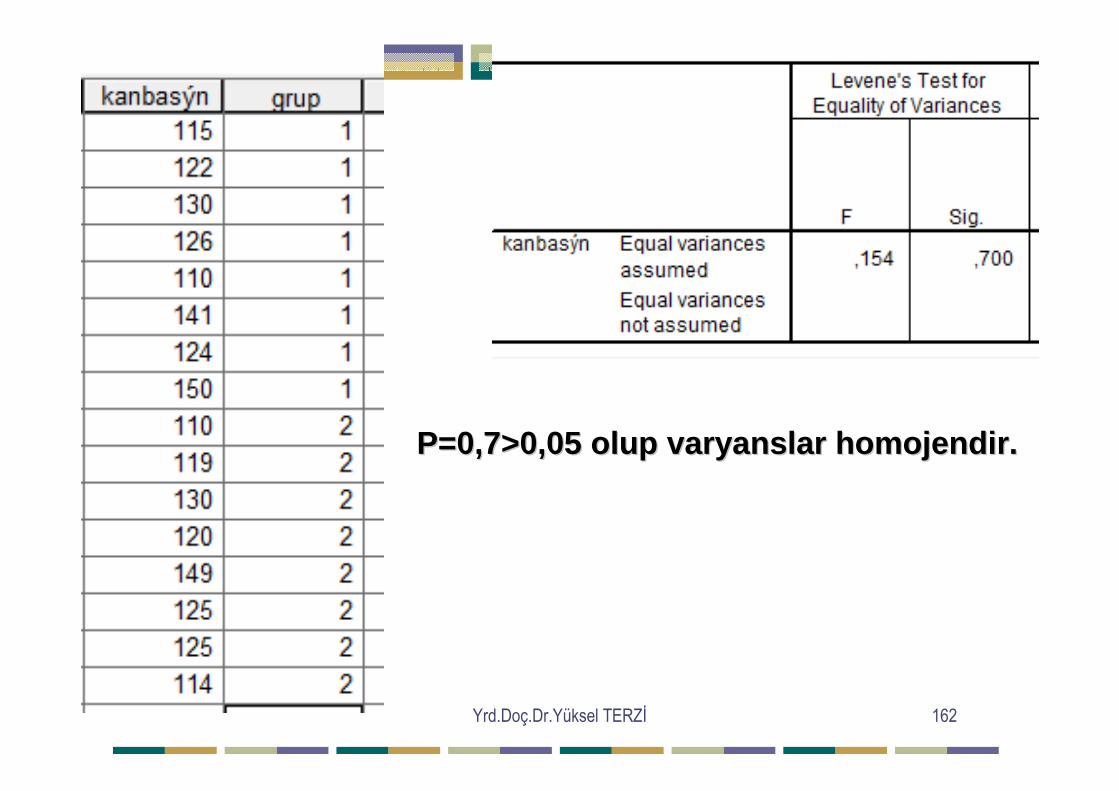
Yrd.Doç.Dr.Yüksel TERZĐ 162
P=0,7>0,05 olup P=0,7>0,05 olup varyanslarvaryanslar homojendir.homojendir.

Yrd.Doç.Dr.Yüksel TERZĐ 163
Bağımsız değişkenin bazı düzeylerinde di ğerinden yüksek ölçe hatası olması e şvaryanslılı ğı (homojenlik) bozabilir.
Çok değişkenli istatistiklerde homojenlik varsayımıVaryans-kovaryans matrislerinin e şitli ği için Box M testi ile incelenir.
Box M Test:H0: Varyans-kovaryans matrisleri e şittir.
Eğer test sonucunda p>0,05 ise H 0 hipotezi kabul edilir. Çok değişkenli istatistiklerde önce normallik
varsayımına bakılır. Daha sonra tek de ğişkenli analizler için homojenlik varsayımına, daha sonrada çok de ğişkenli analizler için e şvaryanslılık varsayımına bakılır (Tabachnick ve Fidell, 1996).

Yrd.Doç.Dr.Yüksel TERZĐ 164
M-ESTIMATORS (M TAHM ĐNCĐLER) Düzeltilmiş aritmetik ortalamada alt ve üst uç değerlerin bir kısmı
değerlendirme dışı tutulur. Bu sakıncayı ortadan kaldırmak ve uç değerlerin etkisini azaltmak için, uç değerlere daha az ağırlık verilerek yapılan hesaplamalara M-tahminciler denir. SPSS’de kullanılan M-tahminciler Huber, Hampel, Tukey ve Andrew’dir. Bu tahminciler aritmetik ortalama ve ortancaya alternatiftirler. B unlardan Huber M -tehmincisi dağılım normale yakın olduğunda tercih edilir. Ancak uç noktaların olduğu durumlarda tercih edilmez.
Analyze>Descriptive statistics>Explore>statistics kutusundan M-estimators işaretlenerek elde edilir.
M-EstimatorsM-EstimatorsM-EstimatorsM-Estimators
50,3593 50,5376 50,7320 50,5429YAS
Huber'sM-Estimatora
Tukey'sBiweightb
Hampel'sM-Estimatorc
Andrews'Waved
The weighting constant is 1,339.a.
The weighting constant is 4,685.b.
The weighting constants are 1,700, 3,400, and8,500
c.
The weighting constant is 1,340*pi.d.

Yrd.Doç.Dr.Yüksel TERZĐ 165
Hipotez Testi Đstatistiksel hipotezler anakütle parametrelerine ilişkin olarak ileri sürülen ve geçerliliği olasılık kanunlarına göre araştırılabilen özel önermelerdir. Đstatistiksel hipotezlerin diğer hipotezlerden farkı, hipotezin bir frekans bölünmesiyle ilgili olmasıdır. Örneğin “belirli bir markayı taşıyan akülerin ortalama ömrünün 2.5 saat olduğu” nu ileri sürdüğümüzde bir hipotez önermiş oluruz. Bunun anlamı normal olan bir dağılımın aritmetik ortalaması 2.5 saate eşittir. Bir hipotez ya doğru ya da yanlıştır. Bunu araştırmak için anakütleden rasgele seçilmiş belli bir örneklemdeki birimler incelenir ve bu örneklemden hareketle hipotezin geçerli olup olmadığı hakkında bir karara varılır. Örneklem istatistiklerinden yararlana rak bir hipotezin geçerli olup olmadığını ortaya koyma işlemine istatistiksel hipotez testi veya hipotez testi denir.

Yrd.Doç.Dr.Yüksel TERZĐ 166
Sıfır Hipotezi ve Karşıt Hipotez Hipotez testinde bir hipotezle onun karşıtı diğer bir hipotezden hangisinin örneklemden elde edilen sonuç ile daha iyi daha iyi bağdaştığı araştırılmaktadır. Kar şılaştırılan iki hipotezden birine sıfır hipotezi(istatistiksel hipotez), diğerine ise karşıt hipotez (araştırma hipotezi) adı verilir. Hipotezler daima örneklem alınmadan oluşturulması gerekir. Sıfır hipotezi H0 ile, karşıt hipotez ise H1 ile gösterilir. H0: Örneklemden elde edilen değer ile anakütlenin bilinen değeri arasında bir fark yoktur. H1: Örneklemden elde edilen değer ile anakütlenin bilinen değeri arasında bir önemli (anlamlı) bir fark vardır.

Yrd.Doç.Dr.Yüksel TERZĐ 167
Genellikle araştırmacılar sıfır hipotezinin reddedilmesini ve karşıt hipotezin kabul edilmesini isterler. Eskiden beri geçerli sayılmış önerme sıfır hipotezi, yeni görüş ise karşıt hipotezi olur. Bu ifadeler araştırırcının konu ile ilgili ön yargısına bağlı olarak değişir. Eğer araştırıcı 1. Uygulamanın 2. Uygulamadan iyi olacağına dair ön yargısı varsa H1: µµµµ1> µµµµ2
şeklinde kurulur. Hiçbir ön yargısı yoksa, H1: µµµµ1≠≠≠≠ µµµµ2
şeklinde kurulur.

Yrd.Doç.Dr.Yüksel TERZĐ 168
H1 Hipotezinin Tek Yönlü Red Bölgesi ( µµµµ1 < µµµµ2 )
H1 Hipotezinin Tek Yönlü Red Bölgesi ( µµµµ1 > µµµµ2 )
H1 Hipotezinin Çift Yönlü Red Bölgesi (µµµµ1 ≠ µµµµ2)

Yrd.Doç.Dr.Yüksel TERZĐ 169
Birinci ve Đkinci Tip Hatalar Bir hipotez testi sonucunda örneklem istatistiklerine göre şu dört durumdan birisi gerçekleşmiş olur.
I. H0 gerçekte doğrudur ve reddedilmemiştir (kabul edilmiştir).
II. H0 gerçekte doğrudur, fakat reddedilmi ştir (kabul edilmemiştir).
III. H0 gerçekte yanlıştır, fakat reddedilmemiştir (kabul edilmiştir).
IV. H0 gerçekte yanlıştır ve reddedilmiştir (kabul edilmemiştir).
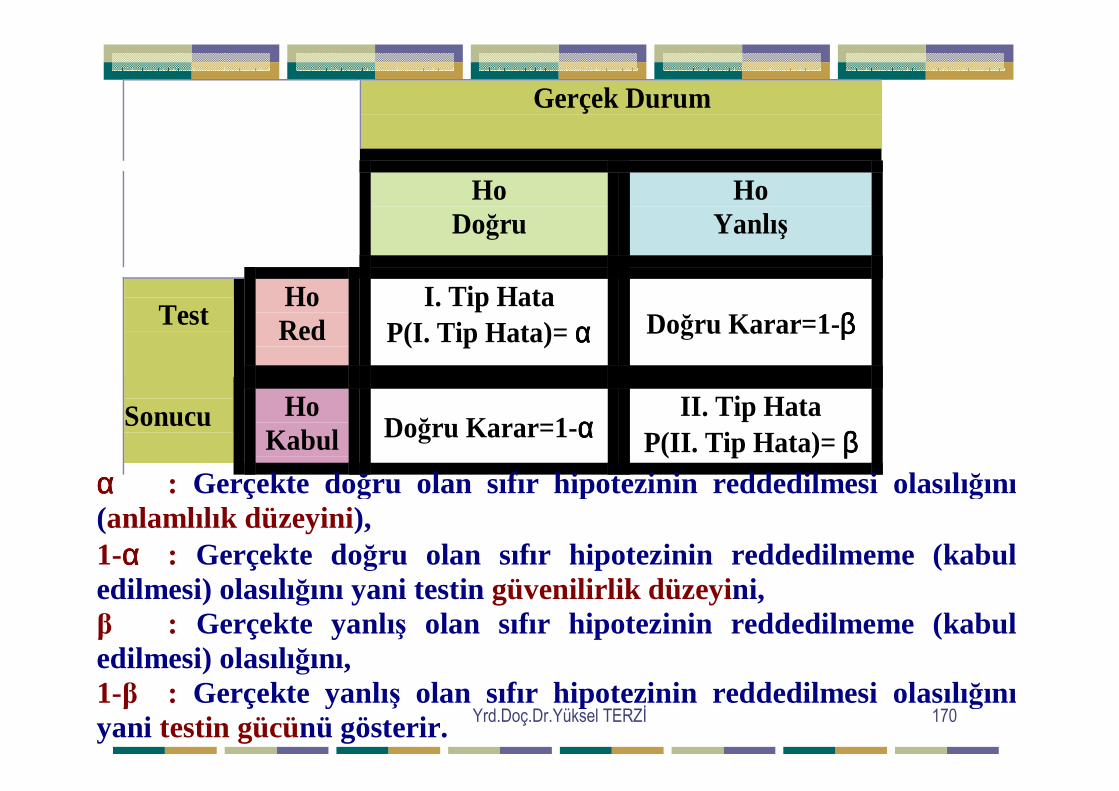
Yrd.Doç.Dr.Yüksel TERZĐ 170
Gerçek Durum
Ho Doğru
Ho Yanlış
Ho Red
I. Tip Hata P(I. Tip Hata)= αααα Doğru Karar=1- ββββ Test
Sonucu Ho
Kabul Doğru Karar=1- αααα II. Tip Hata
P(II. Tip Hata)= ββββ
αααα : Gerçekte doğru olan sıfır hipotezinin reddedilmesi olasılığını (anlamlılık düzeyini), 1-αααα : Gerçekte doğru olan sıfır hipotezinin reddedilmeme (kabul edilmesi) olasılığını yani testin güvenilirlik düzeyi ni, β : Gerçekte yanlış olan sıfır hipotezinin reddedilmeme (kabul edilmesi) olasılığını, 1-β : Gerçekte yanlış olan sıfır hipotezinin reddedilmesi olasılığını yani testin gücünü gösterir.

Yrd.Doç.Dr.Yüksel TERZĐ 171
Ho gerçekten doğru ise araştırıcı bu doğru iddiayı testin sonucundaki hesapladığı değere göre red ederse, hata yapmış olacaktır, istatistikte buna “I. Tip Hata” denir. Bu hatanın yapılması olasılığı da (αααα) ile gösterilir. Bu olasılık “testin önem düzeyi”veya “anlamlılık düzeyi” olarak da adlandırılır. Yani αααα=0.05 önem düzeyinde test yapıldı dendiğinde, bunun anlamı; araştırıcı doğru bir Ho hipotezini red etmek için 0.05 lik bir hata yapma riskini kabulleniyor demektir. Bu genelde hipotez kurulurken pe şinen kabul edilen risktir. Araştırıcı istatistik testi yapabilmesi için belirli bir düzeyde hata yapma riskini de üzerine alması gerekir, aksi halde test yapamaz.

Yrd.Doç.Dr.Yüksel TERZĐ 172
Araştırıcı istatistik test yaparken bir başka şekilde de hata yapabilir. Bu da, Ho ile ileri sürülen iddia gerçekten doğru değilse ve araştırıcı test istatistiğinde elde ettiği değere bakarak bu yanlış iddiayı kabul ederse yine hata yapmış olacaktır. Bu tip hata ya da istatistik de “II. Tip Hata” denir. II Tip Hata yapma olasılığı ββββ ile gösterilir. Hipotez testinde amaç sıfır hipotezini ret veya kabul etmek olduğundan, I. Ve II. Tip hataları aynı anda işlemek mümkün değildir. Đstatistik testler yapılırken bu hata olasılıkları mutlaka vardır ve her ikisini aynı anda küçültmek mümkün değildir. ααααküçülürken ββββ büyür, ββββ küçülürken αααα büyür.

Yrd.Doç.Dr.Yüksel TERZĐ 173
Tek Anakütlenin Parametreleriyle Đlgili Hipotez Testleri Bu tür hipotezlerin testinin amacı, karşıt hipotezde ileri sürülen iddianın kabul edilip edilmeyeceğinin ortaya çıkartılmasıdır. Ancak karşıt hipotezi direk test etmek mümkün olmadığından, sıfır hipotezi test edilir ve elde edilen sonuç karşıt hipotez için genellenir. Tek anakütlenin parametreleriyle ilgili hipotez testlerin varsayımları şunlardır:
i. Örneklemin alındığı anakütle normal dağılıma sahiptir.
ii. Örneklemdeki birimler eşit olasılıkla ve iadeli olarak seçilmiş veya anakütle sonsuz büyüklüktedir.

Yrd.Doç.Dr.Yüksel TERZĐ 174
Anakütle Ortalamasına Đlişkin Testler Bu testlerde ileri sürülebilecek karşıt hipotezlere şu şekilde örnek verebiliriz.
� Bir firmanın tereya ğı paketlerinin ağırlı ğının 250 gr olması gerektiği halde, firma buna uymamaktadır.
� Günlük ortalama üretimi 1000 kg olan bir ilaç fabrikasında uygulanan yeni teknik üretimi artırmı ştır.
� Turistik amaçla yurtdı şına giden vatandaşlarımızın ortama konaklama süresi 20 günden azdır.
Bu örneklere göre sıfır ve karşıt hipotezlerimiz sırasıyla aşağıdaki gibi olacaktır. H0 : µµµµ=µµµµ0=250 gr H0 : µµµµ=µµµµ0=1000 kg H0:µµµµ=µµµµ0=20 gün H1 : µµµµ≠µµµµ0=250 gr H1 : µµµµ>µµµµ0=1000 kg H1 :µµµµ<µµµµ0=20 gün

Yrd.Doç.Dr.Yüksel TERZĐ 175
Anakütle (Popülâsyon) Varyansı (σσσσ2) Biliniyor: Anakütle normal dağılışlı ve anakütle varyansı biliniyorsa ve n≥≥≥≥30 ise, sıfır hipotezinin karşıt hipoteze karşı testi için Z test istatistiği kullanılır.
n
XZ
/σµ−=
Bulunan Z test istatistiği αααα anlamlılık seviyesine göre Z tablo değerleri ile kar şılaştırılır. Kar şıt hipotezin tek (αααα) veya çift (αααα/2) taraflı olmasına göre karar verilir. Tek taraflı : Z<-Z αααα Z>Zαααα Çift taraflı : Z<-Z αααα/2 Z>Zαααα/2 Đse H0 (sıfır) hipotezi reddedilir.

Yrd.Doç.Dr.Yüksel TERZĐ 176
P değeri : Đstatistik paket programlarında genellikle p olasılığı kullanılır. Bu olasılık H 0 doğru olduğunda, test istatistiğinin hesaplanan değerine eşit yada daha uç değerler alması olasılığıdır. Hesaplanan p değeri yanılma olasılığından (αααα) küçük ise H0 reddedilir. p≤ αααα ise H0 hipotezi reddedilir, p> αααα ise H0 hipotezi kabul edilir. p olasılığı Z test istatistiği için aşağıdaki biçimde hesaplanır. Ancak paket programlar bu olasılığı vermektedir.
( )[ ]
<Φ>Φ−
≠Φ−=
01
01
01
:;)(
:;)(1
:;11
µµµµ
µµ
HZ
HZ
HZ
p

Yrd.Doç.Dr.Yüksel TERZĐ 177
Örnek: Bir firmanın tereya ğı paketlerinin ağırlı ğının ortalama 250 gr olması gerektiği halde, firmanın buna uymadığı iddia edilmektedir. Paketleme sırasında rasgele seçilen 100 paketin ortalama ağırlı ğı 245.5 gr olduğu tespit ediliyor. Anakütlenin standart sapması 15 gr olduğu biliniyor. %5 anlamlılık düzeyinde iddianın doğru olup olmadığını araştırınız? Çözüm : H0 : µµµµ=µµµµ0=250 gr Anlamlılık düzeyi=αααα=0.05 H1 : µµµµ≠µµµµ0=250 gr Zαααα/2=1.96
3100/15
2505.245
/−=−=−=
n
XZ
σµ
Z<-Zαααα/2⇒⇒⇒⇒-3<-1.96
H0 reddedilir. Firmanın tereyağı paketlerinin ağırlı ğı ortalama 250 gr olması gerektiği halde, firma buna uymamaktadır.

Yrd.Doç.Dr.Yüksel TERZĐ 178
Anakütle (Popülâsyon) Varyansı (σσσσ2) Bilinmiyor: Anakütle standart sapması bilinmiyorsa, örneklem standart sapması kullanılır. n>30 durumunda dağılım normale uyduğundan test istatistiği olarak yine Z testi kullanılır.
ns
XZ
/
µ−=
Ancak n≤30 olduğunda ve anakütle varyansı bilinmediğinde t dağılımı kullanılır.
ns
Xt
/
µ−=
t istatistiği (n-1) serbestlik dereceli t dağılımına sahiptir. t dağılımı simetrik bir da ğılımdır. Bu dağılımın şekli serbestlik derecesine bağlıdır. n>30 olduğunda dağılım normale yaklaşır.

Yrd.Doç.Dr.Yüksel TERZĐ 179
Serbestlik derecesi (degrees of freedom) : Örnekle ilgili bir istatisti ğin hesaplanmasında veya bir parametrenin tahmin edilmesinde, bağımsız birimlere ait sayının bilgisini ifade eden bir terimdir. Serbestlik derecesi modeldeki parametre sayısına karşılık gelmektedir. Ayrıca serbestlik derecesi verilere getirilen bazı kısıtlamalardan sonra, değişmekte serbest olan değerlerin sayısıdır.

Yrd.Doç.Dr.Yüksel TERZĐ 180
Tek Tek öörnek T Testirnek T Testi
ÖÖğğrencilerin aylrencilerin aylıık masraflark masraflarıınnıın ortalama n ortalama 300 TL oldu300 TL olduğğu iddia ediliyor. Bu iddianu iddia ediliyor. Bu iddianıın n dodoğğruluruluğğunu %5 anlamlunu %5 anlamlııllıık seviyesinde k seviyesinde test ediniz?test ediniz?

Yrd.Doç.Dr.Yüksel TERZĐ 181
One-Sample Statistics
10 284,50 60,985 19,285notlarN Mean Std. Deviation
Std. ErrorMean
One-Sample Test
-,804 9 ,442 -15,500 -59,13 28,13notlart df Sig. (2-tailed)
MeanDifference Lower Upper
95% ConfidenceInterval of the
Difference
Test Value = 300
H0: µ=300
p=0,442>0,05 olup H0 hipotezi kabul edilir.
Tests of Normality
,129 10 ,200* ,973 10 ,913notlarStatistic df Sig. Statistic df Sig.
Kolmogorov-Smirnova Shapiro-Wilk
This is a lower bound of the true significance.*.
Lilliefors Significance Correctiona.
P=0,913>0,05 veriler normal dağılışlıdır.
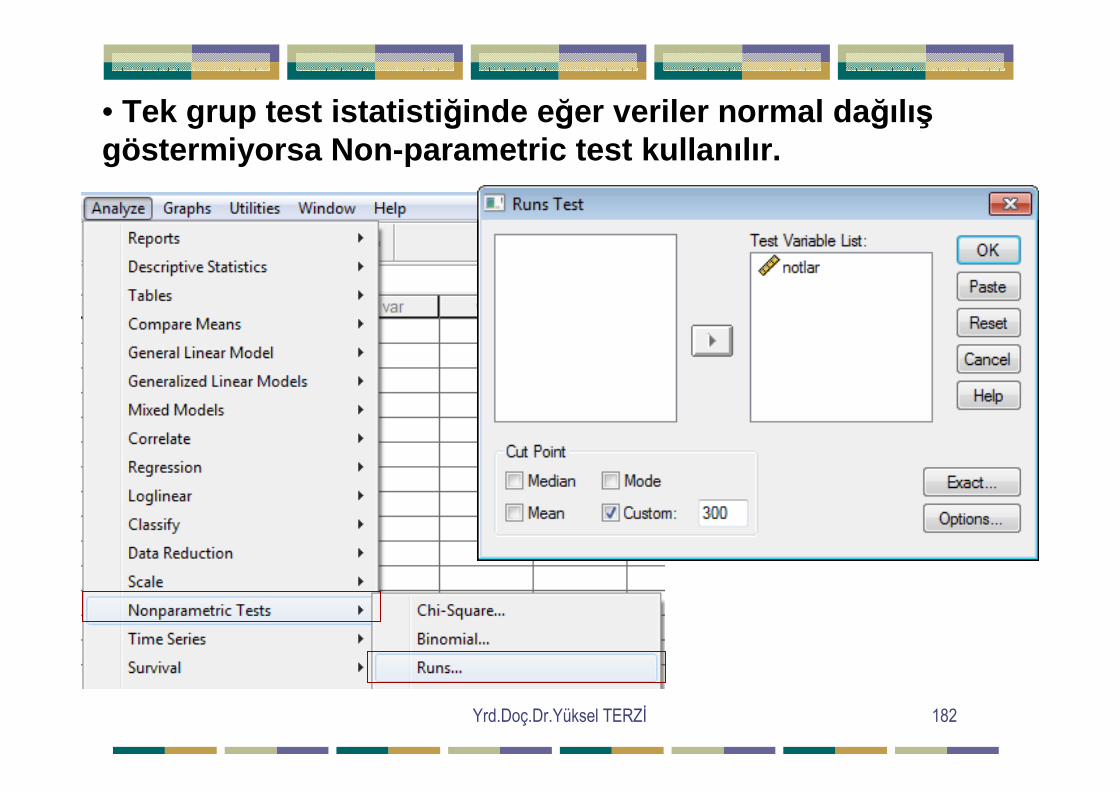
Yrd.Doç.Dr.Yüksel TERZĐ 182
• Tek grup test istatisti ğinde eğer veriler normal da ğılışgöstermiyorsa Non-parametric test kullanılır.

Yrd.Doç.Dr.Yüksel TERZĐ 183
Descriptive Statistics
10 284,50 60,985 200 400notlarN Mean Std. Deviation Minimum Maximum
Runs Test
300,00
10
2
-2,318
,020
Test Valuea
Total Cases
Number of Runs
Z
Asymp. Sig. (2-tailed)
notlar
User-specified.a.
p=0,02<0,05 olup H 0 hipotezi kabul edilemez.

Yrd.Doç.Dr.Yüksel TERZĐ 184
Đki Anakütlenin Parametreleriyle Đlgili Hipotez Testleri Bu testlerin amacı karşıt hipotezde ileri sürülen iddianın kabul edilip edilmeyeceğinin ortaya çıkartılmasıdır. Ancak kar şıt hipotezi test etmek mümkün olmadığından, önce sıfır hipotezi test edilir ve bu sonuç karşıt hipotez için genellenir. Đki anakütlenin parametreleriyle ilgili hipotez testinin varsayımları:
� Örneklemlerin alındığı anakütle normal dağılışlıdır. � Örneklemlerdeki birimler iadeli olarak ve eşit
olasılıkla seçilmiş veya anakütleler sonsuz büyüktür. � Đki anakütledeki örneklem seçimi birbirinden
bağımsızdır.

Yrd.Doç.Dr.Yüksel TERZĐ 185
Đki Anakütle Ortalaması Arasındaki Farka Đlişkin Hipotez Testi Đki ortalama arasındaki farkın testi yapılırken, kul lanılacak test istatistikleri anakütle varyansının bilinmesi ve örnek büyüklüğü dikkate alınarak aşağıdaki şekilde bir sınıflama yapılabilir. Gözlemler Normal dağılış gösteriyorsa ve 1) Popülasyon (anakütle) varyansları ( 2
221 σσ , ) biliniyor veya
popülasyon varyansları bilinmiyor ancak örnekler büyükse (n ≥≥≥≥ 30) 2) Popülâsyon varyansları bilinmiyor fakat eşit kabul
edilebiliyorsa ( 22
21 σ=σ ),
3) Popülâsyon varyansları bilinmiyor fakat eşit kabul edilemiyorsa ( 2
221 σ≠σ ),
4) Gruplar bağımlı ise yani eşli gözlemler varsa, farklı her durum için uygun test istatistikleri kullanılarak ilgili testler yapılabilir.

Yrd.Doç.Dr.Yüksel TERZĐ 186
Bu varsayımları kontrol için yapılacak kontroller: • Normallik ve simetriyi kontrol et – Ortalama ve medyanı incele – Çarpıklık ve basıklık katsayılarını incele – Her grubun histogram ve kutu grafiklerini çiz ve
incele • Varyans homojenliğini kontrol için – Kutu grafiklerini incele – Serpilme grafiklerini incele
• Aşırı gözlemleri belirlemek için – Kutu grafikleri incele – Serpilme grafiklerini incele – Histogramları incele
),(~
),(~2222
2111
σµ
σµ
NX
NX

Yrd.Doç.Dr.Yüksel TERZĐ 187
Popülasyon varyansları ( 22
21 σσ ve ) biliniyor ve
n1>30 , n2>30 ( Z-testi)
H0: µ1- µ2 = 0 H 1: µ1- µ2 ≠ 0 H 1: µ1- µ2 > 0 H 1: µ1- µ2 < 0
H0: µ1- µ2 = 0 H0: µ1- µ2 = 0 H0: µ1- µ2 = 0 H 1: µ1- µ2 ≠ 0 H 1: µ1- µ2 > 0 H 1: µ1- µ2 < 0 Zh>Zt veya Zh<-Zt Zh>Zt Zh<-Zt ise Ho reddedilir.
,)()(
2
22
1
21
2121
nn
XXZ
σσ
µµ
+
−−−=

Yrd.Doç.Dr.Yüksel TERZĐ 188
Popülasyon varyansları bilinmiyor ancak 22
21 σσ = ve n1≤30 , n2≤30 ( t-testi)
H0: µµµµ1- µµµµ2 = 0
H 1: µµµµ1- µµµµ2 ≠≠≠≠ 0 H 1: µµµµ1- µµµµ2 > 0 H 1: µµµµ1- µµµµ2 < 0
Bulunan th hesap değeri t tablo değeri mukayese edilir. tαααα,(n1+n2-2)<th ise H0 reddedilir.
2
)1()1(,
21
)()(
21
222
211
21
2121
−+−+−
=+
−−−=
nn
snsns
nns
XXt
µµ

Yrd.Doç.Dr.Yüksel TERZĐ 189
Popülasyon varyansları bilinmiyor ancak 22
21 σσ ≠ ve n1≤30 , n2≤30 ( t-testi)
22
21 σσ ≠ ise bu tür problemlere Behrens-Fisher Problemi denir.
H0: µµµµ1- µµµµ2 = 0 H 1: µµµµ1- µµµµ2 ≠≠≠≠ 0 H 1: µµµµ1- µµµµ2 > 0 H 1: µµµµ1- µµµµ2 < 0
2
22
1
21
2121 )()(
n
s
n
s
XXt
+
−−−= µµ
Bulunan th hesap değeri t tablo değeri mukayese edilir. tαααα,v<th ise H0 reddedilir. Serbestlik derecesi aşağıdaki formülle bulunur.
2
1
)/(
1
)/(
)//(
2
22
22
1
21
21
22
221
21 −
++
+
+==
n
ns
n
ns
nsnsvsd

Yrd.Doç.Dr.Yüksel TERZĐ 190
Örnek: Bulaşık deterjanını plastik kaplara doldurmak için iki makine kullanılıyor. Birinci makineden n1=10 plastik kap, ikinci makineden n2=12 plastik kap seçiliyor. Bu kaplar incelendiğinde birinci makine ortalama 30.87 birim sıvı, ikinci makine ortalama 30.68 birim sıvı doldurmuştur. Varyansları ise sırasıyla 0.0225 ve 0.0324 bulunmuştur. a) Varyansları homojen ( 2
221 σσ = ) kabul ederek, %95 güven
düzeyinde (%5 anlamlılık düzeyinde) birinci makinenin daha fazla sıvı doldurduğu söylenebilir mi? b) Varyansları heterojen ( 2
221 σσ ≠ ) kabul ederek, %95 güven
düzeyinde birinci makinenin daha fazla sıvı doldurduğu söylenebilir mi? Çözüm :
120324.068.30
100225.087.30
2222
1211
===
===
nsX
nsX
211
210
:
:
µµµµ
>=
H
H

Yrd.Doç.Dr.Yüksel TERZĐ 191
a) 22
21 σσ = ise
167.021210
0324.0)112(0225.0)110(
2
)1()1(
21
222
211 =
−+−+−=
−+−+−
=nn
snsns
657.2
12
2
10
1167.0
0)68.3087.30(
21
)()(
21
2121 =+
−−=+
−−−=
nns
XXt
µµ
tαααα,(n1+n2-2)=t005,(10+12-2)=t0.05,20=1.725 <th=2.657 olduğundan H0
reddedilir. Karar: Đki makineden birinci makinenin daha fazla sıvı doldurduğu %95 güvenilirlikle söylenebilir.

Yrd.Doç.Dr.Yüksel TERZĐ 192
b) 22
21 σσ ≠ ise
02.222
112
)12/0324.0(
110
)10/025.0(
)12/0324.010/025.0(2
1
)/(
1
)/(
)//(22
2
2
22
22
1
21
21
22
221
21 =−
++
+
+=−
++
+
+==
n
ns
n
ns
nsnsvsd
699.2
12
0324.0
10
0225.0
)68.3087.30()()(
2
22
1
21
2121 =+
−=
+
−−−=
n
s
n
s
XXt
µµ
tαααα,v=t0.05, 22.02=1.717 <th =2.699 olduğundan H0 reddedilir. Karar : 2
221 σσ ≠ olduğunda birinci makinenin daha etkin
olduğu söylenebilir.

Yrd.Doç.Dr.Yüksel TERZĐ 193
Varyansların Homojenlik Testi :
i.) Bartlett Homojenlik Testi t,...,2,1i,ˆ 2
i =σ t adet varyansın homojenlik kontrolü için, sıfır hipotezi:
22
2210 : tH σσσ === K ( ) ( )
σν−σν= ∑
=
t
1i
2ei
2e ˆlogˆlog
C
1U
Eğer hesaplanan U değeri 2
)1t(U −αχ> ise Ho reddedilir. Burada
∑∑ νσν
=σν=ν=
2ii2
t
1ii
ˆˆ,
ii df=ν t grubun her grubunun serbestlik derecelerini göstermektedir.
ν−
ν−+= ∑
=
t
1i i
11
)1t(3
11C

Yrd.Doç.Dr.Yüksel TERZĐ 194
ii. Levens’ in Varyans Heterojenlik Testi Denemede (k) tane grup varsa bu grupların varyanslarının heterojenliğini test için kullanılan basit bir testtir. Bartlet t testine benzemektedir, ancak hesabı biraz daha kolaydır.
∑∑
∑
= =
=
−
−⋅
−−=
k
i
ni
jiij
k
iii
ZZ
ZZn
k
kNW
1 1
2.
2
1..
)(
).(
)1(
)(,
Burada k: muamele grup sayısı, ni: i nci gruptaki gözlem sayısıdır, ve Zij hesaplanırken ortalamaya göre, medyana göre veya budanmış ortalamaya göre hesaplanabilir. Şöyle ki; .iij YYZij −= , .iY : i nci grubun aritmetik ortalaması
.
~iij YYZij −= , .
~iY : i nci grubun medyandır.
.iij YYZij ′−= , .iY′ : i nci grubun budanmış ortalamasıdır.
i.Z : i nci grubun ortalamasıdır, ..Z ise genel ortalamadır.

Yrd.Doç.Dr.Yüksel TERZĐ 195
İİki Baki Ba ğığımsms ıız z ÖÖrnek irnek i ççin T testiin T testi

Yrd.Doç.Dr.Yüksel TERZĐ 196
Örnek: Psikolog uykunun hatırlama üzerine etkisini araştırıyor. Günde 12 saat uyuyan 12 öğrenci ile günde 5 saat uyuyan diğer 12 öğrenciye hatırlama testi uyguluyor. Aldığı puanlar aşağıdaki şekilde belirleniyor. 8 saat uyuyanlar: 40 45 52 61 65 75 5 saat uyuyanlar:30 35 48 52 54 60
0::
0::
211211
210210
≠−≠=−=
µµµµµµµµ
HH
HveyaH
1 20,05 , 6 , 6n nα = = =

Yrd.Doç.Dr.Yüksel TERZĐ 197
Tests of Normality
,140 6 ,200* ,973 6 ,910
,273 5 ,200* ,894 5 ,378
grup1
2
puanStatistic df Sig. Statistic df Sig.
Kolmogorov-Smirnova Shapiro-Wilk
This is a lower bound of the true significance.*.
Lilliefors Significance Correctiona.
PP11=0,910>0,05 P=0,910>0,05 P22=0,378>0,05=0,378>0,05Veriler normal daVeriler normal da ğığıll ışışll ııddıır.r.

Yrd.Doç.Dr.Yüksel TERZĐ 198
Group Statistics
6 56,33 13,110 5,352
5 46,20 12,969 5,800
grup1
2
puanN Mean Std. Deviation
Std. ErrorMean
Independent Samples Test
,008 ,929 1,283 9 ,232 10,133 7,901 -7,739 28,006
1,284 8,678 ,232 10,133 7,892 -7,821 28,088
Equal variancesassumed
Equal variancesnot assumed
puanF Sig.
Levene's Test forEquality of Variances
t df Sig. (2-tailed)Mean
DifferenceStd. ErrorDifference Lower Upper
95% ConfidenceInterval of the
Difference
t-test for Equality of Means
Homojenlik Testi :Homojenlik Testi : p=0,929>0,05 p=0,929>0,05 varyanslarvaryanslar homojendir. homojendir.
IndependentIndependent tt--test:test: p=0,232>0,05 H0 kabul. Ortalamalar arasp=0,232>0,05 H0 kabul. Ortalamalar arasıında fark yoktur. nda fark yoktur. Yani 8 saat uyuyan Yani 8 saat uyuyan ööğğrenciler ile 5 saat uyuyan renciler ile 5 saat uyuyan ööğğrencilerin not ortalamalarrencilerin not ortalamalarııarasarasıında %5 nda %5 öönem seviyesinde istatistiksel olarak nem seviyesinde istatistiksel olarak öönemli bir farklnemli bir farklııllıık yoktur.k yoktur.

Yrd.Doç.Dr.Yüksel TERZĐ 199
EEğğer veriler normal daer veriler normal da ğığıll ışış ggööstermiyorsa, stermiyorsa, NonNon ParametircParametirc testlerden testlerden MannMann --WhitneyWhitney U testi kullanU testi kullan ııll ıır.r.

Yrd.Doç.Dr.Yüksel TERZĐ 200
Test Statistics b
10,500
31,500
-1,203
,229
,240a
Mann-Whitney U
Wilcoxon W
Z
Asymp. Sig. (2-tailed)
Exact Sig. [2*(1-tailedSig.)]
puan
Not corrected for ties.a.
Grouping Variable: grupb.
P=0,229>0,05 olduP=0,229>0,05 oldu ğğundan H0 hipotezi undan H0 hipotezi redred edilir, yani iki edilir, yani iki grubun notlargrubun notlar ıı arasaras ıında fark yoktur denilebilir.nda fark yoktur denilebilir.

Yrd.Doç.Dr.Yüksel TERZĐ 201
Đki Bağımlı (Eşli) Anakütle Ortalaması Arasındaki Farkın Hipotez Testi
Aynı fert üzerinde farklı zamanlarda ölçümler alındığında ve bunların karşılaştırılması söz konusu olduğu durumlarda bağımlı (eşli) grup ortaya çıkar. Eşleştirilmi ş fertlerle yapılan testlerde kullanılan test istatistiği daha önceki grup karşılaştırmalarında kullanılanlardan daha farklıdır. Çünkü grup karşılaştırmalarında X 1 ile X2 değişkenlerinin birbirinden ba ğımsız olduğu varsayılmaktaydı. Eşleştirilmi ş gözlemlerde ise X1 ve X2 ölçümleri aynı birey üzerinde veya çok benzer bireyler üzerinden yapıldığı için bağımlı olacaktır. Yani n1 = n2 = n (gözlem çifti sayısı ) olacaktır.

Yrd.Doç.Dr.Yüksel TERZĐ 202
İİki Baki Ba ğığımlml ıı ÖÖrnek irnek i ççin T testiin T testi

Yrd.Doç.Dr.Yüksel TERZĐ 203
P<0.01 olduP<0.01 olduğğundan yokluk hipotezi reddedilir. Yani ilk aundan yokluk hipotezi reddedilir. Yani ilk ağığırlrlıık dek değğerleri ile sonerleri ile sonaağığırlrlıık dek değğerlerinin ortalamalarerlerinin ortalamalarıı birbirinden birbirinden öönemli nemli ööllçüçüde farklde farklııddıır.r.

Yrd.Doç.Dr.Yüksel TERZĐ 204
Örnek:Yürüyü şten önceki ve sonraki PEFR değerleri arasındaki fark:
Hasta Önce Sonra (PEFR) (PEFR)
1 312 300 2 242 201
3 340 232 4 388 312 5 296 220 6 254 256
7 391 328 8 402 330 9 290 231

Yrd.Doç.Dr.Yüksel TERZĐ 205
Paired Samples Statistics
323,89 9 59,826 19,942
267,78 9 50,007 16,669
once
sonra
Pair1
Mean N Std. DeviationStd. Error
Mean
Paired Samples Test
56,111 34,174 11,391 29,843 82,380 4,926 8 ,001once - sonraPair 1Mean Std. Deviation
Std. ErrorMean Lower Upper
95% ConfidenceInterval of the
Difference
Paired Differences
t df Sig. (2-tailed)
P=0,001<0,05 olup P=0,001<0,05 olup HoHo redred edilir. Yani edilir. Yani aağığırlrl ııkta sonradan kta sonradan bir dbir d üüşşme me olmuolmu şştur.tur.

Yrd.Doç.Dr.Yüksel TERZĐ 206
EEğğer verile normal daer verile normal da ğığıll ışış ggööstermeseydi, stermeseydi, NonNon --ParametricParametric testlerden testlerden WilcoxonWilcoxon testi testi kulllankulllan ııll ıırr . .

Yrd.Doç.Dr.Yüksel TERZĐ 207
Test Statistics b
-2,549a
,011
Z
Asymp. Sig. (2-tailed)
sonra - once
Based on positive ranks.a.
Wilcoxon Signed Ranks Testb.
P=0,011<0,05 H0 P=0,011<0,05 H0 redred edilir. edilir.

Yrd.Doç.Dr.Yüksel TERZĐ 208
KĐ-KARE TEST Đ Günümüzde yapılan birçok araştırmada nicel (sayısal) değişkenlerden ziyade nitel (sayısal olmayan) değişkenlerin dikkate alındığı gözlemlenmektedir. Ayrıca bazen nicel değişkenler uygun biçimde gruplandırma ile nitel değişken durumuna getirilebilir. Đşte sayısal olmayan (nitel) değişkenlere ki-kare (χχχχ2) testi uygulanır. Normal dağılan bir anakütleden rasgele çekilen n hacimli örneklem için ki-kare istatistiği hesaplanır.
∑=
=+++=−
++−
+−
=n
iin
n ZZZZXXXXXX
1
2222
2122
22
12 )()()(KK
σσσχ

Yrd.Doç.Dr.Yüksel TERZĐ 209
1. Bir frekans dağılımının herhangi bir teorik dağılıma uyup uymadığının kontrolü için yapılan testler
2. Đki veya daha fazla gruptaki oranların eşitli ğinin testi için yapılan testler
3. Đki özelliğin birbirinden ba ğımsız olup olmadığının testi
4. Örnek frekanslarının homojenlik kontrolü
Yukarıdaki durumlarda χχχχ2 dağılışı kullanılarak hipotez testleri yapılabilir. χχχχ2 dağılışı sürekli ve sağa çarpık bir dağılıştır, üst kuyru ğu daha uzundur. Genelde H1 hipotezi tek yönlü olarak kurulur. E ğer çift yönlü kurulma mecburiyeti doğarsa o zaman alt ve üst bölgedeki kritik red bölgesi ayıran tablo değerleri ayrı ayrı okunur. Süreksiz bir dağılışa yaklaşımda kullanıldığında Yates düzeltmesi zorunludur.

Yrd.Doç.Dr.Yüksel TERZĐ 210
Ki-kare dağılımı pozitif çarpık dağılıştır.

Yrd.Doç.Dr.Yüksel TERZĐ 211
KĐ-KARE ( χχχχ2 )- UYGUNLUK TEST Đ n hacimli bir örneklemin anakütleyi iyi temsil edip
etmediğinin veya hangi dağılıma sahip bir anakütleden geldiği ki-kare uygunluk testi ile belirlenebilir.
H0: Örneklem anakütleyi temsil edebilir (örneklem dağılımı anakütle dağılımına uygundur). H1: Örneklem anakütleyi temsil edemez (örneklem dağılımı anakütle dağılımına uygun değildir).
n
T
G
T
TG r
i i
ir
i i
ii −=−
= ∑∑== 1
2
1
22 )(χ
Gi: Gözlenen frekanslar Ti: Teorik frekanslar Serbestlik derecesi: v=r–1
22tabloχχ ≤ ise H0 reddedilemez.

Yrd.Doç.Dr.Yüksel TERZĐ 212
KĐ-KARE BAĞIMSIZLIK TEST Đ Değişkenlerin 2x2 yada RxC biçiminde ki çapraz tablolarda sınıflandırılması halinde, değişkenlerin arasında bağımlılık yada bir değişim olup olamadığını ortaya koyan testtir. Çift yönlü tablolarda (kontenjans tablosu) yer alan değişkenlerden her ikisi nitel (sayısal olmayan) veya biri nitel değişken diğeri nicel (sayısal) değişken arasındaki ilişkiler ki-kare bağımsızlık testi ile test edilebilir. 2x2 tablolarına Pearson Kikare testi, Yates Kikare (düzeltilmiş) ve Fisher Kikare (kesin) testleri uygulanır. RxC tipindeki tablolara ise Pearson Kikare testi yapılır. Serbestlik derecesi R satır sayısı ve C sütun sayısı olmak üzere (R-1)x(C-1) biçimindedir.
H0: Değişkenler birbirinden ba ğımsızdır (Değişkenler arasında ilişki yoktur). H1: Değişkenler birbirinden ba ğımsız değildir (Değişkenler arasında ilişki vardır).

Yrd.Doç.Dr.Yüksel TERZĐ 213
Sütun Satır
C1 C2 Toplam
S1 A A ’
B B’
N1=A+B
S2 C C’
D D’
N2=C+D
Toplam N3=A+C N4=B+D N
∑∑ −= ijijij TTG /)( 22χ
Burada Gij gözlenen frekansları (A,B,C,D), Tij (A ’,B’, C’, D’) ise beklenen frekansları göstermektedir. Beklenen frekanslar satır ve sütun toplamlarının çarpımının genel toplama bölünmesi ile hesaplanır. A ’=N1*N3/N B’=N1*N4/N C’=N2*N3/N D’=N2*N4/N
Eğer 2
,2
sdαχχ ≤ veya P>0.05 ise H0 kabul edilir. Aksi durumda
Hipotez reddedilir.

Yrd.Doç.Dr.Yüksel TERZĐ 214
Pearson Ki-kare Analizi : 2x2 tablosunda beklenen değerlerin tümü 25’te büyük ise uygulanır. (Tij>25 ise)
∑∑ −= ijijij TTG /)( 22χ Yates Ki-kare Testi : Gözlerdeki beklenen frekanslardan biri 5 ile 25 arasında ise uygulanır. (5< Tij<<25) n<50 olduğunda da Yates süreklilik düzeltmesine başvurulur.
∑∑ −−= ijijij TTG /)5.0( 22χ
Fisher Ki-kare Testi : Gözlerdeki beklenen frekanslardan biri 5 ten küçük ise uygulanır. (Tij<5)
∑= )!!!!!/()!2!2!1!1( dcbaNCRCRP

Yrd.Doç.Dr.Yüksel TERZĐ 215
Örnek: Bir okulda cinsiyet ile düzenli spor yapma arasında ili şki olduğu iddia edilmektedir. Bu amaçla rasgele seçilen 780 öğrenciden elde edilen bilgiler aşağıdaki tabloda verilmi ştir. Cinsiyetin düzenli spor yapma üzerinde etkili olup olmadığına %1 anlamlılık düzeyinde karar veriniz?
Düzenli Spor Yapma Cinsiyet Yapan Yapmayan
Toplam
Bayan 246 122 368 Erkek 125 287 412
Toplam 371 409 780 H0: Cinsiyet ile düzenli spor yapma arasında ilişki yoktur (değişkenler birbirinden ba ğımsızdır). H1: Cinsiyet ile düzenli spor yapma arasında ilişki vardır (değişkenler arasında bir bağıntı vardır).

Yrd.Doç.Dr.Yüksel TERZĐ 216
Düzenli Spor Yapma Cinsiyet
Yapan Yapmayan Toplam
Bayan 246 175
122 193
368
Erkek 125 196
287 216
412
Toplam 371 409 780
87.103
216
)216287(
196
)196125(
193
)193122(
175
)175246()( 222222
=
−+−+−+−=−
=∑∑ij
ijij
T
TGχ
Serbestlik derecesi=(R-1)*(C-1)=(2-1)*(2-1)=1
64.687.103 21,01.0
2 =>= χχ H0 reddedilir. Cinsiyetle düzenli spor
yapma arasında ilişki vardır.

Yrd.Doç.Dr.Yüksel TERZĐ 217

Yrd.Doç.Dr.Yüksel TERZĐ 218
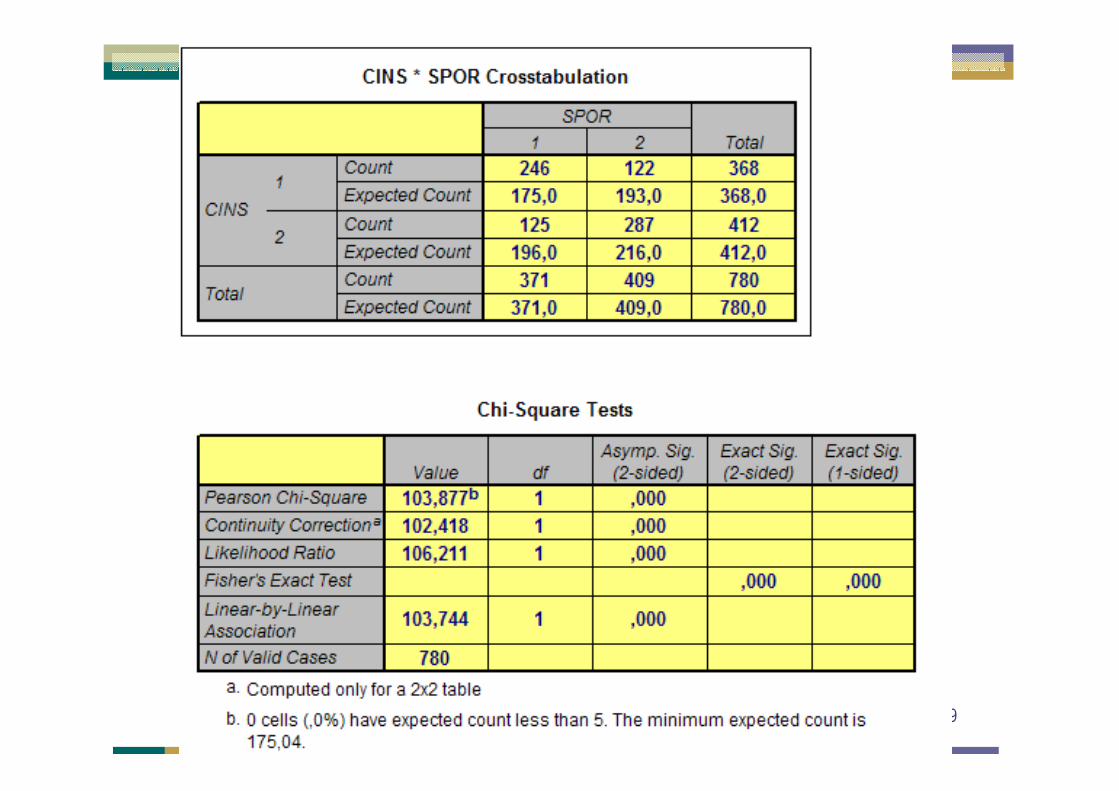
Yrd.Doç.Dr.Yüksel TERZĐ 219

Yrd.Doç.Dr.Yüksel TERZĐ 220
Chi-Square TestsChi-Square TestsChi-Square TestsChi-Square Tests
103,877b 1 ,000
102,418 1 ,000
106,211 1 ,000,000 ,000
103,744 1 ,000
780
Pearson Chi-Square
ContinuityCorrection
a
Likelihood RatioFisher's Exact TestLinear-by-LinearAssociationN of Valid Cases
Value dfAsymp. Sig.(2-sided)
Exact Sig.(2-sided)
Exact Sig.(1-sided)
Computed only for a 2x2 tablea.
0 cells (,0%) have expected count less than 5. The minimum expectedcount is 175,04.
b.
Đşlem sonucunda 4 hesap değeri bulunur. Bunlar Pearson, Continuity Correction (süreklilik düzeltmesi-Yates), Likelihood Ratio (Benzerlik oranı) ve Fisher’in exact testidir. The minimum expected count (en küçük beklenen değer) 5’ten küçük ise Fisher, 5-25 arasında ise Yates, 5’ten büyük ise Pearson Kikare değerine bakılır ve yorum yapılır. Buradaki minimum beklenen değer 175,03 olduğundan Pearson değerine bakılır. O halde ki-kare hesap değerimiz 103,8 olur. Sd:1 P=0 < 0.05 olduğundan H0 reddedilir. Yani spor yapma cinsiyete göre değişmektedir.

Yrd.Doç.Dr.Yüksel TERZĐ 221
Örnek: Dişlerin fırçalanması ile kişilerin eğitim durumlarının arasında bir ilişki olup olmadığı araştırılıyor. Günde di ş Fırçalama sayısı (0,1,2 veya daha fazla), eğitim durumu (ilk öğretim, lise veya daha yüksek) şeklinde sınıflanıyor. Her iki değişkende sıralama ölçeğinde değişkenler olduğu için χχχχ2 bağımsızlık testi ile bu kontrol edilebilir.
0 Fırça
1 Fırça
2+ Fırça
∑∑∑∑
Đlk okul 5 (1.78)
27 (22.06)
5 (13.16)
37
Lise+ 5 (8.22)
97 (101.94)
69 (60.84)
171
∑∑∑∑ 10 124 74 208

Yrd.Doç.Dr.Yüksel TERZĐ 222
Ho: diş fırçalama ile eğitim durumu arasında bağımlılık yoktur.
H1: En az bir kategoride bağımlılık söz konusudur. Khi-Kare=5,833+1,107+5,063+1,262+0,24+1,095= 14,600
Serbestlik derecesi= (2-1)*(3-1)=2
Ho red edilir Çünkü χχχχ2 (2,0.01)=9.21 ve χχχχ2
(k-1,αααα) = χχχχ2 (2, 0.01)=9.21
14.60>9.21 dir. Diş fırçalaması eğitimle yakından ili şkilidir.
∑∑==
−=
c
j ij
ijijr
i T
TG
1
2
1
2 )(χ

Yrd.Doç.Dr.Yüksel TERZĐ 223
FISHER’in Kesin Olasılık Testi Örnek hacmi küçük olduğunda hücrelerin beklenen değerlerinin 5 ten büyük bulunması çok zordur, dolayısıyla χχχχ2 dağılışına yaklaşım uygun olmaz. Bu nedenle 2x2 lik tablolarda hücrelerden herhangi birisinin beklenen değeri 5 den küçük ise Fisher’in kesin olasılık testi uygulanması gerekir. Fisher’ in testi, gözlenen 2x2 lik bir tablonun kesin önem seviyesinin hesaplanmasına dayanır. Bu teste göre sıra ve sütun marjinal (kenar) toplamları ve (n) değişmemek koşulu ile tablo içi hücre değerlerinin değişik kombinasyonları için söz konusu olasılıkları hesaplayarak toplanır. Bu son elde edilen değer gözlenen ve daha ekstrem tabloların elde edilme olasılığıdır. Toplamı (n) olan hücreleri a,b,c,d olan bir tablonun elde edilme olasılığı:
I. Özellik Var Yok ∑∑∑∑
Var a B a+b Yok c D c+d II.
Özellik ∑∑∑∑ a+c b+d n
( ) ( ) ( ) ( )
!!!!!
!!!!ba d)c,b,Prob(a,
dcban
dbcadc +++++++=
ile hesaplanır. Birinci sıra ve birinci sütundaki (a) hücresinin değeri her seferinde 1 küçültülerek yeni tablo ve bunun elde edilme olasılığı hesaplanır. Bu işlem a’ nın değeri sıfır oluncaya kadar devam edilir.

Yrd.Doç.Dr.Yüksel TERZĐ 224
Örnek: Perikardial efüzyon olan ve olmayan hastalarda sigara içme durumu arasında bir ilişki olup olmadığı araştırılıyor. 60 ki şi ile yapılan bir denemede aşağıdaki tablo elde ediliyor.
Sigara içme var Yok ∑∑∑∑
var 2 23 25 yok 5 30 35
Efüzyon olması
∑∑∑∑ 7 53 60 Bu tablonun elde edilme olasılığı:
( ) ( ) ( ) ( )252.0
!30!5!23!2!60
!53!7!35!25 d)c,b,Prob(a, =+++=

Yrd.Doç.Dr.Yüksel TERZĐ 225
Bu tablodan 2 farklı tablo daha elde edilebilir. Sigara içme var Yok ∑∑∑∑
var 1 24 25 yok 6 29 35
Efüzyon olması
∑∑∑∑ 7 53 60 Bu tablonun elde edilme olasılığı:
( ) ( ) ( ) ( )105.0
!29!6!24!1!60
!53!7!35!25 d)c,b,Prob(a, =+++=
Sigara içme var yok ∑∑∑∑
yok 0 25 25 var 7 28 35
Efüzyon olması
∑∑∑∑ 7 53 60 Bu tablonun elde edilme olasılığı:
( ) ( ) ( ) ( )017.0
!28!7!25!0!60
!53!7!35!25 d)c,b,Prob(a, =+++=

Yrd.Doç.Dr.Yüksel TERZĐ 226
Bu olasılıklar toplanırsa, Fisher’in tek yönlü kesin olasılığı elde edilmiş olur. Çift yönlü olasılık istenirse bunun iki katı alınır, yani p=0.688 olur.
Her ne kadar sigara içenlerde efüzyon oranı 5/7=0.71, içmeyenlerde 30/53=0.566 olsa da istatistiksel olarak
P(fisher)=(0.017+0.105+0.252)=0,374>αααα=0.05
olduğundan Sigara ile efüzyonun var olması arasında bir ilişki olmadığı söylenebilir.

Yrd.Doç.Dr.Yüksel TERZĐ 227
Beklenen hBeklenen h üücre cre SaySayııssıı 55’’den kden k üçüüçü kkolanlarolanlar ıın orann oran ıı %25%25olduoldu ğğundan uygun undan uygun bibi ççimde satimde sat ıır yada r yada ssüütun tun birlebirle şştirilmesine tirilmesine gidilir. Bunun igidilir. Bunun i ççin in en uygun olan en uygun olan Trabzon ile Trabzon ile SamsunSamsun ’’un un birlebirle şştirilmesidir. tirilmesidir.

Yrd.Doç.Dr.Yüksel TERZĐ 228

Yrd.Doç.Dr.Yüksel TERZĐ 229
KĐ-KARE HOMOJENL ĐK TESTĐ
Đki yada daha fazla bağımsız örneklemin aynı ana kütleden seçilip seçilmediğini test eder.
H0: Đki örneklem aynı anakütleden seçilmiştir. H1: Đki örneklem farklı anakütleden seçilmiştir.
∑∑ −= ijijij TTG /)( 22χ

Yrd.Doç.Dr.Yüksel TERZĐ 230
Örnek: Bölgesel satış yapan bir üretim işletmesi 2 yeni ürün geliştirerek piyasaya sürmüştür. Tüketicilerin görüşlerini belirlemek amacıyla bir rassal örneklem oluşturulmu ştur. Sonuçlar aşağıdaki gibi bulunmuştur. Seçilen örneklemlerin, aynı anakütleye ait olup olmadığını %5 anlamlılık düzeyinde test edinizi?
Tüketici Görü şleri Ürünler Beğenen Beğenmeyen Đlgisiz
Toplam
I.Ürün 60 30 10 100 II.Ürün 80 50 20 150 Toplam 140 80 30 250
H0: Đki örneklem aynı anakütleden seçilmiştir. H1: Đki örneklem farklı anakütleden seçilmiştir.

Yrd.Doç.Dr.Yüksel TERZĐ 231
Tüketici Görü şleri Ürünler Beğenen Beğenmeyen Đlgisiz
Toplam
I.Ürün 60 (56) 30 (32) 10 (21) 100 II.Ürün 80 (84) 50 (32) 20 (21) 150 Toplam 140 80 30 250
24,1
21
)2120(...
32
)3230(
56
)5660()( 22222
=
−++−+−=−
=∑∑ij
ijij
T
TGχ
Serbestlik derecesi=(R-1)*(C-1)=(2-1)*(3-1)=2 99,524,1 2
2,05.02 =<= χχ H0 kabul edilir. Đki örneklem aynı
anakütleden seçilmiştir.

Yrd.Doç.Dr.Yüksel TERZĐ 232
KONTENJANS KATSAYISI
Nitel iki değişken arasındaki ilişkini derecesini belirleyen bir katsayıdır. rxc tablolarında r>2 ve c>2 ise ki-kare değerinin gösterdiği ili şki düzeyini belirlemede kullanılır. Đki değişken arasında bir ilişki bulunmuyorsa c=0 olur. Đlişki yüksekse c 1’e yakın bir değer verir.
2
2c
n
χχ
=+
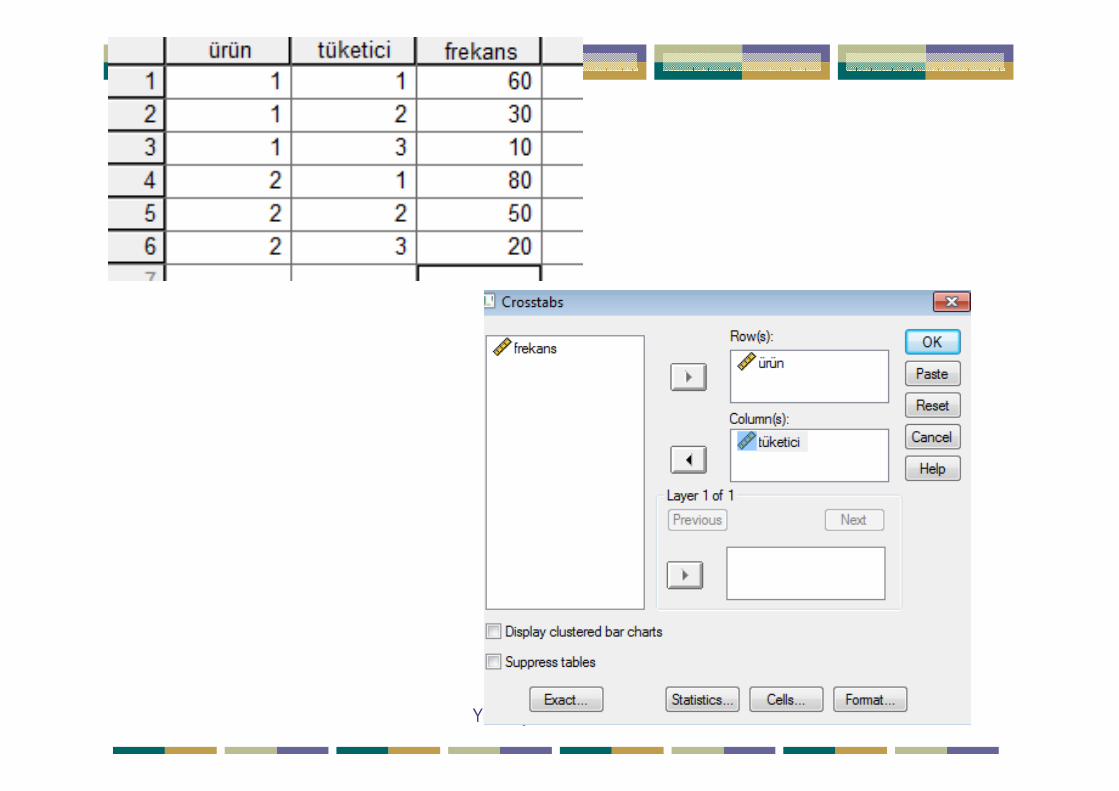
Yrd.Doç.Dr.Yüksel TERZĐ 233

Yrd.Doç.Dr.Yüksel TERZĐ 234

Yrd.Doç.Dr.Yüksel TERZĐ 235
Symmetric Measures
,070 ,538
,070 ,062 1,109 ,269c
,070 ,063 1,105 ,270c
250
Contingency CoefficientNominal by Nominal
Pearson's RInterval by Interval
Spearman CorrelationOrdinal by Ordinal
N of Valid Cases
ValueAsymp.
Std. Errora Approx. Tb Approx. Sig.
Not assuming the null hypothesis.a.
Using the asymptotic standard error assuming the null hypothesis.b.
Based on normal approximation.c.
ürün * tüketici Crosstabulation
Count
60 30 10 100
80 50 20 150
140 80 30 250
1
2
ürün
Total
Beğenen Beğmeyen Đlgisiz
tüketici
Total
Chi-Square Tests
1,240a 2 ,538
250
Pearson Chi-Square
N of Valid Cases
Value dfAsymp. Sig.
(2-sided)
0 cells (,0%) have expected count less than 5. The minimumexpected count is 12,00.
a.

Yrd.Doç.Dr.Yüksel TERZĐ 236
ÇAPRAZ TABLOLARDA KORELASYON
kxk çapraz tablolarında değişkenler arasındaki korelasyon katsayısı aşağıdaki gibi hesaplanır. Korelasyon 0-1 arasında değerler alır.
2
( 1)r
n k
χ=−

Yrd.Doç.Dr.Yüksel TERZĐ 237
Đki Anakütle Oranları Arasındaki Farkın Hipotez Test i Bu testlerde karşıt hipoteze örnek olarak şunlar verilebilir:
� A ve B bölümü öğrencilerinin başarı oranları farklıdır. � Lise mezunlarının üniversiteye girme oranı Anadolu
liselerinkinden düşüktür. � Futbol seyretme oranı erkeklerde daha yüksektir. 0<ππππ1<1 , 0<ππππ2<1 olmak üzere H0 : ππππ1=ππππ2 H0 : ππππ1=ππππ2 H0 : ππππ1=ππππ2 H1 : ππππ1≠ππππ2 H1 : ππππ1<ππππ2 H1 : ππππ1>ππππ2
2
22
1
112121 )1()1(,
)()(21
21n
pp
n
pps
s
ppZ pp
pp
−+
−=
−−−= −
−
ππ
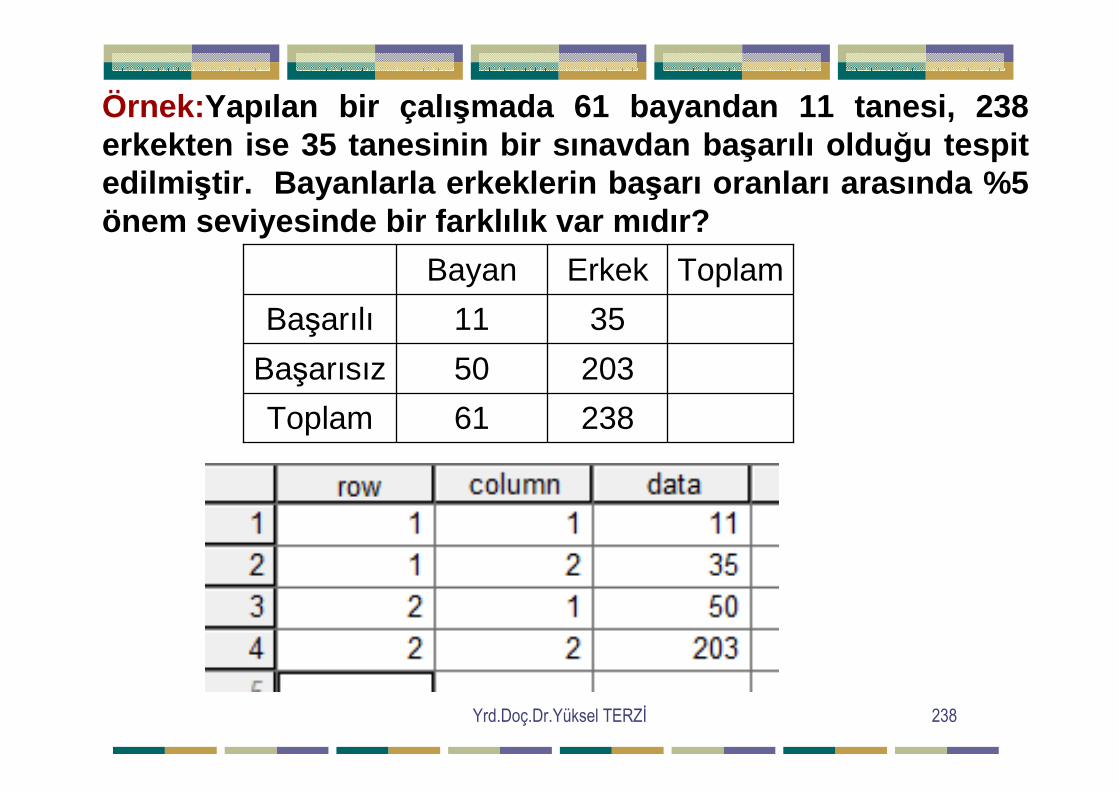
Yrd.Doç.Dr.Yüksel TERZĐ 238
Örnek: Yapılan bir çalı şmada 61 bayandan 11 tanesi, 238 erkekten ise 35 tanesinin bir sınavdan ba şarılı oldu ğu tespit edilmi ştir. Bayanlarla erkeklerin ba şarı oranları arasında %5 önem seviyesinde bir farklılık var mıdır?
23861Toplam
20350Başarısız
3511Başarılı
ToplamErkekBayan

Yrd.Doç.Dr.Yüksel TERZĐ 239

Yrd.Doç.Dr.Yüksel TERZĐ 240

Yrd.Doç.Dr.Yüksel TERZĐ 241
Ki-Kare=0,413 , p=0,521>0,05 H 0 kabul edilir.
P1=11/61=0,18 p2=35/238=0,147 Sp=(11+35)/(61+238)=0,154
64,0
2381
611
846,0.154,0
147,018,0 =
+
−=Z
Z2=0,642=0,42=Ki-kare
H0 : ππππ1=ππππ2
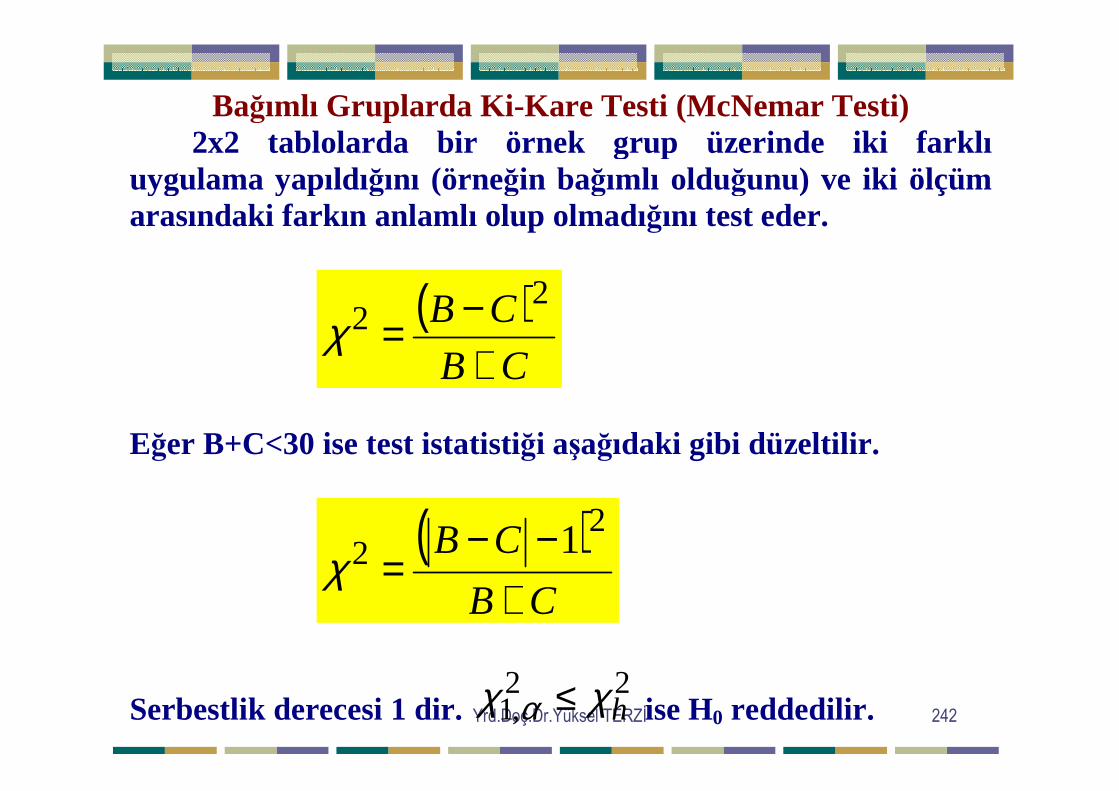
Yrd.Doç.Dr.Yüksel TERZĐ 242
Bağımlı Gruplarda Ki-Kare Testi (McNemar Testi) 2x2 tablolarda bir örnek grup üzerinde iki farklı
uygulama yapıldığını (örneğin bağımlı olduğunu) ve iki ölçüm arasındaki farkın anlamlı olup olmadığını test eder.
( )CB
CB
+−=
22χ
Eğer B+C<30 ise test istatistiği aşağıdaki gibi düzeltilir.
( )CB
CB
+−−
=2
2 1χ
Serbestlik derecesi 1 dir. 22
,1 hχχ α ≤ ise H0 reddedilir.

Yrd.Doç.Dr.Yüksel TERZĐ 243
Örnek: 30 öğrencinin kurs öncesi vermiş oldukları cevap dağılımı ile kurs sonrası vermiş oldukları cevapların değişimini incelemek istiyoruz. Veriler aşağıdaki gibidir. Kurs öncesi sonuçların kurs sonrası değişmesi önemli midir?
Kurs Sonrası Kurs Öncesi Olumlu Olumsuz
Toplam
Olumlu 13 8 21 Olumsuz 6 3 9 Toplam 19 11 30
( ) ( )071.0
68
1681 222 =
+−−
=+
−−=
CB
CBχ
84.3205.0,1 =χ >0.071 olduğundan sıfır hipotezi kabul edilir. Yani
Kurs öncesi ve kurs sonrası sonuçlar arasında uyumluluk vardır. Öğrencilerin kurs öncesi ve kurs sonrası görüşlerinde değişme olmamıştır.

Yrd.Doç.Dr.Yüksel TERZĐ 244

Yrd.Doç.Dr.Yüksel TERZĐ 245
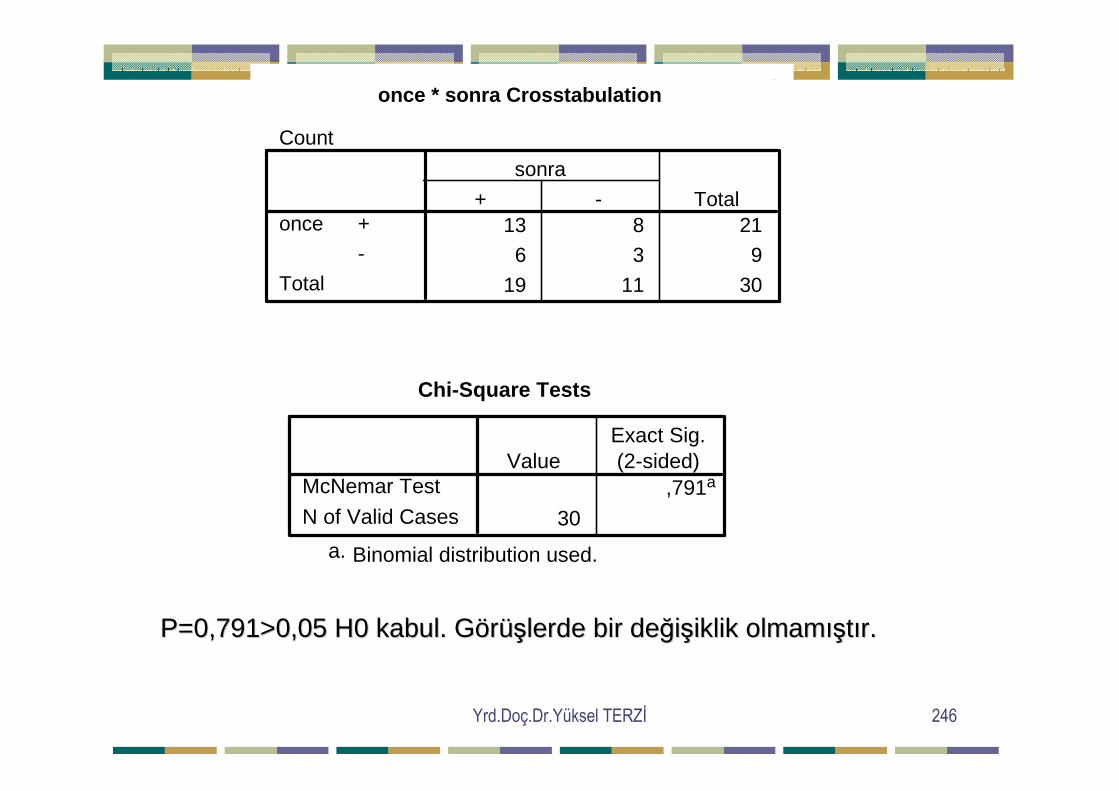
Yrd.Doç.Dr.Yüksel TERZĐ 246
once * sonra Crosstabulation
Count
13 8 21
6 3 9
19 11 30
+
-
once
Total
+ -
sonra
Total
Chi-Square Tests
,791a
30
McNemar Test
N of Valid Cases
ValueExact Sig.(2-sided)
Binomial distribution used.a.
P=0,791>0,05 H0 kabul. GP=0,791>0,05 H0 kabul. Göörrüüşşlerde bir delerde bir değğiişşiklik olmamiklik olmamışışttıır. r.

Yrd.Doç.Dr.Yüksel TERZĐ 247
TESTLERĐN UYUMU- KAPPA DEĞERĐ Eğer Kappa sıfır ise şansın dışında bir uyum söz konusu değildir. Kappa bir ise
iki test arasındaki uyumun tam olduğunu ifade eder. Kappa hangi yöntemin daha iyi olduğunu göstermez yöntemler arasındaki uyumu gösterir.2x2 lik bir tabloda Kappa hesabı yapılması:
Standart Test
+ - Toplam
+ A B A+B
Alternatif
Test
- C D C+D
Toplam A+C B+D N
(A+D) : Đ ki testte de aynı sonucu elde etme sayısı O=(A+D)/N : Her iki test de aynı sonucu elde etme oranı (B+C) : Her iki testte farklı sonuç elde etme sayısı E=[(A+B)/N*(A+C)/N]+[(C+D)/N*(B+D)/N] : Aynı sonucu elde etmenin beklenen şansı 1-E : Beklenen gerçek uyum miktarı [(A+D)/N]-E : Gözlenen gerçek uyum. Buradan Kappa hesaplanabilir
Kappa= {[(A+D)/N]-E}/(1-E)

Yrd.Doç.Dr.Yüksel TERZĐ 248
Kappa=0.5 olması makul uyumu gösterir. Genelde Kappa’nın 0.6-0.8 olması iyi uyumun göstergesidir.
Patalojik analiz sonucu ile BT(Bilgisayarlı Tomografi) sonucu belirlenen + ve - sonuçlardaki uyum araştırılıyor. 50 hastada yapılan tetkiklerde aşağıdaki tablo elde ediliyor.
BT Sonucu
+ - ∑∑∑∑
+ 20 12 32
Pat
oloj
i
- 2 16 18
∑∑∑∑ 22 28 50
(A+D)/N=36/50=0.72 E=[(A+B)/N*(A+C)/N]+[(C+D)/N*(B+D)/N]=32/50*22/50+18/50*28/50=0.483
Gözlenen Gerçek uyum=(Gözlenen Toplam uyum – Şans uyumu)=0.72-0.483=0.237
Beklenen gerçek uyum=1-E=1-0.483=0.517 Kappa=0.237/0.517=0.458
Her iki test arasındaki uyumun fazla olduğu söylenemez.
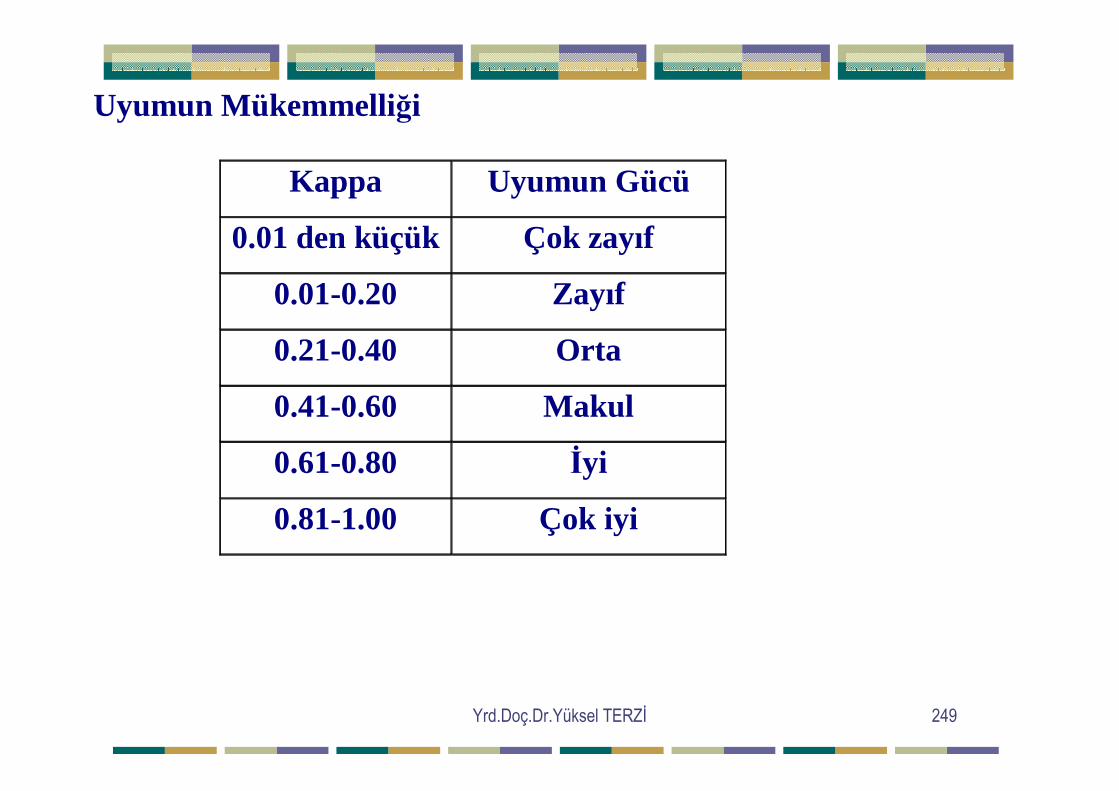
Yrd.Doç.Dr.Yüksel TERZĐ 249
Uyumun Mükemmelliği
Kappa Uyumun Gücü
0.01 den küçük Çok zayıf
0.01-0.20 Zayıf
0.21-0.40 Orta
0.41-0.60 Makul
0.61-0.80 Đyi
0.81-1.00 Çok iyi

Yrd.Doç.Dr.Yüksel TERZĐ 250

Yrd.Doç.Dr.Yüksel TERZĐ 251
patoloji * BT Crosstabulation
Count
20 12 32
2 16 18
22 28 50
+
-
patoloji
Total
+ -
BT
Total
Symmetric Measures
,458 ,114 3,514 ,000
50
KappaMeasure of Agreement
N of Valid Cases
ValueAsymp.
Std. Errora Approx. Tb Approx. Sig.
Not assuming the null hypothesis.a.
Using the asymptotic standard error assuming the null hypothesis.b.
İİki yki yööntem arasntem arasıında iyi uyum oldunda iyi uyum olduğğu su sööylenemez. ylenemez.

Yrd.Doç.Dr.Yüksel TERZĐ 252
Örnek: Tüberküloz basilini yetiştirecek iki farklı ortama 50 şer adet ekim yapılıyor. Bunlardan her iki ortamda yetişme durumuna göre sonuçlar aşağıdaki tabloda veriliyor.
Ortamların eşit derecede etkili olup olmadığını bulunuz (0.05).
A ortamı + - ∑∑∑∑
+ 20 12 32 B
orta
mı
- 2 16 18 ∑∑∑∑ 22 28 50
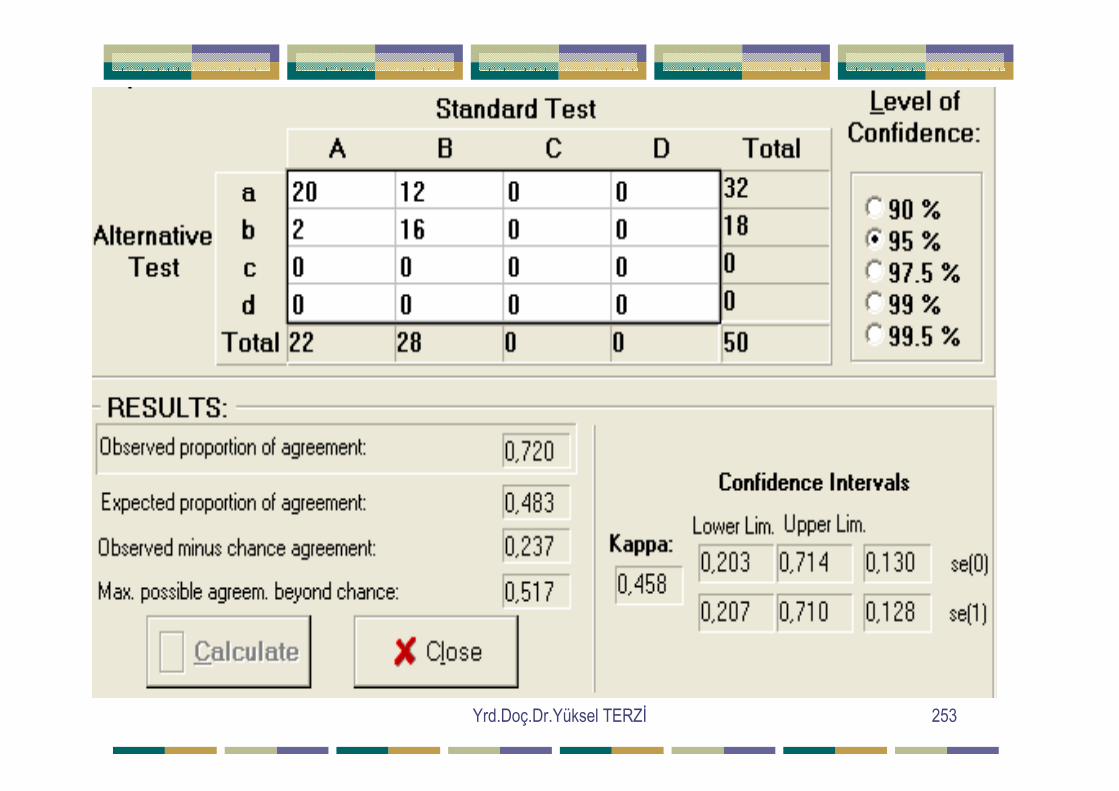
Yrd.Doç.Dr.Yüksel TERZĐ 253

Yrd.Doç.Dr.Yüksel TERZĐ 254
PARAMETR ĐK OLMAYAN ĐSTATĐSTĐK TESTLER
Verilerin Dağılışının Normal Dağılış Olmaması Durumunda Ne Yapılacaktır? Verinin dağılışı ile ilgili varsayımda bulunmayan parametrik olmayan yöntemler kullanılabilir. • Varyansın heterojenlik etkisini yok etmeye çalış • Aşırı gözlem değerlerini incelemeye al
– Đki bağımsız grubun karşılaştırılması için • Mann-Whitney-U (Wilcoxon Sıra sayıları Toplamı) testini
kullan. Ancak bu test bağımsız grup t testi kadar güçlü değildir.
Parametrik olmayan ve Dağılışa Bağlı olmayan Testler Ayırımı • Non-parametrik test: bir istatistik yo ğunluk fonksiyonunun
parametresinin değeri ile ilgili bir hipotez kurmayan testlerdir diye tanımlar.
• Örnek çekilen popülâsyonun tam şekli ile ilgili varsayımda bulunmayan testlerdir diye tanımlar.

Yrd.Doç.Dr.Yüksel TERZĐ 255
Parametrik Olmayan Testlerin Sakıncaları Parametrik olmayan testlerde bilgi kaybı vardır. Örneğin işaret testinde esas gözlemler değil, onların sadece işaretleri kullanılır. Birçok parametrik olmayan testte yine esas gözlemler yerine bu gözlemlerin sıra puanları analiz edilir. Burada da esas gözlemin sahip olduğu bilgi kaybolur. Bu nedenle de parametrik olmayan bir test hiçbir zaman gerçekten uygun olarak kullanılan parametrik e şdeğeri kadar güçlü olamaz.
Parametrik olmayan testlerin diğer bir dezavantajı popülâsyonlar arasındaki gerçek farklar hakkında bir şey söyleyememektir. Örneğin işaret testinde popülasyonlar farklıdır, dendi ğinde bu fark ne kadardır, güven sınırı nedir, bunlarla ilgili bilgi vermek mümkün olamamaktadır. Medyan testi yapıp sonrada ortalamaları ve standart hatalarını verip bunlar farklıdır, demekte doğru bir kullanım şekli değildir.

Yrd.Doç.Dr.Yüksel TERZĐ 256
PARAMETR ĐK OLMAYAN (NONPARAMETR ĐK) ĐSTATĐSTĐK TESTLER
ĐKĐ ÖRNEK DURUMU
K- ÖRNEK DURUMU
ÖLÇME ÖLÇEĞĐ
TEK
ÖRNEK DURUMU
ĐLĐŞKĐLĐ ÖRNEKLER
BAĞIMSIZ ÖRNEKLER
ĐLĐŞKĐLĐ ÖRNEKLER
BAĞIMSIZ ÖRNEKLER
ĐLĐŞKĐNĐN DERECESĐ ĐLE
ĐLGĐLĐ ĐSTATĐSTĐKLER
Binomiyal Test
Mc Nemar Testi
χχχχ2 Đki-Bağımsız Örnek Testi
Cochran Q Testi
χχχχ2 K-Bağımsız Örnek Testi
Olağanlık Katsayısı ADLANDIRMA
χχχχ2 Tek Örnek Testi
Fisher Kesin Olasılık Testi
Kolmogorov-Smirnov Tek Örnek Testi
Đşaret Testi Kolmogorov-Smirnov Đki-Örnek Testi
Friedman Đki-Yönlü
Varyans Analizi
Kruskal-Wallis Tek-Yönlü
Varyans Analizi
Spearman Sıra Sayıları Korelasyonu
Tek Örnek Koşu (Run)
Testi
Wilcoxon Eşli Gözlemler Sıra Sayıları Đşaret
Testi
Mann_whitney- U Testi
Genişletilmi ş Medyan Testi
Kendal Sıra Sayıları Korelasyonu
Medyan Testi Kendal Konkordans Katsayısı
Wald Wolfowitz Koşu (Runs)
Testi
Kendal Kısmi Sıra Sayıları Korelasyonu
SIRALAMA
Moses Aşırı Tepkiler Testi
Eşli Gözlemler için
Randomizasyon Testi
Bağımsız Gözlemler için
Randomizasyon Testi
Walsh Testi
ARALIK
Veriler NORMAL da ğılış göstermiyorsa ve dönüşüm (tarnsformasyon) ile Normalleştirilemiyorsa bu durumda da yine
Parametrik olmayan testlerden uygun olanı seçilerek kullanılır.

Yrd.Doç.Dr.Yüksel TERZĐ 257
BB İİR GRUPTA KOLMOGOROVR GRUPTA KOLMOGOROV --SMIRNOV UYUM SMIRNOV UYUM İİYYİİLL İĞİİĞİ TESTTESTİİ
Bu test rasgele bir Bu test rasgele bir öörneklemin belirli bir darneklemin belirli bir da ğığıll ııma (dma (d üüzgzgüün, n, normal, Poisson ve normal, Poisson ve üüstel) ne kadar iyi uydustel) ne kadar iyi uydu ğğunu belirlemede kullanunu belirlemede kullan ııll ıır. r.

Yrd.Doç.Dr.Yüksel TERZĐ 258
P=0.934>0.05 olduP=0.934>0.05 oldu ğğundanundanveriler normal daveriler normal da ğığıll ışışll ııddıır.r.

Yrd.Doç.Dr.Yüksel TERZĐ 259
Wilcoxon Đşaretli Sıra Testi (Wilcoxon signed ranks test) Veriler normal dağılmadığında bağımlı iki örnek arasındaki
farkın önemlili ğini test eder. Eşleştirilmi ş t testini parametrik olmayan alternatifidir. Ortalama olarak medyan kull anılır. n birimlik örnekten elde edilen iki gözlem seti farkının medyanı sıfır olan toplumdan çekilmiş rasgele bir örnek olup olmadığını test eder. Örnek: Rasgele seçilen 8 bireyin öntest ve sontest puanları aşağıdaki gibidir.
Öntest Sontest Öntest Sontest 53 48 51 53 47 37 67 74 38 51 74 67 48 48 48 57

Yrd.Doç.Dr.Yüksel TERZĐ 260

Yrd.Doç.Dr.Yüksel TERZĐ 261
MANN-WHITNEY U TEST Đ Veriler normal dağılmadığında bağımsız iki örneğin aynı
meydanlı popülasyondan alınmış rasgele örnekler olup olmadığını test eder. Bağımsız iki örneklem t testinin parametrik olmayan alternatifidir.
H0 :n1 ve n2 hacimli veri setleri aynı meydanlı dağılıma sahiptir. Örnek: Kaburga kırı ğı olan hastaların ağrı kesici skorları Đlaç grubu Tens grubu Đlaç grubu Tens grubu
7 15 10 14 6 14 6 12 4 17 9 14 11 16 3 17 16 16 13 16 4 16 5

Yrd.Doç.Dr.Yüksel TERZĐ 262
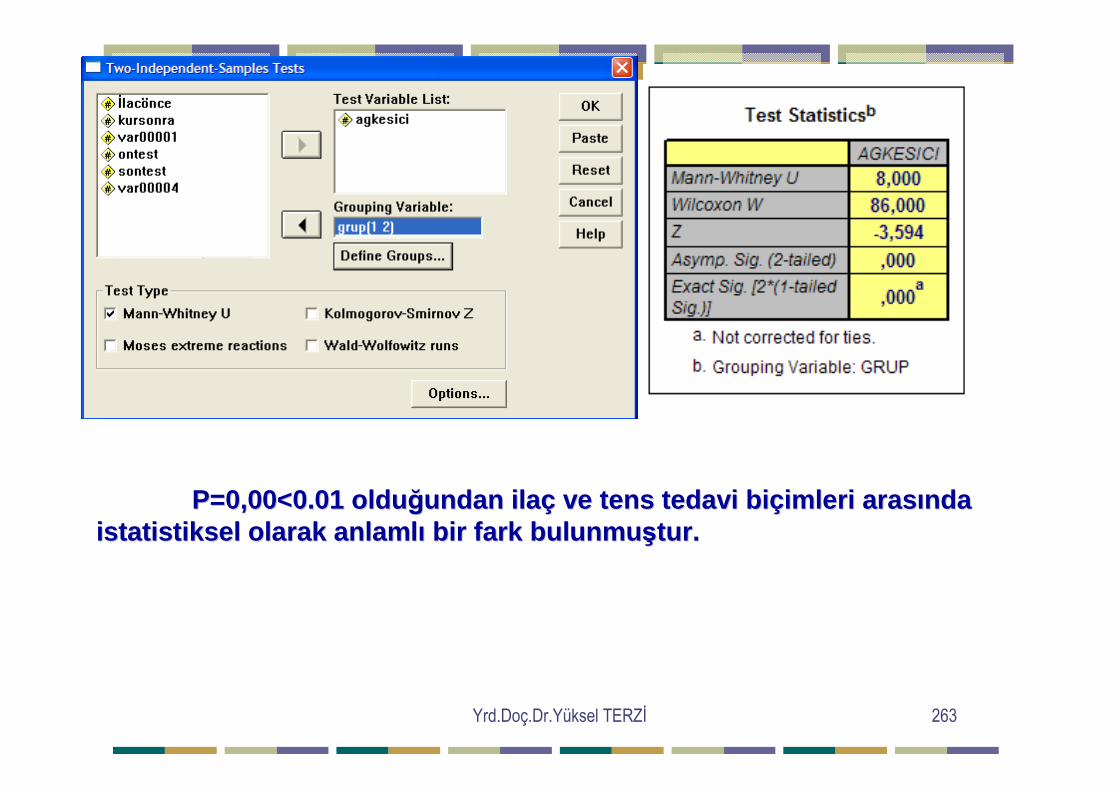
Yrd.Doç.Dr.Yüksel TERZĐ 263
P=0,00<0.01 olduP=0,00<0.01 oldu ğğundan ilaundan ila çç ve ve tenstens tedavi bitedavi bi ççimleri arasimleri aras ıında nda istatistiksel olarak anlamlistatistiksel olarak anlaml ıı bir fark bulunmubir fark bulunmu şştur.tur.

Yrd.Doç.Dr.Yüksel TERZĐ 264
VARYANS ANAL ĐZĐ (ANOVA) Đkiden çok örnek kütle ortalamalarının karşılaştırılmasında kullanılır. Bu yöntemle toplam değişmeye katkıda bulunan çeşitli değişim kaynaklarının değişkenler arası etkileşimi ve deneysel hataları incelenir. Varyans analizi tek yönlü ve çok yönlü olarak uygulanabilir. Tek yönlü varyans analizi elle hesaplanabilir, ancak çok yönlü varyans analizi için bilgisayar kullanılmalıdır. Bu yöntemle ilgili aşağıdaki hususlara dikkat edilmelidir:
1. Gruplardaki bireyler birbirine benzer ve homojen olmalıdır. 2. Gruplar birbirinden ba ğımsız olmalıdır. Bağımlı gruba
uygulanmaz. 3. Veriler ölçümle belirlenmiş sürekli karakter olmalıdır. 4. Gruptaki denek sayıları birbirine eşit veya yakın olmalıdır.
Bu şartlar sağlanamadığı zaman nonparametrik karşılığı "Kruskal Wallis varyans analizi" uygulanmalıdır.

Yrd.Doç.Dr.Yüksel TERZĐ 265
F- Testi Tüm grupları bir arada ele alarak aralarında anlamlı bir fark bulunup bulunmadığı F testi ile yapılır. Normal dağılan bir anakütleden rasgele çekilen birbirinden farklı n hacimli örneklemlerin istatistiklerinden ki-kare istatistiklerini verir v e bunlarda ki-kare dağılımını meydana getirmektedir.
∑=
=+++=−++−+−=n
iin
n ZZZZXXXXXX
1
2222
212
2
2
22
2
212 )()()(
LL
σσσχ
Benzer şekilde normal dağılan iki farklı anakütleden n1 ve n2 hacimli bütün mümkün rasgele örneklemler seçilip aynı işlemler yapılırsa, v1= n1-1serbestlik dereceli 2
1χ dağılımı ve v2= n2-1 serbestlik dereceli 22χ
dağılımı olmak üzere iki dağılım ortaya çıkar. 21χ ve 2
2χ istatistikleri kendi serbestlik derecelerine bölünüp birbirine oranlanırsa F istatistiği elde edilir.
222
121
/
/
v
vF
χ
χ= ,
)(:
:
211
210
farklıortalamaikiazEnH
H
k
k
µµµµµµ
≠≠≠===
K
K

Yrd.Doç.Dr.Yüksel TERZĐ 266
ANOVA TABLOSU Varyasyon Kaynağı
Kareler Toplamı
Serbestlik Derecesi
Kareler Ortalaması F Testi
VK KT SD KO F
Gruplar arası GAKT k-1 GAKO=GAKT/(k-1) GAKO/HKO
Gruplar içi G ĐKT=HKT n-k HKO=HKT/(n-k)
Genel GnKT n-1 GnKO=GnKT/(n-1)
Burada GAKO gruplar arası varyanstır. Gruplar arası varyans grupların ortalamaları arasındaki farklardan doğan değişkenliği ölçer. Gruplar arası varyans ne kadar büyük ise, grup ortalamalarının birbirinden farklı olma olasılığı o kadar fazladır. HKO ise gruplar içi varyanstır . Gruplar içi varyans her gruptaki değerler arasındaki varyansı ifade eder ve rasgele nedenlere bağlı olan değişkenliği ölçer. Gruplar içi varyans ne kadar büyük ise, grup ortalamalarının birbirinden farklı olma olasılığı o kadar azdır. GnKO ise toplam varyansı gösterir. Toplam varyans gruplar arası varyans ile gruplar içi varyansın toplamına eşit değildir.
∑∑−=
n
XXGnKT 2 ,
−
= ∑∑
∑= n
X
n
XGAKT
k
j j
j2
1
2 )()( , GAKTGnKTHKO −=

Yrd.Doç.Dr.Yüksel TERZĐ 267
Çoklu Kar şılaştırma Testleri Varyans analizi ile k tane grup arasında farklılık olup olmadığı araştırılır. E ğer gruplar arasında farklılık varsa, hangi gruplar arasında fark olduğu çoklu karşılaştırma testleri (post-hoc test) ile yapılır. Çeşitli çoklu karşılaştırma testleri bulunmaktadır. Bu testler aynı sonucu vermeyebilir. 1. LSD Testi (En Küçük Önemli Fark Testi) s2 ortak varyans olmak üzere (yani varyanslar homojen) LSD testi aşağıdaki gibi bulunur. s2=HKO ,t (n-k),αααα tablo değeri ve r tekerrür sayısı olmak üzere:
r
stLSD
22=
Eğer n’ler farklı ise
21 n
HKO
n
HKOtLSD +=
LSD değeri her grubun ortalama farkları ile kar şılaştırılır. LSD değeri küçük ise o ortalamalar birbirinden farklıdır. LSD testi deneme başına hatayı korumaz.

Yrd.Doç.Dr.Yüksel TERZĐ 268
2. Bonferroni Testi Varyanslar homojen ise kullanılır. Test başlangıcında αααα t’ye bölünür ve tüm çalışma sonunda toplam hata 0.05 olur. 3. Tukey Testi Varyanslar homojen ise kullanılır. Tukey testi deneme başına hatayı korur. Muamele sayısı arttıkça deneme başına hata artmaz. Ancak Tukey testi küçük farklara önem vermez.
r
sqW vt
2
,,α=
Burada t muamele sayısını, v hata serbestlik derecesini, r tekerrür sayısını ve s2 de HKO göstermektedir. 4. Dunnett Testi Varyanslar homojen ise kullanılır. Uygulama gruplarının her biri kontrol grubu ile kar şılaştırılır. Uygulama gruplarını birbirleriyle karşılaştırmaz. 5. Scheffe Testi Güven sınırlarına dayalı güçlü bir testtir. 6. Tamhane’s Testi Varyanslar heterojen ise bu test kullanılabilir.

Yrd.Doç.Dr.Yüksel TERZĐ 269
7. Duncan Testi Sıraya dizilmiş ortalamalar arasındaki farklılıkları ortalamanın sıralamadaki konumunu dikkate alarak değerlendiren bir testtir. Duncan testi birbiriyle karşılaştırılan ortalamaların konumlarının birbirine göre önemli olduğu karşılaştırmalarda çok sık kullanılır.

Yrd.Doç.Dr.Yüksel TERZĐ 270
ÖRNEK: Bir i şletmede bulunan üç eşdeğer makine üretimi aşağıdaki gibidir. Bu üç makine arasında fark var mıdır?
A B C
4 6 3
5 7 4
5 6 5
4 8 5
6 6 4
6 7 4
4 9 3
5 8 3
4 6 4
4 5 3 Toplam
ΣΣΣΣx 47 68 38 153 (ΣΣΣΣx)
ΣΣΣΣx2 227 476 150 853 (ΣΣΣΣx2)
nj 10 10 10 30 (ΣΣΣΣn)

Yrd.Doç.Dr.Yüksel TERZĐ 271
I. Kareler toplamlarının bulunması:
GnKT:Genel Kareler Toplamı
∑∑−=
n
XXGnKT 2 ,
−
= ∑∑
∑= n
X
n
XGAKT
k
j j
j2
1
2 )()( , GAKTGnKTGĐĐK −=
GAKT: Gruplar arası kareler toplamı
GiKT: Grup içi kareler toplamı

Yrd.Doç.Dr.Yüksel TERZĐ 272
Serbestlik Derecelerinin Bulunması:
Genel serbestlik derecesi: GnSD= n-1 =30-1=29
Gruplar arası serbestlik derecesi: GASD=Grup sayısı-1=3-1=2
Grup içi serbestlik derecesi: GiSD= n-Grup sayısı=30-3=27
Kareler Ortalamasının Bulunması:
Gruplar arası kareler ortalaması:
Grup içi kareler ortalaması:
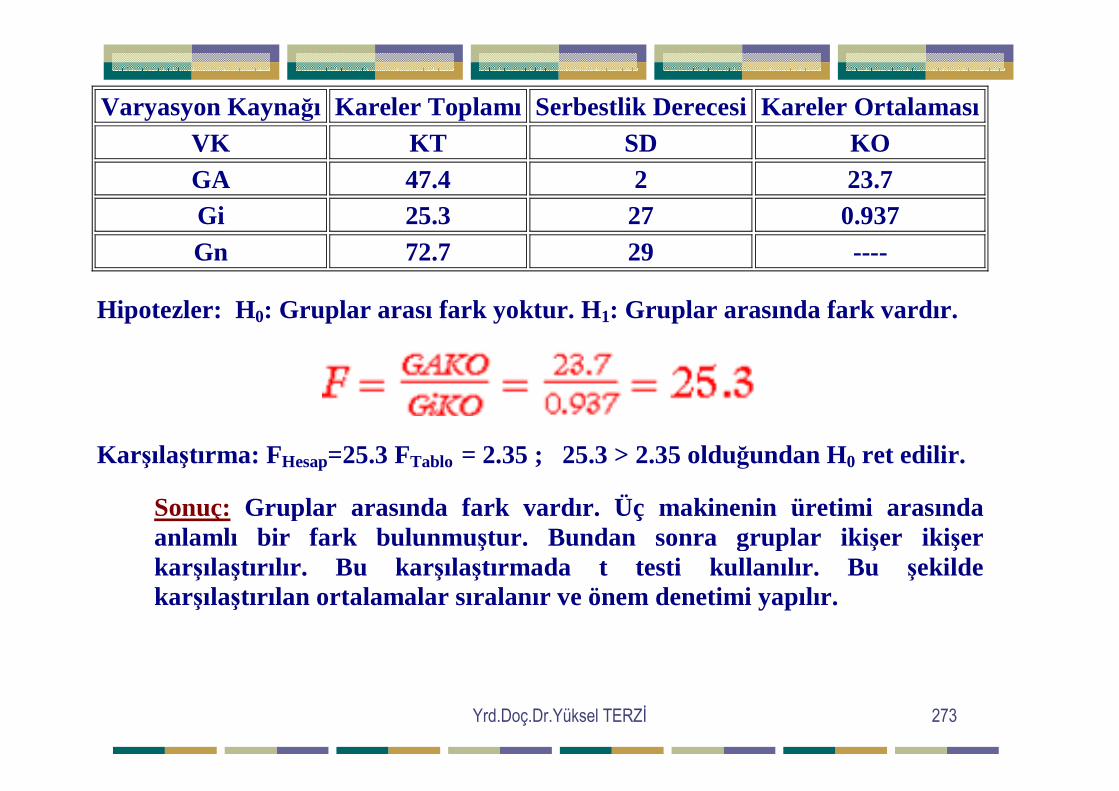
Yrd.Doç.Dr.Yüksel TERZĐ 273
Varyasyon Kaynağı Kareler Toplamı Serbestlik Derecesi Kareler Ortalaması VK KT SD KO GA 47.4 2 23.7 Gi 25.3 27 0.937 Gn 72.7 29 ----
Hipotezler: H0: Gruplar arası fark yoktur. H 1: Gruplar arasında fark vardır.
Kar şılaştırma: F Hesap=25.3 FTablo = 2.35 ; 25.3 > 2.35 olduğundan H0 ret edilir.
Sonuç: Gruplar arasında fark vardır. Üç makinenin üretimi arasında anlamlı bir fark bulunmu ştur. Bundan sonra gruplar iki şer iki şer karşılaştırılır. Bu kar şılaştırmada t testi kullanılır. Bu şekilde karşılaştırılan ortalamalar sıralanır ve önem denetimi yapılır.
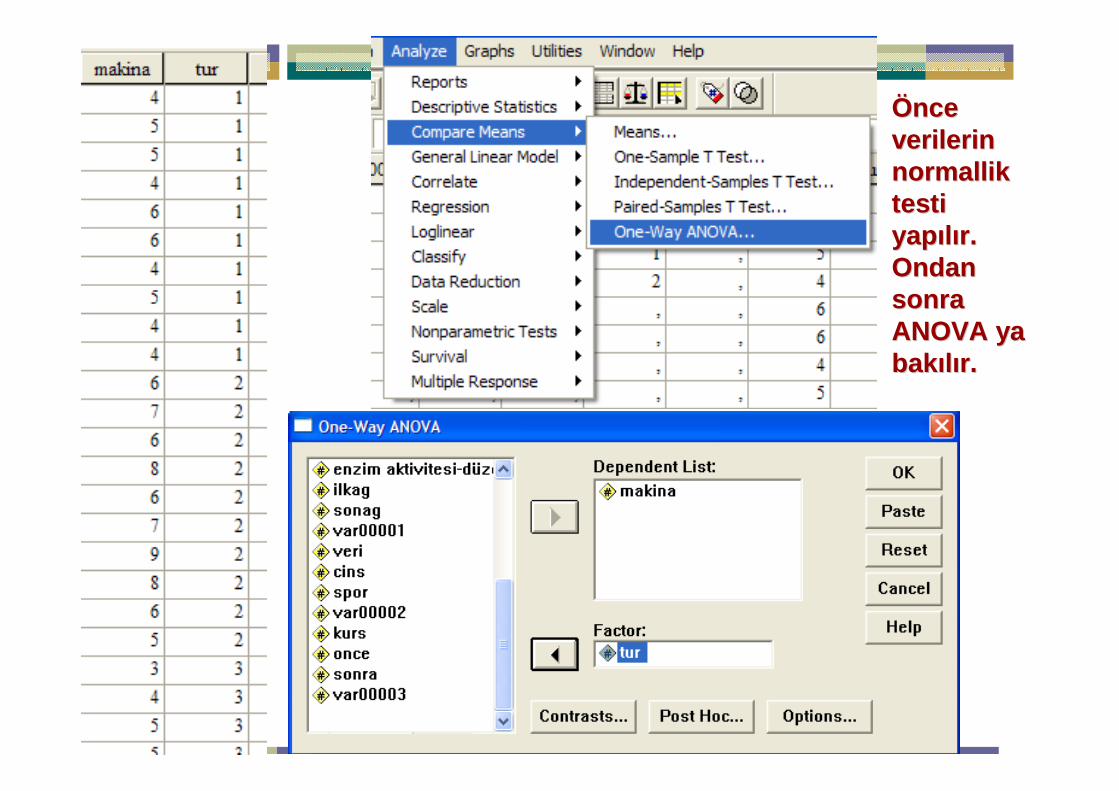
Yrd.Doç.Dr.Yüksel TERZĐ 274
ÖÖnce nce verilerin verilerin normallik normallik testi testi yapyap ııll ıır. r. Ondan Ondan sonra sonra ANOVA ya ANOVA ya bakbak ııll ıır.r.
Yrd.Doç.Dr.Yüksel TERZĐ 275
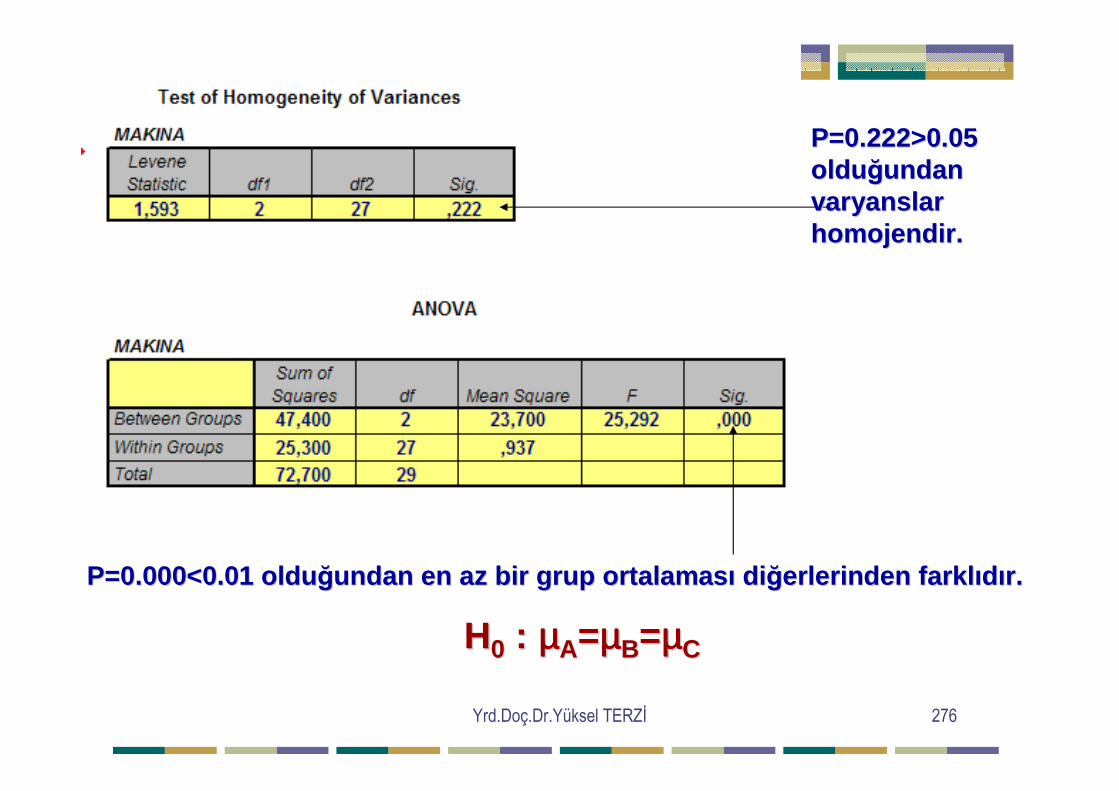
Yrd.Doç.Dr.Yüksel TERZĐ 276
P=0.222>0.05 P=0.222>0.05 olduoldu ğğundan undan varyanslar varyanslar homojendir.homojendir.
P=0.000<0.01 olduP=0.000<0.01 oldu ğğundan en az bir grup ortalamasundan en az bir grup ortalamas ıı didiğğerlerinden farklerlerinden farkl ııddıır. r.
HH00 : : µµµµµµµµAA==µµµµµµµµBB==µµµµµµµµCC

Yrd.Doç.Dr.Yüksel TERZĐ 277MeanMean differencedifference kkıısmsmıında nda * * iişşaretli grup ortalamalararetli grup ortalamalarıı birbirinden farklbirbirinden farklııddıır. r. Buna gBuna gööre A ile B ve B ile C grup ortalamalarre A ile B ve B ile C grup ortalamalarıı birbirinden farklbirbirinden farklııddıır.r.
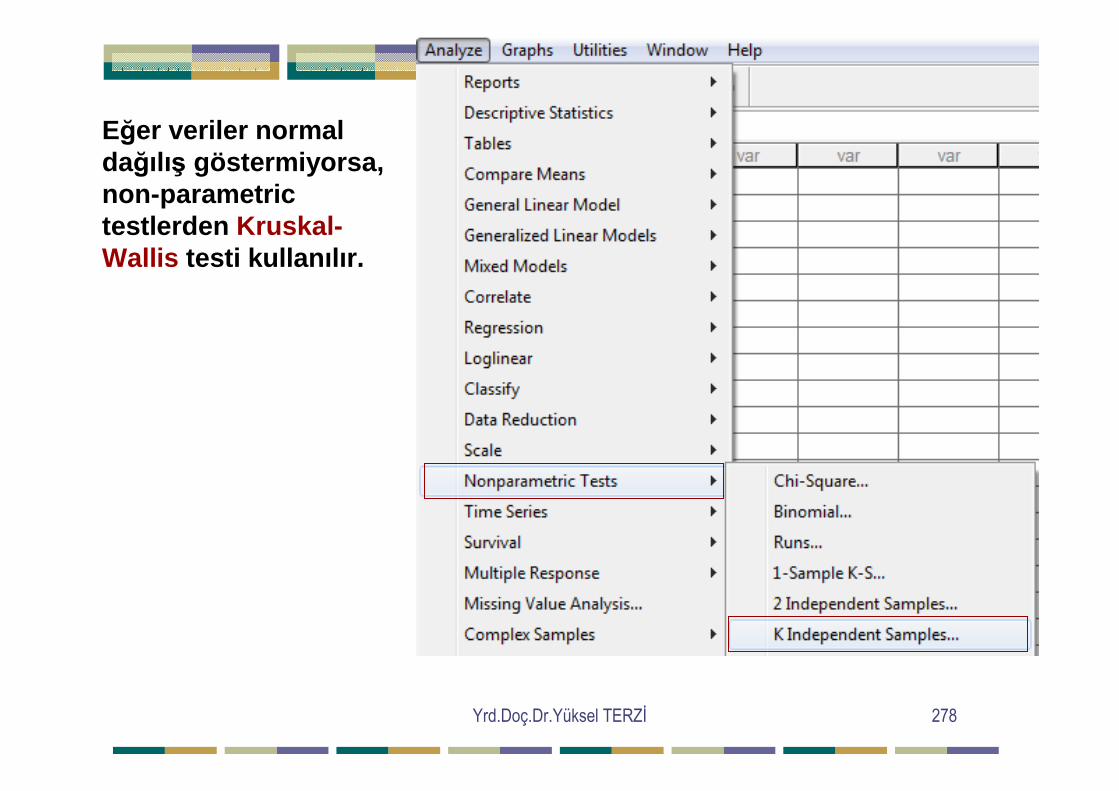
Yrd.Doç.Dr.Yüksel TERZĐ 278
Eğer veriler normal dağılış göstermiyorsa, non-parametrictestlerden Kruskal-Wallis testi kullanılır.

Yrd.Doç.Dr.Yüksel TERZĐ 279
Test Statistics a,b
19,439
2
,000
Chi-Square
df
Asymp. Sig.
makina
Kruskal Wallis Testa.
Grouping Variable: turb.
EEğğer ortalamalar farkler ortalamalar farkl ııççııkarsa, karsa, MannMann --WhitneyWhitney U U testi ile ikili kartesti ile ikili kar şışılalaşştt ıırmalar rmalar yapyap ııll ıır. Ancak dor. Ancak do ğğru bir ru bir hipotezin hipotezin redred edilmesi edilmesi anlamanlam ıına gelen I.Tip hata na gelen I.Tip hata riskinin azaltriskinin azalt ıılmaslmas ıı iiççin in öönemlilik seviyesi yapnemlilik seviyesi yap ıılacak lacak olan karolan kar şışılalaşştt ıırma sayrma say ııssıına na bbööllüünnüür. Mesela r. Mesela öönemlilik nemlilik seviyesi 0.05 ise ve 3 seviyesi 0.05 ise ve 3 karkarşışılalaşştt ıırma yaprma yap ıılacaksa, lacaksa, anlamlanlaml ııll ıık seviyesi k seviyesi 0.05/3=0.0167 al0.05/3=0.0167 alıınnıır. r.
P=0,00<0,05 Ho hipotezi kabul edilemez.

Yrd.Doç.Dr.Yüksel TERZĐ 280
KRUSKALKRUSKAL --WALLIS TESTWALLIS TEST İİÜçÜç veya daha fazla baveya daha fazla ba ğığımsms ıız grup normal daz grup normal da ğığıll ıım gm g ööstermiyorsa, stermiyorsa, bunlarbunlar ıın ortalamalarn ortalamalar ıı parametrik olmayan bir test olan parametrik olmayan bir test olan KruskalKruskal --WallisWallis testi ile test edilir. Etesti ile test edilir. E ğğer ortalamalar farkler ortalamalar farkl ıı ççııkarsa, karsa, MannMann --WhitneyWhitney U testi ile ikili karU testi ile ikili kar şışılalaşştt ıırmalar yaprmalar yap ııll ıır. Ancak dor. Ancak do ğğru bir ru bir hipotezin hipotezin redred edilmesi anlamedilmesi anlam ıına gelen I.Tip hata riskinin azaltna gelen I.Tip hata riskinin azalt ıılmaslmas ııiiççin in öönemlilik seviyesi yapnemlilik seviyesi yap ıılacak olan karlacak olan kar şışılalaşştt ıırma sayrma say ııssıına bna b ööllüünnüür. r. Mesela Mesela öönemlilik seviyesi 0.05 ise ve 3 karnemlilik seviyesi 0.05 ise ve 3 kar şışılalaşştt ıırma yaprma yap ıılacaksa, lacaksa, anlamlanlaml ııll ıık seviyesi 0.05/3=0.0167 alk seviyesi 0.05/3=0.0167 al ıınnıır. r. ÖÖrnek :rnek : DDöört gruptaki hastalarrt gruptaki hastalar ıın n PeakPeak Asit deAsit de ğğerleri veriliyor. Bu derleri veriliyor. Bu d öört rt grup ortalamalargrup ortalamalar ıı birbirinden farklbirbirinden farkl ıı mmııddıır? r?
11
22
41
C
2
4
82
110184
131528
4134
88201
DBA

Yrd.Doç.Dr.Yüksel TERZĐ 281

Yrd.Doç.Dr.Yüksel TERZĐ 282
p=0.005<0.05 oldup=0.005<0.05 olduğğundan en az bir grupundan en az bir gruportalamasortalamasıı didiğğerlerinden farklerlerinden farklııddıır. Bunun ir. Bunun iççin ikiliin ikiliKarKarşışılalaşşttıırmalar irmalar iççin in MannMann--WhitneyWhitney U testineU testinebakbakııllıır. Anlamlr. Anlamlııllıık seviyesi ise 0.05/3=0.00167k seviyesi ise 0.05/3=0.00167alalıınnıır.r.
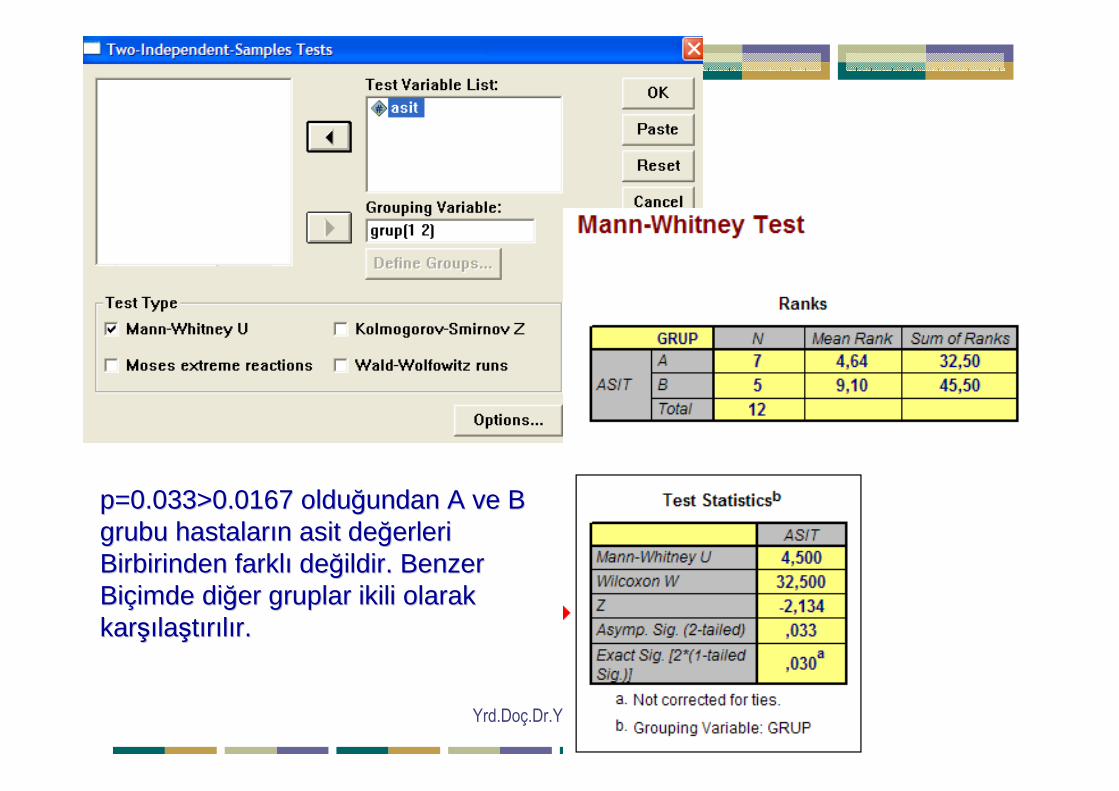
Yrd.Doç.Dr.Yüksel TERZĐ 283
p=0.033>0.0167 oldup=0.033>0.0167 olduğğundan A ve B undan A ve B grubu hastalargrubu hastalarıın asit den asit değğerleri erleri Birbirinden farklBirbirinden farklıı dedeğğildir. Benzer ildir. Benzer BiBiççimde diimde diğğer gruplar ikili olarak er gruplar ikili olarak karkarşışılalaşşttıırrııllıır.r.

Yrd.Doç.Dr.Yüksel TERZĐ 284
Soru : Bir fabrikada aynı i şi yapmakta olan 4 işçinin rasgele belirlenen 6 gün içerisinde ürettikleri parça sayıları aşağıdaki gibidir. Đşçilerin verimliliklerinin da ğılımı normal ve anakütle varyanslarının eşit olduğu kabul ediliyor. Đşçilerin günlük ortalama verimlilikleri arasında önemli bir farklıl ık bulunup bulunmadığını %1 anlamlılık düzeyinde araştırınız?
Đşçi 1 Đşçi 2 Đşçi 3 Đşçi 4 36 55 52 82 43 42 99 83 51 44 31 61 39 49 37 41 48 53 43 48 53 39 50 45

Yrd.Doç.Dr.Yüksel TERZĐ 285
)(:
:
43211
43210
farklıortalamaikiazEnH
H
µµµµµµµµ
≠≠≠===
VK KT SD KO F
Gruplar arası 804 k-1=3 804/3=268 268/256.8=1.04 Gruplar içi 5136 n-k=20 5136/20=256.8
Genel 5940 n-1=23 F3,20;0.05=4.94>Fh=1.04 H0 kabul edilir.
k=4, n=24

Yrd.Doç.Dr.Yüksel TERZĐ 286
İİKK İİ YYÖÖNLNLÜÜ VARYANS ANALVARYANS ANAL İİZZİİ (TWO(TWO--WAY ANOVA)WAY ANOVA)İİki yki y öönlnl üü varyans analizi, deney birimlerini iki varyans analizi, deney birimlerini iki ööllçüçü te gte g ööre re ssıınnııflayabildiflayabildi ğğimizde veya etkileri farklimizde veya etkileri farkl ıı deneysel materyallere deneysel materyallere uyguladuygulad ığıığımmıızda aklzda akl ıımmııza gelmelidir. Bu tza gelmelidir. Bu t üür tasarr tasar ıımda smda s ıınnııflama flama ööllçüçü ttüü etki etki olurken, farklolurken, farkl ıı deneysel materyaller ise deneysel materyaller ise blokblok adadıınnıı alalıır. r. AmaAma çç etki ortalamalaretki ortalamalar ıınnıın blok etkilerinden ban blok etkilerinden ba ğığımsms ıız olmasz olmas ıınnıısasağğlayarak, bloklar nedeniyle ortaya layarak, bloklar nedeniyle ortaya ççııkan dekan de ğğiişşkenlikten hata kenlikten hata dedeğğiişşkenlikenli ğğini ayini ay ıırmaktrmakt ıır. Bunun ir. Bunun i ççin deney birimlerinin homojen in deney birimlerinin homojen bloklarda toplanmasbloklarda toplanmas ıı gerekir. 2 ygerekir. 2 y öönlnl üü ANOVAANOVA ’’dada etkileetkile şşime de ime de bakbak ııll ıır. r. EtkileEtkile şşimle 2 faktimle 2 fakt öörrüün dn d ışıışında anda a ççııklanamayan ancak bu iki klanamayan ancak bu iki faktfakt öörrüün kombinasyonlarn kombinasyonlar ıı ile aile a ççııklanan farklklanan farkl ııll ıık k ööğğrenilebilir. renilebilir.
VarsayVarsay ıımlarmlari.i. knkn tane anaktane anak üütlenin datlenin da ğığıll ıımlarmlar ıı normal danormal da ğığıll ııma sahip olmalma sahip olmal ııddıır.r.ii.ii. Etkilerle bloklar arasEtkilerle bloklar aras ıında etkilenda etkile şşim yoktur.im yoktur.
Bilinmeyen bir sabitBilinmeyen bir sabitDeney birimi i bloDeney birimi i blo ğğuna duna d üüşşttüüğğüünde blok etkisinde blok etkisi
Deney birimi Deney birimi jj ’’ inciinci etkiyi aldetkiyi ald ığıığında ortaya nda ortaya ççııkan etkikan etkiEtki ve blok dEtki ve blok d ışıışındaki tndaki t üüm dem değğiişşkenlik kaynaklarkenlik kaynaklar ıınnıı ggöösteren artsteren art ııkk
ijjiij eX +++= τβµ
:
:
:
:
ij
j
i
e
τβµ

Yrd.Doç.Dr.Yüksel TERZĐ 287
SSTkn-1Toplam
MSE=SSE/(n-1)(k-1)SSE(n-1)(k-1)Hata
MSB/MSEMSB=SSB/(n-1)SSBn-1Bloklar
MSTr/MSEMSTr=SSTr/(k-1)SSTrk-1Etkiler (Faktör)
F Oranı
Kareler OrtalamasıKareler Toplamı
Serbestlik Derecesi
Değişkenlik Kaynağı

Yrd.Doç.Dr.Yüksel TERZĐ 288
ÖÖrnek :rnek :
3,52,12,04,33,44
1,91,50,51,81,73
1,14,00,32,22,32
1,31,20,41,51,21
54321
Kumaş Örneği (Blok)
Kimyasal Tür(Etki)
%5 anlaml%5 anlamlııllıık dk düüzeyinde kimyasallarzeyinde kimyasallarıın etkileri arasn etkileri arasıında anlamlnda anlamlıı bir farklbir farklııllıık olupk olupOlmadOlmadığıığınnıı inceleyiniz?inceleyiniz?

Yrd.Doç.Dr.Yüksel TERZĐ 289

Yrd.Doç.Dr.Yüksel TERZĐ 290
FIXED FACTOS : FIXED FACTOS : Etkileri araEtkileri ara şştt ıırr ııccıı taraftaraf ıından dendan de ğğil, bilinil, bilin ççli olarak seli olarak se ççildiildi ğği i faktfakt öörlerden olurlerden olu şşan modeldir.an modeldir.RANDOM FACTOS : RANDOM FACTOS : Etkileri mEtkileri m üümkmk üün tn t üüm sem se ççenekler ienekler i ççerisinden erisinden tesadtesad üüfen sefen se ççildiildi ğği ve denemeye ali ve denemeye al ıınan faktnan fakt öörlerden olurlerden olu şşan modeldir.an modeldir.

Yrd.Doç.Dr.Yüksel TERZĐ 291

Yrd.Doç.Dr.Yüksel TERZĐ 292
Kimyasal etkilere bakKimyasal etkilere bak ııldld ığıığında P=0,009<0.05 oldunda P=0,009<0.05 oldu ğğundan kimyasallarundan kimyasallar ıın n etkileri arasetkileri aras ıın anlamln anlaml ıı bir farklbir farkl ııll ıık vardk vard ıır.r.

Yrd.Doç.Dr.Yüksel TERZĐ 293
TEKRARLI TEKRARLI ÖÖLLÇÜÇÜMLERDE TEK FAKTMLERDE TEK FAKT ÖÖR VARYANS ANALR VARYANS ANAL İİZZİİ(REPEATED MEASURES)(REPEATED MEASURES)
ANOVAANOVA ’’nnıınn aksine bu taksine bu t üür r ççalal ışışmalarda kullanmalarda kullan ıılan delan de ğğiişşkenler kenler babağığımlml ııddıırlar. rlar. ÜçÜç ççeeşşit tekrarlit tekrarl ıı ööllçüçü m tasarm tasar ıımmıı yapyap ıılabilir:labilir:
i.i. AynAyn ıı deneklerin belirli bir dedeneklerin belirli bir de ğğiişşken aken a ççııssıından zamana bandan zamana ba ğğll ııolarak tekrarlanan olarak tekrarlanan ööllçüçü m yapm yap ıılmaslmas ıı, mesela deneklerden , mesela deneklerden birden fazla kan basbirden fazla kan bas ııncnc ıı iiççin in ööllçüçü m alm al ıınmasnmas ıı buna bir buna bir öörnektir.rnektir.
ii.ii. AynAyn ıı deneklerin farkldeneklerin farkl ıı tedavi bitedavi bi ççimlerine maruz bimlerine maruz b ıırakrak ıılmaslmas ıı, , mesela amesela a ğğrr ııyyıı azaltmada deazaltmada de ğğiişşik tedavi biik tedavi bi ççimlerinin imlerinin karkarşışılalaşştt ıırr ıılmaslmas ıı yapyap ıılabilir. labilir.
Bu iki tasarBu iki tasar ıım bim bi ççimine imine denekler arasdenekler aras ıı tasartasar ıım veya tek m veya tek faktfakt öörlrl üü tasartasar ıımm denir.denir.
iiiiii .. Hem zamana baHem zamana ba ğğll ıı hem de tedavi bihem de tedavi bi ççimini dikkate alan imini dikkate alan karkar ışıışık k tasartasar ıım veya m veya ççok faktok fakt öörlrl üü tasartasar ıımm kullankullan ıılabilir.labilir. öörnerneğğin dein de ğğiişşik ik tedavi bitedavi bi ççimlerinin, hipertansiyonun zaman iimlerinin, hipertansiyonun zaman i ççindeki durumu indeki durumu üüzerindeki etkilerinin incelenmesi bzerindeki etkilerinin incelenmesi b ööyle bir tasaryle bir tasar ıımdmd ıır. r.

Yrd.Doç.Dr.Yüksel TERZĐ 294
TEKRARLI TEKRARLI ÖÖLLÇÜÇÜMLERDE VARYANS ANALMLERDE VARYANS ANAL İİZZİİ VARSAYIMLARIVARSAYIMLARI1. 1. Rasgele Rasgele ÖÖrnekleme rnekleme 2. 2. Tekrarlanan Tekrarlanan ÖÖllçüçü mlermler3. 3. Her FaktHer Fakt öör Seviyesinde Bar Seviyesinde Ba ğığımsms ıız z ÖÖrneklemlerrneklemler4.4. Normal anakNormal anak üütlelerden tlelerden öörneklem elde edilmesi yani faktrneklem elde edilmesi yani fakt öörrüün her n her
seviyesindeki deseviyesindeki de ğğerler normal veya normale yakerler normal veya normale yak ıın olmaln olmal ııddıır.r.5. 5. VaryansVaryans --Kovaryans VarsayKovaryans Varsay ıımmıı ((BoxBox M testi: P>0,05 ise kovaryans matrisleri M testi: P>0,05 ise kovaryans matrisleri
benzerdir.),benzerdir.), yani yani ööllçüçü m dem değğerlerinden oluerlerinden olu şşan an gruplargruplar ıın korelasyonu aynn korelasyonu ayn ııddıırr . . ÇüÇünknk üü aynayn ıı deneklerden tekrarlanan deneklerden tekrarlanan ööllçüçü m alm al ıındnd ığıığından veriler arasndan veriler aras ıında bir nda bir korelasyon mevcuttur. Ayrkorelasyon mevcuttur. Ayr ııca ca gruplardaki varyanslargruplardaki varyanslar ıın en eşşit olmasit olmas ıı gerekir. gerekir. Bu varsayBu varsay ıım m öönemlidir.nemlidir.
VaryanslarVaryanslar ıın en eşşit olup olmamasit olup olmamas ıına na MauchlyMauchly testitesti ile bakile bak ııll ıır. Er. Eğğer test er test sonunda P>0.05 ise varyanslar esonunda P>0.05 ise varyanslar e şşit demektir. it demektir.
ÖÖrnek:rnek: 9 Hastan9 Hastan ıın ban başşlanglang ııçç ve tedavi sonrasve tedavi sonras ıı kalp atkalp at ıımlarmlar ıı veriliyor. Gruplar veriliyor. Gruplar arasaras ıında kalp atnda kalp at ıımlarmlar ıı aaççııssıından fark var mndan fark var m ııddıır?r?
HastaHasta ilaila çç yokyok PropranololPropranolol PlaseboPlasebo AcebutololAcebutolol11 9494 6767 9090 676722 5757 5252 6969 555533 8181 7474 6969 737344 8282 5959 7171 727255 6767 6565 7474 727266 7878 7272 8080 727277 8787 7575 106106 747488 8282 6868 7676 595999 9090 7474 8282 8080

Yrd.Doç.Dr.Yüksel TERZĐ 295

Yrd.Doç.Dr.Yüksel TERZĐ 296
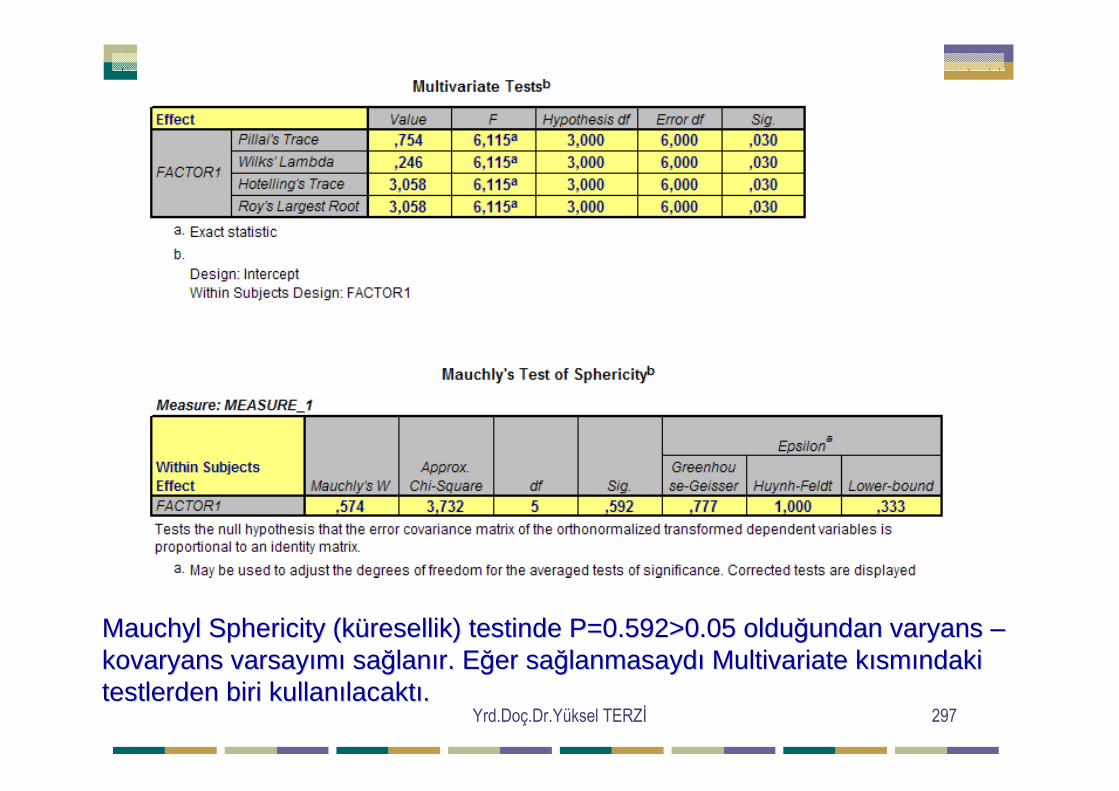
Yrd.Doç.Dr.Yüksel TERZĐ 297
MauchylMauchyl SphericitySphericity (k(küüresellik) testinde P=0.592>0.05 olduresellik) testinde P=0.592>0.05 olduğğundan varyans undan varyans ––kovaryans varsaykovaryans varsayıımmıı sasağğlanlanıır. Er. Eğğer saer sağğlanmasaydlanmasaydıı MultivariateMultivariate kkıısmsmıındaki ndaki testlerden biri kullantestlerden biri kullanıılacaktlacaktıı. .
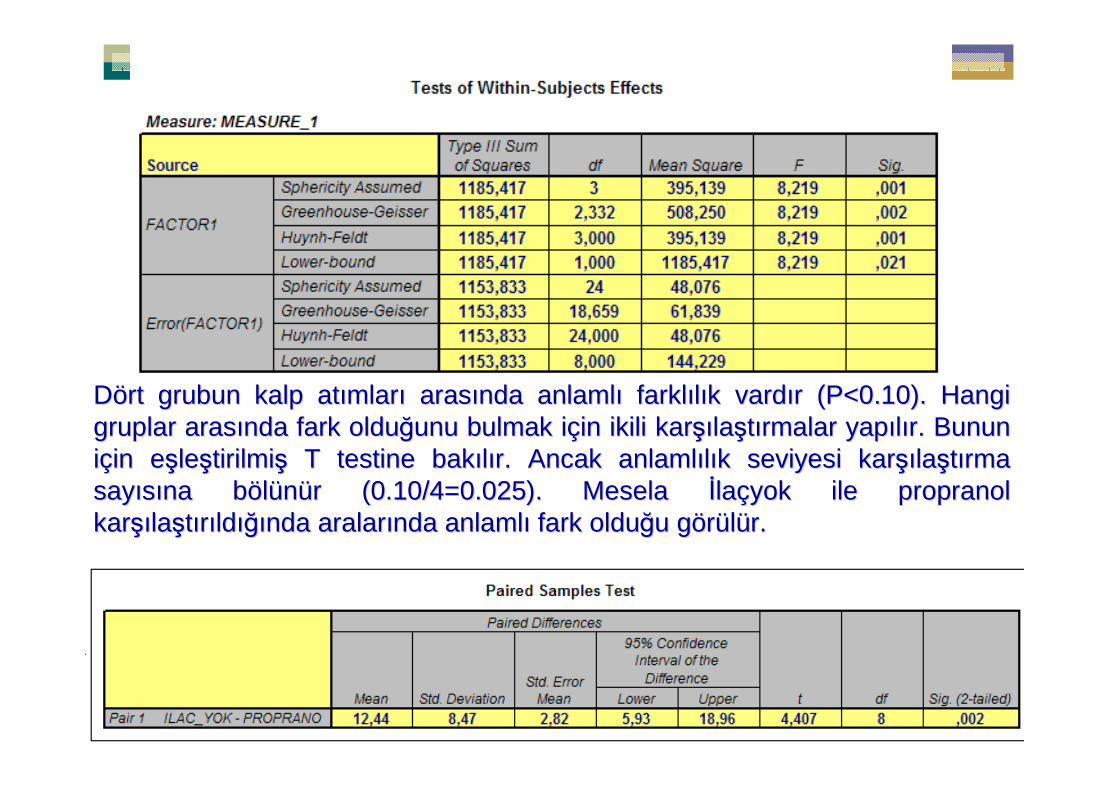
Yrd.Doç.Dr.Yüksel TERZĐ 298
DDöört grubun kalp atrt grubun kalp atıımlarmlarıı arasarasıında anlamlnda anlamlıı farklfarklııllıık vardk vardıır (P<0.10). Hangi r (P<0.10). Hangi gruplar arasgruplar arasıında fark oldunda fark olduğğunu bulmak iunu bulmak iççin ikili karin ikili karşışılalaşşttıırmalar yaprmalar yapııllıır. Bunun r. Bunun iiççin ein eşşleleşştirilmitirilmişş T testine bakT testine bakııllıır. Ancak anlamlr. Ancak anlamlııllıık seviyesi kark seviyesi karşışılalaşşttıırma rma saysayııssıına bna bööllüünnüür (0.10/4=0.025). Mesela r (0.10/4=0.025). Mesela İİlalaççyokyok ile ile propranolpropranolkarkarşışılalaşşttıırrııldldığıığında aralarnda aralarıında anlamlnda anlamlıı fark oldufark olduğğu gu göörrüüllüür.r.

Yrd.Doç.Dr.Yüksel TERZĐ 299
TEKRARLI TEKRARLI ÖÖLLÇÜÇÜMLERDE MLERDE İİKK İİ FAKTFAKT ÖÖR VARYANS ANALR VARYANS ANAL İİZZİİ
VarsayVarsay ıımlar:mlar:-- Rasgele Rasgele öörneklemernekleme-- Tekrarlanan Tekrarlanan ööllçüçü mlermler-- BaBağığımsms ıız z öörneklemlerrneklemler-- Normallik Normallik şşartart ıı-- varyansvaryans --kovaryans varsaykovaryans varsay ıımmıı(gruplar(gruplar ıın korelasyonu aynn korelasyonu ayn ıı olmalolmal ııve gruplardaki varyansve gruplardaki varyans ıın en eşşit olmasit olmas ıı) ) -- TTüüm anakm anak üütle varyanslartle varyanslar ıı eeşşit olmalit olmal ıı

Yrd.Doç.Dr.Yüksel TERZĐ 300
--GraphsGraphs //BoxplotBoxplot//clusteredclustered/data in /data in chartchart areare//SummarizeSummarize osos separateseparate variablevariable/Define//Define/BoxesBoxes representrepresent:haafta1, ay1, ay3, ay6/:haafta1, ay1, ay3, ay6/categorycategory AxisAxis (G)/Ok(G)/Ok

Yrd.Doç.Dr.Yüksel TERZĐ 301
Her bir zaman periyodu eHer bir zaman periyodu eşşit it varyansa sahiptir. (P>0,05) varyansa sahiptir. (P>0,05)
BoxBox’’ss M varyansM varyansıın homojenlin homojenliğği i İİle ilgili le ilgili ççok boyutlu bir testtir. ok boyutlu bir testtir. EEğğer P>0,05 ise varyanser P>0,05 ise varyans--kovaryans matrisi ekovaryans matrisi eşşittir ittir demektir. (tedavi gruplardemektir. (tedavi gruplarıı iiççin in varyans kovaryans matrisi varyans kovaryans matrisi aynaynııddıır.) r.)

Yrd.Doç.Dr.Yüksel TERZĐ 302
EEğğer er MauchlyMauchly testinde P>=0,05 ise testinde P>=0,05 ise univariateunivariate yaklayaklaşışımmıı, de, değğilse ilse multivariatemultivariateyaklayaklaşışım kullanm kullanııllıır. Genelde de r. Genelde de PillaiPillai’’ss kullankullanııllıır. r.

Yrd.Doç.Dr.Yüksel TERZĐ 303
4 zaman grubu birbirinden 4 zaman grubu birbirinden öönemli dnemli düüzeyde farklzeyde farklııddıır. Ayrr. Ayrııca tedavi gruplarca tedavi gruplarıınnıın n zaman ile etkilezaman ile etkileşşimleri anlamlimleri anlamlııddıır (p<0,01). r (p<0,01).

Yrd.Doç.Dr.Yüksel TERZĐ 304
Tedavi gruplarTedavi gruplarıı arasarasıındaki farkndaki farkıı bulmak ibulmak iççin tek yin tek yöönlnlüü anovaanova yapyapııllıır. Burada r. Burada öönem seviyesi 0,10/4=0,025 alnem seviyesi 0,10/4=0,025 alıınnıır. r.

Yrd.Doç.Dr.Yüksel TERZĐ 305
NORMAL DANORMAL DAĞĞILMAYAN TEKRARLI ILMAYAN TEKRARLI ÖÖLLÇÜÇÜMLERDE MLERDE ÜÇÜÇ VEYA DAHA FAZLA VEYA DAHA FAZLA GRUP GRUP İİÇÇİİN UYGULANAN TESTLER: N UYGULANAN TESTLER: FRIEDMAN TESTFRIEDMAN TEST İİ
Burada gruplar tekrarlBurada gruplar tekrarl ıı ööllçüçü mlml üü olduoldu ğğundan baundan ba ğığımlml ııddıırlar. rlar. FridmanFridman testi testi iiççin ain aşşaağığıdaki varsaydaki varsay ıımlar gemlar ge ççerlidir: erlidir:
1. 1. Rasgele Rasgele ÖÖrnekleme rnekleme 2. 2. Tekrarlanan Tekrarlanan ÖÖllçüçü mlermler3.3. Her gruptaki Her gruptaki öörneklemler kendi irneklemler kendi i ççinde bainde ba ğığımsms ıız olmalz olmal ııddıır.r.
HH00 : Herhangi bir denek ile ilgili g: Herhangi bir denek ile ilgili g öözlemlerin bzlemlerin b üüttüün muhtemel sn muhtemel s ııralamalarralamalar ıı eeşşittir. ittir. Yada gruplardan hiYada gruplardan hi ççbirisi dibirisi di ğğerinden daha berinden daha b üüyyüük dek değğer oluer olu şşturmaz.turmaz.
ÖÖrnek:rnek: PerikardiyalPerikardiyal olan hastalarolan hastalar ıın perikart in perikart i ççi basi bas ıınnçç dedeğğerleri veriliyor. erleri veriliyor. HastaHasta TamponadeTamponade OrtaOrta TamTam
11 1717 77 0022 1818 88 0033 1616 55 3344 1010 55 0055 1313 00 0066 1414 88 5577 1010 55 0088 1818 88 0099 1212 66 --11

Yrd.Doç.Dr.Yüksel TERZĐ 306

Yrd.Doç.Dr.Yüksel TERZĐ 307
P<0.10 olduP<0.10 oldu ğğundan en az bir grup undan en az bir grup didiğğerlerinden farklerlerinden farkl ııddıır. Bunun ir. Bunun i ççin ikili in ikili karkarşışılalaşştt ıırmalara bakrmalara bak ııll ıır ve anlamlr ve anlaml ııll ıık k seviyesi yine karseviyesi yine kar şışılalaşştt ıırma sayrma say ııssıına bna b ööllüünnüür r (0.10/3=0.033). (0.10/3=0.033). İİkili karkili kar şışılalaşştt ıırma irma i ççin in Wilcoxon testi kullanWilcoxon testi kullan ııll ıır. r. ÇüÇünknk üü gruplar gruplar babağığımlml ııddıır.r.

Yrd.Doç.Dr.Yüksel TERZĐ 308
KORELASYON
Korelasyon analizinde iki veya daha çok sayıda değişken arasında bir ilişki bulunup bulunmadığı, eğer varsa bu ili şkinin derecesi ve fonksiyonel şekli belirlenmeye çalışılır. Örneğin reklamların satışı arttırdı ğı şeklinde bir düşünce yaygındır. Ancak satışların artı şı sadece reklamlar ile açıklanamaz. Nüfus artışı, moda, fiyat rakiplerle rekabet satışları etkileyen diğer nedenler olarak düşünülebilir. Öyle ise reklamlar ile satış arasında ilişkinin olup olmadığı incelenmelidir.

Yrd.Doç.Dr.Yüksel TERZĐ 309
Doğrusal Korelasyon:
Bir değişkenin değeri artarken di ğer değişkenin değeri düzenli artıyor veya eksiliyorsa iki değişken arasındaki ilişki doğrusaldır. Đlişki grafik üzerinden de incelenebilir.
Korelasyon=+1 Korelasyon=-1 Korelasyon=0

Yrd.Doç.Dr.Yüksel TERZĐ 310
Doğrusal korelasyonun hesaplanmasında Pearson Momentler Çarpımı korelasyonu kullanılır. Bu formülün uygulanabilmesi için veriler en az aralıklı ölçekle toplanmalı ve süreklilik gösteren nicel bir değişken olmalıdır.
Korelasyon katsayısının değeri -1 ile +1 arasında değişir. Sonucun +1 çıkması iki değişken arasında kuvvetli olumlu ilişkinin bulunduğunu, -1 ise kuvvetli olumsuz ilişkinin bulundu ğunu gösterir. Korelasyon katsayısı 0 'a yaklaştıkça ili şkinin kuvveti zayıflar, sıfır ise iki değişken arasında ilişkinin olmadığını gösterir.

Yrd.Doç.Dr.Yüksel TERZĐ 311
Korelasyon katsayısının önem denetimi:
Hesaplanmış olan korelasyon katsayısının tesadüfi mi yoksa gerçek bir ilişkiyi mi gösterdiğinin belirlenmesi için denetlenmesi gerekir.Denetim için kurulan hipotezler H0 : j=0 ; H1 : j ≠ 0 şeklinde belirlenir. Test istatistiği şu formüle göre hesaplanır,
r:Korelasyon katsayısını belirtir.

Yrd.Doç.Dr.Yüksel TERZĐ 312
ÖRNEK: Aşağıda bir işletmede gün olarak kullanılan izin (X) ile performans puanları (Y) verilmiştir. Bu iki değişken arasında ilişki var mıdır?
X Y X2 Y2 XY
1 14 1 196 14
2 13 4 169 26
3 12 9 144 36
3 13 9 169 39
2 11 4 121 22
1 12 1 144 12
4 12 16 144 48
5 11 25 121 55
4 14 16 196 56
3 13 9 169 39
6 12 36 144 72
5 12 25 144 60
10 10 100 100 100
9 11 81 121 99
1 14 1 196 14
8 11 64 121 88
9 10 81 100 90
7 9 49 81 63
6 12 36 144 72
7 10 49 100 70
Sx 96 Sy 236 Sx2 616 Sy2 2824 Sxy 1075

Yrd.Doç.Dr.Yüksel TERZĐ 313
Elde edilen sonuca göre kullanılan izin miktarı ile performans puanları arasında negatif yönlü kuvvetli ilişki vardır. Kullanılan izin miktarı arttıkça performans puanları dü şmektedir. Bulunan korelasyonun gerçekten önemli olup olmadığı incelenirse
Hipotezler, H0 : j=0 ; H1 : j ≠ 0
Serbestlik derecesi :(n-2)=20-2=18
ZHesap> ZTablo; 4.8>2.1 olduğundan H0 reddedilir.
Sonuç: Bulunan korelasyon önemlidir ve tesadüfi değildir.(t=4.8, p<.05)

Yrd.Doç.Dr.Yüksel TERZĐ 314

Yrd.Doç.Dr.Yüksel TERZĐ 315

Yrd.Doç.Dr.Yüksel TERZĐ 316
REGRESYON ANAL ĐZĐ
Regresyon analizinin temelinde; gözlenen bir olayın değerlendirilirken, hangi olayların etkisi içinde olduğunun araştırılması yatmaktadır. Bu olaylar bir veya birden çok olacağı gibi dolaylı veya direkt etkileniyor da olabilirler .
Regresyon analizi yapılırken, gözlem değerlerinin ve etkilenilen olayların bir matematiksel gösterimle yani bir fonksiyon yardımıyla ifadesi gerekmektedir. Kurulan bu modele regresyon modeli denilmektedir. Regresyon analizi incelenirken, genellikle konusunu oluşturan, etkilendiği olaylara değişkenler adı verilir ve bu değişkenlerin yer alacağı matematiksel model incelenir. Đstatistikte değişkenler arasındaki ilişkinin derecesini gösteren katsayıya korelasyon, değişkenler arasındaki ilişkinin fonksiyonel şeklini belirleyen denkleme ise regresyon denklemidenir.

Yrd.Doç.Dr.Yüksel TERZĐ 317
Regresyon modelinin kullanılması, ilgilenilen olayla ilgili olarak, bir sebep-sonuç ilişkisi bulunması gerekmektedir. Örneğin 1990-1997 yılları arasındaki hisse senedi fiyatlarını incelersek, seçilen zaman aralığında bir matematiksel model kurma gereği vardır ve bu modelde bir sebep, sonuç ilişkisi aranmaktadır. Sebep, hisse senedinin fiyatını yükselten veya düşüren unsurlardır. Faiz oranları, ekonomik nedenler, enflasyon oranları vs. olarak incelenebilir. Sonuç ise hisse senedinin fiyatının değişmesidir.
Sebep-sonuç ilişkisi, regresyon modeli kurulurken, bağımlı ve bağımsız değişkenler olarak anlatılmaktadır. Yukarıdaki hisse senedi fiyatı sonuç olan bağımlı değişken, faiz oranları, ekonomik nedenler, enflasyon oranları vs. sebep olan bağımsız değişkenlerdir.Regresyon analizi yapılırken kurulan matematiksel modelde yer alan değişkenler bir bağımlı değişken ve bir veya birden çok bağımsız değişkenden oluşmaktadır.
Bağımsız değişkenler kurulacak modelde bir değişkenli olarak ele alınırsa basit doğrusal regresyon, birden fazla bağımsız değişkenli olarak alınırsa çoklu regresyon modeli konusunu oluşturmaktadır.

Yrd.Doç.Dr.Yüksel TERZĐ 318
Basit Doğrusal Regresyon Modeli: Y = a + bX + ei Çoklu Regresyon Modeli: Y = a + bX1 + cX2 + dX3 + ... + ei Y : Bağımlı değişken X1 , X2 , X3 , .... : Bağımsız değişkenler a, b, c, d, … : Katsayılar ei : Hata terimi
XX
XY
SS
SS
n
XX
n
YXXY
b =∑−∑
∑∑−∑=
22 )(
))((
ˆ
XbYa ˆˆ −=

Yrd.Doç.Dr.Yüksel TERZĐ 319
BAS İT DOĞRUSAL REGRESYON DENKLEM İN VARSAYIMLARI 1. Bağımsız değişkenin değerleri sabit ve rassal olabilir. 2. Bağımsız değişkenin ölçüm hataları ihmal edilebilecek kadar
küçüktür. 3. Her X değeri için Y değerlerinden oluşan bir alt küme vardır.
Bu alt kümelerin dağılımı normaldir. 4. Bu alt küme değerlerinin (Y’lerin) varyansları e şittir. 5. Bu alt kümelerin ortalamaları aynı doğru üzerindedir Bu
varsayım doğrusallık varsayım olarak bilinir.
Hata Terimi (ei) Varsayımları 1. Rassal hataların beklenen değeri sıfırdır. E( ε )=0 2. Rassal hataların dağılımı normaldir. 3. ε ’ların olasılık dağılımının varyansı sabittir. 4. Farklı Y değerlerine ili şkin rassal hatalar birbirinden
bağımsızdır.

Yrd.Doç.Dr.Yüksel TERZĐ 320
ÇÇOKLU DOOKLU DOĞĞRUSAL REGRESYONRUSAL REGRESYON
ÇÇoklu regresyon oklu regresyon çöçö zzüümlemesinde bamlemesinde ba ğığımlml ıı dedeğğiişşken ile baken ile ba ğığımsms ıız z dedeğğiişşkenler araskenler aras ıındaki ilindaki ili şşkiyi matematiksel modelle akiyi matematiksel modelle a ççııklayarak, klayarak, babağığıntnt ıılar bulmak ve balar bulmak ve ba ğığımsms ıız dez değğiişşkenler yardkenler yard ıımmıı ile baile ba ğığımlml ıı dedeğğiişşkenin kenin kestirimi yapkestirimi yap ııll ıır.r.
Modelde amaModelde ama çç;;•• BaBağığımsms ıız dez değğiişşkenler yardkenler yard ıımmıı ile baile ba ğığımlml ıı dedeğğiişşkeni kestirmek,keni kestirmek,•• BaBağığımsms ıız dez değğiişşkenlerden hangisikenlerden hangisi --hangilerinin bahangilerinin ba ğığımlml ıı dedeğğiişşkeni daha keni daha ççok etkilediok etkiledi ğğini bulmak ve aralarini bulmak ve aralar ıındaki karmandaki karma şışık yapk yap ııyyıı tantan ıımlamaktmlamakt ıır. r.
0 1 2
1
: 0
: 0p
j
H
H En az bir
β β ββ
= = = =
≠
L
εββββ +++++= ppxxxy L22110

Yrd.Doç.Dr.Yüksel TERZĐ 321
ÇÇoklu Dooklu Do ğğrusal Regresyonarusal Regresyonaİİlilişşkin Varsaykin Varsay ıımlarmlar
1.1. Normal daNormal da ğığıll ıım m 2.2. DoDoğğrusallrusall ııkk3.3. Hata terimlerinin ortalamasHata terimlerinin ortalamas ıı ssııff ıırdrd ıırr4.4. Sabit Sabit varyansvaryans5.5. OtokorelasyonOtokorelasyon olmamasolmamas ıı6.6. BaBağığımsms ıız dez değğiişşkenler araskenler aras ıında nda ççoklu baoklu ba ğğlantlant ıı
olmamasolmamas ıı
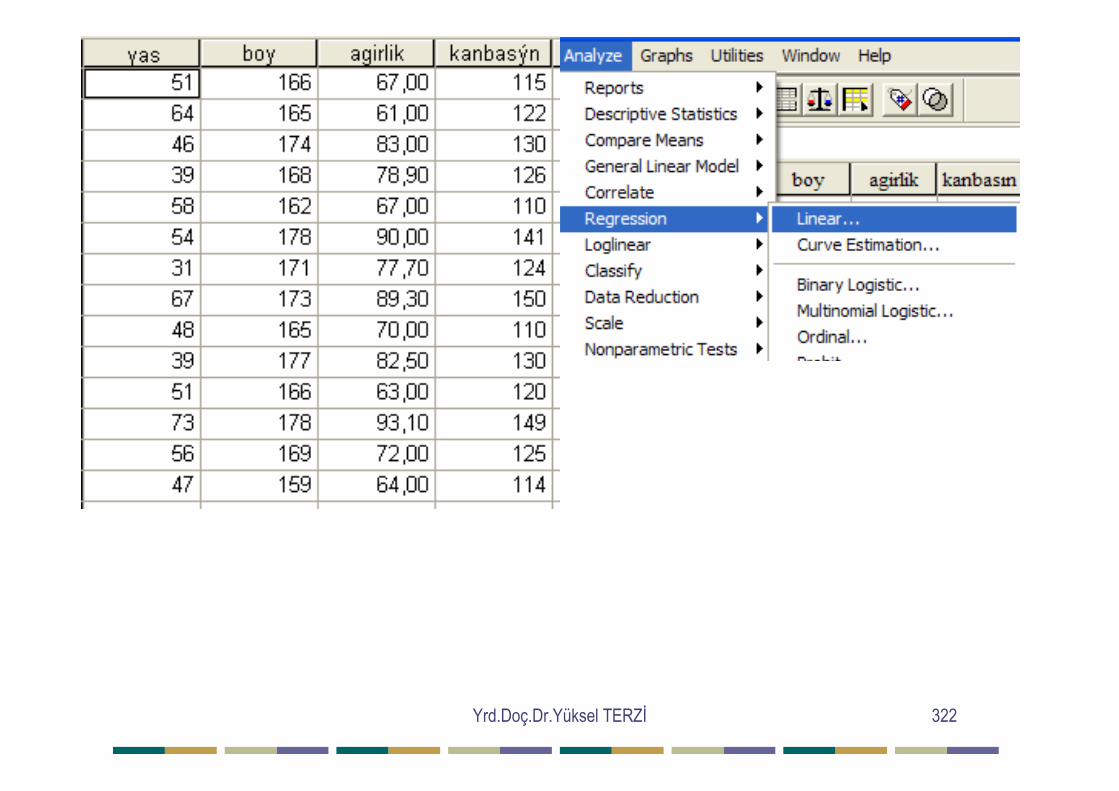
Yrd.Doç.Dr.Yüksel TERZĐ 322

Yrd.Doç.Dr.Yüksel TERZĐ 323

Yrd.Doç.Dr.Yüksel TERZĐ 324
CollinearityCollinearity DiagnosticsDiagnostics : : BaBağığımsmsıız dez değğiişşkenler araskenler arasıında donda doğğrusal bir ilirusal bir ilişşki olup ki olup olmadolmadığıığınnıı araaraşşttıırrıır.r.Model Fit :Model Fit : Modele eklenen ve modelden Modele eklenen ve modelden ççııkarkarıılan delan değğiişşkenler incelenir. Rkenler incelenir. R22 lerlerve ve varyansvaryans tablosu analiz edilir.tablosu analiz edilir.DurbinDurbin Watson : Watson : OtokorelasyonuOtokorelasyonu test eder. 0test eder. 0--4 aras4 arasıında denda değğerler alerler alıır. DW r. DW dedeğğeri 1.5eri 1.5--2.5 aras2.5 arasıında ise nda ise otokorelasyonotokorelasyon olmadolmadığıığınnıı ggöösterir. 0sterir. 0’’a yaka yakıın ise n ise pozitif korelasyonu yani b katsaypozitif korelasyonu yani b katsayıılarlarıınnıın s.hatalarn s.hatalarıınnıın n ççok kok küçüüçük olduk olduğğunu, 4unu, 4’’e e yakyakıın den değğerler ise negatif korelasyonu yani b katsayerler ise negatif korelasyonu yani b katsayıılarlarıınnıın s.hatalarn s.hatalarıınnıın n ççok ok bbüüyyüük olduk olduğğu anlamu anlamıına gelir. na gelir.

Yrd.Doç.Dr.Yüksel TERZĐ 325
ZPRED ZPRED : : StandartlaStandartlaşşttıırrıılmlmışış tahmini detahmini değğerlererlerZRESIDZRESID :: StandartlaStandartlaşşttıırrıılmlmışış artartııklar (klar (residualresidual))DRESIDDRESID :: Silinen artSilinen artııklarklarADJPRED ADJPRED :: DDüüzeltilmizeltilmişş tahmini detahmini değğerlererlerSRESIDSRESID :: StudentStudent artartııklarklarSDRESIDSDRESID :: StudentStudent silinen artsilinen artııklarklar
HistogramHistogram ve ve normal normal probabilityprobability plotplot kkıısmsmıından ndan ççoklu normal daoklu normal dağığıllıım ve m ve dodoğğrusallrusallıık varsayk varsayıımmıı kontrol edilebilir. kontrol edilebilir.

Yrd.Doç.Dr.Yüksel TERZĐ 326
UnstandardizedUnstandardized : : BaBağığımlmlııdedeğğiişşken iken iççin modelin tahmin ettiin modelin tahmin ettiğği i dedeğğerler.erler.StandardizedStandardized: : Tahmin edilen Tahmin edilen dedeğğerin standardize edilmierin standardize edilmişş dedeğğerieriAdjustedAdjusted: : DDüüzeltilmizeltilmişş tahmini tahmini dedeğğerler.erler.S.E. Of S.E. Of meanmean predicrionspredicrions:: Tahmini Tahmini dedeğğerlerin standart hatalarerlerin standart hatalarıı
DistancesDistances : U: Uçç nokta analizlerinokta analizleriMahalanobisMahalanobis: : Bu deBu değğerin berin büüyyüük k ççııkmaskmasıı babağığımsmsıız dez değğiişşkenlerin ukenlerin uççdedeğğerlere sahip olduerlere sahip olduğğunu gunu göösterir.sterir.CookCook’’ss :: Bir gBir göözlemin regresyon zlemin regresyon hesaplanmashesaplanmasıından ndan ççııkarkarıılmaslmasıısonucu katsaysonucu katsayıılarlarıın n öönemli oranda nemli oranda dedeğğiişşeceeceğğini gini göösterir.sterir.LeverageLeverage valuesvalues: : Regresyonun Regresyonun uyumu uyumu üüzerindeki bir noktanzerindeki bir noktanıın n etkisin etkisin ööllççer.er.
PredictionPrediction IntervalsIntervalsMeanMean--IndividualIndividual: : Ortalama tahminiOrtalama tahmini--tek tek bir gbir göözlem izlem iççin tahmin aralin tahmin aralığıığınnıın in iççin alt in alt ve ve üüst sst sıınnıırlarrlarıı hesaplar.hesaplar.

Yrd.Doç.Dr.Yüksel TERZĐ 327
Residuals (Artıklar)Unstandardized: Gözlenen ve tahmini değerler arasındaki farkStandardized: Stndardize artıklar (Pearson residuals ~N(0,1)).Studentized: Student artıklarDeleted: Bağımlı değişkenin de ğeri ile düzeltilmi ş tahmini de ğer arasındaki fark.Studentized deleted: Silinen artı ğın kendi standart hatasına bölümü
Influence Statistics (etki ist.)DfBeta(s): Belli bir de ğişkenin çıkarılması sonucunda olu şan regresyon katsayısındaki de ğişim.Stan. DfBeta(s): Herhangi bir durumun çıkarılması sonucu regresyon katsayısındaki de ğişim. DfFit: Belli bir de ğişken çıkarıldı ğında tahmini değerdeki olu şan değişiklik.StanDfFit: Herhangi bir durumun çıkarılması sonucu tahmini de ğerdeki değişim.

Yrd.Doç.Dr.Yüksel TERZĐ 328
−−−
−−=
1
1
122
pn
n
n
pRRdüz
ÇÇoklu Korelasyon Katsayoklu Korelasyon Katsay ııssıı ( R ) :( R ) : babağığımsms ıız dez değğiişşkenler ile bakenler ile ba ğığımlml ıı dedeğğiişşken arasken aras ıındaki ndaki ne derece iline derece ili şşki olduki oldu ğğunu gunu g öösteren steren ööllçüçü ye denir. Gye denir. G öözlenen yzlenen y ii dedeğğerleri ile tahmin edilen erleri ile tahmin edilen yy ii dedeğğerleri araserleri aras ıındaki korelasyon katsayndaki korelasyon katsay ııssııddıır. R=0,937 oldukr. R=0,937 olduk çça ya yüüksek bir korelasyon ksek bir korelasyon vardvard ıır. r. ÇÇoklu Belirtme Katsayoklu Belirtme Katsay ııssıı (R(R22) :) : BaBağığımsms ıız dez değğiişşkenlerin bakenlerin ba ğığımlml ıı dedeğğiişşkeni akeni a ççııklama klama yyüüzdesidir (Rzdesidir (R 22=0.878). B=0.878). Büüttüün gn g öözlemler regresyon dozlemler regresyon do ğğrusu rusu üüzerinde yer alzerinde yer al ıırsa Rrsa R 22=1, =1, eeğğer baer bağığımlml ıı ve bave bağığımsms ıız dez değğiişşken arasken aras ıında hinda hi çç dodoğğrusal ilirusal ili şşki yoksa Rki yoksa R 22=0 olur. R=0 olur. R 22
modelin uyum iyilimodelin uyum iyili ğği i ööllçüçü ttüü olup, Rolup, R 22=0 olmas=0 olmas ıı dedeğğiişşkenler araskenler aras ıında ilinda ili şşki olmamaski olmamas ııanlamanlam ıına gelmez. Yani dena gelmez. Yani de ğğiişşkenler araskenler aras ıında donda do ğğrusal ilirusal ili şşki olmadki olmad ığıığınnıı ggöösterir. sterir. DDüüzeltilmizeltilmi şş RR22 : : Regresyon denklemine ilgisi olmayan baRegresyon denklemine ilgisi olmayan ba ğığımsms ıız dez değğiişşkenler kenler eklendieklendi ğğinde, inde, ççoklu belirtme katsayoklu belirtme katsay ııssıında dnda d üüzeltme yapzeltme yap ııll ıır. r. ÖÖrneklem Rrneklem R 22 modelin modelin anakanak üütleye ne kadar uydutleye ne kadar uydu ğğu ile ilgilidir. Bunun iu ile ilgilidir. Bunun i ççin din d üüzeltilmizeltilmi şş RR22 kullankullan ıılarak modelin larak modelin anakanak üütleye uyum iyilitleye uyum iyili ğği daha iyi yansi daha iyi yans ııtt ııll ıır. Dr. Düüzeltilmizeltilmi şş RR22 aaççııklayklay ııccıı dedeğğiişşken sayken say ııssıı ççok ok olduoldu ğğunda kullanunda kullan ıılmallmal ııddıır. r.
StdStd..ErrorError of of thethe EstimateEstimate :: ArtArtııklarklarıın standart n standart hatashatasıı (regresyon denkleminin s.h.)(regresyon denkleminin s.h.)
D.W.=2,5 deD.W.=2,5 değğeri 1.5eri 1.5 --2.5 aras2.5 aras ıında oldunda oldu ğğundan modeldeundan modeldeOtokorelasyonOtokorelasyon yoktur. yoktur.
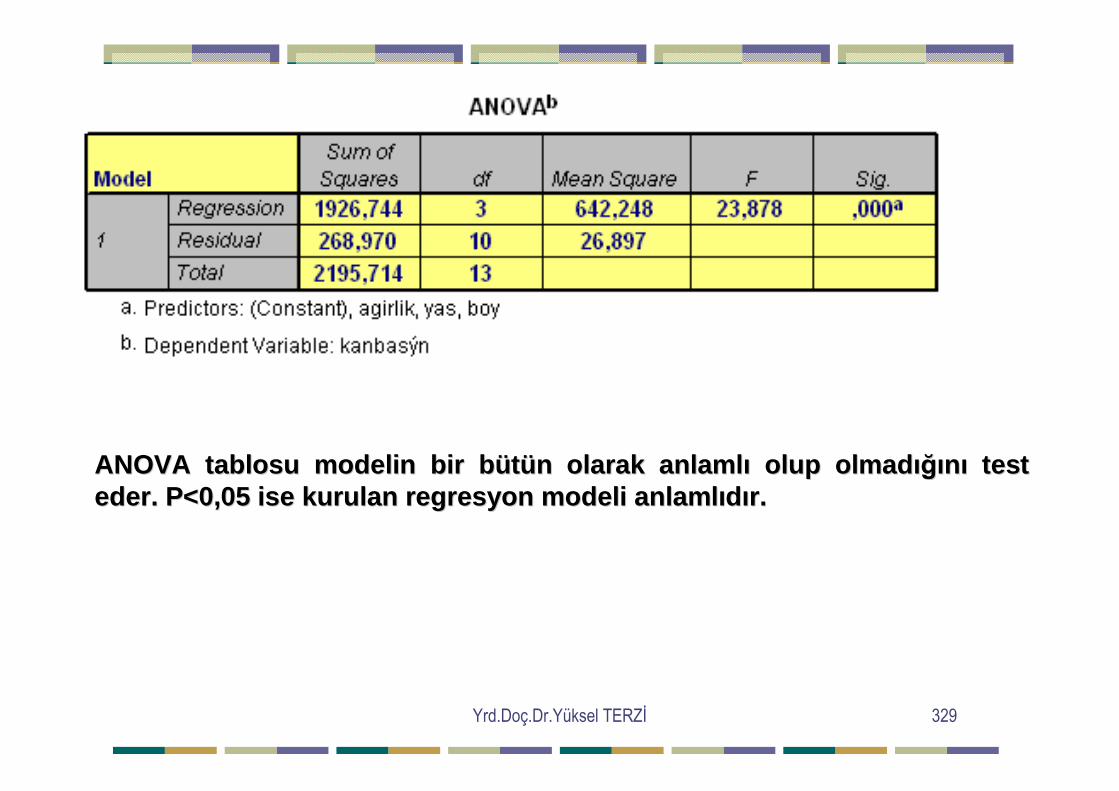
Yrd.Doç.Dr.Yüksel TERZĐ 329
ANOVA tablosu modelin bir bANOVA tablosu modelin bir b üüttüün olarak anlamln olarak anlaml ıı olup olmadolup olmad ığıığınnıı test test eder. P<0,05 ise kurulan regresyon modeli anlamleder. P<0,05 ise kurulan regresyon modeli anlaml ııddıır. r.

Yrd.Doç.Dr.Yüksel TERZĐ 330
Regresyon Regresyon modeli: modeli: Y= =Y= =--58,15+0,357Ya58,15+0,357Yaşş+0,687Boy+0,655A+0,687Boy+0,655Ağığırlrlııkk
StandardizedStandardized CoefficientsCoefficients--Beta: Beta: Beta baBeta bağığımsmsıız dez değğiişşkenlerin kenlerin öönem snem sıırasrasıınnııggöösterir. sterir. İşİşarete bakmadan en yarete bakmadan en yüüksek Beta deksek Beta değğerine sahip olan deerine sahip olan değğiişşken en ken en öönemli banemli bağığımsmsıız dez değğiişşkendir. kendir.
ZeroZero--orderorder (r) (r) :: her bir baher bir bağığımsmsıız dez değğiişşkenin bakenin bağığımlmlıı dedeğğiişşken(Y) ile ken(Y) ile korelasyonukorelasyonu
PartialPartial (k(kıısmsmıı) ) :: DiDiğğer ter tüüm bam bağığımsmsıız dez değğiişşkenlerin kenlerin XiXi ve Y ve Y üüzerindeki etkisini zerindeki etkisini ararııttttııktan sonra baktan sonra bağığımsmsıız dez değğiişşken ile Y arasken ile Y arasıındaki korelasyon katsayndaki korelasyon katsayııssııddıır. r.
PartPart (yar(yarıı kkıısmsmıı kor.)kor.) :: DiDiğğer ter tüüm bam bağığımsmsıız dez değğiişşkenlerin kenlerin XiXi dedeğğiişşkeni keni üüzerindeki etkisini arzerindeki etkisini arııttttııktan sonra Y ile arasktan sonra Y ile arasıındaki korelasyon katsayndaki korelasyon katsayııssııddıır. r.

Yrd.Doç.Dr.Yüksel TERZĐ 331
BaBağığımsmsıız dez değğiişşkenlerin bazkenlerin bazıılarlarıınnıın veya tn veya tüümmüünnüün kendi aralarn kendi aralarıında nda dodoğğrusal ilirusal ilişşki iki iççinde olmasinde olmasıı durumuna durumuna ççoklu baoklu bağğlantlantıı ((multicollinaritymulticollinarity)) denir. Bu denir. Bu ifade doifade doğğrusal regresyon modelinden bir sapmayrusal regresyon modelinden bir sapmayıı ifade eder. Bu durumda ifade eder. Bu durumda parametreler iparametreler iççin bulunan gin bulunan güüven aralven aralııklarklarıınnıın (n (confidenceconfidence intervalinterval) b) büüyyüük k olmasolmasıından dolayndan dolayıı, o parametreler s, o parametreler sııffıırdan farklrdan farklıı dedeğğildir. Yani aildir. Yani aççııklayklayııccııdedeğğiişşken ken öönemsiz demektir. nemsiz demektir.
Varyans enflasyon faktVaryans enflasyon faktöörrüü (VIF)(VIF) arttarttııkkçça regresyon katsaya regresyon katsayıılarlarıınnıın n varyansvaryansıı artar. artar. KKüçüüçük k ToleranceTolerance dedeğğeri ve beri ve büüyyüükk VIF deVIF değğeri varsa (VIF>5), eri varsa (VIF>5), babağığımsmsıız dez değğiişşkenler araskenler arasıında nda ççoklu baoklu bağğlantlantıı olduolduğğunu gunu göösterir. Bu durumda sterir. Bu durumda dedeğğiişşkenlerden sadece birisinin modele dahil edilmesi gerekmektedir. kenlerden sadece birisinin modele dahil edilmesi gerekmektedir. Tabloda Tabloda boy ve aboy ve ağığırlrlığıığın VIF den VIF değğerleri yerleri yüüksek, ksek, tolerancetolerance dedeğğerleri kerleri küçüüçük, aynk, aynıı zamanda zamanda iki deiki değğiişşken arasken arasıında ynda yüüksek korelasyon vardksek korelasyon vardıır. Bu durumda boy yada ar. Bu durumda boy yada ağığırlrlıık k dedeğğiişşkenlerinden biri modelden kenlerinden biri modelden ççııkarkarıılabilir. labilir.

Yrd.Doç.Dr.Yüksel TERZĐ 332
Boy ile aBoy ile a ğığırlrl ıık arask aras ıında ynda y üüksek ksek korelasyon vardkorelasyon vard ıır.r.
ÇÇoklu baoklu ba ğğlantlant ıı öözdezdeğğerer ve durum indeksi (ve durum indeksi ( ConditionCondition IndexIndex ) ve de) ve değğiişşim oranlarim oranlar ıı((VarianceVariance ProportionsProportions ) ile de bulunabilir. A) ile de bulunabilir. A ğığırlrl ıık dek değğiişşkeninin %1keninin %1 ’’ lik delik de ğğiişşimi 2. imi 2. öözdezdeğğerleerle , %21, %21’’ lik delik de ğğiişşimi 3. imi 3. öözdezdeğğerlererler ve %77ve %77’’ lik delik de ğğiişşimi 4. imi 4. öözdezdeğğerleerleiliili şşkilidir. Aynkilidir. Ayn ıı öözdezdeğğerdeerde yyüüksek oranksek oran ıı olan deolan de ğğiişşkenlere bakkenlere bak ııll ıır. 4.r. 4.öözdezdeğğerersabitteki varyanssabitteki varyans ıın %99n %99’’unu, boydaki deunu, boydaki de ğğiişşimin %100imin %100 ’ü’ü nnüü, a, ağığırlrl ııktaki dektaki de ğğiişşimin imin ise %77ise %77 ’’sini asini a ççııklar. Bu bize deklar. Bu bize de ğğiişşkenlerin birbiri ile bakenlerin birbiri ile ba ğığımlml ıı olduoldu ğğunu gunu g öösterir. sterir. 4.4.öözdezdeğğerinerin en ken k üçüüçü k olmask olmas ıı ve durum ve durum indexininindexinin ise en yise en y üüksek olmasksek olmas ıı öönemlidir. nemlidir.

Yrd.Doç.Dr.Yüksel TERZĐ 333
Hata terimleri ve tahmin edilen deHata terimleri ve tahmin edilen de ğğerler araserler aras ıındaki serpme grafindaki serpme grafi ğğinde, inde, noktalar rasgele ve bir ynoktalar rasgele ve bir y ığıığılma olmadan dalma olmadan da ğığılmallmal ııddıır. Er. Eğğer noktalar bir er noktalar bir eeğğri gri g öösteriyorsa dosteriyorsa do ğğrusal ilirusal ili şşki varsayki varsay ıımmıı sasağğlanmaz. lanmaz.

Yrd.Doç.Dr.Yüksel TERZĐ 334
UUçç DeDeğğerler: erler:
ZRE_1 :Standardize artZRE_1 :Standardize artııklara bakklara bakııllıır. Mutlak der. Mutlak değğerce 3erce 3’’den den bbüüyyüük olan standartlak olan standartlaşşttıırrıılmlmışış hata terimi dehata terimi değğerleri uerleri uççdedeğğerler olarak kabul edilir. erler olarak kabul edilir.

Yrd.Doç.Dr.Yüksel TERZĐ 335
CookCook UzaklUzaklığıığı : : Etkili gEtkili göözlemlerin elde edilmesinde zlemlerin elde edilmesinde kullankullanııllıır. r. CookCook dedeğğeri 1 ve daha eri 1 ve daha bbüüyyüük olan gk olan göözlemler etkili gzlemler etkili göözlem zlem olarak nitelenir. olarak nitelenir.

Yrd.Doç.Dr.Yüksel TERZĐ 336
PROBPROB İİT REGRESYON MODELT REGRESYON MODEL İİ
BaBağığımlml ıı dedeğğiişşkenin iki kenin iki şışıklkl ıı (evet(evet --hayhay ıır, bar, başşararııll ıı--babaşşararııssıız gibi) z gibi) olduoldu ğğu kategorik modeller, iki uu kategorik modeller, iki u ççlu yada glu yada g öölge balge ba ğığımlml ıı dedeğğiişşkenli kenli modeller olarak adlandmodeller olarak adland ıırrııll ıır. Bu modelleri tahmin etmek ir. Bu modelleri tahmin etmek i ççin doin do ğğrusal rusal olasolas ııll ıı, , LogitLogit (lojistik) ve (lojistik) ve ProbitProbit gibi yaklagibi yakla şışımlar kullanmlar kullan ııll ıır. r.
ProbitProbit analizi lojistik regresyona benzer. Ancak Lojistik analizi lojistik regresyona benzer. Ancak Lojistik regresyonda regresyonda loglog oddodd larlar kullankullan ııll ıırken, rken, probitprobit analizde kanalizde k üümmüülatif normal latif normal dadağığıll ıım kullanm kullan ııll ıır. r.

Yrd.Doç.Dr.Yüksel TERZĐ 337
KOVARYANS ANALKOVARYANS ANAL İİZZİİ (ANCOVA)(ANCOVA)
Kovaryans Analizi, iki veya daha fazla grupta bir sKovaryans Analizi, iki veya daha fazla grupta bir s üürekli (barekli (ba ğığımlml ıı) ) dedeğğiişşkenin ortalamalarkenin ortalamalar ıınnıın karn kar şışılalaşştt ıırr ıılmaslmas ıı ssıırasras ıında, bu denda, bu de ğğiişşkene etki kene etki eden baeden ba şşka ska s üürekli derekli de ğğiişşkenin etkisinin ortadan kaldkenin etkisinin ortadan kald ıırrıılmaslmas ıı veya bu veya bu etkinin aretkinin ar ııtt ıılmaslmas ıı maksadmaksad ııyla kullanyla kullan ıılan bir tekniktir. lan bir tekniktir.
Bu analizin avantajBu analizin avantaj ıı sonusonu ççtaki hata varyanstaki hata varyans ıınnıı azaltma ve denekler azaltma ve denekler arasaras ıındaki dindaki di ğğer farkler farkl ııll ııklarklar ıı dikkate alarak, grup farkldikkate alarak, grup farkl ııll ııklarklar ıınnıı ortaya ortaya koyar. Bakoyar. Ba ğığımlml ıı dedeğğiişşkendeki dekendeki de ğğiişşmeyi kontrol altmeyi kontrol alt ıına alarak, hata na alarak, hata varyansvaryans ıınnıı azaltazalt ıır. r.
Kovaryans Analizinde bir baKovaryans Analizinde bir ba ğığımlml ıı dedeğğiişşken olmasken olmas ıına karna kar şışıll ıık, k, birden fazla babirden fazla ba ğığımsms ıız dez değğiişşken ve birden fazla ken ve birden fazla covariatecovariate (kod de(kod de ğğiişşken)ken)olabilir. olabilir.
ÜçÜç grup hastangrup hastan ıın san sağğll ıık durumu kark durumu kar şışılalaşştt ıırr ııldld ığıığında ve yanda ve ya şş da da öönemli olarak gnemli olarak g öörrüüllüüyorsa, yayorsa, ya şş dedeğğiişşkeni kontrol altkeni kontrol alt ıında tutularak nda tutularak ANCOVA yapANCOVA yap ıılabilir. Blabilir. B ööylece yaylece ya şştaki detaki de ğğiişşmelerden kaynaklanan melerden kaynaklanan dedeğğiişşiklik aiklik a ççııklanmklanm ışış olur. olur.

Yrd.Doç.Dr.Yüksel TERZĐ 338
KOVARYANS ANALKOVARYANS ANAL İİZZİİ İİÇÇİİN VARSAYIMLARN VARSAYIMLAR
�� Gruplar baGruplar ba ğığımsms ıız olmalz olmal ııddıır. r.
�� GruplarGruplar ıın varyansn varyans ıı eeşşit olmalit olmal ııddıır.r.
�� BaBağığımlml ıı dedeğğiişşkenin verisi oransal veya aralkenin verisi oransal veya aral ııklkl ıı ööllççekli olmalekli olmal ııddıır. r.
�� BaBağığımlml ıı dedeğğiişşken normal veya normale yakken normal veya normale yak ıın dan dağığıll ıım gm g ööstermelidir.stermelidir.
�� Kod deKod de ğğiişşken (ken ( covariatecovariate ) aral) aral ııklkl ıı veya oransal veri veya oransal veri şşeklinde olmaleklinde olmal ııddıır. r. EEğğer kod deer kod de ğğiişşken nominal ise ANCOVA yapken nominal ise ANCOVA yap ıılamaz.lamaz.
�� Kod deKod de ğğiişşken ile baken ile ba ğığımlml ıı dedeğğiişşken doken do ğğrusal bir ilirusal bir ili şşki gki g ööstermelidir.stermelidir. Bu Bu varsayvarsay ıım olmazsa analizin gm olmazsa analizin g üüccüü zayzayııf olur. f olur. ÇüÇünknk üü hata varyanshata varyans ıı az az azaltazalt ıılmlm ışış olur.olur.
�� Kod deKod de ğğiişşken ile baken ile ba ğığımlml ıı dedeğğiişşken arasken aras ıındaki ilindaki ili şşkinin gkinin g üüccüü ve yve yöönnüüher grupta benzer olmalher grupta benzer olmal ııddıır. Yani kod der. Yani kod de ğğiişşken ile baken ile ba ğığımlml ıı dedeğğiişşken ken arasaras ıındaki ilindaki ili şşki ki üüzerinde bazerinde ba ğığımsms ıız dez değğiişşkenin etkisi olmamalkenin etkisi olmamal ııddıır. r.

Yrd.Doç.Dr.Yüksel TERZĐ 339

Yrd.Doç.Dr.Yüksel TERZĐ 340

Yrd.Doç.Dr.Yüksel TERZĐ 341
P=0.204>0.05 olupP=0.204>0.05 olupvaryanslarvaryanslarıın n homojenlik homojenlik şşartartıısasağğlanmlanmışış olur.olur.
HH00: iki grup i: iki grup iççin in eeğğim aynim aynııddıır (iki r (iki gruptaki uyum skoru gruptaki uyum skoru ile hastalile hastalıık skorlark skorlarııdodoğğrularrularıınnıın en eğğimi imi aynaynııddıır). r). P=0.185>0.05 olupP=0.185>0.05 olupBaBağığımsmsıız dez değğiişşken ken ile kod deile kod değğiişşken ken arasarasıındaki etkilendaki etkileşşim im öönemli denemli değğildir. Yani ildir. Yani iki grup iiki grup iççin ein eğğim im aynaynııddıır.r.
BaBağığımsmsıız dez değğiişşken (grup) ile baken (grup) ile bağığımlmlıı dedeğğiişşken arasken arasıında nda ve kod deve kod değğiişşken (ken (hastakodhastakod) ile ba) ile bağığımlmlıı dedeğğiişşken ken arasarasıında nda öönemli bir ilinemli bir ilişşki vardki vardıır (P<0.05). r (P<0.05).

Yrd.Doç.Dr.Yüksel TERZĐ 342
EEğğer kod deer kod değğiişşken (ortak deken (ortak değğiişşken) ile baken) ile bağığımlmlıı dedeğğiişşken arasken arasıındaki ilindaki ilişşki ki dodoğğrusal derusal değğilse, kod deilse, kod değğiişşken baken bağığımsmsıız dez değğiişşken alken alıınarak ANOVA yapnarak ANOVA yapııllıır veya r veya ddöönnüüşşüüm ile yeniden ANCOVA yapm ile yeniden ANCOVA yapıılabilir. Bunun ilabilir. Bunun iççin etkilein etkileşşime bakime bakııllıır, burada r, burada öönemsiz nemsiz ççııktktığıığından ANCOVA yapndan ANCOVA yapıılabilir. labilir.
BaBağığımsmsıız dez değğiişşken ken (Grup) ve kod de(Grup) ve kod değğiişşken ken ((hastakodhastakod) ile ba) ile bağığımlmlııdedeğğiişşken (ken (uyumskoruyumskor) ) arasarasıında nda öönemli bir ilinemli bir ilişşki ki vardvardıır. r.

Yrd.Doç.Dr.Yüksel TERZĐ 343
GruplarGruplarıı karkarşışılalaşşttıırmak irmak iççin, gruplarin, gruplarıın dn düüzeltilmizeltilmişşortalamalarortalamalarıına akmak gerekir. Orijinal ortalamalar hemen hemen na akmak gerekir. Orijinal ortalamalar hemen hemen eeşşittir (8,5 ve 8,00). Hastalittir (8,5 ve 8,00). Hastalıık derecesi skoru dikkate alk derecesi skoru dikkate alıındndığıığında nda ise elde edilen dise elde edilen düüzeltilmizeltilmişş ortalamalar ortalamalar ççok farklok farklııddıır (14,32 ve r (14,32 ve 2,17). Buda 2,17). Buda ANCOVAANCOVA’’nnıınn farkfarkıınnıı ggööstermektedir.stermektedir.

Yrd.Doç.Dr.Yüksel TERZĐ 344
GÜVENĐLĐRLĐK ANAL ĐZĐ (RELIABILITY ANALYSIS) Güvenilirlik bir ölçme aracında (testte) bütün soruların birbirleriyle tutarlılı ğını, ele alınan oluşumu ölçmede türdeşliğini ortaya koyan bir kavramdır. Ölçme araçlarının güvenilirli ğini değerlendirmek amacıyla geliştirilmi ş yöntemlere Güvenilirlik Analizi ve bu araçta yer alan soruların irdelenmesine ise Soru Analizi (Reliability and item analysis) denir. Testlerin güvenilirli ğini analiz etmek amacıyla güvenilirlik katsayıları hesaplanmalıdır. En çok kullanılan güvenilirlik katsayıları Cronbach alfa katsayısı ve Kuder-Richardson katsayılarıdır. Güvenilirlik analizi toplam puanlar üzerine kurulu ölçeklere (Likert Ölçeği) dayalı araçların güvenirliğini ortaya koymaya yarayan Cronbach Alfa katsayılarını hesaplar. Temel varsayımlar: “Her soru toplam skorun bir doğrusal bileşeni olmalıdır” ve “Ölçekte toplanabilirlik özelli ğinin bulunması gerekir”.

Yrd.Doç.Dr.Yüksel TERZĐ 345
Cronbach Alfa Katsayısı : Alfa katsayısı ölçekte yer alan k sorunun varyansları
toplamının genel varyansa oranlaması ile bulunan bir ağırlık standart değişim ortalamasıdır. Cronbach Alfa Katsayısı 0-1 arasında değerler alır. Sorular arasında negatif korelasyon varsa Alfa katsayısı da negatif çıkar. Bu durum güvenilirlik modelin bozulmasına neden olur.
Đkiye Bölünmüş Yöntem (Split Half) : Ölçekte yer alan soruların ikiye ayrılması ve bu iki parça arasında korelasyon hesaplanması yöntemidir. Guttman Katsayıları : 6 katsayı hesaplanır. Güvenirliği kovaryans yada varyans yaklaşımı ile hesaplayan bir yaklaşımdır.

Yrd.Doç.Dr.Yüksel TERZĐ 346
Paralel Yöntem : Soruların varyanslarının e şit oldu ğu varsayımıkullanılarak, en büyük benzerlik güvenirlik tahminl eri yapılı r. Uygunluk için ki-kare testi kullanılır.
Kesin (Strict) Paralel Yöntem : Soru ortalamaları ve varyanslarının eşit oldu ğu varsayımına göre en büyük benzerlik güvenirlik tahminleri yapılır. Uygunluk için ki-kara testi ku llanılır.
Soru ile Bütün Arasındaki Korelasyonlar Yöntemi (It em Total Correlation)
Bir soru ile di ğer soruların toplamından olu şan bütün (total)arasındaki korelasyon hesaplanmasına dayanma ktadır. E ğer soru-bütün korelasyon katsayısı dü şük ise, o sorunun ölçe ğe katkısının dü şük oldu ğu anlamına gelir. E ğer soru-bütün korelasyon katsayısı çok dü şük ise, o sorunun ölçekten çıkarılmasıgerekir.

Yrd.Doç.Dr.Yüksel TERZĐ 347
Soru Silinirse Bütün ortalamalarının Değişimi (Means if item deleted) Eğer soru ölçekten çıkarılırsa bireylerin soru ortalama ve standart sapmalarının değişimi incelenir. Soru Silinirse Güvenilirlik Katsa yısı (Reliability coefficient if item deleted) : Ele alınan soru ölçekten çıkarıldığında güvenirlik katsayısının değişimini incelemek amacıyla yararlanılan bir yaklaşımdır. Eğer soru ölçekte yer almasa idi ölçeğin güvenirliği nasıl değişirdi (azalır mı?, artar mı?) durumunu görmek amacıyla hesaplanır. Genel olarak güvenilirlik analizinde aşağıdaki varsayımların dikkate alınması gerekir:
1. Demografik ve sosyo-ekonomik sorular dışında birbiri ile ili şkili en az 20 soru içermelidir.
2. Araçlar en az 50 tane rasgele seçilen denek üzerinde uygulanmalıdır. Sorulara verilen cevapların toplanabilir özellikte (additivityassumption) olması gerekir.

Yrd.Doç.Dr.Yüksel TERZĐ 348

Yrd.Doç.Dr.Yüksel TERZĐ 349
Item : soru Scale : ölçek F test, Friedman chi-square, Cochran chi-square Model uyumu ve soruların uyumluluğu için ANOVA tablosu seçeneklerinden birisi seçilir. Tukey’s test of additivity : Ölçekte yer alan soruların bir toplamsal ölçek oluşturacak biçimde hazırlanıp hazırlanmadığını, soruların skorlarının toplanabilir olup olmadığını test eder. Interclass correlation coefficient: Olgular arasındaki değerlerin uyumlulu ğunu test eder ve hesaplama modeli için iki yönlü rasgele (Two-way Random) model seçilir. Mutlak uyumluluk için test parametre değeri (Test value) sıfır olarak seçilir. Hotelling’s T-square : Soru ortalamalarının birbirine e şit olup olmadığını test eder. Soru ortalamalarının birbirine e şit olup olmaması kavramı; soruların denekler tarafından aynı yaklaşım ile algılanıp algılanmadığını yani soruların zorluk derecelerinin birbirine eşit olup olmadığıdır. Ölçek değerlendirmede soruların %75’i orta, %12,5’i kolay ve %12,5’i de zor nitelikte olmalıdır.
Alfa katsayısının değerlendirilmesi : 0 -0,39 : ölçek güvenilir değil 0,40-0,59 : ölçek düşük güvenirlikte 0,60-0,79 : ölçek oldukça güvenilir 0,80-1,00 : ölçek yüksek derecede güvenilir bir ölçektir.

Yrd.Doç.Dr.Yüksel TERZĐ 350
Ölçekte yer alan soruların genel ortalaması (item means) 2.8276’dır. Ortalanmaların değişim aralığı (range) 1.9598 olmaktadır.
Soru-Bütün (item-total) korelasyonlara bakıldığında -0,23 ile 0,609 arasında değişim gösterdiği görülür. Soru ile bütün arasındaki korelasyonların negatif olmaması gerekir, hatta 0,25’den büyük olması beklenir.
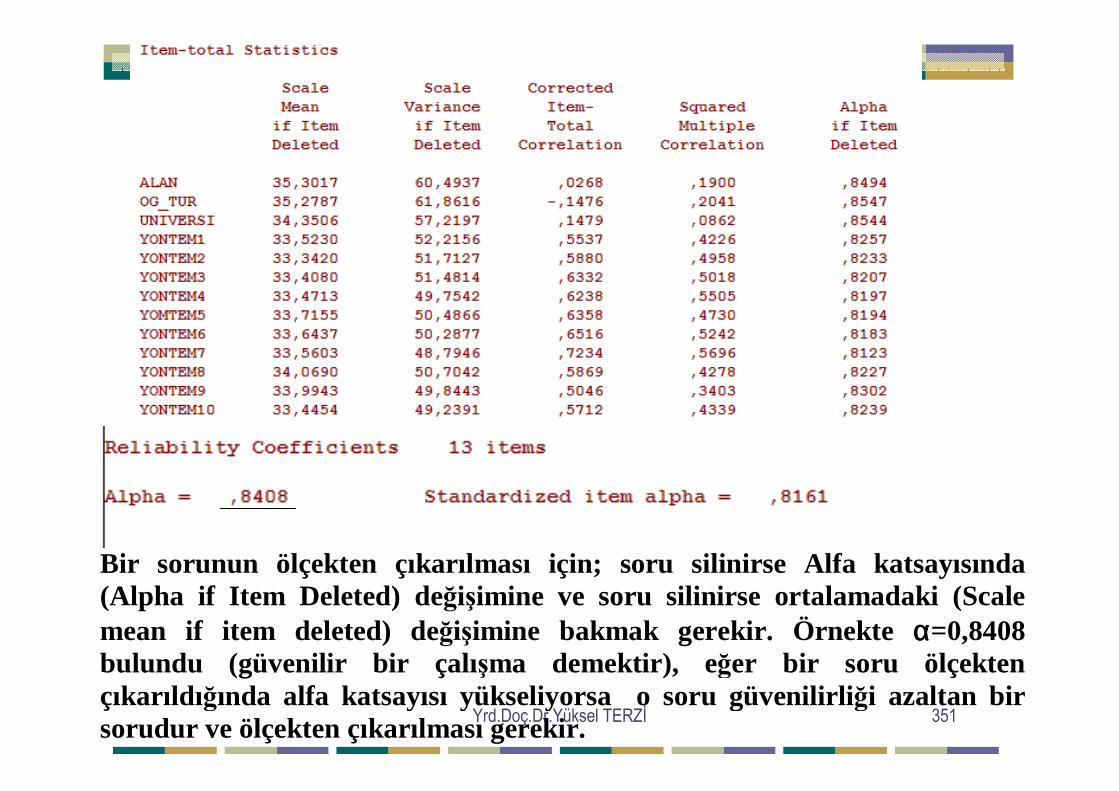
Yrd.Doç.Dr.Yüksel TERZĐ 351
Bir sorunun ölçekten çıkarılması için; soru silinirse Alfa katsayısında (Alpha if Item Deleted) değişimine ve soru silinirse ortalamadaki (Scale mean if item deleted) değişimine bakmak gerekir. Örnekte αααα=0,8408bulundu (güvenilir bir çalı şma demektir), eğer bir soru ölçekten çıkarıldığında alfa katsayısı yükseliyorsa o soru güvenilirliği azaltan bir sorudur ve ölçekten çıkarılması gerekir.

Yrd.Doç.Dr.Yüksel TERZĐ 352
Soru ortalamalarının testi sonucunda, soru ortalamaların farklı oldu ğu görülmektedir (Hotelling's T-Squared = 1606,7 , Prob. = ,0000). Yani soruların zorluk dereceleri birbirinden farklıdır.
Yapılan varyans analizi sonucuna göre ölçek toplanabilir özellikte değildir (Nonadditivity F=447,9 P=0,0000). Ölçümler arası değişime bakıldığında da önemli bir farklılık görülmektedir ( Between Measures, F=209,65 P=0,0000).

Yrd.Doç.Dr.Yüksel TERZĐ 353
FAKTÖR ANAL ĐZĐ (FACTOR ANALYSIS)
Faktör analizi, birbiri ile ili şkili p tane değişkeni bir araya getirerek az sayıda ilişkisiz ve kavramsal olarak anlamlı yeni değişkenler (faktörler, boyutlar) bulmayı amaçlayan çok değişkenli bir istatistiktir.
Faktör analizinin amacı, veri setini küçülterek daha kolay açıklanabilir hale getirmektir. Faktör analizi bir çok değişkenin birkaç başlık altında toplanması tekniğidir. Mesela bir ankette 100 madde olsun. Anket sonucunda deneklerin; sözel, matematiksel ve analitik kabiliyetleri değerlendirilmek istenmiştir. Faktör analizi ile kabiliyetlerin her birisi için “faktör skoru” elde edilebilir. Analiz ile üçten daha az veya daha fazla birbirinden farklı faktörün olup olmadığı ortaya çıkarılır.
Faktör analizi uygulamadan önce, değişkenlerin korelasyon matrisi incelenmelidir. Mutlak değerce 0,4’den küçük olan değişkenin analize dahil edilmesi uygun olmayabilir.

Yrd.Doç.Dr.Yüksel TERZĐ 354
Açıklayıcı (exploratory) ve doğrulayıcı (confirmatory) olmak üzere iki tür faktör analizi yakla şımı vardır. Açıklayıcı faktör analizinde, değişkenler arasındaki ilişkilerden hareketle faktör bulmaya yönelik bir i şlem; doğrulayıcı faktör analizin de ise değişkenler arasındaki ilişkiye dair daha önce saptanan bir hipotezin yada kuramın test edilmesi söz konusudur. SPSS’de faktörlerin ortaya çıkarılması değişik metotlar kullanılır. Bunlardan en yaygın kullanılanı Temel Bileşenler (Principal Components) metodudur. Bu metotla bütün değişkenlerdeki maksimum varyansı açıklayacak varyans hesaplanır. Kalan maksimum miktardaki varyansı açıklamak için, ikinci faktör hesaplanır. Bu süreç değişkenlerdeki bütün varyansın açıklanmasına kadar devam eder. Ancak çok faktörün olması iyi değildir. Bunun için öz değer (eigenvalue) kullanılarak, analizde kaç faktörün kullanılacağına karar verilir.

Yrd.Doç.Dr.Yüksel TERZĐ 355
Faktör Analizinin Adımları : 1. Bütün değişkenler için korelasyon matrisi hesaplanır.Birbiri i le
ili şkisiz olan değişkenler belirlenir. Böylece faktör modelin uygunluğu değerlendirilir.
2. Faktör sayısı belirlenir. Bu adımda seçilen modelin veriye ne kadar uyumlu olduğu tespit edilir.
3. Rotasyonla faktörler dönüştürülerek, daha iyi yorumlanması sağlanır.
4. Her vaka için faktörün skoru hesaplanır. m kadar önemli faktör “ bağımsızlık, yorumlamada açıklık ve anlamlılık” için bir eksen döndürmesine (rolation) tabi tutu lur. Eksenlerin döndürülmesi sonrasında maddelerin bir faktördeki yükü artarken, diğer faktörlerdeki yükleri azalır. Dik (orthogonal) ve eğik (oblique) olmak üzere iki tür döndürme yakla şımı vardır. Döndürme sonunda değişkenlerle ilgili toplam varyans değişmezken, faktörlerin açıkladıkları varyans değişir. Soysal bilimlerde genellikle dik döndürme tercih edilir. Yani faktörler eksenin konumu değiştirilmeksizin (90 derece) döndürülür. Dik döndürme tekniklerinden en sık kullanılan varimax ve quartimax’dır. Bu teknikler maddelerin yüklerini bir faktörde 1’e, di ğerlerinde ise sıfıra yaklaştırmayı amaçlar.

Yrd.Doç.Dr.Yüksel TERZĐ 356

Yrd.Doç.Dr.Yüksel TERZĐ 357
Correlation MatrixCorrelation MatrixCorrelation MatrixCorrelation Matrix
1,000 ,559 ,521 ,445 ,426 ,447 ,455 ,345 ,203 ,294,559 1,000 ,568 ,554 ,407 ,449 ,508 ,402 ,246 ,305,521 ,568 1,000 ,560 ,517 ,456 ,511 ,416 ,322 ,340,445 ,554 ,560 1,000 ,518 ,560 ,502 ,396 ,292 ,447,426 ,407 ,517 ,518 1,000 ,573 ,529 ,367 ,400 ,405,447 ,449 ,456 ,560 ,573 1,000 ,609 ,393 ,351 ,327,455 ,508 ,511 ,502 ,529 ,609 1,000 ,571 ,436 ,436,345 ,402 ,416 ,396 ,367 ,393 ,571 1,000 ,348 ,500,203 ,246 ,322 ,292 ,400 ,351 ,436 ,348 1,000 ,487,294 ,305 ,340 ,447 ,405 ,327 ,436 ,500 ,487 1,000
,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000 ,000
YONTEM1YONTEM2YONTEM3YONTEM4YOMTEM5YONTEM6YONTEM7YONTEM8YONTEM9YONTEM10YONTEM1YONTEM2YONTEM3YONTEM4YOMTEM5YONTEM6YONTEM7YONTEM8YONTEM9YONTEM10
Correlation
Sig. (1-tailed)
YONTEM1 YONTEM2 YONTEM3 YONTEM4 YOMTEM5 YONTEM6 YONTEM7 YONTEM8 YONTEM9 YONTEM10
Değişkenler arasındaki korelasyonlar genelde iyi gözükmekte dir.

Yrd.Doç.Dr.Yüksel TERZĐ 358
KMO and Bartlett's TestKMO and Bartlett's TestKMO and Bartlett's TestKMO and Bartlett's Test
,896,896,896,896
1489,00345
,000,000,000,000
Kaiser-Meyer-Olkin Measure of SamplingAdequacy.
Approx. Chi-SquaredfSig.
Bartlett's Test ofSphericity
KMO örneklem yeterlili ği ölçütü, gözlenen korelasyon katsayıları büyüklüğü ile kısmi korelasyon katsayılarının büyüklüğünü karşılaştıran bir indekstir. KMO ölçütü 0,9- 1,0 arasında mükemmel, 0,8-0,89 arasında çok iyi, 0,7-0,79 arasında iyi, 0,6-0,69 arasında orta, 0,5-0,59 zayıf, 0,5’de aşağı ise kabul edilemez. Örnekte 0,89 bulunmuş ve çok iyi olduğu söylenebilir. Bartlett testi ile korelasyon matrisinin birim matr is olup olmadığı test edilir. H0 : Evren korelasyon matrisi birim matristir. P=0,000<0,01 olduğundan yokluk hipotezi reddedilir. Yani evren korelasyon matrisi birim matris değildir.

Yrd.Doç.Dr.Yüksel TERZĐ 359
Anti-image MatricesAnti-image MatricesAnti-image MatricesAnti-image Matrices
,588 -,159 -,105 8,9E-04 -5,E-02 -6,E-02 -3,E-02 -7,E-03 5,5E-02 -3,1E-02-,159 ,512 -,109 -,118 1,9E-02 -7,E-03 -6,E-02 -4,E-02 4,3E-03 2,47E-02-,105 -,109 ,505 -,104 -9,E-02 1,7E-02 -4,E-02 -5,E-02 -5,E-02 2,60E-02
8,9E-04 -,118 -,104 ,482 -6,E-02 -,122 -4,E-03 6,3E-03 4,6E-02 -,124
-5,E-02 1,9E-02 -9,E-02 -6,E-02 ,531 -,131 -5,E-02 1,9E-02 -8,E-02 -5,5E-02-6,E-02 -7,E-03 1,7E-02 -,122 -,131 ,487 -,137 -9,E-03 -4,E-02 4,97E-02-3,E-02 -6,E-02 -4,E-02 -4,E-03 -5,E-02 -,137 ,432 -,155 -8,E-02 -1,8E-02-7,E-03 -4,E-02 -5,E-02 6,3E-03 1,9E-02 -9,E-03 -,155 ,580 -5,E-03 -,171
5,5E-02 4,3E-03 -5,E-02 4,6E-02 -8,E-02 -4,E-02 -8,E-02 -5,E-03 ,671 -,204-3,E-02 2,5E-02 2,6E-02 -,124 -5,E-02 5,0E-02 -2,E-02 -,171 -,204 ,580
,912a -,290 -,193 1,7E-03 -8,E-02 -,112 -6,E-02 -1,E-02 8,7E-02 -5,4E-02-,290 ,898a -,215 -,237 3,7E-02 -1,E-02 -,130 -8,E-02 7,3E-03 4,53E-02
-,193 -,215 ,917a -,210 -,183 3,4E-02 -8,E-02 -9,E-02 -8,E-02 4,81E-021,7E-03 -,237 -,210 ,897a -,121 -,252 -1,E-02 1,2E-02 8,1E-02 -,234-8,E-02 3,7E-02 -,183 -,121 ,924a -,257 -,104 3,4E-02 -,130 -9,8E-02
-,112 -1,E-02 3,4E-02 -,252 -,257 ,891a -,297 -2,E-02 -8,E-02 9,35E-02-6,E-02 -,130 -8,E-02 -1,E-02 -,104 -,297 ,904a -,309 -,157 -3,5E-02-1,E-02 -8,E-02 -9,E-02 1,2E-02 3,4E-02 -2,E-02 -,309 ,890a -8,E-03 -,2948,7E-02 7,3E-03 -8,E-02 8,1E-02 -,130 -8,E-02 -,157 -8,E-03 ,865a -,327
-5,E-02 4,5E-02 4,8E-02 -,234 -1,E-01 9,4E-02 -4,E-02 -,294 -,327 ,840a
YONTEM1
YONTEM2YONTEM3YONTEM4YOMTEM5
YONTEM6YONTEM7YONTEM8YONTEM9
YONTEM10YONTEM1YONTEM2YONTEM3
YONTEM4YOMTEM5YONTEM6
YONTEM7YONTEM8YONTEM9YONTEM10
Anti-imageCovariance
Anti-imageCorrelation
YONTEM1 YONTEM2 YONTEM3 YONTEM4 YOMTEM5 YONTEM6 YONTEM7 YONTEM8 YONTEM9 YONTEM10
Measures of Sampling Adequacy(MSA)a.
Anti-image correlation matrices’in köşegen elemanları örneklem yeterliliğini gösterir. Makul büyüklükteki değerler (buradaki gibi) iyi faktör analizi için geçer lidir.

Yrd.Doç.Dr.Yüksel TERZĐ 360
CommunalitiesCommunalitiesCommunalitiesCommunalities
1,000 ,6141,000 ,6551,000 ,6231,000 ,6021,000 ,5411,000 ,5611,000 ,6431,000 ,5201,000 ,6591,000 ,660
YONTEM1YONTEM2YONTEM3YONTEM4YOMTEM5YONTEM6YONTEM7YONTEM8YONTEM9YONTEM10
Initial Extraction
Extraction Method: Principal Component Analysis.
Bir değişken ile diğer bütün değişkenler arasındaki çoklu korelasyon katsayısının karesi, değişkenler arasındaki doğrusal ili şkinin bir di ğer göstergesidir. Bu değerlere ortak varyans (Communality) olarak verilir. Burada maddelerle ilgili olarak verilen or tak varyansların 0,520 ile 0,660 arasında değiştiği görülmektedir. Eğer düşük çoklu korelasyon katsayısı varsa, bu değişken analizden çıkarılmalıdır.

Yrd.Doç.Dr.Yüksel TERZĐ 361
Total Variance ExplainedTotal Variance ExplainedTotal Variance ExplainedTotal Variance Explained
4,980 49,80249,80249,80249,802 49,802 4,980 49,802 49,802 3,577 35,771 35,7711,096 10,95610,95610,95610,956 60,75760,75760,75760,757 1,096 10,956 60,757 2,499 24,986 60,757
,735 7,354 68,111,626 6,258 74,370
,575 5,746 80,116,502 5,022 85,138
,477 4,773 89,911,375 3,750 93,661
,333 3,333 96,994,301 3,006 100,000
Component12
34
56
78
910
Total% of
VarianceCumulative
% Total% of
VarianceCumulative
% Total% of
VarianceCumulative
%
Initial EigenvaluesExtraction Sums of Squared
LoadingsRotation Sums of Squared
Loadings
Extraction Method: Principal Component Analysis.
Total variance explained” tablosunda, rotasyona tabi olmamış faktörlerin genel özellikleri vardır. Analizde 10 değişkenin özdeğeri 1’den büyük olan iki faktör altında toplanmıştır. Bu iki faktörün ölçe ğe ilişkin açıkladıkları varyans %60,757 dir.

Yrd.Doç.Dr.Yüksel TERZĐ 362
Scree Plot
Component Number
10987654321
Eigenvalue
6
5
4
3
2
1
0
Şekilde öz değerlerin nispi değerleri verilmi ştir. Burada her faktör ile ili şkili toplam varyans gösterilmiştir. Grafikte 1 ve 2. faktörden sonra belli bir dü şme olduğu görülmektedir. Dolayısıyla faktör sayısı 2 olarak tespit edilir. 3 ve diğer faktörlerden sonra önemli bir düşüş eğilimi görülmemektedir. Yani üçüncü ve sonraki faktörlerin varyansa katkıları birbirine yakındır.

Yrd.Doç.Dr.Yüksel TERZĐ 363
Component MatrixComponent MatrixComponent MatrixComponent Matrix aaaa
,797 8,8E-02
,759 -,161,749 -,249,743 -9,E-02,736 1,6E-02
,717 -,374,670 -,406,668 ,272,629 ,514,557 ,590
YONTEM7YONTEM4YONTEM3YONTEM6YOMTEM5
YONTEM2YONTEM1YONTEM8YONTEM10
YONTEM9
1 2Component
Extraction Method: Principal Component Analysis.
2 components extracted.a.
Component matrix tablosunda birinci faktör yük değerlerinin tamamı 0,557’nin üzerindedir. Bu bulgu ölçeğin genel bir faktöre sahip olduğunu gösterir.
Rotated Component MatrixRotated Component MatrixRotated Component MatrixRotated Component Matrix aaaa
,798,798,798,798 ,132,779,779,779,779 7,8E-02,748,748,748,748 ,251
,703,703,703,703 ,327,648,648,648,648 ,375,584,584,584,584 ,549
,578,578,578,578 ,4559,1E-02 ,807,807,807,807
,194 ,789,789,789,789
,370 ,619,619,619,619
YONTEM2YONTEM1YONTEM3
YONTEM4YONTEM6YONTEM7
YOMTEM5YONTEM9YONTEM10
YONTEM8
1 2
Component
Extraction Method: Principal ComponentAnalysis. Rotation Method: Varimax with KaiserNormalization.
Rotation converged in 3 iterations.a.
Faktör döndürme sonuçları (rotated component matrix) incelendiğinde, 1-7 maddelerin ilk faktörde, 8-10 maddelerin ise ikinci faktörde daha yüksek değerler verdiği görülmektedir. 7. madde iki faktörde de yüksek çıkmıştır (0,578 - 0,549) . Bu yüzden ölçekten çıkarılması daha uygun olacaktır. 7.madde analizden çıkarılıp yeniden analiz yapılır.

Yrd.Doç.Dr.Yüksel TERZĐ 364
LOJLOJ İİSTSTİİK REGRESYONK REGRESYONBaBağığımlml ıı dedeğğiişşken mutlaka ikili sonucu olan (ken mutlaka ikili sonucu olan ( dikotomdikotom ) de) değğiişşken ken
olduoldu ğğunda (saunda (sa ğğ--ööllüü) Lojistik regresyon kullan) Lojistik regresyon kullan ııll ıır. Ayrr. Ayr ııca baca bağığımsms ıız z dedeğğiişşkenlerinde genelde skenlerinde genelde s üürekli olmasrekli olmas ıı istenir.istenir.
Lojistik regresyonda Lojistik regresyonda oddsodds oranoran ıı kullankullan ııll ıır. r. OddsOdds oranoran ıı, olma , olma ihtimalinin olmama ihtimaline oranihtimalinin olmama ihtimaline oran ıı olarak tanolarak tan ıımlanmlan ıır. r.
AAççııklayklay ııccıı dedeğğiişşkenlere gkenlere g ööre cevap dere cevap de ğğiişşkeninin beklenen keninin beklenen dedeğğerleri olaserleri olas ııll ıık olarak elde edilen bir regresyon yk olarak elde edilen bir regresyon y ööntemidir.ntemidir. Normal Normal dadağığıll ıım varsaym varsay ıımmıı yoktur. Bir olayyoktur. Bir olay ıın ihtimali an ihtimali a şşaağığıdaki gibi bulunur.daki gibi bulunur.
Lojistik regresyonda Lojistik regresyonda üçüç temel ytemel y ööntem vardntem vard ıır.r.1.1. İİkili lojistik regresyon (kili lojistik regresyon ( BinaryBinary logisticlogistic )): : İİkili cevap ikili cevap i ççeren baeren ba ğığımlml ıı
dedeğğiişşkenlerle yapkenlerle yap ıılan lojistik regresyon analizidir. Ortak delan lojistik regresyon analizidir. Ortak de ğğiişşkeler keler ssüürekli olmalrekli olmal ııddıır. r.
2. S2. Sııralral ıı lojistik regresyon (lojistik regresyon ( ordinalordinal logisticlogistic ) ) : Cevap de: Cevap de ğğiişşkenin skenin s ııralral ııööllççekli olduekli oldu ğğu durumlarda uygulanan bir yu durumlarda uygulanan bir y ööntem olup, en az ntem olup, en az üçüçkategorisi olmaskategorisi olmas ıı gerekir(hafifgerekir(hafif --ortaorta --aağığır gibi).r gibi).
3. 3. İİsimsel lojistik regresyon (nominal simsel lojistik regresyon (nominal logisticlogistic ) ) : Cevap de: Cevap de ğğiişşkeni isimsel keni isimsel ööllççekli olup, en az ekli olup, en az üçüç kategoriden olukategoriden olu şşmalmal ııddıır (fenr (fen --tt ııpp--eeğğitimitim --iibfiibf gibi).gibi).

Yrd.Doç.Dr.Yüksel TERZĐ 365
ÖÖrnek :rnek : Kayak yapmak isteyenlerle ilgili bir anket yapKayak yapmak isteyenlerle ilgili bir anket yap ııll ııyor. yor. Kayak deKayak de ğğiişşkeni bakeni ba ğığımlml ıı dedeğğiişşken alken al ıınmnm ışış ve evet diyenler ve evet diyenler (1), hay(1), hay ıır diyenler (0) alr diyenler (0) al ıınmnm ışıştt ıır. Tahmin edici der. Tahmin edici de ğğiişşkenler kenler olarak Atletik, yolarak Atletik, y üükselti ve hata alkselti ve hata al ıınmnm ışıştt ıır. Atletik der. Atletik de ğğiişşkende 0 kende 0 hihi çç kabiliyeti olmayanlarkabiliyeti olmayanlar ıı, 10 ise , 10 ise ççok yok y üüksek kabiliyeti ksek kabiliyeti ggööstermektedir. Ystermektedir. Y üükseklikte de yine benzer kseklikte de yine benzer şşekilde kodlama ekilde kodlama yapyap ıılmlm ışıştt ıır. Hata der. Hata de ğğiişşkeni ise evet (1) ve haykeni ise evet (1) ve hay ıır (0) olarak r (0) olarak kodlanmkodlanm ışıştt ıır.r.
nnz
nn
XbXbXbbze
XbXbXbbYP
++++=+
=
++++−+=
− L
L
22110
22110
,1
1
)](exp[1
1)(

Yrd.Doç.Dr.Yüksel TERZĐ 366
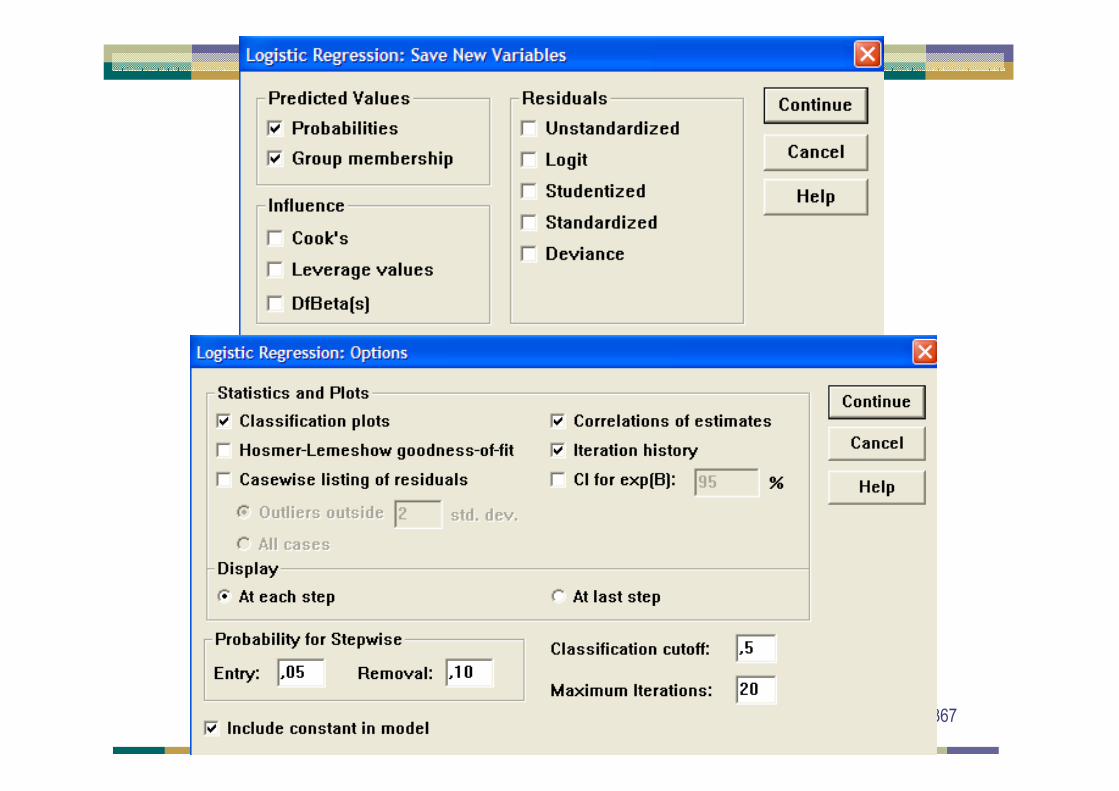
Yrd.Doç.Dr.Yüksel TERZĐ 367

Yrd.Doç.Dr.Yüksel TERZĐ 368
Model uyum iyiliModel uyum iyili ğği testi:i testi:GGöözlenen dezlenen de ğğerlerin tahmin edilen erlerin tahmin edilen dedeğğerlerle karerlerle kar şışılalaşştt ıırmasrmas ıı iiççin in --2logL 2logL dedeğğerlerine bakerlerine bak ııll ıır. r. İİyi model gyi model g öözlenen zlenen sonusonu ççlarlar ıın yn y üüksek ihtimallerini oluksek ihtimallerini olu şşturan turan modeldir yani modeldir yani --2LL de2LL de ğğerinin (serinin (s ııff ııra ra yakyak ıınsa model mnsa model m üükemmeldir) kkemmeldir) k üçüüçü k k olmasolmas ıı gerekir. gerekir.
BlockBlock 0 da sadece sabitin yer 0 da sadece sabitin yer aldald ığıığı model imodel i ççin in --2LL=55.0.51 bulundu.2LL=55.0.51 bulundu.BlockBlock 1 de ise sabit ve t1 de ise sabit ve t üüm bam bağığımsms ıız z dedeğğiişşkenlerin yer aldkenlerin yer ald ığıığı modelin modelin --2LL 2LL dedeğğeri 24.313 bulunmueri 24.313 bulunmu şştur. tur.
Model Model ChiChi --SquareSquare sadece sabiti sadece sabiti olan modelin olan modelin --2LL de2LL de ğğeri ile beri ile b üüttüün n dedeğğiişşkenleri ihtiva eden modelin kenleri ihtiva eden modelin --2LL 2LL arasaras ıındaki farkndaki fark ıı verir. Bu istatistik ile verir. Bu istatistik ile sabit harisabit hari çç, t, tüüm dem değğiişşkenlerin kenlerin katsaykatsay ıılarlar ıınnıın sn s ııff ıır oldur oldu ğğu yokluk hipotezi u yokluk hipotezi test edilir. test edilir.
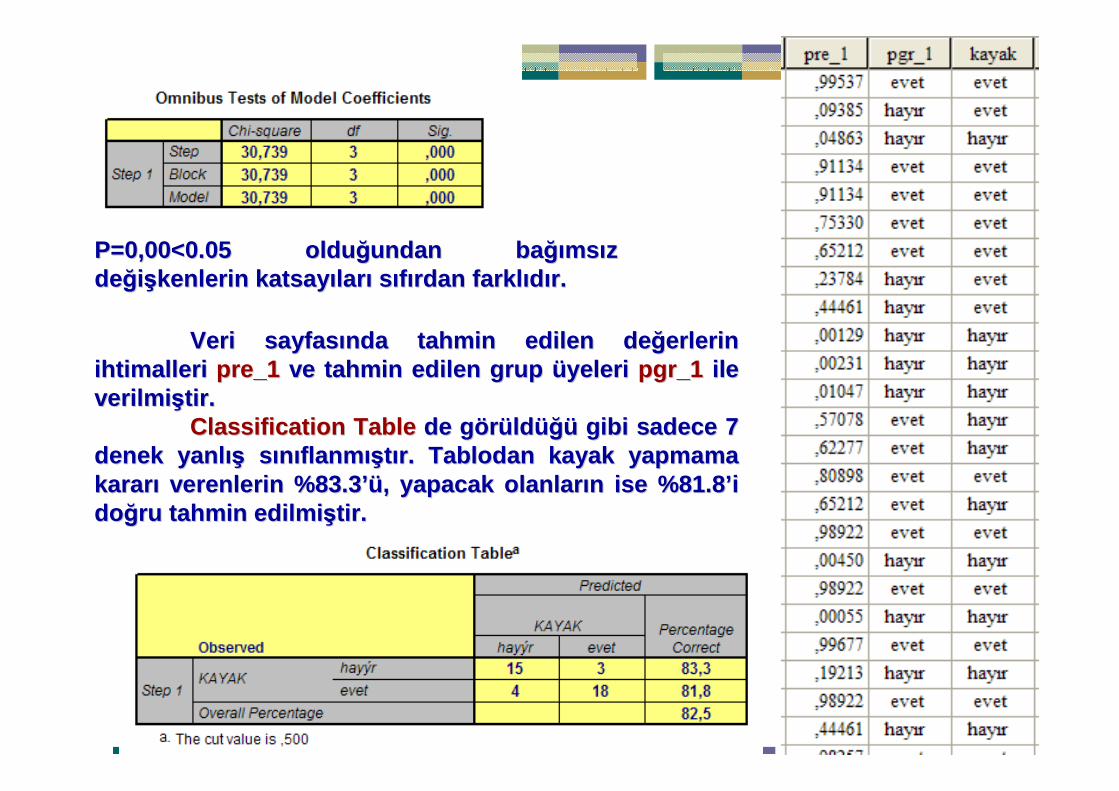
Yrd.Doç.Dr.Yüksel TERZĐ 369
P=0,00<0.05 olduP=0,00<0.05 oldu ğğundan baundan ba ğığımsms ıız z dedeğğiişşkenlerin katsaykenlerin katsay ıılarlar ıı ssııff ıırdan farklrdan farkl ııddıır.r.
Veri sayfasVeri sayfas ıında tahmin edilen denda tahmin edilen de ğğerlerin erlerin ihtimalleri ihtimalleri prepre _1 _1 ve tahmin edilen grup ve tahmin edilen grup üüyeleri yeleri pgrpgr _1_1 ile ile verilmiverilmi şştir. tir.
ClassificationClassification TableTable de gde g öörrüüldld üüğğüü gibi sadece 7 gibi sadece 7 denek yanldenek yanl ışış ssıınnııflanmflanm ışıştt ıır. Tablodan kayak yapmama r. Tablodan kayak yapmama kararkarar ıı verenlerin %83.3verenlerin %83.3 ’ü’ü , yapacak olanlar, yapacak olanlar ıın ise %81.8n ise %81.8 ’’ i i dodoğğru tahmin edilmiru tahmin edilmi şştir. tir.

Yrd.Doç.Dr.Yüksel TERZĐ 370
YukarYukar ııdaki tabloda daki tabloda BB dedeğğerleri katsayerleri katsay ıılar olup, denelar olup, dene ğğin bir iin bir i şşi yada dii yada di ğğerini yapma erini yapma ihtimalini belirlemede kullanihtimalini belirlemede kullan ııll ıır. Burada kayak yapma yada yapmama ihtimali r. Burada kayak yapma yada yapmama ihtimali araaraşştt ıırr ıılmaktadlmaktad ıır. r. İİhtimal 0.5htimal 0.5 ’’ ten bten b üüyyüük ise denek ise dene ğğin kayak yapmaya karar verdiin kayak yapmaya karar verdi ğği tahmin i tahmin edilir. edilir.
B sB s üütunundaki itunundaki i şşaretler ise iliaretler ise ili şşkinin ykinin y öönnüünnüü ggöösterir. Yani daha atletik olan ve sterir. Yani daha atletik olan ve hatalarhatalar ıınnıın sn s ööylenmesini isteyenlerin kayak yapmaya istekli olduylenmesini isteyenlerin kayak yapmaya istekli oldu ğğu, yu, yüükseklikten kseklikten korkanlarkorkanlar ıın ise kayak yapmaya daha az en ise kayak yapmaya daha az e ğğilimli olduilimli oldu ğğu su s ööylenebilir. ylenebilir.
WaldWald ist.ist. =B/S.E. ile bulunur. Burada Atletik katsay=B/S.E. ile bulunur. Burada Atletik katsay ıı öönemli (P=0,006<0.05), dinemli (P=0,006<0.05), di ğğerleri erleri ise ise öönemsiz bulunmunemsiz bulunmu şştur. tur.
ExpExp (B) (B) oddsodds oranlaroranlar ııddıır. Yani kayak yapmaya karar verenlerin ihtimalinin, kayak r. Yani kayak yapmaya karar verenlerin ihtimalinin, kayak istemeyenlerin ihtimaline oranistemeyenlerin ihtimaline oran ııddıır. Mesela atletik kabiliyet bir birim artarsa r. Mesela atletik kabiliyet bir birim artarsa lnln oddsodds 2,342 kat 2,342 kat artar. artar.
9968,0))1(363,0)0(579,0)10(851,0138,3exp(1
1
))363,0579,0851,0138,3(exp(1
1
321
=−+−++
=
+−+−−+=
XXX1.ki1.kişşii
İİhtimal 1htimal 1 ’’e e yakyak ıın n olduoldu ğğundan, undan, birinci kibirinci ki şşinin inin kayak kayak yapacayapaca ğığıtahmin edilir.tahmin edilir.
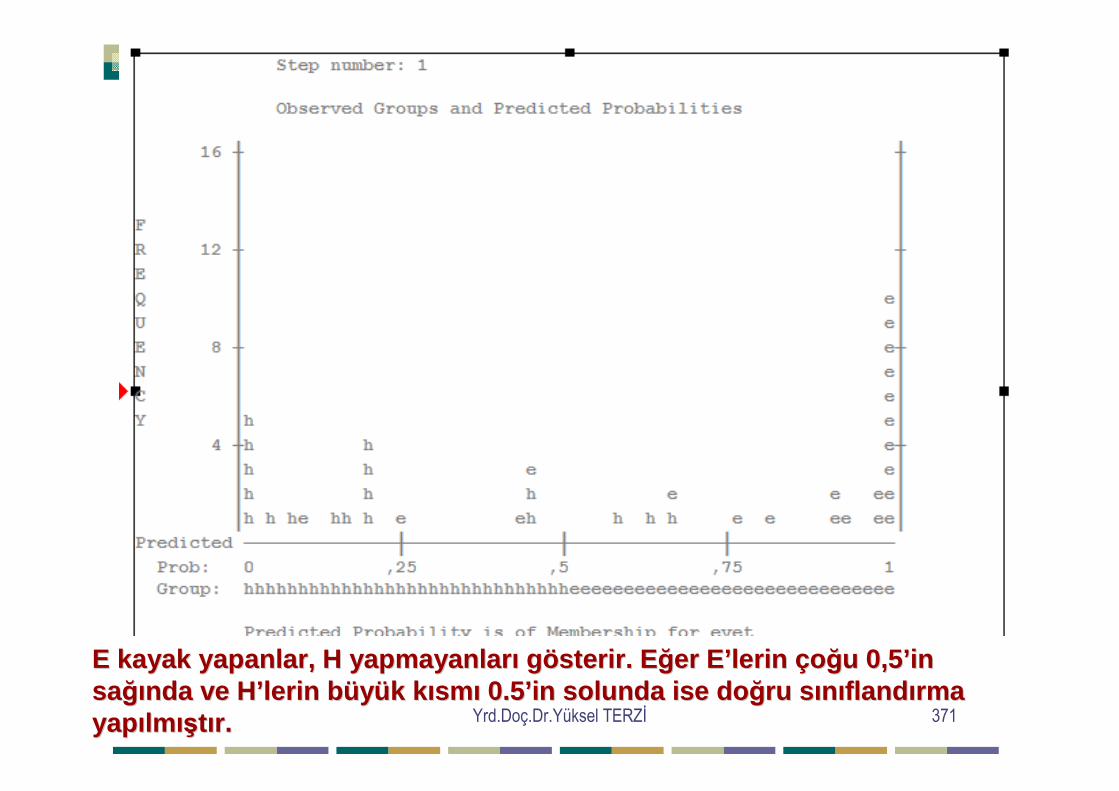
Yrd.Doç.Dr.Yüksel TERZĐ 371
E kayak yapanlar, H yapmayanlarE kayak yapanlar, H yapmayanlar ıı ggöösterir. Esterir. E ğğer er EE’’ lerinlerin ççooğğu 0,5u 0,5’’ in in sasağığında ve nda ve HH’’ lerinlerin bbüüyyüük kk k ıısmsm ıı 0.50.5’’ in solunda ise doin solunda ise do ğğru sru s ıınnııflandfland ıırma rma yapyap ıılmlm ışıştt ıır. r.

Yrd.Doç.Dr.Yüksel TERZĐ 372

Yrd.Doç.Dr.Yüksel TERZĐ 373
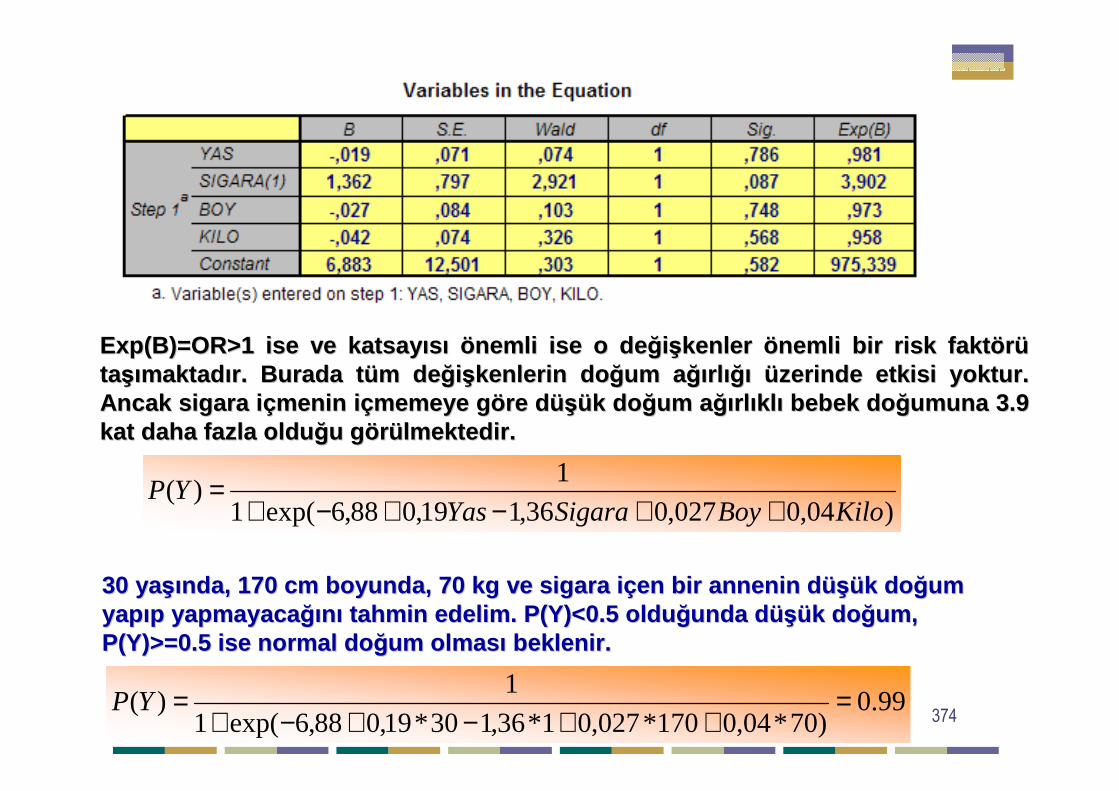
Yrd.Doç.Dr.Yüksel TERZĐ 374
ExpExp (B)=OR>1 ise ve katsay(B)=OR>1 ise ve katsay ııssıı öönemli ise o denemli ise o de ğğiişşkenler kenler öönemli bir risk faktnemli bir risk fakt öörrüütataşışımaktadmaktad ıır. Burada tr. Burada t üüm dem değğiişşkenlerin dokenlerin do ğğum aum ağığırlrl ığıığı üüzerinde etkisi yoktur. zerinde etkisi yoktur. Ancak sigara iAncak sigara i ççmenin imenin i ççmemeye gmemeye g ööre dre d üüşşüük dok do ğğum aum ağığırlrl ııklkl ıı bebek dobebek do ğğumuna 3.9 umuna 3.9 kat daha fazla oldukat daha fazla oldu ğğu gu g öörrüülmektedir. lmektedir.
)04,0027,036,119,088,6exp(1
1)(
KiloBoySigaraYasYP
++−+−+=
30 ya30 yaşışında, 170 cm boyunda, 70 kg ve sigara inda, 170 cm boyunda, 70 kg ve sigara i ççen bir annenin den bir annenin d üüşşüük dok do ğğum um yapyap ııp yapmayacap yapmayaca ğığınnıı tahmin edelim. P(Y)<0.5 oldutahmin edelim. P(Y)<0.5 oldu ğğunda dunda d üüşşüük dok do ğğum, um, P(Y)>=0.5 ise normal doP(Y)>=0.5 ise normal do ğğum olmasum olmas ıı beklenir. beklenir.
99.0)70*04,0170*027,01*36,130*19,088,6exp(1
1)( =
++−+−+=YP

Yrd.Doç.Dr.Yüksel TERZĐ 375
KAYNAKLAR : � Özdamar K. (2002). Đstatistik Paket Programlarıyla Veri Analizi 1,
Kaan Kitabevi, Eskişehir. � Özdamar K. (1999). Đstatistik Paket Programlarıyla Veri Analizi 2,
Kaan Kitabevi, Eskişehir. � Serper Ö. (2000), Uygulamalı Đstatistik I,II. Egi Kitabevi, Bursa. � Ural A., Kılıç Đ. (2005). Bilimsel Araştırma Süreci ve SPSS ile Veri
Analizi, , Detay Yayıncılık, Ankara. � Akgül A. (2003). Tıbbi Araştırmalarda Đstatistiksel Analiz
Teknikleri-SPSS Uygulamaları, Ankara � Kalaycı Ş. Ve ark. (2005). SPSS Uygulamalı Çok Değişkenli Đstatistik Teknikleri, Asil Yayın Dağıtım, Ankara.
� Efe E., Bek Y, Şahin M. (2000). SPSS’te Çözümleri Đle Đstatistik Yöntemler II, Sütçü Đmam Üniversitesi Rektörlüğü, Yayın NO:10, Kahramanmaraş.
� Çokluk Ö., Şekercioğlu G., Büyüköztürk Ş. (2010). Sosyal Bilimler Đçin Çok Değişkenli Đstatistik, Gegem Akademi, Ankara.
� Mertler, C.A. &Vannatta, R.A.(2005). Advanced and multivariate statistical methods: Pratical application and interpretation (Third Ed.), Pyrczak Publishing.
� Tabachnick, B.G. & Fidel, L.S (1996). Using multivariate statistics (Third Ed.), New York.
![[XLS] Object Summary.xlsx · Web view5/26/2010 5/26/2010. 5/2/2011 5/2/2011. 9/30/2011 9/30/2011. 7/6/2011 7/6/2011. 11/28/2011 11/28/2011. 12/6/2011 12/6/2011. 11/28/2011 11/28/2011.](https://static.fdocuments.net/doc/165x107/5ae744ba7f8b9a87048f0cd5/xls-object-summaryxlsxweb-view5262010-5262010-522011-522011-9302011.jpg)



![e ] A Y E ¾ ¹ U Õ]as-space.snu.ac.kr/bitstream/10371/75844/1/전주사고본_실록의_보존과_관리.pdf · 1455 _1s½Yñ vb b=pÑfJua vþ`í (Fs á) E`ÑZÍ Esí` a] 1473 _1s½Yñ](https://static.fdocuments.net/doc/165x107/5cd5386488c993ec188df8a6/e-a-y-e-u-oas-spacesnuackrbitstream10371758441pdf.jpg)



![[GESTIÓN+MEDICIÓN=PROGRESO] · 2015-12-03 · 3 Dic ’ 2010’ Ene’ 2011’ Feb’ 2011’ Mar’ 2011’ Abr’ 2011’ May’ 2011’ Jun’ 2011’ Jul’’ 2011’ Ago’](https://static.fdocuments.net/doc/165x107/5ecede15b16df948656232b5/gestinmedicinprogreso-2015-12-03-3-dic-a-2010a-enea-2011a-feba.jpg)









