
An Empirical Analysis of Sponsored Search Performance in Search Engine Advertising

Sponsored Search Advertising form a Database Perspectiveform a Database Perspective
George Trimponias, CSE
1

The 3 Stages of Sponsored Search
• Ad Selection: Select all candidate ads that may be relevant.– Matchtype is important in this process.
• Ad Ranking: Rank candidate ads and select top-K.• Ad Ranking: Rank candidate ads and select top-K.– Industry Ranking Score: Max Bid × Quality Score
• Ad Pricing: Determine the actual cost per click for every advertiser in the top-K list.– Most prominent pricing scheme is the Generalized
Second-Price Auction (GSP).
2

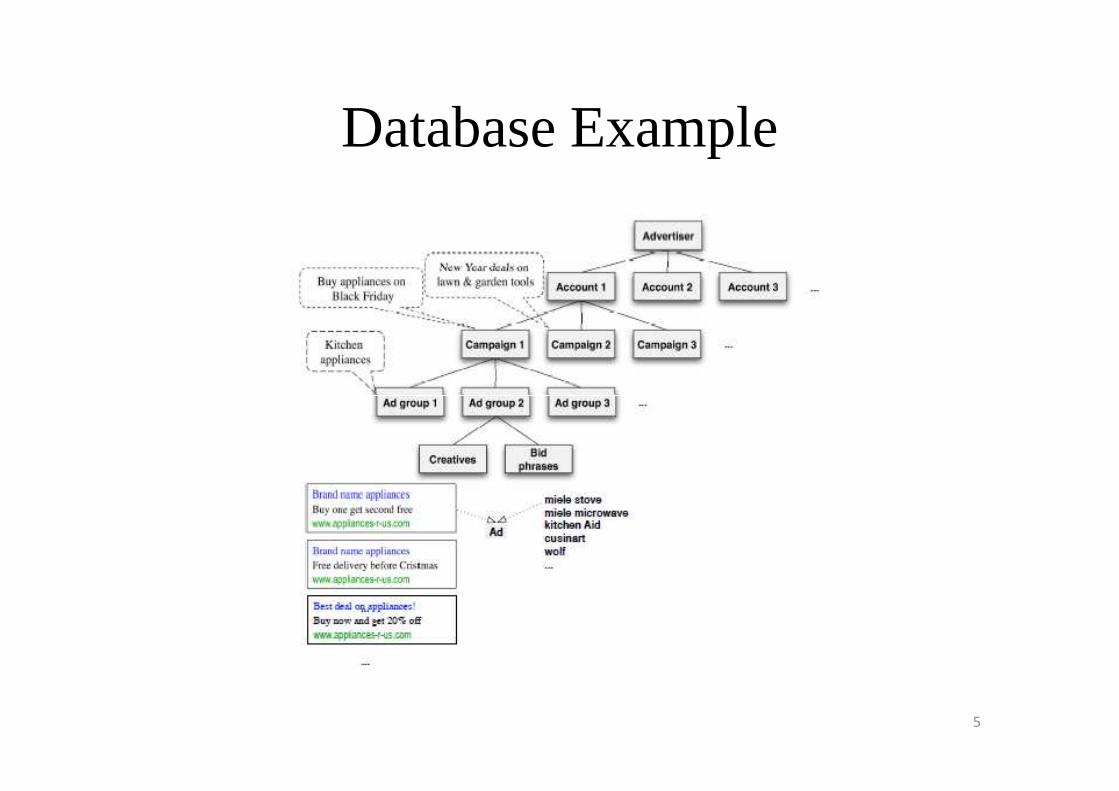
Account Structure
• Recall that advertiser information is hierarchically structured.– Account.
– Ad Campaign.– Ad Campaign.• Related to a specific marketing goal.
• Characterized by a budget.
– Ad Group.• Contains dozens of creatives and hundreds of bid terms.
• Maximum bid for each of the bid terms.
3

Ad Structure
• Headline.
• Lines of text.
• Display URL.
•• Destination URL (Landing Page).
4
Database Example
5
Properties of Ad Corpora
6
Properties of Ad Corpora
7
Properties of Ad Corpora
8

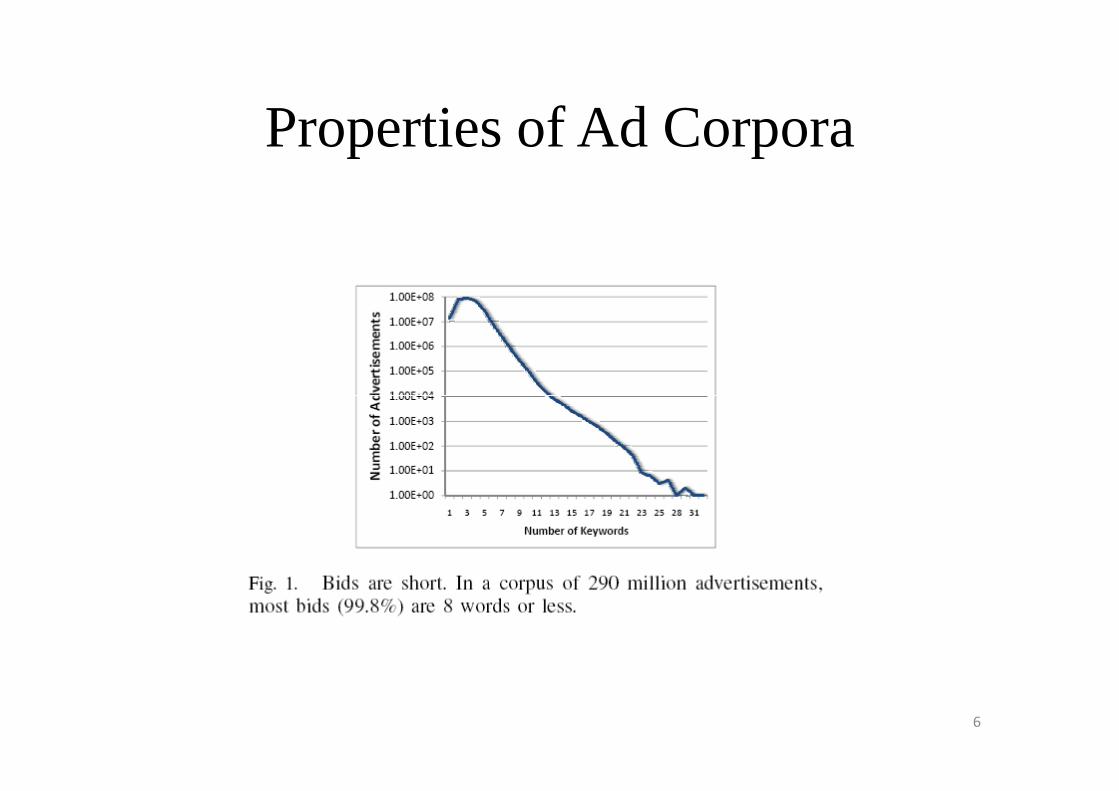
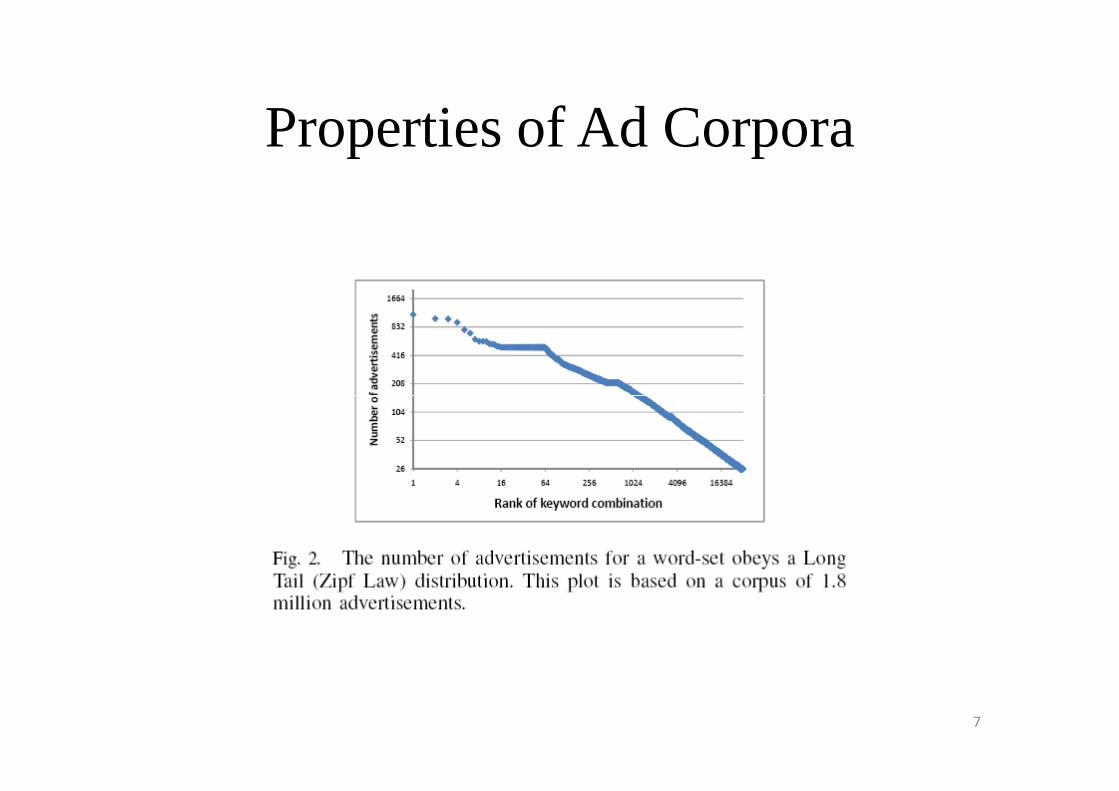
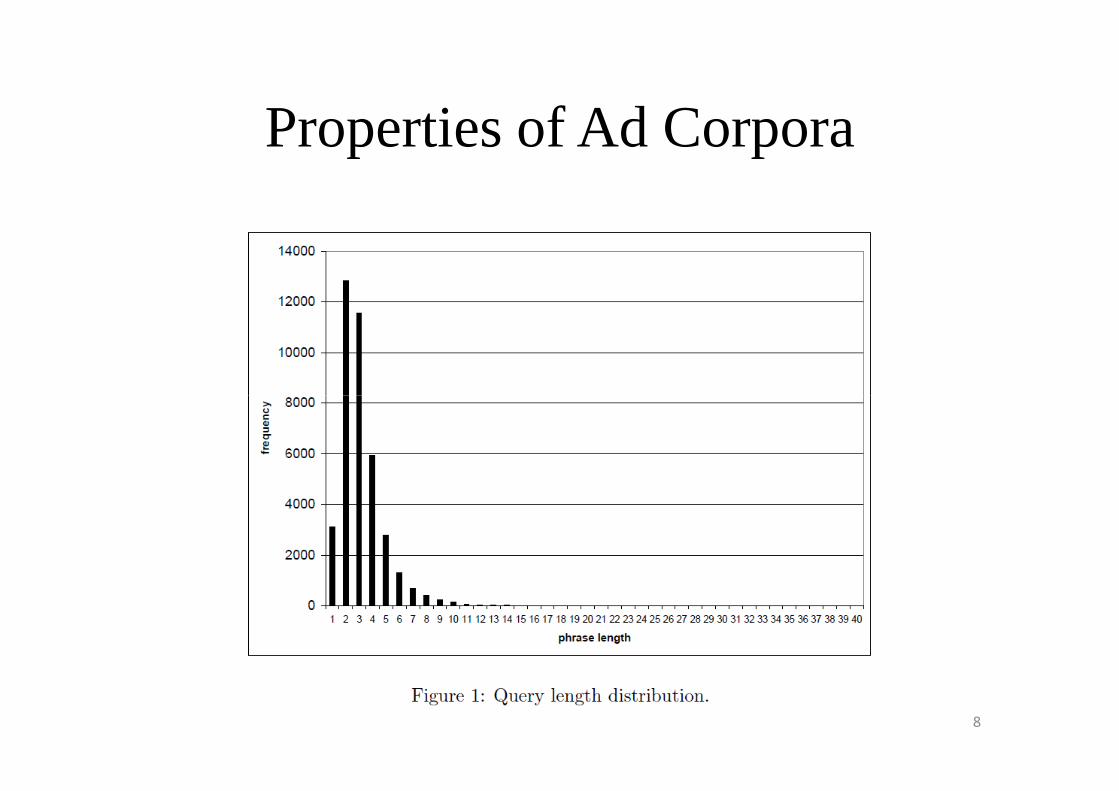
Properties of Ad Corpora
• Ads can be indexed in main memory.
• Retrieving candidate ads for infrequent queries is a difficult problem.
9

Ad Indexing
• The retrieval of <creative, term> pairs from a structured schema.– Structured retrieval problem, where the unit of
retrieval is defined hierarchically.
• Naively indexing all possible retrieval units would result in wasted storage due to the Cartesian product semantics.
• To avoid this, we can utilize hierarchical indexing schemes that reduce the amount of duplication.
10

3 Main Approaches
• Term Coupling Index: Index units that are composed of <creative, term> pairs.
• Creative Coupling Index: The indexing unit is a single creative coupled with all the bid terms a single creative coupled with all the bid terms associated with its ad group.
• Ad Group Coupling Index: The indexing unit is the ad group itself.
• Different indexing strategies have a different impact on ad retrieval effectiveness.
11

Indexing for Broad Matchtype
• Broad Matchtype: a user’s query contains all terms in the keyword in any order, possibly along with other terms.
• Consider the user query cheap used cars– The bid phrase used cars matches the query.– The bid phrase used cars matches the query.– The bid phrase fast cars does not match the query.
• Inverse operation from classical document retrieval.
• In practice, broad match also accounts for singular or plural, synonyms and other variations, misspellings, extensions.
12

Traditional IR Techniques Fail
• Consider the use of inverted indexes containing ad IDs as postings.
• Using them, we obtain the union of the postings in the inverted indexes corresponding postings in the inverted indexes corresponding to keywords in the query.
• It is still necessary to filter out ads whose bid phrase contain words not in the query.– This operation is not directly supported by inverted
indexes!
13
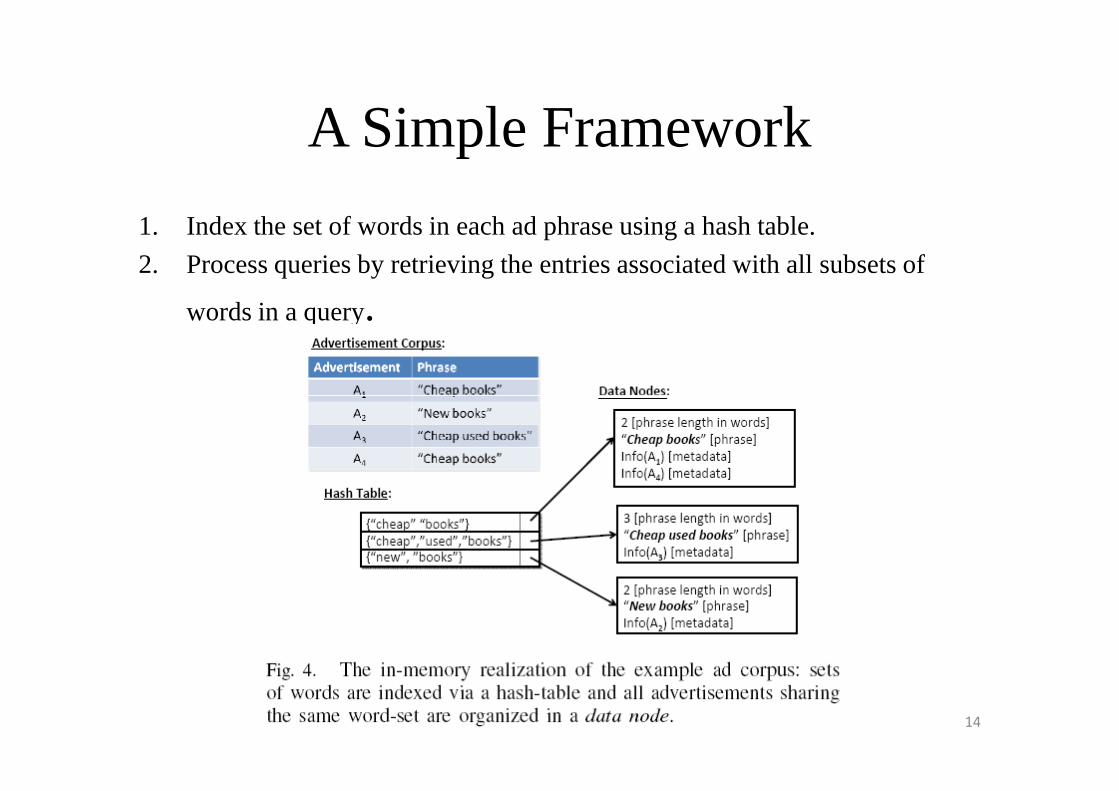
A Simple Framework
1. Index the set of words in each ad phrase using a hash table.
2. Process queries by retrieving the entries associated with all subsets of
words in a query.
14
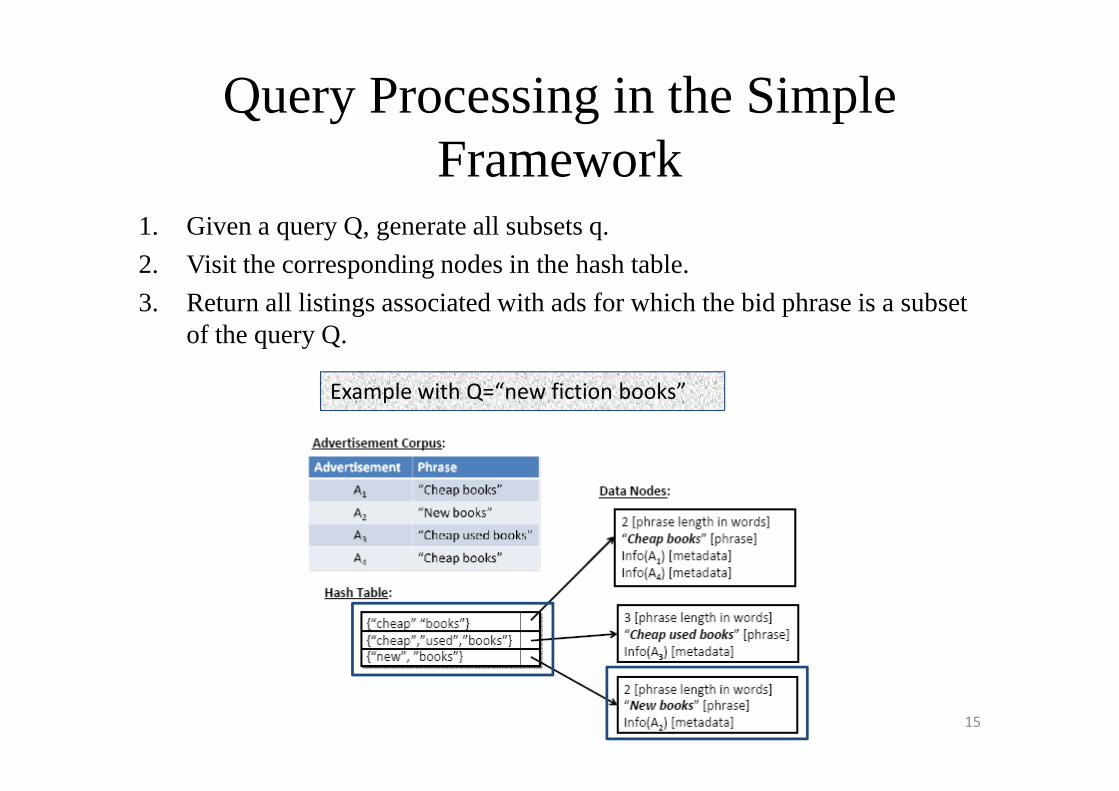
Query Processing in the Simple Framework
1. Given a query Q, generate all subsets q.
2. Visit the corresponding nodes in the hash table.
3. Return all listings associated with ads for which the bid phrase is a subset of the query Q.
Example with Q=“new fiction books”Example with Q=“new fiction books”
15

Reducing Main Memory Latency in the Simple Framework
• Two Strategies1. Traverse fewer data nodes.
2. Perform fewer hash-lookups against the hash table.
16
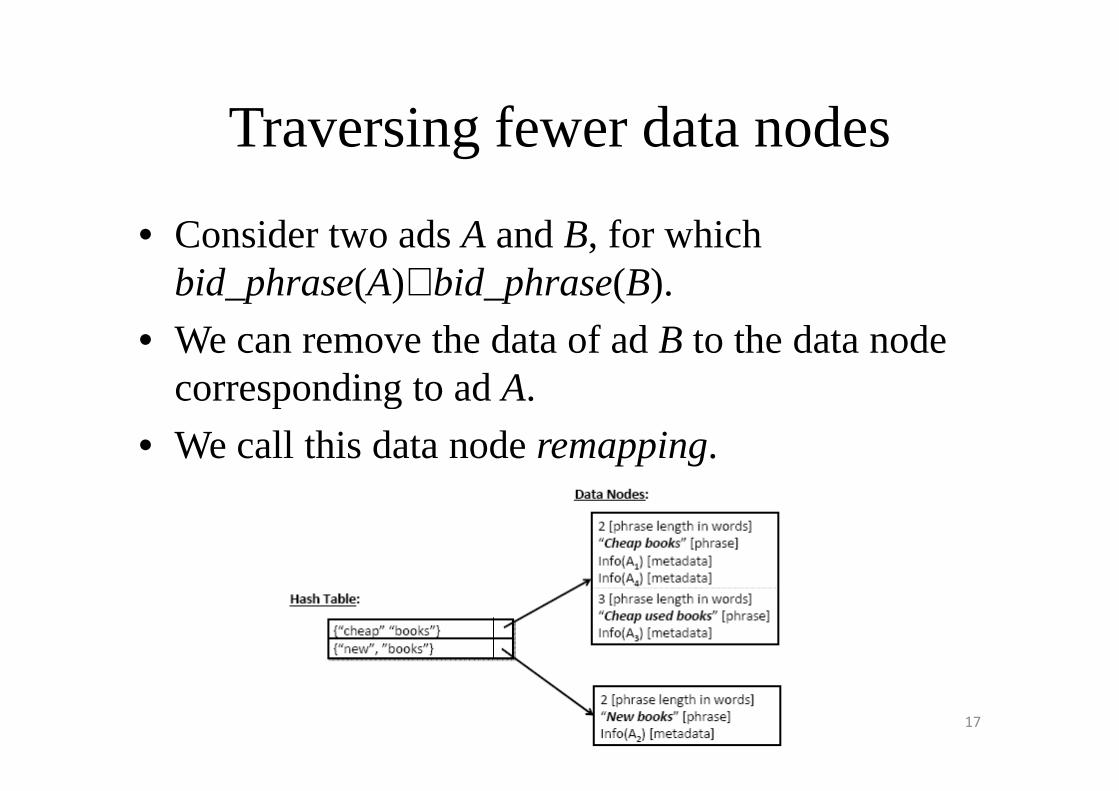
Traversing fewer data nodes
• Consider two ads A and B, for which bid_phrase(A)⊆bid_phrase(B).
• We can remove the data of ad B to the data node corresponding to ad A.corresponding to ad A.
• We call this data node remapping.
17
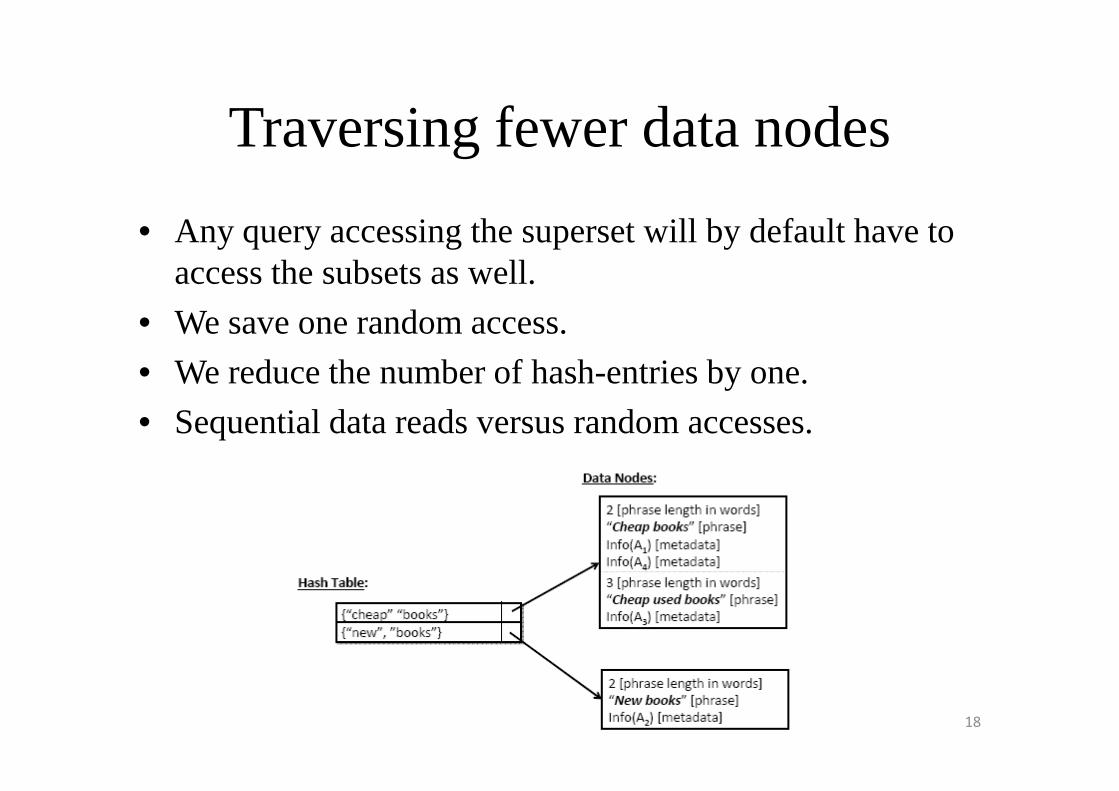
Traversing fewer data nodes
• Any query accessing the superset will by default have to access the subsets as well.
• We save one random access.
• We reduce the number of hash-entries by one.
• Sequential data reads versus random accesses.
18

Reducing the Number of Hash Lookups
• The number of subsets grows exponentially with the query length q.
• Solution: remap all long phrases to data nodes with node locators of length no more than k.
• Number of hash lookups bounded by as ∑
k q
• Number of hash lookups bounded by as opposed to 2q – 1.
∑ =
k
i i
q1
19

Optimizing the Index Structure
• The reduction in the number of data nodes leads to fewer random accesses, but come at the cost of the bigger amount of data we have to access per data node visited.
• We need to find the optimal tradeoff between • We need to find the optimal tradeoff between these two factors.
• For this, we need the actual workload, i.e., the query history with the corresponding frequencies.
• The above problem is actually NP-complete (weighted set cover), but can be approximated within a reasonably good factor.
20

Relevance
• A very critical factor to the search engine’s success.
• During the ad selection process, the search engine must identify low relevance ads and get engine must identify low relevance ads and get rid of them.
• Different from the CTR, which is a measure of how attractive (as opposed to relevant) an ad is.
21

Prior Work on Relevance
1. Direct query-ad matching: ads are treated as documents and are ranked using a standard information retrieval technique.
2. Query Rewriting/Query Substitution: generate 2. Query Rewriting/Query Substitution: generate a relevant rewrite qj for a given query qi.
3. Query Recommendation/Query Clustering: consider the bipartite click graph of queries and ads with edges that correspond to click information.
22

Direct Query/Ad Matching
• Simple text overlap features.– Important but insufficient.– Consider the ad with title “Best Jogging Shoes” and a
user searching for “running gear”.
• Historical click rates for a query-ad pair.• Historical click rates for a query-ad pair.– When there is limited click history for a specific
query-ad pair, back off to higher levels in the account hierarchy.
• Click Propensity in Query/Ad Translation.– Translation-Based Systems.
23

Query Substitution
• Use query substitutions.• A hybrid of exact and broad match.• Has two phases: online and offline.• Offline Phase:• Offline Phase:
– Fix a large set of sufficiently frequent queries– Learn a function that substitutes input queries
• Online Phase:– Use exact match to find ads matching the
substitute query.
24

Substitution Framework
1. For each query, obtain the top S results returned by a Web Search Engine.
2. Find the k ads most related to the input query.
3. The bid phrases of the se ads form a pool of 3. The bid phrases of the se ads form a pool of candidates.
4. The highest scoring bid phrase is selected as the query substitution.
25

Query Recommendation
• Consider the bipartite graph of queries and ads.
• An edge exists if and only if a user who issued the
query clicked on the ad.
• The edge is also weighted with a positive weight, • The edge is also weighted with a positive weight,
which represents the strength of the association.
– For instance, position-normalized CTR, or machine-
learned estimate of the probability click P(click|q,ad).
26

Query Recommendation through Collaborative Filtering
1. Compute the similarities between queries.
2. Compute a prediction of the response
between a query and an ad based on how
similar queries responded to the same ad.similar queries responded to the same ad.
– Reminiscent of PageRank…
27

CTR
• CTR is the most prominent measure of ad quality employed by all large search engines.
• Crucial factor for ad ranking.• Its estimation has attracted considerable • Its estimation has attracted considerable
attention in the scientific community.• Its is usually formulated as a supervised
learning problem.– Maximum Entropy Model (EM).– Nonlinear conjugate gradient descent algorithm.
28

Click Prediction as a Supervised Problem
• There is a set of training query-ad pairs (samples,) containing both click and non-click events.
• We want to estimate P(c|q,a).• We want to estimate P(c|q,a).
• We carefully select a proper set of features to represent the query-ad pair.– Lexical Similarity Features
– Historical Performance of Ads
29

Personalized Click Prediction
• Estimate P(c|q,a,u).
• We need to consider additional user features.– Demographic Features (age, gender, marriage
status, interests, job status, occupation)status, interests, job status, occupation)
– User-Specific Features• Noisy
• Sparse
30

References
• Konig, Church, Markov. A Data Structure for Sponsored Search. ICDE, 2009.
• Bendersky et al. The Anatomy of an Ad: Structured Indexing and Retrieval for Sponsored Search. WWW, 2010.
• Hillard, D., Schroedl, S., Manavoglu, E., Raghavan, H., • Hillard, D., Schroedl, S., Manavoglu, E., Raghavan, H., Leggetter, C. Improving Ad Relevance in sponsored Search. WSDM, 2010.
• Radlinski, F., Broder, A., Ciccolo, P., Gabrilovich, E., Josifovski, V., Riedel, L. Optimizing Relevance and Revenue in Ad Search: A Query Substitution Approach. SIGIR, 2008.
31

References
• Anastasakos, T., Hillard, D., Kshetramade, S., Raghavan, H. A Collaborative Filtering Approach to Ad ecommendation using the Query-Ad Click Graph. CIKM, 2009.
• Cheng, H., Cantu-Paz, E. Personalized Click Prediction • Cheng, H., Cantu-Paz, E. Personalized Click Prediction in Sponsored Search. WSDM, 2010.
• Richardson, M., Dominowska, E., Ragno, R. Predicting Clicks: Estimating the Click-Through Rate for New Ads. WWW, 2007.
• Shen, S., Hu, B., Chen, W., Yang, Q. Personalized Click Model through Collaborative Filtering. WSDM, 2012.
32


















