
Sparse VAR-Models · Diebold and Yilmaz (2015) Christophe Croux Sparse VAR-Models 19 / 32. Granger...
32
Frontiers in Forecasting, Minneapolis February 21-23, 2018 Sparse VAR-Models Christophe Croux EDHEC Business School (France) Joint Work with Ines Wilms (Cornell University), Luca Barbaglia (KU leuven), and Sarah Gelper (TU Eindhoven). Christophe Croux Sparse VAR-Models 1 / 32
Transcript of Sparse VAR-Models · Diebold and Yilmaz (2015) Christophe Croux Sparse VAR-Models 19 / 32. Granger...

Frontiers in Forecasting, MinneapolisFebruary 21-23, 2018
Sparse VAR-Models
Christophe Croux
EDHEC Business School (France)
Joint Work with Ines Wilms (Cornell University), Luca Barbaglia (KU leuven),
and Sarah Gelper (TU Eindhoven).
Christophe Croux Sparse VAR-Models 1 / 32

Section 1
VAR Models
Christophe Croux Sparse VAR-Models 2 / 32

10-dimensional time series
−3
−1
1
CR
UO
−1.
50.
0
GA
SO
−4
−1
1
NAT
G−
3−
11
ET
HA
2013 2014 2015 2016
Time
−6
−3
0
BIO
D
−5
−2
0
CO
RN
−4
−2
0
WH
EA
−1.
50.
0
SU
GA
−4
−2
0
SO
YO
2013 2014 2015 2016
Time
−3
−1
1
CO
FF
Log−volatilies
Christophe Croux Sparse VAR-Models 3 / 32

Network
CRUO
GASO
NATGETHA
BIOD
CORN
WHEA
SUGASOYO
COFF
Christophe Croux Sparse VAR-Models 4 / 32

Vector Autoregressive Model (VAR)
Two stationary time series y1,t and y2,t .
VAR(1) in dimension q = 2:y1,t = Γ1,11 y1,t−1 + Γ1,12y2,t−1 + e1t
y2,t = Γ1,21 y1,t−1 + Γ1,22y2,t−1 + e2t
Covariance matrix of (e1t , e2t)′ is Σ.
Vector notation: yt = Γ1yt−1 + et ,
Christophe Croux Sparse VAR-Models 5 / 32

The VAR model
Let yt be a q-dimensional stationary time series
Vector Autoregressive Model of order p:
yt = Γ1yt−1 + Γ2yt−2 + . . . + Γpyt−p + et ,
Matrices Γj are autoregressive parameters
et error with covariance matrix Σ = Ω−1.
Standard estimation procedure: OLS equation by equation.
Christophe Croux Sparse VAR-Models 6 / 32

Section 2
Sparse VAR
Christophe Croux Sparse VAR-Models 7 / 32

Log-Volatilies for commodities (weekly data)
VAR model for q = 10 time series (and T = 156 observations)
One lag
– 1× (q × q) = 100 regression parameters– 45 unique elements in Σ
Two lags
– 2× (q × q) = 200 regression parameters– 45 unique elements in Σ
→ Explosion of number of parameters
Christophe Croux Sparse VAR-Models 8 / 32

The VAR model: Overparametrization
ML estimators will be
Not computable
Inaccurate
Sparse estimation ≡ many estimated parameters equal to zero
Suitable if T is small relative to the number of parameters
Easier to interpret
Automatic variable selection
Better estimation and prediction performance
Christophe Croux Sparse VAR-Models 9 / 32

Sparse Estimation: Lasso
In the multiple linear regression model
y = β1x1 + β2x2 + . . . + βkxk + ε
Minimization problem
β = argminβ
(y − Xβ)′(y − Xβ) + λk∑
l=1
|βl |.
Tibshirani (1996)
Christophe Croux Sparse VAR-Models 10 / 32

Lasso for the VAR model
Multiple equations
– Partial correlation structure of the error term→ Glasso of Friedman et al. (2008)
Dynamic nature of the model
– Selecting a time series into one of the equations = selecting thevariable and all its lags→ Group lasso (Yuan and Lin, 2006)
Christophe Croux Sparse VAR-Models 11 / 32

Penalized ML estimation
Rewrite the VAR in matrix notation:
Y = YLΓ + E,
where
Y = (yp+1, . . . , yT )′
YL = (Xp+1, . . . ,XT )′ with Xt = (y′t−1, . . . , y′t−p)′
Γ = (Γ1, . . . ,Γp)′
E = (ep+1, . . . , eT )′.
Christophe Croux Sparse VAR-Models 12 / 32

Penalized ML estimation (cont.)
Penalized negative log likelihood:
(Γ, Ω) = argminΓ,Ω
1
Ttr(
(Y − YLΓ)Ω(Y − YLΓ)′)− log|Ω|
+λ1
G∑g=1
||γg ||2 + λ2
∑k 6=k ′
|Ωkk ′ |,
with
γg is subvector of Γ
G = q2 total number of groups.
Christophe Croux Sparse VAR-Models 13 / 32

Algorithm
Solving for Γ|Ω:
Γ|Ω = argminΓ
1
Ttr(
(Y − YLΓ)Ω(Y − YLΓ)′)
+ λ1
G∑g=1
||γg ||2.
→ groupwise lasso
Christophe Croux Sparse VAR-Models 14 / 32

Algorithm (cont.)
Solving for Ω|Γ:
Ω|Γ = argminΩ
1
Ttr(
(Y−YLΓ)Ω(Y−YLΓ)′)−log|Ω|+λ2
∑k 6=k ′
|Ωkk ′|.
→ penalized inverse covariance estimation (glasso)
Christophe Croux Sparse VAR-Models 15 / 32

Selection of tuning parameters
In the iteration step Γ|Ω, select λ1 to minimize
BICλ1 = −2 log Lλ1 + kλ1 log(T ),
Lλ1 is the estimated likelihood using λ1
kλ1 is the number of non-zero estimated regression coefficients.
In the iteration step Ω|Γ, select λ2 analogously.
Christophe Croux Sparse VAR-Models 16 / 32

Commodity prices: log volatilities (weekly data)
−3
−1
1
CR
UO
−1.
50.
0
GA
SO
−4
−1
1
NAT
G−
3−
11
ET
HA
2013 2014 2015 2016
Time
−6
−3
0
BIO
D
−5
−2
0
CO
RN
−4
−2
0
WH
EA
−1.
50.
0
SU
GA
−4
−2
0
SO
YO
2013 2014 2015 2016
Time
−3
−1
1
CO
FF
Log−volatilies
Christophe Croux Sparse VAR-Models 17 / 32

Networks from the VAR coefficients Γ.
Network with q nodes. Each node corresponds with a time series.
draw an edge from node i to node j if
P∑p=1
|Γp,ji | 6= 0
Additionally (if p = 1)
the edge width is the size of the effect
the edge color is the sign of the effect(blue if positive, red if negative)
Christophe Croux Sparse VAR-Models 18 / 32

Network on the AutoRegressive coefficients
CRUO
GASO
NATGETHA
BIOD
CORN
WHEA
SUGASOYO
COFF
Diebold and Yilmaz (2015)
Christophe Croux Sparse VAR-Models 19 / 32

Granger Causality
Time series i is Granger Causing time series j
l
Time series i it has incremental predictive power in forecasting series j
l
In the network there is an arrow going from node i to node j
Granger Causality test in high dimensions: Wilms, Gelper, Croux, 2016
Christophe Croux Sparse VAR-Models 20 / 32
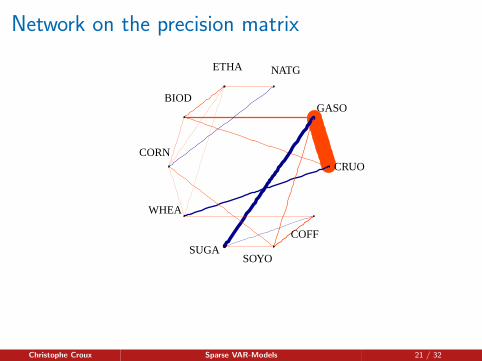
Network on the precision matrix
CRUO
GASO
NATGETHA
BIOD
CORN
WHEA
SUGASOYO
COFF
Christophe Croux Sparse VAR-Models 21 / 32

References
Rothman, Levina, and Zhu (2010), “Sparse multivariate regression with covarianceestimation,” Journal of Computational and Graphical Statistics.
Hsu, Hung, and Chang (2008), “Subset selection for vector autoregressive processesusing lasso,” Computational Statistics and Data Analysis.
Davis, Zang, and Zheng (2016), “Sparse vector autoregressive modeling,” Journal ofComputational and Graphical Statistics.
Basu and Michailidis (2015), “Regularized estimation in sparse high-dimensional timeseries models,” Annals of Statistics.
Nicholson, Matteson, and Bien, J. (2017), VARX-L: Structured regularization for largevector autoregressions with exogenous variables, International Journal of Forecasting.
Wilms, Basu, Bien, and Matteson (2017), bigtime: Sparse Estimation of Large TimeSeries Models, R package.
...
Gelper S., Wilms I. and Croux C. (2016), “Identifying demand effects in a large networkof product categories,” Journal of Retailing.
Christophe Croux Sparse VAR-Models 22 / 32

Section 3
Application: a Market Response Model
Christophe Croux Sparse VAR-Models 23 / 32

Data
Sales, promotion and prices for 17 product categories.
T = 77 weekly observations
VAR model for q = 3× 17 = 51 time series
0 20 40 60
−6
−4
−2
02
46
Time
Christophe Croux Sparse VAR-Models 24 / 32

Christophe Croux Sparse VAR-Models 25 / 32

Sales Forecasting
One-step ahead, using rolling window.Averaged over the 17 product categories, and the 15 stores.
Method Mean Absolute Forecast Error
Sparse 736Bayesian: Minnesota 875Bayesian: Normal-Inverse Wishart 1078
Least Squares 1298Restricted LS 784
Sparse method significantly better (P < 0.01, Diebold-Mariano test)
Christophe Croux Sparse VAR-Models 26 / 32

Simulation Study
Bayesian methods
– Minnesota prior (Koop and Korobilis, 2009)– Normal-Inverse Wishart prior (Banbura et al, 2010)
Simulation Design: Sparse high-dimensional : q = 10, p = 2,T = 50
Christophe Croux Sparse VAR-Models 27 / 32

Method Mean Absolute Estimation Error
Sparse 0.041Bayesian: Minnesota 0.044Bayesian: Normal-Inverse Wishart 0.077
Least Squares 0.157Restricted LS 0.121
Christophe Croux Sparse VAR-Models 28 / 32

Section 4
Extensions
Christophe Croux Sparse VAR-Models 29 / 32

Multi-Class VAR
We have a chain of 17 stores.
Estimate a VAR for each store separately.
Pool the data for the 17 stores in one single class , and estimateone single VAR (or panel-VAR.)
Multi-class estimation, where the data decide what the classesare.
Danaher, Wang, and Witten, D. (2014): joint graphical lasso.Tibshirani, Saunders, Rosset, Zhu, and Knight (2005): Fused Lasso
Christophe Croux Sparse VAR-Models 30 / 32

Multi-class sparse VAR: K classes
Γ(k), k = 1, . . . ,K are minimizing
K∑k=1
T∑t=1
(y(k)t − Γ(k)YL
(k))′Ω(k)
(y(k)t − Γ(k)YL
(k))− TJ log |Ω(k)|
+K∑
k=1
J∑i ,j=1
P∑p=1
|Γ(k)p,ij |+
K∑k 6=k ′
J∑i ,j=1
P∑p=1
|Γ(k)p,ij − Γ
(k ′)p,ij |+ ...
Wilms, I.; Barbaglia, L.; Croux, C. (2018), JRSSS-C
Christophe Croux Sparse VAR-Models 31 / 32

Furtermore
- t-Lasso for estimating VAR
- cointegration
Christophe Croux Sparse VAR-Models 32 / 32





![arXiv:1506.04767v1 [cs.IT] 15 Jun 2015 · statistical causation between non-i.i.d. time-series. In this work, \statistical causation" is in the sense of Granger causality (Granger,](https://static.fdocuments.net/doc/165x107/5fda0c9bfc501f72863591fa/arxiv150604767v1-csit-15-jun-2015-statistical-causation-between-non-iid.jpg)












