
SparkSQL and Dataframe
32
Spark SQL and DataFrame 2015. 8 . 이남기 ( Namgee Lee) 숭실대학교
-
Upload
namgee-lee -
Category
Software
-
view
425 -
download
0
Transcript of SparkSQL and Dataframe

Spark SQL and DataFrame
2015. 8.
이남기 (Namgee L e e )
숭실대학교
2 / 30
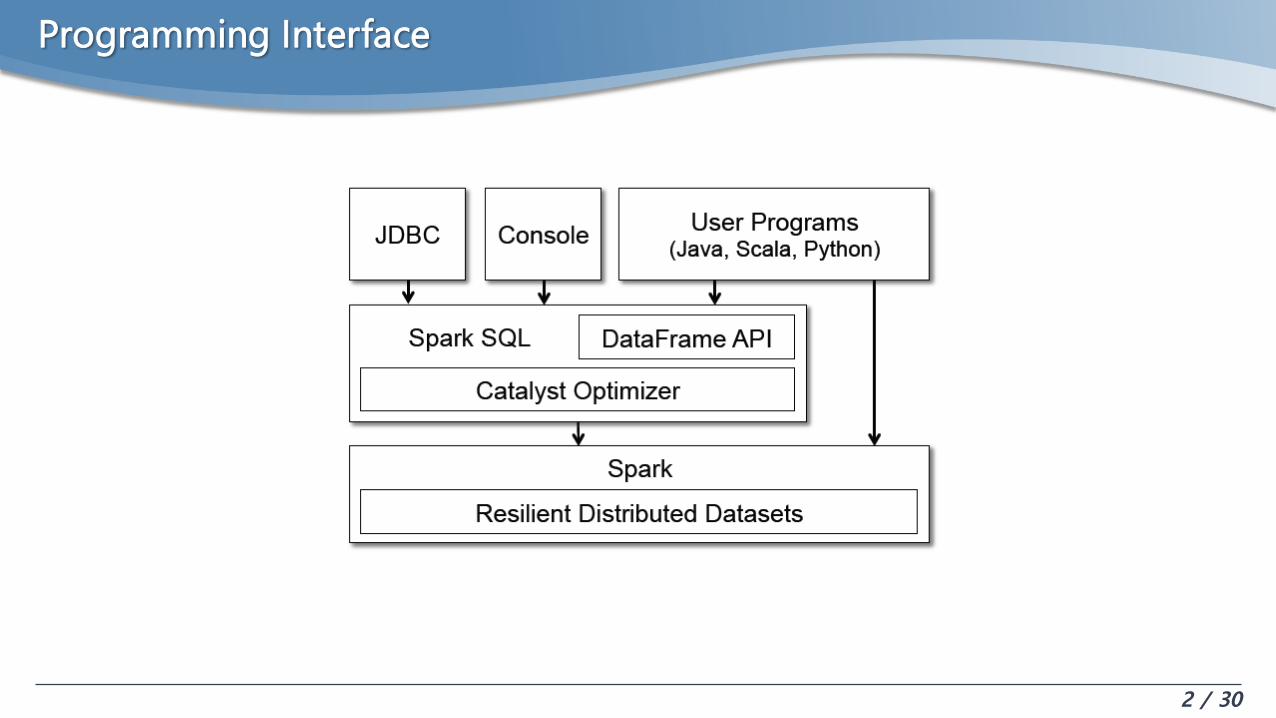
Programming Interface
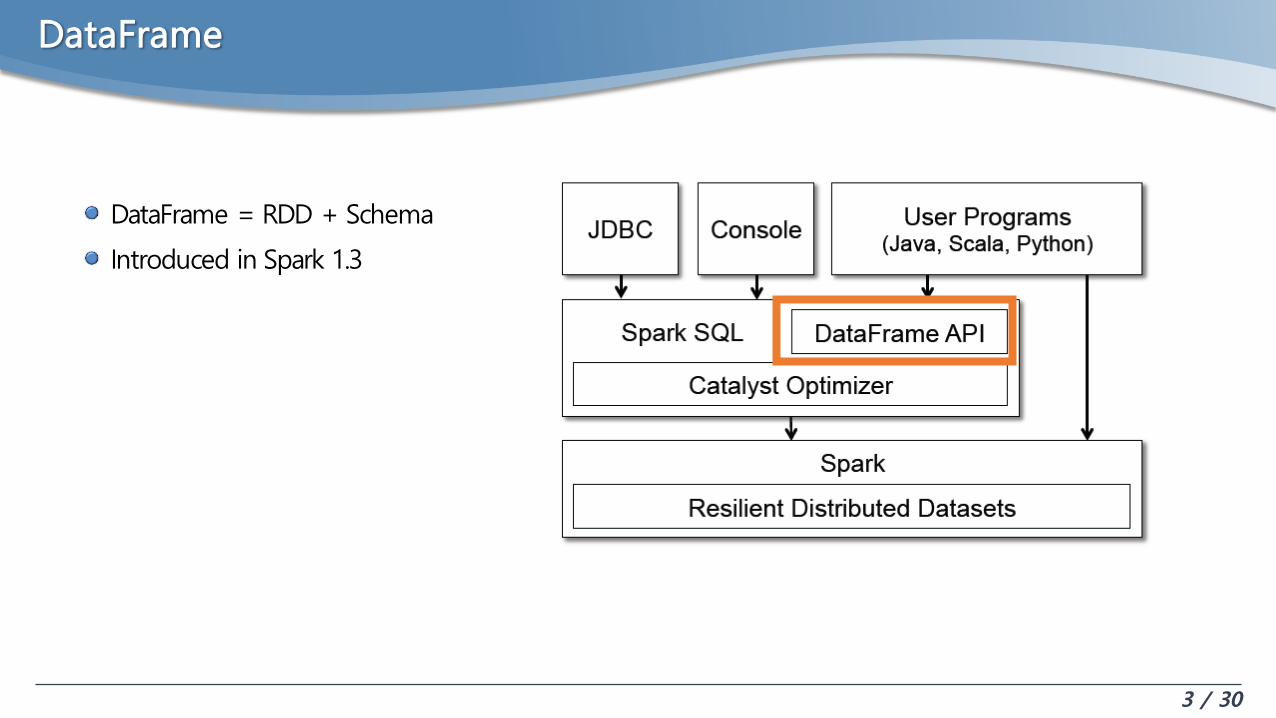
3 / 30
DataFrame
DataFrame = RDD + Schema
Introduced in Spark 1.3

4 / 30
DataFrame
A distributed collection of rows organized into named columns
An abstraction for selecting, filtering, aggregating and plotting structured data
5 / 30
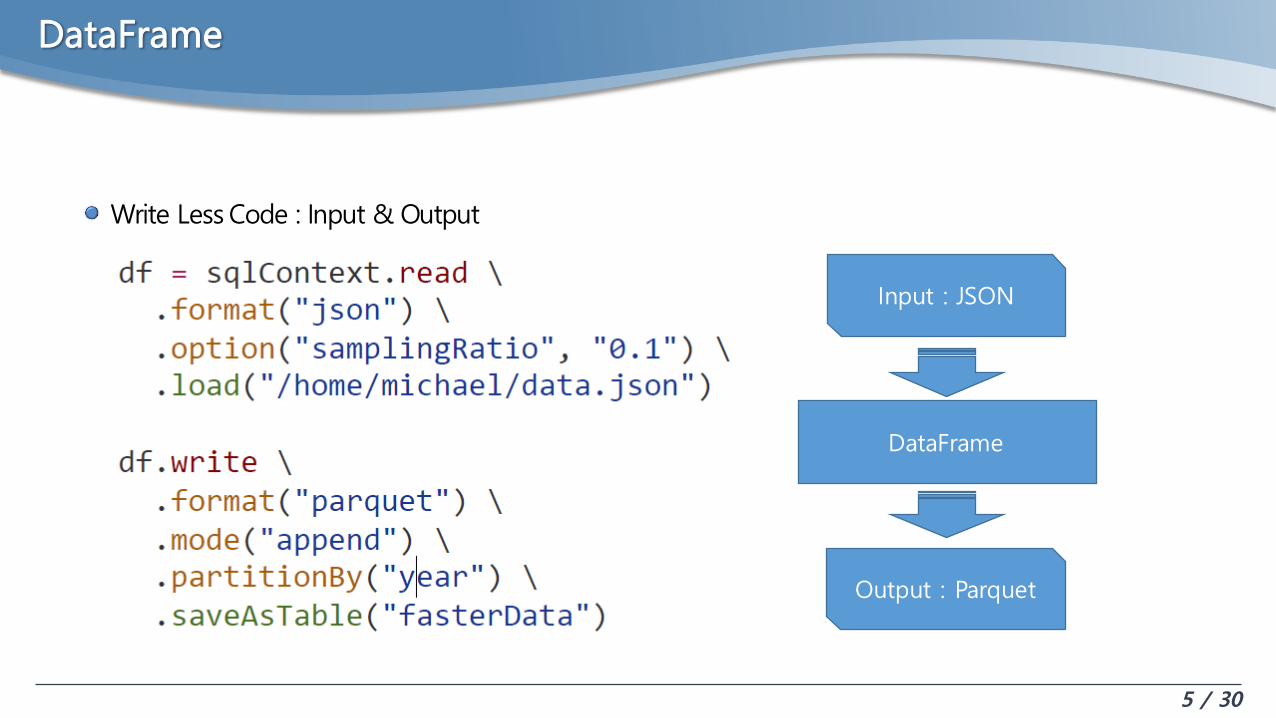
DataFrame
Write Less Code : Input & Output
DataFrame
Input : JSON
Output : Parquet

6 / 30
DataFrame
Spark SQL’s Data Source API can read and write DataFrame using a variety of formats.

7 / 30
DataFrame
Write Less Code
Likely

8 / 30
DataFrame
Write Less Code : Powerful Operation
Common operations can be expressed concisely as calls to the DataFrame API:• Selecting required columns• Joining different data sources• Aggregation (count, sum, average, etc)• Filtering

9 / 30
Creating DataFrames
With a SQLContext, applications can create DataFrames from an existing RDD, from a Hive table, or from data sources.
val sc: SparkContext // An existing SparkContext.val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val df = sqlContext.read.json("examples/src/main/resources/people.json")
// Displays the content of the DataFrame to stdoutdf.show()
// age name
// null Michael
// 30 Andy
// 19 Justin
{"name":"Michael"}{"name":"Andy", "age":30}{"name":"Justin", "age":19}
10 / 30
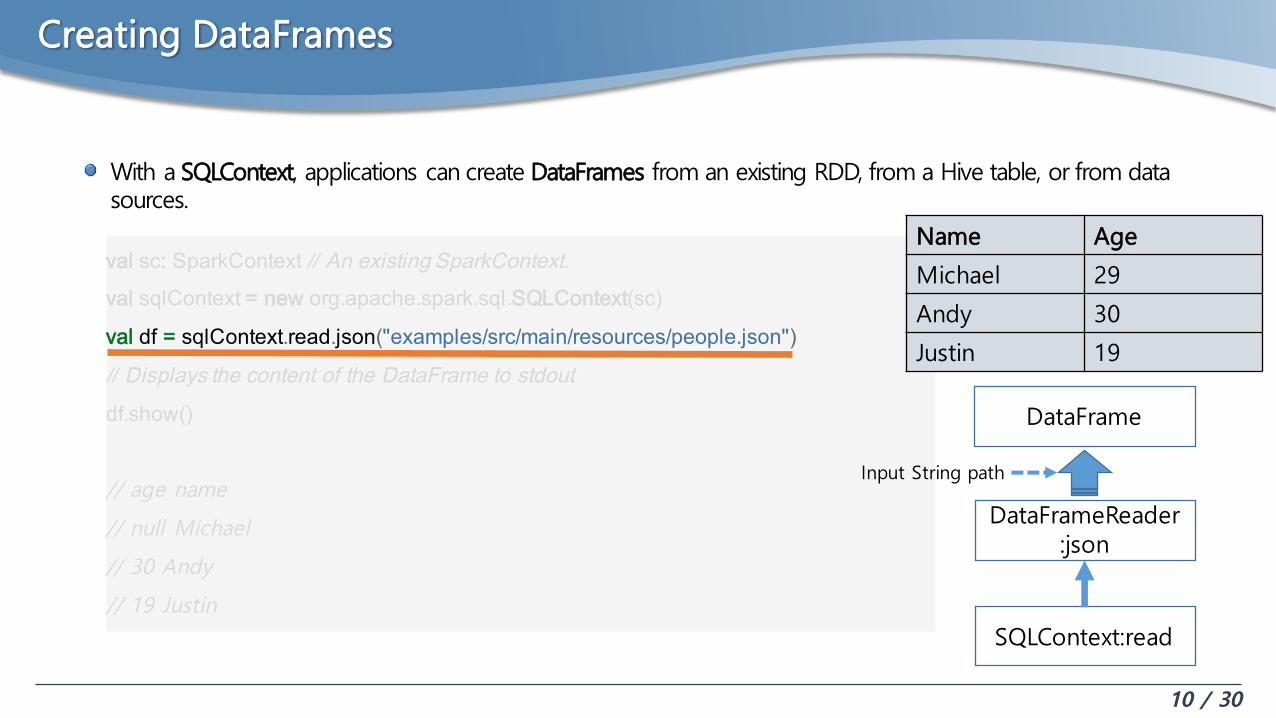
Creating DataFrames
With a SQLContext, applications can create DataFrames from an existing RDD, from a Hive table, or from data sources.
val sc: SparkContext // An existing SparkContext.val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val df = sqlContext.read.json("examples/src/main/resources/people.json")
// Displays the content of the DataFrame to stdoutdf.show()
// age name
// null Michael
// 30 Andy
// 19 Justin
DataFrameReader:json
SQLContext:read
Input String path
DataFrame
Name Age
Michael 29
Andy 30
Justin 19

11 / 30
Creating DataFrames
With a SQLContext, applications can create DataFrames from an existing RDD, from a Hive table, or from data sources.
val sc: SparkContext // An existing SparkContext.val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val df = sqlContext.read.json("examples/src/main/resources/people.json")
// Displays the content of the DataFrame to stdoutdf.show()
// age name
// null Michael
// 30 Andy
// 19 Justin
Name Age
Michael 29
Andy 30
Justin 19
12 / 30
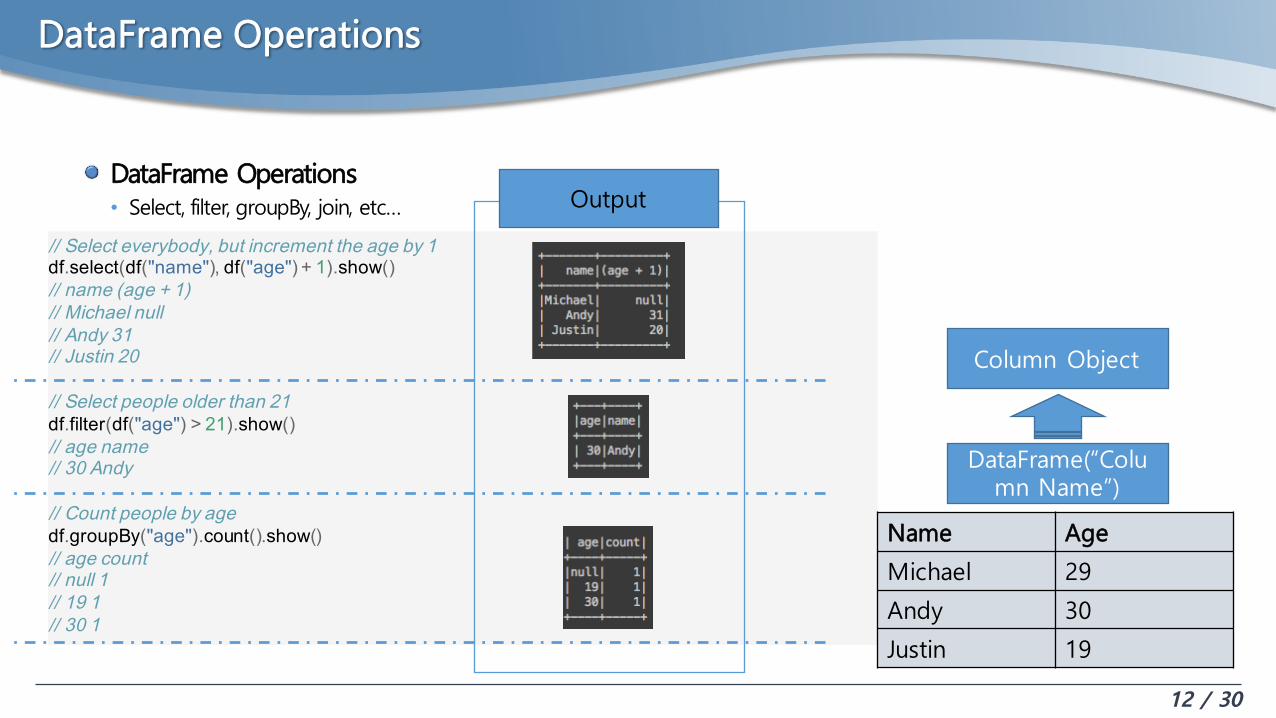
DataFrame Operations
// Select everybody, but increment the age by 1df.select(df("name"), df("age") + 1).show()// name (age + 1)// Michael null// Andy 31// Justin 20
// Select people older than 21df.filter(df("age") > 21).show()// age name// 30 Andy
// Count people by agedf.groupBy("age").count().show()// age count// null 1// 19 1// 30 1
DataFrame(“Column Name”)
Column Object
DataFrame Operations• Select, filter, groupBy, join, etc…
Name Age
Michael 29
Andy 30
Justin 19
Output

13 / 30
DataFrame Operations
val sqlContext = ... // An existing SQLContextval df = sqlContext.sql("SELECT * FROM table")
The sql function on a SQLContext enables applications to run SQL queries programmatically and returns the result as a DataFrame.
SQLContext:sql
DataFrame
Input String Query
14 / 30
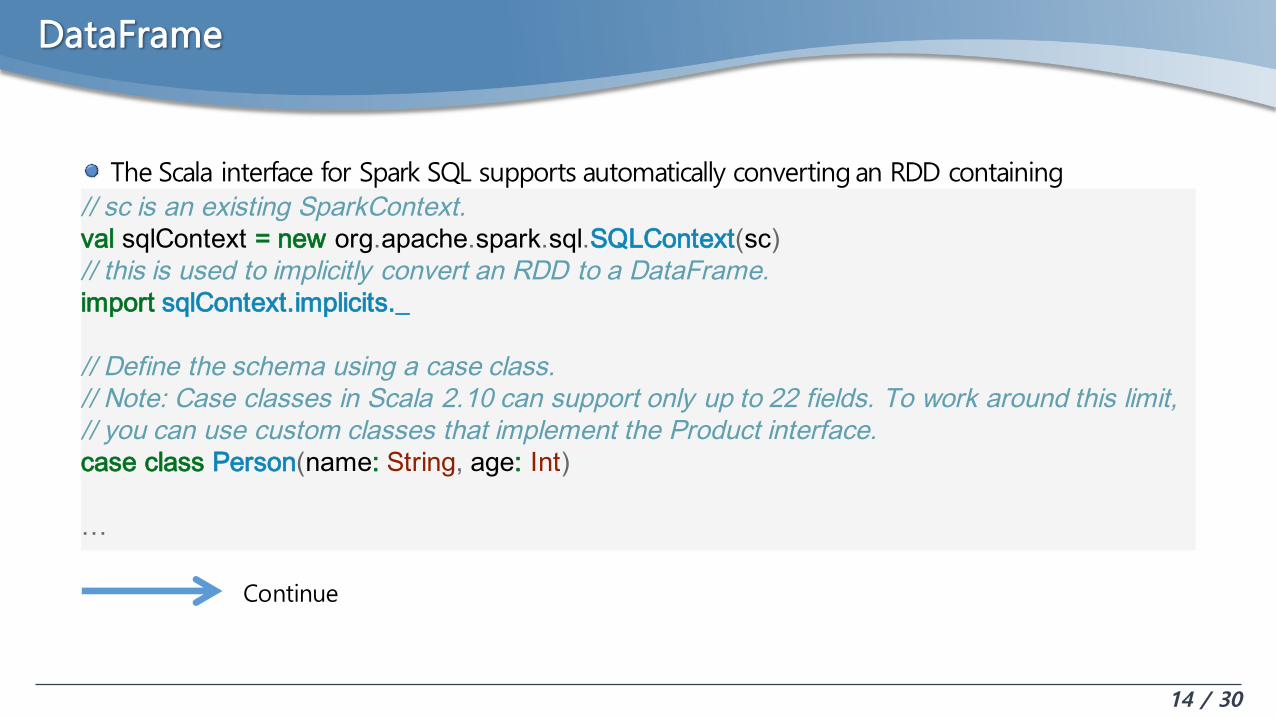
DataFrame
The Scala interface for Spark SQL supports automatically converting an RDD containing case classes to a DataFrame// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)// this is used to implicitly convert an RDD to a DataFrame.import sqlContext.implicits._
// Define the schema using a case class.// Note: Case classes in Scala 2.10 can support only up to 22 fields. To work around this limit,// you can use custom classes that implement the Product interface.case class Person(name: String, age: Int)
…
Continue

15 / 30
case class Person(name: String, age: Int)
// Create an RDD of Person objects and register it as a table.val people = sc.textFile("examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()people.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContextval teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
// The results of SQL queries are DataFrames and support all the normal RDD operations.// The columns of a row in the result can be accessed by field index:teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
// or by field name:teenagers.map(t => "Name: " + t.getAs[String]("name")).collect().foreach(println)
// row.getValuesMap[T] retrieves multiple columns at once into a Map[String, T]teenagers.map(_.getValuesMap[Any](List("name", "age"))).collect().foreach(println)// Map("name" -> "Justin", "age" -> 19)
DataFrame
Inferring the Schema Using Reflection

16 / 30
case class Person(name: String, age: Int)
// Create an RDD of Person objects and register it as a table.val people = sc.textFile("examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()people.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.val teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
// The results of SQL queries are DataFrames and support all the normal RDD operations.// The columns of a row in the result can be accessed by field index:teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
// or by field name:teenagers.map(t => "Name: " + t.getAs[String]("name")).collect().foreach(println)
// row.getValuesMap[T] retrieves multiple columns at once into a Map[String, T]teenagers.map(_.getValuesMap[Any](List("name", "age"))).collect().foreach(println)// Map("name" -> "Justin", "age" -> 19)
DataFrame
Michael, 29Andy, 30Justin, 19
Inferring the Schema Using Reflection

17 / 30
DataFrame
case class Person(name: String, age: Int)
// Create an RDD of Person objects and register it as a table.val people = sc.textFile("examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()people.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.val teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
// The results of SQL queries are DataFrames and support all the normal RDD operations.// The columns of a row in the result can be accessed by field index:teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
// or by field name:teenagers.map(t => "Name: " + t.getAs[String]("name")).collect().foreach(println)
// row.getValuesMap[T] retrieves multiple columns at once into a Map[String, T]teenagers.map(_.getValuesMap[Any](List("name", "age"))).collect().foreach(println)// Map("name" -> "Justin", "age" -> 19)
Michael, 29Andy, 30Justin, 19
Name Age
Michael 29
Andy 30
Justin 19
Text RDDPerson Class
RDD DataFrame
.map(_.split(","))
.map(p => Person(p(0), p(1).trim.toInt)).toDF()
Inferring the Schema Using Reflection
Array(Michael, 29)Array(Andy, 30)Array(Justin, 19)
Person:name Person:age
Michael 29
Person:name Person:age
Andy 30
Person:name Person:age
Justin 19

18 / 30
case class Person(name: String, age: Int)
// Create an RDD of Person objects and register it as a table.val people = sc.textFile("examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()people.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContextval teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
// The results of SQL queries are DataFrames and support all the normal RDD operations.// The columns of a row in the result can be accessed by field index:teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
// or by field name:teenagers.map(t => "Name: " + t.getAs[String]("name")).collect().foreach(println)
// row.getValuesMap[T] retrieves multiple columns at once into a Map[String, T]teenagers.map(_.getValuesMap[Any](List("name", "age"))).collect().foreach(println)// Map("name" -> "Justin", "age" -> 19)
DataFrame
Inferring the Schema Using Reflection
Name Age
Michael 29
Andy 30
Justin 19
DataFrame
19 / 30
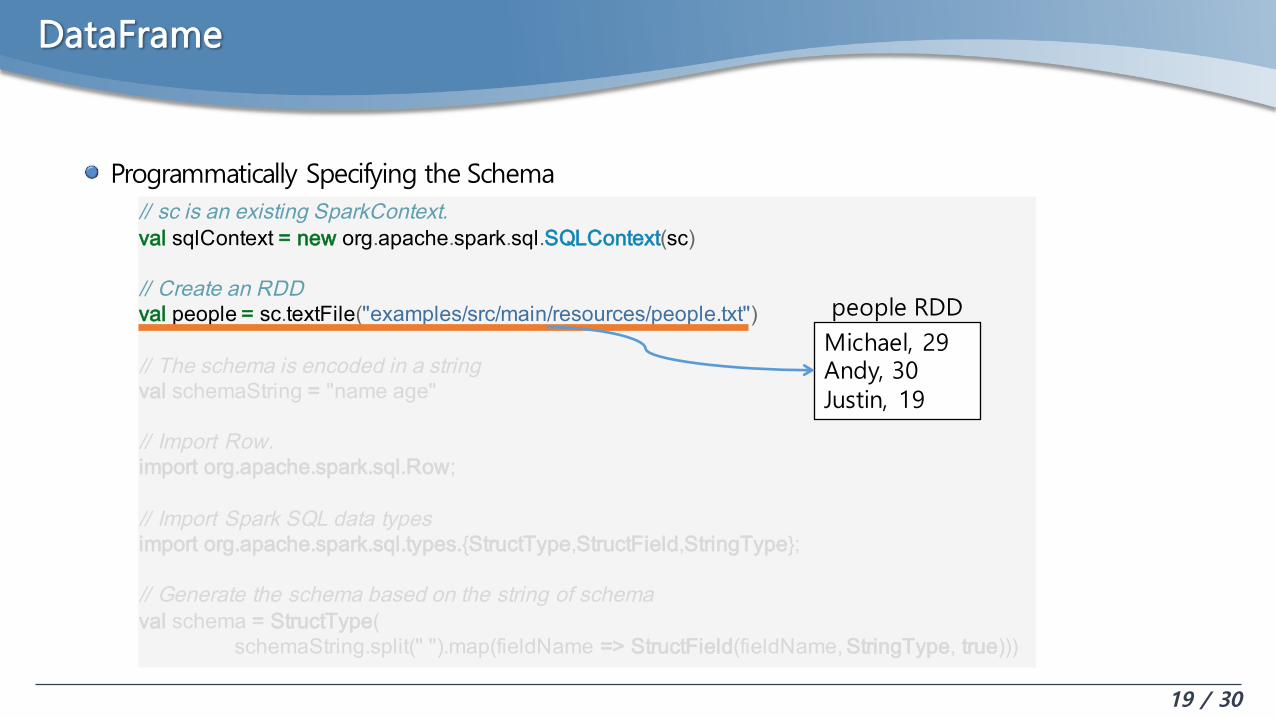
DataFrame
Programmatically Specifying the Schema// sc is an existing SparkContext.val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// Create an RDDval people = sc.textFile("examples/src/main/resources/people.txt")
// The schema is encoded in a stringval schemaString = "name age"
// Import Row.import org.apache.spark.sql.Row;
// Import Spark SQL data typesimport org.apache.spark.sql.types.{StructType,StructField,StringType};
// Generate the schema based on the string of schemaval schema = StructType(
schemaString.split(" ").map(fieldName => StructField(fieldName,StringType, true)))
Michael, 29Andy, 30Justin, 19
people RDD
20 / 30
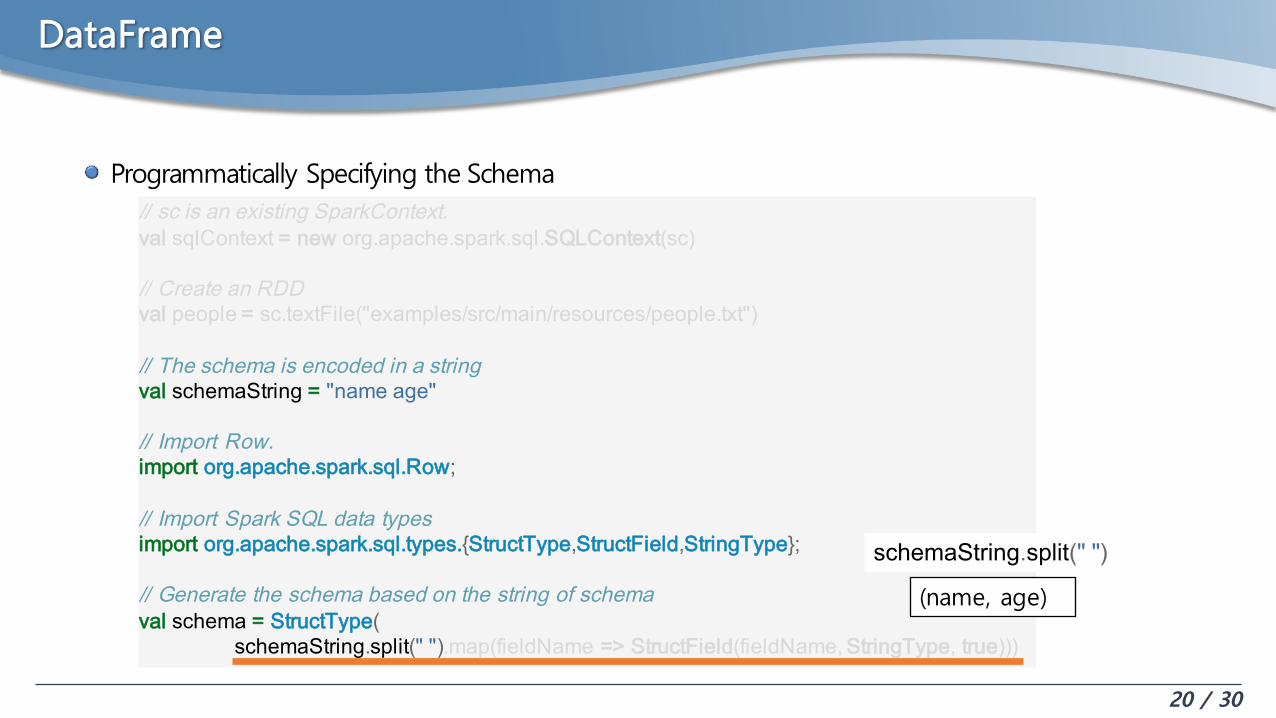
DataFrame
Programmatically Specifying the Schema// sc is an existing SparkContext.val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// Create an RDDval people = sc.textFile("examples/src/main/resources/people.txt")
// The schema is encoded in a stringval schemaString = "name age"
// Import Row.import org.apache.spark.sql.Row;
// Import Spark SQL data typesimport org.apache.spark.sql.types.{StructType,StructField,StringType};
// Generate the schema based on the string of schemaval schema = StructType(
schemaString.split(" ").map(fieldName => StructField(fieldName,StringType, true)))
(name, age)
schemaString.split(" ")

21 / 30
DataFrame
Programmatically Specifying the Schema// sc is an existing SparkContext.val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// Create an RDDval people = sc.textFile("examples/src/main/resources/people.txt")
// The schema is encoded in a stringval schemaString = "name age"
// Import Row.import org.apache.spark.sql.Row;
// Import Spark SQL data typesimport org.apache.spark.sql.types.{StructType,StructField,StringType};
// Generate the schema based on the string of schemaval schema = StructType(
schemaString.split(" ").map(fieldName => StructField(fieldName,StringType, true)))
.map(fieldName => StructField(fieldName, StringType, true))
StructField:”name”StructField:”age”
(name, age)
schemaString.split(" ")

22 / 30
DataFrame
Programmatically Specifying the Schema// sc is an existing SparkContext.val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// Create an RDDval people = sc.textFile("examples/src/main/resources/people.txt")
// The schema is encoded in a stringval schemaString = "name age"
// Import Row.import org.apache.spark.sql.Row;
// Import Spark SQL data typesimport org.apache.spark.sql.types.{StructType,StructField,StringType};
// Generate the schema based on the string of schemaval schema = StructType(
schemaString.split(" ").map(fieldName => StructField(fieldName,StringType, true)))
.map(fieldName => StructField(fieldName, StringType, true))
StructField:”name”StructField:”age”
(name, age)
schemaString.split(" ")
Seq:(StructField:”name”, StructField:”age”)
StructType( …)

23 / 30
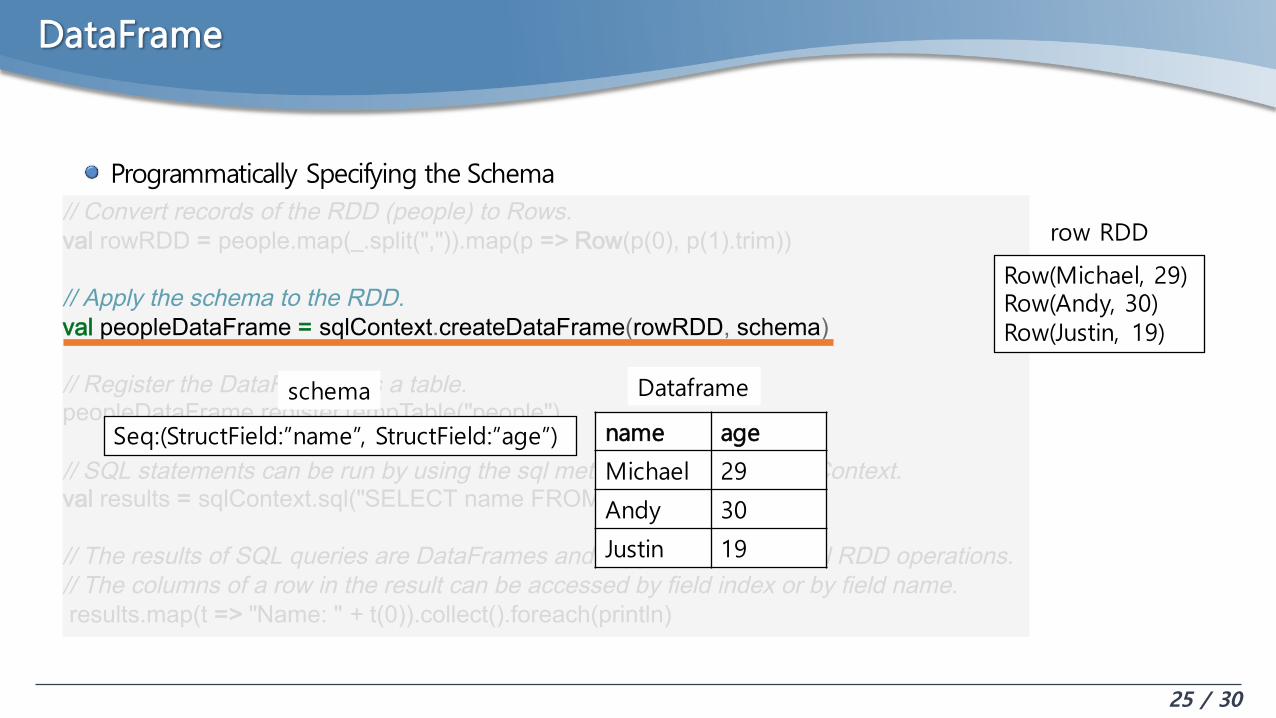
DataFrame
Programmatically Specifying the Schema// Convert records of the RDD (people) to Rows.val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim))
// Apply the schema to the RDD.val peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema)
// Register the DataFrames as a table.peopleDataFrame.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.val results = sqlContext.sql("SELECT name FROM people")
// The results of SQL queries are DataFrames and support all the normal RDD operations.// The columns of a row in the result can be accessed by field index or by field name.results.map(t => "Name: " + t(0)).collect().foreach(println)
// Register the DataFrames as a table.peopleDataFrame.registerTempTable("people")

24 / 30
DataFrame
Programmatically Specifying the Schema// Convert records of the RDD (people) to Rows.val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim))
// Apply the schema to the RDD.val peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema)
// Register the DataFrames as a table.peopleDataFrame.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.val results = sqlContext.sql("SELECT name FROM people")
// The results of SQL queries are DataFrames and support all the normal RDD operations.// The columns of a row in the result can be accessed by field index or by field name.results.map(t => "Name: " + t(0)).collect().foreach(println)
Michael, 29Andy, 30Justin, 19
people RDD
Row(Michael, 29)Row(Andy, 30)Row(Justin, 19)
row RDD
25 / 30
DataFrame
Programmatically Specifying the Schema// Convert records of the RDD (people) to Rows.val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim))
// Apply the schema to the RDD.val peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema)
// Register the DataFrames as a table.peopleDataFrame.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.val results = sqlContext.sql("SELECT name FROM people")
// The results of SQL queries are DataFrames and support all the normal RDD operations.// The columns of a row in the result can be accessed by field index or by field name.results.map(t => "Name: " + t(0)).collect().foreach(println)
Row(Michael, 29)Row(Andy, 30)Row(Justin, 19)
row RDD
Dataframe
name age
Michael 29
Andy 30
Justin 19
Seq:(StructField:”name”, StructField:”age”)
schema

26 / 30
DataFrame
Programmatically Specifying the Schema// Convert records of the RDD (people) to Rows.val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim))
// Apply the schema to the RDD.val peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema)
// Register the DataFrames as a table.peopleDataFrame.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.val results = sqlContext.sql("SELECT name FROM people")
// The results of SQL queries are DataFrames and support all the normal RDD operations.// The columns of a row in the result can be accessed by field index or by field name.results.map(t => "Name: " + t(0)).collect().foreach(println)
results DataFrame
name age
Michael 29
Andy 30
Justin 19

27 / 30
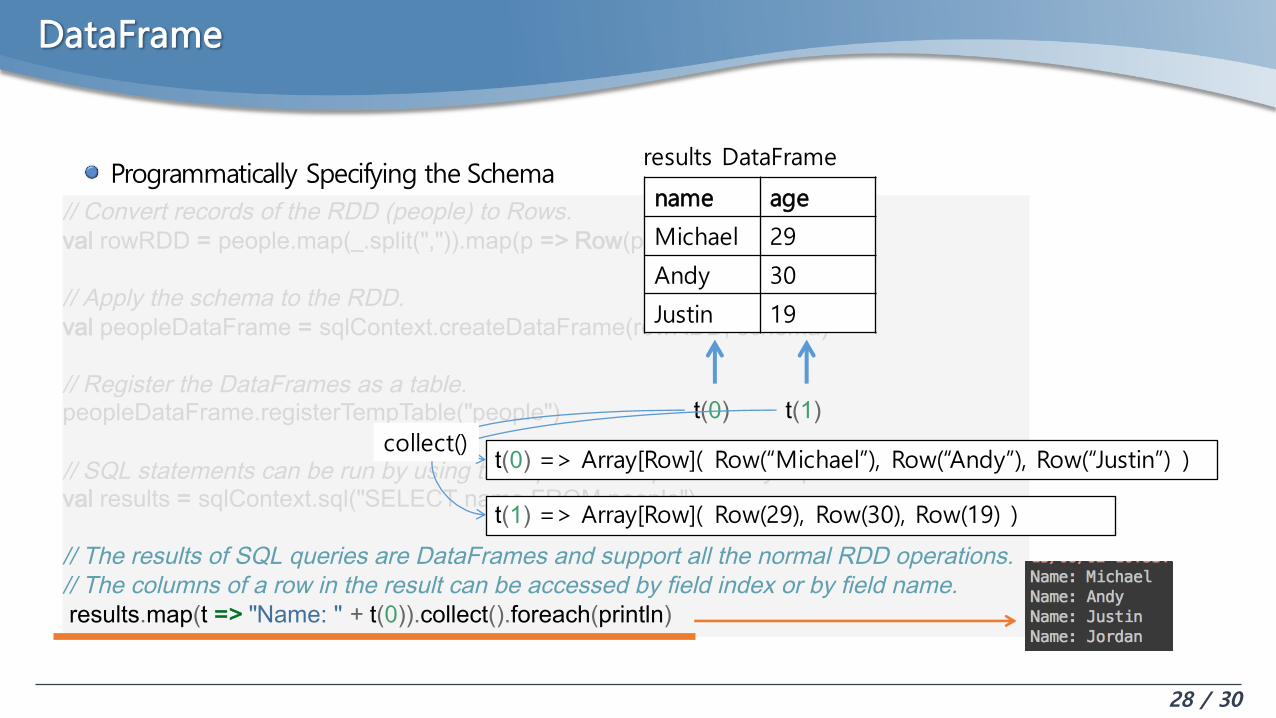
DataFrame
Programmatically Specifying the Schema// Convert records of the RDD (people) to Rows.val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim))
// Apply the schema to the RDD.val peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema)
// Register the DataFrames as a table.peopleDataFrame.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.val results = sqlContext.sql("SELECT name FROM people")
// The results of SQL queries are DataFrames and support all the normal RDD operations.// The columns of a row in the result can be accessed by field index or by field name.results.map(t => "Name: " + t(0)).collect().foreach(println)
results DataFrame
name age
Michael 29
Andy 30
Justin 19
t(0) t(1)
28 / 30
DataFrame
Programmatically Specifying the Schema// Convert records of the RDD (people) to Rows.val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim))
// Apply the schema to the RDD.val peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema)
// Register the DataFrames as a table.peopleDataFrame.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.val results = sqlContext.sql("SELECT name FROM people")
// The results of SQL queries are DataFrames and support all the normal RDD operations.// The columns of a row in the result can be accessed by field index or by field name.results.map(t => "Name: " + t(0)).collect().foreach(println)
results DataFrame
name age
Michael 29
Andy 30
Justin 19
t(0) t(1)
t(0) => Array[Row]( Row(“Michael”), Row(“Andy”), Row(“Justin”) )
t(1) => Array[Row]( Row(29), Row(30), Row(19) )
collect()
29 / 30
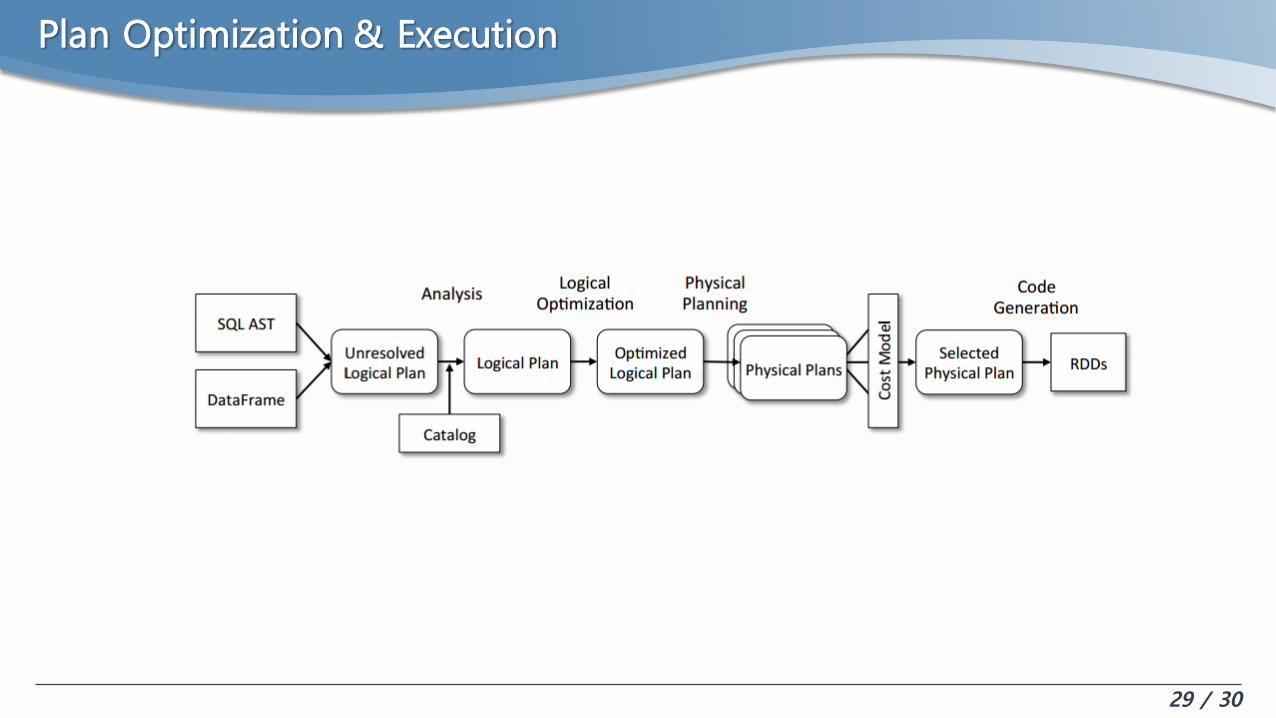
Plan Optimization & Execution

30 / 30
Plan Optimization & Execution
31 / 30
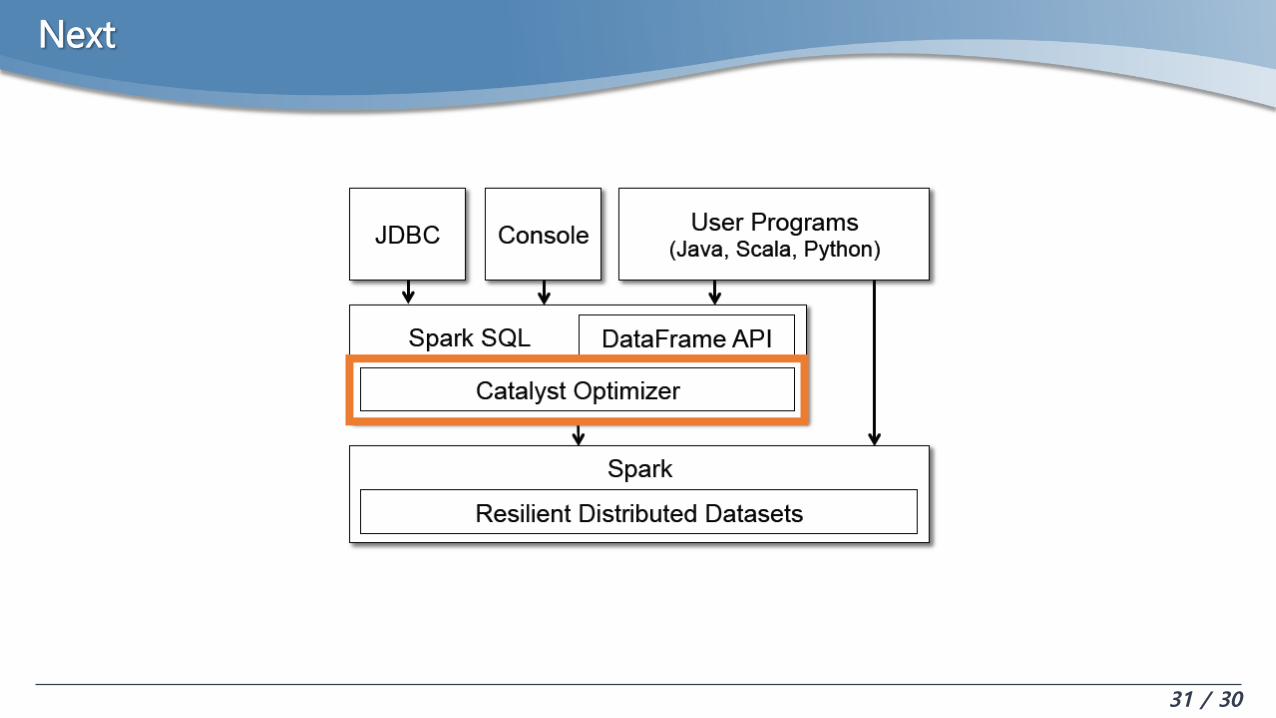
Next

32 / 30
Reference
Michael Armbrust (2015), “Spark SQL: Relational Data Processing in Spark”, SIGMOD '15 Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data Pages 1383-1394
Spark Site, “Spark SQL and DataFrame Guide”, http://spark.apache.org/docs/latest/sql-programming-guide.html#inferring-the-schema-using-reflection
Youtube, “Spark DataFrames Simple and Fast Analysis of Structured Data - Michael Armbrust(Databricks)”, https://www.youtube.com/watch?v=xWkJCUcD55w
Blog ,”Spark SQL Internals”, http://www.trongkhoanguyen.com/2015/08/sparksql-internals.html
DataBricks, “Deep Dive into Spark SQL’s Catalyst Optimizer”, https://databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html
Spark Site, “Spark API Documations : Scala”, http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.package


















![AFrame: Extending DataFrames for Large-Scale Modern Data ... · of DataFrame. AFrame is a data exploration library that provides a Pandas-like DataFrame [27] experience on top of](https://static.fdocuments.net/doc/165x107/5ec6b3d063a53b6c3429a1c4/aframe-extending-dataframes-for-large-scale-modern-data-of-dataframe-aframe.jpg)