
Spark Summit EU 2015: Spark DataFrames: Simple and Fast Analysis of Structured Data
33
Spark DataFrames: Simple and Fast Analytics on Structured Data Michael Armbrust Spark Summit Amsterdam 2015 - October, 28 th
-
Upload
databricks -
Category
Software
-
view
8.385 -
download
0
Transcript of Spark Summit EU 2015: Spark DataFrames: Simple and Fast Analysis of Structured Data

Spark DataFrames:Simple and Fast Analyticson Structured Data
Michael ArmbrustSpark Summit Amsterdam 2015 - October, 28th

Graduated from Alpha
in 1.3
• Spark SQL• Part of the core distribution since Spark 1.0 (April 2014)
SQLAbout Me and
2
0
100
200
300
# Of Commits Per Month
050
100150200
# of Contributors
2

3
SELECT COUNT(*)FROM hiveTableWHERE hive_udf(data)
• Spark SQL• Part of the core distribution since Spark 1.0 (April 2014)• Runs SQL / HiveQL queries, optionally alongside or
replacing existing Hive deployments
SQLAbout Me and
Improved multi-version
support in 1.4

4
• Spark SQL• Part of the core distribution since Spark 1.0 (April 2014)• Runs SQL / HiveQL queries, optionally alongside or
replacing existing Hive deployments• Connect existing BI tools to Spark through JDBC
SQLAbout Me and

• Spark SQL• Part of the core distribution since Spark 1.0 (April 2014)• Runs SQL / HiveQL queries, optionally alongside or
replacing existing Hive deployments• Connect existing BI tools to Spark through JDBC• Bindings in Python, Scala, Java, and R
5
SQLAbout Me and

• Spark SQL• Part of the core distribution since Spark 1.0 (April 2014)• Runs SQL / HiveQL queries, optionally alongside or
replacing existing Hive deployments• Connect existing BI tools to Spark through JDBC• Bindings in Python, Scala, Java, and R
•@michaelarmbrust• Creator of Spark SQL @databricks
6
SQLAbout Me and

The not-so-secret truth...
7
is about more than SQL.SQL

8
Create and runSpark programs faster:
SQL
• Write less code• Read less data• Let the optimizer do the hard work

DataFramenoun – [dey-tuh-freym]
9
1. A distributed collection of rows organized into named columns.
2. An abstraction for selecting, filtering, aggregating and plotting structured data (cf. R, Pandas).
3. Archaic: Previously SchemaRDD (cf. Spark < 1.3).

Write Less Code: Input & Output
Unified interface to reading/writing data in a variety of formats:
df = sqlContext.read \.format("json") \.option("samplingRatio", "0.1") \.load("/home/michael/data.json")
df.write \.format("parquet") \.mode("append") \.partitionBy("year") \
.saveAsTable("fasterData")10

Write Less Code: Input & Output
Unified interface to reading/writing data in a variety of formats:
df = sqlContext.read \.format("json") \.option("samplingRatio", "0.1") \.load("/home/michael/data.json")
df.write \.format("parquet") \.mode("append") \.partitionBy("year") \
.saveAsTable("fasterData")
read and write functions create new builders for
doing I/O
11

Write Less Code: Input & Output
Unified interface to reading/writing data in a variety of formats:
Builder methods specify:• Format• Partitioning• Handling of
existing data
df = sqlContext.read \.format("json") \.option("samplingRatio", "0.1") \.load("/home/michael/data.json")
df.write \.format("parquet") \.mode("append") \.partitionBy("year") \
.saveAsTable("fasterData")12

Write Less Code: Input & Output
Unified interface to reading/writing data in a variety of formats:
load(…), save(…) or saveAsTable(…)
finish the I/O specification
df = sqlContext.read \.format("json") \.option("samplingRatio", "0.1") \.load("/home/michael/data.json")
df.write \.format("parquet") \.mode("append") \.partitionBy("year") \
.saveAsTable("fasterData")13

Read Less Data: Efficient Formats
• Compact binary encoding with intelligent compression (delta, RLE, etc)• Each column stored separately with an index that allows
skipping of unread columns• Support for partitioning (/data/year=2015)• Data skipping using statistics (column min/max, etc)
14
is an efficient columnar storage format:
ORC

Write Less Code: Data Source APISpark SQL’s Data Source API can read and write DataFrames
using a variety of formats.
15
{ JSON }
Built-In External
JDBC
and more…
Find more sources at http://spark-packages.org/
ORCplain text*

ETL Using Custom Data SourcessqlContext.read
.format("com.databricks.spark.jira")
.option("url", "https://issues.apache.org/jira/rest/api/latest/search")
.option("user", "marmbrus")
.option("password", "*******")
.option("query", """|project = SPARK AND |component = SQL AND |(status = Open OR status = "In Progress" OR status = Reopened)""".stripMargin)
.load()
16
.repartition(1).write.format("parquet").saveAsTable("sparkSqlJira")
Load data from (Spark’s Bug Tracker) using a custom data source.
Write the converted data out to a table stored in

Write Less Code: High-Level Operations
Solve common problems concisely using DataFrame functions:
• Selecting columns and filtering• Joining different data sources• Aggregation (count, sum, average, etc)• Plotting results with Pandas
17

Write Less Code: Compute an Average
private IntWritable one =new IntWritable(1)
private IntWritable output =new IntWritable()
proctected void map(LongWritable key,Text value,Context context) {
String[] fields = value.split("\t")output.set(Integer.parseInt(fields[1]))context.write(one, output)
}
IntWritable one = new IntWritable(1)DoubleWritable average = new DoubleWritable()
protected void reduce(IntWritable key,Iterable<IntWritable> values,Context context) {
int sum = 0int count = 0for(IntWritable value : values) {
sum += value.get()count++}
average.set(sum / (double) count)context.Write(key, average)
}
data = sc.textFile(...).split("\t")data.map(lambda x: (x[0], [x.[1], 1])) \
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]]) \
.map(lambda x: [x[0], x[1][0] / x[1][1]]) \
.collect()
18

Write Less Code: Compute an Average
Using RDDsdata = sc.textFile(...).split("\t")data.map(lambda x: (x[0], [int(x[1]), 1])) \
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]]) \
.map(lambda x: [x[0], x[1][0] / x[1][1]]) \
.collect()
Using DataFramessqlCtx.table("people") \
.groupBy("name") \
.agg("name", avg("age")) \
.map(lambda …) \
.collect()
Full API Docs• Python• Scala• Java• R
19
Using SQLSELECT name, avg(age)FROM peopleGROUP BY name

Not Just Less Code, Faster Too!
20
0 2 4 6 8 10
RDD Scala
RDD Python
DataFrame Scala
DataFrame Python
DataFrame R
DataFrame SQL
Time to Aggregate 10 million int pairs (secs)

Plan Optimization & Execution
21
SQL AST
DataFrame
Unresolved Logical Plan Logical Plan Optimized
Logical Plan RDDsSelected Physical Plan
Analysis LogicalOptimization
PhysicalPlanning
Cost
Mod
el
Physical Plans
CodeGeneration
Catalog
DataFrames and SQL share the same optimization/execution pipeline

Seamlessly Integrated
Intermix DataFrame operations with custom Python, Java, R, or Scala code
zipToCity = udf(lambda zipCode: <custom logic here>)
def add_demographics(events):u = sqlCtx.table("users")events \.join(u, events.user_id == u.user_id) \.withColumn("city", zipToCity(df.zip))
Augments any DataFrame
that contains user_id
22

Optimize Full Pipelines
Optimization happens as late as possible, therefore Spark SQL can optimize even across functions.
23
events = add_demographics(sqlCtx.load("/data/events", "json"))
training_data = events \.where(events.city == "Amsterdam") \.select(events.timestamp) \.collect()

24
def add_demographics(events):u = sqlCtx.table("users") # Load Hive tableevents \.join(u, events.user_id == u.user_id) \ # Join on user_id.withColumn("city", zipToCity(df.zip)) # Run udf to add city column
events = add_demographics(sqlCtx.load("/data/events", "json")) training_data = events.where(events.city == "Amsterdam").select(events.timestamp).collect()
Logical Plan
filterby city
join
events file users table
expensive
only join relevent users
Physical Plan
join
scan(events)
filterby city
scan(users)
24

25
def add_demographics(events):u = sqlCtx.table("users") # Load partitioned Hive tableevents \.join(u, events.user_id == u.user_id) \ # Join on user_id.withColumn("city", zipToCity(df.zip)) # Run udf to add city column
Optimized Physical Planwith Predicate Pushdown
and Column Pruning
join
optimized scan
(events)
optimizedscan
(users)
events = add_demographics(sqlCtx.load("/data/events", "parquet")) training_data = events.where(events.city == "Amsterdam").select(events.timestamp).collect()
Logical Plan
filterby city
join
events file users table
Physical Plan
join
scan(events)
filterby city
scan(users)
25
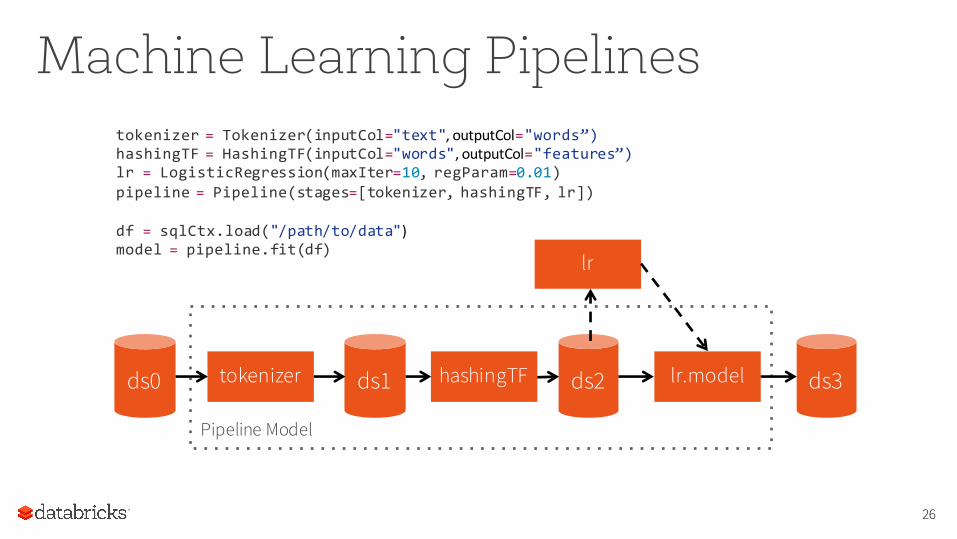
Machine Learning Pipelines
26
tokenizer = Tokenizer(inputCol="text", outputCol="words”)hashingTF = HashingTF(inputCol="words", outputCol="features”)lr = LogisticRegression(maxIter=10, regParam=0.01)pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
df = sqlCtx.load("/path/to/data")model = pipeline.fit(df)
ds0 ds1 ds2 ds3tokenizer hashingTF lr.model
lr
Pipeline Model

• 100+ native functions with optimized codegenimplementations– String manipulation – concat, format_string, lower, lpad
– Data/Time – current_timestamp, date_format, date_add, …
– Math – sqrt, randn, …– Other –monotonicallyIncreasingId, sparkPartitionId, …
27
Rich Function Library
from pyspark.sql.functions import *yesterday = date_sub(current_date(), 1)df2 = df.filter(df.created_at > yesterday)
import org.apache.spark.sql.functions._val yesterday = date_sub(current_date(), 1)val df2 = df.filter(df("created_at") > yesterday)
Added in Spark 1.5

Optimized Execution with Project Tungsten
Compact encoding, cache aware algorithms, runtime code generation
28

The overheads of JVM objects
“abcd”
29
• Native: 4 bytes with UTF-8 encoding• Java: 48 bytes
java.lang.String object internals:OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) ...4 4 (object header) ...8 4 (object header) ...12 4 char[] String.value []16 4 int String.hash 020 4 int String.hash32 0
Instance size: 24 bytes (reported by Instrumentation API)
12 byte object header
8 byte hashcode
20 bytes data + overhead

6 “bricks”
Tungsten’s Compact Encoding
30
0x0 123 32L 48L 4 “data”
(123, “data”, “bricks”)
Null bitmap
Offset to data
Offset to data Field lengths
“abcd” with Tungsten encoding: ~5-‐6 bytes

Runtime Bytecode Generation
31
df.where(df("year") > 2015)
GreaterThan(year#234, Literal(2015))
bool filter(Object baseObject) {int offset = baseOffset + bitSetWidthInBytes + 3*8L;int value = Platform.getInt(baseObject, offset);return value34 > 2015;
}
DataFrame Code / SQL
Catalyst Expressions
Low-level bytecodeJVM intrinsic JIT-ed to
pointer arithmetic
Platform.getInt(baseObject, offset);

• Type-safe: operate on domain objects with compiled lambda functions• Fast: Code-generated
encoders for fast serialization• Interoperable: Easily convert DataFrameßà Datasetwithout boiler plate
32
Coming soon: Datasetsval df = ctx.read.json("people.json")
// Convert data to domain objects.case class Person(name: String, age: Int)val ds: Dataset[Person] = df.as[Person]ds.filter(_.age > 30)
// Compute histogram of age by name.val hist = ds.groupBy(_.name).mapGroups {
case (name, people: Iter[Person]) =>val buckets = new Array[Int](10) people.map(_.age).foreach { a =>
buckets(a / 10) += 1} (name, buckets)
}
Preview in Spark 1.6

33
Create and run your Spark programs faster:
SQL
• Write less code• Read less data• Let the optimizer do the hard work
Questions?
Committer Office HoursWeds, 4:00-5:00 pm MichaelThurs, 10:30-11:30 am Reynold
Thurs, 2:00-3:00 pm Andrew


















