

Spark Streaming @ Berlin Apache Spark Meetup, March 2015
32
Spark Streaming March 2015 A Brief Introduction for Developers @StratioBD
-
Upload
stratio -
Category
Data & Analytics
-
view
619 -
download
2
Transcript of Spark Streaming @ Berlin Apache Spark Meetup, March 2015

Spark Streaming
March 2015
A Brief Introduction for Developers
@StratioBD
Who am I?
SPARK STREAMING OVERVIEW
Big Data Developer at Stratio. Working on ingestion and streaming projects with Spark Streaming and Apache Flume. Currently researching on Spark SQL optimizations and other stuff.
Santiago Mola
@mola_io

SPARK
• What is Apache Spark?
• RDD
• RDD API
1 2 SPARK STREAMING
• What is Spark Streaming?
• Who uses it?
• Receivers
• Discretized Streams (DStream)
• Window functions
• Use case: Twitter text classification
INDEX

WHAT ISAPACHE SPARK?1

1.1. What is Apache Spark?
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
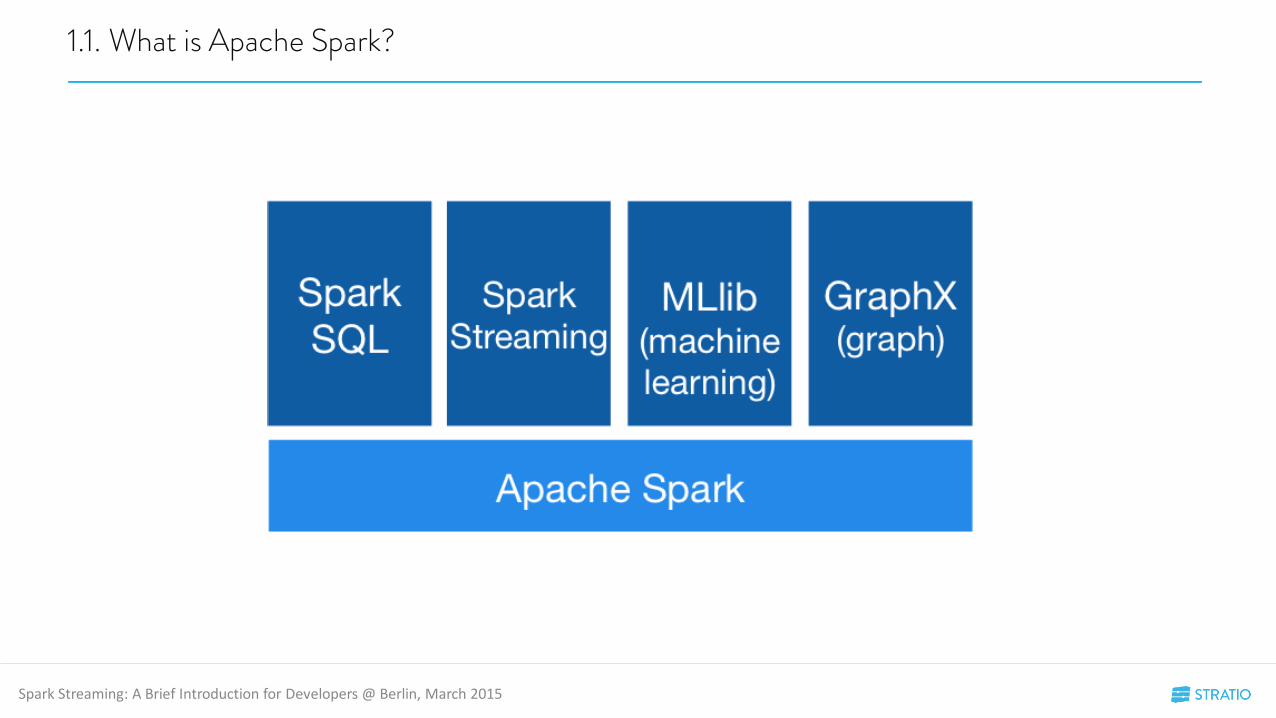
Apache Spark™ is a fast and general engine for large-scale data processing.
“The Spark engine runs in a variety of environments, from cloud services to Hadoop or Mesosclusters. It is used to perform ETL, interactive queries (SQL), advanced analytics (e.g. machine learning) and streaming over large datasets in a wide range of data stores (e.g. HDFS, Cassandra, HBase, S3). Spark supports a variety of popular development languages including Java, Python and Scala.”
Databricks – What is Spark?https://databricks.com/spark/about
1.1. What is Apache Spark?
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015

1.1. What does it look like?
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
Let’s count words…
val textFile = spark.textFile("hdfs://...")
val counts = textFile
.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")

1.2. Resilient Distributed Dataset (RDD)
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
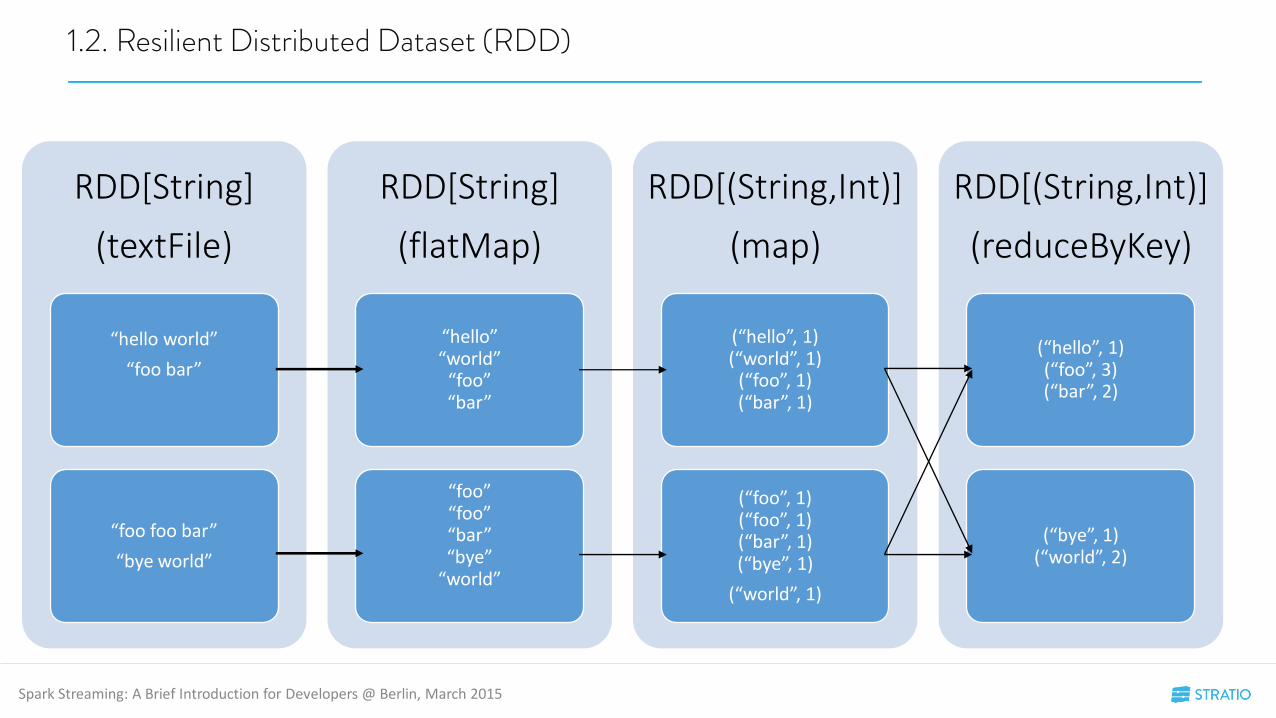
A RDD is a collection of elements that is immutable, distributed and fault-tolerant.
Transformations can be applied to a RDD, resulting in new RDD.
Actions can be applied to a RDD to obtain a value.
RDD is lazy.
Resilient Distributed Dataset (RDD)
1.2. Resilient Distributed Dataset (RDD)
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
RDD[String]
(textFile)
“hello world”
“foo bar”
“foo foo bar”
“bye world”
RDD[String]
(flatMap)
“hello”“world”
“foo”“bar”
“foo”“foo”“bar”“bye”
“world”
RDD[(String,Int)]
(map)
(“hello”, 1)(“world”, 1)
(“foo”, 1)(“bar”, 1)
(“foo”, 1)(“foo”, 1)(“bar”, 1)(“bye”, 1)
(“world”, 1)
RDD[(String,Int)]
(reduceByKey)
(“hello”, 1)(“foo”, 3)(“bar”, 2)
(“bye”, 1)(“world”, 2)

1.2. Resilient Distributed Dataset (RDD)
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
val textFile : RDD[String] = spark.textFile("hdfs://...")
val flatMapped : RDD[String] = textFile.flatMap(line => line.split(" "))
val mapped : RDD[(String,Int)] = flatMapped.map(Word => (word, 1))
val counts : RDD[(String,Int)] = mapped.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")

1.3. RDD API
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
map(func)filter(func) flatMap(func)mapPartitions(func) mapPartitionsWithIndex(func) sample(withReplacement, fraction, seed)union(otherDataset)intersection(otherDataset)distinct([numTasks]))groupByKey([numTasks]) reduceByKey(func, [numTasks]) aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) sortByKey([ascending], [numTasks]) join(otherDataset, [numTasks]) cogroup(otherDataset, [numTasks]) cartesian(otherDataset) pipe(command, [envVars]) coalesce(numPartitions) repartition(numPartitions) repartitionAndSortWithinPartitions(partitioner)
Transformations
reduce(func) collect() count() first() take(n) takeSample(withReplacement, num, [seed]) takeOrdered(n, [ordering]) saveAsTextFile(path)saveAsSequenceFile(path)saveAsObjectFile(path)countByKey()foreach(func)
Actions
https://spark.apache.org/docs/latest/programming-guide.html
Full docs

1. Recap…
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
• Apache Spark is an awesome, distributed, fault-tolerant, easy-to-use processing engine.
• The most important concept is the RDD, which is an immutable and distributed collection of elements.
• RDD API provides a lot of high-level transformations that make distributed processing easier.
• On top of Spark core, we have MLLib (machine learning), Spark SQL (query engine), GraphX (graphalgorithms) and… Spark Streaming (stream processing)!

2. SPARKSTREAMING
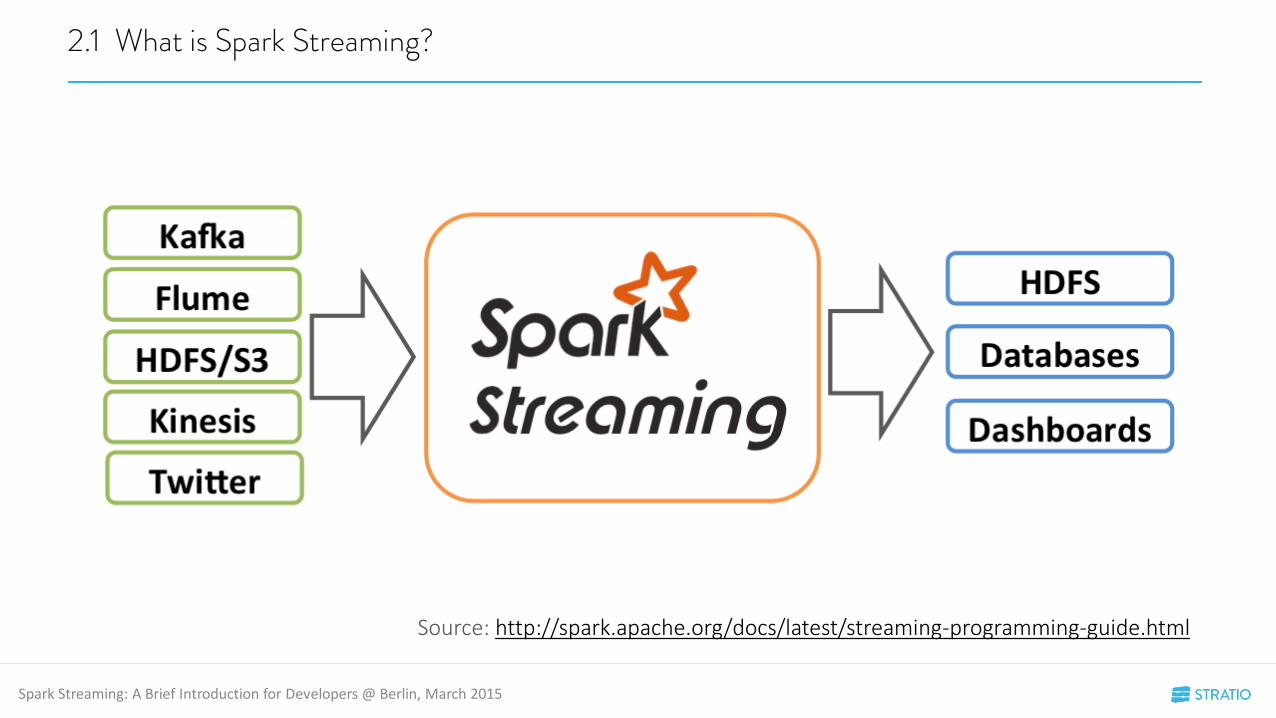
2.1 What is Spark Streaming?
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
Source: http://spark.apache.org/docs/latest/streaming-programming-guide.html
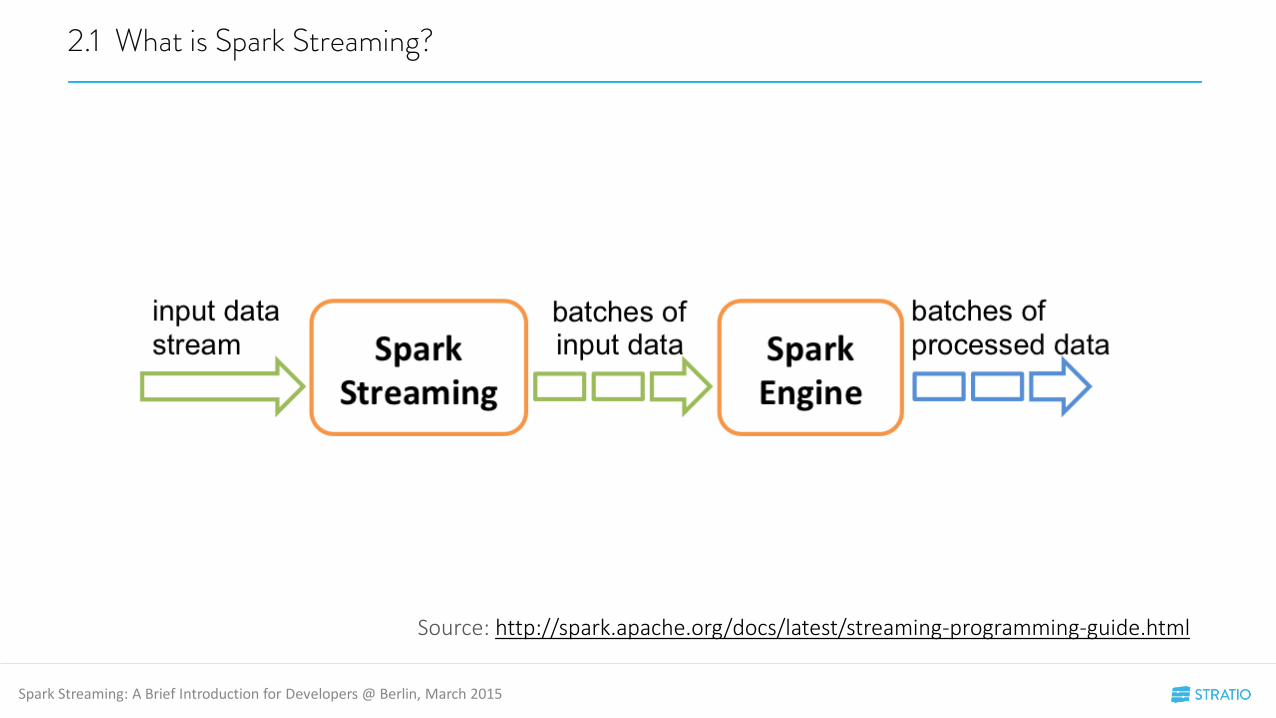
2.1 What is Spark Streaming?
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
Source: http://spark.apache.org/docs/latest/streaming-programming-guide.html

2.1 Who uses it?
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
Source: http://es.slideshare.net/pacoid/databricks-meetup-los-angeles-apache-spark-user-group

2.2. Receivers
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
• File Stream
• Sockets
• Actors (Akka)
• Queue RDDs (Testing)

2.2. Receivers
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
Flume
Kafka
Kinesis
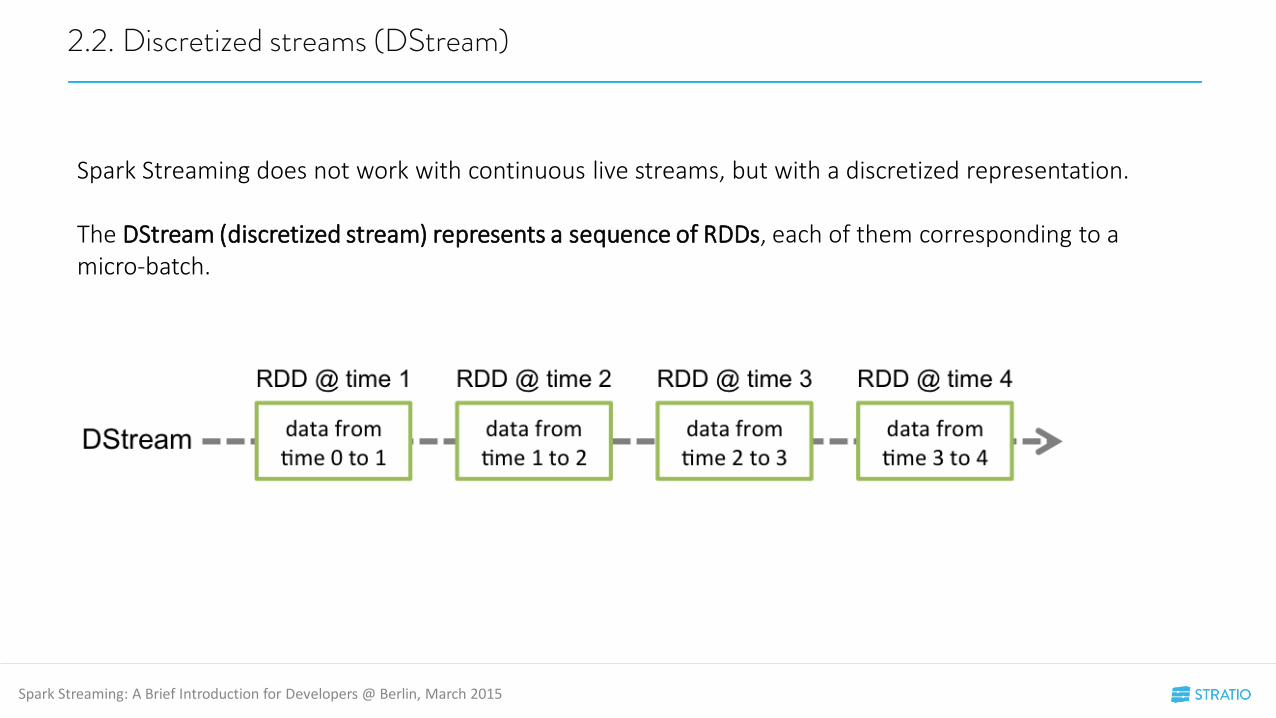
2.2. Discretized streams (DStream)
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
Spark Streaming does not work with continuous live streams, but with a discretized representation.
The DStream (discretized stream) represents a sequence of RDDs, each of them corresponding to a micro-batch.

2.3. What does it look like?
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
Let’s count words… again…
val textStream = ssc.socketTextStream(“localhost“, 9000)
val counts = textStream
.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.print()
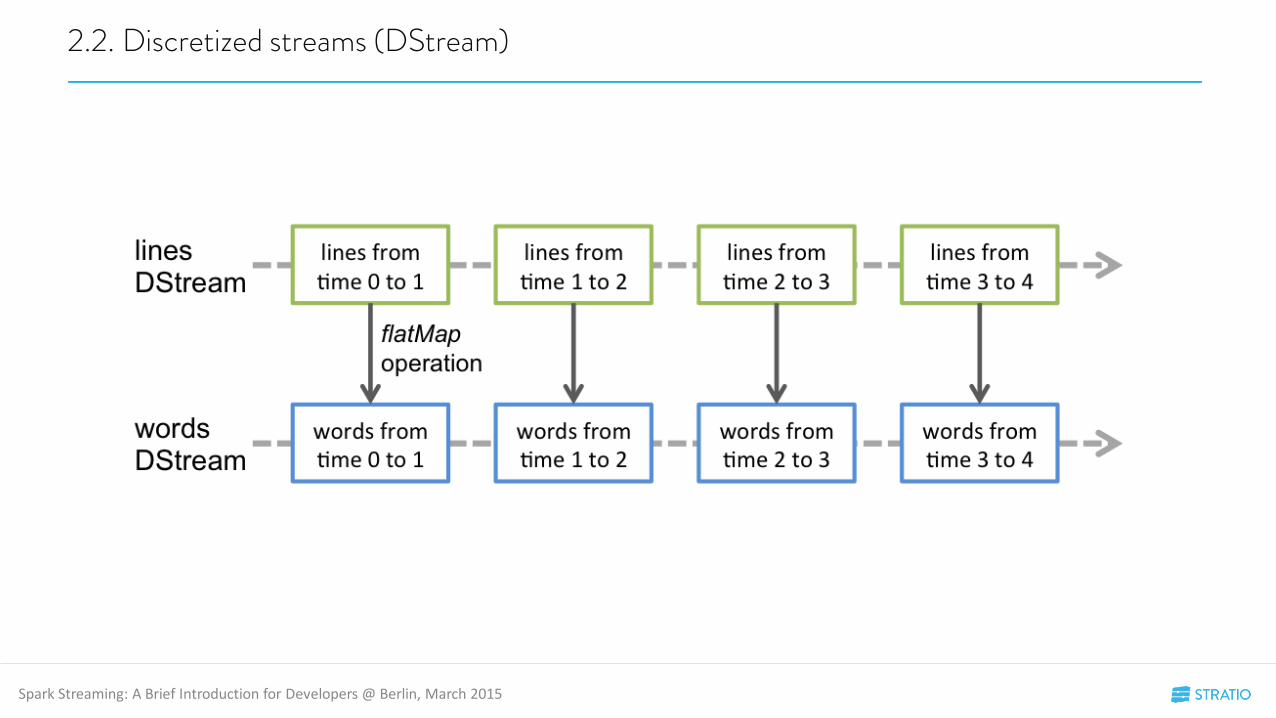
2.2. Discretized streams (DStream)
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
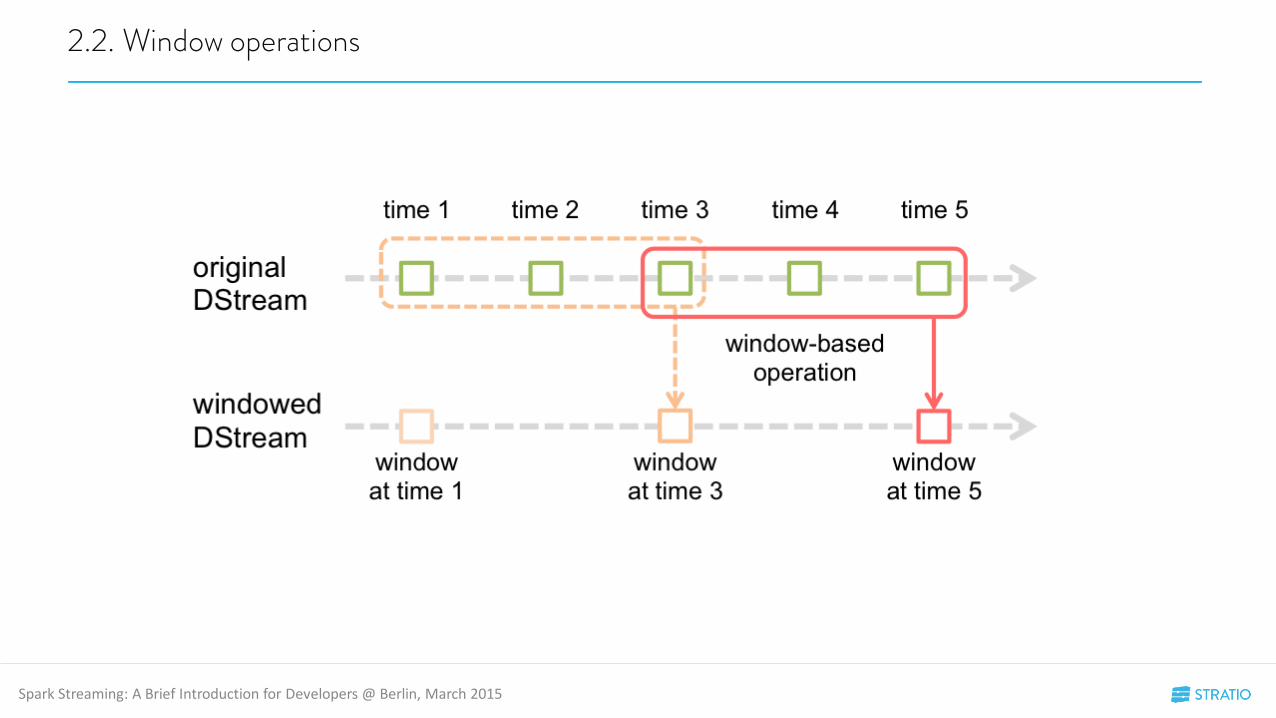
2.2. Window operations
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015

2.3. What does it look like?
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
Let’s count words… and print every 10 seconds the counters of the last 60 seconds
val textStream = ssc.socketTextStream(“localhost“, 9000)
val counts = textStream
.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKeyAndWindow(_ + _, Seconds(60), Seconds(10))
counts.print()
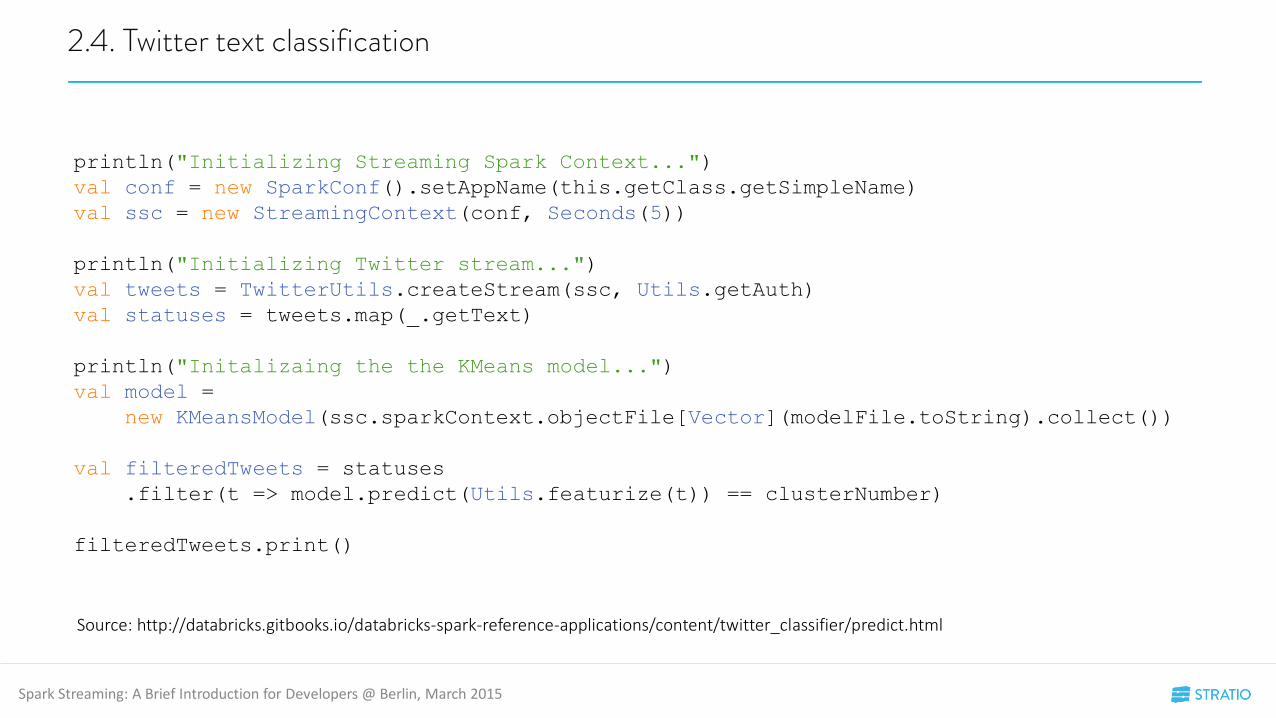
2.4. Twitter text classification
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
println("Initializing Streaming Spark Context...")
val conf = new SparkConf().setAppName(this.getClass.getSimpleName)
val ssc = new StreamingContext(conf, Seconds(5))
println("Initializing Twitter stream...")
val tweets = TwitterUtils.createStream(ssc, Utils.getAuth)
val statuses = tweets.map(_.getText)
println("Initalizaing the the KMeans model...")
val model =
new KMeansModel(ssc.sparkContext.objectFile[Vector](modelFile.toString).collect())
val filteredTweets = statuses
.filter(t => model.predict(Utils.featurize(t)) == clusterNumber)
filteredTweets.print()
Source: http://databricks.gitbooks.io/databricks-spark-reference-applications/content/twitter_classifier/predict.html

2.5. Recap…
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
Source: http://databricks.gitbooks.io/databricks-spark-reference-applications/content/twitter_classifier/predict.html
• Spark Streaming uses a discrete representation of live streams, where each batch is a RDD.
• Data can be received from a wide variety of sources.
• Streaming APIs resemble RDD APIs: learning it is trivial for Spark (batch) users.
• Streaming API has a wide variety of high-level transformations (most transformations available to RDD + window transformations).
• It can be combined with the RDD API… that means integration with Mllib (machine learning), GraphX(graph algorithms), RDD persistence or any other Spark components.


SUPPORT SLIDES
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
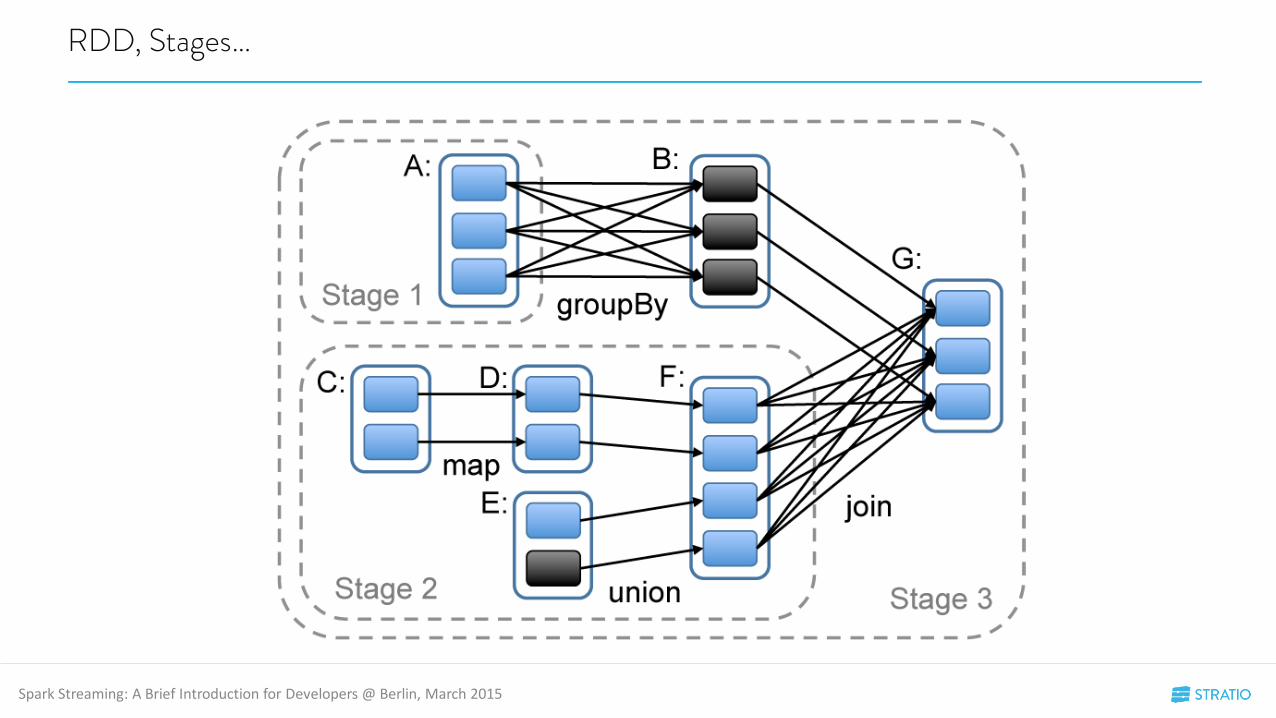
RDD, Stages…
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
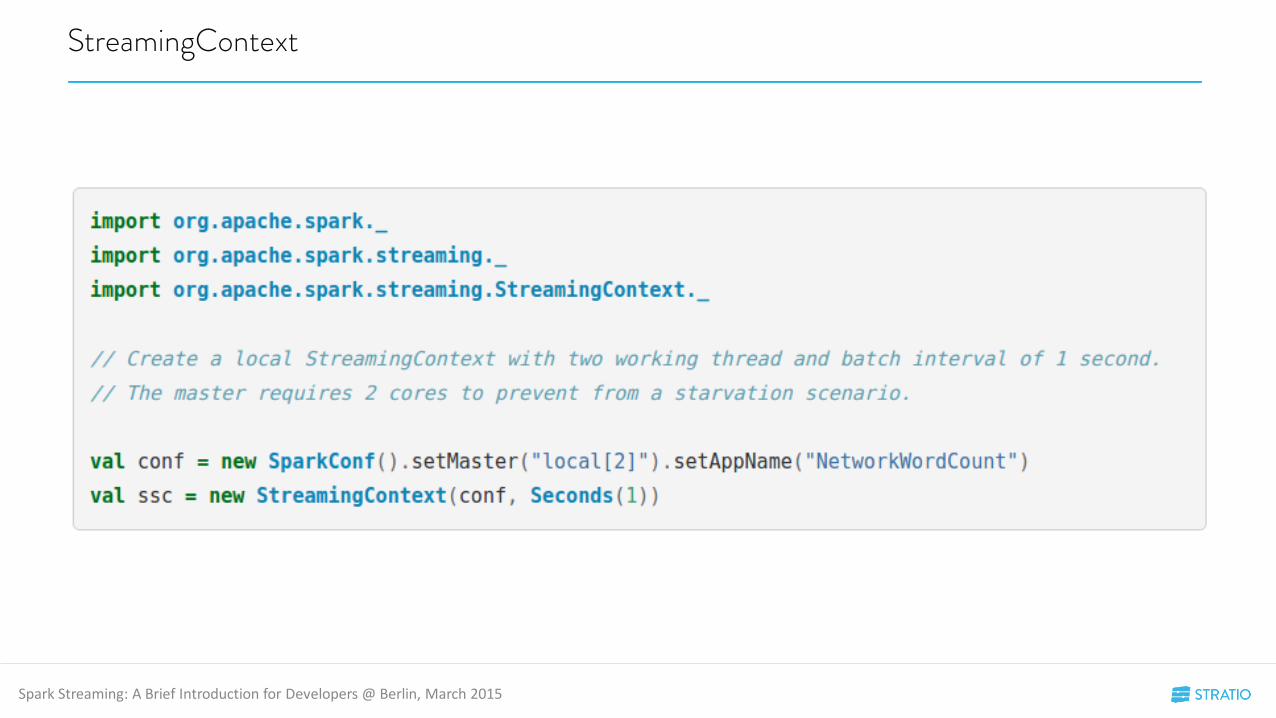
StreamingContext
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
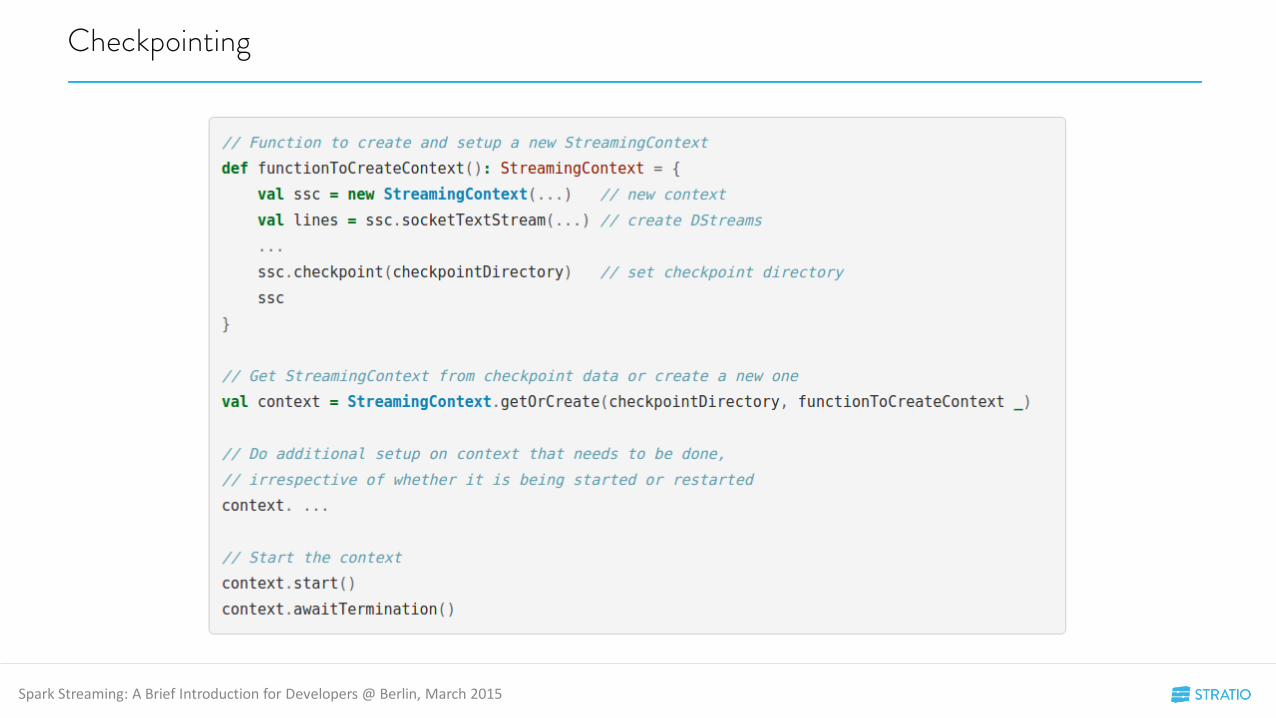
Checkpointing
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015
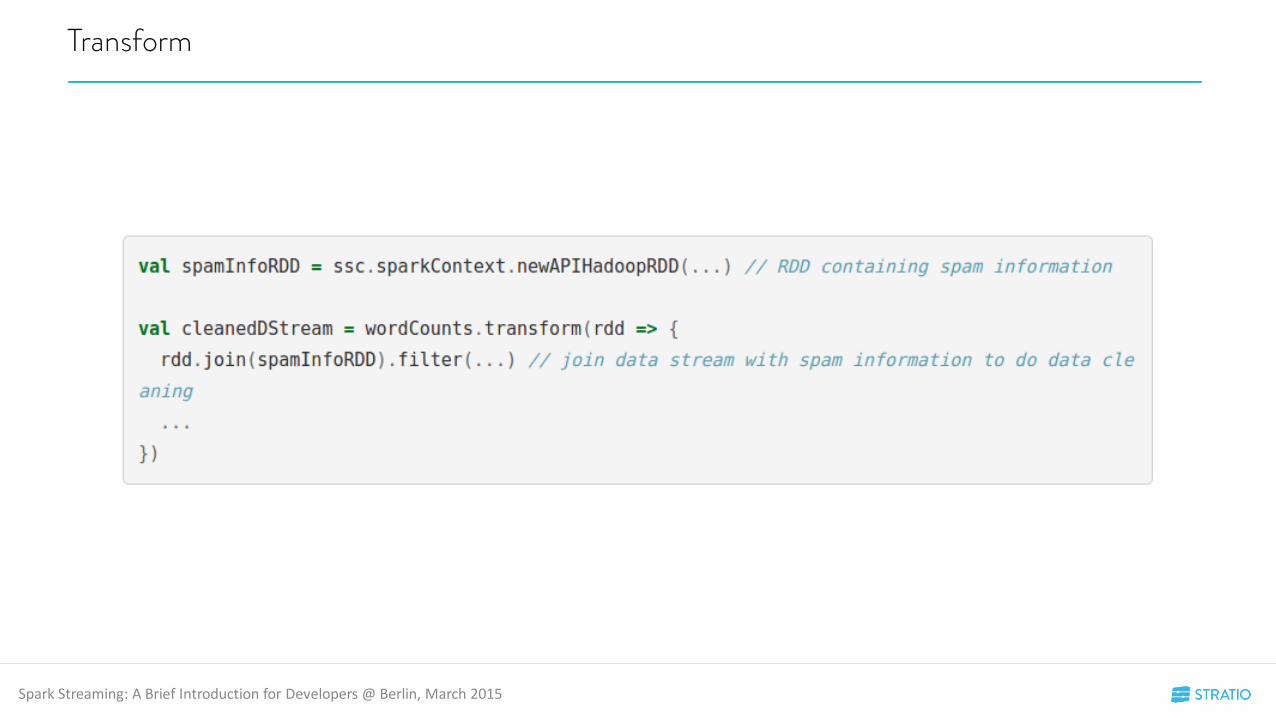
Transform
Spark Streaming: A Brief Introduction for Developers @ Berlin, March 2015


















