
Spark Sql for Training
40
Introduction to Spark SQL Bryan 2015
-
Upload
bryan-yang -
Category
Data & Analytics
-
view
941 -
download
1
Transcript of Spark Sql for Training

Introduction to Spark SQL
Bryan 2015

• ExperienceVpon Data EngineerTWM, Keywear, Nielsen
• Bryan’s notes for data analysishttp://bryannotes.blogspot.tw
• Spark.TW
• Linikedinhttps://tw.linkedin.com/pub/bryan-yang/7b/763/a79
ABOUT ME

Agenda
• Dataframe
• Basic of sqlContext
• Welcome hiveContext



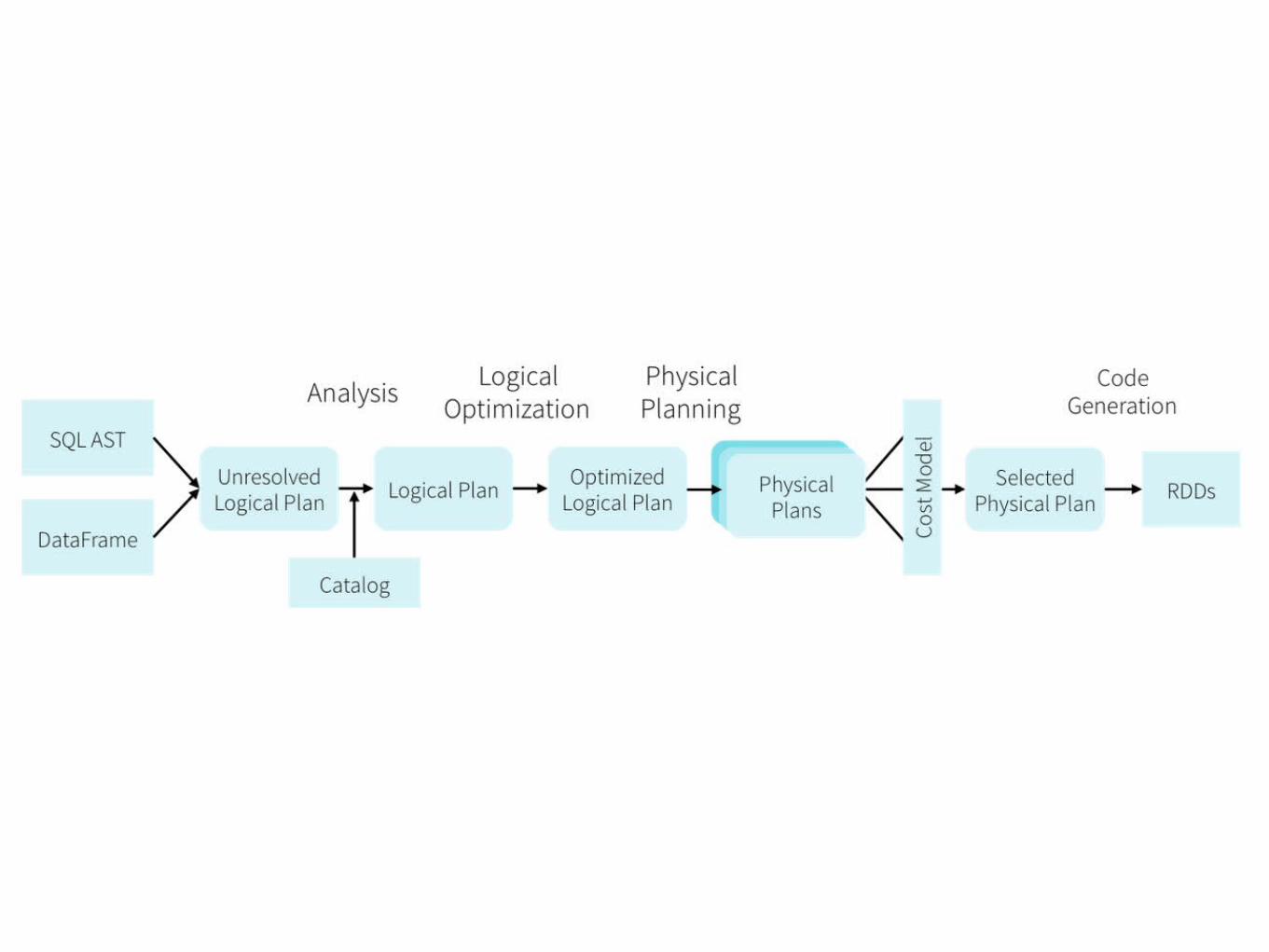
Optimization
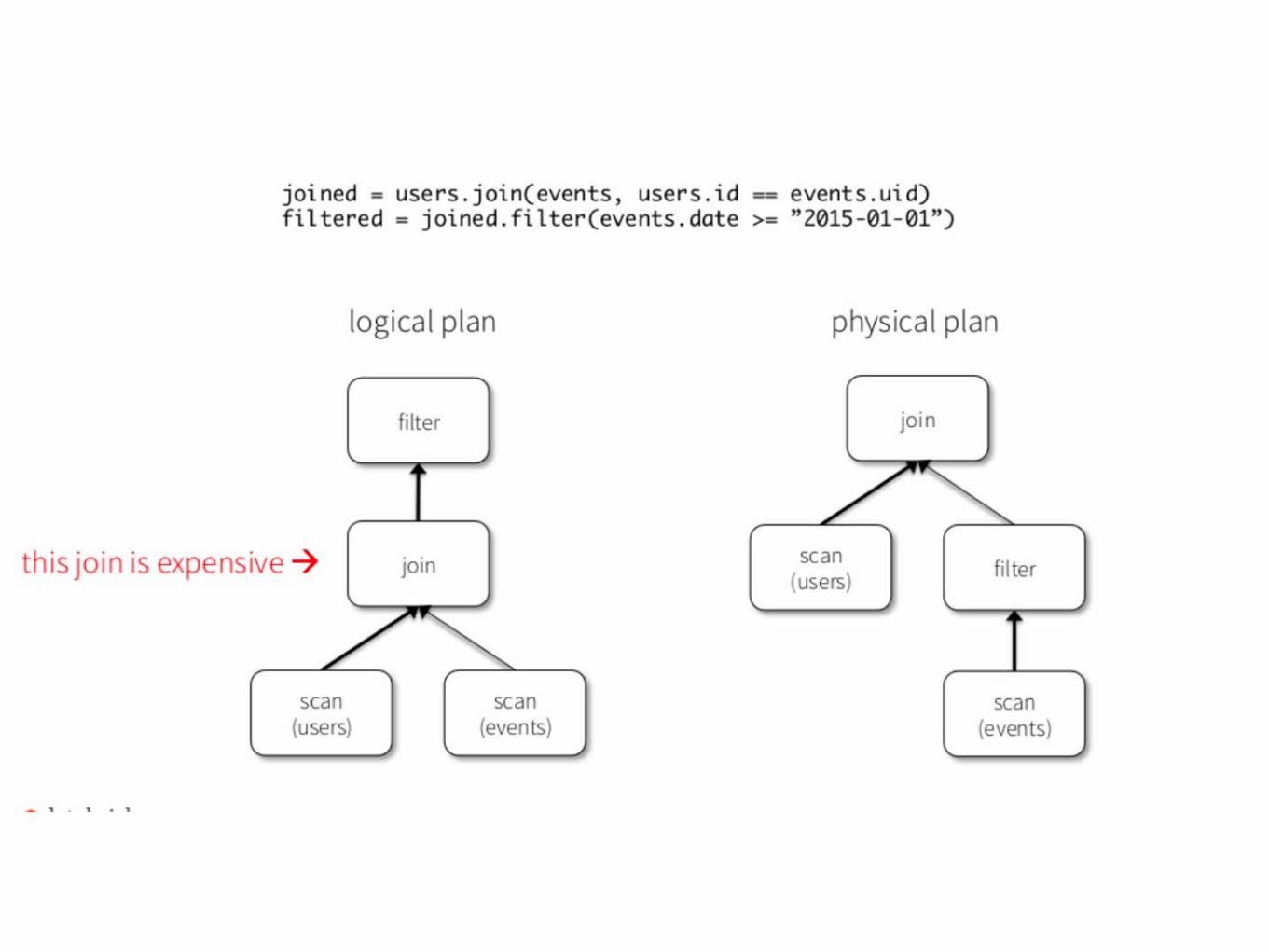
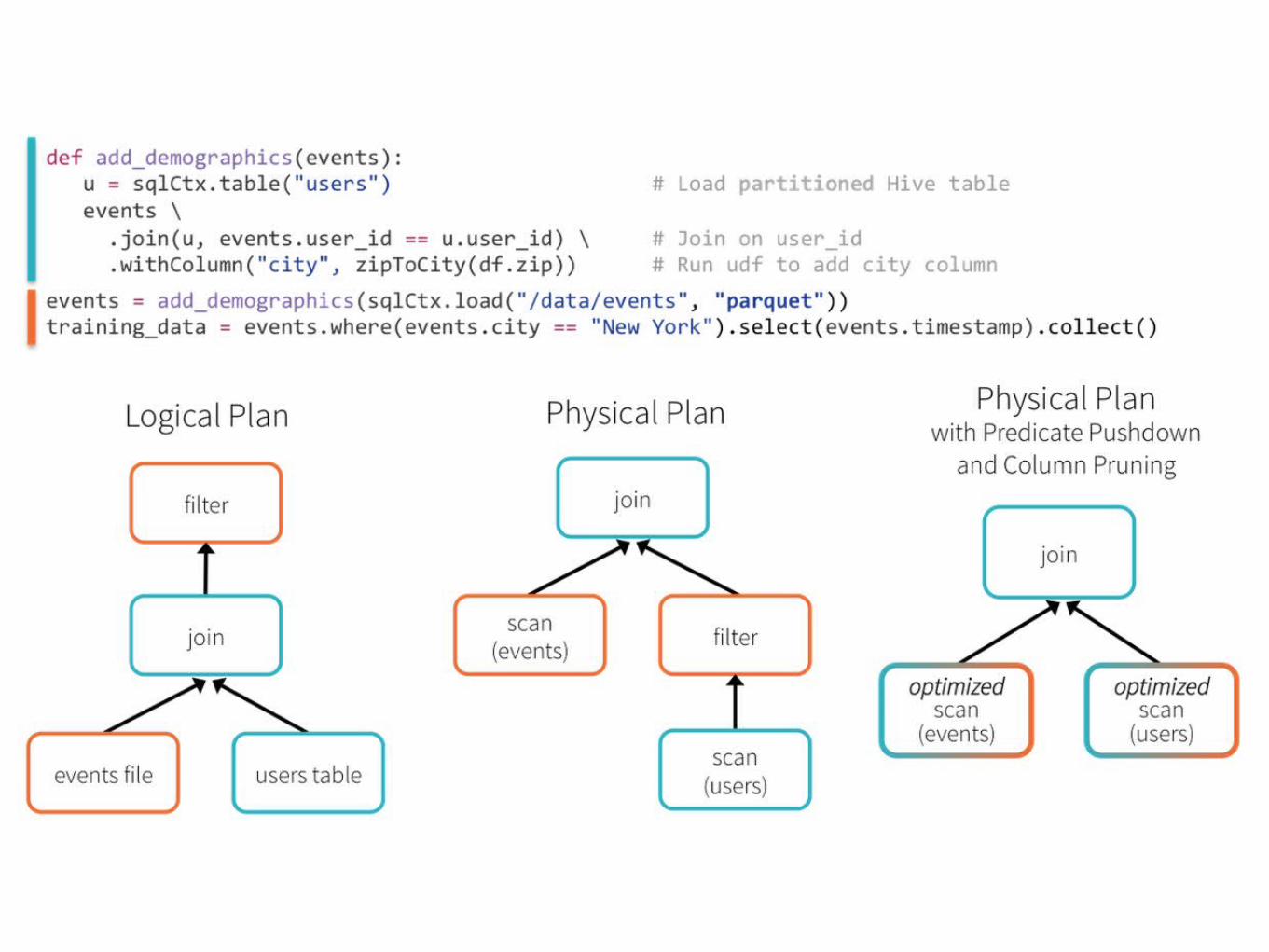
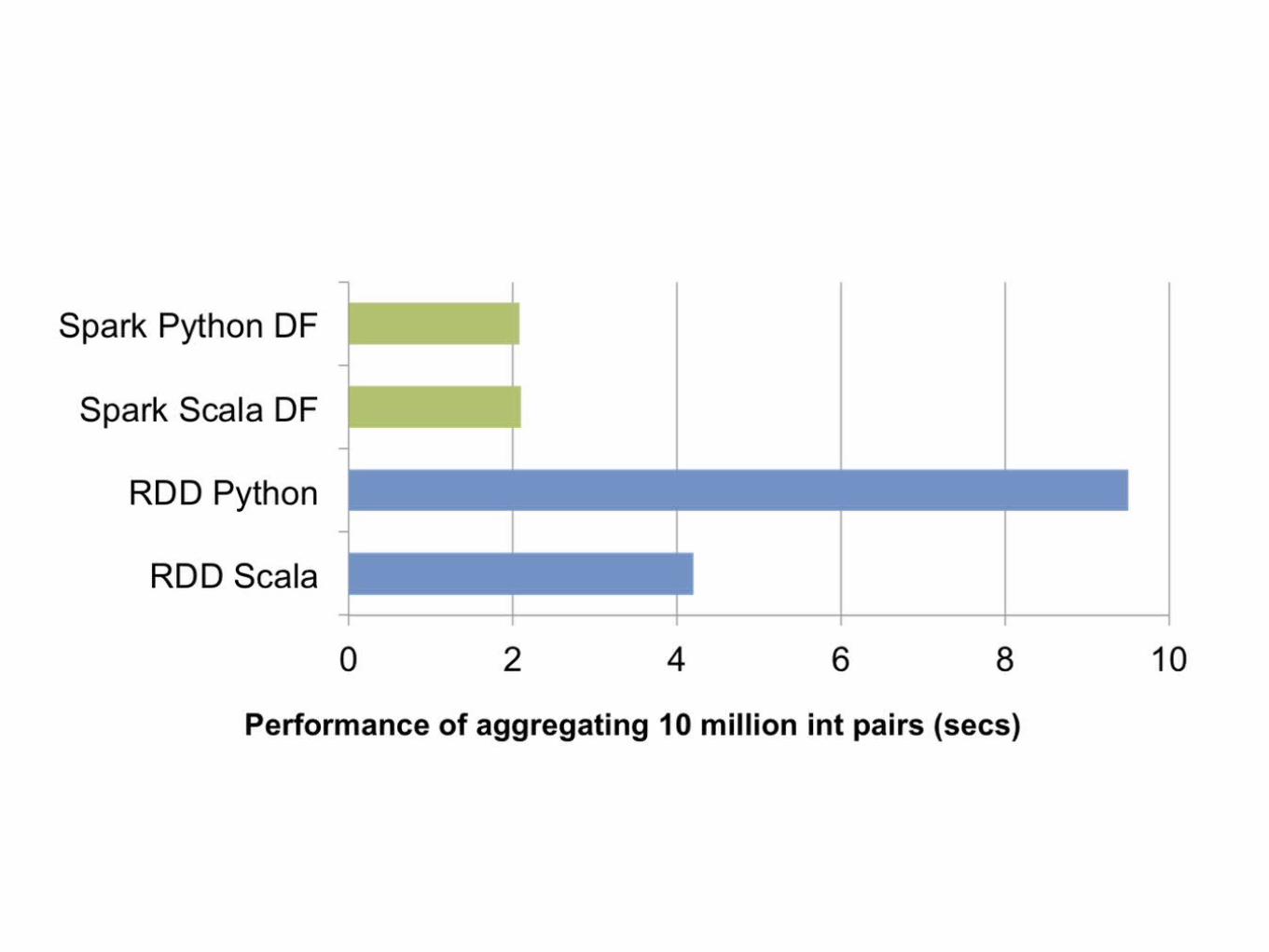
效率提升

SqlContext
主要的物件https://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.package

spark-shell
• 除了 sc 之外,還會起 SQL Context
• Spark context available as sc.
• 15/03/22 02:09:11 INFO SparkILoop: Created sql context (with Hive support)..
• SQL context available as sqlContext.

DF from RDD• 先轉成 RDD
scala> val data = sc.textFile("hdfs://localhost:54310/user/hadoop/ml-100k/u.data")
• 建立 case classcase class Rattings(userId: Int, itemID: Int, rating: Int, timestmap:String)
• 轉成 Data Framescala> val ratting = data.map(_.split("\t")).map(p => Rattings(p(0).trim.toInt, p(1).trim.toInt, p(2).trim.toInt, p(3))).toDF()
ratting: org.apache.spark.sql.DataFrame = [userId: int, itemID: int, rating: int, timestmap: string]

DF from json• 格式
{"movieID":242,"name":"test1"}{"movieID":307,"name":"test2"}
• 可以直接呼叫scala> val movie = sqlContext.jsonFile("hdfs://localhost:54310/user/hadoop/ml-100k/movies.json")

Dataframe Operations
• Show()userId itemID rating timestmap196 242 3 881250949186 302 3 89171774222 377 1 878887116244 51 2 880606923253 465 5 891628467
• head(5)res11: Array[org.apache.spark.sql.Row] = Array([196,242,3,881250949], [186,302,3,891717742], [22,377,1,878887116], [244,51,2,880606923], [166,346,1,886397596])

printSchema()
• printSchema() scala> ratting.printSchema()root|-- userId: integer (nullable = false)|-- itemID: integer (nullable = false)|-- rating: integer (nullable = false)|-- timestmap: string (nullable = true)

Select• Select Column
scala> ratting.select("userId").show()
• Condition Selectscala> ratting.select(ratting("itemID")>100).show()(itemID > 100)true true true
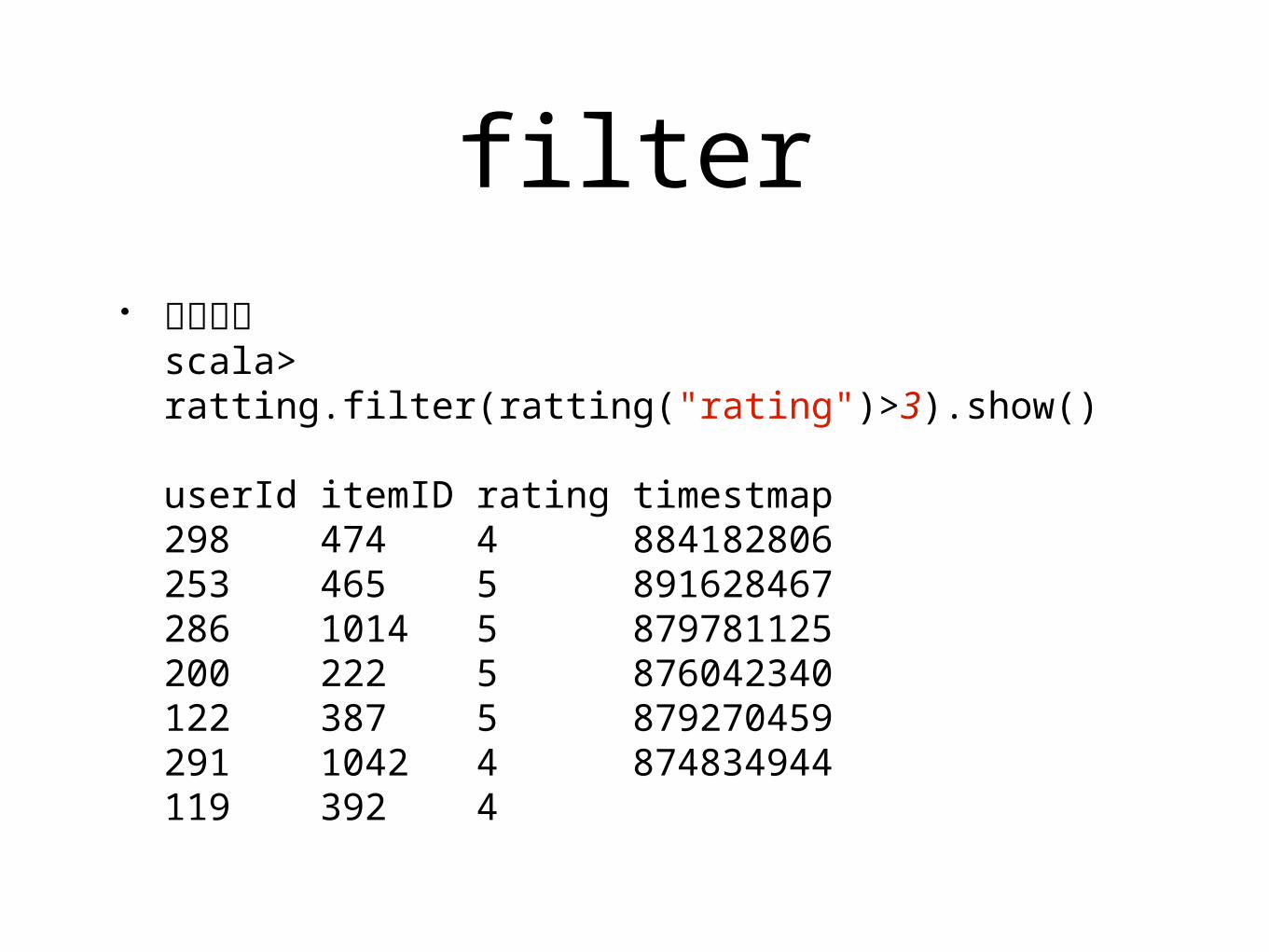
filter• 篩選條件
scala> ratting.filter(ratting("rating")>3).show()
userId itemID rating timestmap298 474 4 884182806253 465 5 891628467286 1014 5 879781125200 222 5 876042340122 387 5 879270459291 1042 4 874834944119 392 4

• 偷懶寫法ratting.filter("rating">3).show()
• 合併使用scala> ratting.filter(ratting("rating")>3).select("userID","itemID").show()
userID itemID298 474 286 1014
• 也可以 ratting.filter("userID">500).select(avg("rating"),max("rating"),sum("rating")).show()

GROUP BY• count()
scala> ratting.groupBy("userId").count().show()userId count831 73 631 20
• agg()scala> ratting.groupBy("userId").agg("rating"->"avg","userID" -> "count").show()
• 可以連用scala> ratting.groupBy("userId").count().sort("count","userID").show()

GROUP BY其他
avgmaxminmeansum更多 Function
https://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.functions$

UnionAll• 合併相同欄位表格
scala> val ratting1_3 = ratting.filter(ratting("rating")<=3)
scala> ratting1_3.count() //res79: Long = 44625
scala> val ratting4_5 = ratting.filter(ratting("rating")>3)
scala> ratting4_5.count() //res80: Long = 55375
ratting1_3.unionAll(ratting4_5).count() //res81: Long = 100000
• 欄位不同無法 UNIONscala> ratting1_3.unionAll(test).count()
java.lang.AssertionError: assertion failed
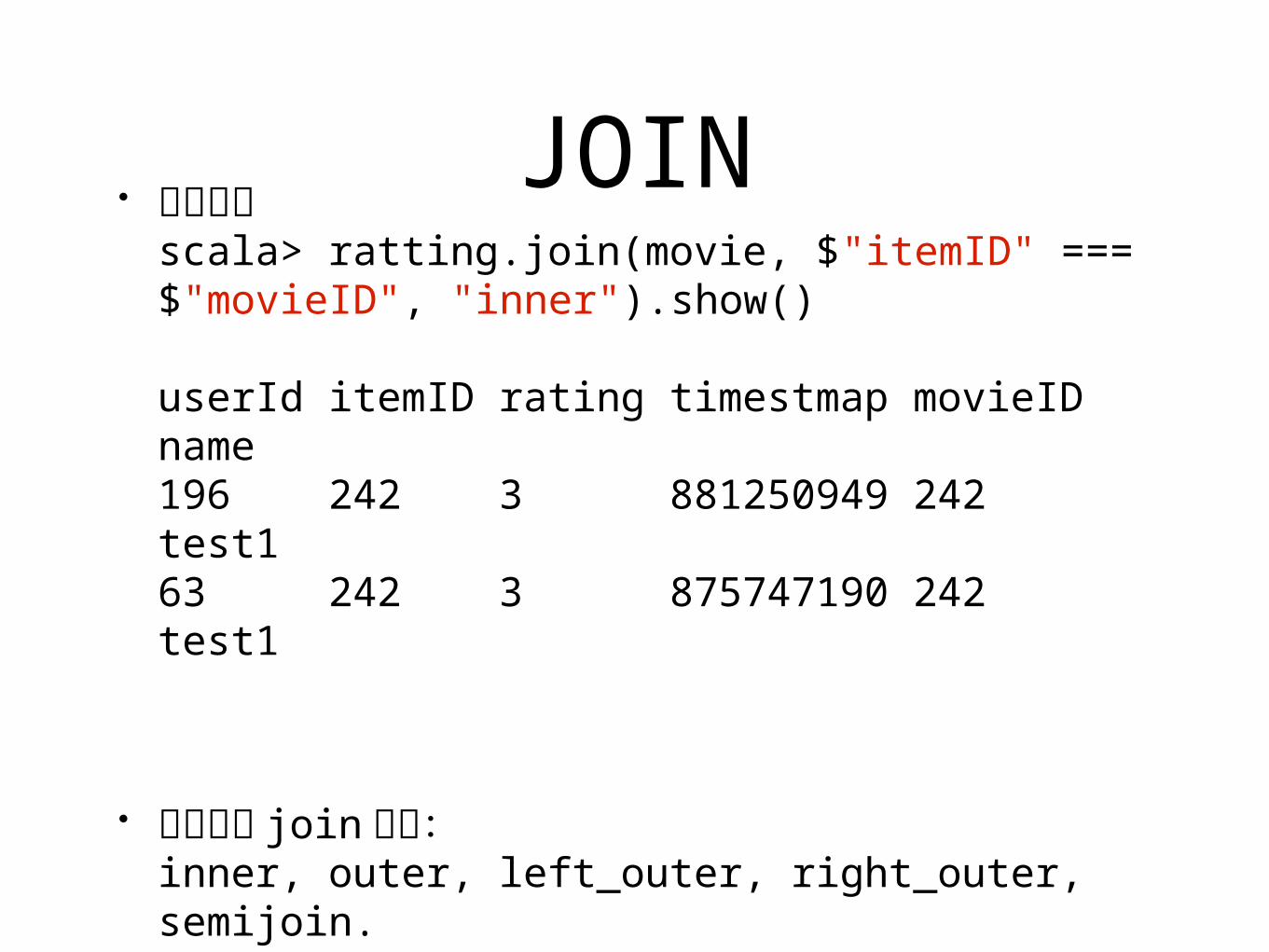
JOIN• 基本語法
scala> ratting.join(movie, $"itemID" === $"movieID", "inner").show()
userId itemID rating timestmap movieID name 196 242 3 881250949 242 test163 242 3 875747190 242 test1
• 可支援的 join 型態:inner, outer, left_outer, right_outer, semijoin.
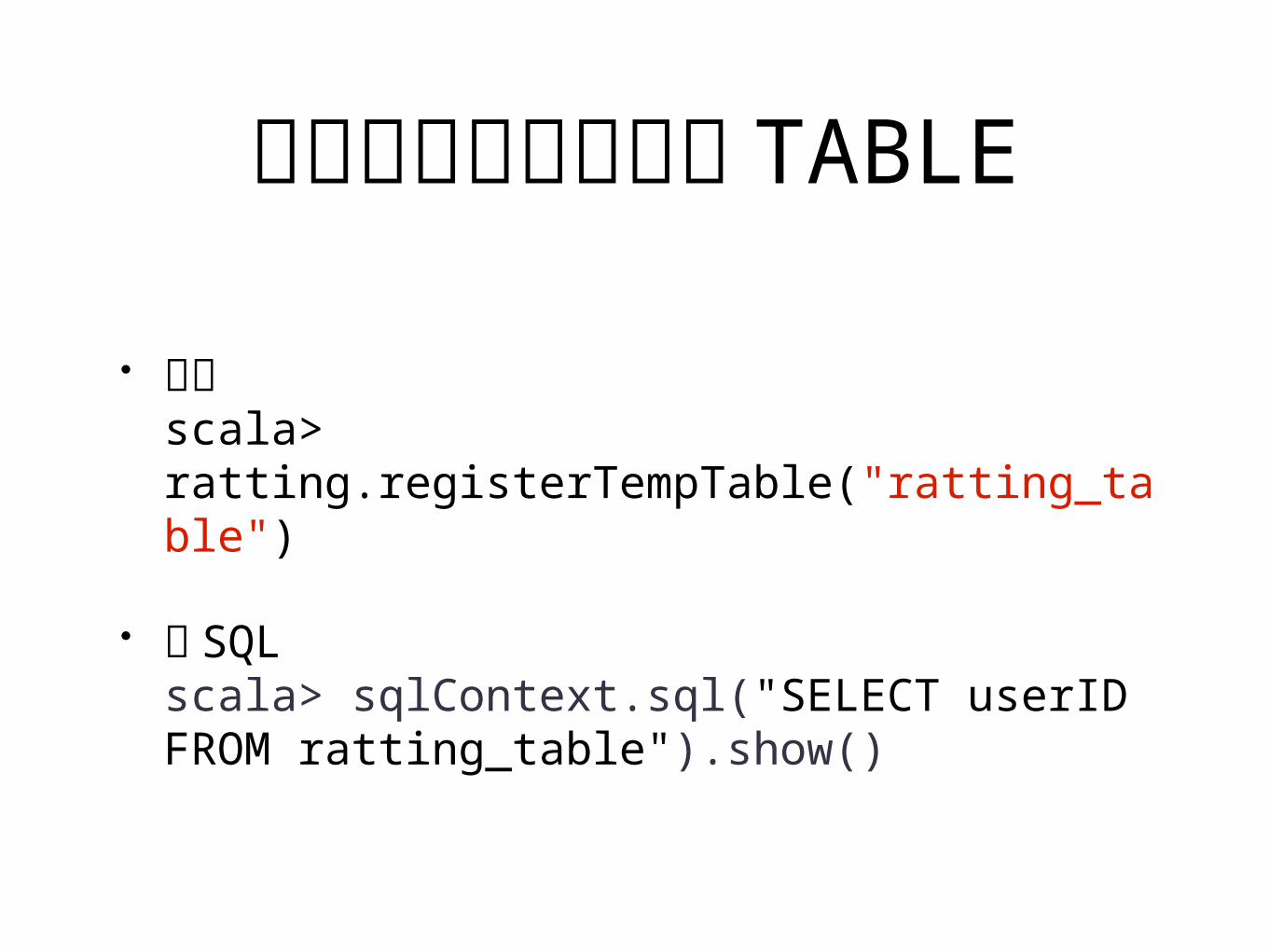
也可以把表格註冊成TABLE
• 註冊scala> ratting.registerTempTable("ratting_table")
• 寫 SQLscala> sqlContext.sql("SELECT userID FROM ratting_table").show()

DF 支援 RDD 操作• MAP
scala> result.map(t => "user:" + t(0)).collect().foreach(println)
• 取出來的物件型態是 Anyscala> ratting.map(t => t(2)).take(5)
• 先轉 string 再轉 intscala> ratting.map(t => Array(t(0),t(2).toString.toInt * 10)).take(5)
res130: Array[Array[Any]] = Array(Array(196, 30), Array(186, 30), Array(22, 10), Array(244, 20), Array(166, 10))

SAVE DATA
• Save()ratting.select("itemID").save("hdfs://localhost:54310/test2.json","json")
• saveAsParquetFile
• saveAsTable(Hive Table)

Hive Context
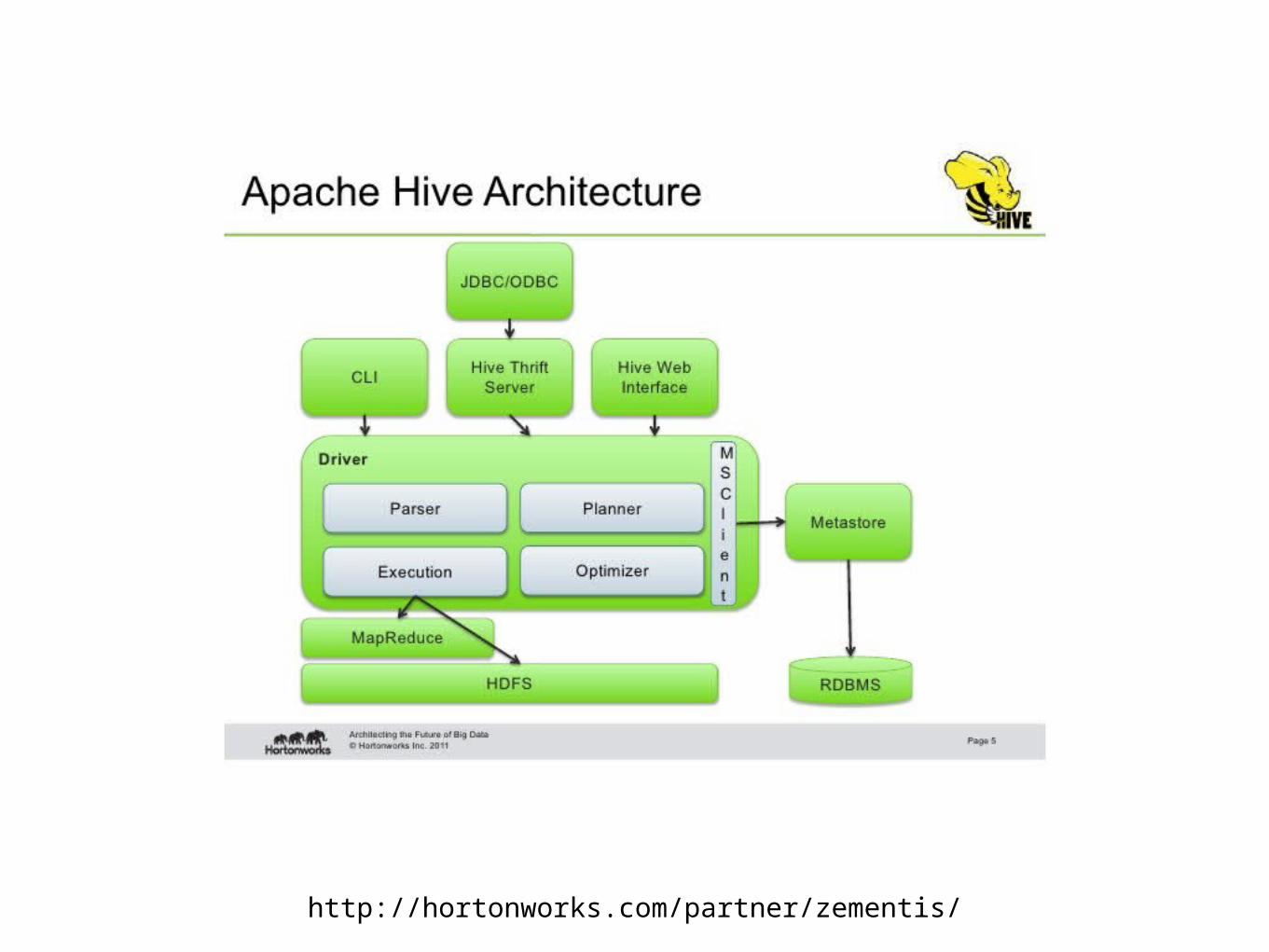
http://hortonworks.com/partner/zementis/
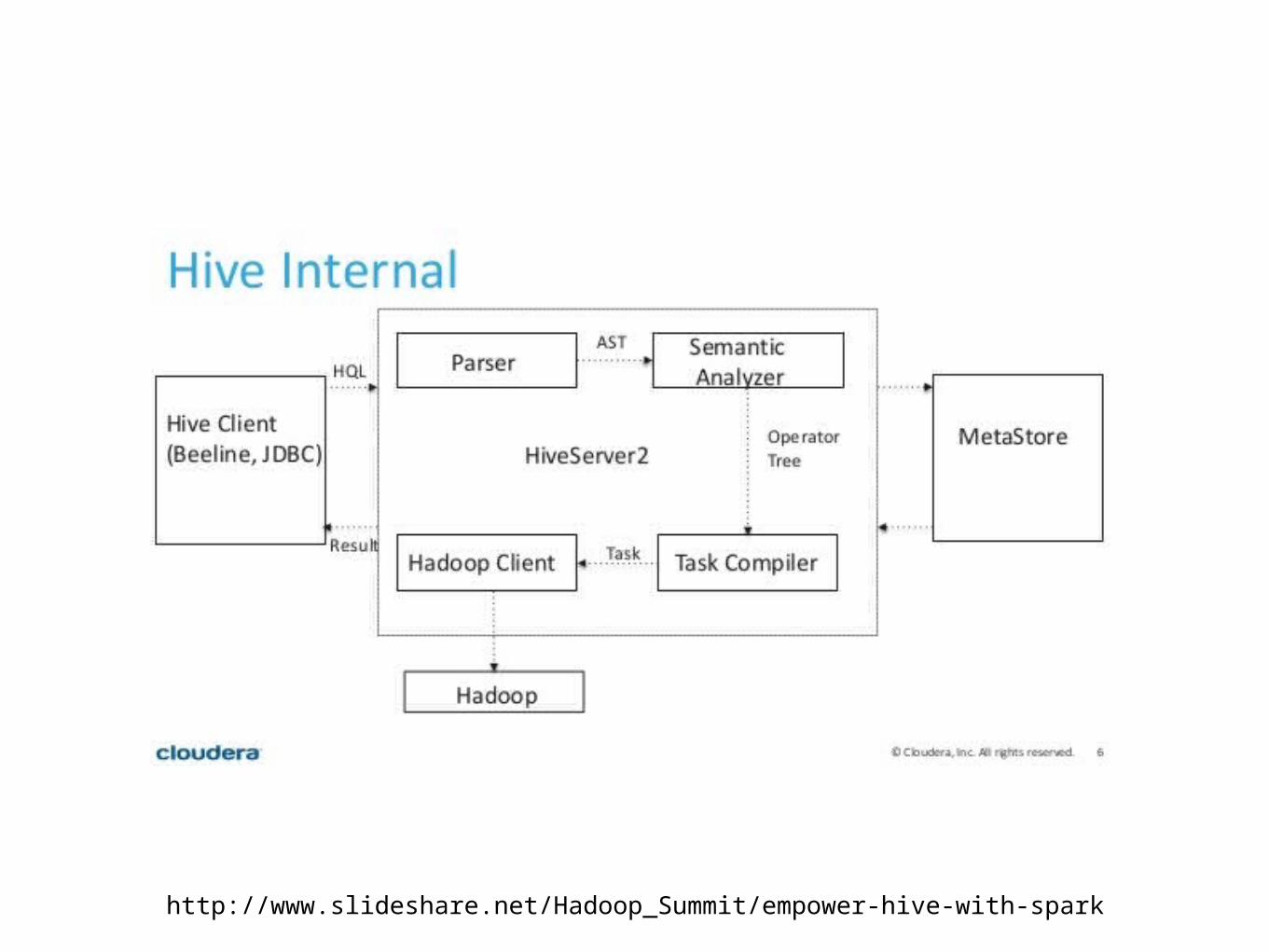
http://www.slideshare.net/Hadoop_Summit/empower-hive-with-spark
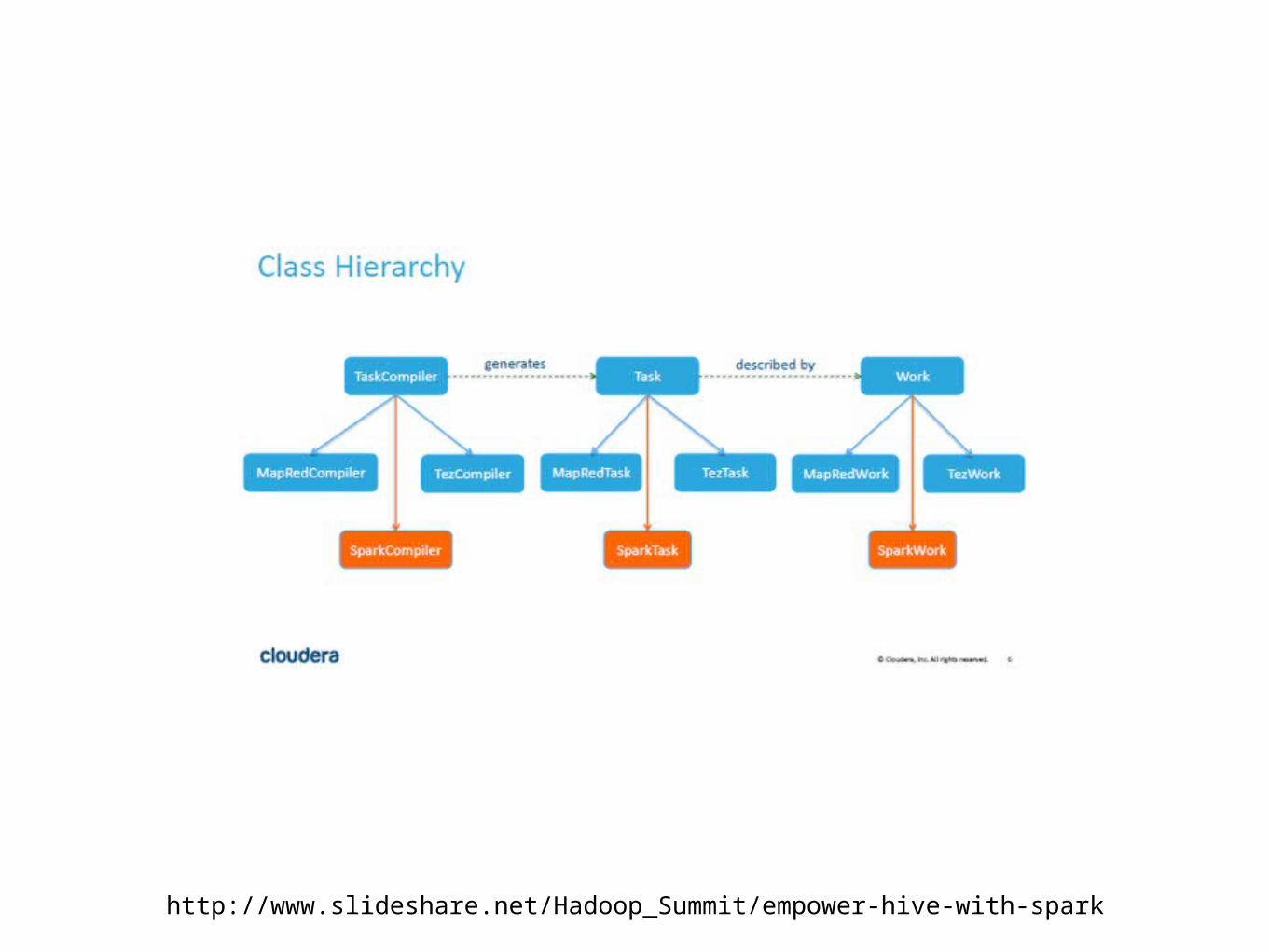
http://www.slideshare.net/Hadoop_Summit/empower-hive-with-spark

HiveContext
• 1.4.0 之後的 sqlContext 就是 hiveContext
• 繼承原有 sqlContext 功能,並加上與 hive 連結

Hive setting
• copy hive-site.xml to $SPARK_HOME/conf

Write SQL• sqlContext.sql(“””
select * from ratings“””).show()
• sqlContext.sql(“””select item, avg(rating)from ratingsgroup by item“””)

Mixed expression
• df = sqlContext.sql(“select * from ratings”)
• df.filter(“ratings < 5”).groupBy(“item”).count().show()

User Defined Function
• from pyspark.sql.functions import udf
• from pyspark.sql.types import *
• sqlContext.registerFunction("hash", lambda x: hash(x), LongType())
• sqlContext.sql(“select hash(item) from ratings”)

DataTypeNumeric types
String type
Binary type
Boolean type
Datetime typeTimestampType: Represents values comprising values of fields year, month,
day, hour, minute, and second.
DateType: Represents values comprising values of fields year, month, day.
Complex types
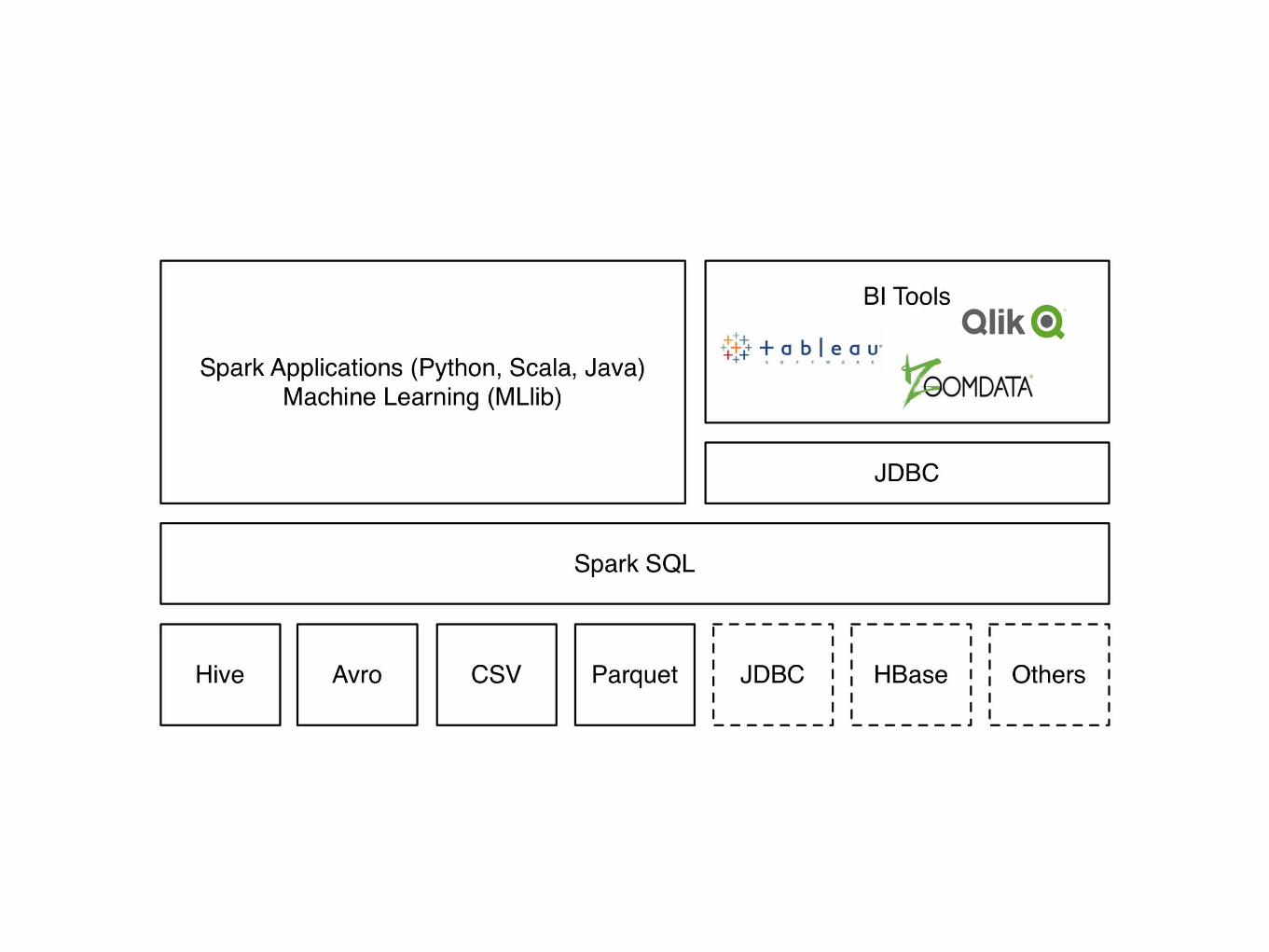
發展方向
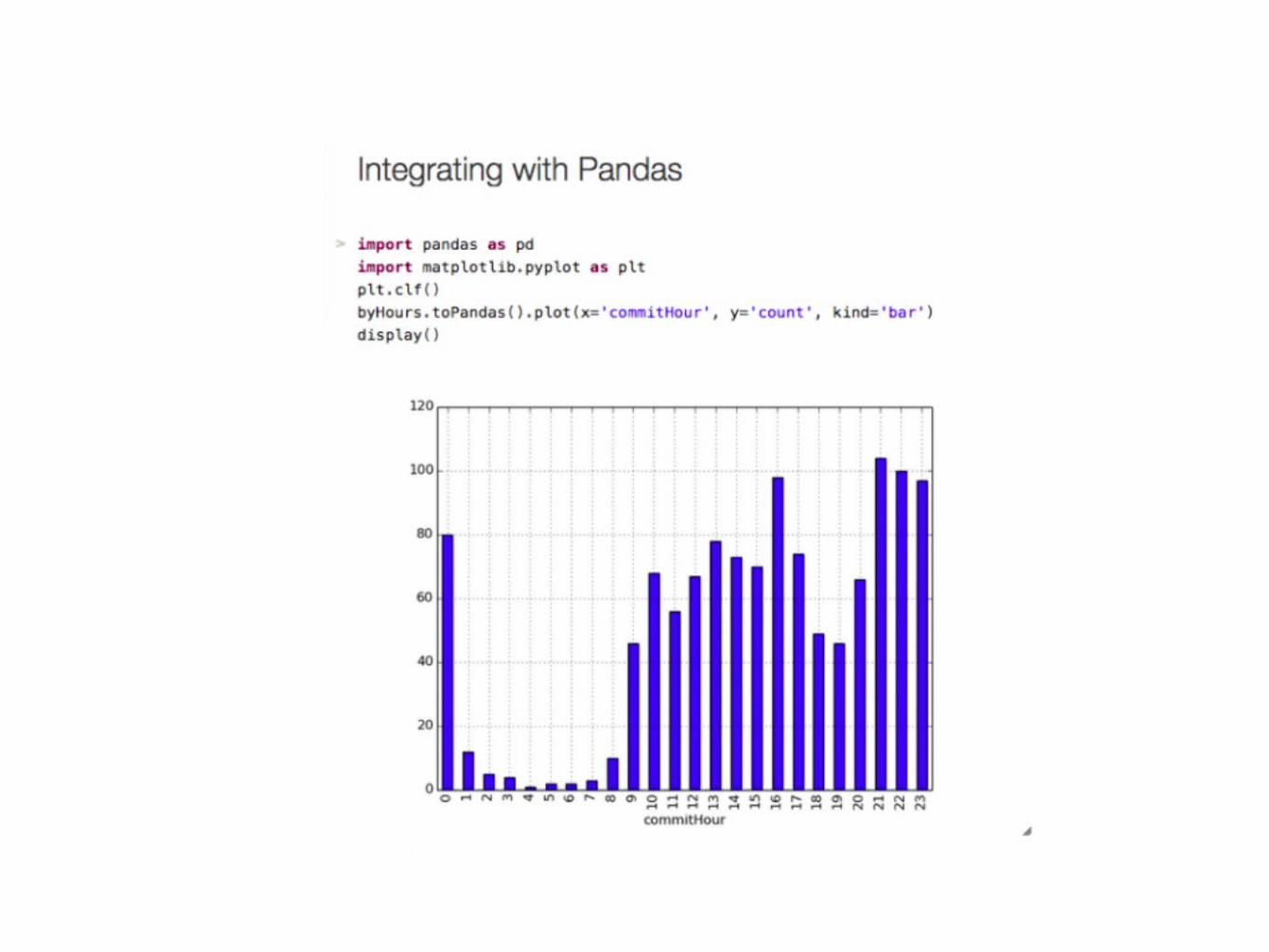

Reference1. https://databricks.com/blog/2015/02/17/introduci
ng-dataframes-in-spark-for-large-scale-data-science.html
2. https://www.youtube.com/watch?v=vxeLcoELaP43. http://www.slideshare.net/databricks/introducing-
dataframes-in-spark-for-large-scale-data-science


















