
Spark mhug2
18
Page 1 © Hortonworks Inc. 2011 – 2014. All Rights Reserved Apache Spark
-
Upload
joseph-niemiec -
Category
Technology
-
view
38 -
download
0
Transcript of Spark mhug2

Page 1 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Apache Spark
Page 2 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
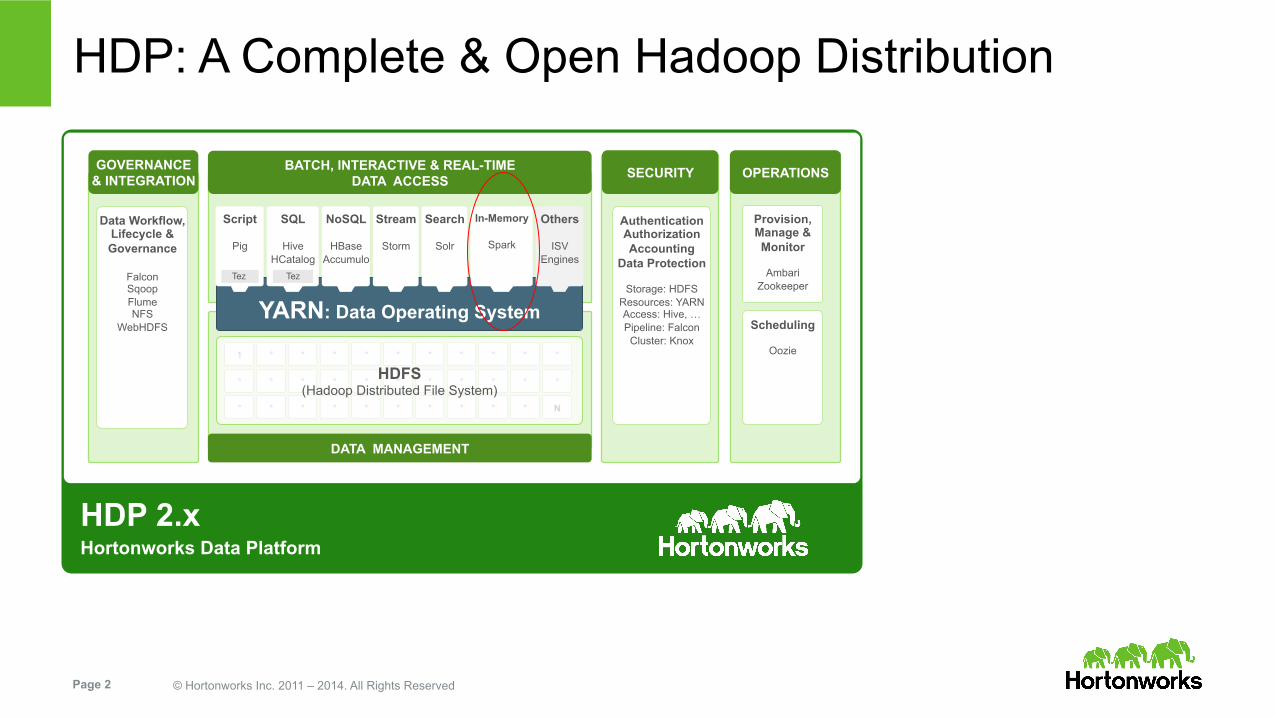
HDP: A Complete & Open Hadoop Distribution
Provision, Manage & Monitor
Ambari
Zookeeper
Scheduling
Oozie
Data Workflow, Lifecycle & Governance
Falcon Sqoop Flume NFS
WebHDFS
YARN: Data Operating System
DATA MANAGEMENT
SECURITY BATCH, INTERACTIVE & REAL-TIME DATA ACCESS
GOVERNANCE & INTEGRATION
Authentication Authorization Accounting
Data Protection
Storage: HDFS Resources: YARN Access: Hive, … Pipeline: Falcon
Cluster: Knox
OPERATIONS
Script
Pig
Search
Solr
SQL
Hive HCatalog
NoSQL
HBase Accumulo
Stream
Storm
Others
ISV Engines
1 ° ° ° ° ° ° ° ° °
° ° ° ° ° ° ° ° ° °
° ° ° ° ° ° ° ° ° °
°
°
N
HDFS (Hadoop Distributed File System)
In-Memory
Spark
Tez Tez
HDP 2.x Hortonworks Data Platform

Page 3 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
What is Spark? • Spark is
– an open-source Software solution that performs rapid calculations on in-memory datasets - Open Source [Apache hosted & licensed]
• Free to download and use in production • Developed by a community of developers [most of whom work for
DataBricks] - In-memory datasets
• RDD (Resilient Distributed Data) is the basis for what Spark enables • Resilient – the models can be recreated on the fly from known state
• Immutable – already defined RDDs can be used as a basis to generate derivative RDDs but are never mutated
• Distributed – the dataset is often partitioned across multiple nodes for increased scalability and parallelism

Page 4 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Why Spark? - It’s About Ramp-Up & Reality
• Spark supports using well known languages such as • Scala* • Python • Java
• Using Spark Streaming Same code can be used on • Data at rest • Data in motion
• Huge Community building around Spark

Page 5 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Spark is Expansive:
• Fast and general processing engine for large scale data processing • Encourages reuse of libraries across several problem domains • Designed for iterative computations and interactive data mining
Spark SQL

Page 6 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Spark Vs MapReduce Vs Tez? MapReduce – On disk to HDFS Tez – On Disk to Local Disk Spark – In memory
Input
Disk Disk Disk Write Read Write

Page 7 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
RDD Primitives - Resilient Distributed Datasets (RDD) - Immutable partitioned collection of objects
- Transformations (map, filter, groupby, join) - Lazy operations to build RDD from RDD
- Actions (count, collect, save) - Return a result or write it to storage

Page 8 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Fault Recovery
RDDs track lineage information that can be used to efficiently re-compute lost data
msgs = textFile.filter(lambda s: s.startsWith(“ERROR”)) .map(lambda s: s.split(“\t”)[2])
HDFS File Filtered RDD Mapped RDD filter
(func = startsWith(…)) map
(func = split(...))

Page 9 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
RDDRDDRDDRDD
Transformations
Action Value
linesWithSpark = textFile.filter(lambda line: "Spark” in line) !
linesWithSpark.count()!74!!linesWithSpark.first()!# Apache Spark!
textFile = sc.textFile(”SomeFile.txt”) !
Working with RDDs
Page 10 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
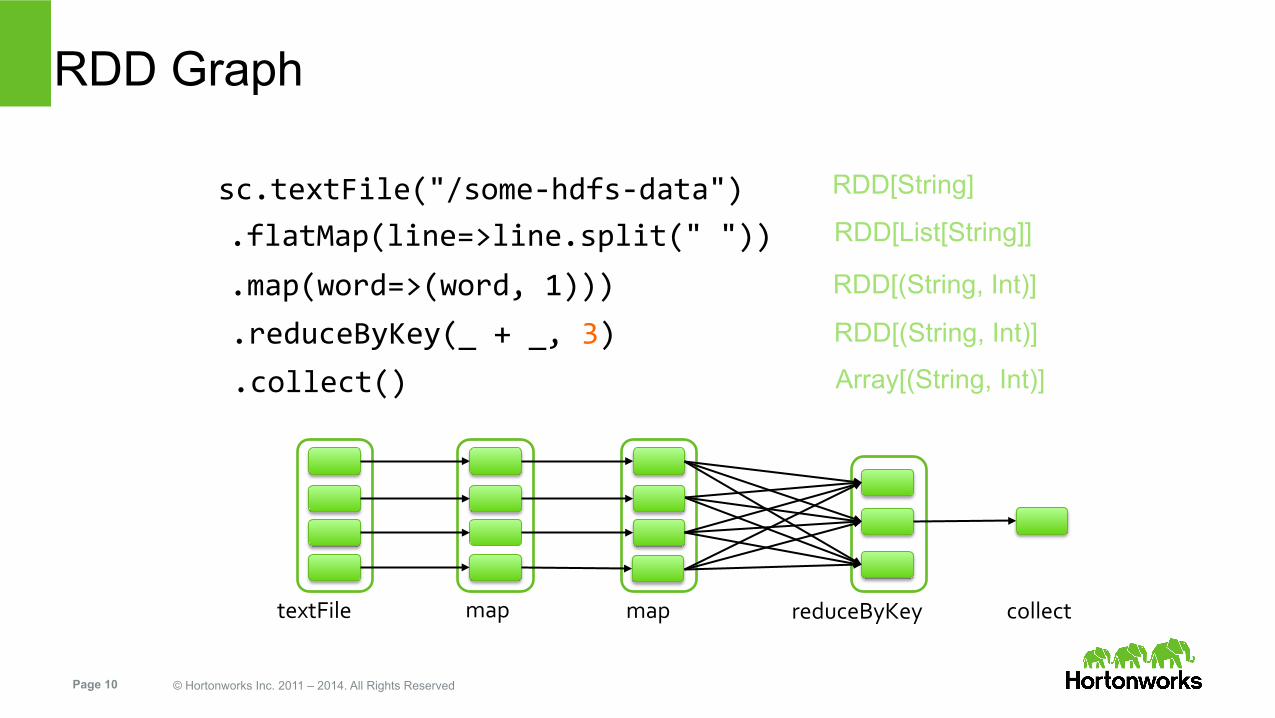
RDD Graph
sc.textFile("/some-‐hdfs-‐data")
map map reduceByKey collect textFile
.flatMap(line=>line.split(" "))
.map(word=>(word, 1)))
.reduceByKey(_ + _, 3)
.collect()
RDD[String]
RDD[List[String]]
RDD[(String, Int)]
Array[(String, Int)]
RDD[(String, Int)]

Page 11 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
DAG Scheduler
map map reduceByKey collect textFile
map
Stage 2 Stage 1
map reduceByKey collect textFile

Page 12 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Task
• Fundamental unit of execution in Spark - A. Fetch input from InputFormat or a shuffle - B. Execute the task - C. Materialize task output as shuffle or driver result
Execute task
Fetch input
Write output
Pipelined Execution

Page 13 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Worker
Execute task
Fetch input
Write output
Execute task
Fetch input
Write output
Execute task
Fetch input
Write output Execute task
Fetch input
Write output
Execute task
Fetch input
Write output
Execute task
Fetch input
Write output
Execute task
Fetch input
Write output
Core 1
Core 2
Core 3

Page 14 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Spark on YARN
YARN RM
App Master
Monitoring UI
Page 15 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
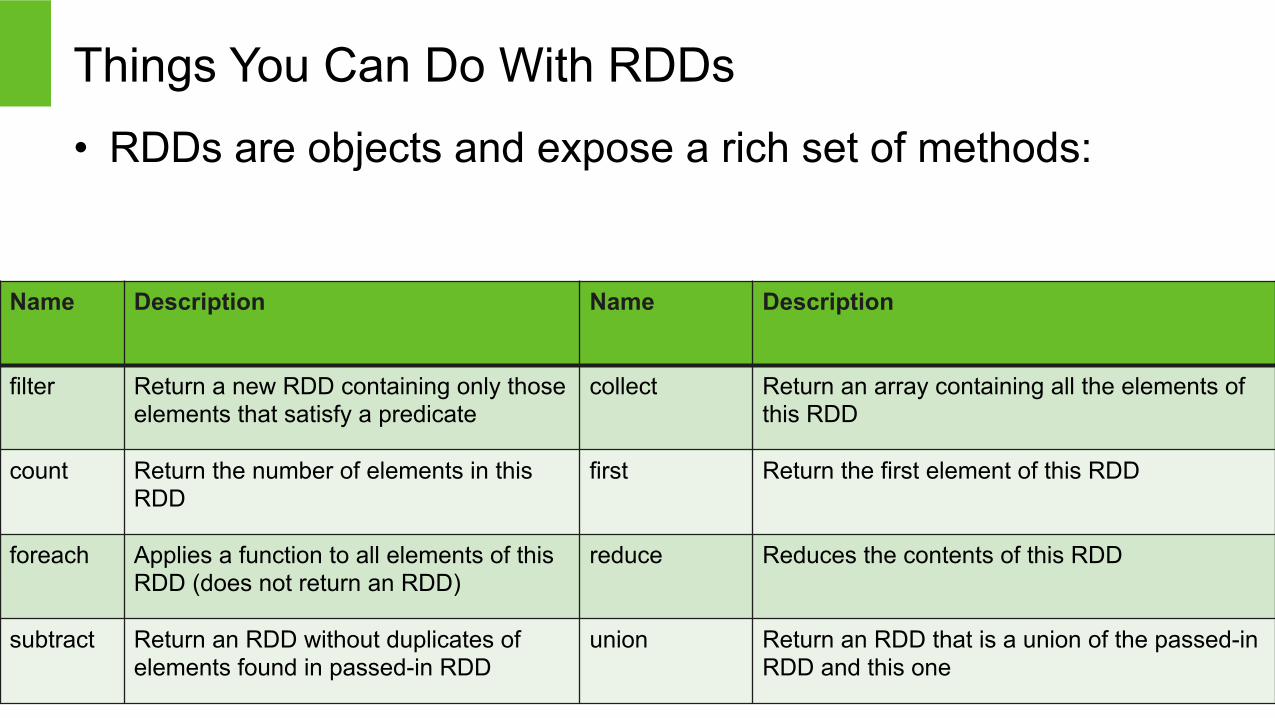
Things You Can Do With RDDs
• RDDs are objects and expose a rich set of methods:
15
Name Description Name Description
filter Return a new RDD containing only those elements that satisfy a predicate
collect Return an array containing all the elements of this RDD
count Return the number of elements in this RDD
first Return the first element of this RDD
foreach Applies a function to all elements of this RDD (does not return an RDD)
reduce Reduces the contents of this RDD
subtract Return an RDD without duplicates of elements found in passed-in RDD
union Return an RDD that is a union of the passed-in RDD and this one
Page 16 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
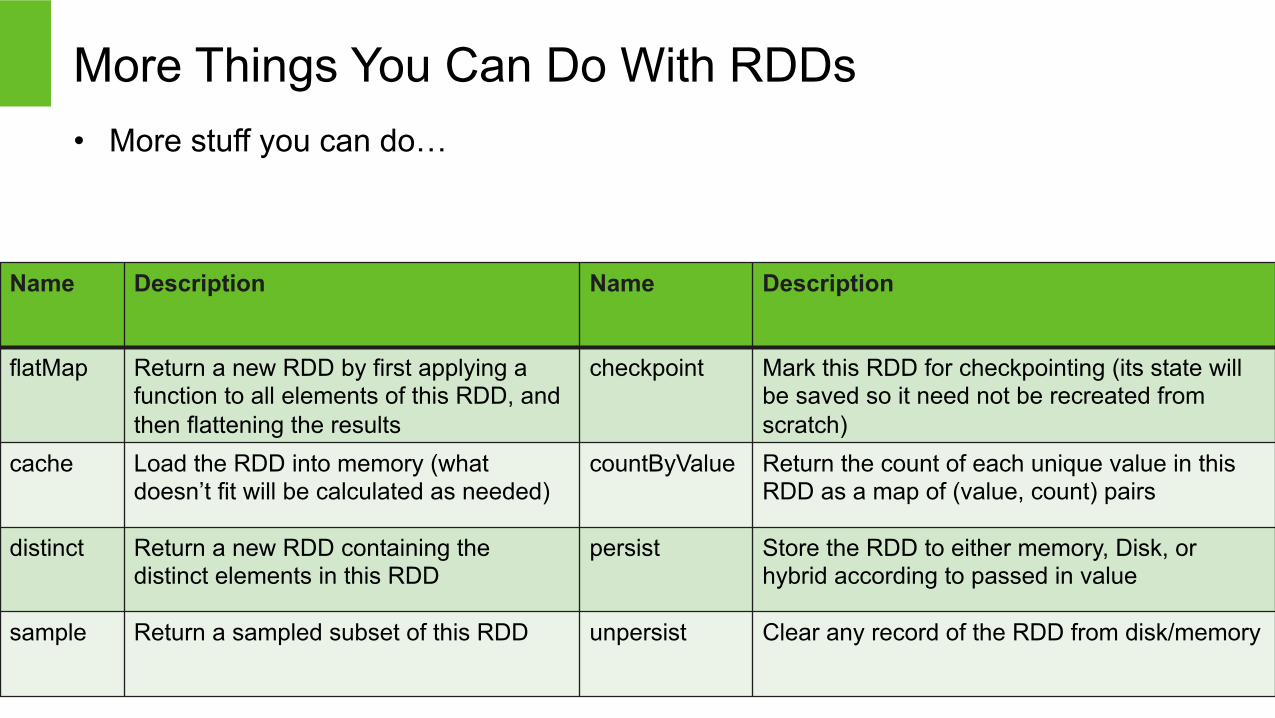
More Things You Can Do With RDDs • More stuff you can do…
16
Name Description Name Description
flatMap Return a new RDD by first applying a function to all elements of this RDD, and then flattening the results
checkpoint Mark this RDD for checkpointing (its state will be saved so it need not be recreated from scratch)
cache Load the RDD into memory (what doesn’t fit will be calculated as needed)
countByValue Return the count of each unique value in this RDD as a map of (value, count) pairs
distinct Return a new RDD containing the distinct elements in this RDD
persist Store the RDD to either memory, Disk, or hybrid according to passed in value
sample Return a sampled subset of this RDD unpersist Clear any record of the RDD from disk/memory

Page 17 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Things You Can Do With PairRDDs
• PairRDDs are RDDs containing Key Value Pairs:
17
Name Description Name Description
join Return an RDD containing all pairs of elements with matching keys in this and other.
groupByKey Group the values for each key in the RDD into a single sequence.
keys Return an RDD containing the keys from each tuple stored in this RDD
countByKey Return the count of number of each element for each key in the form of a Map
lookup Return a list of values stored in this RDD using the passed in key
leftOuterJoin Perform Left outer join
values Return an RDD with the values of each tuple.
subtractByKey Return an RDD with the pairs from this whose keys are not in other.

Page 18 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Spark MLlib – Algorithms Offered
• Classification: logistic regression, linear SVM, – naïve Bayes, least squares, classification tree
• Regression: generalized linear models (GLMs), – regression tree
• Collaborative filtering: alternating least squares (ALS), – non-negative matrix factorization (NMF)
• Clustering: k-means • Decomposition: SVD, PCA • Optimization: stochastic gradient descent, L-BFGS







![[Spark meetup] Spark Streaming Overview](https://static.fdocuments.net/doc/165x107/55a457161a28ab057e8b45fd/spark-meetup-spark-streaming-overview.jpg)










