
Spark - Meetupfiles.meetup.com/3138542/Spark in 2015 - Wendell.pdfmachine learning& Spark& SQL...
31
Transcript of Spark - Meetupfiles.meetup.com/3138542/Spark in 2015 - Wendell.pdfmachine learning& Spark& SQL...


Spark: Looking Back, Looking Forward
Databricks
Patrick Wendell

Welcome to Databricks!
Founded by creators of Spark… donated Spark to Apache foundation in 2013. Databricks cloud – integrated analytics platform based on Apache Spark (limited Beta). http://databricks.com/registration New office, so pardon any kinks!

About Me
Work at Databricks managing the Spark team Spark 1.2 release manager Committer on Spark since Berkeley days

Agenda for Today
Reflections and directions for Spark Deeper dive for new API’s in Spark SQL and Mllib Committer panel / Q&A

Show of Hands!
How familiar are you with Spark? A. Heard of it, but haven't used it before. B. Kicked the tires with some basics. C. Worked or working on a proof-of-concept
deployment. D. Worked or working on a production deployment.
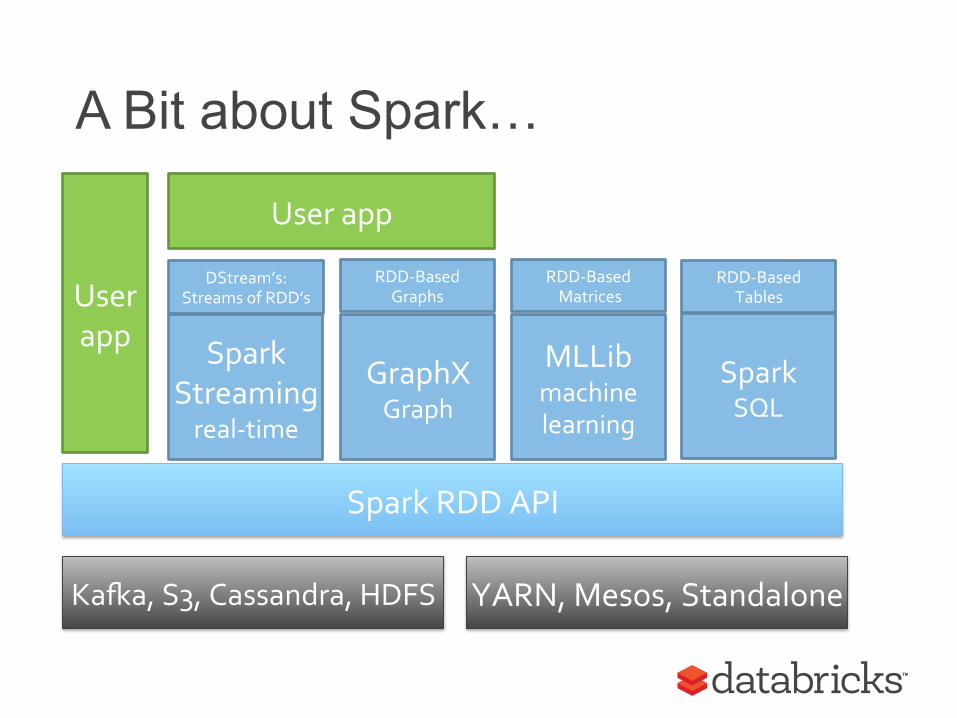
Spark RDD API
Spark Streaming real-‐time
GraphX Graph
MLLib machine learning
DStream’s: Streams of RDD’s
RDD-‐Based Matrices
RDD-‐Based Graphs
Spark SQL
RDD-‐Based Tables
A Bit about Spark…
KaEa, S3, Cassandra, HDFS YARN, Mesos, Standalone
User app
User app
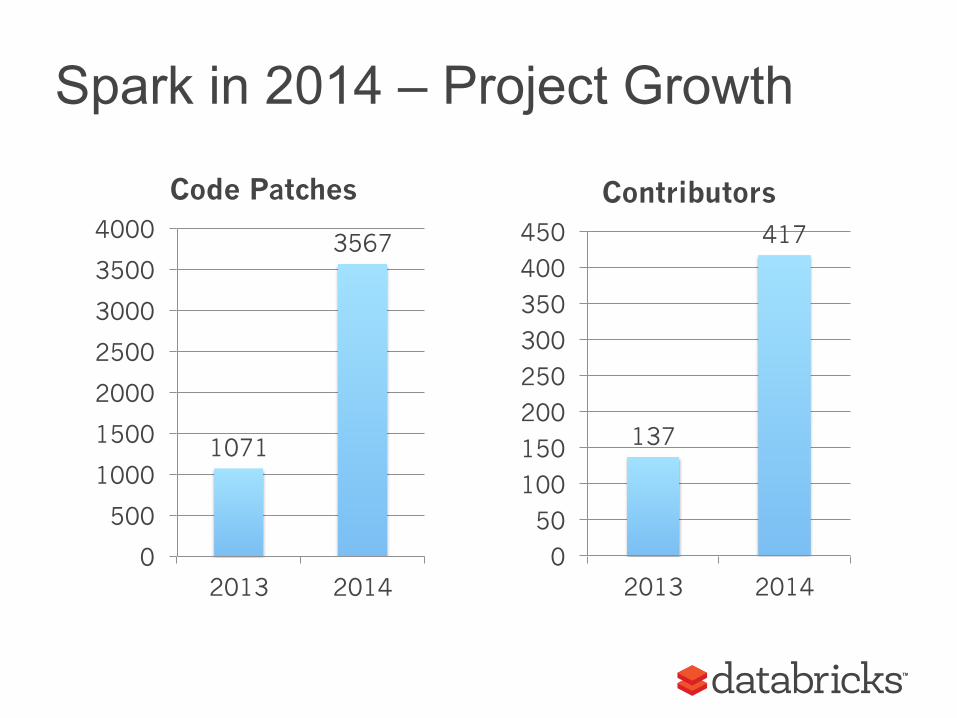
Spark in 2014 – Project Growth
1071
3567
0
500
1000
1500
2000
2500
3000
3500
4000
2013 2014
Code Patches
137
417
0
50
100
150
200
250
300
350
400
450
2013 2014
Contributors
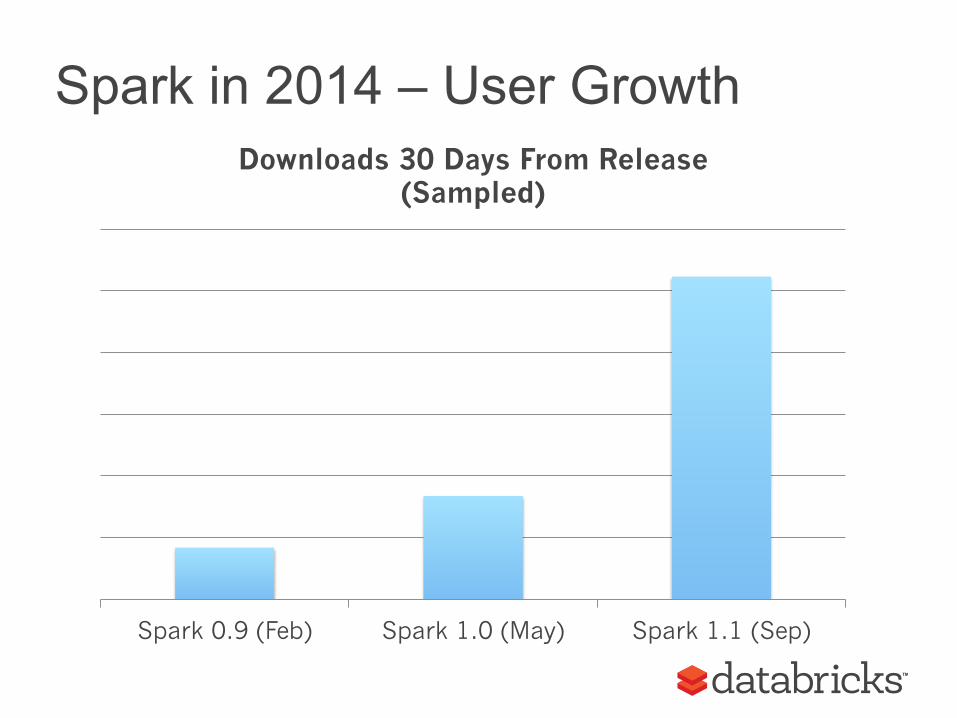
Spark in 2014 – User Growth
Spark 0.9 (Feb) Spark 1.0 (May) Spark 1.1 (Sep)
Downloads 30 Days From Release (Sampled)

Spark in 2014 – Broader Ecosystem
Now supported by all major Hadoop vendors… But also beyond Hadoop…

Spark in 2014 – Major additions
Usability and portability of core engine API stability (Spark 1.0!) Vastly expanded UI and instrumentation Integration with Hadoop security Disk-spilling and shuffle optimizations
Feature coverage for libraries
Spark SQL library and SchemaRDD’s GraphX library Expansion of MLlib

So… what’s coming?


New Technical Directions in 2015
SchemaRDD’s as a common interchange format. Data-frame style API’s From developers to data scientists
Extensibility and pluggable API’s
Data source API (SQL) Pipelines API (Mllib) Receiver API (Streaming) Spark Packages
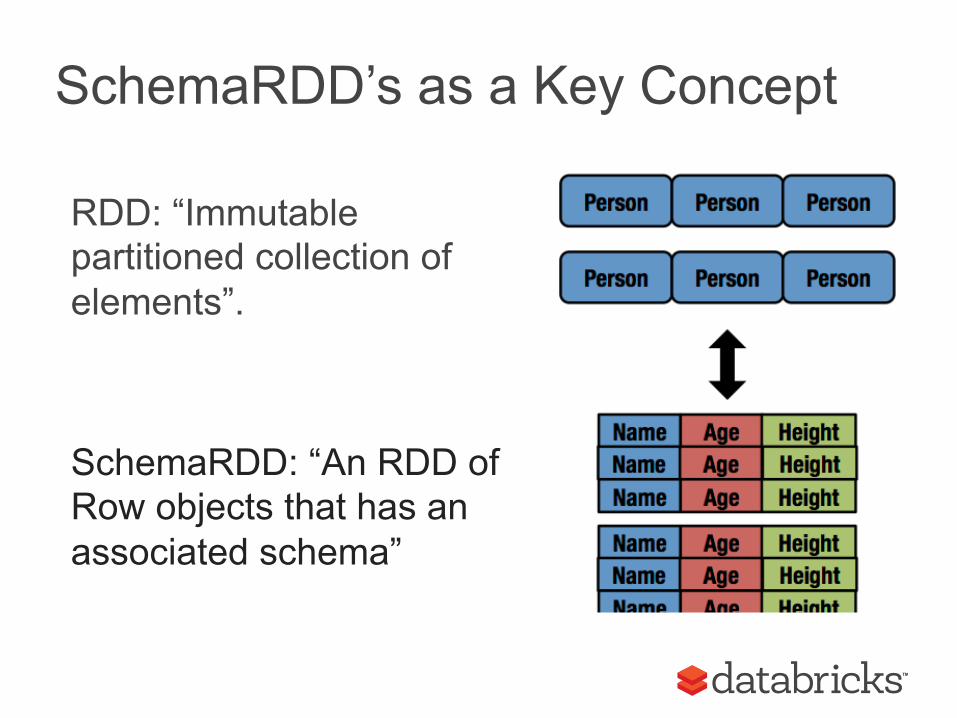
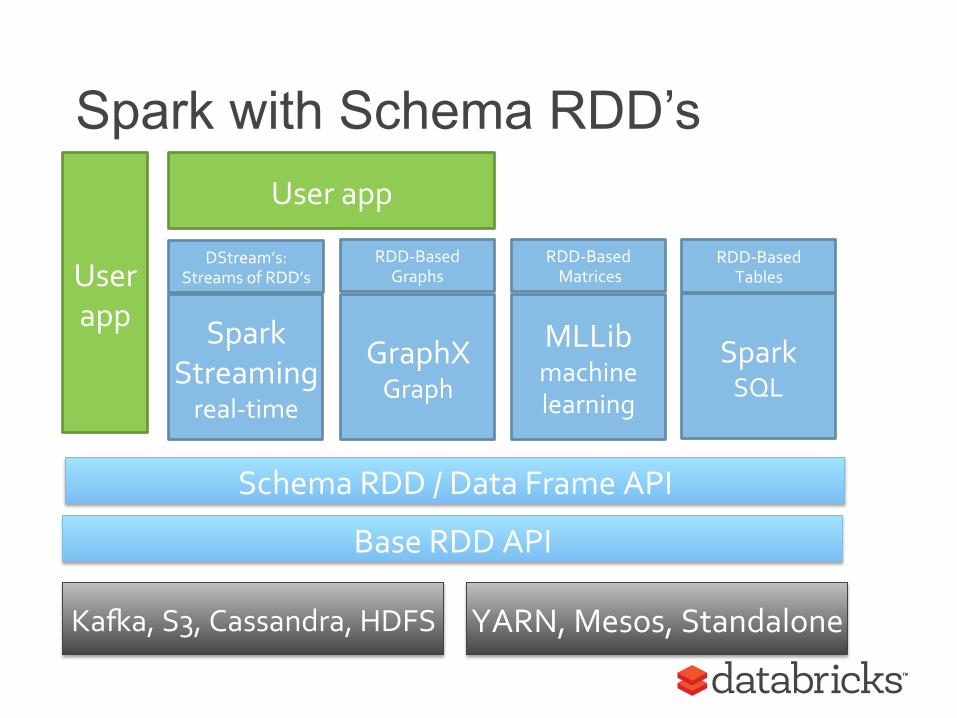
SchemaRDD’s as a Key Concept
RDD: “Immutable partitioned collection of elements”. SchemaRDD: “An RDD of Row objects that has an associated schema”

Why SchemaRDD’s are Useful
Having structure and types is very powerful. Allows us to optimize performance more easily. Fosters interoperability between libraries (Spark’s and third party). Enables higher level and safer user-facing API.

SchemaRDDs - Data Frame API’s
# Pandas ‘data frame’ style lineitems.groupby(‘customer’).agg(Map( ‘units’ -‐> ‘avg’, ‘totalPrice’ -‐> ‘std’
)) # or SQL style SELECT AVG(units), STD(totalPrice) FROM linetiems GROUP BY customer

SchemaRDDs - Data Frame API’s
Data frame API’s are more familiar to data scientists and easier to use. Many user issues would be solved by writing against such API’s.

Schema RDDs - Interoperability
Any data source made available to Spark SQL is instantly available in Java, Python, and R, with correct types. Major internal API’s (such as ML pipelines API) can make assumptions about input RDD’s.
Base RDD API
Spark Streaming real-‐time
GraphX Graph
MLLib machine learning
DStream’s: Streams of RDD’s
RDD-‐Based Matrices
RDD-‐Based Graphs
Spark SQL
RDD-‐Based Tables
Spark with Schema RDD’s
KaEa, S3, Cassandra, HDFS YARN, Mesos, Standalone
User app
User app
Schema RDD / Data Frame API

Technical Directions in 2015
SchemaRDD’s as a common interchange format. “Data frame” style API’s From developers to data scientists
Extensibility and pluggable API’s
Data source API (SQL) Pipelines API (Mllib) Receiver API (Streaming) Spark Packages

Spark SQL – Initial Input Support
Hive metastore tables JSON (built in) Parquet (built in) Any Spark RDD + user-schema creation
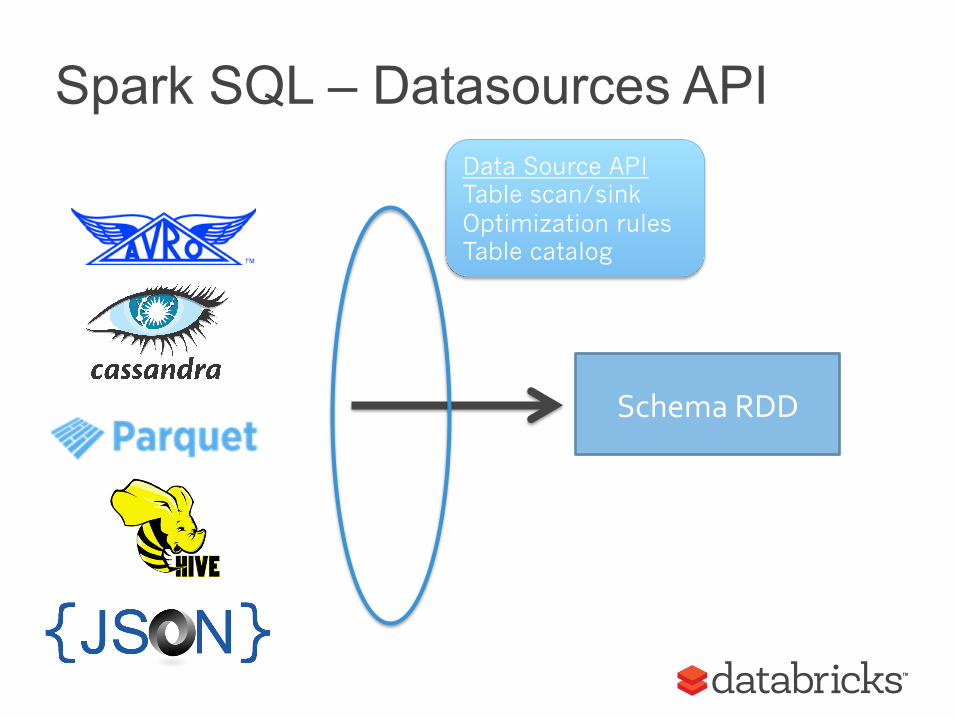
Spark SQL – Datasources API
Schema RDD
Data Source API Table scan/sink Optimization rules Table catalog

Mllib – Pipelines API
Practical ML pipelines involve feature extraction, model fitting, testing, and validation. Pipelines API provides re-usable components and a language for describing workflows. Relies heavily on SchemaRDD’s for inter-operability.

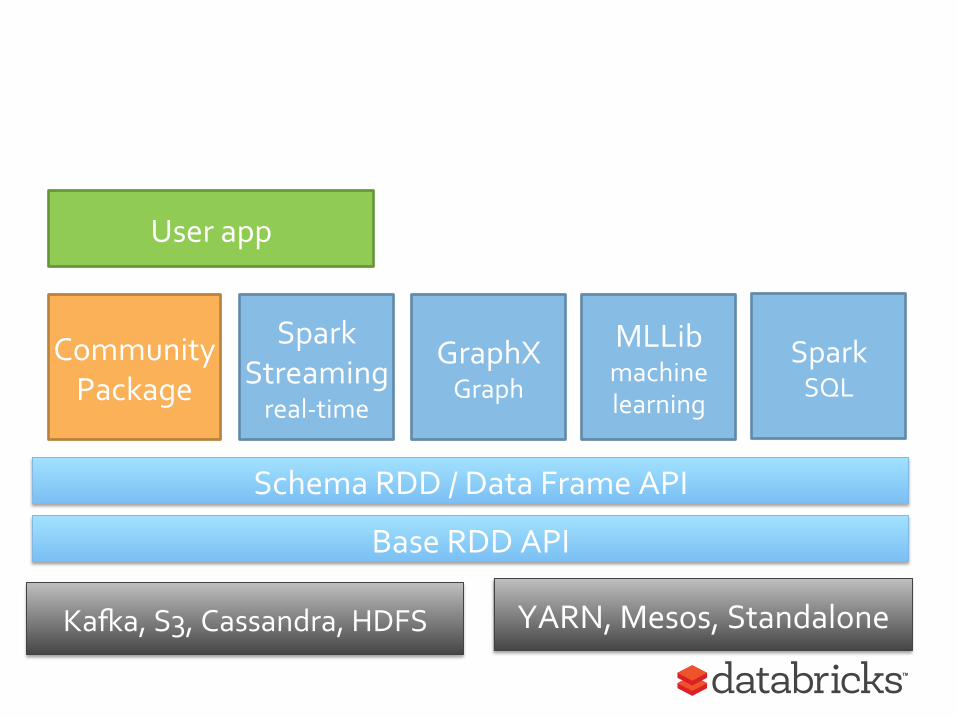
Pluggable APIs
Goal is to stabilize both of these API’s in the next few releases to allow community implementations to proliferate. Now Spark is facilitating feedback from third party library authors.
spark-packages.org

spark-packages.org
Standard library for Spark-related projects (think CRAN, PyPi, etc). Plan is to make installation on Spark a single click.
Base RDD API
Spark Streaming real-‐time
GraphX Graph
MLLib machine learning
Spark SQL
KaEa, S3, Cassandra, HDFS YARN, Mesos, Standalone
User app
Schema RDD / Data Frame API
Community Package

Spark in 2015 – Production Use Cases
Submissions to Spark Summit East show a broad variety of production use cases:
Hadoop workload migration Recommendations
Data pipeline and ETL Fraud detection
User engagement analytics Scientific computing
Medical diagnosis Smart grid/utility
analytics

Community goals in 2015
Maintain a strong, cohesive community, as we grow.
Continue to provide transparency and community involvement in technical roadmap. Maintain trust of users to update to new releases. Encourage ecosystem projects outside of Spark (stable API’s are a huge part of this).

To conclude. In 2015 expect…
- Increasing focus on Schema RDD as an integration point.
- Friendlier, higher level API’s.
- Continued focus on usability and performance.


















