

Dominick Spracklen, Jennifer Logan, Loretta Mickley, Rokjin Park Shiliang Wu, Rose Yevich
Upload
spark-summitCategory
view
255download
2
Spark Autotuning
Lawrence Spracklen Alpine Data

Overview
• Motivation
• Spark Autotuning
• Future enhancements

Motivation

We use Spark • End-2-end support
– Problem inception through model operationalization
• Extensive use of Spark at all stages – ETL – Feature engineering – Model training – Model scoring
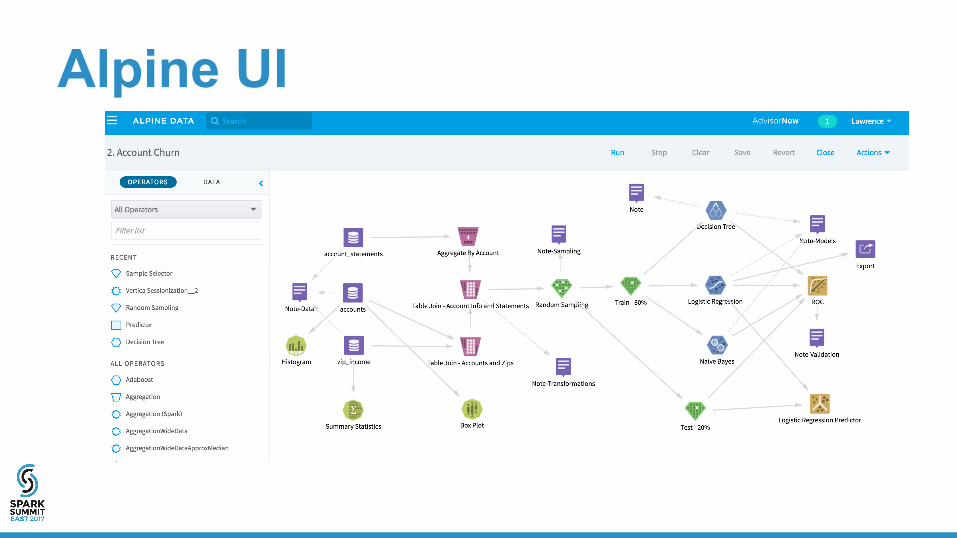
Alpine UI
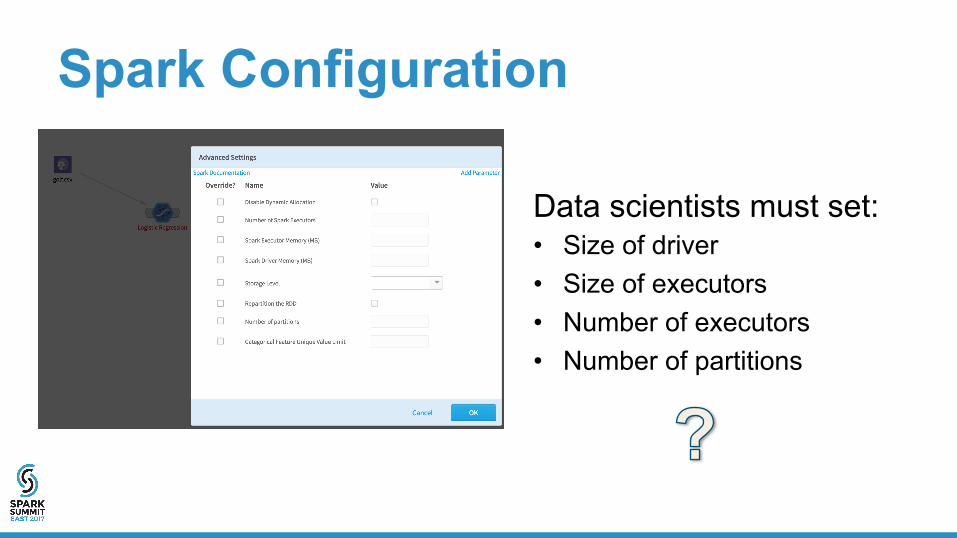
Spark Configuration
Data scientists must set: • Size of driver • Size of executors • Number of executors • Number of partitions

Inefficient • Manual Spark tuning is a time consuming and inefficient
process – Frequently results in “trial-and-error” approach – Can be hours (or more) before OOM fails occur
• Less problematic for unchanging operationalized jobs – Run same analysis every hour/day/week on new data – Worth spending time & resources to fine tune
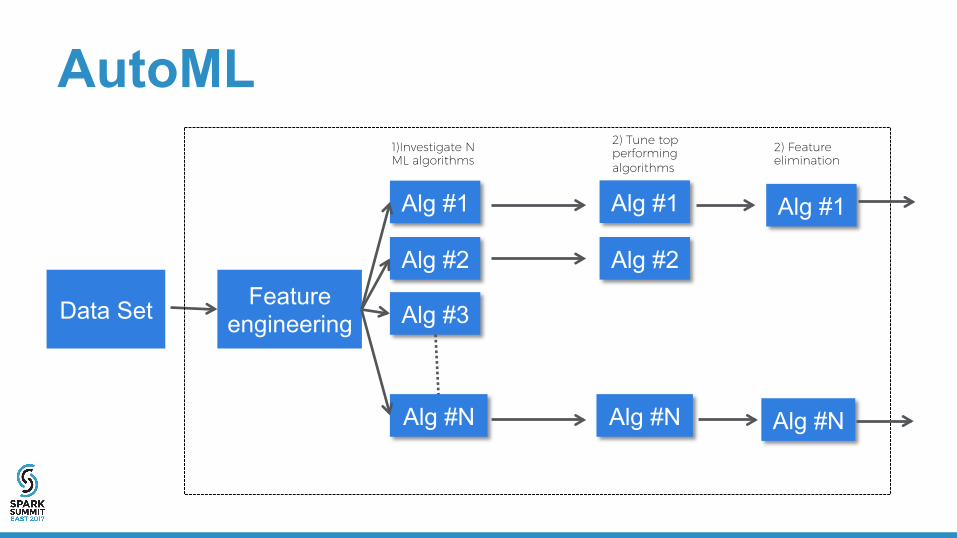
AutoML
Data Set
Alg #1
Alg #2
Alg #3
Alg #N
Alg #1
Alg #N
1)Investigate N ML algorithms
2) Tune top performing algorithms
Feature engineering
Alg #2
Alg #1
Alg #N
2) Feature elimination
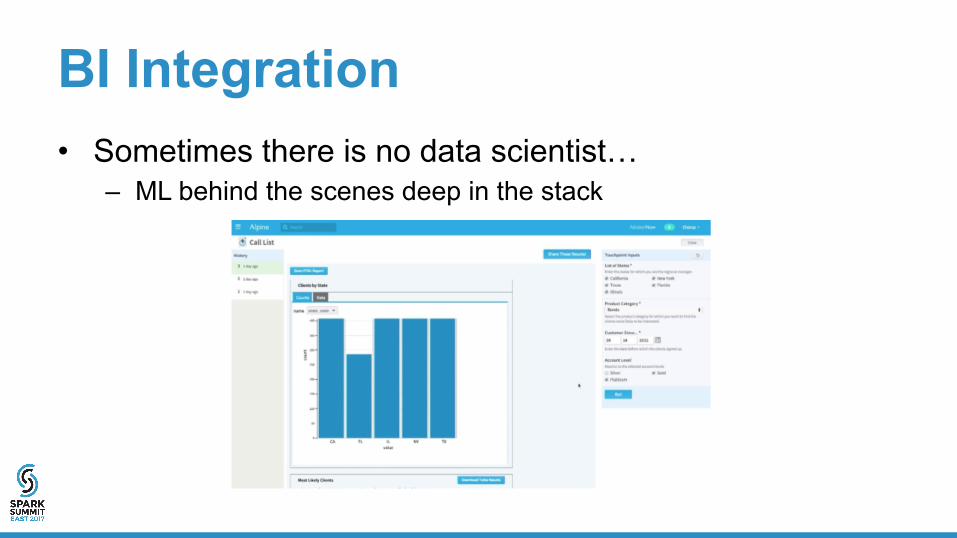
BI Integration • Sometimes there is no data scientist…
– ML behind the scenes deep in the stack

Example Algorithm
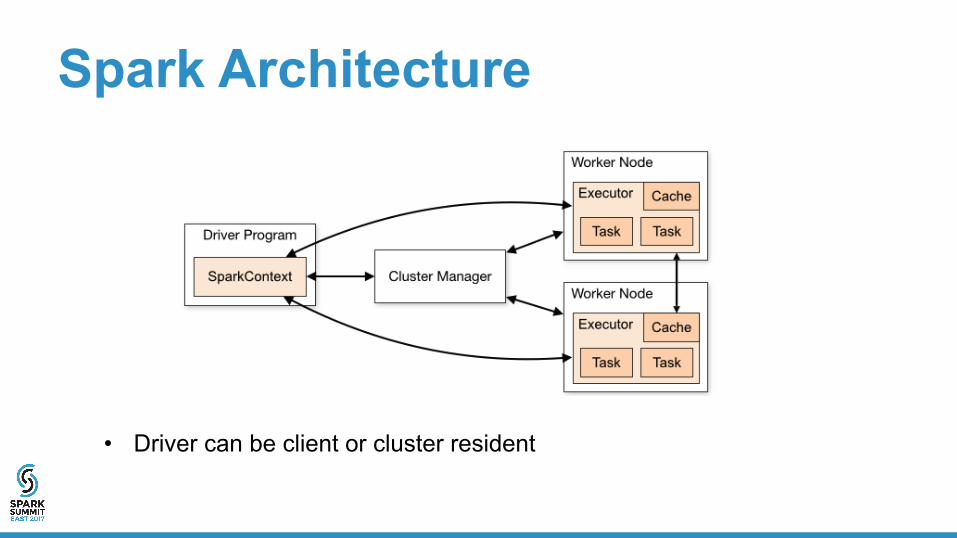
Spark Architecture
• Driver can be client or cluster resident

It depends…. • Size & complexity of data • Complexity of algorithm(s)
• Nuances of the implementation
• Cluster size
• YARN configuration
• Cluster utilization

Default settings? • Spark defaults are targeted at toy data sets & small
clusters – Not applicable to real-world data science
• Resource computations often assume a dedicated cluster – Looking at total vCPU and memory resources
• Enterprise clusters are typically shared – Applying dedicated computations is wasteful
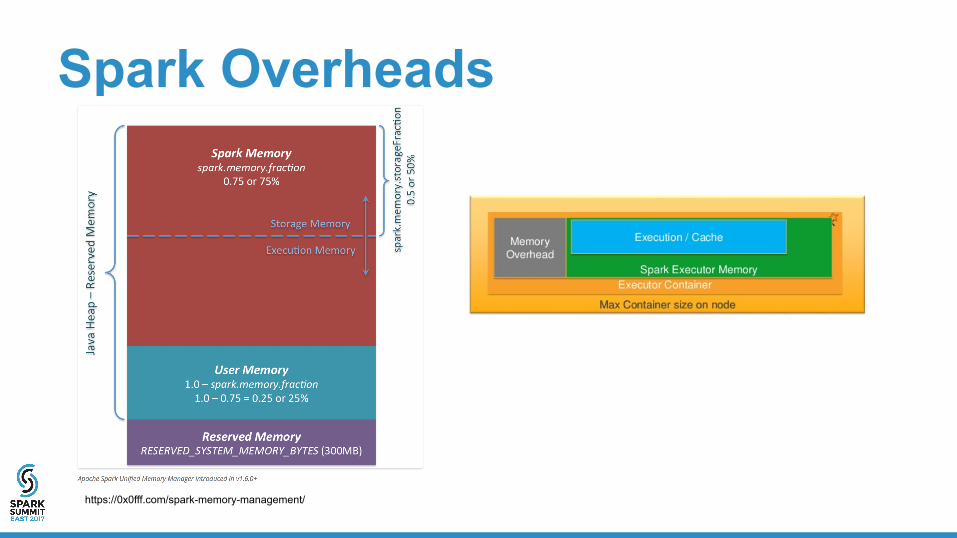
Spark Overheads
https://0x0fff.com/spark-memory-management/

Challenges • Algorithm needs to
– Determine compute requirements for current analysis – Reconcile requirements with available resources – Allow users to set specific variables
• Changing one parameter will generally impact others 1. Increase memory per executor
èDecrease number of executors
2. Increase cores per executor èDecrease memory per core
[N.B. Not just a single “correct” configuration!!!]

Understanding the inputs • Sample from input data set(s) • Estimate
– Schema inference – Dimensionality – Cardinality – Row count
• Remember about compressed formats • Offline background scans feasible
– Retain snapshots in metastore • Take into account impact of downstream operations
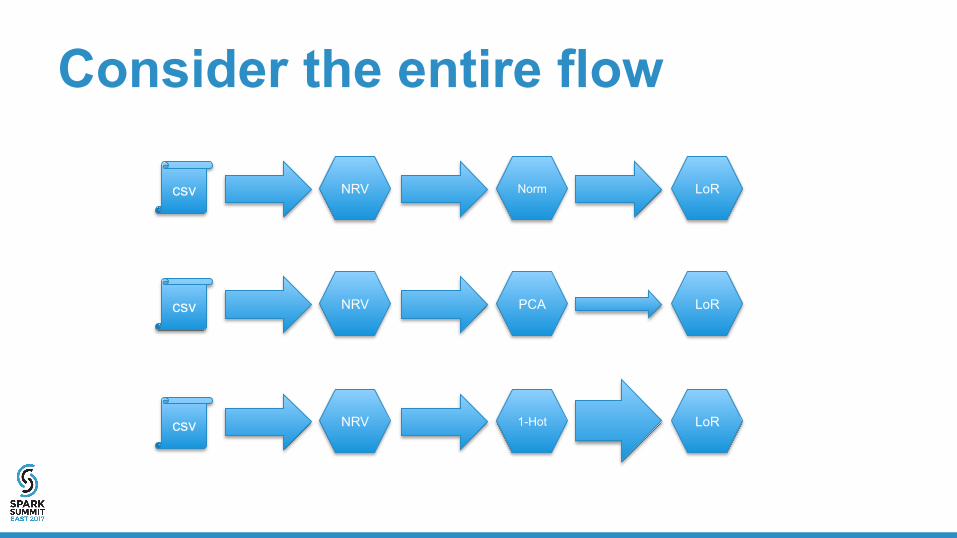
Consider the entire flow
NRV Norm LoR
NRV PCA LoR
NRV 1-Hot LoR
csv
csv
csv

Algorithmic complexity • Each operation has unique requirements
– Wide range in memory and compute requirements across algorithms
• Provide levers for algorithms to provide input on resource asks – Resource heavy or resource light (Memory & CPU)
• Per algorithm modifiers computed for all algorithms in Application toolbox

Wrapping OSS • Autotuning APIs are made available to user & OSS
algorithms wrapped using our extensions SDK – H20 – MLlib – Etc.
• Provide input on relative memory requirements and computational complexity

YARN Queues • Queues frequently used in enterprise settings
– Control resource utilization
• Variety of queuing strategies – Users bound to queues – Groups bound to queues – Applications bound to queues
• Queues can have own maximum container sizes • Queues can have different scheduling polices

Dynamic allocation • Spark provides support for auto-scaling
– Dynamically add/remove executors according to demand
• Is preemption also enabled? – Minimize wait time for other users
• Still need to determine optimal executor and driver sizing

Query cluster • Query YARN Resource Manager to get cluster state
– Kerberised REST API
• Determine key resource considerations – Preemption enabled? – Queue mapping – Queue type – Queue resources – Real-time node utilization

Executor Sizing • Try to make efficient use of the available resources
– Start with a balanced strategy
• Consume resources based on their relative abundance
MemPerCore = QueueMemQueueCores *MemHungry
CoresPerExecutor =min(MaxUsableMemoryPerContainerMemoryPerCore , 5)
MemPerExecutor =max(1GB,MemPerCore*CoresPerExecutor)

Number of executors (1/2) • Determine how many executors can be accommodated
per node
• Consider queue constraints
• Consider testing per node with different core values
AvailableExecutors = Min( AvailableNodeMemoryMemoryPerExecutor+Overheads
n=0
ActiveNodes
∑ , AvailableNodeCoresCoresPerExecutor )
UseableExecutors =Min(AvailableExecutors, QueueMemoryMemoryPerExecutor ,
QueueCoresCoresPerExecutor )

Number of executors (2/2) • Compute executor count required for memory
requirements
• Determine final executor count
NeededExecutors = CacheSizeSparkMemPerExecutor*SparkStorageFraction
FinalExecutors =min(UseableExecutors,NeededExecutors*ComputeHungry)

Data Partitioning • Minimally want a partition per executor core
• Increase number of partitions if memory constrained
MinPartitions = NumExecutors*CoresPerExecutor
MemPerTask = SparkMemPerExecutor*(1−SparkStorageFraction)CoresPerExecutor
MemPartitions = CacheSizeMemPerTask
FinalPartitions =max(MinPartitions,MemPartitions)

Driver sizing • Leverage executor size as baseline • Increase driver memory if analysis requires
– Some algorithms very driver memory heavy
• Reduce executor count if needed to reflect presence of cluster-side driver

Sanity checks • Make sure none of the chosen parameters look
crazy! – Massive partition counts – Crazy resourcing for small files – Complex jobs squeezed for overwhelmed clusters
• Think about edge cases • Iterate if necessary!

Future Improvements

Future opportunities Cloud Scaling • Autoscale cloud EMR clusters
– Leverage understanding of required resources to dynamically manage the number of compute nodes
– Significant performance benefits and cost savings Iterative improvements • Retain decisions from prior runs in metastore • Harvest additional sizing and runtime information
– Spark REST APIs • Leverage data to fine tune future runs

Conclusions • Enterprise clusters are noisy, shared environments • Configuring Spark can be labor intensive & error prone
– Significant trial and error process • Important to automate the Spark configuration process
– Remove requirement for data scientists to understand Spark and cluster configuration details
• Software automatically reconciles analysis requirements with available resources
• Even simple estimators can do a good job

More details? • Too little time…
– Will blog more details, example resourcing and scala code fragments
alpinedata.com/blog

Acknowledgements • Rachel Warren – Lead Developer


















