
経営者持株比率と企業パフォーマンスの関係 - …...経営者持株比率と企業パフォーマンスの関係 - 東証マザーズIPO企業を対象に、 founder-CEOの存在に着目した実証分析
Upload
brainpad-incCategory
view
796download
2
Copyright © BrainPad Inc. All Rights Reserved.
Sparkパフォーマンス検証
2015年5月15日

Copyright © BrainPad Inc. All Rights Reserved.
1. Spark検証環境
2

Copyright © BrainPad Inc. All Rights Reserved.
Spark 1.2.0
YARN 2.5.0
3
• クラスタマネージャ
– YARN
– Sparkはyarn-clusterモードで起動
• データストレージ
– HDFS
• OS
– Centos.6.6
Spark検証環境
HDFS 2.5.0
Centos6.6 * 13台
※回線は、検証に使ったインフラの都合上1Gbps。

Copyright © BrainPad Inc. All Rights Reserved.
1 Resource Manager
– 16コア
– 16GB
12 Node Manager
– 8コア
– 8GB
– HDFSのData Nodeと同居
4
YARNクラスタ

Copyright © BrainPad Inc. All Rights Reserved.
1 Name Node
– 16コア
– 16GB
12 Data Node
– 8コア
– 8GB
– YARNのNode Managerと同居
5
HDFSクラスタ

Copyright © BrainPad Inc. All Rights Reserved.
2. Spark検証
6

Copyright © BrainPad Inc. All Rights Reserved.
アクセスログからPVを日別に集計する時間を計測する。
PV集計は、アクセスログに含まれる日時データから日付を特定し、日付ごとのログ件数を累計する処理。
SparkアプリケーションはScalaで実装。
7
検証内容
HDFS Spark
1. HDFSからログデータをロード 3. 標準出力へ結果を書き込み
2. Sparkで日別にPV集計処理
stdout

Copyright © BrainPad Inc. All Rights Reserved.
データフォーマット
– csv
– カラム数
• 14
データサイズ
– 1行あたりログサイズ
• 約370B
– 1日あたりログサイズ
• 約1GB
– 日数
• 90日
– 全体のログサイズ
• 約90GB
8
検証データ(アクセスログ)

Copyright © BrainPad Inc. All Rights Reserved.
以下のパラメータを変動させ、それぞれの結果を取る。
1. executor-memory (512m, 1g, 2g)
• 1executorに割り当てるメモリ
2. num-executors (13, 26, 39, 52)
• Spark全体で起動するexecutorの数
3. executor-cores (1,2,3,4)
• 1executorに割り当てるコア数
4. 入力ログデータサイズ (1g, 30g, 60g, 90g)
• 入力するデータの合計サイズ
9
検証項目

Copyright © BrainPad Inc. All Rights Reserved.
3. Spark検証結果
10
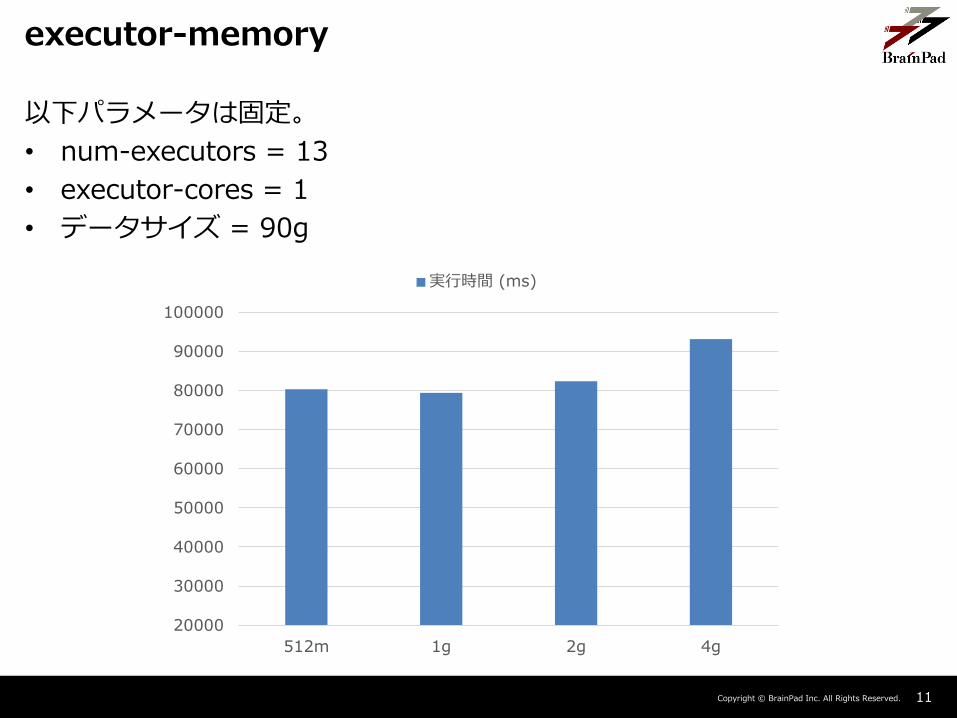
Copyright © BrainPad Inc. All Rights Reserved. 11
以下パラメータは固定。
• num-executors = 13
• executor-cores = 1
• データサイズ = 90g
executor-memory
20000
30000
40000
50000
60000
70000
80000
90000
100000
512m 1g 2g 4g
実行時間 (ms)
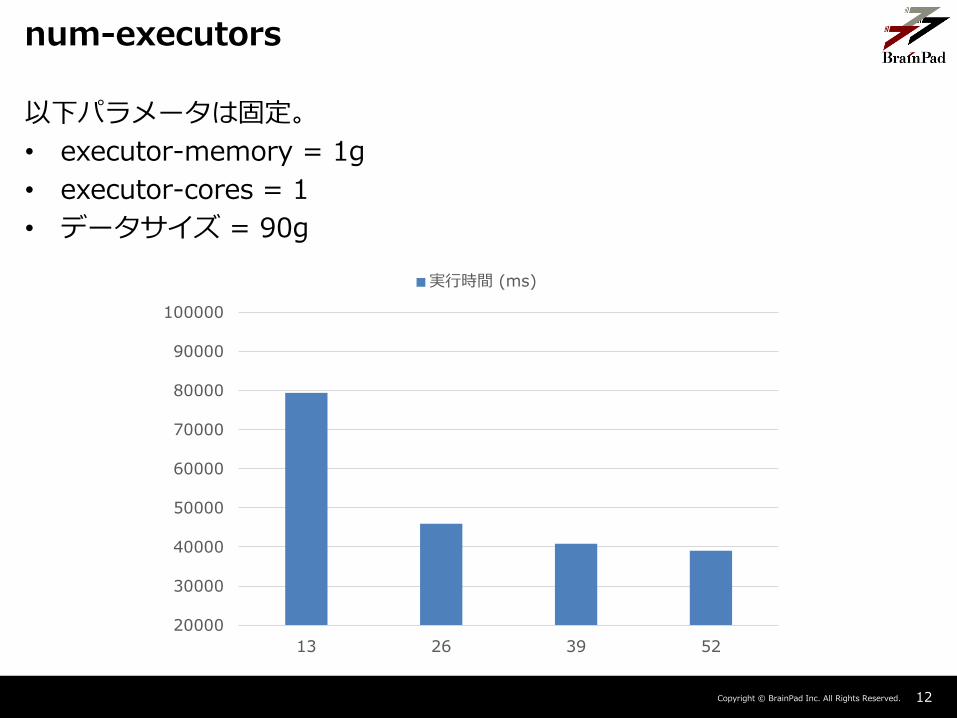
Copyright © BrainPad Inc. All Rights Reserved. 12
以下パラメータは固定。
• executor-memory = 1g
• executor-cores = 1
• データサイズ = 90g
num-executors
20000
30000
40000
50000
60000
70000
80000
90000
100000
13 26 39 52
実行時間 (ms)

Copyright © BrainPad Inc. All Rights Reserved. 13
以下パラメータは固定。
• executor-memory = 1g
• num-executors = 13
• データサイズ = 90g
executor-cores
20000
30000
40000
50000
60000
70000
80000
90000
100000
1 2 3 4
実行時間 (ms)

Copyright © BrainPad Inc. All Rights Reserved. 14
以下パラメータは固定。
• executor-memory = 1g
• num-executors = 13
• executor-cores = 1
入力ログデータサイズ
0
10000
20000
30000
40000
50000
60000
70000
80000
90000
100000
1g 30g 60g 90g
実行時間 (ms)

Copyright © BrainPad Inc. All Rights Reserved.
並列数は、executorの数を増やすよりもexecutorが複数のコアを使えるように増やしたほうが改善の幅が大きい。
– 1 taskあたりのShuffle Write Timeが、コア数増加したときのほうが3倍以上速かった。Executorの数が増えるとそれだけプロセス/ノードをまたぐshuffleが増えるから?
• executor数を52、コア数を1にした場合のShuffle Write Time -> 142,596ms
• executor数を13、コア数を13にした場合のShuffle Write Time -> 47,517ms
executor-memoryの増加は結果に悪影響を与えている。
– 今回のケースでは各executorが扱うデータサイズが512mに収まっており、ディスクへのスワップも発生していないため、メモリ増加は効果がなかった。
3ヶ月分のデータを30秒程度でさばけるのは、体感的にかなり速く感じる。
15
考察

Copyright © BrainPad Inc. All Rights Reserved.
4. Spark Streaming検証
16

Copyright © BrainPad Inc. All Rights Reserved.
アクセスログをKafkaからSpark Streamingに流して、日時別のPVを計算する。10分程度Kafkaからログデータをストリーミングして、各ジョブの平均実行時間を見る。
PV集計はバッチ処理と同様、アクセスログに含まれる日時データからそのログの日時を特定し、日時別のログ件数を累計する処理。
17
検証内容
KafkaSpark
Streaming
1. Kafkaからアクセスログを流す 3. 標準出力へ結果を随時書き込み
2. Spark Streamingでn秒ごとに、時間別PV集計処理(updateStateByKeyを使用)
stdout

Copyright © BrainPad Inc. All Rights Reserved.
Spark検証と同じログデータを使う。
– ログデータを10分間、一定のQPSでKafkaから流す。
18
検証データ(アクセスログ)

Copyright © BrainPad Inc. All Rights Reserved.
以下のパラメータを変動させ、それぞれの結果を取る。
1. executor-memory (512m, 1g, 2g)
2. num-executors (13, 26, 39, 52)
3. executor-cores (1,2,3,4)
4. インターバル (5秒,15秒,30秒,60秒)
• Spark Streamingの、マイクロバッチインターバル
5. QPS (1500, 2000, 2500, 7000)
• Kafkaが1秒間に流すデータの件数
19
検証項目

Copyright © BrainPad Inc. All Rights Reserved.
クラスタ構成
– 5 Broker
• 4コア
• 16GB
– 3 Zookeeper node
• 4コア
• 16GB
アクセスログを流すトピック
– パーティション数1
– レプリケーション数1
Spark Streaming側のレシーバ数
– 1で固定
20
Kafka

Copyright © BrainPad Inc. All Rights Reserved.
5. Spark Streaming検証結果
21
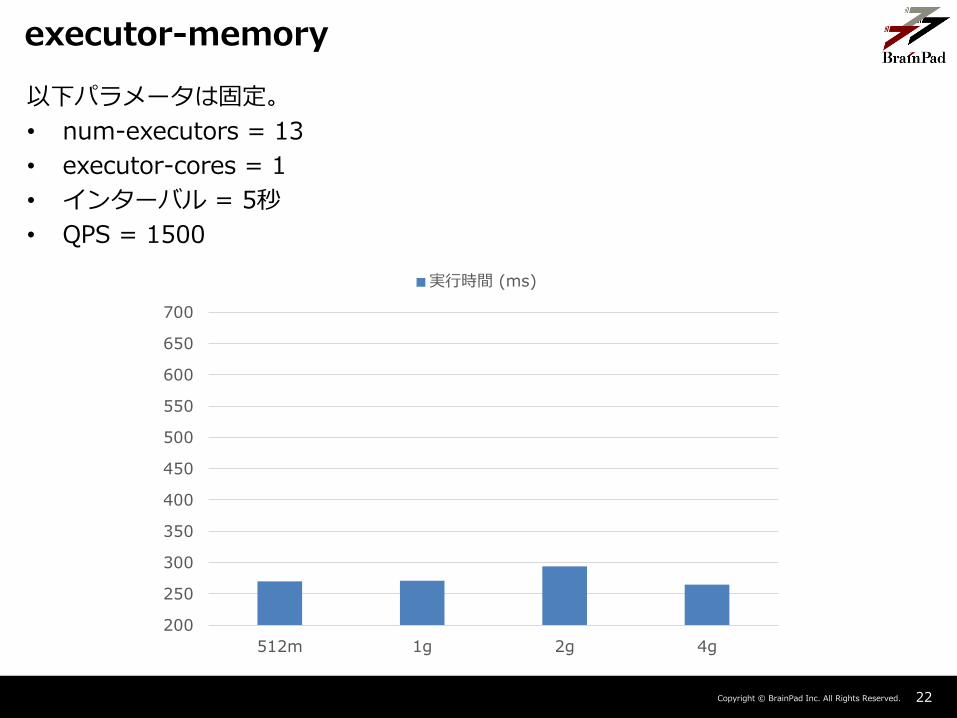
Copyright © BrainPad Inc. All Rights Reserved. 22
以下パラメータは固定。
• num-executors = 13
• executor-cores = 1
• インターバル = 5秒
• QPS = 1500
executor-memory
200
250
300
350
400
450
500
550
600
650
700
512m 1g 2g 4g
実行時間 (ms)

Copyright © BrainPad Inc. All Rights Reserved. 23
num-executors
200
250
300
350
400
450
500
550
600
650
700
13 26 39 52
実行時間 (ms)
以下パラメータは固定。
• executor-memory = 1g
• executor-cores = 1
• インターバル = 5秒
• QPS = 1500
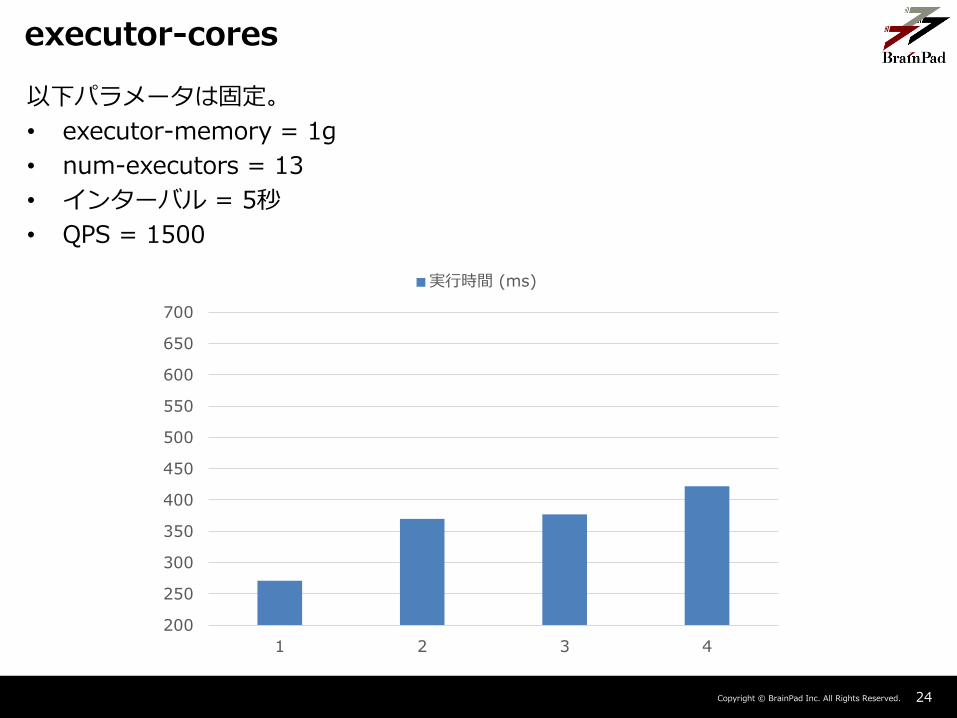
Copyright © BrainPad Inc. All Rights Reserved. 24
executor-cores
200
250
300
350
400
450
500
550
600
650
700
1 2 3 4
実行時間 (ms)
以下パラメータは固定。
• executor-memory = 1g
• num-executors = 13
• インターバル = 5秒
• QPS = 1500

Copyright © BrainPad Inc. All Rights Reserved. 25
インターバル
0
10
20
30
40
50
60
0
200
400
600
800
1000
1200
1400
5 15 30 60
1秒
あた
りの
実行
時間
(ms)
実行
時間
(ms)
実行時間 (ms) 1秒あたりの実行時間 (ms)
以下パラメータは固定。
• executor-memory = 1g
• num-executors = 13
• executor-cores = 1
• QPS = 1500
Copyright © BrainPad Inc. All Rights Reserved. 26
QPS
200
250
300
350
400
450
500
550
600
650
700
1500 2000 2500 7000
実行時間 (ms)
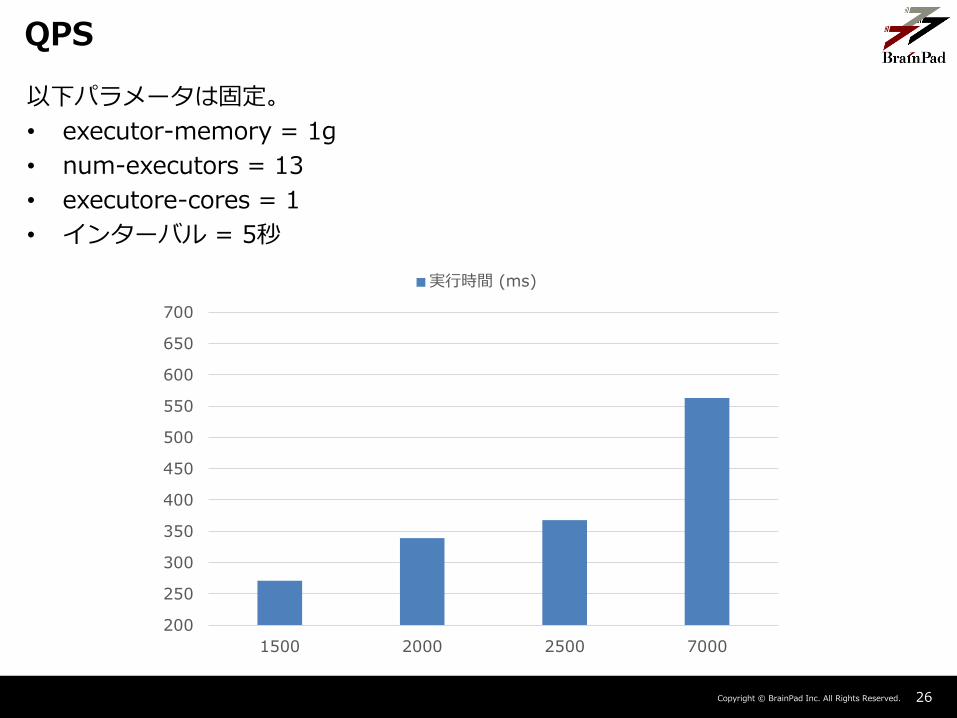
以下パラメータは固定。
• executor-memory = 1g
• num-executors = 13
• executore-cores = 1
• インターバル = 5秒

Copyright © BrainPad Inc. All Rights Reserved.
並列数の増加は結果に悪影響を与えている。
– タスクごとの実行時間は、並列数を増やすと増加していた。
• Shuffle Readのサイズも増えており、並列数が増えることにより無駄なShuffleが発生していたのかもしれない。
– タスクが複雑になったり、マイクロバッチの処理するデータサイズが増えれば並列数の効果が効いてくるんでは?(未検証)
メモリの増加は結果に影響を与えていない。
– Sparkの検証と同じく、512mに収まっているため。
インターバルが長いほうが、より効率的に処理出来ている。
– バッチ実行回数が減るため。アプリケーションの要求とメモリの制約の中で、できるだけ長いインターバルを設定するのがベターか。
今回の実装だと、7000QPS(2500kb / sec)程度ならさばける。
– 5秒インターバルなら単純計算で、22MB / secまでさばける。
• (7000qps * 370b) * (5000ms / 550ms) / 1024 / 1024 ≒ 22MB
27
考察

Copyright © BrainPad Inc. All Rights Reserved.
6. Spark Streamingデモアプリ検証
28

Copyright © BrainPad Inc. All Rights Reserved.
Spark, MLlib, Spark streamingを使ってコンバージョン予測デモアプリを作成し、そのパフォーマンスを測定する。
デモアプリは、以下2つのコンポーネントから成る。
1. Spark Streamingでの特徴量作成〜モデル取得〜予測
2. Spark & MLlibでのモデル構築
29
デモアプリ

Copyright © BrainPad Inc. All Rights Reserved. 30
デモアプリイメージ図
Kafka Spark Streaming
HDFS
Spark
特徴量
特徴量 モデル
モデル 予測結果
アクセスログ
1. アクセスログから特徴量を抽出2. モデルをロードして、アクセスしたユーザーの
コンバージョン予測
1. 特徴量からモデルを作成2. モデルをHDFSに保存

Copyright © BrainPad Inc. All Rights Reserved.
1. Spark Streamingでの特徴量作成〜モデル取得〜予測
– 処理内容
• データは先の検証と同じくアクセスログを使用
• 特徴量はCSVテキスト形式でユーザーID・累計訪問回数・累計ページビュー数・コンバージョンフラグを出力(10秒ごと)
• HDFSからモデルを取得し、ユーザーIDごとに特徴量を作成して予測を実施
– すなわち、ユーザーごとのコンバージョン予測を行っている。
– 今回の検証ではレイテンシに焦点を当てているため、予測精度については特に突き詰めていない。
– 検証項目
• QPS (1000, 2000, 3000)
2. バッチでの学習
– 処理内容
• ストリーミング処理で出力されたCSVデータを取得
• CSVデータから特徴ベクトルを作成し、RandomForestで学習
• 作成されたモデルをHDFSに保存
– 検証項目
• 特徴量の行数 (250万, 500万, 1000万)
• 特徴量の列数 (100, 200, 300)
31
検証内容

Copyright © BrainPad Inc. All Rights Reserved.
Kafka
– Broker数 5
– パーティション数 5
Spark
– num-executors 13
– executor-cores 4
– executor-memory 6GB
– driver-memory 6GB
Spark Streaming
– num-executors 5
– executor-cores 4
– Executor-memory 512m
– Driver-memory 512m
– Kafkaレシーバ数 5
– インターバル 10秒
32
動作環境

Copyright © BrainPad Inc. All Rights Reserved.
7. Spark Streamingデモアプリ検証結果
33

Copyright © BrainPad Inc. All Rights Reserved. 34
ストリーミングでの特徴量作成 – モデル取得 – 予測
0
200
400
600
800
1000
1200
1400
0 1000 2000 3000 4000 5000 6000 7000
QPS
実行時間 (ms)
各ジョブの平均実行時間を計測。

Copyright © BrainPad Inc. All Rights Reserved. 35
バッチでのモデル構築 (入力データ行数を変動)
0
10
20
30
40
50
60
0 2 4 6 8 10 12 14
特徴量行数(100万行)
実行時間 (秒)

Copyright © BrainPad Inc. All Rights Reserved. 36
バッチでのモデル構築 (特徴量の数を変動)
0
20
40
60
80
100
120
140
160
180
200
0 100 200 300 400 500 600
特徴量の数
実行時間 (秒)

Copyright © BrainPad Inc. All Rights Reserved.
ストリーミング
– HDFSへの書き込みやモデルを使った予測など、ある程度複雑な処理をしてもQPS4000程度なら1秒以内にさばける。
バッチ(データサイズの増加)
– ストリーミング側が細かいファイルを多く吐き出すので、どこかでマージするかHBaseを使うなどしたほうがよさそう。
– 今回のように1行あたりのデータが小さいと、データ容量よりはファイル数のほうが影響あり?
バッチ(特徴量数の増加)
– 計測できた範囲では、特徴量数の増加に比例して処理時間が伸びる。
– 特徴量数が大きくなるとOOMが発生する。
• メモリに依存しているのでしょうがないというのはある。
– 今回はExperimentalな実装であるRandomForestを使っていたため、アルゴリズムによって結果は変わりそう。
37
考察

Copyright © BrainPad Inc. All Rights Reserved.
検証内容
– デモアプリの特徴量や予測結果書き込み先をHDFSからHBaseに変えてみる。
– 細かいパフォーマンスというよりは、SparkからHBaseを使う例が欲しかった。
• 実際はHDFSではなくHBaseなどのヘビーライトに耐えられるストレージを使うことになると思われるので。
HBase (0.98.6)
– クラスタ
• Master1台(Name Nodeと同居)
• Regsion Server12台(Data Nodeと同居)
– ヒープサイズ 2GB
– テーブル
• 特徴量テーブル
– ストリーミングから特徴量データを書き込むテーブル。
– 1 Column Familyに、各特徴量ごとにカラムを分けて書き込み
– RowKeyは、{バケットID}-{リバースタイムスタンプ}-{ユーザーID}
– Regsion数13に事前分割
• コンバージョン予測結果テーブル
– ストリーミングからユーザーごとのコンバージョン予測結果を書き込むテーブル。
– RowkeyはユーザーID
– カラムはコンバージョンフラグの1つのみ。
– Region数は13に事前分割
38
HBaseを使った追加検証

Copyright © BrainPad Inc. All Rights Reserved. 39
ストリーミングでの特徴量作成 – モデル取得 – 予測
0
200
400
600
800
1000
1200
1400
1500 3000 6000
QPS
HBase HDFS
各ジョブの平均実行時間を計測。

Copyright © BrainPad Inc. All Rights Reserved. 40
バッチでのモデル構築 (入力データ行数を変動)
0
10
20
30
40
50
60
0 2 4 6 8 10 12 14
特徴量行数(100万行)
HBase HDFS

Copyright © BrainPad Inc. All Rights Reserved.
データ量が少ないうちは差が出ないが、データ量が増えるにしたがってHBaseを使ったほうが書き込みケース(ストリーミング)、読み込みケース(バッチ)ともに、処理時間の伸びが鈍い。
– HBaseは実際にデータをHDFSに書き込むまでラグがある(MemStoreに貯める)ので、直にHDFSに書き込むのに比べて速いのだろう。
– 読み込みは、HDFS経由の場合は大量の小さなファイルを読み込むことになるが(ストリーミング側が数秒ごとに出力するため)、HBaseはそうはならないのでHDFSに比べて良い結果がでているのだろう。
MLlibは内部で(RDDの)collectをコールするなど、メモリを圧迫する処理を複数回行うため、以下の対応が必要だった。
– trainする前にpersistする。
– driverのメモリサイズを大きくする。
41
考察

Copyright © BrainPad Inc. All Rights Reserved.
8. まとめ
42

Copyright © BrainPad Inc. All Rights Reserved.
並列数のチューニングがパフォーマンスを決定している。
– 1 executorに複数コアを割り当てたほうが高速化する。
– 一方、ストリーミングのケースのように、並列数を増やすうことで処理が悪化するケースもある。(メモリについても同じ)
– 処理の内容やデータサイズに合わせて、適切なポイントを選ぶ必要がある。
パフォーマンスを出すには、書き方の工夫が必要。
– このスライドには現れていないが、(RDDオブジェクトの)repartitionやpersistなど、適宜タスク数を調整したりキャッシュを入れたりする必要がある。
MLlibは内部でcollectなどメモリを圧迫する処理を複数回行うため、以下の対応が必要。
– trainする前にpersistする。
– driverのメモリサイズを調整する。
管理UIが使いやすく、チューニングをするのに非常に助かる。
– どのタスクがどのくらい時間をとっているか、など。
43
まとめ

Copyright © BrainPad Inc. All Rights Reserved.
株式会社ブレインパッド
〒108-0071 東京都港区白金台3-2-10 白金台ビル3F
TEL:03-6721-7001
FAX:03-6721-7010
Copyright © BrainPad Inc. All Rights Reserved.
www.brainpad.co.jp














![[iOS 8] 測れる!パフォーマンス](https://static.fdocuments.net/doc/165x107/547ecfc9b379594e2b8b5538/ios-8-.jpg)



