
Sparkストリーミング検証
20
Copyright © BrainPad Inc. All Rights Reserved. ストリーミング検証 - アプリ編 - 2015年5月15日
-
Upload
brainpad-inc -
Category
Data & Analytics
-
view
459 -
download
2
Transcript of Sparkストリーミング検証

Copyright © BrainPad Inc. All Rights Reserved.
ストリーミング検証 - アプリ編 -
2015年5月15日

Copyright © BrainPad Inc. All Rights Reserved.
Spark Streamingを利用したアプリケーションを構築
– 直近数分間など、鮮度の高いデータを用いて予測ができるのがメリット
今回はCVユーザーを推定するアプリケーションに応用
– アクセスユーザーの中から、直近でCVしそうなユーザーを推定
• キャンペーン等の施策を打った直後からその効果を可視化したり、CVしそうなユーザーにはクーポンを付与、そうでないユーザーにレコメンドで回遊促進といった応用が考えられる
– Scalaで実装
• Pythonでも記述可能だが、Sparkのライブラリ対応状況がよいため
Spark Streamingで作成した特徴量にモデルを適用し、HDFSに結果を保存するところまで行う
– 今回やらないこと
• 適用した結果をDBに保存
– パフォーマンス検証編でHBaseに格納できるところまで確認済み
• 保存結果をWebアプリケーションから参照
– DBにデータを入れてしまえば応用は容易
2
目的
Copyright © BrainPad Inc. All Rights Reserved.
バッチ処理
ストリーミング処理
3
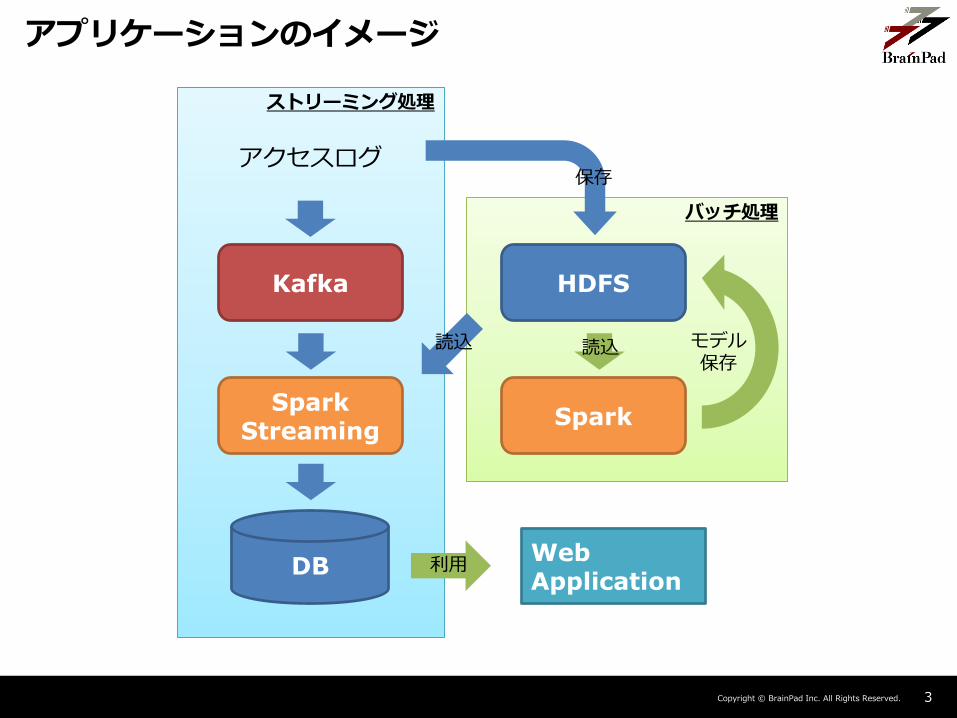
アプリケーションのイメージ
アクセスログ
Kafka
SparkStreaming
DBWebApplication
Spark
HDFS
利用
モデル保存
読込
保存
読込

Copyright © BrainPad Inc. All Rights Reserved.
バッチ処理
ストリーミング処理
4
アプリケーションのイメージ
アクセスログ
Kafka
SparkStreaming
DBWebApplication
Spark
HDFS
利用
モデル保存
読込
保存
読込
特徴量作成
ラベル付与
モデル構築
特徴量作成
モデル読込
モデル適用

Copyright © BrainPad Inc. All Rights Reserved.
特徴量作成
5
Copyright © BrainPad Inc. All Rights Reserved. 6
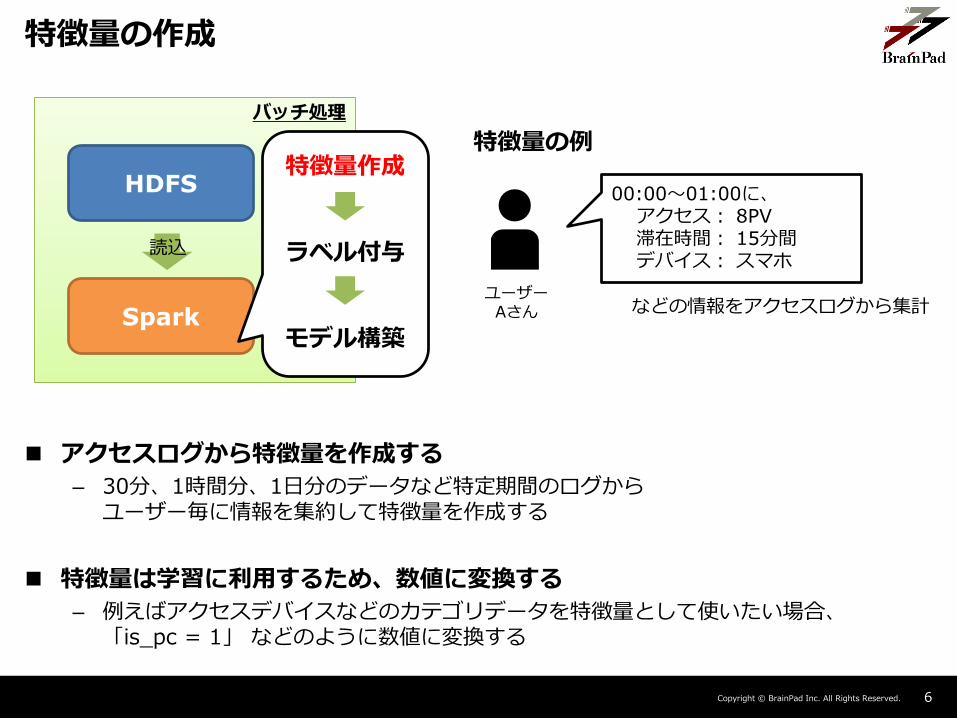
特徴量の作成
バッチ処理
Spark
HDFS
読込
特徴量作成
ラベル付与
モデル構築
00:00~01:00に、アクセス: 8PV滞在時間: 15分間デバイス: スマホ
などの情報をアクセスログから集計
アクセスログから特徴量を作成する
– 30分、1時間分、1日分のデータなど特定期間のログからユーザー毎に情報を集約して特徴量を作成する
特徴量は学習に利用するため、数値に変換する
– 例えばアクセスデバイスなどのカテゴリデータを特徴量として使いたい場合、「is_pc = 1」 などのように数値に変換する
特徴量の例
ユーザーAさん

Copyright © BrainPad Inc. All Rights Reserved.
アクセスログ(1 page viewごとに発生)
– String型のCSV形式
– 各行は「ユーザID」、「セッション番号」、「訪問日時」などを含む
1サイト分のログを利用
– 1日あたり、300万PV・26万UU・1万CV
7
アクセスログについて
カラム 意味
member ユーザID
visit memberの累計訪問回数(セッション番号)
page_view memberの累計ページビュー回数
date 訪問日時(YYYY-MM-DD HH:MM:SS.ZZZ)
site 訪問サブドメイン
page 訪問ページ

Copyright © BrainPad Inc. All Rights Reserved.
(ユーザーID × セッション番号) を1データ点とみなして特徴量作成
主にCV率と相関がありそうな変数を特徴量として利用
– 正例: 「コンバージョンページを訪問した (ユーザID × セッション番号)」
– 今回は、十分なボリュームが確保できる基本的な特徴量のみ利用
• 「過去にCVしたことがあるか」や「複数デバイスからのアクセスか」などはCVとの相関は強かったがボリュームが少なかった
8
アクセスログからの特徴量作成
カラム名 特徴量 備考
total_sec 滞在時間 セッション内での滞在時間
session_pv セッションPV セッション内でのPV数
average_tracking_time 平均滞在時間 セッション内での、1PVあたりの平均時間

Copyright © BrainPad Inc. All Rights Reserved.
モデル構築
9
Copyright © BrainPad Inc. All Rights Reserved. 10
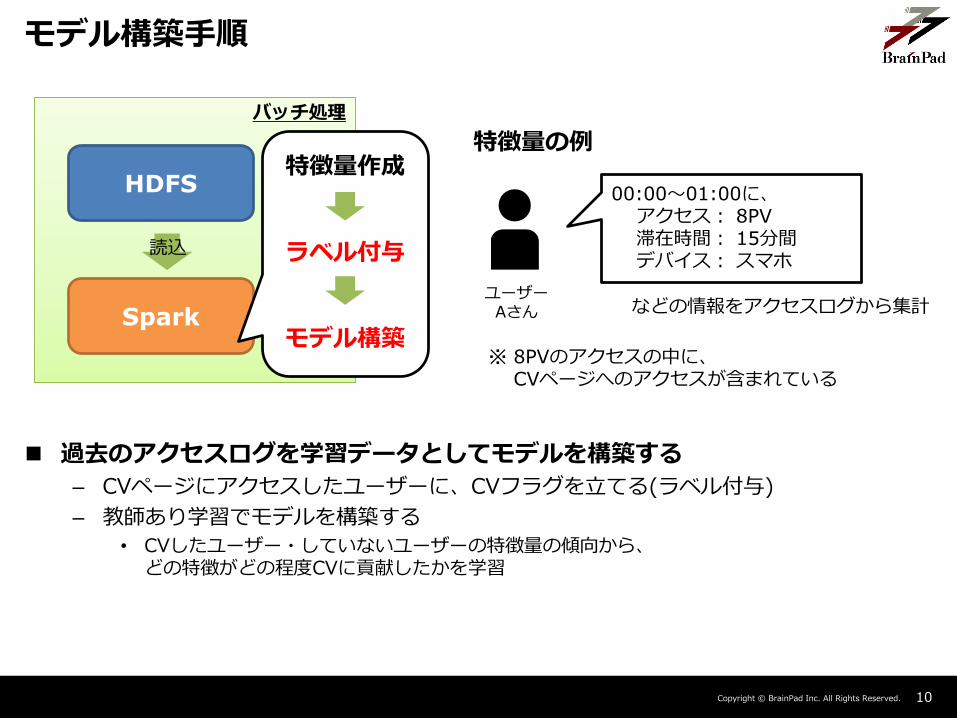
モデル構築手順
バッチ処理
Spark
HDFS
読込
特徴量作成
ラベル付与
モデル構築
過去のアクセスログを学習データとしてモデルを構築する
– CVページにアクセスしたユーザーに、CVフラグを立てる(ラベル付与)
– 教師あり学習でモデルを構築する
• CVしたユーザー・していないユーザーの特徴量の傾向から、どの特徴がどの程度CVに貢献したかを学習
※ 8PVのアクセスの中に、CVページへのアクセスが含まれている
ユーザーAさん
特徴量の例
00:00~01:00に、アクセス: 8PV滞在時間: 15分間デバイス: スマホ
などの情報をアクセスログから集計

Copyright © BrainPad Inc. All Rights Reserved.
MLlibを利用してモデル構築
– MLlib:Sparkで機械学習を行うためのライブラリ
• ロジスティック回帰やSVM、K-meansなどが用意されている
– 今回はロジスティック回帰を利用
• アプリケーションにおいてモデルは疎結合なので、更新や入れ替えは容易
• 今回はアプリケーション化を試すことが目的なので、複数モデルの比較や精度検証などは行っていない
– 定期的にバッチでモデルを作成する方法を想定
• オンライン学習は行わない
11
学習モデルについて

Copyright © BrainPad Inc. All Rights Reserved.
学習に利用したデータ
– ある1日分(24時間分)のアクセスログ
• ユーザー×セッション毎に特徴量を作成
• CVページにアクセスしているか否かラベルを付与
ラベル付与した特徴量から学習する
– LogisticRegressionWithLBFGSを利用
• 準ニュートン法を利用したロジスティック回帰
– LogisticRegressionWithSGD(確率的勾配降下法)もある
– 必要に応じてsetInterceptやsetNumClassなどを利用する
– 正解・不正解の比率が偏る場合、学習データをサンプリングする
• 例えばPythonのscikit-learnではclass_weight=‘auto’ を設定することで自動でダウンサンプリングしてくれる
• LogisticRegressionWithLBFGSでは現状自動でサンプリングしてくれる機能は無さそうなので必要に応じて実装
12
モデル実装

Copyright © BrainPad Inc. All Rights Reserved.
正解ラベルを付与した特徴量群を作成し、ロジスティック回帰で学習
構築したモデルを保存
13
MLlibを利用したロジスティック回帰
import org.apache.spark.mllib.classification.LogisticRegressionWithLBFGS
// ラベル付与した特徴量には Vectors.dense と LabeledPoint を利用
val LabeledData = csvFile.map { line =>...val has_conversion = ...val vector = Vectors.dense(data._1, data._2, data._3, ...)LabeledPoint(has_conversion, vector)
}
val model = new LogisticRegressionWithLBFGS().run(LabeledData)
val fs = FileSystem.get(new Configuration())val path = new Path(“{path}")val oos = new ObjectOutputStream(fs.create(path))oos.writeObject(model)oos.close()

Copyright © BrainPad Inc. All Rights Reserved.
モデル適用
14
Copyright © BrainPad Inc. All Rights Reserved. 15
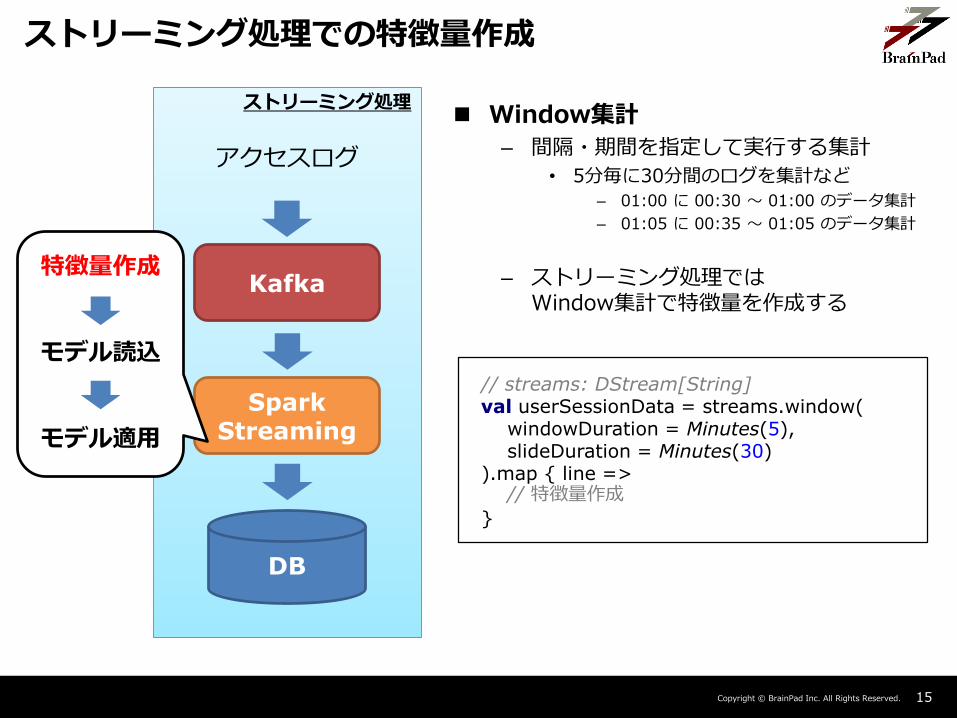
ストリーミング処理での特徴量作成
ストリーミング処理
アクセスログ
Kafka
SparkStreaming
DB
特徴量作成
モデル読込
モデル適用
Window集計
– 間隔・期間を指定して実行する集計
• 5分毎に30分間のログを集計など
– 01:00 に 00:30 ~ 01:00 のデータ集計
– 01:05 に 00:35 ~ 01:05 のデータ集計
– ストリーミング処理ではWindow集計で特徴量を作成する
// streams: DStream[String]val userSessionData = streams.window(
windowDuration = Minutes(5),slideDuration = Minutes(30)
).map { line =>// 特徴量作成
}

Copyright © BrainPad Inc. All Rights Reserved. 16
ストリーミング処理でのモデル適用
ストリーミング処理
アクセスログ
Kafka
SparkStreaming
DB
HDFS
読込
特徴量作成
モデル読込
モデル適用
モデルの読込と適用
– Window集計で作成した特徴量にバッチで作成したモデルを適用
– 各 ユーザー×セッション 毎のCVしそうスコアを算出
– 今回はDBではなくHDFSに結果出力
※ 前項までに構築したモデルをHDFSに保存している

Copyright © BrainPad Inc. All Rights Reserved.
保存されたモデルを適宜読み込んで適用
17
モデルの保存と読み込み
val is = new ObjectInputStream(fs.open(modelFilePath))val model = is.readObject().asInstanceOf[LogisticRegressionModel]
// 結果を0,1ではなく、スコアで出力
model.clearThreshold()
// 学習の際には LabeledPoint を利用したが、// モデル適用の際にはラベル付与されていない特徴量を利用
val predictions = userSessionData.map{ case (key, features) =>(key, model.predict(features))
}
Copyright © BrainPad Inc. All Rights Reserved. 18
結果
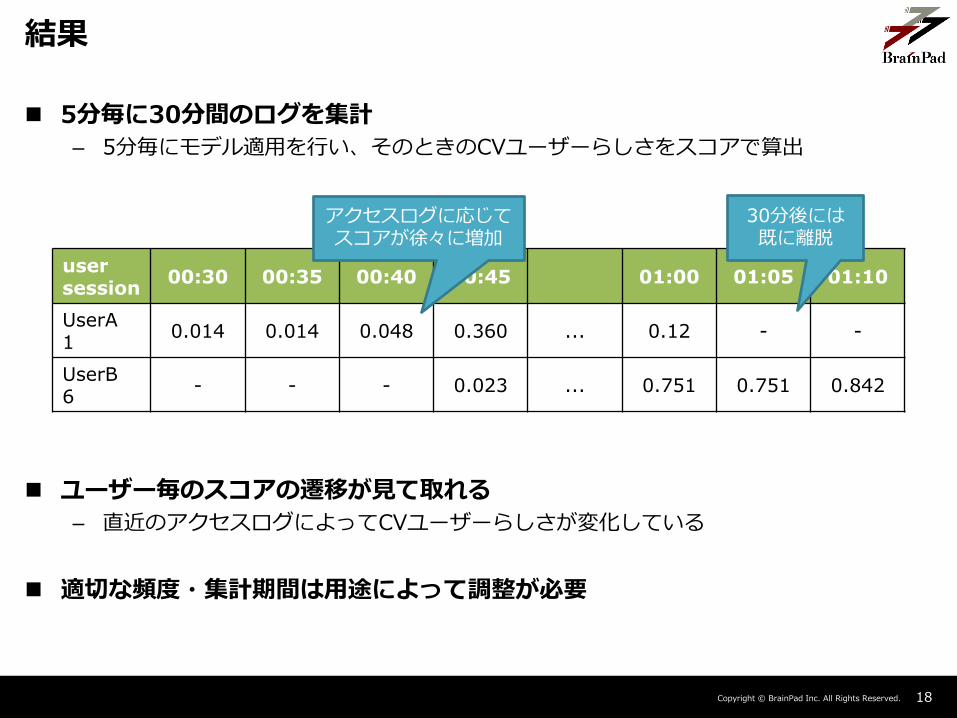
5分毎に30分間のログを集計
– 5分毎にモデル適用を行い、そのときのCVユーザーらしさをスコアで算出
ユーザー毎のスコアの遷移が見て取れる
– 直近のアクセスログによってCVユーザーらしさが変化している
適切な頻度・集計期間は用途によって調整が必要
usersession
00:30 00:35 00:40 00:45 01:00 01:05 01:10
UserA1
0.014 0.014 0.048 0.360 ... 0.12 - -
UserB6
- - - 0.023 ... 0.751 0.751 0.842
アクセスログに応じてスコアが徐々に増加
30分後には既に離脱

Copyright © BrainPad Inc. All Rights Reserved.
ロジスティック回帰でのモデル構築をSparkで実装
実際のアクセスログにストリーム処理でモデル適用し、(ユーザー×セッション) の単位でスコアを出力した
– HBaseなどのストレージにリアルタイムに結果を出力しアプリケーションでの展開に繋げることができる
– リアルタイムに更新される(ユーザー×セッション)単位のスコアを持つことで、以下の様な応用が考えられる
• キャンペーン等の施策を打った直後からその効果を可視化し、ユーザーの傾向が通常時からどう変化したかを測定
• CVしそうなユーザーにはクーポン付与、CVしなさそうなユーザーにはレコメンドで回遊促進というように施策を出しわける
分散処理を意識した特徴量の抽出が必要
– groupByなどを極力利用しない
• グルーピング対象のものを各ノードから取得するため各データがノード間を飛び交い、処理に時間を要してしまう
19
まとめ

Copyright © BrainPad Inc. All Rights Reserved.
株式会社ブレインパッド
〒108-0071 東京都港区白金台3-2-10 白金台ビル3F
TEL:03-6721-7001
FAX:03-6721-7010
Copyright © BrainPad Inc. All Rights Reserved.
www.brainpad.co.jp












![[Spark meetup] Spark Streaming Overview](https://static.fdocuments.net/doc/165x107/55a457161a28ab057e8b45fd/spark-meetup-spark-streaming-overview.jpg)





