
Slides by Olga Sorkine, Tel Aviv University. 2 The plan today Singular Value Decomposition Basic...
26
Slides by Olga Sorkine, Tel Aviv University
-
date post
18-Dec-2015 -
Category
Documents
-
view
217 -
download
0
Transcript of Slides by Olga Sorkine, Tel Aviv University. 2 The plan today Singular Value Decomposition Basic...

Slides by Olga Sorkine, Tel Aviv University

2
The plan today
Singular Value Decomposition Basic intuition Formal definition Applications

3
Geometric analysis of linear transformations
We want to know what a linear transformation A does Need some simple and “comprehendible” representation
of the matrix of A. Let’s look what A does to some vectors
Since A(v) = A(v), it’s enough to look at vectors v of unit length
A

4
The geometry of linear transformations
A linear (non-singular) transform A always takes hyper-spheres to hyper-ellipses.
A
A
5
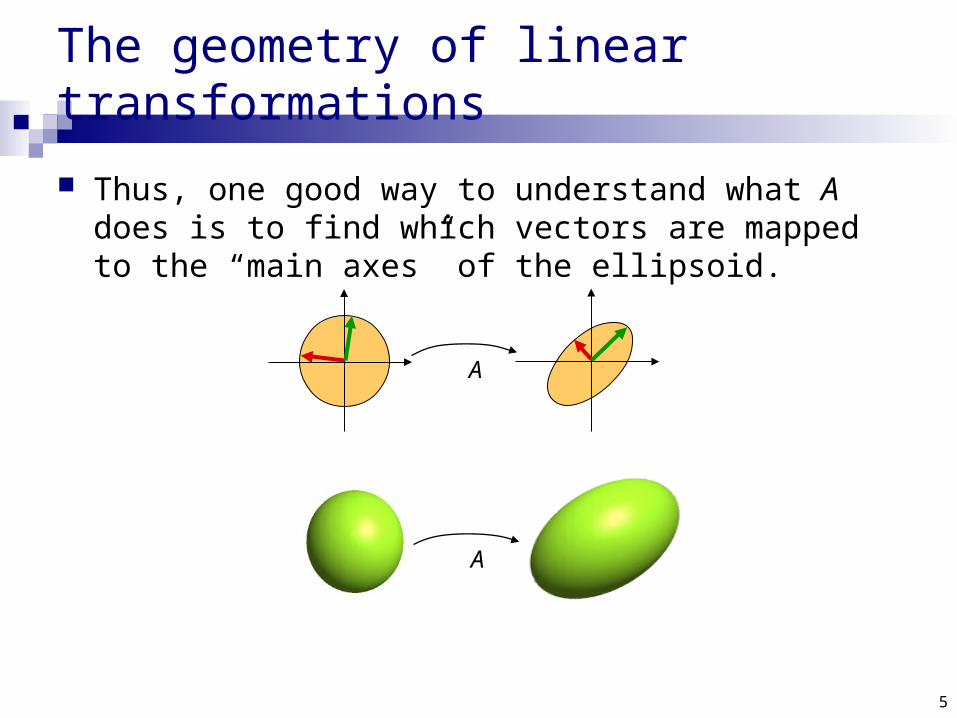
The geometry of linear transformations
Thus, one good way to understand what A does is to find which vectors are mapped to the “main axes” of the ellipsoid.
A
A

6
Geometric analysis of linear transformations
If we are lucky: A = V VT, V orthogonal (true if A is symmetric)
The eigenvectors of A are the axes of the ellipse
A

7
Symmetric matrix: eigen decomposition
In this case A is just a scaling matrix. The eigen decomposition of A tells us which orthogonal axes it scales, and by how much:
1
21 2 1 2
T
n n
n
A
v v v v v v
A
11
2
1
iiiA vv

8
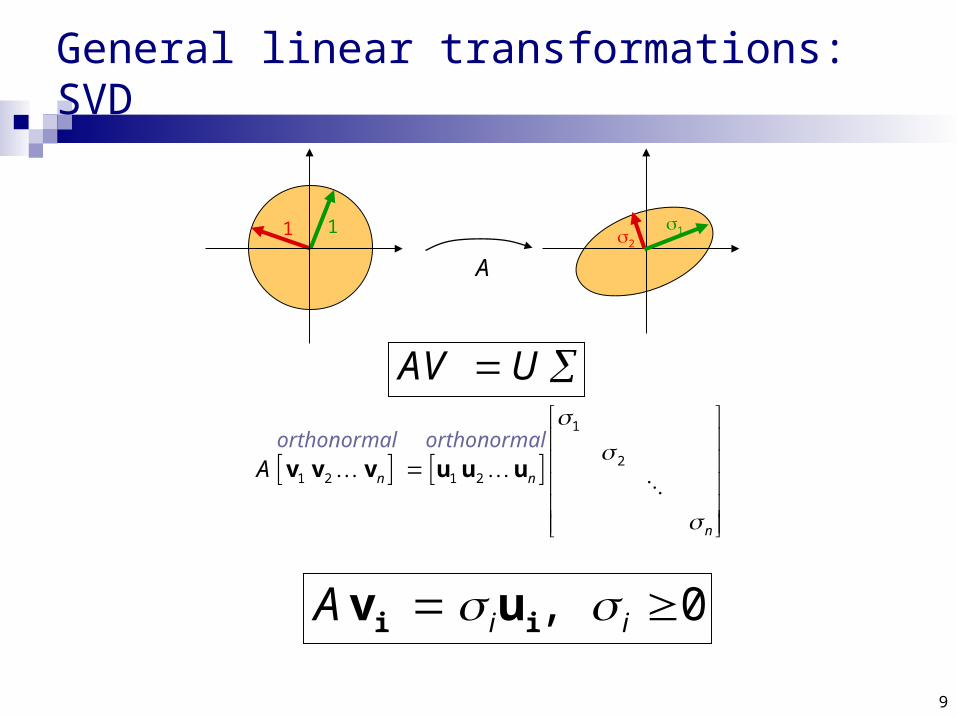
General linear transformations: SVD
In general A will also contain rotations, not just scales:
A
1
21 2 1 2
T
n n
n
A
u u u v v v
1 1 2
1
TA U V
9
General linear transformations: SVD
A
1
21 2 1 2n n
n
A
v v v u u u
1 1 2
1
AV U
, 0i iA i iv u
orthonormal orthonormal

10
SVD more formally
SVD exists for any matrix Formal definition:
For square matrices A Rnn, there exist orthogonal matrices U, V Rnn and a diagonal matrix , such that all the diagonal values i of are non-negative and
TA U V
=
A U TV

11
SVD more formally
The diagonal values of (1, …, n) are called the singular values. It is accustomed to sort them: 1 2 … n
The columns of U (u1, …, un) are called the left singular vectors. They are the axes of the ellipsoid.
The columns of V (v1, …, vn) are called the right singular vectors. They are the preimages of the axes of the ellipsoid.
TA U V
=
A U TV

12
Reduced SVD
For rectangular matrices, we have two forms of SVD. The reduced SVD looks like this: The columns of U are orthonormal Cheaper form for computation and storage
A U TV
=

13
Full SVD
We can complete U to a full orthogonal matrix and pad by zeros accordingly
A U TV
=

14
Shape matching
We have two objects in correspondence Want to find the rigid transformation that aligns
them
15
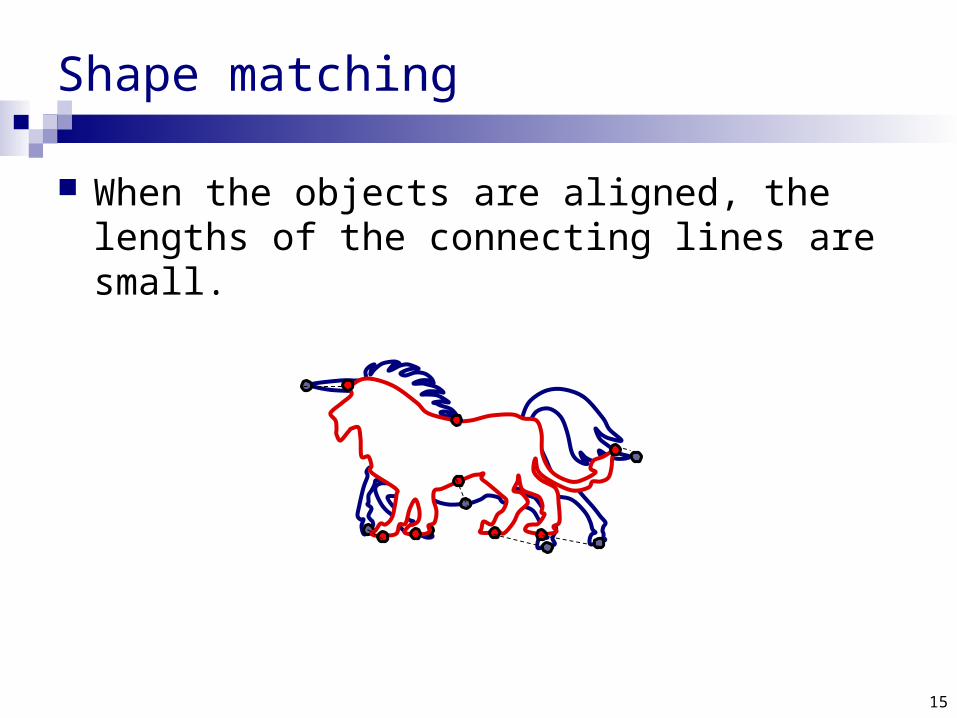
Shape matching
When the objects are aligned, the lengths of the connecting lines are small.

16
Shape matching – formalization
Align two point sets
Find a translation vector t and rotation matrix R so that:
1 1, , and , , .n nP Q p p q q
2
1
( ) is minimizedn
i ii
R
p tq

17
Shape matching – solution
Turns out we can solve the translation and rotation separately.
Theorem: if (R, t) is the optimal transformation, then the points {pi} and {Rqi + t} have the same centers of mass.
1
1 n
iin
p p1
1 n
iin
q q
1
1
1
1
n
ii
n
ii
R
R
n
R Rn
p q
p q q t
t p
t
t
q

18
Finding the rotation R
To find the optimal R, we bring the centroids of both point sets to the origin:
We want to find R that minimizes
i i i i p p p q q q
2
1
n
i ii
R
p q

19
Summary of rigid alignment:
Translate the input points to the centroids:
Compute the “covariance matrix”
Compute the SVD of H:
The optimal rotation is
The translation vector is
i ii i qp p qp q
1
nT
i ii
H
q p
TH U V
TR VU
R t p q

20
Complexity
Numerical SVD is an expensive operation We always need to pay attention to the
dimensions of the matrix we’re applying SVD to.

See you next time

22
Finding the rotation R
2
1 1
1
n nT
i i i i i ii i
nT T T T TT
i i i i i i i ii
R R R
R R R R
p q p q p q
p p p q q p q qI
These terms do not depend on R,so we can ignore them in the minimization

23
Finding the rotation R
1 1
1 1
min max .
max 2 max
n nT T T T
i i i ii i i i iii i
TT T Ti ii i i i i
n nT
T T
T T
Ti i i i
i i
R R R R
R R R
R R
p q q p p q q p
q p q p p q
p q p q
this is a scalar

24
Finding the rotation R
1 1 1
1
n n nT T T
i i i i i ii i i
nT
i ii
Trace Trace
H
R R R
p q q p q p
q p
3 1 1 3 = 3 3
=
1
( )n
iii
Trace A A

25
So, we want to find R that maximizes
Theorem: if M is symmetric positive definite (all eigenvalues of M are positive) and B is any orthogonal matrix then
So, let’s find R so that RH is symmetric positive definite. Then we know for sure that Trace(RH) is maximal.
Finding the rotation R
Trace RH
( )Trace M Trace BM

26
This is easy! Compute SVD of H:
Define R: Check RH:
Finding the rotation R
TH U V TR VU
T T TVU U VR V VH
This is a symmetric matrix,Its eigenvalues are i 0So RH is positive!








![USING Intuition - Laura Silva Quesadalaurasilvaquesada.com/wp-content/uploads/2017/03/Intuition-in... · USING Intuition IN BUSINESS [2] Using INTUITION IN Business INTUITION AND](https://static.fdocuments.net/doc/165x107/5ab27fd57f8b9a7e1d8d5a95/using-intuition-laura-silva-ques-intuition-in-business-2-using-intuition-in.jpg)









