
【SIROK技術勉強会 #4】機械学習と線形代数の基礎
114
-
Upload
shuntaro-tamura -
Category
Technology
-
view
3.714 -
download
0
Transcript of 【SIROK技術勉強会 #4】機械学習と線形代数の基礎


機械学習と線形代数の基礎
株式会社シロク エンジニア 田村俊太郎

アウトライン 1. 田村自己紹介 2. 機械学習 3. 線形代数 4. まとめ

田村自己紹介
(株)シロク エンジニア
田村俊太郎 (25) あだ名は「たむしゅん」
■学生時代1番頑張ったこと 全ての両立、全てに本気 (サークル7個、塾講師、大学の研究)
受験数学 テニス サッカー 合気道 等
線形代数
■経歴 2014年3月:東京大学大学院修了 2014年4月:(株)サイバーエージェント入社 2014年8月:(株)シロク出向
【Qiita】 h0p://qiita.com/shuntaro_tamura 【ブログ】 h0p://ameblo.jp/tamutamu1990/
大学教授 塾講師 就職
エンジニア

アウトライン 1. 田村自己紹介 2. 機械学習 3. 線形代数 4. まとめ

機械学習とは?

「機械」が「学習」すること

「機械」が「学習」すること コンピュータ
過去のデータの中から、問題を解くための規則性を見つけさせる

「機械」が「学習」すること コンピュータ
過去のデータの中から、問題を解くための規則性を見つけさせる
検索エンジン、天気予報、 スパムメール検出、 画像認識、医療診断、 顧客セグメンテーション など
▼応用例

機械学習の種類

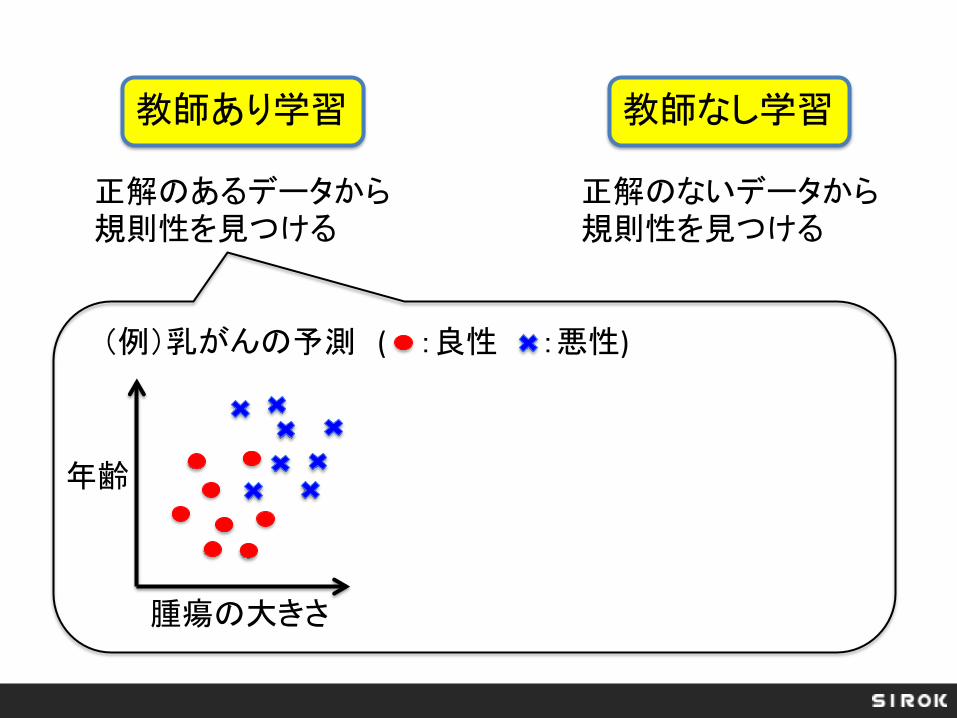
教師あり学習 教師なし学習
正解のあるデータから規則性を見つける
正解のないデータから規則性を見つける
教師あり学習 教師なし学習
正解のあるデータから規則性を見つける
正解のないデータから規則性を見つける
(例)乳がんの予測 ( :良性 :悪性)
年齢
腫瘍の大きさ

教師あり学習 教師なし学習
正解のあるデータから規則性を見つける
正解のないデータから規則性を見つける
(例)乳がんの予測 ( :良性 :悪性)
年齢
腫瘍の大きさ
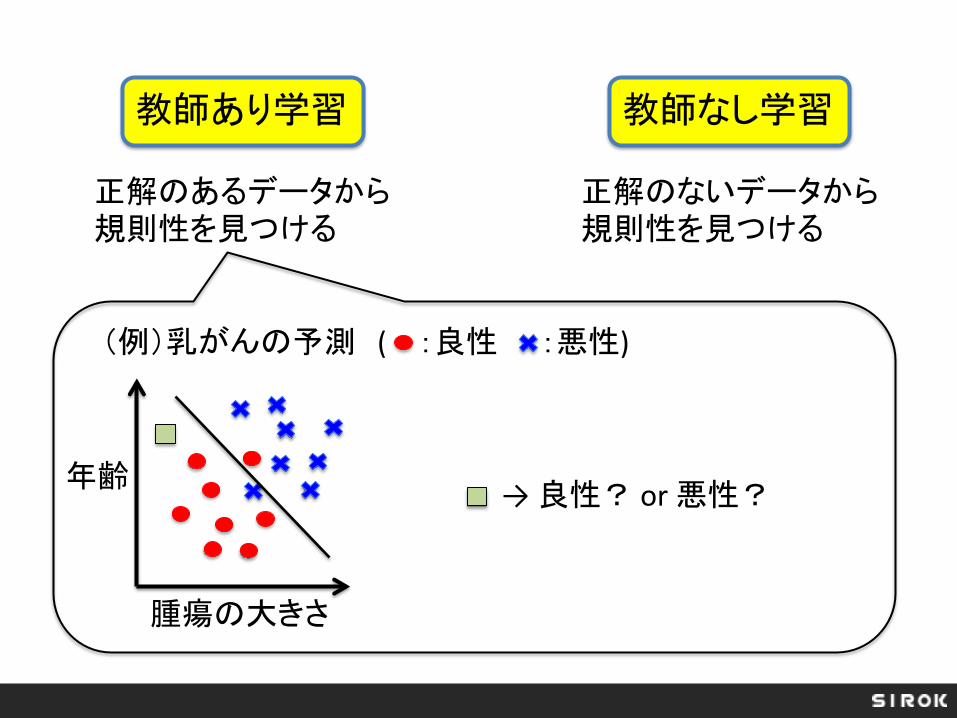
教師あり学習 教師なし学習
正解のあるデータから規則性を見つける
正解のないデータから規則性を見つける
(例)乳がんの予測 ( :良性 :悪性)
→ 良性? or 悪性? 年齢
腫瘍の大きさ
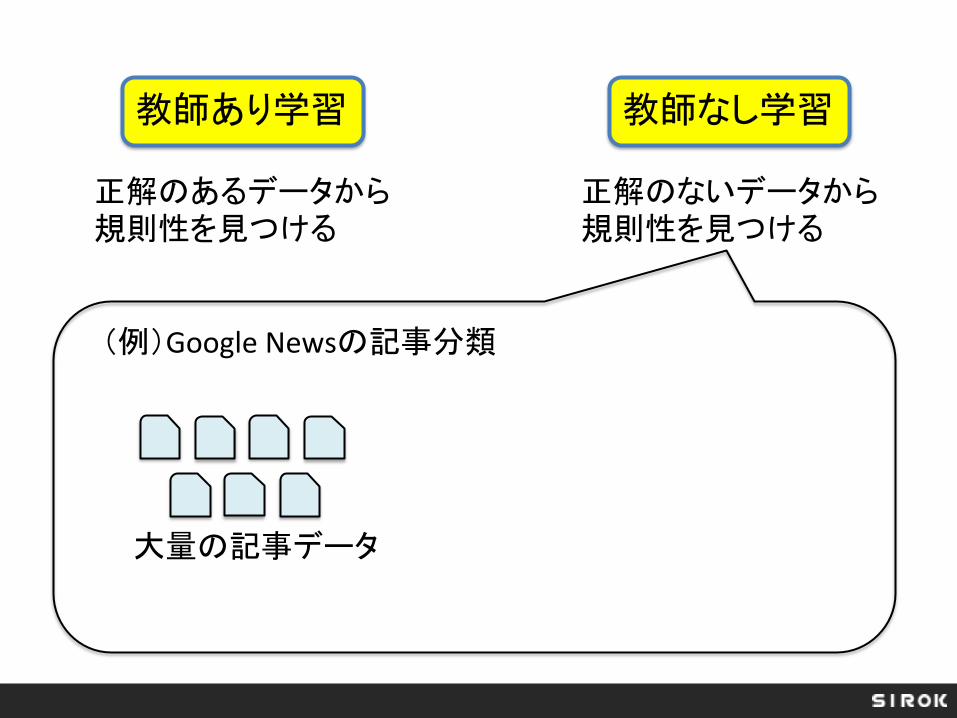
教師あり学習 教師なし学習
正解のあるデータから規則性を見つける
正解のないデータから規則性を見つける
(例)Google Newsの記事分類
大量の記事データ

教師あり学習 教師なし学習
正解のあるデータから規則性を見つける
正解のないデータから規則性を見つける
(例)Google Newsの記事分類
大量の記事データ エンタメ スポーツ
テクノロジー
教師あり学習 教師なし学習
正解のあるデータから規則性を見つける
正解のないデータから規則性を見つける
必ずどちらかに 分類されるか?
教師あり学習 教師なし学習
正解のあるデータから規則性を見つける
正解のないデータから規則性を見つける
必ずどちらかに 分類されるか?
No
教師あり学習 教師なし学習
正解のあるデータから規則性を見つける
正解のないデータから規則性を見つける
中間的手法

教師あり学習 教師なし学習
正解のあるデータから規則性を見つける
正解のないデータから規則性を見つける
中間的手法
半教師あり学習
強化学習 深層学習 Deep Learning

半教師あり学習 正解ありデータ + 正解なしデータ 強化学習 試行錯誤から規則性を見つける 深層学習(Deep Learning) 特徴量(Feature)の自動抽出
高コスト
(例)Deep Q Network によるブロック崩し
(例)IBM Watson、Googleの猫

実際に、実装してみた!

【環境構築】
Mac OS Xに Python(Anaconda)
をインストール

★Anaconda → h0p://conQnuum.io/downloads#all

★Anaconda → h0p://conQnuum.io/downloads#all

$ python -V Python 2.7.10 :: Anaconda 2.3.0 (x86_64) → Anaconda、無事入った。

Python(Anaconda) を選んだ理由

Python vs R ●Pythonのメリット(vs R) 数学、機械学習系のライブラリが豊富 言語として拡張性に富む 他言語との連携がしやすい 動作が速い ●Rのメリット(vs Python) 非エンジニアに取っ付きやすい

Python vs R ●Pythonのメリット(vs R) 数学、機械学習系のライブラリが豊富 言語として拡張性に富む 他言語との連携がしやすい 動作が速い ●Rのメリット(vs Python) 非エンジニアに取っ付きやすい
メリットが 大きい

$ ipython notebook →ブラウザが立ち上がる →対話的にPython実行が可能

Pythonを使って データ分析する流れ

①データの取得 ②データの加工その1 ③機械学習、データ分析 ④データの加工その2 ⑤可視化

①データの取得 API・Webから取得、CSV、SQLなど ②データの加工その1 numpy や pandas などを使った行列計算 ③機械学習、データ分析 scikit learn を使って分析 ④データの加工その2 numpy や pandas などを使って整形 ⑤可視化 matplotlib を使って表現
データ→行列の形で保持

①データの取得

①データの取得 ↓
irisデータ

150個の事前データ from sklearn import datasets iris = datasets.load_iris() X = iris.data ←入力データ Y = iris.target ←正解データ(教師あり学習)
5.1, 3.5, 1.4, 0.2, setosa4.9, 3.0, 1.4, 0.2, setosa (中略)7.0, 3.2, 4.7, 1.4, versicolor (中略)6.3, 3.3, 6.0, 2.5, virginica
左から順に、 ・がく片の長さ(cm) ・がく片の幅(cm) ・花びらの長さ(cm) ・花びらの幅(cm) ・正解の品種(3種類)
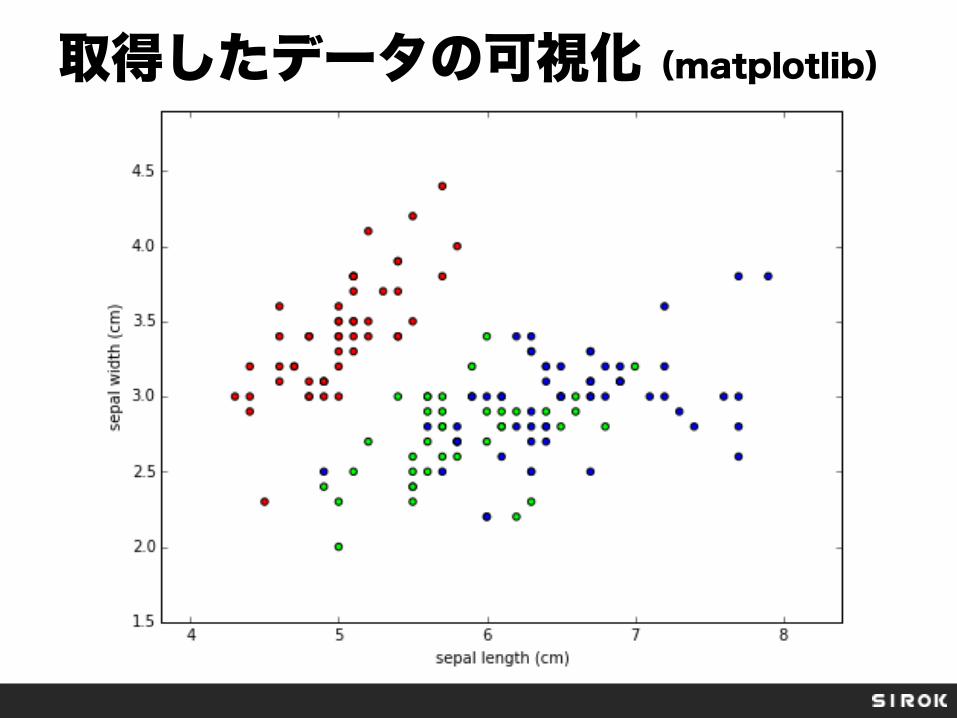
取得したデータの可視化(matplotlib)

②データの加工その1 ↓ (済)

③機械学習、データ分析

③機械学習、データ分析 ↓
ロジスティック回帰 k-近傍法

ロジスティック回帰 from sklearn.linear_model import LogisticRegression logit= LogisticRegression() logit.fit(X,Y) → 学習完了

ロジスティック回帰 from sklearn.linear_model import LogisticRegression logit= LogisticRegression() logit.fit(X,Y) → 学習完了 → 入力データ(4値)を突っ込んでみると、 正解を予測してくれる! print(logit.predict_proba([5.1, 3.5, 1.4, 0.2])) → setosa:88% versicolor:12% virginica:0%

k-近傍法 from sklearn.neighbors import KNeighborsClassifier k = 5 knn = KNeighborsClassifier(k) knn.fit(X,Y) → 学習完了

k-近傍法 from sklearn.neighbors import KNeighborsClassifier k = 5 knn = KNeighborsClassifier(k) knn.fit(X,Y) → 学習完了 → 入力データ(4値)を突っ込んでみると、 正解を予測してくれる! print(logit.predict_proba([5.1, 3.5, 1.4, 0.2])) → setosa:100% versicolor:0% virginica:0%

Cross Validation を用いて モデルの性能を評価

ロジスティック回帰の性能評価 from sklearn.linear_model import LogisticRegression from sklearn import cross_validation cv = 10 logit= LogisticRegression() scores = cross_validation.cross_val_score(logit,X,Y,cv=cv) print(sum(scores)/cv) → 正解率:95%
データセットを10等分し、9割のデータを用いて学習。 → 残り1割の正解率で評価。 → 10回繰り返し、平均をとる。

k-近傍法の性能評価 from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier k = 1 knn = KNeighborsClassifier(k) cv=10 scores = cross_validation.cross_val_score(knn,X,Y,cv=cv) print(sum(scores)/cv) → 正解率:96%
万能なアルゴリズムは存在しない。 問題に応じて適切なものを選択し、使う。

④データの加工その2 ⑤可視化

いずれもk-近傍法を可視化。(コード30行弱) 左図:がく片を特徴量(Feature)にした → 73% 右図:花びらを特徴量(Feature)にした → 97% Featureが大事。アルゴリズムの精度に大きく影響。

まとめ ・教師あり学習と教師なし学習の違い:正解の有無 ・強化学習:試行錯誤から規則性を見つける ・Deep Learning:Feature(特徴量)の自動抽出 ・Pythonで実装:Anaconda入れておけばOK ・CrossValidationで性能評価 ・万能なアルゴリズムは存在しない ・Featureが大事

アウトライン 1. 田村自己紹介 2. 機械学習 3. 線形代数 4. まとめ

線形代数とは?

「線形」な「代数」学のこと

「線形」な「代数」学のこと
一次式で表せるような関係
「集合」(元の集まり) と「演算」により定義 された構造の学問
直線
半群・群・環・体・束など。

「線形」な「代数」学のこと
一次式で表せるような関係
「集合」(元の集まり) と「演算」により定義 された構造の学問
直線 画像処理、座標変換、 検索エンジン、量子力学、 連立方程式の解法、統計学、 回路学、制御論、機械学習 など
▼応用例
半群・群・環・体・束など。

「代数」って何? 「線形」もなんだかよくわからない。

「代数」って何? 「線形」もなんだかよくわからない。
↓ 「行列計算」を扱う学問

行列とは?

行列とは?

行列とは?
ではなく、

長方形状に数字を並べたもの。
2 22 6
!
"#
$
%&
3 2 5 1 10 5 2 2 60 0 8 1 3
!
"
###
$
%
&&&
1 0 00 1 00 0 1
!
"
###
$
%
&&&

言葉の定義

行ベクトル:成分を横に並べて書いたベクトル 列ベクトル:成分を縦に並べて書いたベクトル 成分:ベクトルに含まれる各々の数 次元:ベクトルの成分の個数 行列:数(=成分)を長方形状に並べたもの

行ベクトル:成分を横に並べて書いたベクトル 列ベクトル:成分を縦に並べて書いたベクトル 成分:ベクトルに含まれる各々の数 次元:ベクトルの成分の個数 行列:数(=成分)を長方形状に並べたもの
2 5( )324
!
"
###
$
%
&&&
行ベクトル。2次元。
列ベクトル。3次元。

行ベクトル:成分を横に並べて書いたベクトル 列ベクトル:成分を縦に並べて書いたベクトル 成分:ベクトルに含まれる各々の数 次元:ベクトルの成分の個数 行列:数(=成分)を長方形状に並べたもの
2 5( )324
!
"
###
$
%
&&&
行ベクトル。2次元。
列ベクトル。3次元。
成分

行ベクトル:成分を横に並べて書いたベクトル 列ベクトル:成分を縦に並べて書いたベクトル 成分:ベクトルに含まれる各々の数 次元:ベクトルの成分の個数 行列:数(=成分)を長方形状に並べたもの
2 5( )324
!
"
###
$
%
&&&
行ベクトル。2次元。
列ベクトル。3次元。
成分
1 2 34 5 6
!
"#
$
%& 2行3列の行列(2 x 3 行列)

行ベクトル:成分を横に並べて書いたベクトル 列ベクトル:成分を縦に並べて書いたベクトル 成分:ベクトルに含まれる各々の数 次元:ベクトルの成分の個数 行列:数(=成分)を長方形状に並べたもの
2 5( )324
!
"
###
$
%
&&&
行ベクトル。2次元。
列ベクトル。3次元。
成分
1 2 34 5 6
!
"#
$
%&
行列の「型」
2行3列の行列(2 x 3 行列)

行と列の覚え方
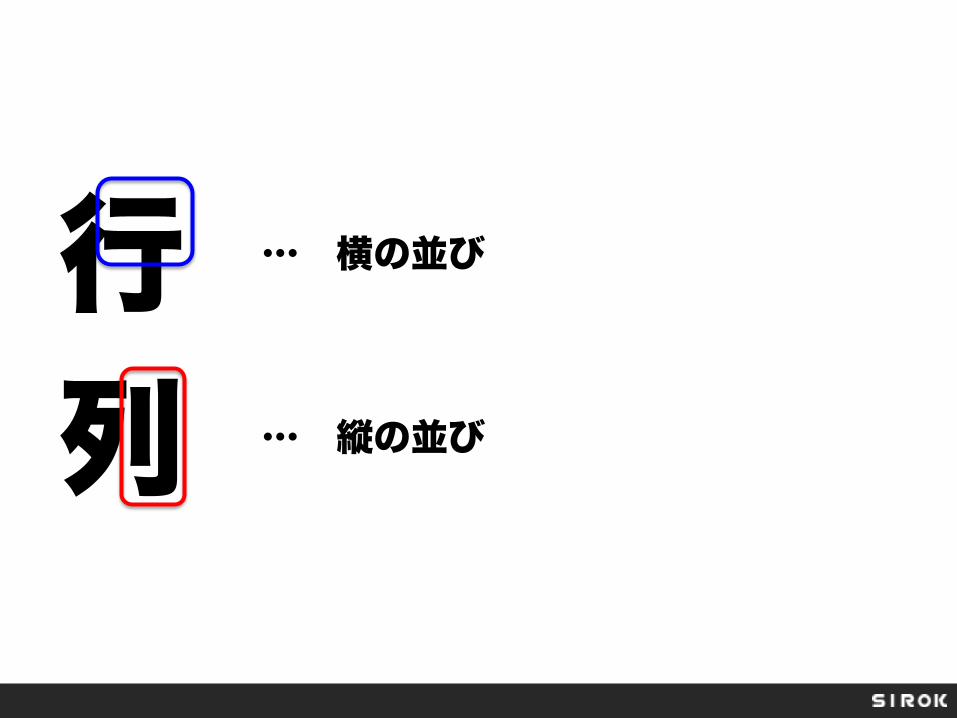
行 列
… 横の並び
… 縦の並び
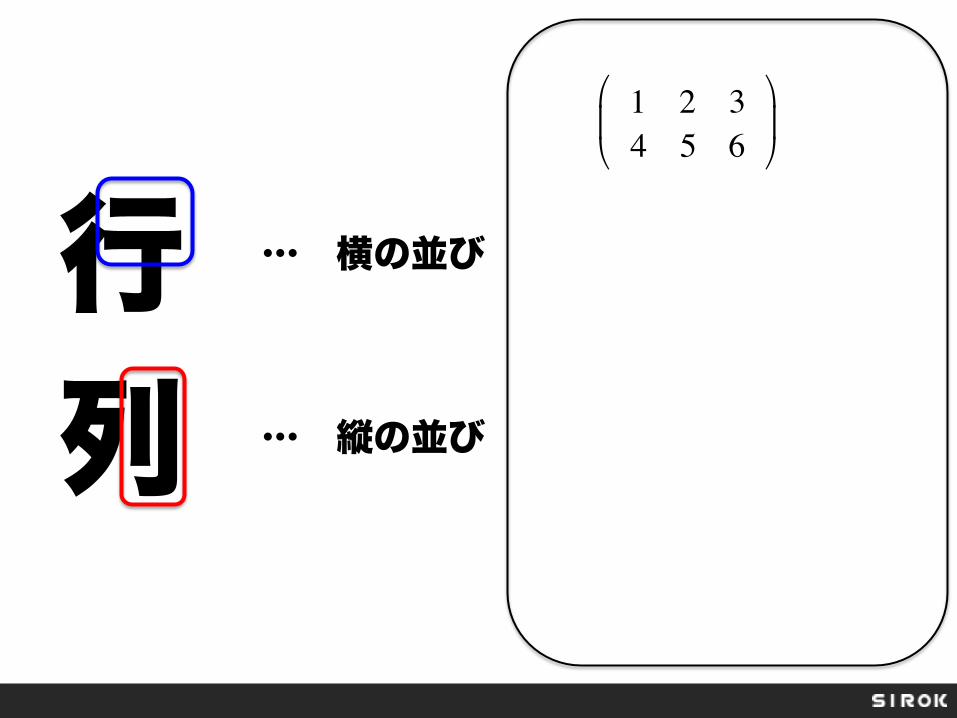
行 列
… 横の並び
… 縦の並び
1 2 34 5 6
!
"#
$
%&

行 列
… 横の並び
… 縦の並び
1 2 34 5 6
!
"#
$
%&
第1行
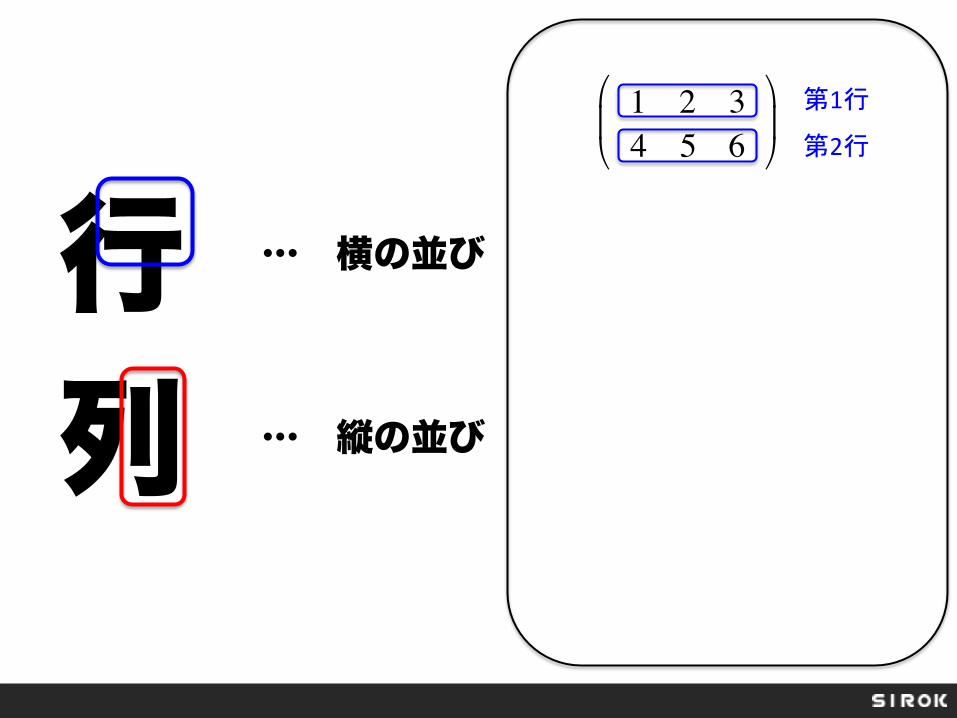
行 列
… 横の並び
… 縦の並び
1 2 34 5 6
!
"#
$
%&
第1行
第2行
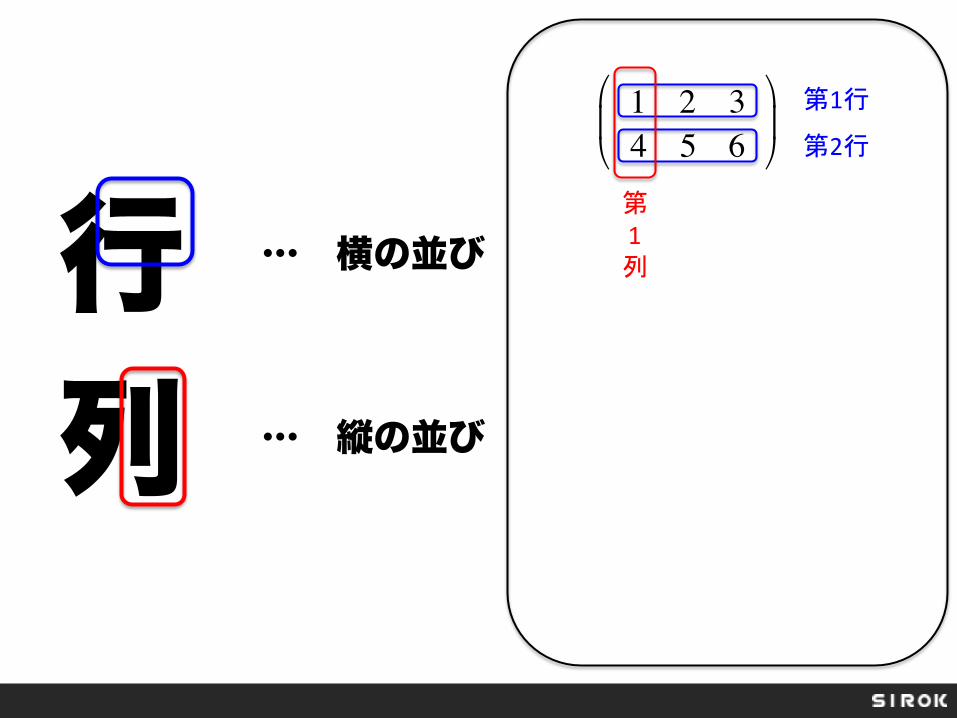
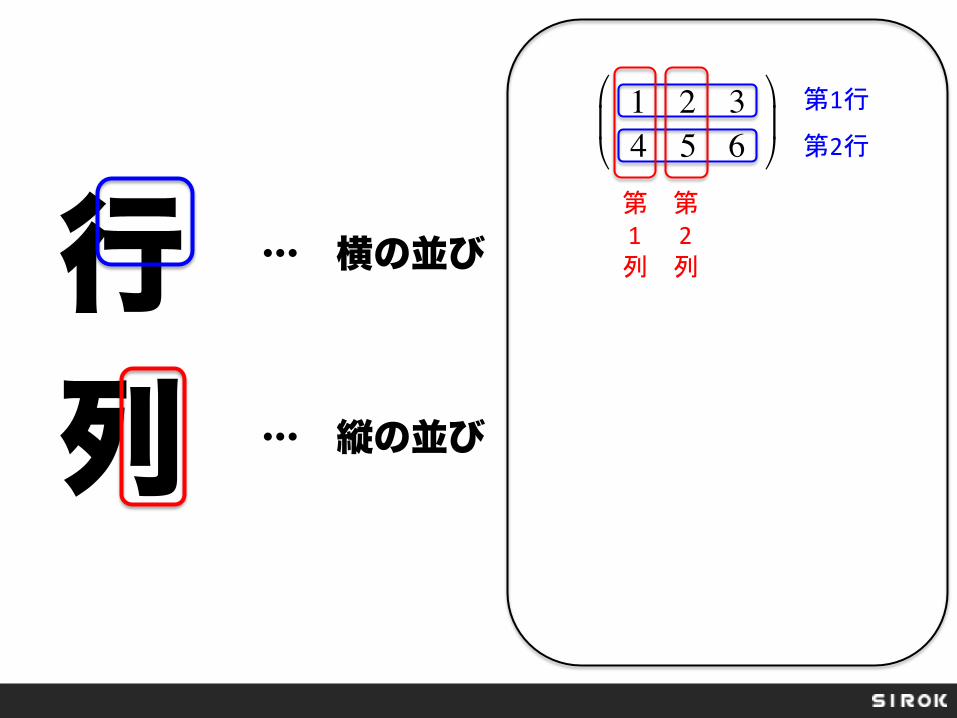
行 列
… 横の並び
… 縦の並び
1 2 34 5 6
!
"#
$
%&
第1行
第2行
第 1 列
行 列
… 横の並び
… 縦の並び
1 2 34 5 6
!
"#
$
%&
第1行
第2行
第 1 列
第 2 列

行 列
… 横の並び
… 縦の並び
1 2 34 5 6
!
"#
$
%&
第1行
第2行
第 1 列
第 2 列
第 3 列
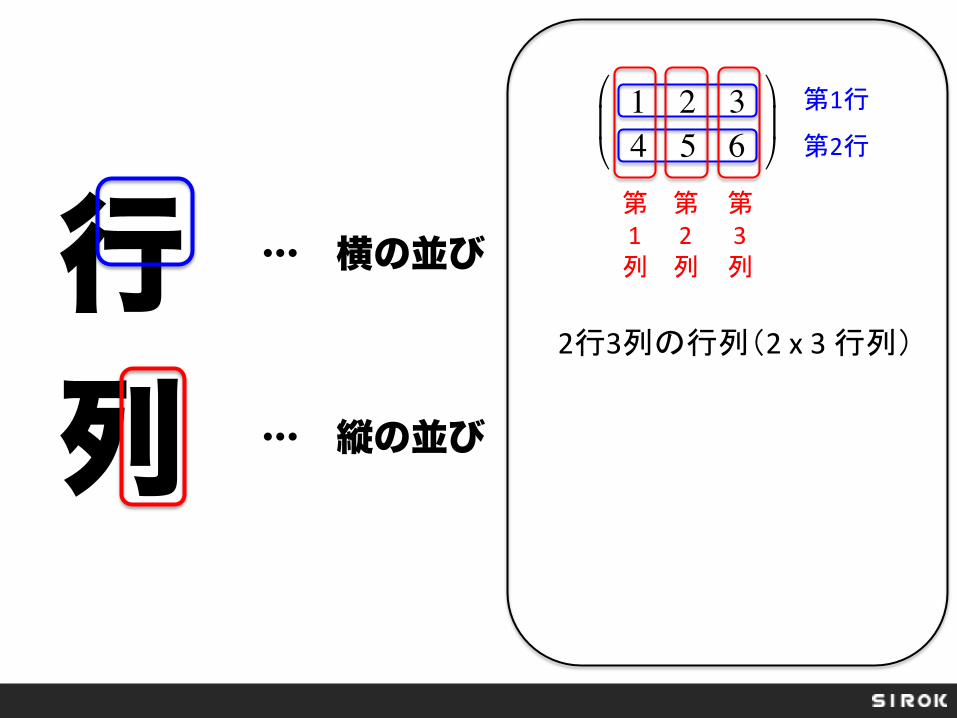
行 列
… 横の並び
… 縦の並び
1 2 34 5 6
!
"#
$
%&
第1行
第2行
第 1 列
第 2 列
第 3 列
2行3列の行列(2 x 3 行列)

行 列
… 横の並び
… 縦の並び
1 2 34 5 6
!
"#
$
%&
第1行
第2行
第 1 列
第 2 列
第 3 列
2行3列の行列(2 x 3 行列)
(1, 1)成分 → 1

行 列
… 横の並び
… 縦の並び
1 2 34 5 6
!
"#
$
%&
第1行
第2行
第 1 列
第 2 列
第 3 列
2行3列の行列(2 x 3 行列)
(1, 1)成分 → 1 (1, 2)成分 → 2 (1, 3)成分 → 3 (2, 1)成分 → 4 (2, 2)成分 → 5 (2, 3)成分 → 6

行列の和・差・スカラー倍

a bc d
!
"#
$
%&+
x yz w
!
"##
$
%&&=
a+ x b+ yc+ z d +w
!
"##
$
%&&
a bc d
!
"#
$
%&−
x yz w
!
"##
$
%&&=
a− x b− yc− z d −w
!
"##
$
%&&
k a bc d
!
"#
$
%&= ka kb
kc kd
!
"#
$
%&
和・差・スカラー倍の次のように定義される

a bc d
!
"#
$
%&+
x yz w
!
"##
$
%&&=
a+ x b+ yc+ z d +w
!
"##
$
%&&
a bc d
!
"#
$
%&−
x yz w
!
"##
$
%&&=
a− x b− yc− z d −w
!
"##
$
%&&
k a bc d
!
"#
$
%&= ka kb
kc kd
!
"#
$
%&
a b cd e f
!
"##
$
%&&+
x yz w
!
"##
$
%&& →定義されない
和・差・スカラー倍の次のように定義される 和・差は「型」が同じ時のみ定義される

行列の積

と、なるのでは…?
a bc d
!
"#
$
%&
x yz w
!
"##
$
%&&=
ax bycz dw
!
"##
$
%&&

と、なるのでは…?
a bc d
!
"#
$
%&
x yz w
!
"##
$
%&&=
ax bycz dw
!
"##
$
%&&
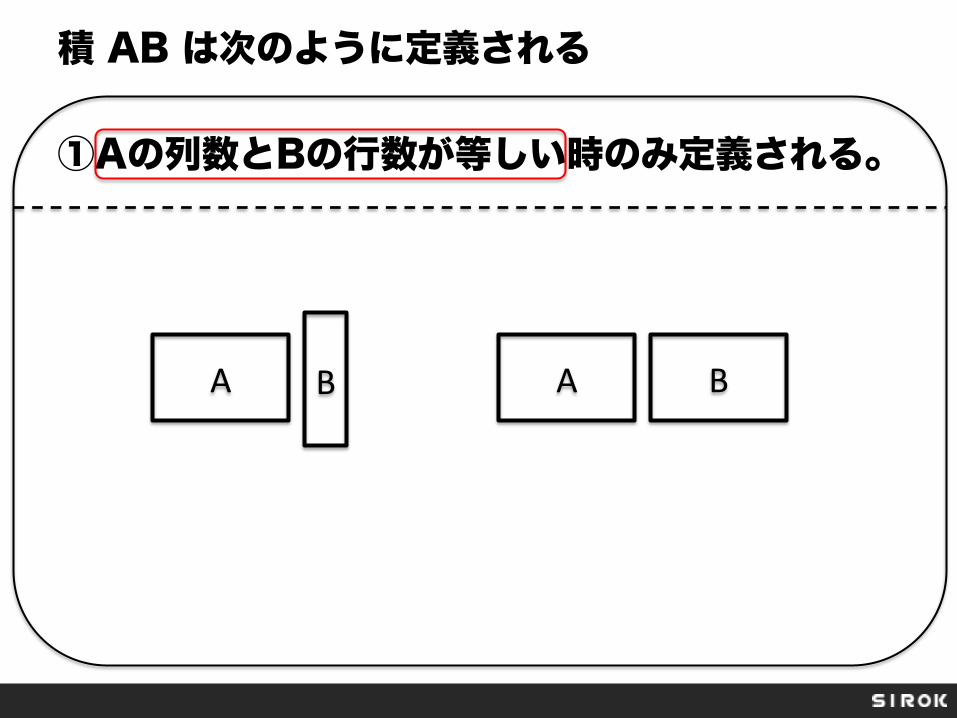
積 AB は次のように定義される ①Aの列数とBの行数が等しい時のみ定義される。
A B A B
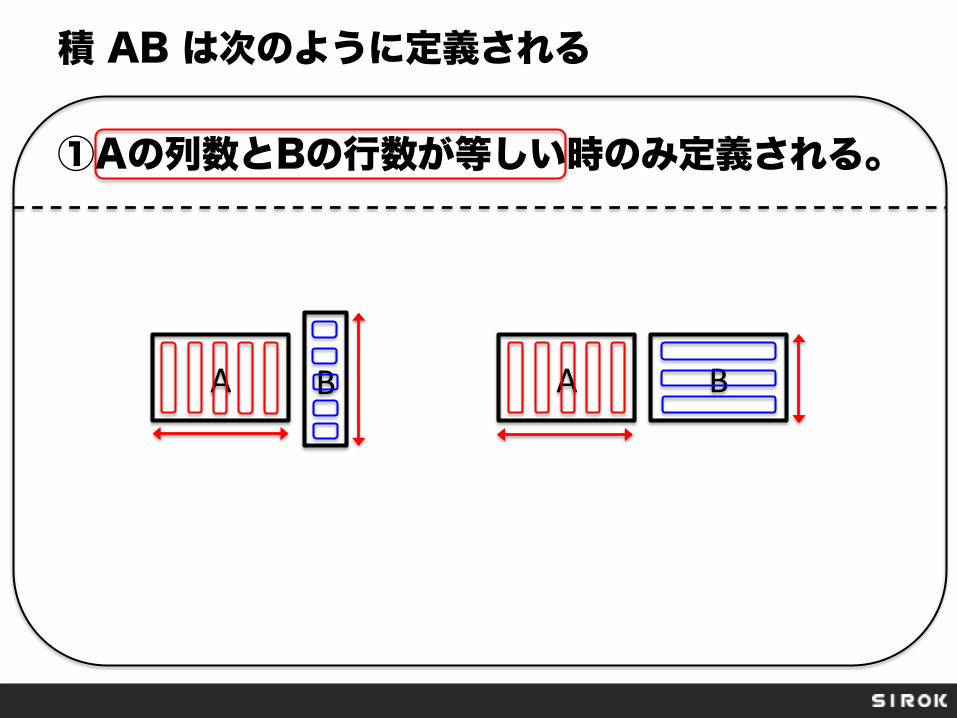
積 AB は次のように定義される ①Aの列数とBの行数が等しい時のみ定義される。
A B A B

積 AB は次のように定義される ①Aの列数とBの行数が等しい時のみ定義される。
A B A B

積 AB は次のように定義される ①Aの列数とBの行数が等しい時のみ定義される。 ②C=ABの時、Cの(i, j)成分は Aの第 i 行ベクトルとBの第 j 列ベクトルの積 とする。 ベクトルの内積!!!
A B 第i行
第j列
Cij = の内積
Cの(i, j)成分

積 AB は次のように定義される ①Aの列数とBの行数が等しい時のみ定義される。 ②C=ABの時、Cの(i, j)成分は Aの第 i 行ベクトルとBの第 j 列ベクトルの積 とする。 ③Aが l x m 行列 Bが m x n 行列の時、 C=ABは l x n 行列。
ベクトルの内積!!! ①より、等しい
a bc de f
!
"
###
$
%
&&&
xy
!
"##
$
%&&=
ax + bycx + dyex + fy
!
"
####
$
%
&&&&
3x2 2x1 3x1
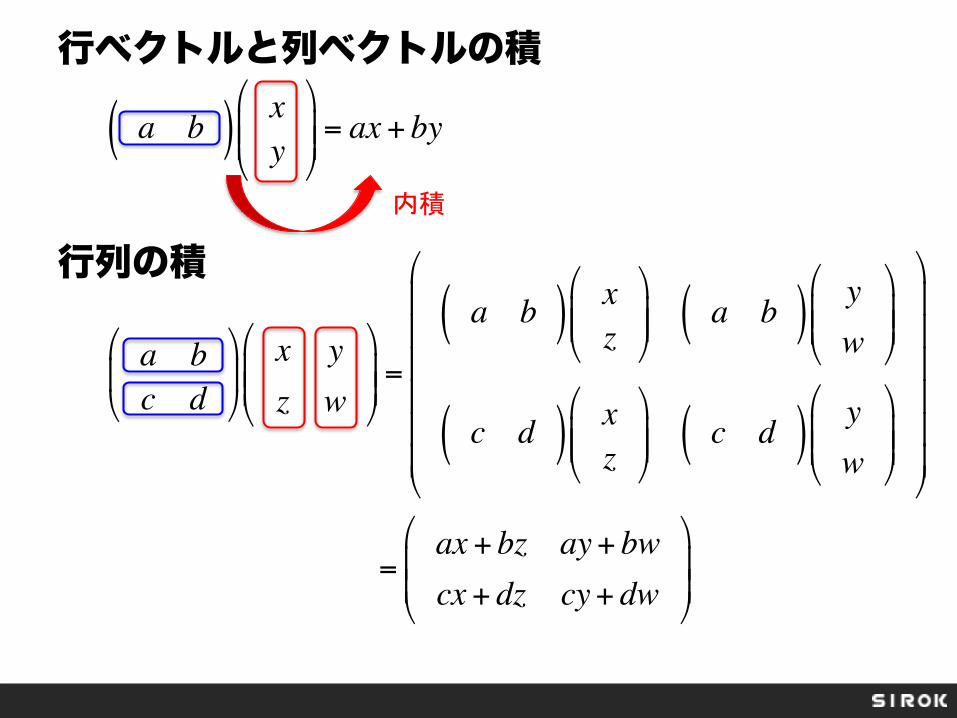
行ベクトルと列ベクトルの積 行列の積
a b( ) xy
!
"##
$
%&&= ax + by
a bc d
!
"#
$
%&
x yz w
!
"##
$
%&&=
a b( ) xz
!
"##
$
%&& a b( ) y
w
!
"##
$
%&&
c d( ) xz
!
"##
$
%&& c d( ) y
w
!
"##
$
%&&
!
"
######
$
%
&&&&&&
=ax + bz ay+ bwcx + dz cy+ dw
!
"##
$
%&&
内積

行列の積の性質 ①交換法則は一般には成り立たない AB≠BA ②零因子の存在 A≠OかつB≠Oでも、AB=Oとなりうる
a b( ) xy
!
"##
$
%&&= ax + by
xy
!
"##
$
%&& a b( ) = xa xb
ya yb
!
"##
$
%&&
1 2( ) −21
"
#$
%
&'=1*(−2)+ 2*1= 0

その他の行列の性質

①行列に割り算は存在しない ②単位行列 ③零行列 ④逆行列 ⑤転置行列
IAI = IA = A
OAO =OA =O
AA−1 = A−1A = IA−1
AT
Aij = AjiT

①行列に割り算は存在しない ②単位行列 ③零行列 ④逆行列 ⑤転置行列
I2 =1 00 1
!
"#
$
%&, I3 =
1 0 00 1 00 0 1
!
"
###
$
%
&&&
IAI = IA = A
OAO =OA =O
O2,2 =0 00 0
!
"#
$
%&,O3,3 =
0 0 00 0 00 0 0
!
"
###
$
%
&&&
AA−1 = A−1A = IA−1
AT
Aij = AjiT
A = 1 00 2
!
"#
$
%&,B =
1 00 1
2
!
"##
$
%&&
⇒ AB = BA = I
A = 1 2 34 5 6
!
"#
$
%&⇔ AT =
1 42 53 6
!
"
###
$
%
&&&

⑥トレース(trace)、行列式(determinant) ⑦固有値 ・固有ベクトル
Ax = λx(x ≠ 0)λ x
A = a bc d
!
"#
$
%&
Tr(A) = a+ d, det(A) = ad − bc

⑥トレース(trace)、行列式(determinant) ⑦固有値 ・固有ベクトル
Ax = λx(x ≠ 0)λ x
A = a bc d
!
"#
$
%&
Tr(A) = a+ d, det(A) = ad − bc ac
!
"#
$
%&
bd
!
"#
$
%&
対角成分の和
平行四辺形の面積

⑥トレース(trace)、行列式(determinant) ⑦固有値 ・固有ベクトル
Ax = λx(x ≠ 0)λ x
A = a bc d
!
"#
$
%&
Tr(A) = a+ d, det(A) = ad − bc ac
!
"#
$
%&
bd
!
"#
$
%&
対角成分の和
平行四辺形の面積
座標変換
x
y
O
行列Aを左から掛ける
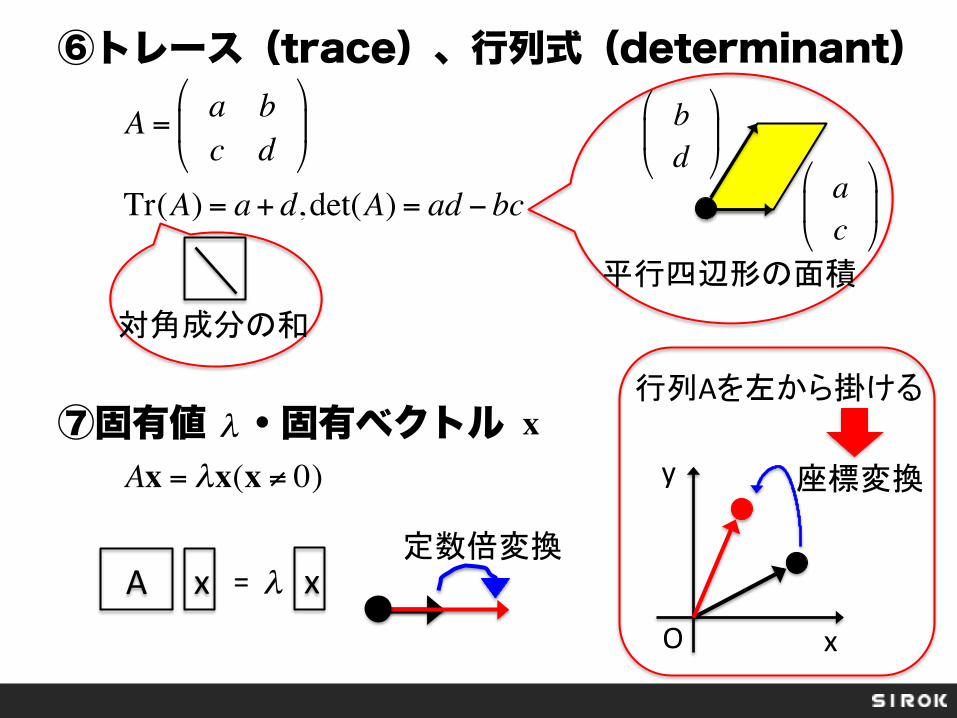
⑥トレース(trace)、行列式(determinant) ⑦固有値 ・固有ベクトル
Ax = λx(x ≠ 0)λ x
A = a bc d
!
"#
$
%&
Tr(A) = a+ d, det(A) = ad − bc ac
!
"#
$
%&
bd
!
"#
$
%&
対角成分の和
平行四辺形の面積
座標変換
x
y
O
行列Aを左から掛ける
定数倍変換 A x = xλ

アウトライン 1. 田村自己紹介 2. 機械学習 3. 線形代数 4. まとめ

今日のまとめ

機械学習 ・教師あり学習と教師なし学習の違い:正解の有無 ・強化学習:試行錯誤から規則性を見つける ・Deep Learning:Feature(特徴量)の自動抽出 ・Pythonで実装:Anaconda入れておけばOK ・CrossValidationで性能評価 ・万能なアルゴリズムは存在しない ・Featureが大事 線形代数 ・行列の積、交換可能性、零因子 ・単位行列、零行列、逆行列、転置行列 ・トレース、行列式、固有値、固有ベクトル

おすすめ書籍・サイト

通称:PRML、黄色本
Andrew Ng先生の動画 (Coursera)

代数系についてわかりやすく解説

初学者におすすめ

もっと勉強したい人におすすめ

数値計算をわかりやすく解説

次回予告

8/26(水) 19:00-21:00 ソーシャルゲームの行動解析
@プライムプラザ4F

8/26(水) 19:00-21:00 ソーシャルゲームの行動解析
@プライムプラザ4F
乞うご期待!!













![机械设备 [Table Industry]机械设备](https://static.fdocuments.net/doc/165x107/62421602bc890036947c0533/-table-industry.jpg)





