Sin título de diapositiva - Jordi Torres · ¡chuleta! 1 Gigabyte (GB) = 1.000.000.000 byte 1...
160
Cloud Computing & Big Data FIB-UPC Master MEI BIG DATA basics November- 2012
-
Upload
phungthien -
Category
Documents
-
view
219 -
download
0
Transcript of Sin título de diapositiva - Jordi Torres · ¡chuleta! 1 Gigabyte (GB) = 1.000.000.000 byte 1...

Cloud Computing
& Big Data
FIB-UPC Master MEI
BIG DATA basics
November- 2012

2
Content (Big Data part)
A. Motivation
B. Big Data Challenges
C. Processing Big Data
D. Big Data Storage
E. Managing Big Data
F. Analyzing Big Data (Data Modelling & Prediction)
G. Apache Hadoop Ecosystem & Commercial solutions
H. Homework & presentations

Cloud Computing
& Big Data
FIB-UPC Master MEI
Big Data motivation
November- 2012

4
My motivation for including it now!
Big Data has become a hot topic in the field of Information and Communication Technology (ICT) in recent years, impossible to separate it from Cloud Computing. Particularly, the exponential and fast growth of very different types of data has quickly raised concerns about how to store, manage, process and analyse the data.
For these reasons I considered that this topic have to be included in this course.
I hope you enjoy it! :-)
Cloud Computing
Cloud Computing
& Big Data
?

5
Motivation
http://techcrunch.com/2012/11/08/a-riddle-wrapped-in-a-mystery-inside-an-enigma/

6
Motivation

7
Motivation

8
Motivation
Source: http://wikibon.org/wiki/v/Big_Data_Market_Size_and_Vendor_Revenues

9
Big Data?
Do you need a definition?
– is data that becomes large enough
that it cannot be processed using
conventional methods.
– enough for you? :-)
Petabytes of data created daily
social networks,
mobile phones,
sensors,
science,
…
Source:http://www.datacenterknowledge.com/archives/2011/06/28/digital-universe-to-add-1-8-zettabytes-in-2011/?utm-source=feedburner&utm-medium=feed&utm-campaign=Feed:+DataCenterKnowledge+%28Data

10
Internet of Things

11
Future of Cloud: “Fog” Computing?

12
New requirements for Cloud:
For example: Barcelona Smart City

13
Result: Traditional Data versus Big Data
“Traditional” Data
Big Data
Gigabytes (109)
to Terabytes (1012)
Petabytes (1015)
to Exabytes (1018)
Centralized Distributed
structured Semi-structured and unstructured
Stable data model Flat schemas
Known complex interrelationships Few complex interrelationships

14
Why is Big Data Important
60%
Potential increase in retailers operating
margins possible with big data
(*) Source: Big Data: The next frontier for innovation, competition and productivity – Mckinsey Global Institute, July 2011
40% projected growth in global data generated per year vs
5% projected growth in global IT spending

15
Why is Big Data Important
Data is more important than ever, but the exponential
growth of data has overwhelmed most company's
ability to manage (and monetize it).
BIG MARKET FOR
NEW COMPANIES:
Your company?

16
Content (Big Data part)
A. Motivation
B. Big Data Challenges
C. Processing Big Data
D. Big Data Storage
E. Managing Big Data
F. Analyzing Big Data (Data Modelling & Prediction)
G. Apache Hadoop Ecosystem & Commercial solutions
H. Homework & presentations

Cloud Computing
& Big Data
FIB-UPC Master MEI
Big Data Challenges
November- 2012

18
Big Data VOLUME
Petabytes?
Exabytes?
Terabytes?
Zettabytes?

19
¡chuleta!
1 Gigabyte (GB) = 1.000.000.000 byte
1 Terabyte (TB) = 1.000 Gigabyte (GB)
1 Petabyte (PB) = 1.000.000 Gigabyte (GB)
1 Exabyte (EB) = 1.000.000.000 Gigabyte (GB)
1 Zettabyte (ZB) = 1.000.000.000.000 (GB)

20
Big Data: VARIETY
Source: Toni Brey – Urbiotica.com

21
Big Data: VARIETY
Data Growth is Increasingly Unstructured
– Structured
• Data containing a defined data type, format, structure
• E.g. Transactional Data Base
– Semi-Structured
• Textual data files with a discernable pattern, enabling parsing
• E.g. XML data file + xml schema
– “Quasi” Structured
• Textual data with erratic data formats
• E. g. Web clickstream (may contain inconsistencies)
– Unstructured
• No inherent structure and different types of files
• E.g. PDFs, images, videos ….

22
Big Data: VELOCITY
Real-time required

23
Summary:
Volume:
– Large Volumes of data
– Terabytes, Petabytes, …
– Data that cannot be stored in conventional RDBMS
Variety:
– Source data is diverse – Web Logs, Application Logs, Machine
generated data, Social network data, etc.
– Doesn't fall into neat relational structures – Unstructured, Semi-
structured
Velocity:
– Streaming data, Complex Event Processing data
– Velocity of incoming data and Speed of responding to it

24
Big Data
VOLUME + VARIETY
+ VELOCITY
BIG DATA
CHALLENGES?

25
Big Data Challenges (at CC-MEI course)
Data storage
Data processing
Data management
Data modelling & prediction

26
Content (Big Data part)
A. Motivation
B. Big Data Challenges
C. Processing Big Data
D. Big Data Storage
E. Managing Big Data
F. Analyzing Big Data (Data Modelling & Prediction)
G. Apache Hadoop Ecosystem & Commercial solutions
H. Homework & presentations

Cloud Computing
& Big Data
FIB-UPC Master MEI
Processing Big Data
November- 2012

28
Motivation: storage affordable

29
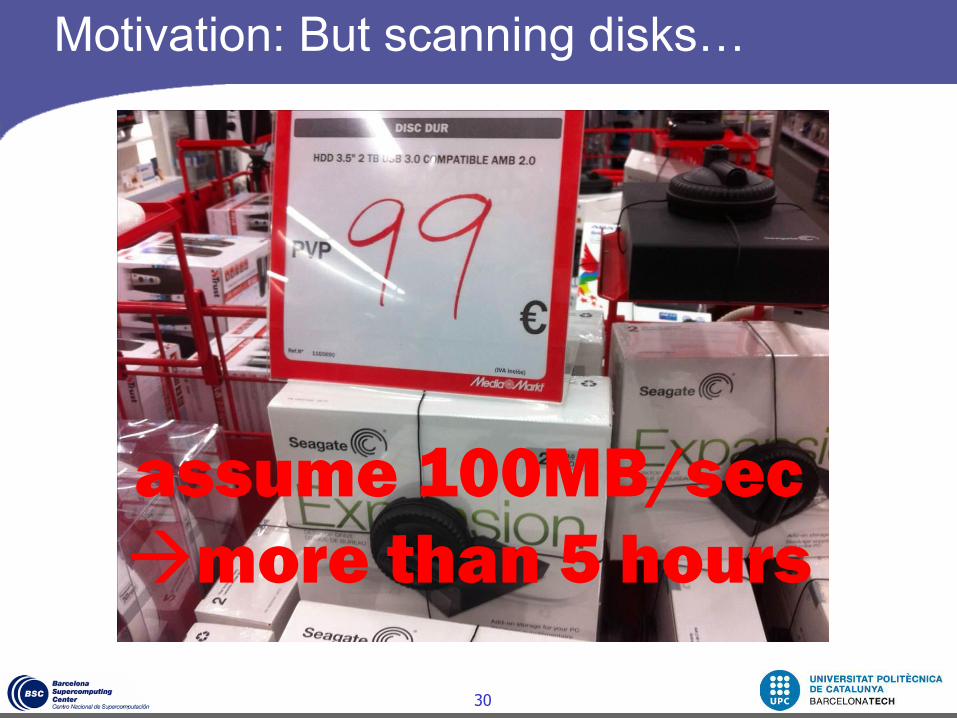
Motivation: But scanning disks…
assume 100MB/sec
30
Motivation: But scanning disks…
assume 100MB/sec
more than 5 hours

31
Solution: massive parallelism
assume 20.000 disks:
scanning 2 TB takes 1 second
Source: http://www.google.com/about/datacenters/gallery/images/_2000/IDI_018.jpg

32
Data Processing Challenges
Source: http://www.google.com/about/datacenters/gallery/images/_2000/IDI_018.jpg
assume 20.000 disks:
scanning 2 TB takes 1 second
Rethinking data processing is
required: MapReduce, …

33
MapReduce
To meet the challenges: MapReduce
– Programming Model introduced by Google in
early 2000s to support distributed computing
on large data sets on clusters of computers
Ecosystem of big data processing tools
– open source, distributed, and run on commodity
hardware.

34
MapReduce
Impact?
– bringing commodity big data processing to a broad audience
– in the same way the commodity LAMP stack changed the
landscape of web applications to WEB 2.0

35
MapReduce
The key innovation of MapReduce is
– the ability to take a query over a data set, divide it, and run it
in parallel over many nodes.
– Solves the issue of data too large to fit onto a single machine
• Distributed computing over many servers
• Batch processing model
Two phases
– Map phase, input data is processed, item by item, and
transformed into an intermediate data set.
– Reduce phase, these intermediate results are reduced to a
summarized data set, which is the desired end result.

36
MapReduce
process data in a batch-oriented fashion and may
take minutes or hours to process.
Source: TDWI.org

37
MapReduce
– Loading the data
• This operation is more properly called Extract, Transform, Load (ETL)
in data warehousing terminology.
• Data must be extracted from its source, structured to make it ready for
processing, and loaded into the storage layer for MapReduce to
operate on it.
– MapReduce
• This phase will retrieve data from storage,
• process it (map, collect and sort map results, reduce)
• and return the results to the storage.
– Extracting the result
• Once processing is complete, for the result to be useful, it must be
retrieved from the storage and presented.
Three distinct
operations:

38
MapReduce
Programming Model
– map / reduce functions
– Suitable for embarrassingly parallel problem.
Distributed Computing Framework
– Clusters of commodity hardware
– Large datasets
– Fault tolerant
– Splits jobs into a number of smaller tasks
Move code to data (local computation)
Allow programs to scale transparently – input size
Abstract away fault tolerance, synchronization, …
…

39
MapReduce
“Map” step: The master node takes the input, chops
it up into smaller sub-problems, and distributes
those to worker nodes. A worker node may do this
again in turn, leading to a multi-level tree structure.
Map(k1,v1) → list(k2,v2)
“Reduce” step: The master node then takes the
answers to all the sub-problems and combines them
in a way to get the output - the answer to the problem
it was originally trying to solve.
Reduce(k2, list (v2)) → list(v3)
Source: HADOOP: presentation at EEDC 2012 seminars by Juan Luis Pérez http://www.jorditorres.org/wp-content/uploads/2012/03/Part2.EEDC_.BigData.HADOOP.pdf

40
MapReduce
Common wordcount
Hello World
Hello MapReduce
Fig1: Sample input
Source: HADOOP: presentation at EEDC 2012 seminars by Juan Luis Pérez http://www.jorditorres.org/wp-content/uploads/2012/03/Part2.EEDC_.BigData.HADOOP.pdf

41
MapReduce
Common wordcount
12 March 2012
void map(string i, string line):
for word in line:
print word, 1
Fig 2: wordcount – map function
Source: HADOOP: presentation at EEDC 2012 seminars by Juan Luis Pérez http://www.jorditorres.org/wp-content/uploads/2012/03/Part2.EEDC_.BigData.HADOOP.pdf

42
MapReduce
Common wordcount
void reduce(string word, list partial_counts):
total = 0
for c in partial_counts:
total += c
print word, total
Fig 3: wordcount – reduce function
Source: HADOOP: presentation at EEDC 2012 seminars by Juan Luis Pérez http://www.jorditorres.org/wp-content/uploads/2012/03/Part2.EEDC_.BigData.HADOOP.pdf

43
MapReduce
Common wordcount
Hello , 2
MapReduce , 1
World , 1 Hello , 1
MapReduce , 1
Second intermediate output
Hello , 1
World , 1
First intermediate output
REDUCE
Final output
MAP
Hello World
Hello MapReduce
Input
Source: HADOOP: presentation at EEDC 2012 seminars by Juan Luis Pérez http://www.jorditorres.org/wp-content/uploads/2012/03/Part2.EEDC_.BigData.HADOOP.pdf

44
MapReduce - Architecture
Source: HADOOP: presentation at EEDC 2012 seminars by Juan Luis Pérez http://www.jorditorres.org/wp-content/uploads/2012/03/Part2.EEDC_.BigData.HADOOP.pdf

45
Hadoop is an open source MapReduce runtime
provided by the Apache Software Foundation
De-facto standard, free, open-source MapReduce
implementation.
Endorsed by: http://wiki.apache.org/hadoop/PoweredBy
Hadoop MapReduce

46
Hadoop MapReduce
Hadoop is the dominant open source
MapReduce implementation
Funded by Yahoo, it emerged in 2006
The Hadoop project is now hosted by
Apache
Implemented in Java,
(The data to be processed must be
loaded into e.g. the Hadoop
Distributed Filesystem)
Source: Wikipedia

47
(default) Hadoop’s Stack
Storage Services
Compute Services
47
Applications
Hadoop Distributed File
System (HDFS)
Hadoop’s MapReduce
Data Services Hbase: NoSQL Databases
Resource Fabrics
more detail in next section!!!

48
Running MapReduce job with Hadoop
Steps:
– Defining the MapReduce stages in a Java program
– Loading the data into the Hadoop Distributed Filesystem
– Submitting the job for execution
– Retrieving the results from the filesystem
MapReduce has been implemented in a variety of other
programming languages and systems,
Several NoSQL database systems have integrated
MapReduce
(later in this course)

49
Hadoop, Why?
Need to process Multi Petabyte Datasets
Expensive to build reliability in each application.
Nodes fail every day – Failure is expected, rather than exceptional.
– The number of nodes in a cluster is not constant.
Need common infrastructure
– Efficient, reliable, Open Source Apache License

50
Is Hadoop really that big a deal?
Yes. According to a survey (*) from July, 2011:
– 54%of organizations surveyed are using or considering Hadoop
– Over 82% users benefit from faster analyses and better utilization
of computing resources
– 94% of Hadoop users perform analytics on large volumes of data
not possible before; 88% analyze data in greater detail; while
82% can now retain more of their data
– Organizations use Hadoop in particular to work with unstructured
data such as logs and event data (63%)
(*) http://www.businesswire.com/news/home/20110726005639/en/Ventana-
Research-Survey-Shows-Organizations-Hadoop-Perform

51
Hadoop and enterprise?
Hadoop is a complement to a relational data warehouse
– Enterprises are generally not replacing their relational
DataWarehouse with Hadoop
Hadoop’s strengths
– Inexpensive
– High reliability
– Extreme scalability
– Flexibility: Data can be added without defining a schema
•
Hadoop’s weaknesses
– Hadoop is not an interactive query environment
– Processing data in Hadoop requires writing code

52
Who is using Hadoop?
eBay is using Hadoop for search optimizing and research via
a 532-node cluster.
Facebook has two big Hadoop clusters for storing internal log
and data sources and for data reporting, analytics and
machine learning.
Twitter uses Hadoop to store and process all it tweets and
other data types generated on the social networking system.
Yahoo has a Hadoop cluster of 4,500 nodes for research
efforts around its ad systems and Web servers. It's also using
it for scaling tests to drive Hadoop development on bigger
clusters.
Source: http://www.smartertechnology.com/c/a/Business-Analytics/Hadoop-Takes-a-Giant-Step-Toward-the-
Enterprise/ (17-01-2012)

53
Hadoop 1.0
04-01-2012:
The Apache Software Foundation delivers Hadoop
1.0, the much-anticipated 1.0 version of the popular
open-source platform for storing and processing
large amounts of data.
– six years of development, production experience, extensive
testing, and feedback from hundreds of knowledgeable users,
data scientists and systems engineers, culminating in a highly
stable, enterprise-ready release of the fastest-growing big data
platform.

54
Content (Big Data part)
A. Motivation
B. Big Data Challenges
C. Processing Big Data
D. Big Data Storage
E. Managing Big Data
F. Analyzing Big Data (Data Modelling & Prediction)
G. Apache Hadoop Ecosystem & Commercial solutions
H. Homework & presentations

Cloud Computing
& Big Data
FIB-UPC Master MEI
Big Data Storage
November- 2012

56
Current constraints of conventional IT
Data Volume GBs PBs
Executio
n T
ime
Conventional
Systems
new
requirements
for real-time
decisions
Interactive or real-
time query for large
datasets is seen as a
key to analyst
productivity (real-
time as in query
times fast enough to
keep the user in the
flow of analysis, from
sub-second to less
than a few minutes).

57
Today IT technology
The existing large-scale data management schemes
aren’t fast enough and reduce analytical effectiveness
when users can’t explore the data by quickly iterating
through various query schemes.
MEMORY (= fast, expensive, volatile )
STORAGE (= slow, cheap, non-volatile)
HHD 100 cheaper than RAM
But 1000 times slower

58
New proposals: in-memory
GBs PBs
Executio
n t
ime
58
In-memory
research

59
In-memory optimizations
BI example:
SOURCE:

60
In-memory optimizations results
SOURCE:

61
Some of the current in-memory tools:
“We see companies with large data stores building out
their own in-memory tools, e.g., Dremel at Google,
Druid at Metamarkets, and Sting at Netflix, and new
tools, like Cloudera’s Impala announcement at the
conference, UC Berkeley’s AMPLab’s Spark, SAP Hana,
and Platfora”
Source: http://strata.oreilly.com/2012/11/four-data-themes-to-watch-from-strata-hadoop-world-2012.html?imm_mid=09b70d&cmp=em-strata-newsletters-nov14-direct#more-52859

62
In-memory: new storage tech required
Data storage challenges:
– Present solutions:
– Research:
Solid- state drive (SSD)
Not volatile
Storage Class Memory (SCM)
Sou
rce:
h
ttp
://w
ww
.alm
aden
.ibm
.co
m/s
t/p
ast_
pro
ject
s/n
ano
_dev
ices
/mem
ory
add
ress
ing/

63
SCM candidates:
should be non-volatile, low-cost, high performance, high reliable solid-state memory
Currently available Flash technology falls short of these requirements
Some new type of SCM technology need to emerge (not my expertise! :-(
• Some Candidates
– Improved Flash
– FeRAM (Ferroelectric RAM)
– MRAM (Magnetic RAM)
– Phase Change Memory
– RRAM (Resistive RAM)
– Solid Electrolyte
– Organic and Polymeric Memory
– …

64
Content (Big Data part)
A. Motivation
B. Big Data Challenges
C. Processing Big Data
D. Big Data Storage
E. Managing Big Data
F. Analyzing Big Data (Data Modelling & Prediction)
G. Apache Hadoop Ecosystem & Commercial solutions
H. Homework & presentations

Cloud Computing
& Big Data
FIB-UPC Master MEI
Managing Big Data
November- 2012

66
Relational DB can’t support everything
The relational DB has
ruled for 2-3 decades
– Superb capabilities,
– Superb implementations,
– ….
(Main problem: scalability)
Data Volume GBs PBs
Execution T
ime
Conventional
Systems
Large Data
Sets, growing
too big for
conventional
storage/tools

67
proposals
GBs PBs
Executio
n t
ime
Hadoop

68
MapReduce: data requirements
Also ... The data expected is not
relational data
– This data does not require a schema
– and may be unstructured
Instead, data is consumed in
chunks
– which are then divided among nodes
– fed to the map phase as key-value pairs
The data must be available in a
distributed fashion, to serve each
processing node.
Map Reduce
Data

69
MapReduce: data requirements
The design and features of the data
layer are important because they
affect the ease with which data
can be loaded and the
results of computation
extracted and searched.
Map Reduce
Data

70
HDFS
Hadoop: standard storage mechanism
Hadoop Distributed File System (HDFS)

71
HDFS
Hadoop Distributed File System (HDFS)
– Fault tolerance
• Assuming that failure will happen allows HDFS to run on
commodity hardware.
– Streaming data access
• HDFS is written with batch processing in mind, and emphasizes
high throughput rather than random access to data.
– Extreme scalability
• HDFS will scale to petabytes.
– Portability
• HDFS is portable across platforms.

72
Hadoop: standard storage mechanism
Hadoop Distributed File System (HDFS)
– Most HDFS applications need a write-once-read-many access
model for files
• By assuming a file will remain unchanged after it is written, HDFS
simplifies replication and speeds up data throughput.
– “Moving Computation is Cheaper than Moving Data”: Locality
of computation
• Due to data volume, it is often much faster to move the program
near to the data HDFS has features to facilitate this.
The project URL is
hadoop.apache.org/hdfs/

73
Hadoop: standard storage mechanism
HDFS Interface
– Interface similar to that of regular filesystems.
– can only store and retrieve data, not index it.
Simple random access to data is not
possible.
Solution: higher-level layers HBase
• have been created to provide
finer-grained functionality to Hadoop
deployments
Map Reduce
Hbase
HDFS

74
Hbase, the Hadoop Database
HBase
– Creates indexes offers fast and random
access to its content
– Modeled after Google's BigTable DB
– is a column-oriented database designed to
store massive amounts of data.
– Uses HDFS as a storage system
It belongs to the NoSQL universe
– similar to Cassandra, Hypertable, …
Map Reduce
Hbase
HDFS

75
Hbase versus HDFS (a simple comparison)
HDFS:
– Optimized For:
– Large Files
– Sequential Access (High Throughput)
– Append Only
– Use for fact tables that are mostly append only and require
sequential full table scans.
HBase:
– Optimized For:
– Small Records
– Random Access
– Atomic Record Updates
– Use for dimension lookup tables which are updated frequently
and require random low-latency lookups.

76
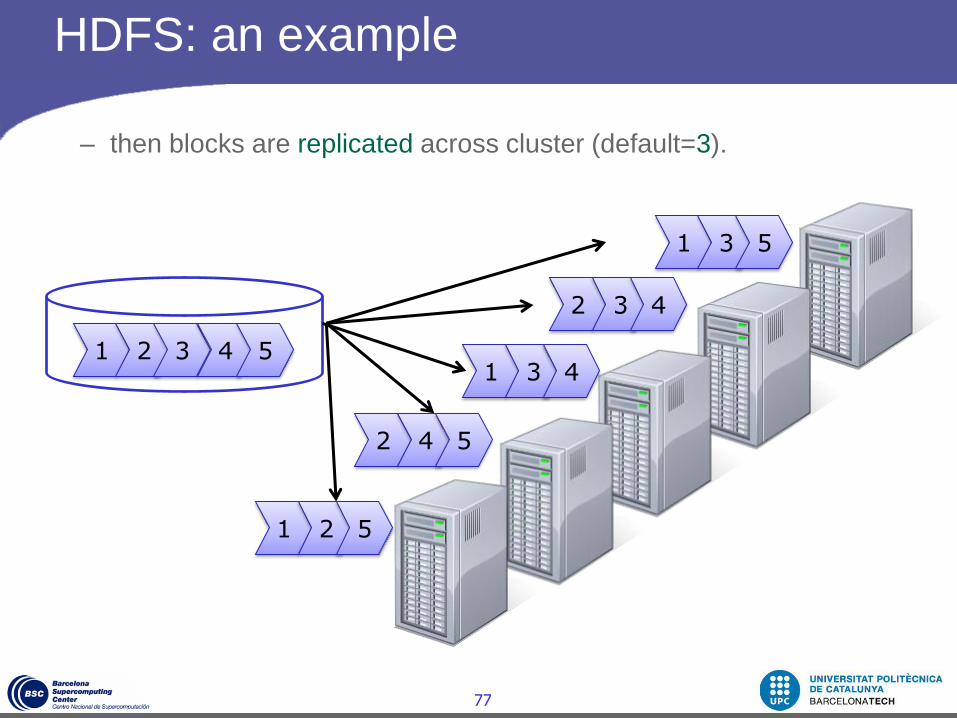
HDFS: an example
A given file
– is broken down into blocks (default=64MB),
– then blocks are replicated across cluster (default=3).
1 2 3 4 5
77
HDFS: an example
– then blocks are replicated across cluster (default=3).
1 2 3 4 5
2 3 4
1 3 5
1 3 4
2 4 5
1 2 5

78
MapReduce: Resource Management
Scheduling
– A given job is broken down into
tasks,
– then tasks are scheduled to be
as close to data as possible.
– Optimized for
• Bach processing
• Failure recovery
2 3 4
1 3 5
1 3 4
2 4 5
1 2 5

79
Alternatives to Hbase?
An Apache project, Cassandra
originated at Facebook and is now
in production in many large-scale
websites.
Hypertable was created at Zvents
and spun out as an open source
project.
Are both scalable column-store
databases that follow the pattern of
BigTable, similar to HBase.
Map Reduce
Cassandra
Map Reduce
Hypertable

80
And … dozens
http://nosql-database.org

81
Different Types of NoSQL Systems
• Distributed Key-Value Systems
– Amazon’s S3 Key-Value Store (Dynamo)
– Voldemort (LinkedIn)
– Cassandra (Facebook)
– …
• Column-based Systems
– BigTable (Google)
– HBase
– Cassandra
– …
• Document-based systems
– CouchDB
– MongoDB
– …
– Graph DB
– …
81

82
DB data model
Relational systems – are the databases we've been using for a while now. RDBMSs and
systems that support ACIDity and joins are considered relational.
Key-value systems – basically support get, put, and delete operations based on a primary key.
Column-oriented systems – still use tables but have no joins (joins must be handled within your
application). Obviously, they store data by column as opposed to
traditional row-oriented databases. This makes aggregations much
easier.
Document-oriented systems – store structured "documents" such as JSON or XML but have no joins
(joins must be handled within your application). It's very easy to map
data from object-oriented software to these systems.

83
DB data model
Relational systems – are the databases we've been using for a while now. RDBMSs and
systems that support ACIDity and joins are considered relational. – Atomicity
• requires that each transaction is "all or nothing": if one part of the transaction fails, the entire
transaction fails, and the database state is left unchanged. An atomic system must guarantee atomicity
in each and every situation, including power failures, errors, and crashes. This guarantees that a
transaction cannot be left in an incomplete state.
– Consistency
• ensures that any transaction will bring the database from one valid state to another. Any data written to
the database must be valid according to all defined rules, including but not limited to constraints,
cascades, triggers, and any combination thereof.
– Isolation
• refers to the requirement that no transaction should be able to interfere with another transaction. One
way of achieving this is to ensure that no transactions that affect the same rows can run concurrently,
since their sequence, and hence the outcome, might be unpredictable. This property of ACID is often
partly relaxed due to the huge speed decrease this type of concurrency management entails.
– Durability
• means that once a transaction has been committed, it will remain so, even in the event of power loss,
crashes, or errors. In a relational database, for instance, once a group of SQL statements execute, the
results need to be stored permanently. If the database crashes immediately thereafter, it should be
possible to restore the database to the state after the last transaction committed.
Source: wikipedia

84
NoS QL
NoSQL
– The concept is something that has gained momentum
in recent years
– Today is a mature and efficient alternative that can help us
solve the problems of scalability and performance
(e.g. online applications with thousands of concurrent users and
million hits a day)
Scalability?
– Vertical:
• CPU, Memory, …. (Price!!!)
– Horizontal
• More servers
• Better Fault Tolerance of the global system

85
The problems with Relational DB
RDBMS scale up well in a single node
price!!!!
Apparent solution: Replication and caches
– Vertical partitioning: Different tables in different servers
– Horizontal partitioning: Rows of same table in different Servers
Good for fault-tolerance, for sure
OK for many concurrent reads
Not much help with writes, if we want to keep ACID

86
There’s a reason: The CAP theorem
Source: Ricard Gavaldà. "Information Retrieval", Erasmus Mundus Master program on Data Mining and Knowledge Discovery

87
There’s a reason: The CAP theorem
Source: Ricard Gavaldà. "Information Retrieval", Erasmus Mundus Master program on Data Mining and Knowledge Discovery

88
The CAP theorem proof
Source: Ricard Gavaldà. "Information Retrieval", Erasmus Mundus Master program on Data Mining and Knowledge Discovery

89
The problem with RDBMS
Source: Ricard Gavaldà. "Information Retrieval", Erasmus Mundus Master program on Data Mining and Knowledge Discovery

90
Scale out requires partitions
IMPORTANT!!!!!
A distributed system only offers simultaneously
two of this three characteristics
Most large web-based systems choose availability
over consistency

91
C
A P
Consistency
Availability Partition-Tolerant
CA: available and consistent, unless there is a partition.
AP: a reachable replica provides service even in a partition, but may be inconsistent.
CP: always consistent, even in a partition, but a reachable replica may deny service without quorum.
CAP – Choose Two Per Operation

92
Source: http://blog.nahurst.com/visual-guide-to-nosql-systems
Visual Guide to NoSQL System

93
Consistent, Available (CA)
Systems have trouble with partitions and typically
deal with it with replication.
Examples of CA systems include:
– Traditional RDBMSs like Postgres, MySQL, etc (relational)
– Vertica (column-oriented)
– Aster Data (relational)
– Greenplum (relational)
Source: http://blog.nahurst.com/visual-guide-to-nosql-systems

94
Consistent, Partition-Tolerant (CP)
Systems have trouble with availability while keeping data consistent across partitioned nodes.
Examples of CP systems include: – BigTable (column-oriented/tabular)
– Hypertable (column-oriented/tabular)
– HBase (column-oriented/tabular)
– MongoDB (document-oriented)
– Terrastore (document-oriented)
– Redis (key-value)
– Scalaris (key-value)
– MemcacheDB (key-value)
– Berkeley DB (key-value)
Source: http://blog.nahurst.com/visual-guide-to-nosql-systems

95
Available, Partition-Tolerant (AP)
Systems achieve "eventual consistency" through
replication and verification.
Examples of AP systems include:
– Dynamo (key-value)
– Voldemort (key-value)
– Tokyo Cabinet (key-value)
– KAI (key-value)
– Cassandra (column-oriented/tabular)
– CouchDB (document-oriented)
– SimpleDB (document-oriented)
– Riak (document-oriented)
Source: http://blog.nahurst.com/visual-guide-to-nosql-systems

96
Eventual Consistency
If no updates occur for a while, all updates
eventually propagate through the system and all the
nodes will be consistent
Eventually, a node is either updated or removed from
service.
Can be implemented with Gossip protocol
Amazon’s Dynamo popularized this approach
Sometimes this is called BASE (Basically Available,
Soft state, Eventual consistency), as opposed to
ACID

Databases NoSQL Systems
Scalability 100’s TB 100’s PB
Functionality Full SQL-based queries, including joins
Optimized access to sorted tables (tables with single keys)
Optimized Databases optimized for safe writes
Clouds optimized for efficient reads
Consistency model
ACID (Atomicity, Consistency, Isolation & Durability) – database always consist
Eventual consistency – updates eventually propagate through system
Parallelism Difficult because of ACID model; shared nothing is possible
Basic design incorporates parallelism over commodity components
Scale Racks Data center 97

98
Content (Big Data part)
A. Motivation
B. Big Data Challenges
C. Processing Big Data
D. Big Data Storage
E. Managing Big Data
F. Analyzing Big Data (Data Modelling & Prediction)
G. Apache Hadoop Ecosystem & Commercial solutions
H. Homework & presentations

Cloud Computing
& Big Data
FIB-UPC Master MEI
Analyzing Big Data
November- 2012

100
Data deluge, is it enough?

101
“Data = Information”?

102
Prediction using data models
The information
is non actionable
knowledge

103
Obtaining value from data
World is becoming instrumented and interconnected
and we can take advantage of it if we can process it
in real time.
Data cannot be taken at face value
Knowledge
Information
Data
+
Vo
lum
e
- +
-
Va
lue
The majority of algorithms function
well in thousands of registers,
however at the moment they are
impractical for thousands of milions.
The information is non
actionable knowledge

104
Why “Learn” ?
Machine learning is programming computers to optimize a performance criterion using example data or past experience.
There is no need to “learn” to calculate payroll
Learning is used when: – Human expertise does not exist,
– Humans are unable to explain their expertise
– Solution changes in time
– Solution needs to be adapted to particular cases
Source: Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

105
What We Talk About When We Talk About“Learning”
Learning general models from a data of particular
examples
Data is cheap and abundant (data warehouses, …);
knowledge is expensive and scarce.
Example in retail: Customer transactions to
consumer behavior:
People who bought “A” also bought “B” (www.amazon.com)
Build a model that is a good and useful
approximation to the data.
Source: Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

106
Where can be appried?
Retail: Market basket analysis, Customer relationship management (CRM)
Finance: Credit scoring, fraud detection
Manufacturing: Control, robotics, troubleshooting
Medicine: Medical diagnosis
Telecommunications: Spam filters, intrusion detection
Bioinformatics: Motifs, alignment
Web mining: Search engines
...
Source: Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

107
What is Machine Learning?
Optimize a performance criterion using example data
or past experience.
Statistics vs Computer science?
Role of Statistics: Inference from a sample
Role of Computer science: Efficient algorithms to
– Solve the optimization problem
– Representing and evaluating the model for inference
Source: Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

108
Example: Learning Associations
Basket analysis:
P (Y | X ) probability that somebody who buys X also
buys Y where X and Y are products/services.
Example: P ( chips | beer ) = 0.7
108
Source: Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

109
Example: Classification
Example: Credit
scoring
Differentiating
between low-risk
and high-risk
customers from
their income and
savings
Discriminant: IF income > θ1 AND savings > θ2
THEN low-risk ELSE high-risk
109
Source: Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

110
Example: Classification Applications
Also know as Pattern recognition
Face recognition: Pose, lighting, occlusion (glasses, beard), make-up, hair style
Character recognition: Different handwriting styles.
Speech recognition: Temporal dependency.
Medical diagnosis: From symptoms to illnesses
Biometrics: Recognition/authentication using physical and/or behavioral characteristics: Face, iris, signature, etc
...
Source: Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

111
Example: Regression
Example: Price of a
used car
x : car attributes
y : price
y = wx+w0
Source: Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

112
Supervised Learning: Uses Prediction of future cases: Use the rule to predict the
output for future inputs
Knowledge extraction: The rule is easy to understand
Compression: The rule is simpler than the data it
explains
Outlier detection: Exceptions that are not covered by
the rule, e.g., fraud
Source: Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)
Usefulness

113
Machine Learning: an impressive world!

114
Machine Learning: an impressive world!

115
Decision Trees (case study bigML)

116
Example of applying “Learning”
Nicolas Poggi, Toni Moreno, Josep
Lluis Berral, Ricard Gavaldà, Jordi
Torres. "Web Customer Modeling for
Automated Session Prioritization on
High Traffic Sites". Proceedings of
the 11th International Conference on
User Modeling. Corfu, Greece, June
25-29, 2007

117
Example of applying “Learning”
What happend when we don’t have more resources to allocate in our data Center and still more clients are arriving at the Request Router? – Heterogeneus demand (peaks,…)
– Resource requirement vary dynamically
– …
Overload occurs
Solutions to overload: Admission control But, still lost of client!

118
Example of applying “Learning”
Increased amount of customer data available If the system is overloaded, we propose prioritize those sessions that are more likely to generate revenue

119
Learning
Data Learning algorithm
Predictor
New data
Predictions

120
Example of applying “Learning”
Web services are more and more CPU-intensive
Session management helps deal with load peaks
Admitted users will be served. Excess users are rejected
session manager
load balancer
servers

121
Example of applying “Learning”
Metric 1: Number of served sessions
– Basically limited by infrastructure
Metric 2: Total utility of served sessions
Example: Buying – nonbuying sessions
We want to accept most
buying sessions Proposal:
– Learn to predict whether session will buy
– Prioritize sessions predicted to buy

122
Example of applying “Learning”
Learn from access log data from the past
Information available:
– Approximate customer identity (IP number, cookies…)
– Date and time
– Referer
– CPU time and memory used
– User is / is not logged
– User visited before
– User bought before
– Sequence of requests (path in website)
– … and whether they bought or not

123
Example of applying “Learning”
Machine learning tools
applied to server logs
We are working in a
static/dynamic
approach
– Static data: request type,
returning customer/new
customer, logged/not
logged
– Dynamic data: customer
navigational path
Our case study:
www.atrapalo.com

124
Example of applying “Learning”
Machine learning techniques:
– Static data: Used Weka libraries
• for logistic regression
• J48 decision tree inducer
• Naïve Bayes
– Dynamic data:
Used first and second
order Markov chains

125
Example of applying “Learning”
Predictor
Access log Preprocessor
Training data
Naive Bayes Learner

126
Example of applying “Learning”
session manager
load balancer
servers
Predictor
prediction

127
Example of applying “Learning”
Results:
Data from online travel agency: web log from flight
information and sales accesses
Data from 1 week, about 120,000 transactions, 20,000
sessions
Only about 6% lead to a purchase

128
Example of applying “Learning”
Fraction of all buying transactions that are admitted
augures
random
0%
20%
40%
60%
80%
100%
120%
100% 90% 80% 70% 60% 50% 40% 30% 20% 10% 2%
%admitted
rec
all

129
Right questions?
Tech problem of business problem?
– what to look for in the data?
– how to model the data?
– where to start???
Effective analysis depends more on asking
the right question or designing a good
experiment than on tools and techniques.

130
DATA vs MODEL
“Large datasets provide the opportunity
to take advantage of ….effective results
from coupling large datasets with
relatively simply algorithms”
http://strata.oreilly.com/2012/11/four-data-themes-to-watch-from-strata-hadoop-world-
2012.html?imm_mid=09b70d&cmp=em-strata-newsletters-nov14-direct#more-52859

131
Content (Big Data part)
A. Motivation
B. Big Data Challenges
C. Processing Big Data
D. Big Data Storage
E. Managing Big Data
F. Analyzing Big Data (Data Modelling & Prediction)
G. Apache Hadoop Ecosystem & Commercial solutions
H. Homework & presentations

Cloud Computing
& Big Data
FIB-UPC Master MEI
Apache Hadoop Ecosystem & Commercial
Solutions
November- 2012

133
The apache ecosystem for Big Data
Source: Ricard Gavaldà. "Information Retrieval", Erasmus Mundus Master program on Data Mining and Knowledge Discovery

134
The apache ecosystem for Big Data
Source: Ricard Gavaldà. "Information Retrieval", Erasmus Mundus Master program on Data Mining and Knowledge Discovery

135
The apache ecosystem for Big Data
Source: Ricard Gavaldà. "Information Retrieval", Erasmus Mundus Master program on Data Mining and Knowledge Discovery

136
Hive – SQL on top of Hadoop
Map/Reduce is great but every one is not a
Map/Reduce expert
– I know SQL and I am a python and php expert
A system for querying and managing structured data
built on top of Map/Reduce and Hadoop
We had:
– Structured logs with rich data types (structs, lists and maps)
– A user base wanting to access this data in the language of their
choice
– A lot of traditional SQL workloads on this data (filters, joins and
aggregations)
– Other non SQL workloads

137
Hive –SQL on top of Hadoop
Hive is a data warehouse framework built on top of
Hadoop.
– Combine SQL and Map-Reduce
• Rich data types (structs, lists and maps)
• Efficient implementations of SQL filters, joins and group-by’s on top
of map reduce
– provides a table-based abstraction over HDFS and makes it easy
to load structured data.
– Hive provides a SQL-like query language to execute MapReduce
jobs, described in the Query section below.
Hive is a natural starting point for more full-featured
business intelligence systems, which offer a user-
friendly interface for non-technical users.

138
The apache ecosystem for Big Data
Source: Ricard Gavaldà. "Information Retrieval", Erasmus Mundus Master program on Data Mining and Knowledge Discovery

139
The apache ecosystem for Big Data
Source: Ricard Gavaldà. "Information Retrieval", Erasmus Mundus Master program on Data Mining and Knowledge Discovery

140
Open Source oportunities: Stack 2.0

141
Big Data vendor landscape
A number of vendors have developed their own
Hadoop distributions,
most based on the Apache open source distribution but with various
levels of proprietary customization.
Probably market leader in terms of distributions:
Cloudera
– Start-up with Doug Cutting and former Facebook Data Scientist
Jeff Hammerbacher.
– In addition to the distribution, Cloudera offers paid enterprise-
level training/services and proprietary Hadoop management
software.

142
Big Data vendor landscape
Other examples: MapR, Greenplum, Hortonworks, …
MapR
– offers its own Hadoop distribution that supplements HDFS with
its proprietary NFS for improved performance.
EMC Greenplum (partnered with MapR)
– Offers a partly proprietary Hadoop distribution
Hortonworks
– Offers its 100% open source Hadoop distribution (Nov 2011).
And dozens more

143
Big Data vendor landscape
A broad market that emphasize different properties
Replication
– E.g. CouchDB is a distributed database, offering semi-structured
document-based storage. Its key features include strong
replication support and the ability to make distributed
updates.
Performance
– E.g. Mongo DB is very similar to CouchDB in nature, but with a
stronger emphasis on performance, and less suitability for
distributed updates, replication, and versioning.
Availability
– E.g. Riak is another database similar to CouchDB and MongoDB,
but places its emphasis on high availability.

144
Big Data vendor landscape
And allows integrate NoSQL with SQL
Example: Sqoop (“SQL-to-Hadoop”)
– developed by Cloudera,
– Sqoop is database-agnostic, as it uses the Java JDBC DB API.
– Tables can be imported either wholesale, or using queries to
restrict the data import.
– Sqoop also offers the ability to re-inject the results of MapReduce
from HDFS back into a relational database.
– As HDFS is a filesystem, Sqoop expects delimited text files and
transforms them into the SQL commands required to insert data
into the database.

145
Integration with SQL databases (cont.)
The Greenplum database
– is based on the open source PostreSQL DBMS, and runs on
clusters of distributed hardware.
– The addition of MapReduce to the regular SQL interface enables
fast, large-scale analytics, reducing query times by several
orders of magnitude.
– Greenplum MapReduce permits the mixing of external data
sources with the database storage.
– MapReduce operations can be expressed as functions in Perl or
Python.

146
Integration with SQL databases (cont.)
Aster Data's nCluster data warehouse system
– also offers MapReduce functionality.
– MapReduce operations are invoked using Aster Data's SQL-MR
– languages including C#, C++, Java, R or Python.
Other data warehousing solutions have opted to
provide connectors with Hadoop, rather than
integrating their own MapReduce functionality.
– E.g. Vertica creator of Zynga, is an MPP column-oriented
database that offers a connector for Hadoop.

147
MPP databases approach for SQL DB
Massively parallel processing (MPP) worlds
– MPP databases have a distributed architecture with independent
nodes that run in parallel.
– Their primary application is in data warehousing and analytics,
and they are commonly accessed using SQL.
The MapReduce and massively parallel processing
(MPP) worlds have been pretty separate,
– Will it remain like this in the future?
– Why?

148
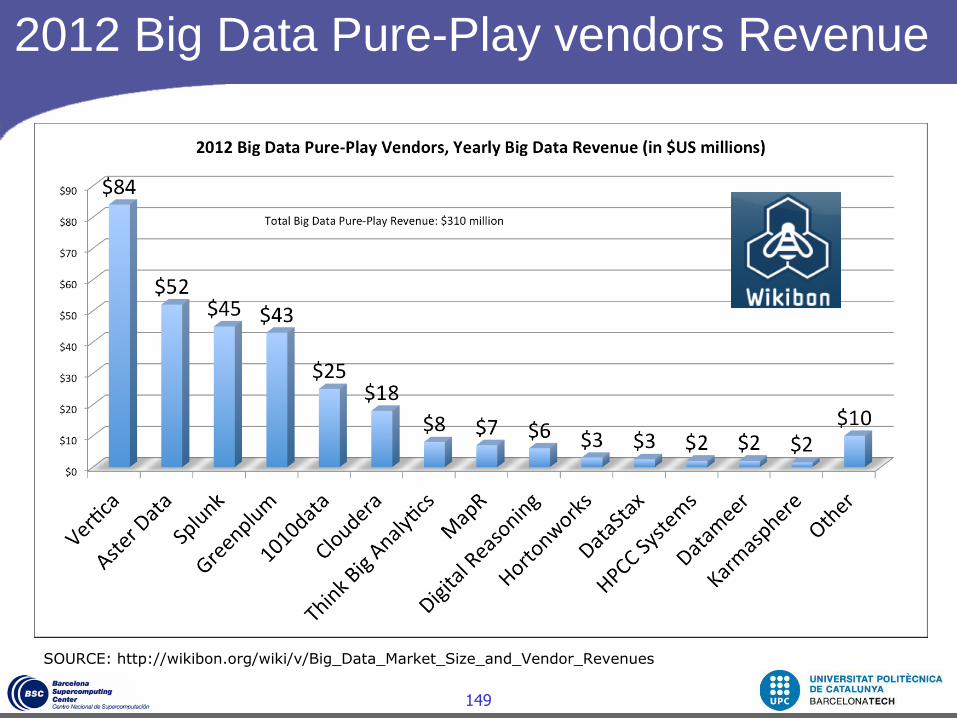
2012 Big Data Pure-Play vendors
SOURCE: http://wikibon.org/wiki/v/Big_Data_Market_Size_and_Vendor_Revenues
149
2012 Big Data Pure-Play vendors Revenue
SOURCE: http://wikibon.org/wiki/v/Big_Data_Market_Size_and_Vendor_Revenues

150
Big Data vendor landscape
Landscape: developing rapidly
IBM
Intel
HP
Oracle
Teradata
Fujitsu
CSC
Accenture
Dell
Seagate
EMC
Capgemini
Hitachi
Atos S.A.
Huawei
Siemens
Xerox
Tata
Consultancy
Services
SGI
Logica
Microsoft
Splunk
1010data
MarkLogic
Cloudera
Red Hat
Informatica
SAS Institute
Amazon
ClickFox
Super Micro
SAP
Think Big
Analytics
MapR
Digital
Reasoning
Pervasive
Software
Datameer
Hortonworks
DataStax
Attivio
QlikTech
HPCC Sys.
Karmasphere
Tableau
Software
…

151
Big Data vendor landscape
Who are the big players?

152
2012 Big Data Revenue by Vendor
Big Data Revenue (in $US millions) Total Revenue (in $US millions) Big Data Revenue as Percentage of
Total Revenue
IBM $1,100 $106,000 1%
Intel $765 $54,000 1%
HP $550 $126,000 0%
Oracle $450 $36,000 1%
Teradata $220 $2,200 10%
Fujitsu $185 $50,700 1%
CSC $160 $16,200 1%
Accenture $155 $21,900 0%
Dell $150 $61,000 0%
Seagate $140 $11,600 1%
EMC $140 $19,000 1%
Capgemini $111 $12,100 1%
Hitachi $110 $100,000 0%
Atos S.A. $75 $7,400 1%
Huawei $73 $21,800 0%
Siemens $69 $102,000 0%
Xerox $67 $6,700 1%
Tata Consultancy Serv $61 $6,300 1%
SGI $60 $690 9%
Logica $60 $6000 1%
Microsoft $50 $70,000 0%
Splunk $45 $63 68%
1010data $25 $30 83%
MarkLogic $20 $80 25%
Cloudera $18 $18 100%
SOURCE: http://wikibon.org/wiki/v/Big_Data_Market_Size_and_Vendor_Revenues
position 25

153
Innovation in the big data market?
Mainly coming from pure-play vendors (e.g.):
– Cloudera, • contributes significantly to Apache HBase, the Hadoop-based
non-relational database that allows for low-latency, quick lookups. The latest of these iterations, to which Cloudera engineers contributed, is HFile v2, a series of patches that improve HBase storage efficiency.
– Hortonworks • working on a next-generation MapReduce architecture that
promises to increase the maximum Hadoop cluster size beyond its current practical limitation of 4,000 nodes.
– MapR • takes a more proprietary approach to Hadoop, supplementing
HDFS with its API-compatible Direct Access NFS in its enterprise Hadoop distribution, adding significant performance capabilities.
SOURCE: http://wikibon.org/wiki/v/Big_Data_Market_Size_and_Vendor_Revenues

154
Innovation in the big data market?
Mainly coming from pure-play vendors (e.g.):
– Cloudera, • contributes significantly to Apache HBase, the Hadoop-based
non-relational database that allows for low-latency, quick lookups. The latest of these iterations, to which Cloudera engineers contributed, is HFile v2, a series of patches that improve HBase storage efficiency.
– Hortonworks • working on a next-generation MapReduce architecture that
promises to increase the maximum Hadoop cluster size beyond its current practical limitation of 4,000 nodes.
– MapR • takes a more proprietary approach to Hadoop, supplementing
HDFS with its API-compatible Direct Access NFS in its enterprise Hadoop distribution, adding significant performance capabilities.
SOURCE: http://wikibon.org/wiki/v/Big_Data_Market_Size_and_Vendor_Revenues

155
Content (Big Data part)
A. Motivation
B. Big Data Challenges
C. Processing Big Data
D. Big Data Storage
E. Managing Big Data
F. Analyzing Big Data (Data Modelling & Prediction)
G. Apache Hadoop Ecosystem & Commercial solutions
H. Homework & presentations

Cloud Computing
& Big Data
FIB-UPC Master MEI
Homework &
Presentations
November- 2012

157
Data engineer, Data scientist, …

158
Approach?
Data Analysis & Prediction
Big Data
Cloud Computing
+ HPC
solution

159
Homework: list of topics
1. Corona
2. Storm
3. Kafka
4. Drill
5. Dremel
6. R
7. Gremlin
8. Giraph
9. SAP Hana
10. D3
11. SlasticSearch
12. Neo4j
Links to start:
[1]
http://techcrunch.com/201
2/11/08/a-riddle-wrapped-
in-a-mystery-inside-an-
enigma/
[2]
http://techcrunch.com/201
2/10/27/big-data-right-now-
five-trendy-open-source-
technologies/

160
Procedure for presentation
Presentation : 10 minutes.
Days 10/des and 13/des
Delivery deadline: after the presentation
Send the presentation to: [email protected]