
SimbaODBCDriverwithSQL ConnectorforApacheSpark ... · TableofContents Introduction 9 WindowsDriver...
59
Simba ODBC Driver with SQL Connector for Apache Spark Installation and Configuration Guide Simba Technologies Inc. April 2, 2015
Transcript of SimbaODBCDriverwithSQL ConnectorforApacheSpark ... · TableofContents Introduction 9 WindowsDriver...

Simba ODBC Driver with SQLConnector for Apache Spark
Installation and ConfigurationGuide
Simba Technologies Inc.
April 2, 2015

Copyright © 2015 Simba Technologies Inc. All Rights Reserved.
Information in this document is subject to change without notice. Companies, names anddata used in examples herein are fictitious unless otherwise noted. No part of thispublication, or the software it describes, may be reproduced, transmitted, transcribed,stored in a retrieval system, decompiled, disassembled, reverse-engineered, or translatedinto any language in any form by any means for any purpose without the express writtenpermission of Simba Technologies Inc.
Trademarks
Simba, the Simba logo, SimbaEngine, SimbaEngine C/S, SimbaExpress and SimbaLibare registered trademarks of Simba Technologies Inc. All other trademarks and/orservicemarks are the property of their respective owners.
Contact Us
Simba Technologies Inc.938 West 8th AvenueVancouver, BC CanadaV5Z 1E5
Tel: +1 (604) 633-0008
Fax: +1 (604) 633-0004
www.simba.com
Cyrus SASL
Copyright (c) 1998-2003 Carnegie Mellon University. All rights reserved.
Redistribution and use in source and binary forms, with or without modification, arepermitted provided that the following conditions are met:1. Redistributions of source code must retain the above copyright notice, this list of
conditions and the following disclaimer.2. Redistributions in binary form must reproduce the above copyright notice, this list of
conditions and the following disclaimer in the documentation and/or other materialsprovided with the distribution.
3. The name "Carnegie Mellon University" must not be used to endorse or promoteproducts derived from this software without prior written permission. For permissionor any other legal details, please contact:Office of Technology TransferCarnegie Mellon University5000 Forbes AvenuePittsburgh, PA 15213-3890(412) 268-4387, fax: (412) [email protected]
4. Redistributions of any form whatsoever must retain the following acknowledgment:
www.simba.com 2
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

"This product includes software developed by Computing Services at CarnegieMellon University (http://www.cmu.edu/computing/)."
CARNEGIE MELLON UNIVERSITY DISCLAIMS ALL WARRANTIES WITH REGARDTO THIS SOFTWARE, INCLUDING ALL IMPLIED WARRANTIES OFMERCHANTABILITY AND FITNESS, IN NO EVENT SHALL CARNEGIE MELLONUNIVERSITY BE LIABLE FOR ANY SPECIAL, INDIRECT OR CONSEQUENTIALDAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE,DATA OR PROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OROTHER TORTIOUS ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USEOR PERFORMANCE OF THIS SOFTWARE.
ICU License - ICU 1.8.1 and later
COPYRIGHT AND PERMISSION NOTICE
Copyright (c) 1995-2010 International Business Machines Corporation and others. Allrights reserved.
Permission is hereby granted, free of charge, to any person obtaining a copy of thissoftware and associated documentation files (the "Software"), to deal in the Softwarewithout restriction, including without limitation the rights to use, copy, modify, merge,publish, distribute, and/or sell copies of the Software, and to permit persons to whom theSoftware is furnished to do so, provided that the above copyright notice(s) and thispermission notice appear in all copies of the Software and that both the above copyrightnotice(s) and this permission notice appear in supporting documentation.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OFMERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE ANDNONINFRINGEMENT OF THIRD PARTY RIGHTS. IN NO EVENT SHALL THECOPYRIGHT HOLDER OR HOLDERS INCLUDED IN THIS NOTICE BE LIABLE FORANY CLAIM, OR ANY SPECIAL INDIRECT OR CONSEQUENTIAL DAMAGES, ORANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA ORPROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHERTORTIOUS ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE ORPERFORMANCE OF THIS SOFTWARE.
Except as contained in this notice, the name of a copyright holder shall not be used inadvertising or otherwise to promote the sale, use or other dealings in this Software withoutprior written authorization of the copyright holder.
All trademarks and registered trademarks mentioned herein are the property of theirrespective owners.
OpenSSL
Copyright (c) 1998-2008 The OpenSSL Project. All rights reserved.
Redistribution and use in source and binary forms, with or without modification, arepermitted provided that the following conditions are met:
www.simba.com 3
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

1. Redistributions of source code must retain the above copyright notice, this list ofconditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice, this list ofconditions and the following disclaimer in the documentation and/or other materialsprovided with the distribution.
3. All advertising materials mentioning features or use of this software must display thefollowing acknowledgment:"This product includes software developed by the OpenSSL Project for use in theOpenSSL Toolkit. (http://www.openssl.org/)"
4. The names "OpenSSL Toolkit" and "OpenSSL Project" must not be used to endorseor promote products derived from this software without prior written permission. Forwritten permission, please contact [email protected].
5. Products derived from this software may not be called "OpenSSL" nor may"OpenSSL" appear in their names without prior written permission of the OpenSSLProject.
6. Redistributions of any form whatsoever must retain the following acknowledgment:"This product includes software developed by the OpenSSL Project for use in theOpenSSL Toolkit (http://www.openssl.org/)"
THIS SOFTWARE IS PROVIDED BY THE OpenSSL PROJECT "AS IS" AND ANYEXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THEIMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULARPURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE OpenSSL PROJECT OR ITSCONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITEDTO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ONANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, ORTORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OFTHE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCHDAMAGE.
Apache Spark
Copyright 2008-2011 The Apache Software Foundation.
Apache Thrift
Copyright 2006-2010 The Apache Software Foundation.
Expat
Copyright (c) 1998, 1999, 2000 Thai Open Source Software Center Ltd
Permission is hereby granted, free of charge, to any person obtaining a copy of thissoftware and associated documentation files (the "Software"), to deal in the Softwarewithout restriction, including without limitation the rights to use, copy, modify, merge,
www.simba.com 4
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons towhom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies orsubstantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OFMERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE ANDNOINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHTHOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHERDEALINGS IN THE SOFTWARE.
libcurl
COPYRIGHT AND PERMISSION NOTICE
Copyright (c) 1996 - 2012, Daniel Stenberg, <[email protected]>.
All rights reserved.
Permission to use, copy, modify, and distribute this software for any purpose with orwithout fee is hereby granted, provided that the above copyright notice and this permissionnotice appear in all copies.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OFMERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE ANDNONINFRINGEMENT OF THIRD PARTY RIGHTS. IN NO EVENT SHALL THEAUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OROTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OROTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWAREOR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Except as contained in this notice, the name of a copyright holder shall not be used inadvertising or otherwise to promote the sale, use or other dealings in this Software withoutprior written authorization of the copyright holder.
www.simba.com 5
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

About This Guide
Purpose
The Simba ODBC Driver with SQL Connector for Apache Spark Installation andConfiguration Guide explains how to install and configure the Simba ODBC Driver withSQL Connector for Apache Spark on all supported platforms. The guide also providesdetails related to features of the driver.
Audience
The guide is intended for end users of the Simba ODBC Driver with SQL Connector forApache Spark, as well as administrators and developers implementing the driver.
Knowledge Prerequisites
To use the Simba ODBC Driver with SQL Connector for Apache Spark, the followingknowledge is helpful:
l Familiarity with the platform on which you are using the Simba ODBC Driver withSQL Connector for Apache Spark
l Ability to use the data source to which the Simba ODBC Driver with SQL Connectorfor Apache Spark is connecting
l An understanding of the role of ODBC technologies and driver managers in con-necting to a data source
l Experience creating and configuring ODBC connectionsl Exposure to SQL
Document Conventions
Italics are used when referring to book and document titles.
Bold is used in procedures for graphical user interface elements that a user clicks and textthat a user types.
Monospace font indicates commands, source code or contents of text files.
Underline is not used.
The pencil icon indicates a short note appended to a paragraph.
The star icon indicates an important comment related to the preceding paragraph.
The thumbs up icon indicates a practical tip or suggestion.
www.simba.com 6
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Table of Contents
Introduction 9
Windows Driver 10System Requirements 10Installing the Driver 10Verifying the Version Number 11Creating a Data Source Name 11Configuring Authentication 12Configuring Advanced Options 17Configuring Server-Side Properties 18
Linux Driver 20System Requirements 20Installing the Driver Using the RPM 20Installing the Driver Using the Tarball Package 22Verifying the Version Number 22Setting the LD_LIBRARY_PATH Environment Variable 22
Mac OS X Driver 24System Requirements 24Installing the Driver 24Verifying the Version Number 25Setting the DYLD_LIBRARY_PATH Environment Variable 25
Configuring ODBC Connections for Non-Windows Platforms 26Files 26Sample Files 27Configuring the Environment 27Configuring the odbc.ini File 28Configuring the odbcinst.ini File 29Configuring the simba.sparkodbc.ini File 30Configuring Authentication 31
Features 35SQL Query versus Spark SQL Query 35SQL Connector 35Data Types 35Catalog and Schema Support 36
www.simba.com 7
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

spark_system Table 37Server-Side Properties 37Get Tables With Query 37
Known Issues in Spark 38Backquotes in Aliases Are Not Handled Correctly 38Filtering on TIMESTAMP Columns Does Not Return Any Rows 38Cannot Use AND to Combine a TIMESTAMP Column Filter with Another Filter 38
Contact Us 39
Appendix A Authentication Options 40Using No Authentication 41Using Kerberos 41Using User Name 41Using User Name and Password 42Using User Name and Password (SSL) 42Using Windows Azure HDInsight Emulator 42Using Windows Azure HDInsight Service 42Using HTTP 42Using HTTPS 42
Appendix B Configuring Kerberos Authentication for Windows 43MIT Kerberos 43
Appendix C Driver Configuration Options 47Configuration Options Appearing in the User Interface 47Configuration Options Having Only Key Names 58
www.simba.com 8
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Introduction
The Simba ODBC Driver with SQL Connector for Apache Spark is used for direct SQL andSpark SQL access to Apache Hadoop / Spark distributions, enabling Business Intelligence(BI), analytics, and reporting on Hadoop-based data. The driver efficiently transforms anapplication’s SQL query into the equivalent form in Spark SQL, which is a subset of SQL-92. If an application is Spark-aware, then the driver is configurable to pass the querythrough to the database for processing. The driver interrogates Spark to obtain schemainformation to present to a SQL-based application. Queries, including joins, are translatedfrom SQL to Spark SQL. For more information about the differences between Spark SQLand SQL, see Features on page 35.
The Simba ODBC Driver with SQL Connector for Apache Spark complies with the ODBC3.52 data standard and adds important functionality such as Unicode and 32- and 64-bitsupport for high-performance computing environments.
ODBC is one the most established and widely supported APIs for connecting to andworking with databases. At the heart of the technology is the ODBC driver, which connectsan application to the database. For more information about ODBC, seehttp://www.simba.com/resources/data-access-standards-library. For completeinformation about the ODBC specification, see the ODBC API Reference athttp://msdn.microsoft.com/en-us/library/windows/desktop/ms714562(v=vs.85).aspx.
The Installation and Configuration Guide is suitable for users who are looking to accessdata residing within Hadoop from their desktop environment. Application developers mayalso find the information helpful. Refer to your application for details on connecting viaODBC.
www.simba.com 9
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Windows Driver
System Requirements
You install the Simba ODBC Driver with SQL Connector for Apache Spark on clientcomputers accessing data in a Hadoop cluster with the Spark service installed andrunning. Each computer where you install the driver must meet the following minimumsystem requirements:
l One of the following operating systems (32- and 64-bit editions are supported):o Windows® XP with SP3o Windows® Vistao Windows® 7 Professional and Enterpriseo Windows® 8 Pro and Enterpriseo Windows® Server 2008 R2
l 25 MB of available disk space
To install the driver, you must have Administrator privileges on the computer.
The driver is suitable for use with all versions of Apache Spark.
Installing the Driver
On 64-bit Windows operating systems, you can execute 32- and 64-bit applicationstransparently. You must use the version of the driver matching the bitness of the clientapplication accessing data in Hadoop / Spark:
l SimbaSparkODBC32.msi for 32-bit applicationsl SimbaSparkODBC64.msi for 64-bit applications
You can install both versions of the driver on the same computer.
For an explanation of how to use ODBC on 64-bit editions of Windows, seehttp://www.simba.com/wp-content/uploads/2010/10/HOW-TO-32-bit-vs-64-bit-ODBC-Data-Source-Administrator.pdf
To install the Simba ODBC Driver with SQL Connector for Apache Spark:1. Depending on the bitness of your client application, double-click to run
SimbaSparkODBC32.msi or SimbaSparkODBC64.msi2. Click Next3. Select the check box to accept the terms of the License Agreement if you agree, and
then click Next4. To change the installation location, click Change, then browse to the desired folder,
and then click OK. To accept the installation location, click Next
www.simba.com 10
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

5. Click Install6. When the installation completes, click Finish7. If you received a license file via e-mail, then copy the license file into the \lib
subfolder in the installation folder you selected in step 4.To avoid security issues, you may need to save the license file on your localcomputer prior to copying the file into the \lib subfolder.
Verifying the Version Number
If you need to verify the version of the Simba ODBC Driver with SQL Connector forApache Spark that is installed on your Windows machine, you can find the version numberin the ODBC Data Source Administrator.
To verify the version number:1. Click the Start button , then click All Programs, then click the Simba Spark ODBC
Driver 1.0 program group corresponding to the bitness of the client applicationaccessing data in Hadoop / Spark, and then click ODBC Administrator
2. In the ODBC Data Source Administrator, click the Drivers tab and then find theSimba Spark ODBC Driver in the list of ODBC drivers that are installed on yoursystem. The version number is displayed in the Version column.
Creating a Data Source Name
After installing the Simba ODBC Driver with SQL Connector for Apache Spark, you needto create a Data Source Name (DSN).
To create a Data Source Name:1. Click the Start button , then click All Programs, then click the Simba Spark ODBC
Driver 1.0 program group corresponding to the bitness of the client applicationaccessing data in Hadoop / Spark, and then click ODBC Administrator
2. In the ODBC Data Source Administrator, click the Drivers tab, and then scroll downas needed to confirm that the Simba Spark ODBC Driver appears in the alphabeticallist of ODBC drivers that are installed on your system.
3. To create a DSN that only the user currently logged into Windows can use, click theUser DSN tab.
ORTo create a DSN that all users who log into Windows can use, click the System DSNtab.
4. Click Add5. In the Create New Data Source dialog box, select Simba Spark ODBC Driver and
then click Finish6. Use the options in the Simba Spark ODBC Driver DSN Setup dialog box to configure
your DSN:
www.simba.com 11
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

a) In the Data Source Name field, type a name for your DSN.b) Optionally, in the Description field, type relevant details about the DSN.c) In the Host field, type the IP address or host name of the Spark server.d) In the Port field, type the number of the TCP port on which the Spark server is
listening.e) In the Database field, type the name of the database schema to use when a
schema is not explicitly specified in a query.You can still issue queries on other schemas by explicitly specifyingthe schema in the query. To inspect your databases and determinethe appropriate schema to use, type the show databases commandat the Spark command prompt.
f) In the Spark Server Type list, select the appropriate server type for the versionof Spark that you are running:
l If you are running Shark 0.8.1 or earlier, then select SharkServerl If you are running Shark 0.9.*, then select SharkServer2l If you are running Spark 1.1 or later, then select SparkThriftServer
g) In the Authentication area, configure authentication as needed. For moreinformation, see Configuring Authentication on page 12.
Shark Server does not support authentication. Most defaultconfigurations of Shark Server 2 or Spark Thrift Server require UserName authentication. To verify the authentication mechanism thatyou need to use for your connection, check the configuration of yourHadoop / Spark distribution. For more information, see AuthenticationOptions on page 40.
h) To configure advanced driver options, click Advanced Options. For moreinformation, see Configuring Advanced Options on page 17.
i) To configure server-side properties, click Advanced Options and then clickServer Side Properties. For more information, see Configuring Server-SideProperties on page 18.
7. To test the connection, click Test. Review the results as needed, and then click OK.If the connection fails, then confirm that the settings in the Simba SparkODBC Driver DSN Setup dialog box are correct. Contact your Spark serveradministrator as needed.
8. To save your settings and close the Simba Spark ODBC Driver DSN Setup dialogbox, click OK
9. To close the ODBC Data Source Administrator, click OK
Configuring Authentication
For information about selecting the appropriate authentication mechanism to use, seeAppendix A Authentication Options on page 40.
www.simba.com 12
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Using No AuthenticationWhen connecting to a Spark server of type Shark Server, you must use NoAuthentication.
To configure a connection without authentication:1. To access authentication options, open the ODBC Data Source Administrator where
you created the DSN, then select the DSN, and then click Configure2. In the Mechanism list, select No Authentication3. To save your settings and close the dialog box, click OK
Using Kerberos
Kerberos must be installed and configured before you can use this authenticationmechanism. For more information, see Appendix B Configuring Kerberos Authenticationfor Windows on page 43.
This authentication mechanism is available only for Shark Server 2 or Spark ThriftServer on non-HDInsight distributions.
To configure Kerberos authentication:1. To access authentication options, open the ODBC Data Source Administrator where
you created the DSN, then select the DSN, and then click Configure2. In the Mechanism list, select Kerberos3. If your Kerberos setup does not define a default realm or if the realm of your Shark
Server 2 or Spark Thrift Server host is not the default, then type the Kerberos realmof the Shark Server 2 or Spark Thrift Server host in the Realm field.
ORTo use the default realm defined in your Kerberos setup, leave the Realm fieldempty.
4. In the Host FQDN field, type the fully qualified domain name of the Shark Server 2 orSpark Thrift Server host.
5. In the Service Name field, type the service name of the Spark server.6. To save your settings and close the dialog box, click OK
Using User Name
This authentication mechanism requires a user name but not a password. The user namelabels the session, facilitating database tracking.
This authentication mechanism is available only for Shark Server 2 or Spark ThriftServer on non-HDInsight distributions. Most default configurations of SharkServer 2 or Spark Thrift Server require User Name authentication.
www.simba.com 13
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

To configure User Name authentication:1. To access authentication options, open the ODBC Data Source Administrator where
you created the DSN, then select the DSN, and then click Configure2. In the Mechanism list, select User Name3. In the User Name field, type an appropriate user name for accessing the Spark
server.4. To save your settings and close the dialog box, click OK
Using User Name and Password
This authentication mechanism requires a user name and a password.
This authentication mechanism is available only for Shark Server 2 or Spark ThriftServer on non-HDInsight distributions.
To configure User Name and Password authentication:1. To access authentication options, open the ODBC Data Source Administrator where
you created the DSN, then select the DSN, and then click Configure2. In the Mechanism list, select User Name and Password3. In the User Name field, type an appropriate user name for accessing the Spark
server.4. In the Password field, type the password corresponding to the user name you typed
in step 3.5. To save your settings and close the dialog box, click OK
Using User Name and Password (SSL)
This authentication mechanism uses SSL and requires a user name and a password. Thedriver accepts self-signed SSL certificates for this authentication mechanism.
This authentication mechanism is available only for Shark Server 2 or Spark ThriftServer on non-HDInsight distributions.
To configure User Name and Password (SSL) authentication:1. To access authentication options, open the ODBC Data Source Administrator where
you created the DSN, then select the DSN, and then click Configure2. In the Mechanism list, select User Name and Password (SSL)3. In the User Name field, type an appropriate user name for accessing the Spark
server.4. In the Password field, type the password corresponding to the user name you typed
in step 3.5. Optionally, configure the driver to allow the common name of a CA-issued certificate
to not match the host name of the Spark server by clicking Advanced Options, andthen selecting the Allow Common Name Host Name Mismatch check box.
www.simba.com 14
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

For self-signed certificates, the driver always allows the common name ofthe certificate to not match the host name.
6. To configure the driver to load SSL certificates from a specific PEM file, clickAdvanced Options, and then type the path to the file in the Trusted Certificatesfield.
ORTo use the trusted CA certificates PEM file that is installed with the driver, leave theTrusted Certificates field empty.
7. To save your settings and close the dialog box, click OK
Using Windows Azure HDInsight Emulator
This authentication mechanism enables you to connect to a Spark server on WindowsAzure HDInsight Emulator.
This authentication mechanism is available only for Shark Server 2 or Spark ThriftServer on an HDInsight distribution.
To configure a connection to a Spark server on Windows Azure HDInsightEmulator:1. To access authentication options, open the ODBC Data Source Administrator where
you created the DSN, then select the DSN, and then click Configure2. In the Mechanism list, select Windows Azure HDInsight Emulator3. In the HTTP Path field, type the partial URL corresponding to the Spark server.4. In the User Name field, type an appropriate user name for accessing the Spark
server.5. In the Password field, type the password corresponding to the user name you typed
in step 4.6. To save your settings and close the dialog box, click OK
Using Windows Azure HDInsight Service
This authentication mechanism enables you to connect to a Spark server on WindowsAzure HDInsight Service. The driver does not accept self-signed SSL certificates for thisauthentication mechanism. Also, the common name of the CA-issued certificate mustmatch the host name of the Spark server.
This authentication mechanism is available only for Shark Server 2 or Spark ThriftServer on HDInsight distributions.
To configure a connection to a Spark server on Windows Azure HDInsightService:1. To access authentication options, open the ODBC Data Source Administrator where
you created the DSN, then select the DSN, and then click Configure2. In the Mechanism list, select Windows Azure HDInsight Service
www.simba.com 15
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

3. In the HTTP Path field, type the partial URL corresponding to the Spark server.4. In the User Name field, type an appropriate user name for accessing the Spark
server.5. In the Password field, type the password corresponding to the user name you typed
in step 4.6. To configure the driver to load SSL certificates from a specific PEM file, click
Advanced Options and type the path to the file in the Trusted Certificates field.OR
To use the trusted CA certificates PEM file that is installed with the driver, leave theTrusted Certificates field empty.
7. To save your settings and close the dialog box, click OK
Using HTTP
This authentication mechanism enables you to connect to a Shark Server 2 or Spark ThriftServer running in HTTP mode.
This authentication mechanism is available only for Shark Server 2 or Spark ThriftServer on non-HDInsight distributions.
To configure HTTP authentication:1. To access authentication options, open the ODBC Data Source Administrator where
you created the DSN, then select the DSN, and then click Configure2. In the Mechanism list, select HTTP3. In the HTTP Path field, type the partial URL corresponding to the Spark server.4. In the User Name field, type an appropriate user name for accessing the Spark
server.5. In the Password field, type the password corresponding to the user name you typed
in step 4.6. To save your settings and close the dialog box, click OK
Using HTTPS
This authentication mechanism enables you to connect to a Shark Server 2 or Spark ThriftServer that is running in HTTP mode and has SSL enabled. The driver accepts self-signedSSL certificates for this authentication mechanism.
This authentication mechanism is available only for Shark Server 2 or Spark ThriftServer on non-HDInsight distributions.
To configure HTTPS authentication:1. To access authentication options, open the ODBC Data Source Administrator where
you created the DSN, then select the DSN, and then click Configure2. In the Mechanism list, select HTTPS
www.simba.com 16
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

3. In the HTTP Path field, type the partial URL corresponding to the Spark server.4. In the User Name field, type an appropriate user name for accessing the Spark
server.5. In the Password field, type the password corresponding to the user name you typed
in step 4.6. Optionally, configure the driver to allow the common name of a CA-issued certificate
to not match the host name of the Spark server by clicking Advanced Options andselecting the Allow Common Name Host Name Mismatch check box.
For self-signed certificates, the driver always allows the common name ofthe certificate to not match the host name.
7. To configure the driver to load SSL certificates from a specific PEM file, clickAdvanced Options, and then type the path to the file in the Trusted Certificatesfield.
ORTo use the trusted CA certificates PEM file that is installed with the driver, leave theTrusted Certificates field empty.
8. To save your settings and close the dialog box, click OK
The HTTPS authentication method can also be used to connect to Shark Server 2or Spark Thrift Server via the Knox gateway. To determine what user credentialsto use and what value to set for the HTTP Path field, refer to the Knoxdocumentation.
Configuring Advanced Options
You can configure advanced options to modify the behavior of the driver.
To configure advanced options:1. To access advanced options, open the ODBC Data Source Administrator where you
created the DSN, then select the DSN, then click Configure, and then clickAdvanced Options
2. To disable the SQL Connector feature, select the Use Native Query check box.3. To defer query execution to SQLExecute, select the Fast SQLPrepare check box.4. To allow driver-wide configurations to take precedence over connection and DSN
settings, select the Driver Config Take Precedence check box.5. To use the asynchronous version of the API call against Spark for executing a query,
select the Use Async Exec check box.6. To retrieve the names of tables in a database by using the SHOW TABLES query,
select the Get Tables With Query check box.This option is applicable only when connecting to Shark Server 2 or SparkThrift Server.
www.simba.com 17
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

7. To enable the driver to return SQL_WVARCHAR instead of SQL_VARCHAR forSTRING and VARCHAR columns, and SQL_WCHAR instead of SQL_CHAR forCHAR columns, select the Unicode SQL character types check box.
8. To enable the driver to return the spark_system table for catalog function calls suchas SQLTables and SQLColumns, select the Show system table check box.
9. In the Rows fetched per block field, type the number of rows to be fetched per block.10. In the Default string column length field, type the maximum data length for STRING
columns.11. In the Binary column length field, type the maximum data length for BINARY
columns.12. In the Decimal column scale field, type the maximum number of digits to the right of
the decimal point for numeric data types.13. In the Async Exec Poll Interval (ms) field, type the time in milliseconds between each
poll for the query execution status.
This option is applicable only to HDInsight clusters.
14.To allow the common name of a CA-issued SSL certificate to not match the hostname of the Spark server, select the Allow Common Name Host Name Mismatchcheck box.
This option is applicable only to the User Name and Password (SSL) andHTTPS authentication mechanisms.
15.To configure the driver to load SSL certificates from a specific PEM file, type thepath to the file in the Trusted Certificates field.
ORTo use the trusted CA certificates PEM file that is installed with the driver, leave theTrusted Certificates field empty.
This option is applicable only to the User Name and Password (SSL),Windows Azure HDInsight Service, and HTTPS authenticationmechanisms.
16.To save your settings and close the Advanced Options dialog box, click OK
Configuring Server-Side Properties
You can use the driver to apply configuration properties to the Spark server.
To configure server-side properties:1. To configure server-side properties, open the ODBC Data Source Administrator
where you created the DSN, then select the DSN and click Configure, then clickAdvanced Options, and then click Server Side Properties
2. To create a server-side property, click Add, then type appropriate values in the Keyand Value fields, and then click OK
www.simba.com 18
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

For a list of all Hadoop and Spark server-side properties that yourimplementation supports, type set -v at the Spark CLI command line. Youcan also execute the set -v query after connecting using the driver.
3. To edit a server-side property, select the property from the list, then click Edit, thenupdate the Key and Value fields as needed, and then click OK
4. To delete a server-side property, select the property from the list, and then clickRemove. In the confirmation dialog box, click Yes
5. To configure the driver to apply each server-side property by executing a querywhen opening a session to the Spark server, select the Apply Server SideProperties with Queries check box.
ORTo configure the driver to use a more efficient method for applying server-sideproperties that does not involve additional network round-tripping, clear the ApplyServer Side Properties with Queries check box.
The more efficient method is not available for Shark Server, and it might notbe compatible with some Shark Server 2 or Spark Thrift Server builds. If theserver-side properties do not take effect when the check box is clear, thenselect the check box.
6. To force the driver to convert server-side property key names to all lower casecharacters, select the Convert Key Name to Lower Case check box.
7. To save your settings and close the Server Side Properties dialog box, click OK
www.simba.com 19
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Linux Driver
System Requirements
You install the Simba ODBC Driver with SQL Connector for Apache Spark on clientcomputers accessing data in a Hadoop cluster with the Spark service installed andrunning. Each computer where you install the driver must meet the following minimumsystem requirements:
l One of the following distributions (32- and 64-bit editions are supported):o Red Hat® Enterprise Linux® (RHEL) 5.0 or 6.0o CentOS 5.0 or 6.0o SUSE Linux Enterprise Server (SLES) 11
l 45 MB of available disk spacel One of the following ODBC driver managers installed:
o iODBC 3.52.7 or latero unixODBC 2.3.0 or later
The driver is suitable for use with all versions of Spark.
Installing the Driver Using the RPM
There are two versions of the driver for Linux:l SimbaSparkODBC-32bit-Version-Release.LinuxDistro.i686.rpm for the 32-bitdriver
l SimbaSparkODBC-Version-Release.LinuxDistro.x86_64.rpm for the 64-bitdriver
Version is the version number of the driver, and Release is the release number for thisversion of the driver. LinuxDistro is either el5 or el6. For SUSE, the LinuxDistroplaceholder is empty.
The bitness of the driver that you select should match the bitness of the client applicationaccessing your Hadoop-based data. For example, if the client application is 64-bit, thenyou should install the 64-bit driver. Note that 64-bit editions of Linux support both 32- and64-bit applications. Verify the bitness of your intended application and install theappropriate version of the driver.
Ensure that you install the driver using the RPM corresponding to your Linuxdistribution.
www.simba.com 20
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

The Simba ODBC Driver with SQL Connector for Apache Spark driver files are installed inthe following directories:
l /opt/simba/sparkodbc contains release notes, the Simba ODBC Driver with SQLConnector for Apache Spark Installation and Configuration Guide in PDF format,and a Readme.txt file that provides plain text installation and configuration instruc-tions.
l /opt/simba/sparkodbc/ErrorMessages contains error message files required bythe driver.
l /opt/simba/sparkodbc/Setup contains sample configuration files named odbc.iniand odbcinst.ini
l /opt/simba/sparkodbc/lib/32 contains the 32-bit shared libraries and the simba.s-parkodbc.ini configuration file.
l /opt/simba/sparkodbc/lib/64 contains the 64-bit shared libraries and the simba.s-parkodbc.ini configuration file.
To install the Simba ODBC Driver with SQL Connector for Apache Spark:1. In Red Hat Enterprise Linux or CentOS, log in as the root user, then navigate to the
folder containing the driver RPM packages to install, and then type the following atthe command line, where RPMFileName is the file name of the RPM packagecontaining the version of the driver that you want to install:yum --nogpgcheck localinstall RPMFileName
ORIn SUSE Linux Enterprise Server, log in as the root user, then navigate to the foldercontaining the driver RPM packages to install, and then type the following at thecommand line, where RPMFileName is the file name of the RPM package containingthe version of the driver that you want to install:zypper install RPMFileName
2. If you received a license file via e-mail, then copy the license file into the/opt/simba/sparkodbc/lib/32 or /opt/simba/sparkodbc/lib/64 folder, depending on theversion of the driver that you installed.To avoid security issues, you may need to save the license file on your localcomputer prior to copying the file into the folder.
The Simba ODBC Driver with SQL Connector for Apache Spark depends on the followingresources:
l cyrus-sasl-2.1.22-7 or abovel cyrus-sasl-gssapi-2.1.22-7 or abovel cyrus-sasl-plain-2.1.22-7 or above
If the package manager in your Linux distribution cannot resolve the dependenciesautomatically when installing the driver, then download and manually install the packagesrequired by the version of the driver that you want to install.
www.simba.com 21
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Installing the Driver Using the Tarball Package
Alternatively, the Simba ODBC Driver with SQL Connector for Apache Spark is availablefor installation using a TAR.GZ tarball package. The tarball package includes thefollowing, where INSTALL_DIR is your chosen installation directory:
l INSTALL_DIR/simba/sparkodbc/ contains the release notes, the Simba ODBCDriver with SQL Connector for Apache Spark Installation and Configuration Guide inPDF format, and a Readme.txt file that provides plain text installation and con-figuration instructions.
l INSTALL_DIR/simba/sparkodbc/lib/32 contains the 32-bit driver and the simba.s-parkodbc.ini configuration file.
l INSTALL_DIR/simba/sparkodbc/lib/64 contains the 64-bit driver and the simba.s-parkodbc.ini configuration file.
l INSTALL_DIR/simba/sparkodbc/ErrorMessages contains error message filesrequired by the driver.
l INSTALL_DIR/simba/sparkodbc/Setup contains sample configuration files namedodbc.ini and odbcinst.ini
If you received a license file via e-mail, then copy the license file into theINSTALL_DIR/simba/sparkodbc/lib/32 or INSTALL_DIR/simba/sparkodbc/lib/64folder, depending on the version of the driver that you installed.
Verifying the Version Number
If you need to verify the version of the Simba ODBC Driver with SQL Connector forApache Spark that is installed on your Linux machine, you can query the version numberthrough the command-line interface.
To verify the version number:At the command prompt, run the following command:yum list | grep SimbaSparkODBC
ORRun the following command:rpm -qa | grep SimbaSparkODBC
The command returns information about the Simba ODBC Driver with SQL Connector forApache Spark that is installed on your machine, including the version number.
Setting the LD_LIBRARY_PATH Environment Variable
The LD_LIBRARY_PATH environment variable must include the path to the installedODBC driver manager libraries.
For example, if ODBC driver manager libraries are installed in /usr/local/lib, then set LD_LIBRARY_PATH as follows:
www.simba.com 22
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
For information about how to set environment variables permanently, refer to your Linuxshell documentation.
For information about creating ODBC connections using the Simba ODBC Driver withSQL Connector for Apache Spark, see Configuring ODBC Connections for Non-WindowsPlatforms on page 26.
www.simba.com 23
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Mac OS X Driver
System Requirements
You install the Simba ODBC Driver with SQL Connector for Apache Spark on clientcomputers accessing data in a Hadoop cluster with the Spark service installed andrunning. Each computer where you install the driver must meet the following minimumsystem requirements:
l Mac OS X version 10.6.8 or laterl 100 MB of available disk spacel iODBC 3.52.7 or later
The driver is suitable for use with all versions of Spark. The driver supports both 32- and64-bit client applications.
Installing the Driver
The Simba ODBC Driver with SQL Connector for Apache Spark driver files are installed inthe following directories:
l /opt/simba/sparkodbc contains release notes and the Simba ODBC Driver withSQL Connector for Apache Spark Installation and Configuration Guide in PDFformat.
l /opt/simba/sparkodbc/ErrorMessages contains error messages required by thedriver.
l /opt/simba/sparkodbc/Setup contains sample configuration files named odbc.iniand odbcinst.ini
l /opt/simba/sparkodbc/lib/universal contains the driver binaries and the simba.s-parkodbc.ini configuration file.
To install the Simba ODBC Driver with SQL Connector for Apache Spark:1. Double-click SimbaSparkODBC.dmg to mount the disk image.2. Double-click SimbaSparkODBC.pkg to run the installer.3. In the installer, click Continue4. On the Software License Agreement screen, click Continue, and when the prompt
appears, click Agree if you agree to the terms of the License Agreement.5. Optionally, to change the installation location, click Change Install Location, then
select the desired location, and then click Continue6. To accept the installation location and begin the installation, click Install7. When the installation completes, click Close8. If you received a license file via e-mail, then copy the license file into the
/opt/simba/sparkodbc/lib/universal folder.
www.simba.com 24
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

To avoid security issues, you may need to save the license file on your localcomputer prior to copying the file into the folder.
Verifying the Version Number
If you need to verify the version of the Simba ODBC Driver with SQL Connector forApache Spark that is installed on your Mac OS X machine, you can query the versionnumber through the Terminal.
To verify the version number:At the Terminal, run the following command:pkgutil --info simba.sparkodbc
The command returns information about the Simba ODBC Driver with SQL Connector forApache Spark that is installed on your machine, including the version number.
Setting the DYLD_LIBRARY_PATH Environment Variable
The DYLD_LIBRARY_PATH environment variable must include the path to the installedODBC driver manager libraries.
For example, if ODBC driver manager libraries are installed in /usr/local/lib, then setDYLD_LIBRARY_PATH as follows:export DYLD_LIBRARY_PATH=$DYLD_LIBRARY_PATH:/usr/local/lib
For information about how to set environment variables permanently, refer to your Mac OSX shell documentation.
For information about creating ODBC connections using the Simba ODBC Driver withSQL Connector for Apache Spark, see Configuring ODBC Connections for Non-WindowsPlatforms on page 26.
www.simba.com 25
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Configuring ODBC Connections for Non-WindowsPlatforms
The following sections describe how to configure ODBC connection when using the SimbaODBC Driver with SQL Connector for Apache Spark with non-Windows platforms:
l Files on page 26l Sample Files on page 27l Configuring the Environment on page 27l Configuring the odbc.ini File on page 28l Configuring the odbcinst.ini File on page 29l Configuring the simba.sparkodbc.ini File on page 30l Configuring Authentication on page 31
Files
ODBC driver managers use configuration files to define and configure ODBC data sourcesand drivers. By default, the following configuration files residing in the user’s homedirectory are used:
l .odbc.ini is used to define ODBC data sources, and it is required.l .odbcinst.ini is used to define ODBC drivers, and it is optional.
Also, by default the Simba ODBC Driver with SQL Connector for Apache Spark isconfigured using the simba.sparkodbc.ini file, which is located in one of the followingdirectories depending on the version of the driver that you are using:
l /opt/simba/sparkodbc/lib/32 for the 32-bit driver on Linuxl /opt/simba/sparkodbc/lib/64 for the 64-bit driver on Linuxl /opt/simba/sparkodbc/lib/universal for the driver on Mac OS X
The simba.sparkodbc.ini file is required.
The simba.sparkodbc.ini file in the /lib subfolder provides default settings for mostconfiguration options available in the Simba ODBC Driver with SQL Connector forApache Spark.
You can set driver configuration options in your odbc.ini and simba.sparkodbc.ini files.Configuration options set in a simba.sparkodbc.ini file apply to all connections, whereasconfiguration options set in an odbc.ini file are specific to a connection. Configurationoptions set in odbc.ini take precedence over configuration options set insimba.sparkodbc.ini. For information about the configuration options available forcontrolling the behavior of DSNs that are using the Simba ODBC Driver with SQLConnector for Apache Spark, see Appendix C Driver Configuration Options on page 47.
www.simba.com 26
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Sample Files
The driver installation contains the following sample configuration files in the Setupdirectory:
l odbc.inil odbcinst.ini
These sample configuration files provide preset values for settings related to the SimbaODBC Driver with SQL Connector for Apache Spark.
The names of the sample configuration files do not begin with a period (.) so that they willappear in directory listings by default. A filename beginning with a period (.) is hidden. Forodbc.ini and odbcinst.ini, if the default location is used, then the filenames must begin witha period (.).
If the configuration files do not exist in the home directory, then you can copy the sampleconfiguration files to the home directory, and then rename the files. If the configurationfiles already exist in the home directory, then use the sample configuration files as a guideto modify the existing configuration files.
Configuring the Environment
Optionally, you can use three environment variables—ODBCINI, ODBCSYSINI, andSIMBASPARKINI—to specify different locations for the odbc.ini, odbcinst.ini, andsimba.sparkodbc.ini configuration files by doing the following:
l Set ODBCINI to point to your odbc.ini file.l Set ODBCSYSINI to point to the directory containing the odbcinst.ini file.l Set SIMBASPARKINI to point to your simba.sparkodbc.ini file.
For example, if your odbc.ini and simba.sparkodbc.ini files are located in /etc and yourodbcinst.ini file is located in /usr/local/odbc, then set the environment variables as follows:export ODBCINI=/etc/odbc.ini
export ODBCSYSINI=/usr/local/odbc
export SIMBASPARKINI=/etc/simba.sparkodbc.ini
The following search order is used to locate the simba.sparkodbc.ini file:1. If the SIMBASPARKINI environment variable is defined, then the driver searches for
the file specified by the environment variable.SIMBASPARKINI must specify the full path, including the file name.
2. The directory containing the driver’s binary is searched for a file namedsimba.sparkodbc.ini not beginning with a period.
3. The current working directory of the application is searched for a file namedsimba.sparkodbc.ini not beginning with a period.
www.simba.com 27
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

4. The directory ~/ (that is, $HOME) is searched for a hidden file named.simba.sparkodbc.ini
5. The directory /etc is searched for a file named simba.sparkodbc.ini not beginningwith a period.
Configuring the odbc.ini File
ODBC Data Source Names (DSNs) are defined in the odbc.ini configuration file. The file isdivided into several sections:
l [ODBC] is optional and used to control global ODBC configuration, such as ODBCtracing.
l [ODBC Data Sources] is required, listing DSNs and associating DSNs with adriver.
l A section having the same name as the data source specified in the [ODBC DataSources] section is required to configure the data source.
The following is an example of an odbc.ini configuration file for Linux:[ODBC Data Sources]
Sample Simba Spark DSN 32=Simba Spark ODBC Driver 32-bit
[Sample Simba Spark DSN 32]
Driver=/opt/simba/sparkodbc/lib/32/libsimbasparkodbc32.so
HOST=MySparkServer
PORT=10000
MySparkServer is the IP address or host name of the Spark server.
The following is an example of an odbc.ini configuration file for Mac OS X:[ODBC Data Sources]
Sample Simba Spark DSN=Simba Spark ODBC Driver
[Sample Simba Spark DSN]
Driver=/opt/simba/sparkodbc/lib/universal/libsimbasparkodbc.dylib
HOST=MySparkServer
PORT=10000
MySparkServer is the IP address or host name of the Spark server.
To create a Data Source Name:1. Open the .odbc.ini configuration file in a text editor.2. In the [ODBC Data Sources] section, add a new entry by typing the Data Source
Name (DSN), then an equal sign (=), and then the driver name.
www.simba.com 28
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

3. In the .odbc.ini file, add a new section with a name that matches the DSN youspecified in step 2, and then add configuration options to the section. Specifyconfiguration options as key-value pairs.
Shark Server does not support authentication. Most default configurationsof Shark Server 2 or Spark Thrift Server require User Name authentication,which you configure by setting the AuthMech key to 2. To verify theauthentication mechanism that you need to use for your connection, checkthe configuration of your Hadoop / Spark distribution. For more information,see Authentication Options on page 40.
4. Save the .odbc.ini configuration file.
For information about the configuration options available for controlling the behavior ofDSNs that are using the Simba ODBC Driver with SQL Connector for Apache Spark, seeAppendix C Driver Configuration Options on page 47.
Configuring the odbcinst.ini File
ODBC drivers are defined in the odbcinst.ini configuration file. The configuration file isoptional because drivers can be specified directly in the odbc.ini configuration file, asdescribed in Configuring the odbc.ini File on page 28.
The odbcinst.ini file is divided into the following sections:l [ODBC Drivers] lists the names of all the installed ODBC drivers.l A section having the same name as the driver name specified in the [ODBC Drivers]section lists driver attributes and values.
The following is an example of an odbcinst.ini configuration file for Linux:[ODBC Drivers]
Simba Spark ODBC Driver 32-bit=Installed
Simba Spark ODBC Driver 64-bit=Installed
[Simba Spark ODBC Driver 32-bit]
Description=Simba Spark ODBC Driver (32-bit)
Driver=/opt/simba/sparkodbc/lib/32/libsimbasparkodbc32.so
[Simba Spark ODBC Driver 64-bit]
Description=Simba Spark ODBC Driver (64-bit)
Driver=/opt/simba/sparkodbc/lib/64/libsimbasparkodbc64.so
The following is an example of an odbcinst.ini configuration file for Mac OS X:[ODBC Drivers]
Simba Spark ODBC Driver=Installed
[Simba Spark ODBC Driver]
Description=Simba Spark ODBC Driver
www.simba.com 29
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Driver=/opt/simba/sparkodbc/lib/universal/libsimbasparkodbc.dylib
To define a driver:1. Open the .odbcinst.ini configuration file in a text editor.2. In the [ODBC Drivers] section, add a new entry by typing the driver name and then
typing =InstalledType a symbolic name that you want to use to refer to the driver inconnection strings or DSNs.
3. In the .odbcinst.ini file, add a new section with a name that matches the driver nameyou typed in step 2, and then add configuration options to the section based on thesample odbcinst.ini file provided in the Setup directory. Specify configuration optionsas key-value pairs.
4. Save the .odbcinst.ini configuration file.
Configuring the simba.sparkodbc.ini File
The simba.sparkodbc.ini file contains configuration settings for the Simba ODBC Driverwith SQL Connector for Apache Spark. Settings that you define in the simba.sparkodbc.inifile apply to all connections that use the driver.
To configure the Simba ODBC Driver with SQL Connector for Apache Spark towork with your ODBC driver manager:1. Open the simba.sparkodbc.ini configuration file in a text editor.2. Edit the DriverManagerEncoding setting. The value is usually UTF-16 or UTF-32,
depending on the ODBC driver manager you use. iODBC uses UTF-32, andunixODBC uses UTF-16. To determine the correct setting to use, refer to yourODBC Driver Manager documentation.
3. Edit the ODBCInstLib setting. The value is the name of the ODBCInst shared libraryfor the ODBC driver manager you use. To determine the correct library to specify,refer to your ODBC driver manager documentation.The configuration file defaults to the shared library for iODBC. In Linux, the sharedlibrary name for iODBC is libiodbcinst.so. In Mac OS X, the shared library name foriODBC is libiodbcinst.dylib.
You can specify an absolute or relative filename for the library. If you intendto use the relative filename, then the path to the library must be included inthe library path environment variable. In Linux, the library path environmentvariable is named LD_LIBRARY_PATH. In Mac OS X, the library pathenvironment variable is named DYLD_LIBRARY_PATH.
4. Save the simba.sparkodbc.ini configuration file.
www.simba.com 30
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Configuring Authentication
You can select the type of authentication to use for a connection by defining the AuthMechconnection attribute in a connection string or in a DSN (in the odbc.ini file). Depending onthe authentication mechanism you use, there may be additional connection attributes thatyou must define. For more information about the attributes involved in configuringauthentication, see Appendix C Driver Configuration Options on page 47.
For information about selecting the appropriate authentication mechanism to use, seeAppendix A Authentication Options on page 40.
Using No AuthenticationWhen connecting to a Spark server of type Shark Server, you must use NoAuthentication.
To configure a connection without authentication:Set the AuthMech connection attribute to 0
Using Kerberos
Kerberos must be installed and configured before you can use this authenticationmechanism. For more information, refer to the MIT Kerberos documentation.
This authentication mechanism is available only for Shark Server 2 or Spark ThriftServer on non-HDInsight distributions.
To configure Kerberos authentication:1. Set the AuthMech connection attribute to 12. If your Kerberos setup does not define a default realm or if the realm of your Spark
server is not the default, then set the appropriate realm using the KrbRealmattribute.
ORTo use the default realm defined in your Kerberos setup, do not set the KrbRealmattribute.
3. Set the KrbHostFQDN attribute to the fully qualified domain name of the SharkServer 2 or Spark Thrift Server host.
4. Set the KrbServiceName attribute to the service name of the Shark Server 2 orSpark Thrift Server.
Using User Name
This authentication mechanism requires a user name but does not require a password.The user name labels the session, facilitating database tracking.
www.simba.com 31
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

This authentication mechanism is available only for Shark Server 2 or Spark ThriftServer on non-HDInsight distributions. Most default configurations of SharkServer 2 or Spark Thrift Server require User Name authentication.
To configure User Name authentication:1. Set the AuthMech connection attribute to 22. Set the UID attribute to an appropriate user name for accessing the Spark server.
Using User Name and Password
This authentication mechanism requires a user name and a password.
This authentication mechanism is available only for Shark Server 2 or Spark ThriftServer on non-HDInsight distributions.
To configure User Name and Password authentication:1. Set the AuthMech connection attribute to 32. Set the UID attribute to an appropriate user name for accessing the Spark server.3. Set the PWD attribute to the password corresponding to the user name you provided
in step 2.
Using User Name and Password (SSL)
This authentication mechanism uses SSL and requires a user name and a password. Thedriver accepts self-signed SSL certificates for this authentication mechanism.
This authentication mechanism is available only for Shark Server 2 or Spark ThriftServer on non-HDInsight distributions.
To configure User Name and Password (SSL) authentication:1. Set the AuthMech connection attribute to 42. Set the UID attribute to an appropriate user name for accessing the Spark server.3. Set the PWD attribute to the password corresponding to the user name you provided
in step 2.4. Optionally, configure the driver to allow the common name of a CA-issued certificate
to not match the host name of the Spark server by setting theCAIssuedCertNamesMismatch attribute to 1.
For self-signed certificates, the driver always allows the common name ofthe certificate to not match the host name.
5. To configure the driver to load SSL certificates from a specific PEM file, set theTrustedCerts attribute to the path of the file.
ORTo use the trusted CA certificates PEM file that is installed with the driver, do notspecify a value for the TrustedCerts attribute.
www.simba.com 32
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Using Windows Azure HDInsight Emulator
This authentication mechanism enables you to connect to a Spark server on WindowsAzure HDInsight Emulator.
This authentication mechanism is available only for Shark Server 2 or Spark ThriftServer on an HDInsight distribution.
To configure a connection to a Spark server on Windows Azure HDInsightEmulator:1. Set the AuthMech connection attribute to 52. Set the HTTPPath attribute to the partial URL corresponding to the Spark server.3. Set the UID attribute to an appropriate user name for accessing the Spark server.4. Set the PWD attribute to the password corresponding to the user name you provided
in step 3.
Using Windows Azure HDInsight Service
This authentication mechanism enables you to connect to a Spark server on WindowsAzure HDInsight Service. The driver does not accept self-signed SSL certificates for thisauthentication mechanism. Also, the common name of the CA-issued certificate mustmatch the host name of the Spark server.
This authentication mechanism is available only for Shark Server 2 or Spark ThriftServer on an HDInsight distribution.
To configure a connection to a Spark server on Windows Azure HDInsightService:1. Set the AuthMech connection attribute to 62. Set the HTTPPath attribute to the partial URL corresponding to the Spark server.3. Set the UID attribute to an appropriate user name for accessing the Spark server.4. Set the PWD attribute to the password corresponding to the user name you typed in
step 3.5. To configure the driver to load SSL certificates from a specific file, set the
TrustedCerts attribute to the path of the file.OR
To use the trusted CA certificates PEM file that is installed with the driver, do notspecify a value for the TrustedCerts attribute.
Using HTTP
This authentication mechanism enables you to connect to a Shark Server 2 or Spark ThriftServer running in HTTP mode.
This authentication mechanism is available only for Shark Server 2 or Spark ThriftServer on non-HDInsight distributions.
www.simba.com 33
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

To configure HTTP authentication:1. Set the AuthMech connection attribute to 72. Set the HTTPPath attribute to the partial URL corresponding to the Spark server.3. Set the UID attribute to an appropriate user name for accessing the Spark server.4. Set the PWD attribute to the password corresponding to the user name you typed in
step 3.
Using HTTPS
This authentication mechanism enables you to connect to a Shark Server 2 or Spark ThriftServer that is running in HTTP mode and has SSL enabled. The driver accepts self-signedSSL certificates for this authentication mechanism.
This authentication mechanism is available only for Shark Server 2 or Spark ThriftServer on non-HDInsight distributions.
To configure HTTPS authentication:1. Set the AuthMech connection attribute to 82. Set the HTTPPath attribute to the partial URL corresponding to the Spark server.3. Set the UID attribute to an appropriate user name for accessing the Spark server.4. Set the PWD attribute to the password corresponding to the user name you typed in
step 3.5. Optionally, configure the driver to allow the common name of a CA-issued certificate
to not match the host name of the Spark server by setting theCAIssuedCertNamesMismatch attribute to 1.
For self-signed certificates, the driver always allows the common name ofthe certificate to not match the host name.
6. To configure the driver to load SSL certificates from a specific file, set theTrustedCerts attribute to the path of the file.
ORTo use the trusted CA certificates PEM file that is installed with the driver, do notspecify a value for the TrustedCerts attribute.
The HTTPS authentication method can also be used to connect to Shark Server 2or Spark Thrift Server via the Knox gateway. To determine what user credentialsto use and what value to set for the HTTPPath attribute, refer to the Knoxdocumentation.
www.simba.com 34
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Features
More information is provided on the following features of the Simba ODBC Driver withSQL Connector for Apache Spark:
l SQL Query versus Spark SQL Query on page 35l SQL Connector on page 35l Data Types on page 35l Catalog and Schema Support on page 36l spark_system Table on page 37l Server-Side Properties on page 37l Get Tables With Query on page 37
SQL Query versus Spark SQL Query
The native query language supported by Spark is Spark SQL. For simple queries, SparkSQL is a subset of SQL-92. However, the syntax is different enough that most applicationsdo not work with native Spark SQL.
SQL Connector
To bridge the difference between SQL and Spark SQL, the SQL Connector featuretranslates standard SQL-92 queries into equivalent Spark SQL queries. The SQLConnector performs syntactical translations and structural transformations. For example:
l Quoted Identifiers— The double quotes (") that SQL uses to quote identifiers aretranslated into back quotes (`) to match Spark SQL syntax. The SQL Connectorneeds to handle this translation because even when a driver reports the back quoteas the quote character, some applications still generate double-quoted identifiers.
l Table Aliases— Support is provided for the AS keyword between a table referenceand its alias, which Spark SQL normally does not support.
l JOIN, INNER JOIN, and CROSS JOIN— SQL JOIN, INNER JOIN, and CROSSJOIN syntax is translated to Spark SQL JOIN syntax.
l TOP N/LIMIT— SQL TOP N queries are transformed to Spark SQL LIMIT queries.
Data Types
The Simba ODBC Driver with SQL Connector for Apache Spark supports many commondata formats, converting between Spark data types and SQL data types.
Table 1 lists the supported data type mappings.
www.simba.com 35
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide
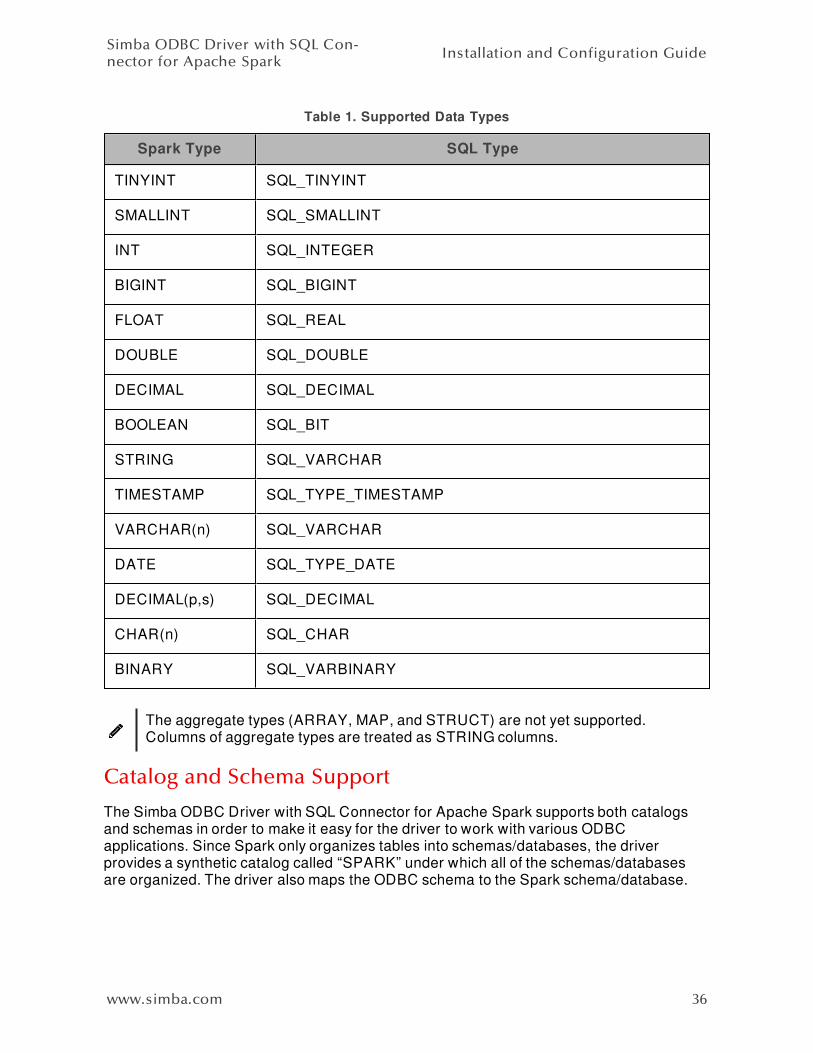
Spark Type SQL Type
TINYINT SQL_TINYINT
SMALLINT SQL_SMALLINT
INT SQL_INTEGER
BIGINT SQL_BIGINT
FLOAT SQL_REAL
DOUBLE SQL_DOUBLE
DECIMAL SQL_DECIMAL
BOOLEAN SQL_BIT
STRING SQL_VARCHAR
TIMESTAMP SQL_TYPE_TIMESTAMP
VARCHAR(n) SQL_VARCHAR
DATE SQL_TYPE_DATE
DECIMAL(p,s) SQL_DECIMAL
CHAR(n) SQL_CHAR
BINARY SQL_VARBINARY
Table 1. Supported Data Types
The aggregate types (ARRAY, MAP, and STRUCT) are not yet supported.Columns of aggregate types are treated as STRING columns.
Catalog and Schema Support
The Simba ODBC Driver with SQL Connector for Apache Spark supports both catalogsand schemas in order to make it easy for the driver to work with various ODBCapplications. Since Spark only organizes tables into schemas/databases, the driverprovides a synthetic catalog called “SPARK” under which all of the schemas/databasesare organized. The driver also maps the ODBC schema to the Spark schema/database.
www.simba.com 36
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

spark_system Table
A pseudo-table called spark_system can be used to query for Spark cluster systemenvironment information. The pseudo-table is under the pseudo-schema called spark_system. The table has two STRING type columns, envkey and envvalue. Standard SQLcan be executed against the spark_system table. For example:SELECT * FROM SPARK.spark_system.spark_system WHERE envkeyLIKE '%spark%'
The above query returns all of the Spark system environment entries whose key containsthe word “spark.” A special query, set -v, is executed to fetch system environmentinformation. Some versions of Spark do not support this query. For versions of Spark thatdo not support querying system environment information, the driver returns an emptyresult set.
Server-Side Properties
The Simba ODBC Driver with SQL Connector for Apache Spark allows you to set server-side properties via a DSN. Server-side properties specified in a DSN affect only theconnection that is established using the DSN.
For more information about setting server-side properties when using the Windows driver,see Configuring Server-Side Properties on page 18. For information about setting server-side properties when using the driver on a non-Windows platform, see DriverConfiguration Options on page 47.
Get Tables With Query
The Get Tables With Query configuration option allows you to choose whether to use theSHOW TABLES query or the GetTables API call to retrieve table names from a database.
Shark Server 2 and Spark Thrift Server both have a limit on the number of tables that canbe in a database when handling the GetTables API call. When the number of tables in adatabase is above the limit, the API call will return a stack overflow error or a timeout error.The exact limit and the error that appears depends on the JVM settings.
As a workaround for this issue, enable the Get Tables with Query configuration option (orGetTablesWithQuery key) to use the query instead of the API call.
www.simba.com 37
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Known Issues in Spark
The following are known issues in Apache Spark that you might encounter while using thedriver.
Backquotes in Aliases Are Not Handled Correctly
In Spark 1.0.x and 1.1.x, the backquotes (`) surrounding identifiers are returned as part ofthe column names in the result set metadata. Backquotes are used to quote identifiers inSpark SQL, and should not be considered as part of the identifier.
This issue is fixed in Spark 1.2.x.
For more information, see the JIRA issue posted by Apache named Backticks Aren'tHandled Correctly in Aliases at https://issues.apache.org/jira/browse/SPARK-3708
Filtering on TIMESTAMP Columns Does Not Return Any Rows
In Spark 0.9.x, 1.0.x, and 1.1.0, using the WHERE statement to filter TIMESTAMPcolumns does not return any rows.
This issue is fixed in Spark 1.1.1 and later.
For more information, see the JIRA issue posted by Apache named Timestamp Support inthe Parser at https://issues.apache.org/jira/browse/SPARK-3173
Cannot Use AND to Combine a TIMESTAMP Column Filterwith Another Filter
In Spark 1.1.x, when you execute a query that uses the AND operator to combine aTIMESTAMP column filter with another filter, an error occurs.
As a workaround, use a subquery as shown in the following example:SELECT * FROM (SELECT * FROM timestamp_table WHERE(keycolumn='TimestampMicroSeconds')) s1 WHERE (column1 ='1955-10-11 11:10:33.123456');
www.simba.com 38
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Contact Us
If you have difficulty using the driver, please contact our Technical Support staff. Wewelcome your questions, comments, and feature requests.
Technical Support is available Monday to Friday from 8 a.m. to 5 p.m. Pacific Time.
To help us assist you, prior to contacting Technical Support please prepare adetailed summary of the client and server environment including operating systemversion, patch level, and configuration.
You can contact Technical Support via:l E-mail—[email protected] Web site—www.simba.coml Telephone—(604) 633-0008 Extension 3l Fax—(604) 633-0004
You can also follow us on Twitter @SimbaTech
www.simba.com 39
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Appendix A Authentication Options
Shark Server does not support authentication. You must select No Authentication as theauthentication mechanism.
Shark Server 2 or Spark Thrift Server on an HDInsight distribution supports the followingauthentication mechanisms:
l Windows Azure HDInsight Emulatorl Windows Azure HDInsight Service
Shark Server 2 or Spark Thrift Server on a non-HDInsight distribution supports thefollowing authentication mechanisms:
l No Authenticationl Kerberosl User Namel User Name and Passwordl User Name and Password (SSL)l HTTPl HTTPS
Most default configurations of Shark Server 2 or Spark Thrift Server on non-HDInsightdistributions require User Name authentication. If you are unable to connect to your Sparkserver using User Name authentication, then verify the authentication mechanismconfigured for your Spark server by examining the hive-site.xml file. Examine the followingproperties to determine which authentication mechanism your server is set to use:
l hive.server2.authenticationl hive.server2.enable.doAs
Table 2 lists the authentication mechanisms to configure for the driver based on thesettings in the hive-site.xml file.
hive.server2.authentication hive.server2.enable.doAs Driver AuthenticationMechanism
NOSASL False No Authentication
KERBEROS True or False Kerberos
NONE True or False User Name
Table 2. Spark Authentication Mechanism Configurations
www.simba.com 40
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

hive.server2.authentication hive.server2.enable.doAs Driver AuthenticationMechanism
LDAP True or False User Name andPassword
ORUser Name andPassword (SSL)
User Name andPassword (SSL)can only be usedif your Sparkserver isconfigured withSSL.
It is an error to set hive.server2.authentication to NOSASL andhive.server2.enable.doAs to true. This configuration will not prevent the servicefrom starting up, but results in an unusable service.
For more information about authentication mechanisms, refer to the documentation foryour Hadoop / Spark distribution. See also the topic Running Hadoop in Secure Mode athttp://hadoop.apache.org/docs/r0.23.7/hadoop-project-dist/hadoop-common/ClusterSetup.html#Running_Hadoop_in_Secure_Mode
Using No Authentication
When hive.server2.authentication is set to NOSASL, you must configure your connectionto use No Authentication.
Using Kerberos
When connecting to a Spark server of type Shark Server 2 or Spark Thrift Server on a non-HDInsight distribution and hive.server2.authentication is set to KERBEROS, you mustconfigure your connection to use Kerberos authentication.
Using User Name
When connecting to a Spark server of type Shark Server 2 or Spark Thrift Server on a non-HDInsight distribution and hive.server2.authentication is set to NONE, you must configureyour connection to use User Name authentication. Validation of the credentials that youinclude depends on hive.server2.enable.doAs:
l If hive.server2.enable.doAs is set to true, then the user name in the DSN or driverconfiguration must be an existing OS user on the host that is running Shark Server 2
www.simba.com 41
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

or Spark Thrift Server.l If hive.server2.enable.doAs is set to false, then the user name in the DSN or driverconfiguration is ignored.
If the user name is not specified in the DSN or driver configuration, then the driver defaultsto using “anonymous” as the user name.
Using User Name and Password
When connecting to a Spark server of type Shark Server 2 or Spark Thrift Server on a non-HDInsight distribution and the server is configured to use the SASL-PLAIN authenticationmechanism with a user name and a password, you must configure your connection to useUser Name and Password authentication.
Using User Name and Password (SSL)
When connecting to a Spark server of type Shark Server 2 or Spark Thrift Server on a non-HDInsight distribution and the server is configured to use SSL and the SASL-PLAINauthentication mechanism with a user name and a password, you must configure yourconnection to use User Name and Password (SSL) authentication.
Using Windows Azure HDInsight Emulator
When connecting to a Spark server on Windows Azure HDInsight Emulator, you mustconfigure your connection to use Windows Azure HDInsight Emulator.
Using Windows Azure HDInsight Service
When connecting to a Spark server on Windows Azure HDInsight Service, you mustconfigure your connection to use Windows Azure HDInsight Service.
Using HTTP
When connecting to a Spark server of type Shark Server 2 or Spark Thrift Server on a non-HDInsight distribution and the server is configured to use the Thrift HTTP transport over aTCP socket, you must configure your connection to use HTTP authentication.
Using HTTPS
When connecting to a Spark server of type Shark Server 2 or Spark Thrift Server on a non-HDInsight distribution and the server is configured to use the Thrift HTTP transport over aSSL socket, you must configure your connection to use HTTPS authentication.
www.simba.com 42
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Appendix B Configuring Kerberos Authenticationfor Windows
MIT Kerberos
Downloading and Installing MIT Kerberos for Windows 4.0.1
For information about Kerberos and download links for the installer, see the MIT Kerberoswebsite at http://web.mit.edu/kerberos/
To download and install MIT Kerberos for Windows 4.0.1:1. To download the Kerberos installer for 64-bit computers, use the following download
link from the MIT Kerberos website: http://web.mit.edu/kerberos/dist/kfw/4.0/kfw-4.0.1-amd64.msi
ORTo download the Kerberos installer for 32-bit computers, use the following downloadlink from the MIT Kerberos website: http://web.mit.edu/kerberos/dist/kfw/4.0/kfw-4.0.1-i386.msi
The 64-bit installer includes both 32-bit and 64-bit libraries. The 32-bitinstaller includes 32-bit libraries only.
2. To run the installer, double-click the .msi file that you downloaded in step 1.3. Follow the instructions in the installer to complete the installation process.4. When the installation completes, click Finish
Setting Up the Kerberos Configuration File
Settings for Kerberos are specified through a configuration file. You can set up theconfiguration file as a .INI file in the default location—the C:\ProgramData\MIT\Kerberos5directory— or as a .CONF file in a custom location.
Normally, the C:\ProgramData\MIT\Kerberos5 directory is hidden. For information aboutviewing and using this hidden directory, refer to Microsoft Windows documentation.
For more information on configuring Kerberos, refer to the MIT Kerberosdocumentation.
To set up the Kerberos configuration file in the default location:1. Obtain a krb5.conf configuration file from your Kerberos administrator.
ORObtain the configuration file from the /etc/krb5.conf folder on the computer that ishosting the Shark Server 2 or Spark Thrift Server instance.
2. Rename the configuration file from krb5.conf to krb5.ini
www.simba.com 43
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

3. Copy the krb5.ini file to the C:\ProgramData\MIT\Kerberos5 directory and overwritethe empty sample file.
To set up the Kerberos configuration file in a custom location:1. Obtain a krb5.conf configuration file from your Kerberos administrator.
ORObtain the configuration file from the /etc/krb5.conf folder on the computer that ishosting the Shark Server 2 or Spark Thrift Server instance.
2. Place the krb5.conf file in an accessible directory and make note of the full pathname.
3. Click the Start button , then right-click Computer, and then click Properties4. Click Advanced System Settings5. In the System Properties dialog box, click the Advanced tab and then click
Environment Variables6. In the Environment Variables dialog box, under the System variables list, click New7. In the New System Variable dialog box, in the Variable name field, type KRB5_
CONFIG8. In the Variable value field, type the absolute path to the krb5.conf file from step 2.9. Click OK to save the new variable.10.Ensure that the variable is listed in the System variables list.11.Click OK to close the Environment Variables dialog box, and then click OK to close
the System Properties dialog box.
Setting Up the Kerberos Credential Cache File
Kerberos uses a credential cache to store and manage credentials.
To set up the Kerberos credential cache file:1. Create a directory where you want to save the Kerberos credential cache file. For
example, create a directory named C:\temp2. Click the Start button , then right-click Computer, and then click Properties3. Click Advanced System Settings4. In the System Properties dialog box, click the Advanced tab and then click
Environment Variables5. In the Environment Variables dialog box, under the System variables list, click New6. In the New System Variable dialog box, in the Variable name field, type
KRB5CCNAME7. In the Variable value field, type the path to the folder you created in step 1, and then
append the file name krb5cache. For example, if you created the folder C:\temp instep 1, then type C:\temp\krb5cache
www.simba.com 44
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

krb5cache is a file (not a directory) that is managed by the Kerberossoftware, and it should not be created by the user. If you receive apermission error when you first use Kerberos, ensure that the krb5cache filedoes not already exist as a file or a directory.
8. Click OK to save the new variable.9. Ensure that the variable appears in the System variables list.10.Click OK to close the Environment Variables dialog box, and then click OK to close
the System Properties dialog box.11.To ensure that Kerberos uses the new settings, restart your computer.
Obtaining a Ticket for a Kerberos Principal
A principal refers to a user or service that can authenticate to Kerberos. To authenticate toKerberos, a principal must obtain a ticket by using a password or a keytab file. You canspecify a keytab file to use, or use the default keytab file of your Kerberos configuration.
To obtain a ticket for a Kerberos principal using a password:1. Click the Start button , then click All Programs, and then click the Kerberos for
Windows (64-bit) or Kerberos for Windows (32-bit) program group.2. ClickMIT Kerberos Ticket Manager3. In the MIT Kerberos Ticket Manager, click Get Ticket4. In the Get Ticket dialog box, type your principal name and password, and then click
OK
If the authentication succeeds, then your ticket information appears in the MIT KerberosTicket Manager.
To obtain a ticket for a Kerberos principal using a keytab file:1. Click the Start button , then click All Programs, then click Accessories, and then click
Command Prompt2. In the Command Prompt, type a command using the following syntax:
kinit -k -t keytab_path principal
keytab_path is the full path to the keytab file. For example:C:\mykeytabs\myUser.keytabprincipal is the Kerberos user principal to use for authentication. For example:[email protected]
3. If the cache location KRB5CCNAME is not set or used, then use the -c option of thekinit command to specify the location of the credential cache. In the command, the -cargument must appear last. For example:kinit -k -t C:\mykeytabs\[email protected] -c C:\ProgramData\MIT\krbcache
Krbcache is the Kerberos cache file, not a directory.
www.simba.com 45
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

To obtain a ticket for a Kerberos principal using the default keytab file:
For information about configuring a default keytab file for your Kerberosconfiguration, refer to the MIT Kerberos documentation.
1. Click the Start button , then click All Programs, then click Accessories, and then clickCommand Prompt
2. In the Command Prompt, type a command using the following syntax:kinit -k principal
principal is the Kerberos user principal to use for authentication. For example:[email protected]
3. If the cache location KRB5CCNAME is not set or used, then use the -c option of thekinit command to specify the location of the credential cache. In the command, the -cargument must appear last. For example:kinit -k -t C:\mykeytabs\[email protected] -c C:\ProgramData\MIT\krbcache
Krbcache is the Kerberos cache file, not a directory.
www.simba.com 46
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Appendix C Driver Configuration Options
Appendix C Driver Configuration Options on page 47 lists the configuration optionsavailable in the Simba ODBC Driver with SQL Connector for Apache Spark alphabeticallyby field or button label. Options having only key names—not appearing in the userinterface of the driver—are listed alphabetically by key name.
When creating or configuring a connection from a Windows computer, the fields andbuttons are available in the Simba Spark ODBC Driver Configuration tool and the followingdialog boxes:
l Simba Spark ODBC Driver DSN Setupl Advanced Optionsl Server Side Properties
When using a connection string or configuring a connection from a Linux or Mac computer,use the key names provided.
You can pass in configuration options in your connection string or set them in yourodbc.ini and simba.sparkodbc.ini files. Configuration options set in asimba.sparkodbc.ini file apply to all connections, whereas configuration optionspassed in in the connection string or set in an odbc.ini file are specific to aconnection. Configuration options passed in using the connection string takeprecedence over configuration options set in odbc.ini. Configuration options set inodbc.ini take precedence over configuration options set in simba.sparkodbc.ini
Configuration Options Appearing in the User Interface
The following configuration options are accessible via the Windows user interface for theSimba ODBC Driver with SQL Connector for Apache Spark, or via the key name whenusing a connection string or configuring a connection from a Linux or Mac computer:
l Allow Common Name Host NameMismatch on page 48
l Apply Properties with Queries onpage 48
l Async Exec Poll Interval on page 49l Binary Column Length on page 49l Convert Key Name to Lower Caseon page 49
l Database on page 50l Decimal Column Scale on page 50l Default String Column Length onpage 50
l Host FQDN on page 52l HTTP Path on page 52l Mechanism on page 52l Password on page 53l Port on page 54l Realm on page 54l Rows Fetched Per Block on page54
l Service Name on page 55l Show System Table on page 55l Spark Server Type on page 55
www.simba.com 47
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

l Driver Config Take Precedence onpage 50
l Fast SQLPrepare on page 51l Get Tables With Query on page 51l Host on page 51
l Trusted Certificates on page 56l Unicode SQL Character Types onpage 56
l Use Async Exec on page 57l Use Native Query on page 57l User Name on page 58
Allow Common Name Host Name Mismatch
Key Name Default Value Required
CAIssuedCertNamesMismatch Clear (0) No
Description
When this option is enabled (1), the driver allows a CA-issued SSL certificate name to notmatch the host name of the Spark server.
When this option is disabled (0), the CA-issued SSL certificate name must match the hostname of the Spark server.
This option is applicable only to the User Name and Password (SSL) and HTTPSauthentication mechanisms.
Apply Properties with Queries
Key Name Default Value Required
ApplySSPWithQueries Selected (1) No
Description
When this option is enabled (1), the driver applies each server-side property by executinga set SSPKey=SSPValue query when opening a session to the Spark server.
When this option is disabled (0), the driver uses a more efficient method for applyingserver-side properties that does not involve additional network round-tripping. However,some Shark Server 2 or Spark Thrift Server builds are not compatible with the moreefficient method.
When connecting to a Shark Server instance, ApplySSPWithQueries is alwaysenabled.
www.simba.com 48
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Async Exec Poll Interval
Key Name Default Value Required
AsyncExecPollInterval 100 No
Description
The time in milliseconds between each poll for the query execution status.
“Asynchronous execution” refers to the fact that the RPC call used to execute a queryagainst Spark is asynchronous. It does not mean that ODBC asynchronous operations aresupported.
This option is applicable only to HDInsight clusters.
Binary Column Length
Key Name Default Value Required
BinaryColumnLength 32767 No
Description
The maximum data length for BINARY columns.
By default, the columns metadata for Spark does not specify a maximum data length forBINARY columns.
Convert Key Name to Lower Case
Key Name Default Value Required
LCaseSspKeyName Selected (1) No
Description
When this option is enabled (1), the driver converts server-side property key names to alllower case characters.
When this option is disabled (0), the driver does not modify the server-side property keynames.
www.simba.com 49
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Database
Key Name Default Value Required
Schema default No
Description
The name of the database schema to use when a schema is not explicitly specified in aquery. You can still issue queries on other schemas by explicitly specifying the schema inthe query.
To inspect your databases and determine the appropriate schema to use, type theshow databases command at the Spark command prompt.
Decimal Column Scale
Key Name Default Value Required
DecimalColumnScale 10 No
Description
The maximum number of digits to the right of the decimal point for numeric data types.
Default String Column Length
Key Name Default Value Required
DefaultStringColumnLength 255 No
Description
The maximum data length for STRING columns.
By default, the columns metadata for Spark does not specify a maximum data length forSTRING columns.
Driver Config Take Precedence
Key Name Default Value Required
DriverConfigTakePrecedence Clear (0) No
www.simba.com 50
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Description
When this option is enabled (1), driver-wide configurations take precedence overconnection and DSN settings.
When this option is disabled (0), connection and DSN settings take precedence instead.
Fast SQLPrepare
Key Name Default Value Required
FastSQLPrepare Clear (0) No
Description
When this option is enabled (1), the driver defers query execution to SQLExecute.
When this option is disabled (0), the driver does not defer query execution to SQLExecute.
When using Native Query mode, the driver will execute the Spark SQL query to retrievethe result set metadata for SQLPrepare. As a result, SQLPrepare might be slow. If theresult set metadata is not required after calling SQLPrepare, then enable FastSQLPrepare.
Get Tables With Query
Key Name Default Value Required
GetTablesWithQuery Clear (0) No
Description
When this option is enabled (1), the driver uses the SHOW TABLES query to retrieve thenames of the tables in a database.
When this option is disabled (0), the driver uses the GetTables Thrift API call to retrievethe names of the tables in a database.
This option is applicable only when connecting to a Shark Server 2 or Spark ThriftServer instance.
Host
Key Name Default Value Required
HOST None Yes
www.simba.com 51
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Description
The IP address or host name of the Spark server.
Host FQDN
Key Name Default Value Required
KrbHostFQDN None Yes, if the authenticationmechanism is Kerberos
Description
The fully qualified domain name of the Shark Server 2 or Spark Thrift Server host.
HTTP Path
Key Name Default Value Required
HTTPPath None Yes, if the authenticationmechanism is one of thefollowing:
l Windows AzureHDInsight Emulator
l Windows AzureHDInsight Service
l HTTPl HTTPS
Description
The partial URL corresponding to the Spark server on HDInsight, HTTP, or HTTPSauthentication mechanisms.
Mechanism
Key Name Default Value Required
AuthMech No Authentication (0) No
Description
The authentication mechanism to use.
www.simba.com 52
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Select one of the following settings, or set the key to the corresponding number:l No Authentication (0)l Kerberos (1)l User Name (2)l User Name and Password (3)l User Name and Password (SSL) (4)l Windows Azure HDInsight Emulator (5)l Windows Azure HDInsight Service (6)l HTTP (7)l HTTPS (8)
Password
Key Name Default Value Required
PWD None Yes, if the authenticationmechanism is one of thefollowing:
l User Name andPassword
l User Name andPassword (SSL)
l Windows AzureHDInsight Service
l HTTPl HTTPS
Description
The password corresponding to the user name that you provided in the User Name field(the UID key).
www.simba.com 53
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Port
Key Name Default Value Required
PORT l non-HDInsightclusters—10000
l Windows AzureHDInsight Emu-lator—10001
l Windows AzureHDInsightService—443
Yes
Description
The number of the TCP port on which the Spark server is listening.
Realm
Key Name Default Value Required
KrbRealm Depends on yourKerberos configuration.
No
Description
The realm of the Shark Server 2 or Spark Thrift Server host.
If your Kerberos configuration already defines the realm of the Shark Server 2 or SparkThrift Server host as the default realm, then you do not need to configure this option.
Rows Fetched Per Block
Key Name Default Value Required
RowsFetchedPerBlock 10000 No
Description
The maximum number of rows that a query returns at a time.
Any positive 32-bit integer is a valid value, but testing has shown that performance gainsare marginal beyond the default value of 10000 rows.
www.simba.com 54
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide
Service Name
Key Name Default Value Required
KrbServiceName None Yes, if the authenticationmechanism is Kerberos
Description
The Kerberos service principal name of the Spark server.
Show System Table
Key Name Default Value Required
ShowSystemTable Clear (0) No
Description
When this option is enabled (1), the driver returns the spark_system table for catalogfunction calls such as SQLTables and SQLColumns
When this option is disabled (0), the driver does not return the spark_system table forcatalog function calls.
Spark Server Type
Key Name Default Value Required
SparkServerType Shark Server (1) No
Description
Select Shark Server or set the key to 1 if you are connecting to a Shark Server instance.
Select Shark Server 2 or set the key to 2 if you are connecting to a Shark Server 2instance.
Select Spark Thrift Server or set the key to 3 if you are connecting to a Spark ThriftServer instance.
www.simba.com 55
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Trusted Certificates
Key Name Default Value Required
TrustedCerts The cacerts.pem file in thelib folder or subfolderwithin the driver'sinstallation directory.
The exact file path variesdepending on the versionof the driver that isinstalled. For example, thepath for the Windowsdriver is different from thepath for the MacOS X driver.
No
Description
The location of the PEM file containing trusted CA certificates for authenticating the Sparkserver when using SSL.
If this option is not set, then the driver will default to using the trusted CA certificates PEMfile installed by the driver.
This option is applicable only to the following authentication mechanisms:l User Name and Password (SSL)l Windows Azure HDInsight Servicel HTTPS
Unicode SQL Character Types
Key Name Default Value Required
UseUnicodeSqlCharacterTypes Clear (0) No
Description
When this option is enabled (1), the driver returns SQL_WVARCHAR for STRING andVARCHAR columns, and returns SQL_WCHAR for CHAR columns.
When this option is disabled (0), the driver returns SQL_VARCHAR for STRING andVARCHAR columns, and returns SQL_CHAR for CHAR columns.
www.simba.com 56
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Use Async Exec
Key Name Default Value Required
EnableAsyncExec Clear (0) No
Description
When this option is enabled (1), the driver uses an asynchronous version of the API callagainst Spark for executing a query.
When this option is disabled (0), the driver executes queries synchronously.
Use Native Query
Key Name Default Value Required
UseNativeQuery Clear (0) No
Description
When this option is enabled (1), the driver does not transform the queries emitted by anapplication, so the native query is used.
When this option is disabled (0), the driver transforms the queries emitted by anapplication and converts them into an equivalent from in Spark SQL.
If the application is Spark-aware and already emits Spark SQL, then enable thisoption to avoid the extra overhead of query transformation.
www.simba.com 57
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

User Name
Key Name Default Value Required
UID For User Nameauthentication only, thedefault value isanonymous
No, if the authenticationmechanism is User Name
Yes, if the authenticationmechanism is one of thefollowing:
l User Name andPassword
l User Name andPassword (SSL)
l Windows AzureHDInsight Service
l HTTPl HTTPS
Description
The user name that you use to access Shark Server 2 or Spark Thrift Server.
Configuration Options Having Only Key Names
The following configuration options do not appear in the Windows user interface for theSimba ODBC Driver with SQL Connector for Apache Spark and are only accessible whenusing a connection string or configuring a connection from a Linux/Mac OS X computer:
l Driver on page 58l SSP_ on page 59
Driver
Default Value Required
The default value varies depending on theversion of the driver that is installed. Forexample, the value for the Windows driveris different from the value of the MacOS X driver.
Yes
www.simba.com 58
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide

Description
The name of the installed driver (Simba Spark ODBC Driver) or the absolute path of theSimba ODBC Driver with SQL Connector for Apache Spark shared object file.
SSP_
Default Value Required
None No
Description
Set a server-side property by using the following syntax, where SSPKey is the name of theserver-side property to set and SSPValue is the value to assign to the server-sideproperty:SSP_SSPKey=SSPValue
For example:SSP_mapred.queue.names=myQueue
After the driver applies the server-side property, the SSP_ prefix is removed from the DSNentry, leaving an entry of SSPKey=SSPValue
The SSP_ prefix must be upper case.
www.simba.com 59
Simba ODBC Driver with SQL Con-nector for Apache Spark Installation and Configuration Guide


















