
Shaping Optimizer's Search Space
61
Shaping the Optimizer’s Search-Space @MarkusWinand
Transcript of Shaping Optimizer's Search Space

Shaping the Optimizer’s Search-Space @MarkusWinand

The Optimizer’s Search-Space is Limited
“the query optimizer determinesthe most efficient execution plan*”
...most efficient? Out of what?
*http://docs.oracle.com/cd/E16655_01/server.121/e15857/pfgrf_perf_overview.htm#TGDBA94082

The Optimizer’s Search-Space is Limited
The Optimizer...
‣Considers existing indexes only ➡ Other indexes might give even better performance
‣Doesn’t de-obfuscate queries very well ➡ Writing it in simpler terms might improve performance
‣Has built-in limitations ➡ Some theoretically possible plans are never considered

Bring the Best Plan in the Search-Space
... it determines the most efficient execution plan out of the remaining ones.
Before the optimizer can find theabsolutely best plan we must first
make sure it is within these boundaries.



Two steps to get the absolutely best access path:
1. Maximize data-locality‣ Plain old B-tree index is the #1 tool for that‣ Partitions are greatly overrated‣ Table clusters are slightly underrated
It’s All About Matching Queries to Indexes
2. Write the query to exploit it‣ Use explicit range conditions‣ Use top-n based termination‣ Exploit index order
Thinking in
OrderedSets

Visualizing Indexes as Pyramids
Visualize Simplify

The Order of Multi-Column Indexes

The Order of Multi-Column Indexes

The Order of Multi-Column Indexes

Using Indexes:
Column Order Defines Row-Locality
Example: WHEREA>:aANDB=:b

Using Indexes:
Column Order Defines Row-Locality
Example: WHEREA>:aANDB=:b

Using Indexes:
Column Order Defines Row-Locality
Simple-man’s guidelines (best in ~97% of the cases):
‣Conjunctive equality conditions are king Column order doesn’t affect data-locality ➡ Put them first into the index and choose the column
order so that other queries can use the index too.
‣Conjunctive range conditions are tricky Column order affects data-locality ➡ Put them after the equality columns. If there are
multiple range conditions, put the most-selective first.

Using Indexes:
Column Order Defines Row-Locality
Common mistakes:‣Arbitrary column order ☠ (bad)
“Just put all columns from the where-clause in the index” ➡ Works only for all-conjunctive all-equality searches ➡ Doesn’t make the index useful for other queries
‣Most-selective first ☠ (bad) “Order the columns according to the selectivity” ➡ Only valid to prioritize among multiple range conditions

Using Indexes:
Finding Bad Index Row-Locality
------------------------------------|Id|Operation|------------------------------------|0|SELECTSTATEMENT||1|TABLEACCESSBYINDEXROWID||*2|INDEXSKIPSCAN|------------------------------------PredicateInformation:------------------------------------2-access("B"=20AND"A">25)filter("B"=20)
Index on (A, B)------------------------------------|Id|Operation|------------------------------------|0|SELECTSTATEMENT||1|TABLEACCESSBYINDEXROWID||*2|INDEXRANGESCAN|------------------------------------PredicateInformation:------------------------------------2-access("B"=20AND"A">25)
Index on (B, A)
Mostefficient s
olution Most efficient
workaround
‣ Index filter predicates are a “bad smell”‣ Index Skip Scan is a “bad smell”‣ Index Fast Full Scan is a “bad smell”

Using Indexes:
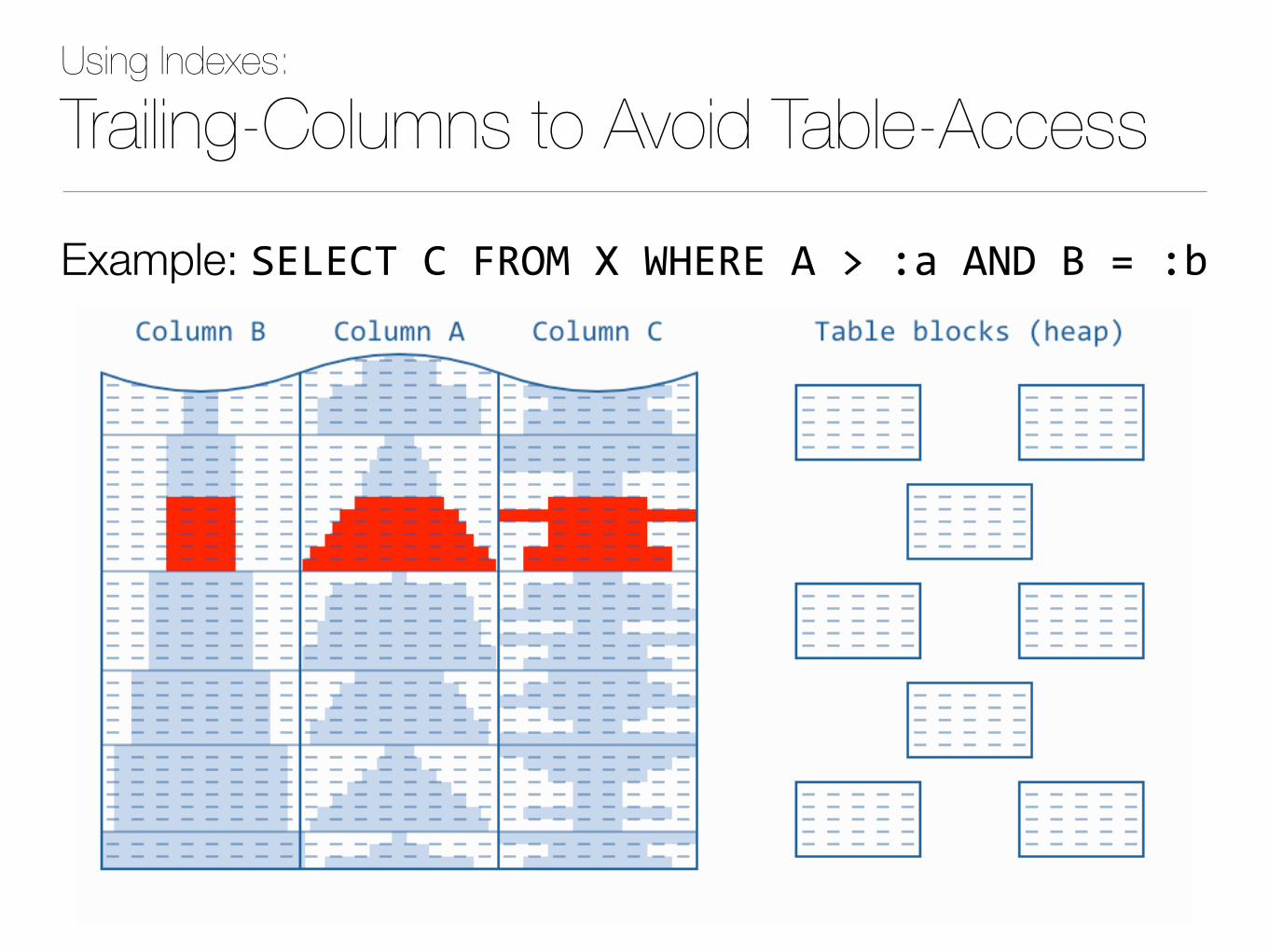
Trailing-Columns to Avoid Table-Access
Example: SELECTCFROMXWHEREA>:aANDB=:b
Using Indexes:
Trailing-Columns to Avoid Table-Access
Example: SELECTCFROMXWHEREA>:aANDB=:b

Using Indexes:
Trailing-Columns to Avoid Table-Access
Add all needed columns to the index to avoid table access.The so-called index-only scan.
‣Useful to nullify a bad clustering factor Consequently, not very useful if ➡ Clustering factor close to the number of table blocks or ➡ Selecting only a few rows
‣A single non-indexed column breaks it No matter where it is mentioned (SELECT, ORDERBY,...) ➡ All or nothing: no benefit from adding some SELECT
columns to the index.

Using Indexes:
Trailing-Columns to Avoid Table-Access
Common mistakes:
‣Selecting unneeded columns* ☠ (bad) SELECT * anybody? ORM-tools in use? Hooray! ➡ Adding many columns to many indexes is a no-no.
‣Pushing too hard ☠ (bad) ➡ Index gets bigger, clustering factor (CF) gets worse ➡ Small benefit for low CF or if selecting a few rows only ➡ You’ll hit the hard limits (32 columns, 6398 bytes@8k)
* http://use-the-index-luke.com/blog/2013-08/its-not-about-the-star-stupid

It’s All About Matching Queries to Indexes
Two steps to get the absolutely best access path:
1. Maximize data-locality ‣ Plain old B-tree index is the #1 tool for that ‣ Partitions are greatly overrated ‣ Table clusters are slightly underrated
2. Write the query to exploit it ‣ Use explicit range conditions ‣ Use top-n based termination ‣ Exploit index order
Thinking in
OrderedSets
✓ ✓

Example:
List yesterday’s orders
CREATETABLEorders(...,order_dtDATENOTNULL,...);
INSERTINTOorders(...,order_dt,...)VALUES(...,sysdate,...);
100k rows Evenly distributed
over 4 weeks.

Example:
List yesterday’s orders
1. Maximize data-locality

Example:
List yesterday’s orders
1. Lower bound:ORDER_DT>=TRUNC(sysdate-1)
2. Upper bound:ORDER_DT<TRUNC(sysdate)
2. Write query using explicit range conditions
----------------------------------------------|Id|Operation|----------------------------------------------|0|SELECTSTATEMENT||*1|FILTER||2|TABLEACCESSBYINDEXROWIDBATCHED||*3|INDEXRANGESCAN|----------------------------------------------PredicateInformation(identifiedbyoperationid):---------------------------------------------------1-filter(TRUNC(SYSDATE@!)>TRUNC(SYSDATE@!-1))3-access("ORDER_DT">=TRUNC(SYSDATE@!-1)AND"ORDER_DT"<TRUNC(SYSDATE@!))

Example:
List yesterday’s orders
Common anti-pattern:
‣TRUNC(order_dt)=:yesterday☠ (bad)This is an “obfuscation” of the actual intention➡Requires function-based indexCREATEINDEX…(TRUNC(order_dt));
➡Doesn’t support ordering by order_dtWHERETRUNC(order_dt)=:yesterdayORDERBYorder_dtDESC;
Indexnot ordered b
y that

--------------------------------------|Id|Operation|--------------------------------------|0|SELECTSTATEMENT||*1|FILTER||2|TABLEACCESSBYINDEXROWID||*3|INDEXRANGESCANDESCENDING|--------------------------------------PredicateInformation(identifiedbyoperationid):---------------------------------------------------1-filter(TRUNC(SYSDATE@!)>TRUNC(SYSDATE@!-1))3-access("ORDER_DT"<TRUNC(SYSDATE@!)AND"ORDER_DT">=TRUNC(SYSDATE@!-1))
Example:
List yesterday’s orders reverse chronologically
1. Lower & upper bounds:ORDER_DT>=TRUNC(sysdate-1)ORDER_DT<TRUNC(sysdate)
2. OrderORDERBYORDER_DTDESC
2. Write query - exploit index order

--------------------------------------|Id|Operation|--------------------------------------|0|SELECTSTATEMENT||*1|FILTER||2|TABLEACCESSBYINDEXROWID||*3|INDEXRANGESCANDESCENDING|--------------------------------------PredicateInformation(identifiedbyoperationid):---------------------------------------------------1-filter(TRUNC(SYSDATE@!)>TRUNC(SYSDATE@!-1))3-access("ORDER_DT"<TRUNC(SYSDATE@!)AND"ORDER_DT">=TRUNC(SYSDATE@!-1))
Example:
List yesterday’s orders reverse chronologically
2. Write query - exploit index order1. Lower & upper bounds:
TRUNC(ORDER_DT) =TRUNC(sysdate)-1
2. OrderORDERBYORDER_DTDESC

Example:
List yesterday’s orders reverse chronologically
2. Write query - exploit index order
----------------------------------------------|Id|Operation|----------------------------------------------|0|SELECTSTATEMENT||1|SORTORDERBY||2|TABLEACCESSBYINDEXROWIDBATCHED||*3|INDEXRANGESCAN|----------------------------------------------PredicateInformation(identifiedbyoperationid):---------------------------------------------------3-access("ORDERS"."SYS_NC00004$"=TRUNC(SYSDATE@!-1))
Tradeoff:
CPU MemoryIO
1. Lower & upper bounds:TRUNC(ORDER_DT) =TRUNC(sysdate)-1
2. OrderORDERBYORDER_DTDESC

Example:
List orders from last 24 hours
1. Data-locality for the TRUNC variant
* http://www.sqlfail.com/2014/05/05/oracle-can-now-use-function-based-indexes-in-queries-without-functions/

2. Write query using explicit range conditions
Example:
List orders from last 24 hours
-------------------------------------------------|Id|Operation|-------------------------------------------------|0|SELECTSTATEMENT||*1|TABLEACCESSBYINDEXROWIDBATCHED||*2|INDEXRANGESCANonTRUNC(ORDER_DT)|-------------------------------------------------PredicateInformation(identifiedbyoperationid):---------------------------------------------------1-filter("ORDER_DT">SYSDATE@!-1)2-access("ORDERS"."SYS_NC00004$">=TRUNC(SYSDATE@!-1))
2. Upper bound: none (unbounded)
1. Lower bound:ORDER_DT>sysdate-1To use FBI Oracle adds (since 11.2.0.2*) TRUNC(ORDER_DT)>=TRUNC(sysdate-1)
* http://www.sqlfail.com/2014/05/05/oracle-can-now-use-function-based-indexes-in-queries-without-functions/

Example:
List orders from last 24 hours
1. Maximize data-locality using straight index

Example:
List orders from last 24 hours
2. Write query using explicit range conditions1. Lower bound:
ORDER_DT>sysdate-12. Upper bound: none (unbounded)
--------------------------------------------|Id|Operation|--------------------------------------------|0|SELECTSTATEMENT||1|TABLEACCESSBYINDEXROWIDBATCHED||*2|INDEXRANGESCAN|--------------------------------------------PredicateInformation:----------------------2-access("ORDER_DT">SYSDATE@!-1)

Example:
List orders from last 24 hours
--------------------------------------------|Id|Operation|--------------------------------------------|0|SELECTSTATEMENT||1|TABLEACCESSBYINDEXROWIDBATCHED||*2|INDEXRANGESCAN|--------------------------------------------PredicateInformation:----------------------2-access("ORDER_DT">SYSDATE@!-1)
--------------------------------------------|Id|Operation|--------------------------------------------|0|SELECTSTATEMENT||*1|TABLEACCESSBYINDEXROWIDBATCHED||*2|INDEXRANGESCAN|--------------------------------------------PredicateInformation:----------------------1-filter("ORDER_DT">SYSDATE@!-1)2-access("ORDERS"."SYS_NC00004$">=TRUNC(SYSDATE@!-1))
Most efficient solution
Most efficient
workaroun
d

It’s All About Matching Queries to Indexes
Two steps to get the absolutely best access path:
1. Maximize data-locality ‣ Plain old B-tree index is the #1 tool for that ‣ Partitions are greatly overrated ‣ Table clusters are slightly underrated
2. Write the query to exploit it ‣ Use explicit range conditions ‣ Use top-n based termination ‣ Exploit index order
Thinking in
OrderedSets
✓
✓
✓
✓

Example:
List 10 Most Recent Orders
1. Maximize data-locality

Example:
List 10 Most Recent Orders
2. Write query using explicit range conditions
1. Lower bound...? After 10 rows...???2. Upper bound? sysdate? Unbounded!

Example:
List 10 Most Recent Orders
1. Lower bound...? After 10 rows...???2. Upper bound? sysdate? Unbounded!
2. Write query using top-n based termination
3. Start with: most recentORDERBYORDER_DTDESC
4. Stop after: 10 rowsFETCHFIRST10ROWSONLY (since 12c)

Example:
List 10 Most Recent Orders
2. Write query using top-n based termination3. Start with: most recent
ORDERBYORDER_DTDESC4. Stop after: 10 rows
FETCHFIRST10ROWSONLY (since 12c)----------------------------------------------------------|Id|Operation|A-Rows|Buffers|----------------------------------------------------------|0|SELECTSTATEMENT|10|8||*1|VIEW|10|8||*2|WINDOWNOSORTSTOPKEY|10|8||3|TABLEACCESSBYINDEXROWID|11|8||4|INDEXFULLSCANDESCENDING|11|3|----------------------------------------------------------PredicateInformation(identifiedbyoperationid):---------------------------------------------------1-filter("from$_subquery$_002"."rowlimit_$$_rownumber"<=10)2-filter(ROW_NUMBER()OVER(ORDERBYORDER_DTDESC)<=10)ROW_NUMBER()OVER(ORDERBYORDER_DTDESC)<=10

SELECTorders.*,ROW_NUMBER()OVER(ORDERBYorder_dtDESC)rnFROMorders
Window-Functions for Top-N Termination

SELECT*FROM(SELECTorders.*,ROW_NUMBER()OVER(ORDERBYorder_dtDESC)rnFROMorders)WHERErn<=10ORDERBYorder_dtDESC;
Window-Functions for Top-N Termination
Select 10 rows

Window-Functions for Top-N Termination
SELECT*FROM(SELECTorders.*,DENSE_RANK()OVER(ORDERBYTRUNC(order_dt)DESC)rnFROMorders)WHERErn<=1ORDERBYorder_dtDESC;
Select 1 group

Window-Functions for Top-N Termination
SELECT*FROM(SELECTorders.*,DENSE_RANK()OVER(ORDERBYTRUNC(order_dt)DESC)rnFROMorders)WHERErn<=1ORDERBYorder_dtDESC;
Useful to
abort on edges

Window-Functions for Top-N Termination
SELECT*FROM(SELECTorders.*,DENSE_RANK()OVER(ORDERBYTRUNC(order_dt)DESC)rnFROMorders)WHERErn<=1ORDERBYorder_dtDESC;
---------------------------------------------------------------------------|Id|Operation|E-Rows|A-Rows|Buffers|Reads|---------------------------------------------------------------------------|0|SELECTSTATEMENT||2057|695|695||1|SORTORDERBY|100K|2057|695|695||*2|VIEW|100K|2057|695|695||*3|WINDOWNOSORTSTOPKEY|100K|2057|695|695||4|TABLEACCESSBYINDEXROWID|100K|2058|695|695||5|INDEXFULLSCANDESCENDING|100K|2058|8|8|---------------------------------------------------------------------------DE
NSE_RANK

Window-Functions for Top-N Termination
SELECT*FROMordersWHERETRUNC(order_dt)=(SELECTTRUNC(MAX(order_dt))FROMorders)ORDERBYorder_dt;
---------------------------------------------------------------------------|Id|Operation|E-Rows|A-Rows|Buffers|Reads|---------------------------------------------------------------------------|0|SELECTSTATEMENT||2057|695|695||1|SORTORDERBY|100K|2057|695|695||*2|VIEW|100K|2057|695|695||*3|WINDOWNOSORTSTOPKEY|100K|2057|695|695||4|TABLEACCESSBYINDEXROWID|100K|2058|695|695||5|INDEXFULLSCANDESCENDING|100K|2058|8|8|---------------------------------------------------------------------------DE
NSE_RANK

Window-Functions for Top-N Termination
---------------------------------------------------------------------------------|Id|Operation|E-Rows|A-Rows|Buffers|Reads|---------------------------------------------------------------------------------|0|SELECTSTATEMENT||2057|1038|694||1|SORTORDERBY|3448|2057|1038|694||2|TABLEACCESSBYINDEXROWIDBATCHED|3448|2057|1038|694||*3|INDEXRANGESCAN|3448|2057|10|8||4|SORTAGGREGATE|1|1|2|2||5|INDEXFULLSCAN(MIN/MAX)|1|1|2|2|---------------------------------------------------------------------------------
---------------------------------------------------------------------------|Id|Operation|E-Rows|A-Rows|Buffers|Reads|---------------------------------------------------------------------------|0|SELECTSTATEMENT||2057|695|695||1|SORTORDERBY|100K|2057|695|695||*2|VIEW|100K|2057|695|695||*3|WINDOWNOSORTSTOPKEY|100K|2057|695|695||4|TABLEACCESSBYINDEXROWID|100K|2058|695|695||5|INDEXFULLSCANDESCENDING|100K|2058|8|8|---------------------------------------------------------------------------DE
NSE_RANK
SUB-SELECT

Top-N vs. Max()-Subquery
Common mistakes:‣Breaking ties with sub-queries ☠ (bad) WHERE(a,b)=(selectmax(a),max(b)...)
➡ max() values coming from different rows... ➡ No rows selected.
‣Selecting Nth largest ☠ (bad) WHEREX<(SELECTMAX()...WHEREX<(SELECTMAX()...))
WHERE(N-1)=(SELECTCOUNT(DISTINCT(DT))...

It’s All About Matching Queries to Indexes
Two steps to get the absolutely best execution plan:
1. Maximize data-locality ‣ Plain old B-tree index is the #1 tool for that ‣ Partitions are greatly overrated ‣ Table clusters are slightly underrated
2. Write the query to exploit it ‣ Use explicit range conditions ‣ Use top-n based termination ‣ Exploit index order
Thinking in
OrderedSets
✓
✓
✓
✓ ✓

1. Maximize data-locality
Example:
List next 10 orders

Example:
List next 10 orders
2. Use explicit range condition & top-n abort 1. Lower bound: unbounded (top-n)2. Upper bound: where we stopped
WHEREORDER_DT<:prev_dt3. ORDERBYORDER_DTDESC
4. FETCHFIRST10ROWSONLY
What about ties?

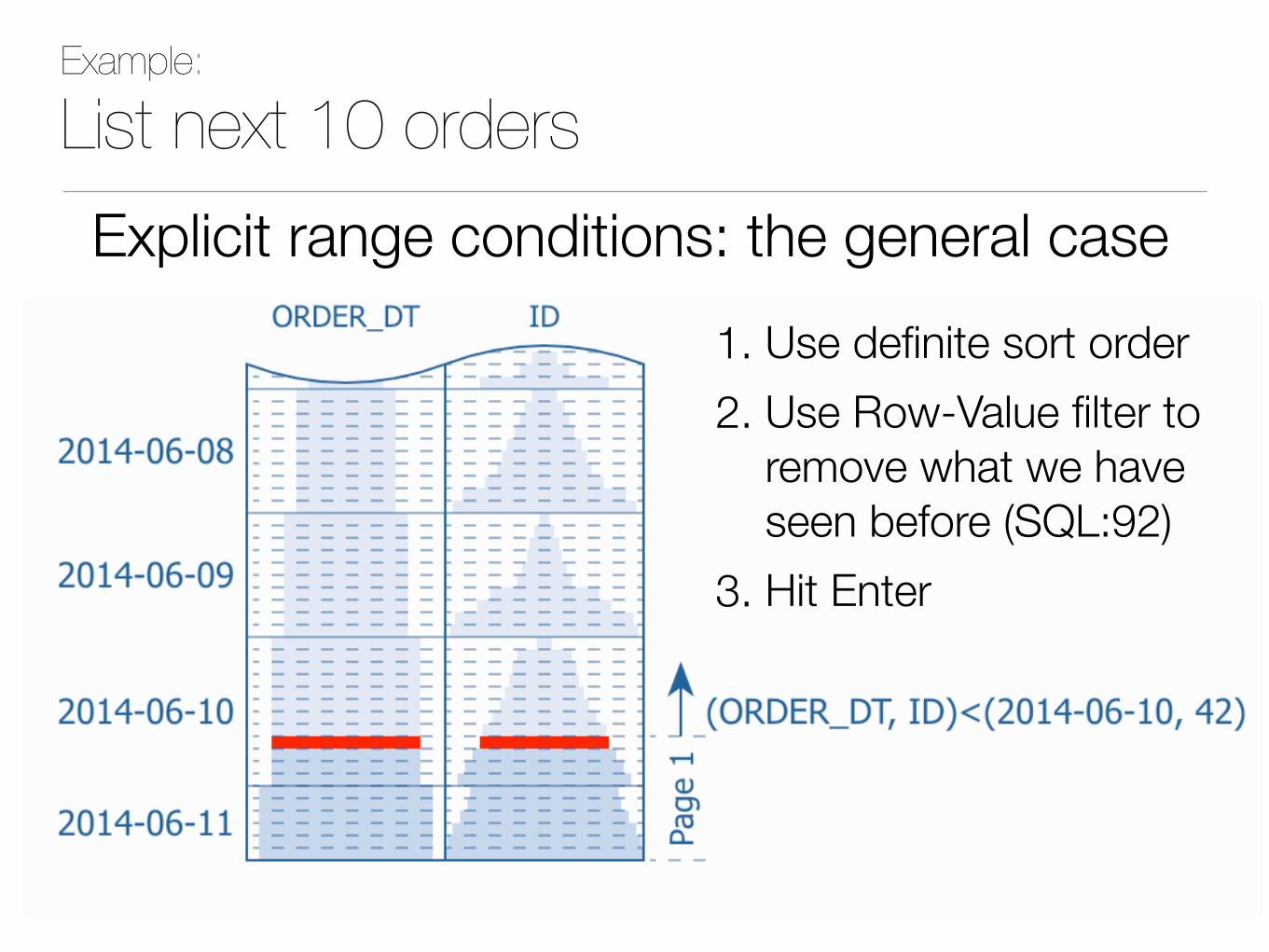
Explicit range conditions: the general case
Example:
List next 10 orders
Explicit range conditions: the general case
Example:
List next 10 orders
1. Use definite sort order 2. Use Row-Value filter to
remove what we have seen before (SQL:92)
3. Hit Enter

Explicit range conditions: the general case
Example:
List next 10 orders

Explicit range conditions: the general case
Example:
List next 10 orders
(x,y)=(a,b)
(x,y)IN((a,b),(c,d))
(x,y)<(a,b)
(x,y)>(a,b)
✓✓
✗
✗ Oracle
limitation

Explicit range conditions: the general case
Example:
List next 10 orders
Oracle
limitation
Two semantically equivalent workarounds:
X<=AANDNOT(X=AANDY>=B)
(X<A)OR(X=AANDY<B)
* http://use-the-index-luke.com/sql/partial-results/fetch-next-page#sb-equivalent-logic
☠No proper index use*

Using OFFSET to fetch next rows
‣After adding FETCHFIRST...ROWSONLY, with SQL:2008, SQL:2011 introduced OFFSET to skip rows.‣Rows can be skipped with the ROWNUM pseudo column too (ROWNUM>:x)‣ROW_NUMBER() can do the trick too.
It doesn’t matter how to write it, ...

Using OFFSET to fetch next rows
OFFSET = SLEEP The bigger the number,
the slower the execution. Even worse: it eats up resources
and yields drifting results.

It’s All About Matching Queries to Indexes
Two steps to get the absolutely best access path:
1. Maximize data-locality ‣ Plain old B-tree index is the #1 tool for that ‣ Partitions are greatly overrated ‣ Table clusters are slightly underrated
2. Write the query to exploit it ‣ Use explicit range conditions ‣ Use top-n based termination ‣ Exploit index order
Thinking in
OrderedSets
✓
✓
✓
✓ ✓✓


Index Smart, Not Hard

About @MarkusWinand‣Training for Developers ‣ SQL Performance (Indexing) ‣ Modern SQL ‣ On-Site or Online
‣SQL Tuning ‣ Index-Redesign ‣ Query Improvements ‣ On-Site or Online
http://winand.at/

About @MarkusWinand@ModernSQL
http://modern-sql.com@SQLPerfTips
http://use-the-index-luke.com


















