


Presentación Seminario Wormhole- Seminario Educación Digital- Noviembre 2012
Upload
federico-castanedo-sotelaCategory
view
608download
0
Del modelado de conocimiento en entornosAAL al descubrimiento de rutinas en redes
de sensores a gran escala
Federico [email protected] http://fcastanedo.com
@fcastanedo

Índice
1. Introducción a Inteligencia Ambiental
2. Modelado del Usuario: Problemas
3. Ámbitos de Aplicación y Técnicas
a)Ontologías
b)Probabilistic Topic Models● Latent Dirichlet Allocation (LDA)
4. Experimentos en Redes de Sensores
5. Conclusiones

Inteligencia Ambiental
~Smart Environments, Computación Ubicua, Pervasive Computing Modelado del usuario, Modelado del comportamiento ….
Entornos que que “aprenden” los hábitos/rutinas del usuario y son capaces de anticipar sus necesidades
Areas: Inteligencia Artificial, Machine Learning, estadística computacional … pero también redes, sistemas escalables, privacidad, etc...

Modelado del Usuario● Similar al problema de reconocimiento de actividades pero con
diferente escala temporal.
● Problemas: El comportamiento humano es cambiante por definición (Concept Drift).
● Problemas (II): Algoritmos escalables capaces de trabajar con información en tiempo real (Online Learning).
● Limitaciones: La mayoría de los trabajos se centran en varias horas o días.
● Limitaciones (II): Los experimentos se suelen realizar con simulaciones o bien utilizando datos ad-hoc.
● Se puede enfocar como un problema de Clasificación no Supervisada = = Clustering

Ámbitos de Aplicación y Técnicas● Web Content. (Low, 2011)
● Click-to-Ratio, Ads Prediction. (Ahmed, 2011)
● Correo Web. (Aberdeen, 2010)
● Fraude en las transacciones: https://siftscience.com/
● Entornos AAL
● Técnicas:
● Ontologías● Probabilistic Topic Models

Ontologías● Representación explícita del conocimiento del dominio.
● Permiten razonar utilizando lógica de primer orden.
● Limitaciones: Open World Assumption, conocimiento incierto, desconocido...
➔ TURAMBAR (Ausín, 2012)
Modelado/Razonamiento Ontológico + Redes Bayesianas
Similar a BayesOWL, Pronto

Probabilistic Topic Models● Métodos para organizar información de forma automática. Pasos:
1. Encuentran los patrones ocultos en los datos
2. Se anotan los documentos en función de los tópicos
3. Se usan las anotaciones para organizar, resumir o buscar en los textos
● Un tópico es una distribución de terminos de un vocabulario
● Representación: Modelo Gráfico Probabilístico
● Modelo Bayesiano Jerárquico
● Modelo generativo de ML
● Aprendizaje no supervisado

Latent Dirichlet Allocation (LDA)
Basado en LSA/LSI, pLSI
(Blei et. Al 2003)
Asume distribuciones de Dirichlet en las priors. Dirichlet es la conjugada de multinomial.


Solo se observan palabras.El objetivo es inferir las variables ocultas.Calcular la distribución condicionada en los documentos.
P (topics, proportions, assignments | documents)

Distribución de Dirichlet
● Es la distribución conjugada de la multinomial
● Una distribución posterior, se dice que sigue la dist. Dirichlet
● Si tiene la pdf
● Ej. Dir (1/2, 1/3, 1/6)
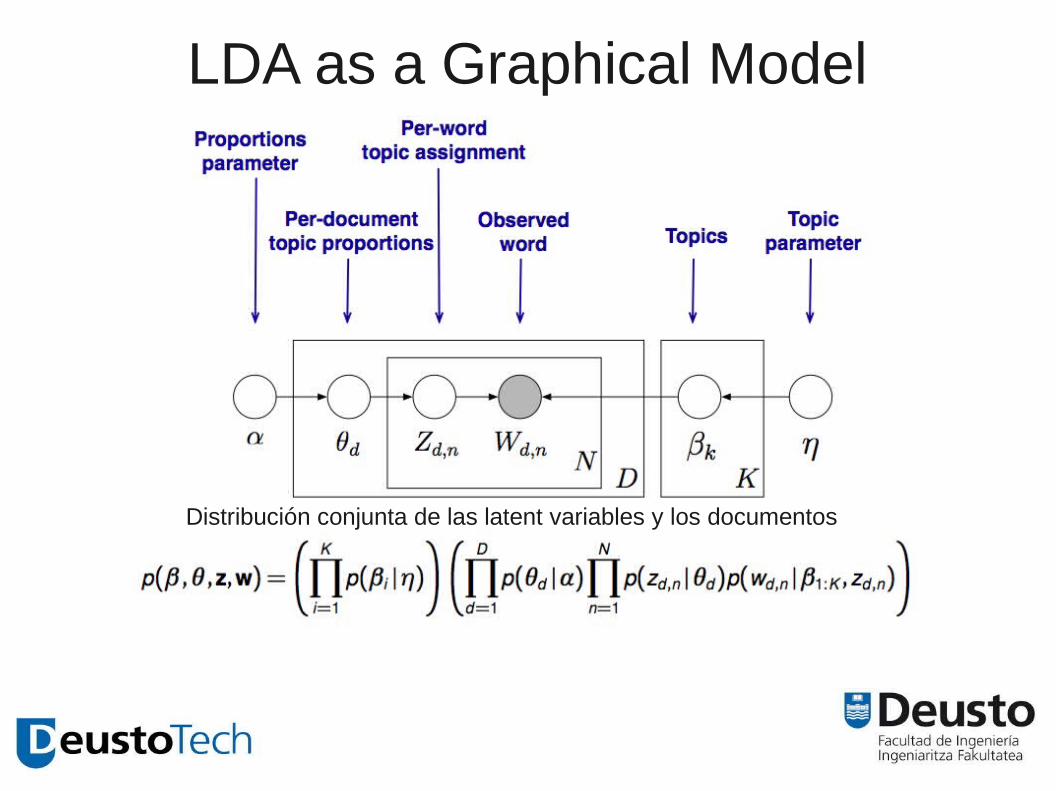
LDA as a Graphical Model
Distribución conjunta de las latent variables y los documentos

LDA
D documentos se representan como un sparse vector de |w| ocurrencias de las palabras de un vocabulario V.
Calcula la distribución de probabilidad de las palabras en cada latent topic.Las palabras que co-ocurren tienen gran probabilidad de aparecer juntas en la posterior.
Para cada documento → p (topic | document)
Para cada tópico → p (word | topic)
Para un corpus, infiere:
-Per-word topic assignment Z_d,n
-Per-document topic proportion \theta_d
-Per-corpus topic proportion \beta_k

Inferencia (entrenando el modelo)
Distribución conjunta de las latent variables y los documentos:
Posterior:
Aplicando Inferencia Bayesiana:
No se puede calcular el denominador de forma exacta. Es necesario utilizar métodos aproximados:
Gibbs Sampling, MCMC, Variational Inference....

¿Porque LDA “funciona”?
LDA busca 2 objetivos:
1. Para cada documento, utilizar sus palabras en el menor número de tópicos posible
2. Para cada tópico, asignar una alta probabilidad al menor número de palabras posibles
Son contradictorios:
-Poner un documento en un único tópico hace #2 díficil
Todas las palabras deben tener prob en ese tópico
-Poner pocas palabras en cada tópico hace #1 díficil
Para cubrir las palabras de un documento, se debe asignar a varios tópicos

Extensiones de LDA ● Correlated Topic Models (CTM)
● Dynamic Topic Models (DTM)
● Supervised Topic Models (sLDA)
● Relational Topic Models (rLDA)
● Hierarchical Topic Models (hLDA)

Experimentos en redes de sensores
● El objetivo es generar un modelo del uso y del comportamiento de las rutinas de los usuarios en una red de sensores a gran escala de una forma no supervisada.
● Usando únicamente sensores PIR. ¿Es posible generar un modelo de ocupación a largo plazo?
● Si consideramos el histórico de las activaciones de los sensores como un conjutno de documentos (corpus) compuestos de palabras, donde cada palabra representa un patrón de activación:

Experimentos (II)
● El problema se puede formular como:
● Descubrir el conjunto de tópicos de un corpus (conjunto de documentos) que serían el conjunto de rutinas.
● LDA asume el modelo Bag of Words. Las palabras son independientes entre sí y tienen la misma probabilidad de ocurrencia.
● En un entorno de trabajo se puede asumir una cierta distribución de las “palabras”.
● (1) 00:00 to 6:00, (2) 6:00 to 7:00, (3) 7:00 to 9:00, (4) 9:00 to 11:00, (5) 11:00 to 14:00, (6) 14:00 to 17:00, (7) 7:00 to 19:00, (8) 19:00 to 21:00 (9) 21:00 to 00:00.

Innotek
Marzo 2010 – Marzo 2011
Log room occupancy at 1 min freq
135 sensores. >3M activaciones
|V| = 38.880. |D| = 9.140

MERL
Marzo 2006 – Dic 2007
290 sensores. >30M activaciones
|V| = 83.520. |D| = 88.795

MERL vs INNOTEKO...Cambridge (US) vs Geel (Belgium)

Ejemplos Rutinas Innotek
T4. 1.02 ocupada 11:00-19:00 ~0.53T10. Relación entre 1.02 y 2.04T27. 0.06 ocupada entre 9:00-14:00 y libre entre 17:00-21:00T33. 1.06 1 minuto libre entre 7:00 y 9:00 y ocupada entre 14:00-15:00T18. 0.01 ocupada de forma constante de 9:00-19:00T35. 2.02 libre de 9:00-11:00 y ocupada al final del día

Ejemplos Rutinas MERL
T0. dejar el edificio entre 19:00-21:00, ocupar la sala de conf entre 17:00-19:00, alguien en la cocina entre 6:00-7:00 y el lobby ocupado entre 14:00-17:00.T375. Actividad cerca de las impresores de 6:00-11:00T643. Activaciones del sensor localizado en los baños entre 7:00-11:00

Conclusiones
● LDA es un modelo no supervisado que se puede aplicar con éxito en redes de sensores.
● A pesar de asumir independencia entre las palabras puede funcionar bien con suficientes datos.
● En aplicaciones reales es necesario utilizar modelos de inferencia online para entrenar el modelo.
● Multitud de variantes sobre el LDA básico.
● Una vez se tiene un modelo entrenado se puede utilizar para: predecir, optimizar energía, detectar desviaciones, etc...

Referencias
Y. Low, D. Agarwal, A. J. Smola. Multiple Domain User Personalization. KDD 2011.
A. Ahmed, Y. Low, M. Aly, V. Josifovsky, A. J. Smola. Scalable distributed inference of dynamic user interests for behavioral targeting. KDD 2011.
Aberdeen, Pacovsky, Slater.The Learning Behind Gmail Priority Inbox. 2010.
D. Ausín, F. Castanedo, D. López-de-Ipiña. TURAMBAR: An Approach to Deal with Uncertainty in Semantic Environments. IWAAL 2012.
D. Blei, A. Y. NG, M. I. Jordan. Latent Dirichlet Allocation. Journal of Machine Learning Research. 2003.
F. Castanedo, D. López-de-Ipiña, H. Aghajan, R. Kleihorst. Building an occupancy model from sensor networks in office environments. ICDSC. 2011.
F. Castanedo, D. López-de-Ipiña, H. Aghajan, R. Kleihorst. Learning Routines Over Long-Term Sensor Data Using Topic Models. Expert Systems. In Press. 2013.

Gracias por la atención¿Preguntas?
Credits Erik Degroof and Luc Peeters (Innotek Dataset)
Chris Wren and Yuri Ivanov (MERL Dataset)
LDA Figures taken from David Blei tutorials


















