

Semantic Web & Semantic Web Processes A course at Universidade da Madeira, Funchal, Portugal June...
80
Semantic Web & Semantic Web Processes A course at Universidade da Madeira, Funchal, Portugal June 16-18, 2005 Dr. Amit P. Sheth Professor, Computer Sc., Univ. of Georgia Director, LSDIS lab CTO/Co-founder, Semagix , Inc Special Thanks: Cartic Ramakrishnan , Karthik Gomadam
-
Upload
gwenda-turner -
Category
Documents
-
view
217 -
download
0
Transcript of Semantic Web & Semantic Web Processes A course at Universidade da Madeira, Funchal, Portugal June...

Semantic Web &
Semantic Web ProcessesA course at Universidade da Madeira, Funchal, Portugal
June 16-18, 2005
Dr. Amit P. ShethProfessor, Computer Sc., Univ. of Georgia
Director, LSDIS labCTO/Co-founder, Semagix, Inc
Special Thanks: Cartic Ramakrishnan, Karthik Gomadam

Agenda 1Part I
• What is Semantic Web? • What makes the Semantic web
• Ontologies – importance of relationships and knowledge• Representation and Languages
• Why XML is not enough • Describe semantic web resources- RDF and RDFS • OWL
• Query processing and storage Part II• Metadata, Enabling techniques and technologies
• Ontology and knowledge engineering: ontology design, ontology population maintaining, ontology freshness
• Automated metadata extraction and annotation• Computation and reasoning with focus on relationships• Example commercial Semantic Web platform

Agenda 2
Part III• Semantic web applications: search, integration, analysis
a. Pan-Web and consumer-centricb. Enterprise
Part IV• Semantic Web Services and Processes
• What are Web Services ?• What are Web processes ?• Creating Web processes: Annotation, discovery,
composition, etc.
• Semantic Web Service/Process tools

Part I• What is Semantic Web? • What makes the Semantic web
• Ontologies – importance of relationships and knowledge• Types and examples of ontologies
• Metadata and Semantic Annotation -- metadata classifications
• Representation and Languages • Why XML is not enough • RDF - Describe semantic web resources and RDFS - RDF
as a triple, RDF as a graph (show example RDF/S) • OWL
• RDF Query processing and storage

Three generation of Information Systems:Where we have come from, where we are going
, Semantic Web technologies and platforms, Semantic Web technologies and platforms
MediaAnywhereMediaAnywhereInfoQuilt, InfoQuilt,
OBSERVEROBSERVER
Semagix FreedomSemagix Freedom
Generation IIIGeneration III
2000s2000s
Semantics (Ontology, Context, Relationships, KB)
Metadata based integration, Mediator Metadata based integration, Mediator Systems, Digital LibrariesSystems, Digital Libraries
Generation IIGeneration II
1990s1990s
VisualHarnessVisualHarnessInfoHarnessInfoHarness
AdaptX/HarnessAdaptX/Harness
Metadata (Domain model)
MermaidMermaidDDTSDDTS
IntervisioIntervisio
Heterogeneous databases/Heterogeneous databases/Federated Databases ResearchFederated Databases Research
Generation IGeneration I
1980s1980s
Data (Schema, “semantic data modeling)

Gen. Purpose,Broad Based
Scope of AgreementTask/ App
Domain Industry
CommonSense
Degre
e o
f Ag
reem
en
t
Info
rmal
Sem
i-Form
al
Form
al
Agreement About
Data/Info.
Function
Execution
Qos
Broad Scope of Semantic (Web)
Technology
Oth
er d
ime
nsio
ns:
how
ag
reem
ents
are
re
ach
ed
,…
Current Semantic Web Focus
Semantic Web Processes
Lots of Useful
SemanticTechnology
(interoperability,Integration)
Cf: Guarino, Gruber

What is the Semantic Web?• "The Semantic Web is an extension of the current web in
which information is given well-defined meaning, better enabling computers and people to work in cooperation." -- Tim Berners-Lee, James Hendler, Ora Lassila, The Semantic Web, Scientific American, May 2001
• Ontologies• RDF/RDFS or OWL Syntax – machine
processable• Semantic Metadata – annotation of web
resources

“An ontology is a specification of a conceptualization” (T. Gruber)
• A conceptualization is the way we think about a domain
• A specification provides a formal way of writing it down
Building Ontologies from the Ground Up When users set out to model their professional activity – Mark Mussen

Conceptualization and Ontology
http://www.w3c.it/events/minerva20040706/guarino.pdf
Everything that can be expressed in the language
OntologyConstrainingPossible InterpretationsOf what can Be expressed

Central Role of Ontology• Ontology represents agreement, represents
common terminology/nomenclature• Ontology is populated with extensive domain
knowledge or known facts/assertions• Key enabler of semantic metadata extraction from
all forms of content:–unstructured text (and 150 file formats)–semi-structured (HTML, XML) and –structured data
• Ontology is in turn the center piece that enables–resolution of semantic heterogeneity –semantic integration–semantically correlating/associating objects and
documents

Types of Ontologies (or things close to ontology)• Upper ontologies: modeling of time, space, process, etc• Broad-based or general purpose ontology/nomenclatures: Cyc,
CIRCA ontology (Applied Semantics), SWETO, WordNet ; • Domain-specific or Industry specific ontologies
– News: politics, sports, business, entertainment– Financial Market– Terrorism– Pharma– GlycO, ProPreO– (GO (a nomenclature), UMLS inspired ontology, …), MGED
• Application Specific and Task specific ontologies– Anti-money laundering– Equity Research– Repertoire Management– Financial irregularity
Fundamentally different approaches in developing ontologies at the two end of the above spectrum

Building ontologyThree broad approaches:
• social process/manual: many years, committees
– Can be based on metadata standard
• automatic taxonomy generation (statistical clustering/NLP): limitation/problems on quality, dependence on corpus, naming
• Descriptional component (schema) designed by domain experts; Description base (assertional component, extension) using automated processes from trusted knowledge sources
Option 2 is being investigated in several research projects;
Option 3 is currently supported by Semagix Freedom

Part of the CYC Upper Ontology
http://www.cyc.com/cyc/technology/whatiscyc_dir/whatdoescycknow

SWETO (Semantic Web Testbed Ontology) Current Status
• Developed using Semagix technology for free non-commercial usage by the SW community; some initial users
• V1.4 population includes over 800,000 entities and over 1,500,000 explicit relationships among them
• Continue to populate the ontology with diverse sources thereby extending it in multiple domains, new smaller and larger release due soon; RDF and OWL versions
• Significant information for provenance/trust support [UMBC partnership]
• 97% of disambiguation performed automatically, 2% manually; not quite a high-quality as an evaluation testset (e.g., low connectivity)
• Working on test harness, quality measures, and benchmarks

Expressiveness Range: Knowledge Representation and Ontologies
Catalog/ID
GeneralLogical
constraints
Terms/glossary
Thesauri“narrower
term”relation
Formalis-a
Frames(properties)
Informalis-a
Formalinstance
Value Restriction
Disjointness, Inverse,part of…
SimpleTaxonomies
Expressive
Ontologies
Wordnet
CYCRDF DAML
OO
DB Schema RDFS
IEEE SUOOWL
UMLS
GO
KEGG TAMBIS
EcoCyc
BioPAX
GlycOSWETO
Pharma
Ontology Dimensions After McGuinness and FininOntology Dimensions After McGuinness and Finin

Gene Ontology (GO)
• Comprises three independent “ontologies”– molecular function of gene products– cellular component of gene products– biological process representing the gene product’s
higher order role.• Uses these terms as attributes of gene products in the
collaborating databases (gene product associations)• Allows queries across databases using GO terms, providing
linkage of biological information across species
http://www.geneontology.org/

GO = Three OntologiesGO = Three Ontologies
• Molecular Function – elemental activity or task– example: DNA binding
• Cellular Component – location or complex– example: cell nucleus
• Biological Process – goal or objective within cell– example: secretion
http://www.geneontology.org/

GlycO GlycOGlycO: a domain Ontology embodying knowledge of the
structure and metabolisms of glycans Contains 770 classes – describe structural features of
glycans URL: http://lsdis.cs.uga.edu/projects/glycomics/glyco is a
focused ontology for the description of glycomics
• models the biosynthesis, metabolism, and biological relevance of complex glycans
• models complex carbohydrates as sets of simpler structures that are connected with rich relationships

GlycO statistics: Ontology schema can be large and complex
• 770 classes• 142 slots• Instances Extracted with Semagix Freedom:
– 69,516 genes (From PharmGKB and KEGG)– 92,800 proteins (from SwissProt)– 18,343 publications (from CarbBank and MedLine)– 12,308 chemical compounds (from KEGG)– 3,193 enzymes (from KEGG)– 5,872 chemical reactions (from KEGG)– 2210 N-glycans (from KEGG)

GlycO taxonomyThe first levels of the GlycO taxonomy
Most relationships and attributes in GlycO
GlycO exploits the expressiveness of OWL-DL.Cardinality constraints, value constraints, Existential and Universal restrictions on Range and Domain of properties allow the classification of unknown entities as well as the deduction of implicit relationships.

Query and visualization

A biosynthetic pathwayGNT-I
attaches GlcNAc at position 2
UDP-N-acetyl-D-glucosamine + alpha-D-Mannosyl-1,3-(R1)-beta-D-mannosyl-R2 <=>
UDP + N-Acetyl-$beta-D-glucosaminyl-1,2-alpha-D-mannosyl-1,3-(R1)-beta-D-mannosyl-$R2
GNT-Vattaches GlcNAc at position 6
UDP-N-acetyl-D-glucosamine + G00020 <=> UDP + G00021
N-acetyl-glucosaminyl_transferase_VN-glycan_beta_GlcNAc_9N-glycan_alpha_man_4

The impact of GlycO
• GlycO models classes of glycans with unprecedented accuracy
• Implicit knowledge about glycans can be deductively derived
• Experimental results can be validated according to the model

N-GlycosylationN-Glycosylation ProcessProcess (NGPNGP)Cell Culture
Glycoprotein Fraction
Glycopeptides Fraction
extract
Separation technique I
Glycopeptides Fraction
n*m
n
Signal integrationData correlation
Peptide Fraction
Peptide Fraction
ms data ms/ms data
ms peaklist ms/ms peaklist
Peptide listN-dimensional arrayGlycopeptide identificationand quantification
proteolysis
Separation technique II
PNGase
Mass spectrometry
Data reductionData reduction
Peptide identificationbinning
n
1
By N-glycosylation Process, we mean the
identification and quantification of
glycopeptides

ProPreO models the phases of proteomics experiment using five fundamental concepts: DataData: (Example: a peaklist file from ms/ms raw data)
Data_processing_applicationsData_processing_applications: (Example: MASCOT* search engine)
HardwareHardware: embodies instrument types used in proteomics (Example: ABI_Voyager_DE_Pro_MALDI_TOF)
Parameter_listParameter_list: describes the different types of parameter lists associated with experimental phases
TaskTask: (Example: component separation, used in chromatography)
ProPreOProPreO - Experimental Proteomics - Experimental Proteomics Process OntologyProcess Ontology
*http://www.matrixscience.com/

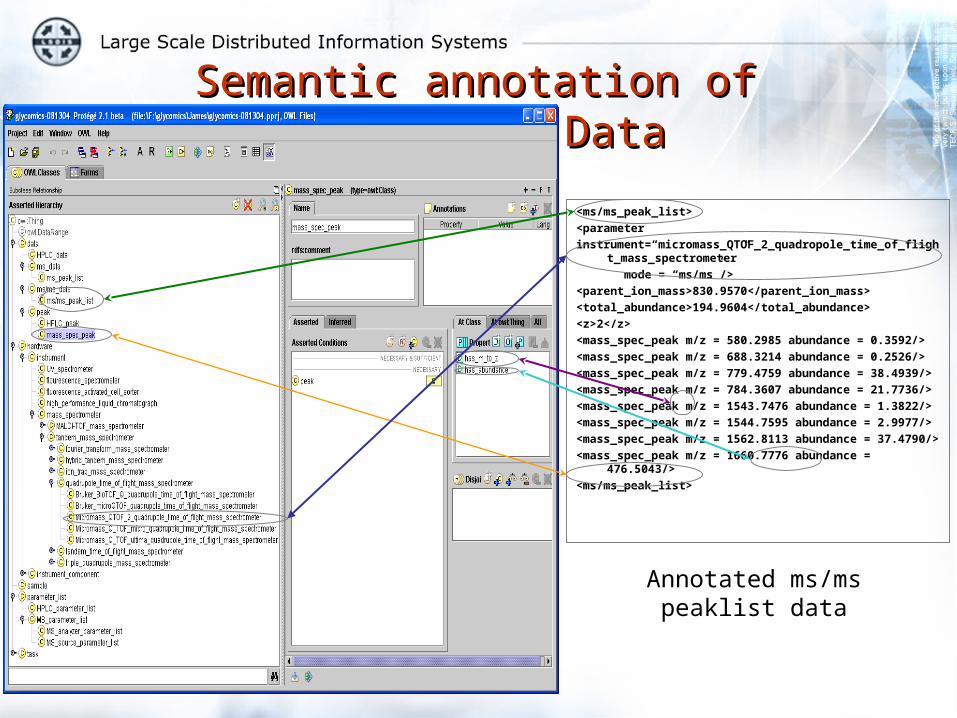
Semantic Annotation of Scientific DataSemantic Annotation of Scientific Data
830.9570 194.9604 2580.2985 0.3592688.3214 0.2526
779.4759 38.4939784.3607 21.77361543.7476 1.38221544.7595 2.9977
1562.8113 37.47901660.7776 476.5043
ms/ms peaklist data
<ms/ms_peak_list>
<parameter instrument=micromass_QTOF_2_quadropole_time_of_flight_mass_spectrometer
mode = “ms/ms”/>
<parent_ion_mass>830.9570</parent_ion_mass>
<total_abundance>194.9604</total_abundance>
<z>2</z>
<mass_spec_peak m/z = 580.2985 abundance = 0.3592/>
<mass_spec_peak m/z = 688.3214 abundance = 0.2526/>
<mass_spec_peak m/z = 779.4759 abundance = 38.4939/>
<mass_spec_peak m/z = 784.3607 abundance = 21.7736/>
<mass_spec_peak m/z = 1543.7476 abundance = 1.3822/>
<mass_spec_peak m/z = 1544.7595 abundance = 2.9977/>
<mass_spec_peak m/z = 1562.8113 abundance = 37.4790/>
<mass_spec_peak m/z = 1660.7776 abundance = 476.5043/>
<ms/ms_peak_list>
Annotated ms/ms peaklist data
Semantic annotation of Scientific Semantic annotation of Scientific DataData
Annotated ms/ms peaklist data
<ms/ms_peak_list>
<parameter
instrument=“micromass_QTOF_2_quadropole_time_of_flight_mass_spectrometer”
mode = “ms/ms”/>
<parent_ion_mass>830.9570</parent_ion_mass>
<total_abundance>194.9604</total_abundance>
<z>2</z>
<mass_spec_peak m/z = 580.2985 abundance = 0.3592/>
<mass_spec_peak m/z = 688.3214 abundance = 0.2526/>
<mass_spec_peak m/z = 779.4759 abundance = 38.4939/>
<mass_spec_peak m/z = 784.3607 abundance = 21.7736/>
<mass_spec_peak m/z = 1543.7476 abundance = 1.3822/>
<mass_spec_peak m/z = 1544.7595 abundance = 2.9977/>
<mass_spec_peak m/z = 1562.8113 abundance = 37.4790/>
<mass_spec_peak m/z = 1660.7776 abundance = 476.5043/>
<ms/ms_peak_list>

Syntax for Onologies and Metadata• Why not use XML?• Why use OWL?• Or for that matter why RDF?• So many questions …

• XML – surface syntax for structured documents– imposes no semantic constraints on the meaning of these documents.
• XML Schema – is a language for restricting the structure of XML documents.
• RDF – is a datamodel for objects ("resources") and relations between them, – provides a simple semantics for this datamodel– these datamodels can be represented in an XML syntax.
• RDF Schema – is a vocabulary for describing properties and classes of RDF resources – with a semantics for generalization-hierarchies of such properties and classes.
• OWL – adds more vocabulary for describing properties and classes:
• relations between classes (e.g. disjointness), • cardinality (e.g. "exactly one"), • equality, richer typing of properties, • characteristics of properties (e.g. symmetry), and enumerated classes.
From XML to OWL
Exp
ressive Po
wer
http://en.wikipedia.org/wiki/Semantic_web#Components_of_the_Semantic_Web
NO SEMANTICS
Relationships as first class objects– key to Semantics
SEMANTICS

From an alphabet to a Language• XML
– “XML is only the first step to ensuring that computers can communicate freely. XML is an alphabet for computers and as everyone traveling in Europe knows, knowing the alphabet doesn’t mean you can speak Italian of French.” – Business Week, March 18th 2002
– Example cited by Nicola Guarino in http://www.w3c.it/events/minerva20040706/guarino.pdf
• RDF/RDFS and OWL would therefore be akin to the language computers use to communicate
• And ontologies represented in these languages would be akin to the exact interpretations of the concepts being communicated

Syntax for Onologies and Metadata• RDF
– A simple W3C standard used to describe Web resources
– Relationships in RDF (Properties), are binary relationships between two resources or a resource and a literal
– Resources take on the roles of Subject and Object respectively.
– The Subject, Predicate and Object compose an RDF statement
http://www.w3.org/RDF/

What is RDF?
• Resource Description Framework• Proposed as the base semantic web
language• Data model for describing properties of
resources• Statements about properties and values of
web resources• Machine-understandable metadata

RDF Elements
• Resource: – Something that can be described/referenced– Identified by a URI
• Property:– Relationship from a resource to a value:
• Another resource• An atomic value/literal
• Statement:– resource -> property -> value

RDF Statement

RDF Model
• Formal Data Model– Directed labeled graph
• Nodes: resources or literals• Edges: properties (relationships/attributes)• Labels: URIs of nodes and edges
– Collection of triples• subject (resource)• predicate (property)• object (resource or literal)
• W3C recommendation

Graph Model

Triple Model
Subject Predicate Object
Shaguille O’Neal plays_for Miami Heat
Kobe Bryant plays_for LA Lakers
LA Lakers competes_with Miami Heat
Phil Jackson coaches LA Lakers

RDF Syntax
• Formal syntax• Encoded in XML• Unambiguous property names and values• RDF adds rules for interpretation• W3C recommendation

Example
<sample:Athlete rdf:about="&sample;Kobe_Bryant"> <rdfs:label xml:lang="en">Kobe Bryant</rdfs:label> <sample:plays_for rdf:resource="&sample;LA_Lakers"/></sample:Athlete><sample:Athlete rdf:about="&sample;Shaquille_ONeal"> <rdfs:label xml:lang="en">Shaquille O'Neal</rdfs:label> <sample:plays_for rdf:resource="&sample;Miami_Heat"/></sample:Athlete><sample:Team rdf:about="&sample;LA_Lakers" <rdfs:label xml:lang="en">LA Lakers</rdfs:label></sample:Team><sample:Team rdf:about="&sample;Miami Heat" <rdfs:label xml:lang="en">Miami Heat</rdfs:label> <sample:competes_with rdf:resource="&sample;LA_Lakers"/></sample:Team><sample:Coach rdf:about="&sample;sample1_Instance_8" <rdfs:label xml:lang="en">sample1_Instance_8</rdfs:label> <sample:coaches rdf:resource="&sample;LA_Lakers"/></sample:Coach>

What is RDFS?
• RDF Vocabulary Description Language • (RDF Schema)• Extension of RDF: same data model
– graph or triples
• A hierarchy of classes • A hierarchy of properties relating classes• W3C recommendation

RDF Schema
RDF Instances

&r4
&r8
&r2
BankAccount
no
FFlyer
Payment
paidby
typeOf(instance)
subClassOf(isA)
subPropertyOf
paidby
“Marwan”
“Al-Shehhi”
&r7
&r1
fname
lname
purchased
purchased
“M’mmed”
“Atta”
Ticket
Flight
forflight
String
num
ber
purchased
Client
fnameln
ame
String
String
Passenger
FFNo
String
Customer
Cash
ffliernocr
edite
dto
fflie
rno
creditedto
paidby
holder
&r9
float
amountpu
rcha
sed
for
&r5 &r6
purchased
for
CCard
fname
lname
“Abdulaziz ”
“Alomari ”
fname
lname
“XYZ123”
&r3
String
ffid
ffid
&r11
holder
paidby
holder

RDFS Core Classes
• rdfs:Class– Class of resources that are RDF classes– Instance of rdfs:Class
• rdfs:Resource– All things being described– The class type of everything in RDF(S)– Instance of rdfs:Class
• rdf:Property– Class of RDF properties– Instance of rdfs:Class
http://www.w3.org/TR/rdf-schema/

RDFS Core Properties
• rdfs:type– A resource is an instance of a class– Instance of rdf:Property
• rdfs:subClassOf– All instances of a class are also instances of another
class– Instance of rdf:Property
• rdfs:subPropertyOf– All resources related by one property are also related by
another property– Instance of rdf:Property

RDF Core Properties
• rdfs:range– All values of a property are instances of one or more
class• The value MUST be an instance of all range classes
– Instance of rdf:Property
• rdfs:domain– All resources with the given property are instances of
one or more class• The resource MUST be an instance of all domain classes
– Instance of rdf:Property

OWL, W3C definition
• “language for defining structured, Web-based ontology
which enables richer integration and interoperability of data across application boundaries”
http://www.w3.org/2004/OWL/

OWL Use Cases
• Web portals• Multimedia Collections• Corporate web site management• Design documentation• Agents and services• Ubiquitous computing

OWL Design Goals
• Shared ontologies• Ontology evolution• Ontology interoperability• Inconsistency detection• Expressivity vs. scalability• Ease of use• Compatibility with other standards• Internationalization

What’s in OWL, but not in RDF
• Ability to be distributed across many systems– By means of owl:imports (similar to ‘include’ in
C/C++)
• Scalable to Web needs (?)• Compatible with Web standards for:
– accessibility, and– Internationalization
• Open and extensible

OWL open and extensible
• RDF Schema (meta-modeling facilities, i.e. classes of classes)
• OWL Full• OWL DL (Description Logics)
• OWL Lite– targeting tool builders

owl:Class
• Sub class of Class in RDF
• Better to forget about classes of classes
• Top-most class: owl:Thing

OWL Properties
ObjectProperties
Ana owns Cuba
Is range aliteral / typed value ?
then ERROR
Data typeProperties
Ana age 25
• XML Schema data types supported– DB people happy

Transitivity of properties
X p1 YY p1 Z
implies X p1 Z
• Transitivity existed already in RDF– “subClassOf”, and “subPropertyOf”
• Example: located_in GeorgiaAtlantalocated_in U.S.A.located_in
located_in

Symmetric properties
X p1 Y
implies X p1 Y
PortugalSpainhas_border_with
SpainPortugalhas_border_with

Functional Properties
X p1 Y X p1 Z
imply Z is the same as Y (they describe the same)
• example, p1 = has_name
&r1Portugalhas_capital
&r2Portugalhas_capital
Result: &r1 and &r2 represent the same entity

Inverse Functional Properties
Y p1 AZ p1 A
imply Z is the same as Y(they describe the same)
• example, p1 = has_email
[email protected]&r1:Tim Fininhas_email
&r2:Timothy Fininhas_email
Result: &r1 and &r2 represent the same entity

OWL Cardinality
• min Cardinality• max Cardinality
• “Cardinality”– When min = max
• has Value– belongs to the class if it has the value

OWL Tools
• Pellet (umd.edu)
– DLbased reasoner implemented in Java
• Euler– an inference engine supporting logic based
proofs. Finds out whether a given set of facts support a given conclusion
• FaCT (Ian Horrocks)
– DL classifier that can also be used for modal logic satisfiability testing

RDF Storages
• Jena• Sesame• Redland• Triple• 3store• RDFSuite• RDFStore• Kowari• Yars• Brahms
developed at LSDIS
• Variety of available storages
• Different APIs and languages
• Support from RDF to OWL-full– even reasoning
• Storage and query approach: graph Vs. triple-centric
http://www.w3.org/2001/sw/Europe/reports/rdf_scalable_storage_report/

Jena
• Implemented in Java by HP Laboratories• Support for RDF, RDFS and OWL• Reasoning / inference engine• Support for reified statements• In-memory and persistent storage
(Oracle, MySQL, PostgreSQL)
• Query language: RDQL, SPARQL• Read/write RDF in RDF/XML, N3 and N-Triples
format• Triple-centric organization and API
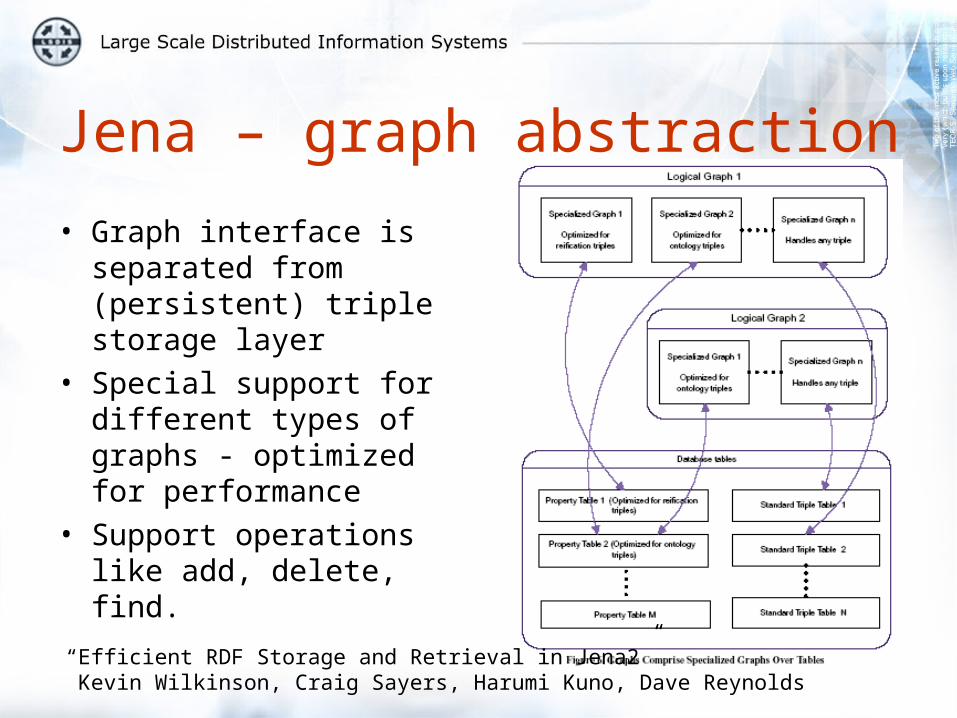
Jena – graph abstraction
• Graph interface is separated from (persistent) triple storage layer
• Special support for different types of graphs - optimized for performance
• Support operations like add, delete, find.
“Efficient RDF Storage and Retrieval in Jena2” Kevin Wilkinson, Craig Sayers, Harumi Kuno, Dave Reynolds

Jena – query processing• Converting multiple patterns in query into one query
to DB• Use DB query optimizer instead of executing multiple
queries from Jena level• Cluster properties that are likely to be accessed
together - optimize for common patterns• Associate a table with pattern (best) or span pattern
between tables (requires join operation)• Query may span between different graphs, but it can
be optimized only if they are in the same database

Redland, Rasqual, Raptor
• Storage for RDF triples - do not implement any language by itself
• This is the main module to include in RDF manipulation system
• Implemented in pure C for portability• Rich API enables to build modules on top of it • Rasqual - RDF query module
– RDQL– SPARQL
• Raptor - a fast RDF parser

Redland
• API available in different languages– C, C#, Java, Perl, Python, PHP, Ruby, Tcl
• API for manipulating– triples, URI/literals, graphs
• Portable - can built in most OSes• Scalable to handle millions of triples
– while using of persistent storage– but indexing is very space-consuming
• Support for context and hierarchy of models

Redland - model
• Abstraction of model to support different storages
• In-memory and persistent models– BerkeleyDB, 3store,
MySQL
• Rich, triple-centric API
„The Design and Implementation of the Redland RDF Application Framework” - David Beckett

Sesame
• Implemented in Java• Database independent
– idea of SAIL (Storage Abstraction Interface Layer)
• Scalable architecture• Implementation of remote models
– can query different models over network
• Graph-centric approach• Language: RQL
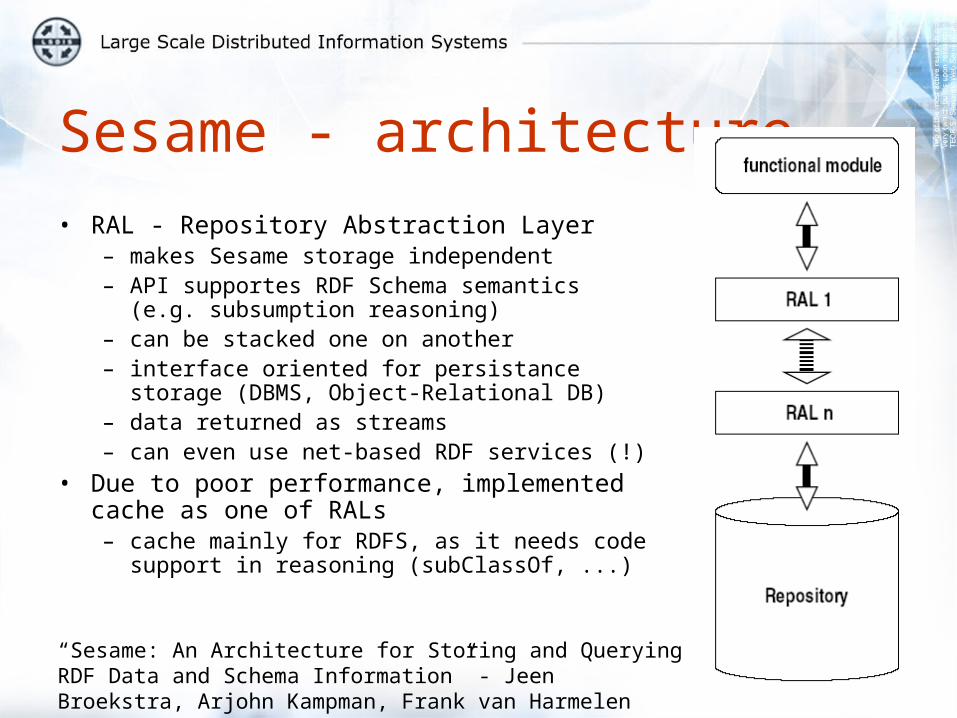
Sesame - architecture• RAL - Repository Abstraction Layer
– makes Sesame storage independent– API supportes RDF Schema semantics (e.g.
subsumption reasoning)– can be stacked one on another– interface oriented for persistance storage
(DBMS, Object-Relational DB)– data returned as streams– can even use net-based RDF services (!)
• Due to poor performance, implemented cache as one of RALs– cache mainly for RDFS, as it needs code
support in reasoning (subClassOf, ...)
“Sesame: An Architecture for Storing and QueryingRDF Data and Schema Information” - Jeen Broekstra, Arjohn Kampman, Frank van Harmelen

Sesame – query module
• Query module– query plan and optimizer similar to already
known DB solutions– query is translated to a set of simple RAL calls– each leaf of the query plan can ‘evaluate itself’
and pull data from RAL– data are returned as streams– lack of optimization on storage level

Brahms
• Implemented in C++ (bindings for Java also available)
• Graph-centric approach• Designed to support large in-memory RDF graphs• Optimized for speed and memory usage
– other storages do not offer optimized in-memory implementation for large graphs
– only main memory offers fastest access - usage of persistent storage decreases performance
• In-memory storage with fast precomputed graph snapshot loading– minimize cold-start time

Brahms• Framework for fast discovery of long association
paths in large RDF bases– memory and CPU intense algorithms
• Rich API, but no query language supported– higher level query languages do not support variable
length association path queries– association path discovery algorithms operate on low-
level graph API• Overperformed Jena, Sesame and Redland during
tests for association discovery– also was able to work efficiently on much larger in-
memory graphs than other storages did not handle
“BRAHMS: A WorkBench RDF Store And High Performance Memory System for Semantic Association Discovery” (Technical report) - Maciej Janik, Krys Kochut

Why RDF languages?
• Find resources based on predicates, values, labels or associations
• SQL is not good for querying RDF data– different models: relational and graph
• XML query languages cannot deal with graph data
• Syntactic approach is not enough• Required semantic querying• Inferencing is desirable

Available query languages
• RQL• RDQL• SeRQL • Triple• SPARQL – (latest)• SquishQL• Versa• N3• RxPath• RDFQL
• Majority of languages have roots in SQL
• No single standard as SQL
• Some languages are tightly coupled with specific storages

RQL
• Based on OQL• Utilizes functional approach with support for
generalized path expressions– both nodes and edges can become variables
• Not completely compatible with RDF specification – has some additional restrictions
• Return bindings to variables (no closure)• Implemented in RDFSuite and partially in Sesame
select Res from {Res} ns:label {x} where x=“foo” using namespace ns=…
“RQL: A Declarative Query Language for RDF” - Greg Karvounarakis, Sofia Alexaki, Vassilis Christophides, Dimitris Plexousakis, Michel Scholl
Maciek
Examle of difference in specification:property must have EXACTLY one range and domain, whereas in RDF it is not set

RDQL
• SQL-like syntax– easy to adopt for DB users
• Can specify patterns of triples to select• Schema is not interpreted• Not closed under queries
– output as bindings to selected variables
• Implemented in Jena
select ?p, ?q where (?p <rdfs:label> “foo”) (?p <rdf:type> ?q)
“RDQL - A Query Language for RDF” (W3C Member Submission) - Andy Seaborne (HP Labs Bristol)

SeRQL
• Sesame RDF Query Language• Based on RQL and RDQL• Support for generalized path expressions
and optional matching• Query filters
– select-from-where – return variable bindings and is not closed
– construct-from-where – return matching subgraph that can be queried (closure)
“SeRQL: Sesame RDF query language” - Jeen Broekstra

Triple
• Derived from F-logic– should be easy to adopt for logic programmers
• Triples are logic expressions– S [ P O ]
• Queries and triples have the same logic representation
• Reasoning is a part of language• Does not fulfill closure property• Implemented in Triple system
FORALL X <- ( X[rdfs:label -> “foo”] )@default:ln.
“TRIPLE - A Query, Inference, and Transformation Language for the Semantic Web” - Michael Sintek, Stefan Decker

SPARQL• W3C effort to standarize query language
– best experience and requirements from different languages (like RQL, RDQL)
• Based on matching graph patterns– triples, paths, subgraphs– optional blocks and matching– matching alternatives (union) and disjunction
• Many additional operators– grouping, sorting, limit results
PREFIX foaf: <http://xmlns.com/foaf/0.1/>SELECT ?name ?mbox WHERE { ?x foaf:name ?name . OPTIONAL { ?x foaf:mbox ?mbox } }
“SPARQL Query Language for RDF” (W3C Working Draft) - Eric Prud'hommeaux , Andy Seaborne

Sample path query
“A Comparison of RDF Query Languages” - Peter Haase, Jeen Broekstra, Andreas Eberhart, Raphael Volz

Expressive power of RDF languages
“Ontology Storage and Querying” (Technical Rreport No 308) - Aimilia Magkanaraki et al.


















