
Semantic Annotation of Medical Images€¦ · Semantic Annotation of Medical Images Sascha...
8
Semantic Annotation of Medical Images Sascha Seifert a , Michael Kelm a , Manuel Moeller b , Saikat Mukherjee c , Alexander Cavallaro d , Martin Huber a , and Dorin Comaniciu c a Integrated Data Systems, Siemens Corporate Technology, Erlangen, Germany, b German Research Center for Artificial Intelligence, Kaiserslautern, Germany, c Integrated Data Systems, Siemens Corporate Research, Princeton, NJ, USA, d University Hospital, Erlangen, Germany. ABSTRACT Diagnosis and treatment planning for patients can be significantly improved by comparing with clinical images of other patients with similar anatomical and pathological characteristics. This requires the images to be annotated using common vocabulary from clinical ontologies. Current approaches to such annotation are typically manual, consuming extensive clinician time, and cannot be scaled to large amounts of imaging data in hospitals. On the other hand, automated image analysis while being very scalable do not leverage standardized semantics and thus cannot be used across specific applications. In our work, we describe an automated and context-sensitive workflow based on an image parsing system complemented by an ontology-based context-sensitive annotation tool. An unique characteristic of our framework is that it brings together the diverse paradigms of machine learning based image analysis and ontology based modeling for accurate and scalable semantic image annotation. Keywords: image parsing, ontological modeling, semantic image annotation 1. INTRODUCTION The clinicians today deeply rely on images for screening, diagnosis, treatment planning and follow up. Due to the huge amount of medical images acquired at the hospitals, new technologies for image search are needed. Current systems only support indexing these images by keywords which cannot be searched and retrieved for their content. The vision of THESEUS-MEDICO is to provide Web 3.0 technologies to perform semantic search in medical image databases taking formal knowledge from ontologies and the image content into account. A potential scenario could be to list all images from patients with lymphoma, which have not been staged yet. Classical search will fail in this scenario, while semantic search could provide the clinician with a ranked list of images, showing enlarged lymph nodes and an involvement of spleen lesions. With the reasoning facilities of the ontology, search queries can also be expanded, 1 such that the search for ’lymphatic system’ results in images labeled with ’spleen’, ’thymus’ or ’lymph node’. With standards such as DICOM SR (structured reports), some commercial systems already started to use ontologies, mostly SNOMED, to label medical images. However, this makes structured reporting necessary, which is not accepted by clinicians yet due to higher efforts compared to conventional natural language reporting and missing automatic tools. The hybrid solution proposed in MEDICO consists of an image parsing system which automatically detects landmarks, segments organs, and maps them to ontological concepts and a context-sensitive annotation tool for the clinician. 2. METHODS 2.1 System Architecture The MEDICO system shows a 3-tier server architecture (see Figure 1). The central processing unit is the Medico Server, which links up all the system modules using CORBA * and socket connections. It mediates the access to the data layer, amongst others to an image and report database, e.g., PACS and RIS system, and provides the data displayed in the presentation layer. The Imaging Client provides an intuitive graphical interface for the clinician to semantically annotate images and formulate queries. It currently builds on the open-source framework MITK 2 but can easily be replaced by another client application. The Anatomy Browser gives easy access to the Foundational Model of Anatomy 3 * CORBA is a trademark of the Object Management Group, Inc. http://www.corba.org
Transcript of Semantic Annotation of Medical Images€¦ · Semantic Annotation of Medical Images Sascha...

Semantic Annotation of Medical Images
Sascha Seiferta, Michael Kelma, Manuel Moellerb, Saikat Mukherjeec, Alexander Cavallarod,Martin Hubera, and Dorin Comaniciuc
aIntegrated Data Systems, Siemens Corporate Technology, Erlangen, Germany, bGerman Research Center for Artificial
Intelligence, Kaiserslautern, Germany, cIntegrated Data Systems, Siemens Corporate Research, Princeton, NJ, USA, d
University Hospital, Erlangen, Germany.
ABSTRACT
Diagnosis and treatment planning for patients can be significantly improved by comparing with clinical images ofother patients with similar anatomical and pathological characteristics. This requires the images to be annotatedusing common vocabulary from clinical ontologies. Current approaches to such annotation are typically manual,consuming extensive clinician time, and cannot be scaled to large amounts of imaging data in hospitals. On theother hand, automated image analysis while being very scalable do not leverage standardized semantics and thuscannot be used across specific applications. In our work, we describe an automated and context-sensitive workflowbased on an image parsing system complemented by an ontology-based context-sensitive annotation tool. Anunique characteristic of our framework is that it brings together the diverse paradigms of machine learning basedimage analysis and ontology based modeling for accurate and scalable semantic image annotation.
Keywords: image parsing, ontological modeling, semantic image annotation
1. INTRODUCTION
The clinicians today deeply rely on images for screening, diagnosis, treatment planning and follow up. Due tothe huge amount of medical images acquired at the hospitals, new technologies for image search are needed.Current systems only support indexing these images by keywords which cannot be searched and retrieved fortheir content. The vision of THESEUS-MEDICO is to provide Web 3.0 technologies to perform semantic searchin medical image databases taking formal knowledge from ontologies and the image content into account. Apotential scenario could be to list all images from patients with lymphoma, which have not been staged yet.Classical search will fail in this scenario, while semantic search could provide the clinician with a ranked list ofimages, showing enlarged lymph nodes and an involvement of spleen lesions. With the reasoning facilities of theontology, search queries can also be expanded,1 such that the search for ’lymphatic system’ results in imageslabeled with ’spleen’, ’thymus’ or ’lymph node’. With standards such as DICOM SR (structured reports), somecommercial systems already started to use ontologies, mostly SNOMED, to label medical images. However, thismakes structured reporting necessary, which is not accepted by clinicians yet due to higher efforts compared toconventional natural language reporting and missing automatic tools. The hybrid solution proposed in MEDICOconsists of an image parsing system which automatically detects landmarks, segments organs, and maps themto ontological concepts and a context-sensitive annotation tool for the clinician.
2. METHODS
2.1 System Architecture
The MEDICO system shows a 3-tier server architecture (see Figure 1). The central processing unit is the MedicoServer, which links up all the system modules using CORBA∗ and socket connections. It mediates the access tothe data layer, amongst others to an image and report database, e.g., PACS and RIS system, and provides thedata displayed in the presentation layer.
The Imaging Client provides an intuitive graphical interface for the clinician to semantically annotate imagesand formulate queries. It currently builds on the open-source framework MITK2 but can easily be replacedby another client application. The Anatomy Browser gives easy access to the Foundational Model of Anatomy3
∗CORBA is a trademark of the Object Management Group, Inc. http://www.corba.org

DataRepository
NavigationSupport
ContextSupport
Image ParsingSystem
MedicoOntology
AnnotationDatabase
Image &Report
Database
Medico Server
Pre
senta
tion
IIOPTCP/IP http
Imaging Client Query InterfaceAnatomy Browser
IIOP
IIOP
Meta Data
Applic
atio
nD
ata
Acc
ess
SesameSharesRDF triples
services
Figure 1. Overall architecture of the MEDICO system.
(FMA) ontology and is controlled by the Imaging Client and enables fast navigation in CT volumes. Additionally,if configured for Apache Tomcat† the server will support a web based Query Interface.
Currently, the server makes use of three services for semantic annotation:
• The Image Parsing System (see section 2.2) automatically detects anatomical structures in CT volumesand maps them to concept labels coming from the Medico Ontology.
• The Context Support Service implements spatial reasoning which enables the filtering of concepts for theinteractive semantic reporting on the basis of image-based contextual information (see section 2.4).
• The Navigation Support Service links the Anatomy Browser with the Medico Ontology (see section 2.4).
The client applications as well as the Image Parsing System use the Annotation Database and Data Repositoryfor persisting meta data needed by semantic queries. The Data Repository stores large data such as surfacemeshes which represent organs, image masks, and annotated textual reports. These data are referenced by theAnnotation Database.
2.2 Image Parsing
The objective of the image parsing system is to automatically annotate anatomical structures in medical images.The parsing is done hierarchically, enabling the system to detect 32 landmarks and segment 8 organs on a PentiumXeon, 2.66 GHz, 3GB RAM in about less than a minute, taking contextual information into account, for detailscf.4 New anatomy is easily incorporated since the framework can be trained and handles the segmentation oforgans and the detection of landmarks are handled in a unified manner. The technology is based on MarginalSpace Learning (MSL)5 which uses a sequence of learned classifiers to estimate the position, orientation, and
†Apache Tomcat is a trademark of the Apache Software Foundation.

scale of the organs and the position of the landmarks. Each learned classifier is a Probabilistic Boosting Tree6
(PBT) with 3D Haar-like7 and steerable features.5
The process chain of the image parsing system is illustrated in Figure 2. It consists of two main parts: theDiscriminative Anatomical Network (DAN) and the database-guided segmentation module. The purpose of the
| 16
Slices Position Orientation Scale Boundary
Database-guided Segmentation
Discriminative AnatomicalNetwork (DAN)
Landmarks
Rigid Organ Detection Organ Refinement
landmark priors
Figure 2. The process chain of the integrated image parsing system.4
DAN is to give an estimate about the scale of the patient, the portion of the volume visible, and to detect a set oflandmarks. To obtain a fast and robust system, the landmarks are connected in a graph (network). Informationregarding the location of each landmark is propagated through the graph, which not only speeds up detection,but also increases detection accuracy. The database-guided segmentation module uses the output of the DANfor the detection of the position, the orientation, and scale of the organs visible in the given volume portion. Bythe use of boundary classifiers the organs are subsequently delineated. The precision of the organ segmentationwithin the image parsing system was evaluated with cross-validation using a mesh-to-mesh error metric (seeTable 3). The organ segmentation accuracy is depicted in Figure 4 which shows projections through the 3Dvolume with overlayed segmentation and ground truth contours. In terms of detection speed, the approach usingthe anatomical network, yielded a speedup of about 50%, compared with one using detectors individually. Thelandmark detection has been trained and cross-validated using up to 591 annotated volumes per landmark. Theaverage detection rate is 89.3% and it takes about 20 sec to process a full body CT volume.
organs annotatedvolumes
mesh to mesh error,3-fold C.V. [mm]
segmentationtime [s/vol]
heart 457 1.30 3.55liver 346 1.07 6.00spleen 203 2.14 9.90kidney right 199 1.03 0.40kidney left 197 1.15 0.40lung left 166 2.64 1.70lung right 163 2.35 1.80bladder 141 1.35 1.00
Figure 3. Evaluation measurements (left) and segmentation results on a full body CT volume in ensemble view (right).
2.3 Ontological Modeling
The rational of the MEDICO Ontology1,8 is to reuse background knowledge already represented in medicalontologies such as the FMA3 and terminologies like RadLex9 and the International Classification of Diseases

spleen bladder right lung liverFigure 4. High quality segmentations of some selected organs. The green contour represents the manual annotation of thestructure, i.e., ground truth. Overlayed is the red contour obtained from automatic segmentation in CT volumes.
version 10 (ICD-10). Each of them cover different dimensions of image annotation.
Figure 5 shows an overview of the components of the MEDICO ontology hierarchy‡. We follow Gruber’sdefinition10 for the term ontology that an ontology is a formal specification of a (shared) conceptualization.Ontologies are usually structured in various layers or levels, based on the assumption that those at higherlevels are more stable, shared among more people, and thus change less often than those at lower levels. Wedifferentiate between three aspects or dimensions of medical annotation. For anatomy we use the FMA, whereasthe concepts for the visual manifestation of an anatomical entity on an image are derived from the modifier andimaging observation characteristic sub-trees of RadLex. We consider the disease aspect as the interpretation ofthe combination of the previous two using ICD-10. The generation of an OWL model for the ICD-10 is describedin1
Test Bed Evaluation (Version: 31.10.09) Page 26 of 42
7. Evaluation of the Ontological Model
Semantic annotation and search within THESEUS MEDICO are based extensively on the MEDICO ontology hierarchy. Below we will just give a short overview about its components. For a more detailed description the reader is refered to [Moeller2009a] and to the description in Deliverable D.7.2. "Report detailing the overall system design and specification".
7.1. Overview of the MEDICO Ontology Hierarchy
Figure 18 shows an overview of the components of the MEDICO ontology hierarchy. We follow Gruber's definition [Gruber1995] for the term ontology that an ontology is a formal specification of a (shared) conceptualization. Ontologies are usually structured in various layers or levels, based on the assumption that those at higher levels are more stable, shared among more people, and thus change less often than those at lower levels. Following [Semy2004], we distinguish representational ontologies, upper-level ontologies, mid-level ontologies, and low-level or domain ontologies. An OWL model of this ontology hierarchy can be browsed online at http://www.dfki.uni-kl.de/~moeller/ontologies/medico-browser. Further details can be found in the publications cited above.
Figure 18 Overview of the components of the MEDICO ontology hierarchy. Figure 5. Medico Ontology.
The Representational Ontology defines the vocabulary with which the other ontologies are represented and canvary for the ontology to include; examples are RDF/S11 and OWL. The Upper Ontology is a domain-independentontology, providing a framework by which disparate systems may utilize a common knowledge base and fromwhich more domain-specific ontologies may be derived.12 It describes concepts like time, space, organization,person, and event which are the same across all domains. The Information Element Ontology bridges betweenabstract concepts defined in the upper ontology and domain specific concepts specified in the domain ontologies.13
‡See http://www.dfki.uni-kl.de/˜moeller/ontologies/medico-browser for an online OWL model of the this ontology.

Here the annotated images and reports are referenced. The Clinical Ontology specifies concepts particular to adomain of interest, e.g., the concepts nurse, doctor, patient, and the medical case.
The ontological model assumes the medical image being decomposed into regions. Figure 6 depicts an examplefor spleen lesions. Ovals denote properties, rectangles denote classes. The image decomposition is done by the im-age parsing system or by the clinician himself using the manual image annotation tool (see section 2.4). The regionis semantically described with class ImageRegion and is connected via the property hasAnnotation to multipleImageAnnotation instances. We differentiate between three medical aspects or dimensions of ImageAnnotation.For anatomy we use the FMA (Anatomical Entity) while visual characteristics are based on the modifier andimaging observation characteristic sub-trees of RadLex (Image Observation Characteristic). Disease aspectsare interpreted as a combination of the previous two and annotated with ICD-10 terms (Disease). Additionally,the name of the user responsible for the annotation is stored within an instance of the Annotator class. In thespleen lesion example, we have ImageAnnotation={multifocal, hypodense lesion, large, spleen}.
ImageRegionhasAnnotation ImageAnnotation
ImageObservation
Characteristic
AnatomicalEntity
DiseasehasDiseaseAnnotation
hasAnatomicalAnnotation
hasComponent
hasModifier
AnnotatorannotatedBy
spleen (FMA)
multifocallargehypodense
Radlex
lymphoma (ICD-10)
Dr. Doe
Figure 6. Semantic annotation of image regions with the MEDICO ontology.
2.4 Semantic Image Annotation Workflow
Due to the vast number of anatomical structures and their pathological changes, the image parsing system isnot yet able to fully capture the content of arbitrary medical images yet. In addition, available data fromprevious examinations or from non-image based databases, e.g., the anamnesis and laboratory findings, shouldbe incorporated. Accordingly, manual image annotation remains an important complement, which enables theclinician to correct, to validate or to extend the automatically generated annotations. The workflow for semanticannotation is given in Figure 7.
DetectLandmarks
ExtendAnnotation
Correct &Validate
SegmentOrgans
AssignConcepts
Image Parsing System Clinician supported by context-sensitive system
Figure 7. The proposed workflow for semantic annotation.

The image parsing system detects the landmarks, segments the organs and automatically assigns ontologicalconcepts. The mapping between anatomy and ontological concept is intrinsic by design, as the detector locates aspecific anatomical structure with an apparent concept class. Subsequently, the user corrects or validates thesefindings and decides if he wants to adopt a validated landmark or organ, i.e., it will be added to the list of theuser specified regions, or create a new region. These specified regions will then be labeled with concepts fromthe Medico Ontology.
The labeling itself is not trivial since the user can select from about 80000 FMA and 5000 Radlex terms. Weaddress this problem with two strategies; first, we provide the user with a powerful search mechanism, based onregular expressions, which additionally filters the items by currently visible body region (this is deduced fromthe landmarks) and provides a context-sensitive selection mechanism, e.g., in the case of the spleen lesion, theuser marks the lesion within an organ with some comprised drawing tools and the lesion is associated with thespleen and automatically labeled with ’spleen’ and ’hypodense lesion’. For lesions outside organs, the systemanalogous searches for the nearest detected anatomical region or manually specified region for labeling, e.g., ifthe user marks a lymph node, the system associates it with the nearest structure and suggests the lymph noderegion. These spatial relations required an extension of the FMA and an algorithm to map measured distancesinto concepts, for details cf.14 The appropriate lymph node region is determined by atlas matching computinga warped volume using automatically detected landmarks. As warping function we use Thin Plate Splines.15
3. RESULTS AND CONCLUSION
Figure 8 shows the customized graph-based FMA visualization of the Anatomy Browser. The browser links tothe Medico Imaging Client and enables fast navigation within 3D full body volumes; Figure 9 illustrates thecontext-sensitive annotation tool build into the Medico Imaging Client.
Figure 8. The Anatomy Browser of the Medico system.
The system is currently under intensive investigation by our clinical partner. By now, we annotated 30patients with lymphoma disease. The aim is to have more than 100 patients annotated soon which will enablemeaningful semantic search. The execution time for the semantic search is about 16 ms, with semantic queryexpansion about 50 ms. The processing time was evaluated running batch tests with 200 randomly chosenconcepts from the FMA. During these tests we compared the processing time for executing a semantic searchAPI call with deactivated versus activated query expansion. Though, the search slows down it allows us to
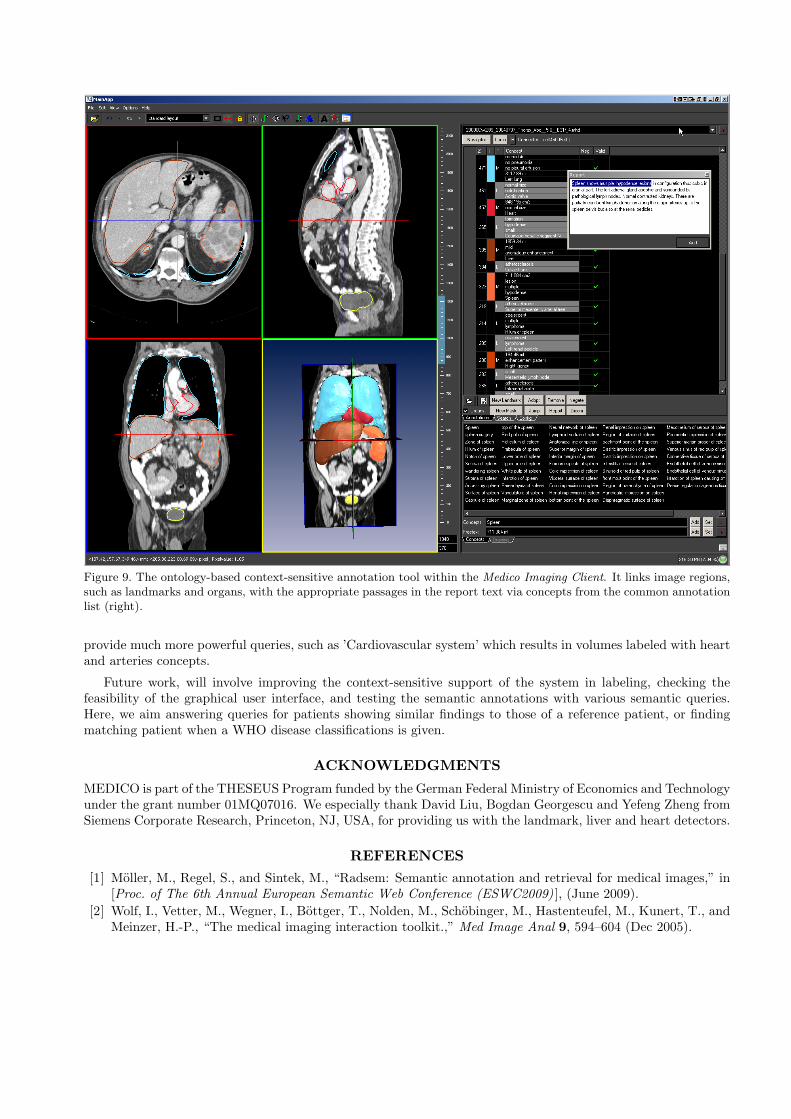
Figure 9. The ontology-based context-sensitive annotation tool within the Medico Imaging Client. It links image regions,such as landmarks and organs, with the appropriate passages in the report text via concepts from the common annotationlist (right).
provide much more powerful queries, such as ’Cardiovascular system’ which results in volumes labeled with heartand arteries concepts.
Future work, will involve improving the context-sensitive support of the system in labeling, checking thefeasibility of the graphical user interface, and testing the semantic annotations with various semantic queries.Here, we aim answering queries for patients showing similar findings to those of a reference patient, or findingmatching patient when a WHO disease classifications is given.
ACKNOWLEDGMENTS
MEDICO is part of the THESEUS Program funded by the German Federal Ministry of Economics and Technologyunder the grant number 01MQ07016. We especially thank David Liu, Bogdan Georgescu and Yefeng Zheng fromSiemens Corporate Research, Princeton, NJ, USA, for providing us with the landmark, liver and heart detectors.
REFERENCES[1] Moller, M., Regel, S., and Sintek, M., “Radsem: Semantic annotation and retrieval for medical images,” in
[Proc. of The 6th Annual European Semantic Web Conference (ESWC2009) ], (June 2009).[2] Wolf, I., Vetter, M., Wegner, I., Bottger, T., Nolden, M., Schobinger, M., Hastenteufel, M., Kunert, T., and
Meinzer, H.-P., “The medical imaging interaction toolkit.,” Med Image Anal 9, 594–604 (Dec 2005).

[3] Rosse, C. and Mejino, J., [Anatomy Ontologies for Bioinformatics: Principles and Practice ], vol. 6, ch. TheFoundational Model of Anatomy Ontology, 59–117, Springer (December 2007).
[4] Seifert, S., Barbu, A., Zhou, K., Liu, D., Feulner, J., Huber, M., Suehling, M., Cavallaro, A., and Comaniciu,D., “Hierarchical parsing and semantic navigation of full body ct data,” in [SPIE Medical Imaging ], (2009).
[5] Zheng, Y., Barbu, A., Georgescu, B., Scheuering, M., and Comaniciu, D., “Fast Automatic Heart ChamberSegmentation from 3D CT Data Using Marginal Space Learning and Steerable Features,” ICCV (2007).
[6] Tu, Z., “Probabilistic Boosting-Tree: Learning Discriminative Models for Classification, Recognition, andClustering,” ICCV 3(5) (2005).
[7] Tu, Z., Zhou, X., Barbu, A., Bogoni, L., and Comaniciu, D., “Probabilistic 3D Polyp Detection in CTImages: The Role of Sample Alignment,” CVPR , 1544–1551 (2006).
[8] Moller, M. and Sintek, M., “A generic framework for semantic medical image retrieval,” in [Proc. of theKnowledge Acquisition from Multimedia Content (KAMC) Workshop, 2nd International Conference onSemantics And Digital Media Technologies (SAMT) ], (November 2007).
[9] Langlotz, C. P., “Radlex: A new method for indexing online educational materials,” RadioGraphics 26,1595–1597 (2006).
[10] Gruber, T. R., “Toward principles for the design of ontologies used for knowledge sharing,” InternationalJournal of Human-Computer Studies 43, 907–928 (1995).
[11] Brickley, D. and Guha, R., “RDF vocabulary description language 1.0: RDF Schema,” tech. rep., W3C(February 2004).
[12] Kiryakov, A., Simov, K., and Dimitrov, M., “OntoMap: Portal for upper-level ontologies,” in [Proc. of theInternational Conference on Formal Ontology in Information Systems ], 47–58 (2001).
[13] Semy, S. K., Pulvermacher, M. K., and Obrst, L. J., “Toward the use of an upper ontology for U.S.government and U.S. military domains: An evaluation,” tech. rep., MITRE Corporation (September 2004).
[14] Moller, M., Folz, C., Sintek, M., Seifert, S., and Wennerberg, P., “Extending the foundational model ofanatomy with automatically acquired spatial relations,” in [Proc. of ICBO ], (July 2009).
[15] Bookstein, F. L., “Principal warps: Thin-plate splines and the decomposition of deformations,” IEEETransactions on Pattern Analysis and Machine Intelligence 11, 567–585 (1989).


















