Selena Deckelmann - Sane Schema Management with Alembic and SQLAlchemy @ Postgres Open
72
Sane Schema Management with Alembic and SQLAlchemy Selena Deckelmann Mozilla @selenamarie chesnok.com
-
Upload
postgresopen -
Category
Technology
-
view
1.009 -
download
0
Transcript of Selena Deckelmann - Sane Schema Management with Alembic and SQLAlchemy @ Postgres Open

Sane Schema Management with Alembic and SQLAlchemy
Selena DeckelmannMozilla
@selenamariechesnok.com

I work on Socorro.
http://github.com/mozilla/socorro
http://crash-stats.mozilla.com

Thanks and apologies to Mike Bayer

What's sane schema management?
Executing schema change in a controled, repeatable way while working with developers and operations.

What's alembic?
Alembic is a schema migration tool that integrates with SQLAlchemy.

My assumptions:
● Schema migrations are frequent.● Automated schema migration is a goal.● Stage environment is enough like
production for testing.● Writing a small amount of code is ok.

No tool is perfect.
DBAs should drive migration tool choice.
Chose a tool that your developers like. Or, don't hate.

Part 0: #dbaproblems
Part 1: Why we should work with developers on migrations
Part 2: Picking the right migration tool
Part 3: Using Alembic
Part 4: Lessons Learned
Part 5: Things Alembic could learn

Part 0: #dbaproblems

Migrations are hard.And messy.
And necessary.


Changing a CHECK constraint on 1000+ partitions.
http://tinyurl.com/q5cjh45

What sucked about this:
● Wasn't the first time (see 2012 bugs)● Change snuck into partitioning UDF
Jan-April 2013● No useful audit trail● Some partitions affected, not others● Error dated back to 2010● Wake up call to examine process!


Process before Alembic:


What was awesome:
● Used Alembic to manage the change● Tested in stage● Experimentation revealed which
partitions could be modified without deadlocking
● Rolled out change with a regular release during normal business hours

Process with Alembic: 1. Make changes to model.py or
raw_sql files2. Run: alembic revision –-auto-generate
3. Edit revision file4.Commit changes5. Run migration on stage after
auto-deploy of a release

Process with Alembic: 1. Make changes to model.py or
raw_sql files2. Run: alembic revision -–auto-generate
3. Edit revision file4.Commit changes5. Run migration on stage after
auto-deploy of a release

Problems Alembic solved:● Easy-to-deploy migrations including
UDFs for dev and stage● Can embed raw SQL, issue multi-
commit changes● Includes downgrades

Problems Alembic solved:● Enables database change discipline● Enables code review discipline● Revisions are decoupled from release
versions and branch commit order

Problems Alembic solved (continued): ● 100k+ lines of code removed● No more post-deploy schema
checkins● Enabling a tested, automated stage
deployment● Separated schema definition from
version-specific configuration

Photo courtesy of secure.flickr.com/photos/lambj
HAPPY
AS A CAT IN A BOX

Part I: Why we should work with developers on migrations

Credit: flickr.com/photos/chrisyarzab/

Schemas change.

Developers find this process reallyfrustrating.

Schemas, what are they good for?
Signal intentCommunicate ideal state of dataHighly customizable in Postgres

Schemas, what are they not so good for?
Rapid iterationDocumenting evolutionMajor changes on big dataData experimentation

Database systems resist change.

Database systems resist change because:
Exist at the center of multiple systems
Stability is a core competency
Schema often is the only API between components

How do we make changes to schemas?

Because of resistance, we treatschema change as a one-off.

Evolution of schema change process

We're in charge of picking up the pieces when a poorly-executed schema change plan fails.

Trick question:
When is the right time to work with developers on a schema change?

How do we safely make changes to schemas?

How do we safely make changes to schemas?
Process and tooling.
Preferably, that we choose and implement.

Migration tools are really configuration management tools.

Migrations are for: ● Communicating change● Communicating process● Executing change in a controled,
repeatable way with developers and operations

Part 2: Picking the right migration tool


Questions to ask: ● How often does your schema change?● Can the migrations be run without you?● Can you test a migration before you run
it in production?

Questions to ask: ● Can developers create a new schema
without your help?● How hard is it to get from an old
schema to a new one using the tool?● Are change rollbacks a standard use of
the tool?

What does our system need to do?● Communicate change● Apply changes in the correct order● Apply a change only once● Use raw SQL where needed● Provide a single interface for change● Rollback gracefully

How you are going to feel about the next slide:

Use an ORM with the migration tool.

Shameful admission:
We had three different ways of defining schema in our code and tests.

A good ORM provides:
● One source of truth about the schema● Reusable components● Database version independence● Ability to use raw SQL

And good ORM stewardship:
● Fits with existing tooling and developer workflows
● Enables partnership with developers● Integrates with a testing framework

And:
● Gives you a new way to think about schemas
● Develops compassion for how horrible ORMs can be
● Gives you developer-friendly vocabulary for discussing why ORM-generated code is often terrible

Part 3: Using Alembic

https://alembic.readthedocs.org
revision: a single migrationdown_revision: previous migrationupgrade: apply 'upgrade' changedowngrade: apply 'downgrade' changeoffline mode: emit raw SQL for a change

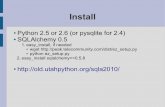
Installing and using:
virtualenv venv-alembic. venv-alembic/bin/activatepip install alembicalembic initvi alembic.inialembic revision -m “new”alembic upgrade headalembic downgrade -1

Defining a schema?
vi env.py
Add: import myproj.model

Helper functions?
Put your helper functions in a custom library and add this to env.py:
import myproj.migrations

Ignore certain schemas or partitions?
In env.py:
def include_symbol(tablename, schema): return schema in (None, "bixie") and re.search(r'_\d{8}$', tablename) is None

Manage User Defined Functions?
Chose to use raw SQL files3 directories, 128 files:procs/ types/ views/
codepath = '/socorro/external/pg/raw_sql/procs'
def load_stored_proc(op, filelist):
app_path = os.getcwd() + codepath
for filename in filelist:
sqlfile = app_path + filename
with open(myfile, 'r') as stored_proc:
op.execute(stored_proc.read())

Stamping database revision?
from alembic.config import Config
from alembic import command
alembic_cfg = Config("/path/to/yourapp/alembic.ini")
command.stamp(alembic_cfg, "head")

Part 4: Lessons Learned

Always roll forward.
1. Put migrations in a separate commit from schema changes.
2. Revert commits for schema change, leave migration commit in-place for downgrade support.

Store schema objects in the smallest, reasonable, composable unit.
1. Use an ORM for core schema.2. Put types, UDFs and views in separate
files.3. Consider storing the schema in a
separate repo from the application.

Write tests. Run them every time.
1. Write a simple tool to create a new schema from scratch.
2. Write a simple tool to generate fake data.
3. Write tests for these tools.4.When anything fails, add a test.

Part 5: What Alembic could learn

1. Understand partitions
2. Never apply a DEFAULT to a new column
3. Help us manage UDFs better
4.INDEX CONCURRENTLY
5. Prettier syntax for multi-commit sequences

1. Understand partitions
2. Never apply a DEFAULT to a new column
3. Help us manage UDFs better
4.INDEX CONCURRENTLY
5. Prettier syntax for multi-commit sequences

Epilogue

No tool is perfect.
DBAs should drive migration tool choice.
Chose a tool that your developers like. Or, don't hate.

Other tools:
Sqitchhttp://sqitch.org/Written by PostgreSQL contributor
Erwinhttp://erwin.com/Commercial, popular with Oracle
Southhttp://south.aeracode.org/ Django-specific, well-supported

Alembic resources:
bitbucket.org/zzzeek/alembic
alembic.readthedocs.org
groups.google.com/group/sqlalchemy-alembic

Sane Schema Management with Alembic and SQLAlchemy
Selena DeckelmannMozilla
@selenamariechesnok.com