
Modèle de fromage / Modèle de hâloir Modèle de hâloir / Modèle de chaine du froid

Sélection de modèle: de la théorie à la pratique
Pascal Massart Université de Paris-Sud, Orsay
http://www.math.u-psud.fr/~massart Paris 7, 20 Septembre 2010

• La Théorie asymptotique
- L’histoire de la sélection de modèle pénalisée commence avec les travaux d’Akaike (’70). - Le critère d’Akaike (AIC) propose de pénaliser la log-vraisemblance par le nombre de paramètres du modèle. - L’heuristique de ce critère s’appuie sur la Théorie Asymptotique et plus précisément sur le Théorème de Wilks
1. Introduction

Théorème de Wilks : sous conditions de régularité, la log-vraisemblance pour n observations indépendantes et de même loi appartenant à un modèle paramétrique avec D paramètres obéit au résultat de convergence en loi suivant
2 L
nθ( ) − L
nθ
0( )( )→ χ2 D( )
L
nθ( )
où désigne l’EMV et la vraie valeur du paramètre.

• La théorie non asymptotique - Dans de nombreuses situations il est
utile de laisser la taille des modèles grandir avec le nombre d’observations n.
- L’analyse asymptotique classique est alors insuffisante.
grandes valeurs de n !
- L’approche alternative, dite non asymptotique autorise la taille des modèles à croître librement. Mais bien sûr nous continuons à apprécier

• Une formule d’intérêt pratique
La pénalité minimale peut-être devinée au vu des données ce qui conduit à une stratégie de pénalisation conduite par les données.
Justification? Birgé, Massart (PTRF’07) dans le cas gaussien. Reste largement un problème ouvert sinon.
Pénalité « optimale » =2 * Pénalité « minimale »
Akaike : D=2*D/2

2. Estimation Fonctionnelle
• Densité i.i.d. de densité inconnue s par
rapport à . • Régression On observe avec Les variables explicatives sont déterministes
ou i.i.d. et les erreurs sont i.i.d. avec
X1,...,X
nµ
X
1,Y
1( ),..., Xn,Y
n( ) Y
i= s X
i( ) + εi
E ε
iX
i⎡⎣ ⎤⎦ = 0
But: Formaliser le problème de sélection de modèle en le situant dans le cadre de l’estimation adaptative d’une fonction inconnue s, liée à la loi de l’observation.

• Classification supervisée On considère un cadre de régression i.i.d.
avec une variable de réponse Y qui est une «étiquette» :0 ou 1.
Apprentissage statistique : estimer le classifieur de Bayes où désigne la fonction de régression .
• Bruit blanc gaussien Soit s une fonction numérique sur (un
signal). On observe le processus sur défini par
Où W désigne un mouvement brownien.
s x( ) = 1
η x( )≥1/2
η x( ) = E Y X = x⎡⎣ ⎤⎦
0,1⎡⎣ ⎤⎦
dY n( ) x( ) = s x( )dx +
1
ndW x( ),Y n( ) 0( ) = 0

3. Estimation sur un modèle Stratégie classique pour estimer une
fonction s : - se donner un contraste empirique i.e.
tel que
atteigne un minimum au point s - se donner un ensemble de fonctions S (un
« modèle ») L’estimateur dit de minimum de contraste
sur S (s’il existe!) est un minimiseur de sur S.
Cette définition généralise le maximum de vraisemblance sur un modèle paramétrique.
t → E γ
nt( )⎡⎣ ⎤⎦
γ n

• Maximum de vraisemblance
Contexte : densité, i.i.d. de loi avec
Le maximum de vraisemblance est donc bien un estimateur de minimum de contraste.
X1,...,X
n
γ
nt( ) = −
1n
logt Xi( )
i=1
n
∑
E γ
nt( ) − γ
ns( )⎡⎣ ⎤⎦ = K s,t( ) ≥ 0
Information de Kullback

Régression
avec
Bruit blanc
avec
Densité
avec
γ
nt( ) = 1
nY
i− t X
i( )( )2i=1
n
∑
E γ
nt( ) − γ
ns( )⎡⎣ ⎤⎦ =
1n
E t − s( )2 Xi( )⎡
⎣⎢⎤⎦⎥i=1
n
∑ ≥ 0
γ
nt( ) = t
2− 2 t x( )dY n( ) x( )∫
E γ
nt( ) − γ
ns( )⎡⎣ ⎤⎦ = t − s
2≥ 0
γ
nt( ) = t
2−
2n
t Xi( )
i=1
n
∑
E γ
nt( ) − γ
ns( )⎡⎣ ⎤⎦ = t − s
2≥ 0
• Moindres carrés

• Calcul exact pour un modèle linéaire Pour le bruit blanc ou la densité, lorsque S
est un sous-espace de dimension finie de (où désigne la mesure de Lebesgue pour le bruit blanc), l’estimateur des moindres carrés se calcule explicitement comme une projection. En effet soit une b.o.n. de S, alors
avec soit soit
s = βλ
λ∈Λ∑ φλ
βλ = φλ x( )dY n( ) x( )∫
βλ =
1n
φλ Xi( )
i=1
n
∑
Bruit blanc Densité

• Paradigme du choix de modèle
Soit S un modèle et un estimateur de minimum de contraste sur S
- Si un modèle S est défini par un petit nombre de paramètres (comparé à n), alors la cible s peut se trouver très éloignée du modèle.
- Si le nombre de paramètres est à l’inverse trop grand, alors est un estimateur médiocre de s quand bien même s appartiendrait réellement à S.

Illustration (bruit blanc) Soit S un espace vectoriel de dimension D, le
risque quadratique se calcule explicitement
- On voit qu’un « bon modèle » au sens de la minimisation du risque est un modèle qui réalise un bon compromis entre le terme de biais et le terme de variance . Il ne contient pas nécessairement s !
- Bien entendu le biais est inconnu donc le risque quadratique n’est pas un critère de choix mais plutôt un indice de performance.
d2 s,S( )
E s − s
2
= d2 s,S( ) + Dn
D / n
d2 s,S( )

4. Sélection de modèle par pénalisation • Cadre : On se donne une collection (au plus
dénombrable) de modèles et un contraste empirique . Chaque modèle est représenté par l’estimateur de minimum de constraste sur
• Oracle : On introduit la fonction de perte naturelle . Le « meilleur » modèle est associé à l’estimateur de risque minimum appelé oracle dont le risque vaut donc
s,t( ) = E γ
nt( )⎡⎣ ⎤⎦ − E γ
ns( )⎡⎣ ⎤⎦
infm∈M
E s,sm( )⎡⎣ ⎤⎦

• But : Sélectionner à partir de l’observation uniquement, un estimateur qui imite l’oracle (au sens du risque), i.e. tel que
soit comparable à • Procédure: pénalisation. On se donne une
fonction de pénalité . On sélectionne minimisant
sur
pen : M → R+
γ
nsm( ) + pen m( )
M
E s,s
m( )⎡⎣ ⎤⎦ infm∈M
E s,sm( )⎡⎣ ⎤⎦

Origine: Akaike (vraisemblance), Mallows (régression)
La fonction de pénalité est proportionnelle au « nombre de paramètres » du modèle .
Akaike : Mallows’ : , où la variance des erreurs du modèle de
régression est fixée, disons égale à 1 pour faire simple.
L’heuristique d’Akaike (‘73) conduisant à la proposition de pénalité s’appuie sur l’hypothèse que le nombre de paramètres de même que le nombre des modèles restent bornés tandis que n tend vers l’infini.
1
Sm
Dm/ n
2Dm
/ n
2
• L’approche asymptotique classique
Dm/ n

Critère (vraisemblance) BIC de Schwartz (‘78) :
- vise à sélectionner un « vrai » modèle plutôt qu’à imiter un oracle
- cependant également asymptotique, avec une pénalité proportionnelle au nombre de paramètres :
ln n( )Dm
/ n
• L’approche non asymptotique Barron,Cover (’91) pour des modèles discrets, Birgé, Massart (‘97) et Barron, Birgé, Massart (’99)) pour des modèles généraux. Elle diffère de l’approche asymptotique paramétrique classique pour la sélection de modèle sur les points suivants.

• Les modèles, leur nombre, leurs dimensions peuvent dépendre de n.
• On peut donc choisir une liste de modèles en raison de leurs propriétés d’approximation :
- développements en ondelettes, - polynômes trigonométriques ou par morceaux, - réseaux de neurones Il peut se faire que de nombreux modèles au sein
de la liste possèdent la même dimension. La « complexité » de la liste de modèles est typiquement prise en compte par une structure de pénalisation de la forme
avec .

Un signal bruité est observé à chaque instant j/n de et on souhaite sélectionner le meilleur estimateur constant par morceaux du signal, sur une partition dont les extrêmités des intervalles se trouvent sur la grille . Même si le nombre D de morceaux est modéré, le nombre de modèles de dimension D croît polynômialement avec n.
• Exemple: détection de ruptures multiples

Question centrale :
Choix de la pénalité
Inégalités de concentration
nouvelles questions
outils connus

5. Sélection de modèle gaussienne Considérons le cadre disons du bruit blanc ou
bien de la régression avec erreurs gaussiennes avec des variables explicatives déterministes. Résultats ci-dessous: avec Lucien Birgé (JEMS’01 et PTRF’07).
Chaque modèle supposé linéaire de dimension est représenté par son estimateur des moindres carrés sur . Alors
Oracle : Modèle idéal atteignant
E s − s
m 2
2=
Dm
n+ d2 s,S
m( )Biais Variance
infm∈M
E s − sm2
2

Soit la projection orthogonale de s sur L’oracle minimise le risque quadratique
ou encore
Substituant à son estimateur sans biais
naturel conduit au critère de Mallows
Clef : il faut préciser comment se concentre autour de uniformément en .
s − s
m 2
2+
Dm
n= s
2− s
m
2+
Dm
n
sm
2
−D
m
n
Pythagore
− s
m
2+
Dm
n
− s
m
2+
2Dm
n
• Heuristique de Mallows
s
m
2
Dm
n m ∈M

Théorème (Birgé, Massart’01) Soit une famille de poids positifs ou nuls tels que
Soit . Supposons que
Considérons
Alors
E s
m− s
2≤ C K( ) inf
m∈Md2 s,S
m( ) + pen m( )⎡⎣ ⎤⎦ +Σn
⎧⎨⎩
⎫⎬⎭

Comparaison avec l’oracle Puisque
Si les poids sont tels que et alors le majorant du risque donné par le Théorème devient
(à constante multiplicative près). Conclusion : L’estimateur sélectionné se
comporte approximativement comme un oracle.
E s
m− s
2
2= d2 s,S
m( ) + Dm
n
xm≤ LD
m
e− xm
m∈M
∑ ≤ 1
inf
m∈ME s
m− s
2
2

Soit une famille de fonctions linéairement indépendantes.
Soit une collection de sous-ensembles de et définissons , . a. Sélection ordonnée désigne alors la collection des sous ensembles de la forme avec .
Alors
Bonne comparaison à oracle.
ϕ
j, j ≤ N{ }
S
m= ϕ
j, j ∈m m ∈M
D ≤ N
pen m( ) = K m
n
E s − s
m
2≤ C K( ) inf
m∈ME s − s
m
2
fine
Sélection de variables

b. Sélection complète Soit la collection des sous-ensembles de . On peut prendre qui conduit à
On choisit ensuite
avec . Si les variables sont orthonormées est simplement l’estimateur par seuillage de
Donoho, Johnstone, Kerkyacharian, Picard.
Σ = e−xm
m∈M
∑ = CNDe−D ln N( )
D≤N∑ ≤ e.
pen m( ) = K
m
n1+ 2ln N( )( )2
s = β
j1β j ≥T
ϕj
j=1
N
∑ , avec βj= ϕ
jdY n( )∫

avec alors
Raffinement : On peut choisir lorsque , ce qui conduit à une borne
de risque optimale (au sens du minimax). Détection de ruptures: Mêmes propriétés
combinatoires pour les partitions par des intervalles sur une grille à N points donc même pénalités et bornes de risque…
T =
Kn
1+ 2ln N( )( )
E s − sm 2
2≤ C ' K( ) inf
D≤Ninf
m =Ds − s
m
2+
D log N( )n
⎧⎨⎪
⎩⎪
⎫⎬⎪
⎭⎪
Rôle de la base
x
m= D ln N / D( ) + 2( )
D = m
fine

• Conclusions • Le critère de Mallows’ peut sous-pénaliser. • La condition K>1 est « nécessaire ». • Quelle pénalité? On peut essayer d’optimiser la
borne de risque. Le résultat est que K=2 est un bon choix (Birgé, Massart PTRF’07))
Intérêt pratique Dans la « vraie vie » on ne connaît pas le niveau de bruit mais on peut s’en dispenser en retenant de la théorie la règle pénalité « optimale » = 2* pénalité « minimale»
L’idée étant qu’on peut deviner la pénalité minimale (et donc l’optimale!) à partir des données.

6. Pénalisation à partir des données
1. Calculer l’estimateur de minimum de contraste sur la réunion des modèles définis par le même nombre D de paramètres
2. Utiliser la théorie pour deviner la forme de la pénalité pen(D), typiquement pen(D)=aD (ou encore aD(2+ln(n/D)))
3. Estimer a en multipliant par 2 la plus petite valeur pour laquelle le critère pénalisé correspondant explose.
sD
« Recette »
Implémentée et testée dans Lebarbier (‘05)

Modèle de mélange gaussien Données simulées, mélange de 4 gaussiennes dans le plan (Baudry’07)
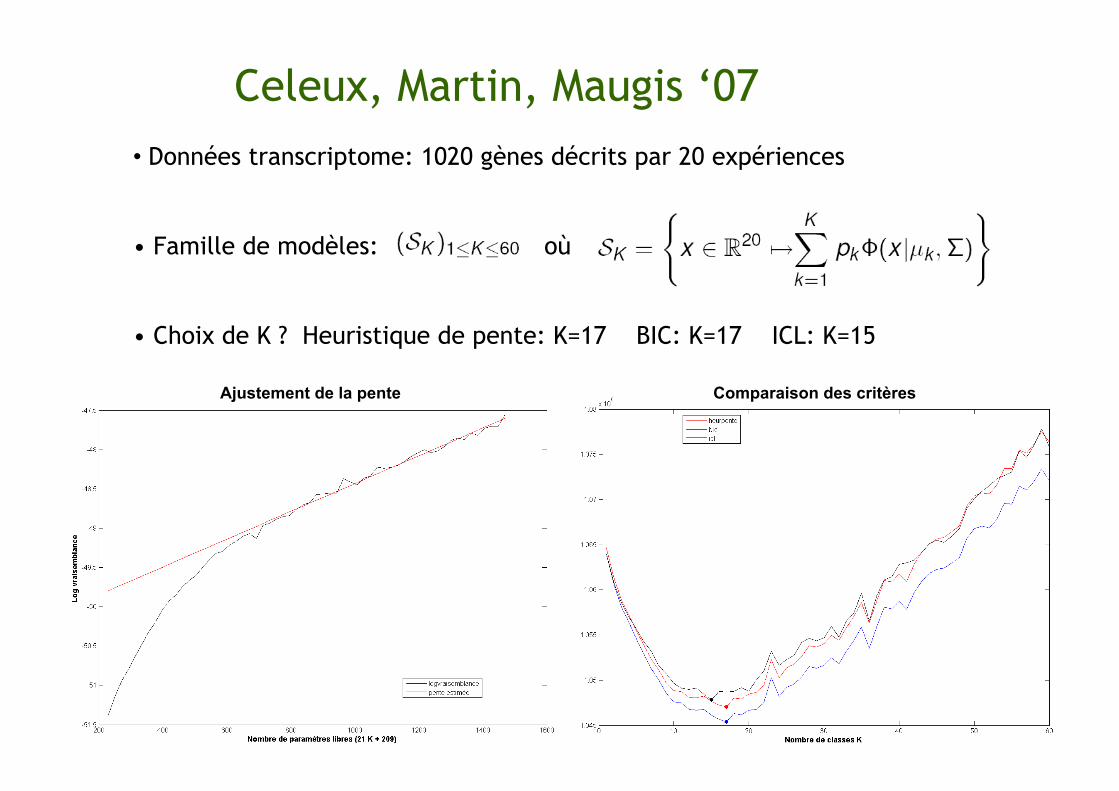
Celeux, Martin, Maugis ‘07 • Données transcriptome: 1020 gènes décrits par 20 expériences
• Famille de modèles: où
• Choix de K ? Heuristique de pente: K=17 BIC: K=17 ICL: K=15
Ajustement de la pente Comparaison des critères

Mallows et Akaike revisités La question principale est de réinterpréter le
principe d’estimation sans biais du risque
minimiser , revient à minimiser
γ
ns
D( ) = γn
sD( ) − γ
ns
D( ) − γn
sD( )⎡⎣ ⎤⎦
γ
ns
D( ) + pen D( )Terme de variance
γ
ns
D( ) − γn
s( ) − vD+ pen D( )
Estime le biais (s,sD)

Idéalement: afin donc de minimiser (approximativement)
La clef : Evaluer les excès de risque
pen
idD( ) = v
D+ s
D, s
D( )
(s, s
D) = (s,s
D) + s
D, s
D( )
C’est à ce point précis que divergent les différentes approches. Le critère d’Akaike repose sur l’approximation
(s
D, s
D) ≈ v
D≈
D2n
Pγ s
D( ) − Pγ sD( )
P
nγ s
D( ) − Pnγ s
D( )

La méthode initiée dans Birgé, Massart (’97) repose pour sa part sur les inégalités de concentration pour les suprema de processus gaussiens ou empiriques (comme l’inégalité de Talagrand ’96) pour majorer
v
D+ s
D, s
D( ) = Pn− P( ) γ s
D( ) − γ sD( )⎡⎣ ⎤⎦
Cette façon de procéder a été développée dans de nombreux travaux, parmi lesquels Baraud (’00) et (’03) pour les moindres carrés pénalisés en régression, Castellan (’03) pour les log-splines en densité, Patricia Reynaud (’03) pour les processus de Poisson, etc…


Inconvénient: constante multiplicative inconnue qui peut même dépendre de la loi (variance des erreurs de régression, sup de la densité, niveau de bruit de classification etc…). D’où l’intérêt d’une méthode de calibration.
Heuristique de pente : cherchons une approximation de de la forme aD avec a inconnu. Lorsque D devient grand, a tendance à devenir constant, il suffit de « lire » a comme une pente sur le graphe de . Ce qui explique la « recette » et conduit à la formule finale
γ
ns
D( )
γ
ns
D( )
pen D( ) = 2 × aD

En réalité et la méthode de pente conduit à son évaluation. Le facteur 2 appliqué ensuite Reflète l’espoir que les excès de risque
soient du même ordre de grandeur. Si tel est le cas alors on a vraiment
P
nγ s
D( ) − Pnγ s
D( ) Pγ s
D( ) − Pγ sD( )
Pénalité « optimale » =2 * Pénalité « minimale »
pen
minD( ) = v
D

Avancées récentes
• Justification de l’heuristique de pente: Arlot et Massart (JMLR’08) pour le choix
d’histogramme en régression et Boucheron et Massart (PTRF’10) sur la concentration de l’excès de risque empirique (phénomène de Wilks). Thèse de Saumard (2010) pour les modèles réguliers.
• Pénalisation avec deux dimensions
Bertrand, Maugis sélection de variables plus choix du nombre de composants dans un mélange

• Calibration de la régularisation
Régression ridge (Arlot et Bach 2009)
Lasso: Thèse de Connault (2010)
Persistence des notions de pénalité minimale et de pénalité optimale mais plus nécessairement dans un rapport égal à 2.

Pause!

High dimensional Wilks’ phenomenon
Wilks’ Theorem: under some proper regularity conditions the log-likelihood based on n i.i.d. observations with distribution belonging to a parametric model with D parameters obeys to the following weak convergence result
2 Ln θ( ) − Ln θ0( )( )→ χ 2 D( )
Ln θ( )
where denotes the MLE and is the true value of the parameter.
θ0

Question: what’s left if we consider possibly irregular empirical risk minimization procedures and let the dimension of the model tend to infinity? Obviously one cannot expect similar asymptotic results. However it is still possible to exhibit some kind of Wilks’ phenomenon (in the spirit of Fan (2001)) Motivation: modification of Akaike’s heuristics for model selection
Data-driven penalties

We consider the i.i.d. framework where one observes independent copies of a random variable with distribution . We have in mind the regression framework for which . is an explanatory variable and is the response variable. Let be some target function to be estimated. For instance, if denotes the regression function The function of interest may be the regression function itself.
• A statistical learning framework
s
s

In the binary classification case where the response variable takes only the two values 0 and 1, it may be the Bayes classifier
We consider some criterion , such that the target function achieves the minimum of
over some set . For example
• with leads to the regression function as a minimizer
• with leads to the Bayes classifier
s = 1Ι η≥1/ 2{ }
t → Pγ t,.( )
S
S = L2
S = t :X → 0,1{ }{ }
s

Introducing the empirical criterion
in order to estimate one considers some subset of (a « model ») and defines the minimum contrast estimator as a minimizer of over . This commonly used procedure includes LSE and also MLE for density estimation. In this presentation we shall assume that (makes life simpler but not necessary) and also that (boundedness is necessary).
s S S
S
s ∈S
s
0 ≤ γ ≤ 1

Introducing the natural loss function
We are dealing with two « dual » estimation errors • the excess loss
• the empirical excess loss
Note that for MLE and Wilks’ theorem provides the asymptotic behavior of when is a regular parametric model.
s, s( ) = Pγ s,.( ) − Pγ s,.( )
n s, s( ) = Pnγ s,.( ) − Pnγ s,.( )
s,t( ) = Pγ t,.( ) − Pγ s,.( )
n s, s( )
γ t,.( ) = − log t .( )
S

Crucial issue: Concentration of the empirical excess loss: connected to empirical processes theory because
Difficult problem: Talagrand’s inequality does not make directly the job (the rate is hard to gain). Let us begin with the related but easier question: What is the order of magnitude of the excess loss and the empirical excess loss?
n s, s( ) = sup
t∈SPn γ s,.( ) − γ t,.( )( )
1 / n

We need to relate the variance of with the excess loss
Introducing some pseudo-metric d such that
We assume that for some convenient function
In the regression or the classification case d is simply the distance and is either identity for regression or is related to a margin condition for classification.
s,t( ) = P γ t,.( ) − γ s,.( )( )
γ t,.( ) − γ s,.( )
P γ t,.( ) − γ s,.( )( )2
≤ d 2 s,t( )
d s,t( ) ≤ w s,t( )( )
Risk bounds for the excess loss
w
w

• Tsybakov’s margin condition (AOS 2004)
where and with
Since for binary classification
this condition is closely related to the behavior of around . For example margin condition is achieved whenever
d 2 s,t( ) = E s X( ) − t X( )⎡
⎣⎤⎦
κ = 1
2η −1 ≥ h

• Heuristics Let us introduce
Then
Now the variance of is bounded by hence empirical process theory tells you that the uniform fluctuation of
remains under control in the ball
γ n t( ) = Pn − P( )γ t,.( )
s, s( ) + n s, s( ) = γ n s( ) − γ n s( )
s, s( ) ≤ γ n s( ) − γ n s( )

Introducing some modulus of continuity such that
Concentration inequalities garantee that
holds (at least with high probability). Now
and « therefore »
where
φ σ( ) ≥ E sup
t∈S ,d s,t( )≤σn γ n s( ) − γ n t( )( )⎡
⎣⎢
⎤
⎦⎥
n γ n s( ) − γ n s( )( ) ≤ φ d s, s( )( )
n s,s( ) ≤ n γ n s( ) − γ n s( )( ) ≤ φ w s,s( )⎛
⎝⎜⎞⎠⎟

(Massart, Nédélec AOS 2006) Theorem : Let , such that , with and . Assume that
and
for every such that . Then, defining as
one has
where is an absolute constant.
E sup
t∈S ,d s,t( )≤σn γ n s( ) − γ n t( )( )⎡
⎣⎢
⎤
⎦⎥ ≤ φ σ( )
E s,s( )⎡⎣⎢
⎤⎦⎥≤ Cε*
2

Application to classification • Tsybakov’s framework Tsybakov’s margin condition means that An entropy with bracketing condition implies that one can take and we recover Tsybakov’s rate • VC-classes under margin condition one has . If is a VC-class with VC-dimension
so that (whenever )
ε*2 n−κ / 2κ +ρ−1( )
w ε( ) = ε / h
φ σ( ) ≈ σ D 1+ log 1 / σ( )( )
ε*
2 =Cnh
D 1+ lognh2
D⎛
⎝⎜⎞
⎠⎟⎛
⎝⎜
⎞
⎠⎟
2η −1 ≥ h
S D
nh2 ≥ D

Main points
• Local behavior of the empirical process
• Connection between and .
Better rates than usual in VC-theory
These rates are optimal (minimax)

Concentration of the empirical excess loss
Joint work with Boucheron (PTRF 2010). Since
the proof of the above Theorem also leads to an upper bound for the empirical excess risk for the same price. In other words is also bounded by up to some absolute constant. Concentration: start from identity
s, s( ) + n s, s( ) = γ n s( ) − γ n s( )
E γ n s( ) − γ n s( )⎡⎣
⎤⎦
n s, s( ) = sup
t∈SPn γ s,.( ) − γ t,.( )( )

Let be some independent copy of . Defining and setting
Efron-Stein’s inequality asserts that
A Burkholder-type inequality (BBLM, AOP2005) For every such that is integrable, one has
ξ1' ,...ξn
' ξ1,...ξn
V + = E Z − Zi
'( )+
2ξ
i=1
n
∑⎡⎣⎢
⎤
⎦⎥
Zi
' = ζ ξ1,...,ξi−1,ξi' ,ξi+1,...ξn( )
• Concentration tools
Z − E Z⎡⎣ ⎤⎦( )
+ q≤ 3q V +
q / 2

Comments This inequality can be compared to Burkholder’s martingale inequality
where denotes the quadratic variation w.r.t. Doob’s filtration , and trivial -field. It can also be compared with Marcinkiewicz Zygmund’s inequality which asserts that in the case where

Note that the constant in Burkhölder’s inequality cannot generally be improved. Our inequality is therefore somewhere « between » Burkholder’s and Marcinkiewicz-Zygmund’s inequalities. We always get the factor instead of which turns out to be a crucial gain if one wants to derive sub-Gaussian inequalities. The price is to make the substitution
which is absolutely painless in the Marcinkiewicz-Zygmund case. More generally, for the examples that we have in view, will turn to be a quite manageable quantity and explicit moment inequalities will be obtained by applying iteratively the preceding one.

• Fundamental example The supremum of an empirical process
provides an important example, both for theory and applications. Assuming that , Talagrand’s inequality (Inventiones 1996) ensures the existence of some absolute positive contants and , such that
Z = sup
t∈Sft ξi( )
i=1
n
∑ ,
where W = sup
t∈Sft
2 ξi( )i=1
n
∑

Why? Example: for empirical processes, one can
prove that for some absolute positive constant
Optimize Markov’s inequality w.r.t. q
Talagrand’s concentration inequality
• Moment inequalities in action

Refining Talagrand’s inequality
The key: In the process of recovering Talagrand’s inequality via the moment method above, we may improve on the variance factor. Indeed, setting and
we see that
and therefore
Z = sup
t∈Sft ξi( )
i=1
n
∑ = fs ξi( )i=1
n
∑ = n n s, s( )
Z − Zi
' ≤ fs ξi( ) − fs ξi'( )
V + = E Z − Zi
'( )+
2ξ
i=1
n
∑⎡⎣⎢
⎤
⎦⎥ ≤ 2 Pfs
2 + fs2 ξi( )( )
i=1
n
∑

at this stage instead of using the crude bound
we can use the refined bound
Now the point is that on the one hand
V +
n≤ 2 sup
t∈SPft
2 + supt∈S
Pn ft2⎛
⎝⎜⎞⎠⎟
V +
n≤ 2Pfs
2 + 2Pn fs2( ) ≤ 4Pfs
2 + 2 Pn − P( ) fs2( )
P f
s2( ) ≤ w2 s,s( )⎛
⎝⎜⎞⎠⎟

and on the other hand we can handle the second term by using some kind of square root trick. can indeed shown to behave not worse than
So finally it can be proved that
and similar results for higher moments.
Pn − P( ) fs
2( )
Pn − P( ) fs2( )
Pn − P( ) fs( ) = n s, s( ) + s, s( )
Var Z⎡⎣ ⎤⎦ ≤ E V +⎡⎣ ⎤⎦ ≤ Cnw2 ε*( )

Illustration 1 In the (bounded) regression case. If we consider the regressogram estimator on some partition with pieces, it can be proved that
In this case can be shown to be approximately proportional to . This exemplifies the high dimensional Wilks phenomenon. Application to model selection with adaptive penalties: Arlot and Massart, JMLR 2009. .
n n s, s( ) − E n s, s( )⎡⎣ ⎤⎦ q
≤ C qD + q⎡⎣
⎤⎦
nE n s, s( )⎡⎣ ⎤⎦
D
D

Illustration 2 It can be shown that in the classification case, If is a VC-class with VC-dimension , under the margin condition
provided that . Application to model selection: work in progress with Arlot and Boucheron.
nh n s, s( ) − E n s, s( )⎡⎣ ⎤⎦ q
≤ C qD 1+ lognh2
D⎛
⎝⎜⎞
⎠⎟⎛
⎝⎜
⎞
⎠⎟ + q
⎡
⎣
⎢⎢
⎤
⎦
⎥⎥
nh2 ≥ D
2η −1 ≥ h
S D
![Calcul asymptotique - bessadiq.e-monsite.combessadiq.e-monsite.com/medias/files/calcul-asymptotique.pdf · []éditéle17février2015 Enoncés 1 Calcul asymptotique Comparaison de](https://static.fdocuments.net/doc/165x107/5e030591d9e2ea2f2041643a/calcul-asymptotique-bessadiqe-ditle17fvrier2015-enoncs-1-calcul-asymptotique.jpg)




![Calcul asymptotique - Accueilmp.cpgedupuydelome.fr/pdf/Calcul asymptotique.pdf · [] édité le 3 novembre 2017 Enoncés 1 Calcul asymptotique Comparaison de suites numériques Exercice](https://static.fdocuments.net/doc/165x107/5ab57c197f8b9a156d8ce274/calcul-asymptotique-asymptotiquepdf-dit-le-3-novembre-2017-enoncs-1-calcul.jpg)












