
Search: Probabilistic Information Retrieval
27
Probabilistic Information Retrieval Search - Week 6 Keerthi Nuthi Vipul Munot Arun Ram Sankaranarayanan
-
Upload
vipul-munot -
Category
Data & Analytics
-
view
47 -
download
0
Transcript of Search: Probabilistic Information Retrieval

Probabilistic Information RetrievalSearch - Week 6
Keerthi NuthiVipul Munot
Arun Ram Sankaranarayanan

Basic Probability TheoryFor events A and B
● P(A,B) : Joint Probability● P(A / B) : Conditional Probability● Chain Rule :
● Partition Rule :
● Bayes Rule :

● Prior probability P(A) : (initial estimate of how likely event A is in the absence of any other information).
● Posterior probability P(A|B) : after having seen the evidence B, based on the likelihood of B occurring in the two cases that A does or does not hold.
● Odds of an event provide a kind of multiplier for how probabilities change.
Odds :
Basic Probability Theory

The 1/0 loss case● Ranked retrieval setup: given a collection of documents, the user
issues a query, and an ordered list of documents is returned.
● Assume binary notion of relevance: Rd,q is a random dichotomous
variable, such that
● Rd,q = 1 if document d is relevant w.r.t query q
● Rd,q = 0 otherwise

The Probability Ranking Principle● If a retrieval system responds to the query of an user by giving a set of
documents in the decreasing order of their probability of relevance, the overall effectiveness of the system will be the best that is obtainable.
● It is assumed that probabilities are calculated based on the entire data available to the system.

The Binary Independence Model (BIM)
● Binary (equivalent to Boolean) : Documents and Queries are both
represented as binary term vectors.
● E.g., document d represented by vector x = (x1, . . . , xM), where
xt = 1 if term t occurs in d and xt = 0 otherwise.● Different documents may have the same vector representation.

Binary Independence ModelTo make a probabilistic retrieval strategy precise, need to estimate
how terms in documents contribute to relevance
● Find measurable statistics (term frequency, document frequency, document length)
that affect judgments about document relevance
● Combine these statistics to estimate the probability of document relevance
● Order documents by decreasing estimated probability of relevance P(R|d, q)
● Assume that the relevance of each document is independent of the relevance of
other documents (not true, in practice allows duplicate results).

Binary Independence Model●●
○○
○●

Deriving a ranking function for query terms● Aim: Given a query q,
○ return documents by descending P(R=1 | d,q) in BIM
○ As we are interested only in ranking the documents, we rank them by their odds of relevance.

Deriving a ranking function for query terms● Since each xt is either 0 or 1, we can separate the terms to give:
● let = probability of a term appearing in a document relevant to the query
● = be the probability of a term appearing in a nonrelevant document

Deriving a ranking function for query terms
▪
▪

Retrieval Status Value (RSV)
●
●
▪

Retrieval Status Value (RSV)
▪− −
▪
▪

Deriving a ranking function for query terms

Probability Estimates in Practice▪
▪
− − ≈
▪

Probability Estimates in Practice
●
●▪ −
▪
▪
▪

An appraisal and some extensions
●●
●
●●●

Tree structured dependencies between terms
●
●
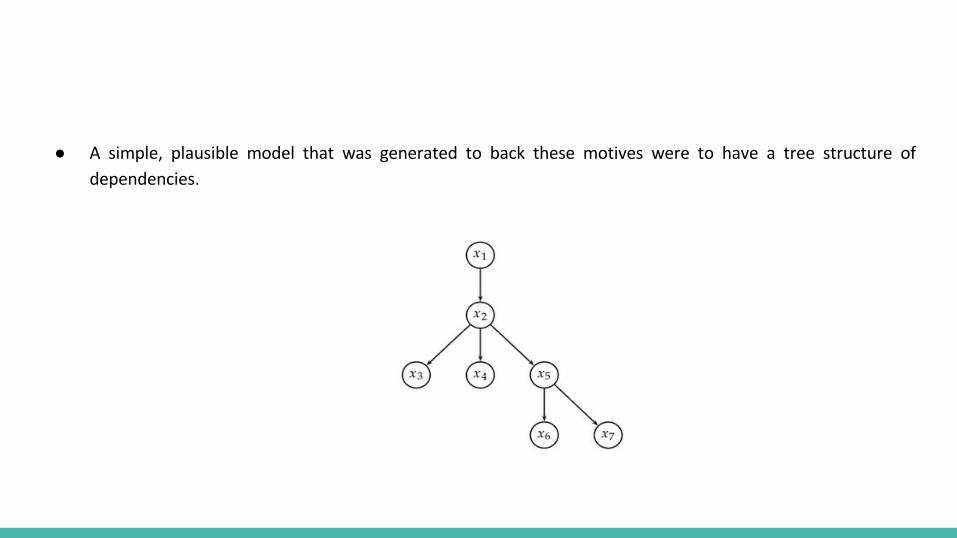
●

Okapi BM25, a non binary model●
●



≤ ≤


Bayesian network approaches to IR

Thank You

References● http://nlp.stanford.edu/IR-book/html/htmledition/probabilistic-information-retrieval-1.html
● nlp.stanford.edu/IR-book/ppt/11prob.pptx









![Probabilistic Information Retrieval Approach for …vagelis/publications/PIR-TODS...Information Search and Retrieval - H.2.4 [Database Management]: Systems General Terms: Automatic](https://static.fdocuments.net/doc/165x107/5f07ee5a7e708231d41f7a15/probabilistic-information-retrieval-approach-for-vagelispublicationspir-tods.jpg)








